PENDEKATAN BARU PADA PEMBENTUKAN
KANDIDAT MODEL AVERAGING
REGRESI DIMENSI TINGGI
SEPTIAN RAHARDIANTORO
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Pendekatan Baru pada Pembentukan Kandidat Model Averaging Regresi Dimensi Tinggi adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
SEPTIAN RAHARDIANTORO. Pendekatan Baru pada Pembentukan Kandidat Model Averaging Regresi Dimensi Tinggi. Dibimbing oleh ANANG KURNIA dan BAGUS SARTONO.
Regresi dimensi tinggi terjadi ketika banyaknya peubah bebas melebihi banyaknya ukuran contoh . Kondisi data seperti ini seringkali dijumpai pada penelitian bidang biologi, terutama terkait penelitian genetika. Atas dasar salah satu tujuan analisis regresi yaitu untuk prediksi peubah respon, penelitian ini mengangkat konteks data dimensi tinggi di dalamnya. Metode utama yang dikaji ialah model averaging.
Penelitian ini diawali dengan mengevaluasi dua metode yang ada di literatur yaitu Randomized Model Averaging (RMA) dan General-Model Averaging (GMA). Selanjutnya dikembangkan pendekatan baru yaitu Principal Component Model Averaging (PCMA). Metode PCMA disulkan sebagai pendekatan baru dengan menggunakan matriks rotasi pada rotation forest untuk membentuk struktur data baru. Proses rotasi ini dilakukan untuk membuat data regresi agar saling bebas.
Suatu simulasi dilakukan yaitu dengan mengkaji kinerja pendekatan baru yang diusulkan, PCMA, dengan GMA dan RMA, dengan cara membandingkan beberapa ukuran seperti keakuratan prediksi (MAPE, MAE, MSE), ketakbiasan prediksi, kebebasan dan ragam antar prediksi kandidat model, serta ragam prediksi model final. Pada simulasi tersebut diatur beberapa hal yaitu =100, = 2000, banyaknya kandidat model =50, dan ulangan 1000 kali. Hasilnya, terungkap bahwa PCMA lebih baik dalam prediksi peubah respon daripada RMA dan GMA, yaitu memiliki akurasi tinggi dalam prediksi dan ragam model final yang kecil.
Selanjutnya, kajian prediksi pada peubah paparan ke aflatoksin B1 (AFB1) dari wanita hamil dengan metilasi DNA sel darah putih bayinya pada data penelitian di Negara Gambia menjadi sajian studi kasus. Hasilnya ialah PCMA juga memberikan prediksi yang paling baik pada peubah paparan ke aflatoksin B1 dari wanita hamil dengan metilasi DNA sel darah putih bayinya.
SUMMARY
SEPTIAN RAHARDIANTORO. A New Approach for Constructing Model Averaging Candidates in High-Dimensional Regression. Supervised by ANANG KURNIA and BAGUS SARTONO.
High-dimensional regression problems occur when the number of predictors exceeds the sample size . This data conditions are often found in the field of biological research, especially research related to genetics. On the basis of one goal, namely regression analysis for prediction of response variable, this study raised the context of high-dimensional data in it. The main method being studied in this research is a model averaging.
This study begins by evaluating two methods exist in the literature, namely Randomized Model Averaging (RMA) and the General-Model Averaging (GMA). Subsequently developed a new approach that is Principal Component Model Averaging (PCMA). PCMA has been proposed to be the new approach by using a rotation matrix in the forest rotation to form a new data structure. The rotation process is done to make the regression data in order to be independent.
A simulation has been designed by reviewing the performance of the new approach proposed, PCMA, with GMA and RMA, by comparing several sizes such as the accuracy of prediction (MAPE, MAE, MSE), bias of prediction, independence and variance among candidates prediction models, and ensamble variance of final model predictions. In this simulation set some criterias: = 100, = 2000, the number of model candidates =50, and 1000 replications. As a result, it was revealed that PCMA is the best approach than RMA and GMA in the predicting response variable, it has high accuration of prediction and less the ensamble variances
Furthermore, the study of predictive variables, exposure to aflatoxin B1 (AFB1) of the pregnant woman with a white blood cell DNA methylation baby on research data in the State Gambia became a case study presentation. The result is PCMA also provide the best prediction at the variable exposure to aflatoxin B1 of the pregnant woman with a white blood cell DNA methylation baby.
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
PENDEKATAN BARU PADA PEMBENTUKAN
KANDIDAT MODEL AVERAGING
REGRESI DIMENSI TINGGI
SEPTIAN RAHARDIANTORO
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains
pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT karena hanya dengan lindungan, rahmat dan karuniaNya-lah penulis telah menyelesaikan karya ilmiah yang berjudul Pendekatan Baru pada Pembentukan Kandidat Model Averaging Regresi Dimensi Tinggi.
Terselesainya penyusunan karya ilmiah ini tidak lepas dari dukungan, motivasi, saran, dan kerjasama dari berbagai pihak. Oleh karena itu, penulis mengucapkan terima kasih kepada:
1. Bapak Dr. Anang Kurnia, M.Si selaku ketua komisi pembimbing yang telah membimbing dan mengarahkan sesuai dengan dasar teori yang kuat untuk menghasilkan karya ilmiah yang impresif.
2. Bapak Dr. Bagus Sartono, M.Si selaku anggota komisi pembimbing atas keleluasaan waktu untuk diskusi mengenai penyusunan karya ilmiah ini. 3. Bapak Prof. Dr. Ir. Khairil Anwar Notodiputro, MS selaku penguji luar
ujian tesis penulis yang telah sangat teliti dan kritis memberikan saran dan catatan perbaikan kepada penulis agar menghasilkan karya ilmiah yang lebih bernilai.
4. Istri tercinta, Yusma Yanti, M.Si, yang senantiasa bersabar mendampingi penulis dan selalu memberikan semangat dalam menyusun karya ilmiah ini meski pada saat itu dalam kondisi mengandung si buah hati.
5. Rekan-rekan pascasarjana angkatan 2014, serta rekan-rekan bapak dan ibu dosen Departemen Statistika yang telah membantu penulis dalam diskusi untuk menyelesaikan karya ilmiah ini.
6. Staf Tata Usaha Departemen Statistika Pascasarjana, Bapak Heriawan, yang telah mendukung penulis dalam hal administrasi penyusunan karya ilmiah ini.
7. Bapak, ibu, abak, mama, serta seluruh keluarga, atas doa dan kasih sayangnya, yang selalu mendukung penulis untuk mewujudkan cita-citanya. Demi penyempurnaan karya ilmiah ini, penulis sangat mengharapkan saran, kritik, dan masukan dari para pembaca. Besar harapan penulis semoga karya ilmiah ini bermanfaat.
