ABSTRAK
NOVI APRIYANTI. Optimasi Jaringan Syaraf Tiruan dengan Algoritma Genetika untuk Peramalan Curah Hujan. Dibimbing oleh AGUS BUONO dan AZIZ KUSTIYO.
Informasi tentang banyaknya curah hujan sangat berguna bagi para petani dalam mengantisipasi kemungkinan terjadinya peristiwa-peristiwa ekstrim (kekeringan dan kebanjiran) yang akan berakibat kegagalan dalam proses produksinya. Dengan demikian, ketersediaan informasi ini memerlukan suatu metode peramalan curah hujan yang akurat. Beberapa penelitian yang sudah dilakukan belum memberikan hasil yang memuaskan.
Algoritma genetika standar adalah metode yang digunakan untuk optimasi konfigurasi neuron pada lapisan tersembunyi dalam Jaringan Syaraf Tiruan (JST) ini. Teknik pembelajaran JST yang digunakan dalam metode peramalan curah hujan ini adalah JST propagasi balik standar dengan arsitektur banyak lapis yaitu satu lapisan input, satu lapisan tersembunyi, dan satu lapisan output. Keakuratan hasil prediksi JST diukur berdasarkan R2 dan RMSE-nya.
Ujicoba terhadap sistem telah dilakukan JST dalam peramalan curah hujan dan hasilnya dibandingkan dengan metode principal component regression (PCR) dan JST propagasi balik standar dengan hasil terbaiknya dengan jumlah neuron 9 dan laju pembelajaran 0.02. Hasil peramalan curah hujan menggunakan metode PCR menghasilkan R2 sebesar 63%, sedangkan peramalan dengan menggunakan metode jaringan syaraf tiruan propagasi balik menghasilkan R2 sebesar 74%, dan JST yang dioptimasi menjadi 87%. Hal ini menunjukkan adanya peningkatan R2. Berdasarkan ujicoba tersebut dapat diperoleh kesimpulan bahwa optimasi JST dengan algoritma genetika dapat digunakan untuk memperbaiki tingkat pendugaan curah hujan dengan menggunakan data GCM daripada metode PCR dan JST propagasi balik standar.
OPTIMASI JARINGAN SYARAF TIRUAN DENGAN ALGORITMA
GENETIKA UNTUK PERAMALAN CURAH HUJAN
Oleh:
Novi Apriyanti
G64101004
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
OPTIMASI JARINGAN SYARAF TIRUAN DENGAN ALGORITMA
GENETIKA UNTUK PERAMALAN CURAH HUJAN
Oleh:
Novi Apriyanti
G64101004
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
NOVI APRIYANTI. Optimasi Jaringan Syaraf Tiruan dengan Algoritma Genetika untuk Peramalan Curah Hujan. Dibimbing oleh AGUS BUONO dan AZIZ KUSTIYO.
Informasi tentang banyaknya curah hujan sangat berguna bagi para petani dalam mengantisipasi kemungkinan terjadinya peristiwa-peristiwa ekstrim (kekeringan dan kebanjiran) yang akan berakibat kegagalan dalam proses produksinya. Dengan demikian, ketersediaan informasi ini memerlukan suatu metode peramalan curah hujan yang akurat. Beberapa penelitian yang sudah dilakukan belum memberikan hasil yang memuaskan.
Algoritma genetika standar adalah metode yang digunakan untuk optimasi konfigurasi neuron pada lapisan tersembunyi dalam Jaringan Syaraf Tiruan (JST) ini. Teknik pembelajaran JST yang digunakan dalam metode peramalan curah hujan ini adalah JST propagasi balik standar dengan arsitektur banyak lapis yaitu satu lapisan input, satu lapisan tersembunyi, dan satu lapisan output. Keakuratan hasil prediksi JST diukur berdasarkan R2 dan RMSE-nya.
Ujicoba terhadap sistem telah dilakukan JST dalam peramalan curah hujan dan hasilnya dibandingkan dengan metode principal component regression (PCR) dan JST propagasi balik standar dengan hasil terbaiknya dengan jumlah neuron 9 dan laju pembelajaran 0.02. Hasil peramalan curah hujan menggunakan metode PCR menghasilkan R2 sebesar 63%, sedangkan peramalan dengan menggunakan metode jaringan syaraf tiruan propagasi balik menghasilkan R2 sebesar 74%, dan JST yang dioptimasi menjadi 87%. Hal ini menunjukkan adanya peningkatan R2. Berdasarkan ujicoba tersebut dapat diperoleh kesimpulan bahwa optimasi JST dengan algoritma genetika dapat digunakan untuk memperbaiki tingkat pendugaan curah hujan dengan menggunakan data GCM daripada metode PCR dan JST propagasi balik standar.
Cukuplah Allah menjadi Penolong kami dan Allah adalah sebaik-baik Pelindung, Maka mereka kembali dengan nikmat dan karunia (yang besar dari) Allah, Mereka tidak mendapat bencana apa-apa,mereka mengikuti keridhaan Allah. Dan, Allah mempunyai karunia yang besar.
OPTIMASI JARINGAN SYARAF TIRUAN DENGAN ALGORITMA
GENETIKA UNTUK PERAMALAN CURAH HUJAN
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
Pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
Novi Apriyanti
G64101004
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Skripsi : OPTIMASI JARINGAN SYARAF TIRUAN DENGAN
ALGORITMA GENETIKA UNTUK PERAMALAN
CURAH HUJAN
Nama : Novi Apriyanti
NIM : G64101004
Menyetujui,
Pembimbing I
Ir. Agus Buono, M.Si., M.Kom.
NIP. 132 045 532
Pembimbing II
Aziz Kustiyo, S.Si., M.Kom.
NIP. 132 206 241
Mengetahui,
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Dr. Ir. H. Yonny Koesmaryono, MS.
NIP. 131 473 999
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas limpahan nikmat dan hidayah-Nya sehingga penulis dapat menyelesaikan karya ilmiah ini. Sholawat serta salam semoga selalu tercurah kepada Nabi besar Nabi Muhammad SAW, keluarga, para sahabat, serta para pengikutnya yang tetap istiqomah mengemban risalah-Nya.
Melalui lembar ini, penulis ingin menyampaikan penghargaan dan terima kasih kepada semua pihak atas bantuan, dorongan, saran, kritik serta koreksi yang ditujukan selama penulisan karya ilmiah ini. Ucapan terima kasih penulis ucapkan kepada :
1. Ibu, Bapak, dan adik atas doa, kasih sayang, dukungan, dan pengorbanan yang diberikan sehingga mendorong penulis untuk menyelesaikan karya ilmiah ini. Hanya Allah SWT saja yang dapat membalasnya dengan setara.
2. Bapak Ir. Agus Buono, M.Si, M.Komp. dan Bapak Aziz Kustiyo, S.Si, M.Kom. sebagai pembimbing skripsi I dan II atas segala bimbingan, saran, dan kesabarannya atas penelitian ini.
3. Bapak Irman Hermadi, S.Kom, MS atas segala bimbingannya di sela-sela kesibukan beliau dan kesediaan membimbing sebagai wujud kecintaannya terhadap ilmu dan mahasiswanya.
4. Seluruh staf pengajar yang telah memberikan bekal ilmu dan wawasan selama penulis menuntut ilmu di Departemen Ilmu Komputer IPB.
5. Seluruh staf administrasi atas bantuannya dan juga staf perpustakaan yang tidak bosan melayani kebutuhan buku untuk penulis.
6. Teman-teman kos Cidangiang 46 A Baranangsiang, Khamam yang telah memberikan bantuan banyak, teman-teman Az Zahra yang tidak bisa disebutkan satu persatu, rekan-rekan Departemen Ilmu Komputer angkatan 38 dan 37 atas persaudaraan, nasehat, do’a, dorongannya yang tulus sehingga memberikan motivasi bagi penulis untuk cepat menyelesaikan penelitian ini. Semoga Allah SWT selalu memberikan petunjuk-Nya kepada kita semua.
7. Teman-teman satu penelitian : Yani, Lisa, Elmi, Kak Arif dan teman-teman pembahas seminar : Inu, Nepha, Diku.
8. Kak Pesi atas penjelasan skripsi yang tak pernah berhenti serta Kak Aris atas librarinya. 9. Semua instansi yang telah memberikan beasiswa kuliah kepada penulis selama ini. 10. Teman-teman dekat yang senantiasa memberikan do’a dan semangat kepada penulis agar
tetap konsisten untuk menyelesaikan penelitian ini.
11. Setiap rakyat di negeri ini yang telah memberikan subsidi terhadap pendidikan dan setiap anak negeri ini yang tidak berkesempatan mengenyam pendidikan layak sehingga menjadikan penulis menghargai, mensyukuri serta berusaha semaksimal mungkin menjalani pendidikan selama ini. Semoga suatu saat penulis dapat memberikan kontribusi yang terbaik bagi mereka.
Sebagaimana manusia yang tidak luput dari kesalahan, penulis menyadari bahwa karya ilmiah ini jauh dari sempurna namun penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi siapapun yang membacanya.
Bogor, Oktober 2005
RIWAYAT HIDUP
Penulis dilahirkan di Baturaja, Sumatera Selatan pada tanggal 25 April 1983 sebagai anak pertama dari dua bersaudara, anak dari pasangan Bapak Paino Handoko dan Ibu Tri Supriyani.
Penulis menyelesaikan sekolah menengah umum di SMUN 1 Baturaja, lulus pada tahun 2001. Setelah lulus melanjutkan pendidikannya di Departemen Ilmu Komputer Institut Pertanian Bogor melalui program USMI (Undangan Seleksi Masuk IPB). Penulis aktif di berbagai kegiatan dan organisasi kemahasiswaan seperti Dewan Perwakilan Mahasiswa TPB IPB, Badan Eksekutif Mahasiswa FMIPA IPB, Badan Eksekutif Mahasiswa Keluarga Mahasiswa IPB, Kesatuan Aksi Mahasiswa Muslim Indonesia Komisariat IPB, Himpunan Mahasiswa Ilmu Komputer, Teater Garis FMIPA IPB, Kelompok Lingkar Studi Lokomotif Baranangsiang IPB, dan anggota Beswan Djarum. Selama kuliah penulis juga pernah menjadi staf pengajar di Lembaga Bimbingan Belajar Nurul Ilmi dan Nurul Hikmah Bogor. Pada tahun 2004 penulis menjadi operator data entry pada PEMILU legislatif dan eksekutif serta magang di Kantor Direktorat Kemahasiswaan Institut Pertanian Bogor. Pada tahun 2005 penulis melakukan Praktik Kerja Lapang di kantor Balai Besar Penelitian dan Pengembangan Bioteknologi dan Sumberdaya Genetik Pertanian Bogor.
