KLASIFIKASI KEPUTUSAN NASABAH DALAM PENGAMBILAN KREDIT
MENGGUNAKAN MODEL REGRESI LOGISTIK BINER
DAN METODE CLASSIFICATION AND REGRESSION TREES (CART)
(Studi Kasus pada Nasabah bank bjb Cabang Utama Bandung)
SKRIPSI
Diajukan untuk Memenuhi Sebagian dari Syarat untuk Memperoleh Gelar Sarjana Sains
Program Studi Matematika Konsentrasi Statistika
Oleh
YUNI MELAWATI 0900138
JURUSAN PENDIDIKAN MATEMATIKA
FAKULTAS PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS PENDIDIKAN INDONESIA
KLASIFIKASI KEPUTUSAN NASABAH DALAM PENGAMBILAN KREDIT
MENGGUNAKAN MODEL REGRESI LOGISTIK BINER
DAN METODE CLASSIFICATION AND REGRESSION TREES (CART)
(Studi Kasus pada Nasabah bank bjb Cabang Utama Bandung)
Oleh Yuni Melawati
Sebuah skripsi yang diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana pada Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
© Yuni Melawati 2013 Universitas Pendidikan Indonesia
Oktober 2013
Hak Cipta dilindungi undang-undang.
YUNI MELAWATI
KLASIFIKASI KEPUTUSAN NASABAH DALAM PENGAMBILAN KREDIT
MENGGUNAKAN MODEL REGRESI LOGISTIK BINER
DAN METODE CLASSIFICATION AND REGRESSION TREES (CART)
(Studi Kasus pada Nasabah bank bjb Cabang Utama Bandung)
DISETUJUI DAN DISAHKAN OLEH
PEMBIMBING:
Pembimbing I
Drs. Nar Herrhyanto, M.Pd. NIP. 196106181987031001
Pembimbing II
Dr. Bambang Avip P., M.Si. NIP. 196412051990031001
Mengetahui,
Ketua Jurusan Pendidikan Matematika
KLASIFIKASI KEPUTUSAN NASABAH DALAM PENGAMBILAN KREDIT MENGGUNAKAN MODEL REGRESI LOGISTIK BINER
DAN METODE CLASSIFICATION AND REGRESSION TREES (CART) (Studi Kasus pada Nasabah bank bjb Cabang Utama Bandung)
ABSTRAK
Kredit merupakan salah satu fasilitas bank yang sangat diminati oleh kalangan masyarakat pada zaman sekarang. Banyak faktor yang berpengaruh terhadap keputusan nasabah dalam pengambilan kredit. Pada penelitian ini dilakukan klasifikasi keputusan nasabah dalam pengambilan kredit menggunakan model Regresi Logistik Biner dan Metode Classification and Regression Trees (CART) untuk melihat karakteristik dan faktor-faktor yang paling berpengaruh terhadap keputusan nasabah dalam pengambilan kredit di bank bjb Cabang Utama Bandung. Keputusan nasabah dalam mengambil kredit dibagi menjadi dua kategori yaitu diambil dan tidak diambil. Variabel prediktor yang digunakan dalam dalam penelitian ini sebanyak 13 buah. Dari hasil Regresi Logistik Biner, variabel prediktor yang berpengaruh secara signifikan terhadap keputusan nasabah dalam pengambilan kredit adalah variabel usia, pendidikan, informasi kredit dan prosedur kredit. Model Regresi Logistik Biner menghasilkan nilai ketepatan klasifikasi sebesar 72,8%. Metode pohon klasifikasi CART dalam penelitian ini menghasilkan pohon optimum dengan dua simpul terminal. Variabel prediktor yang masuk kedalam pohon klasifikasi adalah variabel prosedur kredit. Metode pohon klasifikasi CART menghasilkan nilai ketepatan klasifikasi sebesar 66,8%. Nilai ketepatan klasifikasi untuk hasil dari Model Regresi Logistik Biner lebih tinggi daripada nilai ketepatan klasifikasi dari Metode Pohon Klasifikasi CART, artinya Model Regresi Logistik Biner lebih cocok digunakan untuk kasus klasifikasi keputusan nasabah dalam pengambilan kredit.
CLASSIFICATION IN DECISION MAKING CUSTOMERS CREDIT USING BINARY LOGISTIC REGRESSION MODEL
AND CLASSIFICATION AND REGRESSION TREES METHOD (CART) (Case Study on the Customers of Main Branch Bank bjb Bandung)
ABSTRACT
Credit is one of the bank facility that is in demand by the public today. Many factors that influence customers in making credit decision at this moment. In this research, the classification of the customer in making credit decision using Binary Logistic Regression Model and Method of Classification and Regression Trees (CART) to look at the characteristics and the factors as that most influencing factors of the client’s decision for taking credit at bjb Main Branch bank Bandung. Customer's decision to take the credit is divided into two categories namely taken and not taken. Predictor variables used in this study are 13 pieces. From the Binary Logistic Regression outcome, predictor variables that significantly influence the customer's decision-making credit is variable age, education, credit information and credit procedures. Binary logistic regression model obtains 72,8% as the value of classification accuracy. CART classification tree method in this study produces optimum tree with two terminal nodes. Predictor variable that were into this classification tree is the credit procedures variable. CART classification tree method produces value of classification accuracy as 66.8%. Classification accuracy values for the results of the binary logistic regression model is higher than the value of the classification accuracy of CART classification tree method, it means that a Binary Logistic Regression model is more suitable for the case of classification of customers in making credit decisions.