Bogor, September 2016
DAFTAR ISI
DAFTAR GAMBAR xvi
DAFTAR TABEL xvi
DAFTAR LAMPIRAN xvi
DAFTAR SIMBOL xvii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 3
TINJAUAN PUSTAKA ... 4
Model Averaging ... 4
Randomized Model Averaging (RMA) ... 4
General Model Averaging (GMA) ... 5
Bobot Model Averaging ... 5
Rotation Forest ... 6
Bootstrap ... 7
Principal Component Analysis (PCA) ... 7
Aspek-aspek Pengukuran Penelitian ... 8
1. Keakuratan Prediksi ... 8
2. Ketakbiasan Prediksi ... 10
3. Kebebasan dan Ragam Antar Prediksi Kandidat Model ... 10
4. Ragam Prediksi Model Final ... 11
PENDEKATAN BARU: Principal Component Model Averaging (PCMA) ... 12
EVALUASI RMA, GMA, & PCMA ... 14
APLIKASI RMA, GMA, & PCMA ... 21
Prediksi AFB1 Melalui Profil Metilasi DNA Darah Bayi dari Kelompok Ibu/Anak di Gambia ... 21
SIMPULAN ... 25
Simpulan ... 25
DAFTAR PUSTAKA ... 26
LAMPIRAN ... 27
DAFTAR GAMBAR
1. Tahapan metode PCMA 13
2. Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas yang berbeda ( ) dengan pembobot sama untuk data simulasi 16 3. Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas
yang berbeda ( ) dengan pembobot AIC untuk data simulasi 17 4. Kurva rataan nilai bias pada banyak peubah bebas yang berbeda
( ) untuk data simulasi 18
5. Kurva rataan nilai maksimum akar ciri dan rataan determinan matriks korelasi prediksi kandidat model pada banyak peubah bebas yang berbeda ( ) untuk data simulasi 19 6. Kurva rataan ragam prediksi model final pada banyak peubah
bebas yang berbeda ( ) data simulasi 20 7. Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas
yang berbeda ( ) dengan pembobot AIC untuk data studi kasus 22 8. Plot pencaran nilai aktual peubah AFB1 dengan nilai prediksi
peubah AFB1 terbaik 24
DAFTAR TABEL
1. Rataan korelasi antara prediksi peubah AFB1 dengan peubah AFB1 aktual untuk semua kondisi peubah bebas dalam kandidat
model 23
DAFTAR LAMPIRAN
1. Algoritme simulasi Randomized Model Averaging (RMA) 28 2. Algoritme simulasi General Model Averaging (GMA) 29 3. Algoritme simulasi Principal Component Model Averaging
DAFTAR SIMBOL
Simbol Makna simbol
: banyaknya peubah bebas pada data regresi : banyaknya amatan pada data regresi
: banyaknya kandidat model pada model averaging : banyaknya peubah bebas yang digunakan pada
kandidat model
� : banyaknya anak matriks yang dibentuk pada proses awal metode PCMA
: banyaknya ulangan yang dilakukan pada simulasi � : nilai skalar akar ciri
: indeks yang menyatakan kandidat model, = , , … , : indeks yang menyatakan anak matriks peubah bebas
pada proses metode PCMA, = , , … , �
: indeks yang menyatakan amatan data, = , , … , ℎ : indeks yang menyatakan ulangan pada simulasi,
ℎ = , , … ,
: indeks yang menyatakan peubah bebas pada kandidat model, = , , … ,
: indeks yang menyatakan vektor peubah bebas terpilih, ∈ { , , … , }, sehingga misalkan , = { , , } maka vektor peubah bebas yang terpilih ialah
, ,dan
: vektor peubah bebas ukuran × , dengan merupakan vektor peubah bebas pertama, dan seterusnya
: vektor peubah respon ukuran × � : vektor faktor acak (galat) ukuran ×
� : vektor komponen proses PCA, ukuran × pada suatu tertentu (vektor ciri)
: matriks peubah bebas ukuran × , dengan kolomnya merupakan sebanyak vektor peubah bebas
̃ : matriks peubah bebas dengan kolom pertama ditambahkan dengan vektor 1, ukuran × +
� : matriks blok diagonal yang berisi vektor ciri pada proses rotation forest
� : matriks hasil rotasi pada proses PCMA, ukuran × : nilai skalar bobot model averaging pada kandidat
model
ke-: nilai skalar AIC pada kandidat model ke-
Simbol Makna simbol … : fungsi untuk komponen yang dituju
… : simpangan baku untuk komponen yang dituju …̂ : tanda prediksi pada komponen yang dituju …̅ : tanda rataan pada komponen yang dituju
…[… ] : tanda indeks dengan urutan yang dituju (sudah melalui
proses pengurutan terlebih dahulu
… : tanda komponen yang sudah dilakukan proses bootstrap
PENDAHULUAN
Latar Belakang
Persoalan analisis regresi berganda mengasumsikan terdapat peubah bebas dengan amatan, , , … , dinyatakan dalam matriks × dan vektor × peubah respon , yang memiliki hubungan linear antara keduanya: = + �, �~� , � . Persamaan stokastik tersebut lebih dikenal dengan sebutan model regresi berganda. Secara garis besar, dua tujuan utama analisis regresi berganda ialah untuk menentukan peubah-peubah bebas yang mempengaruhi peubah respon, dan untuk memprediksi peubah respon dengan akurat. Berdasarkan dua tujuan utama inilah terdapat banyak variasi metode pada analisis regresi berganda. Adakalanya data berdimensi besar dijumpai pada gugus data peubah bebas. Data seperti ini dapat disebut data dimensi tinggi (high-dimensional data), yakni ketika jumlah peubah bebas jauh lebih banyak daripada jumlah pengamatan, ≫ . Kondisi data tersebut seringkali dijumpai pada bidang biologi, khususnya penelitian genetika yang melibatkan data ekspresi gen manusia yang berukuran besar. Berdasarkan kondisi data tersebut dan untuk menjawab dua tujuan regresi, peneliti dapat menggunakan alternatif modifikasi analisis regresi yang sesuai. Metode regresi yang dapat digunakan untuk tujuan pertama, menentukan peubah bebas yang mempengaruhi peubah respon, diantaranya best subset regression, forward regression, dan stepwise regression. Pilihan lainnya dapat berupa penalized regression, seperti LASSO regression (Tibshirani 1996) , ridge regression (Hoerl dan Kennard 1970), SCAD-penalised regression (Xie dan Huang 2009), dan elastic net (Zou dan Hastie 2005). Pada lain sisi, untuk tujuan kedua yaitu memprediksi peubah respon setepat mungkin, dapat menggunakan reduksi dimensi pada analisis regresi seperti principal component regression, dan partial least square. Alternatif lain yang dapat digunakan ialah dengan model averaging.
Penelitian ini menitikberatkan pada tujuan kedua untuk memprediksi peubah respon , dengan menggunakan model averaging (MA). Metode MA berkembang dari ide yang dikemukakan oleh Perrone tahun 1993 untuk meningkatkan akurasi prediksi dalam analisis regresi. Berdasarkan model stokastik = + �, MA mengkombinasikan sebagian atau keseluruhan prediksi regresi ̂ untuk menduga fungsi , dengan ̂ = ̂ disebut prediksi kandidat model. Seluruh prediksi kandidat model yang terbentuk dikombinasikan dengan cara rata-rata terboboti untuk membentuk prediksi model final. Prediksi peubah respon dari model final inilah yang dijadikan sebagai prediksi akhir pada persoalan yang dihadapi.
2
Misalkan merupakan bobot pada kandidat model ke- , sehingga ̂ = ∑ ̂ , , ∑ = , merupakan prediksi final peubah respon MA. Akibatnya ̂ dapat dijabarkan hanya sebagai total dari ̂ dengan asumsi ̂ dibentuk oleh peubah bebas yang saling bebas, , = , ≠
. Namun, dengan kondisi data regresi ≫ , maka dapat dipastikan bahwa ada , ≠ , ≠ . Selain itu kondisi data yang ditelaah pada penelitian genetika pada umumnya dijumpai kondisi , > , ≠ , mengakibatkan nilai ̂ akan ditambah dengan komponen kovarian-nya. Kondisi-kondisi ini berdampak nilai ̂ akan semakin besar. Berdasarkan hal tersebut, pada metode pembentukan kandidat model pada MA masih banyak celah untuk dilakukan pengembangan supaya memperoleh prediksi yang lebih akurat dengan keragaman yang lebih rendah.
Oleh karena itu, tahapan awal penelitian ini ialah melakukan kajian pada dua metode pembentukan kandidat model pada MA untuk melihat keakuratan dan keragaman prediksi peubah responnya. Metode pertama ialah kandidat model dibentuk berdasarkan pemilihan sebagian peubah bebas secara acak, yang dalam penelitian ini disebut Randomized Model Averaging (RMA) (Perrone, 1993). Selanjutnya metode kedua yakni kandidat model dibentuk berdasarkan urutan korelasi terbesar antara seluruh peubah bebas dengan peubah responnya. Metode ini disebut General Model Averaging (GMA) yang dikemukakan oleh Ando dan Li pada tahun 2014.
Berdasarkan sudut pandang lain, MA merupakan salah satu metode ensamble yang tidak hanya diterapkan dalam analisis regresi, melainkan permasalahan klasifikasi. Proses penentuan classifier (pengklasifikasi) pada metode ensamble sebanding dengan penentuan kandidat model dalam MA. Dimulai dari konsep boosting, bagging, random forest, sampai rotation forest, metode ensamble menawarkan berbagai konsep pendekatan dalam penentuan classifier. Random Forest (Breiman 2001) dikembangkan dengan langkah penentuan classifier berdasarkan pemilihan acak pada amatan dan peubah bebas tertentu. Metode ini diperbaiki oleh Rodriguez dan Kuncheva (2006) dengan usulannya Rotation Forest, yang melakukan rotasi pada peubah bebasnya melalui Principal Component Analysis (PCA). Pendekatan ini dapat diterapkan dalam menentukan kandidat model pada MA karena metode yang diajukan berawal dari gagasan untuk membentuk model final dengan pengkombinasian peubah bebas yang saling bebas, dengan harapan mampu memperbaiki kualitas akurasi dan ragam prediksi peubah responnya. Dengan demikian, tahapan kedua penelitian ini berupaya untuk memberikan pendekatan baru dalam penentuan kandidat model dalam MA dengan merotasi peubah bebasnya, disebut dengan Principal Component Model Averaging (PCMA).
aplikasi penerapan metode kajian dalam MA pada studi kasus regresi dimensi tinggi. Studi kasus yang digunakan yakni prediksi peubah AFB1 (paparan intra-uterus ke aflatoksin B1) melalui profil metilasi DNA darah bayi dari kelompok ibu/anak di Gambia.
