STUDI PERBANDINGAN ALGORITMA HUFFMAN DAN LZW (LEMPEL ZIV WELCH) PADA PEMAMPATAN FILE TEKS
SKRIPSI
Diajukan untuk melengkapi tugas akhir dan memenuhi syarat mencapai gelar Sarjana Komputer
CANGGIH PRAMILO 041401010
PROGRAM STUDI S1 ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
Medan, 24 November 2008
LEMBAR PENGESAHAN
STUDI PERBANDINGAN ALGORITMA HUFFMAN DAN LZW ( LEMPEL ZIV WELCH ) PADA PEMAMPATAN FILE TEKS
Oleh
Canggih Pramilo NIM. 041401010
Telah diperiksa dan disetujui untuk diseminarkan oleh :
Dosen Pembimbing I Dosen Pembimbing II
PERSETUJUAN
Judul : STUDI PERBANDINGAN ALGORITMA
HUFFMAN DAN LZW PADA PEMAMPATAN FILE TEKS
Kategori : SKRIPSI
Nama : CANGGIH PRAMILO
Nomor Induk Mahasiswa : 041401010
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Desember 2008 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Drs. Agus Salim Harahap, M.Si Syahriol Sitorus, S.Si, MIT
NIP. 130 936 279 NIP. 132 174 687
Diketahui/Disetujui oleh Prog. Studi Ilmu Komputer S-1 Ketua,
PENGHARGAAN
Syukur alhamdulillah penulis nyatakan kehadirat ALLAH SWT Yang Maha Pengasih dan Maha Penyayang, dengan limpahan rahmat dan karunia-Nya skripsi ini berhasil diselesaikan dalam waktu yang telah ditetapkan.
PERNYATAAN
STUDI PERBANDINGAN ALGORITMA HUFFMAN DAN LZW (LEMPEL ZIV WELCH) PADA PEMAMPATAN FILE TEKS
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya
Medan, Desember 2008
STUDY OF COMPARISON OF HUFFMAN AND LZW ALGORITHM IN COMPRESSION OF TEXT FILE
ABSTRACT
ABSTRAK
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
2.4 Pengertian Pemampatan Data 10
2.5 Metode Pemampatan 11
3.2 Karakteristik Algoritma Huffman dan LZW (Lempel Ziv Welch) 25
3.3 Analisis Pemampatan File Teks 26
3.4 Analisis Fungsional Sistem 34
3.4.1 DFD Level 0 ( Context Diagram ) 34
3.4.2 DFD Level 1 35
3.4.3 DFD Level 2 Untuk Proses Encoding (Pemampatan) 36 3.4.4 DFD Level 2 Untuk Proses Decoding (Penirmampatan) 38
Bab 4 Implementasi dan Pengujian 39
4.1 Lingkungan Implementasi 39
4.2 Perangkat Keras yang Digunakan 39
4.3 Perangkat Lunak yang Digunakan 39
4.4 Implementasi Antar Muka 40
4.5 Pengujian Sistem Kompresi Teks Sederhana 44
4.5.1 Analisis Ukuran File 45
4.5.2 Analisis Kecepatan Proses 51
Bab 5 Penutup 60
5.1 Kesimpulan 60
5.2 Saran 61
Daftar Pustaka 62
Lampiran A: Pembentukan Pohon Huffman 63
Lampiran B: Perbandingan Teks dengan Kamus 71 Lampiran C: Kode LZW yang Dicocokkan dengan Kamus 79
DAFTAR TABEL
Halaman Tabel 2.1 Frekuensi Kemunculan Karakter yang Telah Diurutkan 16 Tabel 2.2 Tabel Kode Huffman untuk Masing-Masing Karakter 19
Tabel 2.3 Proses Pemampatan LZW 22
Tabel 2.4 Proses Penirmampatan LZW 23
Tabel 3.1 Karakter yang telah Diurutkan Berdasarkan Frekuensinya 27
Tabel 3.2 Kode Huffman yang telah Terbentuk 29
Tabel 4.1 Hasil Pengujian Sistem 45
Tabel 4.2 Rasio Pemampatan 16 File (*.txt) dengan Algoritma Huffman dan LZW 46
Tabel 4.3 Rasio Pemampatan 16 File (*.doc) dengan Algoritma Huffman dan LZW 47 Tabel 4.4 Rasio Pemampatan 16 File (*.htm) dengan Algoritma Huffman dan LZW48 Tabel 4.5 Rasio Pemampatan 16 File (*.rtf) dengan Algoritma Huffman dan LZW 49 Tabel 4.6 Kecepatan Proses Pemampatan 16 File (*.txt) dengan Algoritma
Huffman dan LZW 51
Tabel 4.7 Kecepatan Proses Pemampatan 16 File (*.doc) dengan Algoritma
Huffman dan LZW 53
Tabel 4.8 Kecepatan Proses Pemampatan 16 File (*.htm) dengan Algoritma
Huffman dan LZW 55
Tabel 4.9 Kecepatan Proses Pemampatan 16 File (*.rtf) dengan Algoritma
DAFTAR GAMBAR
Halaman Gambar 2.1 Pohon Berakar dengan v1 Sebagai Akar 9
Gambar 2.2 Pohon Biner 9
Gambar 2.3 Pembentukan Pohon Huffman 18
Gambar 3.1 Pohon Huffman yang telah Terbentuk 28
Gambar 3.2 Diagram Level 0 34
Gambar 3.3 Diagram Level 1 35
Gambar 3.4 Diagram Level 2 untuk ProsesEncoding (Pemampatan) 36 Gambar 3.5 Diagram Level 2 untuk Proses Decoding (Penirmampatan) 38
Gambar 4.1 Tampilan Halaman Utama 40
Gambar 4.2 File Teks yang akan Dimampatkan ( Compression ) 41 Gambar 4.3 Pemampatan File Teks dengan Algoritma Huffman 42 Gambar 4.4 Penirmampatan File Teks dengan Algoritma Huffman 42 Gambar 4.5 Pemampatan File Teks dengan Algoritma LZW 43 Gambar 4.6 Penirmampatan File Teks dengan Algoritma LZW 43
Gambar 4.7 Grafik Rasio Pemampatan File (*.txt) 46
Gambar 4.8 Grafik Rasio Pemampatan File (*.doc) 47
Gambar 4.9 Grafik Rasio Pemampatan File (*.htm) 48
Gambar 4.10 Grafik Rasio Pemampatan File (*.rtf) 49
Gambar 4.11 Grafik Perbandingan Rasio Pemampatan 50
STUDY OF COMPARISON OF HUFFMAN AND LZW ALGORITHM IN COMPRESSION OF TEXT FILE
ABSTRACT
ABSTRAK
BAB 1
PENDAHULUAN
1.1 LATAR BELAKANG
Kemajuan teknologi memicu kebutuhan informasi yang semakin besar. Sayangnya kebutuhan informasi yang besar ini berdampak pada kebutuhan storage (media penyimpanan) yang semakin besar pula. Informasi yang dimaksud adalah informasi yang berupa file text (file berisi tulisan biasa). Teks adalah kumpulan dari karakter – karakter atau string yang menjadi satu kesatuan. Teks yang memuat banyak karakter didalamnya selalu menimbulkan masalah pada media penyimpanan dan kecepatan waktu pada saat transmisi data.
Media penyimpanan yang terbatas, membuat semua orang mencoba berpikir untuk menemukan sebuah cara yang dapat digunakan untuk memampatkan data teks. pemampatan ialah proses pengubahan sekumpulan data menjadi suatu bentuk kode untuk menghemat kebutuhan tempat penyimpanan dan waktu untuk transmisi data .
1.2 Rumusan Masalah
Dari latar belakang di atas dapatlah dirumuskan beberapa masalah yang menjadi latar belakang penelitian ini, yaitu:
1. Bagaimana cara menerapkan algoritma huffman dan LZW dalam pemampatan data yang berupa data teks dan bagaimana proses encoding pada algoritma Huffman dan LZW untuk data yang akan dimampatkan dari ukuran yang besar menjadi ukuran yang lebih kecil serta bagaimana proses decoding pada algoritma Huffman dan LZW untuk data yang telah dimampatkan agar kembali ke ukuran semula .
2. Menghitung berapa kecepatan pemampatan pada masing-masing algoritma .
3. Berapa rasio/perbandingan ukuran file hasil pemampatan terhadap file asli .
1.3 Batasan masalah
Untuk memfokuskan pada tujuan penelitian maka penulis membatasi pembahasan penelitian ini. Adapun yang menjadi pembatasan masalah adalah sebagai berikut:
1. Data yang dimampatkan berupa text, tidak berupa image, video dan audio.
2. Operating System yang digunakan yaitu Windows XP.
3. File yang dimampatkan adalah file teks (*.txt), file rtf (*.rtf), file html (*.htm) dan file dokumen (*.doc) .
4. Rasio ( perbandingan ) yang dilakukan berdasarkan kecepatan pemampatan dan ukuran file hasil pemampatan terhadap ukuran semula .
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk mengetahui performansi dari masing-masing algoritma baik itu Algoritma Huffman dan Algoritma LZW dalam pemampatan teks serta mengetahui kelebihan dan kekurangan algoritma Huffman dan LZW
1.5 Manfaat Penelitian
Manfaat dari penelitian ini yaitu memahami dan mengetahui bagaimana memilih teknik pemampatan yang tepat, sehingga dapat bermanfaat juga untuk melakukan penyimpanan data dalam ruang penyimpanan yang terbatas .
