Tempat/tanggal lahir : Bojonegoro, 30 juli 1987 Jenis kelamin : laki-laki
Status : Mahasiswa
Agama : Islam
Alamat : Jln. Babakan Cianjur Rt. 01 Rw. 07 kel.Campaka kec.Andir Bandung.
E-mail : [email protected]
PENDIDIKAN 1993-1999 : SD Negeri 1 Mayangkawis 1999-2002 : SMP Negeri 2 Balen 2002-2005 : SMA PGRI 1 Bojonegoro
SKRIPSI
Diajukan Untuk Menempuh Ujian Akhir Sarjana
AGUS RIYANTO
10112917
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Alhamdulillahi Rabbil ‘Alamiin, segala puji dan syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan karunia-Nya, shalawat serta salam semoga tercurah kepada Rasulullah SAW, sehingga penulis dapat
menyelesaikan tugas akhir yang berjudul “TEXT SUMMARIZATION DENGAN
METODE K-MEANS PADA ARTIKEL BERITA BERBAHASA INDONESIA” untuk memenuhi salah satu syarat dalam menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika Universitas Komputer Indonesia.
Dengan keterbatasan ilmu dan pengetahuan serta pengalaman penulis, maka penulis mendapat banyak bantuan serta dukungan dari berbagai pihak. Oleh karena itu, penulis mengucapkan terimakasih yang sebesar –besarnya kepada:
1. Allah SWT karena dengan izin-Nya lah tugas akhir ini dapat terselesaikan 2. Yth. Bapak Prof. Dr. Ir. Eddy Suryanto Soegoto, M.Sc., selaku Rektor
Universitas Komputer Indonesia (UNIKOM) Bandung.
3. Yth. Ibu Prof. Dr. Hj. Ria Ratna Ariawati, M.S, Ak, selaku Pembantu Rektor I Universitas Komputer Indonesia (UNIKOM) Bandung.
4. Yth. Bapak Prof. Dr. Moh Tadjuddin, M.A., selaku Pembantu Rektor II Universitas Komputer Indonesia (UNIKOM) Bandung.
5. Yth. Ibu Dr. Hj. Aelina Surya, selaku Pembantu Rektor III Universitas Komputer Indonesia (UNIKOM) Bandung.
iv
7. Yth. Bapak Irawan Afrianto, M.T. selaku ketua program studi Teknik Informatika Universitas Komputer Indonesia (UNIKOM) Bandung.
8. Ibu Ken Kinanti Purnamasari, S.Kom., M.T selaku dosen wali IF-19k/2012 dan juga selaku pembimbing yang selalu mengarahkan dan memberikan masukan dengan penuh kesabaran dalam menyelesaikan tugas akhir ini. 9. Yth. Segenap tim dosen dan staf program studi Teknik Informatika
Universitas Komputer Indonesia (UNIKOM) Bandung.
10.Yth. Segenap staf front office Universitas Komputer Indonesia (UNIKOM) Bandung.
Penulis menyadari bahwa penulisan tugas akhir ini masih jauh dari sempurna. Untuk perbaikan dan pengembangan, penulis mengharapkan saran dan kritik yang bersifat membangun. Akhir kata, semoga penulisan tugas akhir ini dapat bermanfaat bagi penulis khususnya, dan semua yang membaca.
Bandung, 25 Agustus 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xv
DAFTAR LAMPIRAN ... xviii
BAB 1 PENDAHULUAN ... 1
1.1. Latar Belakang Masalah ... 1
1.2. Identifikasi Masalah ... 2
1.3. Maksud dan Tujuan ... 2
1.4. Batasan Masalah... 2
1.5. Metodologi Penelitian ... 3
1.5.1. Metode Pengumpulan Data ... 3
1.5.2. Metode Pembangunan Perangkat Lunak ... 3
1.6. Sistematika Penulisan... 5
BAB 2 LANDASAN TEORI ... 7
2.1 Artikel ... 7
2.2 Kalimat ... 7
vi
2.4 Peringkasan Teks ... 9
2.4.1 Tahapan Membuat Ringkasan ... 9
2.5 TextMining ... 10
2.6 Peringkasan Teks Otomatis ... 10
2.6.1 Pendekatan Peringkasan Teks Otomatis ... 10
2.6.2 Preprocessing ... 10
2.7 Metode TF-IDF (Term Frequency – Inversed Document Frequency)... 12
2.8 Metode K-Means Clustering ... 13
2.9 Generating... 16
2.10 Teknik Evaluasi Peringkasan Teks ... 16
2.11 Flowchart ... 17
2.12 Data flow diagram(DFD) ... 17
2.13 Perangkat Lunak Pendukung... 18
2.13.1 Pengertian XAMPP ... 19
2.13.2 Pengertian PHP ... 19
2.13.3 Sublimtext... 19
BAB 3 ANALISIS DAN PERANCANGAN ... 21
3.1 Analisis Masalah ... 21
3.2 Arsitektur Sistem ... 21
3.3 Analisis Sistem ... 22
3.3.1 Analisis Data Masukan ... 24
3.3.2 Analisis Preprocessing ... 25
vii
3.3.4 Algoritma TD-IDF... 36
3.3.5 Algoritma K-Means ... 39
3.4 Analisis Kebutuhan Non-Fungsional ... 50
3.4.1 Kebutuhan Perangkat Keras (hardware). ... 50
3.4.2 Kebutuhan Perangkat Lunak (Software) ... 50
3.4.3 Kebutuhan Pengguna ... 51
3.5 Analsisi Kebutuhan Fungsional ... 51
3.5.1 Diagram Konteks ... 51
3.5.2 Data Flow Diagram (DFD)... 52
3.5.3 Spesifikasi Proses ... 56
3.5.4 Kamus Data ... 60
3.6 Perancangan Struktur Menu ... 62
3.6.1 Perancangan Antarmuka ... 62
3.6.1.1 Antarmuka Halaman Utama(T01) ... 62
3.6.1.2 Antarmuka Halaman Mencari/Pilih Dokumen(T02) ... 63
3.6.1.3 Antarmuka Halaman Hasil Ringkasan(T03) ... 64
3.6.2 Perancangan Pesan ... 66
3.6.2.1 Perancangan Pesan Berita Kosong(M01)... 66
3.6.3 Jaringan Semantik ... 66
3.7 Perancangan Prosedural ... 67
3.7.1 Perancangan Algoritma Utama... 67
3.7.2 Perancangan Algoritma Pemecahan Kalimat ... 68
viii
3.7.4 Perancangan Algoritma Filtering ... 70
3.7.5 Perancangan Algoritma Tokenizing ... 71
3.7.6 Perancangan Algoritma Stopword removal ... 72
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 73
4.1 Implementasi Sistem ... 73
4.1.1 Implementasi Perangkat Keras ... 73
4.1.2 Implementasi Perangkat Lunak ... 74
4.1.3 Implementasi Antarmuka ... 74
4.2 Pengujian ... 77
4.2.1 Pengujian Sistem ... 78
4.2.1.1 Pengujian Fungsionalitas ... 78
4.2.2 Skenario Pengujian Performasi ... 78
4.3 Hasil Pengujian ... 78
4.3.1.1 Hasil Pengujian Fungsionalitas ... 78
4.3.1.2 Hasil Pengujian Performasi ... 82
4.3.2 Evaluasi Pengujian ... 97
4.3.3 Kesimpulan Pengujian Akurasi ... 100
BAB 5 KESIMPULAN DAN SARAN... 101
5.1 KESIMPULAN ... 101
5.2 SARAN ... 101
102
[2]. Wardhana, Wisnu Linggakusuma. 2008. “Peringkas Multi-Dokumen untuk Bahasa Indonesia Menggunakan Teknik Centroid-Based Summarization dan Teknik K-Means-Based Summarization“. Skripsi. Fakultas Ilmu Komputer. Universitas Indonesia. Depok
[3]. Sommerfille, Ian. 2007. “Software Engineering Eight Edition”. s.l. : AddisonWisley, 2007.
[4]. Sudarman, Paryati. 2008. “Menulis di Media Massa”. Cetakan Pertama. Yogyakarta:Pustaka Pelajar
[5]. Zaman B. dan E. Winarko. 2011. “Analisis Fitur Kalimat untuk Peringkas Teks Otomatis pada Bahasa Indonesia”. Indonesian Journal of Computing and Cybernetics Systems 5 (2): 60-68.
[6]. Juhara, E., Budiman, E., dan Rohayati, R. 2005. “Cendekia Berbahasa”. Bahasa dan Sastra Indonesia. Bandung: PT Setia Purna Inves.
[7]. Mustaqhfiri, Muchammad. 2011. “Peringkasan Teks Otomatis Berita Berbahasa Indonesia Menggunakan Metode Maximum Marginal Relevance”. Skripsi. Jurusan Teknik Informatika. Fakultas Sains dan Teknologi Universitas Islam Negeri Maulana Malik Ibrahim. Malang.
[8]. Agusta, Yudi. 2007. “K-Means - Penerapan, Permasalahan dan Metode Terkait”. Jurnal Sistem dan Informatika Vol. 3: 47-60.
[10]. HM, Jogiyanto. 1989. “Analisis & Desain Sistem Informasi: Pendekatan Terstruktur Teori dan Praktek Aplikasi Bisnis”. Yogyakarta: Penerbit ANDI. [11]. Madcoms. 2009. “Aplikasi Program PHP + MySQL untuk membuat website
interaktif”. Yogyakarta: Andi.
