PERBANDINGAN METODE DISKRETISASI DALAM
MODEL REGRESI LOGISTIK
(Studi Kasus: Pembentukan Model Penskoran Kredit Bank X)
DIAN ILMIATI ARDITA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Perbandingan Metode Diskretisasi Dalam Model Regresi Logistik (Studi Kasus: Pembentukan Model Penskoran Kredit Bank X) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Dian Ilmiati Ardita
ABSTRAK
DIAN ILMIATI ARDITA. Perbandingan Metode Diskretisasi Dalam Model Regresi Logistik (Studi Kasus: Pembentukan Model Penskoran Kredit Bank X). Dibimbing oleh AJI HAMIM WIGENA dan I MADE SUMERTAJAYA .
Jumlah nasabah KPR pada bank X mengalami penurunan sejak Februari 2012 hingga Agustus 2012. Regresi logistik yang digunakan dalam model penskoran kredit (credit scoring model) tidak hanya untuk mengetahui faktor-faktor apa saja yang berpengaruh terhadap keputusan pengambilan KPR, tetapi dapat diketahui pula seberapa besar nilai skor di setiap kategori peubah penjelas. Data yang digunakan dalam model penskoran kredit haruslah data kategorik. Data bertipe kontinu perlu didiskretisasi agar menjadi data kategorik. Proses diskretisasi dapat menggunakan metode chimerge (model I) dan metode dengan selang yang sama (equal with interval) (model II). Berdasarkan analisis regresi logistik peubah yang berpengaruh terhadap respon adalah jenis kelamin, status pekerjaan, pendidikan, tanggungan, jenis pekerjaan, usia, dan pendapatan. Hasil tabel ketepatan klasifikasi, menunjukkan bahwa model I memiliki kemampuan untuk pengklasifikasian yang lebih baik dibandingkan dengan model II, sehingga kartu skor (scorecard) dibuatberdasarkan pada model I.
Kata kunci: chimerge, credit scoring, equal with interval, regresi logistik, scorecard
ABSTRACT
DIAN ILMIATI ARDITA. Comparing Discretization Method In Logistic Regression Model (Case Study: Establishment of Credit Scoring Model Bank X). Supervised by AJI HAMIM WIGENA and I MADE SUMERTAJAYA.
The number of KPR customers of bank X decreased since February 2012 until August 2012. Logistic regression which is used in credit scoring model is not only able to identify the significance factors but also to know the scoring value in each category of explanatory variable. The data used in credit scoring model must be categorical data. Continuous data needs to be discretized in order to get categorical data. Discretization process can use chimerge method (model I) and equal with interval method (model II). Based on logistic regression, the factors that affect the respon are sex, employment status, education, occupation, age, and income. Correct classification table, shows that model I is better to classify than model II, therefore the scorecard is made based on model I.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
PERBANDINGAN METODE DISKRETISASI DALAM
MODEL REGRESI LOGISTIK
(Studi Kasus: Pembentukan Model Penskoran Kredit Bank X)
DIAN ILMIATI ARDITA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Perbandingan Metode Diskretisasi Dalam Model Regresi Logistik (Studi Kasus : Pembentukan Model Penskoran Kredit Bank X) Nama : Dian Ilmiati Ardita
NIM : G14100099
Disetujui oleh
Dr Ir Aji Hamim Wigena, MSc Pembimbing I
Dr Ir I Made Sumertajaya, MSi Pembimbing II
Diketahui oleh
Dr Anang Kurnia, MSi Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Sholawat serta salam semoga selalu tercurahkan kepada pimpinan umat nabi Muhammad SAW beserta keluarga, sahabat, dan umatnya.
Terima kasih penulis ucapkan kepada ayah, ibu, kakak, adik, serta semua keluarga penulis atas doa, semangat, dan dukungannya yang tanpa henti kepada penulis, serta Bapak Dr Ir Aji Hamim Wigena, MSc dan Bapak Dr Ir I Made Sumertajaya, MSi selaku pembimbing, serta Bapak Bagus Sartono, M.Si yang telah banyak memberi saran. Di samping itu, penghargaan penulis sampaikan kepada Bapak Hendrayana Kartiman, Ibu Utami Rahayu, Ibu Nia Sofura beserta staf SAS Institute Indonesia, serta Bapak dan Ibu dosen beserta staf Departemen Statistika yang telah membantu selama proses pembuatan skripsi. Ungkapan terima kasih juga disampaikan kepada rekan-rekan statistika angkatan 47 dan angkatan 46 yang telah memberi sumbangan pikiran dan bantuannya selama ini.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
TINJAUAN PUSTAKA 2
Lembaga Keuangan Bank 2
Diskretisasi 2
Weight Of Evidence (WOE) 4
Information Value 4
Regresi Logistik 5
Model Penskoran Kredit (Credit Scoring Model) 6
Validasi Model 7
METODE 8
Data 8
Metode Analisis 8
HASIL DAN PEMBAHASAN 9
Eksplorasi Data 9
Deskripsi WOE Peubah Kontinu 11
Deskripsi WOE Peubah Kategorik 13
Information Value 16
Analisis Regresi Logistik 17
Perbandingan Model 18
Ilustrasi Penilaian Kredit 19
SIMPULAN DAN SARAN 20
Simpulan 20
Saran 21
DAFTAR PUSTAKA 21
LAMPIRAN 22
DAFTAR TABEL
1. Tabel ketepatan klasifikasi 8
2. Diskretisasi chimerge peubah pendapatan 12
3. Diskretisasi dengan selang yang sama peubah pendapatan 12
4. Diskretisasi chimerge peubah usia 13
5. Diskretisasi dengan selang yang samapeubah usia 13
6. Nilai WOE peubah jenis kelamin 13
7. Nilai WOE peubah status pekerjaan 14
8. Nilai WOE peubah status pernikahan 14
9. Nilai WOE peubah pendidikan terakhir 15
10.Nilai WOE peubah Tanggungan 15
11.Nilai Inv didiskretisasi chimerge 16
12.Nilai Inv didiskretisasi dengan selang yang sama 16
13.Nilai statistik uji G, nilai-P 17
14.Nilai-P uji Wald dan dugaan koefisien parameter 17
15.Tabel ketepatan klasifikasidata training 18
16.Tabel ketepatan klasifikasidata validasi 18
DAFTAR GAMBAR
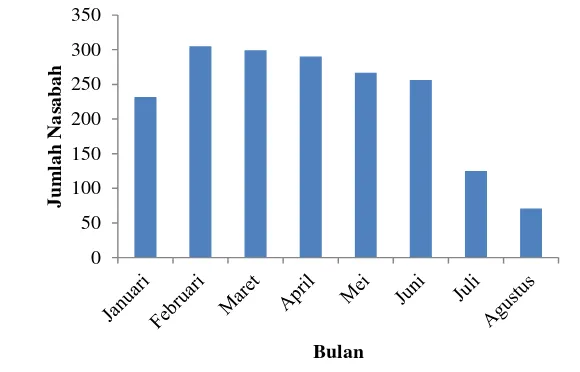
1. Jumlah nasabah kredit KPR (Januari-Agustus 2012) 10
DAFTAR LAMPIRAN
1. Daftar peubah penjelas dan keterangannya 22
2. Distribusi grafik nasabah 23
3. Nilai WOE peubah jenis pekerjaan 30
4. Hasil kartu skor pada model II 31
PENDAHULUAN
Latar Belakang
Bank X merupakan salah satu lembaga keuangan yang ada di Indonesia. Selama lebih dari 140 tahun bank X memberikan kontribusi dalam dunia perbankan dan perekonomian Indonesia. Kredit Pemilikan Rumah (KPR) merupakan suatu produk unggulan dari bank X, namun pada bulan Februari sampai bulan Agustus tahun 2012 mengalami penurunan jumlah nasabahnya. Bulan Januari ke Februari mengalami peningkatan sebesar 31.46%, namun saat bulan Maret mengalami penurunan sebesar 1.96%. penurunan jumlah nsabah pengambil KPR kian menurun disetiap bulannya. Penurunan nasabah pengambil KPR terbesar terjadi saat bulan Juni ke bulan Juli sebesar 51.17%. Pada bulan Agustus 2012 nasabah yang mengambil KPR hanya sebanyak 71 nasabah. Bank X perlu melakukan suatu usaha untuk mengetahui faktor-faktor apa saja yang mempengaruhi keputusan nasabah dalam pengambilan KPR.
