MARSANI ASFI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa Tesis Pelabelan Otomatis Citra Menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra, adalah karya saya sendiri dan belum diajukan dalam bentuk apapun kepada Perguruan Tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Juli 2008
MARSANI ASFI. Pelabelan Otomatis Citra menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra. Dibimbing oleh Fahren Bukhari dan Yeni Herdiyeni.
Pelabelan citra secara manual memiliki kelemahan karena memerlukan waktu yang banyak dan sangat tergantung pada subjektifitas pengguna dalam mendeskripsikan citra. Oleh karena itu diperlukan pelabelan citra secara otomatis berdasarkan isi citra. Penelitian ini menggunakan Fuzzy C-Means untuk mengelompokkan informasi warna dan tekstur ke dalam beberapa region berdasarkan objek citra. Dari pengelompokkan ini diperoleh kamus kata untuk setiap citra. Dengan adanya kamus kata tersebut diharapkan dapat mempercepat proses temu kembali. Hasil penelitian menunjukkan bahwa nilai presisi temu kembali citra berdasarkan proses pelabelan ini mencapai 86.68 %.
MARSANI ASFI. Automatic Image Labeling using Fuzzy C-Means for Image Retrieval Systems. Under the direction of Fahren Bukhari and Yeni Herdiyeni.
With the rapid development of digital photography, digital image data has increased tremendously in recent years. Consequently image retrieval has drawn the attention of many user. The need for manually image labeling, which is depends on user subjectivity and time-consuming, especially for image databases. This research propose an automatic image labeling based on image content using Fuzzy C-Means to cluster the color and texture information’s into regions. Label of image from clustering is used to retrieve image. The experiments results showed the average of precision of the proposed method is show 86.68 %.
MARSANI ASFI. Pelabelan Otomatis Citra Menggunakan Fuzzy C Means untuk Sistem Temu Kembali Citra. Di bawah bimbingan Fahren Bukhari dan Yeni Herdiyeni.
Perkembangan internet dan banyaknya aplikasi multimedia saat ini, menyebabkan pengguna sulit untuk mendapatkan citra yang tersimpan dalam komputer. Citra memiliki subjek dan objek citra. Subjek citra merupakan persepsi umum pengguna terhadap objek-objek yang dimiliki citra. Persepsi dan intepretasi pengguna dalam mendeskripsikan citra yang sama sering terdapat perbedaan.
Pelabelan citra secara manual memiliki kelemahan karena memerlukan waktu yang banyak dan sangat tergantung pada subjektifitas pengguna dalam mendeskripsikan citra. Oleh karena itu diperlukan pelabelan citra secara otomatis berdasarkan isi citra.
Citra sumber penelitian diperoleh dari web ALIPR (http://www.alipr.com). Citra sumber berhubungan dengan kelas pemandangan, bangunan, alam. Jumlah objek yang terkandung dalam citra dapat berisi 3 (tiga), 4 (empat) atau 5 (lima) objek. Citra sumber digunakan sebagai data pelatihan dan data pengujian. Data pelatihan digunakan sebagai data untuk pembentukan basis data ciri. Basis data ciri menjadi acuan untuk proses penemuan kembali citra pada saat diujikan. Data pengujian digunakan untuk pengujian pelabelan citra, sedangkan untuk pengujian temu kembali citra menggunakan kata-kata dalam kamus kata. Pengujian dengan kamus kata terdiri dari pengujian subjek citra serta objek-objek citra.
Tahapan penelitian terdiri atas pengindeksan untuk pemilihan citra sumber, segmentasi citra, ektraksi warna dan tekstur, serta pengukuran kemiripan ciri subjek citra menggunakan Euclid. Pelabelan citra secara otomatis. Temu kembali citra untuk menentukan kueri teks sebagai masukan dan penentuan indeks yang digunakan sebagai dasar temu kembali citra. Evaluasi kinerja sistem sebagai evaluasi hasil temu kembali citra berdasarkan nilai precision dan recall.
Penelitian ini menggunakan Fuzzy C-Means untuk mengelompokkan informasi warna dan tekstur ke dalam beberapa region berdasarkan objek citra. Dari pengelompokkan ini diperoleh kamus kata untuk setiap citra. Dengan adanya kamus kata tersebut diharapkan dapat mempercepat proses temu kembali.
Hasil penelitian menunjukkan bahwa proses pelabelan otomatis citra menghasilkan pelabelan yang cukup baik. Definisi kata-kata berupa subjek dan objek citra dalam kamus kata berguna dalam proses temu kembali. Model pelabelan citra otomatis menggunakan Fuzzy C-means (FCM) dilakukan berdasarkan kata-kata yang terdefinisi dalam kamus kata. Tabel indeks citra disusun berdasarkan proses pelabelam otomatis citra dan digunakan sebagai dasar untuk proses temu kembali. Hasil penelitian juga menunjukkan bahwa nilai presisi temu kembali citra berdasarkan proses pelabelan ini mencapai 86.68 %.
© Hak cipta milik IPB, tahun 2008 Hak cipta dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah
b. Pengutipan tidak merugikan kepentingan yang wajar IPB
MARSANI ASFI
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
NRP : G651050014
Disetujui Komisi Pembimbing
Ir. Fahren Bukhari, M.Sc Yeni Herdiyeni, S.Si, M.Kom Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Sugi Guritman Prof. Dr. Khairil Anwar A. Notodiputro, M.S.
Alhamdulillahirabbil ‘alamin, Penulis panjatkan puji dan syukur ke hadirat Allah SWT yang telah memberikan rahmat, hidayah, serta karuniaNya sehingga Penulis dapat menyelesaikan tesis yang berjudul Pelabelan Otomatis Citra menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra.
Penulis mengucapkan terima kasih kepada Bapak Ir. Fahren Bukhari, M.Sc. dan Ibu Yeni Herdiyeni S.Si, M.Kom selaku komisi pembimbing yang telah memberikan banyak masukan kepada Penulis dalam penyusunan tesis ini. Ucapan terimakasih juga Penulis sampaikan kepada Bapak Ir. Julio Adisantoso, M.Kom sebagai dosen penguji. Penulis juga ingin mengucapkan terima kasih kepada:
1. Ayah (alm) dan Ibu tercinta yang selalu mendukung kelancaran masa studi Penulis.
2. Bapak Chandra Lukita, S.E, M.M. dan Keluarga yang memberikan dukungan materi dan semangat pada saat kuliah dan penyusunan tesis ini.
3. Istri tercinta Erna Agustriani, yang mendukung, mendampingi dan selalu memberikan motivasi dan doa. Banyak yang telah kita korbankan selama ini. 4. Rekan rekan dosen dan staf di CIC serta rekan-rekan ‘ilkomp 7’ IPB : Agus
Hasim, Dwi Prasetyo, Prihastuti Harsani, Titi Ratnasari, Diah Widiastuti, Adhi Kusnadi, Roni Salambue, Husmul Beze dan Sahzam. Sukses selalu.
5. Departemen Ilmu Komputer beserta dosen dan staf yang telah banyak membantu Penulis dalam penyusunan tesis ini.
6. Kepada semua pihak yang telah membantu dalam penyusunan tesis ini yang tidak bisa disebutkan satu per satu, terima kasih.
Semoga penelitian ini dapat memberikan manfaat, Amien.
Penulis dilahirkan di Bangka pada tanggal 01 Maret 1976 dari ayah Aslah Tamin (alm.) dan Ibu Fatimah. Penulis merupakan putra kedua dari enam saudara. Penulis beristrikan Erna Agustriani, A.md.
MARSANI ASFI
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Dengan ini saya menyatakan bahwa Tesis Pelabelan Otomatis Citra Menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra, adalah karya saya sendiri dan belum diajukan dalam bentuk apapun kepada Perguruan Tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Juli 2008
MARSANI ASFI. Pelabelan Otomatis Citra menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra. Dibimbing oleh Fahren Bukhari dan Yeni Herdiyeni.
Pelabelan citra secara manual memiliki kelemahan karena memerlukan waktu yang banyak dan sangat tergantung pada subjektifitas pengguna dalam mendeskripsikan citra. Oleh karena itu diperlukan pelabelan citra secara otomatis berdasarkan isi citra. Penelitian ini menggunakan Fuzzy C-Means untuk mengelompokkan informasi warna dan tekstur ke dalam beberapa region berdasarkan objek citra. Dari pengelompokkan ini diperoleh kamus kata untuk setiap citra. Dengan adanya kamus kata tersebut diharapkan dapat mempercepat proses temu kembali. Hasil penelitian menunjukkan bahwa nilai presisi temu kembali citra berdasarkan proses pelabelan ini mencapai 86.68 %.
MARSANI ASFI. Automatic Image Labeling using Fuzzy C-Means for Image Retrieval Systems. Under the direction of Fahren Bukhari and Yeni Herdiyeni.
With the rapid development of digital photography, digital image data has increased tremendously in recent years. Consequently image retrieval has drawn the attention of many user. The need for manually image labeling, which is depends on user subjectivity and time-consuming, especially for image databases. This research propose an automatic image labeling based on image content using Fuzzy C-Means to cluster the color and texture information’s into regions. Label of image from clustering is used to retrieve image. The experiments results showed the average of precision of the proposed method is show 86.68 %.
MARSANI ASFI. Pelabelan Otomatis Citra Menggunakan Fuzzy C Means untuk Sistem Temu Kembali Citra. Di bawah bimbingan Fahren Bukhari dan Yeni Herdiyeni.
Perkembangan internet dan banyaknya aplikasi multimedia saat ini, menyebabkan pengguna sulit untuk mendapatkan citra yang tersimpan dalam komputer. Citra memiliki subjek dan objek citra. Subjek citra merupakan persepsi umum pengguna terhadap objek-objek yang dimiliki citra. Persepsi dan intepretasi pengguna dalam mendeskripsikan citra yang sama sering terdapat perbedaan.
