APLIKASI ANDROID PENERJEMAH BAHASA NON-LATIN
DENGAN PENGENALAN CITRA KARAKTER
ADI KIRANA WIJAYAJATI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Aplikasi Android Penerjemah Bahasa non-Latin dengan Pengenalan Citra Karakter adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, April 2015
ABSTRAK
ADI KIRANA WIJAYAJATI. Aplikasi Android Penerjemah Bahasa non-Latin dengan Pengenalan Citra Karakter. Dibimbing oleh KARLINA KHIYARIN NISA.
Bahasa dengan karakter nonlatin merupakan bahasa yang sulit untuk dipelajari karena penulisannya yang relatif rumit. Beberapa bahasa yang menggunakan karakter nonlatin antara lain Arab, Cina (sederhana), Rusia, Jepang, Korea, dan Thailand. Pada penelitian ini, suatu sistem pengenalan karakter nonlatin berbasis Android dirancang untuk mengenali citra karakter nonlatin menggunakan Tesseract library OCR (Optical Character Recognition) dan menerjemahkannya menjadi bahasa Indonesia dan Inggris menggunakan Microsoft Translator. OCR adalah teknik untuk mengubah teks nondigital menjadi teks digital atau dapat diartikan sebagai pengenalan karakter optik. Pada penelitian ini terdapat 8 kebutuhan fungsional, yaitu memilih bahasa asal, mengambil citra menggunakan kamera dan memotongnya, mengambil citra melalui galeri, melakukan konversi dari citra ke teks, mengedit teks nonlatin hasil OCR, memilih bahasa tujuan, menampilkan hasil terjemahannya, dan me-reset aplikasi. Berdasarkan 650 contoh karakter nonlatin yang terdiri dari 5 bahasa telah diuji, nilai akurasi terbaik yang didapat adalah 95.03% pada kondisi pencahayaan normal. Adapun faktor-faktor yang dapat mempengaruhi akurasi tersebut antara lain: intensitas cahaya, kemiringan, fokus, dan penulisan secara vertikal. Evaluasi usability menghasilkan nilai 82.4%.
Kata Kunci: Android, citra, nonlatin, OCR, teks, Tesseract.
ABSTRACT
ADI KIRANA WIJAYAJATI. Android Application Language Interpreter with Recognition of non-Latin Character Image. Supervised by KARLINA KHIYARIN NISA.
Languages with nonlatin characters are more difficult to learn because the writing is relatively complicated. Some languages that use nonlatin characters are Chinese (simplified), Russian, Japanese, Korean, and Thai. In this study, a nonlatin character recognition system based on Android is designed to recognize the image of nonlatin characters using the Tesseract library OCR (Optical Character Recognition) and translated into Bahasa Indonesia and English. OCR is a technique to convert nondigital text into digital text. In this study, there were 8 functional requirements which are choosing origin language, taking image with a camera and cropping, taking an image from the gallery, converting an image to text, editing nonlatin text of OCR result, choosing target language, displaying the translation, and resetting. Based on 650 examples of nonlatin characters that consisted of 5 languages that have been tested, the best accuracy for the result is 95.03% on normal light. Factors that effect the accuracy are the intensity of light, tilted text, motion bluring, and vertical writing. The value of usability evaluation is 82.4%.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
APLIKASI ANDROID PENERJEMAH BAHASA NON-LATIN
DENGAN PENGENALAN CITRA KARAKTER
ADI KIRANA WIJAYAJATI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji: 1 Dr Ir Agus Buono, MSi MKom
Judul Skripsi : Aplikasi Android Penerjemah Bahasa non-Latin dengan Pengenalan Citra Karakter
Nama : Adi Kirana Wijayajati NIM : G64124041
Disetujui oleh
Karlina Khiyarin Nisa, SKom MT Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Alhamdulillahi rabbil ‘alamin, puji syukur penulis panjatkan ke hadirat Allah subhanahu wa Ta'ala atas berkat, rahmat, taufik, dan hidayah-Nya sehingga penyusunan skripsi yang berjudul Aplikasi Android Penerjemah Bahasa non-Latin dengan Pengenalan Citra Karakter dapat diselesaikan dengan baik. Sholawat serta salam semoga selalu tercurahkan kepada Nabi Muhammad shalallahu 'alaihi wassallam beserta keluarga, sahabat, dan para pengikutnya yang telah memberikan contoh dalam meraih kebahagiaan di dunia dan akhirat.
Terima kasih penulis ucapkan kepada orang tua penulis, ayahanda tercinta Purwoto yang selalu menjadi inspirasi kebijaksanaan dalam tutur dan laku penulis. Ibunda Morita, yang tak pernah lelah memberikan motivasi wejangan, doa, cinta, dan kasih sayang dalam mendidik. Dosen pembimbing Ibu Karlina Khiyarin Nisa, SKom MT atas waktu, ilmu, kesabaran, nasihat, dan masukan yang selalu diberikan selama pengerjaan tugas akhir ini, Bapak Dr Ir Agus Buono, MSi MKom dan Bapak Muhammad Asyhar Agmalaro, SSi MKom selaku penguji atas waktu, masukan, dan koreksinya. Serta teman-teman Ilmu Komputer alih jenis angkatan 7 atas pengalaman berbagi ilmu serta atas kebersamaan dan dukungannya selama penulis menjalani waktu di Departemen Ilmu Komputer IPB.
Semoga karya ilmiah ini bermanfaat.
