ANALISIS DAN PERBANDINGAN
STEMMING TEKS BAHASA INDONESIA MENGGUNAKAN
ALGORITMA VEGA DAN ALGORITMA CONFIX-STRIPPING
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
HELMI AGUSTIAN
10111988
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Assalamualaikum Wr. Wb.
Alhamdulilahi Rabbil’ Alamiin
, puji dan syukur penulis panjatkan ke hadirat Allah
SWT atas rahmat dan karunia-Nya sehingga penulis dapat menyelesaikan skripsi
yang berjudul “Analisis Dan Perbandingan Stemming Teks Bahasa Indonesia
Menggunakan Algoritma Vega Dan Algoritma Confix-Stripping
” untuk memenuhi
salah satu syarat dalam menyelesaikan studi jenjang strata satu di Program Studi
Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer
Indonesia.
Penulisan skripsi ini tidak luput tanpa dukungan, bantuan dan masukan dari berbagai
pihak. Melalui kata pengantar ini, Penulis ingin menyampaikan terima kasih kepada :
1.
Allah SWT atas segala nikmat yang telah diberikan hingga Penulis dapat
menyelesaikan skripsi ini.
2.
Kedua orang tua beserta adik-adiku yang telah memberikan dukungan moril,
kasih sayang, maupun doa sampai Penulis dapat menyelesaikan skrips ini.
3.
Keluarga cianjur nenek, kakek, abah, umi dan seluruh keluarga besar di sana.
Terima kasih atas dukungan selama ini.
4.
Ibu Tati Harihayati M., S.T., M.T., selaku dosen pembimbing. Terimakasih
karena selama ini telah sabar dalam memberikan arahan, dukungan, saran,
dan nasehatnya serta meluangkan waktunya selama proses penyusunan skripsi
ini.
5.
Ibu Nelly Indriani W, S.Si., M.T., selaku reviewer. Terimakasih karena telah
meluangkan waktunya, memberikan bimbingan, saran, nasehat serta masukan
dalam proses penyusunan skripsi ini
iv
7.
Teman-teman seperjuangan, sumedi, swaji, anggi, rully dan lainnya. Risma,
arif, reni, gian, ade, jesika, dan teman-teman lain yang tidak bisa Penulis
sebutkan, terima kasih atas bantuannya selama ini.
8.
Teman-teman kantor wiradipa, terima kasih karena telah memberikan
keceriaan di tengah proses penyusunan skripsi ini. Buat eja, yang mau
digangu subuh-subuh buat pinjam c
onverter vga. Nuhun ja…
9.
Serta seluruh pihak yang tidak dapat Penulis sebutkan satu-persatu,
terimakasih atas segala bentuk dukungan untuk menyelesaikan skripsi ini.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari sempurna. Oleh
karena itu, penulis mengharapkan saran dan masukan yang bersifat membangun
untuk perbaikan dan pengembangan skripsi ini. Akhir kata, semoga penulisan
skripsi ini dapat bermanfaat bagi penulis khususnya dan bagi pembaca pada
umumnya.
Wassalamualaikum Wr. Wb.
Bandung, 27 Februari 2016
v
DAFTAR ISI
ABSTRAK ...
i
ABSTRACT ...
ii
KATA PENGANTAR ...
iii
DAFTAR ISI ...
v
DAFTAR GAMBAR ...
ix
DAFTAR TABEL ...
xii
DAFTAR SIMBOL ...
xv
DAFTAR LAMPIRAN ...
xxii
BAB 1 PENDAHULUAN ...
1
1.1
Latar Belakang ...
1
1.2
Rumusan Masalah ...
3
1.3
Maksud dan Tujuan ...
3
1.4
Batasan Masalah ...
4
1.5
Metodologi Penelitian ...
4
1.5.1
Alur Penelitian ...
4
1.5.2
Pembangunan Perangkat Lunak ...
6
1.6
Sistematika Penulisan ...
7
BAB 2 LANDASAN TEORI ...
9
2.1
Morfologi Bahasa Indonesia ...
9
vi
2.1.2
Sufiks (akhiran) ...
14
2.1.3
Partikel ...
14
2.2
Pengertian Stemming ...
14
2.2.1
Macam-macam Metode Stemming ...
15
2.2.2
Algoritma Vega ...
17
2.2.3
Algoritma Confix-stripping ...
20
2.3
Pengujian ...
21
2.3.1
Ukuran rata-rata word conflation class ...
21
2.3.2
Index compression factor ...
22
2.3.3
Jumlah kata yang berbeda antara kata masukan dan stem ...
25
2.3.4
Nilai rata-rata huruf yang dihapus ...
25
2.3.5
Nilai mean dan median modified hamming distance ...
25
2.4
Ruby on rails ...
26
2.5
Unified Modelling Language ...
27
BAB 3ANALISIS DAN PERANCANGAN SISTEM ...
31
3.1
Analisis Sistem ...
31
3.1.1
Analisis Masalah ...
31
3.1.2
Analisis Kebutuhan Data ...
31
3.1.3
Analisis Algoritma ...
31
3.1.3.1
Analisis Proses Tokenizing ...
33
vii
3.1.3.3
Analisis Proses Stemming ...
35
3.1.4
Analisis Kebutuhan Nonfungsional ...
65
3.1.4.1
Analisis Kebutuhan Perangkat Keras ...
66
3.1.4.2
Analisis Kebutuhan Perangkat Lunak ...
66
3.1.4.3
Analisis Kebutuhan Pengguna ...
67
3.1.5
Analisis Kebutuhan Fungsional ...
67
3.1.5.1
Diagram Use Case ...
68
3.1.5.2
Diagram Aktivitas ...
76
3.1.5.3
Diagram Sekuen ...
82
3.1.5.4
Diagram Kelas ...
87
3.2
Perancangan Sistem ...
89
3.2.1
Perancangan Basis Data ...
90
3.2.1.1
Diagram Relasi ...
90
3.2.1.2
Struktur Tabel ...
91
3.2.2
Perancangan Antarmuka ...
95
3.2.3
Jaringan Semantik ...
103
3.2.4
Perancangan Method ...
104
BAB 4 IMPLEMENTASI DAN PENGUJIAN ...
111
4.1
Implementasi ...
111
4.1.1
Implementasi Perangkat Keras ...
111
viii
4.1.3
Implementasi Basis Data ...
112
4.1.4
Implementasi Antarmuka ...
115
4.2
Hasil pengujian parameter uji algoritma vega dan algoritma confix-
stripping ...
120
4.2.1
Ukuran rata-rata word per conflation class ...
121
4.2.2
Index compresssion factor ...
122
4.2.3
Jumlah kata yang berbeda antara kata masukan dan stem
124
4.2.4
Nilai rata-rata huruf yang dihapus ...
125
4.2.5
Nilai mean modified hamming distance ...
126
4.2.6
Nilai median modified hamming distance ...
127
4.3
Kesimpulan pengujian parameter uji ...
129
BAB 5 KESIMPULAN DAN SARAN ...
