SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
ARIEF FIRMANSYAH
10110516
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
Segala puji dan syukur penulis panjatkan kehadirat Allah SWT, atas segala rahmat dan hidayah–Nya sehingga penulis dapat menyelesaikan tugas akhir ini
dengan mengambil judul “Analisis Performansi Algoritma Arifin Setiono Dan Algoritma Porter Untuk Stemming Berbahasa Indonesia”. Adapun tujuan dari penyusunan tugas akhir ini adalah untuk memenuhi salah satu syarat dalam menyelesaikan jenjang studi stara satu (S1) di Program Studi Teknik Informatika, Universitas Komputer Indonesia.
Dengan selesainya penyusunan tugas akhir ini, penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
1. Kedua orang tua, terima kasih atas doa dan dukungan yang tidak pernah ada hentinya, baik secara moril dan materil.
2. Ibu Nelly Indriani W, S.Si., M.T. selaku dosen pembimbing yang telah banyak meluangkan waktu untuk membimbing serta mengarahkan dalam proses penyusunan tugas akhir.
3. Bapak Alif Finandhita S.Kom selaku dosen wali IF12 Angkatan 2010.
4. Ibu Ednawati Rainarli, S.Si., M.Si. selaku dosen reviewer yang telah memberikan inspirasi dan membimbing dengan sangat teliti dalam proses penyusunan tugas akhir.
5. Teman-teman mahasiswa seperjuangan dari semester awal hingga akhir yaitu Fatahudin Aziz, Giri Muria Shaleh, Muhammad Tevin Adiman, Margadena C.P dan Muhammad Septiana yang selalu berbagi pemikiran akan penyusunan tugas akhir.
6. Teman-teman yang telah mendukung proses seminar
iv
Penulis menyadari tugas akhir ini masih jauh dari kata sempurna dengan segala kekurangan yang dimiliki. Untuk itu penulis mengharapkan adanya kritik dan saran yang bersifat membangun dari semua pihak demi kesempurnaan tugas akhir ini. Akhir kata, semoga tugas akhir ini dapat bermanfaat bagi pembaca.
Bandung, Juli 2015
v
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... ix
DAFTAR SIMBOL ... xi
DAFTAR LAMPIRAN ... xv
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 3
1.5 Metode Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pengembangan Perangkat Lunak ... 3
1.6 Sistematika Penulisan ... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Text Minning ... 7
2.2 Parsing ... 7
2.3 Tokenizing... 7
2.4 Stopword Removal ... 8
2.5 Stemming ... 8
2.6 Algoritma ... 8
2.7 Algoritma Arifin Setiono ... 9
2.8 Algoritma Porter... 10
2.9 MySQL ... 14
2.10.1 Pengertian UML ... 17
2.11 Pengujian Software ... 24
2.11.1 Blackbox Testing ... 24
2.12 Konsep Perangkat Lunak Pendukung ... 25
2.12.1 Microsoft Visual Studio ... 25
2.13 Teori Pengujian Metode ... 27
BAB 3 ANALISIS DAN PERANCANGAN SISTEM ... 29
3.1 Analisis Masalah ... 30
3.2 Analisis data masukan ... 30
3.3 Analisis Metode ... 26
3.4 Analisis Penggabungan Algoritma Porter dan Arifin Setiono ... 34
3.5 Analisis Kebutuhan Perangkat lunak ... 44
3.5.1 Analisis Kebutuhan Non-Fungsional ... 44
3.5.1.1 Analisis Perangkat keras ... 44
3.5.1.2 Analisis Perangkat lunak ... 45
3.5.1.3 Analisis Perangkat piker ... 45
3.5.2 Analisis Kebutuhan Fungsional ... 45
3.5.2.1 Usecase ... 46
3.5.2.1.1 Identifikasi Aktor ... 46
3.5.2.1.2 Usecase Skenario Ambil File ... 47
3.5.2.1.3 Usecase Skenario Proses ... 48
3.5.2.1.4 Usecase Skenario Hapus ... 49
3.5.2.1.5 Usecase Skenario Konversi ... 49
3.5.2.2 Activity Diagram ... 50
3.5.2.3 Class Diagram ... 53
3.5.2.4 Sequnce Diagram ... 53
3.5.3 Perancangan Sistem ... 56
3.5.3.1 Perancangan Antarmuka ... 56
3.5.3.1.1 Perancangan Antarmuka T01 ... 56
3.5.3.1.2 Perancangan Antarmuka T02 ... 57
3.6 Jaringan Semantik ... 58
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 59
4.1 Implementasi ... 59
4.1.1 Implementasi Perangkat Keras ... 59
4.1.2 Implementasi Perangkat Lunak ... 59
4.1.3 Implementasi Database ... 60
4.1.4 Implementasi Antarmuka ... 60
4.2 Kompleksitas Waktu ... 61
4.3 Pengujian metode ... 61
4.3.1 Skenario Pengujian ... 61
4.4 Kesimpulan Pengujian ... 76
BAB 5 KESIMPULAN DAN SARAN ... 77
5.1 Kesimpulan ... 77
5.2 Saran ... 77
79
UNTUK STEMMING DOKUMEN TEKS BAHASA INDONESIA," November 2009.
[2] Willet P, ELECTRONIC LIBRARY AND INFORMATION SYSTEM. UK: University Of Sheffield, 2006.
[3] Gregorius S Budhi, Ibnu Gunawan, and Ferry Yuwono, "ALGORITMA STEMMER FOR BAHASA INDONESIA UNTUK PROCESSING TEXT MINNING BERBASIS METODE BASKET ANALYSIS," p. 63.
[4] Amir Hamzah, PENGARUH STEMMING KATA DALAM PENINGKATAN UNTUK KERJA DOCUMENT
CLUSTERING UNTUK DOKUMEN TEKS BERBAHASA INDONESIA. Yogyakarta: Seminar Nasional
Riset Teknologi Informasi, Juli 2006.
[5] Jelita Asian, EFFECTIVE TECHNIQUES FOR INDONESIAN TEXT RETRIEVAL. Australia: RMIT University, March 2007.
[6] Meisya Fitri, PERANCANGAN SISTEM TEMU BALIK INFORMASI DENGAN METODE PEMBOBOTAN
KOMBINASI TF-IDF UNTUK PENCARIAN DOKUMEN BERBAHASA INDONESIA.: Universitas
Tanjungpura.
[7] Hugh E William, Jelita Asian, and S.M.M Tahaghoghi, STEMMING INDONESIAN. Melbourne, Australia: RMIT University.
[8] Eko Nugroho, PERANCANGAN SISTEM DETEKSI PLAGARISME DOKUMEN TEKS DENGAN
MENGGUNAKAN ALGORITMA RABIN-KARP. Malang: Universitas Brawijaya, 2011.
[9] Dini Nopiyanti, APLIKASI PENCARIAN KATA DASAR DOKUMEN TEKS BERBAHASA INDONESIA
DENGAN MENGGUNAKAN METODE STEMMING PORTER MENGGUNAKAN PHP & MySQL.
Depok: Universitas Guna Dharma, oktober 2014, vol. 8.
[10] Andita Dwiyoga Tahitoe and Diana Purwitasari, IMPLEMENTASI MODIFIKASI CONFIX STRIPPING
STEMMER UNTUK BAHASA INDONESIA DENGAN METODE CORPUS BASED STEMMING.: Institut
Teknologi Sepuluh November.
[11] Lasmedi Afuan, STEMMING DOKUMEN TEKS BERBAHASA INDONESIA MENGGUNAKAN
ALGORITMA PORTER.: Universitas Jenderal Soedirman.
[12] Favorisen Rosyking Lumbanraja, SISTEMPENCARIAN DATA TEKS DENGAN MENGGUNAKAN
METODE KLASIFIKASI ROCCHIO. Lampung: Universitas Lampung, 2013.
