PENGENALAN AKSARA JAWA TULISAN TANGAN
DENGAN MENGGUNAKAN EKSTRAKSI FITUR
ZONING
DAN KLASIFIKASI
K-NEAREST NEIGHBOUR
RIZKINA MUHAMMAD SYAM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Pengenalan Aksara Jawa Tulisan Tangan dengan Menggunakan Ekstraksi Fitur Zoning dan Klasifikasi K-Nearest Neighbour adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir disertasi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juni 2013
Rizkina Muhammad Syam
ABSTRAK
RIZKINA MUHAMMAD SYAM. Pengenalan Aksara Jawa Tulisan Tangan dengan Menggunakan Ekstraksi Fitur Zoning dengan Klasifikasi
K-Nearest Neighbour. Dibimbing oleh MUSHTHOFA.
Berbagai studi mengenai pengenalan aksara tradisional terus dikembangkan dengan menggunakan berbagai metode. Salah satu contohnya adalah pengenalan aksara Jawa tulisan tangan. Penelitian ini bertujuan untuk menentukan akurasi dengan metode ekstraksi ciri Zoning dan Klasifikasi K-Nearest Neighbour. Data yang digunakan pada penelitian ini adalah aksara Jawa tulisan tangan dari 20 orang berbeda. Masing-masing citra karakter yang ditulis oleh tiap orang diubah dalam ukuran 120 x 120 pixel dan akan menerapkan metode thinning. Ekstraksi
Kata kunci: pengenalan pola, aksara Jawa, K-Nearest Neighbour, Image Centroid
and Zone (ICZ), Zone Centroid and Zone (ZCZ)
ABSTRACT
RIZKINA MUHAMMAD SYAM. Handwritten Javanese Script Recognition Using Zoning Feature Extraction and K-Nearest Neighbour Classification. Supervised by MUSHTHOFA.
Various studies on traditional script recognition continued to be developed using various methods. One of them is handwritten Javanese script recognition. This research aims to determine the accuracy of the Zoning Feature Extraction and K-Nearest Neighbour Classification method. The data used in this this research are handwritten Javanese script from 20 different peoples. Each of character images will be transformed into 120 x 120 pixels dimension and will undergo the thinning method. The feature extraction method used is the combination of the zoning method ICZ-ZCZ with the number of zones are 4, 6, 8, 9, 10, 12, 15, 16, 18, 20 and 24. K-Nearest Neighbour is used as the classifier with k values are 1, 3, 5 and 7. The highest accuracy was obtained on 12 zones with k = 1 on K-Nearest Neighbour with a value of 71.5%.
Keywords: pattern recognition, Javanese script, K-Nearest Neighbour, Image
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
PENGENALAN AKSARA JAWA TULISAN TANGAN
DENGAN MENGGUNAKAN EKSTRAKSI FITUR
ZONING
DAN KLASIFIKASI
K-NEAREST NEIGHBOUR
RIZKINA MUHAMMAD SYAM
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pengenalan Aksara Jawa Tulisan Tangan dengan Menggunakan Ekstraksi Fitur Zoning dan Klasifikasi K-Nearest Neighbour
Nama : Rizkina Muhammad Syam
NIM : G64104013
Disetujui oleh
Mushthofa, SKom, MSc Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah subhanahu wata’ala, yang telah memberikan nikmat yang begitu banyak, sehingga penulis dapat menyelesaikan penelitian dan tulisan ini. Shalawat dan salam penulis sampaikan kepada Nabi Muhammad shallallahu ‘alaihi wasallam, keluarganya, sahabatnya, serta umatnya hingga akhir zaman. Tulisan ini merupakan hasil penelitian yang penulis lakukan sejak Agustus 2012 hingga Februari 2013. Tulisan ini mengambil topik pengenalan pola, dan bertujuan membangun model pengenalan pola karakter aksara Jawa tulisan tangan.
Tak lupa penulis mengucapkan terima kasih kepada seluruh pihak yang telah berperan dalam penelitian ini, yaitu:
1 Ayahanda Syamsudin, Ibunda Nanik Hartati, serta Adik Dhani Nur Indra Syamputra dan Permana Ahmad Syamputra atas kasih sayang, doa, semangat, dan dorongan kepada penulis agar dapat segera menyelesaikan penelitian ini.
2 Bapak Mushthofa, SKom, MSc, selaku dosen pembimbing, yang telah memberikan banyak ide, masukan, dan dukungan kepada penulis.
3 Bapak Aziz Kustiyo, SSi, MKom dan Bapak Toto Haryanto, SKom, MSi, yang telah bersedia menjadi penguji.
4 Para sahabat: Dedi Kiswanto, Asep Haryono, Leonardo Siagian, sahabat kontrakan FAT32 (Agung Widyo Utomo, Septiandi Wibowo, Yusrizal Ihya, Galih Eka, dll) serta teman-teman Ilkom Alih Jenis angkatan 5 yang lain atas kebersamaannya selama 2.5 tahun ini.
5 Rekan satu bimbingan: Putri Ayu Pramesti, Hafara Fisca, Intan Ayu Octavia dan Rahmi Juwita Sukma yang telah sharing informasi serta semangat selama pengerjaan skripsi.