131
5.1 KESIMPULAN ...
131
5.2 SARAN ...
132
133
DAFTAR PUSTAKA
[1]
Adipathy, A. 2010. “
Analisis Dan Implementasi Perbandingan Stemming
Dengan Menggunakan Algoritma Jelita Asian Dan Algoritma Arifin &
Setiono Pada Information Retrieval”. Telkom University. Bandung.
[2]
A.S. Rosa dan Shalahudin. 2013.
“Rekayasa Perangkat Lunak”. Bandung:
Informatika.
[3]
Asian, J. 2007. “Effective Techniques for Indonesian Text Retrieval”.
Melbourne: RMIT University, Australia.
[4]
Asian, J., Williams, H.E. and Tahaghoghi, S.M.M. “Stemming
Indonesian”. RMIT University, Melb
ourne, Australia.
[5]
Frakes, W.B., Fox, C.J. “Strength and Similarity of Affix Removal
Stemming Algorithms”. Computer Science Department. Virginia Tech
and James Madison University.
[6]
Jivani, A.G.
2011. “
A comparative s
tudy of Stemming Algoritm”.
Gujarat:
Departement of Computer Science & Enginering. India.
[7]
Marsya, J.M. & Abidin, T.F. “Analisa dan Evaluasi Afiks Stemming
untuk Bahasa Indonesia”. Universitas Syiah Kualasa Banda Aceh,
Indonesia.
[8]
Moeliono, A.M. dan Darjowidjojo, S. 1988. "Tata Bahasa Baku Bahasa
Indonesia". Jakarta: Departemen Pendidikan dan Kebudayaan, Republik
Indonesia.
[9]
Nugraha, L.M
. 2010. “
Analisis Penggunaan Algoritma Stemming Vega
Pada Information Retrieval System”. Telkom University. Bandung.
[10]
Sharma, D. 2012. “Stemming Algorithms: A
Comparative Study and their
134
[11]
Paice, C.D. 1994. "An Evaluation method for stemming algoritms".
Springer-Verlag: New York.
[12]
Senddon, J.N.. 1996. "Indonesian: A Comprehensive Grammar". London
dan Newyork: Routledge.
[13]
Wilujeng, A. 2002. "Inti Sari Kata Bahasa Indonesia Lengkap". Surabaya:
Serba Jaya.
1
BAB 1
PENDAHULUAN
1.1.
Latar Belakang Masalah
Digital library
adalah sebuah koleksi objek digital yang dapat berupa teks,
materi visual, ataupun materi audio, yang disimpan dalam media elektronik. Salah
satu keunggulan yang ditawarkan
digital library
adalah dalam hal pencarian. Dalam
melakukan pencarian dalam
digital library
diperlukan penerapan teknik tertentu
supaya hasil pencarian sesuai dengan apa yang dicari. Salah satunya adalah dengan
menerapkan algoritma
stemming
dalam pencarian dokumen di dalam
digital library
.
Stemming
adalah proses pemotongan imbuhan dari suatu kata ke bentuk asal atau
kata dasarnya [7]. Algoritma
stemming
merupakan fitur penting bagi sistem
pengindeksan dan pencarian, karena dapat meningkatkan kemampuan
recall
dengan
secara otomatis mengubah suatu kata ke bentuk dasarnya [6]. Algoritma
stemming
juga dapat meningkatan
index compression
yang merupakan hal penting karena dapat
menjaga agar penggunaan tempat penyimpanan seminimal mungkin.
Masalah yang kemudian muncul adalah bagaimana menentukan algoritma
stemming yang baik dari segi
recall
dan
index compression
. Menurut jurnal karya W.
B. Frakes salah satu faktor penentu baik tidaknya suatu algoritma stemming adalah
dengan menghitung
stemmer strength
[5], semakin baik
stemmer strength
suatu
algoritma maka semakin baik pula nilai
recall
dan
index compression
, walaupun
memiliki kelemahan karena dapat menguarangi nilai dari
precission
.
Parameter-parameter
stemmer strength
yaitu: ukuran rata-rata
word per conflation class
,
index
compression factor
, jumlah kata yang berbeda antara kata masukan dan kata keluaran
(
stem
), rata-rata huruf yang dihilangkan untuk membentuk
stem
, dan terakhir nilai
2
Parameter-parameter
stemmer strength
tersebut di atas akan diuji pada algoritma
stemming untuk Bahasa Indonesia. Algoritma stemming pada Bahasa Indonesia
diantaranya adalah Ahmad Yusoff Sembok (1996) yang sebenarnya dibuat untuk
bahasa melayu, Nazief & Adriani (1996) merupakan algoritma stemming awal untuk
Bahasa Indonesia, Idris (2001) merupakan pengembangan dari algoritma Ahmad
Yusoff Sembok untuk Bahasa Indonesia, Vega (2001), Arifin & Setiono (2002)
merupakan penyederhanaan dari Nazief & Adriani, dan Confix-stripping (2005)
merupakan pengembangan dari Nazief & Adriani. Algoritma stemming pada Bahasa
Indonesia yang dipilih pada penelitian ini adalah Algoritma vega yang dibuat untuk
meningkatkan performa
retrieval
dokumen dalam hal ini
recall
dan
precission,
dan
algoritma confix-stripping yang memiliki nilai kompresi lebih baik dari Arifin &
Setiono.
Berdasarkan jurnal karya Lusiano Marga N. yang berjudul “Analisis Penggunaan
Algoritma Stemming Vega Pada Information Retrieval System”, Algoritma Vega
adalah algoritma stemming yang hanya menggunakan aturan morfologi tanpa
menggunakan kamus kata dasar dalam menentukan
stem
. Keakuratan
stem
dengan
kata dasar bukanlah hal yang ditonjolkan oleh Algoritma Vega, akan tetapi algoritma
ini dibuat untuk meningkatkan performa
retrieval
dokumen dalam hal ini
recall
dan
precission
[9].
Berdasarkan jurnal karya Asriko Adipathy yang berjudul "Analisis Dan
Implementasi Perbandingan Stemming Dengan Menggunakan Algoritma Jelita Asian
Dan Algoritma Arifin & Setiono Pada Information Retrieval", Algoritma
Confix-Stripping dimana penulis di sini menyebutnya sebagai Algoritma Jelita Asian,
memiliki nilai kompresi yang lebih baik dari pada algoritma Arifin & Setiono.
Algoritma Confix-Stripping adalah algoritma stemming yang selain menggunakan
aturan morfologi juga menggunakan kamus kata dasar dalam menentukan stem [1].
3
Dokumen sample uji yang dipakai adalah
digital library
Sarihusada yang berisi
tutorial-tutorial seputar ibu dan anak saat masih di dalam kandungan hingga balita.
Dengan dilakukannya analisis dan perbandingan kedua algoritma ini agar diketahui
algoritma terbaik yang dapat menghasilkan
stem
(kata dasar) dari kata berimbuhan
pada Bahasa Indonesia pada
digital library
tersebut.
1.2.
Rumusan Masalah
Berdasarkan latar belakang yang telah disebutkan di atas dapat ditemukan
masalah yang dapat dirumuskan dalam satu rumusan masalah , yaitu bagaimana
melakukan analisis dan perbandingan Algoritma Stemming Vega dan
Confix-stripping pada Bahasa Indonesia dengan menentukan kemampuan
recall
dan
index
compression
.