80
[15] F. Z. Tala, A Study of Stemming Effect on information Retrieval in Bahasa Indonesia. M. S. thesis.
M.Sc. Thesis. Master of Logic Projecy. Institute for logic, Language and Computation., Ed.:
Universiteti van Amsterdam the Netherlands.
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Stemming adalah suatu proses pencarian bentuk dasar dari suatu term. Yang dimaksud dengan term itu adalah tiap kata yang berada pada suatu dokumen teks. Stemming diperlukan selain untuk memperkecil jumlah indeks yang berbeda dari suatu dokumen, juga untuk melakukan pengelompokan kata-kata lain yang memiliki kata dasar dan arti yang serupa namun memiliki bentuk atau form yang berbeda karena mendapatkan imbuhan yang berbeda, metode stemming adalah salah satu cara yang digunakan untuk mengubah kata untuk menemukan akar kata dengan menerapkan aturan morfologi bahasa yang baik dan benar. Proses stemming dilakukan dengan menghilangkan semua imbuhan (affiks) baik yang terdiri dari awalan (prefiks) sisipan (infiks) maupun akhiran (suffiks) dan kombinasi awalan dan akhiran (konfiks)[1,6,7,9,10].
Beberapa algoritma yang termasuk kedalam metode stemming yaitu Algoritma Nazief Adriani,Algoritma Porter,Algoritma Arifin Setiono,Algoritma Confix Stripping (CS), Algoritma Vega, Algoritma Enhanded Confix Stripping (ECS),Algoritma Connected Component.Algoritma Porter adalah algoritma stemming yang digunakan untuk stemming dokumen teks berbahasa Inggris namun pada penelitian ini Algoritma Porter digunakan pada dokumen text berbahasa Indonesia, dari penelitian dalam lingkup analisis performansi algoritma ini maka menjadi dasar penelitian ini.
Terdapat penelitian sebelumnya mengenai perbandingan Algoritma Porter
yang berjudul “Perbandingan Algoritma Stemming Porter dan Algoritma Stemming Adriani Nazief Untuk Stemming Dokumen Teks Bahasa Indonesia”
Penelitian lainnya dari algoritma Arifin Setiono yang berjudul “Pengaruh Stemming Kata Dalam Peningkatan Untuk Kerja Dokumen Clustering Untuk
Dokumen Teks Berbahasa Indonesia”[4]. Algoritma Arifin Setiono digunakan
karena memiliki kelebihan dalam hal mengatasi Overstemming yaitu jika kata tidak ditemukan setelah penghapusan maka algoritma ini kemudian mencoba untuk mengembalikan semua kombinasi yang dihapus untuk mendapatkan kata yang valid [5].
Dalam penelitian ini akan dilakukan analisis performansi pada dokumen dengan menggunakan metode stemming. Berdasarkan hal tersebut maka akan dilakukan analisis performansi metode stemming dengan menggabungkan dari kedua algoritma Arifin setiono dan Porter yang nantinya akan diterapkan pada dokumen berbahasa Indonesia agar menghasilkan hasil yang lebih baik. Parameter yang akan diuji yaitu waktu proses,akurasi yang berpengaruh pada presentasi algoritma yang di implementasikan.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang diuraikan, maka dapat dirumuskan masalah dalam penelitian ini yaitu Bagaimana performansi penggabungan Algoritma Arifin Setiono dan Algoritma Porter.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah untuk mengimplementasikan dengan menggabungkan Algoritma Arifin Setiono dan Algoritma Porter dalam mentransformasi kata-kata dalam sebuah dokumen teks berbahasa indonesia.
1.4 Batasan Masalah
Batasan masalah dari penelitian ini yaitu:
1. Penerapan algoritma pada sistem hanya memproses dokumen berbahasa Indonesia.
2. Parameter yang akan di hasilkan pada aplikasi ini adalah kecepatan,ketepatan, dan jumlah langkah dari kedua algoritma.
3. Dokumen yang akan digunakan adalah dokumen jurnal berbahasa Indonesia berextensi *.txt.
4. Keluaran sistem yang diharapkan berupa kata dasar yang sesuai dengan kamus bahasa Indonesia.
5. Kamus sebagai pembanding kata yang di stemming.
1.5 Metodologi Penelitian
Metode yang digunakan dalam penelitian ini adalah metode deskriptif. Tujuan dari penelitian deskriptif ini adalah untuk membuat deskripsi, gambaran atau lukisan secara sistematis, faktual dan akurat mengenai fakta-fakta, sifat-sifat serta hubungan antarfenomena yang diselidiki.
1.5.1 Tahap Pengumpulan Data
Pengumpulan data adalah cara atau prosedur yang sistematis dan standar untuk memperoleh data yang diperlukan. Adapun metode pengumpulan data pada penelitian ini yaitu studi pustaka dengan cara mengkaji buku, media, atau hasil penelitian orang lain yang memiliki keterkaitan dengan penelitian ini.
1.5.2 Metode Pembangunan Perangkat Lunak
1. Communication
Komunikasi antara developer dan customer mengenai tujuan pembuatan dari software, mengindetifikasi apakah kebutuhan diketahui.
2. Quick Plan
Perancangan cepat setelah terjalin komunikasi antara developer dan customer.
3. Modeling, Quick design
Segera membuat model, dan quick design fokus pada gambaran dari segi software apakah visible menurut customer.
4. Construction of Prototype
Quick design menuntun pada pembuatan dari prototype 5. Deployment, Delivery & Feedback
Prototype yang dikirimkan kemudian dievaluasi oleh customer, feedback digunakan untuk menyaring kebutuhan untuk software.
1.6 Sistematika Penulisan
Sistematika penulisan proposal penelitian ini disusu untuk memberikan gambaran umum tentang penelitia yang dijalankan. Sistematika penulisan tugas akhir ini adalah sebagai berikut :
BAB 1 PENDAHULUAN
Bab ini menjelaskan secara singkat mengenai latar belakang masalah, identifikasi masalah, maksud dan tujuan, metodologi penelitian, batasan masalah, serta sistematika penulisan.
BAB 2 LANDASAN TEORI
Pada bab ini berisi teori – teori yang melatarbelakangi penulisan tugas akhir ini, yaitu teori tentang stemming,dan khususnya Algoritma Arifin Setiono dan Algoritma Porter.
BAB 3 ANALISIS DAN PERANCANGAN SISTEM
Bab ini menerangkan analisis kecepatan,keakuratan,dan jumlah langkah kedua algoritma pada aplikasi stemming dengan pendekatan analisis UML. Selain itu terdapat juga perancangan untuk aplikasi yang akan dibangun sesuai dengan analisis yang sedang dibuat.
BAB 4 IMPLEMENTASI SISTEM DAN PENGUJIAN
Pada bab ini berisi tentang analisis kebutuhan dalam membangun aplikasi ini yang sesuai dengan metode pembangunan perangkat lunak yang digunakan. Selain itu terdapat juga perancangan antarmuka dan pengujian untuk aplikasi yang akan dibangun sesuai dengan hasil analisis.
BAB 5 KESIMPULAN DAN SARAN
7 2.1 Text Mining
Text mining merupakan proses mendapatkan informasi penting yang berasal dari sekumpulan dokumen dengan melakukan pencarian kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisa keterhubungan antar dokumen.
Proses yang dilakukan oleh text mining diawali dengan penerapan struktur terhadap sumber data teks dan dilanjutkan dengan ekstraksi informasi dan pengetahuan yang relevan dari data teks terstruktur ini. Ada beberapa hal yang perlu dilakukan pada tahap pre-processing ini yaitu parsing,tokenizing,stopword dan stemming[3].