Bogor, April 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Pengumpulan Data 3
Analisa Pengenalan Karakter 3
Penerjemahan Karakter non-Latin 4
Perancangan Aplikasi 4
Implementasi 4
Pengujian 5
Evaluasi 5
HASIL DAN PEMBAHASAN 5
Pengumpulan Data 5
Analisa Pengenalan Karakter 6
Penerjemahan Karakter non-Latin 11
Perancangan Aplikasi 12
Implementasi 15
Pengujian 16
Evaluasi 19
SIMPULAN DAN SARAN 20
Simpulan 20
Saran 20
DAFTAR PUSTAKA 21
LAMPIRAN 22
DAFTAR TABEL
1 Data uji citra karakter nonlatin 6
2 Rancangan antarmuka pengguna 15
3 Implementasi sistem 16
4 Pengujian sistem menggunakan metode black box 17
5 Skenario pengujian 17
6 Contoh pengujian karakter Cina (sederhana) 18
7 Akurasi pada masing-masing skenario 18
8 Contoh pengujian penerjemahan 19
9 Klasifikasi penarikan kesimpulan hasil evaluasi usability 19
10 Evaluasi usability 20
DAFTAR GAMBAR
1 Metode penelitian 3
2 Alur kerja Tesseract OCR Engine 3
3 Diagram alur Grayscaling 7
4 Ilustrasi Gaussian Smoothing 2 dimensi 8
5 Algoritme Otsu 9
6 Identifikasi outline 10
7 Contoh fitted baseline 10
8 Contoh pemisahan karakter 11
9 Use case diagram 12
10 Activity diagram 14
DAFTAR LAMPIRAN
1 Pengujian pengenalan karakter dan terjemahannya 22
PENDAHULUAN
Latar BelakangBahasa merupakan protokol dalam berkomunikasi, penggunaan bahasa yang sesuai sangat penting dalam terciptanya komunikasi untuk mengirim maupun menerima pesan yang akan diolah menjadi informasi. Namun, dalam pengaplikasiannya sangat sulit untuk mengetahui pesan yang yang disampaikan secara tertulis dan menggunakan bahasa dengan karakter nonlatin seperti Cina, Jepang, Korea, Rusia, dan Thailand.
Dalam proses pembelajarannya, untuk mengenali dan menerjemahkan karakter nonlatin yang kita jumpai cukup sulit. Hal ini dikarenakan proses menterjemahkan memerlukan masukan berupa teks dengan karakter nonlatin. Untuk mengatasi masalah tersebut, teknik optical character recognition (OCR) dapat dimanfaatkan. OCR merupakan teknik pengenalan karakter optik yang berfungsi untuk mengubah karakter teks nondigital menjadi teks dalam bentuk digital. Namun, dalam implementasinya diperlukan suatu perangkat mobile untuk menjalankan teknik pengenalan karakter optik agar proses pengenalan karakter nonlatin dapat dilakukan di mana saja dan kapan saja, misalnya ketika sedang melakukan perjalanan pariwisata ke negara yang menggunakan karakter nonlatin sebagai huruf resmi negara tersebut.
Android merupakan sistem operasi mobile phone open source yang berbasis Linux menggunakan bahasa pemograman Java. Selain mendukung pengembangan standar terbuka pada perangkat mobile. Adapun fitur pendukung yang disediakan oleh Android agar memudahkan pengembang untuk mengembangkan aplikasi antara lain: storage, network, multimedia, GPS, dan phone service (Fajaruddin 2011).
2
Perumusan Masalah
Perumusan masalah pada penelitian ini antara lain:
1 Bagaimana Tesseract OCR engine dapat diterapkan dalam pengenalan citra karakter nonlatin pada perangkat Android?
2 Seberapa besar keakuratan Tesseract OCR engine dalam mengenali karakter nonlatin?
3 Bagaimana pengaruh intensitas cahaya, kemiringan, fokus, dan penulisan karakter secara vertikal terhadap keakuratan pengenalan karakter?
4 Bagaimana hasil evaluasi usability melalui kuesioner kepada pengguna? Tujuan
Tujuan pada penelitian ini antara lain:
1 Menerapkan tesseract OCR engine pada perangkat Android untuk mengenali citra karakter nonlatin.
2 Mengetahui keakuratan Tesseract OCR engine dalam mengenali citra karakter nonlatin.
3 Mengetahui pengaruh intensitas cahaya, kemiringan, fokus, dan penulisan secara vertikal terhadap keakuratan pengenalan karakter.
4 Mengetahui hasil evaluasi usability melalui kuesioner kepada pengguna. Manfaat Penelitian
Pada penelitian ini, manfaat yang diperoleh adalah membantu masyarakat dalam mengenali karakter nonlatin dengan bahasa Cina (sederhana), Jepang, Korea, Rusia, dan Thailand dalam bentuk nondigital ke dalam bentuk digital serta menerjemahkannya ke dalam bahasa Indonesia dan Inggris pada suatu aplikasi mobile.
Ruang Lingkup Penelitian
Ruang lingkup pada penelitian ini antara lain:
1 Pengenalan karakter nonlatin dilakukan pada citra yang bukan hasil tulisan tangan.
2 Karakter nonlatin hanya bahasa dengan karakter yang didukung oleh Tesseract OCR dan Microsoft Translator yaitu Cina (sederhana), Jepang, Korea, Rusia, dan Thailand.
3 Pengguna sudah mengetahui bahasa untuk karakter yang akan dikenali. 4 Masukan citra memiliki ekstensi yang didukung oleh Android dan
tesseract OCR, yaitu format JPEG, GIF, PNG,dan BMP.
5 Pengujian pengenalan karakter dilakukan pada citra yang divariasikan pada intensitas cahaya, kemiringan, fokus, dan penulisan secara vertikal.
METODE
3
Gambar 1 Metode penelitian Pengumpulan Data
Pada tahap awal penelitian, dilakukan pengumpulan data uji citra karakter nonlatin berupa citra digital dan citra nondigital. Pada penelitian ini, pemilihan bahasa dengan karakter nonlatin antara lain: Cina (sederhana), Jepang, Korea, Rusia, dan Thailand. Pemilihan karakter Cina sederhana dengan pertimbangan bahwa dalam pengaplikasiannya lebih banyak digunakan dan lebih mudah dalam pengenalannya dibandingkan karakter Cina (tradisional) (Shi-zong 2009).
Analisa Pengenalan Karakter
Pada penelitian ini, proses pengenalan citra karakter dilakukan dengan menggunakan Tesseract OCR Engine. Mesin OCR dikembangkan di Hewlett-Packard (HP) pada tahun 1984 dan 1994 (Smith 2007). Adapun alur kerja dalam pengenalan citra karakter dapat dilihat pada Gambar 2.