1.3.
Maksud dan Tujuan
Penelitian ini memiliki maksud dan tujuan yaitu:
1.3.1.
Maksud
Berdasarkan permasalahan yang diteliti, maksud dilakukannya penelitian ini
adalah untuk melakukan analisis dan perbandingan Algoritma Stemming Vega dan
Algoritma Stemming Confix-stripping pada Bahasa Indonesia dengan menghitung
parameter ukuran rata-rata
word per conflation class
,
index compression factor
,
jumlah kata yang berbeda antara kata masukan dan kata keluaran (
stem
), rata-rata
huruf yang dihilangkan untuk membentuk
stem
, dan terakhir nilai
median
dan
mean
modified hamming distance
antara kata masukan dan
stem
.
1.3.2.
Tujuan
Tujuan yang ingin dicapai dari penelitian ini adalah untuk mengetahui algoritma
terbaik yang dapat menghasilkan
stem
(kata dasar) dari kata berimbuhan dalam hal
recall
dan
index compression
pada Bahasa Indonesia khususnya pada
digital library
4
1.4.
Batasan Masalah
Agar pembahasan penelitian terfokuskan pada lingkup masalah yang diinginkan,
maka ada batasan masalah yang diterapkan, yaitu :
1.
Dokumen-dokumen yang dipakai untuk melakukan penelitian adalah
dokumen berformat pdf pada
digital library
Sarihusada.
2.
Sistem dibangun menggunakan ruby on rails.
3.
Penelitian berpusat pada proses stemming tidak sampai mengimplementasikan
ke proses pembuatan indeks ataupun proses pencarian.
4.
Parameter uji yang dilakukan antar lain: ukuran rata-rata
word per conflation
class
,
index compression factor
, jumlah kata yang berbeda antara kata
masukan dan kata keluaran (
stem
), rata-rata huruf yang dihilangkan untuk
membentuk
stem
, dan terakhir nilai
median
dan
mean modified hamming
distance
antara kata masukan dan
stem
1.5.
Metodologi Penelitian
Metodologi penelitian yang digunakan dalam penulisan tugas akhir ini adalah
metodologi deskriptif yang bertujuan untuk mengumpulkan informasi aktual secara
rinci, melukiskan gejala yang ada, mengindetifikasi masalah atau memeriksa kondisi
dan praktik-praktik yang berlaku, membuat perbandingan atau evaluasi.
1.5.1.
Alur Penelitian
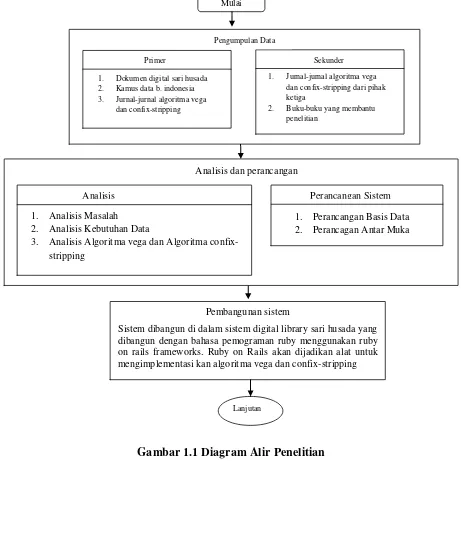
5
Gambar 1.1
Diagram Alir Penelitian
Pembangunan sistem
Sistem dibangun di dalam sistem digital library sari husada yang dibangun dengan bahasa pemograman ruby menggunakan ruby on rails frameworks. Ruby on Rails akan dijadikan alat untuk mengimplementasi kan algoritma vega dan confix-stripping
Analisis dan perancangan
1. Perancangan Basis Data 2. Perancagan Antar Muka
Analisis Perancangan Sistem
1. Analisis Masalah 2. Analisis Kebutuhan Data
3. Analisis Algoritma vega dan Algoritma confix-stripping
Mulai
Pengumpulan Data
1. Dokumen digital sari husada 2. Kamus data b. indonesia 3. Jurnal-jurnal algoritma vega
dan confix-stripping
Primer Sekunder
1. Jurnal-jurnal algoritma vega dan confix-stripping dari pihak ketiga
2. Buku-buku yang membantu penelitian
6
Gambar 1.1
Diagram Alir Penelitian (lanjutan)
1.5.2.
Pembangunan Perangkat Lunak
Dalam membangun perangkat lunak pada penelitian ini, digunakan metode
pengembangan perangkat lunak, yaitu dengan menggunakan metode waterfall yang
bisa digambarkan seperti Gambar 1.2 berikut :
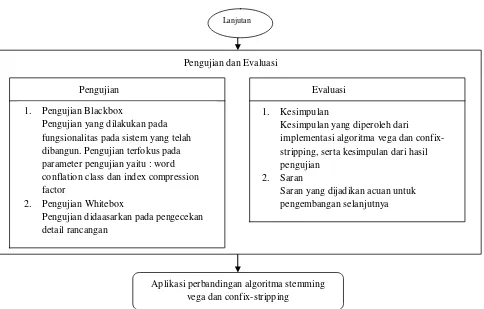
Aplikasi perbandingan algoritma stemming vega dan confix-stripping
Pengujian dan Evaluasi
1. Kesimpulan
Kesimpulan yang diperoleh dari implementasi algoritma vega dan confix-stripping, serta kesimpulan dari hasil pengujian
2. Saran
Saran yang dijadikan acuan untuk pengembangan selanjutnya
Pengujian Evaluasi
1. Pengujian Blackbox
Pengujian yang dilakukan pada fungsionalitas pada sistem yang telah dibangun. Pengujian terfokus pada parameter pengujian yaitu : word conflation class dan index compression factor
2. Pengujian Whitebox
Pengujian didaasarkan pada pengecekan detail rancangan
7
Gambar 1.2
Waterfall Model
1.6.
Sistematika Penulisan
Sistematika penulisan pada penelitian ini disusun untuk memberikan gambaran
secara umum mengenai penelitian yang dilakukan. Sistematika penulisan pada
penelitian ini sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini menguraikan tentang latar belakang masalah, rumusan masalah, menentukan
maksud dan tujuan, batasan masalah, metodologi penelitian serta sistematika
penulisan.
BAB 2 LANDASAN TEORI
Bab ini membahas berbagai konsep dasar dan teori - teori yang berkaitan dengan
stemming bahasa Indonesia dan algoritma-algoritma stemming. Konsep atau teori
yang dijelaskan dimulai dari penjelasan mengenai morfologi bahasa Indonesia,
pengertian stemming, pengertian algoritma vega dan algoritma confix-stripping
8
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menguraikan penjelasan tentang analisis dan perancangan sistem. Analisis
sistem berisi analisis masalah, analisis kebutuhan data, analisis algoritma yang terdiri
dari algoritma vega dan confix-stripping, analisis kebutuhan nonfungsional, dan
analisis kebutuhan fungsional. Perancangan sistem berisi perancangan basis data yang
terdiri dari diagram relasi dan struktur table, kemudian perancangan antar muka yang
memberikan gambaran antarmuka sistem
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang implementasi yang bertujuan untuk memastikan bahawa
aplikasi telah berhasil diimplementasikan dan dapat berjalan sesuai dengan yang
diinginkan, Kemudian disertai hasil pengujian dari aplikasi yang telah dilakukan.