1.6 Metode Penelitian
Penelitian ini dilakukan dengan beberapa tahapan yaitu :
1) Pembelajaran secara literatur
Metode ini dilaksanakan dengan melakukan studi kepustakaan melalui membaca buku-buku maupun artikel–artikel yang dapat mendukung penelitian.
2) Analisis Masalah
Mencari penyebab dan solusi permasalahan yang telah diidentifikasikan pada rurmusan masalah.
3) Perancangan
4) Implementasi aplikasi
Tahap ini adalah adalah tahap untuk menterjemahkan rancangan aplikasi ke dalam bentuk yang lebih nyata, dalam hal ini adalah bahasa pemrograman Visual C++.
5) Pengujian
Melakukan serangkaian ujicoba terhadap hasil dari implementasi aplikasi, dan memperbaiki jika masih terdapat kesalahan dan menarik kesimpulan dari analisis yang dilakukan.
6) Penyusunan laporan dalam bentuk skripsi
1.7 Sistematika Penulisan
Dalam penulisan tugas akhir ini, Penulis membagi sistematika penulisan menjadi 5 Bab, yang lebih jelasnya dapat dilihat di bawah ini :
BAB 1 : PENDAHULUAN
Berisi tentang latar belakang diambilnya judul Tugas Akhir “Studi Perbandingan Algoritma Huffman dan LZW (Lempel-Ziv-Welch) pada Pemampatan File Teks” , tujuan dari pembuatan Tugas Akhir ini, batasan masalah dalam perancangan aplikasi, dan sistematika penulisan Tugas Akhir yang menjelaskan secara garis besar susbstansi yang diberikan pada masing-masing bab.
BAB 2 : LANDASAN TEORI
BAB 3 : ANALISIS DAN PERANCANGAN SISTEM
Berisi analisa dari algoritma Huffman dan LZW, karakteristik dan perancangan kode untuk algoritma Huffman dan LZW.
BAB 4 : IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini menjelaskan bagaimana mengimplementasikan aplikasi dirancang dan dilanjutkan dengan menguji aplikasi yang dibangun dengan menggunakan bahasa pemrograman Visual C++.
BAB 5 : KESIMPULAN DAN SARAN
BAB 2
LANDASAN TEORI
2.1 Pengertian File Teks
Teks adalah kumpulan dari karakter – karakter atau string yang menjadi satu kesatuan. Teks yang memuat banyak karakter didalamnya selalu menimbulkan masalah pada media penyimpanan dan kecepatan waktu pada saat transmisi data. File teks merupakan file yang berisi informasi-informasi dalam bentuk teks. Data yang berasal dari dokumen pengolah kata, angka yang digunakan dalam perhitungan, nama dan alamat dalam basis data merupakan contoh masukan data teks yang terdiri dari karakter, angka dan tanda baca.
2.1.1 Tipe Teks
Tipe teks merupakan tipe dasar yang sudah sangat dikenal dalam kehidupan sehari-hari. Tipe teks terdiri dari tipe karakter (char) dan tipe string. Tipe karakter (char) terdiri atas satu huruf, angka, tanda baca, atau karakter khusus seperti “c”,”1”,”#” dan sebagainya. Tipe string terdiri atas nol atau lebih karakter seperti “teks” dan “algoritma” dan sebagainya (Purnomo, Herry et al, 2005, hal: 99).
2.1.2 Format Teks
Secara umum, format data teks dibagi menjadi dua bagian, yaitu (Purnomo, Herry et al, 2005, hal: 410) :
1. Teks terformat (formatted text)
Merupakan teks yang terformat dan mengandung styles. Format data dokumen Microsoft Word (*.doc) merupakan contoh format teks jenis ini yang paling popular.
2. Teks sederhana (plain text)
Format data teks (*.txt) merupakan contoh format teks yang paling populer.
Contoh format data teks di atas beserta perangkat lunak yang biasa digunakan diantaranya adalah (Purnomo, Herry et al, 2005, hal: 410):
1. Rich Text Format (*.rtf)
Format teks ini dikembangkan oleh Microsoft yang dapat dibaca oleh berbagai macam platform, seperti Windows, Linux, Mac OS, dan sebagainya.
2. Format data teks (*.txt)
sebagainya. Satu huruf, angka, karakter, kontrol atau simbol pada arsip teks memakan tempat satu byte. Berbeda dengan jenis teks terformat yang satu huruf saja dapat memakan tempat beberapa byte untuk menyimpan format dari huruf tersebut seperti font, ukuran, tebal atau tidak dan sebagainya. Kelebihan dari format data teks ini adalah ukuran datanya yang kecil karena tiadanya fitur untuk memformat tampilan teks. Saat ini perangkat lunak yang paling banyak digunakan untuk memanipulasi format data ini adalah Notepad.
3. Hyper Text Markup Language (*.html atau *.htm)
Merupakan format teks standard untuk tampilan dokumen web.
4. Format data dokumen (*.doc)
Doc merupakan ekstensi arsip dokumen perangkat lunak Microsoft Word yang paling banyak digunakan dalam penulisan laporan, makalah dan sebagainya. Doc merupakan jenis teks terformat yang tidak hanya dapat mengatur tampilan teks seperti styles (font, ukuran huruf dan sebagainya), namun juga dapat menyisipkan gambar. Kekurangan format teks dokumen ini terletak pada ukuran datanya yang besar.
2.2 Pohon (Tree)
Secara sederhana tree dapat didefinisikan sebagai kumpulan elemen yang salah satu elemennya disebut root, dan sisa elemen yang lain (yang disebut node) terpecah menjadi sejumlah himpunan yang saling tidak berhubungan satu sama lain (disjoint), yang disebut dengan subtree. Node yang tidak mempunyai cabang disebut terminal node atau leaf, sedangkan node yang mempunyai cabang disebut branch node. Jumlah
node pada sebuah tree merupakan bilangan terbatas (finite number) (Muthohar, Fiqri, 2004).
v1
v2 v3
v4 v5 v6 v7
Gambar 2.1 Pohon Berakar dengan v1 Sebagai Akar
Pohon secara luas digunakan dalam struktur data ilmu komputer seperti pohon biner, pohon perentang, tumpukan dan lain-lain.
2.3 Pohon Biner (Binary Tree)
Pohon biner merupakan kasus khusus pohon n-ary jika n = 2. Pohon biner adalah himpunan dengan jumlah terbatas yaitu m buah node (m ≥ 0), yang selain kosong (m = 0) hanya dapat berisi sebuah node root yang memiliki dua buah subtree yang masing-masing disebut sub binary tree kiri dan sub binary tree kanan. Jika m = 0 maka disebut empty binary tree (Muthohar, Fiqri, 2004).
Misalkan T adalah pohon biner dan vєV(T)adalah suatu titik cabang dalam T. Subpohon kiri v adalah pohon biner yang (Johnsonbaugh, Richard, 1998) :
1. Titik-titiknya adalah anak kiri v dan semua turunannya.
2. Garis-garisnya adalah garis-garis dalam E(T) yang menghubungkan titik-titik subpohon kiri v.
3. Anaknya adalah anak kiri v.
v
w x
Gambar di atas merupakan pohon biner dengan dua subpohon, yaitu subpohon kiri v dengan w sebagai akar dan subpohon kanan v dengan x sebagai akar.
2.4 Pengertian Pemampatan Data
Pemampatan (kompresi) adalah proses pengubahan sekumpulan data menjadi bentuk kode dengan tujuan untuk menghemat kebutuhan tempat penyimpanan dan waktu untuk transmisi data (Linawaty et al,2004, hal:7). Pemampatan hanya mungkin untuk dilakukan apabila data yang direpresentasikan dalam bentuk normal mengandung informasi yang tidak dibutuhkan. Ketika data tersebut sudah ditampilkan dalam format yang seminimal mungkin, maka data tersebut sudah tidak akan bisa dimampatkan lagi. File yang demikian disebut random file.
Pemampatan merupakan salah satu dari teori informasi yang diperkenalkan oleh Shannon yang bertujuan untuk menghilangkan redundansi dari sumber. Pemampatan bermanfaat dalam membantu mengurangi konsumsi sumber daya yang mahal, seperti ruang hard disk atau perpindahan data melalui internet.
Pemampatan data memiliki beberapa aplikasi, diantaranya (Munir, Rinaldi, 2004, hal: 166):
1. Pengiriman data (data transmission) pada saluran komunikasi data
Data yang telah dimampatkan membutuhkan waktu yang lebih singkat dibandingkan data yang tidak dimampatkan.
2. Penyimpanan data (data storing) di dalam media sekunder ( storage )
2.5 Metode Pemampatan
Metode pemampatan berdasarkan output ada 2 jenis, yaitu:
1. Metode Lossless
Pemampatan data yang menghasilkan file data hasil pemampatan yang dapat dikembalikan menjadi file data asli sebelum dimampatkan secara utuh tanpa perubahan apapun. Pemampatan data lossless bekerja dengan menemukan pola yang berulang di dalam pesan yang akan dimampatkan tersebut dan melakukan proses pengkodean pola tersebut secara efisien. Pemampatan ini juga dapat berarti proses untuk mengurangi redundancy. Pemampatan jenis ini ideal untuk pemampatan text. Algoritma yang termasuk dalam metode pemampatan
lossless diantaranya adalah teknik dictionary coding dan Huffman coding
(Fernando, Hary, 2004).