PPDAFTAR GAMBAR
Gambar Halaman
2.1 Contoh Pohon Keputusan untuk Mengklasifikasikan Pembelian
Komputer ... 19
3.1 Diagram CART ... 29
3.2 Pohon Keputusan Sementara ... 37
3.3 Pohon Keputusan Optimum ... 38
3.4 Pohon Klasifikasi Optimum dari Contoh Kasus ... 39
DAFTAR TABEL
Tabel Halaman
4.1 Faktor-faktor Keputusan Nasabah dalam Mengambil Kredit ... 41
4.2 Keputusan Pengambilan Kredit ... 44
4.3 Case Procesing Summary Crosstab ... 44
4.4 Keputusan Pengambilan Kredit * Jenis Kelamin Crosstabulation ... 46
4.5 Keputusan Pengambilan Kredit * Usia Crosstabulation ... 47
4.6 Keputusan Pengambilan Kredit * Pendidikan Crosstabulation ... 48
4.7 Keputusan Pengambilan Kredit * Pekerjaan Crosstabulation ... 49
4.8 Keputusan Pengambilan Kredit * Pendapatan Crosstabulation .. 50
4.9 Keputusan Pengambilan Kredit * Banyak Tanggungan Crosstabulation ... 51
4.10 Keputusan Pengambilan Kredit * Kualitas Pelayanan Crosstabulation ... 52
4.11 Keputusan Pengambilan Kredit * Persyaratan Kredit Crosstabulation ... 53
4.12 Keputusan Pengambilan Kredit * Informasi Kredit Crosstabulation ... 54
4.13 Keputusan Pengambilan Kredit * Tingkat Suku Bunga Crosstabulation ... 55
4.14 Keputusan Pengambilan Kredit * Jaminan Crosstabulation ... 56
4.15 Keputusan Pengambilan Kredit * Lokasi Bank Crosstabulation ... 57
4.16 Keputusan Pengambilan Kredit * Prosedur Kredit Crosstabulation ... 58
4.17 Case Processing Summary Regresi Logistik Biner ... 59
4.18 Dependent Variable Encoding ... 59
4.19 Iteration History ... 60
4.20 Variables in the Equation ... 61
4.21 Classification Table Regresi Logistik Biner ... 69
DAFTAR ISI
Halaman
LEMBAR PERNYATAAN ... i
ABSTRAK ... ii
KATA PENGANTAR ... iii
UCAPAN TERIMAKASIH ... iv
DAFTAR ISI ... v
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... ix
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Penelitian ... 1
1.2 Rumusan Masalah ... 2
1.3Batasan Masalah ... 3
1.4 Tujuan Penelitian ... 3
1.5 Manfaat Penelitian ... 3
BAB II KAJIAN PUSTAKA ... 4
2.1 Definisi Bank ... 4
2.2 Kredit Bank ... 5
2.3 Arti dan Jenis Data ... 5
a. Arti Data ... 5
b. Jenis Data ... 6
1. Data Kualitatif ... 6
2. Data kuantitatif ... 6
2.4 Jenis Skala Pengukuran ... 6
1. Skala Nominal ... 6
2. Skala Ordinal ... 7
3. Skala Interval ... 7
4. Skala Rasio ... 8
2.5 Teknik dan Pengumpulan Data ... 10
1. Angket (Questionnaire) ... 10
2. Wawancara ... 10
3. Pengamatan (Observation) ... 11
4. Tes (test) ... 11
2.6 Populasi dan Sampel ... 11
2.6.1 Penentuan Ukuran Sampel ... 12
2.6.2 Teknik Sampling ... 12
2.7 Regresi Logistik ... 15
2.7.1 Asumsi Regresi Logistik ... 15
2.7.2 Jenis-jenis Regresi Logistik ... 16
2.8 Classification and Regression Trees ... 16
2.8.1 Data Mining ... 16
2.8.2 Klasifikasi ... 17
2.8.3 Decision Tree (Pohon Keputusan) ... 18
2.8.4 Binary Recursive Partitioning ... 20
BAB III REGRESI LOGISTIK BINER DAN CLASSIFICATION AND REGRESSION TREES (CART) ... 21
3.1 Regresi Logistik Biner ... 21
3.2 Penaksiran Parameter ... 23
3.3 Uji Signifikansi Parameter ... 26
3.4 Classification and Regression Trees (CART) ... 28
3.5 Langkah-langkah Algoritma Pohon Klasifikasi CART ... 30
1. Pemilihan Pemilah ... 31
2. Penentuan Simpul Terminal ... 32
3. Penandaan Label Kelas ... 32
4. Penentuan Pohon Klasifikasi Optimal ... 32
3.6 Contoh Kasus Pembentukan Pohon Keputusan dengan Algoritma CART ... 34
BAB IV HASIL PENELITIAN DAN PEMBAHASAN ... 40
4.1 Gambaran Umum Objek Penelitian... 40
4.2 Variabel Penelitian ... 41
4.3 Penentuan Ukuran Sampel Kuesioner Penelitian ... 43
4.4 Penyebaran Angket (Questionnaire) Penelitian ... 43
4.5 Pengolahan Data ... 43
4.5.1 Deskripsi Karakteristik Keputusan Nasabah dalam Mengambil Kredit ... 43
4.5.2 Model Regresi Logistik Biner ... 59
4.5.3 Metode Classification and Regression Trees (CART) ... 70
BAB V KESIMPULAN DAN SARAN ... 72
5.1 Kesimpulan ... 72
5.2 Saran ... 72
DAFTAR PUSTAKA ... 73
LAMPIRAN ... 76
1
BAB I
PENDAHULUAN
1.1 Latar Belakang Penelitian
Semua orang atau perusahaan pasti memiliki kebutuhan. Kebutuhan ada yang bersifat mendesak dan ada yang tidak. Kebutuhan yang mendesak menuntut untuk segera dipenuhui, namun pemenuhan tersebut tidak terlepas dari masalah biaya atau dana. Dana yang diperlukan biasanya tidak sedikit jumlahnya, sementara dana yang tersedia seringkali tidak mencukupi.