BAB 5 KESIMPULAN DAN SARAN
131
BAB 5
KESIMPULAN DAN SARAN
5.1.
KESIMPULAN
Berdasarkan hasil pengujian yang telah dilakukan dalam analisis dan
perbandingan algoritma vega dan algoritma confix-stripping, dapat disimpulkan
bahwa keenam parameter uji tidak menunjukan kekonsistenan dalam menentukan
algoritma mana yang lebih baik. Hasil pengujian terhadap sepuluh dokumen uji
menunjukan algoritma vega lebih baik pada empat parameter uji yaitu jumlah kata
yang berbeda antara kata masukan dan
stem
, nilai rata-rata huruf yang dihapus, nilai
mean modified hamming distance
, dan nilai
median modified hamming distance
.
Sedangkan algoritma confix-stripping lebih baik pada dua parameter uji lainnya yaitu
ukuran rata-rata
word per conflation class
dan
index compression factor
.
Masing-masing parameter pengujian dapat menunjukan karakteristik dari kedua
algoritma. Parameter pengujian dimana algoritma vega lebih unggul dari pada
algoritma confix-stripping merupakan parameter yang menunjukan seberapa sering
algoritma tersebut merubah kata masukan (
term
) dengan menghapus ataupun
mengganti huruf-hurufnya, sehingga menjadi
stem
. Sedangkan parameter pengujian
dimana algoritma confix-stripping lebih unggul dari algoritma vega merupakan
parameter yang menunjukan seberapa sering algoritma tersebut dalam mengubah
beberapa kata berimbuhan menjadi satu kata dasar (
stem
) yang sama.
Hal di atas berarti kedua algoritma masing-masing memiliki kelebihan untuk
kasus tertentu. Algoritma vega memiliki kelebihan dalam mengubah term menjadi
kata yang berbeda atau baru. Sedangkan algoritma confix-stripping memiliki
kelebihan dalam mengurangi jumlah term, seperti mereduksi
index size
pada proses
132
5.2.
SARAN
Berdasarkan hasil pengujian yang telah dilakukan, maka saran yang diharapkan
setelah dilakukannya analisis dan perbandingan algoritma vega dan algoritma
confix-stripping pada teks bahasa indonesia adalah sebagai berikut :
1.
Melakukan pengujian terhadap stem yang dihasilkan algoritma vega apakah
dapat mempengaruhi proses
indexing
.
2.
Melakukan analisis performansi algoritma confix-stripping dalam mereduksi
ukuran
index size
.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
Analisis Dan Perbandingan Stemming Teks
Bahasa Indonesia Menggunakan Algoritma Vega
Dan Algoritma Confix-Stripping
Helmi Agustian1, Tati Harihayati2
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
Email : [email protected], [email protected]
ABSTRAK
Algoritma stemming merupakan sebuah algoritma yang dapat mengubah kata berimbuhan ke bentuk kata dasarnya. Penerapan algoritma stemming salah satunya pada sistem pencarian dokumen, dengan meningkatkan kemampuan pada segi recall dan
index compression. Pengukuran
parameter-parameter stemmer strength dapat mewakili kemampuan algoritma stemming dalam hal recall
dan index compression [2]. Algoritma vega
berdasarkan pengukuran parameter-parameter
stemmer strength yaitu ukuran rata-rata word per conflation class, index compression factor, jumlah kata yang berbeda antara kata masukan dan stem, rata-rata huruf yang dihilangkan untuk membentuk stem, dan terakhir nilai median dan mean modified hamming distance antara kata masukan dan stem, terhadap dokumen-dokumen sample uji menunjukan kecenderungan untuk selalu mengubah kata berimbuhan lebih sering dari pada algoritma confix-stripping. Sedangkan algoritma confix-stripping menunjukan kecenderungan untuk mengubah beberapa kata berimbuhan menjadi satu kata dasar yang sama lebih banyak dari pada algoritma vega.
Kata Kunci : Stemming, Vega, Confix-stripping
1. PENDAHULUAN
Stemming merupakan suatu proses untuk
menemukan kata dasar dari sebuah kata bentukan atau kata berimbuhan. Dengan menghilangkan semua imbuhan baik yang terdiri dari awalan, sisipan, akhiran dan kombinasi awalan akhiran pada kata turunan. Stemming digunakan untuk mengganti bentuk dari suatu kata menjadi kata dasar dari kata tersebut yang sesuai dengan struktur morfologi Bahasa Indonesia yang baik dan benar. Stemming adalah alat dasar pemrosesan teks yang digunakan untuk text retrieval secara efisien dan efektif.
Imbuhan pada Bahasa Indonesia lebih kompleks bila dibandingkan dengan imbuhan pada Bahasa Inggris.
Karena seperti yang telah disebutkan di atas bahwa imbuhan pada Bahasa Indonesia terdiri dari awalan, sisipan, akhiran, bentuk perulangan dan kombinasi awalan akhiran. Imbuhan-imbuhan yang melekat pada suatu kata harus dihilangkan untuk mengubah bentuk kata tersebut menjadi bentuk kata dasarnya.
Proses stemming biasanya juga disebut conflation, yang digunakan pada search engine untuk ekspresi
query dan indexing dan untuk permasalahan natural
language processing. Proses conflation dapat
dilakukan secara manual maupun otomatis. Program untuk conflation otomatis ini disebut sebagai "stemmer". Stemmer digunakan di information retrieval system untuk mengurangi ukuran file indeks. Term bisa di-stemming pada saat indexing
maupun searching. Keuntungan dari stemming saat
indexing adalah effisiensi dan kompresi file indeks. Sehingga bisa dikatakan dengan stemming mampu meningkatkan performansi information retrieval system.
Ada beberapa cara yang dilakukan stemmer untuk menjalankan proses stemming diantaranya: Table look-up, affix removal stemmers, successor variety dan n-gram stemmer. Pada penelitian ini akan dilakukan analisis dan perbandingan algoritma vega dan confix-stripping yang sama-sama merupakan metode affix removal stemmers.
Pengujian di dalam penelitian ini menggunakan parameter penggujian yang dijelaskan di dalam jurnal karya Frakes W.B. dan Fox C.J. [2]. Parameter-parameter ini digunakan untuk mengukur
stemmer strength, dimana penting dalam kasus
algoritma penghilangan imbuhan, karena dapat memprediksi kemampuan recall dan precision serta
index compression dari algoritma tersebut. Stemmer strength adalah suatu ukuran bagaimana sebuah
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
huruf yang dihilangkan untuk membentuk stem, dan terakhir nilai median dan mean modified hamming distance antara kata masukan dan stem.
1.1. Algoritma Vega
Algoritma vega merupakan algoritma stemming yang diperkenalkan oleh Vinsensius Berlian Vega pada tahun 2001. Algoritma vega tidak menggunakan kamus data dalam melakukan pengecekan kata dasar.