Sebagai rangkuman, penelitian ini terdiri dari tiga tahapan besar: (1) kajian dua metode pembentukan kandidat model pada MA (RMA dan GMA), (2) kajian alternatif baru pembentukan kandidat model pada MA (PCMA), dan (3) aplikasi penerapan metode kajian dalam MA pada studi kasus regresi dimensi tinggi. Karya ilmiah ini disusun secara sistematis berdasarkan tiga tahapan besar tersebut dengan urutan bab-nya ialah Pendahuluan; Tinjauan Pustaka; Pendekatan Baru: PCMA; Evaluasi RMA, GMA, dan PCMA; Aplikasi RMA, GMA, dan PCMA; Simpulan.
Tujuan
Tujuan utama dari penelitian ini ialah untuk memberikan alternatif metode dalam pembentukan kandidat model pada MA, yaitu PCMA, dengan kualitas akurasi dan ragam prediksi yang lebih baik jika dibandingkan RMA dan GMA. Aspek evaluasi kajian ketiga metode di atas adalah sebagai berikut.
1. aspek banyaknya peubah bebas yang digunakan pada kandidat model 2. kebaikan/ keakuratan prediksi yang dilihat dari kriteria evaluasi MAPE,
MAE, dan MSE
3. nilai ketakbiasan prediksi, diukur nilai bias 4. bobot MA: pembobot sama dan AIC
5. determinan dan nilai maksimum akar ciri dari matriks korelasi dari kandidat model yang mengindikasikan kebebasan dan pola dari ragam kandidat model
6. serta ragam dari prediksi model final.
4
TINJAUAN PUSTAKA
Pada bagian ini akan diulas seluk beluk landasan teori mengenai metode-metode yang digunakan dalam penelitian. Bahasan yang pertama dibahas ialah mengenai MA dan bobotnya, kemudian ulasan mengenai rotation forest, bootstrap, dan PCA yang digunakan dalam upaya pengembangan metode alternatif pembentukan kandidat model pada MA. Selain itu, ulasan mengenai aspek-aspek pengukuran yang diterapkan juga dibahas pada akhir dari bagian ini.
Model Averaging
Model Averaging dikembangkan dengan tujuan untuk memperoleh prediksi peubah respon pada suatu permasalahan regresi. Metode yang digunakan dan dikembangkan pada penelitian ini didasarkan pada kondisi data regresi ≫
. Misalkan diketahui data peubah bebas × = [ … ] dengan peubah respon × . Tahapan utama dalam MA ialah pembentukan kandidat model, yaitu dengan memilih sebanyak < peubah bebas , ∈ { , , … , }, yang selanjutnya dilakukan analisis regresi antara peubah bebas terpilih dengan peubah responnya. Model yang dihasilkan digunakan untuk memprediksi peubah respon, ̂ = ̂ × , dengan × merupakan matriks yang berisi vektor-vektor
Berikut akan diulas mengenai dua metode pembentukan kandidat model averaging yang digunakan pada penelitian ini, meliputi RMA, GMA.
Randomized Model Averaging (RMA)
Metode RMA didasarkan pada proses acak dalam membentuk kandidat model (Perrone 1993). Hal ini memungkinkan untuk memperoleh semua kemungkinan kandidat model yang terbentuk, yang disesuaikan dengan kondisi data dimensi besar. Misalkan diketahui vektor kolom peubah bebas pada matrikx × = [ … ], maka selanjutnya dibentuk matriks ��; =
, … , melalui pemilihan secara acak vektor peubah bebas , ∈ { , , … , }
�� = [ ]
× ; ∈ { , , … , }
General Model Averaging (GMA)
Metode GMA diaplikasikan berdasarkan metode yang dikembangkan oleh Ando dan Li (2014). Perbedaan tahapan RMA dengan GMA terletak pada proses pembentukan kandidat model yaitu diawali dengan menghitung korelasi setiap peubah bebas dengan peubah responnya. Proses GMA selanjutnya terdapat pembagian peubah bebas tersebut berdasarkan urutan tertinggi korelasinya. Misalkan diketahui vektor kolom peubah bebas pada matriks × = [ … ], maka matriks peubah bebas untuk kandidat model dibentuk berdasarkan urutan nilai korelasi peubah bebas tehadap peubah responnya, yaitu
���= [
[ ] [ ]… [ ]], dengan [ℎ] merupakan peubah bebas dengan nilai
korelasi terbesar urutan ke-ℎ. Selanjutnya dari matriks ���dibentuk sebanyak matriks dengan setiap matriks terdiri dari vektor peubah bebas, yaitu
���= [
[ ] [ ]… [ ]], ��� = [ [ + ] [ + ] … [ ]], … , ���=
[ [ − + ] [ − + ]… [ ]]. Matriks ���, = , , … , , inilah yang akan
dibentuk kandidat model melalui pemodelan regresi dengan peubah respon, ̂ = ̂ ( ���).
Bobot Model Averaging
Pada penelitian ini, terdapat dua jenis bobot MA yang diterapkan, pembobotan sama dan AIC. Pemilihan kedua jenis bobot tersebut didasarkan pada konteks kesederhanaan dan mayoritas penggunaan.
Misalkan dari proses MA diperoleh sebanyak kandidat model, maka prediksi final peubah respon dapat dinyatakan
̂ = ∑ ̂
=
Pembobotan sama menyajikan pembobotan setiap ̂ , = , , … , dengan nilai yang sama, yaitu = , = , , … , (Zhou 2012). Sehingga prediksi final peubah respon dapat dituliskan menjadi
̂ = ∑ ̂
=
Penggunaan bobot sama ini tidak memperhatikan pembedaan dalam pemberian kontribusi setiap kandidat model pada prediksi final peubah respon. Akibatnya prediksi pada kandidat model yang baik akan memiliki bobot yang sama dengan prediksi kandidat model yang kurang baik.
Pada sisi lain, pembobotan AIC didasarkan dari nilai AIC yang dihasilkan oleh setiap kandidat model ̂ , dengan AIC kandidat model ke- , ̂ , didefinisikan sebagai
6
dengan � ̂ merupakan fungsi kemungkinan berlandaskan asumsi bahwa galat kandidat model menyebar normal, dan merupakan jumlah parameter dari kandidat model ̂ . Semakin baik kandidat model dalam memprediksi peubah respon, maka nilai dari � ̂ semakin besar, sehingga kandidat model ke- dengan prediksi yang baik akan memiliki nilai yang besar, dan berlaku sebaliknya. Selanjutnya pembobot AIC didefinisikan sebagai (Claeskens dan Hjort 2008)
= ∑=
Kandidat model ke- yang terindikasi baik ialah dengan nilai yang tinggi, sehingga memiliki bobot yang lebih tinggi pula. Akibatnya terdapat kandidat model dengan nilai pembobot yang berbeda-beda.
Rotation Forest
Rotation forest merupakan metode yang sangat penting pada penelitian ini, mengingat gagasan baru PCMA mengacu pada algoritmenya. Metode ini merupakan metode ensamble yang biasa digunakan pada proses klasifikasi dengan melibatkan banyak peubah dan amatan. Metode ini dikembangkan oleh Rodriguez dan Kuncheva (2006), dengan maksud memperbaiki metode ensamble untuk klasifikasi sebelumnya yaitu random forest dan AdaBoost.
Metode rotation forest melibatkan proses pemilihan sebagian amatan melalui proses bootstrap, dan pemilihan sebagian peubah untuk dilakukan PCA. Proses inilah yang disebut sebagai proses rotasi pada data yang digunakan untuk klasifikasi. Kelebihan rotation forest terletak pada pemilihan metode PCA untuk menentukan kelayakan dan mencari tahu apakah prediksi dari kandidat model berkontribusi terhadap peningkatan akurasi dan keragaman. Berdasarkan penelitian yang dilakukan oleh Skurichina dan Duin (2005), metode ensamble dengan menggunakan PCA menghasilkan hasil yang lebih baik dibandingkan jika melalui pemilihan peubah secara acak. Oleh karena itu, penerapan PCA pada MA dengan pengembangan metode PCMA diyakini mampu memberikan hasil prediksi peubah respon yang lebih akurat dengan ragam rendah.
