Fakultas Ilmu Komputer
1198
Peringkasan Teks Otomatis Pada Artikel Berita Kesehatan Menggunakan
K-Nearest Neighbor Berbasis Fitur Statistik
Rachmad Indrianto1, Mochammad Ali Fauzi2, Lailil Muflikhah3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Pada masa kini informasi tentang kesehatan sudah banyak bertebaran dan sangat mudah didapatkan melalui website online. Namun dengan banyaknya informasi yang terkandung dalam teks artikel tersebut membuat pembaca kurang dapat memahami tentang isi dari bacaan tersebut, sehingga diperlukan sistem yang dapat meringkas suatu bacaan guna mempermudah pembaca dalam memahami isi suatu bacaan. Peringkasan teks otomatis menggunakan k-nearest neighbor berbasis fitur statistik dapat menjadi solusi dari permasalahan tersebut. Fitur-fitur statistik seperti posisi kalimat dalam paragraf, posisi keseluruhan kalimat, data numerik, tanda koma terbalik, panjang kalimat dan kata kunci memiliki peran yang penting untuk dijadikan parameter peringkasan. Dari pengujian fitur statistik yang telah dilakukan dengan memakai nilai k=3, metode ini menghasilkan nilai rata-rata precision, recall dan f –measure terbaik pada set fitur 9 dengan nilai masing-masing sebesar 0.75, 0.71 dan 0.72. Dari pengujian tersebut disimpulkan bahwa fitur yang memiliki pengaruh signifikan terhadap naik dan turunnya nilai precision dan recall adalah fitur posisi kalimat dalam paragraf dan fitur posisi keseluruhan kalimat. Kemudian dari hasil pengujian variasi k pada set fitur terbaik, didapatkan nilai set fitur yang maksimal ketika k=1 dengan nilai rata-rata precision, recall dan f-measure sebesar 0.89, 0.74 dan 0.81.
Kata Kunci: text mining, peringkasan teks, K-Nearest Neighbor, fitur statistik
Abstract
Now days, information about healthy has been widely scattered and very easily obtained through the
online website. But, within largest information that contain in the text of article make the reader can’t
understand about contents of the text. So, we need a system that can summarize a text to make easy the reader in understanding the contents of the text. Automatic text summary using k-nearest neighbor based on statistical features can be solution about the problem. Statistical features such as position of a sentence in a paragraph, overall sentence position, numerical data, inverted commas, the length of the sentence and keyword has important influence become parameter in summarization. From testing of statistical features that have been done by using k = 3, this method get result the best value of precision, recall and f -measure on feature set 9 with values 0.75, 0.71 and 0.72. From the test can concluded that the features that have a significant influence on the rise and fall of precision and recall values are position of a sentence in paragraph and sentence overall position. And then, from the test of k variation on the best feature set, we get maximum feature set value when k = 1 with the average value of precision, recall and f-measure of 0.89, 0.74 and 0.81.
Keywords: text mining, text summarization, K-Nearest Neighbor, statistical feature
1. PENDAHULUAN
Berkembangnya internet dengan pesat berdampak terhadap bertambahnya jumlah informasi yang mengakibatkan sangat sulit untuk mendapatkan informasi secara efisien (Desai & Shah, 2016). Berita merupakan sebuah informasi yang berguna untuk menyampaikan
dan lain sebagainya. Namun dalam penelitian ini topik yang digunakan adalah kesehatan. Alasan memilih topik kesehatan dikarenakan jumlah perbandingan orang Indonesia yang sakit lebih banyak dibandingkan dengan yang sehat, hal tersebut disampaikan oleh menteri kesehatan Nila juwita Moelek dalam Seminar Kupas Tuntas Dua Tahun Pelaksanaan JKN di Jakarta. Hal ini dibuktikan berdasarkan data BPJS Kesehatan, misalnya pada tahun 2014, terdapat 4,8 juta kasus penyakit jantung yang memakan dana Rp 8,189 triliun. Kemudian di tahun 2015 hingga triwulan III ada 3,9 juta kasus hingga memakan dana Rp5,462 triliun. Kemudian untuk gagal ginjal sebanyak 1,4 juta menyerap dana sebesar Rp2,2 triliun selama tahun 2014 (Pujiono, 2015). Sehingga dengan memberikan wawasan seputar kesehatan kepada pembaca, harapannya agar pembaca dapat memperoleh beragam informasi tentang kesehatan yang berguna untuk dirinya dan kemudian dapat disampaikan kepada sekitarnya, sehingga dapat mengurangi resiko terkena berbagai penyakit. Dengan memanfaatkan internet, untuk pencarian informasi seputar kesehatan tersebut bisa didapatkan dengan mudah.
Meskipun demikian, untuk mendapatkan informasi berita online sangatlah mudah, pembaca hanya perlu mengakses berita tersebut dalam sebuah situs, sehingga pembaca tidak akan pernah ketinggalan informasi seputar kesehatan. Meskipun akses informasi sudah sangat mudah, untuk mendapatkan informasi yang diinginkan dengan waktu yang pendek menjadi masalah yang serius di era informasi sekarang ini (Bhole & Agrawal, 2014). Oleh karena itu diperlukan sebuah sistem yang dapat menyajikan informasi secara singkat namun mengandung informasi yang penting dari teks aslinya, hal itu disebut sebagai ringkasan (babar & patil, 2014). Dengan penyajian informasi berupa inti dokumen secara singkat tetapi mencakup semua informasi dokumen dapat mempermudah pembaca tanpa membaca dokumen secara keseluruhan (Ridok, 2014).
Beberapa metode yang dapat digunakan untuk melakukan peringkasan teks secara umum terbagi menjadi dua, yaitu supervised dan
unsupervised (Mani dalam Ridok, 2014). Metode supervised hasilnya berupa model peringkasan yang berasal dari data latih dari ringkasan buatan manusia, sehingga ringkasan sistem akan bergantung pada data latih (Ridok, 2014). Sedangkan, metode unsupervised tidak membutuhkan data latih ringkasan dari manusia
untuk menghasilkan ringkasan sistem (Ridok, 2014). Berdasarkan penelitian-penelitian terdahulu, antara lain penelitian yang dilakukan oleh Ridok (2014) tentang peringkasan dokumen Bahasa Indonesia berbasis non-negative matrix factorization (NMF) yang memanfaatkan matrix fitur semantic non-negatif(W) dan matrik variabel semantik non-negative(H) menghasilkan rata-rata precision dan recall
masing-masing 0.19724 dan 0.34085. Kemudian penelitian yang dilakukan oleh Foong (2014) dengan judul peringkasan teks dengan Latent Semantic Analisis pada platform android berbasis sentence selection menggunakan
Singular Value Decomposition (SVD)
menghasilkan rata-rata f-score 0,386. Dan Penelitian yang dilakukan oleh Luthfiarta dkk. (2014) dengan judul Integrasi peringkas dokumen teks otomatis dengan algoritma Latent Semantic Analysis pada dokumen peringkas teks otomatis untuk clustering dokumen, menggunakan fitur judul, panjang kalimat, bobot kata, posisi kalimat, kesamaan antar kata, kata tematik dan data numerik menghasilkan tingkat akurasi mencapai 71,04 %.
Oleh karena itu, berdasarkan penelitian-penelitian sebelumnya, penulis mengajukan penelitian dengan judul Peringkasan Teks Otomatis pada Artikel Berita Kesehatan Menggunakan k-Nearest Neighbor Berbasis Fitur Statistik. Penelitian ini diajukan dengan menambahkan beberapa fitur-fitur statistik yang lain sebab fitur-fitur lain seperti posisi kalimat dalam paragraf, posisi keseluruhan kalimat dalam dokumen, data numerik, tanda koma terbalik, panjang kalimat, dan kata kunci termasuk penting (Desai & Shah, 2016). Kemudian untuk melakukan perankingan bobot setiap fitur tersebut digunakan K-NN, dikarenakan K-NN berbasis teknik pembelajaran lebih cocok daripada naïve bayes dan term-graph untuk kasus teks mining atau dokumen, karena K-NN memiliki akurasi yang lebih tinggi dibanding naïve bayes dan term-graph
(Bijalwan, 2014). Sehingga harapannya dengan adanya penambahan fitur-fitur statistik tersebut beserta perangkingan dengan K-NN dapat meningkatkan akurasi pada sistem peringkas teks.
2. DASAR TEORI
2.1 Data yang digunakan
diambil dari website www.kompas.com dengan kategori kesehatan, dataset berjumlah 40 artikel, 30 dijadikan sebagai data latih dan 10 dijadikan sebagai data uji.
2.2 Preprocessing
Preprocessing merupakan langkah awal dilakukan pemrosesan teks guna membuat teks menjadi lebih terstruktur. Preprocessing
dilakukan dengan beberapa tahap, yaitu segmentasi, case folding, tokenisasi, stopword removal dan stemming.
2.2.1 Segmentasi
Pada proses segmentasi, dokumen dipecah berdasarkan tanda pemisah kalimat. Setiap dokumen yang telah dipecah akan dimasukkan kedalam list kalimat. Keluaran dari hasil segmentasi berupa kumpulan kalimat yang akan digunakan pada proses berikutnya (Desai & shah, 2016).
2.2.2 Case folding
Pada proses case folding dilakukan pengubahan semua kata kedalam huruf kecil dan
penghapusan tanda baca selain ‘a-z’, angka, dan tanda baca yang dianggap tidak perlu.
2.2.3 Tokenisasi
Pada bagian tokenisasi, kalimat hasil case folding di pecah kedalam kata. Pemecahan kalimat kedalam kata berdasarkan tanda spasi antar kalimat, sehingga dibuatlah list yang terdiri dari kumpulan kata yang disebut token (Desai & Shah, 2016).
2.2.4 Stopword removal
Stopword removal merupakan penghilangan kata yang tidak relevan dalam penentuan topik
dalam sebuah dokumen, seperti kata “dari”, ”adalah”, “atau”, “sebuah”, dan lain-lain dalam dokumen bahasa Indonesia.(Luthfiarta et al, 2014).
2.2.5 Stemming
Stemming merupakan suatu langkah yang dilakukan dengan tujuan mendapatkan kata dasar dengan cara menghapus imbuhan (Novitasari, 2016).
2.3 Ekstraksi fitur
Ekstraksi fitur merupakan tahap processing. Processing adalah jantung dari peringkasan teks yang mana dilakukan analisis lebih dalam pada
dokumen (Desai & Shah, 2016). Berikut ini merupakan fitur-fitur yang digunakan pada penelitian.
2.3.1 Posisi kalimat dalam paragraf
Posisi kalimat merupakan bagian penting dalam dokumen. Kalimat awal dalam paragraf merupakan bagian penting hampir dalam semua kasus karena menyampaikan topik dokumen dan memiliki kemungkinan besar untuk diekstrak menjadi ringkasan (Desai & Shah, 2016). Berikut merupakan rumus perhitungan posisi kalimat dalam paragraf yang ditunjukkan pada persamaan 1.
posisi_kalimat = 𝑛−𝑖𝑛 (1)
Keterangan :
- n = total kalimat dalam paragraf - i = posisi kalimat ke –i
2.3.2 Posisi keseluruhan kalimat
Nilai dari posisi keseluruhan kalimat dihitung dalam konteks keseluruhan dokumen. Perhitungan posisi keseluruhan kalimat akan diberikan nilai terbesar pada awal kalimat, sedangkan nilai terkecil diberikan pada akhir kalimat dalam sebuah dokumen. Berikut merupakan rumus perhitungan posisi keseluruhan kalimat ditunjukkan pada persamaan 2.
pos_keseluruhan = 𝑛−𝑖𝑛 (2)
Keterangan :
- n = total kalimat dalam dokumen - i = posisi kalimat ke –i
2.3.3 Data numerik
Data numerik merepresentasikan beberapa informasi penting seperti tanggal, umur, rupiah, alamat, dan lain sebagainya (Desai & Shah, 2016). Data numerik dihitung menggunakan persamaan 3.
data_numerik = 𝑝𝑎𝑛𝑗𝑎𝑛𝑔 𝑘𝑎𝑙𝑖𝑚𝑎𝑡𝑡𝑜𝑡𝑎𝑙 𝑑𝑎𝑡𝑎 (3)
Keterangan :
- Total data = total data numerik dalam kalimat.
- Panjang kalimat = total kata dalam kalimat.
2.3.4 Tanda Koma terbalik
penting (Desai & Shah, 2016). Tanda koma terbalik dihitung menggunakan persamaan 4.
koma_terbalik = 𝑝𝑎𝑛𝑗𝑎𝑛𝑔 𝑘𝑎𝑙𝑖𝑚𝑎𝑡𝑡𝑜𝑡𝑎𝑙 𝑘𝑎𝑡𝑎 (4)
Keterangan :
- Total kata = total banyaknya kata dalam tanda koma terbalik.
- Panjang kalimat = total kata dalam kalimat.
2.3.5 Panjang kalimat
Kalimat yang pendek mungkin tidak merepresentasikan topik dokumen karena kata yang terkandung didalamnya sedikit, meskipun demikian, memilih kalimat yang panjang juga tidak baik untuk peringkasan (Desai & Shah, 2016). Sehingga, kalimat yang panjang dan pendek diberikan nilai yang rendah. Nilai panjang kalimat dihitung berdasarkan persamaan 5.
panjang kalimat = 𝑘𝑎𝑙𝑖𝑚𝑎𝑡 𝑡𝑒𝑟𝑝𝑎𝑛𝑗𝑎𝑛𝑔𝑡𝑜𝑡𝑎𝑙 𝑘𝑎𝑡𝑎 (5)
Keterangan :
- Total kata = total kata dalam kalimat. - kalimat terpanjang = total kata dalam
kalimat terpanjang pada sebuah paragraf.
2.3.6 Kata kunci
Kata kunci merupakan kata yang muncul dengan frekuensi tinggi dalam sebuah dokumen (Desai & Shah, 2016). Mengidentifikasi dan melakukan komputasi pada kata kunci berguna untuk menentukan kalimat yang penting. Kata kunci dalam kalimat dihitung berdasarkan persamaan 6.
kata_kunci = 𝑝𝑎𝑛𝑗𝑎𝑛𝑔 𝑘𝑎𝑙𝑖𝑚𝑎𝑡𝑡𝑜𝑡𝑎𝑙 𝑑𝑎𝑡𝑎 (6)
Keterangan :
- Total data = total banyaknya kata kunci dalam kalimat.
- Panjang kalimat = total kata dalam kalimat.
2.4 K-Nearest Neighbor
Ide dasar KNN adalah mengelompokkan kategori pada query yang diberikan bukan hanya berdasar kedekatan dokumen terdekat dalam ruang dokumen, namun pada kategori dari k dokumen yang terdekat (Bijalwan dkk., 2014). Berikut merupakan langkah-langkah algoritma k-Nearest Neighbor antara lain:
1. Masukkan data latih dan data uji
2. Tentukan julah nilai k tetangga terdekat 3. Hitung jarak antara data uji dengan data latih menggunakan Euclidian distance 4. Urutkan hasil jarak berdasarkan nilai
terkecil
5. Mengambil data latih sejumlah k tetangga terdekat
6. Menentukan kelas data baru berdasarkan mayoritas k tetangga terdekat.
Pada tahap ini, kalimat akan dipilih menjadi suatu ringkasan berdasarkan kedekatan jarak antara data uji ke data latih dengan mengacu pada nilai hasil ekstraksi fitur. Posisi kalimat hasil ringkasan akan sama urutannya dengan kalimat asli dari dokumen (Desai & Shah, 2016)
3. IMPLEMENTASI
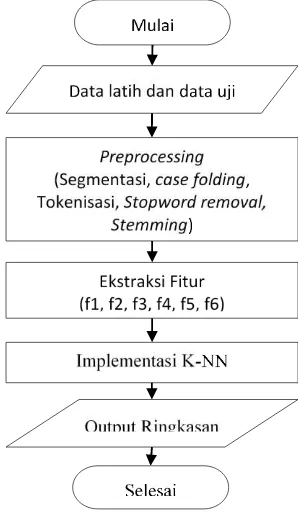
Tahap-tahap yang dilakukan dalam implementasi sistem ditunjukkan pada Gambar 1 berikut.
Gambar 1. Implementasi Sistem
Berdasarkan alur fowchart tersebut, hal pertama yang dilakukan dalam penelitian yaitu menginputkan data uji dan data latiih, kemudian dilakukan preprocessing meliputi segmentasi,
case folding, tokenisasi, stopword removal dan
data uji dan data latih menggunakan k–NN untuk klasifikasi kalimat ringkasan atau bukan.
4. PENGUJIAN DAN ANALISIS
Dalam pengujian ini dibagi menjadi dua yaitu pengujian fitur statistik dan pengujian nilai k. Output dari hasil pengujian yaitu nilai
rata-Pengertian correct merupakan jumlah kalimat yang tepat diekstrak sistem dengan kalimat hasil seorang pakar. Wrong merupakan jumlah kalimat yang diekstrak sistem namun tidak terdapat pada hasil seorang pakar dan
missed merupakan jumlah kalimat yang diekstrak pakar tetapi sistem tidak mengekstraknya (Pal et al, 2013).
4.1Pengujian Fitur Statistik
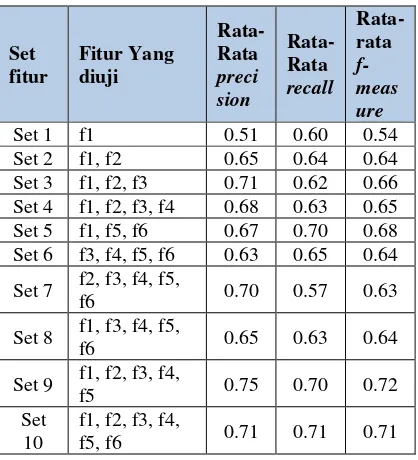
Pengujian ini mengacu pada penelitian sebelumnya yang dilakukan oleh Desai & shah (2016) yang menggunakan variasi set fitur, dan dalam pengujian ini nilai k dibuat k=3. Berikut Merupakan hasil pengujian fitur statistik yang ditunjukkan pada Tabel 1.
Tabel 1. Hasil pengujian set fitur
Set yang hanya menggunakan fitur posisi kalimat dalam paragraf(f1), mendapatkan nilai
precision, recall dan f-measure yang rendah, yaitu 0.51, 0.60 dan 0.54. Kemudian pada set 2 ditambah menggunakan fitur posisi keseluruhan kalimat(f2), hasilnya meningkatkan precision,
recall dan f-measure masing-masing sebesar 0.65, 0.64 dan 0.64. Kemudian pada set 3, 4 dan 5 dengan penambahan fitur 3, fitur 4, fitur 5 dan fitur 6 hasilnya tidak meningkat signifikan. Dan dari set 6, 7, 8, 9 dan 10 dapat disimpulkan bahwa fitur yang memiliki dampak paling besar terhadap naik dan turunnya nilai precision dan
recall merupakan fitur 1, fitur 2. Fitur 1 yaitu posisi kalimat dalam paragraf memiliki pengaruh besar terhadap naiknya recall namun membuat turun nilai precision, hal ini dikarenakan dengan penambahan fitur 1, kalimat ringkasan yang diambil semakin banyak sehingga membuat rendah nilai precisionnya. Kemudian fitur 2 yaitu posisi keseluruhan kalimat, memiliki pengaruh terhadap naiknya nilai precision namun menurunkan nilai recall, hal ini dikarenakan dengan penambahan fitur 2 kalimat ringkasan yang diambil semakin sedikit, sehingga precisionnya semakin tinggi.
4.2 Pengujian Nilai k
Pengujian terhadap nilai k pada fitur set terbaik dilakukan dengan nilai yang bervariasi yaitu k=1, k=3, k=5 dan k=7, gunanya yaitu untuk mengetahui pengaruh nilai k terhadap
precision, recall dan f-measure terhadap fitur set yang terbaik. Berikut merupakan hasil pengujian nilai k yang ditunjukkan pada Gambar 2.
Gambar 2. Hasil pengujian nilai k
Berdasarkan hasil pengujian tersebut dapat
dilihat bahwa ketika k bernilai 1, nilai precision,
recall dan f-measure yang dihasilkan sangat tinggi. Kemudian ketika k bernilai 3, nilai
precision, recall dan f-measure menurun, hal itu juga terjadi pada k ketika bernilai 5 dan k bernilai 7. Sehingga dapat dilihat bahwa semakin besar nilai k yang diujikan pada set fitur terbaik (set 9), maka nilai precision, recall dan f-measure rata-rata semakin menurun. Hal ini dikarenakan ketika nilai k semakin besar menyebabkan semakin banyak kelas yang tidak relevan masuk kedalam ringkasan sehingga menyebabkan nilai dari precision, recall dan f-measure pun menjadi turun.
5. KESIMPULAN
Berdasarkan hasil pengujian dan analisis dari Peringkasan teks otomatis pada artikel berita kesehatan menggunakan k-nearest neighbor berbasis fitur statistik dapat disimpulkan bahwa Algoritma k-nearest neighbor dapat diterapkan dalam peringkasan teks otomatis pada artikel berita kesehatan dengan melakukan preprocessing, ekstraksi fitur dan menghitung jarak Euclid untuk kelas terdekat. Nilai rata-rata precision, recall dan f-measure terbaik didapatkan pada fitur set 9 dengan nilai masing-masing sebesar 0.75, 0.71 dan 0.72. Kemudian, Semakin besar nilai k maka nilai precision, recall dan f-measure semakin menurun dikarenakan semakin banyak kelas yang tidak relevan masuk kedalam kelas ringkasan.
Berdasarkan penelitian yang telah dilakukan, beberapa saran yang dapat diberikan yaitu, dalam proses pemecahan dokumen kedalam paragraf masih dilakukan pemberian
tanda “*#” dengan manual, sehingga
dimungkinakan untuk penelitian selanjutnya dapat ditambahkan proses pemecahan paragraf secara langsung, baik berupa deteksi adanya
karakter ‘\n’ dan lainnya sehingga dokumen dapat langsung dipecah. Kemudian dalam pemecahan kalimat sebaiknya diperhatikan delimiternya dikarenakan ada beberapa kalimat yang ambigu jika dipecah seperti gelar dan alamat.
DAFTAR PUSTAKA
Babar, S. A., & Patil, P. D., 2015. Improving Performance of Text Summarization. Procedia Computer Science. pp.354–363.
Bhole, P., & Agrawal, A. J., 2014. Single Document Text Summarization Using
Clustering Approach Implementing for News Article. International Journal of Engineering Trends and Technology (IJETT). Volume 15, no.7, pp.364–368.
Bijalwan, V., Kumar, V., Kumari, P., & Pascual, J., 2014. KNN based Machine Learning Aproach for Text and Document Mining. International Journal of Database Theory and Application. Volume 7, no.1,pp.61-70.
Desai, N., & Shah, P., 2016. Automatic Text Summarization Using Supervised Machine Learning Technique for Hindi Langauge. International Journal of Research in Engineering and Technology. Volume 5, pp.361–367.
Luthfiarta, A., Zeniarja, J., Salam, A., 2014. Integrasi peringkas dokumen otomatis dengan algoritma latent semantic analysis (LSA) pada peringkas dokumen otomatis untuk proses clustering dokumen. Vol. 13, No. 1, pp.61-68.
Novitasari, D., 2016. Perbandingan Algoritma Stemming Porter dengan Arifin Setiono untuk Menentukan Tingkat Ketepatan. Jurnal String Vol.1 ,No.2.
Pal, A. R., Maiti, P. K., & Saha, D., 2013. An approach to automatic text summarization using simplified lesk algorithm and wordnet. International Journal of Control Theory and Computer Modeling. Vol.3, No.4, pp. 15–23
Pujiono J, 2015. Orang Indonesia lebih banyak yang sakit daripada yang sehat.[Online] Tersedia
di:https://beritagar.id/artikel/kesehatan/or ang-indonesialebih-banyak-yang-sakit-daripada-yang-sehat [Diakses 30 Maret 2017]