Gambar 2 Alur kerja Tesseract OCR Engine Image Preprocessing
Grayscaling Removing noise
Thresholding
Feature Extraction Connected Component Labelling
Segmentation Line Finding Baseline Fitting Fixed Pitch Detection Non Fixed Pitch Detection
Word Recognition Adaptive Classifier Teks
Citra Biner
4
Penerjemahan Karakter non-Latin
Setelah karakter nonlatin berhasil dikenali dengan baik. Proses selajutnya adalah penerjemahan karakter nonlatin ke dalam bahasa Indonesia atau Inggris. Pemilihan bahasa Indonesia dan Inggris sebagai bahasa tujuan dalam penerjemahan dikarenakan penelitian ini dibuat di negara Indonesia menggunakan bahasa Indonesia, sedangkan bahasa Inggris merupakan bahasa internasional yang secara resmi dipelajari oleh hampir semua negara di dunia.
Perancangan Aplikasi
Pada tahap perancangan aplikasi terdiri dari beberapa proses yaitu use case diagram, activity diagram dan perancangan antarmuka.
Use Case Diagram
Use case diagram merupakan salah satu dari UML (Unified Modelling Language) diagram yang bertujuan untuk memodelkan proses bisnis dari perspektif pengguna. Pada use case diagram terdiri dari aktor sebagai pengguna aplikasi dan aksi-aksi yang dapat dilakukan oleh aktor tersebut.
Activity Diagram
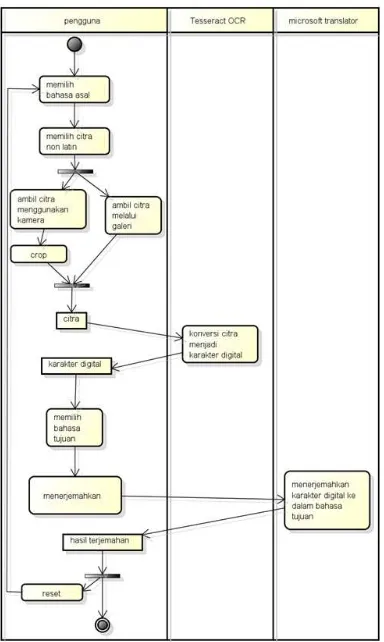
Activity diagram menggambarkan alur aktivitas dalam sistem yang akan dibangun sehingga dapat mencerminkan perancangan alur sistem dari awal, proses yang mungkin terjadi di dalamnya, dan akhir dari alur sistem yang telah diaplikasikan.
Perancangan Tampilan Antarmuka
Tampilan antarmuka merupakan media komunikasi yang digunakan antara pengguna dan sistem. Sistem yang akan dibangun diharapkan mudah dipahami dan dimengerti oleh pengguna agar fungsi dari sistem dapat dioperasikan dengan baik oleh pengguna.
Implementasi
Pada penelitian ini, sistem dibangun dan diimplementasikan menggunakan perangkat keras dan perangkat lunak dengan rincian sebagai berikut.
1 Perangkat keras
a Sony Ericsson ST18i (Xperia Ray) dengan sistem operasi Android Ice Cream Sandwich v4.0.4
i CPU 1 GHz Scorpion
ii Memory internal 512 MB dan microSD 8 GB
iii Kamera 8 MP, 3264 x 2448 pixels, autofocus, LED flash b Dell inspiron dengan sistem operasi Windows 7 Home Basic
i Intel Core i3-2370M Processor
5 iv Harddisk 500 GB 5400 RPM
2. Perangkat lunak
a Eclipse Juno ADT b Android SDK c Tesseract OCR d Tesseract Traineddata
e API Microsoft Translaor 0.6.1 Pengujian
Tahap pengujian menggunakan metode black box terhadap fungsi-fungsi utama pada sistem yang telah diimplementasikan pada perangkat mobile Android. Pengujian pengenalan karakter oleh Tesseract OCR menggunakan data uji karakter nonlatin dari masing-masing bahasa dengan skenario pengujian yang berbeda-beda. Adapun skenario pengujian yang dimaksud mencakup pengujian secara normal, pengujian dengan intensitas cahaya sangat terang dan redup, pengujian dengan kemiringan 30 dan 60 derajat, pengujian dengan citra blur atau kabur, dan pengujian dengan karakter vertikal. Hal ini diperlukan untuk mengetahui tingkat akurasi pada masing-masing skenario pengujian dalam mengenali citra karakter nonlatin.
Evaluasi
Pada tahap terakhir yaitu evaluasi dilakukan dengan cara memberikan kuesioner kepada pengguna aplikasi yang telah dibangun ini. Kuesioner dirancang dengan memperhatikan lima aspek usability yang terdiri dari learnability, efficiency, memorability, errors,dan satisfaction (Nielsen 2012). Tujuan utama kuesioner adalah untuk mengumpulkan informasi dari responden berupa tingkat kepuasan mengenai kekurangan dan kelebihan suatu aplikasi (Rubin dan Chissnell 2008). Kepuasan pengguna diukur menggunakan skala Likert 1 sampai 5 untuk membantu pengguna mengekspresikan kepuasan mereka terhadap aplikasi. Adapun penilaian kuesioner untuk mengukur tingkat usability adalah sebagai berikut.
1 SS (Sangat Setuju) nilai 5 2 S (Setuju) nilai 4
3 RR (Ragu-ragu) nilai 3 4 TS (Tidak Setuju) nilai 2
5 STS (Sangat Tidak Setuju) nilai 1
HASIL DAN PEMBAHASAN
Pengumpulan Data6
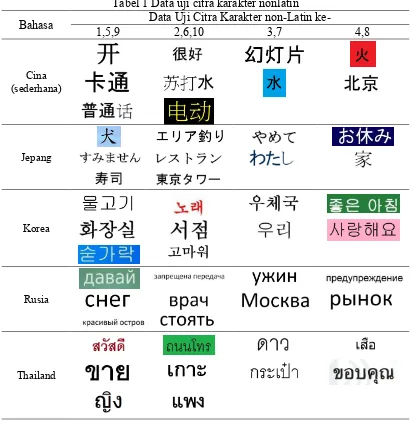
menggunakan fungsi kamera pada perangkat mobile Android. Adapun data uji tersebut untuk lebih lengkapnya dapat dilihat pada Tabel 1.