2.2 Parsing
Parsing merupakan proses memilah isi dokumen menjadi unit-unit kecil yang akan menjadi penciri misalnya berupa kata,frase atau kalimat. Unit terkecil ini yang disebut token. Proses parsing merujuk pada proses pengidentifikasian token dalam rangkaian teks sehingga bagian dalam parsing dari dokumen teks disebut tokenizer. Proses ini memerlukan pengetahuan tentang bahasa untuk menangani karakter-karakter khusus dan menentukan batasan satuan unit dalam dokumen [12].
2.3 Tokenizing
2.4 Stopword Removal
Stopword adalah kata-kata umum yang sering muncul. Stopword removal adalah proses penghapusan kata-kata yang termasuk ke dalam stopword biasanya dilakukan agar stemming menjadi efektif dan efisien. Contoh stopword bahasa Indonesia antara lain “yang”,”di”,”ke”,dll.
2.5 Stemming
Stemming adalah suatu proses pencarian bentuk dasar dari tiap kata yang berada pada suatu dokumen teks, selain untuk memperkecil jumlah indeks yang berbeda dari suatu dokumen, juga untuk melakukan pengelompokan kata-kata lain yang memiliki kata dasar dan arti yang serupa namun memiliki bentuk atau form yang berbeda karena mendapatkan imbuhan yang berbeda dengan menerapkan aturan morfologi bahasa Indonesia yang baik dan benar [1,6,7,10].
Proses stemming dilakukan dengan menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (preffixes) sisipan (infixes) maupun akhiran (suffixes), stemming dilakukan atas dasar asumsi bahwa kata-kata yang memiliki stem yang sama memiliki makna dasar yang sama[9].
Teknik stemming dapat dikategorikan menjadi 3 yaitu berdasarkan aturan dalam bahasa tertentu,berdasarkan kamus, dan berdasarkan kemunculan bersama. Salah satu tujuan utama dilakukan proses stemming adalah meningkatkan efisiensi dengan cara memilah isi dokumen menjadi unit-unit kecil yang akan menjadi penciri misalnya berupa kata,frase atau kalimat[12].
2.6 Algoritma
Algoritma adalah suatu perintah yang berisi langkah-langkah untuk menyelesaikan masalah. Algoritma berasal dari nama tokoh ilmuan islam pada masa itu yaitu Abu Ja’far Muhammad Ibu Musa Al Khawārizmi yang hidup sekitar abad ke-9. Dengan karya bukunya yang terkenal yaitu Al Jabar Wal Muqabala yang berarti “Buku Pemugaran dan Pengurangan”.
atau urutan langkah yang jelas dan diperlukan untuk menyelesaikan suatu permasalahan.
2.7 Algoritma Arifin Setiono
Algoritma Arifin Setiono merupakan algoritma yang digunakan untuk pencarian kata dasar pada dokumen teks dengan teknik stemming[5]. Input dari algoritma ini adalah dokumen teks yang diproses sehingga menghasilkan output berupa kata dasar. Algoritma Arifin Setiono mengasumsikan bahwa setiap kata memiliki dua awalan dan tiga akhiran,yaitu:
[AW1] + [AW2] + KD + [AK3] + [AK2] + [AK1]
Dimana AW = awalan, KD = kata dasar dan AK = akhiran [4].
Langkah – langkah algoritma arifin setiono dalam proses stemming isi dokumen teks.
1. Lakukan pemeriksaan setiap kata, siapkan variabel p1,p2,s1,s2,
2. Pemotangan dilakukan secara berurut, yaitu: a. Awalan I, hasil disimpan pada p1 b. Awalan II, hasil disimpan pada p2 c. Akhiran I, hasil disimpan dalam s1 d. Akhiran II, hasil disimpan dalam s2 e. Akhiran III, hasil disimpan dalam s3
Setiap tahap pemotongan hasil dicek dalam kamus, jika ada dalam kamus algoritma selesai, jika tidak ada proses dilanjutnya ke pemotongan berikutnya.Jika sampai pada langkah 2.e. belum ditemukan dalam kamus, maka dilakukan proses kombinasi. Kata dasar yang dihasilkan dikombinasikan dengan imbuhan-imbuhan dalam 12 kombinasi, yaitu:
a. Kata Dasar
b. Kata Dasar + AK III
d. Kata Dasar + AK III + AK II + AK I
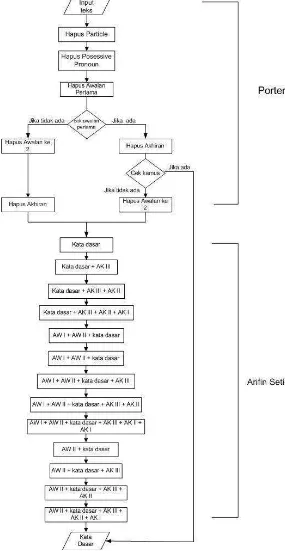
Algoritma kedua yang digunakan adalah algoritma Porter. Adapun langkah – langkah algoritma ini adalah sebagai berikut :
1. Hapus Particle,
2. Hapus Possesive Pronoun.
3. Hapus awalan pertama. Jika tidak ada lanjutkan ke langkah 4a, jika ada cari maka lanjutkan ke langkah 4b.
4. a. Hapus awalan kedua, lanjutkan ke langkah 5a.
b. Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan sebagai root word. Jika ditemukan maka lanjutkan ke langkah 5b.
5. a. Hapus akhiran. Kemudian kata akhir diasumsikan sebagai kata dasar b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word.
Terdapat 5 kelompok aturan pada Algoritma Porter untuk bahasa indonesia ini.
Tabel 2.1 Aturan Untuk Inflectional Particle[3] Akhiran Pengganti Kondisi
Tabel 2.2 Aturan Untuk inflectional Possesive Pronoun[3] Akhiran Pengganti Kondisi
Ukuran
Tabel 2.3 Aturan Untuk First Order Derivational Prefix[3] Awalan Pengganti Kondisi
Tabel 2.4 Aturan untuk Second order Derivational Prefix[3] Awalan Pengganti Kondisi
Ukuran
Tabel 2.5. Aturan untuk Derivational Suffix[3] Akhiran Pengganti Kondisi
Ukuran (per)janjian →janji
i NULL 2 V|K..c1c1,c1 ≠ s,c2≠i
Pada Porter Stemmer untuk Indonesia perlu ditambahkan beberapa aturan dalam algoritma agar memberikan hasil yang lebih maksimal dan untuk mempermudah proses stem maka dibuatlah beberapa kamus kecil,antara lain sebagai berikut :
1. Kamus kata dasar yang dilekati partikel, untuk menyimpan kata dasar yang memiliki suku kata terakhir (partikel infleksional) serta kata tersebut tidak mendapat imbuhan apapun.Seperti : masalah
3. Kamus kata dasar yang dilekati kata ganti milik, untuk menyimpan kata dasar yang memiliki suku kata terakhir (kata ganti infleksional) serta kata dasar tersebut tidak mendapatkan imbuhan apapun. Seperti : bangku. 4. Kamus kata dasar yang dilekati kata ganti milik berprefiks, untuk
menyimpan kata dasar yang memiliki suku kata terakhir (kata ganti infleksional) dan mempunyai prefiks. Seperti : bersuku.
5. Kamus kata dasar yang dilekati prefiks pertama, untuk menyimpan kata dasar yang memiliki suku kata pertama (prefiks derivasional pertama) serta kata dasar tersebut tidak mendapatkan imbuhan apapun.. Seperti : median.
6. Kamus kata dasar yang dilekati prefiks pertama bersufiks, untuk menyimpan kata dasar yang memiliki suku kata pertama (prefiks derivasional pertama) dan mempunyai sufiks derivasional.Seperti : terapan.