Secara garis besar tahapan dalam algoritma vega berturut-turut adalah pembuangan partikel, pembuangan kata kepunyaan, pembuangan circumfix, pembuangan awalan, dan terakhir pembuangan akhiran.
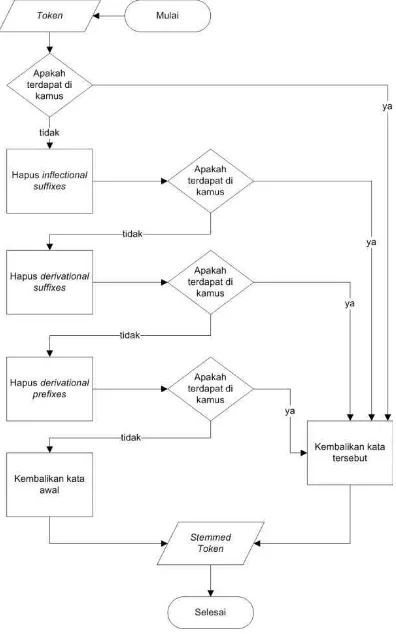
1.2. Algoritma Confix-stripping
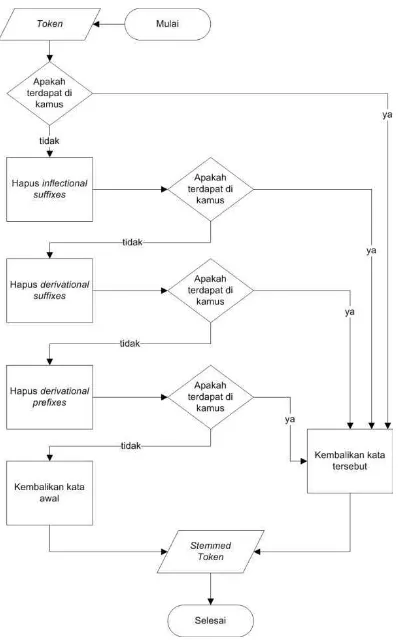
[image:22.595.78.276.405.722.2]Algoritma stemming Confix-stripping (CS) adalah sebuah metode stemming pada Bahasa Indonesia yang diperkenalkan oleh Jelita Asian yang merupakan pengembangan dari metode stemming yang dibuat oleh Nazief dan Adriani [1]. Algoritma ini menggunakan kamus data untuk melakukan pengecekan kata dasar. Secara garis besar tahapan algoritma confix-stripping dapat dijelaskan seperti Gambar 1.
Gambar 1 Langkah-langkah algoritma confix-stripping
1.3. Parameter-parameter Uji
Pengujian di dalam penelitian ini menggunakan parameter penggujian yang dijelaskan di dalam jurnal karya Frakes W.B. dan Fox C.J. [2]. Parameter pertama adalah ukuran rata-rata word per conflation class, yaitu menunjukan jumlah rata-rata kata yang menghasilkan stem yang sama dari
corpus, dengan rumus sebagai berikut:
��= �
�
Dimana :
wcc = Word per conflation class
n = Jumlah kata unik sebelum stemming s = Jumlah kata unik hasil stemming
Suatu algoritma stemming menginginkan nilai per conflation class yang lebih besar dari algoritma lainnya, untuk menunjukan algoritma tersebut lebih baik.
Parameter kedua yaitu index compression factor, menunjukan seberapa besar tingkat kompresi indeks dari algoritma stemming, atau seberapa besar tingkat pengurangan dari index size setelah dilakukan
stemming. Apabila jumlah kata-kata di dalam
corpus (kata unik sebelum stemming) sebanyak n, kemudian setelah dilakukan stemming apabila menghasilkan beberapa kata yang sama dilakukan penghapusan sehingga seluruh hasil stemming merupakan kata unik sebanyak s. Maka untuk menghitung parameter index compression factor (icf) adalah :
���= (� − �)
� %
Dimana :
icf = Index compression factor
n = Jumlah kata unik sebelum stemming
s = Jumlah kata unik hasil stemming
Suatu algoritma stemming menginginkan nilai index compression factor yang lebih besar dari algoritma lainnya, untuk menunjukan algoritma tersebut lebih baik.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
Parameter keempat adalah nilai rata-rata huruf yang dihapus, yaitu nilai rata-rata huruf dari kata masukan yang dihapus untuk membentuk sebuah stem. Algoritma stemming yang kuat akan menghapus huruf lebih banyak untuk membentuk sebuah stem.
Parameter kelima dan keenam berturut-turut adalah nilai mean dan median modified hamming distance. Nilai hamming distance antara dua string yang memiliki panjang yang sama didefinisikan sebagai jumlah karakter yang berbeda di posisi yang sama. Nilai hamming distance antara dua string yang memiliki panjang berbeda didefinisikan sebagai perbedaan panjang antara dua string tersebut.
Sebagai contoh terdapat tiga kata, membaca, dibaca, dan membacakan. Apabila sebuah algoritma
stemming mengubahnya ke stem „baca‟, maka :
1. membaca beda 3 huruf dengan „baca‟
2. dibacabeda 2 huruf dengan „baca‟
3. membacakan beda 6 huruf dengan „baca‟
Sehingga nilai mean modified hamming distance dapat dihitung sebagai nilai rata-ratanya yaitu sebagai berikut:
(3+2+6) / 3 = 3,66
Didapat nilai mean modified hamming distance sebesar 3,66 kata.
Nilai median modified hamming distance juga dapat diperoleh sebagai nilai tengah dari ketiga nilai tersebut setelah diurutkan. Sehingga didapat nilai median modified hamming distance sebesar 3.
2. ISI PENELITIAN
Hasil pengujian algoritma vega dan algoritma confix-stripping merupakan pengujian terhadap parameter uji pada dokumen-dokumen uji. Dokumen-dokumen yang diambil merupakan dokumen sample dari digital library Sarihusada sebanyak sepuluh dokumen. Kesepuluh dokumen memiliki jumlah kata masukan (kata uji) berupa
corpus untuk diuji ke masing-masing algoritma yang telah melalui hasil filtering, sebagai berikut :
2.1. Ukuran Rata-rata Word Per Conflation
[image:23.595.306.528.83.136.2]Class
Tabel 1 ukuran rata-rata word per conflation class
Dok No
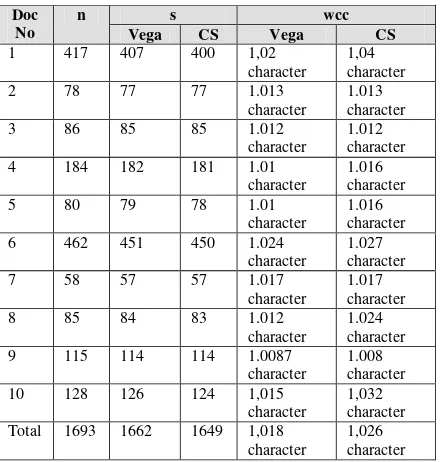
n s wcc
Vega CS Vega CS
1 417 407 400 1,02 kata 1,04 kata
2 78 77 77 1.013 kata 1.013 kata
3 86 85 85 1.012 kata 1.012 kata
4 184 182 181 1.01 kata 1.016 kata
5 80 79 78 1.01 kata 1.016 kata
6 462 451 450 1.024 kata 1.027 kata
7 58 57 57 1.017 kata 1.017 kata
8 85 84 83 1.012 kata 1.024 kata
9 115 114 114 1.0087 kata 1.008 kata 10 128 126 124 1,015 kata 1,032 kata Total 1693 1662 1649 1,018 kata 1,026 kata
Algoritma stemming yang bagus dalam hal stemmer strength menginginkan nilai mean word per conflation class yang lebih besar dari algoritma stemming lainnya. Berdasarkan pengujian pada Tabel 1 parameter mean word per conflation class algoritma confix-stripping lebih baik dengan rata-rata 1,026 kata.