Pelabelan citra secara manual memiliki kelemahan karena memerlukan waktu yang banyak dan sangat tergantung pada subjektifitas pengguna dalam mendeskripsikan citra. Oleh karena itu diperlukan pelabelan citra secara otomatis berdasarkan isi citra.
Citra sumber penelitian diperoleh dari web ALIPR (http://www.alipr.com). Citra sumber berhubungan dengan kelas pemandangan, bangunan, alam. Jumlah objek yang terkandung dalam citra dapat berisi 3 (tiga), 4 (empat) atau 5 (lima) objek. Citra sumber digunakan sebagai data pelatihan dan data pengujian. Data pelatihan digunakan sebagai data untuk pembentukan basis data ciri. Basis data ciri menjadi acuan untuk proses penemuan kembali citra pada saat diujikan. Data pengujian digunakan untuk pengujian pelabelan citra, sedangkan untuk pengujian temu kembali citra menggunakan kata-kata dalam kamus kata. Pengujian dengan kamus kata terdiri dari pengujian subjek citra serta objek-objek citra.
Tahapan penelitian terdiri atas pengindeksan untuk pemilihan citra sumber, segmentasi citra, ektraksi warna dan tekstur, serta pengukuran kemiripan ciri subjek citra menggunakan Euclid. Pelabelan citra secara otomatis. Temu kembali citra untuk menentukan kueri teks sebagai masukan dan penentuan indeks yang digunakan sebagai dasar temu kembali citra. Evaluasi kinerja sistem sebagai evaluasi hasil temu kembali citra berdasarkan nilai precision dan recall.
Penelitian ini menggunakan Fuzzy C-Means untuk mengelompokkan informasi warna dan tekstur ke dalam beberapa region berdasarkan objek citra. Dari pengelompokkan ini diperoleh kamus kata untuk setiap citra. Dengan adanya kamus kata tersebut diharapkan dapat mempercepat proses temu kembali.
Hasil penelitian menunjukkan bahwa proses pelabelan otomatis citra menghasilkan pelabelan yang cukup baik. Definisi kata-kata berupa subjek dan objek citra dalam kamus kata berguna dalam proses temu kembali. Model pelabelan citra otomatis menggunakan Fuzzy C-means (FCM) dilakukan berdasarkan kata-kata yang terdefinisi dalam kamus kata. Tabel indeks citra disusun berdasarkan proses pelabelam otomatis citra dan digunakan sebagai dasar untuk proses temu kembali. Hasil penelitian juga menunjukkan bahwa nilai presisi temu kembali citra berdasarkan proses pelabelan ini mencapai 86.68 %.
© Hak cipta milik IPB, tahun 2008 Hak cipta dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah
b. Pengutipan tidak merugikan kepentingan yang wajar IPB
MARSANI ASFI
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
NRP : G651050014
Disetujui Komisi Pembimbing
Ir. Fahren Bukhari, M.Sc Yeni Herdiyeni, S.Si, M.Kom Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Sugi Guritman Prof. Dr. Khairil Anwar A. Notodiputro, M.S.
Alhamdulillahirabbil ‘alamin, Penulis panjatkan puji dan syukur ke hadirat Allah SWT yang telah memberikan rahmat, hidayah, serta karuniaNya sehingga Penulis dapat menyelesaikan tesis yang berjudul Pelabelan Otomatis Citra menggunakan Fuzzy C-Means untuk Sistem Temu Kembali Citra.
Penulis mengucapkan terima kasih kepada Bapak Ir. Fahren Bukhari, M.Sc. dan Ibu Yeni Herdiyeni S.Si, M.Kom selaku komisi pembimbing yang telah memberikan banyak masukan kepada Penulis dalam penyusunan tesis ini. Ucapan terimakasih juga Penulis sampaikan kepada Bapak Ir. Julio Adisantoso, M.Kom sebagai dosen penguji. Penulis juga ingin mengucapkan terima kasih kepada:
1. Ayah (alm) dan Ibu tercinta yang selalu mendukung kelancaran masa studi Penulis.
2. Bapak Chandra Lukita, S.E, M.M. dan Keluarga yang memberikan dukungan materi dan semangat pada saat kuliah dan penyusunan tesis ini.
3. Istri tercinta Erna Agustriani, yang mendukung, mendampingi dan selalu memberikan motivasi dan doa. Banyak yang telah kita korbankan selama ini. 4. Rekan rekan dosen dan staf di CIC serta rekan-rekan ‘ilkomp 7’ IPB : Agus
Hasim, Dwi Prasetyo, Prihastuti Harsani, Titi Ratnasari, Diah Widiastuti, Adhi Kusnadi, Roni Salambue, Husmul Beze dan Sahzam. Sukses selalu.
5. Departemen Ilmu Komputer beserta dosen dan staf yang telah banyak membantu Penulis dalam penyusunan tesis ini.
6. Kepada semua pihak yang telah membantu dalam penyusunan tesis ini yang tidak bisa disebutkan satu per satu, terima kasih.
Semoga penelitian ini dapat memberikan manfaat, Amien.
Penulis dilahirkan di Bangka pada tanggal 01 Maret 1976 dari ayah Aslah Tamin (alm.) dan Ibu Fatimah. Penulis merupakan putra kedua dari enam saudara. Penulis beristrikan Erna Agustriani, A.md.
DAFTAR TABEL ... xi
DAFTAR GAMBAR... xii
DAFTAR LAMPIRAN ... xiv
I. PENDAHULUAN A. Latar Belakang ... 1
B. Tujuan Penelitian ... 3
C. Manfaat Penelitian ... 3
D. Ruang Lingkup Penelitian ... 3
II. TINJAUAN PUSTAKA A. Temu Kembali Citra ... 4
B. Segmentasi, Ekstraksi Ciri Citra dan Clustering ... 5
Normalized Cuts ... 5
Expectation-Maximation ... 7
Ekstraksi Ciri Tekstur ... 7
Transformasi Wavelet Gabor ... 8
Filter Gabor ... 9
Ekstraksi Ciri Warna ... 11
Clustering ... 12
C. Fuzzy C-Means(FCM) ... 13
D. Metodologi Pelabelan Otomatis Citra ... 16
E. Pengukuran Kinerja Sistem ... 16
III.METODOLOGI PENELITIAN A. Kerangka Pemikiran... 18
B. Alat Bantu Prnelitian ... 19
C. Tata Laksana Penelitian ... 19
Pengindeksan ... 19
Pelabelan Citra ... 23
Temu Kembali Citra ... 24
Citra Sumber ... 26 Kamus Kata ... 27
B. Desain Proses Sistem ... 27 Segmentasi Citra ... 28
Ekstraksi Ciri ... 28 C. Perancangan Proses Sistem ... 29 Modul Segmentasi ... 29 Modul Clustering ... 30
Modul Pelabelan Citra ... 31 Modul Temu Kembali ... 32 Modul Evaluasi ... 32
Modul Representasi Hasil ... 32 D. Desain Antar Muka ... 32 V. HASIL DAN PEMBAHASAN
A. Karakteristik Citra Masukan ... 34 B. Pengindeksan Citra ... 34 Segmentasi Warna Citra ... 34
Format Tekstur Citra ... 35 Segmentasi Region ... 36
Ekstraksi Ciri Warna ... 37 Ekstraksi Ciri Tekstur ... 38 Penggabungan Ciri Warna dan Tekstur ... 39 C. Pelabelan Citra ... 39
Labeling Capture ... 39
Labeling Coding ... 40
Labeling Reuse ... 41 D. Hasil Temu Kembali ... 43 E. Evaluasi Temu Kembali ... 44
Halaman 1
2 3 4 5 6
Enam parameter filter Gabor ... Kamus Kata... Matrik Keanggotaan ... Subjek, Jumlah, serta Objek yang terkandung pada Citra Sumber... Matrik Keanggotaan Region berdasarkan hasil clustering ... Nilai rataan precision hasil temu kembali citra ...
10 27 30 34 40 45
Halaman 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
Alur Sistem Temu Kembali Citra ………... Citra sebagai suatu graf dalam Normalized Cuts ... Grap Citra setelah di Segmentasi ... Ilustrasi Pemotongan dalam Normalized Cuts ... Contoh tekstur visual dari Album Tekstur Brodatz ... Parameter filter Gabor dalam domain frekuensi spasial ... Tahapan Segmentasi Tekstur ... Tahapan Algoritma fuzzy c-mean Clustering ... Kerangka Pemikiran Penelitian ... Tata Laksana Pengindeksan... Ekstraksi ciri warna ... Ekstraksi ciri tekstur ... Tata Laksana Pelabelan Otomatis... Tata Laksana Temu Kembali Citra ... Arsitektur Sistem Pelabelan Otomatis ... Rancangan Antar Muka Pelabelan Citra ... Rancangan Desain Antarmuka Sistem Temu Kembali ... Contoh Citra sebelum dan sesudah segmentasi menggunakan algoritma EM ... Contoh Citra RGB ke Citra Gray Scale ... Contoh Citra sebelum dan sesudah segmentasi menggunakan algoritma ... Pemisahan Region Citra kedalam 6 Region... Contoh Citra Langit ... Hasil FCH dengan FCM 30 bin ... Contoh Citra Region Rumput ... Region Rumput dengan frekuensi tertentu ... Grafik Total Cluster per Subjek ... Citra Contoh Proses Labeling Coding... Contoh Citra proses penggabungan region... Contoh Citra hasil pelabelan otomatis ...