7. Kamus kata dasar yang dilekati prefiks kedua, untuk menyimpan kata dasar yang memiliki suku kata pertama (prefiks derivasional kedua) serta kata dasar tersebut tidak mendapatkan imbuhan apapun. Seperti : percaya. 8. Kamus kata dasar yang dilekati prefiks kedua bersufiks, untuk menyimpan
kata dasar yang memiliki suku kata pertama (prefiks derivasional) dan mempunyai sufiks derivasional. Seperti :perasaan.
Gambar 2.1 Algoritma Porter [3]
2.9 MySQL
MySQL adalah sebuah perangkat lunak sistem manajemen basis data SQL (bahasa Inggris: database management system) atau DBMS yang multithread, multi-user, dengan sekitar 6 juta instalasi di seluruh dunia. MySQL AB membuat MySQL tersedia sebagai perangkat lunak gratis dibawah lisensi GNU General Public License (GPL), tetapi mereka juga menjual dibawah lisensi komersial untuk kasus-kasus dimana penggunaannya tidak cocok dengan penggunaan GPL.
Tidak sama dengan proyek-proyek seperti Apache, dimana perangkat lunak dikembangkan oleh komunitas umum, dan hak cipta untuk kode sumber dimiliki oleh penulisnya masing-masing, MySQL dimiliki dan disponsori oleh sebuah perusahaan komersial Swedia MySQL AB, dimana memegang hak cipta hampir atas semua kode sumbernya. Kedua orang Swedia dan satu orang Finlandia yang mendirikan MySQL AB adalah: David Axmark, Allan Larsson, dan Michael "Monty" Widenius.
MySQL, namun dengan batasan perangkat lunak tersebut tidak boleh dijadikan produk turunan yang bersifat komersial. MySQL sebenarnya merupakan turunan salah satu konsep utama dalam basisdata yang telah ada sebelumnya; SQL (Structured Query Language). SQL adalah sebuah konsep pengoperasian basisdata, terutama untuk pemilihan atau seleksi dan pemasukan data, yang memungkinkan pengoperasian data dikerjakan dengan mudah secara otomatis.
Kehandalan suatu sistem basisdata (DBMS) dapat diketahui dari cara kerja pengoptimasi-nya dalam melakukan proses perintah-perintah SQL yang dibuat oleh pengguna maupun program-program aplikasi yang memanfaatkannya. Sebagai peladen basis data, MySQL mendukung operasi basisdata transaksional maupun operasi basisdata transaksional. Pada modus operasi non-transaksional, MySQL dapat dikatakan unggul dalam hal unjuk kerja dibandingkan perangkat lunak peladen basisdata kompetitor lainnya. Namun demikian pada modus non-transaksional tidak ada jaminan atas reliabilitas terhadap data yang tersimpan, karenanya modus non-transaksional hanya cocok untuk jenis aplikasi yang tidak membutuhkan reliabilitas data seperti aplikasi blogging berbasis web (wordpress), CMS, dan sejenisnya. Untuk kebutuhan sistem yang ditujukan untuk bisnis sangat disarankan untuk menggunakan modus basisdata transaksional, hanya saja sebagai konsekuensinya unjuk kerja MySQL pada modus transaksional tidak secepat unjuk kerja pada modus non-transaksional.
MySQL memiliki beberapa keistimewaan, antara lain :
1. Portabilitas. MySQL dapat berjalan stabil pada berbagai sistem operasi seperti Windows, Linux, FreeBSD, Mac Os X Server, Solaris, Amiga, dan masih banyak lagi.
2. Perangkat lunak sumber terbuka. MySQL didistribusikan sebagai perangkat lunak sumber terbuka, dibawah lisensi GPL sehingga dapat digunakan secara gratis.
MySQL memiliki kecepatan yang menakjubkan dalam menangani query sederhana, dengan kata lain dapat memproses lebih banyak SQL per satuan waktu.
4. Ragam tipe data
MySQL memiliki ragam tipe data yang sangat kaya, seperti signed / unsigned integer, float, double, char, text, date, timestamp, dan lain-lain.
5. Perintah dan Fungsi
MySQL memiliki operator dan fungsi secara penuh yang mendukung perintah Select dan Where dalam perintah (query).
6. Keamanan
MySQL memiliki beberapa lapisan keamanan seperti level subnetmask, nama host, dan izin akses user dengan sistem perizinan yang mendetail serta sandi terenkripsi.
7. Skalabilitas dan Pembatasan
MySQL mampu menangani basis data dalam skala besar, dengan jumlah rekaman (records) lebih dari 50 juta dan 60 ribu tabel serta 5 milyar baris. Selain itu batas indeks yang dapat ditampung mencapai 32 indeks pada tiap tabelnya.
8. Konektivitas
MySQL dapat melakukan koneksi dengan klien menggunakan protokol TCP/IP, Unix soket (UNIX), atau Named Pipes (NT).
9. Lokalisasi
MySQL dapat mendeteksi pesan kesalahan pada klien dengan menggunakan lebih dari dua puluh bahasa. Meski pun demikian, bahasa Indonesia belum termasuk di dalamnya.
10. Antar Muka
MySQL memiliki antar muka (interface) terhadap berbagai aplikasi dan bahasa pemrograman dengan menggunakan fungsi API (Application Programming Interface).
MySQL dilengkapi dengan berbagai peralatan (tool)yang dapat digunakan untuk administrasi basis data, dan pada setiap peralatan yang ada disertakan petunjuk online.
12. Struktur tabel
MySQL memiliki struktur tabel yang lebih fleksibel dalam menangani ALTER TABLE, dibandingkan basis data lainnya semacam PostgreSQL ataupun Oracle
2.10 Pengenalan UML
Dalam merancang tugas akhir ini penyusun akan menggunakan UML sebagai alat bantu (tools) dalam perancangan dan pendokumentasian sistem yang akan dibuat.
2.10.1 Pengertian UML
Unified Modelling Language (UML) adalah sebuah "bahasa" yang telah menjadi standar dalam industri untuk visualisasi, merancang dan mendokumentasikan sistem perangkat lunak. UML menawarkan sebuah standar untuk merancang model sebuah sistem. UML mendefinisikan notasi dan syntax/semantik. Notasi UML merupakan sekumpulan bentuk khusus untuk menggambarkan berbagai diagram piranti lunak. Setiap bentuk memiliki makna tertentu, dan UML syntax mendefinisikan bagaimana bentuk-bentuk tersebut dapat dikombinasikan. Notasi UML terutama diturunkan dari 3 notasi yang telah ada sebelumnya: Grady Booch OOD (Object-Oriented Design), Jim Rumbaugh OMT (Object Modeling Technique), dan Ivar Jacobson OOSE (Object-Oriented Software Engineering). UML Menggabungkan konsep berarah objek seperti Booch, OMT, OOSE, dsb sehingga menjadi bahasa pemodelan tunggal. UML menekankan pada apa yang dapat dikerjakan dengan metode-metode tersebut.
UML terdiri dari diagram-diagram, dimana setiap diagram didalam UML memperlihatkan sistem dari berbagai sudut pandang yang berbeda.
a. Class Diagram
Sebuah kelas diagram terdiri dari sejumlah kelas yang dihubungkan dengan garis yang menunjukan hubunga antar kelas yang disebut Associations, contoh class diagram dapat dilihat pada Gambar 2.2.
Jenis-jenis Associations [13] yaitu : 1. Aggregation
Associations yang menggambarkan hubungan antar kelas dimana kelas yang satu merupakan bagian dari kelas yang lainnya.
2. Composition
Associations yang menggambarkan hubungan erat antar kelas dimana kelas composite mempunyai segala tanggung jawab untuk mengatur kelas lainnya
dan kedua kelas mempunyai lifetime yang sama. 3. Bidirectionality
Associations yang menghubungkan antara dua kelas atau lebih tapi tidak bergantung satu sama lainnya, sehingga apabila salah satu kelas dihilangkan, kelas yang lain dapat tetap digunakan.