[image:23.595.312.532.287.438.2]2.2. Index Compression Factor
Tabel 2 index compression factor
Algoritma stemming yang bagus dalam hal stemmer strength menginginkan nilai index compression factor yang lebih besar dari algoritma stemming lainnya. Berdasarkan pengujian pada Tabel 2 parameter index compression factor algoritma confix-stripping lebih baik sebesar 2,598 %
2.3. Jumlah Kata Yang Berbeda Antara
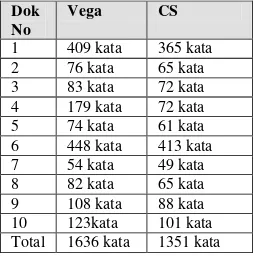
Kata Masukan Dan Keluaran
Tabel 3 jumlah kata yang berbeda antara kata masukan dan keluaran
Dok No
Vega CS
1 409 kata 365 kata 2 76 kata 65 kata 3 83 kata 72 kata 4 179 kata 72 kata 5 74 kata 61 kata 6 448 kata 413 kata 7 54 kata 49 kata 8 82 kata 65 kata 9 108 kata 88 kata 10 123kata 101 kata Total 1636 kata 1351 kata
Dok No
n s icf
Vega CS Vega CS
1 417 407 400 2.398 % 4.076 %
2 78 77 77 1.282 % 1.28 %
3 86 85 85 1.162 % 1.162 %
4 184 182 181 1.086 % 1.63 %
5 80 79 78 1.25 % 2.5 %
6 462 451 450 2.381 % 2.597%
7 58 57 57 1.724 % 1.724 %
8 85 84 83 1.176 % 2.353 %
9 115 114 114 0.869 % 0.869 %
10 128 126 124 1,562 % 3,125 %
Tota l
[image:23.595.306.433.605.733.2]Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
Algoritma stemming yang bagus dalam hal stemmer strength lebih sering merubah kata dari algoritma stemming lainnya, sehingga menghasilkan kata yang berbeda. Berdasarkan pengujian pada Tabel 3 algoritma vega lebih baik dengan total perbedaan 1636 kata dari 10 dokumen sampel uji.
[image:24.595.65.271.211.442.2]2.4. Nilai Rata-rata Huruf Yang Dihapus
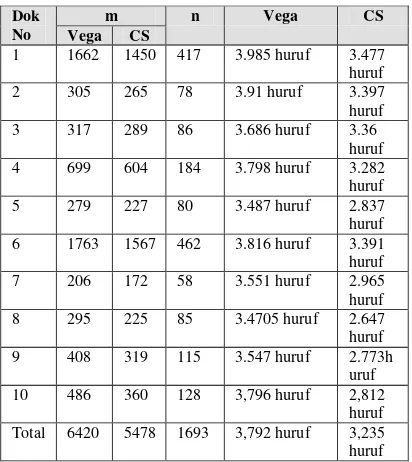
Tabel 4 nilai rata-rata huruf yang dihapus
Dok No
m n Vega CS
Vega CS
1 1662 1450 417 3.985 huruf 3.477 huruf
2 305 265 78 3.91 huruf 3.397
huruf
3 317 289 86 3.686 huruf 3.36
huruf 4 699 604 184 3.798 huruf 3.282 huruf
5 279 227 80 3.487 huruf 2.837
huruf 6 1763 1567 462 3.816 huruf 3.391 huruf
7 206 172 58 3.551 huruf 2.965
huruf 8 295 225 85 3.4705 huruf 2.647 huruf
9 408 319 115 3.547 huruf 2.773h
uruf 10 486 360 128 3,796 huruf 2,812
huruf Total 6420 5478 1693 3,792 huruf 3,235 huruf
Algoritma stemming yang bagus dalam hal stemmer strength lebih sering menghapus huruf untuk membentuk sebuah stem. Berdasarkan pengujian pada Tabel 4 algoritma vega lebih baik karena rata-rata menghapus 3,792 huruf dari 10 dokumen uji.
2.5. Nilai Mean Modified Hamming
Distance
Tabel 5 nilai mean modified hamming distance
No h n Vega CS
Vega Cs
1 1662 1528 417 3.985 kata
3.664 kata
2 305 280 78 3.91
kata 3.589 kata
3 317 304 86 3.686
kata 3.534 kata
4 699 646 184 3.798
kata 3.51 kata
5 279 239 80 3.487
kata 2.987 kata 6 1763 1641 462 3.816
kata 3.552 kata
7 206 180 58 3.551
kata 3.103 kata
8 295 240 85 3.47
kata 2.823 kata 9 408 333 115 3.547 2.895
kata kata 10 486 382 128 3,796
kata 2,984 kata Total 6420 5773 1693 3,792
kata 3,409 kata
Algoritma stemming yang bagus dalam hal stemmer strength memiliki nilai hamming distance lebih besar dari algoritma stemming lainnya, atau memiliki rata-rata hamming distance yang lebih besar untuk sejumlah kata di dalam dokumen uji. Berdasarkan pengujian pada Tabel 5 algoritma vega lebih baik karena memiliki rata-rata hamming distance sebanyak 3,792 kata.
2.6. Nilai Median Modified Hamming
[image:24.595.306.417.311.458.2]Distance
Tabel 6 nilai median modified hamming distance
Dok No Vega CS
1 4 4
2 4 3
3 3 3
4 4 3
5 3 3
6 4 3
7 3 3
8 3 3
9 3 3
10 4 3
Rata-rata Total
3,5 3,1
Algoritma stemming yang bagus dalam hal stemmer strength memiliki nilai hamming distance lebih besar dari algoritma stemming lainnya, dapat berarti juga untuk sejumlah kata di dalam dokumen memiliki nilai tengah (median) yang paling besar. Berdasarkan pengujian pada Tabel 6 dari 10 dokumen algoritma vega rata-rata memiliki nilai median yang lebih baik sebesar 3,5.
3. PENUTUP
3.1. Kesimpulan
[image:24.595.66.234.584.768.2]Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
rata-rata word per conflation class dan index compression factor.