6 Pihak-pihak lain yang tidak dapat penulis sebutkan satu persatu.
Penulis berharap penelitian dan tulisan ini dapat memberikan manfaat untuk kemajuan masyarakat Indonesia pada umumnya dan masyarakat Jawa pada khususnya.
Bogor, Juni 2013
DAFTAR TABEL
1 Pembagian fold pada 5-fold Cross Validation 7
2 Daftar ukuran data hasil ekstraksi ciri 10
3 Akurasi tiap zona dengan KNN untuk nilai k = 1 11 4 Akurasi tiap zona dengan KNN untuk nilai k = 3 11 5 Akurasi tiap zona dengan KNN untuk nilai k = 5 12 6 Akurasi tiap zona dengan KNN untuk nilai k = 7 12
7 Perbandingan akurasi terbaik tiap k 13
8 Nilai rata-rata akurasi tiap zona 13
DAFTAR GAMBAR
1 Huruf dasar aksara Jawa 2
2 Pixel ketetanggaan 3
3 Skema metode penelitian 5
4 Ilustrasi ekstraksi fitur ICZ-ZCZ zona 6
5 Contoh formulir pengambilan data 8
6 Praproses citra 10
7 Perbandingan nilai akurasi tiap zona 14
8 Contoh hasil praproses citra sebelum segmentasi pada penelitian
Wibowo (2012) 15
DAFTAR LAMPIRAN
1 Gambar citra hasil akuisisi dari responden 17
PENDAHULUAN
Latar Belakang
Sistem pengenalan pola (pattern recognition) merupakan konsep keilmuan yang telah dikembangkan bertahun-tahun. Pengenalan pola adalah disiplin ilmu yang bertujuan mengklasifikasikan objek dalam banyak kategori atau kelas. Pengenalan pola juga merupakan bagian penting dalam banyak sistem cerdas yang dibangun untuk membantu dalam pengambilan keputusan (Theodoridis dan Koutroumbas 2008).
Optical Character Recognition (OCR) merupakan salah satu bentuk
pengenalan pola yang dapat mengenali karakter pada media tertentu, baik yang bersifat on-line maupun off-line. Tujuan dari pengenalan karakter ini adalah untuk menerjemahkan karakter yang dikenal manusia agar bisa dikenal oleh sistem komputer. Alur kerja dari OCR terdiri atas 5 tahapan, yaitu: proses input citra, praproses, segmentasi, ekstraksi ciri, dan klasifikasi serta hasil pengenalan citra (Sinha et al. 2012).
Pengenalan pola dapat digunakan untuk mengenali tulisan tangan maupun tulisan dalam bentuk cetakan, baik tulisan aksara Latin maupun aksara non-Latin seperti yang dilakukan oleh Rajashekararadhya dan Ranjan (2008). Salah satu bentuk tulisan dengan aksara non-Latin adalah tulisan dengan menggunakan aksara Jawa.
Aksara Jawa merupakan khazanah budaya yang telah diwariskan secara turun-temurun oleh nenek moyang masyarakat suku Jawa. Aksara Jawa ini juga telah menjadi disiplin ilmu yang wajib disertakan pada pelajaran bahasa Jawa dari tingkat dasar (SD) sampai menengah (SMA) terutama di daerah Jawa Tengah, Jawa Timur dan Yogyakarta. Untuk lebih mempertegas eksistensi aksara Jawa, beberapa daerah turut menyertakan penulisan dalam aksara Jawa untuk mendeskripsikan nama jalan, nama tempat, serta fasilitas publik lainnya.
Namun, tidak semua orang dapat membaca tulisan dalam aksara Jawa, terutama bagi para warga pendatang dan turis. Hal ini disebabkan bentuk karakter pada aksara Jawa berbeda dengan karakter pada aksara Latin. Oleh karena itu, untuk mempermudah dalam pengenalan aksara Jawa diperlukan sebuah sistem komputer yang dapat membaca dan dan mengenali tulisan dengan aksara Jawa, terutama dalam bentuk tulisan tangan.
Penelitian mengenai pengenalan aksara tradisional telah banyak dilakukan. Salah satu penelitian yang terkait yaitu penelitian yang dilakukan oleh Wibowo (2012) tentang pengenalan aksara Jawa tulisan tangan menggunakan Fuzzy
Feature Extraction dengan metode Jaringan Syaraf Tiruan Propagasi Balik
dengan akurasi mencapai 84.1%. Mulia (2012) juga telah melakukan penelitian tentang pengenalan karakter aksara Sunda tulisan cetak dengan menggunakan metode klasifikasi Support Vector Machine (SVM). Akurasi terbaik terdapat pada ekstraksi fitur gabungan ICZ dan ZCZ dengan akurasi mencapai 93.99%.
Mengacu pada penelitian yang telah dilakukan oleh Rajashekararadhya dan Ranjan (2008) serta Mulia (2012), penelitian ini dilakukan dengan menggunakan ekstraksi fitur Zoning gabungan ICZ dan ZCZ dengan K-Nearest Neighbour
2
Ranjan (2008) memperoleh tingkat pengenalan karakter tulisan tangan Kannada, Tamil, Telugu, dan Malayalam sebesar 90% dengan menggunakan ekstraksi fitur gabungan ICZ-ZCZ dengan proses klasifikasi menggunakan Jaringan Syaraf Tiruan (JST) dan KNN.
Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1 Menerapkan teknik pengenalan pola untuk karakter aksara Jawa tulisan tangan menggunakan ekstraksi fitur Zoning dengan metode klasifikasi
K-Nearest Neighbour (KNN).
2 Menentukan nilai akurasi dari metode yang digunakan. Ruang Lingkup Penelitian
Ruang lingkup dari penelitian ini sebagai berikut:
1 Karakter aksara Jawa yang digunakan dalam penelitian adalah huruf dasar (aksaranglegena atau aksara carakan) tunggal.
2 Model yang akan dikembangkan hanya mengenali pola aksara Jawa dalam bentuk tulisan tangan yang tegak (tidak miring).
3 Ekstraksi fitur zoning yang digunakan adalah gabungan ICZ-ZCZ.
TINJAUAN PUSTAKA
Aksara Jawa
Huruf-huruf dalam aksara Jawa dibagi dalam beberapa jenis, antara lain huruf dasar (aksara carakan/nglegena) yang merupakan huruf utama dan terdiri atas 20 karakter seperti pada Gambar 1.
Gambar 1 Huruf dasar aksara Jawa
Selain itu, aksara Jawa juga memiliki jenis huruf yang lain, antara lain huruf pasangan (aksara pasangan) yang berjumlah 20 huruf, huruf kapital (aksara
murda) yang berjumlah 7 huruf, huruf vokal mandiri (aksara swara) sebanyak 5
3 huruf bilangan (aksara wilangan) yang berjumlah 10 huruf, serta huruf tambahan
(aksara rekan) yang berjumlah 7 huruf.
Algoritme Thinning
Thinning adalah proses morfologi citra yang mengubah bentuk asli citra biner menjadi citra yang menampilkan batas-batas objek atau foreground dengan ketebalan hanya 1 pixel. Algoritme thinning secara iteratif akan mengubah nilai
pixel pada citra biner dari 0 ke 1 sampai terpenuhinya suatu keadaan ketika satu
himpunan dari lebar per unit (satu pixel) terhubung menjadi satu garis (Zurnawita dan Suar 2009). Setiap iterasi dari metode ini terdiri atas dua sub-iterasi yang berurutan yang dilakukan terhadap contour points dari wilayah citra. Contour
point adalah setiap pixel dengan nilai 1 dan memiliki setidaknya satu 8-neighbour
yang memiliki nilai 0. Contoh pixel ketetanggaan terlihat pada Gambar 2.
p9 p2 p3
p8 p1 p4
p7 p6 p5
Gambar 2 Pixel ketetanggaan
Langkah pertama dari metode ini adalah menandai contour point p untuk dihapus jika memenuhi kondisi seperti berikut :
1 2 ≤N(p1)≤ 6
N(p1) merupakan jumlah tetangga dari p1 yang tidak 0, yaitu :
N(p1) = p2 + p3+ … + p8 + p9
selesai diproses. Prosedur penandaan dan penghapusan ini akan dilakukan secara iteratif sampai tidak ada lagi titik yang dapat dihapus sehingga pada saat algoritme ini selesai maka akan dihasilkan skeleton dari citra awal.
Metode Ekstraksi Ciri Zoning
4
metode ekstraksi ciri ICZ (image centroid and zone), metode ekstraksi ciri ZCZ
(zone centroid and zone), dan metode ekstraksi ciri gabungan (ICZ + ZCZ).
Pendekatan yang dilakukan dalam penelitian ini adalah dengan metode ekstraksi gabungan (ICZ + ZCZ) dengan langkah-langkah sebagai berikut:
1 Hitung centroid dari citra masukan.
2 Bagi citra masukan menjadi n zona yang sama.
3 Hitung jarak antara centroid citra dengan setiap pixel yang ada dalam zona. 4 Ulangi langkah 3 untuk semua pixel yang ada dalam zona.
5 Hitung jarak rata-rata antara titik-titik tersebut. 6 Hitung centroid tiap zona.
7 Hitung jarak antara centroid zona dengan setiap pixel yang ada dalam zona. 8 Ulangi langkah 7 untuk semua pixel yang ada dalam zona.
9 Hitung jarak rata-rata antara titik-titik tersebut.
10 Ulangi langkah 3-9 untuk semua zona secara berurutan.
11 Akhirnya, akan didapatkan 2n ciri untuk klasifikasi dan pengenalan.
K-Nearest Neighbour
K-Nearest Neighbour (KNN) merepresentasikan setiap data sebagai titik
dalam k-ruang dimensi. Jika ada sebuah data uji maka akan dihitung kedekatan titik data lainnya pada data latih untuk diklasifikasikan berdasarkan kedekatannya yang didefinisikan dengan ukuran jarak. Fungsi jarak yang umumnya digunakan adalah jarak Euclidean yang direpresentasikan dalam persamaan sebagai berikut (Han dan Kamber 2006).