32 33
Antar Muka Sistem dan Pelabelan Citra... Antar Muka Temu Kembali Citra...
46 47
Halaman 1
2 3
Segmentasi Warna Citra Sumber ... Segmentasi Region Citra Sumber ... Warna Kuantisasi untuk 30 Bin Histogram ...
53 54 55
A. Latar Belakang
Perkembangan internet dan banyaknya aplikasi multimedia saat ini, menyebabkan pengguna sulit untuk mendapatkan citra yang tersimpan dalam komputer. Citra memiliki subjek dan objek citra. Subjek citra merupakan persepsi umum pengguna terhadap objek-objek yang dimiliki citra. Pada citra dengan subjek pemandangan, identifikasi objek yang dimiliki citra dapat berupa awan, rumput atau objek lainnya. Setelah menghubungkan satu objek dengan objek yang dimiliki citra, maka pengguna dapat melakukan penafsiran (interpretation) citra. Persepsi dan intepretasi pengguna dalam mendeskripsikan citra yang sama sering terdapat perbedaan.
Oleh karena itu, perlu dikembangkan metode pencarian citra sehingga mempermudah pencarian data. Pencarian citra dapat dilakukan berdasarkan karakteristik visual citra berupa warna, bentuk dan tekstur yang disebut
Content-Based Image Retrieval (CBIR). Pencarian berdasarkan karakteristik visual citra memiliki keuntungan dimana hasil pencarian sangat sesuai dengan persepsi pengguna terhadap citra yang dimaksud. Pencarian dengan teknik ini ternyata memiliki kekurangan yaitu membutuhkan waktu yang lama untuk pemrosesan awal. Karakteristik visual citra masukan berupa warna, tekstur ataupun bentuk harus diekstraksi terlebih dahulu. Pencarian lain dapat dilakukan menggunakan teks sebagai kata kunci pencarian. Keuntungan pencarian berbasis teks adalah waktu yang lebih singkat untuk menampilkan hasil dibandingkan pencarian berbasis citra. Kekurangan dari teknik ini adalah pemberian informasi tekstual untuk setiap citra dilakukan secara manual, untuk jumlah citra yang banyak sangat membutuhkan waktu. Kesalahan deskripsi sangat mungkin terjadi sehingga hasil pencarian tidak sesuai dengan persepsi awal pengguna.
menghitung frekuensi kata untuk masing-masing cluster. Duygulu et. al.
(2002) melakukan metode translasi kumpulan-kumpulan blob yang terbentuk dari hasil segmentasi. Segmentasi otomatis dilakukan untuk mendapatkan vektor ciri, kemudian pengklasteran blob-blob yang terbentuk. Suatu citra terbentuk atas blob-blob dan kata-kata diasosiasikan dengan blob tersebut. Proses pengasosian ini menggunakan metode Expectation Maximization
sehingga diperoleh suatu label baru untuk blob tersebut.
Selanjutnya Lavrenko et. al. (2003) menggunakan metode CRM (Continuous-space Relevance Model) untuk melakukan pelabelan citra serta menggunakan algoritma smoothed KNN. Ciri-ciri citra dimodelkan menggunakan kernel-based density dan segmentasi otomatis citra dilakukan berdasarkan ciri warna, tekstur dan bentuk. Ciri-ciri kata yang digunakan dimodelkan menggunakan distribusi multinomial. Kemudian Feng et. al.
(2004) menggunakan metode CRM-rect. Penelitian Feng et. al. (2004) sama dengan penelitian Lavrenko et. al. (2003) tetapi metode CRM yang digunakan adalah dengan mendekomposisi blok-blok citra. Feng et. al. (2004) juga menggunakan MBRM (Multiple-Bernoulli Relevance Model) yaitu metode yang sama dengan CRM-rect dimana ciri-ciri kata yang digunakan dimodelkan dengan MBRM. Penelitian lain adalah dengan menerapkan hirarki teks sebagai bentuk teks ontologi, pemetaan teks ke citra dilakukan dengan kamus visualisasi yang terbentuk secara hirarki Srikanth et. al.(2005). Penelitian lain berkaitan dengan pelabelan citra yaitu pelabelan otomatis terhadap 50 (lima puluh) citra yang mengandung teks dari web Yahoo!News. Proses awal dilakukan dengan mendeteksi dan mengklasifikasi semua entitas teks berupa orang dan objek yang ada, kemudian dibandingkan dengan teks yang dominan dan terlihat secara visual Deschacht(2007).
lebih baik dalam pencarian citra berdasarkan semantik objek (Schober et. al., 2004). Fokus penelitian ini adalah pada pelabelan citra sehingga dapat digunakan untuk dasar proses temu kembali citra.
B. Tujuan Penelitian
Penelitian ini bertujuan untuk :
1. Mendefinisikan kata-kata yang merepresentasikan subjek dan objek citra. 2. Membuat model pelabelan citra menggunakan Fuzzy C-means (FCM)
secara otomatis berdasarkan kata-kata yang telah didefinisikan. 3. Membuat tabel indeks citra berdasarkan pelabelan otomatis citra.
C. Manfaat Penelitian
Manfaat penelitian ini diharapkan mempercepat proses pencarian citra berdasarkan proses pelabelan citra.
D. Ruang Lingkup Penelitian
Ruang lingkup penelitian ini mencakup : 1. Objek penelitian adalah citra berwarna. 2. Segmentasi citra berbasis region.
3. Ekstraksi ciri berdasarkan tekstur dan warna.
A. Temu Kembali Citra
Temu kembali citra adalah salah satu metodologi untuk penemuan
kembali citra berdasarkan isi (content) citra. Citra memiliki informasi
karakteristik visual berupa warna, bentuk, tekstur, dan karakteristik spasial.
Karakteristik visual tersebut diproses melalui ekstraksi ciri, sehingga
diperoleh ciri-ciri citra. Hasil ekstraksi ciri tersebut kemudian disusun dalam
vektor-vektor ciri multi dimensi. Vektor ciri dari citra disusun sebagai basis
data ciri (Long et. al., 2003).
Gambar 1. Frame work Sistem Temu Kembali Citra (Hua et. al., 2008).
Alur sistem temu kembali citra pada Gambar 1 diawali dengan masukan
dalam bentuk kueri masukan untuk sistem. Citra masukan yang memiliki
karakteristik visual berupa warna, bentuk ataupun tekstur selanjutnya
diekstraksi sehingga diperoleh data-data ciri dalam bentuk vektor ciri.
Citra-citra dalam basis data yang memiliki karakteristik visual Citra-citra juga diekstraksi
karakteristiknya kemudian disusun dalam vektor-vektor ciri. Kumpulan
vektor-vektor ciri disimpan menjadi basis data ciri. Basis data ciri dan vektor
ciri dari kueri masukan kemudian dihitung kemiripannya. Proses
pengindeksan dilakukan untuk mempermudah proses temu kembali. Hasil
feedback, begitu juga untuk kueri masukan, karakteristik visual citra dan
vektor ciri yang terbentuk (Long et. al., 2003).
B. Segmentasi, Ekstraksi Ciri Citra dan Clustering
Secara umum, segmentasi merupakan langkah awal dalam analisis
citra. Segmentasi dilakukan untuk membagi citra ke dalam bagian-bagian
yang memiliki kemiripan karakteristik (Gonzales & Woods, 2002).
Normalized Cuts
Metode Normalized Cuts menerapkan teori graf untuk membagi citra ke
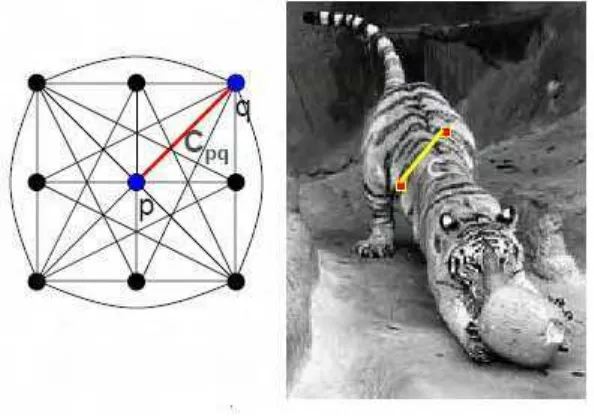
dalam ukuran terbaik. Dalam Gambar 2 citra dalam Normalized Cuts
dipandang sebagai suatu graf yang saling berhubungan secara penuh (
Fully-connected graph). Setiap piksel merupakan node untuk graf. Hubungan
menyatakan keterkaitan dalam graf antara pasangan piksel yang dinotasikan
dengan p dan q. Masing-masing edge memiliki biaya (Shi & Malik,
2000).
pq
[image:32.595.158.455.443.651.2]C
Gambar 2. Citra sebagai suatu graf dalam Normalized Cuts.
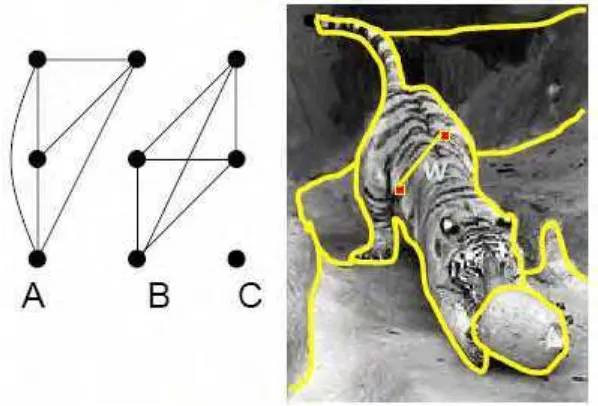
Proses segmentasi citra berdasarkan graf adalah proses memecah
menghapus semua edge yang memotong di antara segmen citra atau edge-edge
yang memiliki biaya terkecil. Semua piksel yang memiliki kemiripan akan
[image:33.595.157.456.168.371.2]digabungkan dalam segmen yang sama (Shi & Malik, 2000).