2. Metode Lossy
Pemampatan data yang menghasilkan file data hasil pemampatan yang tidak dapat dikembalikan menjadi file data sebelum dimampatkan secara utuh. Ketika data hasil pemampatan di-decode kembali, data hasil decoding tersebut tidak dapat dikembalikan menjadi sama dengan data asli tetapi ada bagian data yang hilang. Oleh karena itu, pemampatan jenis ini tidak baik untuk kompresi data yang kritis seperti data teks. Bentuk pemampatan ini sangat cocok untuk digunakan pada file-file gambar, suara, dan film. Contoh penggunaan pemampatan lossy adalah pada format file JPEG, MP3 dan MPEG . ( Nelson, Mark et al, 1996).
Efek pemampatan pada metode pemampatan losseless dapat diukur melalui sejumlah penyusutan suatu file asal dalam membandingkan ukuran dari jenis-jenis pemampatan, yaitu :
x 100% (2.1) 2. Kecepatan proses pemampatan (ditulis dalam satuan Kbyte/s):
Kecepatan Proses Pemampatan (2.2)
Ada beberapa kriteria yang sering menjadi pertimbangan dalam memilih suatu metode pemampatan yang tepat diantaranya kecepatan pemampatan, sumber daya yang dibutuhkan, kualitas, ukuran file, kompleksitas algoritma dan lain-lain (Munir, Rinaldi, 2004, hal: 166). Kualitas pemampatan dengan kebutuhan memori biasanya berbanding terbalik. Kualitas pemampatan yang bagus umumnya dicapai pada proses pemampatan yang menghasilkan pengurangan memori yang tidak begitu besar dan begitu juga sebaliknya.
2.6 Algoritma Huffman
Algoritma Huffman, yang dibuat oleh seorang mahasiswa MIT bernama David Huffman pada tahun 1952, merupakan salah satu metode paling lama dan paling terkenal dalam pemampatan teks. Algoritma Huffman menggunakan prinsip pengkodean yang mirip dengan kode Morse, yaitu tiap karakter (simbol) dikodekan hanya dengan rangkaian beberapa bit, dimana karakter yang sering muncul dikodekan dengan rangkaian bit yang pendek dan karakter yang jarang muncul dikodekan.dengan rangkaian bit yang lebih panjang. Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal (isi data yang diinputkan) menjadi sekumpulan codeword, algoritma Huffman termasuk kedalam kelas algoritma yang menggunakan metode statik (Ida, Mengyi Pu, 2006).
Huffman menggunakan metode symbolwise. Metoda symbolwise adalah metode yang menghitung peluang kemunculan dari setiap simbol dalam satu waktu, dimana simbol yang lebih sering muncul diberi kode lebih pendek dibandingkan simbol yang jarang muncul. Dalam tugas akhir ini algoritma Huffman yang dibahas yaitu algoritma Huffman yang menggunakan metode statik ( Ida, Mengyi Pu, 2006).
Pada awalnya David Huffman hanya menencoding karakter dengan hanya menggunakan pohon biner biasa, namun setelah itu David Huffman menemukan bahwa penggunaan algoritma greedy dapat membentuk kode prefiks yang optimal. Penggunaan algoritma greedy pada algoritma Huffman adalah pada saat pemilihan dua pohon dengan frekuensi terkecil dalam membuat pohon Huffman. Algoritma greedy ini digunakan pada pembentukan pohon Huffman agar meminimumkan total
cost yang dibutuhkan. Cost yang digunakan untuk menggabungkan dua buah pohon pada akar setara dengan jumlah frekuensi dua buah pohon yang digabungkan, oleh karena itu total cost pembentukan pohon Huffman adalah jumlah total seluruh penggabungan. penggabungan dua buah pohon dilakukan setiap langkah dan algoritma Huffman selalu memilih dua buah pohon yang mempunyai frekuensi terkecil untuk meminimumkan total cost (Wardoyo, Irwan et al, 2003, hal:1).
2.6.1 Kode Prefix (Prefix Code)
2.6.2 Kode Huffman
Huffman memberikan sebuah algoritma untuk memangun sebuah kode Huffman dengan masukan string teks S={s1,s2,…,sn} dan frekuensi kemunculan karakter
F={f1,f2,…,fn}, dihasilkan keluaran berupa kode string biner C={c1,c2,…,cn} atau disebut kode Huffman (Liliana et al, 2003, hal:4).
Algoritma Pemampatan Huffman:
1. Baca file text yang akan dimampatkan (file asal).
2. Hitung frekuensi dari setiap karakter yang ada. Jenis karakter dan frekuensinya disimpan sebagai tree dalam sebuah list.
3. Selama list masih mempunyai node lebih dari satu maka
a. Urutkan list berdasarkan frekuensinya, secara ascending.
b. Buat tree baru, kaki kiri diisi dengan node pertama list dan kaki kanannya diisi dengan node kedua list. Karakter yang disimpan berupa “a“ dan frekuensinya merupakan jumlahan dari frekuensi kedua kakinya.
4. Sebelum hasil pemampatan disimpan dalam file hasil, maka simpan terlebih dahulu tree huffman nya. Pertama simpan jumlah karakter keseluruhan. Kemudian telusuri tree secara preorder, kaki kiri diberi kode “0“ dan kaki kanan diberi kode “1“. Setelah sampai pada leaf maka simpan karakter pada leaf tersebut baru kemudian simpan deretan kode yang dihasilkan. Setiap kode disimpan dengan dibatasi “a“. Setelah tree selesai disimpan, untuk membatasi penyimpanan tree dengan hasil kompresi, disisipkan “A“.
5. Telusuri tree secara preorder, kaki kiri diberi kode “0“ dan kaki kanan diberi kode “1“. Setelah sampai pada leaf maka deretan kode yang didapat digunakan untuk mengkodekan karakter pada leaf tersebut. Setelah penelusuran selesai maka akan didapat daftar karakter dan kode binernya.
Tabel karakter-karakter yang diurutkan berdasarkan frekuensi kemunculan karakter tersebut berhubungan dengan distribusi probabilitas atau distribusi peluang. Distribusi probabilitas ini berhubungan pada kemungkinan penempatan akar atau subpohon baru yang telah terbentuk. Probabilitas untuk masing-masing karakter adalah frekuensi karakter tersebut dibagi jumlah frekuensi keseluruhan.
Untuk proses penirmampatan (decompression) merupakan kebalikan dari proses pemampatan (compression), Decompression berarti menyusun kembali data dari string biner menjadi sebuah karakter kembali. Decompression dapat dilakukan dengan dua cara, yang pertama dengan menggunakan tabel dan yang kedua dengan menggunakan algoritma penirmampatan (decompression).
Algoritma penirmampatan
1. Baca sebuah bit dari string biner. 2. Mulai dari akar
3. Untuk setiap bit pada langkah 1, lakukan traversal pada cabang yang bersesuaian.
4. Ulangi langkah 1, 2 dan 3 sampai bertemu daun. Kodekan rangkaian bit yang telah dibaca dengan karakter di daun.
5. Ulangi dari langkah 1 sampai semua bit di dalam string habis.
Contoh 2.1
Dengan menggunakan algoritma Huffman untuk mengkodekan setiap karakter dapat diperoleh kode Huffman sebagai berikut :
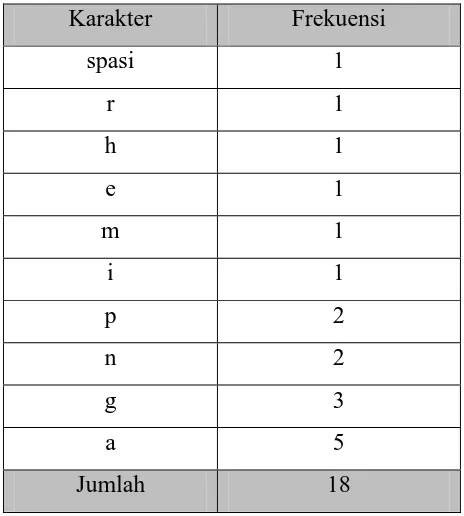
Masukan : 18 karakter yang telah diurutkan dan table frekuensi Keluaran : Kode Huffman
1. Pengurutan karakter berdasarkan frekuensi kemunculannya. Karakter pada data diurutkan di dalam tabel secara menaik (ascending order).