Keputusan nasabah dalam mengambil KPR di bank X diduga dipengaruhi oleh beberapa faktor. Faktor-faktor tersebut diantaranya adalah jenis kelamin, status pekerjaan, status pernikahan, pendidikan, tanggungan, jenis pekerjaan, usia, dan pendapatan. Model penskoran kredit (credit scoring model) dengan regresi logistik dapat digunakan untuk mengetahui faktor-faktor apa saja yang berpengaruh nyata terhadap keputusan nasabah dalam pengambilan KPR. Model penskoran kredit menghasilkan suatu kartu skor (scorecard), yang berisikan nilai skor di setiap kategori peubah penjelas. Saat menggunakan kartu skor, bank dapat menentukan nasabah seperti apa yang akan ditawari KPR berdasarkan skor pada kartu skor sehingga tidak perlu semua nasabah ditawari KPR. Hal tersebut menjadikan bank dapat menghemat waktu pengerjaan aplikasi kredit dan menghemat biaya.
Saat membangun model penskoran kredit pada data nasabah yang digunakan haruslah bertipe kategorik. Data peubah yang ada pada penelitian ini memiliki skala pengukuran kategorik dan numerik, sehingga data yang bertipe numerik perlu dilakukan diskretisasi. Kelebihan dari proses diskretisasi dapat memberikan kemudahan bagi pihak bank, karena data nasabah yang ada menjadi kategorik, hal tersebut mempermudah bank untuk memberikan skor pada nasabahnya sehingga mampu mengurangi waktu proses pengerjaan aplikasi kredit. Pada penelitian ini proses diskretisasi dilakukan dengan dua metode yaitu
chimerge dan dengan selang yang sama (equal with interval). Metode diskretisasi
chimerge sebelumnya pernah dilakukan oleh Stephanie (2008) untuk mendiskretisasi data kredit ritel. Menurut Han dan Kamber (2006) chimerge
adalah metode diskretisasi yang algoritmanya menggunakan statistik khi kuadrat untuk mendiskretisasi peubah numerik, sedangkan metode dengan selang yang sama membagi selang-selang kategori dengan jarak yang sama berdasarkan subjektifitas peneliti.
2
didiskretisasi menggunakan chimerge dibandingkan dengan model kedua adalah model regresi logistik saat peubah penjelas bertipe numerik didiskretisasi menggunakan dengan selang yang sama.
Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Menentukan faktor-faktor yang berpengaruh terhadap peubah respon menggunakan regresi logistik.
2. Membandingan model hasil diskretisasi yang selanjutnya dipilih untuk membuat kartu skorberdasarkan model yang terbaik.
TINJAUAN PUSTAKA
Lembaga Keuangan Bank
Pengertian bank menurut Undang-Undang Nomor 10 tahun 1998 tentang perbankan (penggantian Undang-Undang Nomor 7 tahun 1997) adalah badan usaha yang menghimpun dana dari masyarakat dalam bentuk simpanan dan menyalurkan kepada masyarakat dalam bentuk kredit dan bentuk-bentuk lainnya dalam rangka meningkakan taraf hidup rakyat banyak.
Berdasarkan pengertian tersebut dapat disimpulkan bahwa yang dimaksud dengan bank adalah lembaga keuangan yang menghimpun dana dari masyarakat yang kelebihan dana dan menyalurkan lagi kepada masyarakat yang kekurangan dana, juga memberikan pelayanan jasa di bidang-bidang lainnya, seperti mengirim uang (wesel/transfer), pemindah bukuan (giro), dan menyediakan jaminan bank (bank guarantee) (Supriatna et al. 2008).
Bank memberikan bentuk layanan produk kredit. Pengertian kredit menurut Undang-Undang No. 7 Tahun 1992 tentang perbankan adalah penyediaan uang atau tagihan yang dapat dipersamakan dengan itu, berdasarkan persetujuan kesepakatan pinjam-meminjam antara bank dengan pihak lain yang mewajibkan pihak meminjam untuk melunasi hutangnya setelah jangka waktu tertentu dengan jumlah bunga, imbalan atau pembagian hasil keuntungan. Salah satu jenis produk kredit yang bank tawarkan adalah kredit Kepemilikan Rumah. Kredit Kepemilikan Rumah (KPR) adalah kredit pemilikan rumah dari suatu bank yang diberikan kepada perorangan untuk keperluan pembelian rumah tinggal/apartemen/ruko/rukan yang dijual melalui pembangun (developer) atau bukan pembangun (non developer).
Diskretisasi
3 1. Mengurutkan nilai kontinu yang akan didiskretisasi.
2. Mengevaluasi titik potong sebagai pemisah selang atau penggabung selang yang berdekatan.
3. Berdasarkan kriteria tertentu dilakukan pemisahan atau penyatuan selang nilai. 4. Menghentikan proses pada titik tertentu.
Salah satu metode diskretisasi adalah tersupervisi dan tidak tersupervisi. Metode tersebut dipilih dikarenakan lebih mudah dibandingkan metode lainnya. Metode tersupervisi menggunakan informasi kelas pada peubah respon saat melakukan proses diskretisasi, sedangkan metode tidak tersupervisi tidak membutuhkan peubah respon sebagai dasar diskretisasinya. Berdasarkan perbedaan itulah ingin dilihat metode mana yang lebih baik dalam membangun model regresi logistik, metode yang menggunakan peubah respon ataukah metode yang tidak menggunakan peubah respon.
Metode DiskretisasiTersupervisi
Metode tersupervisi adalah metode diskretisasi dimana algoritma metode ini hanya bisa dijalankan jika terdapat sebuah peubah kategorik sebagai peubah respon yang dijadikan dasar diskretisasinya. Metode ini menggunakan informasi kelas pada peubah respon ketika memilih titik-titik potong alat pemisah antar kategori. Contoh metode diskretisasi tersupervisi : IRD, chimerge, entropy, zeta, ID3. Pada penelitian ini metode tersupervisi yang digunakan adalah chimerge.
Chimerge adalah metode diskretisasi peubah numerik yang menggunakan statistik khi kuadrat. Hipotesis nol dari metode chimerge ini adalah dua selag yang berdekatan pada peubah penjelas saling bebas terhadap peubah respon. Jika hipotesis diterima maka selang yang berdekatan akan digabung. Menurut Han dan Kamber (2006) proses chimerge yakni pada tahapan awal disetiap nilai pada
peubah numerik dijadikan sebagai satu interval. Uji χ2
digunakan pada setiap pasang interval yang berdekatan. Sepasang interval yang berdekatan memilki nilai
χ2 hitung lebih kecil dari χ2
tabel maka kedua interval yang berdekatan tersebut akan digabungkan. Proses ini dilakukan secara rekursif hingga kriteria
penghentian algoritma χ2
terjadi. Pertama, kriteria penghentian terjadi saat proses penggabungan interval berhenti jika nilai χ2 hitung di semua pasang selang yang berdekatan sudah lebih besar dari batas yang dipengaruhi oleh level signifikansi. Kedua, jumlah banyaknya interval tidak boleh melebihi banyaknya maksimum selangyang telah ditentukan. Perhitungan rumus χ2 di berikan sebagai berikut :
χ2=∑ ∑ ij ij 2
Aij = jumlah data aktual selang ke-i, kelas ke-j
Eij = frekuensi harapan
Eij = (Rj * Cj)/N
Ri = jumlah data aktual selang ke-i
Cj = jumlah data aktual kelas ke-j
4
Metode DiskretisasiTidak Tersupervisi
Metode diskretisasi tidak tersupervisi adalah metode yang tidak membutuhkan peubah respon yang dijadikan sebagai dasar diskretisasinya. Metode ini membagi interval nilai kontinu berdasarkan pertimbangan penulis. Pertimbangan yang diambil bersifat subjektif dimana pengguna menentukan mekanisme diskretisasinya. Contoh : dengan selang yang sama (equal with interval) dan dengan frekuensi selang yang sama (equal frequency interval).