Untuk dapat mencari dana dalam jumlah yang tergolong cukup besar tidak gampang apalagi dengan cara menggali dana sendiri dalam waktu yang singkat. Kebanyakan orang maupun perusahaan dalam menghadapi kekurangan dana, salah satu jalan keluar yang dapat dilakukan adalah dengan berhutang kepada pihak lain (kredit). Dengan kata lain, meminjam dana dulu pada kreditur dan akan dibayar kembali setelah jatuh tempo.
Dari uraian di atas dapat disimpulkan bahwa seseorang atau perusahaan melakukan kredit karena kurangnya dana untuk memenuhi kebutuhan-kebutuhan dalam hidupnya, seperti untuk modal usaha, biaya sekolah, dan lain-lain. Oleh karena itu, penulis tertarik untuk melakukan penelitian terhadap faktor-faktor apa saja yang mempengaruhi keputusan seseorang atau perusahaan yang sudah menjadi nasabah bank dalam pengambilan kredit.
Untuk menelusuri faktor-faktor apa saja yang berpengaruh secara signifikan terhadap keputusan nasabah dalam pengambilan kredit, maka perlu dilakukan pengelompokan atau klasifikasi. Metode-metode statistika nonparametrik yang dapat digunakan untuk membuat klasifikasi, diantaranya model Regresi Logistik Biner, metode Classification and Regression Trees (CART), metode Chi-Square Automatic Interaction Detection (CHAID), Neural
Network (NN), dan Multivariate Adaptive Regression Spline (MARS). Dalam
2
Regresi Logistik Biner merupakan suatu metode regresi yang menggambarkan hubungan antara suatu variabel respon (dependent variable) dengan satu atau lebih variabel prediktor (independent variable). Perbedaan antara model regresi logistik dengan model regresi linear adalah variabel respon dari regresi logistik bersifat dikotomus (biner). Varibel respon yang bersifat biner tidak berdistribusi normal, tetapi berdistribusi Bernoulli.
Metode CART merupakan metode atau algoritma dari salah satu teknik eksplorasi data, yaitu teknik pohon keputusan yang dikembangkan oleh Leo Breiman, Jerome H. Friedman, Richard A. Olshen dan Charles J. Stone sekitar tahun 1980-an. Pendekatan CART untuk mengklasifikasikan data statistik telah banyak digunakan dalam berbagai bidang. Tujuan dari CART adalah mengklasifikasikan suatu kelompok observasi atau sebuah observasi ke dalam suatu sub kelompok dari kelas-kelas yang diketahui.
Berdasarkan uraian di atas, penulis tertarik untuk meneliti tentang penerapan model Regresi Logistik Biner dan metode CART dibidang perbankan yaitu meneliti faktor-faktor yang mempengaruhi keputusan nasabah dalam mengambil kredit dan terbentuk sebuah judul “Klasifikasi Keputusan Nasabah
dalam Mengambil Kredit Menggunakan Model Regresi Logistik Biner dan Metode Classification And Regression Trees (CART)”
1.2 Rumusan Masalah
Berdasarkan uraian pada latar belakang penelitian, maka disusun perumusan masalah sebagai berikut:
1. Faktor-faktor apa yang mempengaruhi keputusan nasabah dalam pengambilan kredit ditinjau berdasarkan Model Regresi Logistik Biner?
2. Faktor-faktor apa yang mempengaruhi keputusan nasabah dalam pengambilan kredit ditinjau berdasarkan Metode CART?
3
1.3Batasan Masalah
Dalam skripsi ini, analisis yang digunakan adalah model Regresi Logistik Biner dan metode CART serta program komputer statistika yang digunakan adalah program SPSS versi 18.0.
1.4 Tujuan Penelitian
Berdasarkan rumusan penelitian di atas, maka tujuan penelitian dari skripsi ini adalah sebagai berikut :
1. Mengetahui Faktor-faktor apa yang mempengaruhi keputusan nasabah dalam pengambilan kredit ditinjau berdasarkan model Regresi Logistik Biner.
2. Mengetahui Faktor-faktor apa yang mempengaruhi keputusan nasabah dalam pengambilan kredit ditinjau berdasarkan metode CART.
3. Mengetahui metode manakah yang paling cocok untuk kasus klasifikasi keputusan nasabah dalam mengambil kredit berdasarkan nilai ketepatan prediksi yang dihasilkan antara model Regresi Logistik Biner dan metode CART.
1.5 Manfaat Penelitian
Manfaat yang diharapkan penulis adalah:
1. Manfaat Teoritis
Menambah pemahaman mengenai Model Regresi Logistik Biner dan Metode CART dalam menentukan faktor-faktor yang mempengaruhi keputusan nasabah dalam mengambil kredit.