� = −� 2
=1
Dij merupakan jarak antara vektor pi yang merupakan sebuah titik yang telah diketahui kelasnya dan qi yang merupakan titik baru yang merepresentasikan data yang akan dijadikan data uji. Jarak antara vektor dan titik dari data latih akan dihitung dan diambil k buah vektor terdekat.
Langkah-langkah dalam teknik klasifikasi dengan K-Nearest Neighbour
sebagai berikut :
1 Menentukan parameter k (jumlah tetangga terdekat).
2 Menghitung jarak antara data yang masuk dan semua sampel latih yang sudah ada dengan metode Euclidean Distance.
3 Menentukan k label data yang mempunyai jarak yang minimal. 4 Mengklasifikasikan data baru ke dalam label data yang mayoritas.
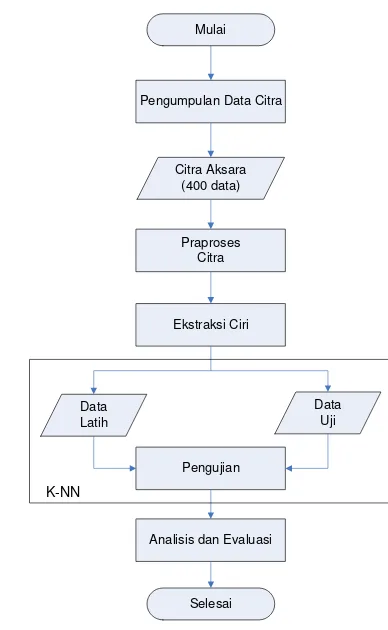
METODE PENELITIAN
5
Gambar 3 Skema metode penelitian
Pengumpulan Data Citra
Data citra yang akan digunakan selama penelitian dikumpulkan pada tahapan ini. Data citra diambil dari 20 orang berbeda yang sebelumnya pernah mempelajari aksara Jawa. Setiap responden akan menuliskan setiap karakter aksara Jawa dasar (nglegena) yang berjumlah 20 karakter pada selembar formulir yang telah disediakan.
Praproses Data
Agar citra dapat diekstraksi dan dilakukan pengenalan pola, maka perlu dilakukan tahapan praproses terlebih dahulu. Metode praproses yang digunakan meliputi:
1 Melakukan proses binerisasi (mengubah citra RGB atau grayscale menjadi citra biner) dengan nilai threshold tertentu, yakni 0.5 serta mengubah nilai
pixel dari citra menjadi 0 dan 1.
6
3 Memotong (cropping) bagian karakter dari citra karena hanya bagian karakter saja yang akan diproses, sementara bagian latar akan dibuang. 4 Mengubah dimensi dari citra aksara dalam ukuran 120 x 120 pixel.
5 Melakukan proses thinning untuk mendapatkan kerangka inti dari citra karakter.
Ekstraksi Ciri
Tahapan ini dilakukan untuk mendapatkan fitur yang menjadi ciri dari setiap karakter aksara Jawa. Fitur tersebut nantinya akan dijadikan acuan dalam proses klasifikasi dan pengenalan pola. Pendekatan yang digunakan dalam penelitian ini adalah ekstraksi fitur gabungan Image Centroid and Zone dan Zone Centroid and Zone (ICZ - ZCZ). Ilustrasi mengenai ekstraksi fitur ICZ-ZCZ dapat dilihat pada Gambar 4.
Sebelum memulai tahapan ini, citra yang akan diolah harus memiliki dimensi yang sama besar. Setelah itu, dihitung nilai centroid citra dengan rumus seperti berikut:
Gambar 4 Ilustrasi ekstraksi fitur ICZ-ZCZ zona
7 metode Euclidean Distance (d1, d2, .., dn) dan dihitung rata-rata jarak antar titik tersebut.
Tahapan selanjutnya adalah menghitung centroid tiap zona dengan masing-masing pixel pada citra (D1, D2, .. Dn) lalu menghitung jarak rata-rata pixel yang ada pada masing-masing zona tersebut sehingga akan diperoleh 2 nilai fitur untuk tiap zona (f1, f2, …, fn).
K-Fold Cross Validation
Data yang sudah melalui proses ekstraksi ciri kemudian akan dibagi menjadi data latih dan data uji dengan menggunakan k-fold cross validation. Nilai k yang digunakan adalah 5 sehingga akan diperoleh 5 buah fold, yaitu fold1, fold2, fold3,
fold4, dan fold5. Pembagian fold terlihat seperti pada Tabel 1.
K-Nearest Neighbour (KNN)
Proses klasifikasi dengan KNN dilakukan menggunakan data latih hasil ekstraksi ciri yang sebelumnya sudah dibagi menggunakan k-fold
cross-validation. Dalam melakukan pelatihan dan pengujian data, karakter akan diambil
satu persatu dari kumpulan citra yang ada. Jumlah kelas yang ada dalam pengenalan aksara Jawa ini yaitu 20 kelas.
Dalam proses klasifikasi sebelumnya harus ditentukan dahulu nilai k, yaitu jumlah tetangga terdekat yang akan dilihat kelasnya untuk menentukan kelas terbanyak yang merupakan kelas dari titik baru. Nilai k akan sangat berpengaruh pada akurasi hasil klasifikasi. Nilai k yang akan dicobakan pada penelitian ini adalah 1, 3, 5, dan 7.