4. Generalization
Associations yang menghubungkan dua kelas atau lebih untuk membedakan antara kelas yang umum dengan kelas yang khusus.
5. Inheritance
Associations yang meghubungkan duakelas atau lebih yang dapat menurunkan properties seperti attributes, operations antara kelas induk dengan kelas anak.
Tabel 2.6 komponen Class Diagram[13] Nama
Komponen Keterangan Simbol
class. Bagian akhir mendefinisikan method-method dari sebuah class
Association Sebuah asosiasi merupakan sebuah relationship paling umum antara 2 class dan di lambangkan olwh sebuah garis yang menghubungkan antara 2 class. Garis ini bisa melambangkan tipe-tipe relationship dan jiga dapat menampilkan hukum-hukum multiplisitas pada sebuah relationship.(contoh : One-to one, one-to-many, many-to-many)
1..n owned by 1
Composition Jika sebuah class tidak bisa berdiri sendiri dan harus merupakan bagian dari class yang lain, maka class tersebut memiliki relasi Composition terhadap class tempat dia bergantung tersebut. Sebuah relationship composition digambarkan sebagai garis dengan ujung berbentuk jajaran genjang berisi/solid
Depedency Kadangkala sebuah class menggunakan class yang lain. Hal ini disebut dependency. Umumnya penggunaan dependency digunakan untuk menunjukkan operasi pada suatu class yang menggunakan class yang lain. Sebuah dependency dilambangkan sebagai sebuah panah bertitik-titik
b. UseCase Diagram
Usecase diagram adalah sebuah gambaran dari fungsi sistem yang dipandang dari sudut pandang pemakai yang memperkenalkan suatu sistem yang akan dibangun.
1. Actor adalah segala sesuatu yang perlu berinteraksi dengan sistem untuk pertukaran informasi.
2. System boundary menunjukan cakupan dari sistem yang dibuat dan fungsi dari sistem tersebut.
3. Usecase adalah gambaran fungsionalitas dari suatu sistem sehingga customer atau pengguna sistem paham dan mengerti mengenai kegunaan sistem yang akan dibangun.
Berikut ini dari gambar 2.2 tiga komponen sistem dalam use case diagram :
Gambar 2.2 Komponen-komponen Use case [13]
Jenis-jenis Use Case Relationships [13] antara lain : 1. Association
Garis yang menghubungkan antara actor dengan use case. 2. Extend
Menghubungkan antara dua atau lebih use case yang merupakan tambahan dari base use case yang biasanya untuk mengatasi kasus pengecualian. 3. Generalization
Hubungan antara use case umum dengan use case yang lebig khusus. 4. Include
Untuk lebih jelasnya diberikan contoh diagram dari gambar 2.3. pada gambar 2.3 dijelakan tentang pendaftaran.
siswa mendaftar kemudian petugas memberikan kwitansi pembayaran.
Daftar
Memberikan kwitansi penbayaran
Siswa Petugas
Gambar 2.3 Usecase Diagram[13] c. Activity diagram
Menggambarkan rangkaian aliran dari aktivitas, digunakan untuk mendeskripsikan aktifitas yang dibentuk dalam suatu operasi sehingga dapat juga digunakan untuk aktifitas lainnya seperti usecase. Contoh activity diagram dapat dilihat pada Gambar 2.4. Untuk lebih jelasnya diberikan contoh diagram dari gambar 2.4. pada gambar 2.4 terdapat diagram pendaftaran.
Siswa Petugas Anggota
Daftar
Registrasi
Membuat kartu
Mendapat kartu
Gambar 2.4 Activity diagram[13]
Berikut ini merupakan komponen-komponen yang digunakan dalam Activity Diagram :
Tabel 2.7 komponen-komponen Activity Diagram[13] Simbol keterangan
Initial State
Final State
State
d. Sequence Diagram
Sebuah sequence diagram [13], menunjukan urutan pertukaran pesan yang dilakukan oleh sekumpulan objek atau aktor yang mengerjakan pekerjaan. Contoh sequence dapat dilihat pada Gambar 2.5.
Untuk lebih jelasnya diberikan contoh diagram dari gambar 2.5. pada gambar 2.5 terdapat diagram pendaftaran. Pada diagram pendaftaran petugas dan daftar anggota sebagai objek, petugas memasukan data siswa pada taftar anggota, setelah itu disimpan data tersebut kedalam database daftar anggota kemudian sistem memberikan pesan kepada petugas bahwa pesan tersebut sudah berhasil disimpan.
Petugas Pinjam
Masukan id buku dan id siswa ()
Proses Query ()
Tampilkan data buku () Simpan data peminjaman
Simpan berhasil
Gambar 2.5 Sequence diagram[13]
Berikut ini merupakan komponon-komponen yang digunakan dalam Sequence Diagram :
Tabel 2.8 komponen-komponen Sequence Diagram[13]
Simbol Keterangan
Object Lifeline
Activation
Message
Message Call
Message return
2.11 Pengujian Software
Pengujian dilakukan dengan mengeksekusi data uji dan mengecek apakah fungsional perangkat lunak bekerja dengan baik.
2.11.1 Black box Testing
Pengujian Black Box adalah pengujian aspek fundamental sistem tanpa memperhatikan struktur logika internal perangkat lunak. Metode ini digunakan untuk mengetahui apakah perangkat lunak berfungsi dengan benar. Pengujian black box merupakan metode perancangan data uji yang didasarkan pada
spesifikasi perangkat lunak. Data uji dieksekusi pada perangkat lunak dan kemudian keluar dari perangkat lunak dicek apakah telah sesuai yang diharapkan.
2. Kesalahan interface Kesalahan dalam struktur data atau akses database eksternal Kesalahan kinerja
3. Inisialisasi dan kesalahan terminasi
2.12 Konsep Perangkat Lunak pendukung
perangkat lunak pendukung merupakan perangkat yang digunakan untuk mendukung dalam perencanaan perancangan sistem yang akan digunakan.
2.12.1 Microsoft Visual Studio
Microsoft Visual Studio merupakan sebuah perangkat lunak lengkap (suite) yang dapat digunakan untuk melakukan pengembangan aplikasi, baik itu aplikasi bisnis, aplikasi personal, ataupun komponen aplikasinya, dalam bentuk aplikasi console, aplikasi Windows, ataupun aplikasi Web. Visual Studio mencakup kompiler, SDK, Integrated Development Environment (IDE), dan dokumentasi (umumnya berupa MSDN Library). Kompiler yang dimasukkan ke dalam paket Visual Studio antara lain Visual C++, Visual C#, Visual Basic, Visual Basic .NET, Visual InterDev, Visual J++, Visual J#, Visual FoxPro, dan Visual SourceSafe.
Microsoft Visual Studio dapat digunakan untuk mengembangkan aplikasi dalam native code (dalam bentuk bahasa mesin yang berjalan di atas Windows) ataupun managed code (dalam bentuk Microsoft Intermediate Language di atas .NET Framework). Selain itu, Visual Studio juga dapat digunakan untuk mengembangkan aplikasi Silverlight, aplikasi Windows Mobile (yang berjalan di atas .NET Compact Framework).