Tabel 1 Data uji citra karakter nonlatin Bahasa Data Uji Citra Karakter non-Latin ke-
1,5,9 2,6,10 3,7 4,8
Cina (sederhana)
Jepang
Korea
Rusia
Thailand
Analisa Pengenalan Karakter
Image Preprocessing
Pada bagian image preprocessing dilakukan proses grayscaling, removing noise dan thresholding. Pada bagian ini diharapkan menghasilkan citra biner yang nantinya menjadi masukan pada tahap berikutnya tahap feature extraction.
1 Grayscaling
7 ARGB_8888 yaitu mendefinisikan nilai alpha channel, merah, hijau, dan biru yang kemudian dapat dirumuskan dengan persamaan di bawah agar menjadi citra dengan derajat keabuan.
gs= ((r + g +b)/3) & 0xFF
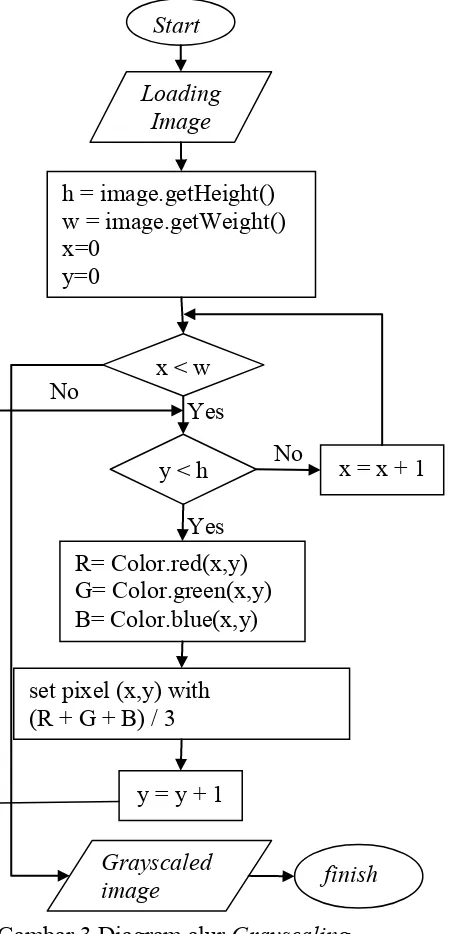
Dengan format warna ini dihasilkan citra grayscale dengan intensitas keabuan yang dipengaruhi oleh variabel warna merah hijau, dan biru. Sedangkan nilai alpha channel berupa 0xFF merupakan ketransparanan dengan nilai 0. Adapun diagram alur dari proses grayscaling dapat dilihat pada Gambar 3.
Gambar 3 Diagram alur Grayscaling Start
Loading Image
h = image.getHeight() w = image.getWeight() x=0
y=0
x < w
y < h ?
x = x + 1
R= Color.red(x,y) G= Color.green(x,y) B= Color.blue(x,y)
y = y + 1 set pixel (x,y) with (R + G + B) / 3
Grayscaled
image finish
No
Yes
No
8
2 Removing Noise
Pada penelitian ini, proses removing noise menggunakan unsharp mask yang merupakan hasil pengurangan citra asli dengan citra yang telah diperhalus atau telah melalui proses smoothing.
g(x,y) = f(x,y) – ℎ ( , )
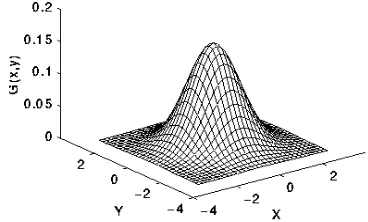
Proses smoothing pada penelitian ini menggunakan gaussian smoothing dengan konvolusi matriks 3x3. Smoothing dilakukan dengan tujuan untuk menghaluskan citra dan mendekatkan simbol yang berbentuk karakter yang memiliki ruang menjadi lebih mudah dikenali oleh program aplikasi sebagai suatu karakter yang utuh dan bukan simbol-simbol yang terpisah (Fisher et al. 2003). Adapun distribusi gaussian smoothing dalam citra 2 dimensi dapat dirumuskan sebagai berikut.
ℎ ( , ) = 2��12
− 2+ 22�2
Dari perumusan gaussian smoothing dalam berntuk 2 dimensi tersebut, maka dapat diilustrasikan dengan Gambar 4.
Gambar 4 Ilustrasi Gaussian Smoothing 2 dimensi
3 Thresholding
Pada proses selanjutnya citra akan berubah menjadi citra biner yang hanya mempunyai dua kemungkinan nilai yaitu 0 untuk hitam dan 1 untuk putih. Pada proses ini tiap piksel pada citra akan diklasifikasikan berdasarkan ambang batas tertentu, jika nilai piksel kurang dari ambang batas, maka piksel tersebut akan bernilai 0. Namun, jika nilai piksel lebih dari atau sama dengan ambang batas, maka piksel tersebut akan bernilai 1. Dalam proses binerisasi citra ini menggunakan global thresholding metode Otsu dengan tujuan untuk membagi histogram citra gray ke dalam dua daerah yang berbeda secara otomatis tanpa membutuhkan masukan nilai ambang batas. Probabilitas setiap piksel pada level ke-i dapat dinyatakan sebagai berikut.
�= � / N
� = jumlah piksel pada level ke-i
9
Dalam menentukan nilai ambang batas pada metode Otsu, ada beberapa hal yang perlu diketahui, nilai zeroth cumulative moment, first cumulative moment, dan nilai mean berturut-turut dapat dinyatakan dengan rumus berikut (Putra 2004).
ω(k)= �=1�� μ(k)= �=1�.�� �� = ��=1�.��
Nilai ambang k dapat ditentukan dengan memaksimumkan persamaan:
��2( ∗) = 1≤�<��2( ) dengan ��2(k) =
[��� −�( )]2
� [1−�( )]
Algoritme untuk menentukan nilai ambang batas citra menggunakan metode Otsu dapat dilihat pada Gambar 5.