Bootstrap
Proses bootstrap merupakan teknik resampling yang diperlukan pada tahapan awal PCMA, untuk matriks data peubah bebas × sebelum dilakukan proses pembentukan kandidat model dalam MA. Proses ini dilakukan pada amatan terpilih dengan peluang pengambilan tertentu.
Berikut ialah uraian tahapan pada proses bootstrap yang diterapkan. Misalkan diketahui anak matriks peubah bebas dengan dimensi × ( < ) yang menjadi target proses bootstrap. Tahapan yang dilakukan ialah dengan memilih secara acak sebanyak 75%× vektor amatan (vektor baris) dengan memperbolehkan pengulangan. Hasil dari proses ini ialah terbentuknya matriks peubah bebas baru dengan dimensi ∗× ; ∗=75%× ( ∗ <
< ).
Principal Component Analysis (PCA)
Adanya konsep PCA diterapkan pada pengembangan metode alternatif pembentukan kandidat model dalam MA, yakni PCMA. Proses PCA nantinya digunakan pada matriks data peubah bebas × sebelum dilakukan proses pembentukan kandidat model dalam MA. PCA diterapkan setelah proses bootstrap digunakan pada matriks data peubah bebas. Ide dasar pada PCA ialah adanya proses reduksi dimensi tanpa menghilangkan terlalu banyak informasi.
Berikut ini akan diulas mengenai tahapan yang dilakukan pada PCA. Misalkan diketahui anak matriks peubah bebas dengan dimensi ∗× ( ∗ < < ), selanjutnya proses PCA akan diterapkan matriks . Tahapan pertama pada PCA ialah membentuk matriks korelasi antar vektor kolom pada matriks . Didefinisikan matriks satu = [ ] × , serta matriks rataan
8
Selang Kepercayaan Optimum
Salah satu metode yang berguna untuk menentukan suatu nilai sama atau berbeda secara statistik ialah selang kepercayaan. Selang yang terbentuk merupakan gambaran wilayah nilai kisaran pada proses pendugaan yang dilakukan. Apabila pada dua nilai dugaan memiliki wilayah selang yang saling tumpang-tindih, maka secara statistik dapat dikatakan bahwa dua nilai tersebut sama.
Konsep utama dalam penentuan selang kepercayaan ialah mencari suatu batas bawah dan batas atas selang yang paling pendek dari setiap kemungkinan selang yang dapat terbentuk (Casella dan Berger, 2002). Pada konteks penelitian ini, selang kepecayaan digunakan untuk menggambarkan apakah performa metode kajian sama ataukah berbeda. Selanjutnya, karena keterbatasan informasi mengenai sebaran dari nilai yang diteliti, maka penentuan selang kepercayaan pada penelitian ini memanfaatkan konsep kuantil. Rumus kuantil pada persentase
ialah
� = ∑ℎ= � ℎ≤ =
Batasan persentase kesalahan yang ditoleransi ialah 5%, sehingga selang kepercayaan dibentuk berdasarkan selisih kuantil terpendek dengan total persentase kesalahan ialah 5%. Penentuan selang terpendek ini dilakukan dengan menetapkan kandidat pasangan kuantil yang terdiri dari kuantil bawah dan kuantil atas. Nilai pasangan persentase kuantil tersebut ialah � , � . , � . , � . ,
� . , � . , � . , � . , � . , � . , � . , � . , � . , � . , � . , � . ,
� . , � . , � . , � . , � . , � .
Aspek-aspek Pengukuran Penelitian
Seperti yang telah disebutkan pada bagian sebelumnya, aspek-aspek pengukuran untuk proses evaluasi pada penelitian ini meliputi keakuratan prediksi (MAPE, MAE, MSE), ketakbiasan prediksi, kebebasan dan ragam antar kandidat model, serta ragam prediksi model final. Berikut ini merupakan bahasan mengenai landasan teori aspek-aspek pengukuran yang digunakan.
1. Keakuratan Prediksi
Aspek keakuratan prediksi diukur melalui tiga (3) nilai pengukuran simpangan, yakni melalui MAPE (Mean Absolute Percentage Error), MAE (Mean Absolute Error), dan MSE (Mean Square Error). Adapun penjelasan dari ketiga nilai ini sebagai berikut.
a. MAPE (Mean Absolute Percentage Error)
utama dari MAPE ialah mencari nilai rataan mutlak selisih antara nilai prediksi dengan aktualnya relatif dengan nilai aktualnya. Nilai MAPE yang kecil menunjukkan semakin kecil galat yang terjadi, sehingga prediksi model yang diteliti akan semakin akurat. Rumus MAPE yang MAPE tentunya dilakukan untuk setiap kali ulangan. Akibatnya diperoleh sebanyak nilai MAPEℎ, ℎ = , , … , . Rataan dari nilai MAPE tersebut ialah MAPE̅̅̅̅̅̅̅̅ =∑ℎ= M PEℎ, dan simpangan baku dari nilai MAPE tersebut ialah (MAPE)= √∑ℎ= M PEℎ−M PE̅̅̅̅̅̅̅̅̅
− .
b. MAE (Mean Absolute Error)
MAE adalah ukuran kualitas prediksi yang sering juga digunakan dalam kasus pemodelan regresi. Konsepnya yakni dengan mencari rataan dari nilai mutlak galat. Nilai MAE yang kecil menunjukkan akurasi prediksi model yang diteliti semakin akurat. Rumus MAE yang digunakan ialah
MAE= ∑��= | ̂�− �|
Seperti MAPE, pada bagian simulasi perhitungan MAE dilakukan sebanyak kali sesuai dengan kali ulangan, sehingga diperoleh
MSE merupakan nilai kuadrat tengah galat yang mengindikasikan besarnya kontribusi dugaan model yang dibentuk terhadap keragaman yang tidak mampu dijelaskan oleh dugaan model tersebut. Indikasi suatu model yang dibentuk tersebut baik ialah dengan nilai MSE yang cukup rendah. Berikut ini merupakan rumus MSE yang digunakan.
10
2. Ketakbiasan Prediksi
Setelah diukur keakuratan prediksi model yang terbentuk, selanjutnya ketakbiasan prediksi menjadi bahasan yang penting untuk diterapkan. Secara definisi bias merupakan selisih antara nilai dugaan dengan nilai sesungguhnya. Apabila nilai bias adalah sama dengan nol, maka nilai dugaan akan sama dengan nilai sesungguhnya, sehingga dapat dikatakan kondisi tersebut takbias. Hal tersebut yang diinginkan dalam kaitannya dengan penelitian ini. Pada praktiknya, nilai bias disesuaikan dengan topik penelitian ini yaitu perihal ketakbiasan prediksi peubah respon. Rumus yang digunakan ialah
Bias=∑��= ̂�− �
Pada proses simulasi yang dilakukan sebanyak kali ulangan, nilai bias dihitung untuk masing-masing ulangan tersebut. Akibatnya diperoleh sebanyak nilai bias, yakni Biasℎ, ℎ = , , … , . Rataan dari nilai bias tersebut ialah Bias̅̅̅̅̅̅ =∑ℎ= iasℎ, dan simpangan baku dari nilai bias tersebut ialah (Bias)= √∑ℎ= iasℎ− ias̅̅̅̅̅̅
− .
3. Kebebasan dan Ragam Antar Prediksi Kandidat Model
Aspek pengukuran kebebasan dan ragam antar prediksi kandidat model digunakan untuk mengevaluasi metode MA yang diterapkan. Matriks korelasi prediksi kandidat model dimanfaatkan sebagai dasar penentuan pengukuran aspek-aspek pada bagian ini. Misalkan terdapat sebanyak kandidat model, maka terbentuk sebanyak prediksi peubah respon dari masing-masing kandidat model. Matriks korelasi dibentuk berdasarkan korelasi setiap prediksi peubah respon yang dihasilkan, sehingga matriks yang terbentuk memiliki ukuran × .
Evaluasi kebebasan antar prediksi kandidat model diukur melalui nilai determinan matriks korelasi prediksi setiap kandidat model. Nilai determinan yang sama dengan nol mengindikasikan bahwa matriks korelasi prediksi yang terbentuk bersifat singular. Dengan kata lain, prediksi kandidat model tersebut tidak saling bebas. Makna prediksi kandidat model yang tidak saling bebas ialah untuk memperoleh prediksi model final, dapat digunakan kombinasi linear dari masing-masing prediksi kandidat model tersebut.
karena itu, peninjauan dengan memanfaatkan nilai maksimum akar ciri sepadan artinya dengan penelaahan besarnya keragaman maksimum pada prediksi kandidat model.