Menurut Kotsiantis dan Kanellopoulos (2006), metode dengan selang yang sama membagi selang kategori dengan jarak yang sama.
Weight Of Evidence (WOE)
Perhitungan nilai Weight Of Evidence (WOE) dilakukan disetiap kategori peubah penjelas kemudian nilai awal peubah penjelas ditransformasi ke dalam WOE sehingga peubah penjelas yang berisikan nilai Weight Of Evidence (WOE) yang akan dijadikan input dalam regresi logistik. Fungsi dari WOE adalah untuk membangun model penskoran kredit. WOE untuk setiap kategori didefinisikan sebagai berikut :
j = (ff j j )
dimana f j =100 nn j = Persentase nasabah yang mengambil KPR dalam kategori ke-j
f j =100 n j
n = Persentase nasabah yang tidak mengambil KPR dalam kategori ke-j
Jumlah nasabah yang mengambil KPR kategori ke-j
Total nasabah yang mengambil KPR
Jumlah nasabah yang tidak mengambil KPR kategori ke-j
Total nasabah yang tidak mengambil KPR Information Value
Information value (Inv) digunakan untuk mengukur tingkat prediksi dan asosiasi peubah penjelas setelah didiskretisasi terhadap peubah respon. Inv umum digunakan untuk menyeleksi peubah penjelas yang berpotensi untuk dimasukan kedalam model dengan nilai batastertentu. Semakin besar nilai Inv maka semakin besar peluang peubah penjelas untuk masuk kedalam model. Information Value
(Inv) dirumuskan sebagai berikut :
nv= ∑f j100f j j q
j=1
WOE(j) = WOE dari tiap kategori ke-j dari satu peubah penjelas
Berdasarkan SAS Institute Inc (2012) Tingkat prediksi Inv dibagi kedalam beberapa kategori, yakni :
5 2. Jika 0.02 < nv ≤ 0.1 nv maka peubah penjelas memiliki tingkat prediksi
yang lemah.
3. Jika nilai 0.1 < Inv ≤ 0.3 maka peubah penjelas memliki tingkat prediksi yang medium.
4. Jika Inv > 0.3 memiliki nilai prediksi yang kuat. Regresi Logistik
Regresi logistik sebenarnya mirip dengan analisis regresi berganda, hanya peubah responnya merupakan peubah dummy (0 dan 1). Model regresi logistik merupakan model dasar bagi analisis data berskala biner. Peubah respon Y mengikuti sebaran Bernouli dengan fungsi sebaran peluang sebagai berikut (Hosmer dan Lemeshow 2000; Agresti 2002; Kantardzic 2003; ’Connell dan Ann 2006 ) :
f =y = y 1 1 y
dengan y Є{0,1} atau bernilai ‘ya’ atau ‘tidak’ dan adalah peluang terjadinya kejadian sukses (y=1) sedangkan (1- adalah peluang kejadian gagal. Secara umum model respon biner pada regresi untuk p peubah bebas yang memiliki skala kategorik atau kontinu adalah
y= |x
dengan adalah komponen acak.
Model regresi logistik biner digunakan untuk melihat apakah peubah respon yang berskala kategorik dipengaruhi oleh peubah penjelas yang berskala numerik atau kategorik. Bentuk umum model peluang regresi logistik dengan p peubah di rumuskan sebagai berikut :
x = exp 0 1x1 pxp
1 exp 0 1x1 pxp
dengan x adalah peluang suksessuatu kejadian yang ditentukan oleh x tertentu.Transformasi logit sebagai fungsi x didefinisikan sebagai :
g x =ln[1 x x ] = 0 1x1 kxk dengan { x / 1- x } merupakan resiko dari y=1 untuk x tertentu.
Model regresi logistik menggunakan metode kemungkinan maksimum untuk menduga parameter-parameternya. Fungsi kemungkinan maksimum yang diperoleh jika antara amatan yang satu dengan amatan yang lain diasumsikan bebas adalah :
l =∏ xi yi 1 xi 1 yi i=1
Parameter i diduga dengan memaksimumkan persamaan diatas. Pendekatan
logaritma dilakukan untuk memudahkan perhitungan, sehingga fungsi log-kemungkinan sebagai berikut :
L = ln l
6
Nilai dugaan i dapat diperoleh dengan membuat turunan pertama L( terhadap i kemudia disamakan dengan nol, sehingga merupakan penduga
kemungkinan maksimum bagi parameter-parameter model dengan cara metode kuadrat terkecil terboboti secara iteratif (Hosmer dan Lemeshow 2000).
Uji yang dilakukan terhadap parameter model untuk memeriksa apakah peubah penjelas berpengaruh terhadap model maka dilakukan statistik uji-G. Menurut Hosmer dan Lemeshow (2000) statistik tersebut merupakan rasio kemungkinan maksimum yang digunakan untuk melihat pengaruh peranan peubah penjelas didalam model secara bersama-sama. Statistik uji-G didefinisikan sebagai berikut :
= 2ln LL0
p
dengan L0 adalah fungsi kemungkinan tanpa peubah penjelas dan Lp adalah fungsi
kemungkinan dengan p peubah penjelas. Hipotesis yang diuji adalah : H0: 1= 2= = p=0
H1: minimal ada satu i≠0, i=1,2, p. Hipotesis nol ditolak jika > χ2p α .
Pengujian parameter secara parsial menggunakan uji Wald. Didefinisikan sebagai berikut :
= ̂i
S ̂i
Hipotesis yang diuji adalah : H0: i=0
H1: i≠0, i=1,2, p. Hipotesis nol ditolak jika | | > Zα/2.
Interpretasi koefisien untuk model regresi logistik biner dapat dilakukan dengan menggunakan nilai rasio oddsnya. Rasio odds didefinisikan sebagai :
̂ ( ̂)
Interpretasi dari rasio odds ini adalah untuk peubah penjelas X yang berskala nominal, yaitu kecenderungan untuk =1 pada X=1 sebesar Ψ kali dibandingkan pada X=0.
Model Penskoran Kredit (Credit Scoring Model)
Model penskoran kredit menghasilkan suatu kartu skor (scorecard), yang berisikan nilai skor di setiap kategori peubah penjelas. Menurut Koh et al. (2006) kelebihan dari penskoran kredit tidak hanya untuk bank saja tetapi juga untuk nasabah, contohnya penskoran kredit mampu mereduksi diskriminasi karena penskoran kredit memberikan analisis yang objektif. Penskoran kredit menghasilkan suatu hasil perhitungan statistik dari setiap kategori pada setiap peubah penjelas yang dapat digunakan untuk memisahakan apakah suatu nasabah
‘baik’ atau ‘buruk’ atau dalam penelitian ini ‘perlu ditawari KPR’ atau ‘Tidak perlu ditawari KPR’. Saat pembentukan kartu skor diperlukan adanya teknik penskalaan. Teknik ini mengacu pada jangkauan dan format skor dalam kartu skor (Siddiqi 2006). Teknik penskalaanini tidak berpengaruh terhadap tingkat prediksi kartu skor, teknik penskalaan digunakan agar pengguna lebih mudah memahami data yang bertipe diskret. Penskalaan dihitung dengan menggunakan persamaan berikut :
7 Nilai factor dan offset dapat diperoleh jika telah didefinisikan :
1. nilai skor yang diinginkan untuk odds tertentu
2. nilai pdo (points to double the odds), yaitu besarnya kenaikan skor yang menyebabkan odds-nya menjadi dua kali lipat
sehingga
score=offset factor ln odds
score pdo=offset factor ln 2 odds
pdo=factor ln 2 factor= ln 2pdo
offset=score factor ln odds
Misal, kartu skor yang diinginkan memiliki odds of 50:1 pada nilai 600 dan odds-nya akan dua kali lipat kalau skorodds-nya bertambah 20 points (pdo = 20). Maka diperoleh :
factor= 20
ln 2 =28.853
offset=600 28.853 ln 50 =487.123
Perhitungan skor untuk setiap kategori pada satu peubah penjelas, disajikan sebagai berikut :
j i an factor offsetn
dengan WOE = Nilai WOE pada setiap kategori ke-j peubah penjelas. i = Koefisien regresi logistik untuk setiap peubah penjelas ke-i.