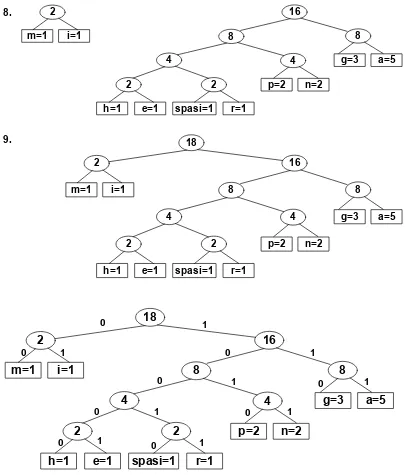
Tabel 2.1 Frekuensi Kemunculan Karakter yang Telah Diurutkan
Karakter Frekuensi
spasi 1
r 1
h 1
e 1
m 1
i 1
p 2
n 2
g 3
a 5
Jumlah 18
2. Pembentukan pohon Huffman
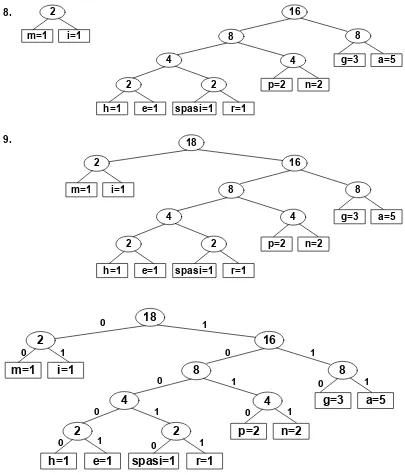
Pengurutan kembali akar yang baru terbentuk berhubungan dengan distribusi probabilitas. Pada contoh ini, ada lebih dari satu kemungkinan tempat yang tersedia pada penggabungan karakter “spasi” dan “r” dengan frekuensi 2. Untuk mencegah penggabungan akar baru terlalu cepat maka akar ditempatkan pada posisi terendah. Jadi, akar baru “spasi” dan “r” ditempatkan sesudah karakter “a”.
Pembentukan pohon biner dari string “piagam penghargaan” adalah :
h=1 e=1
Gambar 2.3 Pembentukan Pohon Huffman
Keterangan gambar :
3. Kode Huffman yang diperoleh dari pohon Huffman yang telah terbentuk adalah :
Tabel 2.2 Tabel Kode Huffman untuk Masing-Masing Karakter
Karakter Frekuensi (f)
Kode Huffman Panjang Kode ( shf )
Total Panjang ( f x shf )
Spasi 1 10110 5 5
r 1 10111 5 5
h 1 10100 5 5
e 1 10101 5 5
m 1 00 2 2
i 1 01 2 2
p 2 1000 4 8
n 2 1001 4 8
g 3 110 3 9
a 5 111 3 15
Total 18 34 64
Dengan demikian, jumlah bilangan bit yang dibutuhkan oleh algoritma Huffman untuk merepresentasikan string “piagam penghargaan” adalah 64 bit. String tersebut dimampatkan dengan rasio sebesar :
x 100% x 100%
= 44,4%
Dengan demikian string “piagam penghargaan” dimampatkan menjadi rangkaian bit : 1000011111101110010110100010101100111010100111101111101111111001
telah terbentuk atau menggunakan algoritma penirmampatan. Pada proses penirmampatan, rangkaian bit biner
1000011111101110010110100010101100111010100111101111101111111001 Dimulai dengan membaca bit pertama yaitu “1”, tidak terdapat bit “1” pada tabel kode Huffman. Lalu baca bit berikutnya, sehingga menjadi “10”, tidak terdapat juga bit “10”, kemudian baca lagi bit berikutnya, sehingga menjadi “100”, tidak terdapat juga bit “100”, kemudian baca lagi bit berikutnya, sehingga menjadi “1000”. Rangkaian bit “1000” ini ditemukan pada tabel kode Huffman yaitu bit yang merepresentasikan karakter “p”. Proses ini terus dilakukan hingga tidak terdapat lagi bit biner.
2.7 Algoritma LZW (Lempel Ziv Welch)
Algoritma Lempel-Ziv-Welch (LZW) menggunakan teknik adaptif dan berbasiskan “kamus” Pendahulu LZW adalah LZ77 dan LZ78 yang dikembangkan oleh Jacob Ziv dan Abraham Lempel pada tahun 1977 dan 1978. Terry Welch mengembangkan teknik tersebut pada tahun 1984. LZW banyak dipergunakan pada UNIX, GIF, V.42 untuk modem ( Cormen et al, 2001).
Algoritma ini melakukan kompresi dengan menggunakan dictionary, di mana fragmen-fragmen teks digantikan dengan indeks yang diperoleh dari sebuah “kamus”. Prinsip sejenis juga digunakan dalam kode Braille, di mana kode-kode khusus digunakan untuk merepresentasikan kata-kata yang ada. Pendekatan ini bersifat
adaptif dan efektif karena banyak karakter dapat dikodekan dengan mengacu pada
string yang telah muncul sebelumnya dalam teks. Prinsip kompresi tercapai jika referensi dalam bentuk pointer dapat disimpan dalam jumlah bit yang lebih sedikit dibandingkan string aslinya (Dobb, 1989).
2.7.1 Kode LZW ( Lempel-Ziv-Welch )
1. Dictionary diinisialisasi dengan semua karakter dasar yang ada : {‘A’..’Z’,’a’..’z’,’0’..’9’}.
2. P = karakter pertama dalam stream karakter. 3. C = karakter berikutnya dalam stream karakter. 4. Apakah string (P + C) terdapat dalam dictionary ?
• Jika ya, maka P =P + C (gabungkan P dan C menjadi string baru). • Jika tidak, maka :
i. Output sebuah kode untuk menggantikan string P.
ii. Tambahkan string (P + C) ke dalam dictionary dan berikan nomor/kode berikutnya yang belum digunakan dalam dictionary untuk string tersebut. iii. P = C.
5. Apakah masih ada karakter berikutnya dalam stream karakter ? • Jika ya, maka kembali ke langkah 2.
• Jika tidak, maka output kode yang menggantikan string P, lalu terminasi proses (stop).
Isi dictionary pada awal proses diset dengan tiga karakter dasar yang ada. Kolom posisi menyatakan posisi sekarang dari stream karakter dan kolom karakter
menyatakan karakter yang terdapat pada posisi tersebut. Kolom dictionary
menyatakan string baru yang sudah ditambahkan ke dalam dictionary dan nomor indeks untuk string tersebut ditulis dalam kurung siku. Kolom output menyatakan kode output yang dihasilkan oleh langkah kompresi (Linawati et al, 2004, hal: 10).
Algoritma penirmampatan LZW :
1. Dictionary diinisialisasi dengan semua karakter dasar yang ada : {‘A’..’Z’,’a’..’z’,’0’..’9’}. 2. CW = kode pertama dari stream kode (menunjuk ke salah satu karakter dasar).
3. Lihat dictionary dan output string dari kode tersebut (string.CW) ke stream karakter. 4. PW = CW; CW = kode berikutnya dari stream kode.
5. Apakah string.CW terdapat dalam dictionary ? Jika ada, maka :
iii. C = karakter pertama dari string.CW
iv. tambahkan string (P+C) ke dalam dictionary Jika tidak, maka :
i. P = string.PW
ii. C = karakter pertama dari string.PW
iii. output string (P+C) ke stream karakter dan tambahkan string tersebut ke dalam dictionary (sekarang berkorespondensi dengan CW);
6. Apakah terdapat kode lagi di stream kode ? Jika ya, maka kembali ke langkah 4. Jika tidak, maka terminasi proses (stop).
Contoh 2.2
String “ABBABABAC” akan dikompresi dengan LZW. Isi dictionary pada awal proses diset dengan tiga karakter dasar yang ada: “A”, “B”, dan “C”. Tahapan proses kompresi ditunjukkan pada Tabel di bawah ini.
Tabel 2.3 Proses Pemampatan LZW
Langkah Posisi Karakter Dictionary Output
1 1 A [4] A B [1]
2 2 B [5] B B [2]
3 3 B [6] B A [2]
4 4 A [7] A B A [4]
5 6 A [8] A B A C [7]
6 9 C --- [3]
Steam karakter: a b b ab aba c
Kode output : [1] [2] [2] [4] [7] [3]
Proses penirmampatan pada LZW dilakukan dengan prinsip yang sama seperti proses kompresi. Pada awalnya, dictionary diinisialisasi dengan semua karakter dasar yang ada. Lalu pada setiap langkah, kode dibaca satu per satu dari stream kode, dikeluarkan string dari dictionary yang berkorespondensi dengan kode tersebut, dan ditambahkan string baru ke dalam dictionary. Tahapan proses dekompresi ini ditunjukkan pada Tabel di bawah ini (Linawati et al, 2004, hal: 11).
Tabel 2.4 Proses Penirmampatan LZW
Langkah Kode Output Dictionary
1 [1] A ---
2 [2] B [4] A B
3 [2] B [5] B B
4 [4] A B [6] B A
5 [7] A B A [7] A B A
6 [3] C [8] A B A C
BAB 2
LANDASAN TEORI
2.1 Pengertian File Teks
Teks adalah kumpulan dari karakter – karakter atau string yang menjadi satu kesatuan. Teks yang memuat banyak karakter didalamnya selalu menimbulkan masalah pada media penyimpanan dan kecepatan waktu pada saat transmisi data. File teks merupakan file yang berisi informasi-informasi dalam bentuk teks. Data yang berasal dari dokumen pengolah kata, angka yang digunakan dalam perhitungan, nama dan alamat dalam basis data merupakan contoh masukan data teks yang terdiri dari karakter, angka dan tanda baca.
2.1.1 Tipe Teks
Tipe teks merupakan tipe dasar yang sudah sangat dikenal dalam kehidupan sehari-hari. Tipe teks terdiri dari tipe karakter (char) dan tipe string. Tipe karakter (char) terdiri atas satu huruf, angka, tanda baca, atau karakter khusus seperti “c”,”1”,”#” dan sebagainya. Tipe string terdiri atas nol atau lebih karakter seperti “teks” dan “algoritma” dan sebagainya (Purnomo, Herry et al, 2005, hal: 99).