Analisis dan Evaluasi
Tahapan ini merupakan tahapan terakhir dalam mengevaluasi kelebihan serta kekurangan dari metode yang digunakan. Hal ini terlihat dari hasil perbandingan antara hasil klasifikasi citra aksara Jawa dengan citra aksara Jawa asli. Proses perhitungan akurasi hasil klasifikasi menggunakan rumus berikut:
8
� � = ���
� 100%
Dengan :
ΣNbenar : jumlah citra yang tepat terklasifikasi
ΣN : jumlah citra yang ada
Lingkungan Penelitian
Lingkungan yang digunakan untuk penelitian ini memiliki spesifikasi sebagai berikut:
Perangkat keras:
Processor Intel Dual Core 2,31 GHz.
Memory RAM dengan kapasitas 2 GB.
Harddisk dengan kapasitas 250 GB.
Perangkat lunak:
Sistem Operasi Microsoft Windows 7 Ultimate Service Pack 2 32-bit
MATLAB R2008b.
HASIL DAN PEMBAHASAN
Pengumpulan Data Citra
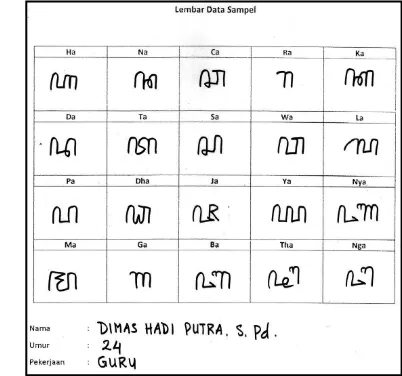
Data yang digunakan dalam penelitian ini didapat dari hasil penyebaran formulir yang dilakukan ke 20 responden yang pernah mempelajari aksara Jawa. Responden akan diminta untuk mengisi formulir tersebut dengan menuliskan 20 aksara Jawa dasar (aksara nglegena) dengan menggunakan sebuah spidol kecil berwarna hitam. Kertas yang digunakan adalah kertas A4 80 gram dengan dimensi area penulisan tiap karakter sebesar 2.16 x 3.23 cm. Contoh formulir pengambilan data terlihat pada Gambar 5, sedangkan data seluruh formulir pengambilan data serta satu contoh formulir berukuran satu halaman penuh tercantum pada Lampiran 1.
9 Setelah semua formulir telah terisi dan terkumpul, formulir-formulir tersebut diubah menjadi data citra digital dengan melakukan proses scanning
dengan menggunakan scanner. Kemudian, citra hasil scan tersebut dipotong untuk diambil citra hurufnya saja sehingga dari tiap responden akan didapat 20 citra aksara Jawa.
Praproses Data
Pada tahapan praproses data, data citra yang telah diperoleh dari proses pengumpulan data akan diubah menjadi citra biner (binerisasi), dibuang noise-nya (noise removal), dipotong (crop), diubah ukurannya (resize), serta dilakukan proses thinning.
Data citra aksara yang telah diperoleh sebelumnya harus dibinerisasikan untuk memastikan bahwa komponen warna yang terdapat pada citra aksara hanya terdiri atas warna hitam dan putih. Selain itu, nilai pixel citra harus dikomplemenkan agar bagian karakter pada citra tersebut bernilai 1, sedangkan pada bagian background bernilai 0.
Citra aksara hasil dari proses pengumpulan data memungkinkan munculnya
noise, baik yang disebabkan dari noda spidol selama proses penulisan aksara Jawa
oleh responden maupun debu yang berasal dari proses scanning. Proses penghilangan noise menggunakan metode 8-connected. Metode ini dipilih karena metode median filter tidak bisa digunakan untuk menghilangkan noise yang berukuran besar. Luas area dari tiap pixel yang terhubung akan dihitung dan dijadikan satu label. Jika luas sebuah area kurang dari 100 pixel, maka nilai pixel
dari area tersebut akan diubah menjadi 0.
Setelah noise berhasil dibuang, citra tersebut akan dipotong (crop) karena hanya bagian karakter saja yang akan diproses, sedangkan bagian latar akan dibuang. Cara memotongnya adalah dengan menentukan batas kanan, kiri, atas dan bawah dari area karakter yang akan diambil. Setelah itu, elemen citra yang berada di dalam batas akan diambil sebagai data citra baru.
Setelah dilakukan proses pemotongan, diperoleh citra hasil yang ukurannya tidak seragam antara satu dengan lainnya. Agar ukurannya sama, maka citra hasil harus diubah ukurannya menjadi 120 x 120 pixel. Kemudian, akan dilakukan proses thinning pada citra untuk mendapatkan bentuk kerangka inti dari citra karakter.