α = Nilai intercept pada regresi logistik. n = Banyaknya peubah penjelas.
Validasi Model
Validasi model memiliki fungsi untuk mengukur sejauh mana hasil model mendekati kondisi sebenarnya. Suatu model dapat dikatakan valid jika model tersebut semakin dekat dengan data aktual serta mampu menggambarkan kondisi sesungguhnya. Salah satu metode yang digunakan untuk validasi adalah tabel ketepatan klasifikasi.
Berdasarkan SAS Inc (2012a) tabel ketepatan klasifikasi (correct classification table) dapat digunakan untuk mengetahui ketepatan prediksi dari model yang dibangun. Tabel ketepatan klasifikasi merupakan tabel frekuensi dua arah antara data aktual dengan data prediksi. Tabel 1 merupakan tabel ketepatan klasifikasi.
8
Tabel 1 Tabel Ketepatan klasifikasi
Amatan Prediksi
0 1
0 Benar (-) Spesifisitas Salah (+)
1 Salah (-) Benar (+) Sensitifitas
Tabel ketepatan klasifikasi memiliki tiga jenis presisi yaitu presisi total ketepatan klasifikasi, spesifisitas, dan sensitifitas. Presisi total ketepatan klasifikasi adalah perbandingan jumlah spesifisitas dan sensitifitas terhadap banyaknya contoh. spesifisitas adalah kemampuan model dalam memprediksi nasabah tidak mengambil KPR maka diduga sebagai nasabah tidak mengambil KPR. Sensitifitas adalah kemampuan model dalam memprediksi nasabah pengambil KPR maka diduga sebagai nasabah pengambil KPR. Keakuratan klasifikasi diukur berdasarkan sensitifitas dan spesifisitas sehingga perlu dicari batasan dugaan peluang yang dapat memprediksi sensitifitas dan spesifisitas dengan baik.
METODE
Data
Data yang digunakan dalam penelitian ini merupakan data sekunder nasabah yang terdapat pada bank X pada tahun 2012. Total keseluruhan nasabah yang terambil menjadi sampel adalah 499.989, sebanyak 1442 digunakan untuk data
training (data untuk membangun model regresi logistik), dan sebanyak 744 digunakan untuk validasi. Peubah penjelas yang digunakan yaitu, jenis kelamin, status pekerjaan, status pernikahan, pendidikan, tanggungan, jenis pekerjaan, usia, dan pendapatan. Penjelasan pada setiap peubah dapat dilihat pada Lampiran 1, sedangkan peubah respon adalah status nasabah dalam pengambilan KPR, yakni mengambil KPR (1) dan tidak mengambil KPR (0).
Metode Analisis
Langkah-langkah metode penelitian :
9 2. Melakukan pembersihan data. Proses pembersihan data terhadap peubah pendapatan, mereduksi peubah penjelas yang digunakan dan menghilangkan observasi yang terdapat data hilang didalamnya. Pada peubah pendapatan terdapat banyak sekali nilai pendapatan suatu nasabah yang hanya sebesar 1, karena nilai tersebut tidak logis sehingga diperlukannya pembersihan data, selain itu data yang digunakan pada penelitian ini adalah nasabah yang besarnya pendapatan perbulan antara 2 juta rupiah hingga 25 juta rupiah. Pereduksian peubah penjelas dilakukan karena terdapat banyak sekali data hilang di dalam peubah-peubah penjelas tersebut.
3. Melakukan eksplorasi data untuk data keseluruhan, data training, dan data validasi.
4. Melakukan diskretisasi data training pada peubah penjelas yang memiliki skala numerik dengan metode chimerge dan metode dengan selang yang sama. Berdasarkan kedua proses diskretisasi tersebut dibangun 2 model. Model I adalah diskretisasi data numerik dengan metode chimerge dan model II merupakan diskretisasi data numerik dengan metode dengan selang yang sama.
5. Berdasarkan hasil diskretisasi dilakukan perhitungan nilai WOE untuk setiap kategori pada peubah penjelas yang berfungsi sebagai input untuk membangun model penskoran kredit.
6. Menghitung nilai Information Value (Inv) untuk memilih peubah penjelas hasil diskretisasi yang memiliki pengaruh besar terhadap peubah respon 7. Melihat peubah penjelas mana saja yang perlu dimasukan ke dalam model
berdasarkan nilai Inv.
8. Berdasarkan nilai WOE pada setiap peubah penjelas, digunakan untuk membangun model regresi logistik, untuk mengetahui faktor-faktor apa saja yang berpengaruh nyata terhadap respon.
9. Membandigkan model I dan model II dengan nilai tabel ketepatan klasifikasi berdasarkan data training dan data validasi.
10.Berdasarkan hasil nilai tabel ketepatan klasifikasi dipilih salah satu dari kedua model yang lebih baik untuk dilakukan perhitungan nilai kartu skor.
HASIL DAN PEMBAHASAN
Eksplorasi Data
10
sebanyak 71 nasabah. Sementara itu, penurunan suku bunga pinjaman yang dilakukan oleh BI Rate yaitu sebesar 5.750% sejak Februari 2012 berdampak pada penurunan suku bunga dasar kredit (SBDK) (Bangun 2012). Penurunan tersebut dilakukan oleh beberapa bank salah satunya adalah bank X. Bank X menurunkan suku bunga dasar kredit KPR namun hal ini tidak sejalan dengan bertambahnya nasabah yang mengambil KPR sehingga perlu diadakannya suatu upaya untuk meningkatkan kembali nasabah yang mengambil KPR. Salah satu caranya adalah dengan melihat faktor-faktor apa saja yang mempengaruhi suatu nasabah mengambil KPR.
Gambar 1 Jumlah nasabah kredit KPR (Januari-Agustus 2012)
Lampiran 2 menyajikan grafik untuk data keseluruhan, data training, dan data validasi. Pola sebaran data keseluruhan, data training, dan data validasi memiliki pola sebaran yang tidak jauh berbeda sehingga dapat dikatakan pengambilan contoh untuk data training dan data validasi dapat mempresentasikan data keseluruhan.