2. Manfaat Praktis
21
BAB III
REGRESI LOGISTIK BINER DAN
CLASSIFICATION AND REGRESSION TREES (CART)
3.1 Regresi Logistik Biner
Regresi logistik berguna untuk meramalkan ada atau tidaknya karakteristik berdasarkan prediksi seperangkat variabel prediktor. Regresi logistik menghasilkan rasio peluang (odds ratio/OR) terkait dengan nilai setiap variabel prediktor. Odds ratio dari suatu kejadian diartikan sebagai peluang peristiwa yang terjadi dibagi dengan peluang suatu peristiwa yang tidak terjadi.
Odds Ratio
(3.1)
dengan:
= peluang dari peristiwa yang terjadi = peluang dari peristiwa yang tidak terjadi
Regresi logistik biasanya digunakan untuk memprediksi variabel yang bersifat kategorik (biasanya dikotomi) oleh seperangkat variabel prediksi. Dengan adanya sifat variabel yang kategorikal, analisis fungsi diskriminan biasanya digunakan jika semua variabel prediktor berbentuk data kontinu dan terdistribusi dengan baik. Analisis logit digunakan jika semua variabel prediktor bersifat kategorik dan regresi logistik dipilih jika variabel prediktor memuat campuran variabel kontinu dan kategorik.
22
Jika data hasil pengamatan memiliki buah variabel prediktor yaitu dan satu variabel respon , dengan mempunyai dua kemungkinan nilai yaitu 0 dan 1, maka:
menyatakan bahwa respon memiliki kriteria yang ditentukan menyatakan bahwa respon tidak memiliki kriteria yang ditentukan
Jika variabel berdistribusi Bernoulli dengan parameter , maka fungsi distribusi peluang menjadi:
(3.2)
sehingga diperoleh:
untuk untuk
Hosmer dan Lemeshow (2000: 31), model umum regresi logistik dengan buah variabel prediktor dibentuk dengan nilai | , dinotasikan sebagai berikut:
(3.3)
dengan
Fungsi merupakan fungsi non linear sehingga untuk membuatnya menjadi fungsi linear harus dilakukan transformasi logit agar dapat dilihat hubungan antara variabel respon (y) dengan variabel prediktornya (x). Bentuk logit dari adalah
sehingga diperoleh:
23 Bukti: = = [ ] = [ ] = [ ] = [ ] = =
3.2 Penaksiran Parameter
24
∏
, (3.5)
dengan:
=
= pengamatan pada variabel respon ke-i = peluang untuk variabel prediktor ke-i
Untuk mempermudah perhitungan, maka dilakukan penaksiran parameter dengan cara memaksimumkan fungsi logaritma kemungkinannya
(log-likelihood), yaitu:
∑
(3.6)
Bukti:
∏
= (∏
)
= ∑
= ∑
= ∑{ ( ) }
Untuk mendapatkan nilai penaksiran koefisien regresi logistik (̂) dilakukan dengan membuat turunan pertama terhadap dan disamakan dengan nol (Herrhyanto, 2003:97).
25 = ∑{ } ∑{( ) } = ∑{ } (∑ ∑ ) = ∑{ } ( ∑ )
turunkan ln L( terhadap ), yaitu:
= ∑ ∑ ∑ ∑ ∑ ∑ ( ) ∑ ( ∑ )
( ̂ ) ∑ ̂ ( ∑ )= 0
∑ ∑ ̂ ̂ ∑ ̂ ∑ ̂ ∑ ̂ ̂ ∑ ̅
Karena , maka didapatkan ̂ yang merupakan penduga kemungkinan maksimum.
3.3 Uji Signifikansi Parameter
26
Pengujian terhadap parameter ini dilakukan melalui statistik G. Maharani et al. (2007: 39), statistik uji G yaitu uji rasio kemungkinan maksimum (maximum
likelihood ratio test) yang digunakan untuk menguji peranan variabel prediktor di
dalam model secara bersama-sama dengan rumusannya sebagai berikut:
(3.7)
dengan:
= likelihood tanpa variabel prediktor = likelihood dengan p variabel prediktor Langkah-lagkah pengujiannya sebagai berikut:
1). Rumusan Hipotesis
: paling sedikit ada satu , 2). Besaran yang diperlukan
Hitung 3). Statistik Uji
4). Kriteria Pengujian
Dengan mengambil taraf nyata , maka tolak jika . 5). Kesimpulan
Penafsiran diterima atau ditolak
Selanjutnya dengan menggunakan uji Wald, akan dilakukan pengujian secara individu terhadap signifikansi parameter model. Menurut Hosmer dan Lemeshow (2000: 16), statistik Uji Wald didefinisikan sebagai:
̂
̂ (3.8)
dengan:
27
̂ = penaksir galat baku dari
Uji Wald ini akan menunjukkan apakah suatu variabel prediktor signifikan atau layak untuk masuk dalam model atau tidak. Uji Wald ini diperoleh dengan membandingkan penaksir kemungkinan maksimum dari parameter, yaitu dengan penaksir galat bakunya. Adapun langkah-langkah pengujiannya adalah sebagai berikut:
1). Rumusan hipotesis 2). Besaran yang diperlukan
̂ dan ̂ √ ( ̂ ) 3). Statistik Uji
̂
̂ 4). Kriteria Pengujian
Tolak jika | | 5). Kesimpulan
Penafsiran diterima atau ditolak
3.4 Classification and Regression Trees (CART)
28
CART merupakan metode statistika nonparametrik yang dapat menggambarkan hubungan antara variabel respon dengan satu atau lebih variabel prediktor. CART dikembangkan untuk topik analisis klasifikasi, baik untuk variabel respon kategorik maupun kontinu. CART menghasilkan sebuah pohon klasifikasi (classification trees), jika variabel responnya kategorik dan menghasilkan pohon regresi (regression trees), jika variabel responnya kontinu. Variabel respon dalam penelitian ini berskala kategorik, sehingga metode yang akan digunakan adalah metode pohon klasifikasi.