2.1.2 Format Teks
Secara umum, format data teks dibagi menjadi dua bagian, yaitu (Purnomo, Herry et al, 2005, hal: 410) :
1. Teks terformat (formatted text)
Merupakan teks yang terformat dan mengandung styles. Format data dokumen Microsoft Word (*.doc) merupakan contoh format teks jenis ini yang paling popular.
2. Teks sederhana (plain text)
Format data teks (*.txt) merupakan contoh format teks yang paling populer.
Contoh format data teks di atas beserta perangkat lunak yang biasa digunakan diantaranya adalah (Purnomo, Herry et al, 2005, hal: 410):
1. Rich Text Format (*.rtf)
Format teks ini dikembangkan oleh Microsoft yang dapat dibaca oleh berbagai macam platform, seperti Windows, Linux, Mac OS, dan sebagainya.
2. Format data teks (*.txt)
sebagainya. Satu huruf, angka, karakter, kontrol atau simbol pada arsip teks memakan tempat satu byte. Berbeda dengan jenis teks terformat yang satu huruf saja dapat memakan tempat beberapa byte untuk menyimpan format dari huruf tersebut seperti font, ukuran, tebal atau tidak dan sebagainya. Kelebihan dari format data teks ini adalah ukuran datanya yang kecil karena tiadanya fitur untuk memformat tampilan teks. Saat ini perangkat lunak yang paling banyak digunakan untuk memanipulasi format data ini adalah Notepad.
3. Hyper Text Markup Language (*.html atau *.htm)
Merupakan format teks standard untuk tampilan dokumen web.
4. Format data dokumen (*.doc)
Doc merupakan ekstensi arsip dokumen perangkat lunak Microsoft Word yang paling banyak digunakan dalam penulisan laporan, makalah dan sebagainya. Doc merupakan jenis teks terformat yang tidak hanya dapat mengatur tampilan teks seperti styles (font, ukuran huruf dan sebagainya), namun juga dapat menyisipkan gambar. Kekurangan format teks dokumen ini terletak pada ukuran datanya yang besar.
2.2 Pohon (Tree)
Secara sederhana tree dapat didefinisikan sebagai kumpulan elemen yang salah satu elemennya disebut root, dan sisa elemen yang lain (yang disebut node) terpecah menjadi sejumlah himpunan yang saling tidak berhubungan satu sama lain (disjoint), yang disebut dengan subtree. Node yang tidak mempunyai cabang disebut terminal node atau leaf, sedangkan node yang mempunyai cabang disebut branch node. Jumlah
node pada sebuah tree merupakan bilangan terbatas (finite number) (Muthohar, Fiqri, 2004).
v1
v2 v3
v4 v5 v6 v7
Gambar 2.1 Pohon Berakar dengan v1 Sebagai Akar
Pohon secara luas digunakan dalam struktur data ilmu komputer seperti pohon biner, pohon perentang, tumpukan dan lain-lain.
2.3 Pohon Biner (Binary Tree)
Pohon biner merupakan kasus khusus pohon n-ary jika n = 2. Pohon biner adalah himpunan dengan jumlah terbatas yaitu m buah node (m ≥ 0), yang selain kosong (m = 0) hanya dapat berisi sebuah node root yang memiliki dua buah subtree yang masing-masing disebut sub binary tree kiri dan sub binary tree kanan. Jika m = 0 maka disebut empty binary tree (Muthohar, Fiqri, 2004).
Misalkan T adalah pohon biner dan vєV(T)adalah suatu titik cabang dalam T. Subpohon kiri v adalah pohon biner yang (Johnsonbaugh, Richard, 1998) :
1. Titik-titiknya adalah anak kiri v dan semua turunannya.
2. Garis-garisnya adalah garis-garis dalam E(T) yang menghubungkan titik-titik subpohon kiri v.
3. Anaknya adalah anak kiri v.
v
w x
Gambar di atas merupakan pohon biner dengan dua subpohon, yaitu subpohon kiri v dengan w sebagai akar dan subpohon kanan v dengan x sebagai akar.
2.4 Pengertian Pemampatan Data
Pemampatan (kompresi) adalah proses pengubahan sekumpulan data menjadi bentuk kode dengan tujuan untuk menghemat kebutuhan tempat penyimpanan dan waktu untuk transmisi data (Linawaty et al,2004, hal:7). Pemampatan hanya mungkin untuk dilakukan apabila data yang direpresentasikan dalam bentuk normal mengandung informasi yang tidak dibutuhkan. Ketika data tersebut sudah ditampilkan dalam format yang seminimal mungkin, maka data tersebut sudah tidak akan bisa dimampatkan lagi. File yang demikian disebut random file.
Pemampatan merupakan salah satu dari teori informasi yang diperkenalkan oleh Shannon yang bertujuan untuk menghilangkan redundansi dari sumber. Pemampatan bermanfaat dalam membantu mengurangi konsumsi sumber daya yang mahal, seperti ruang hard disk atau perpindahan data melalui internet.
Pemampatan data memiliki beberapa aplikasi, diantaranya (Munir, Rinaldi, 2004, hal: 166):
1. Pengiriman data (data transmission) pada saluran komunikasi data
Data yang telah dimampatkan membutuhkan waktu yang lebih singkat dibandingkan data yang tidak dimampatkan.
2. Penyimpanan data (data storing) di dalam media sekunder ( storage )
2.5 Metode Pemampatan
Metode pemampatan berdasarkan output ada 2 jenis, yaitu:
1. Metode Lossless
Pemampatan data yang menghasilkan file data hasil pemampatan yang dapat dikembalikan menjadi file data asli sebelum dimampatkan secara utuh tanpa perubahan apapun. Pemampatan data lossless bekerja dengan menemukan pola yang berulang di dalam pesan yang akan dimampatkan tersebut dan melakukan proses pengkodean pola tersebut secara efisien. Pemampatan ini juga dapat berarti proses untuk mengurangi redundancy. Pemampatan jenis ini ideal untuk pemampatan text. Algoritma yang termasuk dalam metode pemampatan
lossless diantaranya adalah teknik dictionary coding dan Huffman coding
(Fernando, Hary, 2004).
2. Metode Lossy
Pemampatan data yang menghasilkan file data hasil pemampatan yang tidak dapat dikembalikan menjadi file data sebelum dimampatkan secara utuh. Ketika data hasil pemampatan di-decode kembali, data hasil decoding tersebut tidak dapat dikembalikan menjadi sama dengan data asli tetapi ada bagian data yang hilang. Oleh karena itu, pemampatan jenis ini tidak baik untuk kompresi data yang kritis seperti data teks. Bentuk pemampatan ini sangat cocok untuk digunakan pada file-file gambar, suara, dan film. Contoh penggunaan pemampatan lossy adalah pada format file JPEG, MP3 dan MPEG . ( Nelson, Mark et al, 1996).
Efek pemampatan pada metode pemampatan losseless dapat diukur melalui sejumlah penyusutan suatu file asal dalam membandingkan ukuran dari jenis-jenis pemampatan, yaitu :
x 100% (2.1) 2. Kecepatan proses pemampatan (ditulis dalam satuan Kbyte/s):
Kecepatan Proses Pemampatan (2.2)
Ada beberapa kriteria yang sering menjadi pertimbangan dalam memilih suatu metode pemampatan yang tepat diantaranya kecepatan pemampatan, sumber daya yang dibutuhkan, kualitas, ukuran file, kompleksitas algoritma dan lain-lain (Munir, Rinaldi, 2004, hal: 166). Kualitas pemampatan dengan kebutuhan memori biasanya berbanding terbalik. Kualitas pemampatan yang bagus umumnya dicapai pada proses pemampatan yang menghasilkan pengurangan memori yang tidak begitu besar dan begitu juga sebaliknya.
2.6 Algoritma Huffman
Algoritma Huffman, yang dibuat oleh seorang mahasiswa MIT bernama David Huffman pada tahun 1952, merupakan salah satu metode paling lama dan paling terkenal dalam pemampatan teks. Algoritma Huffman menggunakan prinsip pengkodean yang mirip dengan kode Morse, yaitu tiap karakter (simbol) dikodekan hanya dengan rangkaian beberapa bit, dimana karakter yang sering muncul dikodekan dengan rangkaian bit yang pendek dan karakter yang jarang muncul dikodekan.dengan rangkaian bit yang lebih panjang. Berdasarkan tipe peta kode yang digunakan untuk mengubah pesan awal (isi data yang diinputkan) menjadi sekumpulan codeword, algoritma Huffman termasuk kedalam kelas algoritma yang menggunakan metode statik (Ida, Mengyi Pu, 2006).
Huffman menggunakan metode symbolwise. Metoda symbolwise adalah metode yang menghitung peluang kemunculan dari setiap simbol dalam satu waktu, dimana simbol yang lebih sering muncul diberi kode lebih pendek dibandingkan simbol yang jarang muncul. Dalam tugas akhir ini algoritma Huffman yang dibahas yaitu algoritma Huffman yang menggunakan metode statik ( Ida, Mengyi Pu, 2006).