Lampiran 2 terlihat bahwa pada data awal untuk peubah jenis kelamin, nasabah pria lebih banyak mengambil KPR dibandingkan nasabah wanita. Sebanyak 12884 nasabah pria mengambil KPR dan nasabah wanita yang mengambil KPR sebanyak 4936. Pada peubah status pekerjaan, nasabah yang berstatus sebagai karyawan tetap lebih banyak mengambil KPR dibandingkan status lainnya sebanyak 15087, sedangkan nasabah yang berstatus karyawan honorer dan karyawan paruh waktu sedikit sekali yang mengambil KPR, masing masing hanya sebanyak 6 nasabah dan 4 nasabah saja. Pada peubah status pernikahan nasabah yang telah menikah memiliki jumlah terbanyak sebagai nasabah yang mengambil KPR maupun nasabah yang tidak mengambil KPR, masing-masing sebesar 14061 nasabah dan 359556 nasabah. Pada peubah pendidikan terlihat bahwa disetiap kategorinya lebih banyak nasabah yang tidak mengambil KPR dibandingkan nasabah yang mengambil KPR. Nasabah yang berpendidikan S1 adalah nasabah terbanyak yang mengambil KPR, ada sebanyak 9265 nasabah, namun nasabah terbanyak yang tidak mngambil KPR juga berada dikategori S1. Pada peubah tanggungan kategori nasabah yang tidak memiliki tanggungan adalah nasabah yang paling banyak mengambil KPR ada sebanyak
11 6413 nasabah, namun ada sebanyak 205290 nasabah tersebut yang tidak mengambil KPR. Jumlah tanggungan yang semakin besar mengindikasikan terjadinya penurunan jumlah nasabah yang mengambil KPR.
Deskripsi WOE Peubah Kontinu
Proses diskretisasi dilakukan terlebih dahulu sebelum melakukan deskripsi WOE pada peubah kontinu. Diskretisasi data menggunakan metode chimerge dan dengan selang yang sama dilakukan hanya pada peubah numerik saja yakni peubah pendapatan dan usia. Algoritma metode chimerge menggunakan statistik khi kuadrat untuk mendiskretisasi peubah numerik. Hipotesis nol dari metode
chimerge ini adalah dua selang yang berdekatan pada peubah penjelas saling bebas terhadap peubah respon. Selang yang berdekatan akan digabung jika hipotesis tersebut diterima. Kriteria penghentian algoritmanya dengan nilai maksimum interval observasi dalam kategori sebesar 20 dan taraf nyata yang digunakan sebesar 0.05, sedangkan diskretisasi dengan dengan selang yang sama adalah diskretisasi yang membagi jarak yang sama pada setiap kategori dalam satu peubah penjelas.
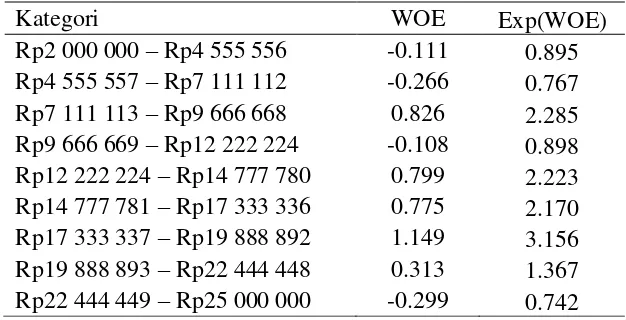
Peubah usia hasil diskretisasi menggunakan metode chimerge diperoleh 6 kategori, agar metode dengan selang yang sama memiliki jumlah kategori yang sama dengan chimerge maka diskretisasi metode dengan selang yang sama membagi 6 kategori dengan jarak yang sama disetiap kategorinya. Pada peubah pendapatan hasil diskretisasi menggunakan metode chimerge diperoleh 9 kategori dan pada metode dengan selang yang sama untuk peubah pendapatan menghasilkan 9 kategori dengan jarak yang sama disetiap kategeorinya.
12
Tabel 2 Diskretisasi chimerge peubah pendapatan
Kategori WOE Exp(WOE)
Tabel 3 Diskretisasi dengan selang yang samapeubah pendapatan
Kategori WOE Exp(WOE) nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 4.561 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama. Kategori dengan selang [Rp9 500 000 – Rp10 610 000] memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah yang tidak mengambil KPR 1.773 kali dibandingkan proporsi nasabah yang mengambil KPR dalam satu kategori yang sama. Berdasarkan Tabel 2 dapat diketahui bahwa selang [Rp15 459 600 - Rp19 500 000] memiliki proporsi nasabah yang mengambil KPR lebih banyak dibanding yang tidak mengambil KPR, sedangkan pada selang [Rp9 500 000 – Rp10 610 000] memiliki proporsi nasabah yang tidak mengambil KPR lebih banyak dibanding yang mengambil KPR.
13 nasabah yang mengambil KPR dengan yang tidak mengambil KPR tidak terlalu jauh berbeda.
Tabel 4 Diskretisasi chimerge peubah usia
Kategori WOE Exp(WOE)
22 – 29 Tahun -0.801 0.449 30 – 36 Tahun 0.223 1.250 37 – 43 Tahun 0.567 1.763 44 – 48 Tahun 0.092 1.097 49 – 57 Tahun -0.451 0.637 58 – 90 Tahun -3.029 0.048
Tabel 5 Diskretisasi dengan selang yang samapeubah usia
Kategori WOE Exp(WOE)
22 – 33 Tahun -0.198 0.820
34 – 44 Tahun 0.473 1.605
45 – 55 Tahun -0.132 0.877 56 – 66 Tahun -1.988 0.137 67 – 77 Tahun -3.488 0.031 78 – 90 Tahun -0.849 0.428
Tabel 4 nasabah yang berkategori [37 – 43 Tahun] memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 1.763 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama.
Tabel 5 nasabah yang berkategori [34 – 44 Tahun] memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 1.605 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama.
Deskripsi WOE Peubah Kategorik
Peubah penjelas bertipe kategori pada data bank X ini tidak dilakukan proses diskretisasi. Hasil nilai WOE peubah penjelas jenis kelamin, status pekerjaan, status pernikahan, pendidikan, jumlah tanggungan, dan jenis pekerjaan. Disajikan pada Tabel 6 sampai 10 dan Lampiran 3.
Tabel 6 Nilai WOE peubah jenis kelamin Kategori WOE Exp(WOE) Wanita -0.573 0.564
Pria 0.350 1.419
14
KPR 1.419 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama. Kategori wanita memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah yang tidak mengambil KPR 1.773 kali dibandingkan proporsi nasabah yang mengambil KPR dalam satu kategori yang sama.
Tabel 7 Nilai WOE peubah status pekerjaan
Kategori WOE Exp(WOE)
Karyawan Honorer -0.842 0.431 Karyawan Kontrak -1.153 0.316 Karyawan Paruh Waktu -1.403 0.246
Karyawan Tetap 0.343 1.409
Tidak Diketahui -1.953 0.142
Wiraswasta -1.888 0.151
Berdasarkan Tabel 7 kategori nasabah yang berstatus karyawan tetap memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 1.409 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama. Kategori nasabah yang status kerjanya tidak diketahui memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah yang tidak mengambil KPR 7.042 kali dibandingkan proporsi nasabah yang mengambil KPR dalam satu kategori yang sama. Berdasarkan Tabel 7 dapat diketahui bahwa kategori karyawan tetap memiliki proporsi nasabah yang mengambil KPR tidak jauh berbeda dengan proporsi yang tidak mengambil KPR, sedangkan kategori tidak diketahui memiliki perbedaan proporsi yang cukup besar antara nasabah yang tidak mengambil KPR dengan nasabah yang mengambil KPR.