DAFTAR ISI
Halaman
DAFTAR TABEL ...viii
DAFTAR GAMBAR ...viii
DAFTAR LAMPIRAN ...viii
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup Penelitian... 1
TINJAUAN PUSTAKA Model Sirkulasi Umum ... 1
Curah Hujan ... 1
Normalisasi ... 2
Principal Component Analysis (PCA) ... 2
Jaringan Syaraf Tiruan (JST) ... 3
JST Propagasi Balik Standar... 3
Algoritma Genetika ... 4
Ketepatan Pendugaan Model Regresi Linear ... 5
METODOLOGI Data ... 5
Faktor dan Taraf ... 6
Preprocessing data dengan PCA ... 6
Spesifikasi Algoritma Genetika yang Digunakan ... 6
Representasi Solusi pada Algoritma Genetika ... 7
Respon (Fungsi Fitness) ... 7
Perangkat Keras dan Lunak yang Digunakan ... 7
Perancangan Penelitian ... 7
HASIL DAN PEMBAHASAN Perbandingan R2 dan RMSE JST Standar... 8
Perbandingan R2 dan RMSE JST Optimasi dengan GA ... 8
Perbandingan R2 dan RMSE JST Standar dan JST Optimasi ... 9
Arsitektur Terbaik...10
Pengaruh Laju Pembelajaran terhadap R2...10
Perbandingan Waktu Testing JST Standar dan JST Optimasi ...11
Perbandingan dengan Hasil Penelitian Sebelumnya ...11
KESIMPULAN DAN SARAN Kesimpulan ...12
Saran ...12
DAFTAR PUSTAKA ...12
DAFTAR TABEL
Halaman
1. Faktor dan taraf ... 6
2. Struktur jaringan syaraf tiruan yang digunakan dalam penelitian ... 7
3. Perbandingan R2 dan RMSE JST standar ... 8
4. Perbandingan R2 dan RMSE JST optimasi ... 8
5. Perbandingan R2 JST standar dan JST optimasi ... 9
6. Perbandingan RMSE JST standar dan JST optimasi ... 9
7. Perbandingan rata-rata waktu testing JST standar dan JST optimasi ... 11
8. Perbandingan nilai R2 dan RMSE dengan penelitian sebelumnya ... 11
DAFTAR GAMBAR
Halaman 1. Regresi linear sederhana ... 32. Grafik fungsi sigmoid biner dengan range (0,1) ... 4
3. Grafik fungsi linear ... 4
4. Diagram proses pendugaan ... 8
5. Perbandingan nilai R2 metode JST standar dan JST optimasi ... 9
6. Perbandingan RMSE JST standar dan JST optimasi ... 9
7. Nilai prediksi dan aktual arsitektur terbaik JST standar ... 10
8. Nilai prediksi dan aktual arsitektur terbaik JST optimasi ... 10
9. Pengaruh laju pembelajaranterhadap R2 JST standar ... 10
10. Pengaruh laju pembelajaranterhadap R2 JST optimasi ... 11
11. Perbandingan rata-rata waktu testing terkecil JST standar dan JST optimasi ... 11
12. Perbandingan R2 beberapa penelitian ... 12
13. Perbandingan RMSE beberapa penelitian ... 12
DAFTAR LAMPIRAN
Halaman 1. Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Pertama 50% Learning, 50% Testing ... 152. Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Kedua 70% Learning, 30% Testing ... 16
3. Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Ketiga 90% Learning, 10% Testing ... 17
4. Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Keempat 95% Learning, 5% Testing ... 18
5. Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Pertama 50% Learning, 50% Testing ... 29
6. Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Kedua 70% Learning, 30% Testing ... 20
7. Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Ketiga 90% Learning, 10% Testing ... 21
8. Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Keempat 95% Learning, 5% Testing ... 22
9. Pengaruh Laju Pembelajaran pada JST Standar terhadap Rata-Rata Nilai R2... 23
PENDAHULUAN
Latar Belakang
Informasi tentang banyaknya curah hujan sangat berguna bagi para petani dalam mengantisipasi kemungkinan terjadinya peristiwa-peristiwa ekstrim yang tidak diinginkan seperti kekeringan dan kebanjiran yang akan berakibat kegagalan dalam proses produksinya. Informasi curah hujan yang diperlukan petani harus tersedia sebelum kegiatan proses produksi dimulai sehingga perlu diadakannya kajian tentang peramalan curah hujan.
Dengan menggunakan teknologi di bidang Artificial Intellegence, yaitu teknologi Jaringan Syaraf Tiruan (JST), maka identifikasi pola data dari sistem peramalan curah hujan dapat dilakukan dengan metode pendekatan pembelajaran. Berdasarkan kemampuan belajar yang dimilikinya, maka JST dapat dilatih untuk mempelajari dan menganalisa pola data masa lalu dan berusaha mencari suatu formula atau fungsi yang akan menghubungkan pola data pada masa lalu. JST juga dapat mencari formula atau fungsi yang akan menghubungkan pola data pada masa lalu dengan keluaran yang diinginkan pada saat ini.
Saat ini model-model peramalan yang ada belum menggunakan data sirkulasi atmosfir (data spasial-temporal) yang diperoleh dari luaran (output) model sirkulasi umum (General Circulation Model – GCM), untuk mengantisipasi keragaman perubahan curah hujan dalam ruang dan waktu. Penelitian yang pernah dilakukan menggunakan data GCM yaitu menggunakan Principal Component Regression (PCR) atau regresi komponen utama dalam statistical downscaling (Fitriadi 2004) dan JST propagasi balik standar (Normakristagaluh 2004).
Untuk itulah dalam tugas akhir ini, penulis berusaha untuk melakukan pendugaan dengan menggunakan JST yang dioptimasi menggunakan Genetic Algorithm (GA) untuk mendukung peramalan curah hujan berdasarkan faktor-faktor dominan yang mempengaruhi curah hujan di Indonesia.
Tujuan
Tujuan penelitian ini adalah mengembangkan model JST dengan optimasi struktur neuron lapis tersembunyi menggunakan GA untuk peramalan curah hujan.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini meliputi : 1. Dilakukan preprocessing terhadap data
input yang digunakan, yaitu dengan mengelompokkan data. Setiap kelompok data dinormalisasi, kemudian dilakukan Principal Components Analysis (PCA) untuk mereduksi dimensi data spasial suhu.
2. Teknik pembelajaran JST yang digunakan adalah propagasi balik standar dengan satu lapisan input, satu lapisan tersembunyi, dan satu lapisan output. 3. Jumlah neuron pada lapis tersembunyi
berjumlah 16, baik pada percobaan JST standar maupun pada percobaan JST optimasi menggunakan algoritma genetika.
4. Optimasi struktur neuron lapis tersembunyi menggunakan GA berada pada selang solusi 0-16 dan tujuan fungsi fitness-nya adalah untuk mengoptimalkan nilai R2.
5. Pada tahap postprocessing, hasil prediksi (nilai output) JST diukur berdasarkan R2 dan RMSE-nya.
TINJAUAN PUSTAKA
Model Sirkulasi Umum
Model sirkulasi umum merupakan model matematika yang menggambarkan hubungan atau interaksi berbagai proses fisik yang berlangsung di atmosfir, laut dan daratan (Ratag 2002 dalam Normakristagaluh 2004). Model ini menduga perubahan unsur-unsur cuaca secara regional pada grid-grid yang berukuran 3o atau 4o sampai 10o menurut lintang dan bujur, dan dapat digunakan untuk peramalan atau menilai dampak yang mungkin timbul apabila terjadi perubahan di udara, laut, dan daratan.
Curah Hujan
Beberapa informasi untuk menggambarkan keadaan suatu wilayah adalah data curah hujan rata-rata tahunan, hari hujan, pola musiman, dan peluang kejadian hujan. Curah hujan rata-rata tahunan sangat bervariasi menurut tempat. Di gurun, penerimaan hujan tahunan berkisar dari 70 mm per tahun, sementara di beberapa wilayah tropika basah, curah hujan dapat melebihi 4000 mm per tahun.
a a a a a F λ λ δ δ = Σ = − Σ
=2 2 0
permukaan, evaporasi, dan peresapan/perembesan ke dalam tanah (Handoko 1993 dalam Normakristagaluh 2004). Jumlah hari hujan umumnya dibatasi dengan jumlah hari dengan curah hujan 0.5 mm atau lebih. Jumlah hari hujan dapat dinyatakan per minggu, dekade, bulan, tahun, atau satu periode tanam (tahap pertumbuhan tanaman), dimana curah hujan rata-ratanya dapat dihitung dengan cara menjumlahkan curah hujan harian hasil pengukuran sesuai dengan periode waktu yang diperlukan dan dibagi dengan periode waktu tersebut (Hidayati 1983 dalam Normakristagaluh 2004).
Data hujan mempunyai variasi yang sangat besar dibandingkan unsur-unsur iklim yang lain, baik variasi menurut tempat maupun waktu. Untuk mendapatkan gambaran wilayah diperlukan pengamatan yang cukup panjang dan kerapatan jaringan stasiun pengamatan yang memadai. Curah hujan yang diamati pada stasiun klimatologi meliputi tinggi hujan (curah hujan), jumlah hari hujan, dan intensitas hujan.
Normalisasi
Normalisasi data GCM dilakukan dengan mengurangi nilai setiap grid dengan nilai rataan seluruh grid dibagi standar deviasinya.
grid_normali = (gridi – rataan)/stddev
2 1 1 ) ( 1 1 rataan grid n stdev grid n rataan n i i n i i − = =
∑
∑
= −Tujuan normalisasi adalah untuk mendapatkan nilai rataan nol dan standar deviasi satu.