Untuk membuat suatu program aplikasi pada visual studio, maka diperlukan suatu struktur aplikasi atau komponen yang digunakan, berikut beberapa aplikasi yang penulis gunakan pada visual studio antara lain :
a. Toolbar
Gambar 2.6 ToolBar Visual Studio b. Toolbox
Toolbox Adalah sebuah jendela yang berisi tombol kontrol yang akan user gunakan untuk mendesain atau membangun sebuah form atau report. Toolbox terdiri atas beberapa tombol untuk mengendalikan tampilan, berikut gambar toolbox pada visual studio dapat dilihat pada gambar 2.7:
Gambar 2.7 Tampilan Toolbox Visual Studio c. Jendela Propertis
Jendela propertis adalah jendela yang berfungsi sebagai tempat mengedit properti pada suatu objek yang terpilih pada saat mendesain atau membangun aplikasi bagi user. Berikut gambar jendela propertis dapat dilihat pada gambar 2.8
d. Form
Form merupakan tempat untuk mendesain atau membangun sebuah program, didalamnya bisa ditanamkan sebuah coding agar form tersebut dapat menjalankan program yang telah didesain oleh user. Berikut gambar form dapat dilihat pada gambar 2.9:
Gambar 2.9 Tampilan Form
2.13 Teori pengujian metode
Pengujian dengan menggunakan data ujin untuk menguji semua eleme program (datainternal,loop,logika,keputusan dan jalur). Data uji dibangkitkan dengan mengetahui struktur internal. Pada aplikasi stemming akan dilakukan pengukuran akurasi dilakukan dengan membandingkan term hasil stemming dengan kamus sebagai pembandingnya.
Perhitungan akurasi dilakukan dengan rumus sebagai berikut :
Akurasi =
X 100%
[16]29 3.1 Analisis Masalah
Metode stemming merupakan metode yang digunakan untuk proses pencarian bentuk dasar dari suatu kata pada sebuah dokumen teks. Hal ini telah dibuktikan pada jurnal “Algoritma porter stemmer for bahasa indonesia untuk pre-processing text mining berbasis metode market basket analysis” karya Gregorius S. Budhi, Ibnu Gunawan,dan Ferry Yuwono[3] . Pada jurnal ini, metode stemming digunakan untuk mengatasi masalah pencarian informasi yang tersimpan didalam dokumen secara efektif dan efisien. Penelitian ini mendapatkan kesimpulan bahwa metode stemming dalam tahap pre-processing sangat berguna karena dapat mengurangi lama waktu proses dan kesalahan proses stem kata cukup kecil, yaitu 2% sehingga dapat diatasi dengan cepat menggunakan pemeriksaaan kembali secara manual terhadap hasil stemmer[3].
Algoritma stemming porter memiliki kelebihan dalam hal kecepatan dan memiliki kelemahan dalam hal keakuratan, hal ini dibuktikan pada penelitian sebelumnya yang berjudul “perbandingan Algoritma stemming Porter dan algoritma stemming Adriani Nazief untuk dokumen teks berbahasa indonesia” oleh Ledy Agusta dalam jurnalnya[1].
Algoritma Arifin setiono memiliki kelebihan dalam hal mengatasi overstemming atau dalam hal keakuratan hal ini dibuktikan pada penelitian sebelumnya yang berjudul“Pengaruh Stemming Kata Dalam Peningkatan Untuk
Kerja Dokumen Clustering Untuk Dokumen Teks Berbahasa Indonesia” oleh amir
hamzah dalam jurnalnya[4].
3.2 Analisis data masukan
Data yang digunakan dalam menstemming kata dasar pada sistem adalah data berupa teks dari jurnal berekstensi dot(.)*txt. Untuk penelitian ini data diambil kemudian selain teks maka akan dihilangkan dengan tahapan tokenizing dan kamus sebagai pembanding kata yang di stemming.
3.3 Analisis metode
Analisis metode menjelaskan tentang bagaimana stemming itu terjadi dan menjelaskan tentang tahap-tahap yang dilakukan untuk melakukan proses stemming. Secara umum sistem ini terdiri dari beberapa proses, proses-proses
tersebut adalah sebagai berikut: 1. Proses Tokenizing 2. Proses Filtering 3. Proses Stemming
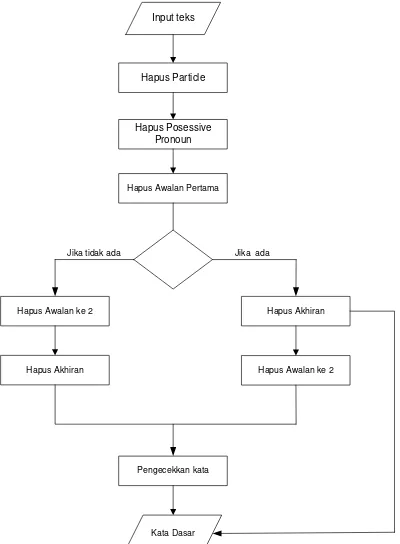
Berikut ini flowchart dari proses-proses yang akan digunakan untuk melakukan stemming.
Hapus Particle
Hapus Posessive Pronoun
Hapus Awalan Pertama
Hapus Awalan ke 2
Hapus Akhiran
Hapus Akhiran
Hapus Awalan ke 2
Pengecekkan kata
Input teks
Jika tidak ada Jika ada
Kata Dasar
Untuk mengetahui lebih jelas dari proses-proses tersebut maka akan dijelaskan sebagai berikut:
1. Proses Tokenizing
Berikut ini adalah langkah-langkah untuk melakukan tokenizing pada sebuah data yang berada dalam dokumen untuk menghilangkan tanda baca, spasi. data dalam dokumen tersebut adalah sebagai berikut:
Gambar 3.2 Proses Tokenizing
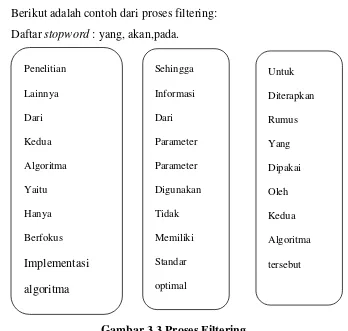
2. Proses Filtering
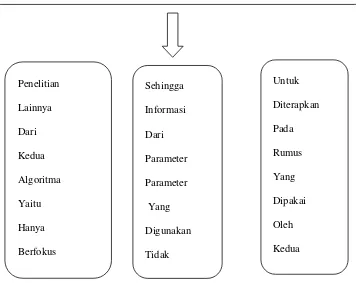
Proses filtering merupakan proses mengambil kata-kata penting yang terdapat dari hasil tokenizing. Untuk melakukan filtering bisa menggunakan stoplist atau word list. Data hasil tokenizing akan dibandingkan dengan Penelitian lainnya dari kedua algoritma yaitu hanya berfokus pada implementasi algoritma sehingga informasi dari parameter-parameter yang digunakan tidak memiliki standar optimal untuk diterapkan pada rumus yang dipakai oleh kedua algoritma tersebut
kamus. Jika tidak terdapat terdapat dalam kamus maka kata tersebut akan dihapus. Kata-kata yang tersisa merupakan kata yang dianggap penting. Untuk lebih jelasnya tahapan proses filtering adalah sebagai berikut:
a. Kata hasil proses tokenizing dibandingkan dengan tabel stopword.
b. Jika data hasil tokenizing sama dengan kata di tabel stopword maka akan dihapus.
c. Jika tidak sama dengan tabel stopword maka kata tersebut akan disimpan. Berikut adalah contoh dari proses filtering:
Daftar stopword : yang, akan,pada.