CART dapat menyeleksi variabel-variabel dan interaksi-interaksi variabel yang paling penting dalam penentuan hasil. Tujuan utama CART adalah untuk mendapatkan suatu kelompok data yang akurat sebagai penciri dari suatu pengklasifikasian. CART mempunyai beberapa kelebihan dibandingkan dengan metode pengelompokan yang klasik, seperti hasilnya lebih mudah diinterpretasikan, lebih akurat, dan lebih cepat penghitungannya. Menurut Yohannes dan Webb (Otok, 2009: XVI-2), tingkat kepercayaan yang dapat digunakan dalam pengklasifikasian data baru pada CART adalah akurasi yang dihasilkan oleh pohon klasifikasi yang murni dibentuk dari data yang mempunyai kesamaan kondisi.
CART merupakan metode yang bisa diterapkan untuk himpunan data yang memiliki jumlah besar, variabel prediktornya banyak dengan skala variabel campuran dilakukan melalui prosedur pemilahan biner, sejauh terlihat dalam Gambar 3.1 berikut.
simpul induk/akar (root)
puas tidak puas
simpul dalam (internal)
C
A
29
rusuk (edge)
simpul terminal (leaf)
Gambar 3.1 Diagram CART
Keterangan:
= simbol keputusan
= simbol kejadian tidak pasti
Pada Gambar 3.1 di atas A, B, C, D dan E merupakan variabel prediktor yang terpilih untuk menjadi simpul. A merupakan simpul induk atau simpul akar, B merupakan simpul dalam, sementara C, D dan E merupakan simpul akhir atau simpul terminal yang tidak bercabang lagi. Setiap simpul terminal merupakan titik akhir dari suatu pemilahan berstruktur pohon, simpul ini tidak bisa dipilah kembali menjadi simpul lain atau dengan kata lain simpul terminal merupakan simpul yang mengandung amatan-amatan yang homogen dan akhirnya akan dimasukkan sebagai suatu kelas tertentu. Variabel prediktor yang dianggap berpengaruh terhadap variabel respon adalah variabel prediktor yang muncul sebagai pemisah.
Tahapan dalam pembuatan pohon klasifikasi adalah membuat pohon yang besar yaitu dengan simpul yang banyak. Pohon yang terbentuk kemudian disederhanakan dengan cara memangkas beberapa cabang untuk mendapatkan struktur pohon yang layak dengan aturan-aturan tertentu sehingga terbentuk sebuah pohon optimal.
3.5 Langkah-langkah Algoritma Pohon Klasifikasi CART
Algoritma penyusunan pohon klasifikasi dan pohon regresi telah banyak digunakan dalam berbagai macam penelitian. Beberapa algoritma tersebut,
30
diantaranya C4.5 dan C5, CHAID, CART, dan QUEST. Pada prinsipnya algoritma-algoritma tersebut sebagai berikut:
1. Identifikasi variabel penjelas dan nilainya (atau levelnya kalau itu adalah variabel kategorik) yang dapat digunakan sebagai pemisah keseluruhan data menjadi dua atau lebih subset data.
2. Lakukan iterasi terhadap proses nomor 1 terhadap subset-subset yang ada sampai ditemukan salah satu dari dua hal berikut:
a. semua subset sudah homogen nilainya
b. tidak ada lagi variabel prediktor yang bisa digunakan
c. jumlah amatan di dalam subset sudah terlalu sedikit untuk menghasilkan pemisahan yang memuaskan
3. Lakukan pemangkasan (pruning), jika pohon yang dihasilkan dinilai terlalu besar.
Proses identifikasi variabel prediktor dan nilai yang menjadi batas pemisah dapat dilakukan dengan berbagai cara dan berbagai kriteria. Namun tujuan dari pemisahan ini pada berbagai metode adalah sama, yaitu mendapatkan subset-subset yang memiliki nilai variabel respon yang lebih homogen daripada sebelum dilakukan pemisahan.
Algoritma pembentukan pohon klasifikasi CART terdiri dari empat tahapan, yaitu:
1). Pemilihan pemilah (Classifier) 2). Penentuan simpul terminal 3). Penandaan label kelas
4). Penentuan pohon klasifikasi optimal
1. Pemilihan Pemilah
31
impurity yang tinggi menunjukkan simpul tersebut belum homogen, sedangkan
sebuah simpul dengan derajat impurity yang rendah menunjukkan simpul tersebut sudah homogen. Jika kelas obyek dinyatakan dengan k, k = 1,2,..,m, dimana m adalah jumlah kelas untuk variabel/output respon y, maka nilai impuritas dari simpul menggunakan Indeks Gini dapat dituliskan persamaannya sebagai berikut:
∑ |
(3.9) dengan
| = frekuensi relatif dari kelas j pada simpul t
m = jumlah kelas
Jika nilai Indeks Gini, , maka semua data dari simpul tersebut sudah berada pada kelas yang sama (homogen). Misalkan dilakukan pemisahan (spliting) sebuah simpul menggunakan Indeks Gini. Jika simpul t di split kedalam
k partisi (anak), maka kualitas split dihitung sebagai berikut:
∑
(3.10)
dengan
= Jumlah record pada anak ke-i = Jumlah record pada simpul
2. Penentuan Simpul Terminal
32
apabila hal itu terpenuhi maka pengembangan pohon dihentikan. Sementara itu, menurut Steinberg dan Colla (Otok, 2009: XVI-3), jumlah kasus yang terdapat dalam simpul terminal yang homogen adalah kurang dari 10 kasus.