Principal Components Analysis (PCA)
PCA atau analisis komponen utama yang disebut juga transformasi Karhunen-Loeve merupakan suatu teknik untuk mereduksi p peubah (variabel) pengamatan menjadi q peubah baru yang saling ortogonal, dimana masing-masing q peubah baru tersebut merupakan kombinasi linear dari p peubah lama. Pemilihan q peubah baru tersebut sedemikian rupa sehingga keragaman yang dimiliki oleh p peubah lama, sebagian besar dapat diterangkan atau dimiliki oleh q peubah baru. PCA akan cukup efektif jika antar p peubah asal memiliki korelasi yang cukup tinggi.
Misalnya diberikan objek pengamatan vektor Grid dengan dimensi p (peubah), Grid=[grid1 grid2 grid3 ... gridp] yang akan direduksi menjadi vektorY=[y1 y2 y3 ... yq ], dimana q <<< p tanpa kehilangan informasi secara berarti, yang dapat dilihat sebagai berikut: . g g g * ) a ... a (a grid a ... grid a grid a y g g g * ) a ... a a grid a ... grid a grid a y g g g * ) a ... a (a grid a ... grid a grid a y p 2 1 qp q2 q1 p qp 2 q2 1 q1 q p 2 1 2p 22 21 p 2p 2 22 1 21 2 p 2 1 1p 12 11 p 1p 2 12 1 11 1 grid a rid rid rid grid a rid rid rid grid a rid rid rid T T T = = + + + = = = + + + = = = + + + =
untuk memaksimumkan ragam pada y maka harus dicari nilai a sehingga y=aTΣa dengan kendala aTa=1. Dengan menggunakan
pengganda Lagrange dibuat suatu fungsi
) 1
( −
− Σ
=a a a a
F T λ T yang selanjutnya akan dimaksimumkan dengan cara menurunkan F terhadap parameter-parameternya dan turunannya sama dengan 0, sehingga diperoleh:
dimana Ó adalah matriks peragam (covariance):
=
Σ
pp p p p pτ
τ
τ
τ
τ
τ
τ
τ
τ
✁ ✂ ✄ ✂ ✂ ✄ ✄ 2 1 2 22 21 1 12 11 dengan∑
= − − − = p i k ik j ijjk grid grid grid grid
n 1 ) )( ( 1 1 τ
a
adalah vektor ciri (eigenvectors),λadalah akar ciri (eigenvalue).
Setelah didapatkan matriks covariance Ó selanjutnya akan dicari vektor dan akar ciri yang bersesuaian dengan matriks covariance tersebut, melalui persamaan berikut:
a
a=λ
Dari persamaan tersebut dapat disimpulkan Σ−λI =0, dan akan diperoleh suatu persamaan polinom derajat p di dalam ë. Persamaan polinom tersebut akan memiliki p akar, yaitu λ1,λ2, ,λp
☎
yang merupakan akar ciri dari matriks covariance Ó. Akar-akar ciri tersebut kemudian digunakan untuk menentukan vektor-vektor cirinya. Vektor-vektor ciri tersebut sebagai koefisien komponen utama.
Akar-akar ciri dengan vektor ciri yang bersesuaian tersebut kemudian disusun terurut menurun sehingga memenuhi
0 3
2
1≥λ ≥λ ≥ ≥λp≥
λ ✆ .
Penentuan proporsi dari nilai vektor-vektor ciri yang digunakan dapat dihitung dengan persamaan:
∑
∑
= ==
n i i q i i 1 1Proposi
λ
λ
Pada akhirnya PCA ini hanyalah akan mentransfer variabel-variabel yang berkorelasi menjadi variabel-variabel yang tidak berkorelasi.
Tujuan metode PCA di atas adalah untuk menentukan faktor-faktor yang menunjukkan seluruh kemungkinan variasi pada keseluruhan data melalui sebagian kecil faktor-faktor dari keseluruhan data (Dillon dan Goldstein 1984).
Jaringan syaraf tiruan (JST)
JST merupakan suatu sistem pemroses informasi yang memiliki persamaan secara umum dengan cara kerja jaringan syaraf biologis. Di dalam JST, input akan diproses oleh neuron-neuron JST dengan bobot tertentu. Bobot hubungan antarelemen atau neuron pada jaringan syaraf disesuaikan berdasarkan galat hasil perbandingan antara output dengan target. Penyesuaian bobot dilakukan sampai jaringan mencapai pola target (Mathwork 2000 dalam Normakristagaluh 2004).
Menurut Fauset (1994), jaringan syaraf tiruan memiliki karakteristik-karakteristik sebagai berikut:
1. Pola hubungan antar-neuron yang disebut arsitektur.
2. Metode penentuan bobot pada hubungan yang disebut pelatihan (training) atau pembelajaran (learning).
3. Fungsi aktivasi yang dijalankan masing-masing neuron pada input jaringan untuk menentukan output.
JST seperti beberapa metode statistik mampu mengolah data yang besar dan
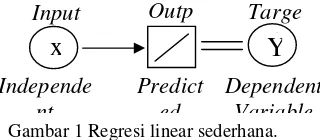
membuat suatu prediksi dimana kadang-kadang keakuratannya lebih baik, tetapi biasanya lebih lambat. Meskipun beberapa model JST sama atau mirip dengan model statistik, ada beberapa istilah yang berbeda, dapat dilihat pada Gambar 1 yang mengilustrasikan model untuk regresi linear sederhana (Weisberg 1985 dan Myers 1986 dalam Normakristagaluh 2004).
Gambar 1 Regresi linear sederhana. Pada Gambar 1, tanda panah mengindikasikan adanya pembobotan untuk nilai X dimana dalam model statistik dinamakan sebagai parameter estimasi. Dua garis yang paralel mengindikasikan bahwa nilai masing-masing target dapat didekati (diduga) baik dengan metode kuadrat terkecil, maximum likelihood, atau pendekatan estimasi lainnya.
Nilai output hasil pembelajaran pada model JST sama dengan suatu nilai ramalan dari suatu analisis data pada model statistik. Peramalan suatu keadaan sistem yang kompleks merupakan suatu domain aplikasi yang luas untuk JST. Sebagian besar pendekatan JST untuk masalah peramalan banyak menggunakan arsitektur jaringan lapis banyak dengan algoritma pembelajaran propagasi balik.
JST Propagasi Balik Standar
Menurut Fauset (1994), ada tiga tahap pelatihan pada JST propagasi balik, yaitu pelatihan input yang bersifat umpan maju (feedforward), penghitungan propagasi balik galat yang diperoleh, dan penyesuaian bobot. Jaringan ini menggunakan metode pembelajaran terbimbing (supervised learning). Adapun cara kerja JST diawali dengan inisialisasi bobot dan bias. Hal ini berpengaruh dalam kecepatan JST memperoleh kekonvergenan.
Teknik inisialisasi yang digunakan dalam penelitian ini adalah inisialisasi Nguyen-Widrow. Inisialisasi ini umumnya mempercepat proses pembelajaran dibandingakan dengan inisialisasi acak (Fauset 1994).
Inisialisasi Nguyen-Widrow didefinisikan sebagai persamaan berikut:
a. Hitung harga faktor pengali β
x
Y
Input
Outp
Targe
n
p
17
.
0
=
β
dimana:
β = faktor pengali
n = jumlah neuron lapisan input p = jumlah neuron lapisan tersembunyi
b. Untuk setiap unit tersembunyi (j=1, 2, ... ,p):
- Hitung vij (lama) yaitu bilangan acak diantara -0.5 dan 0.5 (atau di antara -γ dan +γ). Pembaharuan bobot vij (lama) menjadi vij baru yaitu:
) (
) ( )
(
lama v
lama v baru
v
ij ij ij
β =
- Tetapkan Bias.
voj = Bobot pada bias bernilai antara -β dan β. Selanjutnya pola input (masukan) dan target dimasukkan ke dalam jaringan. Pola masukan ini akan berubah bersamaan dengan propagasi pola tersebut ke lapisan-lapisan berikutnya hingga menghasilkan output (keluaran). Keluaran ini akan dibandingkan dengan target, jika hasil perbandingan menghasilkan nilai yang sama maka proses pembelajaran akan berhenti. Namun jika berbeda maka JST mengubah bobot yang ada pada hubungan antar neuron dengan suatu aturan tertentu agar nilai keluaran lebih mendekati nilai target. Proses pengubahan bobot adalah dengan cara mempropagasikan kembali nilai koreksi galat keluaran JST ke lapisan-lapisan sebelumnya (propagasi balik). Kemudian dari lapisan masukan, pola akan diproses lagi untuk mengubah nilai bobot sampai akhirnya memperoleh keluaran JST baru. Demikian seterusnya proses ini dilakukan berulang-ulang sampai nilai yang sama atau minimal sesuai dengan galat yang telah didefinisikan. Proses penyesuaian bobot ini disebut pembelajaran.
Dalam metode pembelajaran propagasi balik, fungsi pada masukan dan keluaran haruslah berbentuk fungsi yang dapat dideferensialkan karena pada proses propagasi (umpan maju atau propagasi balik) penghitungan nilai didasarkan pada fungsi yang dipakai. Pada umpan maju, fungsi yang dipakai adalah fungsi yang telah ditentukan untuk JST, sedangkan pada propagasi balik, fungsi yang digunakan adalah fungsi diferensialnya.
Fungsi yang digunakan dalam penelitian ini adalah sigmoid biner pada lapisan tersembunyi dan fungsi linear pada lapisan output. Fungsi sigmoid ini memiliki daerah
hasil pada interval 0 sampai dengan 1. Turunan fungsi sigmoid biner didefinisikan sebagai persamaan berikut:
f’(x) = f(x) [1 – f(x)]
Grafik fungsi sigmoid biner dapat dilihat pada Gambar 2.
Gambar 2 Grafik fungsi sigmoid biner dengan range (0,1).
Grafik fungsi linear dapat dilihat pada Gambar 3.
Gambar 3 Grafik fungsi linear.
Algoritma Genetika
Algoritma genetika merupakan evolusi/perkembangan dunia komputer dalam bidang kecerdasan buatan. Sebenarnya algoritma ini terinspirasi oleh teori evolusi Darwin. Algoritma genetika adalah algoritma pencarian yang berdasarkan pada mekanisme sistem natural, yakni genetika dan seleksi alam. Dalam aplikasi algoritma genetika, variabel solusi dikodekan ke dalam struktur string yang merepresentasikan barisan gen, yang merupakan karakteristik dari solusi problem.