Hal di atas berarti kedua algoritma masing-masing memiliki kelebihan untuk kasus tertentu. Algoritma vega memiliki kelebihan dalam mengubah term
menjadi kata yang berbeda atau baru. Sedangkan algoritma confix-stripping memiliki kelebihan dalam mengurangi jumlah term, seperti mereduksi index size pada proses indexing.
3.2. Saran
Berdasarkan hasil pengujian yang telah dilakukan, maka saran yang diharapkan setelah dilakukannya analisis dan perbandingan algoritma vega dan algoritma confix-stripping pada teks bahasa indonesia adalah sebagai berikut :
1. Melakukan pengujian terhadap stem yang dihasilkan algoritma vega apakah dapat mempengaruhi proses indexing.
2. Melakukan analisis performansi algoritma confix-stripping dalam mereduksi ukuran index size.
3. Melakukan implementasi terhadap proses pencarian pada information retrieval.
4. DAFTAR PUSTAKA
[1] Asian, J., Williams, H.E. and Tahaghoghi,
S.M.M. “Stemming Indonesian”. RMIT
University, Melbourne, Australia.
[2] Frakes, W.B., Fox, C.J. “Strength and Similarity of Affix Removal Stemming
Algorithms”. Computer Science Department.
Virginia Tech and James Madison University.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
Analysis And Comparison Stemming Indonesian Text
Using Vega Algorithm And Confix-stripping Algorithm
Helmi Agustian1, Tati Harihayati2
Teknik Informatika – Universitas Komputer Indonesia Jl. Dipatiukur 112-114 Bandung
Email : [email protected], [email protected]
ABSTRAK
Stemming algorithm is an algorithm that can transform word to its root word. In the document searching, stemming expected to increase recall and index compression. Calculating the stemmer strength can predict how well a stemming algorithm in the abillity to recall and index compression[2]. Based on the results to calculate six measures of stemmer strength which is mean number of word per conflation class, index compression factor, the number of words and stems that differ, the mean number of characters removed in forming stems, and the last median and mean modified hamming distance between words and their stems. Vega algorithm tend to often transform word rather than confix-stripping algorithm. The results also show that confix-stripping algorithm tend to often transform words that correspond to the same stemm for a corpus.
Kata Kunci : Stemming, Vega, Confix-stripping
1. INTRODUCTION
Stemming is a process of finding the root word of a term by eliminating affix, prefix, confix, suffix and combination of both prefix suffix on the word derivative. Stemming is used to transform word to its root word that accordance with Indonesian morphological structure. Stemming algorithms are used in many types of language processing and text analysis, and can make process of text retrival efficiently and effectively
Indonesian affixes is more complex when compared with the English affixes. Because affixes in Indonesian language consists of a prefix, confix, suffix, and combination of both prefix-suffix. The affixes that attached to a word must be removed to change to its root word
Stemming process can also becalled conflation, which are used in search engines for indexing and query expression and also for natural language processing problems. Conflation process can be
done manually or automatically. The program that can automatic conflate word is called 'stemmer'. Stemmer used in information retrieval system to reduce the size of index file. The term can be stemmed at the time indexing and saarching happened. The advantage of stemming at the process of indexing is compression and efficiency of index file. Which mean that stemming can improve the performance of information retrieval system.
There are several type of stemming process, including : Table look-up, affix removal stemmers, successor variety dan n-gram stemmer. In this research about analysis and comparison of vega algorithm and confix-stripping algorithm, both of them are affix removal stemmers type.
The tests in this study are using metrics that describe in the journal by Frakes W.B. and Fox C.J. [2]. These metrics are used to measure the stemmer strength, which is important in the case of a particle removal algorithms, because it can predict the ability of recall and precision as well as index compression of the stemmer algorithm. Stemmer strength is a measure of how well stemmer algorithm can change word into a stem. The parameters that used to measure stemmer strength are, mean number of words per conflation class, index compression factor, the number of words and stems that differ, the mean number of characters removed in forming stems, and the last median and mean modified hamming distance between words and their stems
1.1. Vega Algorithm
Vega stemming algorithm is an algorithm that was introduced by Vinsensius Berlian Vega in 2001. Vega algorithm does not use the dictionary to check the root words.
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
1.2. Confix-stripping Algorithm
[image:27.595.78.277.193.515.2]Confix-stripping algorithm (CS) is a stemming algorithm for Indonesian Language introduced by Jelita Asian. Confix-stripping algorithm is algorithm that developed from stemming algorithm by Nazief and Adriani [1]. This algorithm uses the dictionary to check the root words. Confix-stripping algorithm stages can be described as Figure 1.
Figure 1 Confix-stripping algorithm steps
1.3. Metrics measure
Tests measure in this study using the parameters described in the journal by Frakes W.B. and Fox C..J. [2]. The first parameter is mean word per conflation class, a measure of the average number of words that correspond to the same stem for a corpus, with the following formula:
��= �
�
where :
wcc = word per conflation class
n = total of unique corpus
s = total of uniqe stems
Stronger stemming algorithm tend to have word per conflation class value greater, to show that algorithm better
The second metrics is the index compression factor, shows how much the level of index compression an algorithms stemming can get, or fractional reduction in index size achieved through stemming. If the number of words in the corpus is n, then after stemming process resulting numbers of stem and removing duplicate word that is s. So to calculate the index compression factor (icf) are:
���= (� − �)
� %
where :
icf = index compression factor
n = total of unique corpus s = total of uniqe stems
Stronger stemming algorithm tend to have index compression factor value greater, to show that algorithm is better.
The third parameter is the number of different words between term and stem. A stemming algorithm often leave words unchanged. Stronger stemmers will change words more often than weaker stemmers.
The fourth parameter is the mean number of character removed in forming stems. Stronger stemming algorithm remove more character from word to form stems
The fifth and sixth metrics respectively are the mean and median modified hamming distance between word and their stems. The hamming distance between two strings of equal length is defined as the number of character in the two strings that are different at the same position. For strings of unequal length add the difference in length to the hamming distance function.
For example, there are three words “membaca”,
“dibaca” and “membackan”. If a stemming algorithm can convert all three to stem “baca”, then:
1. membaca have 3 difference character with
„baca‟
2. dibaca have 2 difference character with „baca‟
3. membacakan have 6 difference character with
„baca‟
So the mean modified hamming distance can be calculated as the average (mean) value as follows:
(3+2+6) / 3 = 3,66
Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
The value of median modified hamming distance can also be obtained as the median of these values after sorted. So the median modified hamming distance obtained as 3.
2. RESEARCH CONTENT
Result of testing vega algorithm and confix-stripping algorithm obtained from calculated the six metrics measure. The sample documents taken from sarihusada digital library at the total of 10 sample documents. Every document have through preprocessing that resulting corpus that ready to calculate the metrics, as follows
2.1. Mean number of words per conflation
[image:28.595.311.531.60.230.2]class
Table 1 Mean number of words per conflation class
Doc No
n s wcc
Vega CS Vega CS
1 417 407 400 1,02
character
1,04 character
2 78 77 77 1.013
character
1.013 character
3 86 85 85 1.012
character
1.012 character
4 184 182 181 1.01
character
1.016 character
5 80 79 78 1.01
character
1.016 character
6 462 451 450 1.024
character
1.027 character
7 58 57 57 1.017
character
1.017 character
8 85 84 83 1.012
character
1.024 character
9 115 114 114 1.0087
character
1.008 character
10 128 126 124 1,015
character
1,032 character Total 1693 1662 1649 1,018
character
1,026 character
Stemming algorithm that good in terms of stemmer strength want a mean word per conflation class larger than the other stemming algorithm. Based on the Table 1 the mean word per conflation class of confix-stripping algorithm is better with an average of 1,026 words.