Pada awalnya David Huffman hanya menencoding karakter dengan hanya menggunakan pohon biner biasa, namun setelah itu David Huffman menemukan bahwa penggunaan algoritma greedy dapat membentuk kode prefiks yang optimal. Penggunaan algoritma greedy pada algoritma Huffman adalah pada saat pemilihan dua pohon dengan frekuensi terkecil dalam membuat pohon Huffman. Algoritma greedy ini digunakan pada pembentukan pohon Huffman agar meminimumkan total
cost yang dibutuhkan. Cost yang digunakan untuk menggabungkan dua buah pohon pada akar setara dengan jumlah frekuensi dua buah pohon yang digabungkan, oleh karena itu total cost pembentukan pohon Huffman adalah jumlah total seluruh penggabungan. penggabungan dua buah pohon dilakukan setiap langkah dan algoritma Huffman selalu memilih dua buah pohon yang mempunyai frekuensi terkecil untuk meminimumkan total cost (Wardoyo, Irwan et al, 2003, hal:1).
2.6.1 Kode Prefix (Prefix Code)
2.6.2 Kode Huffman
Huffman memberikan sebuah algoritma untuk memangun sebuah kode Huffman dengan masukan string teks S={s1,s2,…,sn} dan frekuensi kemunculan karakter
F={f1,f2,…,fn}, dihasilkan keluaran berupa kode string biner C={c1,c2,…,cn} atau disebut kode Huffman (Liliana et al, 2003, hal:4).
Algoritma Pemampatan Huffman:
1. Baca file text yang akan dimampatkan (file asal).
2. Hitung frekuensi dari setiap karakter yang ada. Jenis karakter dan frekuensinya disimpan sebagai tree dalam sebuah list.
3. Selama list masih mempunyai node lebih dari satu maka
a. Urutkan list berdasarkan frekuensinya, secara ascending.
b. Buat tree baru, kaki kiri diisi dengan node pertama list dan kaki kanannya diisi dengan node kedua list. Karakter yang disimpan berupa “a“ dan frekuensinya merupakan jumlahan dari frekuensi kedua kakinya.
4. Sebelum hasil pemampatan disimpan dalam file hasil, maka simpan terlebih dahulu tree huffman nya. Pertama simpan jumlah karakter keseluruhan. Kemudian telusuri tree secara preorder, kaki kiri diberi kode “0“ dan kaki kanan diberi kode “1“. Setelah sampai pada leaf maka simpan karakter pada leaf tersebut baru kemudian simpan deretan kode yang dihasilkan. Setiap kode disimpan dengan dibatasi “a“. Setelah tree selesai disimpan, untuk membatasi penyimpanan tree dengan hasil kompresi, disisipkan “A“.
5. Telusuri tree secara preorder, kaki kiri diberi kode “0“ dan kaki kanan diberi kode “1“. Setelah sampai pada leaf maka deretan kode yang didapat digunakan untuk mengkodekan karakter pada leaf tersebut. Setelah penelusuran selesai maka akan didapat daftar karakter dan kode binernya.
Tabel karakter-karakter yang diurutkan berdasarkan frekuensi kemunculan karakter tersebut berhubungan dengan distribusi probabilitas atau distribusi peluang. Distribusi probabilitas ini berhubungan pada kemungkinan penempatan akar atau subpohon baru yang telah terbentuk. Probabilitas untuk masing-masing karakter adalah frekuensi karakter tersebut dibagi jumlah frekuensi keseluruhan.
Untuk proses penirmampatan (decompression) merupakan kebalikan dari proses pemampatan (compression), Decompression berarti menyusun kembali data dari string biner menjadi sebuah karakter kembali. Decompression dapat dilakukan dengan dua cara, yang pertama dengan menggunakan tabel dan yang kedua dengan menggunakan algoritma penirmampatan (decompression).
Algoritma penirmampatan
1. Baca sebuah bit dari string biner. 2. Mulai dari akar
3. Untuk setiap bit pada langkah 1, lakukan traversal pada cabang yang bersesuaian.
4. Ulangi langkah 1, 2 dan 3 sampai bertemu daun. Kodekan rangkaian bit yang telah dibaca dengan karakter di daun.
5. Ulangi dari langkah 1 sampai semua bit di dalam string habis.
Contoh 2.1
Dengan menggunakan algoritma Huffman untuk mengkodekan setiap karakter dapat diperoleh kode Huffman sebagai berikut :
Masukan : 18 karakter yang telah diurutkan dan table frekuensi Keluaran : Kode Huffman
1. Pengurutan karakter berdasarkan frekuensi kemunculannya. Karakter pada data diurutkan di dalam tabel secara menaik (ascending order).
Tabel 2.1 Frekuensi Kemunculan Karakter yang Telah Diurutkan
Karakter Frekuensi
spasi 1
r 1
h 1
e 1
m 1
i 1
p 2
n 2
g 3
a 5
Jumlah 18
2. Pembentukan pohon Huffman
Pengurutan kembali akar yang baru terbentuk berhubungan dengan distribusi probabilitas. Pada contoh ini, ada lebih dari satu kemungkinan tempat yang tersedia pada penggabungan karakter “spasi” dan “r” dengan frekuensi 2. Untuk mencegah penggabungan akar baru terlalu cepat maka akar ditempatkan pada posisi terendah. Jadi, akar baru “spasi” dan “r” ditempatkan sesudah karakter “a”.
Pembentukan pohon biner dari string “piagam penghargaan” adalah :
h=1 e=1
Gambar 2.3 Pembentukan Pohon Huffman
Keterangan gambar :
3. Kode Huffman yang diperoleh dari pohon Huffman yang telah terbentuk adalah :
Tabel 2.2 Tabel Kode Huffman untuk Masing-Masing Karakter
Karakter Frekuensi (f)
Kode Huffman Panjang Kode ( shf )
Total Panjang ( f x shf )
Spasi 1 10110 5 5
r 1 10111 5 5
h 1 10100 5 5
e 1 10101 5 5
m 1 00 2 2
i 1 01 2 2
p 2 1000 4 8
n 2 1001 4 8
g 3 110 3 9
a 5 111 3 15
Total 18 34 64
Dengan demikian, jumlah bilangan bit yang dibutuhkan oleh algoritma Huffman untuk merepresentasikan string “piagam penghargaan” adalah 64 bit. String tersebut dimampatkan dengan rasio sebesar :
x 100% x 100%
= 44,4%
Dengan demikian string “piagam penghargaan” dimampatkan menjadi rangkaian bit : 1000011111101110010110100010101100111010100111101111101111111001
telah terbentuk atau menggunakan algoritma penirmampatan. Pada proses penirmampatan, rangkaian bit biner
1000011111101110010110100010101100111010100111101111101111111001 Dimulai dengan membaca bit pertama yaitu “1”, tidak terdapat bit “1” pada tabel kode Huffman. Lalu baca bit berikutnya, sehingga menjadi “10”, tidak terdapat juga bit “10”, kemudian baca lagi bit berikutnya, sehingga menjadi “100”, tidak terdapat juga bit “100”, kemudian baca lagi bit berikutnya, sehingga menjadi “1000”. Rangkaian bit “1000” ini ditemukan pada tabel kode Huffman yaitu bit yang merepresentasikan karakter “p”. Proses ini terus dilakukan hingga tidak terdapat lagi bit biner.
2.7 Algoritma LZW (Lempel Ziv Welch)
Algoritma Lempel-Ziv-Welch (LZW) menggunakan teknik adaptif dan berbasiskan “kamus” Pendahulu LZW adalah LZ77 dan LZ78 yang dikembangkan oleh Jacob Ziv dan Abraham Lempel pada tahun 1977 dan 1978. Terry Welch mengembangkan teknik tersebut pada tahun 1984. LZW banyak dipergunakan pada UNIX, GIF, V.42 untuk modem ( Cormen et al, 2001).
Algoritma ini melakukan kompresi dengan menggunakan dictionary, di mana fragmen-fragmen teks digantikan dengan indeks yang diperoleh dari sebuah “kamus”. Prinsip sejenis juga digunakan dalam kode Braille, di mana kode-kode khusus digunakan untuk merepresentasikan kata-kata yang ada. Pendekatan ini bersifat
adaptif dan efektif karena banyak karakter dapat dikodekan dengan mengacu pada
string yang telah muncul sebelumnya dalam teks. Prinsip kompresi tercapai jika referensi dalam bentuk pointer dapat disimpan dalam jumlah bit yang lebih sedikit dibandingkan string aslinya (Dobb, 1989).
2.7.1 Kode LZW ( Lempel-Ziv-Welch )
1. Dictionary diinisialisasi dengan semua karakter dasar yang ada : {‘A’..’Z’,’a’..’z’,’0’..’9’}.
2. P = karakter pertama dalam stream karakter. 3. C = karakter berikutnya dalam stream karakter. 4. Apakah string (P + C) terdapat dalam dictionary ?
• Jika ya, maka P =P + C (gabungkan P dan C menjadi string baru). • Jika tidak, maka :
i. Output sebuah kode untuk menggantikan string P.
ii. Tambahkan string (P + C) ke dalam dictionary dan berikan nomor/kode berikutnya yang belum digunakan dalam dictionary untuk string tersebut. iii. P = C.
5. Apakah masih ada karakter berikutnya dalam stream karakter ? • Jika ya, maka kembali ke langkah 2.
• Jika tidak, maka output kode yang menggantikan string P, lalu terminasi proses (stop).