Berbeda dengan teknik pencarian konvensional, algoritma genetika berangkat dari himpunan solusi yang dihasilkan secara acak. Himpunan ini disebut populasi. Sedangkan setiap individu dalam populasi disebut kromosom yang merupakan representasi dari solusi. Kromosom-kromosom berevolusi dalam suatu proses iterasi yang berkelanjutan yang disebut generasi. Pada setiap generasi, kromosom dievaluasi berdasarkan suatu fungsi evaluasi. Setelah beberapa generasi maka algoritma genetika akan konvergen pada kromosom terbaik, yang diharapkan merupakan solusi optimal.
Struktur umum dari algoritma genetika sebagai berikut (Gen & Cheng, 1997) :
Prosedur Algoritma Genetika Begin
t • 0 ;
inisialisasi P(t) ; evaluasi P(t) ;
while (kondisi berhenti belum dicapai) do
rekombinasi P(t) menghasilkan C(t) ;
evaluasi C(t) ;
seleksi P(t + 1) dari P(t) dan C(t) ;
t • t + 1 ; end End
Fungsi evaluasi merupakan dasar untuk proses seleksi. Langkah-langkahnya yaitu string dikonversi ke parameter fungsi, fungsi objektifnya dievaluasi, kemudian mengubah fungsi objektif tersebut ke dalam fitness. Di mana untuk maksimasi problem, fitness sama dengan fungsi objektifnya. Output dari fungsi fitness dipergunakan sebagai dasar untuk menyeleksi individu pada generasi berikutnya.
Pada proses seleksi digunakan roulette whell yang merupakan salah satu metode seleksi yang banyak dipergunakan. Roulette whell menyeleksi populasi baru dengan distribusi probabilitas yang berdasarkan nilai fitness.
Operator genetika dipergunakan untuk mengkombinasi (modifikasi) individu dalam aliran populasi guna mencetak individu pada generasi berikutnya. Ada dua operator genetika yaitu crossover dan mutasi.
Crossover membangkitkan generasi baru dengan mengganti sebagian informasi dari parents (orang tua/induk).
Mutasi menciptakan individu baru dengan melakukan modifikasi satu atau lebih gen dalam individu yang sama. Mutasi berfungsi untuk menggantikan gen yang hilang dari populasi selama proses seleksi serta menyediakan gen yang tidak ada dalam populasi awal, sehingga mutasi akan meningkatkan variasi populasi.
Ketepatan Pendugaan Model Regresi Linear
Ketepatan atau keakuratan sebuah model regresi dapat dilihat dari koefisien determinasi (R2) dan Root Mean Square Error (RMSE). R2 menunjukkan proporsi jumlah kuadrat total
yang dapat dijelaskan oleh sumber keragaman peubah bebas, sedangkan RMSE menunjukkan seberapa besar simpangan nilai dugaan terhadap nilai aktualnya. Kita juga dapat menunjukkan bahwa R2 adalah kuadrat dari korelasi antara nilai vektor observasi (the vector of observations) y dengan nilai vektor penduganya (the vector of fitted values) • (Douglas dan Elizabeth 1992 dalam Normakristagaluh 2004). Menurut Walpole (1982) R2 dan RMSE dirumuskan sebagai berikut:
∑
∑
∑
= = = − − − − = n i i n i i n i i i y y y y y y y y R 1 2 1 2 2 1 2 ) ( ) ˆ ˆ ( ) )( ˆ ˆ ( dimana:yi = nilai-nilai aktual. •i = nilai-nilai prediksi.
n F X RMSE n t t t
∑
= − = 1 2 ) ( dimana:Xt = nilai aktual pada waktu ke-t Ft = nilai dugaan pada waktu ke-t
Nilai R2 berada pada selang 0 sampai 1. Kecocokkan model dikatakan semakin baik jika R2 mendekati 1 dan RMSE mendekati 0.
METODOLOGI
Data
Data yang diperlukan dalam
penelitian ini adalah:(1.)Data GCM∗ (X(t x g))
Data ini diperoleh dari NCEP/NCAR sebagai salah satu sumber luaran model GCM dengan skala (grid) 2.8o x 2.8o (1o = 110 km). Domain cakupan data GCM ini adalah 23o LU - 23o LS dan 80o BT - 160o BT, yang mencakup wilayah Indonesia dan lautan Pasifik. Pada penelitian ini, domain yang digunakan adalah 21.90 LU-21.90 LS dan 82.50 BT-157.50 BT yang mencakup wilayah DAS Saguling Jawa Barat. Peubah-peubahnya akan ditentukan berdasarkan mekanisme fisik yang berkaitan erat dengan curah hujan, seperti sea surface temperature (suhu) pada 41 × 24 grid dari tahun 1986–2002. Data GCM (domain) yang digunakan dipilih berdasarkan kriteria oleh Von Storch (Bergant 1999 dalam Normakristagaluh
2004) yang menyatakan bahwa jumlah domain minimal 8 × 8 grid di sekitar wilayah respon. Domain yang dipilih adalah yang berkorelasi tinggi dengan wilayah respon.
(2.) Data Curah Hujan (Y(t))
Respon yang digunakan dalam penelitian ini adalah curah hujan rata-rata dari tahun 1986 – 2002 di DAS Saguling yang diperoleh dari Badan Pengkajian dan Penerapan Teknologi (BPPT).
Faktor dan Taraf
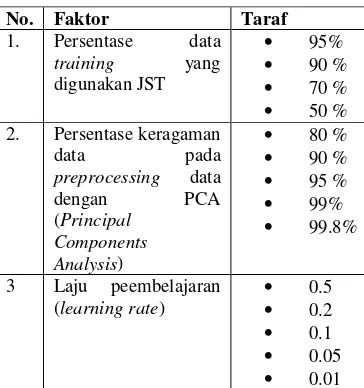
Faktor dan taraf yang digunakan dalam penelitian ini ditampilkan pada Tabel 1. Tabel 1Faktor dan taraf
No. Faktor Taraf
1. Persentase data training yang digunakan JST
• 95%
• 90 %
• 70 %
• 50 % 2. Persentase keragaman
data pada preprocessing data dengan PCA (Principal
Components Analysis)
• 80 %
• 90 %
• 95 %
• 99%
• 99.8%
3 Laju peembelajaran (learning rate)
• 0.5
• 0.2
• 0.1
• 0.05
• 0.01
Penggunaan algoritma genetika dalam optimasi jaringan syaraf buatan dilakukan untuk mendapatkan struktur neuron pada lapis tersembunyi yang mendekati optimal. Tingkat pengenalan JST dalam peramalan yang tinggi akan didapat apabila seluruh neuron pada lapis tersembunyi memberikan kontribusi nilai objektif yang tinggi, dalam hal ini penulis menekankan nilai R2. Apabila neuron yang memberikan kontribusi R2 yang kecil dapat dihilangkan, sedangkan yang memberikan kontribusi R2 besar dapat dipertahankan, maka jaringan syaraf buatan ini dapat diharapkan memberikan nilai R2 yang lebih tinggi.
Penghilangan neuron yang kurang bermanfaat ini dapat dilakukan dengan dua cara, yaitu dengan membuang sejumlah bobot dari setiap neuron yang memberi kontribusi R2 kecil atau dengan membuang sejumlah neuron yang berarti membuang seluruh bobot
keterhubungan dari neuron yang kurang bermanfaat (Kusumoputro 2004). Pada penelitian ini digunakan pendekatan kedua yaitu membuang bobot keterhubungan dari neuron yang memberikan kontribusi R2 kecil. Dalam penelitian ini jumlah perlakuan dengan menggunakan optimasi algoritma genetika dan tanpa menggunakan algoritma genetika masing-masing sebanyak 4 (faktor 1) X 5 (faktor 2) X 5 (faktor 3) yaitu 100 perlakuan dengan perulangan sebanyak 10 kali untuk tiap perlakuan dengan tujuan untuk memperoleh rata-rata R2 dan RMSE yang memiliki simpangan baku terkecil.
Preprocessing data dengan PCA
Pertama, dilakukan normalisasi terhadap sejumlah data training yang akan digunakan dan dihasilkan rataan dan simpangan bakunya. Kedua, dilakukan proses PCA pada data training hasil normalisasi tersebut sehingga didapatkan kombinasi linear atau komponen-komponen utamanya (principal components) yang selanjutnya disebut sebagai matriks transformasi. Dengan dilakukan perkalian antara data training dengan matriks transformasi tersebut didapatkan data training yang baru. Ketiga, dilakukan normalisasi data testing dengan menggunakan rataan dan standar deviasi yang diperoleh dari data training kemudian dilakukan perkalian dengan matriks transformasi sehingga diperoleh data testing yang baru. Selanjutnya data training dan data testing yang baru tersebut digunakan oleh proses pada JST standar dan JST optimasi menggunakan algoritma genetika.
Spesifikasi Algoritma Genetika yang Digunakan
Pada penelitian ini digunakan algoritma genetika dengan parameter sebagai berikut : 1. Representasi Solusi : Binary String. 2. Populasi : 60 individu. 3. Jumlah Generasi : 100 generasi. 4. Pindah Silang : Simple Crossover (0.6) 5. Mutasi : Binary Mutation
(0.0333)
dibuang. Penggunaan parameter seperti dijelaskan di atas dinilai mencukupi bagi algoritma genetika untuk melakukan pencarian solusi optimal bagi jumlah neuron lapis tersembunyi. Hal ini dilakukan berdasarkan hasil observasi yang dilakukan bahwa solusi yang didapat oleh algoritma genetika sudah mengalami konvergen (tidak mendapatkan solusi baru yang lebih baik).
Representasi Solusi pada Algortima Genetika
Pengkodean string biner sepanjang 16 bit diambil dari jumlah neuron maksimum yang ditentukan pada lapis tersembunyi. Hal ini berdasarkan penelitian oleh Kusumoputro (2004). Selanjutnya bit-bit yang panjangnya 16 tersebut (mulai dari semua bit yang bernilai 0 semua sampai dengan bit yang bernilai 1 semua) masing-masing dikonversi menjadi bilangan berbasis sepuluh sehingga diperoleh selang pencarian bilangan bulat antara 0-65535. Proses konversi dari deret biner sepanjang 16 bit menjadi bilangan bulat
x
dengan selang [0,65535] dilakukan dengan cara : ' ) 2 . ( ) ( 10 16 0 2 0 14 1516b b b b x
b i i i = = > <
∑
= ✝ Proses konversi bilangan berbasis sepuluh, dalam hal ini merupakan ruang pencarian [0,65535] dihitung dengan cara :1
2
65535
' .