Gambar 3. Graf Citra setelah di Segmentasi.
Proses pemotongan edge dilakukan untuk membuat graf-graf tersebut
menjadi tidak terhubung (Gambar 4). Nilai biaya pemotongan edge dinyatakan
dengan persamaan (1) (Shi & Malik, 2000) :
∑
∈ ∈ =
B q A p
q p
C B
A Cut
, ,
) ,
( (1)
Gambar 4. Ilustrasi Pemotongan dalam Normalized Cuts
Proses pemotongan graf dilakukan untuk menghasilkan segmen terbesar.
Dalam normalized cuts (Ncut) proses pemotongan ini diperbaiki dengan
menormalkan ukuran dari segmen dengan cara menggunaakan persamaan (2)
[image:33.595.211.443.486.616.2]) ( ) , ( ) ( ) , ( ) , ( B volume B A Cut A volume B A Cut B A
Ncut = + (2)
dengan volume(A) dan volume(B) adalah jumlah biaya untuk semua edge
yang ada dalam segmen A dan segmen B.
Expectation-Maximization
Expectation-Maximization (EM) adalah salah satu metode optimisasi
untuk mencari dugaan parameter maximum likelihood ketika ada data yang
hilang atau tidak lengkap. Di dalam algoritma EM, dilakukan perhitungan
dugaan kemungkinan untuk mengisi data yang tidak lengkap (E-step) dan
perhitungan dugaan parameter maximum likelihood dengan memaksimalkan
dugaan kemungkinan yang diperoleh dari E-step (M-step). Nilai parameter
yang diperoleh dari M-step digunakan kembali untuk memulai E-step
selanjutnya. Proses ini akan berulang hingga mencapai konvergensi nilai
likelihood (Belongie et. al., 1998).
Ekstraksi Ciri Tekstur
Tekstur merupakan karakteristik intrinsik dari suatu citra yang terkait
dengan tingkat kekasaran (roughness), butiran (granulation), dan keteraturan
(regularity) susunan struktural piksel. Aspek tekstural dari sebuah citra dapat
dimanfaatkan sebagai dasar dari segmentasi, klasifikasi, maupun interpretasi
citra (Gonzales & Woods, 2002).
Tekstur dicirikan sebagai distribusi dari derajat keabuan piksel-piksel
yang bertetangga. Tekstur tidak dapat didefinisikan hanya melalui sebuah
piksel, tapi harus dalam sekumpulan piksel. Resolusi citra yang diamati dapat
ditentukan oleh tekstur citra tersebut. Apabila resolusi atau skala meningkat,
tekstur yang diamati akan berubah dari tekstur halus (fine) menjadi tekstur
kasar (coarse) (Gonzales & Woods, 2002).
Tekstur dapat didefinisikan sebagai fungsi dari variasi spasial
intensitas piksel (nilai keabuan) dalam citra. Berdasarkan strukturnya, tekstur
1. Makrostruktur
Tekstur makrostruktur memiliki perulangan pola lokal secara periodik
pada suatu daerah citra, biasanya terdapat pada pola-pola buatan manusia
dan cenderung mudah untuk direpresentasikan secara matematis.
2. Mikrostruktur
Pada tekstur mikrostruktur, pola-pola lokal dan perulangan tidak terjadi
begitu jelas, sehingga tidak mudah untuk memberikan definisi tekstur yang
[image:35.595.231.411.328.425.2]komprehensif.
Gambar 5 menunjukkan perbedaan tekstur makrostruktur dan
mikrostruktur yang diambil dari album tekstur Brodatz (Brodatz, 1966).
Gambar 5. Contoh tekstur visual dari Album Tekstur Brodatz. Atas: makrostruktur Bawah: mikrostruktur
Transformasi Wavelet Gabor
Pendekatan umum dalam melakukan analisa citra adalah penggunaan
fungsi Fourier untuk menarik ciri citra sehingga diperoleh distribusi ciri energi
global sinyal sebagai fungsi terhadap frekuensi. Ciri global tidak dapat
menarik karakteristik sebagian citra. Oleh karena itu diperlukan ciri lokal yang
dapat dinyatakan dalam frekuensi lokal. Frekuensi lokal ini menggunakan
fungsi wavelet (Daubechies, 1995).
Wavelet adalah fungsi matematika yang membagi data (sinyal) ke dalam
komponen-komponen frekuensi yang berbeda. Salah satu fungsi wavelet
adalah Gabor. Transformasi Wavelet menggunakan pendekatan penyaring
multikanal (mutichannel filtering), dengan fungsi Gabor sebagai penyaring
Filter Gabor
Filter Gabor merupakan salah satu filter yang mampu mensimulasikan
karakteristik sistem visual manusia dalam mengisolasi frekuensi dan orientasi
tertentu citra. Karakteristik ini membuat filter Gabor sesuai untuk aplikasi
pengenalan tekstur dalam computer vision (Seo, 2006).
Secara spasial, sebuah fungsi Gabor merupakan sinusoida yang
dimodulasi oleh fungsi Gauss. Respon impuls sebuah filter Gabor kompleks
dua dimensi adalah menggunakan persamaan (3) (Seo, 2006 ):
⎪⎩ ⎪ ⎨ ⎧ ⎪⎭ ⎪ ⎬ ⎫ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ + −
= (2 )
2 1 exp 2 1 ) , ( 2 2 2 2 jFx y x y x h y x y x π σ σ σ
πσ (3)
dengan σxdanσymerupakan standar deviasi fungsi Gauss x dan y.
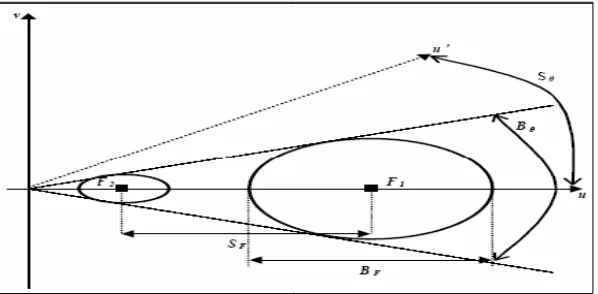
Dalam domain frekuensi spasial, parameter-parameter filter Gabor dapat
[image:36.595.168.467.425.572.2]digambarkan seperti pada Gambar 6.
Gambar 6. Parameter filter Gabor dalam domain frekuensi spasial
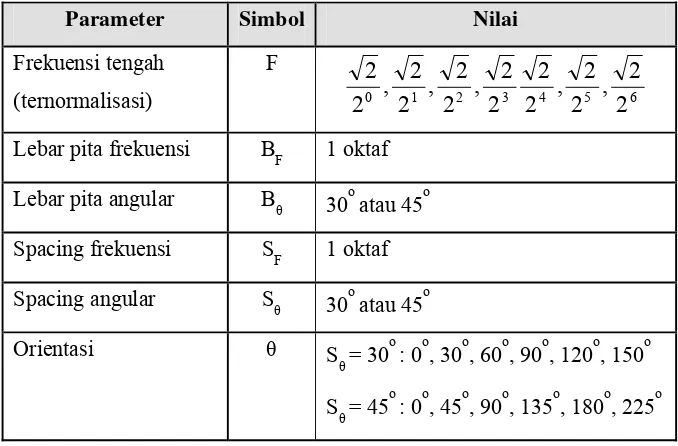
Ada enam parameter yang harus ditetapkan dalam implementasi filter
Gabor (Tabel 1). Keenam parameter tersebut adalah: F,θ,σx,σy,BF,danBθ.
1. Frekuensi (F) dan orientasi (θ) mendefinisikan lokasi pusat filter.
2. menyatakan konstanta lebar pita frekuensi dan jangkauan
angular filter. θ
3. Variabel σ
x berkaitan dengan respon sebesar -6 dB untuk komponen
frekuensi spasial. Nilai variabel σ
x dapat dinyatakan dalam persamaan (4).
) 1 2 ( 2 ) 1 2 ( 2 ln − + = F F B B x F π
σ (4)
4. Variabel σ
y berkaitan dengan respon sebesar -6dB untuk komponen
angular. Nilai Variabel σ
y dapat dinyatakan dalam persamaan (5).
) 2 / tan( 2 2 ln θ π σ B F
y = (5)
5. Posisi (F, θ) dan lebar pita (σ
x, σy) dari filter Gabor dalam domain
frekuensi harus ditetapkan dengan cermat agar dapat menangkap informasi
tekstural dengan benar. Frekuensi tengah dari filter kanal harus terletak
dekat dengan frekuensi karakteristik tekstur.
6. Setelah mendapatkan ciri Gabor maka dapat dilakukan ekstraksi ciri. Salah
satu ciri yang dapat dipilih adalah ciri energi, yang didefinisikan dalam
persamaan (6). 2 M 1 i N 1 ) , ( 1 ) (
∑∑
= = = j n m x MN xe (6)
[image:37.595.142.481.522.745.2]Enam parameter filter Gabor beserta nilainya seperti pada tabel 1.