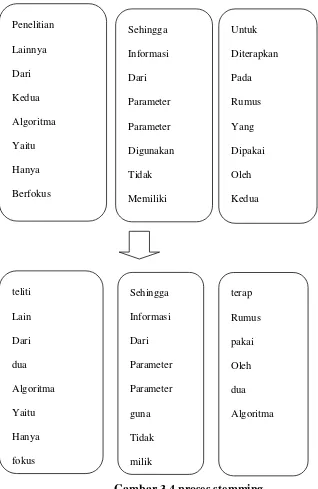
Gambar 3.3 Proses Filtering 3. Proses Stemming
Proses stemming merupakan pengelolaan kata hasil filtering menjadi kata dasar yaitu dengan cara menghilangkan imbuhan yang diantaranya adalah ”di”, “ke”, “me”, “meng”, “-an”, “-kan” untuk lebih jelasnya tahapan dari proses stemming adalah sebagai berikut:
a. Data hasil filtering diperiksa apakah mengandung imbuhan atau tidak.Jika terdapat imbuhan maka akan dilakukan pembuangan imbuhan,terus diulang sampai kata tersebut tidak mengandung imbuhan.
b. Jika sudah tidak mengandung imbuhan maka akan disimpan. Contoh dari proses stemming adalah sebagai berikut :
3.4 Analisis Penggabungan Algoritma Porter dan Arifin Setiono
1. Langkah 1:
Contoh kalimat: Berdirinya Pusat Penelitian Informatika tidak dapat dipisahkan dengan sejarah terbentuknya Lembaga Elektroteknika Nasional. Lembaga Elektroteknika Nasional sebagai lembaga penelitian dalam bidang elektronika diresmikan pada tanggal 10 Juni 1965.
Langkah awal pada algoritma yaitu melakukan hapus particle pada setiap kata, Karakter selain huruf pada tahap ini akan dihilangkan. Maka kalimat diatas akan menjadi :
Berdirinya
Gambar 3.6 langkah ke 1
2. Langkah 2:
Langkah berikutnya yaitu proses filetring dan melakukan penghapusan Possesive pronoun, maka teks akan menjadi :
Dipisahkan
Gambar 3.7 langkah ke 2 3. Langkah 3:
tanggal Juni
Gambar 3.8 langkah ke 3
4. Langkah 4:
Juni
Gambar 3.9 langkah ke 4 5. Langkah 5:
Dikarenakan hasil dari algoritma porter diatas ada beberapa kata yang belum sesuai dengan kamus maka dilakukan proses kombinasi dari algoritma Arifin Setiono. Pada langkah ini akan dilakukan kombinasi dikarenakan ada beberapa kata yang tidak sesuai dengan kamus ,yaitu dengan menggunakan kombinasi kata dasar + akhiran 3 maka kata
Gambar 3.10 langkah ke 5 6. Langkah 6:
Pada langkah ini akan dilakukan kombinasi dari hasil langkah ke 6 yaitu kata dasar + akhiran 3 + akhiran 2 maka kata akan menjadi :
Elektroteknika
Gambar 3.11 langkah ke 6
7. Langkah 7:
Gambar 3.12 langkah ke 7 8. Langkah 8:
Pada langkah ini akan dilakukan kombinasi dari hasil langkah ke 6 yaitu awalan 1 + awalan 2 + kata dasar maka kata akan menjadi :
Nasional
Gambar 3.13 langkah ke 8 9. Langkah 9:
Dikarenakan kata masih belum sesuai dengan kata dasar yang berada pada kamus maka langkah dilanjutkan dengan menggunakan kombinasi awalan 1 + awalan 2 + kata dasar + akhiran 3 maka
Gambar 3.14 langkah ke 9 10.Langkah 10 :
Dikarenakan kata masih belum sesuai dengan kata dasar yang berada pada kamus maka langkah dilanjutkan dengan menggunakan kombinasi awalan 1 + awalan 2 + kata dasar + akhiran 3 + akhiran 2 maka menjadi:
Peneliti
Gambar 3.15 langkah ke 10 11.Langkah 11:
Dikarenakan kata masih belum sesuai dengan kata dasar yang berada pada kamus maka langkah dilanjutkan dengan menggunakan kombinasi awalan 1 + awalan 2 + kata dasar + akhiran 3 + akhiran 2 + akhiran 1 maka menjadi:
Berdirinya
Dikarenakan kata masih belum sesuai dengan kata dasar yang berada pada kamus maka langkah dilanjutkan dengan menggunakan kombinasi awalan 2 + kata dasar maka menjadi:
Diri
Gambar 3.17 langkah ke 12
13.Langkah 13:
Setelah ditemukan kata yang sesuai dengan kamus maka proses kombinasi berhenti dan beberapa kata agar lebih sesuai dengan kamus digunakan kata pengganti dan menjadi kata dasar yang sesuai.
Elektroteknika
Gambar 3.18 langkah ke 13 3.5 Analisis kebutuhan perangkat lunak
Analisis kebutuhan perangkat lunak dilakukan bertujuan untuk mensimulasikan kedua algoritma kedalam sebuah perangkat lunak. Analisis kebutuhan perangkat lunak terbagi menjadi dua bagian yaitu:
1. Analisis Kebutuhan Non-Fungsional 2. Analisis Kebutuhan Fungsional 3.5.1 Analisis kebutuhan Non-Fungsional
Analisis kebutuhan non fungsional adalah langkah dimana seorang pembangun perangkat lunak (software developer) menganalisis sumber daya yang akan digunakan dan menggunakan perangkat lunak yang dibangun. Perangkat keras dan perangkat lunak yang dimiliki harus sesuai dengan kebutuhan sehingga dapat ditentukan kompabilitas aplikasi yang dibangun terhadap sumber daya yang ada.
Analisis kebutuhan non fungsional yang dilakukan dibagi dalam tiga tahap, yaitu:
3.5.1.1. Analisis Perangkat Keras
Spesifikasi perangkat keras minimum yang butuhkan untuk menjalankan sistem Deteksi similaritas dokumen dapat dilihat pada tabel 3.1.
Tabel 3.1 Spesifikasi Perangkat Keras
No Perangkat Keras Spesifikasi
1 Prosesor Kecepatan Minimal 1.8 GHz
2 Monitor Monitor 14.1’’
3 Memori 1024
3.5.1.2. Analisis Perangkat Lunak
Komponen perangkat lunak pendukung yang dibutuhkan untuk menjalankan sistem Deteksi Similaritas Dokumen ini, dapat dilihat pada table 3.2
Tabel 3.2 Spesifikasi Perangkat Lunak
No Perangkat Lunak
1 Sistem operasi Windows XP/ 7 2 Visual Studio 2010
3 Notepad++ 4 Wampserver
5 Mysql
3.5.1.3Analisis Perangkat Pikir
Analisis kebutuhan perangkat pikir merupakan uraian mengenai penguji yang akan menggunakan sistem dan terlibat dalam pengolahan data beserta karakteristiknya sehingga dapat diketahui tingkat pengalaman dan pemahaman pengguna terhadap sistem. Adapun karakteristik dari pengguna adalah sebagai berikut:
1. Pengguna dapat membaca tulisan.
2. Pengguna minimal mampu menggunakan keyboard dan mouse sebagai untuk berinteraksi dengan sistem.
3.5.2 Analisis Kebutuhan Fungsional
Spesifikasi kebutuhan fungsional adalah spesifikasi tentang hal-hal yang akan dilakukan sistem ketika diimplementasikan. Analisis kebutuhan ini diperlukan untuk menentukan keluaran yang akan dihasilkan sistem, masukan yang diperlukan sistem, lingkup proses yang digunakan untuk mengolah masukan menjadi keluaran.