0
16−
+
=
x
x
Dengan selang pencarian 0-65535 maka diambil bilangan acak untuk dikonversi menjadi bilangan berbasis dua (biner) dengan panjang 16 bit yang digunakan dalam inisialisasi populasi.
Respon (Fungsi Fitness)
Respon yang diambil dalam penelitian ini adalah nilai R2 yang dicapai oleh jaringan syaraf buatan setelah dilakukan optimasi oleh algoritma genetika berdasarkan persentase data training, persentase keragaman PCA yang digunakan, dan berbagai nilai learning rate yang digunakan.
Sedang fungsi fitness yang dipakai adalah memaksimumkan nilai r (koefisien korelasi) yang secara otomatis memaksimumkan nilai R2. Perhitungannya dilakukan sebagai berikut.
001 , 0 1 ) , ( + + = RMSE r RMSE r f dimana :
r = koefisien korelasi.
RMSE = besar simpangan nilai dugaan terhadap nilai aktualnya.
0,001 pada persamaan di atas merupakan suatu konstanta (bilangan) yang dianggap sangat kecil sehingga dalam proses GA fungsi fitness tersebut tidak menghasilkan nilai tak hingga (ketika RMSE bernilai 0). Nilai 0,001 merupakan nilai toleransi galat yang digunakan dalam JST standar.
Penambahan nilai 1/(RMSE+0,001) dalam fungsi fitness diharapkan dapat dihasilkan sebuah nilai R2 yang optimum berpasangan dengan dengan nilai RMSE yang lebih baik. Akan tetapi dalam penelitian ini fungsi fitness yang dibuat bukan untuk meminimumkan nilai RMSE melainkan memaksimumkan nilai R2 sehingga untuk hasil RMSE dalam percobaan sangat bervariasi (bisa lebih tinggi dari pada JST standar atau lebih rendah). Tabel 2Struktur JST yang digunakan dalam penelitian
KARAKTERISTIK SPESIFIKASI
Arsiktektur 1 layer hidden
Neuron Input Dimensi PCA (untuk
grid-grid lokal GCM)
Neuron Layer Hidden Tanpa GA, dengan GA
Neuron Layer Output 1 (target data Curah Hujan)
Fungsi Aktivasi Layer Hidden
Sigmoid Biner
Fungsi Aktivasi Layer Output
Linear
Inisialisasi Bobot Nguyen-Widrow
Toleransi galat 0.001
Target Epoch 1500
Laju Pembelajaran 0.01 0.05 0.1 0.2 0.5
Perangkat Keras dan Lunak yang Digunakan
Penelitian ini akan menggunakan perangkat keras dan lunak, di antaranya : a. Microsoft Windows XP Professional b. Matlab 6.5
c. Microsoft Excel XP d. AMD Athlon XP 2400 GHz e. Memori DDR 256 MB f. Hardisk 80 GB
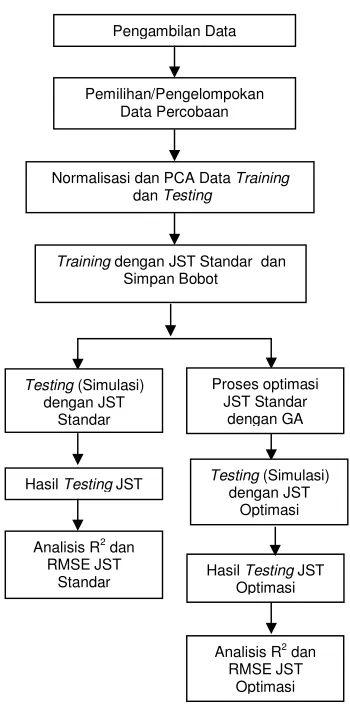
Perancangan Penelitian
data mentah yang diperoleh menjadi masukan yang dapat diolah yang kemudian bermanfaat untuk menentukan metode pembelajaran dalam JST propagasi balik standar. Selanjutnya setelah dilakukan pembelajaran akan didapatkan bobot pelatihan yang akan digunakan dalam testing pada JST standar dan proses optimasi JST dengan GA.
Gambar 4 Diagram proses pendugaan.
HASIL DAN PEMBAHASAN
Data hasil seluruh percobaan dapat dilihat pada Lampiran 1- 10.
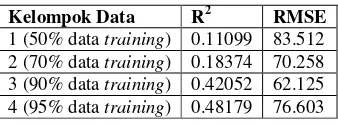
Perbandingan R2 dan RMSE JST Standar
Dalam percobaan JST standar , kelompok data pertama (50% data training) diperoleh R2 maksimum sebesar 0.11099 (11,099%) pada keragaman data 99,8% dan laju pembelajaran 0,1 dengan RMSE sebesar 83.512. Untuk kelompok data kedua (70% data training) diperoleh R2 maksimum sebesar 0.18374 (18.374%) pada keragaman data 95% dan laju pembelajaran 0.05 dengan RMSE 70.258.
Untuk kelompok data ketiga (90% data training) diperoleh R2 maksimum sebesar 0.42052 (42.052%) pada keragaman data 95% dan laju pembelajaran 0.5 dengan RMSE 62.125. Untuk kelompok data keempat (95% data training) diperoleh R2 maksimum sebesar 0.48179 (48.179%) pada keragaman data 95% dan laju pembelajaran 0.1 dengan RMSE 76.603. Hasil selengkapnya dapat dilihat dalam Tabel 3.
Tabel 3Perbandingan R2 dan RMSE JST standar
Kelompok Data R2 RMSE
1 (50% data training) 0.11099 83.512 2 (70% data training) 0.18374 70.258 3 (90% data training) 0.42052 62.125 4 (95% data training) 0.48179 76.603 Berdasarkan Tabel 3 terlihat bahwa pembagian data menjadi data taining dan data testing sangat berpengaruh terhadap nilai R2. Semakin besar data training yang digunakan, maka semakin tinggi nilai R2. Untuk nilai RMSE terjadi penurunan ketika data training ditingkatkan akan tetapi hal ini tidak terjadi pada kelompok data keempat (95% data training) yang nilai RMSE-nya meningkat kembali. Dengan demikian, penambahan data training tidak selalu menyebabkan penurunan nilai RMSE.
Perbandingan R2 dan RMSE JST Optimasi dengan GA
Dalam percobaan menggunakan JST yang sudah dioptimasi dengan GA, kelompok data pertama (50% data training) diperoleh R2 maksimum sebesar 0.38732(38,732%) pada keragaman 95% dan laju pembelajaran 0,01 dengan RMSE sebesar 189.083. Kelompok data kedua (70% data training) diperoleh R2 maksimum sebesar 0.37746 (37.746%) pada keragaman 99.8% dan laju pembelajaran 0,2 dengan RMSE 61.893. Kelompok data ketiga (90% data training) diperoleh R2 maksimum sebesar 0.51598 (51.598%) pada keragaman 99% dan laju pembelajaran 0,05 dengan RMSE 132.864. Kelompok data keempat (95% data training) diperoleh R2 maksimum sebesar 0.87717 (87.717%) pada keragaman 99.8% dan laju pembelajaran 0,1 dengan RMSE 78.472. Hasil selengkapnya dapat dilihat dalam Tabel 4.
Pengambilan Data
Pemilihan/Pengelompokan Data Percobaan
Normalisasi dan PCA Data Training
dan Testing
Training dengan JST Standar dan
Simpan Bobot
Testing (Simulasi)
dengan JST Standar
Proses optimasi JST Standar
dengan GA
Hasil Testing JST
Hasil Testing JST Optimasi Analisis R2 dan
RMSE JST Standar
Analisis R2 dan
RMSE JST Optimasi
Testing (Simulasi)
Tabel 4Perbandingan R2 dan RMSE JST optimasi
Kelompok Data R2 RMSE
1 (50% data training) 0.38732 189.083 2 (70% data training) 0.37746 61.893 3 (90% data training) 0.51598 132.864 4 (95% data training) 0.87717 78.472
Berdasarkan Tabel 4 terlihat bahwa pembagian data menjadi data taining dan data testing dalam berbagai kelompok data masih relatif sangat berpengaruh terhadap nilai R2. Semakin besar data training yang digunakan, maka relatif semakin tinggi nilai R2. Akan tetapi hal ini tidak terjadi pada kelompok data kedua yang cenderung menurun. Untuk nilai RMSE terjadi perbedaaan nilai yang bervariasi ketika data training ditingkatkan. Dengan demikian, penambahan data training tidak memberikan pengaruh terhadap penurunan nilai RMSE.
Perbandingan R2 dan RMSE JST Standar dan JST Optimasi
Perbandingan R2 dan RMSE antara JST Standar dan JST yang dioptimasi dapat dilihat pada Tabel 5 dan Tabel 6.
Tabel 5Perbandingan R2 JST standar dan JST optimasi
R2 Kelompok Data JST
Standar JST Optimasi
1 (50% data training) 0.11099 0.38732 2 (70% data training) 0.18374 0.37746 3 (90% data training) 0.42052 0.51598 4 (95% data training) 0.48179 0.87717
Tabel 6Perbandingan RMSE JST standar dan JST optimasi
RMSE Kelompok Data JST
Standar
JST Optimasi
1 (50% data training) 83.512 189.083 2 (70% data training) 70.258 61.893 3 (90% data training) 62.125 132.864 4 (95% data training) 76.603 78.472
Sesuai hasil yang terdapat di dalam Tabel 5 terlihat bahwa untuk kedua metode yang digunakan, nilai R2 terbaik terletak pada kelompok data keempat (95% data training). Hal ini berarti bahwa pembagian data menjadi data training dan data testing cukup berpengaruh terhadap peningkatan nilai R2. Sedangkan untuk perbandingan nilai R2 bagi kedua metode bisa dilihat bahwa nilai R2 JST yang sudah dioptimasi lebih tinggi dari pada JST standar. 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 2 3 4
Kelom pok Data
JS T_S tandar JS T_Optim asi
Gambar 5Perbandingan nilai R2 metode JST standar dan JST optimasi. Jika dibandingkan nilai R2 antara kedua metode, maka terlihat bahwa untuk semua kelompok data nilai R2 JST yang sudah dioptimasi selalu lebih tinggi dari pada nilai R2 JST standar.