[12]. Manjula, KS, S Begum, dan DVS Ramana. 2013. “Extracting Summary from Documents Using K-Mean Clustering Algorithm”. dalam: International Journal of Advanced Research in Computer and Communication Engineering 2 (8), p. 3244.
[13]. Agrawal, Ayush, dan Utsay Gupta. 2014. “Extraction Based Approach for Text Summarization Using KMeans Clustering”. dalam: IJSRP 4 (11).
[14]. Hovy, E.H.,U. Hermjakob, C-Y. Lin, and D. Ravichandran. 2001. “Toward Semantic-Based Answer Pinpointing”. Proceedings of the Human Language Technologies Confrence (HLT). San Diego, CA
[16]. Vijayasekaran, D., Kumar, R.A., Gowrishankar, N.C., Nedunchelian, K., Sethuraman, S. 2006. “Mantoux and Contact Positivity in Tuberculosis” . Indian Journal of Pediatr.
[17]. R. Feldman dan J. Sanger. 2007. “The Text Mining Handbook”. Cambridge
[18]. Pratama. Fendra. 2014. “Rancang Bangun Aplikasi Peringkas Teks Otomatis Artikel Berbahasa Indonesia Menggunakan Metode Term Frequency Inverse Document Frequency (TF-IDF) dan K-Mean Clustering “. Skripsi. Fakultas
Sains dan Teknologi Komputer. Universitas Islam Negeri Sultan Syarif Kasim Riau. Pekanbaru.
1
BAB 1 PENDAHULUAN
1.1.Latar Belakang Masalah
Perkembangan teknologi semakin pesat menyebabkan kebutuhan akan informasi yang sangat besar dan tidak terbatas, terutama informasi dalam bentuk jurnal, artikel, dan berita. Artikel yang ada pada situs portal berita umumnya bersifat
real time dan up to date yang menyebabkan artikel berita memiliki jumlah kalimat/paragraf yang sangat banyak[4]. Dibutuhkan waktu yang lama untuk membaca secara keseluruhan untuk dapat memehami dan mengetahui isi dari berita tersebut. Sehingga diperlukan sebuah sistem peringkasan teks otomatis. Dengan adanya sistem peringkasan teks otomatis diharapkan pembaca akan lebih mudah untuk memahami dan mengetahui isi dari berita tersebut.
Banyak metode penelitian yang membahas tentang peringkasan teks otomatis salah satunya, yaitu Rendra Pratama pada tahun 2014. Rendra Pratama menggunakan
K-means clustering untuk meringkas dokumen tunggal berita artikel dalam bahasa Indonesia. Pada penelitiannya jumlah kluster yang sudah ditetapkan atau konstan, sedangkan jumlah kluster sangat berpengaruh terhadap ringkasan[13]. Pada penelitian tersebut pemilihan kalimat penting berdasarkan bobot kalimat paling besar pada tiap cluster dengan mengambil compression sebesar 25% dan 40%. Pengujian hasil ringkasan sistem pada compression 40% menghasilkan rata-rata recall 60%, precision 62%, dan f-measure 61%. Sedangkan untuk compression 25% menghasilkan rata-rata recall 37%, precision 44%, dan f-measure 40%. Penilaian hasil ringkasan sistem oleh expert judgement pada compression 40% menghasilkan nilai rata-rata 3,15 atau pada range diterima, sedangkan pada compression 25% menghasilkan nilai rata-rata 1,83 atau berada pada range cukup diterima[18]. Dalam hal ini seberapa besar tingkat akurasi apabila tingka tidak menggunakan tingkat compression dan penentuan jumlah
Berdasarkan pada hal tersebut, maka penulis dalam penelitian ini akan membuat Text Summarization dengan metode k-means pada artikel berita berbahasa Indonesia. Hasil ringkasan nantinya diharapkan dapat memberikan informasi yang lebih akurat.
1.2. Identifikasi Masalah
Berdasarkan uraian pada latar belakang masalah diatas, identifikasi masalah dalam penelitian ini adalah seberapa besar tingkat akurasi ringkasan yang dihasilkan sistem peringkasan teks pada artikel berita berbahasa Indonesia jika tingkat
compression dan penentuan jumlah cluster disesuaikan berdasarkan pada jumlah kalimat.
1.3. Maksud dan Tujuan
Penelitian ini bermaksud membuat sistem peringkas teks pada artikel berita berbahasa Indonesia. Sedangkan tujuan yang ingin dicapai dari penelitian ini adalah mengetahui tingkat akurasi pada sistem peringkasan teks otomatis dengan metode K
-Means pada artikel berita berbahasa Indonesia. 1.4. Batasan Masalah
Agar penelitian ini tidak menyimpang dari latar belakang dan tujuan yang akan dicapai, maka terdapat batasan masalah sebagai berikut.
1. Dokumen yang digunakan sebagai inputan berupa dokumen berita berbahasa Indonesia dengan ekstensi .txt dan dokumen tunggal berita berbahasa Indonesia.
2. Proses preprocessing yang dilakukan dalam penelitian ini terdiri dari
Token Kalimat, casefolding, Filtering, Tokenizing dan Stopword Removal.
1.5. Metodologi Penelitian
Metode penelitian implementasi text suummarization dengan metode K-Means ini menggunakan metode deskriptif. Metode deskriptif adalah metode yang digunakan untuk menggambarkan atau menganalisis suatu hasil penelitian tetapi tidak digunakan untuk membuat kesimpulan yang lebih [15]. Metode penelitian meliputi metode pengumpulan data dan metode pembangunan perangkat lunak. Adapun skema dalam penelitian ini, untuk lebih jelasnya lihat gambar 1.1 berikut.
Mengidentifikasi Masalah
Mengidentifikasi Masalah Merumuskan Tujuan Penelitian Merumuskan Tujuan
Penelitian Mengumpulkan DataMengumpulkan Data
Perancangan Sistem
Perancangan Sistem Evaluasi DataEvaluasi Data LaporanLaporan
Gambar 1. 1 Skema Penelitian 1.5.1. Metode Pengumpulan Data
Dalam penelitian ini, penulis melakukan beberapa metode untuk memperoleh data atau informasi dalam menyelesaikan permasalahan. Metode yang dilakukan tersebut adalah Studi literatur. Studi literatur dilakukan dengan mempelajari teori-teori melalui buku, artikel, jurnal dan bahan lain yang berkaitan dengan metode tahap yang digunakan untuk meringkas teks dan algoritma K-Means.
1.5.2. Metode Pembangunan Perangkat Lunak
Analisa kebutuhan
Desain sistem
Penulisan Kode Program
Pengujian Program
Operasi dan perawatan
Gambar 1. 2 Diagram Waterfall Sommerfille[3] 1. Analisa kebutuhan
Pada tahap ini dilakukan pengumpulan kebutuhan penelitian secara lengkap mengenai peringkasan teks menggunakan motode k-means. Data yang digunakan dalam format .txt.
2. Desain sistem
Setelah kebutuhan data telah dikumpulkan, tahap selanjutnya adalah perancangan sistem secara keseluruhan. Untuk kebutuhan perangkat lunak dalam pengolahan data diperlukan software yang berjalan pada operasi sistem windows dalam hal ini peneliti menggunakan bahasa pemrograman PHP. Yang akan berjalan disebuah halaman website.
3. Penulisan kode program
Setelah perancangan sistem secara keseluruhan, maka tahap selanjutnya adalah mengimplementasikan ke dalam bahasa pemrograman. Tahap preprocessing(pemisahan kalimat, casefolding, filtering, tokenisasi dan
TF-IDF. Hasil dari TF-IDF ini kemudian akan dilakukan clustering dengan metode K-Means.
4. Pengujian program
Tahapan ini digunakan untuk mengintegrasikan program, apabila program yang dibuat berjalansesuai dengan harapan maka text summarization siap digunakan oleh pengguna sistem.
5. Operasi dan perawatan
Pada tahapan ini sistem sudah siap untuk digunakan, lalu dilakukan pengembangan sistem seperti penambahan fitur dan fungsi baru yang mungkin akan muncul untuk kebutuhan pengguna.
1.6. Sistematika Penulisan
Sistematika penulisan pada penelitian ini disusun untuk memberikan gambaran umum tentang kasus yang akan dilakukan. Sistematika penulisan tugas akhir ini adalah sebagai berikut.
BAB 1 PENDAHULUAN
Bab ini menerangkan secara umum mengenai latar belakang, rumusan masalah, menentukan maksud dan tujuan, batasan masalah, metodologi penelitian, metode pembangunan perangkat lunak, serta sistematika penulisan penelitian text summarization artikel berita berbahasa indonesia.
BAB 2 LANDASAN TEORI
Pada bab ini membahas berbagai konsep dasar dan teori-teori yang berkaitan dengan topik penelitian tugas akhir. Pembahasan dimulai dari penjelasan berita, jenis-jenis berita. Dilanjutkan dengan peringkasan teks dan metode yang digunakan. BAB 3 ANALISIS DAN PERANCANGAN
Bab ini berisi mengenai perancangan untuk melakukan text summarization
filtering, tokenizing, stopword removal), pembobotan kata dengan TF-IDF dan
clustering dengan metode k-means.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Pada bab ini berisi tentang tahapan yang dilakukan dalam penelitian secara garis besar dimulai dari tahapan persiapan sampai pada penarikan kesimpulan, pada tahap ini text summarization akan diuji dengan menggunakan data testing.