Tabel 1. Enam parameter filter Gabor
Parameter Simbol Nilai
Frekuensi tengah (ternormalisasi) F 6 5 4 3 2 1 0 2 2 , 2 2 , 2 2 2 2 , 2 2 , 2 2 , 2 2
Lebar pita frekuensi BB
F 1 oktaf Lebar pita angular BB
θ 30
o
atau 45o
Spacing frekuensi S
F 1 oktaf Spacing angular Sθ 30o atau 45o
Orientasi θ S
θ= 30
o
: 0o, 30o, 60o, 90o, 120o, 150o
Algoritma segmentasi tekstur menggunakan wavelet Gabor dilakukan
melalui tahapan berikut (Seo, 2006) :
1. Mendekomposisi citra masukan menggunakan filter bank,
2. Mengekstraksi ciri, dan
3. Clustering.
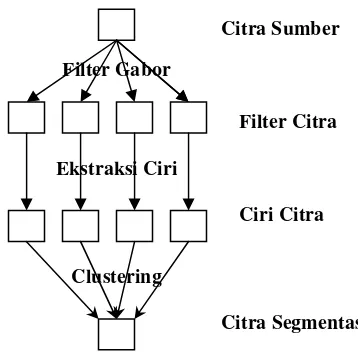
Alur segmentasi tekstur terlihat seperti pada Gambar 7.
Filter Gabor
Ekstraksi Ciri
Clustering
Filter Citra
Ciri Citra
[image:38.595.235.414.240.421.2]Citra Segmentasi Citra Sumber
Gambar 7. Tahapan Segmentasi Tekstur (Seo, 2006)
Ektraksi Ciri Warna
Setiap piksel mempunyai warna yang dapat dinyatakan dalam Red,
Green dan Blue (RGB). Nilai RGB ini merupakan gabungan nilai R, nilai G
dan nilai B yang tidak bisa dipisahkan satu dengan lainnya. Hal ini dapat
dituliskan dengan P(r,g,b).
Ekstraksi ciri warna merupakan salah satu cara untuk menentukan arti
fisik suatu citra melalui proses pengindeksan warna. Proses ini bisa dilakukan
dengan pendekatan histogram warna(Belongie et. al., 1998).
Histogram warna merupakan representasi peluang keberadaan setiap
warna dalam sebuah citra. Banyaknya nilai warna (bin) ditetapkan sesuai
kebutuhan pembuatan histogram. Dengan bin sejumlah n, maka histogram
warna untuk citra I yang mengandung N piksel dapat dirumuskan seperti
dengan persamaan (7).
] ,..., 2 , 1 [ )
(I h h hn
∑ =
= N
j Pi j
N i h
1 |
1
, (7)
⎩
⎨
⎧
= selainnya ; 0 i -ke bin ke sasi terkuanti j piksel ; 1 |j i P .Histogram warna seperti ini disebut juga conventional color histogram
(CCH) (Han & Ma, 2002).
Clustering
Proses Clustering adalah proses pengelompokan data ke dalam cluster
berdasarkan parameter tertentu sehingga objek-objek dalam sebuah cluster
memiliki tingkat kemiripan yang tinggi satu sama lain dan sangat tidak mirip
dengan obyek lain pada cluster yang berbeda (Kantardzic, 2001).
Pada clustering tidak diperlukan kelas yang telah didefinisikan
sebelumnya atau kelas hasil training, sehingga clustering dapat dinyatakan
sebagai bentuk pembelajaran berdasarkan observasi dan bukan berdasarkan
contoh (Jiawei et. al., 2001). Proses clustering dilakukan sebagai tahapan
terakhir dari segmentasi warna dan tekstur dari vektor-vektor ciri.
Clustering secara umum memiliki tahapan sebagai berikut (Jain et. al., 1999) :
1. Representasi pola
2. Pengukuran kedekatan pola (Pattern Proximity)
3. Clustering
4. Abstraksi data (jika dibutuhkan)
5. Penilaian output (jika dibutuhkan).
Jarak Euclidean
Kedekatan pola diukur berdasarkan fungsi jarak antara dua ciri. Jarak
digunakan untuk mengukur ketidakmiripan antara dua obyek data. Bila p dan
q menyatakan piksel dengan koodinat (x,y) dan (s,t) maka jarak euclidean
antara p dan q adalah seperti persamaan (8) (Gonzales & Woods, 1992).
2 2 ) ( ) ( ) ,
(p q x s y t
C. Fuzzy C-Means (FCM)
Fuzzy C-Mean Clustering (FCM) juga dikenal sebagai fuzzy
ISODATA. Pengelompokan setiap titik data dalam sebuah cluster ditentukan
oleh derajat keanggotaannya. Bezdek mengusulkan algoritma ini tahun 1973
sebagai pengembangan awal dari hard C-mean (HCM) clustering (Jang et.
al., 1997).
FCM membagi sebuah koleksi ke-n dari vektor xi, dengan i = 1,2,3,...,n
ke dalam c grup fuzzy dan mencari pusat cluster pada masing-masing grup
yakni fungsi biaya dari ukuran ketidakmiripan yang paling minimal.
Fuzzy c mean memiliki dua proses yakni menghitung pusat cluster dan
menandai poin untuk pusat cluster menggunakan sebuah jarak euclidean.
Proses ini dilakukan berulang hingga pusat cluster stabil. Keberadaan setiap
titik data pada FCM dalam suatu cluster ditentukan oleh derajat keanggotaan
antara 0 hingga 1 (Jang et. al., 1997 dan Cox, 2005).
Untuk mengakomodasi fuzzy partisi, keanggotaan matrik U harus
memiliki nilai antara 0 dan 1 (Jang et. al., 1997 dan Pedrycz, 2005).
Normalisasi penetapan hasil derajat keanggotaan dari set data menggunakan
persamaan (9). n j u c i
ij 1, 1,2,3,...,
1 = ∀ =
∑
= (9)dengan µij adalah derajat keanggotaan point data terhadap pusat-pusat cluster,
C adalah jumlah cluster C, serta n adalah jumlah data.
Fungsi objektif pada fuzzy c-mean digunakan persamaan (10).
∑
∑
∑
= = = = n j ij m ij c i c i ic J u d
c c U J 2 1 1
1,..., )
,
( (10)
dengan J adalah fungsi objektif, uij adalah derajat keanggotaan poin data
terhadap cluster-cluster dengan nilai antara 0 dan 1, c adalah jumlah cluster,
n adalah banyaknya poin data, m adalah nilai parameter fuzzy dan dij adalah
Jarak antar pusat cluster ke-i hingga ke ke-j dari titik data didapatkan dari
persamaan dij = ||ci-xj|| ;
Nilai minimum dari pusat cluster digunakan persamaan (11) di bawah ini :
∑
∑
= = = n j m ij n j j m ij i u x u c 1 1 (11)dengan ci adalah pusat cluster ke-i, n adalah banyaknya poin data, uij adalah
derajat keanggotaan poin data terhadap cluster-cluster dengan nilainya antara
0 dan 1, m adalah nilai parameter fuzzy, serta xj adalah data poin ke-j.
Untuk menghitung perubahan matrik partisi (derajat keanggotaan poin
data terhadap semua cluster yang baru) digunakan persamaan (12).
∑
= − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ = c k m kj ij ij d d u 1 ) 1 /( 2 1 (12).dengan uij adalah derajat keanggotaan poin data terhadap cluster-cluster yang
nilainya antara 0 dan 1, c adalah jumlah pusat cluster dari grup fuzzy ke-i, m
adalah parameter fuzzy, dij adalah jarak euclidian antara pusat cluster ke-i
hingga ke-j dari poin data, dkj adalah jarak euclidian antara pusat cluster ke-k
hingga ke-j dari poin data.
Algoritma FCM diawali dengan menentukan derajat keanggotaan
(secara acak) setiap titik data terhadap cluster. Berdasarkan derajat
keanggotaan, kemudian ditentukan pusat cluster. Pada kondisi awal, pusat
cluster tentu saja masih belum akurat. Derajat keanggotaan selanjutnya
diperbaiki berdasarkan fungsi jarak antara titik data dengan pusat cluster
(Nascimento et. al., 2003).
Dengan memperbaiki pusat cluster dan derajat keanggotaan tiap titik
data secara berulang dan terus menerus maka pusat cluster akan bergeser ke
titik yang tepat. Kinerja FCM tergantung pada inisialisasi pusat cluster.
Keluaran FCM adalah deretan pusat cluster dan derajat keanggotaan data
FCM menentukan pusat cluster ci dan keanggotaan matriks U (Jang et.
al., 1997) dengan langkah-langkah sebagai berikut :
1. Inisialisasi keanggotaan matrik U dengan nilai random antara 0 dan 1
dengan persamaan (9).
2. Menghitung c pusat cluster fuzzy ci, i = 1,2,3,...c menggunakan persamaan
(11).
3. Menghitung fungsi objektif berdasarkan persamaan (10). Berhenti jika
hasil fungsi objektifnya mencapai nilai toleransi atau hasil fungsi
objektifnya setelah iterasi maksimal yang ditetapkan.
4. Menghitung matrik partisi baru menggunakan persamaan (12) dan kembali
ke langkah ke-2.
Diagram alir proses clustering data pada algoritma fuzzy c-mean dapat
dilihat pada Gambar 8.
Gambar 8. Tahapan algoritma fuzzy c-mean clustering (Jiang, 2003)
dengan U adalah matrik partisi, C adalah pusat cluster, D adalah
jarak antar matrik, m adalah nilai parameter fuzzifikasi, k adalah jumlah
cluster, n adalah jumlah data serta p jumlah atribut data.
Kemudian untuk nilai E-step dan M-Step dapat dihitung dengan
E-step : mk = α α ik n i i ik n i U X U
∑
∑
= = 1 1 (13)M-step : Uik =
∑
= − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − 1 1 1 1l i l
k i m x m x α (14)
dengan mk adalah pusat cluster ke-k dan Uik adalah derajat keanggotaan
poin data terhadap pusat cluster (M-step).
Dalam algoritma FCM ada beberapa hal yang perlu diperhatikan
saat membangun sistem diantaranya iterasi maksimal, error terkecil yang
diinginkan (ξ), pemangkat (m > 1) dan inisialisasi terhadap pusat awal
cluster (c ≥ 2).