Pada kajian simulasi yang dilakukan sebanyak kali ulangan, proses perhitungan determinan dan nilai maksimum akar ciri matriks korelasi prediksi setiap kandidat model juga dilakukan sebanyak kali. Misalkan
ℎdan �[ ]ℎ masing-masing menyatakan nilai determinan dan maksimum
akar ciri matriks korelasi prediksi setiap kandidat model pada ulangan ke-ℎ. Nilai rataannya masing-masing didefinisikan oleh ̅̅̅̅̅ = ∑ℎ= ℎ dan
Keragaman pada prediksi model final juga merupakan indikator yang sangat bermakna untuk menelaah karakteristik kebaikan metode MA. Idealnya, hasil suatu prediksi memiliki keakuratan yang tinggi serta ragam setiap nilai prediksinya cukup rendah. Perhitungan ragam prediksi model final diperoleh setelah proses MA pada ketiga metode tersebut dilakukan. Pengukuran ragam ini dilakukan secara empiris melalui simulasi dengan melibatkan banyak ulangan. Misalkan simulasi proses MA dilakukan sebanyak kali ulangan, maka akan diperoleh sebanyak prediksi model final untuk masing-masing metode MA. Perhitungan ragam prediksi model final untuk amatan ke- , = , , … , , dilakukan dengan menggunakan rumus berikut ini
� ̂ =∑ℎ= (̂−ℎ− ̂̅ )
12
PENDEKATAN BARU: Principal Component Model Averaging
(PCMA)
Bahasan utama pada penelitian yang dilakukan terdapat pada bagian ini. Secara tersendiri, bagian ini disusun untuk menjelaskan tahapan dari pengembangan metode MA dengan memasukkan proses rotation forest, yang disebut PCMA. Meskipun algoritme yang dikembangkan mengacu pada algoritme rotation forest, namun beberapa penyesuaian dilakukan dalam kaitannya dengan penerapan pada kasus MA.
Seperti yang disebutkan sebelumnya, metode PCMA dikembangkan berdasarkan algoritme rotation forest (Rodriguez dan Kuncheva 2006). Konsep utama yang digunakan pada metode MA yaitu dengan memasukkan proses PCA untuk membentuk komponen-komponen yang saling bebas. Adanya proses ini diharapkan dapat menurunkan keragaman prediksi model akhir yang terbentuk yakni dengan mengurangi komponen kovarian dalam penentuan ragam prediksi.
Misalkan diketahui vektor kolom peubah bebas pada matriks × = [ … ], selanjutnya dibagi secara acak menjadi � anak matriks yang berisi ; = , , … , � vektor peubah bebas < , , = , , … , �; dengan ketentuan untuk yang berbeda, vektor peubah bebas pada jugaberbeda. Pada setiap anak matriks tersebut, dilakukan proses resampling dengan metode bootstrap dengan ukuran 75% dari amatan di dalamnya. Misalkan merupakan hasil proses bootstrap pada anak matriks , maka PCA dilakukan pada untuk diperoleh koefisien dari komponen utamanya, � , � , … , � �, dengan ukuran masing-masing × . Selanjutnya dibentuk matriks rotasi �
� × = [
� , � , … , � � ⋱
� , � , … , � � ]
Langkah selanjutnya membentuk komponen peubah bebas � × = [� � … � ] = � , dengan � merupakan matriks rotasi � yang telah
dilakukan operasi pemindahan kolom untuk peubah bebas yang sesuai dengan . Analisis regresi dilakukan pada terhadapkandidat model dari komponen peubah bebas matriks �.
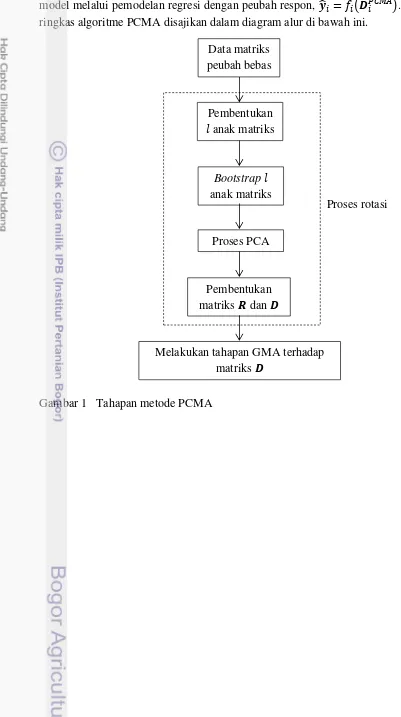
model melalui pemodelan regresi dengan peubah respon, ̂ = ̂ (� ���). Secara ringkas algoritme PCMA disajikan dalam diagram alur di bawah ini.
Gambar 1 Tahapan metode PCMA
Data matriks peubah bebas
Pembentukan � anak matriks peubah bebas
Bootstrap � anak matriks peubah bebas
Proses PCA
Pembentukan matriks �dan�
Melakukan tahapan GMA terhadap matriks �
14
EVALUASI RMA, GMA, & PCMA
Pada bagian ini akan dibahas karakteristik metode RMA, GMA, dan PCMA dalam memprediksi peubah respon pada permasalahan regresi dimensi tinggi ( ≫ ) dengan data simulasi menggunakan software R. Data regresi × = [ … ] ditetapkan dengan kondisi ≫ , = , dan = . Berdasarkan = peubah bebas, ditetapkan pula sebanyak = peubah peubah bebas yang mempengaruhi peubah respon yang ditandai dengan nilai koefisien regresi bernilai 1. Pengaruh acak � dibangkitkan mengikuti sebaran normal dengan rataan 0 dan simpangan baku 4. Misalkan matriks ̃ =
Penerapan RMA, GMA, dan PCMA dilakukan dengan jumlah peubah bebas pada kandidat model berbeda-beda, = { , , … , , , , , , , }, ukuran = , dengan ulangan = , serta dengan dua jenis tipe bobotnya, pembobotan sama dan AIC. Kajian empiris pada data simulasi yakni dengan mengukur aspek-aspek sebagai berikut:
1. kebaikan prediksi yang dilihat dari kriteria evaluasi rataan MAPE, rataan MAE, dan rataan MSE dari 1000 ulangan
2. ketakbiasan prediksi, melalui rataan bias dari 1000 ulangan
3. nilai rataan determinan dan rataan maksimum akar ciri dari matriks korelasi dari kandidat model untuk 1000 kali ulangan
4. serta ragam prediksi model final dari 1000 ulangan.
Pada bagian selanjutnya akan dibahas mengenai hasil simulasi yang telah dilakukan. Hasil ini pada prinsipnya didasarkan setiap aspek-aspek pengukuran yang diteliti, yang dibagi menjadi dua bagian yakni berdasarkan data training dan testing. Hasil simulasi disajikan dalam grafik garis yang disertai wilayah selang kepercayaannya yang paling optimum melalui pengukuran kuantil 5%. Berdasarkan hasil ini nantinya dapat diperoleh visualisasi secara grafik metode mana yang lebih baik dari metode lainnya, serta kesamaan antar hasil metode tersebut. Jika wilayah selang kepercayaan yang terbentuk antar metode saling tumpang tindih, dapat dikatakan bahwa hasil antar metode tersebut tidak berbeda secara nyata.