Isi dictionary pada awal proses diset dengan tiga karakter dasar yang ada. Kolom posisi menyatakan posisi sekarang dari stream karakter dan kolom karakter
menyatakan karakter yang terdapat pada posisi tersebut. Kolom dictionary
menyatakan string baru yang sudah ditambahkan ke dalam dictionary dan nomor indeks untuk string tersebut ditulis dalam kurung siku. Kolom output menyatakan kode output yang dihasilkan oleh langkah kompresi (Linawati et al, 2004, hal: 10).
Algoritma penirmampatan LZW :
1. Dictionary diinisialisasi dengan semua karakter dasar yang ada : {‘A’..’Z’,’a’..’z’,’0’..’9’}. 2. CW = kode pertama dari stream kode (menunjuk ke salah satu karakter dasar).
3. Lihat dictionary dan output string dari kode tersebut (string.CW) ke stream karakter. 4. PW = CW; CW = kode berikutnya dari stream kode.
5. Apakah string.CW terdapat dalam dictionary ? Jika ada, maka :
iii. C = karakter pertama dari string.CW
iv. tambahkan string (P+C) ke dalam dictionary Jika tidak, maka :
i. P = string.PW
ii. C = karakter pertama dari string.PW
iii. output string (P+C) ke stream karakter dan tambahkan string tersebut ke dalam dictionary (sekarang berkorespondensi dengan CW);
6. Apakah terdapat kode lagi di stream kode ? Jika ya, maka kembali ke langkah 4. Jika tidak, maka terminasi proses (stop).
Contoh 2.2
String “ABBABABAC” akan dikompresi dengan LZW. Isi dictionary pada awal proses diset dengan tiga karakter dasar yang ada: “A”, “B”, dan “C”. Tahapan proses kompresi ditunjukkan pada Tabel di bawah ini.
Tabel 2.3 Proses Pemampatan LZW
Langkah Posisi Karakter Dictionary Output
1 1 A [4] A B [1]
2 2 B [5] B B [2]
3 3 B [6] B A [2]
4 4 A [7] A B A [4]
5 6 A [8] A B A C [7]
6 9 C --- [3]
Steam karakter: a b b ab aba c
Kode output : [1] [2] [2] [4] [7] [3]
Proses penirmampatan pada LZW dilakukan dengan prinsip yang sama seperti proses kompresi. Pada awalnya, dictionary diinisialisasi dengan semua karakter dasar yang ada. Lalu pada setiap langkah, kode dibaca satu per satu dari stream kode, dikeluarkan string dari dictionary yang berkorespondensi dengan kode tersebut, dan ditambahkan string baru ke dalam dictionary. Tahapan proses dekompresi ini ditunjukkan pada Tabel di bawah ini (Linawati et al, 2004, hal: 11).
Tabel 2.4 Proses Penirmampatan LZW
Langkah Kode Output Dictionary
1 [1] A ---
2 [2] B [4] A B
3 [2] B [5] B B
4 [4] A B [6] B A
5 [7] A B A [7] A B A
6 [3] C [8] A B A C
BAB 4
IMPLEMENTASI DAN PENGUJIAN
4.1Lingkungan Implementasi
Implementasi perangkat lunak sistem pemampatan ini dilakukan dalam lingkungan berbasis Windows. Sistem operasi yang digunakan adalah Microsoft Windows XP.
4.2 Perangkat Keras yang Digunakan
Implementasi perangkat lunak dilakukan dengan menggunakan komputer yang memiliki spesifikasi perangkat keras sebagai berikut :
1. Prosesor Intel Core 2 Duo 1.73 GHz 2. RAM 1 GB
3. Harddisk 80 GB
4. Monitor LCD 14” dengan resolusi layar 1024 x 768 pixel
4.3 Perangkat Lunak yang Digunakan
4.4 Implementasi Antar Muka
Untuk memudahkan penggunaannya, perangkat lunak sistem ini dilengkapi dengan antarmuka grafis, yang memiliki elemen-elemen sebagai berikut :
1. Tampilan Halaman Utama
Tampilan utama menampilkan menu run untuk memilih algoritma yang akan kita gunakan untuk melakukan pemampatan dan penirmampatan teks, serta menu exit untuk keluar dari aplikasi.
Gambar 4.1 Tampilan Halaman Utama
2. Tampilan Halaman Hasil
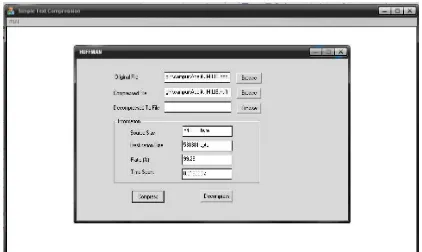
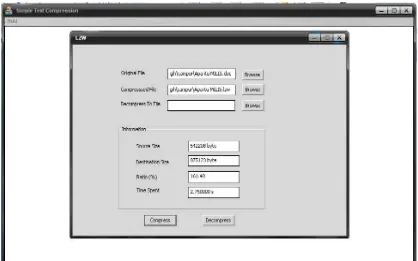
Halaman hasil menampilkan kotak teks untuk masukan file asli, file yang akan dimampatkan dan file yang akan dinirmampatkan. Masukan tidak dapat diketikkan langsung pada kotak teks, melainkan harus dipilih dengan menggunakan dialog yang dibuka dengan mengklik tombol “Browse” yang terletak disamping kotak teks yang ingin diisi. Masukan untuk original file
adalah nama file yang telah dinirmampatkan dan berekstensikan (*.huff.file asli) atau (*.lzw.file asli). Dan tampilan informasi yang berisikan source size
yang merupakan ukuran file asli dalam satuan byte, destination size yang merupakan ukuran file yang telah dimampatkan atau dinirmampatkan dalam satuan byte, ratio yang merupakan persentasi file yang telah dimampatkan atau dinirmampatkan dengan simbol %, time spent yang merupakan waktu yang dibutuhkan untuk melakukan pemampatan atau penirmampatan teks dalam satuan second. Dan tampilan informasi ini juga menampilkan kotak teks yang akan terisi secara otomatis apabila kita mengklik tombol “compress” atau “decompress”. Sedangkan tampilan tombol “compress” adalah tombol yang akan melakukan proses pemampatan data teks dan tampilan tombol “decompress” adalah tombol yang akan melakukan proses penirmampatan data teks.
Gambar 4.3 Pemampatan File Teks dengan Algoritma Huffman
Gambar 4.5 Pemampatan File Teks dengan Algoritma LZW
File yang telah dimampatkan dapat dikembalikan seperti file semula atau file asal dengan melakukan proses penirmampatan atau mengembalikan file hasil pemampatan menjadi file asal.
4.5 Pengujian Sistem Kompresi Teks Sederhana
Pengujian adalah elemen kritis dari jaminan kualitas perangkat lunak dan merepresentasikan kajian pokok dari spesifikasi, desain, dan pengkodean. Pentingnya pengujian perangkat lunak dan implikasinya yang mengacu pada kualitas perangkat lunak tidak dapat terlalu ditekan karena melibatkan sederetan aktivitas produksi di mana peluang terjadinya kesalahan manusia sangat besar dan arena ketidakmampuan manusia untuk melakukan dan berkomunikasi dengan sempurna maka pengembangan perangkat lunak diiringi dengan aktivitas jaminan kualitas.
Sasaran utama dalam pengujian adalah untuk mendapatkan serangkaian pengujian yang memiliki kemungkinan tertinggi di dalam pengungkapan kesalahan pada perangkat lunak. Dalam penelitian ini penulis menggunakan teknik pengujian
black box.
Teknik pengujian black-box berfokus pada domain informasi dari perangkat lunak, dengan melakukan test case dengan mempartisi domain input dari suatu program dengan cara yang memberikan cakupan pengujian yang mendalam.
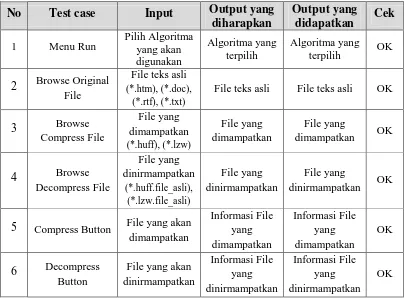
Tabel 4.1 Hasil Pengujian Sistem
No Test case Input Output yang
diharapkan
Output yang
didapatkan Cek
1 Menu Run Pilih Algoritma yang akan
2 Browse Original File
dimampatkan OK
4 Browse
dinirmampatkan OK
5 Compress Button File yang akan dimampatkan
File yang akan dinirmampatkan
Setelah algoritma Huffman dan algoritma LZW diimplementasikan ke dalam bahasa pemrograman, 16 tipe file teks diuji untuk dilakukan proses pemampatan. Program diuji pada file teks (*.txt), file dokumen (*.doc dan *.rtf) dan file HTML (*.htm) dimana masing-masing tipe file dengan ukuran yang berbeda-beda. Dari pengujian tersebut diperoleh ukuran file hasil pemampatan, rasio dan waktu yang dibutuhkan selama proses komputasi. Hasil-hasil pengujian yang diperoleh akan digunakan untuk membandingkan kinerja ke dua algoritma.