Tabel 8 Nilai WOE peubah status pernikahan
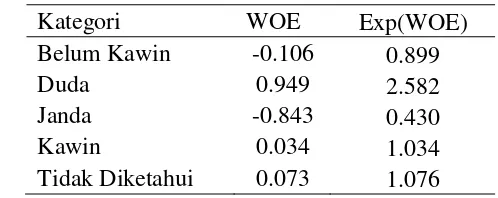
Kategori WOE Exp(WOE)
Belum Kawin -0.106 0.899
Duda 0.949 2.582
Janda -0.843 0.430
Kawin 0.034 1.034
Tidak Diketahui 0.073 1.076
15 Tabel 9 Nilai WOE peubah pendidikan terakhir
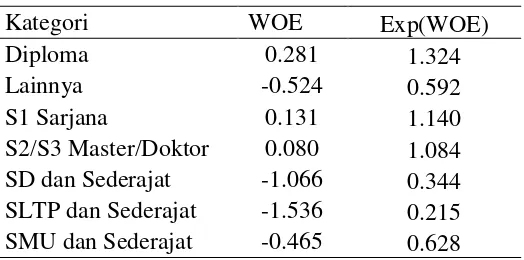
Kategori WOE Exp(WOE)
Diploma 0.281 1.324
Lainnya -0.524 0.592
S1 Sarjana 0.131 1.140
S2/S3 Master/Doktor 0.080 1.084 SD dan Sederajat -1.066 0.344 SLTP dan Sederajat -1.536 0.215 SMU dan Sederajat -0.465 0.628
Berdasarkan Tabel 9 kategori nasabah yang berpendidikan S1 Sarjana memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 1.140 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama. Kategori nasabah yang pendidikannya SLTP dan Sederajat memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah yang tidak mengambil KPR 4.651 kali dibandingkan proporsi nasabah yang mengambil KPR dalam satu kategori yang sama. Berdasarkan Tabel 9 dapat diketahui bahwa kategori S1 Sarjana memiliki proporsi nasabah yang mengambil KPR yang tidak jauh berbeda dengan yang tidak mengambil KPR, sedangkan kategori SLTP dan Sederajat memiliki perbedaan proporsi yang cukup besar antara nasabah yang tidak mengambil KPR dengan nasabah yang mengambil KPR.
Tabel 10 Nilai WOE peubah Tanggungan
Kategori WOE Exp(WOE)
Tanggungan 1 Orang 0.531 1.701 Tanggungan 2 Orang 0.153 1.166 Tanggungan 3 Orang -0.105 0.901 Tanggungan 4 Orang -0.473 0.623 Tanggungan lebih 4 orang -0.487 0.615 Tidak Punya Tanggungan -0.160 0.852
Tidak Diketahui -0.797 0.451
Tabel 10 kategori nasabah yang memiliki tanggungan 1 orang memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah pengambil KPR 1.701 kali dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama. Kategori nasabah yang jumlah tanggungannya tidak diketahui memiliki nilai dari exp(WOE) yang dapat diinterpretasikan bahwa kategori tersebut memiliki proporsi nasabah yang tidak mengambil KPR 2.217 kali dibandingkan proporsi nasabah yang mengambil KPR dalam satu kategori yang sama.
16
dibandingkan proporsi nasabah yang tidak mengambil KPR dalam satu kategori yang sama.
Information Value
Information value (Inv) digunakan untuk mengukur asosiasi setiap peubah penjelas terhadap peubah respon. Inv umum digunakan untuk menyeleksi peubah penjelas yang berpotensi untuk dimasukan kedalam model dengan nilai batas sebesar 0.02. Berdasarkan SAS Institute Inc (2012) jika nilai Inv kurang dari 0.02 maka peubah dikatakan tidak prediktif sehingga peubah tersebut tidak dimasukan kedalam model. Pada Tabel 11 dan 12 merupakan urutan nilai Inv dari terbesar hingga terkecil dengan metode chimerge dan dengan selang yang sama secara berurutan.
Tabel 11 Nilai Inv didiskretisasi chimerge
Peubah Penjelas Inv
nilai information value kurang dari 0.02
Tabel 12 Nilai Inv didiskretisasi dengan selang yang sama
Peubah Penjelas Inv
nilai information value kurang dari 0.02
17 keduanya memiliki tingkat prediksi yang kuat. Berdasarkan Tabel 11 dan 12 peubah penjelas yang nilai Inv kurang dari 0.02 adalah peubah status pernikahan, sehingga peubah status tidak dimasukkan kedalam model regresi logistik.
Analisis Regresi Logistik
Analisis regresi logistik menggunakan tujuh peubah penjelas, yakni jenis kelamin, status pekerjaan, pendidikan, tanggungan, jenis pekerjaan, usia, dan pendapatan. Peubah respon yang digunakan adalah nasabah yang mengambil KPR, disimbolkan dengan 1 dan nasabah yang tidak mengambill KPR disimbolkan dengan 0. Model regresi logistik biner digunakan untuk menduga besarnya peluang kejadian tertentu dari kategori peubah respon.
Statistik uji G digunakan untuk melihat hubungan keseluruhan peubah penjelas terhadap respon secara bersama-sama. Pada Tabel 13 disajikan nilai statistik uji G untuk model I (didiskretisasi dengan metode chimerge) dan model II (didiskretisasi dengan metode dengan selang yang sama).
Tabel 13 Nilai statistik uji G dan nilai-P
Model I Model II
Statistik-G 483.269 462.913
Nilai-P 0.000 0.000
Statistik uji G pada kedua model menunjukkan hasil yang signifikan karena nilai-P (0.000) lebih kecil dari α = 0.05. Hal ini menunjukkan bahwa minimal ada satu peubah penjelas yang signifikan terhadap model baik pada model I maupun model II. Setelah peubah penjelas diuji secara simultan dengan uji G. kemudian peubah penjelas diuji secara parsial dengan uji Wald. Nilai-P dari uji Wald dan dugaan koefsisien parameter disajikan pada Tabel 14.
Tabel 14 Nilai-P uji Wald dan dugaan koefisien parameter
18
x =1 expexp
Model logit untuk model II sebagai berikut :
Nilai dugaan koefisien parameter setiap peubah penjelas nantinya akan digunakan untuk menghitung skor pada kartu skor di setiap kategori-kategori peubah penjelas.
Perbandingan Model
Setelah pembuatan model yang dibangun dengan diskretisasi metode
chimerge dan metode dengan selang yang sama, kemudian perlu dilihat seberapa baik kedua model tersebut dalam memprediksi. Alat statistik yang dapat digunakan untuk melihat kebaikan model antara lain tabel ketepatan klasifikasi, kurva ROC, c-statistik, Kolmogorov-Smirnov, dan lain sebagainya. Pada penelitian ini tabel ketepatan klasifikasi digunakan untuk melihat kebaikan model. Tabel ketepatan klasifikasidigunakan untuk melihat ketepatan suatu model dalam memprediksi. Tabel 15 merupakan tabel ketepatan klasifikasiuntuk model I dan model II.
Tabel 15 Tabel ketepatan klasifikasidata training
Amatan Prediksi (%) Ketepatan
Tidak Ya
Model I Tidak 399 268 59.820
Ya 99 676 87.225
Totalketepatan klasifikasi 74.549
Model II Tidak 396 271 59.370
Ya 103 672 86.709
Totalketepatan klasifikasi 74.063
Tabel 16 Tabel ketepatan klasifikasidata validasi
Amatan Prediksi (%) Ketepatan
Tidak Ya
Model I Tidak 248 123 66.846
Ya 75 298 79.892
Totalketepatan klasifikasi 73.387
Model II Tidak 256 115 69.002
Ya 103 270 72.386
19 Tabel ketepatan klasifikasi merupakan tabel frekuensi dua arah antara nilai amatan dengan nilai prediksi. Model dengan nilai total ketepatan klasifikasi yang mendekati 100% merupakan model yang baik. Pada Tabel 15 dengan data
training, untuk model I memiliki nilai spesifisitas sebesar 59.820% dapat diinterpretasikan sebagai sebesar 59.820% nasabah yang tidak mengambil KPR diprediksi secara tepat sebagai nasabah yang tidak mengambil KPR, nilai sensitifitas sebesar 87.225% mengindikasikan bahwa sebesar 87.225% nasabah yang mengambil KPR diprediksi secara tepat sebagai nasabah yang mengambil KPR, dan nilai total ketepatan klasifikasi sebesar 74.549% mengindikasikan bahwa secara keseluruhan sebanyak 74.549% nasabah yang tidak mengambil KPR dan yang mengambil KPR diprediksi secara tepat, nilai tersebut cukup baik untuk memprediksi suatu data. Pada model II memiliki nilai spesifisitas sebesar 59.4%, nilai sensitifitas sebesar 86.709%, dan nilai total ketepatan klasifikasi sebesar 74.063%. Berdasarkan tabel ketepatan klasifikasi, model I memprediksi lebih baik dibandingkan model II karena memiliki nilai total ketepatan klasifikasi yang lebih besar.