D. Metodologi Pelabelan Otomatis Citra
Metode pelabelan otomatis mengadopsi metode pengembangan
ontologi yang dikenal dengan metodologi Uschold yaitu (Benjamins et. al.,
2004):
1. Mendefinisikan tujuan dan cakupan dari pelabelan otomatis;
2. Membangun pelabelan otomatis dengan langkah labeling capture yang
merupakan pengumpulan subjek-subjek/konsep citra, labeling coding
membangun model subjek/konsep dan mengintegrasikan pelabelan yang
telah ada (reuse) secara visual;
3. Melakukan evaluasi melalui verifikasi dan validasi;
E. Pengukuran Kinerja Sistem
Dua parameter utama yang dapat digunakan untuk mengukur
keefektifan temu kembali citra, yaitu recall dan precision. Recall adalah
perbandingan jumlah materi relevan yang ditemukembalikan terhadap jumlah
materi yang relevan, sedangkan precision adalah perbandingan jumlah materi
relevan yang ditemukembalikan terhadap jumlah materi yang
data basis dalam relevan citra
jumlah
kembali temu
hasil relevan citra
jumlah
=
recall (15)
terambil yang
citra seluruh jumlah
terambil yang
relevan citra
jumlah
=
precision (16)
Average precision adalah suatu ukuran evaluasi yang diperoleh dengan
menghitung rata-rata tingkat precision pada berbagai tingkat recall
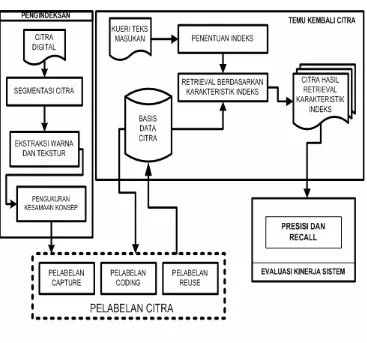
A. Kerangka Pemikiran
Penelitian dilakukan dalam empat tahapan utama, yaitu pengindeksan,
[image:45.595.130.497.218.561.2]pelabelan otomatis, temu kembali citra dan evaluasi kinerja sistem
(Gambar 9).
Gambar 9. Kerangka Pemikiran Penelitian
Keempat tahapan tersebut terdiri dari beberapa proses yang saling
berhubungan, yaitu :
1. Pengindeksan : pada tahapan ini dilakukan pemilihan citra sumber,
segmentasi citra, ektraksi warna dan tekstur, serta pengukuran kemiripan
ciri subjek citra menggunakan Euclid.
2. Pelabelan citra : mencakup pembentukan label citra secara otomatis.
3. Temu kembali citra : mencakup kueri teks sebagai masukan, penentuan
indeks digunakan sebagai dasar temu kembali citra.
4. Evaluasi kinerja sistem : pengukuran hasil temu kembali citra berdasarkan
nilai precision dan recall.
B. Alat Bantu Penelitian
Peralatan yang diperlukan untuk melaksanakan penelitian dibagi menjadi
dua, yaitu perangkat keras dan lunak. Perangkat keras berupa satu unit
komputer PC dengan spesifikasi Intel Pentium IV, RAM 512 MB, Harddisk
80 GB dan Kartu grafis serta layar monitor minimal mempunyai resolusi
warna 8 bit, sedangkan perangkat lunak yang diperlukan untuk perancangan
dan pengujian sistem adalah Matlab 7.1 dengan platform sistem operasi
Microsoft Windows XP.
C. Tata Laksana Penelitian
1. Pengindeksan
Pengindeksan dilakukan dalam empat tahapan utama (Gambar 10),
yaitu pemilihan jenis dan sumber data menjadi basis data citra, segmentasi
citra, ekstraksi ciri (warna dan tekstur) serta pengukuran kemiripan. Proses
pengindeksan masing-masing dijelaskan berikut ini.
Gambar 10. Tata Laksana Pengindeksan
BASIS DATA
CITRA SEGMENTASI CITRA
EKSTRAKSI CIRI CITRA
PENGINDEKSAN CITRA
EKSTRAKSI CIRI WARNA (HISTOGRAM)
EKSTRAKSI CIRI TEKSTUR (WAVELET GABOR)
UKURAN KEMIRIPAN
(EUCLID)
Jenis dan Sumber Data
Citra sumber merupakan data sekunder yang diambil dari situs internet
kemudian dikelompokkan dalam tiga kelas citra dengan masing-masing kelas
berjumlah 40 citra dan memiliki berbagai jenis objek. Format citra adalah JPG
berukuran 50×50 piksel serta merupakan citra berwarna.
Segmentasi Warna Citra
Pada tahapan segmentasi ini, setiap citra akan disegmentasi untuk
mengelompokkan warna yang dikandung oleh setiap piksel dari citra ke
beberapa segmen yang sudah ditentukan jumlahnya, yaitu dua, tiga, empat,
dan lima. Segmen ini merupakan representasi dari warna-warna dominan citra.
Setiap piksel dari citra dibangkitkan dari salah satu g segmen. Peluang sebuah
piksel masuk ke dalam segmen dapat dihitung dengan persamaan (17).
(
|)
(
|)
. 1 l g l l x p xp
∑
θ π=
=
Θ (17)
Masing-masing segmen diasumsikan mempunyai distribusi normal
Gauss, sehingga peluang piksel dari segmen l dapat dihitung dapat dihitung dengan persamaan (18).
( ) ( ) ( ) . 2 1 exp ) det( ) 2 ( 1 | 1 2 1 2 ⎭ ⎬ ⎫ ⎩ ⎨ ⎧− − Σ − Σ = − l l T l l d
l x x
x
p μ μ
π
θ (18)
Algoritma EM mempunyai dua tahapan utama yaitu tahapan Expectation
(E-step) dan Maximization (M-step). Pada tahapan Expectation, data
X diasumsikan sebagai data yang tidak lengkap dengan missing value berupa label yang menyatakan keanggotaan tiap piksel dari X ke dalam salah satu g
segmen. Pada tahapan ini yang dilakukan adalah menghitung peluang tiap
piksel dari tiap segmen dan membentuk matriks Zyang akan melengkapi data
X , sehingga data yang lengkap dapat dinyatakan sebagai . Label
tiap piksel didapatkan dari segmen yang mempunyai peluang tertinggi dalam
(
X Z Y = ,)
Z. Nilai likelihood dari data yang lengkap dapat dihitung dengan persamaan (19).
(
| . ) | ( 1 1∑∑
= = Θ = Θ n i g l x p YPada tahapan Maximization, parameter untuk iterasi berikutnya ditentukan sesuai dugaan variabel dari Z. Formulasi untuk menduga kembali
parameter segmen adalah menggunakan persamaan (20),(21) dan (22).
∑
=
+ = N
i i l t l z N 1 1 1
π (20)
∑
∑
= = + = N i i l N i i i l t l z x z 1 1 1μ (21)
(
)(
)
. 1 1 1 1 1∑
∑
= = + + + − − = ∑ N i i l N i T t l i t l i i l t l z x xz μ μ
(22)
Nilai parameter yang baru dari M-step ini akan digunakan kembali untuk
E-step pada iterasi berikutnya. Proses E-step dan M-step akan terus berulang sampai didapatkan nilai likelihood yang kecil sehingga hasil perhitungan sudah tidak terlalu banyak mengalami perubahan. Ketika nilai likelihood
hanya sedikit berubah, maka hasil dianggap konvergen.
Ektraksi Ciri Warna
Proses ekstraksi warna dengan FCH dilakukan pada ruang warna RGB
untuk mempermudah pengolahan citra (Vertan & Boujemaa, 2000).
CITRA SUMBER
SEGMENTASI
WARNA
VEKTOR CIRI
WARNA HISTOGRAM
Gambar 11. Ektraksi ciri warna
Langkah pertama yang dilakukan untuk menghitung FCH adalah
menghitung histogram awal (Gambar 11). Pada penelitian ini, nilai warna
kuantisasi awal tersebut didasarkan pada sebaran warna citra dalam basis data
tiap kelas citra diambil 10 warna piksel yang muncul terbanyak sehingga
dihasilkan 300 warna yang tidak sama.
Dari histogram awal dihasilkan jumlah ciri yang terlalu banyak
sehingga diperlukan waktu komputasi yang besar untuk ekstraksi ciri sebuah
citra. Oleh karena itu perlu dilakukan pengelompokan warna (clustering) dari 300 warna semesta tersebut ke dalam beberapa pusat cluster warna
menggunakan Fuzzy C-Means (FCM). Setiap pusat cluster FCM
merepresentasikan bin FCH. Jumlah bin FCH yang digunakan sebanyak 30. Untuk perhitungan FCH selanjutnya diperlukan matriks derajat
keanggotaan, dimana nilai keanggotaannya dapat diperoleh menggunakan
fungsi Cauchy, yang dihitung menggunakan persamaan (23).
α
σ
μ
) / ) , ' ( ( 1 1 ) ( ' c c d c c += , (23)
dimana
d(c’,c) = jarak Euclid antara warna c dengan c’,
c’ = warna pada bin FCH,
c = warna semesta,
α = untuk menentukan kehalusan dari fungsi,
σ = untuk menentukan lebar dari fungsi keanggotaan.