Gambar 5 Algoritme Otsu Feature Extraction
Pada tahap feature extraction, untuk mendapatkan fitur dari citra teks, outline karakter harus diidentifikasi terlebih dahulu pada proses ekstraksi fitur menggunakan connected component labelling. Adapun ilustrasi pengidentifikasian outline pada proses connected component labelling dapat dilihat pada Gambar 6.
tMean = 0;
variance = maxVariance = 0; firstCM = zerothCM = 0
for (i=0,i<h;i++){
for (j=0;j<w;j++){ n = Image[j][i]; histogram[n]++;} }
for (k=0;k<level;k++){
tMean +=k*histogram[k]/(w*h);} for (k=0;k<level;k++){
zerothCM += histogram[k] / (w*h); firstCM +=k* histogram[k] / (w*h);
variance = (tMean * zerothCM - firstCM); variance *= variance;
variance /= zerothCM * (1 - zerothCM); if (maxVariance < variance){
maxVariance = variance; T = k;}
10
Gambar 6 Identifikasi outline
Pada Gambar 19 dapat dijelaskan bahwa karakter (a) mengalami proses pelabelan berupa outline (b), setelah proses pelabelan, outline akan membentuk blob yang merupakan tipe data untuk binary file (c), yang pada akhirnya outline karakter berhasil diidentifikasi (d) (Smith 2007).
Segmentation
Proses selanjutnya adalah segmentation. Ada beberapa tahap dalam segmentation agar karakter pada citra berhasil dikenali, antara lain: line finding, baseline fitting, dan chopping.
1 Line Finding
Algoritme line finding dirancang agar dapat membaca teks dengan derajat kemiringan tertentu tanpa harus meng-skew (proses mengubah halaman miring menjadi tegak) sehingga tidak menurunkan akurasi pengenalan citra karakter (Smith 2007). Hasil dari identifikasi outline dapat diasumsikan telah menyediakan informasi berupa region teks dengan ukuran seragam, dengan begitu karakter proses line finding dapat mengidentifikasi karakter yang bersentuhan secara vertikal sebagai teks yang lebih dari satu baris.
2 Baseline Fitting
Setelah baris teks ditemukan, baseline dicocokan dengan lebih tepat menggunakan quadratic spline. Fungsi ini digunakan untuk mengatasi citra karakter dengan baseline miring atau berbentuk kurva. Baseline dicocokan dengan partisi blob ke dalam kelompok-kelompok. Pada baseline fitting terdapat 3 pengelompokan garis, yaitu garis tengah (meanline), garis menaik (ascender), dan garis menurun (descender). Contoh fitted baseline dapat dilihat pada Gambar 7.
11
3 Chopping
Pada bagian ini, baris karakter yang berhasil diidentifikasi akan dilakukan proses chopping atau dipisahkan untuk tiap karakternya agar proses pengenalan karakter menjadi lebih akurat. Akan tetapi, syarat dari proses pemisahan karakter adalah jarak antarkarakter terdeteksi dengan jarak yang tetap atau fixed pitch detection, jika jarak antarkarakter tidak tetap atau non-fixed pitch detection, maka akan dicari dulu ambang batas jarak antarkarakter untuk menentukan karakter yang terhubung dan karakter yang terpisah. Adapun contoh pemisahan karakter dapat dilihat pada Gambar 8.
Gambar 8 Contoh pemisahan karakter Word Recognition
Hasil dari pengenalan karakter nonlatin pada bagian segmentation di atas kemudian akan dicocokan dengan data latih Tesseract yang dapat diunduh secara gratis di http://code.google.com/p/tesseract-ocr/downloads/list. Pada penelitian ini mengidentifikasi berdasarkan 5 bahasa yang menggunakan karakter nonlatin. Data latih yang digunakan adalah sebagai berikut:
1 chi_sim.traineddata : data latih karakter Cina (sederhana) 2 jpn.traineddata : data latih karakter Jepang
3 kor.traineddata : data latih karakter Korea 4 rus.traineddata : data latih karakter Rusia 5 tha.traineddata : data latih karakter Thailand
Proses klasifikasi dilakukan dengan terlebih dahulu mengukur jarak antara karakter yang diuji terhadap karakter-karakter yang telah tersedia pada data latih Tesseract dengan mengoptimalkan rumus jarak Euclidean.
d
x,y = ( 1− 1)2+ ( 2− 2)2Selanjutnya untuk mencocokkan fitur dilakukan pencarian jarak terdekat dengan algoritme pencarian best first search. Hasil keluaran pada proses ini harus berupa karakter string (UTF-8). Oleh karena itu, terdapat fungsi getUTF(8) pada class TessBaseApi di library Tesseract OCR yang bertujuan untuk mengubah unicode karakter nonlatin yang terdiri dari bilangan hexadesimal menjadi karakter string (UTF-8).
Penerjemahan Karakter non-Latin
12
Penerjemahan dilakukan dari bahasa karakter nonlatin ke dalam bahasa Indonesia dan Inggris. Proses penerjemahan dapat berlangsung dengan baik dengan cara memberikan tautan berupa Microsoft Translator API dalam format .JAR dan dengan menambahkan client ID serta client secret pada kode program.
Perancangan Aplikasi
Use Case Diagram
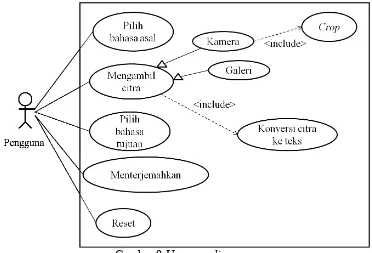
Pada penelitian ini, perancangan aplikasi dapat digambarkan dengan use case seperti pada Gambar 9. Dari use case diagram tersebut, dapat dijelaskan bahwa seorang pengguna diharuskan memilih bahasa asal, mengambil citra menggunakan kamera dengan tambahan fungsi crop atau dari galeri, dan memilih bahasa tujuan untuk selanjutnya sistem menterjemahkan hasil konversi teks dari citra ke dalam bahasa tujuan. Pada bagian pilih bahasa asal, bahasa yang tersedia antara lain: Cina (sederhana), Jepang, Korea, Rusia, dan Thailand. Sedangkan untuk pilih bahasa tujuan, bahasa yang digunakan adalah Indonesia dan Inggris.