2.2. Index Compression Factor
Table 2 Index compression factor
Stemming algorithm which is good in terms of stemmer strength want index compression factor value greater than the other stemming algorithms. Based on testing at Table 2 index compression factor parameter confix-stripping algorithm is better at 2,598%
2.3. The number of words and stems that
[image:28.595.67.287.339.570.2]differ
Table 3 The number of words and stems that differ
Doc No
Vega CS
1 409 character 365 character 2 76 character 65 character 3 83 character 72 character 4 179 character 72 character 5 74 character 61 character 6 448 character 413 character
7 54 character 49 character 8 82 character 65 character
9 108 character 88 character 10 123character 101 character Total 1636 character 1351 character
Stemming algorithm which is good in terms of stemmer strength is more often change the words than the other stemming algorithms, resulting in different words. Based on testing at Table 3 vega algorithm is better with total difference 1636 words from 10 sample documents.
Doc No
n s icf
Vega CS Vega CS
1 417 407 400 2.398 % 4.076 %
2 78 77 77 1.282 % 1.28 %
3 86 85 85 1.162 % 1.162 %
4 184 182 181 1.086 % 1.63 %
5 80 79 78 1.25 % 2.5 %
6 462 451 450 2.381 % 2.597%
7 58 57 57 1.724 % 1.724 %
8 85 84 83 1.176 % 2.353 %
9 115 114 114 0.869 % 0.869 %
10 128 126 124 1,562 % 3,125 %
Tota l
[image:28.595.306.492.384.531.2]Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
2.4. The mean number of characters
[image:29.595.64.273.161.391.2]removed in forming stems
Table 4 The mean number of characters removed in forming stems
Dok No
m n Vega CS
Vega CS
1 1662 1450 417 3.985 word 3.477 word
2 305 265 78 3.91 word 3.397
word
3 317 289 86 3.686 word 3.36
word
4 699 604 184 3.798 word 3.282
word
5 279 227 80 3.487 word 2.837
word 6 1763 1567 462 3.816 word 3.391 word
7 206 172 58 3.551 word 2.965
word
8 295 225 85 3.4705 word 2.647
word
9 408 319 115 3.547 word 2.773w
ord 10 486 360 128 3,796 word 2,812
word Total 6420 5478 1693 3,792 word 3,235 word
Stemming algorithm which is good in terms of stemmer strength remove more often the character to form a stem. Based on testing at Table 4 vega algorithm is better because the average erase 3,792 characters from 10 test documents.
2.5. Mean Modified Hamming Distance
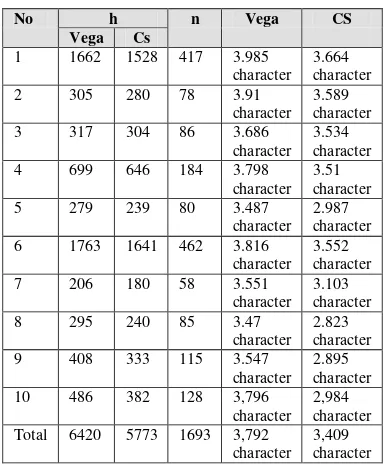
Table 5 Mean modified hamming distance
No h n Vega CS
Vega Cs
1 1662 1528 417 3.985 character
3.664 character
2 305 280 78 3.91
character 3.589 character
3 317 304 86 3.686
character 3.534 character
4 699 646 184 3.798
character 3.51 character
5 279 239 80 3.487
character 2.987 character 6 1763 1641 462 3.816
character 3.552 character
7 206 180 58 3.551
character 3.103 character
8 295 240 85 3.47
character 2.823 character
9 408 333 115 3.547
character 2.895 character
10 486 382 128 3,796
character 2,984 character Total 6420 5773 1693 3,792
character 3,409 character
Stemming algorithm which is good in terms of stemmer strength have hamming distance value greater than the other stemming algorithms, or have mean modified hamming distance value greater for numbers of corpus in the test document. Based on testing at Table 5 vega algorithm is better because it has an average hamming distance as much as 3,792 words.
[image:29.595.305.415.252.398.2]2.6. Median Modified Hamming Distance
Table 6 Median modified hamming distance
Dok No Vega CS
1 4 4
2 4 3
3 3 3
4 4 3
5 3 3
6 4 3
7 3 3
8 3 3
9 3 3
10 4 3
Average total
3,5 3,1
Stemming algorithm which is good in terms of stemmer strength have hamming distance value greater than the other stemming algorithms, that mean also for numbers of curpus in the document have middle value (median) greater. Based on testing Table 6 from 10 documents vega algorithm have better average median value of 3.5.
3. CONCLUDING
3.1. Conclusion
Based on the results of testing that has been done in the research content about analysis and comparison vega algorithms and confix-stripping algorithms, it can be concluded that all six test parameters did not show consistency in deciding which one is better algorithms. The test results from 10 documents show that vega algorithm better on four test parameters, which is the number of words and stems that differ, mean number of characters removed in forming stems, the mean modified hamming distance, and the median modified hamming distance. Confix-stripping algorithm better on two other test parameters, which is the mean number of words per conflation class and index compression factor.
[image:29.595.64.257.519.754.2]Jurnal Ilmiah Komputer dan Informatika (KOMPUTA)
Edisi...Volume..., Bulan 20..ISSN :2089-9033
terms, such as reducing the size index in the indexing process.
3.2. Suggestions
Berdasarkan hasil pengujian yang telah dilakukan, maka saran yang diharapkan setelah dilakukannya analisis dan perbandingan algoritma vega dan algoritma confix-stripping pada teks bahasa indonesia adalah sebagai berikut :
1. Melakukan pengujian terhadap stem yang dihasilkan algoritma vega apakah dapat mempengaruhi proses indexing.
2. Melakukan analisis performansi algoritma confix-stripping dalam mereduksi ukuran index size.
3. Melakukan implementasi terhadap proses pencarian pada information retrieval.
Based on the results of testing that has been done, then the suggestions are expected after doing an analysis and comparison vega algorithms and confix-stripping algorithms the Indonesian text is as follows:
1. Perform testing to stems result from vega algorithm whether it can affect the indexing process.
2. Analyze the performance of confix-stripping algorithm in reducing the size of the index size.
3. Conduct an implementation for searching process of an information retrieval.
4. BIBLIOGRAPHY
[1] Asian, J., Williams, H.E. and Tahaghoghi,
S.M.M. “Stemming Indonesian”. RMIT
University, Melbourne, Australia.
[2] Frakes, W.B., Fox, C.J. “Strength and Similarity of Affix Removal Stemming
Algorithms”. Computer Science Department.
Virginia Tech and James Madison University.