4.5.1 Analisis Ukuran File
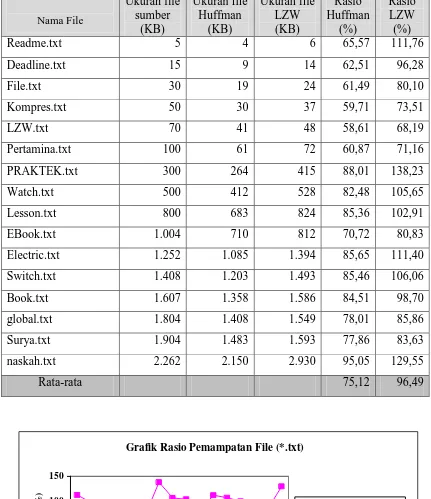
Tabel 4.2 Rasio Pemampatan 16 File (*.txt) dengan Algoritma Huffman dan
Grafik Rasio Pemampatan File (*.txt)
0 50 100 150
5 30 70 300 800 1252 1607 1904
Ukuran File Sumber (KB)
R
Tabel 4.3 Rasio Pemampatan 16 File (*.doc) dengan Algoritma Huffman dan
Grafik Rasio Pemampatan File (*.doc)
0
Ukuran File Sumber (KB)
R
Tabel 4.4 Rasio Pemampatan 16 File (*.htm) dengan Algoritma Huffman dan
Grafik Rasio Pemampatan File (*.htm)
0
Ukuran File Sumber (KB)
R
Tabel 4.5 Rasio Pemampatan 16 File (*.rtf) dengan Algoritma Huffman dan
Grafik Rasio Pemampatan File (*.rtf)
0
Ukuran File Sumber (KB)
R
75.12
(*.txt) (*.doc) (*.htm) (*.rtf) rata-rata
Kategori File
Grafik Rasio Pemampatan
Huffman
LZW
Gambar 4.11 Grafik Perbandingan Rasio Pemampatan
Berdasarkan hasil pengujian yang telah dilakukan pada aplikasi pemampatan file teks diperoleh bahwa:
1. Secara rata-rata algoritma Huffman menghasilkan rasio pemampatan yang lebih baik (71,58%) dari pada LZW (90.51%).
2. Dalam penelitian ini ternyata file berekstensi .rtf mampu dimampatkan oleh kedua algoritma Huffman dan Lempel Ziv Welch (LZW). Namun algoritma
Huffman mempunyai unjuk kerja yang baik.
3. Algoritma lempel Ziv Welch ( LZW ) dalam penelitian ini ternyata tidak cocok untuk memampatkan data-data web (.htm) karena dalam berbagai ukuran file
sampel jenis menghasilkan rasio pemampatan bernilai negatif, ini berarti tidak terjadi pemampatan melainkan pemekaran data. Untuk algoritma Huffman
4.5.2 Analisis Kecepatan Proses
Pengujian terhadap file teks juga dilakukan untuk mengetahui kecepatan pemampatan file teks. Pengujian ini bertujuan untuk mengetahui seberapa besar pengaruh faktor kecepatan proses pada pemampatan suatu file. Untuk melakukan pengujian, dipilih sejumlah file seperti file-file yang terdapat pada Tabel 4.1 kemudian dilakukan analisis yang ditampilkan dalam bentuk tabel dan grafik.
Tabel 4.6 Kecepatan Proses Pemampatan 16 File (*.txt) dengan Algoritma Huffman dan LZW
PRAKTEK.txt 300 0,015000 7,594000 20.000 39,50
Watch.txt 500 0,016000 1,734000 31.250 288,35
Lesson.txt 800 0,016000 4,172000 50.000 191,75
EBook.txt 1.004 0,032000 2,828000 31,38 0,36
Electric.txt 1.252 0,031000 5,562000 40,39 0,23
Switch.txt 1.408 0,031000 5,391000 45,42 0,26
Book.txt 1.607 0,031000 5,906000 51,84 0,27
global.txt 1.804 0,031000 5,609000 58,19 0,32
Surya.txt 1.904 0,047000 5,828000 40,51 0,33
naskah.txt 2.262 0,047000 11,937000 48,13 0,19
Grafik Kecepatan Pemampatan
0 10000 20000 30000 40000 50000
5 30 70 300 800 1.25 1.61 1.9
Ukuran File Sumber (KB)
Kecep
a
ta
n
(
KB
/s
)
Algoritma Huffman Algoritma LZW
Tabel 4.7 Kecepatan Proses Pemampatan 16 File (*.doc) dengan Algoritma Huffman dan LZW
Proposal.doc 207 0,016000 1,688000 12.937,5 122,63 kompresiFile.doc 430 0,016000 2,047000 26.875 210,06
Grafik Kecepatan Pemampatan
Ukuran File Sumber (KB)
Kecep
Tabel 4.8 Kecepatan Proses Pemampatan 16 File (*.htm) dengan Algoritma Huffman dan LZW
Notebook.htm 1.004 0,016000 2,891000 62,75 0,35
Sound.htm 1.308 0,032000 5,203000 40,88 0,25
Network.htm 1.504 0,047000 5,688000 32 0,26
View.htm 1.804 0,047000 5,688000 38,38 0,32
Table.htm 2.262 0,063000 12,078000 35,90 0,19
Script.htm 2.604 0,062000 13,063000 42 0,20
Grafik Kecepatan Pemampatan
Ukuran File Sumber (KB)
Kecep
Tabel 4.9 Kecepatan Proses Pemampatan 16 File (*.rtf) dengan Algoritma Huffman dan LZW
PROPOSAL.rtf 703 0,015000 1,062000 46.866,7 661,95
Qwerty.rtf 959 0,032000 6,000000 29.968,8 159,83
New.rtf 1.319 0,031000 1,188000 42,55 1,11
Paper.rtf 1.536 0,031000 1,516000 49,55 1,01
Ticket.rtf 1.607 0,031000 6,078000 51,84 0,26
Religi.rtf 1.804 0,047000 5,750000 38,38 0,31
Lesson 1c.rtf 2.256 0,062000 1,875000 36,39 1,20
Grafik Kecepatan Pemampatan
Ukuran File Sumber (KB)
Kecep
6347.86
(*.txt) (*.doc) (*.htm) (*.rtf) rata-rata
Kategori File
Grafik Perbandingan Kecepatan Pemampatan
Huffman
LZW
Gambar 4.16 Grafik Perbandingan Kecepatan Pemampatan
Dari hasil pengujian yang telah dilakukan pada aplikasi pemampatan file teks diperoleh bahwa:
1. Secara rata-rata algoritma Huffman membutuhkan waktu pemampatan yang tersingkat, kecepatan pemampatannya adalah 7.289, 93 KB/s dari pada algoritma LZW yang kecepatan pemampatannya 139,58 KB/s. LZW mengorbankan kecepatan pemampatan untuk mendapatkan rasio hasil pemampatan yang baik. File yang berukuran besar membutuhkan waktu yang sangat lama bila dimampatkan dengan LZW (contoh: file SMS KOMPRES.htm dengan ukuran 134 KB membutuhkan waktu kompresi 3,7 detik).
BAB 5
PENUTUP
5.1 Kesimpulan
Dari penelitian ini dapat disimpulkan beberapa hal mengenai perbandingan kinerja kedua metode pemampatan yang telah diimplementasikan, yaitu :
Berdasarkan analisis ukuran file didapat bahwa :
1. Secara rata-rata algoritma Huffman menghasilkan rasio pemampatan yang lebih baik dari pada LZW.
2. Dalam penelitian ini ternyata file berekstensi .rtf mampu dimampatkan oleh kedua algoritma Huffman dan Lempel Ziv Welch (LZW). Namun algoritma
Huffman mempunyai unjuk kerja yang baik.
3. Algoritma lempel Ziv Welch ( LZW ) dalam penelitian ini ternyata tidak cocok untuk memampatkan data-data web (.htm) karena dalam berbagai ukuran file
sampel jenis menghasilkan rasio pemampatan bernilai negatif, ini berarti tidak terjadi pemampatan melainkan pemekaran data. Untuk algoritma Huffman
walaupun terjadi pemampatan namun nilai rasionya kecil (dibawah 100% atau sama).
Berdasarkan analisis kecepatan proses didapat bahwa :
1. Secara rata-rata algoritma Huffman membutuhkan waktu pemampatan yang tersingkat dari pada algoritma LZW.
Secara umum dapat disimpulkan bahwa berdasarkan analisis terhadap ukuran file diperoleh bahwa algoritma yang paling baik untuk pemampatan setiap file teks tergantung dari karakteristik file yang akan dimampatkan. Sedangkan analisis terhadap kecepatan pemampatan file teks diperoleh bahwa jika ukuran file semakin besar maka semakin lama waktu yang dibutuhkan untuk memampatkan file teks.
5.2 Saran
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
3.1 Analisis Algoritma
Pemampatan data menggambarkan suatu sumber data digital seperti file gambar, teks, suara dengan jumlah bit yang sedikit yang bertujuan untuk mengurangi ukuran file sebelum menyimpan atau memindahkan data tersebut ke dalam media penyimpanan. Algoritma pemampatan yang digunakan pada penelitian ini yaitu Algoritma Huffman dan Algoritma LZW (Lempel Ziv Welch).
Kedua algoritma ini diawali dengan memberikan masukan berupa string, dan bagaimana menghasilkan keluaran algoritma berupa string yang mempunyai jumlah bit yang sedikit dibandingkan dengan string yang tidak dimampatkan. Dengan demikian, masalahnya adalah bagaimana menghasilkan string yang lebih pendek sehingga dapat menghemat kebutuhan tempat penyimpanan dan waktu transmisi data.