3. Penandaan Label Kelas
Penandaan label kelas pada simpul terminal dilakukan berdasarkan aturan jumlah terbanyak. Misalkan pada kasus klasifikasi keputusan pembelian komputer (ya, tidak), dalam salah satu simpul terminal yang dihasilkan terdapat jumlah keputusan ya dan keputusan tidak. Jumlah terbanyak dari keputusan tersebut dijadikan label kelas simpul terminal.
4. Penentuan Pohon Klasifikasi Optimal
Pohon klasifikasi yang berukuran besar akan memberikan nilai penaksir pengganti paling kecil, sehingga pohon ini cenderung dipilih untuk menaksir nilai dari variabel respon. Tetapi ukuran pohon yang besar akan menyebabkan nilai kompleksitas yang tinggi, karena struktur data yang digambarkan cenderung kompleks, sehingga perlu dipilih pohon optimal yang berukuran sederhana tetapi memberikan nilai penaksir pengganti cukup kecil. Ada dua jenis penaksir pengganti, yaitu penaksir sampel uji (test sample estimate) dan penaksir validasi silang lipat (cross validation K-fold estimate).
Validasi silang merupakan salah satu teknik untuk menduga error rate. Beberapa teknik yang lain diantaranya adalah: holdout, leave one dan
bootstrapping. K-fold cross validation membagi data menjadi k bagian terpisah,
satu data menjadi data testing dan k-1 bagian menjadi data training sehingga terdapat k pasang data training-testing. K-fold cross validation dapat digunakan untuk data berukuran kecil ataupun besar. Aspek terpenting dalam validasi silang adalah kestabilan dari penaksiran yang diperoleh. Kestabilan pohon dapat bernilai rendah, jika mengandung terlalu banyak variabel prediktor.
33
pemangkasan yang digunakan untuk memperoleh ukuran pohon yang layak adalah
cost complexity minimum.
Sebagai ilustrasi, untuk sembarang pohon T yang merupakan sub pohon dari pohon terbesar ukuran cost complexity yaitu:
|̃ | (3.11)
dengan:
= tingkat kesalahan klasifikasi dari pohon bagian untuk k =1 ̃ = himpunan simpul terminal pada
|̃ | = banyak simpul terminal pada ̃ = parameter cost-complexity
Untuk binary tree, parameter cost-complexity bernilai 0,5 yang berarti sebuah simpul selalu dikembangkan menjadi dua simpul anak. Tingkat kesalahan klasifikasi (misclassification error) pada simpul t dinyatakan dengan:
|
(3.12) Contoh menghitung misclassification error jika sebuah simpul sudah diketahui:
3.6 Contoh Kasus Pembentukan Pohon Keputusan dengan Algoritma CART
Data keputusan pembelian komputer
Age Income Student Credit_rating Class: buys_computer
Youth High No Fair No
34
Senior Low No Fair Yes
Senior High Yes Fair Yes
Youth Low Yes Excellent Yes
Klasifikasi dibagi menjadi dua kelas, yaitu: C0 : No dan C1 : Yes
Atribut age mempunyai dua kemungkinan nilai yaitu {youth, senior}, dimana masing-masing nilai dapat diuraikan sebagai berikut:
1) Record yang mempunyai atribut age=youth ada 2; 1 record dikelas No (record ke-1) dan 1 record dikelas Yes (record ke-5), berarti C0 : 1 dan C1 : 1. Besarnya Indeks Gini dari simpul ini (A), adalah:
= (
) ( ) =
2) Record yang mempunyai atribut age=senior ada 3; ketiganya ada dikelas Yes (record ke-2, ke-3, dan ke-4), berarti C0 : 0 dan C1 : 3. Besarnya Indeks Gini dari simpul ini (B), adalah:
= (
) ( ) =
Selanjutnya, hitung Ginisplit untuk atribut age:
=
35
Atribut income mempunyai dua kemungkinan nilai yaitu {high, low}, dimana masing-masing nilai dapat diuraikan sebagai berikut:
1) Record yang mempunyai atribut income=high ada 3; 1 record dikelas No (record ke-1) dan 2 record dikelas Yes (record ke-2 dan ke-4), berarti C0 : 1 dan C1 : 2. Besarnya Indeks Gini dari simpul ini (A), adalah:
= (
) ( ) =
2) Record yang mempunyai atribut income=low ada 2; keduanya berada dikelas
Yes (record ke-3 dan ke-5), berarti C0 : 0 dan C1 : 2. Besarnya Indeks Gini
dari simpul ini (B), adalah:
= (
) ( ) =
Selanjutnya, hitung Ginisplit untuk atribut income:
=
=
Atribut student mempunyai dua kemungkinan nilai yaitu {no, yes}, dimana masing-masing nilai dapat diuraikan sebagai berikut:
1) Record yang mempunyai atribut student=no ada 3; 1 record dikelas No (record ke-1) dan 2 record dikelas Yes (record ke-2 dan ke-3), berarti C0 : 1 dan C1 : 2. Besarnya Indeks Gini dari simpul ini (A), adalah:
36
= (
) ( ) =
2) Record yang mempunyai atribut student=yes ada 2; keduanya berada dikelas
Yes (record ke-4 dan ke-5), berarti C0 : 0 dan C1 : 2. Besarnya Indeks Gini
dari simpul ini (B), adalah:
= (
) ( ) =
Selanjutnya, hitung Ginisplit untuk atribut student:
=
=
Atribut credit_rating mempunyai dua kemungkinan nilai yaitu {fair, excellent}, dimana masing-masing nilai dapat diuraikan sebagai berikut:
1) Record yang mempunyai atribut credit_rating=fair ada 4; 1 record dikelas No (record ke-1) dan 3 record dikelas Yes (record ke-2, ke-3, dan ke-4), berarti C0 : 1 dan C1 : 3. Besarnya Indeks Gini dari simpul ini (A), adalah:
= (
) ( ) =
2) Record yang mempunyai atribut credit_rating=excellent ada 1; record berada dikelas Yes (record ke-5), berarti C0 : 0 dan C1 : 1. Besarnya Indeks Gini dari simpul ini (B), adalah:
37
= (
) ( ) =
Selanjutnya, hitung Ginisplit untuk atribut credit_rating:
=
=
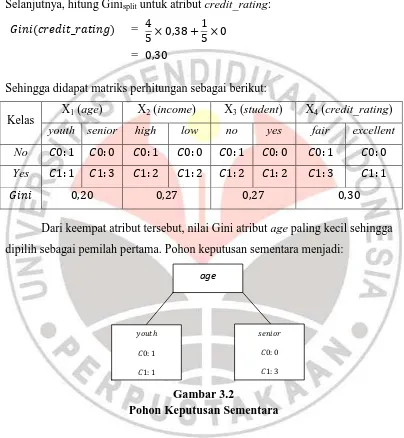
Sehingga didapat matriks perhitungan sebagai berikut:
Kelas X1 (age) X2 (income) X3 (student) X4 (credit_rating)
youth senior high low no yes fair excellent
No
Yes
[image:30.595.108.512.190.628.2]
Dari keempat atribut tersebut, nilai Gini atribut age paling kecil sehingga dipilih sebagai pemilah pertama. Pohon keputusan sementara menjadi:
Gambar 3.2
Pohon Keputusan Sementara
Dari kedua simpul atribut age, simpul youth belum homogen sehingga perlu memilih calon pemilah selanjutnya (income, student, credit_rating) untuk data di record 1 dan 5. Dengan langkah yang sama seperti di atas, maka diperoleh matriks perhitungan sebagai berikut:
age
38
high low no yes fair excellent
No
Yes
[image:31.595.117.510.254.630.2]
Karena nilai Indeks Gini semua simpul sudah nol, artinya setiap record dalam simpul berada dalam kelas yang sama (homogen) maka proses pembuatan pohon dihentikan sehingga didapatkan pohon optimum sebagai berikut:
Gambar 3.3
Pohon Keputusan Optimum
Pengolahan data menggunakan SPSS diperoleh pohon optimum sebagai berikut:
age
39
Gambar 3.4
Pohon Klasifikasi Optimum
Berdasarkan pohon optimum yang diperoleh dari kedua proses pengolahan data diatas, terlihat bahwa variabel yang berpengaruh secara signifikan dalam klasifikasi pembelian komputer adalah variabel X1 (age) serta menghasilkan dua
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Berdasarkan analisis dari hasil pengolahan data yang telah dilakukan pada bab sebelumnya, maka dapat ditarik kesimpulan sebagai berikut:
1. Faktor-faktor yang berpengaruh secara signifikan terhadap keputusan nasabah dalam mengambil kredit dari hasil analisis Regresi Logistik Biner dengan taraf nyata 5% adalah usia, pendidikan, informasi kredit dan prosedur kredit.
2. Faktor-faktor yang berpengaruh secara signifikan terhadap keputusan nasabah dalam mengambil kredit berdasarkan metode klasifikasi CART adalah prosedur kredit. Prosedur kredit merupakan variabel yang dominan berpengaruh terhadap keputusan nasabah dalam mengambil kredit karena temuat pada hasil dari dua metode yang digunakan dalam penelitian ini. Jadi, cepat atau lambatnya prosedur kredit bank akan mempengaruhi keputusan seseorang nasabah untuk mengambil atau tidak kredit tersebut.
3. Model Regresi Logistik Biner memiliki nilai ketepatan prediksi 6% lebih tinggi daripada metode klasifikasi CART. Sehingga model Regresi Logistik Biner lebih tepat digunakan untuk kasus keputusan nasabah dalam mengambil kredit.
5.2 Saran
Metode klasifikasi yang digunakan dalam penelitian ini adalah model regresi logistik biner dan metode klasifikasi CART, penelitian selanjutnya dapat membandingkan metode klasifikasi yang lainnya seperti metode Chi-Square
Automatic Interaction Detection (CHAID), Neural Network (NN), dan
DAFTAR PUSTAKA
Allison, P. D. (1999). Logistic Regression Using SAS® System: Theory and Application. Cary, NC: SAS Institute Inc.