Nilai parameter α=2 dan σ=15 diperoleh dari hasil percobaan
sebelumnya (Balqis, 2006). Perhitungan akhir FCH dengan FCM dinotasikan
sebagai berikut (persamaan 24) :
∑
∈=
μμ
cc
c
h
c
c
h
2(
'
)
'(
)
*
(
)
, (24)dimana :
2
h = fuzzy color histogram,
) (c
h = conventional color histogram,
) (
' c c
Ekstraksi Ciri Tekstur
Setiap citra mempunyai tekstur yang sebenarnya unik meskipun
terkadang secara sepintas terlihat sama. Untuk menentukan ciri tekstur
digunakan nilai energi dari beberapa frekuensi sampling pada transformasi
Fourier 2D. Proses penentuan vektor ciri tekstur pada citra dengan
memanfaatkan energi pada transformasi Fourier (Gambar 12).
CITRA SUMBER
RGB Gray FFT dengan fs1
FFT dengan fs2
FFT dengan fs3
SORT ENERGI
SORT ENERGI
SORT ENERGI
MERGE VEKTOR CIRI
TEKSTUR
Gambar 12. Ekstraksi ciri tekstur
Penggabungan Ciri Warna dan Tekstur
Penggabungan ciri warna dan tekstur dilakukan dengan menggunakan
pembobot tertentu. Nilai pembobot tersebut menyatakan hubungan keterkaitan
masing-masing vektor ciri dengan vektor ciri total. Selanjutnya untuk istilah
penggabungan ciri warna dan tekstur ini disebut dengan vektor ciri.
Pengukuran Kemiripan Ciri
Vektor yang terbentuk dijadikan acuan untuk melakukan proses
pencocokan pola untuk mendapatkan kesamaan ciri. Untuk menyatakan dua
region citra sebagai cita yang mirip dilakukan proses perhitungan jarak Euclid
antara vektor ciri dari kedua citra region tersebut.
2. Pelabelan Citra
Pelabelan citra disusun berdasarkan topik atau subjek pengetahuan
citra. Topik atau subjek pengetahuan citra ditentukan berdasarkan indeks
visual yang diperoleh pada saat proses pengindeksan. Tahapan pelabelan
Gambar 13. Tata Laksana Pelabelan Otomatis Tahapan pelabelan citra terdiri dari (Benjamins et. al., 2004) :
1. Labeling Capture : pengumpulan pengetahuan berupa konsep-konsep citra. Hasil dari tahapan ini adalah kamus kata.
2. Labeling Coding : membangun model dari konsep-konsep yang ada dalam kamus kata. Hasil dari tahapan ini adalah kamus visual citra.
3. Labeling Reuse : Integrasi dari konsep-konsep beserta komponen-komponennya. Hasil dari tahapan ini adalah visualisasi pelabelan citra.
3. Temu Kembali Citra
Proses temu kembali citra dilakukan melalui penentuan indeks dari kueri yang berdasarkan teks. Proses retrieval data citra dilakukan sesuai
dengan karakteristik citra terlabel dalam basis data (Gambar14).
PENENTUAN INDEKS KUERI TEKS
MASUKAN
RETRIEVAL BERDASARKAN KARAKTERISTIK INDEKS BASIS
DATA CITRA TERLABEL
CITRA HASIL RETRIEVAL KARAKTERISTIK
INDEKS
TEMU KEMBALI CITRA
4. Evaluasi Kinerja Sistem
Evaluasi kinerja sistem dilakukan penilaian tingkat keefektifan
proses temu kembali terhadap sejumlah koleksi. Pengujian dilakukan
dengan menghitung nilai recall dan precision dari proses temu kembali citra berdasarkan penilaian relevansinya. Penentuan relevansi citra hasil
Bagian ini menguraikan proses perancangan dan implementasi sistem. Bagian utama bab ini adalah desain data, desain proses sistem serta desain antar muka sistem. Desain data berisi citra sumber dan kamus kata. Desain proses sistem berisi proses segmentasi, proses pelabelan citra, proses temu tembali dan evaluasi sistem temu kembali sedangkan disain antar muka sistem berisi rancangan antar muka sistem.
A. Desain Data
Desain data menggambarkan proses tranformasi data dalam sistem. Dalam penelitian ini data mengalami perubahan dari data citra, menjadi basis data citra, matrik representasi citra, matrik keanggotaan dan data cluster. Desain data lain adalah kumpulan kata-kata (kamus kata) yang berisi aturan-aturan yang sesuai dengan kelas citra.
1. Citra Sumber
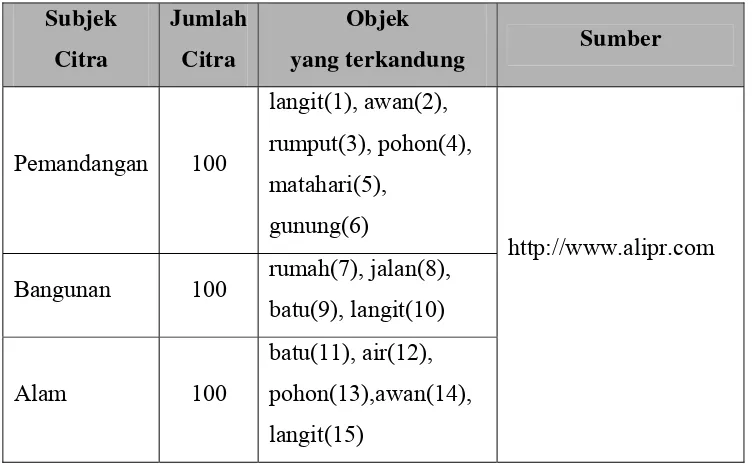
Citra sumber penelitian diperoleh dari web ALIPR (http://www.alipr.com). Terlihat dalam Tabel 2, citra sumber yang berhubungan dengan kelas pemandangan, bangunan, alam. Jumlah objek yang terkandung dalam citra dapat berisi 3 (tiga), 4 (empat) atau 5 (lima) objek. Contoh salah satu citra dengan subjek pemandangan memiliki objek citra berupa gunung, rumah, rumput.
2. Kamus Kata
Kamus kata (Tabel 2) berisi kumpulan kata-kata yang memuat aturan-aturan tentang citra. Aturan-aturan tersebut merupakan subjek dan objek citra. Kata-kata dalam kamus kata bersumber dari kosa kata bahasa Indonesia. Kamus kata disusun berdasarkan dua hal, yaitu subjek yang merupakan topik utama citra serta objek yang dimiliki subjek citra. Terdapat beberapa objek citra untuk suatu subjek dalam satu kelas citra sumber memiliki label atau identitas yang sama.
Tabel 2. Kamus Kata Subjek
Citra
Jumlah Citra
Objek yang dimiliki
Pemandangan 100 langit(1), awan(2), rumput(3), pohon(4), matahari(5), gunung(6)
Bangunan 100 rumah(7), jalan(8), batu(9), langit(10) Alam 100 batu(11), air(12), pohon(13),awan(14),
langit(15)
Masing-masing objek pada kamus kata diberikan nomor urut yang menyatakan urutan identitas. Identitas tersebut berupa urutan objek kesatu, kedua, ketiga dan seterusnya. Pemberian id digunakan sebagai penanda objek hasil clustering. Jumlah objek yang didefinisikan untuk kamus kata adalah berjumlah 15 objek.
B. Desain Proses Sistem
1. Segmentasi Citra
Citra sumber disegmentasi menggunakan metode Normalized Cuts
(Shi & Malik, 2000). Metode Normalized Cuts merupakan segmentasi berbasis region yang menghasilkan sub citra. Sub citra tersebut dinamakan dengan region. Dalam penelitian ini digunakan enam region untuk setiap citra sumber. Beberapa citra sumber kemudian di segmentasi sehingga diperoleh region-region yang bersesuaian. Pembentukan region-region ini dimaksudkan untuk mendapatkan objek citra.
Masing-masing region pada citra sumber, kemudian dilakukan pemisahan region dari citra utama. Pemisahan ini dilakukan untuk mempermudah mendapatkan ciri masing-masing region sebagai ciri objek. Pemisahan setiap region dari citra sumber dilakukan melalui pemberian tanda tertentu untuk area tertentu. Tanda yang dimaksud adalah dengan pemberian warna putih untuk area diluar target area yang dimakud.
Ukuran citra yang dihasilkan tetap sesuai dengan citra hasil praproses awal yaitu 50 x 50, tapi untuk area yang dihasilkan dalam pembentukan region ini tidak memiliki format ukuran yang standar.
2. Ektraksi Ciri
Setiap region yang telah dipisahkan, dilakukan perhitungan nilai ciri (Daubechies, 1995). Hasil perhitungan ciri akan diperoleh matrik representasi ciri suatu citra untuk setiap region. Representasi nilai ciri citra pada setiap region kemudian menjadi acuan untuk pembentukan ciri subjek citra.
Pada tahapan ekstraksi ciri warna, setiap piksel pada citra akan direpresentasikan dengan peluang atau frekuensi piksel-piksel tersebut terhadap nilai warna (bin) yang sudah ditentukan sebanyak 30. Bin
C. Perancangan Proses Sistem
Rancangan proses sistem menggambarkan hubungan antara elemen-elemen (modul) pada sistem yang dikembangkan. Prototipe sistem dan
interface sistem dikembangkan dengan menggunakan perangkat lunak Matlab Versi 7.1. Sistem ini terdiri dari empat modul yaitu : modul segmentasi, modul pelabelan region, modul temu kembali dan modul kinerja (Gambar 15). Keempat modul tersebut digunakan dalam pengerjaan penelitian ini.
Gambar 15 . Arsitektur Sistem Pelabelan Otomatis
1. Modul Segmentasi.
Modul segmentasi berfungsi untuk melakukan segmentasi,
penarikan ciri serta clustering citra sumber. Modul ini bekerja dengan memanfaatkan algoritma Normalized Cuts untuk segmentasi. Penarikan ciri berdasarkan warna dan tekstur serta FCM untuk clustering, hasil akhirnya akan terbentuk region-region pada citra sumber beserta matrik ciri.