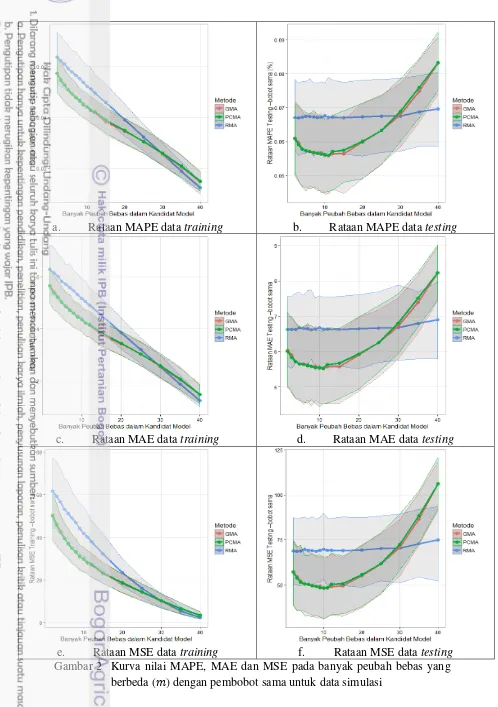
Berdasarkan aspek pengukuran yang digunakan, MAPE, MAE, dan MSE, kebaikan prediksi pada pembobotan sama memiliki pola yang sama (Gambar 2). Sebagian besar, hasil evaluasi pada data training menunjukkan bahwa PCMA relatif serupa dengan GMA dalam ketepatan nilai prediksi peubah respon, yakni semakin besar nilai maka prediksinya akan semakin tepat. Hal ini berlaku juga pada RMA, namun dengan tingkat ketepatan yang sedikit lebih kecil. Pada data testing, pola hasil evaluasi PCMA tidak berbeda dengan GMA, yang memiliki pola non-linear. Semakin besar nilai maka akan menurunkan ketepatan prediksinya. Hal ini dikarenakan akibat dari kondisi pembangunan model dengan peubah bebas yang lebih banyak, akan membuat model tersebut overfit. Sebaliknya, hasil evaluasi RMA memiliki pola yang linear.
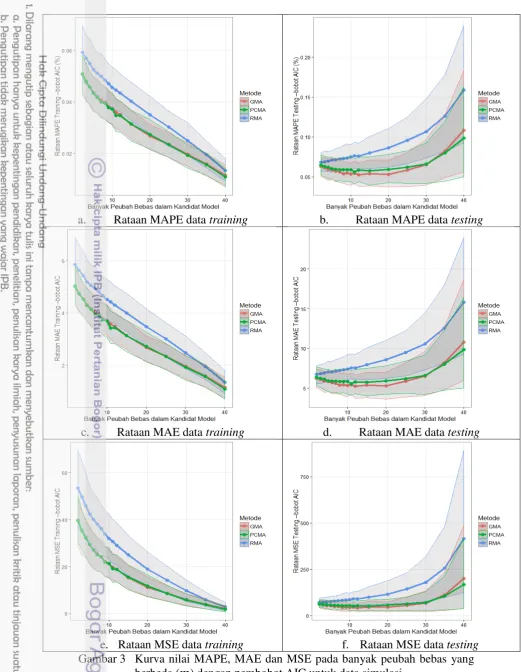
Gambar 3 menyajikan hasil evaluasi dengan pembobotan AIC. Hasil evaluasi dengan pembobotan AIC pada data testing memiliki kondisi yang serupa ketika menggunakan pembobotan sama. Pada data testing, metode yang paling akurat dalam melakukan prediksi ialah PCMA untuk nilai yang besar, yakni nilai evaluasi yang dihasilkan lebih kecil dibandingkan RMA dan GMA. Meskipun wilayah selang pada PCMA tumpang tindih dengan metode GMA. Hal ini mengindikasikan bahwa PCMA menghasilkan nilai evaluasi yang lebih kecil namun tidak berbeda nyata dengan hasil GMA ketika menggunakan pembobot AIC.
16
a. Rataan MAPE data training b. Rataan MAPE data testing
c. Rataan MAE data training d. Rataan MAE data testing
e. Rataan MSE data training f. Rataan MSE data testing Gambar 2 Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas yang
a. Rataan MAPE data training b. Rataan MAPE data testing
c. Rataan MAE data training d. Rataan MAE data testing
e. Rataan MSE data training f. Rataan MSE data testing Gambar 3 Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas yang
18
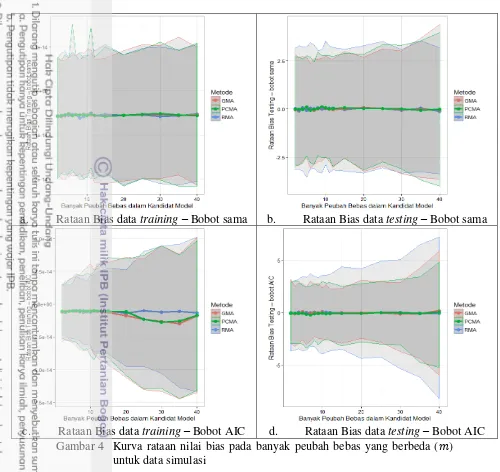
a. Rataan Bias data training – Bobot sama b. Rataan Bias data testing – Bobot sama
c. Rataan Bias data training – Bobot AIC d. Rataan Bias data testing – Bobot AIC Gambar 4 Kurva rataan nilai bias pada banyak peubah bebas yang berbeda ( )
untuk data simulasi
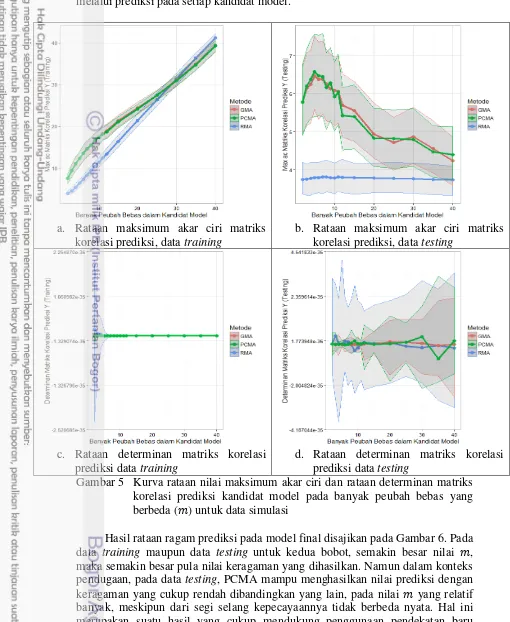
Berikutnya, dari segi aspek pengukuran rataan nilai maksimum akar ciri dan rataan determinan dari matriks korelasi keseluruhan prediksi kandidat model, diperoleh hasil yang relatif serupa antara PCMA dengan GMA (Gambar 5). Nilai maksimum akar ciri mengindikasikan pola keragaman dari prediksi kandidat model yang diperoleh. Hasil simulasi memperlihatkan bahwa untuk data training nilai maksimum akar ciri yang diperoleh relatif sama dengan kecenderungan meningkat sejalan dengan . Namun pada data testing diperoleh informasi bahwa semakin meningkatnya , maka semakin kecil nilai maksimum akar ciri yang diperoleh. Hal ini mengindikasikan semakin banyak peubah bebas dalam kandidat model maka semakin tidak beragam prediksi dari model yang diperoleh.
menghasilkan prediksi peubah respon pada setiap kandidat model yang tidak saling bebas, akibatnya pembentukan model averaging yang diinginkan dapat melalui prediksi pada setiap kandidat model.
a. Rataan maksimum akar ciri matriks korelasi prediksi, data training
b. Rataan maksimum akar ciri matriks korelasi prediksi, data testing
c. Rataan determinan matriks korelasi prediksi data training
d. Rataan determinan matriks korelasi prediksi data testing
Gambar 5 Kurva rataan nilai maksimum akar ciri dan rataan determinan matriks korelasi prediksi kandidat model pada banyak peubah bebas yang berbeda ( ) untuk data simulasi
20
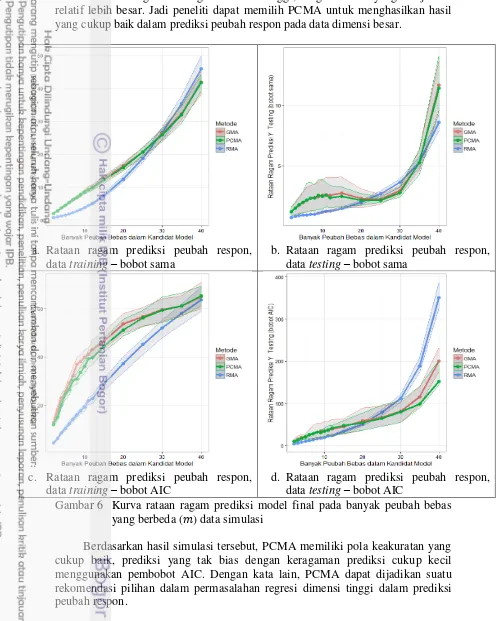
PCMA untuk menganalisis regresi dimensi tinggi, dengan nilai yang dianjurkan relatif lebih besar. Jadi peneliti dapat memilih PCMA untuk menghasilkan hasil yang cukup baik dalam prediksi peubah respon pada data dimensi besar.
a. Rataan ragam prediksi peubah respon, data training – bobot sama
b. Rataan ragam prediksi peubah respon, data testing – bobot sama
c. Rataan ragam prediksi peubah respon, data training – bobot AIC
d. Rataan ragam prediksi peubah respon, data testing – bobot AIC
Gambar 6 Kurva rataan ragam prediksi model final pada banyak peubah bebas yang berbeda ( ) data simulasi
APLIKASI RMA, GMA, & PCMA
Prediksi AFB1 Melalui Profil Metilasi DNA Darah Bayi dari Kelompok Ibu/Anak di Gambia
Pada bagian sebelumnya sudah dikemukakan bahwa PCMA dapat dijadikan suatu rekomendasi metode ketika berhadapan pada kasus prediksi peubah respon dengan kondisi data peubah bebas sangat besar. Selanjutnya, bagian ini akan disajikan aplikasi PCMA dalam kasus permasalahan regresi untuk prediksi peubah respon pada data dimensi besar. Bahasan ini ditujukan sebagai gambaran contoh kasus yang dapat dijadikan acuan dalam pesoalan nyata yang berkaitan dengan prediksi pada data dimensi besar.