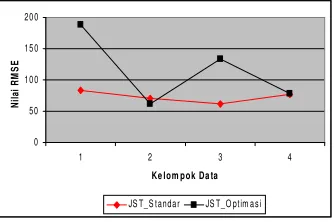
Berdasarkan Tabel 6 terlihat bahwa nilai RMSE untuk kedua metode cenderung bervariasi tidak tergantung pada pembagian kelompok data. Hal ini berarti bahwa pembagian data menjadi data training dan data testing tidak berpengaruh terhadap penurunan nilai RMSE.
0 50 10 0 15 0 20 0
1 2 3 4
Ke lom pok Da ta
N
il
ai R
M
SE
JS T_S tanda r JS T_O ptim a s i
Gambar 6 Perbandingan RMSE JST standar dan JSToptimasi. Jika dibandingkan nilai RMSE antara kedua metode , maka terlihat bahwa untuk semua kelompok data nilai RMSE-nya selalu bervariasi. Seperti pada kelompok data pertama terlihat perbedaan RMSE yang cenderung sangat besar. Sebagian besar JST yang sudah dioptimasi nilai RMSE-nya selalu lebih besar dibanding JST standar kecuali pada kelompok data kedua. Hal ini disebabkan karena dalam optimasi menggunakan GA fungsi fitness yang digunakan adalah memaksimumkan nilai R2 bukanlah meminimumkan nilai RMSE sehingga konfigurasi neuron yang didapat merupakan neuron-neuron yang memberikan kontribusi nilai R2 yang tinggi.
Arsitektur Terbaik
Pola input ternyata sangat berpengaruh terhadap nilai R2 dalam JST. Seperti telah dijelaskan di atas bahwa dalam penelitian ini data dikelompokkan dalam berbagai kelompok percobaan dengan membagi data menjadi data training dan data testing.
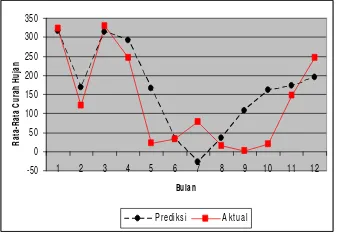
Pada percobaan menggunakan JST standar diperoleh arsitektur terbaik pada kelompok data keempat dengan nilai R2 sebesar 0.48179 (48.179%) dan RMSE sebesar 76.603. Gambar 7 merupakan grafik pendugaan terbaik yang didapat pada percobaan menggunakan JST standar.
-50 0 50 100 150 200 250 300 350
1 2 3 4 5 6 7 8 9 10 11 12
Bu lan R at a-R at a C u ra h H uj an
P redik s i A k tual
Gambar 7Nilai prediksi dan aktual
arsitektur terbaik JST standar. Pada kasus ini, semakin banyak bulatan pada nilai prediksi yang menempel pada kotak nilai aktual, maka error pun semakin kecil. Nilai R2 sebesar 0.48179 dapat diartikan bahwa 48.179% di antara keragaman dalam nilai-nilai prediksi dapat dijelaskan oleh hubungan linearnya dengan nilai aktual. Pada grafik di atas curah hujan prediksi pada bulan Juli bernilai negatif. Hal ini dapat diartikan bahwa pada bulan tersebut curah hujan dianggap 0 atau tidak ada hujan.
Pada percobaan menggunakan JST yang sudah dioptimasi menggunakan GA diperoleh arsitektur terbaik pada kelompok data keempat dengan nilai R2 sebesar 0.87717 (87.717%) dan RMSE sebesar 78.472 dengan konfigurasi struktur neuron pada lapis tersembunyi 0 1 0 1 1 1 0 0 1 0 1 1 0 1 0 0 yang berarti sebanyak delapan neuron pada lapis tersembunyi yang dibuang. Grafik pada Gambar 8 merupakan grafik pendugaan terbaik yang didapat pada percobaan menggunakan JST yang sudah dioptimasi. 0 50 10 0 15 0 20 0 25 0 30 0 35 0
1 2 3 4 5 6 7 8 9 10 11 12
Bula n R a ta -R a ta C u ra h H u ja n
P redik s i A k tual
Gambar 8 Nilai prediksi dan aktual arsitektur terbaik JST optimasi.
Pada Gambar 8 terdapat beberapa bulatan nilai prediksi yang hampir berhimpit dengan nilai aktual sehingga nilai error pun bisa semakin kecil. Nilai R2 sebesar 0.87717 dapat diartikan bahwa 87.717% di antara keragaman dalam nilai-nilai prediksi dapat dijelaskan oleh hubungan linearnya dengan nilai aktual.
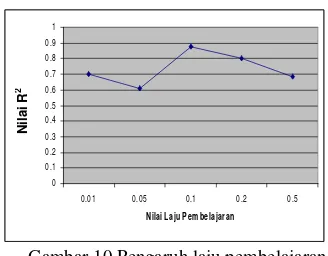
Pengaruh Laju Pembelajaran terhadap R2
Berdasarkan Gambar 9 bisa dilihat bahwa nilai laju pembelajaran terhadap nilai R2 JST standar pada kelompok data dan PCA arsitektur terbaik, yaitu 95% data training dan PCA 95% sangat bervariasi. Pada grafik bisa dilihat bahwa laju pembelajaran 0.1 memiliki nilai R2 maksimum.
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5
0.01 0.05 0.1 0.2 0.5
Nilai L aju Pe m be lajaran
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0.01 0.05 0.1 0.2 0.5
Nilai Laju Pem belajaran
Gambar 10Pengaruh laju pembelajaran terhadap R2 JST optimasi. Dari Gambar 9 dan Gambar 10, untuk setiap laju pembelajaran hasil R2 rata-rata pada JST optimasi selalu lebih baik dari hasil R2 rata-rata pada JST standar.
Perbandingan Waktu Testing JST Standar dan JST yang Dioptimasi
Perbandingan rata-rata waktu testing antara JST standar dan JST yang sudah dioptimasi dapat dilihat dalam Tabel 7. Tabel 7 Perbandingan rata-rata waktu testing
JST standar dan JST optimasi Rata-Rata Waktu
Testing (detik) Kelompok Data
JST Standar
JST Optimasi
1 (50% data training) 0.0047 0.0048 2 (70% data training) 0.0016 0.0015
3 (90% data training) 0 0.0031
4 (95% data training) 0.0031 0
Waktu testing pada Tabel 7 diperoleh dari waktu rata-rata testing yang paling kecil dari masing-masing kelompok data.
0 0.001 0.002 0.003 0.004 0.005 0.006
1 2 3 4
Kelom pok Data
R at a-R at a W ak tu T es ti ng
JS T_S tandar JS T_Optim asi
Gambar 11 Perbandingan rata-rata waktu testing terkecil JST standar dan JST optimasi.
Pada grafik diperoleh bahwa rata-rata waktu testing nilainya bervariasi antara kedua metode. Hal ini disebabkan karena data yang digunakan untuk testing masih relatif sedikit dan jumlah neuron pada lapis tersembunyi
tidak terlalu banyak sehingga perbedaan antara metode JST standar dan JST optimasi tidak terlalu jelas (masih bervariasi). Bahkan bisa dilihat bahwa terdapat nilai 0 yang artinya waktu yang digunakan untuk testing sangat kecil sekali sehingga nilainya menjadi 0.
Perbandingan dengan Hasil Penelitian Sebelumnya
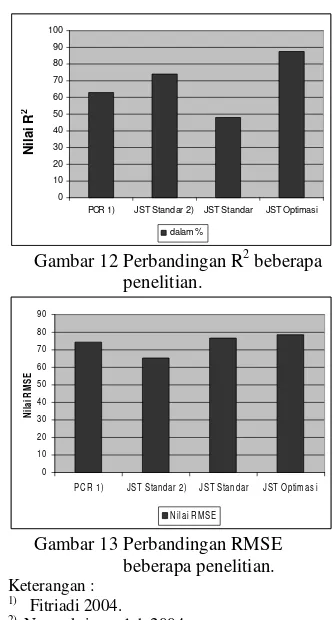
Hasil R2 dalam penelitian menggunakan JST yang dioptimasi lebih baik dari pada penelitian sebelumnya yang menggunakan JST propagasi balik standar dan metode PCR.
Pada metode PCR, R2 yang dihasilkan sebesar 63.16% dan RMSE sebesar 74.24 sedangkan JST propagasi balik standar menghasilkan nilai R2 sebesar 74.02% dan RMSE 65.16. Sedangkan pada penelitian sekarang yang menggunakan JST yang sudah dioptimasi dengan algoritma genetika diperoleh nilai R2 yang sedikit lebih tinggi yaitu 87.717% dan RMSE sebesar 78.472.
Tabel 8 Perbandingan nilai R2 dan RMSE dengan penelitian sebelumnya
Metode R2 RMSE
PCR1) 63.16% 74.24
JST Standar2) 74.02% 65.16
JST Standar 48.179% 76.603
JST Optimasi 87.717% 78.472
Keterangan : 1) Fitriadi 2004.
2) Normakristagaluh 2004.
Nilai R2 74.02% pada percobaan dengan JST standar oleh Normakristagaluh (2004) terletak pada jumlah neuron lapis tersembunyi sebanyak 9 dan laju pembelajaran 0.02 yang merupakan arsitektur terbaik.
Dari Tabel 8 terlihat bahwa nilai R2 penelitian ini yang menggunakan optimasi lebih besar disebabkan karena di dalam algoritma genetika terdapat pembuangan neuron yang memberikan kontribusi nilai R2 yang kecil dibuang sehingga yang tersisa adalah neuron-neuron yang memberikan kontribusi nilai R2 yang lebih besar.
0 10 20 30 40 50 60 70 80 90 100
PCR 1) JST Standar 2) JST Standar JST Optimasi
dalam %
Gambar 12 Perbandingan R2 beberapa penelitian.