Gambar 9 Use case diagram Activity Diagram
Pada penelitian ini proses bisnis dijelaskan menggunakan activity diagram yang menghubungkan aksi yang dilakukan antar komponen. Adapun komponen dalam mengoperasikan aplikasi pengenalan bahasa nonlatin hingga tahap penerjemahan antara lain:
1 Pengguna
13 2 Tesseract OCR
Pada bagian Tesseract OCR proses yang dilakukan adalah melakukan konversi citra menjadi karakter digital. Proses konversi dilakukan dalam beberapa tahapan antara lain: preprocessing, feature extraction, segmentation, dan word recognition.
a Preprocessing
Pada bagian preprocessing, proses yang dilakukan antara lain grayscaling yaitu mengubah citra RGB menjadi citra grayscale dengan rumus (R+G+B)/3. Tahap berikutnya adalah removing noise dengan menggunakan metode unsharp mask yaitu mengurangi nilai tiap piksel citra grayscale dengan nilai tiap piksel citra grayscale yang telah melalui tahap smoothing menggunakan metode gaussian smoothing. Setelah tahap removing noise selesai, tahap berikutnya adalah thresholding menggunakan metode Otsu yaitu dengan mencari nilai maksimum dari variance sebagai nilai threshold atau nilai ambang batas.
b Feature extraction
Pada bagian feature extraction, proses yang dilakukan adalah connected component labelling yaitu dengan cara mengidentifikasi komponen yang terhubung sehingga membentuk outline pada karakter yang diuji untuk selanjutnya dilakukan tahap segmentation.
c Segmentation
Pada bagian segmentation, proses yang dilakukan antara lain line finding, baseline fitting, dan chopping. Pada bagian line finding, Tesseract OCR Engine dirancang agar dapat membaca karakter dengan derajat kemiringan tertentutanpa harus meng-skew karakter tersebut. Proses selanjutnya adalah baseline fitting yaitu pencocokan garis pangkal menggunakan quadratic spline, sehingga dapat mengidentifikasi karakter pada teks dengan ketinggian beragam dalam satu baris. Proses selanjutnya adalah chopping dengan cara menentukan jarak antarkarakter terlebih dahulu. Jika jarak antarkarakter tetap, karakter dalam suatu baris teks dapat langsung dipotong agar lebih mudah dalam pengenalan tiap karakternya. Namun, jika jarak antarkarakter beragam, akan diidentifikasi terlebih dahulu nilai ambang batas antarkarakter untuk mengetahui pemisahan antarkarakter menggunakan jeda atau tidak.
d Word recognition
Pada bagian word recognition, proses yang dilakukan adalah mencocokan data uji hasil tahap segmentation dengan data latih dengan mengoptimalkan rumus pencarian jarak euclidian dan best first search untuk pemilihan jarak terdekat. Setelah karakter berhasil diidentifikasi, proses selanjutnya adalah mengubah karakter set unicode hasil pengenalan data uji menjadi karakter string (UTF8) untuk selanjutnya hasil dari word recognition akan ditampilkan kepada pengguna.
3 Microsoft Translator
14
15 Perancangan Tampilan Antarmuka
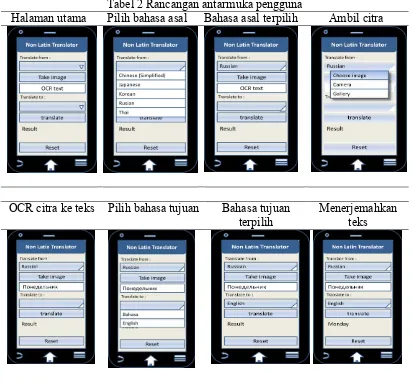
Pada penelitian ini dihasilkan aplikasi Android pengenalan citra karakter nonlatin menggunakan Tesseract OCR dan menerjemahkannya menggunakan Microsoft Translator. Berdasarkan activity diagram tersebut, dibuatlah perancangan antarmuka pengguna seperti pada Tabel 2, dengan adanya perancangan antarmuka di bawah, diharapkan perancangan alur sistem yang dilakukan pada activity diagram akan terwujud.
Tabel 2 Rancangan antarmuka pengguna
Halaman utama Pilih bahasa asal Bahasa asal terpilih Ambil citra
OCR citra ke teks Pilih bahasa tujuan Bahasa tujuan terpilih
Menerjemahkan teks
Implementasi
16
Tabel 3 Implementasi sistem Tampilan awal Pilihan bahasa
asal
Pilihan masukan citra
Kamera
Crop / pemotongan Galeri Pengenalan karakter Pilihan bahasa
tujuan
Terjemahan Indonesia Terjemahan Inggris
Pengujian
17 pada aplikasi yang dibangun berjalan dengan baik sesuai yang direncanakan pada bagian analisa kebutuhan dan desain. Berikut hasil pengujian menggunakan metode black box dapat dilihat pada Tabel 4.
Tabel 4 Pengujian sistem menggunakan metode black box
No. Nama fungsi Hasil pengujian
1 Memilih bahasa asal Berhasil
2 Mengambil citra melalui kamera dan memotongnya Berhasil
3 Mengambil citra melalui galeri Berhasil
4 Menampilkan teks hasil OCR Berhasil
5 Mengubah teks hasil OCR Berhasil
6 Memilih bahasa tujuan Berhasil
7 Menterjemahkan teks hasil OCR ke bahasa tujuan Berhasil
8 Me-reset aplikasi Berhasil
Pada bagian pengujian, selain pengujian fungsi sistem menggunakan metode black box, dilakukan pula pengujian untuk mengetahui besarnya akurasi pengenalan karakter yang dihasilkan pada aplikasi yang dibangun serta untuk mengetahui pengaruh dari intensitas cahaya, kemiringan citra karakter, dan kabur tidaknya citra dalam pengenalan karakter pada citra. Oleh karena itu, diperlukan beberapa skenario untuk memanipulasi citra agar dapat diuji untuk mengetahui pengaruh dari intensitas cahaya, kemiringan citra dan kabur tidaknya citra. Adapun skenario pengujian untuk lebih lengkapnya dan contoh pengujian pengenalan karakter dapat dilihat pada Tabel 5 dan Tabel 6.