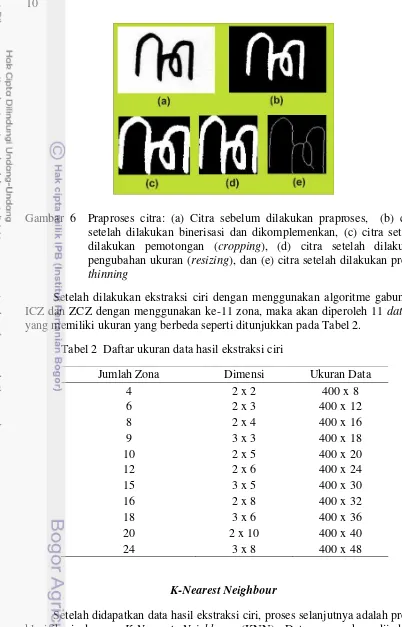
Perbandingan antara citra sebelum dilakukan praproses, saat binerisasi, pemotongan, pengubahan ukuran, serta thinning ditunjukkan oleh Gambar 6.
Ekstraksi Ciri
10
Gambar 6 Praproses citra: (a) Citra sebelum dilakukan praproses, (b) citra setelah dilakukan binerisasi dan dikomplemenkan, (c) citra setelah dilakukan pemotongan (cropping), (d) citra setelah dilakukan pengubahan ukuran (resizing), dan (e) citra setelah dilakukan proses
thinning
Setelah dilakukan ekstraksi ciri dengan menggunakan algoritme gabungan ICZ dan ZCZ dengan menggunakan ke-11 zona, maka akan diperoleh 11 dataset
yang memiliki ukuran yang berbeda seperti ditunjukkan pada Tabel 2.
K-Nearest Neighbour
Setelah didapatkan data hasil ekstraksi ciri, proses selanjutnya adalah proses klasifikasi dengan K-Nearest Neighbour (KNN). Data yang akan dijadikan sebagai data uji akan dibandingkan dengan data latih hasil ekstraksi ciri.
Data yang digunakan sebagai data latih pada KNN sebanyak 320 buah, sedangkan untuk data uji yang digunakan sebanyak 80 buah. Pembagian data dilakukan dengan 5-fold cross-validation. Setelah data dibagi menggunakan k-fold
Tabel 2 Daftar ukuran data hasil ekstraksi ciri
Jumlah Zona Dimensi Ukuran Data
11
cross-validation, dilakukan proses klasifikasi menggunakan KNN dengan nilai k
yang akan diujicobakan adalah 1, 3, 5, dan 7.
Analisis Hasil
Untuk KNN dengan k = 1
Nilai akurasi dengan k = 1 pada KNN untuk setiap zona yang digunakan terlihat pada Tabel 3. Dari Tabel 3 terlihat bahwa nilai akurasi tertinggi pada k = 1terdapat pada zona 12 dengan nilai akurasi mencapai 71.50%.
Untuk KNN dengan k = 3
Nilai akurasi pada KNN dengan k = 3 untuk setiap zona yang digunakan terlihat pada Tabel 4. Dari Tabel 4 terlihat bahwa nilai akurasi tertinggi pada k = 3 terdapat pada zona 12 dengan nilai akurasi yang diperoleh mencapai 69.75%.
Tabel 3 Akurasi tiap zona dengan KNN untuk nilai k = 1 Jumlah Zona Nilai Akurasi (dalam %)
4 54.50 Jumlah Zona Nilai Akurasi (dalam %)
12
Untuk KNN dengan k = 5
Nilai akurasi pada KNN dengan k = 5 untuk setiap zona yang digunakan terlihat pada Tabel 5. Dari Tabel 5 terlihat bahwa nilai akurasi tertinggi pada k = 5 terdapat pada zona 12 dengan akurasi yang diperoleh mencapai 67.00%.
Untuk KNN dengan k = 7
Nilai akurasi pada KNN dengan k = 7 untuk setiap zona yang digunakan terlihat pada Tabel 6. Dari Tabel 6 terlihat bahwa nilai akurasi tertinggi pada k = 7 terdapat pada zona 10 dengan akurasi yang diperoleh mencapai 67.25%.
Dari keempat percobaan yang dilakukan pada tiap nilai k pada KNN, nilai akurasi dari tiap nilai k akan dibandingkan satu sama lain untuk memperoleh nilai
k yang mempunyai rata-rata nilai akurasi terbaik. Perbandingan nilai akurasi untuk zona terbaik pada setiap nilai k pada KNN terlihat pada Tabel 7.
Tabel 5 Akurasi tiap zona dengan KNN untuk nilai k = 5 Jumlah Zona Nilai Akurasi (dalam %)
4 58.25 Jumlah Zona Nilai Akurasi (dalam %)
13
Berdasarkan data pada Tabel 7, nilai rata-rata tertinggi terdapat pada k = 1 dengan nilai akurasi rata-rata mencapai 62.86% dan nilai rata-rata akurasinya semakin menurun untuk nilai k selanjutnya. Sedangkan secara keseluruhan nilai akurasi terbaik pada penelitian ini terdapat pada zona 12 dengan nilai k = 1 pada KNN dengan akurasi mencapai 71.50%.