0 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0
PCR 1 ) JST Sta nd ar 2 ) JST Sta nd ar JST Optim as i
N
ila
i R
M
S
E
N ila i R MSE
Gambar 13 Perbandingan RMSE beberapa penelitian.
Keterangan : 1)
Fitriadi 2004. 2) Normakristagaluh 2004.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan penelitian yang telah dilakukan, maka dapat ditarik kesimpulan sebagai berikut :
1. Algoritma genetika dapat digunakan dalam optimasi salah satu parameter dalam JST, dalam hal ini struktur neuron pada satu lapis tersembunyi untuk meningkatkan nilai pendugaan berupa nilai R2, yaitu meningkat dari 48.179% menjadi 87.717% dengan RMSE 78.472.
2. Arsitektur terbaik dengan nilai R2 terbaik pada percobaan ini terjadi pada kelompok data keempat yaitu 95% data training dan 5% data testing untuk kedua percobaan dan pada learning rate 0,1, yaitu 48.179% untuk JST standar dan 87.717% untuk JST optimasi.
3. Pada penelitian ini, model JST optimasi selalu menghasilkan nilai R2 yang lebih tinggi dari pada JST standar (sekitar bertambah 9.546% sampai 38.538%).
Saran
Penelitian ini masih memiliki banyak kekurangan sehingga masih perlu pengembangan penelitian selanjutnya. Oleh sebab itu disarankan hal-hal sebagai berikut : 1. Penambahan parameter GCM selain suhu
dan curah hujan, seperti kelembaban, arah angin, dan parameter lain yang berkorelasi dengan curah hujan.
2. Menambahkan mekanisme pada optimasi algoritma genetika, misalnya dengan menambahkan mekanisme elitisme dan pengunaan operator crossover yang berbeda seperti dengan n-point crossover. 3. Penelitian terhadap optimasi nilai RMSE.
DAFTAR PUSTAKA
Dillon, WR. & Goldstein, M. 1984. Multivariate Analysis Method and Applications. John Wiley & Sons, New York.
Fauset, L. 1994. Fundamentals of Neural Networks. Prentice Hall, New Jersy.
Fitriadi. 2004. Kombinasi Model Regresi Komponen Utama dan Arima dalam Statistical Downscaling. Skripsi. Departemen Statistika FMIPA IPB, Bogor.
Fu, LM. 1994. Neural Networks in Computer Intellegence. Singapore : Mc Graw-Hill.
Gen, M. & Runwei C. 1997. Genetics Algorithms and Engineering Design. John Wiley & Sons, Inc. Canada.
Kusumadewi, S. 2004. Membangun Jaringan Syaraf Tiruan Menggunakan matlab & Excel Link. Yogyakarta : Graha Ilmu.
Kusumoputro, B. 2004. Pengembangan Sistem Pengenal Wajah secara 3 Dimensi menggunakan Hemisphere Structure of Neural Networks dan Optimasi Struktur menggunakan Algoritma Genetika. Makalah Seminar Nasional dan Ilmu Komputer dan Teknologi Informasi V. Fakultas Ilmu Komputer, UI, Depok.
Michalewicz, Z. 1995. Genetic Algorithms + Data Structures = Evolution Programs. W. H. Freeman and Company. New York.
N
il
a
i
R
Normakristagaluh, P. 2004. Penerapan Jaringan Syaraf Tiruan untuk Peramalan Curah Hujan dalam Statistical Downscaling. Skripsi. Departemen Ilmu Komputer FMIPA IPB. Bogor.
Suyanto. 2005. Algoritma Genetika dalam Matlab. Yogyakarta : Andi
15 Lampiran 1 Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Pertama 50% Learning, 50% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0078 0.0092109 0.020093 0.0129 0.0036762 92,074 99,805 96,838 2.71 0.05 0.0062 0.013721 0.023601 0.016716 0.0029671 90,692 96,332 93,542 1.75 0.1 0.0063 9.0434E-07 0.015839 0.0016057 0.0050012 97,358 241.92 186.79 42.4 0.2 0.0093 0.01034 0.022 0.01325 0.0040742 91,244 98,215 96,302 2.51 80%(0,2)
0.5 0.0078 0.00053525 0.011634 0.0039371 0.0038542 99,111 112.24 105.73 4.96 0.01 0.0079 0.0053582 0.028599 0.015897 0.0093617 109.55 134.9 116.57 8.80 0.05 0.0048 0.0035523 0.037631 0.024131 0.009711 102.72 121.79 108.9 5.17 0.1 0.0094 0.0065063 0.095791 0.043695 0.038787 86,374 115.83 100.86 11,037 0.2 0.0157 0.020106 0.095918 0.046508 0.02972 88,887 145.26 122.25 21.67 90%(0,1)
0.5 0.0062 0.0071346 0.015491 0.0097889 0.0031261 110.4 124.62 119.85 4.91 0.01 0.0126 0.021596 0.055472 0.031391 0.012382 103.6 138.29 126.68 13.31 0.05 0.0063 0.031215 0.10425 0.053255 0.021387 85.56 119.87 106.28 11.20 0.1 0.0126 0.0017689 0.04675 0.01286 0.01281 92.16 140.19 118.23 12.58 0.2 0.0093 0.067776 0.10227 0.079805 0.014373 84,072 107.62 97,491 8.40 95%(0,05)
0.5 0.0016 0.0056295 0.02734 0.010054 0.0073929 115.81 142.6 135.63 9.18 0.01 0.0079 0.01329 0.023284 0.016058 0.0026486 120.01 134.23 131.01 4.21 0.05 0.0048 0.0034161 0.038625 0.013431 0.010195 109.12 147.67 132.48 11.34 0.1 0.0125 0.029648 0.049888 0.03841 0.0070779 108.79 138.47 126.38 10.50 0.2 0.0156 0.0068526 0.014276 0.010083 0.0026511 109.71 137.39 126.42 9.82 99%(0,01)
0.5 0.0048 0.0034161 0.038625 0.013431 0.010195 109.12 147.67 132.48 11.34 0.01 0.0095 0.0019591 0.0019591 0.0019591 0 111.28 111.28 111.28 0 0.05 0.0095 0.059773 0.059773 0.059773 1.46E-13 96,885 96,885 96,885 0 0.1 0.0126 0.11099 0.11099 0.11099 1.46E-13 83,512 83,512 83,512 0 0.2 0.0108 0.016278 0.016278 0.016278 0 100.16 100.16 100.16 0 99,8%(0,002)
16 Lampiran 2 Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Kedua 70% Learning, 30% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0157 0.011329 0.028165 0.020007 0.0058415 85.8 95,861 91,697 2.61 0.05 0.0109 8.78E-04 0.029066 0.0075235 0.011787 83,192 144.48 112.15 22.85 0.1 0.0094 0.0043347 0.020212 0.011106 0.0059687 88,531 103.73 97,173 4.61 0.2 0.0125 0.0082455 0.020317 0.013624 0.0041508 91,592 103.28 98,843 3.60 80%(0,2)
0.5 0.003 0.014237 0.041486 0.019366 0.0080252 80,852 94,117 90.73 3.96 0.01 0.0095 0.034574 0.13488 0.095062 0.0393 72.74 94,059 79,416 8.35 0.05 0.0077 0.055524 0.096117 0.084826 0.012315 78,485 84.15 80,285 2.04 0.1 0.0095 4.84E-01 0.058482 0.021369 0.0257 79.43 120.36 97,824 16.16 0.2 0.0139 4.84E-01 0.058482 0.021369 0.0257 79.43 120.36 97,824 16,158 90%(0,1)
0.5 0.0031 0.023543 0.069425 0.043719 0.015816 82,788 96,167 89,496 4.75 0.01 0.0016 0.080758 0.15584 0.10165 0.026877 83,032 107.01 100.78 8.21 0.05 0.0079 0.094739 0.18374 0.11554 0.028832 70,258 81,695 79.22 3.55 0.1 0.0078 0.037089 0.082292 0.04618 0.014858 84,106 101.04 96,514 5.80 0.2 0.0048 0.044406 0.10544 0.058649 0.018988 80,834 89,682 87,843 2.67 95%(0,05)
0.5 0.0047 0.022531 0.028115 0.033556 0.0040015 104.02 106.7 105.13 0.92 0.01 0.011 0.045499 0.063773 0.052714 0.0067753 90,196 95,369 93,668 2.09 0.05 0.0031 0.053745 0.083439 0.064204 0.0096127 88,945 94,453 93,353 1.61 0.1 0.0079 0.00014048 0.0027308 0.00084128 0.00085371 108.61 141.98 129.57 12.27 0.2 0.0047 0.022953 0.049985 0.029277 0.0075626 100.22 113.09 109.3 3.60 99%(0,01)
0.5 0.0126 0.034682 0.085534 0.046311 0.01499 88,079 110.6 102.72 6.52 0.01 0.0109 0.028313 0.028313 0.028313 0 98,814 98,814 98,814 0
0.05 0.0109 0.090509 0.090509 0.090509 0 84.97 84.97 84.97 0
0.1 0.0093 0.13404 0.13404 0.13404 2.93E-13 92,518 92,518 92,518 0 0.2 0.022 0.087642 0.087642 0.087642 1.46E-13 84,293 84,293 84,293 0 99,8%(0,002)
17 Lampiran 3 Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Ketiga 90% Learning, 10% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0046 0.038366 0.14049 0.062346 0.028905 79,861 91,968 87.74 3.29 0.05 0.0079 0.043076 0.10707 0.058713 0.020286 81,114 88,722 86,869 2.50 0.1 0.0108 0.0064668 0.088889 0.021168 0.026014 84,798 170.74 136.72 32.22 0.2 0.0031 0.12683 0.14176 0.13175 0.0043996 79,166 80,622 80,145 0.43 80%(0,2)