Secara umum algoritma segmentasi Normalized Cuts seperti berikut (Shi & Malik, 2000) :
1. Mendefinisikan sekumpulan matrik dari citra yang akan di segmentasi 2. Menentukan bobot graf G=(V,E), lalu menghitung bobot edge dan
menyimpan informasi dalam W dan D.
4. Menggunakan nilai eigen vektor tersebut untuk mempartisi graf menjadi 2 dengan membagi masing-masing titik menjadi NCut yang minimum.
5. Membaca nilai NCut yang dihasilkan, lalu mengulangi partisi ke langkah 2.
6. Jika NCuts untuk setiap segmen > nilai maksimum dari Ncuts yang didefinisikan maka proses dihentikan.
2. Modul Clustering
Modul ini berfungsi untuk mengelompokkan data ciri yang telah tersedia dalam bentuk matrik menjadi kelompok-kelompok berdasarkan kemiripannya. Pengelompokkan data ciri tersebut menggunakan algoritam FCM. Tingkat kemiripan tersebut ditentukan dengan mengukur jarak
euclid point data ke pusat cluster. Hasil dari modul ini adalah berupa matrik U yang merepresentasikan derajat keanggotaan data dan titik pusat cluster. Matrik keanggotaan (U) yang dihasilkan berdimensi k x n, dimana k adalah jumlah cluster dan n adalah jumlah data yang digunakan sebagai masukan. Matrik Keanggotaan hasil clustering terlihat seperti pada tabel 3.
Tabel 3. Matrik Keanggotaan (U) Hasil Clustering Jumlah
Data Cluster 1 Cluster 2 ... Cluster k
1 U11 U12 ... U1k
2 U21 U22 ... U2k
... .... ... ... ...
... ... ... ... ...
n Un1 Un2 ... Unk
3. Modul Pelabelan Citra
Pada suatu citra terdapat lebih dari satu objek, maka perlu dibedakan antara sebuah objek dengan objek lain yang terdapat pada citra tersebut. Proses pelabelan menggunakan teknik rekursi. Mula-mula dideteksi lokasi sebuah titik yang merupakan bagian dari sebuah objek, lalu dengan rekursi dilakukan pengisian dengan suatu nilai (label) terhadap objek tersebut dari lokasi tersebut sampai menemui batas luarnya (menabrak titik latar). Kemudian dilanjutkan mendeteksi lokasi yang merupakan titik objek yang belum terisi oleh proses tadi atau belum diberi label (dengan kata lain merupakan bagian dari objek yang lain). Lakukan pengisian lagi dengan nilai label yang berbeda. Ulangi sampai semua titik dalam citra tersebut diperiksa.
Secara umum algoritma pelabelan citra adalah sebagai berikut : 1. Menentukan titik awal pengisian pada objek yang akan diisi. 2. Menentukan titik tersebut menjadi titik objek
2.1. Memeriksa apakah titik tetangga atasnya adalah titik latar. a. Jika ya maka lakukan hal yang sama untuk titik tersebut. b. Jika tidak maka lanjutkan.
2.2. Memeriksa apakah titik tetangga kanannya adalah titik latar. a. Jika ya maka lakukan hal yang sama untuk titik tersebut. b. Jika tidak maka lanjutkan.
2.3. Memeriksa apakah titik tetangga bawahnya adalah titik latar. a. Jika ya maka lakukan hal yang sama untuk titik tersebut. b. Jika tidak maka lanjutkan.
2.4. Memeriksa apakah titik tetangga kirinya adalah titik latar. a. Jika ya maka lakukan hal yang sama untuk titik tersebut. b. Jika tidak maka lanjutkan.
1. Membaca region setiap citra.
2. Memetakan setiap region yang terbaca dengan id region yang bersesuaian
3. Mengulangi langkah 1 dan 2 sampai semua region terbaca.
4. Modul Temu Kembali
Modul temu-kembali membaca dan menghasilkan output dari dan ke memori. Modul ini dikembangkan sebagai representasi hasil akhir sistem. Pada sistem ini dilakukan inputan berupa kueri teks dengan kata kunci masukan dan informasi yang ditampilkan berupa kumpulan citra yang berkaitan beserta derajat keanggotaannya.
5. Modul Evaluasi
Modul evaluasi digunakan untuk mengukur tingkat keefektifan proses temu kembali terhadap sejumlah koleksi pengujian dengan menghitung nilai recall dan precision dari proses temu kembali citra berdasarkan penilaian relevansinya. Penentuan relevansi citra hasil temu kembali dibuat berdasarkan kelas citra di dalam basis data.
6. Modul Representasi Hasil
Modul ini berfungsi untuk mentransformasikan hasil dari proses pencarian dan clustering menjadi bentuk yang lebih ramah pengguna (user friendly), dimana pengguna dapat dengan cepat mengetahui jumlah citra (beserta derajat keanggotaan) yang menjadi anggotanya.
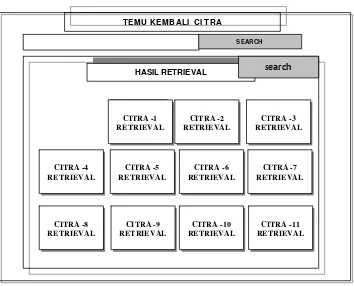
D. Disain Antarmuka
Desain antar muka sistem ini terdiri dari 2 bagian utama, yaitu : antar muka untuk pelabelan otomatis citra (Gambar 16) dan antar muka untuk pencarian citra berdasarkan kata kunci tekstual (Gambar 17).
Gambar 16. Antar Muka Pelabelan Citra
SEARCH
HASIL RETRIEVAL search
CITRA -2 RETRIEVAL
CITRA -3 RETRIEVAL
CITRA -4 RETRIEVAL
CITRA -5 RETRIEVAL
CITRA -6 RETRIEVAL
CITRA -7 RETRIEVAL
CITRA -8 RETRIEVAL
CITRA -9 RETRIEVAL
CITRA -10 RETRIEVAL
CITRA -11 RETRIEVAL
TEM U KEM BALI CI TRA
CITRA -1 RETRIEVAL
A. Karakteristik Citra Masukan
Sebanyak 300 citra yang digunakan pada penelitian ini dikelompokkan
menjadi 3 subjek : pemandangan (100 citra), bangunan (100 citra), alam (100
[image:61.595.125.502.255.490.2]citra). Masing-masing subjek terdiri dari 4 sampai dengan 6 objek (Tabel 4).
Tabel 4. Subjek, jumlah, serta objek citra sumber
Subjek Citra
Jumlah Citra
Objek
yang terkandung Sumber
Pemandangan 100
langit(1), awan(2),
rumput(3), pohon(4),
matahari(5),
gunung(6)
Bangunan 100 rumah(7), jalan(8),
batu(9), langit(10)
Alam 100
batu(11), air(12),
pohon(13),awan(14),
langit(15)
http://www.alipr.com
B. Pengindeksan Citra
1. Segmentasi Warna Citra
Pada tahapan segmentasi ini, setiap citra disegmentasi untuk
mengelompokkan warna yang dikandung oleh setiap piksel dari citra ke
beberapa segmen (cluster) yang sudah ditentukan jumlahnya, yaitu dua,
tiga, empat, dan lima. Cluster ini merupakan representasi warna-warna
dominan citra. Tahapan segmentasi ini bertujuan mendapatkan
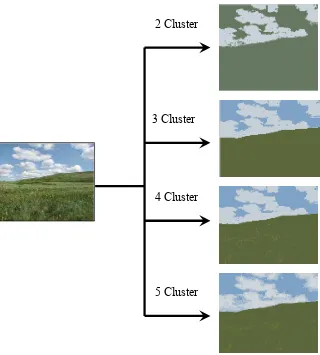
kelompok-kelompok warna dominan dan mengurangi jumlah warna citra asli seperti
Gambar 18. Contoh citra sebelum dan sesudah segmentasi menggunakan algoritma EM.
Selanjutnya dilakukan pemilihan keempat hasil segmentasi tersebut
secara manual untuk dijadikan masukan pada tahap ekstraksi warna.
Berdasarkan Gambar 18, dapat dilihat bahwa hasil segmentasi keempat
adalah hasil segmentasi yang paling baik. Hal ini dikarenakan citra hasil
segmentasi tersebut paling mirip dengan citra aslinya. Hasil segmentensi
yang sudah terpilih sebagai masukan pada tahap ekstraksi warna untuk
seluruh citra di dalam basis data dapat dilihat pada lampiran 1 4 Cluster
3 Cluster 2 Cluster
5 Cluster
2. Format Tekstur Citra
Sedangkan untuk proses ekstraksi ciri tekstur, citra sumber
perubahan format dari format RGB ke format gray scale. Hasilnya
[image:62.595.144.464.81.436.2]Citra RGB ke Gray
Gambar 19. Contoh citra RGB ke citra gray scale
3. Segmentasi Region
Semua citra sumber di segmentasi untuk menghasilkan
region-region yang bersesuaian dengan objek yang ada dalam citra. Jumlah
region untuk setiap citra masukan ditentukan sebanyak 6 region.
Penentuan enam region ini dilakukan berdasarkan asumsi jumlah
maksimum objek yang terkandung dalam citra.
(a) Citra Sumber
(b) Citra Hasil Segmentasi
Gambar 20. Contoh citra sebelum dan sesudah segmentasi menggunakan algoritma Normalized Cuts
Selanjutnya citra hasil segmentasi dilakukan pemisahan region.
Pemisahan region dilakukan dengan membaca setiap piksel yang
memiliki nilai batasan (garis putih). Region yang diinginkan disimpan
dalam file dengan format JPG, sedangkan untuk region yang lain
komponen-komponen pikselnya digantikan dengan warna putih.