Tabel 5 Skenario pengujian
Pengujian Kategori Kamera Galeri
Intensitas Cahaya
Terang Lampu putih 15W (jarak lampu kurang dari 20cm)
Brightness = 50 (Microsoft office picture manager) Normal Lampu putih 15W (jarak
lampu + 2 meter)
Brightness = 0 (Microsoft office picture manager) Redup Lampu kuning 10W Brightness = -50
(Microsoft office picture manager)
Fokus
Fokus Menunggu fokus Langsung Kabur /
Blur
Langsung ambil tanpa menunggu fokus
Gaussian blur 1,5px (Adobe imageready)
Kemiringan
0° Posisi kamera sejajar dengan citra karakter
Rotate 0° 30° Posisi kamera miring 30°
dengan citra karakter
Rotate 30° 60° Posisi kamera miring 60°
dengan citra karakter
18
Tabel 6 Contoh pengujian karakter Cina (sederhana)
No Skenario Citra OCRed teks Terjemahan Akurasi
Dari skenario pengujian dan contoh pengujian dalam pengenalan karakter di atas yang dilakukan pada masing-masing bahasa dengan karakter nonlatin, maka diperoleh akurasi pengenalan karakter pada masing-masing bahasa dengan masing-masing skenario seperti pada Tabel 7 dengan rincian hasil pengujian yang terdapat pada Lampiran 1.
Tabel 7 Akurasi pada masing-masing skenario No
. Pengujian
Bahasa Rata-rata
akurasi
19 pengujian karakter dengan penulisan secara vertikal pada bahasa Cina dan Jepang, tetapi hal tersebut tidak berlaku pada karakter Korea.
Akurasi juga akan menurun tajam ketika citra dimiringkan maupun dibuat kabur karena proses pengenalan karakter pada citra tidak invariant terhadap kemiringan walaupun pada tahap line finding terdapat fungsi untuk skewing / memiringkan karakter pada citra. Akurasi pada pengujian citra kabur atau blur juga menurun cukup tajam karena proses removing noise menggunakan metode unsharp mask yaitu dengan cara mengurangi nilai citra asli dengan citra yang sudah melalui tahap smoothing. Oleh sebab itu, jika citra asli yang digunakan sudah dalam keadaan kabur, tentunya akan lebih sulit untuk menemukan outline pada karakter yang diuji. Adapun contoh pengujian penerjemahan karakter secara online menggunakan Microsoft Translator dapat dilihat pada Tabel 8.
Tabel 8 Contoh pengujian penerjemahan No. Bahasa Hasil pengenalan
karakter
Terjemahan Indonesia Inggris
1 Cina Geser Slide
Pada tahap evaluasi usability ini diberikan sejumlah task atau tugas berupa kuesioner yang sudah dipersiapkan sebelumnya kepada pengguna saat berinteraksi dengan sistem. Bentuk dari lembar kuesioner dan tanggapan dari para responden terdapat pada Lampiran 2. Kuesioner dirancang menggunakan bahasa yang mudah dimengerti oleh pengguna. Klasifikasi penarikan kesimpulan berdasarkan rata-rata nilai evaluasi kuesioner terdapat pada Tabel 9.
Tabel 9 Klasifikasi penarikan kesimpulan hasil evaluasi usability
Nilai Kesimpulan
<20% Sangat tidak setuju bahwa aplikasi sangat mudah dipahami
20
dengan perhitungan, � �� ℎ� � �
� �� � � � x 100%. Berikut penilaian evaluasi
usability menggunakan kuesioner pada tiap responden terdapat pada Tabel 10.
Tabel 10 Evaluasi usability
No. Responden Penilaian Nilai (%)
SS S RR TS STS
1 Pertama 5 20 84
2 Kedua 5 13 7 78.4
3 Ketiga 14 10 1 90.4
4 Keempat 2 18 5 77.6
5 Kelima 6 15 4 81.6
Rata-rata penilaian tiap responden (%) 82.4
Pada tabel evaluasi usability di atas dapat disampaikan bahwa pada rata-rata nilai evaluasi usability menggunakan kuesioner adalah 82.4% yang berarti aplikasi yang dibangun pada penelitian ini yaitu aplikasi Android penerjemah bahasa nonlatin dengan pengenalan citra karakter sangat mudah dimengerti dan sangat mudah untuk dipelajari dalam penggunaanya.
SIMPULAN DAN SARAN
SimpulanPada penelitian ini menghasilkan aplikasi Android untuk pengenalan citra karakter nonlatin dengan Tesseract library. Dari pengujian terhadap 650 data uji citra yang terdiri dari 5 bahasa (Cina sederhana, Jepang, Korea, Rusia, dan Thailand), sistem mampu mengenali citra karakter nonlatin dengan akurasi terbaik sebesar 95.03% pada kondisi pencahayaan normal dengan kemiringan 0°, serta mampu menerjemahkannya ke dalam bahasa Indonesia dan Inggris. Pengujian pada citra yang divariasikan pada intensitas cahaya, kemiringan, blur atau kabur tidaknya citra, dan penulisan secara vertikal pada bahasa yang mendukung penulisan secara vertikal, menunjukkan bahwa faktor-faktor tersebut dapat menurunkan tingkat akurasi pengenalan karakter.
Hasil pengujian usability responden mendapatkan nilai sebesar 82.4%, hal ini menunjukkan bahwa aplikasi Android yang dibangun sangat mudah dipelajari dan dimengerti oleh pengguna.
Saran
21
DAFTAR PUSTAKA
Fisher R, Perkins S, Walker A, Wolfart E. 2003. Gaussian Smoothing. Alertbox [Internet]. [diunduh 2015 Februari 01]. Tersedia pada http://homepages.inf.ed.ac.uk/rbf/HIPR2/gsmooth.htm.
Goodman S. 2014. Machine Translation – Google Translate vs Bing Translator. Linnworks [Internet]. (2014 Januari 15 [diunduh pada 2015 maret 1]). Tersedia pada http://blog.linnworks.com/google-bing-translate/.
Khan M, Khan F. 2012. A Comparative Study of White Box, Black Box and Grey Box Testing Techniques. International Journal of Computer Science and Applications. 3:12-15.doi:10.14569/IJACSA.2012.030603.
Nielsen J. 2012. Usability 101: Introduction to Usability. Nielsen Norman Group [Internet]. (2012 januari 4 [diunduh 2014 Desember 01]). Tersedia pada http://www.nngroup.com/articles/usability-101-introduction-to-usability/. Putra D. 2004. Binerisasi Citra Tangan dengan Metode Otsu. Jurnal Teknologi
Elektro. 3(2).