Sajian kasus yang digunakan ialah kasus prediksi peubah paparan intra-uterus ke aflatoksin B1 (AFB1) ibu hamil dengan menggunakan profil metilasi DNA sel darah putih bayinya. Dengan kata lain, peubah responnya ialah AFB1 serta peubah bebasnya merupakan profil metilasi DNA. Terdapat sebanyak 124 amatan ibu hamil yang diteliti. Peubah AFB1 berasal dari ibu hamil pada trimester pertama kehamilan, yang menyatakan gambaran banyaknya kandungan racun pada tubuh ibu hamil tersebut akibat memakan jagung dan kacang tanah yang tercemar. Setelah ibu hamil tersebut melahirkan, bayinya ketika umur 3 s.d. 6 bulan diambil sel darah putihnya untuk dilakukan metilasi DNA. Hasil dari metilasi DNA sel darah putih bayi tersebut memiliki 485577 profil (Vargas et al 2015). Akibatnya data peubah respon memiliki ukuran = 124 dan = 485577, yang dapat digolongkan data dimensi besar, ≫ .
Tahapan pertama pada pengolahan data yang dilakukan meliputi penyisihan profil metilasi DNA dan AFB1 yang terdapat data kosong (tidak lengkap). Proses penyisihan ini dilakukan sebagai upaya menghindari tidak berjalannya algoritme RMA, GMA, serta PCMA yang didefinisikan, karena metode yang dibangun pada penelitian ini tidak kekar terhadap data kosong. Jika terdapat data kosong pada peubah AFB1, maka baris peubah profil metilasi DNA yang bersesuaian dengan data kosong tersebut akan disisihkan. Serta jika terdapat data kosong pada peubah profil metilasi DNA, maka kolom pada profil metilasi DNA yang bersesuaian dengan data kosong tersebut akan disisihkan. Akibatnya diperoleh =480050 dan = 118 tanpa data kosong. Selanjutnya terhadap data ini, dilakukan upaya prediksi peubah respon AFB1 dengan metode RMA, GMA, dan PCMA.
22
a. Nilai MAPE data training b. Nilai MAPE data testing
c. Nilai MAE data training d. Nilai MAE data testing
e. Nilai MSE data training f. Nilai MSE data testing Gambar 7 Kurva nilai MAPE, MAE dan MSE pada banyak peubah bebas yang
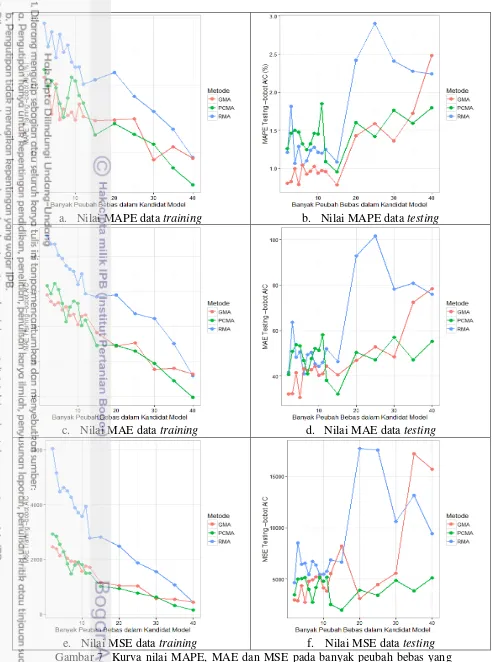
Hasil evaluasi kebaikan antara metode RMA, GMA, dan PCMA dengan pembobot AIC disajikan pada Gambar 7. Berdasarkan grafik tersebut, PCMA menghasilkan nilai evaluasi yang lebih kecil dibandingkan RMA dan GMA. Hasil ini menunjukkan bahwa PCMA sangat efektif dalam prediksi peubah respon meskipun dengan jumlah peubah bebas yang sangat banyak. Penggunaan PCMA juga disarankan agar peubah bebas yang digunakan pada kandidat model dengan ukuran cukup banyak.
Selanjutnya, pada Tabel 1, menyajikan besarnya rataan nilai korelasi antara prediksi peubah AFB1 dengan peubah AFB1 aktualnya, yang diperoleh berdasarkan rataan semua banyaknya peubah bebas dalam kandidat model yang digunakan. Pada data training nilai rataan korelasi untuk ketiga metode tersebut yang dihasilkan cukup besar, hal ini menandakan model untuk prediksi yang dibentuk sudah sangat baik. Nilai rataan korelasi pada data testing digunakan untuk melihat pola prediksi apakah sesuai dengan aktualnya. Ternyata dengan data yang cukup besar, nilai korelasi yang dihasilkan pada data testing tidak cukup tinggi, sehingga dapat dikatakan polanya cukup beragam. Namun, pada data secara keseluruhan nilai korelasi yang dihasilkan sudah cukup baik. Pada sudut pandang lain, dari sisi metode, PCMA menghasilkan nilai rataan korelasi yang lebih besar daripada RMA dan GMA untuk data training, data testing, maupun data secara keseluruhan. Hal ini mengindikasikan pada studi kasus ini PCMA dapat diaplikasikan dengan cukup baik.
Tabel 1 Rataan korelasi antara prediksi peubah AFB1 dengan peubah AFB1 aktual untuk semua kondisi peubah bebas dalam kandidat model
Keterangan data Metode
RMA GMA PCMA
Data training 0.742 0.879 0.886 Data testing 0.003 -0.002 0.033 Keseluruhan data 0.411 0.484 0.503
24
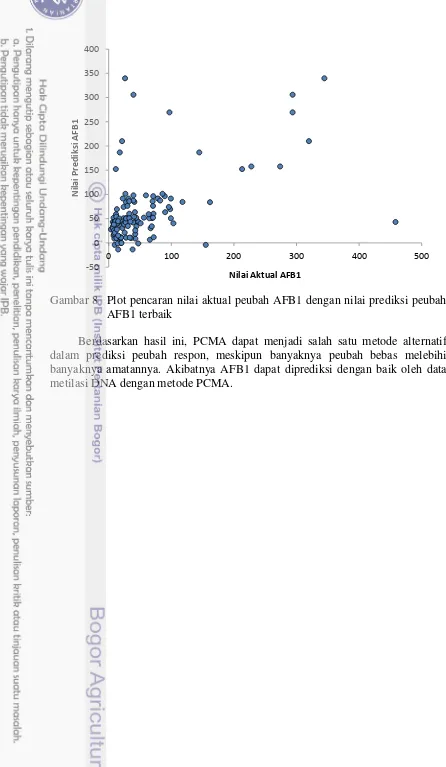
Gambar 8 Plot pencaran nilai aktual peubah AFB1 dengan nilai prediksi peubah AFB1 terbaik
Berdasarkan hasil ini, PCMA dapat menjadi salah satu metode alternatif dalam prediksi peubah respon, meskipun banyaknya peubah bebas melebihi banyaknya amatannya. Akibatnya AFB1 dapat diprediksi dengan baik oleh data metilasi DNA dengan metode PCMA.