0.5 0.0078 0.044397 0.079964 0.052842 0.010317 84,569 90,211 88.79 1.64 0.01 0 0.099053 0.15767 0.11155 0.017001 76,846 82,177 80,986 1.52 0.05 0.0047 0.0106 0.087297 0.040046 0.028808 83,902 99.05 91,572 5.39 0.1 0.014 0.26404 0.32273 0.28969 0.022475 66,211 70,691 68,179 1.35 0.2 0.0072 0.17276 0.38776 0.25346 0.086387 63,439 77,542 72,039 5.79 90%(0,1)
0.5 0.0064 0.092578 0.22598 0.1748 0.055314 72,611 84,788 76,893 4.99 0.01 0.0048 0.27726 0.31055 0.29189 0.011657 66,359 68,961 67,903 0.95 0.05 0.0063 0.20407 0.30974 0.24048 0.030052 66,221 74,214 71,517 2.27 0.1 0.0016 0.097218 0.15469 0.10811 0.018339 78,989 87,657 85,567 2.82 0.2 0.0063 0.081276 0.22928 0.1133 0.046057 73,182 93,307 88.87 6.41 95%(0,05)
0.5 0.0048 0.24744 0.42052 0.37357 0.064785 59,508 70,339 63,271 3.61 0.01 0.0078 0.013175 0.020516 0.015261 0.0022935 103.87 107.69 106.57 1.18 0.05 0.0047 0.018056 0.059051 0.028618 0.013579 92,569 102.83 99,831 3.40 0.1 0.0063 0.0029235 0.03257 0.014906 0.010846 113.04 145.17 127.85 11.62 0.2 0.0047 0.0040314 0.006954 0.0049567 0.00079759 107.49 110.38 109.56 0.92 99%(0,01)
0.5 0.0047 0.0085886 0.024322 0.011013 0.0049108 98,466 113.3 110.75 4.40 0.01 0.0063 0.23601 0.23601 0.23601 2.93E-13 84,844 84,844 84,844 0 0.05 0.0093 0.0067029 0.0067029 0.0067029 9.14E-15 107.14 107.14 107.14 0 0.1 0.0031 0.013774 0.024495 0.014846 0.0033903 118.76 130.5 129.32 3.71 0.2 0.0094 0.061803 0.061803 0.061803 0 105.41 105.41 105.41 0 99,8%(0,002)
18 Lampiran 4 Hasil Testing dengan JST Propagasi Balik Standar Kelompok Percobaan Data Keempat 95% Learning, 5% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0047 0.10647 0.11141 0.10935 0.0016853 97,923 98,423 98,167 0.16 0.05 0.0032 0.018172 0.072485 0.032916 0.018024 102.08 116.34 110.3 4.79 0.1 0.0062 0.087714 0.13054 0.11507 0.014542 96,018 101.12 97.64 1.66 0.2 0.0031 0.0036742 0.062535 0.020446 0.016377 103.85 117.49 111.3 3.52 80%(0,2)
0.5 0.0031 0.0002852 0.088588 0.015404 0.027189 101.32 135.35 120.25 10.77 0.01 0.0094 0.26052 0.35736 0.29197 0.036399 78,603 83,603 81.73 1.86 0.05 0.0079 0.23586 0.28043 0.25377 0.01625 83,161 85,877 84,892 0.91 0.1 0.0094 0.0014037 0.2297 0.090672 0.080378 104.65 127.72 104.65 11.90 0.2 0.0047 0.034712 0.12248 0.053653 0.02608 96,167 108.98 105.63 3.80 90%(0,1)
0.5 0.0079 0.11991 0.31981 0.26237 0.070402 79,539 96,435 84,172 5.95 0.01 0.0062 0.09823 0.37378 0.20531 0.086969 80,266 106.98 95,339 8.54 0.05 0.0064 0.023353 0.038172 0.030183 0.0062146 109.72 114.22 112.16 1.81 0.1 0.0109 0.40625 0.48179 0.45441 0.020833 73,951 76,969 75,238 1.24 0.2 0.0079 0.039135 0.060866 0.051905 0.0083316 104.23 110.02 106.03 1.93 95%(0,05)
0.5 0.0063 0.092117 0.21072 0.11557 0.034499 88,011 99,599 97,225 3.38 0.01 0.0062 0.00019906 0.011442 0.0015896 0.0034876 120.6 141.84 137.48 6.73 0.05 0.0063 0.014374 0.067416 0.022892 0.016453 102.51 113.93 111.76 3.60 0.1 0.0079 0.010953 0.049565 0.027013 0.0098591 109.24 133.85 126.31 6.89 0.2 0.0078 0.17543 0.39562 0.34458 0.076017 82,723 98,525 87.08 5.04 99%(0,01)
0.5 0.0063 0.017705 0.065334 0.043051 0.013653 110.89 133.86 125 5.96 0.01 0.0109 0.020136 0.040484 0.022171 0.0064345 110.11 118.62 117.77 2.69 0.05 0.0061 0.10714 0.23293 0.11972 0.039778 88,316 104.22 102.63 5.03 0.1 0.0124 0.23982 0.27352 0.24319 0.010656 96,031 100.64 100.18 1.46 0.2 0.0062 0.0018186 0.0028733 0.001924 0.00033354 142.56 146.46 146.07 1.23 99,8%(0,002)
19 Lampiran 5 Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Pertama 50% Learning, 50% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0077 0.22734 0.2328 0.22844 0.0023022 66.48 128.16 78,817 26,008 0.05 0.0063 0.20945 0.20945 0.20945 0 179.67 179.67 179.67 0 0.1 0.0078 0.19129 0.19772 0.19708 0.0020339 118.12 127.79 126.83 3 0.2 0.0109 0.20348 0.20348 0.20348 0 66,634 66,634 66,634 0 80%(0,2)
0.5 0.0141 0.24104 0.25599 0.25001 0.0077178 179.07 201.97 192.81 11,827 0.01 0.0063 0.22428 0.22428 0.22428 0 64,065 64,065 64,065 0 0.05 0.0076 0.19038 0.19038 0.19038 0 205.05 205.05 205.05 0 0.1 0.0062 0.24447 0.24447 0.24447 0 105.34 105.34 105.34 0 0.2 0.0124 0.21704 0.21704 0.21704 0 92,299 92,299 92,299 0 90%(0,1)
0.5 0.0155 0.23974 0.2425 0.24002 0.00087035 101.25 141.57 105.28 12,749 0.01 0.0108 0.38732 0.38732 0.38732 0 189.08 189.08 189.08 0 0.05 0.0127 0.33999 0.33999 0.33999 0 122.63 122.63 122.63 0 0.1 0.0047 0.30804 0.30804 0.30804 0 148.94 148.94 148.94 0 0.2 0.0078 0.30209 0.30209 0.30209 0 115.59 115.59 115.59 0 95%(0,05)
0.5 0.0062 0.31392 0.31392 0.31392 0 279.34 279.34 279.34 0 0.01 0.0061 0.11976 0.11976 0.11976 0 74,634 74,634 74,634 0 0.05 0.0109 0.15671 0.15671 0.15671 0 136.58 136.58 136.58 0 0.1 0.0076 0.25167 0.26577 0.26154 0.0068102 59,427 71,647 63,093 5,903 0.2 0.0077 0.17433 0.17474 0.17437 0.00012807 70,757 75,142 71,196 1 99%(0,01)
0.5 0.0062 0.28295 0.28295 0.28295 0 110.6 110.6 110.6 0 0.01 0.0062 0.040852 0.040852 0.040852 0 91,772 91,772 91,772 0 0.05 0.0094 0.22013 0.22013 0.22013 0 139.68 139.68 139.68 0 0.1 0.011 0.2388 0.2397 0.23889 0.00028474 71,768 80,784 72,669 3 0.2 0.0093 0.1645 0.1645 0.1645 0 75,864 75,864 75,864 0 99,8%(0,002)
20 Lampiran 6 Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Kedua 70% Learning, 30% Testing
Proses Uji
PCA Laju
Pembelajaran
Rata-rata Waktu
Testing Min R2 Maks R2
Rata-rata
R2 Std R2 Min RMSE Maks RMSE
Rata-rata
RMSE Std RMSE
0.01 0.0108 0.16819 0.16819 0.16819 0 92,092 92,092 92,092 0 0.05 0.0061 0.18448 0.18448 0.18448 0 114.95 114.95 114.95 0 0.1 0.0032 0.16397 0.16776 0.16738 0.0012005 81,933 82,082 82,067 0.047185 0.2 0.0061 0.22792 0.23033 0.22985 0.001016 69,341 73,368 72,562 2 80%(0,2)
0.5 0.0047 0.18334 0.18334 0.18334 0 132.96 132.96 132.96 0 0.01 0.0077 0.2825 0.2825 0.2825 0 66,116 66,116 66,116 0 0.05 0.0031 0.29835 0.29835 0.29835 0 100.07 100.07 100.07 0 0.1 0.0094 0.17368 0.17368 0.17368 0 89,833 89,833 89,833 0 0.2 0.0031 0.17368 0.17368 0.17368 0 89,833 89,833 89,833 0 90%(0,1)
0.5 0.0047 0.22817 0.22817 0.22817 0 80,122 80,122 80,122 0 0.01 0.0016 0.30686 0.30686 0.30686 0 62,207 62,207 62,207 0 0.05 0.0047 0.25444 0.28276 0.27627 0.010802 67,448 120.67 90.13 15 0.1 0.0047 0.26968 0.27076 0.27065 0.00034093 86,047 88,196 86,262 0.67954 0.2 0.0063 0.29134 0.29134 0.29134 0 71.21 71.21 71.21 0 95%(0,05)
0.5 0.0143 0.37744 0.37744 0.37744 0 63,387 63,387 63,387 0 0.01 0.0077 0.35454 0.35454 0.35454 0 61,348 61,348 61,348 0 0.05 0.0047 0.25907 0.25907 0.25907 0 61,945 61,945 61,945 0 0.1 0.0031 0.13094 0.15731 0.15467 0.0083378 68,184 125.44 73,909 18,105 0.2 0.0093 0.33123 0.33123 0.33123 0 58,152 58,152 58,152 0 99%(0,01)
0.5 0.0031 0.29835 0.29835 0.29835 0 100.07 100.07 100.07 0 0.01 0.0015 0.2543 0.2543 0.2543 0 63,014 63,014 63,014 0 0.05 0.0016 0.29519 0.29519 0.29519 0 113.58 113.58 113.58 0 0.1 0.0063 0.17112 0.17112 0.17112 0 68,546 68,546 68,546 0 0.2 0.0015 0.3713 0.37746 0.37684 0.0019477 61,893 72,492 62,953 3 99,8%(0,002)
21 Lampiran 7 Hasil Testing dengan Optimasi GA Kelompok Percobaan Data Ketiga 90% Learning, 10% Testing
Proses Uji
PCA Laju