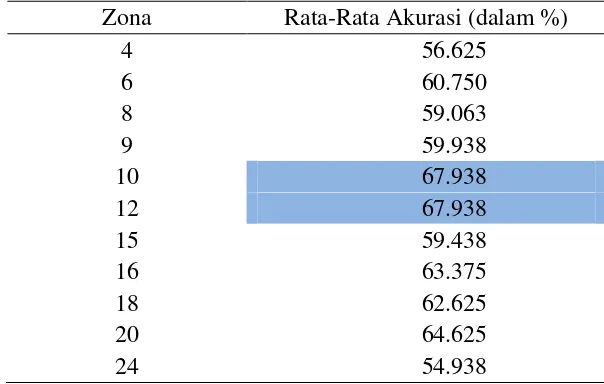
Analisis Faktor Zona
Nilai rata-rata akurasi yang diperoleh untuk setiap zona yang digunakan dari semua nilai k pada KNN dalam penelitian ini dapat dilihat pada Tabel 8. Dari Tabel 8 terlihat bahwa nilai rata-rata akurasi tertinggi terdapat pada zona 10 dan 12 dengan nilai akurasi mencapai 67.938%. Grafik pola perbandingan dari nilai rata-rata akurasi dapat dilihat pada Gambar 7.
Tabel 7 Perbandingan akurasi terbaik tiap k
Zona Rata-Rata Akurasi (dalam %)
14
Gambar 7 Perbandingan nilai akurasi tiap zona Faktor Kesalahan
Ada beberapa faktor yang dapat menyebabkan akurasi yang diperoleh dari penelitian ini masih rendah, antara lain dari sisi citra tulisan aksara Jawa yang meliputi:
1 Citra aksara berupa tulisan tangan lebih bervariasi daripada citra aksara yang berasal dari tulisan cetak (printed). Hal ini akan berpengaruh terhadap nilai akurasi karena setiap huruf pada tulisan cetak memiliki tingkat kemiripan yang lebih tinggi terhadap huruf yang sama dibandingkan pada aksara Jawa.
2 Pada aksara Jawa, setiap orang memiliki gaya penulisan yang berbeda. Perbedaan itu dapat dilihat dari kemiringan tulisan, jarak antar kaki tiap huruf, dan sebagainya.
3 Beberapa karakter dalam aksara Jawa memiliki bentuk yang hampir serupa dengan karakter lainnya. Hal ini dapat mengakibatkan sebuah karakter dalam aksara Jawa yang menjadi data uji bisa teridentifikasi ke dalam kelas yang salah.
Dari tabel confusion matrix yang terdapat pada Lampiran 2, beberapa karakter aksara Jawa yang diujikan terklasifikasi ke dalam kelas tertentu yang merupakan kelas yang salah atau bukan kelas aslinya. Karakter aksara Jawa yang salah tersebut secara bentuk memiliki kemiripan dengan satu atau beberapa aksara lainnya. Karakter tersebut antara lain:
1 Na (10 data karakter Na teridentifikasi benar) memiliki kemiripan dengan Ka (4 data karakter Na teridentifikasi ke dalam kelas Ka) dan Da (5).
2 Ca (14) memiliki kemiripan dengan Dha (4). 3 Wa (11) memiliki kemiripan dengan Dha (4). 4 Nga (13) memiliki kemiripan dengan Tha (5).
Sementara itu, karakter yang paling sering terklasifikasi dengan benar adalah karakter Ya (20) dan Ga (19). Daftar lengkap mengenai analisis perbedaan dari karakter-karakter yang salah tersebut tercantum pada Lampiran 3.
15 Perbandingan dengan Penelitian Wibowo (2012)
Setelah diperoleh nilai akurasi secara keseluruhan, hasil dari penelitian ini akan dibandingkan dengan hasil penelitian yang dilakukan Wibowo (2012) tentang pengenalan huruf Jawa tulisan tangan dengan menggunakan Jaringan Saraf Tiruan (JST) dengan Fuzzy Feature Extraction. Jika dibandingkan dengan penelitian tersebut, nilai akurasi yang dihasilkan dari penelitian ini lebih kecil dari penelitian yang dilakukan oleh Wibowo (2012) tersebut yang mencapai 84.1 %. Hal ini disebabkan karena penelitian tersebut menggunakan pendekatan berupa proses segmentasi tiap karakter citra aksara Jawa, sedangkan penelitian ini menggunakan pendekatan pembagian zona citra karakter. Contoh hasil praproses citra yang dilakukan oleh Wibowo (2012) sebelum dilakukan proses segmentasi terlihat pada Gambar 8.
Gambar 8 Contoh hasil praproses citra sebelum segmentasi pada penelitian Wibowo (2012)
SIMPULAN DAN SARAN
Simpulan
Dari penelitian yang telah dilakukan dalam pengenalan karakter aksara Jawa ini dapat diambil beberapa kesimpulan sebagai berikut:
1 Metode zoning gabungan ICZ dan ZCZ dengan KNN sebagai classifier
dapat diimplementasikan dalam pengenalan karakter aksara Jawa tulisan tangan.
2 Klasifikasi KNN dengan nilai k = 1 memiliki rata-rata hasil pengenalan yang lebih baik dibandingkan dengan k yang bernilai 3, 5, dan 7.