-50 0 50 100 150 200 250 300 350 400
0 100 200 300 400 500
N
il
ai
Pr
e
d
iksi
A
FB
1
SIMPULAN
Simpulan
Melalui kajian simulasi terungkap bahwa PCMA dapat dijadikan alternatif metode untuk prediksi peubah respon pada data regresi dimensi tinggi. Indikatornya ialah nilai evaluasi kebaikan MAPE, MAE, dan MSE yang cukup kecil dengan bias relatif disekitar nol (tak bias), disertai dengan rataan ragam prediksi final yang sangat kecil. Meskipun hasil evaluasi kebaikan pada PCMA tidak berbeda nyata dengan GMA, namun dari segi rataan ragam prediksi model final, PCMA mampu menghasilkan nilai yang cukup kecil dan mampu dijadikan patokan sebagai alternatif metode.
26
DAFTAR PUSTAKA
Ando T, Li KC. 2014. A Model-Averaging Approach for High-Dimensional Regression, Journal of the American Statistical Association. 194: 254-265. Breiman L. 2001. Random Forests, Machine Learning. 45: 5-32.
Casella G, Berger RL. Statistical Inference Second Edition. Pacific Grove (US): Duxbury Thomson Learning.
Claeskens G, Hjort NL. 2008. Model Selection and Model Averaging. New York (US): Cambridge University Press.
Hoerl AE, Kennard RW. 1970. Ridge Regression: Biased Estimation for Nonorthogonal Problems, Technometrics. 12: 55-67.
Myttenaere AD, Golden B, Grand BL, Rossi F. 2015. Using the Mean Absolute Percentage Error for Regression Models. Proceedings of the 23-th European Symposium on Articial Neural Networks, Computational Intelligence and Machine Learning (ESANN 2015). hal-01162980.
Perrone MP. 1993. Improving Regression Estimation: Averaging Methods for Variance Reduction with Extensions to General Convex Measure Optimization [disertasi]. Providence(US): Brown University.
Rodriguez JJ, Kuncheva LI. 2006. Rotation Forest: A New Classifier Ensemble Method, IEEE Transactions on Pattern Analysis and Machine Intelligence. 28: 1619-1630.
Skurichina M, Duin RPW. 2005. Combining Feature Subsets in Feature Selection. LNCS. 3541: 165-175.
Tibshirani R. 1996. Regression Shrinkage and Selection via the LASSO, Journal of the Royal Statistics Society Series B. 58: 267-288.
Vargas HH, Castelino J, Silver MJ, Salas PD, Cros MP, Durand G, Kelm FLC, Prentice AM, Wild CP, Moore SE et al. 2015. Exposure to aflatoxin B1 in
utero is associated with DNA methylation in white blood cells of infants in The Gambia. International Journal of Epidemiology.1-11.
Xie H, Huang J. 2009. SCAD-Penalized Regression in High-Dimensional Partially Linear Models, The Annals of Statistics. 37: 673-696.
Zhou ZH. 2012. Ensemble Methods Foundations and Algorithms. Boca Raton(US): CRC Press
LAMPIRAN
28
Lampiran 1 Algoritme simulasi Randomized Model Averaging (RMA) Lakukan untuk = { , , … , , , , , , , };
Mulai : Ulangi dari ℎ = , , … , ;
Bagi amatan data secara acak menjadi 2 bagian sama besar sebagai training dan testing;
Lakukan pada data training:
Tentukan ��; = , … , berisi peubah bebas secara acak (tanpa pengembalian);
Regresikan setiap �� dengan , simpan prediksinya ̂ ��;
Hitung prediksi model final dengan bobot sama �̂ �� & bobot AIC ���̂ ��; Hitung akar ciri terbesar matriks korelasi dari semua ̂ ��; = , … , ;
Hitung determinan matriks korelasi dari semua ̂ ��; = , … , ; Hitung MAPE, MAD, dan MSE dari �̂ �� dan ���̂ ��;
Hitung bias relatif (BR) dari �̂ �� dan ���̂ ��; Lakukan pada data testing:
Hitung akar ciri terbesar matriks korelasi dari semua ̂ ��; = , … , ; Hitung determinan matriks korelasi dari semua ��; = , … , ; Hitung MAPE, MAD, dan MSE dari �̂ �� dan ���̂ ��;
Hitung bias relatif (BR) dari �̂ �� dan ���̂ ��; Selesai
Hitung rataan MAPE, MAD, dan MSE dari �̂ �� dan ���̂ �� untuk seluruh ℎ; Hitung rataan akarciri terbesar dari seluruh ulangan ℎ;
Lampiran 2 Algoritme simulasi General Model Averaging (GMA)
Lakukan untuk = { , , … , , , , , , , } Mulai : Ulangi dari ℎ = , , … ,
Bagi amatan data secara acak menjadi 2 bagian sama besar sebagai training dan testing;
Lakukan pada data training:
Korelasikan setiap peubah bebas dengan peubah respon; Urutkan peubah bebas berdasarkan nilai korelasinya, ���; Bagi ���menjadi bagian, ��� = [ [ − + ]]
= ,…, ; = , … , ;
Regresikan setiap ��� dengan , simpan prediksinya ̂���
Hitung prediksi model final dengan bobot sama �̂��� & bobot AIC ���̂���; Hitung akar ciri terbesar matriks korelasi dari semua ̂���; = , … , ;
Hitung determinan matriks korelasi dari semua ̂���; = , … , ; Hitung MAPE, MAD, dan MSE dari �̂��� dan ���̂���;
Hitung bias relatif (BR) dari �̂��� dan ���̂���; Lakukan pada data testing:
Hitung akar ciri terbesar matriks korelasi dari semua ̂���; = , … , ; Hitung determinan matriks korelasi dari semua ̂���; = , … , ; Hitung MAPE, MAD, dan MSE dari �̂��� dan ���̂���;
Hitung bias relatif (BR) dari �̂��� dan ���̂���; Selesai
Hitung rataan MAPE, MAD, dan MSE dari �̂��� dan ���̂��� untuk seluruh ℎ; Hitung rataan akarciri terbesar dari seluruh ulangan ℎ;
30
Lampiran 3 Algoritme simulasi Principal Component Model Averaging (PCMA)
Tentukan himpunan bagian secara acak berisi peubah bebas, ; = , … , �; Lakukan bootstrap 75% bagi amatan , ;
Lakukan PCA pada setiap , lalu bentuk matriks �;
Kembalikan urutan peubah bebas (kolom) pada � sesuai dengan , � ; Hitung � × = [� � … � ] = � ;
Lakukan untuk = { , , … , , , , , , , } Mulai : Ulangi dari ℎ = , , … ,
Bagi amatan data � secara acak menjadi 2 bagian sama besar sebagai training dan testing;
Lakukan pada data training:
Korelasikan setiap peubah bebas pada � dengan peubah respon; Urutkan peubah bebas berdasarkan nilai korelasinya, � ���; Bagi � ��� menjadi bagian, � ��� = [�[ − + ]] Hitung rataan akarciri terbesar dari seluruh ulangan ℎ;
RIWAYAT HIDUP
Penulis dilahirkan di Rembang pada tanggal 6 September 1991 dari bapak Iman Sugiyantoro dan ibu Sudarti. Penulis adalah putra pertama dari dua bersaudara. Tahun 2009 penulis lulus dari SMA Negeri 1 Rembang dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur Undangan Seleksi Masuk IPB dan diterima di Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan S1, penulis menjadi asisten praktikum Fisika TPB pada semester ganjil dan genap tahun ajaran 2010/2011, asisten Kalkulus II dan Metode Statistika pada semester ganjil tahun ajaran 2011/2012, asisten Kalkulus III dan Metode Penarikan Contoh pada semester genap tahun ajaran 2011/2012, serta asisten Komputasi Statistika dan Analisis Data Kategorik pada semester ganjil tahun ajaran 2012/2013. Penulis juga aktif mengajar mata kuliah TPB dan Statistika di bimbingan belajar dan privat mahasiswa Klinik Studi Expert. Penulis juga pernah menjadi ketua panitia Komstat Jr dalam rangkaian acara Pesta Sains Nasional IPB 2012. Bulan Februari-Maret 2013 penulis melaksanakan Praktik Lapang di PT. Ewaysindo Makmur.
Penulis juga aktif mengikuti lomba tingkat mahasiswa pada jenjang S1. Beberapa lomba yang pernah penulis ikuti yaitu sebagai finalis Olimpiade Nasional Matematika 2011, finalis Olimpiade Nasional Matematika 2012, finalis Kompetisi Statistika Ria 2012.
Tahun 2013 penulis lulus S1 dari Departemen Statistika IPB, kemudian menjadi staf pengajar pada Departemen Statistika IPB. Penulis melanjutkan studi pada jenjang S2 pada tahun 2014 di Program Studi Statistika Pascasarjana IPB dengan beasiswa Fresh Graduate DIKTI.