Berry, M. J. A. & Linoff, G. S. (2004). (2nd Edn). Data Mining Techniques for
Marketing, Sales, and Customer Relationship Management. Indiana:
Wiley Publishing, Inc.
Firdaus, R. dan Ariyanti, M. (2009). (Edisi Keempat). Manajemen Perkreditan
Bank Umum. Bandung: Alfabeta.
Han, J. et al. (2012). (3rd Edn). Data Mining Concepts and Techniques. United States of America: Elsevier Inc.
Hermawati, F. A. (2013). Data Mining. Yogyakarta: Andi.
Herrhyanto, N. (2003). Statistika Matematis Lanjutan. Bandung: CV Pustaka Setia.
Herrhyanto, N. dan Gantini, T. (2009). Pengantar Statistika Matematis. Bandung: Yrama Widya.
Hosmer, D. W. & Lemeshow, S. (2000). Applied Logistic Regression. (Edisi Kedua). New York: John Wiley & Sons, Inc.
Kardiana, A. et al. (2006). “Metode Klasifikasi Berstruktur Pohon Biner”. Seminar Nasional Aplikasi Teknologi Informasi (SNATI), Yogyakarta. Kasmir. (2008). Pemasaran Bank. (Edisi Revisi). Jakarta: Kencana.
Komalasari, W. B. (2007). Metode Pohon Regresi untuk Eksploratori Data dengan Peubah yang Banyak dan Kompleks. Informatika Pertanian. 16, (1), 967-980.
Kotler, P. & Keller, K. L. (2012). Marketing Management. (14th Ed). Prentice
Hall: Pearson Education, Inc., p. cm.
Kustiyo, A. dan Tjandrasa. (2004). “Model Neural Network dengan Inisialisasi
Pembobot Awal Menggunakan Regresi Logistik Biner untuk Memprediksi Jenis Penyakit Erythematho-Squamous”. Jurnal Ilmiah-Ilmu Komputer. 2,
(2), 14-25.
Lailiyah, E. (2010). Aplikasi Regresi Logistik untuk Mengetahui Variabel yang
Mempengaruhi Kebiasaan Merokok. Tugas Akhir pada FPMIPA
Lewis, R. J. (2000). An Introduction to Classification and Regression Tree
(CART) Analysis. Department of Emergency Medicine Harbor-UCLA
Medical Center. Torrance, California.
Loh, W.-L. & Kim, H. (2001). “Classification Trees With Unbiased Multiway Splits”. Journal of the American Statistical Association. 96, 598-604.
Maharani, I. I. et al. (2007). “Aplikasi Regresi Logistik dalam Analisis Faktor
Risiko Anemia Gizi pada Mahasiswa Baru IPB”. Jurnal Gizi dan Pangan.
2, (2), 36-43.
Mardiani. (2012). Penerapan Klasifikasi dengan Algoritma CART untuk Prediksi
Kuliah bagi Mahasiswa Baru. Seminar Nasional Aplikasi Teknologi
Informasi.
Otok, B. W. (2009). Bagging Cart pada Klasifikasi Anak Putus Sekolah. Seminar Nasional Statistika IX. Hlm: XVI-1-XVI-9.
Prasetyo, E. (2012). Data Mining: Konsep dan Aplikasi Menggunakan Matlab. Yogyakarta: Andi.
Riduwan. (2011). Skala Pengukuran Variabel-Variabel Penelitian. Bandung: Alfabeta.
Santosa, B. (2007). Data Mining: Teknik pemanfaatan Data untuk keperluan
Bisnis. Yogyakarta: Graha Ilmu.
Sartono, B. & Syafitri, U. D. (2010). Metode Pohon Gabungan: Solusi Pilihan untuk Mengatasi Kelemahan Pohon Regresi dan Klasifikasi Tunggal.
Forum Statistika dan Komputasi. 15, (1), 1-7.
Sugiyono. (1994). Metode Penelitian Administrasi. (Edisi Ketiga). Bandung: Alfabeta.
Sujarweni, V. W. & Endrayanto, P. (2012). Statistika untuk Penelitian. Yogyakarta: Graha Ilmu.
Supramono, G. (2009). Perbankan dan Masalah Kredit. Jakarta: Rineka Cipta. T. Larose, D. (2005). Discovering Knowledge in Data: An Introduction to Data
Mining. New Jersey: John Wiley & Sons, Inc.
Universitas Pendidikan Indonesia. (2012). Pedoman Penulisan Karya Ilmiah. Bandung: UPI Press.
Wahyu, N. D. (2012). Pengaruh Lokasi, Pelayanan, dan Prosedure Kredit
terhadap Keputusan Nasabah dalam Mengambil Kredit pada PD. BPR
Bank Boyolali. [Online]. Tersedia:
Yaneliza, Y. (2006). Faktor-Faktor yang Mempengaruhi Keputusan Petani dalam
Pengambilan Kredit di Bank Rakyat Indonesia (BRI) Unit Sambit Kab.
Ponorogo. [Online]. Tersedia:
http://pilnas.ristek.go.id/karya/index.php/record/view/76455 [01 Juli 2013] Yohannes, Y. & Hoddinott, J. (1999). Classification and Regression Trees: An
Introduction. International Food Policy Research Institute (IFPRI).
Washington, D.C., U.S.A.