3.5.2.1Usecase
Use case merupakan gambaran umum dari perancangan sistem yang akan dibangun. Terdapat tiga buah point yang merincikan use case diagram ini, yaitu :
1. Identifikasi Use Case 2. Identifikasi Aktor 3. Skenario Use Case
Adapun rincian dari use case diagram sistem stemming:
3.5.2.1.1 Identifikasi Aktor
Bagian ini diisi dengan daftar actor dan deskripsi role untuk actor tersebut. Deskripsi role harus menjelaskan wewenang pada role tersebut dalam perangkat lunak. Bisa dibuat dalam bentuk tabel berikut:
Tabel 3.3 Identifikasi Aktor
No Actor Deskripsi
1 User User menginputkan document, user input text manual, user merefresh document
3.5.2.1.2 Use Case Skenario Ambil File
Tabel 3.4 Usecase Skenario Ambil File Use Case Name Ambil file
mengambil file berekstensi .txt
Preconditions Menampilkan tombol Ambil file Succesfull
End
Conditions
Text Terinput ke dalam Form Input
Failed And Condition
Text Tidak Berhasil diinput
Primary
Trigger Aplikasi aktif Included
Case
-
1 Pengguna Masuk ke form 2 Sistem menampilkan form 3 Pengguna menekan tombol ambil
4 mengambil document/file berektensi .txt ke directori komputer
5 Sistem menampilkan hasil inputan
3.5.2.1.3 Use Case Skenario Proses
Tabel 3.5 Usecase Skenario Proses Use Case Name Proses
Melakukan proses kata dari form inputan document/file
Preconditions Dokument berhasil di input ke form input Succesfull End
Conditions
Proses kata berhasil dilakukan dan menampilkan hasil
Failed And Condition
Proses kata gagal dilakukan
Primary Actors Pengguna Secondary
Actors
-
Trigger Pemilihan tombol proses Included Case -
Main Flow Step Action
.txt ke directori komputer
2 Pengguna menekan tombol proses
3 Sistem melakukan proses preprocessing, tokenizing,stemming kemudian melakukan perhitungan kemunculan
4 Sistem menampilkan hasil
3.5.2.1.4 Use Case Skenario Hapus
Tabel 3.6 Usecase Skenario Hapus Use Case Name Hapus
Melakukan Proses hapus dari document inputan
Preconditions Proses hapus berhasil dilakukan Succesfull End
Conditions
Proses hapus berhasil dilakukan
Failed And Condition
Proses hapus gagal dilakukan
Primary Actors Pengguna Secondary
Actors
-
Trigger Pemilihan tombol hapus Included Case -
Main Flow Step Action
3.5.2.1.5Use Case Skenario Konversi
Tabel 3.7 Usecase Skenario Konversi Use Case Name Konvert
Related
Preconditions Dokument berhasil di konvert Succesfull End
Conditions
Proses konvert berhasil dilakukan dan menampilkan hasil
Failed And Condition
Proses konvert gagal dilakukan
Primary Actors Pengguna Secondary
Actors
-
Trigger Pemilihan tombol konvert Included Case -
Main Flow Step Action
1 Pengguna mengambil document/file berektensi .pdf ke directori komputer
2 Pengguna menekan tombol konvert
3 Sistem melakukan proses konvert menjadi .txt 4 Sistem menampilkan hasil
3.5.2.2Activity Diagram
menggambarkan proses paralel yang mungkin terjadi pada beberapa eksekusi. Activity diagram merupakan state diagram khusus, di mana sebagian besar state adalah action dan sebagian besar transisi di-trigger oleh selesainya state sebelumnya (internal processing). Oleh karena itu activity diagram tidak menggambarkan behaviour internal sebuah sistem (dan interaksi antar subsistem) secara eksak, tetapi lebih menggambarkan proses-proses dan jalur-jalur aktivitas dari level atas secara umum
Gambar 3.21 Activity Diagram Proses Stemming
Gambar 3.23 Activity diagram konversi 3.5.2.3Class Diagram
Class diagram adalah diagam yang digunakan untuk menampilkan beberapa kelas serta paket-paket yang ada dalam sistem/perangkat lunak yang sedang kita gunakan.Class diagram memberi kita gambaran (diagram statis) tentang sistem/perangkat lunak dan relas-relasi yang ada didalamnya. Berikut adalah class diagram dari sistem yang dibangun:
3.5.2.4Sequence Diagram
Sequence diagram adalah suatu diagram yang menggambarkan interaksi antar obyek dan mengindikasikan komunikasi diantara obyek-obyek tersebut. Diagram ini juga menunjukkan serangkaian pesan yang dipertukarkan oleh obyek-obyek yang melakukan suatu tugas atau aksi tertentu. Obyek-obyek tersebut kemudian diurutkan dari kiri ke kanan, aktor yang menginisiasi interaksi biasanya ditaruh di paling kiri dari diagram.
Gambar 3.26 Sequence Diagram Proses Stemming
Gambar 3.28 Sequence Diagram konversi 3.5.3 Perancangan sistem
Pada tahap ini digambarkan rancangan sistem yang akan dibangun sebelum dilakukan pengkodean ke dalam suatu bahasa pemrograman.
3.5.3.1Perancangan antarmuka
Perancangan antar muka Sistem Stemming Dokumen teks berbahasa Indonesia dilakukan agar membantu dalam proses implementasi antar muka sistem dari hasil analisis yang telah dilakukan.
3.5.3.1.1 Perancangan Antar Muka T01
Gambar 3.29 Antar Muka Menu Utama 3.5.3.1.2 Perancangan Antar Muka T02
Gambar 3.30 Antar Muka Form Utama 3.5.3.1.3 Perancangan antar muka T03
Gambar 3.31 Antarmuka konversi dari PDF
3.6 Jaringan Semantik
Jaringan semantik menggambarkan keterkaitan antar halaman yang dibangun. Jaringan semantik sistem dapat dilihat pada gambar 3.28
T01 T02 T03
77
BAB 5
KESIMPULAN
Pada bab ini berisikan kesimpulan dari hasil penelitian yang telah dilakukan serta saran untuk perbaikan dan pengembangan penelitian lebih lanjut.
5.1Kesimpulan
Berdasarkan hasil yang didapat dari penelitian secara keseluruhan, dapat ditarik kesimpulan sebagai berikut:
1. Berdasarkan pengujian yang telah dilakukan pada 15 dokumen rata-rata akurasi dari ke 15 dokumen adalah sebesar 46 %
2. Berdasarkan pengujian yang telah dilakukan pada 15 dokumen rata-rata kecepatan dari ke 15 dokumen adalah sebesar 56,7817995 s
5.2Saran
1. DATA PRIBADI
Nama : Arief Firmansyah
Jenis Kelamin : Laki-Laki
Tempat, Tanggal Lahir :Bandung, 22 Desember 1992
Agama : Islam
Kewarganegaraan : Indonesia
Status : Belum Kawin
Anak ke : 3 dari 3 bersaudara
Alamat : Jl. Cimuncang No.88 RT/RW 03/06 Kel.Sukapada Kec.Cibeunying Kidul
No. Telepon : 08172345163
Email : [email protected]
2. RIWAYAT PENDIDIKAN
1. Sekolah Dasar : SDN Saluyu 1
Tahun Ajaran (1998-2004) 2. Sekolah Menengah Pertama : SMP PELITA Bandung
Tahun Ajaran (2004-2007) 3. Sekolah Menengah Atas : SMA YAS Bandung
Tahun Ajaran (2007-2010) 4. Perguruan Tinggi : Universitas Komputer Indonesia
Tahun Ajaran (2010-2014) Demikian riwayat hidup ini saya buat dengan sebenar-benarnya dalam keadaan sadar dan tanpa paksaan.
Bandung, 31 Juli 2015
![Gambar 2.4 Activity diagram[13]](https://thumb-ap.123doks.com/thumbv2/123dok/1341926.796044/30.595.194.374.493.737/gambar-activity-diagram.webp)
![Gambar 2.5 Sequence diagram[13]](https://thumb-ap.123doks.com/thumbv2/123dok/1341926.796044/31.595.191.454.429.693/gambar-sequence-diagram.webp)
![Tabel 2.8 komponen-komponen Sequence Diagram[13]](https://thumb-ap.123doks.com/thumbv2/123dok/1341926.796044/32.595.150.420.133.462/tabel-komponen-komponen-sequence-diagram.webp)