Tabel 16 menggunakan data validasi, nilai batas yang digunakan untuk dugaan peluang sebesar 0.55, artinya nasabah dengan peluang lebih besar dari 0.55 diklasifikasikan sebagai nasabah yang mengambil KPR, sedangkan nasabah dengan nilai dugaan peluang kurang dari 0.55 diklasifikasikan sebagai nasabah yang tidak mengambil KPR. Pemilihan batas dugaan peluang sebesar 0.55 dikarenakan memiliki nilai spesifisitas dan sensitifitas yang lebih baik dibandingkan batasan lainnya, selain itu batasan tersebut memiliki nilai total ketepatan klasifikasi yang cukup baik. Model I memiliki nilai total ketepatan klasifikasi sebesar 73.387%, sedangkan model II memiliki nilai total ketepatan klasifikasi sebesar 70.698%. Berdasarkan tabel ketepatan klasifikasi. Model I lebih baik dibandingkan model II, baik menggunakan data training maupun data validasi.
Ilustrasi Penilaian Kredit
Model regresi logistik yang diperoleh sebenarnya dapat digunakan untuk menghasilkan skor. Skor yang dihasilkan berupa nilai peluang seorang nasabah untuk mengambil KPR atau nasabah yang tidak mengambil KPR dengan nilai diatara 0 sampai 1. Skor tersebut diperoleh dengan memasukkan nilai-nilai peubah penjelas ke dalam model regresi logistik. Apabila bank menggunakan peluang yang ada pada regresi logistik untuk menilai skor nasabah, hal tersebut kurang efektif, karena dapat memakan waktu yang lama sehingga dibuatlah kartu skor. Kartu skor berguna untuk memberikan kemudahan bagi bank untuk memilih kriteria nasabahnya. Manfaat lain dari kartuskoradalah mengurangi waktu proses pengerjaan aplikasi kredit.
Contoh perhitungan nilai skor untuk kategori pria pada peubah penjelas jenis kelamin dirumuskan sebagai berikut :
j i an factor offsetn
Diketahui nilai WOEj untuk pria adalah 0.350, nilai dugaan koefisien
20
penjelas (n) adalah 7, dan nilai factor dan offset berdasarkan hasil perhitungan pada halaman 7 masing masing sebesar 28.853 dan 487.123 maka diperoleh :
0.350 0.534 0.094 7 28.853 487.1237 =75
Lampiran 4 menyajikan kartu skor untuk model I. Pembuatan kartu skor dibangun menggunakan model I dikarenakan nilai total ketepatan klasifikasi yang lebih besar dibandingkan model II. Hasil dari kartu skor berupa skor-skor yang ada pada setiap kategori peubah penjelas. Berdasarkan Lampiran 4 nasabah akan memiliki skor maksimum jika nasabah tersebut pria, bekerja sebagai karyawan tetap, berpendidikan diploma, memiliki jumlah tanggungan 1 orang, berprofesi sebagai polisi, usia diantara 37-43 tahun, dan berpenghasilan sekitar 15 juta sampai 19 juta perbulannya. Pada penelitian ini peneliti tidak menentukan besar batas nilai pada kartu skor. Hal ini disebabkan karena penentuan batasan nilai ditentukan oleh besarnya keuntungan dan kerugian yang hanya diketahui oleh pihak bank. Lampiran 5 adalah contoh simulasi penerapan kartu skor.
Berdasarkan Lampiran 5 nasabah dengan jenis kelamin pria, memiliki status pekerjaan sebagai karyawan tetap, berpendidikan S1, memiliki tanggungan 1 orang, berprofesi sebagi polisi, usia di antara 37-43 tahun dan berpendapatan Rp6 042 100 – Rp9 450 000 akan memiliki total skor sebesar 567. Apabila nasabah tersebut dihitung peluangnya dengan model regresi logistik sebagai berikut :
x = exp 0 1x1 pxp 1 exp 0 1x1 pxp
x =1 exp 0.094 0.534 0.530 0.529 0.782 exp 0.094 0.534 0.530 0.529 0.782
nilai dugaan peluang hasil regresi logistik sebesar 0.941 jika batas dugaan peluang yang digunakan sebesar 0.55 maka nasabah tersebut diklasifikasikan sebagai nasabah yang akan mengambil KPR. Hasil dugaan peluang nasabah tersebut yang mendekati 1 sesuai dengan perhitungan skor yang ada pada kartu skor, karena skor pada nasabah tersebut merupakan skor dengan nilai nilai tertinggi, kecuali untuk skor kategori Rp6 042 100 – Rp9 450 000 pada peubah pendapatan.
SIMPULAN DAN SARAN
Simpulan
21 lebih besar nilainya baik menggunakan data training maupun data validasi sehingga pembuatan kartu skordibangun berdasarkan model I.
Saran
Validasi model yang dapat digunakan pada penelitian selanjutnya untuk memperkuat ketepatan prediksi model adalah kurva ROC, c-statistik, Kolmogorov-Smirnov (KS), dan lain sebagainya.
DAFTAR PUSTAKA
Agresti A. 2002. An Introduction To Categorical Data Analysis. New York (US) : John Willey and Sons.
Bangun AK. 2012 Apr 13. Suku Bunga Bank Turun. Kompas. Bisnis dan
Keuangan [Internet]. Tersedia pada:
http://www.bisniskeuangan.kompas.com/read/2012/04/13/11252110/Suku.Bu nga.Bank.Turun
Han J, Kember M. 2006. Data Mining : Concepts And Techniques. San Francisco (US) : Diane Cerra.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regresion. New York (US) : John Wiley and Sons.
Kantardzic M. 2003. Data Mining Concepts, Models, Methods, And Algorithms.
New York (US) : IEEE and Wiley Inter-Science.
Koh HC, Tan WC, Goh CP. 2006. A Two Step Method To Construct Credit Scoring Models With Data Mining Techniques. Internasional Journal Of Business and Information, 1 : 96-118
Kotsiantis S, Kanellopoulos D. 2006. Discretization Techniques : A recent survey.
International Transactions On Computer Science and Engineering, Vol.32(1) : 47-58
’Connell, nn . 2006. Logistic Regression Model For Ordinal Response Variables. India (IN) : Sage Publication Inc.
SAS Institute Inc. 2012. Developing Credit Scorecards Using Credit Scoring for SAS Enterprise Miner 12.1. Cary. North Carolina (US) : SAS Institute Inc. SAS Institute Inc. 2012. SAS/STAT 9.2 User’s Guide The Logistic Procedure
(Book Excerpt). Cary. North Carolina (US) : SAS Institute Inc.
Siddiqi N.2006. Credit Risk Scorecard Developing and Implementing Intelligent Credit Scoring. New Jersey (US) : John Willey & Sons.
Stephanie V,2008. Diskretisasi Peubah Menggunakan Metode Entropy dan
Chimerge pada Data Kredit Ritel [skripsi]. Bogor (ID): Institut Pertanian Bogor.
22
Lampiran 1 Daftar peubah penjelas dan keterangannya No
.
Peubah Keterangan
1 Jenis kelamin Digolongkan menjadi, pria dan wanita.
2 Status pekerjaan Digolongkan menjadi, karyawan honorer, karyawan kontrak, karyawan paruh waktu, karyawan tetap, wiraswasta, dan tidak diketahui.