Rubin J, Chisnell D. 2008. Handbook of Usability Testing : How to Plan, Design, and Conduct Effective Test. Indianapolis (US): Wiley Publishing Inc. Shi-zhong D. 2009. The Choice of Traditional vs. Simplified Character in US
Classroom. Di dalam: Charles C, Shelly R, Lily R, Nydia L, Jennifer L, Max S, Jean Z, Rae Z, editor. US-China Education Review; 2009 Desember; Illinois, Amerika Serikat. Illinois(US): David Publishing Company. hlm: 67-73.
22
LAMPIRAN
Lampiran 1 Pengujian pengenalan karakter dan terjemahannya Pengujian citra karakter bahasa Cina (sederhana)
No Skenario Citra OCRed teks Terjemahan Akurasi
23
24 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris Sangat
25 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris Miring
26 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris Miring
60°
0
Vertikal 4/4
Pengujian citra karakter bahasa Jepang
No Skenario Citra OCRed teks Terjemahan Akurasi
27 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
28 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris 5. Normal
Permisi Excuse me
10/10 Sangat
terang
5/10
Redup 10/10
Blur
2/10
Miring
30° 3/10
Miring 60°
0
Vertikal 10/10
6. Normal
restoran Restau-rant
10/10 Sangat
terang
7/10
Redup 10/10
Blur 4/10
Miring 30°
0
Miring 60°
0
29 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
30 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris Miring
Pengujian citra karakter bahasa Korea
No Skenario Citra OCRed teks Terjemahan Akurasi
31 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
32 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris 4.
33 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris
34 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
35 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris
Vertikal 5/6
Pengujian citra karakter bahasa Rusia
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
1.
Normal Kamera
36 Lanjutan
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
Miring
Normal Kamera
Peringa-37 Lanjutan
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
Redup
Normal Kamera
Salju Snow
Normal Kamera
Dokter Doctor
38 Lanjutan
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
Redup
Normal Kamera
Mos-39 Lanjutan
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
Sangat
Normal Kamera
40 Lanjutan
No Skenario Pengujian Citra OCRed teks Terjemahan Akurasi Indonesia Inggris
Miring
Berdiri Stand
41 Lanjutan
Pengujian citra karakter bahasa Thailand
No Skenario Citra OCRed teks Terjemahan Akurasi
Kamera Galeri Kamera Galeri Indonesia Inggris 1. Normal
42 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
43 Lanjutan
No Skenario Citra OCRed teks Terjemahan Akurasi
44 Lanjutan
No Skenario
Citra OCRed teks Terjemahan
Akurasi Kamera Galeri Kamera Galeri Indonesia Inggris
Sangat terang
8/8
Redup 8/8
Blur 4/8
Miring 30°
5/8
Miring 60°
0
Lampiran 2 Lembar kuesioner dengan tanggapan responden PENGUJIAN USABILITY
APLIKASI ANDROID PENERJEMAH BAHASA NON-LATIN DENGAN PENGENALAN CITRA KARAKTER
DEPARTEMEN ILMU KOMPUTER INSTITUT PERTANIAN BOGOR
2015
Nama Lengkap : ________________________________________
Usia : ____ tahun
Tempat/tanggal Lahir : ________________________________________ Jenis Kelamin : 1. Laki-laki 2. Perempuan
KETERANGAN:
SS= Sangat Setuju RR=Ragu-ragu STS=Sangat Tidak Setuju
S=Setuju TS=Tidak Setuju
Bubuhkan tanda ceklist (√) pada kolom yang nilainya paling sesuai menurut
45 Lanjutan
No Pertanyaan Penilaian
SS S RR TS STS Aspek Learnability
1 Apakah anda berhasil menemukan aplikasi Android sebagai penerjemah bahasa nonlatin dengan pengenalan citra karakter?
1 4
2 Apakah ikon aplikasi mudah dikenali? 5 3 Apakah anda berhasil membuka aplikasi
Android “Non-Latin Translator”?
2 3 Aspek Efficiency
4 Apakah tampilan aplikasi mudah dikenali? 4 1 5 Apakah tulisan pada layar mudah dibaca? 2 3 6 Apakah komposisi warna sudah sesuai? 1 3 1 7 Apakah aplikasi mudah dioperasikan? 2 3 Aspek Memorability
8 Apakah nama aplikasi mudah diingat? 1 2 2 9 Apakah fungsi aplikasi mudah diingat? 1 4 10 Apakah tombol-tombol pada aplikasi mudah
dimengerti?
2 3 11 Apakah tombol-tombol pada aplikasi mudah
digunakan?
2 3 12 Apakah bahasa yang digunakan mudah
dimengerti?
4 1 Aspek Errors
13 Apakah aplikasi dapat melakukan pemilihan bahasa asal dengan baik?
4 1 14 Apakah anda berhasil menggunakan tombol
Take Image?
1 4 15 Apakah anda berhasil melakukan fungsi crop? 3 2 16 Apakah aplikasi berhasil mengambil gambar
dari kamera dan galeri?
3 1 1
17 Apakah aplikasi dapat mengenali karakter nonlatin dengan baik?
2 2 1
18 Apakah aplikasi dapat melakukan pemilihan bahasa tujuan dengan baik?
5 19 Apakah aplikasi dapat menerjemahkan karakter
nonlatin ke dalam bahasa Indonesia dan Inggris?
5
20 Apakah anda berhasil menggunakan tombol Reset?
2 2 1
Aspek Satisfaction
21 Apakah anda setuju aplikasi ini cukup membantu dalam mengenali citra karakter nonlatin?
1 4
22 Apakah anda setuju aplikasi ini cukup membantu menerjemahkan teks nonlatin?
46 Lanjutan
No Pertanyaan Penilaian
SS S RR TS STS 23 Apakah spesifikasi aplikasi yang ditawarkan
sesuai dengan kebutuhan?
1 2 2 24 Apakah anda ingin menggunakan aplikasi ini
pada perangkat mobile anda?
1 1 3 25 Apakah anda akan menyarankan teman
menggunakan aplikasi ini?
47