Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI
LEMPEL ZIV 77, LEMPEL ZIV 78
DAN LEMPEL ZIV WELCH
PADA FILE TEXT
SKRIPSI
ANDRE PRATAMA
051401030
PROGRAM STUDI S1 ILMU KOMPUTER
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
2009
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI LEMPEL ZIV 77, LEMPEL ZIV 78
DAN LEMPEL ZIV WELCH PADA FILE TEXT
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Komput er
ANDRE PRATAMA 051401030
PROGRAM STUDI S1 ILMU KOMPUTER DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
MEDAN 2009
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
ii PERSETUJUAN
Judul : STUDI PERBANDINGAN KINERJA ALGORITMA
KOMPRESI LEMPEL ZIV 77, LEMPEL ZIV 78 DAN LEMPEL ZIV WELCH PADA FILE TEXT
Kategori : SKRIPSI
Nama : ANDRE PRATAMA
Nomor Induk Mahasiswa : 051401030
Program Studi : SARJANA (S1) ILMU KOMPUTER
Departemen : ILMU KOMPUTER
Fakultas : MATEMATIKA DAN ILMU PENGETAHUAN
ALAM (FMIPA) UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, 17 November 2009 Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Syahril Efendi, S.Si, MIT Syahriol Sitorus, S.Si, MIT NIP. 196711101996021001 NIP. 197103101997031004
Diketahui/Disetujui oleh
Program Studi S1 Ilmu Komputer Ketua,
Prof. Dr. Muhammad Zarlis NIP. 195707011986011003
STUDI PERBANDINGAN KINERJA ALGORITMA KOMPRESI LEMPEL ZIV 77, LEMPEL ZIV 78
DAN LEMPEL ZIV WELCH PADA FILE TEXT
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, 17 November 2009
Andre Pratama 051401030
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
iv PENGHARGAAN
Alhamdulillah, puji syukur saya sampaikan kehadirat Allah SWT, yang telah memberikan rahmat dan hidayah-Nya serta segala sesuatunya dalam hidup, sehingga saya dapat menyelesaikan penyusunan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer, Program Studi S1 Ilmu Komputer Universitas Sumatera Utara. Shalawat beriring salam saya persembahkan kepada Nabi Besar Muhammad SAW.
Ucapan terima kasih saya sampaikan kepada bapak Syahriol Sitorus, S.Si, MIT sebagai Dosen Pembimbing I dan Bapak Syahril Efendi, S.Si, MIT sebagai Dosen Pembimbing II yang telah memberikan bimbingan, saran, dan masukan kepada saya untuk menyempurnakan kajian ini. Panduan ringkas, padat dan profesional telah diberikan kepada saya sehingga saya dapat menyelesaikan tugas ini. Selanjutnya kepada Dosen Penguji Bapak Prof. Dr. Muhammad Zarlis dan Ibu Maya Silvi Lydia, B.Sc.,M.Sc atas saran dan kritikan yang sangat berguna bagi saya. Ucapan terima kasih juga ditujukan kepada Ketua dan Sekretaris Program Studi S1 Ilmu Komputer, Bapak Prof. Dr. Muhammad Zarlis dan Bapak Syariol Sitorus, S.Si,MIT, Dekan dan Pembantu Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara, semua dosen serta pegawai di Program Studi S1 Ilmu Komputer FMIPA USU.
Skripsi ini terutama saya persembahkan untuk kedua orang tua dan keluarga saya yang telah memberikan dukungan dan motivasi, ayahanda Alfi Syahrir dan ibunda Maryati yang selalu sabar dalam mendidik saya. Untuk kedua adik saya, Friska Lestari dan Velya Ramadhani yang selalu memberikan dorongan kepada saya selama menyelesaikan skripsi ini. Kepada teman-teman terbaik yang selalu memberikan dukungan, Qori Mutia, Jerry Rahmat, Sarmedi Sitohang, Muhammad Andri, Lipantri Mashur Gultom, Hery Wibowo, Silvina Irwanti, Fadlan, Zulkarnain Lubis, dan Muhammad Husli Khairi. Untuk teman-teman sekelas dan satu angkatan yang sedang berjuang tanpa patah semangat dan tiada pupus harapan. Terima kasih pula kepada semua pihak-pihak yang tidak dapat saya sebutkan satu persatu, terima kasih atas ide, saran, dan kerjasama yang baik.
Saya menyadari bahwa skripsi ini masih jauh dari kesempurnaan, oleh karena itu saya menerima saran dan kritik yang bersifat membangun demi kesempurnaan skripsi ini. Sehingga dapat bermanfaat bagi kita semuanya.
ABSTRAK
Meningkatnya penggunaan komputer dalam kegiatan sehari-hari, secara tidak langsung juga membuat kebutuhan akan penyimpanan data semakin meningkat. Semakin besar data, semakin besar ruang yang dibutuhkan dan semakin lama waktu yang diperlukan untuk mengirimkan data. Untuk mengatasinya, telah dikembangkan berbagai algoritma kompresi yang digunakan untuk memampatkan data. Diantaranya, terdapat 3 algoritma kompresi yang menggunakan metoda dictionary : LZ77, LZ78 dan LZW. Ketiga algoritma dibandingkan untuk mengetahui algoritma mana yang memiliki kinerja tertinggi dalam memampatkan file text. Parameter kinerja diukur dari kompleksitas algoritma, rasio kompresi, dan berapa lama waktu yang diperlukan untuk proses kompresi. File yang diuji meliputi *.txt, *.doc, *.rtf, dan *.html. Setelah dianalisis dan diimplementasikan ke dalam program PHP, diperoleh bahwa algoritma LZ77 memiliki kompleksitas tertinggi. Algoritma LZW unggul dalam rasio kompresi file *.txt. Untuk file *.doc, *.rtf, dan *.html rasio kompresi terbaik diperoleh algoritma LZ77, tetapi algoritma LZ77 memerlukan waktu paling lama untuk hampir semua file uji.
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
vi
STUDY OF PERFORMANCE COMPARISON LEMPEL ZIV 77, LEMPEL ZIV 78 AND LEMPEL ZIV WELCH
COMPRESSION ALGORITHM ON TEXT FILE
ABSTRACT
The increasing use of computers in daily activities, indirectly also makes the need for increased data storage. The bigger the data, the greater the space required and the longer time required to transmit data. To overcome this problem, has been developed a variety of compression algorithm used to compress the data. Among them, there are 3 compression algorithm that uses dictionary method: LZ77, LZ78 and LZW. All three algorithms is compared to determine which algorithm has the highest performance to compress text file. Performance is measured by complexity of the algorithm, compression ratio, and how much time is needed in compression process. Files that are tested include *. txt, *. doc, *. rtf, and *. html. Having analyzed and implemented into a PHP program, LZ77 algorithm has the highest complexity. LZW algorithm has the best compression ratio in *. txt files. For *. doc, *. rtf, and *. html file, the best compression ratio is obtained by LZ77 algorithm, but the LZ77 algorithm takes the longest time for almost all test files.
DAFTAR ISI Halaman Persetujuan ii Pernyataan iii Penghargaan iv Abstrak v Abstract vi
Daftar Isi vii
Daftar Tabel ix Daftar Gambar xi Bab 1 Pendahuluan 1 1.1 Latar Belakang 1 1.2 Rumusan Masalah 2 1.3 Batasan Masalah 2 1.4 Tujuan Penelitian 2 1.5 Manfaat Penelitian 3 1.6 Diagram Konsepsi 3 1.7 Metodologi Penelitian 4 1.8 Sistematika Penulisan 5
Bab 2 Landasan Teori 6
2.1 Definisi dan Klasifikasi Algoritma Kompresi Data 6
2.2 Algoritma Lempel Ziv 77 8
2.3 Algoritma Lempel Ziv 78 11
2.4 Algoritma Lempel Ziv Welch 14
2.5 Kompleksitas Algoritma dan Notasi O-besar (big O) 16
Bab 3 Perancangan Sistem 24
3.1 Perancangan Fungsi 24
3.1.1 Perancangan Fungsi Dasar 24
3.1.1.1 Fungsi Konversi Bilangan Desimal ke Bilangan Biner 25 3.1.1.2 Fungsi Konversi Bilangan Biner ke Bilangan Desimal 26
3.1.1.3 Fungsi Pemotongan String 27
3.1.1.4 Fungsi Zero Left Pad 27
3.1.1.5 Fungsi Zero Right Pad 28
3.1.2 Perancangan Fungsi Khusus 29
3.1.2.1 Fungsi Bit Stream to String 29
3.1.2.2 Fungsi String to Bit Stream 31
3.2 Perancangan Algoritma Kompresi 32
3.2.1 Algoritma LZ77 32 3.2.1.1 Algoritma LZ77 Encoding 34 3.2.1.2 Algoritma LZ77 Decoding 40 3.2.2 Algoritma LZ78 44 3.2.2.1 Algoritma LZ78 Encoding 46 3.2.2.2 Algoritma LZ78 Decoding 51 3.2.3 Algoritma LZW 55
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
viii
Algoritma LZW Encoding 57
3.2.3.2 Algoritma LZW Decoding 62
3.3 Pengukuran Kecepatan Algoritma 66
3.4 Pengukuran Rasio Kompresi 68
3.5 Perancangan Aplikasi 68
3.5.1 Data Flow Diagram dan Kamus Data 68
3.5.1.1 Data Flow Diagram Proses Kompresi 69 3.5.1.2 Data Flow Diagram Proses Dekompresi 71
3.5.1.3 Kamus Data 73
3.5.2 Perancangan Interface 74
3.6 Implementasi Sistem 81
3.6.1 Halaman Home 81
3.6.2 Halaman Upload File Kompresi 82
3.6.3 Halaman Pilih Algoritma Kompresi 83
3.6.4 Halaman Pengaturan Parameter Kompresi LZ77 83 3.6 5 Halaman Pengaturan Parameter Kompresi LZ78 86
3.6.6 Halaman Bandingkan Algoritma 87
3.6.7 Halaman Upload File Dekompresi 89
3.6.8 Halaman Pengaturan Parameter Dekompresi 89
Bab 4 Analisa dan Pengujian Sistem 91
4.1 Analisa Perbandingan Kompleksitas Algoritma 91
4.1.1 Kompleksitas Proses Kompresi 91
4.1.2 Kompleksitas Proses Dekompresi 92
4.2 Pengujian Implementasi Algoritma dan Analisa Hasil 93
4.2.1 Perangkat Pengujian 94
4.2.2 File Pengujian 94
4.2.3 Pengujian Parameter Algoritma 97
4.2.3.1 Pengujian Parameter Algoritma LZ77 97 4.2.3.2 Pengujian Parameter Algoritma LZ78 100 4.2.3.3 Pengujian Parameter Algoritma LZW 101
4.2.4 Pengujian Algoritma 103
4.2.4.1 Pengujian File Plain Text ASCII (*.txt) 103 4.2.4.2 Pengujian File Microsoft Word Document (*.doc) 105 4.2.4.3 Pengujian File Rich Text Format (*.rtf) 108 4.2.4.4 Pengujian File hipertext markup language (*.htm/*.html) 110
Bab 5 Kesimpulan dan Saran 114
5.1 Kesimpulan 114
5.2 Saran 115
DAFTAR TABEL
Halaman
Tabel 2.1 Algoritma Dasar LZ77 Encoding 9
Tabel 2.2 Algoritma Dasar LZ77 Decoding 11
Tabel 2.3 Contoh Cara Kerja Algoritma LZ78 12
Tabel 2.4 Algoritma Dasar LZ78 Encoding 13
Tabel 2.5 Algoritma Dasar LZ78 Decoding 13
Tabel 2.6 Algoritma Dasar LZW Encoding 14
Tabel 2.7 Contoh Cara Kerja Algoritma LZW 15
Tabel 2.8 Algoritma Dasar LZW Decoding 16
Tabel 2.9 Perbandingan Pertumbuhan Kompleksitas (Growth Rates) 17
Tabel 2.10 Algoritma Konversi Suhu 19
Tabel 2.11 Algoritma Bilangan Ganjil atau Genap 20
Tabel 2.12 Algoritma Perulangan Sederhana 20
Tabel 2.13 Algoritma Perulangan Sederhana 20
Tabel 2.14 Perbandingan Pertumbuhan Kompleksitas 22 Tabel 3.1 Algoritma Fungsi Konversi Bilangan Desimal ke Bilangan Biner 25 Tabel 3.2 Algoritma Fungsi Konversi Bilangan Biner ke Bilangan Desimal 26
Tabel 3.3 Algoritma Fungsi Pemotongan String 27
Tabel 3.4 Algoritma Fungsi Zero Left Pad 28
Tabel 3.5 Algoritma Fungsi Zero Right Pad 29
Tabel 3.6 Algoritma Fungsi Bit stream to String 30 Tabel 3.7 Algoritma Fungsi String to Bit Stream 31
Tabel 3.8 Algoritma LZ77 Encoding 35
Tabel 3.9 Algoritma LZ77 Decoding 41
Tabel 3.10 Algoritma Fungsi Dalam Array LZ78 47
Tabel 3.11 Algoritma Fungsi Cari Array LZ78 47
Tabel 3.12 Algoritma LZ78 Encoding 48
Tabel 3.13 Algoritma LZ78 Decoding 53
Tabel 3.14 Algoritma Dalam Array LZW 57
Tabel 3.15 Algoritma Cari Array LZW 58
Tabel 3.16 Algoritma LZW Encoding 60
Tabel 3.17 Algoritma LZW Decoding 64
Tabel 3.18 Spesifikasi Proses DFD Kompresi Level 0 69 Tabel 3.19 Spesifikasi Proses DFD Kompresi Level 1 70 Tabel 3.20 Spesifikasi Proses DFD Dekompresi Level 0 71 Tabel 3.21 Spesifikasi Proses DFD Dekompresi Level 0 72
Tabel 3.22 Kamus Data 73
Tabel 4.1 Perbandinga n Kompleksitas Kompresi 1 91 Tabel 4.2 Perbandinga n Kompleksitas Kompresi 2 92 Tabel 4.3 Perbandingan Kompleksitas Dekompresi 1 92 Tabel 4.4 Perbandingan Kompleksitas Dekompresi 2 93
Tabel 4.5 File Uji Plain Text ASCII 95
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
x
Tabel 4.7 File Uji Rich Text Format 96
Tabel 4.8 File Uji Hipertext Markup Language 96
Tabel 4.9 Hasil Pengujian Parameter Algoritma LZ77 98 Tabel 4.10 Hasil Pengujian Parameter Algoritma LZ78 100 Tabel 4.11 Hasil Pengujian Parameter Algoritma LZW 101
Tabel 4.12 Rasio Kompresi File *.txt 103
Tabel 4.13 Lama Proses File *.txt 104
Tabel 4.14 Rasio Kompresi File *.doc 106
Tabel 4.15 Lama Proses File *.doc 107
Tabel 4.16 Rasio Kompresi File *.rtf 108
Tabel 4.17 Lama Proses File *.rtf 109
Tabel 4.18 Rasio Kompresi File *.htm/*.html 111
DAFTAR GAMBAR
Halaman
Gambar 1.1 Diagram Konsepsi 3
Gambar 2.1 Contoh Cara Kerja Algoritma LZ77 Bagian 1 10 Gambar 2.2 Contoh Cara Kerja Algoritma LZ77 Bagian 2 10 Gambar 2.3 Urutan Spektrum Kompleksitas Waktu Algoritma 23 Gambar 2.4 Grafik Perbandingan Pertumbuhan Kompleksitas 23 Gambar 3.1 Konversi token ke bit stream algoritma LZ77 33 Gambar 3.2 Konversi bit stream ke token algoritma LZ77 33
Gambar 3.3 Flowchart Algoritma LZ77 Encoding 34
Gambar 3.4 Proses Pencarian Pola Karakter LZ77 38
Gambar 3.5 Flowchart Algoritma LZ77 Decoding 41
Gambar 3.6 Proses Decoding Token Algoritma LZ77 43 Gambar 3.7 Konversi Token Ke Bit Stream Algoritma LZ78 45 Gambar 3.8 Konversi bit stream ke token algoritma LZ78 45
Gambar 3.9 Flowchart Algoritma LZ78 Encoding 46
Gambar 3.10 Flowchart Algoritma LZ78 Decoding 52 Gambar 3.11 Konversi Token Ke Bit Stream Algoritma LZW 56 Gambar 3.12 Konversi Bit Stream Ke Token Algoritma LZW 56
Gambar 3.13 Flowchart Algoritma LZW Encoding 59
Gambar 3.14 Flowchart Algoritma LZW Decoding 63
Gambar 3.15 Pengukuran Kecepatan Algoritma 67
Gambar 3.16 Data Flow Diagram Proses Kompresi Level 0 69 Gambar 3.17 Data Flow Diagram Proses Kompresi Level 1 70 Gambar 3.18 Data Flow Diagram Proses Dekompresi Level 0 71 Gambar 3.19 Data Flow Diagram Proses Dekompresi Level 1 72 Gambar 3.20 Struktur Perancangan Halaman Website 74
Gambar 3.21 Tampilan Rancangan Halaman Home 75
Gambar 3.22 Tampilan Rancangan Halaman Upload File Source Kompresi 76 Gambar 3.23 Tampilan Rancangan Halaman Pilih Algoritma Kompresi 76 Gambar 3.24 Tampilan Rancangan Halaman Pengaturan Parameter Algoritma 78 Gambar 3.25 Tampilan Rancangan Halaman Upload File Dekompresi 79 Gambar 3.26 Tampilan Rancangan Halaman Pengaturan Parameter Dekompresi 80
Gambar 3.27 Tampilan Halaman Home 82
Gambar 3.28 Tampilan Halaman Upload File Kompresi 82 Gambar 3.29 Tampilan Halaman Pilih Algoritma Kompresi 83 Gambar 3.30 Tampilan Halaman Pengaturan Parameter Kompresi LZ77 84
Gambar 3.31 Tampilan Hasil Kompresi LZ77 85
Gambar 3.32 Tampilan Halaman Pengaturan Parameter Kompresi LZ78 86
Gambar 3.33 Tampilan Hasil Kompresi LZ78 87
Gambar 3.34 Tampilan Halaman Bandingkan Algoritma 88 Gambar 3.35 Tampilan Halaman Upload File Dekompresi 89 Gambar 3.36 Tampilan Pengaturan Parameter Dekompresi 89
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
xii
Gambar 4.1 Grafik Rasio Kompresi Parameter Algoritma LZ77 99 Gambar 4.2 Grafik Rasio Kompresi Parameter Algoritma LZ78 100 Gambar 4.3 Grafik Lama Proses Kompresi Parameter Algoritma LZ78 101 Gambar 4.4 Grafik Rasio Kompresi Parameter Algoritma LZW 102 Gambar 4.5 Grafik Lama Proses Kompresi Parameter Algoritma LZW 102
Gambar 4.6 Grafik Rasio Kompresi File *.txt 104
Gambar 4.7 Grafik Lama Proses Kompresi File *.txt 105
Gambar 4.8 Grafik Performa File *.txt 105
Gambar 4.9 Grafik Rasio Kompresi File *.doc 106
Gambar 4.10 Grafik Lama Proses Kompresi File *.doc 107
Gambar 4.11 Grafik Performa File *.doc 108
Gambar 4.12 Grafik Rasio Kompresi File *.rtf 109 Gambar 4.13 Grafik Lama Proses Kompresi File *.rtf 110 Gambar 4.14 Grafik perbandingan Performa File *.rtf 110 Gambar 4.15 Grafik Rasio Kompresi File *.html 111 Gambar 4.16 Grafik Lama Proses Kompresi File *.html 112 Gambar 4.17 Grafik Perbandingan Performa Kompresi File *.html 113
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Meningkatnya penggunaan komputer dalam kegiatan sehari-hari, secara tidak langsung juga membuat kebutuhan akan penyimpanan data semakin meningkat. Data tersebut, dapat berupa file text, gambar, suara, dan video. Semakin besar ukuran file, semakin besar pula tempat penyimpanan yang dibutuhkan. Untuk keperluan pengiriman data melalui media transmisi, akan semakin lama juga waktu yang dibutuhkan untuk mengirimkan data tersebut. Oleh karena itu, mulailah dikembangkan algoritma-algoritma kompresi yang bertujuan untuk memampatkan data.
Kompresi data adalah ilmu atau seni merepresentasikan informasi dalam bentuk yang lebih compact. (Ida Mengyi Pu, 2006). Berbagai algoritma telah dikembangkan untuk keperluan kompresi data. Namun, algoritma tersebut sebahagian besar lebih efisien digunakan untuk tipe data tertentu saja. Misalnya untuk kompresi
text, terdapat algoritma Huffman, Ziv and Lempel 77 (LZ77), Ziv and Lempel 78
(LZ78), Lempel Ziv Welch (LZW), Dinamic Markov Compression (DMC), Run
Length Encoding (RLE) dan lain-lain.
Dalam tugas akhir ini, akan dibandingkan tiga algoritma kompresi : Ziv and Lempel 77 (LZ77), Ziv and Lempel 78 (LZ78), dan Lempel Ziv Welch (LZW), yang semuanya memakai metode kompresi dictionary. Ketiga algoritma ini dipilih karena merupakan algoritma dasar dan algoritma yang populer untuk metode kompresi
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
2
Algoritma LZW memberikan hasil kompresi yang buruk untuk file multimedia, seperti gambar, suara dan video (Linawati dan Panggabean, H.P., 2004). Karena Algoritma LZ77 dan LZ78 menggunakan konsep yang relatif sama, implementasi akan dilakukan hanya untuk file text.
Dalam menentukan algoritma yang tepat, ada 3 faktor yang akan dipertimbangkan, yaitu: kompleksitas algoritma, waktu yang dibutuhkan untuk melakukan kompresi, dan rasio perbandingan file hasil kompresi.
1.2 Rumusan Masalah
Permasalahan yang akan diteliti dan diuraikan dalam tugas akhir ini adalah:
1. Bagaimana perbandingan kompleksitas algoritma antara LZ77, LZ78, dan LZW. 2. Algoritma mana yang lebih efisien, dilihat dari waktu yang diperlukan untuk
kompresi dan dekompresi file, serta rasio perbandingan antara file hasil kompresi dengan file sebelum dikompresi.
1.3 Batasan Masalah
Batasan-batasan masalah dalam penelitian ini adalah:
1. Jenis file yang akan dikompresi adalah file plain text ASCII (.txt), microsoft word
document (.doc), rich text format (.rtf) dan hipertext markup language (.html).
2. Studi perbandingan kinerja yang dilakukan mencakup kompleksitas, waktu yang diperlukan, dan rasio perbandingan kompresi file.
3. Pengukuran kompleksitas dilakukan dengan perbandingan notasi Big O.
4. Aplikasi untuk implementasi algoritma dibuat menggunakan bahasa pemograman PHP dan JavaScript.
1.4 Tujuan Penelitian
Tujuan dari penelitian ini adalah:
1. Mengetahui algoritma mana yang lebih efektif dalam mengkompresi file text, 2. Mengembangkan aplikasi sebagai bentuk implementasi dari algoritma
3. Dengan aplikasi yang dikembangkan, ukuran file text dapat dikompresi menjadi lebih kecil, sehingga mengefisiensikan penggunaan memori penyimpanan.
1.5 Manfaat Penelitian
Dengan membandingkan 3 algoritma ini, dapat diambil manfaat algoritma mana yang lebih baik dalam melakukan kompresi file text, dan kelebihan serta kekurangan masing-masing algoritma. Selain itu, dengan membandingkan konsep-konsep dalam ketiga algoritma ini dapat dilihat bagaimana proses perancangan algoritma yang lebih baik, karena ketiga algoritma ini merupakan bentuk perbaikan dari algoritma sebelumnya.
1.6 Diagram Konsepsi
Konsep kerja studi perbandingan ketiga algoritma ini adalah sebagai berikut:
Gambar 1.1 Diagram Konsepsi Algoritma Kompresi
Algoritma LZ77 Algoritma LZ78 Algoritma LZW
Mengukur kompleksitas algoritma LZ77 Mengukur kompleksitas algoritma LZ78 Mengukur kompleksitas algoritma LZW
Implementasi ke dalam program komputer
Kompresi dan dekompresi file text ketiga algoritma
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
4
1.7 Metodologi Penelitian
Metodologi penelitian yang akan digunakan adalah: 1. Studi Literatur
Dengan melakukan studi literatur, penulis mempelajari teori tentang algoritma kompresi dari berbagai sumber, seperti buku, artikel, jurnal, dan situs-situs internet. Selain itu juga mempelajari beberapa teori lainnya yang dirasakan perlu. 2. Merancang Desain Sistem
Desain yang akan dirancang adalah struktur program yang akan digunakan untuk implementasi algoritma kompresi LZ77, LZ78, dan LZW.
3. Implementasi Sistem
Sistem akan diimplementasikan dalam bentuk aplikasi berbasis web menggunakan bahasa pemograman PHP dan JavaScript.
4. Pengujian dan Analisa Sistem
Pengujian ini mencakup apakah implementasi telah sesuai dengan teori, atau apakah program mengalami kesalahan. Perbaikan program akan dilakukan jika ditemukan kesalahan.
5. Dokumentasi Sistem
Pembuatan dokumentasi sistem, lengkap dengan analisis yang telah diperoleh.
1.8 Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari beberapa bagian utama sebagai berikut:
BAB I . PENDAHULUAN
Bab ini akan menjelaskan mengenai latar belakang masalah yang dibahas dalam skripsi ini, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian, dan sistematika penulisan skripsi.
BAB II. LANDASAN TEORI
Bab ini merupakan tinjauan teoritis yang berkaitan dengan algoritma kompresi, algoritma LZ77, LZ78 dan LZW, serta membahas teori Big O yang akan digunakan untuk membandingkan kompleksitas ketiga algoritma.
BAB III. PERANCANGAN DAN IMPLEMENTASI SISTEM
Dalam bab ini akan dibahas tentang perancangan untuk ketiga algoritma, pembuatan
psoude code untuk masing-masing algoritma dan menghitung kompleksitasnya. Lalu
diimplementasikan dalam bahasa pemograman PHP dan Javascript, beserta fungsi-fungsi program yang digunakan
BAB IV. ANALISA DAN PENGUJIAN SISTEM
Dalam bab ini akan berisi pengujian terhadap program yang sudah diimplementasikan, lalu dilakukan analisa perbandingan kinerja dari ketiga algoritma tersebut.
BAB V. KESIMPULAN DAN SARAN
Bab terakhir akan memuat kesimpulan isi dari keseluruhan uraian bab-bab sebelumnya dan saran-saran dari hasil yang diperoleh yang diharapkan dapat bermanfaat dalam pengembangan selanjutnya.
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
BAB 2
LANDASAN TEORI
Pada bab ini dijelaskan tentang defenisi dan klasifikasi kompresi data, lalu masing-masing teori tentang algoritma Ziv and Lempel 77 (LZ77), Ziv and Lempel 78 (LZ78), dan Lempel Ziv Welch (LZW). Selanjutnya dibahas teori tentang pengitungan kompleksitas algoritma menggunakan Big O.
2.1 Definisi dan Klasifikasi Algoritma Kompresi Data
Menurut Ida Mengyi Pu (2006, hal: 1) kompresi data adalah ilmu atau seni merepresentasikan informasi dalam bentuk yang lebih compact. Sedangkan David Salomon (2007, hal: 2) mengatakan bahwa data kompresi adalah proses mengkonversikan sebuah input data stream (stream sumber, atau data mentah asli) menjadi data stream lainnya (bit stream hasil, atau stream yang telah terkompresi) yang berukuran lebih kecil.
Tujuan dari kompresi data adalah untuk merepresentasikan suatu data digital dengan sesedikit mungkin bit, tetapi tetap mempertahankan kebutuhan minimum untuk membentuk kembali data aslinya. Data digital ini dapat berupa text, gambar, suara, dan kombinasi dari ketiganya, seperti video.
Untuk membuat suatu data menjadi lebih kecil ukurannya daripada data asli, diperlukan tahapan-tahapan (algoritma) untuk mengolah data tersebut. Menurut Thomas H. Cormen (2001, hal: 2) algoritma adalah suatu prosedur komputasi yang didefinisikan secara baik, membutuhkan sebuah atau sekumpulan nilai sebagai input, dan menghasilkan sebuah atau sekumpulan nilai sebagai output. Dalam algoritma
kompresi data, tidak ada algoritma yang cocok untuk semua jenis data. Hal ini disebabkan karena data yang akan dimampatkan harus dianalisis terlebih dahulu, dan berharap menemukan pola tertentu yang dapat digunakan untuk memperoleh data dalam ukuran yang lebih kecil. Karena itu, muncul banyak algoritma-algoritma kompresi data.
Secara garis besar, terdapat 2 penggolongan algoritma kompresi data: kompresi lossy, dan kompresi lossless.
a. Kompresi Lossy
Algoritma kompresi dikatakan lossy atau disebut juga irreversible jika tidak dimungkinkan untuk membentuk data asli yang tepat sama dari data yang sudah dikompresi. Ada beberapa detail yang hilang selama proses kompresi. Contoh penggunaan algoritma lossy seperti pada data gambar, suara dan video. Karena cara kerja sistem pengelihatan dan pendengararn manusia yang terbatas, beberapa detail dapat dihilangkan, sehingga didapat data hasil kompresi yang seolah-olah sama dengan data asli.
b. Kompresi Lossless
Algoritma kompresi dikatakan lossless atau disebut juga reversible jika dimungkinkan untuk membentuk data asli yang tepat sama dari data yang sudah dikompresi. Tidak ada informasi yang hilang selama proses kompresi dan dekompresi. Teknik ini digunakan jika data tersebut sangat penting, jadi tidak di mungkinkan untuk menghilangkan beberapa detail.
Untuk kompresi Lossless, berdasarkan cara mereduksi data yang akan dikompresi, terbagi lagi menjadi 2 kelompok besar algoritma:
a. Algoritma berbasis Entropi
Algoritma berbasis Entropi, atau disebut juga berbasis statistik, menggunakan model statistik dan probabilitas untuk memodelkan data, keefisienan kompresi bergantung kepada berapa banyak karakter yang digunakan dan seberapa besar
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
8
distribusi probabilitas pada data asli. Contoh algoritma yang berbasis entropi adalah: Huffman Coding, Adaptive Huffman, dan Shannon Fano.
b. Algoritma berbasis dictionary
Algoritma berbasis dictionary, bekerja dengan cara menyimpan pola masukan sebelumnya, dan menggunakan index dalam mengakses pola tersebut jika terdapat perulangan. Contoh algoritma yang berbasis dictionary adalah: LZ77, LZ78, LZW,
DEFLATE, dan LZMA.
Dari beberapa algoritma kompresi berbasis dictionary, LZ77, LZ78, dan LZW adalah yang paling populer. Banyak algoritma lainnya yang merupakan variasi dari tiga algoritma dasar tersebut. Pengembangan algoritma LZ77, LZ78, dan LZW tidak dalam waktu yang sama, algoritma LZ77 dikembangkan pada tahun 1977, LZ78 pada tahun 1978, dan LZW yang merupakan pengembangan dari LZ78, dipublikasikan pada tahun 1984.
Proses kompresi melibatkan 2 buah proses, yaitu proses kompresi (compression) dan dekompresi (decompression). Pada proses kompresi file asli dibaca, lalu dilakukan pengkodean untuk membuat file hasil kompresi. Proses ini disebut juga dengan proses encoding. Untuk memperoleh kembali file asli dari file yang sudah dimampatkan tersebut, proses pengkodean kembali dilakukan. Proses ini disebut juga proses decoding.
2.2 Algoritma Lempel Ziv 77
Algoritma Lempel-Ziv 77 (LZ77), atau dikenal juga dengan LZ1, dipublikasikan dalam sebuah paper oleh Abraham Lempel dan Jacob Ziv pada tahun 1977. Algoritma ini merupakan tipe algoritma lossless. Algoritma LZ77 disebut juga dengan ’sliding
windo ws’, atau jendela berjalan karena proses kerjanya (wikipedia, 2008).
Prinsip dari algoritma ini adalah menggunakan sebahagian input karakter yang telah dikodekan sebelumnya sebagai dictionary (kamus). Bagian input ini seolah-olah diibaratkan dengan sebuah jendela (window) yang dapat digeser dari kiri ke kanan. Jendela ini secara dinamis merupakan dictionary untuk mencari simbol
input dengan pola tertentu. Ketika jendela ini bergerak dari kiri ke kanan, isi dari dictionary dan input karakter yang akan dicari polanya juga akan berubah.
Jendela ini dibagi menjadi dua bagian, bagian pertama disebut history buffer (H), atau search buffer, yang berisi sebahagian input karakter yang sudah dikodekan. Jendela kedua adalah lookahead buffer (L), yang berisi sebahagian input karakter yang akan dikodekan. Ukuran dari masing-masing buffer ini telah ditetapkan sebelumnya, dalam implementasinya nanti, history buffer akan memiliki panjang beberapa ribu
byte, dan lookahead buffer panjangnya hanya puluhan byte (Salomon, D., 2007 ).
Algoritma kompresi LZ77 secara sederhana dapat dilihat pada tabel 2.1, dimana input berupa sebuah string karakter. Output algoritma adalah kumpulan token.
Tabel 2.1 Algoritma Dasar LZ77 Encoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
a ← batasan panjang history_buffer; b ← batasan panjang lookahead_buffer; history_buffer ← ””;
lookahead_buffer ← a karakter pertama dari string
input;
while not EOF do
temukan pola karakter terpanjang pada history_buffer yang cocok dengan pola yang terdapat pada
lookahead_buffer;
l ← jumlah karakter terpanjang yang ditemukan; f ← jarak antara ujung history_buffer dengan
karakter yang ditemukan;
c ← karakter pertama setelah karakter yang
ditemukan;
output token (f,l,c);
history_buffer ← history buffer + karakter yang
sudah dikodekan + c;
if ukuran history_buffer > a do
hapus beberapa karakter di awal history_buffer supaya tidak melebihi batas a;
end if
lookahead_buffer←lookahead_buffer + (l+1) karakter
berikutnya;
if ukuran lookahead_buffer > b do
hapus beberapa karakter di awal lookahead_buffer supaya tidak melebihi batas b;
end if end while
Sebagai contoh, pada gambar 2.1, H adalah: ”gian_input_yang_dikode kan._Bagian_”, sepanjang 34 byte (1 karakter = 1 byte). Lalu L adalah: ”inputan_ini_merup”, sepanjang 12 byte. Data input karakter pada dan sebelum H
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
10
sudah dikodekan sebelumnya, tetapi karakter pada dan sesudah L, adalah yang akan dikodekan.
Algoritma LZ77 akan mencari apakah karakter yang terdapat pada jendela L, terdapat juga pada jendela H. Pencarian ini untuk menemukan karakter terpanjang yang cocok dengan karakter yang ada pada jendela L. Kode yang dihasilkan dengan algoritma LZ77 berupa token dengan bentuk (f, l,c). Dimana f adalah jumlah karakter dari ujung jendela H kepada karakter yang ditemukan, dalam contoh ini adalah 29 karakter. Sedangkan l adalah jumlah panjang dari karakter yang ditemukan cocok pada H, dalam contoh ini sepanjang 5 karakter. Dan c adalah karakter pertama setelah karakter yang sudah dikodekan, yaitu ’a’.sehingga token yang dihasilkan adalah (29,5,a). Setelah token (29,5,a), jendela akan bergeser sebanyak 6 karakter, yaitu banyak karakter yang ditemukan + 1, ke kiri. Sehingga tampak seperti gambar 2.2.
Gambar 2.1 Contoh Cara Kerja Algoritma LZ77 Bagian 1
Gambar 2.2 Contoh Cara Kerja Algoritma LZ77 Bagian 2
Pada tahap ini, dilakukan cara yang sama seperti tahap sebelumnya, algoritma akan mencari apakah karakter yang terdapat pada jendela L, terdapat juga pada jendela H, dan menghasilkan token (8,4,i). Lalu jendela akan bergeser sebanyak 4+1 karakter ke kanan. Langkah ini dilakukan terus menerus sampai akhir dari file. Kumpulan token inilah yang menjadi file terkompresi dari file asli.
Sebahagian_input_yang_dikodekan._Bagian_inputan_ini_merup
History Buffer Lookahead Buffer 5
29
gian_input_yang_dikodekan._Bagian_inputan_ini_merupak
History Buffer Lookahead Buffer 4
Dekompresi algoritma LZ77, dilakukan dengan cara membaca semua token hasil kompresi dan mengkodekannya kembali menjadi string asli. Algoritma dasar dekompresi LZ77 dapat dilihat pada tabel 2.2.
Tabel 2.2 Algoritma Dasar LZ77 Decoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 11 output ← ””;
while not EOF do
f ← sub token 1 dari token; l ← sub token 2 dari token; c ← sub token 3 dari token; outlen ← panjang string output;
output ← output.ambil sebanyak l karakter
dari string output dimulai pada karakter ke (outlen-f).c;
end while
tampilkan output;
Ukuran dari history buffer dan lookahead buffer merupakan faktor penting dalam kinerja kompresi. Proses pencarian string yang efisien juga mempengaruhi kinerja dari algoritma kompresi LZ77.
2.3 Algoritma Lempel Ziv 78
Algoritma Lempel Ziv 78 (LZ78), dikembangkan 1 tahun setelah LZ77, yaitu pada tahun 1978. Oleh Abraham Lempel dan Jacob Ziv. Karena dipublikasikan oleh pihak yang sama, algoritma ini disebut juga dengan LZ2.
Pada algoritma LZ78, Abraham Lempel dan Jacob Ziv mencoba mengatasi permasalah yang ditemukan pada LZ77, yaitu berkaitan dengan kemampuan dalam menemukan pola karakter. Pada LZ77, algoritma ini tidak dapat menemukan pola karakter, jika karakter tersebut sudah dilewati oleh history buffer. Untuk mengatasinya, algoritma LZ78 dikembangkan dengan cara membuat suatu dictionary yang dapat menyimpan pola secara permanen selama proses pengkodean berlangsung.
Token yang digunakan sebagai index untuk menemukan pola tersebut,
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
12
adalah pointer yang merujuk pada dictionary dimana pola yang ditemukan, dan c adalah karakter pertama sesudah pola.
Dictionary pada LZ78 dapat dibayangkan sebagai sebuah array. Pada saat
proses pengkodean dimulai, array ini kosong. Sewaktu algoritma membaca sebuah karakter input, ia akan mencari dalam array, apakah karakter itu ada pada array atau tidak. Jika tidak ditemukan, karakter itu akan dimasukkan ke dalam array, dan dihasilkan token: (0,c), dimana c adalah karakter yang tidak ditemukan tersebut. Tetapi jika didalam array ditemukan, akan dibuat sebuah string yang bersisi karakter yang ditemukan tadi, disambung dengan karakter berikutnya dari input, dan kembali dicari didalam array, apakah pola ini ada atau tidak. Jika ada, string tadi ditambahkan kembali, sampai tidak ditemukan pola yang sesuai dengan string didalam array. Lalu
string ini akan dimasukkan ke dalam array, dan dihasilkan token: (f,c). Dimana f
adalah index dari array untuk pola string yang ditemukan, dan c adalah karakter terakhir dari string. Proses ini berlangsung terus menerus sampai akhir file (Pu , Ida M., 2006).
Tabel 2.3 adalah contoh 9 langkah pertama dalam mengkodekan string input : ”ada_beberapa_data_yang_hilang”. Kumpulan token inilah yang menjadi file kompresi pada algoritma LZ78. Salah satu masalah yang ada pada algoritma LZ78, adalah jumlah index, atau besar dari dictionary yang diperlukan. Dictionary ini akan bertambah banyak dengan sangat cepat. Salah satu cara sederhana adalah dengan membuat batas maksimum pada jumlah dictionary. Dan jika batas ini tercapai, algoritma tidak akan memasukkan karakter ke dalam dictionary lagi, tetapi hanya memakai dictionary yang sudah ada.
Tabel 2.3 Contoh Cara Kerja Algoritma LZ78
Index Isi dictionary Token Index Isi dictionary Token
0 null 5 ”e” (0,”e”)
1 ”a” (0,”a”) 6 ”be” (4,”e”)
2 ”d” (0,”d”) 7 ”r” (0,”r”)
3 ”a_” (1,”_”) 8 ”ap” (1,”p”)
Algoritma kompresi LZ78 secara sederhana dapat dilihat pada tabel 2.4, dimana input berupa sebuah string karakter, dan sebuah dictionary dengan index pertama berisi dengan nilai null. Output algoritma adalah kumpulan token.
Tabel 2.4 Algoritma Dasar LZ78 Encoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 11 dictionary[0] ← ””;
while not EOF do
word ← ””;
c←baca 1 karakter selanjutnya;
while word+c ada dalam dictionary do
word←word+c;
c ← baca 1 karakter selanjutnya;
end while
key ← index dictionary untuk word;
output (key,c);
tambahkan word+c kedalam dictionary pada lokasi yang tersedia;
end while
Dekompresi algoritma LZ78, dilakukan dengan cara membaca semua token hasil kompresi dan membuat kembali dictionary yang sama persis seperti proses kompresi. Misalkan (f,c) adalah pasangan token, maka algoritma dekompresi LZ78 dapat dilihat pada tabel 2.5.
Tabel 2.5 Algoritma Dasar LZ78 Decoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 dictionary[0] ← ””;
baca input dalam bentuk stream token
while not EOF stream token do
a ← karakter f pada token berikutnya; b ← karakter c pada token berikutnya; word ← isi dictionary pada index ke a;
output word.b;
tambahkan word.b kedalam dictionary pada lokasi yang tersedia
end while
Dibandingkan dengan algoritma LZ77 yang menggunakan 3 karakter untuk 1 token, algoritma LZ78 memakai token yang terdiri dari 2 karakter. Karena keterbatasan sumber daya memori, jumlah dictionary dalam LZ78 akan dibatasi. Sebuah algoritma pencarian untuk array juga merupakan faktor penting dalam kinerja algoritma LZ78.
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
14
2.4 Algoritma Lempel Ziv Welch
Algoritma Lempel Ziv Welch (LZW), dikembangkan oleh Abraham Lempel, Jacob Ziv, dan Terry Welch. Algoritma ini dipublikasikan pada tahun 1984 oleh Terry Welch. LWZ dirancang sebagai peningkatan dari algoritma LZ78.
Algoritma ini mereduksi jumlah token yang dibutuhkan menjadi 1 simbol saja. Simbol ini merujuk kepada index dalam dictionary. Proses kerjanya mirip dengan algoritma LZ78, tetapi jika pada algoritma LZ78 dictionary dimulai dari keadaan kosong, LZW mengisi dictionary ini dengan seluruh simbol karakter yang akan digunakan. Pada kasus yang umum, 256 index pertama dari dictionary akan diisi dengan karakter ASCII dari 0-255. Karena dictionary telah diisi dengan semua kemungkinan karakter terlebih dahulu, maka karakter input pertama akan selalu dapat ditemukan dalam dictionary. Inilah yang menyebabkan token pada LZW hanya memerlukan 1 simbol saja yang merupakan pointer pada dictionary.
Tabel 2.6 Algoritma Dasar LZW Encoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 word←””;
inisialisasi dictionary dengan 256 karakter ASCII;
while not EOF do
x←baca karakter selanjutnya;
if word+x ada dalam dictionary do
word←word+x;
else
output index dictionary untuk word; tambahkan word+x kedalam dictionary pada lokasi yang tersedia;
word←x;
end if end while
output index dictionary untuk word;
Prinsip kerja LZW, dimulai dengan membaca karakter input satu persatu dan diakumulasi pada sebuah string I. Lalu dilakukan pencarian dalam dictionary, apakah terdapat string I. Selama string I ditemukan didalam dictionary, string ini ditambahkan dengan satu karakter berikutnya, lalu dicari lagi dalam dictionary. Pada saat tertentu, menambahkan satu karakter x pada string I akan menyebabkan tidak ditemukan dalam dictionary. String I ditemukan, tetapi string I+x tidak. Dalam tahap
ini, algoritma akan akan menulis index dari string I sebagai output, menambahkan
string I+x kedalam dictionary, dan menginisialisasikan string I dengan x, lalu proses
dimulai lagi dari awal. Algoritma kompresi LZW secara sederhana dapat dilihat pada tabel 2.6, dimana input berupa sebuah string karakter. Output algoritma adalah kumpulan token.
Sebagai contoh, input adalah string : ”ada_beberapa_data_yang_hilang”.
Langkah pertama adalah mengisi dictionary dengan semua kemungkinan karakter, yaitu karakter ASCII dari 0-255, yang berarti index dictionary 0-255 telah berisi. Lalu
string I diisi dengan karakter ”a”. Didalam dictionary, karakter ”a” ada pada index ke
97. Lalu string I ditambah dengan karakter selanjutnya ”d”. Frase ”ad” tidak ditemukan, maka akan dihasilkan token 97, dan frase ”ad” ditambahkan pada index ke 256 dalam dictionary. String I sekarang berisi ”d”, karena d ada pada index ke 100, maka string I ditambahkan dengan karakter selanjutnya, menjadi ”da”. Untuk langkah selanjutnya dapat dilihat dari tabel 2.7.
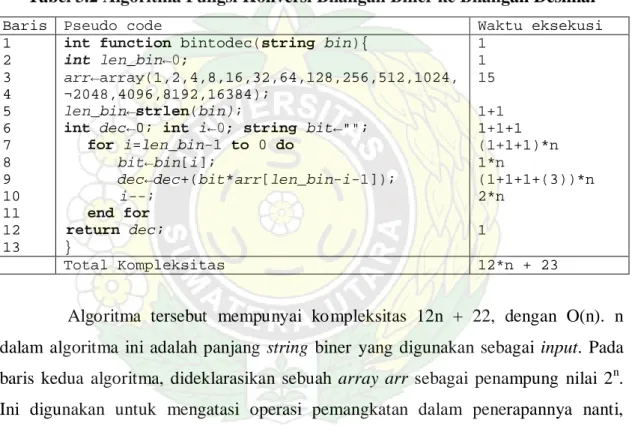
Tabel 2.7 Contoh Cara Kerja Algoritma LZW
String I Di dalam dictionary? Entry baru Output keterangan
a ada - -
ad tidak [256] = ad 97 97 adalah index dari ”a”
d ada - -
da tidak [257] = da 100 100 adalah index dari ”d”
a ada - -
a_ tidak [258] = a_ 97 97 adalah index dari ”a”
_ ada - -
_b tidak [259] = _b 95 95 adalah index dari ”_”
b ada - -
be tidak [260] = be 98 98 adalah index dari ”b”
e ada - -
eb tidak [261] = eb 101 101 adalah index dari ”e”
b ada - -
be ada - -
ber tidak [262] = be 260 262 adalah index dari ”be”
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
16
Kumpulan output yang berupa angka-angka inilah sebagai hasil kompresi. Karena menggunakan konsep dictionary yang sama seperti LZ78, pengorganisasian
dictionary juga diperlukan, misalnya seperti seberapa besar dictionary yang
disediakan, dan apa yang akan dilakukan jika dictionary sudah penuh.
Dekompresi algoritma LZW, dilakukan dengan cara membaca semua token hasil kompresi dan membuat kembali dictionary yang sama persis seperti proses kompresi. Misalkan (x) adalah token hasil proses kompresi, maka algoritma dekompresi LZ78 dapat dilihat pada tabel 2.8.
Tabel 2.8 Algoritma Dasar LZW Decoding
Baris Pseudo code 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
x←baca token x dari file;
element←isi dictionary pada index x;
output element;
word←element;
while not EOF do
x←baca token x selanjutnya;
if tidak ada index ke x pada dictionary then
element←word+karakter_pertama_pada_word;
else
element←isi dictionary pada index x;
end if
output element;
tambahkan word + karakter pertama dari word kedalam dictionary;
word←element;
end while
Banyak algoritma berbasis dictionary lainnya dikembangkan dari tiga algoritma ini. Misalnya algortima LZMW, LZAP dan LZY adalah variasi dari LZW. Algoritma LZFG yang merupakan gabungan dari LZ77 dan LZ78. Atau algoritma DEFLATE yang merupakan gabungan antara algoritma HUFFMAN dengan LZ77 dan banyak diimplementasikan dalam aplikasi kompresi populer seperti PKZIP dan 7-Zib (Feldspar A, 2009).
2.5 Kompleksitas Algoritma dan Notasi O-besar (big O)
Dalam ilmu komputer, sebuah algoritma tidak hanya dilihat dari apakah algoritma tersebut dapat memecahkan suatu masalah atau tidak, tetapi juga dari seberapa efisien algortima tersebut melakukannya. Keefisienan suatu algoritma biasanya berkaitan erat
dengan waktu dan ruang yang dibutuhkan algoritma tersebut dalam memecahkan masalah. Jika algoritma B dapat memecahkan masalah yang sama dengan waktu yang lebih cepat dibandingkan algoritma B, dapat dikatakan bahwa algoritma B lebih efisien daripada algoritma A.
Efisiensi suatu algortima dapat diukur dengan:
1. Waktu (time): yakni banyaknya komputasi elementer dalam algoritma.
2. Ruang (space): adalah banyaknya sel memori yang dibutuhkan oleh algoritma.
Ukuran ini secara berturut-turut disebut sebagai kompleksitas komputasi (computational complexity) dan kompleksitas ruang (space complexity) (Suksmono, 2009). Kedua kompleksitas ini tidak begitu berarti untuk input yang relatif sedikit, namun untuk input yang besar, keduanya dapat digunakan untuk mengetahui algoritma mana yang lebih efisien.
Salah satu hal yang paling penting dalam menghitung kompleksitas komputasi algoritma adalah pertumbuhan dari fungsi kompleksitas. Seperti contoh pada tabel 2.9, jika algoritma A mempunyai kompleksitas: 100n+50, dan algoritma B dengan kompleksitas: n2+10n+4, maka algoritma A dapat disimpulkan lebih efisien dibandingkan dengan algortima B untuk input yang besar dari 100. Hal ini dapat dilihat dimana dengan jumlah input (n) yang semakin membesar, algoritma B akan membutuhkan waktu yang lebih lama.
Tabel 2.9 Perbandingan Pertumbuhan Kompleksitas (Growth Rates) Algoritma A (100n+50) dengan Algoritma B ( n2+10n+4)
n Algoritma A (100n+50) Algoritma B (n2+10n+4) 10 50 100 200 500 1.000 1.050 5.050 10.050 20.050 50.050 100.050 204 3.004 11.004 42.004 255.004 1.010.004
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
18
Dengan jumlah input (n) kurang dari 100, algoritma B lebih efisien daripada algoritma B, namun jika jumlah input sudah diatas 100, algoritma B akan membutuhkan waktu yang lebih banyak daripada algoritma A. Pertumbuhan dari kompleksitas dengan meningkatnya besarnya input (n), adalah ukuran yang sesuai untuk membandingkan algoritma. Pertumbuhan fungsi kompleksitas dilambangkan dengan notasi O (dibaca big-O).
Dalam bidang matematika, notasi big O menggambarkan batasan ruang lingkup (limiting behavior) dari suatu fungsi, ketika argumen fungsi tersebut condong ke suatu nilai tertentu atau nilai yang tak berhingga. Notasi big O akan menyederhanakan suatu fungsi agar dapat diketahui tingkat pertumbuhan kompleksitasnya (growth rates) (wikipedia, 2009). Walaupun dikembangkan sebagai bagian dari perhitungan di bidang matematika, notasi big O juga dapat digunakan dalam bidang ilmu komputer untuk mengukur kompleksitas suatu algoritma.
Definisi big O: misalkan f dan g adalah dua buah fungsi dari bilangan bulat ke bilangan riil. Dapat dikatakan bahwa f(x) adalah O(g(x)) jika ada suatu konstanta C dan k sedemikian hingga |f(x)| ≤ C| g(x)|, saat x > k. (Suksmono, 2009). Saat menganalisa perumbuhan dari fungsi kompleksitas, f(x) dan g(x) selalu positif. Oleh karena itu, persyaratan big-O diatas dapat disederhanakan menjadi f(x) ≤ C⋅g(x) saat x > k.
Untuk menunjukkan bahwa f(x) adalah O(g(x)), hanya perlu ditentukan satu buah pasangan (C, k) (yang tidak pernah unik). Ide dibelakang notasi big-O adalah penentuan batas atas (upper boundary) dari perumbuhan suatu fungsi f(x) untuk x besar. Batas ini diberikan oleh fungsi g(x) yang biasanya jauh lebih sederhana daripada f(x). dengan konstanta C dalam persyaratan f(x) ≤ C⋅g(x) saat x > k. Karena C tidak pernah tumbuh sejalan dengan tumbuhnya x. Kita hanya tertarik pada x besar, sehingga jika f(x) > C⋅g(x) untuk x ≤ k, bukanlah suatu masalah.
Contoh Soal : Tunjukkan bahwa f(x) = x2 + 2x + 1 adalah O(x2). Jawab: Untuk x > 1: x2 + 2x + 1 ≤ x2 + 2x2 + x2
⇒ x2
Karena itu, untuk C = 4 dan k = 1: f(x) ≤ C x2 ketika x > k. ⇒ f(x) adalah O(x2).
Notasi big O dapat ditulis sebagai pangkat tertinggi (higest order) dari suatu fungsi polinomial. Ini dikarenakan untuk input (n) yang besar dalam fungsi polinomial, pangkat tertinggi akan sangat mendominasi. Jadi fungsi f(n) = 100n+50, ditulis dengan O(n), dan untuk f(n) = (n2+10n+4) ditulis sebagai O(n2).
Kompleksitas suatu algoritma dihitung untuk setiap langkah atau instruksi yang dikerjakan. Beberapa ketetapan waktu yang diterapkan :
1. Operasi pengisian nilai (assignment), perbandingan, operasi aritmatika, read and
write, membutuhkan waktu O(1).
2. Pengaksesan elemen array membutuhkan waktu O(1).
3. Operasi if-then-else waktu yang diambil adalah yaktu yang paling besar diantara 2 kondisi.
4. Operasi perulangan (for, repeat-until, dan while-do) membutuhkan waktu
sebanyak jumlah perulangan dikalikan dengan banyak instruksi dalam perulangan tersebut.
Contoh algoritma konversi suhu:
Tabel 2.10 Algoritma Konversi Suhu
Baris Pseudo code Waktu eksekusi
1 2 3 a←read(x); fahrenheit←(x*1.8)+32; print fahrenheit; 1 1+1+1=3 1
Pada contoh algoritma diatas, total waktu eksekusi adalah 1+3+1=4, maka notasi big O adalah O(1).
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
20
Contoh algoritma membedakan bilangan ganjil atau genap: Tabel 2.11 Algoritma Bilangan Ganjil atau Genap
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 a←read(x); b←0; if (a mod 2 = 0)
hasil←”bilangan genap”; b=b+a;
else
hasil←”bilangan genap”; end if 1 1 1+1=2 1 1+1=2 1
Pada contoh algoritma diatas, total waktu eksekusi adalah 1+1+2+ max(3,1)=1+1+2+3=7, maka notasi big O adalah O(1).
Contoh algoritma perulangan:
Tabel 2.12 Algoritma Perulangan Sederhana
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 a←read(x); b←0; i←0; for i=1 to a do b=b+i; i←i+1; end for 1 1 1 (1+1)*n=2n (1+1)*n=2n (1+1)*n=2n
Pada contoh algoritma diatas, total waktu eksekusi adalah 1+1+1+2n+2n+2n =6n+3, maka notasi big O adalah O(n).
Contoh algoritma perulangan bersarang (nested loop): Tabel 2.13 Algoritma Perulangan Sederhana
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 12 a←read(x); b←0;c←0;i←0;j←0; for i=1 to a do b←i; for j=1 to b do c←c+j j←j+1; end for i←i+1; end for 1 1+1+1+1=4 (1+1)*n=2n 1*n=1n (1+1)*n*n=2n2 (1+1)*n*n=2n2 (1+1)*n*n=2n2 (1+1)*n=2n
Pada contoh algoritma diatas, total waktu eksekusi adalah 1+4+2n+1n+2n2 +2n2+2n2 +2n=6n2+5n+5, maka notasi big O adalah O(n2).
Notasi big O yang sering diperoleh dari suatu algoritma adalah: 1. O(1) - constant time
Kompleksitas O(1) teradapat pada algoritma yang menghasilkan nilai selalu tetap tanpa bergantung kepada banyak masukan.
Contoh:
a. Operasi push dan pop pada suatu stack (yang terdiri dari n elemen). b. Inisialisasi suatu variabel.
c. Operasi aritmatika sederhana.
2. O(2log n) - logarithmic time
Algoritma yang berdasarkan pada binary tree biasanya memiliki kompleksitas O(log n).
Contoh:
a. Algoritma binary search pada list berurutan yang terdiri dari n elemen. b. Operasi insert dan search pada binary tree yang terdiri dari n node.
3. O(n) - linear time
Algoritma dengan kompleksitas O(n) membutuhkan 1 kali proses untuk masing-masing masukan.
Contoh:
a. Penelusuran suatu list/array yang terdiri dari n elemen.
b. Pencarian suatu nilai dalam list/array dengan algoritma linear search. c. Mencari nilai maksimum atau minimum dari suatu list.
4. O(n 2log n) - linearithmic time
Kompleksitas O(n log n) terdapat pada algoritma yang memecahkan masalah menjadi masalah yang lebih kecil, lalu menyelesaikan tiap masalah secara
independen.
Contoh:
a. Algoritma pengurutan list quicksort. b. Algoritma pengurutan list mergesort.
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
22
5. O(n2) - quadratic time
Umumnya algoritma dengan kompleksitas O(n2) melibatkan proses perulangan bersarang (nested loop).
Contoh:
a. Beberapa algoritma pengurutan sederhana, seperti selection sort. b. Membandingkan array 2 dimensi dengan ukuran n * n.
c. Mencari duplikasi dalam sebuah list yang tidak terurut dengan n elemen (menggunakan 2 loop bersarang).
6. O(n3) - cubic time
Algoritma dengan kompleksitas O(n3), mirip dengan O(n2), namun menggunakan
loop bersarang sebanyak 3 kali. Algoritma jenis ini hanya cocok jika n kecil. Jika
n besar, waktu yang dibutuhkan akan sangat lama.
7. O(2n) - exponential time
Salah satu algoritma yang mempunyai kompleksitas O(2n) adalah brute force dalam menebak suatu password. Setiap penambahan karakter, akan melipatgandakan waktu yang dibutuhkan.
8. O(n!) - factorial time
O(n!) merupakan kompleksitas yang sangat cepat pertumbuhan waktu yang diperlukannya. Algoritma ini memproses tiap masukan dan menghubungkannya dengan n-1 masukan lainnya.
Tabel 2.14 Perbandingan Pertumbuhan Kompleksitas
Input (n) O(1) O(log n) O(n) O(n log n) O(n2) O(n3) O(2n) O(n!)
1 1 1 1 1 1 1 2 1 2 1 1 2 2 4 8 4 2 8 1 3 8 24 64 512 256 40.320 64 1 6 64 384 4096 262.144 1019 1088 512 1 9 512 4.608 262.144 108 10153 101165 1.024 1 10 1.024 10.240 106 109 10307 102638 1.048.576 1 20 106 2*107 1012 1018 ∞ ∞
Pada tabel 2.4 terlihat perbandingan tingkat pertumbuhan (growth rates) dari masing-masing notasi big O. Untuk masukan (n) yang semakin membesar, O(n2), O(n3), O(2n) dan O(n!) membutuhkan waktu eksekusi yang sangat lama. Sedangkan O(1), O(log n) dan O(n) peningkatan waktu yang dibutuhkan tidak terlalu cepat untuk n yang besar. Urutan spektrum kompleksitas waktu algoritma dapat dilihat pada gam-bar 2.3, dan dalam grafik, pertumbuhan kompleksitas dapat dilihat pada gamgam-bar 2.4.
(1)< (log )< ( )< ( log )< ( )< ( )<...< 3 2 n O n O n n O n O n O O O( 2n)< O(n!)
algoritma polinomial algoritma eksponensial Gambar 2.3 Urutan Spektrum Kompleksitas Waktu Algoritma
Gambar 2.4 Grafik Perbandingan Pertumbuhan Kompleksitas Sumber : Growth of Functions (2009).
Suatu masalah dikatakan tractable (mudah dari segi komputasi) jika ia dapat diselesaikan dengan algoritma yang memiliki kompleksitas polinomial kasus terburuk (artinya dengan algoritma yang mangkus), karena algoritma akan menghasilkan solusi dalam waktu yang lebih pendek. Sebaliknya, sebuah masalah dikatakan
intractable (sukar dari segi komputasi) jika tidak ada algoritma yang mangkus untuk
menyelesaikannya. Masalah yang sama sekali tidak memiliki algoritma untuk memecahkannya disebut masalah tak-terselesaikan (unsolved problem) (Munir, 2009).
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
BAB 3
PERANCANGAN SISTEM
Perancangan sistem terdiri dari 5 bagian, bagian pertama adalah perancangan fungsi-fungsi yang digunakan pada perancangan algoritma kompresi. Bagian kedua merupakan perancangan masing-masing algoritma dalam bentuk pseudo code, lalu menghitung kompleksitasnya. Bagian ketiga berisi tentang perancangan pengukuran kecepatan algoritma, bagian keeampat tentang pengukuran rasio kompresi, dan bagian kelima tentang perancangan aplikasi yang mencakup DFD, kamus data dan interface program yang digunakan sebagai implementasi dari ketiga algoritma.
3.1 Perancangan Fungsi
Fungsi-fungsi yang dirancang digunakan dalam perancangan algoritma nantinya. Setiap algoritma membutuhkan beberapa fungsi yang hampir sama dalam melakukan proses kompresi (encoding) dan dekompresi (decoding), sehingga akan lebih efisien jika fungsi tersebut dipisahkan dari algoritma inti. Perancangan fungsi terdiri dari 2 bagian, yaitu perancangan fungsi dasar dan perancangan fungsi khusus.
3.1.1 Perancangan Fungsi Dasar
Perancangan fungsi dasar adalah perancangan fungsi-fungsi yang banyak digunakan dalam pemograman umum. Untuk bahasa pemograman tingkat tinggi, biasanya fungsi-fungsi ini sudah tersedia, termasuk bahasa pemograman PHP yang akan digunakan untuk implementasi ketiga algoritma. Tetapi untuk mengukur kompleksitas suatu algoritma, dihitung berdasarkan langkah demi langkah instruksi yang digunakan. Dengan merancang kembali fungsi-fungsi tersebut, akan dapat dihitung
kompleksitas dan big O untuk masing-masing fungsi. Namun ada beberapa batasan yang digunakan, dimana ada beberapa fungsi dasar yang tidak dirancang ulang, dan dianggap memiliki kompleksitas 1. Fungsi tersebut adalah:
1. Fungsi untuk mencari panjang dari suatu string : strlen().
2. Fungsi untuk mencari banyak elemen dalam suatu array : count(). 3. Fungsi konversi integer ke karakter ASCII : chr().
4. Fungsi konversi karakter ASCII ke integer : ord().
3.1.1.1 Fungsi Konversi Bilangan Desimal ke Bilangan Biner
Tujuan dari fungsi konversi bilangan desimal ke bilangan biner adalah untuk memperoleh output nilai biner dari input nilai desimal. Misalkan input dalam fungsi ini adalah 14, maka output yang dihasilkan adalah 1110. Tipe data masukan adalah integer, dan tipe data keluaran berupa string. Konversi bilangan desimal ke biner, dirancang dengan algoritma sebagai berikut:
Tabel 3.1 Algoritma Fungsi Konversi Bilangan Desimal ke Bilangan Biner
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 10 11 12 13 14
string function dectobin (int dec){ int sisa←0; string biner←””;
repeat {
sisa←dec modulus 2; dec←dec div 2;
if (sisa == 0) then biner←"0".biner; else biner←"1".biner; end if } until (dec > 0) return biner; } 1 1+1 (1+1)*2log n (1+1)*2log n 1*2log n (1+1)*2log n (1+1)*2log n 1*2log n 1
Total Kompleksitas 8 * 2log n + 4
Algoritma tersebut mempunyai kompleksitas 8 * 2log n + 4, dengan dalam percabangan if pada baris ke-6 hanya diambil salah satu nilai, sehingga O(2log n). Namun pada desain ketiga algoritma kompresi nantinya, batasan input dari fungsi konversi bilangan desimal ke bilangan biner ini adalah 214 = 16.384. Oleh karena n maksimum adalah 16.384, worst case fungsi ini menjadi 8 * 2log 16.384 + 4 = 116, dengan O(1).
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
26
3.1.1.2 Fungsi Konversi Bilangan Biner ke Bilangan Desimal
Tujuan dari fungsi konversi bilangan biner ke bilangan desimal adalah untuk memperoleh output nilai desimal dari input nilai biner. Misalkan input dalam fungsi ini adalah 11010, maka output yang dihasilkan adalah 26. Tipe data masukan adalah
string, dan tipe data keluaran adalah integer. Konversi bilangan desimal ke biner,
dirancang dengan algoritma sebagai berikut:
Tabel 3.2 Algoritma Fungsi Konversi Bilangan Biner ke Bilangan Desimal
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 10 11 12 13
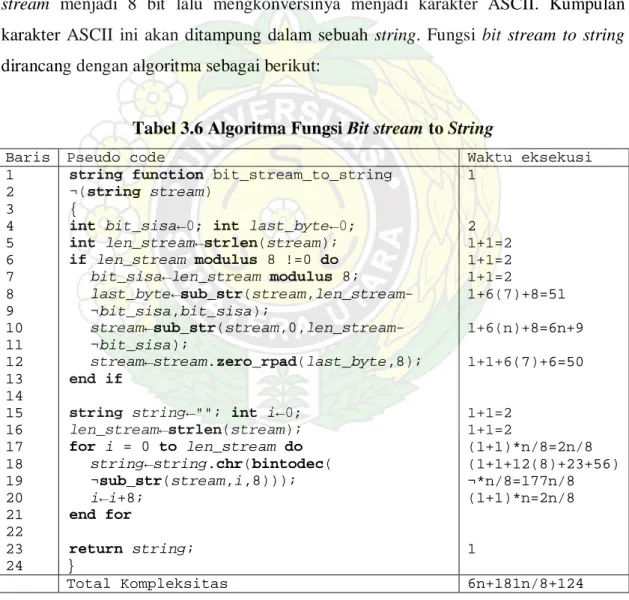
int function bintodec(string bin){
int len_bin←0;
arr←array(1,2,4,8,16,32,64,128,256,512,1024,
¬2048,4096,8192,16384);
len_bin←strlen(bin);
int dec←0; int i←0; string bit←""; for i=len_bin-1 to 0 do bit←bin[i]; dec←dec+(bit*arr[len_bin-i-1]); i--; end for return dec; } 1 1 15 1+1 1+1+1 (1+1+1)*n 1*n (1+1+1+(3))*n 2*n 1 Total Kompleksitas 12*n + 23
Algoritma tersebut mempunyai kompleksitas 12n + 22, dengan O(n). n dalam algoritma ini adalah panjang string biner yang digunakan sebagai input. Pada baris kedua algoritma, dideklarasikan sebuah array arr sebagai penampung nilai 2n. Ini digunakan untuk mengatasi operasi pemangkatan dalam penerapannya nanti, bahasa pemograman PHP membutuhkan fungsi khusus untuk operasi pemangkatan, yang menyebabkan nilai kompleksitas akan sulit dihitung.
Dalam desain ketiga algoritma, konversi dari biner ke desimal maksimal hanya membutuhkan 13 digit, atau nilai maksimum desimalnya 16383. Dengan pembatasan ini, kompleksitas fungsi konversi bilangan biner ke bilangan desimal menjadi konstan, karena perulangan yang terjadi maksimal hanya 13 kali, sehingga dapat ditulis sebagai O(1).
3.1.1.3 Fungsi Pemotongan String
Fungsi pemotongan string adalah untuk menggantikan fungsi substr() pada PHP, yang digunakan untuk mengambil sebagian isi string. Fungsi ini membutuhkan 3 parameter, yaitu string input, awal dari pemotongan dan panjang pemotongan. Parameter pertama bertipe string, dan yang lainnya bertipe integer. Output fungsi bertipe string. Fungsi pemotongan string dirancang dengan algoritma sebagai berikut:
Tabel 3.3 Algoritma Fungsi Pemotongan String
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 10
string function sub_str(string input, int
¬awal, int length){
int akhir←length+awal; string output←””; int i←0;
for i=awal to akhir do
output←output.input[i]; i++; end for return output; } 3 1+1 1+1 (1+1)*n (1+1)*n 2*n 1 Total Kompleksitas 6*n + 8
Algoritma tersebut mempunyai kompleksitas 6n + 8, sehingga O(n). n adalah panjang pemotongan. Prinsip kerja algoritma tersebut adalah menyambung karakter demi karakter dalam batas yang telah ditentukan. Dalam perancangan algoritma kompresi nantinya, nilai n untuk fungsi ini terbatas pada nilai tertentu, sehingga kompleksitas akan menjadi konstan dengan O(1).
3.1.1.4 Fungsi Zero Left Pad
Fungsi ini digunakan untuk menambahkan beberapa karakter nol pada sisi kiri sebuah
string dengan jumlah tertentu. Misalnya ditetapkan panjang string akhir adalah 8
karakter, jika input adalah 1101, output akan menjadi 00001101. Jika input adalah 1010010, output yang dihasilkan adalah 01010010. Fungsi ini membutuhkan 2 buah parameter, yang pertama adalah string input, yang kedua adalah panjang pad yang diinginkan dengan tipe data integer. Output fungsi bertipe string. Fungsi zero left pad dirancang dengan algoritma sebagai berikut:
Andre Pratama : Studi Perbandingan Kinerja Algoritma Kompresi Lempel Ziv 77, Lempel Ziv 78 Dan Lempel Ziv Welch Pada File Text, 2010.
28
Tabel 3.4 Algoritma Fungsi Zero Left Pad
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 10
string function zero_lpad( string input,
¬int pad_length){
int in_len←strlen(input); int i←0;
for i=in_len to pad_length do
input←"0".input; i++; end for return input; } 2 1+1 1 (1+1)*n (1+1)*n 2*n 1 Total Kompleksitas 6*n + 6
Algoritma tersebut mempunyai kompleksitas 6n + 6, dengan O(n). n adalah banyaknya karakter “0” yang akan ditambahkan. Algoritma tersebut menambahkan karakter “0” pada sisi kiri sebanyak panjang pad - panjang string input.
Dalam desain ketiga algoritma kompresi yang dirancang, maksimum panjang pad yang digunakan adalah 14 karakter. Sehingga nilai n maksimum adalah 14, dan kompleksitas fungsi zero left pad akan konstan menjadi 6(14) + 6 = 90 pada
worst case dengan O(1).
3.1.1.5 Fungsi Zero Right Pad
Fungsi ini mirip dengan zero left pad. Namun penambahan “0” dilakukan pada sisi kanan. Misalnya ditetapkan panjang string akhir adalah 8 karakter, jika input adalah 1101, output akan menjadi 11010000. Jika input adalah 1010010, output yang dihasilkan adalah 10100100. Fungsi ini membutuhkan 2 buah parameter, yang pertama adalah string input, yang kedua adalah panjang padding yang diinginkan bertipe integer. Output fungsi bertipe string. Fungsi zero right pad dirancang dengan algoritmaseperti pada tabel 3.5.
Tabel 3.5 Algoritma Fungsi Zero Right Pad
Baris Pseudo code Waktu eksekusi
1 2 3 4 5 6 7 8 9 10
string function zero_rpad(string input,
¬int pad_length){
int in_len←strlen(input); int i←0;
for i= in_len to pad_length do
input←input."0"; i++; end for return input; } 2 1+1 1 (1+1)*n (1+1)*n 2*n 1 Total Kompleksitas 6*n + 6
Untuk kompleksitas fungsi sama dengan zero left pad, 6n + 6, dengan O(n). n adalah banyaknya karakter “0” yang akan ditambahkan.
Kedua fungsi ini sengaja dipisahkan untuk efisiensi, karena dalam desain algoritma nantinya fungsi zero left pad akan sering digunakan, sedangkan fungsi zero
rightpad hanya beberapa kali digunakan.
3.1.2 Perancangan Fungsi Khusus
Perancangan fungsi khusus adalah perancangan fungsi atau sub program yang digunakan dalam perancangan algoritma LZ77, LZ78 dan LZW. Karena dalam beberapa tahap ketiga algoritma memerlukan fungsi yang sama, maka lebih efisien untuk memisahkannya menjadi sebuah sub program. Berbeda dengan desain fungsi dasar yang bersifat umum, desain fungsi khusus sedikit lebih kompleks dan merupakan bagian dari perancangan algoritma kompresi yang akan dibahas.
3.1.2.1 Fungsi Bit Stream to String
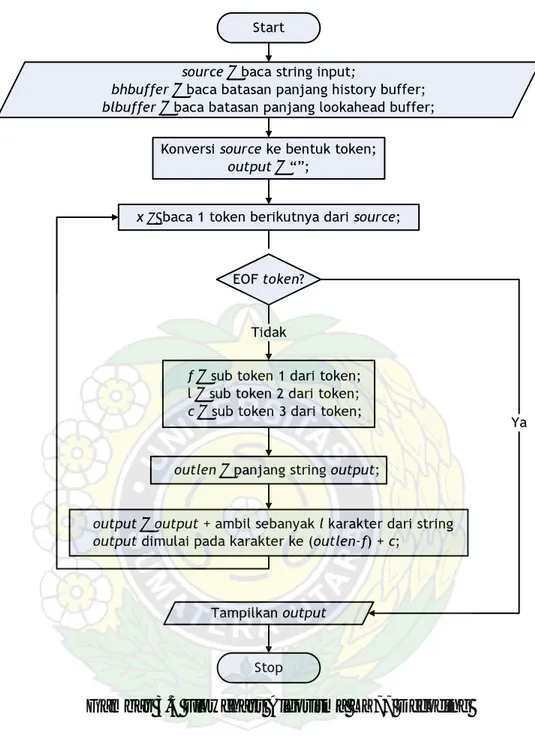
Fungsi bit stream to string digunakan oleh ketiga algoritma kompresi untuk mengkonversi bit stream menjadi string yang terdiri dari karakter-karakter ASCII sebelum di tulis kedalam file akhir. Fungsi ini diperlukan pada proses kompresi (encoding).
Bit stream yang akan dikompresi berupa sebuah string yang berisi angka
biner, seperti “0100101010110”. Bit stream ini adalah output dari proses encoding masing-masing algoritma kompresi. Untuk menyimpan hasil encoding ke dalam