3 Nilai akurasi tertinggi diperoleh pada zona 12 dengan nilai k = 1 pada KNN dengan nilai akurasi mencapai 71.5%.
4 Dari 11 bentuk zona yang diuji, zona 10 dan 12 memiliki dengan nilai akurasi rata-rata terbaik sebesar 67.938%.
16
Saran
Beberapa hal yang perlu dikembangkan lebih lanjut dari penelitian ini antara lain:
1 Melakukan pengenalan aksara Jawa dengan menggunakan metode ekstraksi ciri dan klasifikasi yang lain (jaringan syaraf tiruan, Support Vector
Machine, Probabilistic Neural Network, dan sebagainya).
2 Mengakomodasi citra aksara Jawa tulisan tangan dengan tanpa memperhatikan gaya penulisan responden, seperti tingkat kemiringan dan sebagainya.
3 Melakukan pengembangan dalam sistem yang bersifat mobile sehingga pengenalan aksara Jawa dapat diterapkan secara langsung di lapangan.
DAFTAR PUSTAKA
Han J, Kamber M. 2006. Data Mining Concepts and Techniques. Ed ke-2. San Francisco (US): Elsevier.
Mulia I. 2012. Pengenalan aksara Sunda berbasis citra menggunakan Support
Vector Machine [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Rajashekararadhya SV, Ranjan PV. 2008. Efficient zone based feature extraction algorithm for handwritten numeral recognition of four popular South Indian scripts. Journal of Theoretical and Applied Information Technology. 4(12): 1171-1181.
Sinha G, Rani A, Dhir R, Rani R. 2012. Zone-Based Feature Extraction Techniques and SVM for Handwritten Gurmukhi Character Recognition.
International Journal of Advanced Research in Computer Science and
Software Engineering. 2(6): 106:111.
Theodoridis S, Koutroumbas K. 2008. Pattern Recognition. Ed ke-4. Burlington (US) : Academic Press.
Wibowo A. 2012. Pengenalan huruf Jawa tulisan tangan menggunakan jaringan saraf tiruan perambatan balik dengan Fuzzy Feature Extraction [skripsi]. Semarang (ID): Universitas Diponegoro.
17 Lampiran 1 Gambar citra hasil akuisisi dari responden
18
Lampiran 1 Gambar citra hasil akuisisi dari responden
19 Lampiran 1 Gambar citra hasil akuisisi dari responden
20
Lampiran 1 Gambar citra hasil akuisisi dari responden
22
Lampiran 2 Tabel Confusion matrix untuk pada zona 12 dengan k = 1
HASIL KLASIFIKASI
HA NA CA RA KA DA TA SA WA LA PA DHA JA YA NYA MA GA BA THA NGA
HA 14 1 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 2 0 0
NA 0 10 0 0 4 5 1 0 0 0 0 0 0 0 0 0 0 0 0 0
CA 0 0 14 0 0 0 0 0 1 0 1 4 0 0 0 0 0 0 0 0
RA 0 0 0 17 0 0 0 0 0 0 0 0 0 0 0 0 2 0 0 1
KA 2 1 0 0 15 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0
DA 0 2 0 0 0 15 0 1 0 0 0 2 0 0 0 0 0 0 0 0
TA 0 0 0 0 0 0 18 0 0 0 0 0 0 2 0 0 0 0 0 0
SA 0 1 1 0 0 1 0 15 0 1 1 0 0 0 0 0 0 0 0 0
WA 0 0 1 0 0 0 0 0 11 0 1 4 0 0 0 2 0 1 0 0
LA 0 1 0 0 0 0 1 0 0 16 0 0 0 0 0 2 0 0 0 0
PA 1 0 0 0 0 2 0 1 1 0 11 0 0 0 0 2 0 0 2 0
DHA 0 0 1 0 0 0 0 0 4 0 3 10 0 0 0 0 0 1 0 1
JA 2 0 0 0 0 1 1 1 0 0 0 0 15 0 0 0 0 0 0 0
YA 0 0 0 0 0 0 0 0 0 0 0 0 0 20 0 0 0 0 0 0
NYA 2 0 0 0 0 0 0 0 0 0 0 0 0 0 15 0 0 3 0 0
MA 0 2 2 0 0 0 0 0 0 3 1 0 0 0 0 11 0 1 0 0
GA 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 19 0 0 0
BA 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 0 1
THA 0 0 2 0 0 1 0 1 0 0 1 2 0 0 0 0 0 1 9 3
NGA 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 5 13
23 Lampiran 3 Contoh perbandingan kemiripan antarkarakter aksara Jawa
1. Karakter Na dengan Da
Karakter Na yang terklasifikasi Da Karakter Da Benar Terklasifikasi
Pembagian zona karakter Na Pembagian zona karakter Da
Grafik karakter Na Grafik karakter Da 2. Karakter Ca dengan Dha
Karakter Ca yang terklasifikasi Dha Karakter Dha Benar Terklasifikasi
24
Grafik karakter Ca Grafik karakter Dha 3. Wa dengan Dha
Karakter Wa yang terklasifikasi Dha Karakter Dha Benar Terklasifikasi
Pembagian zona karakter Wa Pembagian zona karakter Dha
Grafik karakter Wa Grafik karakter Dha 4. Nga dengan Tha
25
Pembagian zona karakter Nga Pembagian zona karakter Tha
26