BAB 5 KESIMPULAN DAN SARAN
7 BAB 2 LANDASAN TEORI
2.1 Artikel
Artikel adalah tulisan lepas berisi opini seseorang yang mengupas tuntas suatu masalah tertentu yang sifatnya aktual dan atau kontroversial dengan tujuan untuk memberitahu (informatif), memengaruhi dan meyakinkan (persuatif argumentatif), atau menghibur khalayak pembaca (rekreatif). Disebut lepas, karena siapa pun pembaca boleh menulis artikel dengan topik bebas sesuai dengan minat dan keahliannya masing-masing. Selain itu juga artikel yang ditulis tersebut tidak terkait dengan berita atau laporan tertentu. Ditulisnya pun boleh kapan saja, di mana saja, dan oleh siapa saja. Secara teknis jurnalistik, artikel adalah salah satu bentuk opini yang terdapat dalam surat kabar atau majalah. Disebut salah satu, karena masih ada bentuk opini yang lain. Analoginya sederhana, kalau kita membuka halaman demi halaman surat kabar atau majalah maka secara umum isinya dapat digolongkan ke dalam tiga kelompok besar. Kelompok pertama adalah berita (news), kelompok kedua disebut opini (views), kelompok ketiga dinamakan iklan (advertising)[4].
Kelompok berita, meliputi berita langsung (straight news), berita foto (photo news), berita suasana-berwarna (colour news), berita menyeluruh (comprehensive news) berita mendalam (depth news), berita penafsiran (interpretative news), dan berita penyelidikan (investigative news). Kelompok opini, meliputi tajuk rencana atau editoril, karikatur, pojok, artikel, kolom, dan surat pembaca. Untuk memisahkan secara tegas antara berita (news) dan opini (views), maka tajuk rencana, karikatur, pojok artikel, dan surat pembaca ditempatkan pada satu halaman khusus. Pemisahan secara tegas berita dan opini tersebut merupakan konsekuensi dari norma dan etika luhur jurnalistik yang tidak menghendaki berita sebagai fakta objektif, diwarnai atau dibaurkan dengan opini sebagai pandangan yang bersifat subjektif [4].
Kalimat adalah satuan bahasa terkecil dalam wujud lisan atau tulisan, yang mengungkapkan pikiran yang utuh. Kalimat terdiri atas deret kata yang dimulai dengan huruf kapital dan diakhiri dengan tanda titik. Unsur-unsur kalimat terdiri dari kata, kelompok kata dan lagu kalimat. Di dalam kalimat terdapat pengaturan hubungan kedudukan antara bagian-bagiannya. Ada bagian didalam kalimat yang menunjukkan sebagai “pelaku”, ada bagian yang menunjukkan sebagai “perbuatan”, ada bagian yang menunjukkan “bagaimana perbuatan itu dilakukan”. Berdasarkan jabatannya kalimat terdiri dari.
1. Subyek, yaitu bagian yang menjadi pangkal atau pokok pembicaraan.
2. Predikat, yaitu bagian yang menerangkan subyek, biasanya berdiri sesudah subyek.
3. Obyek, yaitu bagian yang menjadi tujuan.
4. Keterangan, yaitu bagian yang menunjukkan waktu (keterangan waktu), tempat (keterangan tempat), alat (keterangan alat) dan sebagainya. Sedangkan kalimat berdasarkan fungsinya, dapat dikategorikan sebagai berikut.
a. Kalimat pernyataan. b. Kalimat pertanyaan. c. Kalimat perintah. d. Kalimat seruan.
2.3 Kata
Kata adalah kesatuan terkecil yang diperoleh sesudah kalimat dibagi atas bagianbagiannya dan mengandung suatu ide. Kategori kata berdasarkan sintaksisnya terdiri dari lima kata [7] yaitu :
1. Kata Benda (Nomina) Kata benda adalah kata yang mengacu pada manusia, binatang, benda dan konsep atau pengertian.
3. Kata Sifat (Adjektiva) Kata sifat adalah kata yang memberi keterangan yang lebih khusus tentang sesuatu yang dinyatakan oleh nomina dalam kalimat.
4. Kata Keterangan (adverbia) Kata keterangan adalah kategori yang dapat mendampingi adjektiva, numeralia atau preposisi dalam konstruksi sintaksis.
5. Kata tugas adalaah kata yang hanya memiliki arti gramatikal dan tidak memiliki arti leksikal.
2.4 Peringkasan Teks
Konsep sederhana ringkasan adalah mengambil bagian penting dari keseluruhan isi dari artikel. Ringkasan adalah mengambil isi yang paling penting dari sumber informasi yang kemudian menyajikan kembali dalam bentuk yang lebih ringkas bagi penggunanya[5].
2.4.1 Tahapan Membuat Ringkasan
Ada beberapa tahapan dalam membuat ringkasan [6], yaitu sebagai berikut. 1. Membaca naskah asli secara menyeluruh untuk mengetahui kesan umum,
gagasan pengarang dan sudut pandangnya.
2. Mencatat semua gagasan u utama atau gagasan penting.
3. Menyusun kembali suatu karangan singkat berdasarkan gagasan tersebut.
2.5 Text Mining
Text mining adalah proses mencari informasi dengan menggunakan tools
analisis berupa kategorisasi. Proses text mining dapat menjadi solusi dari permasalah pemrosesan data berupa teks yang tidak terstruktur dalam jumlah yang banyak. Text mining sering digunakan dalam kasus information retrieval. Tujuan adanya text mining yaitu untuk mendapatkan informasi yang bermanfaat dari sekumpulan data, salah satunya adalah dokumen teks [17].
2.6 Peringkasan Teks Otomatis
Peringkasan teks otomatis adalah teknik pembuatan ringkasan dari sebuah teks secara otomatis dengan memanfaatkan aplikasi yang dijalankan pada komputer untuk menghasilkan informasi yang paling penting dari dokumen aslinya [5].
2.6.1 Pendekatan Peringkasan Teks Otomatis Terdapat 2 pendekatan peringkas teks[5], yaitu:
1. Ekstraksi(extractive summari). Pada teknik ekstraksi, sistem manyalin unit-unit teks yang dianggap paling penting dari sumber teks menjadi ringkasan. Unit-unit teks yang disalin dapat berupa klausa utama, kalimat utama, atau tidak terdapat pada paragraf utama tanpa ada penambahan-penambahan kalimat baru yang tidak teradapat pada dokumen aslinya.
2. Abstraksi (abstraksi summary). Teknik abstraksi menggunakan metode linguistik
untuk memeriksa dan menafsirkan teks dokumen menjadi ringkasan. Ringkasan teks tersebut dihasilkan dengan cara menambahkan kalimat-kalimat yang ada pada teks sumber.
2.6.2 Preprocessing
menjadi kalimat, casefolding, filtering, dokumen menjadi kata (tokenizing), dan menghapus stopword.
1. Pemisahan Kalimat.
Memecah dokumen menjadi kalimat-kalimat merupakan langkah awal tahapan preprocessing. Pemecahan kalimat yaitu proses memecah string teks dokumen yang panjang menjadi kumpulan kalimat-kalimat. Dalam memecah dokumen menjadi kalimat-kalimat menggunakan fungsi split (), dengan tanda titik (“.”) sebagai pemisah (delimiter) untuk memotong string dokumen[7].
2. Case Folding
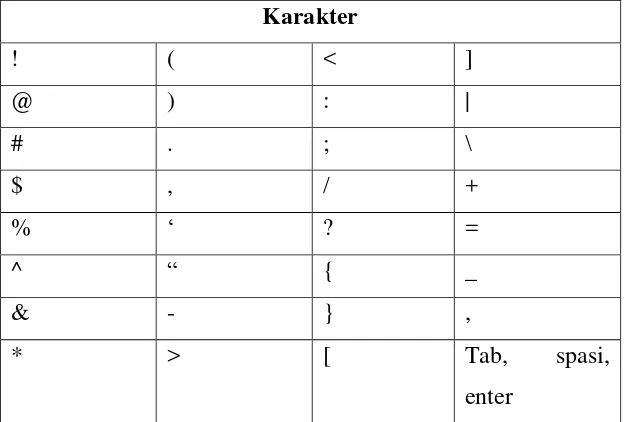
Case folding adalah tahapan proses mengubah semua huruf dalam teks dokumen menjadi huruf kecil, serta menghilangkan karakter selain a-z. [7].
3. Filtering
Data teks dalam dokumen yang sebelumnya sudah diubah ke dalam huruf kecil semua. Selanjutnya dilakukan proses filtering teks. Filtering adalah tahapan pemrosesan teks dimana semua teks selain karakter “a” sampai “z” dan titik “.” akan dihilangkan dan hanya menerima spasi[7].
4. Tokenizing
Tokenizing adalah proses pemotongan string input berdasarkan tiap kata yang menyusunnya. Pemecahan kalimat menjadi kata-kata tunggal dilakukan dengan men-scan kalimat dengan pemisah (delimiter) whitespace (spasi, tab, dan newline)[7].
5. Stopword
2.7 Metode TF-IDF (Term Frequency – Inversed Document Frequency)
Metode Term Frequency - Inverse Document Frequency (TF-IDF) merupakan suatu cara untuk memperoleh pembobotan berdasarkan jumlah II-8 kemunculan suatu kata (term) dalam sebuah dokumen term frequency (TF) dan jumlah kemunculan term dalam koleksi dokumen inverse document frequency (IDF).
TF merupakan banyak kata yang muncul pada sebuah dokumen, sedangkan DF merupakan banyaknya dokumen yang mengandung sebuah kata. Nilai IDF sebuah kata (term) dapat dihitung menggunakan persamaan berikut.
IDF = log
(2.1)
N adalah jumlah dokumen yang berisi term (t) dan df adalah jumlah kemunculan kata (term) terhadap N. Adapun rumus yang digunakan untuk menghitung bobot (W) masing-masing dokumen, yaitu dapat dilihat pada rumus berikut.
Wdt = tfdt * IDFt (2.2)
dengan:
d = kalimat ke–d t = kata (term) ke–t
TF = term frequency / frekuensi kata
W = bobot kalimat ke–d terhadap kata (term) ke–t IDF = Inverse Document Frequency
Berikut ilustrasi dari TF-IDF:
dokumen 1 (d1) : Manajemen transaksi logistik. dokumen 2 (d2) : Pengetahuan antar individu.
Setelah melalui proses filtering, maka kata “antar” pada dokumen 2 serta kata “dalam” dan “terdapat” pada dokumen 3 dihapus.
Tabel 2. 1 Contoh perhitungan TF-IDF
Token Tf DF IDF W (TF-IDF)
D1 D2 D3 D1 D2 D3
Manajemen 1 0 1 2 0.1761 0.1761 0 0.1761
transaksi 1 0 0 1 0.4771 0.4771 0 0
Logistik 1 0 1 2 0.1761 0.1761 0 0.1761 Pengetahuan 0 1 1 2 0.1761 0 0.1761 0.3522
Individu 0 1 0 1 0.4771 0 0.4771 0
transfer 0 0 1 1 0.4771 0 0 0.4771
Dari tabel di atas didapat : Bobot (w) untuk d1 = 0.8293 Bobot (w) untuk d2 = 0.6532 Bobot (w) untuk d3 = 1.1815
2.8 Metode K-Means Clustering
K-Means Clustering merupakan salah satu metode data clustering non hirarki yang berusaha mempartisi data yang ada ke dalam bentuk satu atau lebih cluster/kelompok[8].
memaksimalisasikan variasi antar cluster. Manfaat Clustering adalah sebagai
Identifikasi Object (Recognition) misalnya dalam bidang Image Processing, Computer Vision atau robot vision. Selain itu adalah sebagai Sistem Pendukung Keputusan dan Data Mining seperti Segmentasi pasar, pemetaan wilayah, Manajemen marketing dll.
Data clustering menggunakan metode K-Means ini secara umum dilakukan dengan algoritma dasar[9]. Algoritma K-means dapat dilihat pada gambar 2.1 berikut.
Mulai
Tentukan Jumlah Cluster K
Tentukan asumsi titik pusat cluster (centroid)
Hitung Jarak Objek ke
Centroids
Kelompokkan Jarak Berdasarkan Jarak Minimum
Adakah Objek Yang Berpindah
Selesai Tidak
Ya
1. Tentukan jumlah cluster
2. Menentukan nilai centroid
Dalam menentukan nilai centroid untuk awal iterasi, nilai awal centroid
dilakukan secara acak. Sedangkan jika menentukan nilai centroid yang merupakan tahap dari iterasi dihitung berdasarkan nilai rata-rata dari data yang terletak pada
centroid yang sama.
3. Menghitung jarak antara data dengan pusat cluster.
Untuk menghitung jarak tersebut dapat menggunakan Euclidean Distance. Euclidean sering digunakan karena penghitungan jarak dalam distance space ini merupakan jarak terpendek yang bisa didapatkan antara dua titik yang diperhitungkan[8]. Berikut persamaan dengan Euclidean Distance.
De = √ (2.3) dengan:
De = euclidean distance. i = banyaknya data. x = bobot dokumen. y = pusat cluster.
4. Pengelompokan Data
Untuk menentukan anggota cluster adalah dengan memperhitungkan jarak terpendek data. Nilai yang diperoleh dalam keanggotaan data pada distance matriks adalah 0 atau 1, dimana nilai 1 untuk data yang dialokasikan ke cluster dan nilai 0 untuk data yang dialokasikan ke cluster yang lain.
2.9 Generating
Tahapan ini adalah pembangkitan atau pembentukan hasil akhir. Terdiri dari penggabungan frase, pencetakan kata atau frase dan pembangkitan kalimat. Metode
generating yang digunakan yaitu Topic list yang merupakan teknik hasil akhir yang berisi kata-kata yang sering muncul atau penggabungan pengertian yang telah diinterpretasi [7].
2.10 Teknik Evaluasi Peringkasan Teks
Pengujian yang dilakukan dalam penelitian ini menggunakan pengujian akurasi. Standar pengukuran yang biasa digunakan dalam penelitian text summarization yaitu recall, precision, dan f-measure[19].
Recall adalah tingkat keberhasilan ringkasan. Perhitungan recall dapat dilihat pada persamaan sebagai berikut.
dimana
recall : tingkat keberhasilan
correct : jumlah kalimat yang berhasil di ekstrak sistem sesuai dengan kalimat yang diekstrak manusia
missed : jumlah kalimat yang diekstrak manusia tetapi tidak terdapat dalam kalimat yang diekstrak sistem
Precision adalah tingkat ketepatan hasil ringkasan. Perhitungan precision dapat dilihat pada persamaan berikut:
dimana,
precision : tingkat ketepatan
correct : jumlah kalimat yang berhasil di ekstrak sistem sesuai dengan kalimat yang diekstrak manusia
wrong : jumlah kalimat yang diekstrak sistem tetapi tidak terdapat dalam kalimat yang diekstrak manusia
F-measure adalah gabungan antara recall dan precision. Perhitungan f-measure
dapat dilihat pada persamaan berikut:
2.11 Flowchart
Flowchart adalah bagan (chart) yang menunjukkan alir (flow) di dalam program atau prosedur sistem secara logika. Bagan alir program (program flowchart) merupakan bagan alir yang mirip dengan bagan alir sistem, yaitu untuk menggambarkan prosedur di dalam sistem [7].
2.12 Data flow diagram(DFD)
Pengertian Data Flow Diagram (DFD) adalah Diagram yang menggunakan notasi simbol untuk menggambarkan arus data system [7]. DFD sering digunakan untuk menggambarkan suatu sistem yang telah ada atau sistem yang baru yang akan dikembangkan secara logika dan menjelaskan arus data dari mulai pemasukan sampai dengan keluaran data tingkatan diagram arus data mulai dari diagram konteks yang menjelaskan secara umum suatu system atau batasan system dari level 0 dikembangkan menjadi level 1 sampai system tergambarkan secara rinci. Gambaran ini tidak tergantung pada perangkat keras, perangkat lunak, struktur data atau organisasi file.
1. Kesatuan Luar (External Entity)
Kesatuan luar (external entity) merupakan kesatuan (entity) di lingkungan luar sistem yang dapat berupa orang, organisasi, atau sistem lain yang berada pada
lingkungan luarnya yang memberikan input atau menerima output dari sistem. 2. Arus Data (Data Flow)
Arus Data (data flow) di DFD diberi simbol suatu panah. Arus data ini mengalir di antara proses, simpan data dan kesatuan luar. Arus data ini menunjukan arus dari data yang dapat berupa masukan untuk sistem atau hasil dari proses sistem.
3. Proses (Process)
Proses (process) menunjukan pada bagian yang mengubah input menjadi output, yaitu menunjukan bagaimana satu atau lebih input diubah menjadi beberapa output. Setiap proses mempunyai nama, nama dari proses ini menunjukan apa yang dikerjakan proses.
4. Simpanan Data (Data Store)
Data Store merupakan simpanan dari data yang dapat berupa suatu file atau database pada sistem komputer.
2.13 Perangkat Lunak Pendukung
2.13.1 Pengertian XAMPP
XAMPP adalah satu paket software web server yang terdiri dari Apache, Mysql, PHP dan phpMyadmin. Mengapa menggunakan XAMPP? Karena XAMPP sangat mudah penggunaanya, terutama bagi pemula. Proses instalasi XAMPP sangat mudah, karena tidak memerlukan konfigurasu Apache, PHP dan MySQL secara manual, XAMPP melakukan instalasi dan konfigurasi secara otomatis [11].
2.13.2 Pengertian PHP
PHP merupakan kependekan dari kata Hypertext Prepocessor. PHP tergolong sebagai perangkat lunak open source yang diataur dalam aturan general purpose licences (GPL).
Pemograman PHP sangat cocok dikembangkan dalam lingkungan web, karena PHP bisa dilekatkan pada script HTML atau sebaliknya. PHP dikhususkan untuk pengembangan web dinamis. Maksudnya, PHP mampu menghasilkan website yang secara terus menerus hasilnya bisa berubah-ubah sesuai dengan pola yang diberikan. Hal tersebut bergantung pada permintaan client browser yang digunakan. Pada umumnya, pembuatan web dinamis berhubungan erat dengan database sebagai sumber data yang akan ditampilkan.
PHP tergolong juga sebagai bahasa pemograman yang berbasis server (server side cripting). Ini berarti bahwa semua script PHP diletakkan diserver dan diterjemahkan oleh web server terlebih dahulu, kemudian hasil terjemahan itu dikirim ke browser client. Tetu hal tersebut berbeda dengan JavaScript selalu tampak dihalaman web bersangkutan, jika dilakukan penyimpanan terhadap file web. Secara teknologi, bahasa pemograman PHP memiliki kesamaan dengan bahasa ASP (Active Server Page), Cold Fusion, JSP (Java Server Page), ataupun Perl.
2.13.3 Sublimtext
21
BAB 3
ANALISIS DAN PERANCANGAN
3.1Analisis Masalah
Analisis masalah adalah gambaran masalah yang diangkat dalam penelitian tentang text summarization dalam artikel berita berbahasa Indonesia. Analisis masalah menjelaskan tentang proses identifikasi masalah serta evaluasi mengenai sistem peringkas teks otomatis dalam artikel berita berbahasa Indonesia.
3.2Arsitektur Sistem
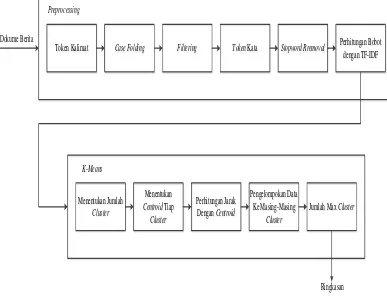
Arsitektur sistem menggambarkan perancangan sistem peringkasan teks otomatis secara keseluruhan. Adapun gambaran arsitektur sistem peringkasan teks otomasis seperti pada gambar 3.1 berikut.
Token Kalimat
Token Kalimat Case FoldingCase Folding FilteringFiltering TokenToken Kata Kata Stopword RremovalStopword Rremoval Perhitungan Bobot dengan TF-IDF
Gambar 3. 1 Arsiteksur Sistem 3.3Analisis Sistem
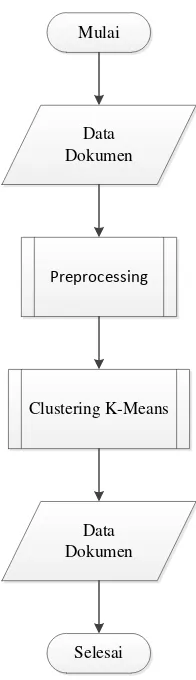
Mulai
Data Dokumen
Preprocessing
Clustering K-Means
Selesai Data Dokumen
Gambar 3. 2 Alur Sistem
Analisis sistem peringkasan teks otomatis yang akan dibangun pada penelitian ini memiliki 3 tahapan, yaitu preprocessing, penghitungan bobot dengan TF-IDF,
clusteringK-Means. Untuk penjelasan tiap tahapan dapat dilihat sebagai berikut : 1. Datadokumen
Pada tahap ini pengguna memilih data yang akan diringkas. Data ini merupakan artikel berita berbahasa Indonesia dengan ektensi .txt.
2. Preprocessing
meliputi : pemecahan kalimat, case folding(merubah menjadi lowercase),
filtering, tokenizing dan hapus stopword. Kemudian dilanjutkan dengan pembobotan kata menggunakan TF-IDF.
3. Clustering dengan K-means
Clustering yang kalimat yang berada pada satu kelas yang memiliki makna yang sama, sehingga nantinya akan dilakukan seleksi kalimat dengan cara mengambil salah satu kalimat dari setiap cluster sebagai perwakilan akan makna tertentu.
3.3.1 Analisis Data Masukan
Analisis data masukan (input data) pada peringkasan teks(text summarization) artikel berita berbahasa Indonesia menjelaskan proses data masukan yang dibuat merupakan sistem peringkasan dengan inputan data training berupa single dokumen untuk menghasilkan ringkasan (summary).
Data masukan pada penelitian ini didapat dari artikel berita megapolitan.kompas.com dengan judul “lulung dukung waarga bukit duri gugat pemprofDKI”,
http://megapolotan.kompas.com/read/2016/05/13/10104761/Lulung.Dukung.Warga.
Tabel 3. 1 Data Masukan Artikel Berita
Rencana warga Bukit Duri, Jakarta Selatan, menggugat Pemprov dan didukung Wakil Ketua DPRD Abraham "Lulung" Lunggana. Lulung menyatakan, gugatan memang harus dilakukan warga Bukit Duri untuk memberikan pelajaran bagi Pemprov DKI agar tidak sewenang-wenang. "Baguslah, Pemprov harus mengerti mana yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata Lulung di Masjid Luar Batang, Kamis (12/5/2016) malam. Ia mencontohkan tanah negara yang menjadi aset pemerintah, seperti kawasan Monumen Nasional (Monas) dan kantor Balai Kota. Sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan Pasar Ikan yang telah digusur Pemprov DKI. "Dia (Ahok) jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya, RT, RW-nya, dan mereka bayar kewajiban pajak enggak? Ada nilai keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar Lulung. Warga Bukit Duri memutuskan untuk mengajukan gugatan class action terhadap Pemerintah Provinsi DKI Jakarta yang berencana menertibkan permukiman tersebut. Gugatan telah didaftarkan ke Pengadilan Negeri Jakarta Pusat pada 10 Mei.
3.3.2 Analisis Preprocessing
mulai
Pemecahan kalimat
Case folding
Tokenizing
Stopword removal
selesai Data uji hasil
stopword removal Dokumen
berita
Filtering
Gambar 3. 3 Tahap Preprocessing
1. Pemecahan Kalimat
Pada tahap pemecahan kalimat adalah memecah string menjadi kalimat-kalimat berdasarkan tanda titik ( . ) sebagai pemisah. Hasil pemecahan dokumen menjadi kalimat-kalimat dapat dilihat pada Tabel 3.2 berikut.
Tabel 3. 2 Pemecahan Kalimat
No Kalimat
S1 Rencana warga Bukit Duri, Jakarta Selatan, menggugat Pemprov dan didukung Wakil Ketua DPRD Abraham "Lulung" Lunggana
S2 Lulung menyatakan, gugatan memang harus dilakukan warga Bukit Duri untuk memberikan pelajaran bagi Pemprov DKI agar tidak sewenang-wenang
S3 "Baguslah, Pemprov harus mengerti mana yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata Lulung di Masjid Luar Batang, Kamis (12/5/2016) malam.
S4 Ia mencontohkan tanah negara yang menjadi aset pemerintah, seperti kawasan Monumen Nasional (Monas) dan kantor Balai Kota.
S5 Sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan Pasar Ikan yang telah digusur Pemprov DKI.
S6 . "Dia (Ahok) jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya, RT, RW-nya, dan mereka bayar kewajiban pajak enggak? Ada nilai keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar Lulung.
S7 Warga Bukit Duri memutuskan untuk mengajukan gugatan class action terhadap Pemerintah Provinsi DKI Jakarta yang berencana menertibkan permukiman tersebut.
Keterangan
Pada tahap casefolding adalah membuat karakter/huruf menjadi lowercase. Hasil dari case folding dapat dilihat pada Tabel 3.3 berikut.
Tabel 3. 3 Case Folding
No Kalimat Hasil case folding
S1 Rencana warga Bukit Duri, Jakarta Selatan, menggugat Pemprov dan didukung Wakil Ketua DPRD Abraham "Lulung" Lunggana
rencana warga bukit duri, jakarta selatan, menggugat pemprov dan didukung wakil ketua dprd abraham "lulung" lunggana
S2 Lulung menyatakan, gugatan memang harus dilakukan warga Bukit Duri untuk memberikan pelajaran bagi Pemprov DKI agar tidak sewenang-wenang
agar tidak sewenang-wenang S3 "Baguslah, Pemprov harus mengerti mana
yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata Lulung di Masjid Luar Batang, Kamis (12/5/2016) malam.
"baguslah, pemprov harus mengerti mana yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata lulung di masjid luar batang, kamis (12/5/2016) malam. S4 Ia mencontohkan tanah negara yang
menjadi aset pemerintah, seperti kawasan Monumen Nasional (Monas) dan kantor Balai Kota.
ia mencontohkan tanah negara yang menjadi aset pemerintah, seperti kawasan monumen nasional (monas) dan kantor balai kota.
S5 Sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan Pasar Ikan yang telah digusur Pemprov DKI.
sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan pasar ikan yang telah digusur pemprov dki.
S6 "Dia (Ahok) jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya, RT, RW-nya, dan mereka bayar kewajiban pajak enggak? Ada nilai keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar Lulung.
"dia (ahok) jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya, rt, rw-nya, dan mereka bayar kewajiban pajak enggak? ada nilai keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar lulung. S7 Warga Bukit Duri memutuskan untuk
mengajukan gugatan class action terhadap
Pemerintah Provinsi DKI Jakarta yang berencana menertibkan permukiman tersebut.
class action terhadap pemerintah provinsi dki jakarta yang berencana menertibkan permukiman tersebut.
S8 Gugatan telah didaftarkan ke Pengadilan Negeri Jakarta Pusat pada 10 Mei.
gugatan telah didaftarkan ke pengadilan negeri jakarta pusat pada 10 mei.
Keterangan
S1 = Kalimat ke-1. S2 = Kalimat ke-2. S3 = Kalimat ke-3. S4 = Kalimat ke-4.
S5 = Kalimat ke-5. S6 = Kalimat ke-6. S7 = Kalimat ke-7 S8 = Kalimat ke-8.
3. Filtering
Tabel 3. 4 Karakter yang akan dihapus
Hasil filtering dapat dilihat pada Tabel 3.5 berikut.
Tabel 3. 5 Hasil Filtering
No Data hasil case folding Seteleh Filtering
S1 rencana warga bukit duri, jakarta selatan, menggugat pemprov dan didukung wakil ketua dprd abraham "lulung" lunggana
rencana warga bukit duri jakarta selatan menggugat pemprov dan didukung wakil ketua dprd abraham lulung lunggana
S2 lulung menyatakan, gugatan memang harus dilakukan warga bukit duri untuk memberikan pelajaran bagi pemprov dki agar tidak sewenang-wenang
lulung menyatakan gugatan memang harus dilakukan warga bukit duri untuk memberikan pelajaran bagi pemprov dki agar tidak sewenang wenang
S3 "baguslah, pemprov harus mengerti mana yang menjadi tanah negara,
mana yang dikelola oleh rakyat," yang menjadi aset pemerintah, seperti kawasan monumen nasional (monas) dan kantor balai kota.
ia mencontohkan tanah negara yang menjadi aset pemerintah seperti kawasan monumen nasional monas dan kantor balai kota
S5 sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan pasar ikan yang telah digusur pemprov dki.
sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan pasar ikan yang telah digusur pemprov dki
S6 "dia (ahok) jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya, rt, rw-nya, dan mereka bayar kewajiban pajak
enggak? ada nilai
keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar lulung.
dia ahok jangan mengklaim saja, lihat dulu di sana ada enggak penduduknya rt rw nya dan mereka bayar kewajiban pajak enggak ada nilai keekonomiannya terus warga yang sudah bertahun tahun di sana enggak boleh main gusur aja ujar lulung
S7 warga bukit duri memutuskan untuk mengajukan gugatan class action terhadap pemerintah provinsi dki jakarta yang berencana menertibkan permukiman tersebut.
warga bukit duri memutuskan untuk mengajukan gugatan class action terhadap pemerintah provinsi dki jakarta yang berencana menertibkan permukiman tersebut
S8 gugatan telah didaftarkan ke pengadilan negeri jakarta pusat pada 10 mei.
Keterangan
S1 = Kalimat ke-1.
S2 = Kalimat ke-2. S3 = Kalimat ke-3. S4 = Kalimat ke-4. S5 = Kalimat ke-5. S6 = Kalimat ke-6. S7 = Kalimat ke-7
4. Tokenizing
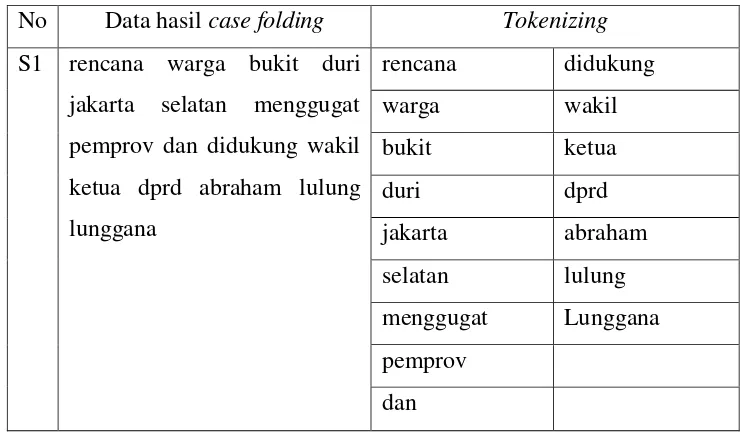
Pada tahap Tokenizing kata adalah menghilangkan karakter pemisah yang menyusunya berupa katakter spasi. Hasil tokenizing dapat dilihat pada Tabel 3.6 berikut..
Tabel 3. 6 Tokenizing
No Data hasil case folding Tokenizing
S1 rencana warga bukit duri jakarta selatan menggugat pemprov dan didukung wakil ketua dprd abraham lulung lunggana
rencana didukung
warga wakil
bukit ketua
duri dprd
jakarta abraham selatan lulung menggugat Lunggana pemprov
Keterangan
S1 = Kalimat ke-1
(Selengkapnya Lihat Lampiran A.)
5. Stopword Removal
Proses stopword removal adalah proses menghapus kata yang tidak penting yang diambil dari tahap tokenizing. Pada tahap stopword ini menggunakan algoritma
stoplist dengan membuang kata yang kurang penting. Contoh stopword adalah”di”,
“dari”, “yang” dan lain-lain. Hasil dari stop word removal dapat dilihat pada Tabel 3.8. Adapun isi dari sebagian daftar kata stopword yang disajikan pada Tabel 3.7 berikut.
Tabel 3. 7 Daftar Sebagian Stopword Removal
telah punya mendapatkan Dari
antara agar juga Semua
setelah jadi ada Setelah
(Selengkapnya Lihat Lampiran B)
Tabel 3. 8 Hasil Stopword Removal
No Data hasil tokenizing stopword
S1 rencana didukung Rencana didukung
warga wakil warga wakil
bukit ketua bukit ketua
duri dprd duri dprd
menggugat lunggana menggugat lunggana
pemprov pemprov
dan
(Selangkapnya Lihat Lampiran C)
3.3.3 Analisis Summarization
Pada alanisis simmarization akan menjelaskan proses peringkasan teks artikel berita berbahasa Indonesia dengan metode pembobotan kata TF-IDF dan metode
Clustering K-Means. Berikut adalah flowchart proses peringkasan teks berita artikel berbahasa Indonesia dengan metode TF-IDF dan metode Clustering K-Means:
Mulai
Data uji dari preprocessing
Pembobotan kata dengan TF-IDF
Clustering K-means
Hasil Ringkasan
Selesai
3.3.4 Algoritma TD-IDF
Hasil proses text preprosessing dilakukan pembobotan TF-IDF. Pembobotan secara otomatis biasanya berdasarkan jumlah kemunculan suatu kata dalam sebuah dokumen (term frequency) dan jumlah kemunculannya dalam koleksi dokumen (inverse document frequency). Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan semakin kecil jika muncul dalam banyak dokumen. Rumus TF-IDF dapat dilihat pada persamaan 2.2 Proses awal dilakukan perhitungan kata (term) pada tiap dokumen, sehingga mendapatkan frekuensi term (tf). Selanjutnya mencari
documen frequency (df), df merupakan banyaknya dokumen dimana satu kata (term) muncul. Contoh kata “warga” maka.
Diketahui
Jumlah kalimat (S(n)) = 8,
df = 4 (karena kata “warga” muncul di S1,S2,S6,S7),
Idf(t) = log(D/df) = log(8/4) = 0.301.
Untuk lebih jelasnya dapat dilihat pada Tabel 3.9 berikut.
Tabel 3. 9 Perhitungan IDF Dari Tiap Kata(Term).
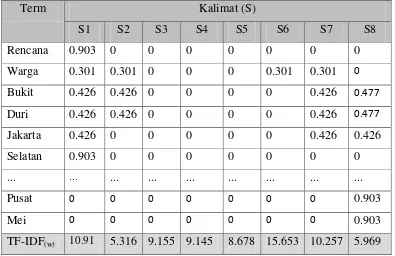
Term Tf df S(n)/df Idf =log(S(n)/df)
S1 S2 S3 S4 S5 S6 S7 S8
rencana 1 0 0 0 0 0 0 0 1 8 0.903
Warga 1 1 0 0 0 1 1 0 4 2 0.301
Bukit 1 1 0 0 0 0 1 0 3 2.67 0.426 Duri 1 1 0 0 0 0 1 0 3 2.67 0.426 ... ... ... ... ... ... ... ... ... ... ... ...
Pusat 0 0 0 0 0 0 0 1 1 8 0.903
Keterangan
Term = Daftar kata yang terdapat pada artikel.
S1 = Kalimat ke-1. S2 = Kalimat ke-2. S3 = Kalimat ke-3. S4 = Kalimat ke-4. S5 = Kalimat ke-5. S6 = Kalimat ke-6. S7 = Kalimat ke-7 S8 = Kalimat ke-8.
df = Frekuensi Dokumen (dokumen frequence).
S(n) = Jumlah Sentence/Kalimat.
Idf = Perhitungan jumlah dokumen yang mengandung sebuah kata (term) yang dicari dari kumpulan dokumen yang ada.
(Selengkapnya Lihat Lampiran D)
Untuk memperoleh bobot pada kata “warga” maka dilakukan perhitungan perkalian tf
dengan idf
tf-idf(t) = tf(t,d) x idf(t)= 1 x 0.301 = 0.301
Tabel 3. 10 Perhitungan TF-IDF
Term Kalimat (S)
S1 S2 S3 S4 S5 S6 S7 S8
Rencana 0.903 0 0 0 0 0 0 0
Warga 0.301 0.301 0 0 0 0.301 0.301 0
Bukit 0.426 0.426 0 0 0 0 0.426 0.477
Duri 0.426 0.426 0 0 0 0 0.426 0.477
Jakarta 0.426 0 0 0 0 0 0.426 0.426
Selatan 0.903 0 0 0 0 0 0 0
... ... ... ... ... ... ... ... ...
Pusat 0 0 0 0 0 0 0 0.903
Mei 0 0 0 0 0 0 0 0.903
TF-IDF(w) 10.91 5.316 9.155 9.145 8.678 15.653 10.257 5.969
Keterangan
Term = Daftar kata yang terdapat pada artikel. S1 = Kalimat ke-1.
S2 = Kalimat ke-2. S3 = Kalimat ke-3. S4 = Kalimat ke-4. S5 = Kalimat ke-5.
S8 = Kalimat ke-8.
TF-IDF(w) = Bobot kalimat.
(Selengkapnya Lihat Lampiran E)
3.3.5 Algoritma K-Means
Dari hasil pembobotan kalimat dengan TF-IDF pada topik artikel tersebut selanjutnya dijumlahkan nilai tiap kalimat yang digunakan sebagai data inputan algoritma K-Means Clustering [13]. untuk lebih jelasnya perhatikan tabel 3.11 berikut.
Tabel 3. 11 Data Inputan K-Means Kalimat (S) TF-IDF(w)
S1 10.91
S2 5.316
S3 9.155
S4 9.145
S5 8.678
S6 15.653
S7 10.257
S8 5.969
Keterangan
S5 = Kalimat ke-5. S6 = Kalimat ke-6.
S7 = Kalimat ke-7 S8 = Kalimat ke-8.
TF-IDF = hasil perhitungan TF-IDF pada tiap kalimat.
Penentuan Jumlah Cluster
Adapun cara untuk menentukan jumlah cluster (K) yaitu dengan membagi 2 jumlah kalimat yang ada pada berita artikel kemudian hasil dari pembagian diakarkuadrat[12]. Pada kasus ini terdapat 8 jumlah kalimat berikut untuk lebih jelasnya.
√ (3.1)
Maka diperoleh √ = 2
Dimana :
jumlah cluster/kelompok
Jumlah Kalimat
Jika hasil dari pembagian berupa bilangan desimal maka dibulatkan bawah. Misalnya terdapat 10 kalimat maka
Menentukan Nilai Centroid / titik pusat cluster
Dalam menentukan nilai centroid untuk awal iterasi, nilai awal centroid
dilakukan secara acak. Contohnya pada kasus ini terpilih bobot kalimat(TF-IDF) ke-1 dan ke-5. Misalnya :
Diambil data ke-1 sebagai pusat cluster ke-1 (wC1) = 10.91 Diambil data ke-5 sebagai pusat cluster ke-2 (wC2) = 8.678 Keterangan
wC1 = Cluster (kelompok) ke-1 wC2 = Cluster (kelompok) ke-2
Menghitung Jarak Antara Data Dengan Pusat Cluster.
Untuk menghitung jarak dengan pusat Cluster tersebut dapat menggunakan persamaan (2.3) agar nilai yang dihasilkan selalu positif. Centroid terdekat akan menjadi cluster yang diikuti oleh data tersebut. Kemudian akan didapatkan matrik jarak yaitu wC1 dan wC2. Berikut perhitungan jarak antara data ke setiap centroid. Perhitungan pada Cluster 1 (wC1)
De (w1,wC1) = √ = 0
De (w2,wC1) = √ = 5.594
De (w3,wC1) = √ = 1.755
De (w4,wC1) = √ = 1.454
De (w5,wC1) = √ = 2.232
De (w7,wC1) = √ = 0.653
De (w8,wC1) = √ = 4.941
Perhitungan pada Cluster 2 (wC2)
De (w1,wwC2) = √ = 2.232
De (w2,wC2) = √ = 3.362
De (w3,wC2) = √ = 0.477
De (w4,wC2) = √ = 0.778
De (w5,wC2) = √ = 0
De (w6,wC2) = √ = 6.975
De (w7,wC2) = √ = 1.579
De (w8,wC2) = √ = 2.709
Setelah mendapatkan nilai dari masing-masing cluster, kemudian ditetapkan jarak terpendeknya, untuk mengetahui bobot kalimat(TF-IDF) tersebut berada di salah satu cluster(kelompok). Untuk lebih jelasnya perhatikan tabel 3.12 berikut.
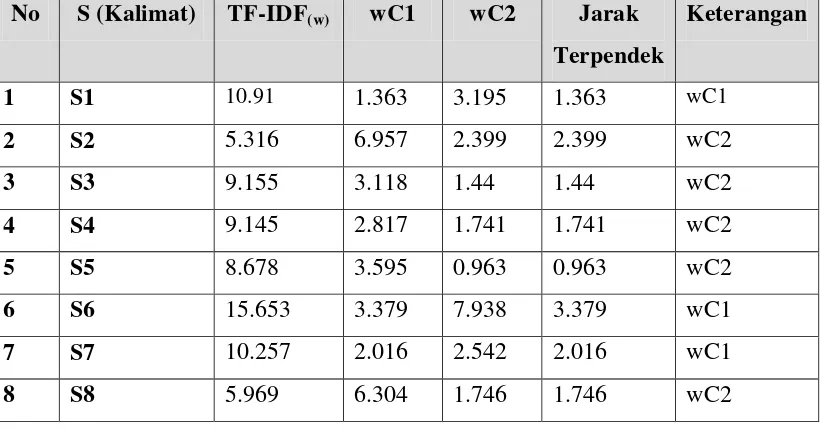
Tabel 3. 12 Euclidian Distance Iterasi 1 No S (Kalimat) TF-IDF(w) wC1 wC2 Jarak
Terpendek
Keterangan
1 S1 10.91 0 2.232 0 wC1
2 S2 5.316 5.594 3.362 3.362 wC2
4 S4 9.145 1.454 0.778 0.778 wC2
5 S5 8.678 2.232 0 0 wC2
6 S6 15.653 4.473 6.975 4.473 wC1
7 S7 10.257 0.653 1.579 0.653 wC1
8 S8 5.969 4.941 2.709 2.709 wC2
Pengelompokan Data
Jarak hasil perhitungan akan dilakukan perbandingan dan dipilih jarak terdekat antara data dengan pusat cluster, jarak ini menunjukkan bahwa data tersebut berada dalam satu kelompok dengan pusat cluster terdekat. Berikut data matrik penglompokan grup, nilai 1 berati data tersebut berada dalam grup tersebut. Untuk lebih jelasnya perhatikan tabel 3.13 berikut.
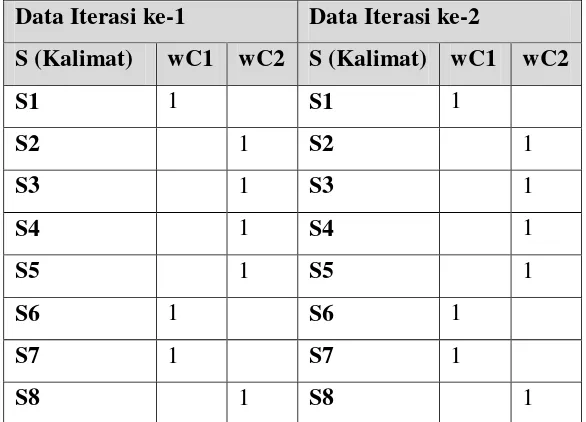
Tabel 3. 13 Pengelompokan Data Iterasi ke-1 S (Kalimat) wC1 wC2
S1 1
S2 1
S3 1
S4 1
S5 1
S6 1
S7 1
Penentuan Pusat Cluster Baru
Setelah anggota tiap cluster diketahui kemudian menentukan pusat cluster
baru berdasarkan nilai rata-rata dari data yang terletak pada centroid yang sama. Perhitungan pusan cluster baru dapat dilihat pada tabel 3.14 berikut.
Tabel 3. 14 Pusat Cluster Baru Iterasi ke-1 S / Kalimat TF-IDF(w) wC1 wC2
S1 10.91 10.91
S2 5.316 5.316
S3 9.155 9.155
S4 9.145 9.145
S5 8.678 8.678
S6 15.653 15.653
S7 10.257 10.257
S8 5.969 5.969
Centroid Baru 12.273 7.714
Iterasi Ke-2
Untuk iterasi ke-2 maka proses dilakukan dengan menentukan titik pusat cluster, kemudian menghitung jarak antara data dengan pusat cluster hingga posisi data tidak mengalami perubahan.
Centroid baru wC1 = 12.273
Centroid baru wC2 = 7.714
Menghitung Jarak Antara Data Dengan Pusat Cluster Pada Iterasi ke-2
Perhitungan pada Cluster 1 (wC1)
De (w1,wC1) = √ = 1.363
De (w2,wC1) = √ = 6.957
De (w3,wC1) = √ = 3.118
De (w4,wC1) = √ = 2.817
De (w5,wC1) = √ = 3.595
De (w6,wC1) = √ = 3.379
De (w7,wC1) = √ = 2.016
De (w8,wC1) = √ = 6.304
Perhitungan pada Cluster 2 (wC2)
De (w1,wC2) = √ = 3.195
De (w2,wC2) = √ = 2.399
De (w3,wC2) = √ = 1.44
De (w4,wC2) = √ = 1.741
De (w5,wC2) = √ = 0.963
De (w6,wC2) = √ = 7.938
De (w8,wC2) = √ = 1.746
Setelah mendapatkan nilai dari masing-masing cluster, kemudian ditetapkan jarak terpendeknya. Untuk lebih jelasnya perhatikan tabel 3.15 berikut.
Tabel 3. 15 Euclidian Distance Iterasi ke-2 No S (Kalimat) TF-IDF(w) wC1 wC2 Jarak
Terpendek
Keterangan
1 S1 10.91 1.363 3.195 1.363 wC1
2 S2 5.316 6.957 2.399 2.399 wC2
3 S3 9.155 3.118 1.44 1.44 wC2
4 S4 9.145 2.817 1.741 1.741 wC2
5 S5 8.678 3.595 0.963 0.963 wC2
6 S6 15.653 3.379 7.938 3.379 wC1
7 S7 10.257 2.016 2.542 2.016 wC1
8 S8 5.969 6.304 1.746 1.746 wC2
Pengelompokan Data
Tabel 3. 16 perbandingan Data Iterasi ke-1 dan Data Iterasi ke-2 Data Iterasi ke-1 Data Iterasi ke-2
S (Kalimat) wC1 wC2 S (Kalimat) wC1 wC2
S1 1 S1 1
S2 1 S2 1
S3 1 S3 1
S4 1 S4 1
S5 1 S5 1
S6 1 S6 1
S7 1 S7 1
S8 1 S8 1
Karena hasil Clustering pengelompokan data ke-1 sama dengan pengelompokan data ke-2 maka tidak perlu dilakukan perhitungan lagi. Maka selanjutnya mendapatkan hasil ringkasan, yaitu dengan menjumlahakan data pada masing-masing cluster nilai yang tertinggi yang akan menjadi hasil ringkasan berdasarkan urutan data asli [13].
Tabel 3. 17 Hasil Penjumlahan Pada Tiap-Tiap Cluster No S (Kalimat) TF-IDF(w) wC1 wC2
1 S1 10.91 10.91
2 S2 5.316 5.316
3 S3 9.155 9.155
4 S4 9.145 9.145
5 S5 8.678 8.678
6 S6 15.653 15.653
7 S7 10.257 10.257
8 S8 5.969 5.969
Hasil dari penjumlahan masing-masing cluster adalah wC1 memiliki jumlah 36.82 dan wC2 memiliki jumlah 38.574, sehingga wC2 menunjukkan nilai tertinggi. Maka untuk mendapatkan hasil ringkasan berada pada cluster wC2 dengan anggota S2,S3,S4,S5,dan S8. Untuk lebih jelasnya dapat dilihat pada tabel berikut.
Tabel 3. 18 Data Cluster C2
No Kalimat
S2 Lulung menyatakan, gugatan memang harus dilakukan warga Bukit Duri untuk memberikan pelajaran bagi Pemprov DKI agar tidak sewenang-wenang
S3 "Baguslah, Pemprov harus mengerti mana yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata Lulung di Masjid Luar Batang, Kamis (12/5/2016) malam.
S4 Ia mencontohkan tanah negara yang menjadi aset pemerintah, seperti kawasan Monumen Nasional (Monas) dan kantor Balai Kota.
S5 Sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan Pasar Ikan yang telah digusur Pemprov DKI.
S8 Gugatan telah didaftarkan ke Pengadilan Negeri Jakarta Pusat pada 10 Mei.
Untuk hasil ringkasan dapat dilihat pada tabel berikut ini.
Tabel 3. 19 Hasil Ringkasan
Dokumen asli Hasil ringkasan
Rencana warga Bukit Duri, Jakarta Selatan, menggugat Pemprov dan didukung Wakil Ketua DPRD Abraham "Lulung" Lunggana. Lulung
sewenang-menyatakan, gugatan memang harus dilakukan warga Bukit Duri untuk memberikan pelajaran bagi Pemprov DKI agar tidak sewenang-wenang. "Baguslah, Pemprov harus mengerti mana yang menjadi tanah negara, mana yang dikelola oleh rakyat," kata Lulung di Masjid Luar Batang, Kamis (12/5/2016) malam. Ia mencontohkan tanah negara yang menjadi aset pemerintah, seperti kawasan Monumen Nasional (Monas) dan kantor Balai Kota. Sementara lahan negara yang dikelola oleh masyarakat salah satunya di kawasan Pasar Ikan yang telah keekonomiannya, terus warga yang sudah bertahun-tahun di sana enggak boleh main gusur aja," ujar Lulung. Warga Bukit Duri memutuskan untuk mengajukan gugatan class action terhadap Pemerintah Provinsi DKI Jakarta yang berencana menertibkan permukiman tersebut. Gugatan telah
didaftarkan ke Pengadilan Negeri Jakarta Pusat pada 10 Mei.
3.4Analisis Kebutuhan Non-Fungsional
Analisis kebutuhan non-fungsional pada penelitian ini terdiri dari kebutuhan perangkat keras, kebutuhan perangkat lunak, dan kebutuhan pengguna.
3.4.1 Kebutuhan Perangkat Keras (hardware).
Kebutuhan perangkat keras yang digunakan dalam pembangunan text summarization menggunakan metode K-Means pada artikel berita berbahasa Indonesia adalah dapat dilihat pada tabel 3.20 berikut.
Tabel 3. 20 Kebutuhan Perangkat Keras
Perangkat Keras Spesifikasi
Processor Intel(R) Dual Core 1.5GHz
RAM 2048 MB
Monitor 10.1 inch
Keyboard Standar
Mouse Standar
3.4.2 Kebutuhan Perangkat Lunak (Software)
kebutuhan perangkat lunak (software) yang digunakan dalam pembangunan text summarization dengan metode K-Means pada artikel berita berbahasa Indonesia adalah sebagai berikut.
1. Sistem Operasi Windows Ultimate 7 32bit 2. Web Browser Google Chrome
3. Code editor SublimeText3 Portable 4. Bahasa Pemrograman PHP
3.4.3 Kebutuhan Pengguna
Kebutuhan pengguna pada text summarization menggunakan metode MMR pada artikel berbahasa Indonesia adalah sebagai berikut:
a. Menguasai penggunaan komputer.
b. Mengerti secara teknis tools dan software pendukung dalam menjalankan aplikasi.
Mengerti tahap-tahap dalam menjalankan aplikasi text summarization.
3.5 Analsisi Kebutuhan Fungsional
Analisis kebutuhan fungsional bertujuan untuk menganalisis proses yang akan diterapkan dalam sistem yang akan dibangun. Analisis kebutuhan fungsional pada aplikasi ini menggunakan Diagram konteks,pembuatan DFD, Spesifikasi proses, dan kamus data.
3.5.1 Diagram Konteks
Pengguna
Peringkasan Berita Data Berita
Info Berita
Info Ringkasan
Gambar 3. 5 Diagram konteks 3.5.2 Data Flow Diagram (DFD)
Data Flow Diagram (DFD) merupakan diagram konteks dalam bentuk yang lebih detail. DFD menguraikan proses-proses yang terjadi dalam sistem sampai prosesyang lebih detail.
1. DFD level 1
Pengguna
1.0
Preprocessing
2.0
K-Means Clustering
Data Berita
Info ringkasan
Data Preprocessing
Gambar 3. 6 DFD Level 1 2. DFD level 2 Preprocessing
Pengguna
1.1 Token Kalimat
1.2 Case Folding Data Berita
Data Kalimat
1.3 Filtering Data Kalimat
1.4 Token kata
1.5 Stopword Removal
Data Kalimat
Data Token
1.6 TF-IDF Data Bobot Kalimat
Data Stopword Removal Data Kalimat
Data Bobot Kalimat stoplist List Stopword
3. DFD level 2 K-Means Clustering
DFD level 2 K-Means Clustering berikut ini menjelaskan proses pengelompokkan menggunakan metode K-Means. Untuk lebih jelasnya bisa dilihat pada gambar 3.8 berikut.
Pengguna
2.1 Random Centroid
2.2 Pengelompokkan
Bobot Kalimat Data Bobot Kalimat
Data Centroid
2.4 Ringkasan Data Centroid
2.3 Indeks Ringkasan Data Pengelompokkan
Data Indeks Ringkasan Data indeks
Info ringkasan
3.5.3 Spesifikasi Proses
Spesifikasi proses digunakan untuk menggambarkan proses model aliran yang terdapat pada DFD. Spesifikasi proses dari gambaran DFD pada subbab sebelumnya akan dijelaskan pada tabelberikut ini.
Tabel 3. 21 Spesifikasi Proses
No Proses Keterangan
1 No proses 1.1
Nama proses Token Kalimat
Sumber Pengguna
Input Data Berita
Output Token Kalimat
Destination Pengguna
Logika user 1. Sistem telah mengambil data berita yang telah dipilih
2. Sistem akan memisahkan suatu teks menjadi sebuah kalimat dengan delimeter titik (“.”)
2 No proses 1.2
Nama proses Case Folding
Sumber Pengguna
Input Data Token Kalimat
Output Data Case Folding
Destination Pengguna
Logika user 1. Sistem mengambil data berita yang telah diubah menjadi per kalimat
2. Sistem akan mengubah semua huruf menadi huruf kecil (lowcase)
Nama proses Filtering
Sumber Pengguna
Input Data Case Folding
Output Data Filtering
Destination Pengguna
Logika user 1. Data telah terdiri dari huruf kecil (lowcase) 2. Sistem akan menghapus semua simbol dan
angka, kecuali huruf, spasi, dan titik (“ ”)
4 No proses 1.4
Nama proses Token Kata
Sumber Pengguna
Input Data Filtering
Output Data Token Kata
Destination Pengguna
Logika user 1. Sistem telah menghapus semua simbol dan angka, kecuali huruf, spasi, dan titik (“ ”) 2. Sistem akan memisahkan kalimat tersebut
menjadi sebuah kata-kata dengan delimeter spasi (“ ”)
5 No proses 1.5
Nama proses Stopword Removal
Sumber Pengguna
Input Data Token Kata
Output Data Stopword Removal
Destination Pengguna
Logika user 1. Sistem telah memisahkan kalimat menjadi kata