3 Status pernikahan Digolongkan menjadi, kawin, belum kawin, duda, janda, dan tidak diketahui
4 Pendidikan Digolongkan menjadi, diploma, S1 sarjana, S2/S3 master/doktor, SD dan sederajat, SMU dan sederajat 5 Tanggungan Digolongkan menjadi, tanggungan
1 orang, tanggungan 2 orang, tanggungan 3 orang, tanggungan 4 orang, tanggungan lebih dari 4 orang, tidak punya tanggungan, dan tidak diketahui.
6 Jenis pekerjaan Digolongkan menjadi, dokter, enginer/teknisi. Guru/dosen. Ibu rumah tangga, konsultan, mahasiswa/pelajar, militer (AU,AD,AL,PM), notaris,
paramedis, pegawai
BUMN/BUMD, pegawai negeri sipil, pegawai swasta, pegawai yayasan, pejabat negara, pekerja sosial/LSM, pengacara, polisi, profesional, wiraswasta, dan lainnya
7 Usia Umur nasabah
23 Lampiran 2 Distribusi grafik nasabah
24
Lampiran 2 Distribusi grafik nasabah 2. Status Pekerjaan
2.1 Data Keseluruhan
2.2 Data training
0 200 400 600 800
Non KPR KPR
Fre
k
u
ens
i
Jenis Nasabah
Karyawan Honorer Karyawan Kontrak Karyawan Paruh Waktu
Karyawan Tetap Tidak Diketahui Wirswasta
0 50000 100000 150000 200000 250000
Non KPR KPR
F
re
k
uens
i
Jenis Nasabah
Karyawan Honorer Karyawan Kontrak Karyawan Paruh Waktu
25
Lampiran 2 Distribusi grafik nasabah
2.3 Data Validasi
3. Status perkawinan
3.1 Data Keseluruhan 0
100 200 300 400
Non KPR KPR
F
re
k
uens
i
Jenis Nasabah
Karyawan Honorer Karyawan Kontrak Karyawan Paruh Waktu
Karyawan Tetap Tidak Diketahui Wirswasta
0 50000 100000 150000 200000 250000 300000 350000 400000
Non KPR KPR
F
re
k
uens
i
Jenis Nasabah
26
Lampiran 2 Distribusi grafik nasabah
3.2 Data training
3.3 Data validasi 0 100 200 300 400 500 600 700
Non KPR KPR
F
re
k
uens
i
Jenis Nasabah
Belum Kawin Duda Janda Kawin Tidak Diketahui
0 50 100 150 200 250 300 350
Non KPR KPR
F
re
k
uens
i
Jenis Nasabah
27 Lampiran 2 Distribusi grafik nasabah
4. Pendidikan
S2/S3 Master/Doktor SD dan Sederajat SLTP dan Sederajat
SMU dan Sederajat
S2/S3 Master/Doktor SD dan Sederajat SLTP dan Sederajat
28
Lampiran 2 Distribusi grafik nasabah
4.3 Data validasi
5. Tanggungan
5.1 Data Keseluruhan 0
50 100 150 200 250
Non KPR KPR
F
r
e
k
uensi
Jenis Nasabah
Diploma Lainnya S1 Sarjana
S2/S3 Master/Doktor SLTP dan Sederajat SMU dan Sederajat
0 50000 100000 150000 200000 250000
Non KPR KPR
Fre
k
u
ens
i
Jenis Nasabah
Tanggungan 1 Orang Tanggungan 2 Orang Tanggungan 3 Orang
Tanggungan 4 Orang Tanggungan lbh 4 org Tdk Punya Tanggungan
29
Lampiran 2 Distribusi grafik nasabah
5.2 Data training
Tanggungan 1 Orang Tanggungan 2 Orang Tanggungan 3 Orang
Tanggungan 4 Orang Tanggungan lbh 4 org Tdk Punya Tanggungan
Tidak Diketahui
Tanggungan 1 Orang Tanggungan 2 Orang Tanggungan 3 Orang
Tanggungan 4 Orang Tanggungan lbh 4 org Tdk Punya Tanggungan
30
Lampiran 3 Nilai WOE peubah jenis pekerjaan
Kategori WOE Exp(WOE)
Dokter -0.843 0.430
Enginer/Teknisi 0.949 2.582
Guru/Dosen 1.459 4.303
Ibu Rumah Tangga -2.011 0.134
Konsultan -0.843 0.430
Lainnya -1.482 0.227
Mahasiswa / Pelajar -2.347 0.096
Militer (AU,AD,AL,PM) -1.942 0.143
Notaris -1.942 0.143
Paramedis -1.249 0.287
Pegawai BUMN / BUMD 0.469 1.598
Pegawai Negeri Sipil 0.452 1.572
Pegawai Swasta 0.560 1.751
Pegawai Yayasan -2.096 0.123
Pejabat Negara -1.249 0.287
Pekerja Sosial / LSM -1.066 0.344
Pengacara -1.536 0.215
Polisi 1.642 5.164
Professional -2.176 0.113
31 Lampiran 4 Hasil kartu skor pada model II
Peubah Penjelas Kategori Skor
Jenis kelamin Wanita 61
Pria 75
Status pekerjaan
Karyawan Honorer 58
Karyawan Kontrak 54
Karyawan Paruh Waktu 50
Karyawan Tetap 75
Tidak Diketahui 43
Wiraswasta 44
Pendidikan
SD dan Sederajat 56
SLTP dan Sederajat 50
SMU dan Sederajat 64
Diploma 74
S1 Sarjana 72
S2/S3 Master/Doktor 71
Lainnya 63
Tanggungan
Tidak Punya Tanggungan 67
Tanggungan 1 Orang 81
Tanggungan 2 Orang 73
Tanggungan 3 Orang 68
Tanggungan 4 Orang 60
Tanggungan lebih 4 orang 60
32
Lampiran 4 Hasil kartu skor pada model II
Peubah Penjelas Kategori Skor
Jenis Pekerjaan
Mahasiswa / Pelajar 26
Militer (AU,AD,AL,PM) 34
Notaris 34
Paramedis 47
Pegawai BUMN / BUMD 79
Pegawai Negeri Sipil 78
Pegawai swasta 80
Pegawai yayasan 30
Pejabat negara 47
Pekerja sosial /LSM 50
33 Lampiran 5 Simulasi skor calon nasabah
Peubah
Skor Nasabah
Nasabah ke-1 Skor Nasabah ke-2 Skor Nasabah ke-3 Skor Jenis
Kelamin Pria 75 Pria 75 Wanita 61
Status Pekerjaan
Karyawan
Tetap 75
Karyawan
Honorer 58 Wiraswasta 44 Pendidikan S1 Sarjana 72 Diploma 74 SMU dan
Sederajat 64 Tanggungan Tanggungan 1
orang 81
Tanggungan 2
orang 73
Tanggungan 4
orang 60
Jenis
Pekerjaan Polisi 101
Pegawai
Swasta 80
Ibu Rumah
Tangga 32
Usia 37 - 43 81 30 - 36 74 49 - 57 61
Pendapatan Rp6 042 100 -Rp9 450 000 82
Rp4 875 000 - Rp6 000 000 61
Rp2 000 000 - Rp3 700 000 65
34
RIWAYAT HIDUP
Penulis dilahirkan di DKI Jakarta pada tanggal 19 Januari 1992 dari ayah Sukirman dan ibu Nurwidiasari. Penulis adalah anak kedua dari tiga bersaudara. Penulis semenjak kecil tinggal di DKI Jakarta dan sebelum memasuki perguruan tinggi di IPB, penulis berhasil menyelesaikan pendidikan di SMAN 34 Jakarta Selatan pada tahun 2010, SMPN 41 Jakarta Selatan tahun 2007. SDN 03 Pagi Kebagusan Jakarta Selatan tahun 2004, dan TK Fatahillah. Penulis memasuki perguruan tinggi pada tahun 2010 di Institut Pertanian Bogor melalui jalur SMPTN dengan memilih mayor Statistika di Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA).