ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
TESIS
Oleh
YUNIAR ANDI ASTUTI
097038020/ TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Komputer dalam Program Studi Magister
Teknik Informatika pada Program Pascasarjana
Fakultas MIPA Universitas Sumatera Utara
Oleh
YUNIAR ANDI ASTUTI
097038020/ TINF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
MEDAN
PENGESAHAN TESIS
Judul Tesis : ANALISIS PERBANDINGAN TEKNIK
SUPPORT VECTOR REGRESSION (SVR) DAN DECISION TREE C4.5 DALAM DATA MINING
Nama Mahasiswa : YUNIAR ANDI ASTUTI
Nomor Induk Mahasiswa : 097038020
Program Studi : Magister Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
Drs Sawaluddin, MIT
Anggota Ketua
Prof. Dr. Opim Salim Sitompul
Ketua Program Studi Dekan
Prof. Dr. Muhammad Zarlis
NIP. 195707011986011003 NIP. 196310261991031001
PERNYATAAN ORISINALITAS
ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
TESIS
Dengan ini penulis menyatakan bahwa penulis mengakui semua karya tesis ini adalah hasil karya saya sendiri kecuali kutipan dan ringkasan yang tiap satunya telah di jelaskan sumbernya dengan benar.
Medan, 25 Juli 2011
PERNYATAAN PERSETUJUAN PUBLIKASI
KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan di bawah ini:
N a m a : Yuniar Andi Astuti N I M : 097038020
Program Studi : Magister ( S2 ) Teknik Informatika Jenis Karya Ilmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive Royalty free Right) atas Tesis saya yang berjudul:
ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media, memformat, mengelola dalam bentuk data-base, merawat dan mempublikasikan Tesis saya tanpa meminta izin dari saya selama tetap mencantumkan nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, 25 Juli 2011
Yuniar Andi Astuti
Telah diuji pada Tanggal: 28 Juli 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Opim Salim Sitompul Anggota : 1. Prof. Dr. Muhammad Zarlis
2. Prof. Dr. Iryanto
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : Yuniar Andi Astuti, S. Kom Tempat dan Tanggal Lahir : Palembang, 12 Juni 1967 Alamat Rumah : Jl. Setiabudi gg. Anggrek No. 2 Depan Kopertis Medan
HP : 085373741500
E-mail :
Instansi Tempat Bekerja : Politeknik Unggul LP3M Alamat Kantor : Jln. Iskandar Muda No. 3 EF Telepon : 061-4530701
DATA PENDIDIKAN
KATA PENGANTAR
Pertama-tama penulis panjatkan puji syukur kehadirat Allah SWT Tuhan Yang Maha Esa atas segala limpahan rakhmad dan karunia-Nya sehingga tesis ini dapat diselesaikan.
Dengan selesainya tesis ini, perkenankanlah penulis mengucapkan terima kasih yang sebesar-besarnya kepada:
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu, DTMH, M. Sc (CTM), Sp. A(K) atas kesempatan yang diberikan kepada penulis untuk mengikuti dan menyelesaikan pendidikan Program Magister (S2).
Dekan Fakultas MIPA Universitas Sumatera Utara, Dr. Sutarman, M.Sc atas kesempatan yang telah diberikan kepada penulis menjadi mahasiswa Program Magister (S2) pada Program Pascasarjana FMIPA Universitas Sumatera Utara.
Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr. Muhammad Zarlis, Sekretaris Program Studi Teknik Informatika M. Andri Budiman, ST, M. Comp. Sc, M.EM beserta seluruh Staff dan Staff Pengajar pada Program Studi Magister (S2) Teknik Informatika Program Pascasarjana Fakultas MIPA Universitas Sumatera Utara, yang telah bersedia membimbing penulis, sehingga dapat menyelesaikan pendidikan tepat pada waktunya.
Terima kasih yang tak terhingga dan penghargaan setinggi-tingginya penulis ucapkan kepada Prof. Dr. Opim Salim Sitompul selaku Pembimbing Utama yang dengan penuh perhatian dan telah memberikan dorongan dan bimbingan, demikian juga kepada Drs. Sawaluddin, MIT selaku Pembimbing kedua yang dengan penuh kesabaran menuntun dan membimbing penulis hingga selesainya tesis ini.
Terima kasih yang tak terhingga dan penghargaan setinggi-tingginya penulis ucapkan kepada Prof. Dr. Muhammad Zarlis, Prof. Dr. Iryanto dan Dr. Erna Budhiarti Nababan sebagai pembanding yang telah memberikan saran, masukan dan arahan yang baik demi penyelesaian tesis ini.
maupun materil, budi baik ini tidak dapat dibalas hanya diserahkan kepada Allah SWT, Tuhan Yang Maha Esa.
Kepada semua pihak yang tidak dapat penulis sebutkan satu persatu dalam tesis ini, terima kasih atas segala bantuan yang diberikan. Sekecil apapun yang Anda berikan untuk penulis turut menghantarkan penulis untuk menyelesaikan pendidikan yang ditempuh selama ini. Dengan segala kekurangan dan kerendahan hati, semoga kiranya Tuhan Yang Maha Kuasa membalas segala bantuan, kebaikan yang telah diberikan.
Medan, Juli 2011
Penulis,
Yuniar Andi Astuti
ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
ABSTRAK
COMPARATIVE ANALYSIS OF TECHNICAL SUPPORT VECTOR
REGRESSION (SVR) and C4.5 DECISION TREE IN DATA
MINING
ABSTRACT
This study examines techniques Support Vector Regression and Decision Tree C4.5 has been used in studies in various fields, in order to know the advantages and disadvantages of both techniques that appear in Data Mining. From the ten studies that use both techniques, the results of the analysis showed that the accuracy of the SVR technique for 59,64% and C4.5 for 76,97% So in this study obtained a statement that C4.5 is better than SVR
DAFTAR ISI
BAB I PENDAHULUAN ...1
1.1 LatarBelakang ...1
1.2 Penelitian Terdahulu ...3
1.3 Perumusan Masalah ...4
1.4 Batasan Masalah ...4
1.5 Tujuan Penelitian ...4
1.6 Manfaat Penelitian ...5
BAB II TINJAUAN TEORITIS ...6
2.1 Data Mining ...6
2.2 Metode Klasifikasi ...8
2.2.1 Klasifikasi oleh Induksi Pohon Keputusan ...8
2.3 Machine Learning ...9
2.4 Support Vector Machine ...10
2.5 Support Vector Regression ...10
2.6 Pohon Keputusan ...13
BAB III METODE PENELITIAN ...15
3.1 Rancangan Penelitian ...15
3.2 Metode Penelitian ...15
3.3 Kerangka Penelitian ...15
3.3.1 Penelitian dalam bidang Pengembangan Ilmu Pengetahuan ...15
3.3.2 Penelitian dalam bidang Kesehatan ...22
3.3.3 Penelitian dalam bidang Internet ...23
3.3.4 Penelitian dalam bidang Musik ...28
3.3.5 Penelitian dalam bidang Time Series ...31
3.3.6 Penelitian dalam bidang Jaringan Komputer ...32
BAB IV ANALISIS TEKNIK SUPPORT VECTOR REGRESSION DAN DECISION
TREE C4.5 ...37
4.1 Penelitian dalam bidang Pengembangan Ilmu Pengetahuan ...37
4.2 Penelitian dalam bidang Kesehatan ...39
4.3 Penelitian dalam bidang Internet ...40
4.4 Penelitian dalam bidang Musik ...41
4.5 Penelitian dalam bidang Time Series ...42
4.6 Penelitian dalam bidang Jaringan Komputer ...43
4.7 Penelitian dalam bidang Pemasaran ...44
BAB V KESIMPULAN DAN SARAN ...46
5.1 Kesimpulan ...46
GAMBAR
Gambar 2.1 Konsep Pohon Keputusan untuk membeli komputer ...9
DAFTAR TABEL Tabel 1.1 Daftar Judul dan Penulis Penelitian yang akan dianalisis ...1
Tabel 3.1 Statistik untuk gabungan Broadcast dan Pengurangan Pohon Keputusan ..22
Tabel 3.2 Penggunaan Waktu CPU dan Angka Support Vector ...32
Tabel 3.3 Summary of classification accuracies averaged over time ...34
Tabel 4.1 Hasil Penelitian dalam Bidang Pengembangan Ilmu Pengetahuan ...39
Tabel 4.2 Hasil Penelitian dalam Bidang Kesehatan ...40
Tabel 4.3: Hasil Penelitian dalam Bidang Internet ...41
Tabel 4.4: Hasil Penelitian dalam Bidang Musik ...42
Tabel 4.5: Hasil Penelitian dalam Bidang Time Series ...43
Tabel 4.6: Hasil Penelitian dalam Bidang Jaringan Komputer ...44
Tabel 4.7: Hasil Penelitian dalam Bidang Pemasaran ...44
ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR
REGRESSION (SVR) DAN DECISION TREE C4.5
DALAM DATA MINING
ABSTRAK
COMPARATIVE ANALYSIS OF TECHNICAL SUPPORT VECTOR
REGRESSION (SVR) and C4.5 DECISION TREE IN DATA
MINING
ABSTRACT
This study examines techniques Support Vector Regression and Decision Tree C4.5 has been used in studies in various fields, in order to know the advantages and disadvantages of both techniques that appear in Data Mining. From the ten studies that use both techniques, the results of the analysis showed that the accuracy of the SVR technique for 59,64% and C4.5 for 76,97% So in this study obtained a statement that C4.5 is better than SVR
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pengolahan data dalam jumlah yang besar tentu saja tidak bisa menggunakan cara manual atau konvensional, ada beberapa teknik dan metode dalam data mining untuk mengolah data tersebut. Setiap teknik tentunya mempunyai kelebihan dan kekurangan dalam mengolah data tersebut.
Teknik Support Vector Regression (SVR) dan klasifikasi dengan metode Decision Tree (Pohon Keputusan) algoritma C4.5 adalah teknik-teknik dalam data mining yang
sering digunakan oleh para peneliti, diantaranya yaitu:
Dalam bidang pengembangan ilmu pengetahuan: Basak et al. (2007), Gangrade (2009), Grbovic (2006); Dalam bidang kesehatan: Gupta et al. (2011); Dalam bidang Internet: Bermolen et al. (2008), Rastegari et al. (2010); Dalam bidang musik: Han et al. (2009); Dalam bidang pemasaran: Kim (2006); Dalam bidang time series: Cao (2002); Dalam bidang jaringan komputer: Amershi dan Conati (2009).
Ringkasan lengkap penelitian-penelitian tersebut, dapat dilihat pada tabel 1.1
Tabel 1.1 Daftar judul dan penulis penelitian yang akan dianalisis
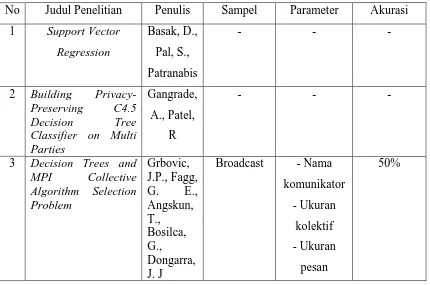
No Bidang Judul Penelitian Tahun Penulis Metode 1 Pengembangan
Ilmu
Pengetahuan
Support Vector Regression
2007 Basak, D., Pal, S., Patranabis
SVR
2 Pengembangan Ilmu
Pengetahuan
Building
Privacy-Preserving C4.5 Decision Tree Classifier
on Multi Parties
2009 Gangrade, A., Patel, R
C4.5
3 Pengembangan Ilmu
Pengetahuan
Decision Trees and MPI Collective Algorithm Selection Problem
2006 Grbovic, J.P., Fagg, G. E., Angskun, T., Bosilca, G., Dongarra, J. J
C4.5
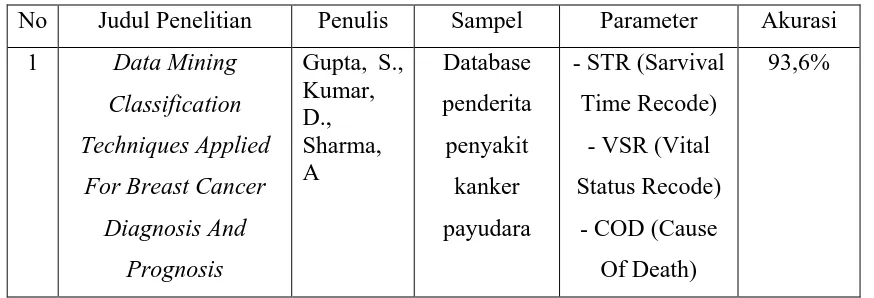
Classification
Techniques Applied For Breast Cancer Diagnosis And Prognosis
Kumar, D., Sharma, A
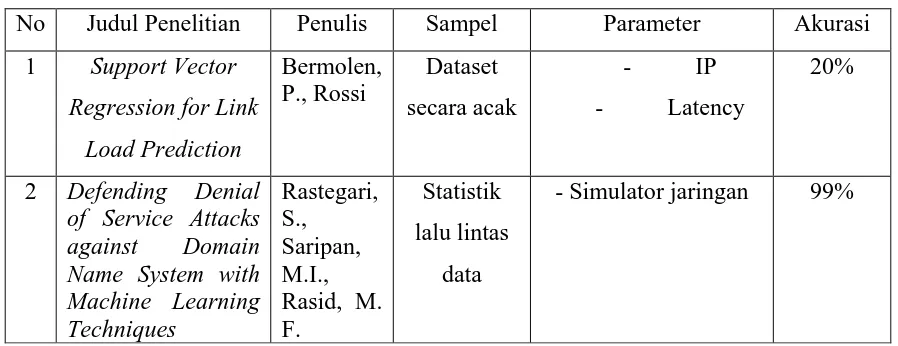
5 Internet Support Vector Regression for Link Load
Prediction
2008 Bermolen, P., Rossi
SVR
6 Internet Defending Denial of Service Attacks against Domain Name System with Machine Learning Techniques
2010 Rastegari, S., Saripan, M.I., Rasid, M. F.
SVM
7 Music Smers: Music Emotion Recognition Using Support Vector Regression
2009 Han, B., Dannenberg, R.,
Hwang, E
SVR
8 Time Series Support vector machines experts for time series forecasting
2002 Lijuan Cao SVM
9 Jaringan Komputer
Combining Unsupervised and Supervised Classification to Build User Models for Exploratory Learning Environments
2009 Amershi, Saleema, Conati, Cristina
Data Mining
10 Pemasaran Response Modeling with
Support Vector Regression
2006 Kim, D., Lee, H., Cho
SVR
Dari uraian di atas terlihat bahwa metode SVR dan Decision Tree C4.5 banyak digunakan dalam penelitian-penelitian di berbagai bidang.
Dalam penelitian ini, penulis akan menganalisis metode Support Vector Regression dan akan membandingkannya dengan teknik data mining yang lain yaitu
metode klasifikasi decision tree (pohon keputusan) menggunakan algoritma C4.5, kemudian mengidentifikasi kelebihan dan kekurangan dari kedua metode tersebut.
kekurangan-kekurangan kemudian akan didapat metode mana yang lebih baik dari kedua metode tersebut.
Dari uraian di atas, penulis tertarik untuk membuat penelitian dengan judul ”ANALISIS PERBANDINGAN TEKNIK SUPPORT VECTOR REGRESSION DAN DECISION TREE C4.5 DALAM DATA MINING”
1.2 Penelitian Terdahulu
Basak et al. (2007) dalam tulisannya meninjau teori metode support vector regression (SVR), ide SVR didasarkan pada perhitungan fungsi regresi linier dalam fitur ruang dimensi tinggi dimana data input dipetakan melalui fungsi nonlinier
Gangrade (2009) melakukan penelitian dalam melestarikan penggunaan klasifikasi pohon keputusan algoritma C4.5 dengan tujuan untuk membangun klasifikasi yang akurat tanpa mengungkapkan informasi pribadi dalam menambang data.
.
Grbovic (2006) melakukan penelitian dalam mengeksplorasi penerapan pohon keputusan C4.5 dalam menyelesaikan masalah. Hasil dari penelitian ini diharapkan, metode pohon keputusan C4.5 dapat menghasilkan kinerja yang baik.
Gupta et al. (2011) melakukan penelitian dalam diagnosa dan prognosa penyakit kanker payudara, merupakan dua aplikasi medis yang menimbulkan tantangan besar bagi para peneliti. Penggunaan mesin pembelajaran dan penambangan data telah merevolusi seluruh proses diagnosis dan prognosis penyakit kanker payudara. Diagnosis penyakit kanker payudara untuk membedakan kanker yang ganas atau jinak dan prognosis penyakit kanker payudara untuk memprediksi apakah penyakit tersebut akan kambuh
Bermolen et al.,, (2008) melakukan penelitian penggunaan SVR (support vector regression) untuk prediksi link beban dengan menggunakan model Moving Average
(MA) dan Auto Regresif (AR). lagi atau tidak.
Rastegari et al., (2010) melakukan penelitian dalam mengatasi serangan Denial of Service (DOS) terhadap Domain Name System dengan teknik Machine Learning.
Han et al., (2009) melakukan penelitian pengenalan emosi musik menggunakan support vector regression. Emosi musik memainkan peran penting dalam menentukan
ilmu seperti fisiologi, ilmu psikologi, kognitif dan musikologi. Penyajikan sebuah support vector regression (SVR) musik berdasarkan sistem pengenalan emosi
Cao (2002) melakukan penelitian yang mengusulkan penggunaan SVM untuk peramalan time series.
.
Amershi dan Conati (2009) melakukan penelitian yang menyajikan suatu kerangka pemodelan pengguna berbasis data, untuk membangun model eksplorasi lingkungan belajar.
Kim (2006) melakukan penelitian untuk memprediksi apakah seorang pelanggan yang diberikan mail atau katalog suatu produk akan menanggapi atau tidak, berdasarkan database informasi demografi pelanggan dan sejarah pembelian, menggunakan support vector regression.
1.3 Perumusan Masalah
Berdasarkan latar belakang diatas, maka rumusan masalah dalam penelitian ini adalah bagaimana perbandingan teknik Support Vector Regression dan decision tree C4.5 dalam data mining?
1.4 Batasan Masalah
Dalam penelitian ini, penulis membatasi masalah yaitu:
1. Penelitian ini hanya pada teknik data mining metode Support Vector Regression dan dibandingkan dengan metode klasifikasi decision tree algoritma C4.5
2. Jumlah penelitian yang akan dianalisis hanya ada sepuluh.
3. Analisis yang dilakukan hanya sebatas dalam penelitian yang telah dibuat sebelumnya.
1.5 Tujuan Penelitian
Tujuan yang ingin dicapai pada penulisan tesis ini adalah:
1. Membuat hasil perbandingan teknik SVR dan metode klasifikasi decision tree algoritma C4.5 dalam data mining yang telah dibuat peneliti sebelumnya.
1.6 Manfaat Penelitian
Penelitian ini diharapkan dapat bermanfaat sebagai referensi atau masukan untuk metode Support Vector Regression dan teknik klasifikasi metode decision tree algoritma C4.5
BAB II
TINJAUAN TEORITIS
2.1 DATA MINING
Data mining terdiri dari berbagai metode. Berbagai metode mempunyai tujuan yang berbeda, masing-masing menawarkan metode yang memiliki kelebihan dan kekurangan. Namun, penambangan data metode yang umum digunakan untuk review ini adalah kategori klasifikasi sebagai teknik prediksi. Dalam data mining, klasifikasi adalah salah satu tugas yang paling penting. Tujuan klasifikasi adalah untuk membangun sebuah classifier yang didasarkan pada beberapa kasus dengan beberapa atribut untuk menggambarkan benda atau satu atribut untuk menggambarkan kelompok objek. Kemudian, classifier digunakan untuk memprediksi kelompok atribut kasus baru dari domain yang didasarkan pada nilai-nilai lain atribut. Metode yang umum digunakan untuk tugas-tugas klasifikasi data mining dapat diklasifikasikan menjadi kelompok sebagai berikut:
- Decision Tree (Han, 2001)
- Support Vector Machine - Genetic Algorithm - Fuzzy Sets
- Neural Network - Rough Sets
Metode data mining diambil dari berbagai literatur, termasuk penambangan data dan pembelajaran mesin, psikometri dan bidang statistik, informasi visualisasi, dan pemodelan komputasi. Han dan Kamber (2001) mengkategorikan pekerjaan dalam data mining ke dalam kategori sebagai berikut:
• Statistik dan visualisasi
• P
-
enambangan web
- Penambangan aturan asosiai dan penambangan pola sekuensial - Penambangan teks
Istilah Knowlegde Discovery Database (KDD) dan Data Mining sering digunakan secara bergantian. KDD adalah proses untuk mengubah data low-level menjadi pengetahuan tingkat tinggi. Oleh karena itu, KDD mengacu pada trivial ekstraksi informasi implisit, yang sebelumnya tidak dikenal dan berpotensi berguna dari data dalam database. Sedangkan penambangan data dan KDD sering diperlakukan sebagai kata-kata yang sama tetapi dalam data mining yang sebenarnya merupakan langkah penting dalam KDD proses. (Gupta et al., 2011)
Proses knowledge discovery dalam Database terdiri dari beberapa langkah terkemuka dari koleksi data mentah ke beberapa bentuk pengetahuan baru. (Osmar, 2011) Proses iteratif terdiri dari langkah-langkah berikut
(1)
:
Data cleaning (pencucian data): juga dikenal sebagai pembersihan data itu adalah
fase di mana kebisingan data dan data yang tidak relevan dikeluarkan dari koleksi (2)
. Data integration (integrasi data): pada tahap ini, sumber data yang sering heterogen,
dapat dikombinasikan dalam sumber umum (3)
.
Data selection (pemilihan data): pada langkah ini, data yang relevan untuk dianalisis
dipilih untuk diambil dari koleksi data (4)
.
Data transformasi: juga dikenal sebagai konsolidasi data, itu adalah tahap di mana data yang dipilih diubah menjadi bentuk yang sesuai untuk prosedur pertambangan (5)
. Data mining: itu adalah langkah penting di mana teknik pintar diterapkan untuk
mengekstrak pola berpotensi berguna (6)
.
Evaluasi Pola: langkah ini, benar-benar pola yang menarik mewakili pengetahuan diidentifikasi berdasarkan pada langkah-langkah yang diberikan
(7)
.
2.2 METODE KLASIFIKASI
Klasifikasi data yang paling umum diterapkan dalam teknik mining, yang mengolah satu set pra-diklasifikasikan contoh untuk mengembangkan model yang dapat mengklasifikasikan populasi pada umumnya. Penipuan deteksi dan creditrisk aplikasi sangat cocok untuk jenis analisis. Pendekatan ini sering menggunakan pohon keputusan atau algoritma klasifikasi berbasis jaringan saraf tiruan. Proses klasifikasi data melibatkan belajar dan klasifikasi. Dalam Pembelajaran data pelatihan dianalisis dengan algoritma klasifikasi. Dalam klasifikasi data uji digunakan untuk memperkirakan ketepatan aturan klasifikasi. Jika ketepatan akan diterima aturan dapat diterapkan pada tupel data baru. Untuk aplikasi deteksi penipuan, ini akan termasuk catatan lengkap dari kedua kegiatan penipuan dan berlaku ditentukan berdasarkan catatan-oleh-record. Algoritma classifier-pelatihan menggunakan contoh-contoh ini pra-diklasifikasikan untuk menentukan set parameter diperlukan untuk diskriminasi yang tepat. Algoritma ini kemudian encode parameter ini ke dalam model yang disebut classifier. (Bharati, 2006)
Jenis-jenis model klasifikasi:
Classification by decision tree induction
Bayesian Classification
Neural Networks
Support Vector Machines (SVM)
Classification Based on Associations
2.2.1 Klasifikasi oleh Induksi Induksi
Pohon Keputusan
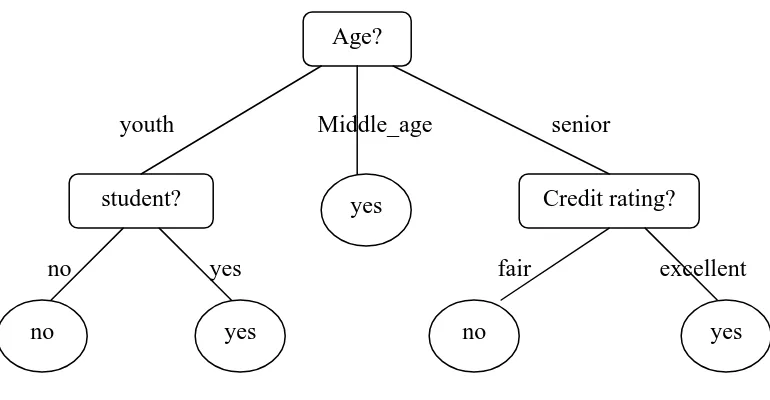
Gambar 2.1 Konsep pohon keputusan untuk membeli komputer (Han, 2006)
Sebuah jenis pohon keputusan ditunjukkan dalam gambar 2.1 yang merupakan konsep membeli komputer, yaitu, untuk memprediksi apakah semua pelanggan di toko elektronik cenderung untuk membeli komputer. Simpul dalam ditandai dengan empat persegi panjang dan node daun dinotasikan dengan oval. Beberapa algoritma pohon keputusan hanya menghasilkan pohon biner (di mana setiap cabang simpul dalam untuk dua simpul lain dengan tepat) sedangkan yang lain dapat menghasilkan pohon non biner.
2.3 MACHINE LEARNING
Machine learning adalah bagian dari kecerdasan buatan yang menjelaskan bagaimana
membuat program atau mesin pembelajaran. Dalam Data Mining, machine learning sering digunakan untuk prediksi atau klasifikasi, dengan machine learning komputer membuat suatu prediksi dan kemudian pembelajaran (Dunham, 2003).
Age?
Credit rating? student? yes
no yes no yes
youth Middle_age senior
2.4 SUPPORT VECTOR MACHINE (SVM)
Support Vector Machines (SVM) adalah satu kumpulan teknik klasifikasi dan regresi,
yang merupakan pengembangan algoritma non-linear dan dikembangkan di Rusia pada tahun enam puluhan. Seperti yang telah diuraikan, SVM dapat digunakan baik untuk klasifikasi atau regresi, yang membatasi perhatian untuk sisa pekerjaan ini. Dalam berikut ini, ikhtisar singkat teori di balik menggunakan SVM untuk estimasi fungsi, memperkenalkan pada saat yang sama dan waktu yang paling relevan pengertian dan parameter, dengan khusus memperhatikan parameter yang dampaknya diselidiki di kemudian hari. Dalam arti, ikhtisar ini untuk memahami kinerja bagian evaluasi, tetapi untuk cakupan yang lebih menyeluruh dari SVM merujuk pada survei pembaca yang sangat baik.
SVM
(Bermolen, 2008) adalah suatu algoritma yang mencoba menemukan pemisah linear (hyper-plane) antara titik data dari dua kelas dalam ruang multidimensi. SVM cocok untuk berurusan dengan interaksi antara fitur dan fitur berlebihan. (Gupta et al., 2011)
2.5 SUPPORT VECTOR REGRESSION (SVR)
SVR merupakan penerapan support vector machine (SVM) untuk kasus regresi. Dalam kasus regresi output berupa bilangan riil atau kontinue. SVR merupakan metode yang dapat mengatasi overfitting, sehingga akan menghasilkan performansi yang bagus (Smola dan Scholkopf, 2004).
Misalnya ada λ set data training, (xj.,yj N
x x x
x={ 1, 2, 3 }⊆ℜ
) dimana j = 1,2,… λ dengan input dan output yang bersangkutan y={yi,...,yλ}⊆ℜ. Dengan SVR, akan ditemukan suatu fungsi f(x) yang mempunyai deviasi paling besar ε dari target aktual yi
Misalnya kita mempunyai fungsi berikut sebagai garis regresi
untuk semua data training. Maka dengan SVR, manakala ε sama dengan 0 akan didapatkan regresi yang sempurna.
b x w x
dimana φ(x) menunjukkan suatu titik didalam feature space F hasil pemetaan x di dalam input space. Koefisien w dan b diestimasi dengan cara meminimalkan fungsi resiko (risk function) yang didefinisikan dalam persamaan (2)
( )
(
)
∑
= ∈ + λ λ 1 2 , 1 2 1 min i i i f xy L C
w (2)
Subject to
( )
( )
ε λ ϕ ϕ− + ≤ε, =1,2,...,≤ − − i b y x w b x w y i i i i Dimana
( )
( )
( )
− − − ≥ = lain yang untuk x f y x f y x f yL i i i i i i
, 0 0 ) , ( ε
ε (3)
Faktor w dinamakan reguralisasi. Meminimalkan2 w akan membuat suatu 2 fungsi setipis mungkin, sehingga bisa mengontrol kapasitas fungsi. Faktor kedua dalam fungsi tujuan adalah kesalahan empirik (empirical error) yang diukur dengan ε -insensitive loss function. Menggunakan ide ε-insensitive loss function harus
meminimalkan norm dari w agar mendapatkan generalisasi yang baik untuk fungsi regresi f. Karena itu perlu menyelesaikan problem optimasi berikut:
2
2 1
min w (4) Subject to
( )
( )
ε λ ϕ ϕ− + ≤ε, =1,2,...,≤ − − i b y x w b x w y i i i i
Asumsikan bahwa ada suatu fungsi f yang dapat mengaproksimasi semua titik
rentang f ±ε (feasible). Dalam hal ketidaklayakan (infeasible), dimana mungkin ada beberapa titik yang mungkin keluar dari rentang f ±ε , bisa ditambahkan variabel slack
ξ, ξ* untuk mengatasi masalah pembatas yang tidak layak (infeasible constraint) dalam
problem optimasi. Selanjutnya problem optimasi di atas bisa diformulasikan sebagai berikut:
( )
∑
= + λ ξ ξ λ 1 * 2 , 1 2 1 min i i i Cw (5)
Subject to
( )
( )
0 , ,..., 2 , 1 , ,..., 2 , 1 , * * ≥ = ≤∈ − + − = ≤∈ − − − i i i i i i i T i i b y x w i b x w y ξ ξ λ ξ ϕ λ ξ ϕKonstanta C>0 menentukan tawar menawar (trade off) antara ketipisan fungsi f dan batas
atas deviasi lebih dari ε masih ditoleransi. Semua deviasi lebih besar daripada ε akan
dikenakan pinalty sebesar C. Dalam SVR, ε ekuivalen dengan akurasi dari aproksimasi
terhadap data training. Nilai ε yang kecil terkait dengan nilai yang tinggi pada variabel slack ξi(*) dan akurasi aproksimasi yang tinggi. Sebaliknya, nilai yang tinggi untuk ε berkaitan dengan nilai ξi(*) yang kecil dan aproksimasi yang rendah. Menurut persamaan (5) nilai yang tinggi untuk variabel slack akan membuat kesalahan empirik mempunyai pengaruh yang besar terhadap faktor regulasi. Dalam SVR, support vector adalah data training yang terletak pada dan diluar batas f dari fungsi keputusan, karena itu jumlah support vector menurun dengan naiknya ε.
Dalam formulasi dual, problem optimisasi dari SVR adalah sebagai berikut:
(
)
λ α λ α α α λ ,..., 2 , 1 , 0 ,..., 2 , 1 , 0 0 * 1 * = ≤ ≤ = ≤ ≤ = −∑
= i C i C i i i i iDimana C didefinisikan oleh user, K xi,xj adalah dot-product kernel yang didefinisikan sebagai K xi,xj =ϕT
( )
xi ϕ( )
xj . Dengan menggunakan langrange multiplier dan kondisi optimalitas, fungsi regresi secara eksplisit dirumuskan sebagaiberikut:
( )
x(
)
K( )
x x b fi
i i
i − +
=
∑
= λ α α 1 *, (7)
2.6 POHON KEPUTUSAN
Sebuah model pohon keputusan terdiri dari satu set aturan untuk membagi suatu populasi heterogen besar menjadi lebih kecil, kelompok yang lebih homogen dengan memperhatikan suatu variabel target tertentu (Larose, 2005).
Sebuah pohon keputusan adalah pohon di mana setiap simpul non-terminal merupakan tes atau keputusan pada item data dipertimbangkan. Pilihan cabang tertentu tergantung pada hasil tes. Untuk mengklasifikasikan item data tertentu, Mulai dari akar simpul dan mengikuti asersi bawah sampai mencapai node terminal (atau daun). Sebuah keputusan dibuat ketika terminal node didekati. Pohon Keputusan juga dapat diartikan sebagai bentuk khusus dari suatu set aturan, yang ditandai oleh organisasi hirarkis mereka aturan
Banyak algoritma dikembangkan untuk melakukan membuat pohon keputusan, diantaranya ID3, CART dan C4.5. Algoritma C4.5 merupakan pengembangan dari algoritma ID3 (Larose, 2005).
(Gupta et al., 2011).
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut (Craw, 2005):
a. Pilih atribut sebagai root
c. Bagi kasus dalam cabang
d. Ulangi proses untuk masing-masing cabang sampai semua kasus pada cabang memiliki kelas yang sama.
CART (Classification and Regression Tree) adalah algoritma data-eksplorasi dan prediksi mirip dengan C4.5, yang merupakan algoritma konstruksi pohon (Breiman et al. 1984). Klasifikasi dan pohon regresi, pada entropi informasi, memperkenalkan ukuran node yang dibuang. Hal ini digunakan pada berbagai masalah yang berbeda, seperti deteksi klorin dari data yang terdapat dalam spektrum massa. Meskipun pohon keputusan mungkin bukan metode terbaik untuk akurasi klasifikasi. Menggunakan lingkaran sebagai node keputusan dan sebuah persegi sebagai node terminal. Setiap node keputusan mempunyai kondisi yang diwakili oleh fungsi F, dan parameter adalah titik pemecahan atribut split. Setiap node terminal memiliki label kelas C, nilai yang mewakili sebuah kelas. Hal ini jelas bahwa adalah mudah digunakan pohon keputusan untuk menafsirkan pohon aturan, dari analisa yang bisa kita lakukan, dan mudah untuk menafsirkan representasi dari pemetaan input-output nonlinier.
BAB III
METODE PENELITIAN
3.1 Rancangan Penelitian
Rancangan penelitian ini pertama-tama dilakukan dengan menganalisis dan membandingkan metode Support Vector Regression (SVR) dan klasifikasi dengan pohon keputusan algoritma C4.5 yang telah dibuat pada penelitian sebelumnya dan mengidentifikasi kelebihan dan kekurangan dari teknik data mining tersebut.
3.2 Metode Penelitian
Menganalisis bentuk data yang digunakan dalam Support Vector Regression (SVR) dan klasifikasi dengan pohon keputusan algoritma C4.5 serta melihat bagaimana kelebihan dan kekurangan dari kedua teknik terebut.
Jenis data yang dikumpulkan dalam penelitian ini adalah bersumber dari data penelitian-penelitian yang menggunakan Support Vector Regression (SVR) dan klasifikasi dengan pohon keputusan algoritma C4.5 yang mendukung penelitian ini.
3.3 Kerangka Penelitian
3.3.1 Penelitian dalam bidang Pengembangan Ilmu Pengetahuan
Basak et al., (2007) dalam tulisannya meninjau teori metode support vector regression (SVR), ide SVR didasarkan pada perhitungan fungsi regresi linier dalam fitur
ruang dimensi tinggi dimana data input dipetakan melalui fungsi nonlinier. SVR telah diterapkan di berbagai bidang time series, keuangan, prediksi, pendekatan analisis rekayasa dan lain lain. Dalam tulisan ini, telah dilakukan tinjauan teori yang ada, metode, perkembangan terbaru dan lingkup SVR.
Algoritma support vector adalah gambaran umum generalisasi nonlinear yang dikembangkan di Rusia pada tahun enam puluhan. (Vapnik and Chervonenkis, 1964)
Burges (1998) menerbitkan sebuah tutorial komprehensif pada pengklasifikasi support vector, baik digunakan dalam regresi time series dan aplikasi prediksi. Teori pembelajaran statistik telah memberikan kerangka yang sangat efektif untuk tugas-tugas klasifikasi dan regresi.
SVR adalah mengamati pelatihan dengan meminimalkan kesalahan dalam upaya mencapai kinerja yang umum. SVR adalah sebuah versi dari SVM untuk regresi yang telah diusulkan pada tahun 1997 oleh Vapnik (1997). SVR adalah teknik yang kuat untuk analisis prediksi data. Tujuan dari masalah regresi adalah untuk memperkirakan suatu fungsi. Solusi untuk masalah SVR adalah fungsi yang menerima sebuah titik data dan mengembalikan nilai terus menerus.
- Masalah penentuan usia perkembangan embrio dari pola segmentasi ekspresi gen pada Drosophila telah dibahas (Myasnikova et al., 2002). Dengan menerapkan SVR, telah dikembangkan metode cepat untuk pementasan otomatis embrio berdasarkan pola ekspresi gen nya. SVR adalah metode statistik untuk menciptakan jenis fungsi regresi dari satu set data pelatihan. Set data pelatihan terdiri dari embrio yang usia perkembangan yang tepat telah ditentukan dengan mengukur tingkat invaginasi membran. Pengujian kualitas regresi pada set pelatihan telah menunjukkan akurasi prediksi yang baik. Fungsi regresi yang optimal telah digunakan untuk prediksi ekspresi gen berdasarkan usia embrio di mana usia yang tepat belum diukur dengan morfologi membran.
Kegunaan SVR:
Hasil Penelitian:
Algoritma SVR telah dimanfaatkan untuk melakukan kompresi gambar. Blok gambar telah diwakili oleh nilai-nilai pengali support vector Lagrange menggunakan fungsi linear, fungsi polinomial dan dasar fungsi radial Gaussian sebagai fungsi kernel.
Sebuah pendekatan penyaringan SVR telah diperkenalkan untuk mengurangi sinyal Positif Palsu dalam suatu sistem deteksi massa otomatis. Pendekatan yang diusulkan terdiri dari dua langkah: pertama milik kelompok filter saraf namun telah didasarkan pada SVM, kelas dari algoritma pembelajaran yang telah terbukti dalam beberapa tahun terakhir menjadi lebih unggul dengan metode konvensional Jaringan Syaraf untuk kedua klasifikasi dan tugas regresi, maka penerapannya pada saraf-seperti pengolahan gambar terlihat sangat menarik. Langkah kedua adalah cara sederhana untuk mempertimbangkan informasi account yang diberikan oleh SVR filter, untuk memutuskan apakah sinyal dianalisis adalah False Positive (FP) atau tidak. (ν-SVR) telah dipertimbangkan untuk regresi estimasi. Algoritma SVR telah bertindak sebagai filter karena telah mampu untuk menghubungkan ke setiap input output gambar.
Gangrade (2009) melakukan penelitian dalam melestarikan penggunaan klasifikasi pohon keputusan algoritma C4.5 dengan tujuan untuk membangun klasifikasi yang akurat tanpa mengungkapkan informasi pribadi dalam menambang data.
Dalam dunia modern jumlah informasi pelanggan yang banyak disimpan dalam database. Dengan demikian penambangan data sangat efektif untuk mengekstraksi pengetahuan dari sejumlah besar data. Klasifikasi memiliki banyak aplikasi dalam dunia nyata, seperti perencanaan stok besar superstore, diagnosis medis, dan lain-lain. Klasifikasi adalah pemisahan atau memesan objek ke kelas. Ada berbagai teknik klasifikasi yaitu Pohon Keputusan, K-nearest neigbour, Naive Bayes classifier dan neural network. Dalam penelitian ini akan membahas pohon keputusan.
aturan yang dimengerti. Mereka melakukan klasifikasi tanpa memerlukan banyak perhitungan. Mereka mampu menangani keduanya terus-menerus dan variabel kategoris. Mereka memberikan indikasi yang jelas tentang bidang yang yang paling penting untuk klasifikasi. Algoritma pohon keputusan seperti ID3 atau C4.5 adalah salah satu metode yang paling kuat dan populer untuk klasifikasi. Algoritma ID3 digunakan untuk merancang pohon keputusan berdasarkan database yang diberikan. Pohon dibangun atas-bawah secara rekursif. Pada akar, atribut masing-masing diuji untuk menentukan seberapa baik mengklasifikasikan transaksi sendiri kemudian, atribut terbaik yang dipilih dan catatan yang tersisa dipartisi (Arun, 2007). ID3 ini kemudian disebut rekursif pada setiap partisi. C4.5 adalah ekstensi dari dasar perangkat lunak algoritma ID3 dirancang oleh J. R. Quinlan. Untuk mengatasi masalah berikut ini tidak diselesaikan dengan ID3:
- Menghindari data yang lebih pas. - Mengurangi kesalahan pemangkasan.
- Penanganan atribut kontinyu juga Example temperature.
- Penanganan data pelatihan dengan atribut nilai-nilai yang hilang.
Dalam penelitian ini, mempelajari, melestarikan privasi aturan klasifikasi penambangan. Tujuan Privacy preserving klasifikasi adalah untuk membangun pengklasifikasi akurat tanpa mengungkapkan informasi pribadi dalam penambangan data. Penelitian ini mengatasi masalah perhitungan multiparty yang aman untuk aturan klasifikasi penambangan. Secara khusus, memungkinkan Privacy preservation tanpa pihak ketiga yang terpercaya, merupakan salah satu prestasi besar dalam kriptografi modern, memungkinkan satu set pihak untuk menghitung setiap fungsi input pribadi mereka tanpa menunjukkan apa-apa tetapi hasil dari fungsi. Penelitian ini menjalankan algoritma klasifikasi pohon keputusan C4.5 dalam melestarikan privasi pada database mereka, tanpa mengungkapkan informasi pribadi.
melestarikan privasi klasifikasi pohon keputusan C4.5 pada data dipartisi secara vertikal tanpa menggunakan ketiga partai. Hal ini didasarkan pada menghitung gabungan dari semua database, tidak peduli bahwa hanya satu pihak yang memiliki atribut kelas atau lebih dari satu atau semua pihak. Menerapkan algoritma data mining pada data ini dan mengirimkan output.
Hasil Penelitian:
Penelitian ini layak untuk membangun sebuah privasi melestarikan classifier pohon keputusan yang dapat menggunakan teknik SMC (Secure Multiparty Computation). Pengembangan lebih lanjut dari protokol diharapkan dalam arti bahwa untuk bergabung multi-partai atribut menggunakan pihak ketiga yang terpercaya dan dapat digunakan. Selanjutnya, baik untuk mengembangkan classifier baru dalam Privasi membangun pohon keputusan-melestarikan dan analisis baru serta pengklasifikasi yang ada untuk memecahkan masalah yang berbeda yaitu atribut yang hilang dan lain-lain.
Grbovic (2006) melakukan penelitian dalam mengeksplorasi penerapan pohon keputusan C4.5 dalam menyelesaikan masalah. Hasil dari penelitian ini diharapkan, metode pohon keputusan C4.5 dapat menghasilkan kinerja yang baik.
Untuk memastikan kinerja yang baik dari aplikasi MPI, operasi kolektif dapat disetel untuk sistem tertentu. Proses tuning sering melibatkan profil rinci dari sistem, mungkin dikombinasikan dengan pemodelan komunikasi, menganalisis data yang dikumpulkan, dan menghasilkan fungsi keputusan. Saat run-time, fungsi keputusan memilih dekat ke metode optimal untuk contoh kolektif tertentu. Pendekatan ini bergantung pada kemampuan keputusan fungsi yang secara akurat memprediksi ukuran algoritma dan segmen yang akan digunakan untuk kolektif tertentu misalnya. Orang bisa membangun sebuah sistem di memori keputusan, bisa dicari pada saat run-time untuk memberikan informasi metode yang optimal. Salah satu dari pendekatan-pendekatan ini layak, jejak memori dan waktu yang dibutuhkan untuk membuat keputusan harus minimal.
tersedia dalam metode komunikasi. Dengan informasi ini, difokuskan usaha pada menyelidiki apakah algoritma C4.5 adalah cara yang layak untuk menghasilkan fungsi keputusan statis.
Suatu kategori yang benar, sebuah metode dalam kasus ini, untuk digunakan pada waktu berjalan. Manfaat utama dari pendekatan ini adalah bahwa proses pengambilan keputusan adalah topik yang dipelajari dengan baik di bidang teknik dan mesin pembelajaran sehingga bidang literatur sudah tersedia. Pohon-pohon keputusan ekstensif digunakan dalam pengakuan pola, desain CAD, pemrosesan sinyal, kedokteran, dan biologi (Murthy, 1998). Vuduc et al. (2004) membangun model pembelajaran statistik untuk membuat keputusan yang berbeda fungsi dari matriks-matriks pemilihan algoritma perkalian. Dalam pekerjaan ini mempertimbangkan tiga metode untuk konstruksi fungsi keputusan: pemodelan parametrik; parametrik pemodelan geometri; dan non-parametrik pemodelan geometri. Pemodelan geometri non-parametrik menggunakan metode pembelajaran statistik untuk membangun model implisit dari batas-batas antara algoritma berdasarkan data eksperimental aktual. Untuk mencapai hal ini, Vuduc et al. (2004) menggunakan metode support vector Secara konseptual, pekerjaan yang diberikan dalam penelitian ini dekat dengan geometri non-parametrik, pekerjaan pemodelan dilakukan oleh Vuduc dkk. Namun, domain masalah berbeda: operasi MPI kolektif bukan matriks-matriks perkalian, dan menggunakan algoritma C4.5 bukan metode support vector. Untuk yang terbaik berdasarkan pengetahuan, satu-satunya kelompok
yang telah mendekati proses tuning MPI kolektif dengan cara ini, algoritma C4.5. Algoritma C4.5 adalah algoritma klasifikasi pembelajaran yang diawasi yang digunakan untuk membangun pohon keputusan dari data (Quinlan, 1993). C4.5 dapat diterapkan pada data yang memenuhi persyaratan sebagai berikut:
- Atribut-nilai description: informasi tentang satu entri dalam data harus dijelaskan dalam istilah atribut. Nilai-nilai atribut dapat diskrit atau kontinu, dan dalam beberapa kasus, nilai atribut mungkin hilang atau dapat diabaikan; - kelas Predefined: data pelatihan harus dibagi dalam kelas atau kategori standar.
- Diskrit kelas: kelas harus jelas dipisahkan dan kasus pelatihan tunggal baik milik kelas atau tidak. C4.5 tidak dapat digunakan untuk memprediksi nilai-nilai kelas kontinyu seperti biaya transaksi;
- Data yang cukup: algoritma C4.5 menggunakan proses generalisasi induktif dengan mencari pola dalam data. Untuk pendekatan ini untuk bekerja, pola harus dibedakan dari kejadian acak. Apa yang merupakan jumlah data "cukup" tergantung pada satu set data tertentu dan atribut dan nilai-nilai kelas, tetapi secara umum, metode statistik yang digunakan dalam C4.5 untuk menghasilkan tes membutuhkan jumlah data cukup besar;
- Model klasifikasi logis: model klasifikasi yang dihasilkan harus direpresentasikan sebagai pohon keputusan dari salah satu atau seperangkat aturan produksi (Quinlan, 1993).
Operasi MPI kolektif dapat dikelompokkan menjadi empat kategori berdasarkan pola pertukaran data mereka: satu-ke-banyak, banyak-ke-satu, banyak-ke-banyak, dan "lain" (seperti Scan dan Exscan). Ini adalah wajar untuk mengharapkan bahwa kolektif yang sama memiliki fungsi keputusan serupa pada sistem yang sama. Penelitian ini menganalisis pohon keputusan yang dihasilkan dari data eksperimen dikumpulkan untuk broadcast dan mengurangi kolektif pada sistem. Implementasi dari kolektif ini adalah simetris: masing-masing memiliki Linear, Binomial, Biner, dan Pipeline berbasis implementasi. Broadcast mendukung algoritma Binary splitted yang kami tidak memiliki setara dalam Mengurangi implementasi, tapi diharapkan akan mampu C4.5 untuk menangani kasus ini dengan benar. Data pelatihan untuk percobaan ini berisi tiga atribut (nama komunikator, kolektif ukuran, dan ukuran pesan) dan set kelas yang telah ditentukan adalah sama seperti di kasus broadcast.
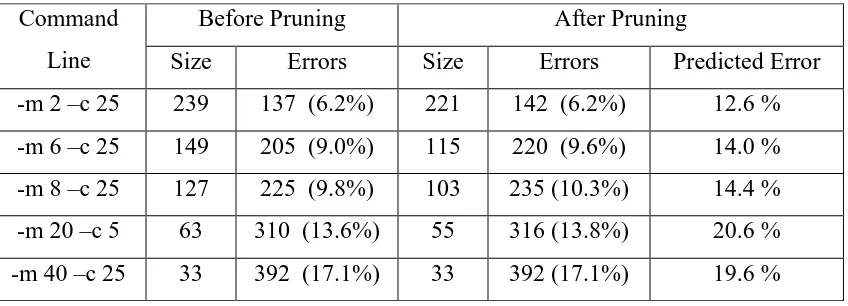
Tabel 3.1: Statistik untuk gabungan Broadcast dan pengurangan Command
Line
pohon keputusan Before Pruning After Pruning
Size Errors Size Errors Predicted Error -m 2 –c 25 239 137 (6.2%) 221 142 (6.2%) 12.6 % -m 6 –c 25 149 205 (9.0%) 115 220 (9.6%) 14.0 % -m 8 –c 25 127 225 (9.8%) 103 235 (10.3%) 14.4 % -m 20 –c 5 63 310 (13.6%) 55 316 (13.8%) 20.6 % -m 40 –c 25 33 392 (17.1%) 33 392 (17.1%) 19.6 %
Tabel 3.1: Statistik untuk gabungan Broadcast dan Mengurangi pohon keputusan sesuai dengan data yang disajikan. Ukuran mengacu pada jumlah node daun pada pohon. Kesalahan dalam hal kasus pelatihan kesalahan klasifikasi. Kumpulan data memiliki 2286 kasus
Hasil penelitian menunjukkan bahwa pohon keputusan C4.5 dapat digunakan untuk menghasilkan cukup dan sangat akurat keputusan fungsi: hasil kinerja berarti pada data kinerja yang ada berada di dalam kesalahan pengukuran untuk semua pohon yang dipertimbangkan. Misalnya, Broadcast Keputusan pohon dengan hanya 21 daun bisa mencapai hukuman kinerja rata-rata 2,08%. Selain itu, menggunakan pohon ini, hanya enam poin dalam communicator, ukuran pesan berkisar dari data yang diuji akan dikenakan lebih dari 50% kinerja.
pelatihan.
3.3.2 Penelitian dalam bidang kesehatan
diterapkan dalam penelitian ini untuk meningkatkan diagnosis dan prognosis kanker payudara
Sarvestan et al., (2010) memberikan perbandingan antara kemampuan berbagai jaringan saraf dalam diagnosa penyakit kanker payudara. Hasil pengujian menunjukkan bahwa jaringan saraf efektif untuk digunakan dalam diagnosa penyakit kanker payudara.
.
Anunciacao et al., (2010) mengeksplorasi penerapan pohon keputusan untuk mendeteksi kelompok penderita penyakit kanker payudara yang berisiko tinggi, menggunakan program aplikasi Weka. Hasil menunjukkan bahwa mungkin ditemukan hubungan statistik yang signifikan dengan penyakit kanker payudara dengan menurunkan pohon keputusan dan memilih daun terbaik.
Hasil Penelitian:
Penelitian ini memberikan kajian teknis dan berbagai review tentang diagnosis kanker payudara dan prognosis masalah dan mengeksplorasi bahwa teknis penambangan data menawarkan janji besar untuk menemukan pola-pola yang tersembunyi dalam data yang dapat membantu dokter dalam pengambilan keputusan
- Neural network (NN), pohon keputusan, regresi logistik, dan algoritma genetik digunakan untuk studi perbandingan dan akurasi dan nilai prediktif positif masing-masing algoritma digunakan sebagai indikator evaluasi.
.
- Akurasi Pohon keputusan 93,6% dan NN dengan 91,2% ditemukan lebih unggul dari regresi logistik dengan akurasi 89,2%.
- Keakuratan NN (88,8%) dan Jaringan Hybrid (87,2%) sangat mirip dan mereka berdua mengungguli Jaringan Bayesian. Mereka menemukan model Hibrid yang diusulkan juga dapat berguna untuk mengambil keputusan.
3.3.3 Penelitian dalam bidang Internet
Bermolen et al.,, (2008) melakukan penelitian penggunaan SVR (support vector regression) untuk prediksi link beban dengan menggunakan model Moving Average
(MA) dan Auto Regresif (AR).
pada semua jaringan IP, dan oleh fakta bahwa pengguna-mobilitas kemungkinan akan menerjemahkan ke layanan mobilitas juga. Di sisi lain, ledakan aplikasi internet telephon, televisi dan game menyiratkan bahwa kita mungkin dipaksa untuk berpikir ulang apa yang kita maksud oleh lalu lintas data. Selain itu, penggunaan luas dari aplikasi lapisan lapisan langsung diterjemahkan menjadi jauh lebih tinggi variabilitas dari lalu lintas data disuntikkan ke jaringan.
Dalam penelitian ini, mempertanyakan apakah variabilitas tersebut dapat diperkirakan secara efisien, dan jika demikian, dengan apa tingkat akurasinya. Teknik prediksi diawasi yang dipilih yaitu Support Vector Machines (SVM), satu set klasifikasi dan regresi teknik, diperkenalkan pada awal tahun sembilan puluhan [1], yang didasarkan dalam rangka pembelajaran teori statistik. Pada dasarnya, Support Vector Regression (SVR) menggunakan data pelatihan untuk membangun model prediksi
yang bekerja dengan baik dalam situasi pembelajaran karena generalisasi untuk data tak terlihat dan setuju untuk online terus menerus dan pembelajaran adaptif, properti yang sangat diinginkan dalam lingkungan jaringan.
Awalnya terikat pada pengenalan konteks karakter optik, penggunaan SVM dengan cepat menyebar ke bidang lainnya, termasuk prediksi time series (Muller et al., 1999) dan, baru-baru ini, jaringan. Termotivasi dengan mendorong seperti hasilnya, penelitian ini fokus pada perkiraan beban link yang hanya didasarkan pada pengukuran masa lalu, menyusul pendekatan yang dikenal sebagai ''proses tertanam proses "Masalah ini sangat menarik dalam jaringan untuk kedua perencanaan kapasitas dan manajemen aplikasi (misalnya pengadaan bandwidth, masuk kontrol, memicu mekanisme backpressure, dan lain lain).
Meskipun pendekatan SVM cocok juga untuk rentang waktu lebih lama, yang lebih perhatian untuk kapasitas perencanaan, dalam makalah ini kita fokus pada estimasi beban variasi pada skala waktu pendek: mengadopsi pendekatan tangan untuk regresi SVM, mengevaluasi efektivitas SVR untuk perkiraan beban dengan menjelajahi link yang agak ekstensif dari parameter dan ruang desain. Tujuan penelitian adalah:
yang dicapai dengan menggunakan Moving Average dan Auto-Regresif Model: hasil kami menunjukkan bahwa, meskipun sesuai baik dengan data aktual, SVR keuntungan dicapai selama metode prediksi yang sederhana tidak cukup untuk membenarkannya penyebaran untuk prediksi link yang load pada skala waktu pendek.
Namun, SVR mempunyai sejumlah aspek sangat positif aspek: misalnya, model SVR agak kuat untuk Parameter variasi, dan kompleksitas komputasi jauh dari yang mahal, yang membuat cocok untuk prediksi secara online. Selain itu, memverifikasi eksperimental bahwa kesalahan dihitung selama sampel berturut-turut adalah independen dan terdistribusi secara identik, yang memungkinkan evaluasi interval. Akhirnya, penelitian ini juga menyelidiki metode untuk memperpanjang cakrawala perkiraan menggunakan nilai yang diprakirakan sebagai masukan untuk prediksi baru: pendekatan ini SVR rekursif secara signifikan dapat memperpanjang cakrawala perkiraan yang dicapai dan melibatkan hanya sangat akurasi degradasi tebatas.
jalan. Berfokus pada prediksi latency ke alamat IP yang tidak diketahui, berdasarkan latency pengetahuan arah lain alamat IP yang sebelumnya dihubungi. Menggunakan sebagai fitur vektor input bit alamat IP (Berubah menjadi ruang input 32 dimensi, dimana setiap bit alamat sesuai dengan dimensi yang berbeda), menunjukkan bahwa kinerja estimasi dalam 30% dari nilai sebenarnya selama kurang lebih tiga perempat dari prediksi latency pada set data internet yang besar. Lebih rinci, regresi SVM pada acak yang besar dikumpulkan data set 30.000 (IP, latency) pasangan, menghasilkan prediksi berarti kesalahan 30 ms (25 ms) hanya menggunakan 6% (20%) dari sampel untuk pelatihan.
Dalam konteks regresi SVM, masalah peramalan nilai masa depan dari seri hanya didasarkan pada pengamatan sebelumnya dari fenomena yang sama dikenal sebagai ''Embedding proses ". Namun, penerapannya yang biasanya selain konteks jaringan ditargetkan domain, dan seri yang SVR telah berjalan sampai sekarang sangat jauh berbeda dari yang mewakili kedatangan paket proses pada antrian router: dengan demikian, tujuan penelitian adalah untuk menguji apakah SVR dapat membuktikan menjadi alat yang berguna juga untuk menghubungkan perkiraan beban.
Rastegari et al., (2010) melakukan penelitian dalam mengatasi serangan Denial of Service (DOS) terhadap Domain Name System (DNS) dengan teknik Machine Learning.
DNS Orisinalitas dirancang berdasarkan sebuah protokol pengiriman dapat diandalkan bernama User Datagram Protocol (UDP) dan keamanan DNS yang bukan masalah besar pada titik waktu karena desain asli cukup untuk memenuhi kebutuhan Internet. Saat ini, DNS telah menjadi layanan penting untuk operasi Internet dan dari setiap jaringan pribadi dengan ukuran tertentu, jadi ini adalah waktu untuk mengamankan sistem DNS dari akses yang tidak sah.
mengirimkan lalu lintas yang berlebihan dari sumber tunggal atau ganda. Oleh karena itu, akan menyebabkan sejumlah besar paket permintaan yang akan diterima oleh server nama target. Server nama dibanjiri oleh serangan DoS akan mengalami packet loss dan tidak dapat selalu merespon setiap permintaan DNS. Referensi [3], poin ukuran paket aliran data DNS adalah kecil dan ini kesamaan dengan paket anomali membuat proses deteksi lebih sulit.
Di sisi lain, penyerang membangun jenis yang paling canggih dan modern dari serangan DoS dikenal sebagai serangan amplifikasi untuk meningkatkan efek serangan DoS yang normal. Alasan bahwa jenis serangan bernama amplifikasi adalah bahwa penyerang memanfaatkan fakta bahwa permintaan kecil dapat menghasilkan paket UDP yang jauh lebih besar dalam menanggapi. Saat ini, DNS protokol (RFC 2671) digunakan oleh penyerang untuk memperbesar faktor amplifikasi. Misalnya 60 byte DNS permintaan dapat dijawab dengan jawaban lebih dari 4000 byte. Ini menghasilkan faktor amplifikasi lebih dari 60. Beberapa peneliti telah mempelajari efek dari serangan amplifikasi tercermin. Berdasarkan analisis mereka, pola serangan ini mencakup sejumlah besar paket yang tidak standar lebih besar dari ukuran paket DNS standar yang 512 byte. Ada beberapa upaya untuk mengusulkan solusi untuk mempertahankan DNS terhadap serangan tersebut, tetapi menurut pengetahuan kami, tidak ada sistem deteksi yang spesifik untuk ancaman Denial of Service (DoS) terhadap DNS.
Ketika mengakses ke lingkungan yang nyata untuk simulasi lalu lintas adalah kuat, penelitian ini memanfaatkan kekuatan simulator jaringan. Menurut pengetahuan peneliti, tidak ada dataset yang dihasilkan tersedia untuk serangan DoS terhadap DNS. Oleh karena itu, digunakan simulasi untuk menghasilkan data yang dibutuhkan untuk percobaan. Pensimulasian model digunakan program OTcl di NS-2 (versi 2.28). Hal ini digunakan untuk model yang berbeda
Penelitian ini menyajikan sistem deteksi serangan baru untuk DoS terhadap DNS, yang menggunakan mesin pembelajaran untuk mendeteksi dan mengklasifikasikan serangan. IDS adalah jaringan-simpul berbasis IDS (NNIDS), yang dapat diimplementasikan pada server nama untuk tujuan deteksi serangan.
DoS
terhadap lalu lintas DNS mendorong untuk menemukan perilaku yang mencurigakan. Berdasarkan pola-pola lalu lintas data yang diperlukan untuk analisis pengukuran adalah simulasi menggunakan simulator jaringan yang paling fleksibel, NS-2. Akhirnya, model mesin pembelajaran berbasis diusulkan untuk mendeteksi dan mengklasifikasikan serangan DoS terhadap DNS menggunakan statistik lalu lintas. Dua algoritma pembelajaran mesin yang berbeda dievaluasi untuk mesin detektor yang mengklasifikasi jaringan saraf dan SVM. Untuk menemukan classifier yang optimal, tiga dari jaringan saraf yang terbaik dilakukan untuk deteksi dan klasifikasi dalam sistem deteksi intrusi diselidiki. Pengklasifikasi ini dibandingkan dengan metode mesin pembelajaran lain yang modern, SVM dalam hal tingkat deteksi, akurasi, dan tingkat alarm palsu. Hasil perbandingan menunjukkan bahwa jaringan saraf propagasi kembali performanya melebihi pengklasifikasi lain dengan tingkat deteksi 99,55% untuk serangan DoS langsung, 97,82% tingkat deteksi untuk serangan amplifikasi, akurasi 99%, dan 0,28% tingkat alarm palsu. Masa Depan kerja akan mempelajari jenis lain ancaman keamanan terhadap DNS. Menyediakan semua pola arus lalu lintas akan membantu untuk menyelidiki fitur yang diperlukan untuk mendeteksi semua bentuk serangan terhadap DNS. Bidang lain pekerjaan di masa depan akan mengimplementasikan model yang diusulkan dalam lingkungan yang nyata yang dapat menyelidiki perbaikan yang diperlukan dalam model seperti waktu pemantauan.
3.3.4 Penelitian dalam bidang Musik
Han et al., (2009) melakukan penelitian pengenalan emosi musik menggunakan support vector regression. Emosi musik memainkan peran penting dalam menentukan
jenis musik, deteksi mood dan aplikasi yang berhubungan dengan musik lainnya. Berbagai masalah untuk pengenalan musik emosi telah ditangani oleh berbagai disiplin ilmu seperti fisiologi, ilmu psikologi, kognitif dan musikologi. Penyajikan sebuah support vector regression (SVR) musik berdasarkan sistem pengenalan emosi
Dengan kemajuan terbaru di bidang informasi musik, muncul minat untuk menganalisis dan memahami isi emosional musik. Karena keragaman dan kekayaan konten musik, banyak peneliti telah mengejar topik penelitian di bidang ini, mulai dari ilmu pengetahuan komputer, pengolahan sinyal digital, matematika, dan statistik
diterapkan untuk musik dan psikologi. Banyak ilmuwan komputer (Birmingham et al., 2006) telah berfokus pada pengambilan musik dengan menggunakan musik meta-data (seperti judul, genre atau suasana hati) serta analisis fitur tingkat rendah (seperti pitch, tempo atau irama), sementara psikolog musik (Lie et al., 2006) telah tertarik dalam mempelajari bagaimana emosi musik berkomunikasi. Saat ini, tidak ada metode standar untuk mengukur dan menganalisis emosi dalam musik. Namun, psikologis model emosi telah menemukan meningkatnya penggunaan dalam komputasi studi. Thayer dua dimensi Model emosi (Thayer, 1989) menawarkan sebuah model sederhana namun cukup efektif untuk menempatkan emosi dalam ruang dua dimensi. Dalam model, jumlah gairah dan valensi diukur masing-masing sepanjang sumbu vertikal dan horizontal. Tujuan dari makalah ini adalah untuk mengembangkan emosi musik pengakuan sistem untuk memprediksi gairah dan valensi sebuah lagu yang didasarkan pada konten audio.
Pada penelitian ini menganalisis tujuh fitur musik yang berbeda (seperti pitch, kenyaringan tempo, tonality, kunci, ritme dan harmonik) dan dipetakan ke dalam sebelas kategori emosi: marah, bosan, tenang, senang, bahagia, gugup, damai, senang, santai, sedih dan mengantuk. Kategorisasi ini didasarkan pada teori Juslin dan Sloboda (2001) bersama dengan model emosi Thayer emosi (Thayer, 1989). Kedua, mengadopsi SVR sebagai classifier untuk melatih dua fungsi regresi untuk memprediksi gairah dan nilai-nilai valensi berdasarkan fitur tingkat rendah, seperti pitch, ritme dan tempo, diekstrak dari musik. Selain itu, kami membandingkan metode SVR dengan algoritma klasifikasi lain seperti GMM (Gaussian Mixture Model) dan SVM (Support Vector Machine) untuk mengevaluasi kinerja.
Banyak peneliti telah mengeksplorasi model emosi dan faktor yang menimbulkan persepsi emosi dalam musik. Juga banyak peneliti lain menyelidiki masalah otomatis mengenali emosi dalam musik. Suasana tradisional dan penelitian emosi dalam musik telah difokuskan untuk menemukan faktor-faktor psikologis dan fisiologis bahwa emosi mempengaruhi pengakuan dan klasifikasi. Selama tahun 1980-an, beberapa model emosi yang diusulkan, yang sebagian besar didasarkan pada pendekatan dimensi untuk rating emosi.
Model sirkumfleksa memiliki dampak yang signifikan pada penelitian emosi. Model ini mendefinisikan dua dimensi, struktur melingkar melibatkan dimensi aktivasi dan valensi. Dalam struktur ini, emosi yang di lingkaran dari satu sama lain, seperti kesedihan dan kebahagiaan, berkorelasi terbalik. Thayer (1989) mengusulkan model emosi dua dimensi yang sederhana namun kuat dalam mengatur tanggapan emosi yang berbeda: stres dan energi. Dimensi stres disebut valensi sedangkan dimensi energi yang disebut gairah.
Salah satu dari studi pertama deteksi emosi dalam musik disajikan oleh Feng et al. (2003). Mereka bekerja, berdasarkan Komputasi Media Estetika (CMA), analisis dua dimensi tempo dan artikulasi yang dipetakan menjadi empat kategori mood: kebahagiaan, marah, sedih dan ketakutan. Lie et al., (2006) mengembangkan suatu kerangka hirarkis untuk mengekstraksi emosi musik otomatis dari data musik akustik. Mereka menggunakan intensitas musik untuk mewakili dimensi energi model Thayer, dan timbre dan ritme untuk dimensi stres. FEELTRACE (Cowie, 2000) adalah perangkat lunak yang dirancang untuk membiarkan pengamat melacak isi emosional rangsangan (seperti kata-kata, wajah, musik, dan video) mereka merasakan dan memperhitungkan penuh gradasi dan variasi dari waktu ke waktu. Yang (2008) mengembangkan pengakuan emosi musik (MER) sistem dari perspektif yang terus menerus dan mewakili setiap lagu sebagai titik di bidang emosi. Mereka juga mengusulkan gairah baru/ valensi perhitungan metode yang didasarkan pada teori regresi.
Dataset musik untuk pelatihan terdiri dari 165 lagu pop barat. Penelitian ini mengumpulkan 15 lagu dalam masing-masing sebelas kategori emosi dari musik besar database, Semua Panduan Musik, yang menyediakan 180 emosional kategori untuk mengklasifikasikan seluruh lagu. Untuk membangun pengklasifikasi kami menggunakan SVR dan implementasi didasarkan pada LIBSVM di perpustakaan (Chung et al., 2001), yang memberikan fungsi hampir penuh untuk pelatihan SVR.
harus dipertimbangkan dan algoritma klasifikasi lain seperti fuzzy dan kNN (k-Nearest Neighbour). Juga berencana untuk membandingkan hasil mesin pembelajaran (ML) berdasarkan emosi pengakuan dengan gairah yang dilakukan manusia / valensi data.
3.3.5 Penelitian dalam bidang Time Series
Cao (2002) melakukan penelitian yang mengusulkan penggunaan SVM untuk peramalan time series.
SVM telah diusulkan sebagai teknik baru dalam peramalan time series (Mukherjee et al., 1997). SVM adalah jenis yang sangat special dari algoritma pembelajaran ditandai oleh kontrol kapasitas fungsi keputusan, penggunaan fungsi kernel dan sparsity dari solusi. Didirikan pada teori yang unik prinsip minimisasi risiko struktural untuk memperkirakan fungsi dengan meminimalkan sebuah batas atas dari kesalahan generalisasi, SVM yang terbukti sangat tahan terhadap masalah, akhirnya mencapai kinerja generalisasi tinggi dalam memecahkan masalah peramalan time series berbagai. Properti lain adalah kunci SVM pelatihan yang setara dengan memecahkan pemrograman linear kuadrat dibatasi masalah sehingga solusi dari SVM selalu unik, global dan optimal, seperti pelatihan jaringan lain yang membutuhkan non-linear optimasi dengan bahaya dari terjebak dalam minimum lokal.
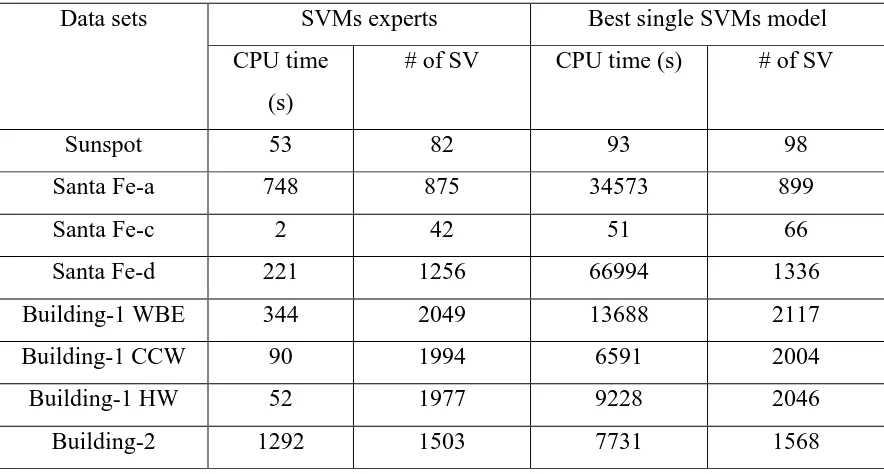
Tabel 3.2: Penggunaan waktu CPU dan angka support vectors
Data sets SVMs experts Best single SVMs model CPU time
(s)
# of SV CPU time (s) # of SV
Sunspot 53 82 93 98
Santa Fe-a 748 875 34573 899
Santa Fe-c 2 42 51 66
Santa Fe-d 221 1256 66994 1336 Building-1 WBE 344 2049 13688 2117 Building-1 CCW 90 1994 6591 2004 Building-1 HW 52 1977 9228 2046 Building-2 1292 1503 7731 1568
Berdasarkan tabel 3.2 terlihat bahwa Selain itu, waktu CPU yang digunakan dan jumlah support vector SVMs dan model tunggal SVMs, yang dihitung untuk semua set data. Tabel tersebut menunjukkan bahwa waktu yang dihabiskan untuk solusi sebagian besar kurang untuk SVMs dari model SVMs tunggal yang terbaik.
Semua hasil simulasi menunjukkan bahwa model SVMs lebih efektif dan efisien dalam peramalan time series dibandingkan model tunggal SVM.
3.3.6 Penelitian dalam bidang Jaringan Komputer
Amershi dan Conati (2009) melakukan penelitian yang menyajikan suatu kerangka pemodelan pengguna berbasis data, untuk membangun model eksplorasi lingkungan belajar.
Dalam teori, jenis pembelajaran aktif harus memungkinkan siswa untuk memperoleh lebih dalam, pemahaman yang lebih terstruktur konsep dalam domain. Dalam praktek, evaluasi empiris telah menunjukkan bahwa ELEs (Exploratory learning environments) tidak selalu efektif untuk semua siswa misalnya dan bahwa beberapa siswa dapat mengambil manfaat dari yang lebih terstruktur dukungan (Kirschner et al., 2006).
Dalam penelitian ini, beberapa peneliti telah bekerja pada pengembangan adaptif dukungan untuk eksplorasi efektif dalam ELEs misalnya (Bunt dan Conati, 2002). Merancang dukungan ini membutuhkan memiliki model mahasiswa yang memantau peserta didik dalam mengeksplorasi perilaku dan mendeteksi ketika mereka membutuhkan bimbingan dalam proses eksplorasi.
Merten dan Conati (2007) juga telah mengeksplorasi pendekatan berdasarkan mesin pembelajaran diawasi, di mana ahli domain manual berlabel episode interaksi berdasarkan apakah siswa atau tidak tercermin pada hasil dari tindakan eksplorasi mereka. Kumpulan data yang dihasilkan kemudian digunakan untuk melatih classifier untuk perilaku siswa refleksi yang diintegrasikan dengan model berbasis pengetahuan sebelumnya dikembangkan mahasiswa perilaku eksplorasi. Sedangkan penambahan secara signifikan meningkatkan classifier model akurasi, pendekatan ini mempunyai kelemahan yang sama pengetahuan berbasis pendekatan dijelaskan sebelumnya. Hal ini memakan waktu dan rawan kesalahan, karena manusia harus menyediakan label untuk dataset.
Dalam penelitian ini kami mengeksplorasi pendekatan yang lebih ringan: kerangka pemodelan pengguna yang membahas keterbatasan di atas dengan mengandalkan data mining untuk secara otomatis mengidentifikasi secara umum interaksi perilaku dan kemudian untuk melatih perilaku model pengguna.
hambatan dari domain target, dan dapat mengambil manfaat dari inklusi bimbingan adaptif yang dapat membantu siswa memperoleh hasil dari proses eksplorasi mereka.
Dalam eksperimen kedua, analisis cluster menunjukkan bahwa pengelompokan tanpa pengawasan di pengunjung komponen kerangka adalah mampu mengidentifikasi kelompok yang berbeda dari siswa (yaitu, kelompok siswa menunjukkan perbedaan dalam hasil belajar dari pra dan pasca ujian). Selain itu, analisis mengungkapkan beberapa perilaku karakteristik belajar yang berbeda cluster. Beberapa dari karakteristik perilaku yang intuitif dan dengan demikian cukup dijelaskan baik hasil pembelajaran efektif atau tidak efektif. Namun, seperti yang diharapkan, Beberapa perilaku tidak memiliki implikasi belajar jelas, memerlukan pertimbangan kombinasi dimensi (seperti k-berarti tidak untuk menentukan cluster nya), atau pengetahuan siswa hasil pembelajaran untuk dijelaskan. Perilaku terakhir ini akan sulit untuk mengenali label dengan tangan, bahkan oleh para ahli aplikasi. Namun demikian, dua perbedaan dalam hasil percobaan yaitu:
1. Clustering menemukan cluster yang berbeda ketika k ditetapkan untuk 2 dan 3 dalam percobaan pertama dengan applet CSP, tetapi hanya cluster yang berbeda ditemukan untuk k set ke 2 di percobaan kedua dengan ACE.
2. Clustering mampu menemukan cluster dalam data applet CSP menggunakan antarmuka tindakan sendiri, padahal hanya menemukan cluster yang berbeda untuk ACE ketika menggunakan dataset yang mencakup tindakan antarmuka baik dan mata pelacakan data.
proses belajar. Karena pendekatan ini sehingga domain/ aplikasi spesifik, sulit untuk menggeneralisasi ke domain lain dan aplikasi
Dalam
.
[image:51.612.83.534.298.421.2]eksperimen dengan menerapkan kerangka kerja untuk membangun model pengguna untuk dua seperti lingkungan eksplorasi: Applet CSP bagi siswa membantu memahami algoritma untuk kepuasan kendala, dan lingkungan ACE untuk eksplorasi matematika fungsi. Presentasi hasil menunjukkan bahwa, meskipun keterbatasan karena ketersediaan data, pendekatannya adalah mampu mendeteksi cluster bermakna perilaku siswa, dan dapat mencapai akurasi yang wajar untuk kategorisasi online mahasiswa baru dalam hal efektivitas perilaku belajar mereka.
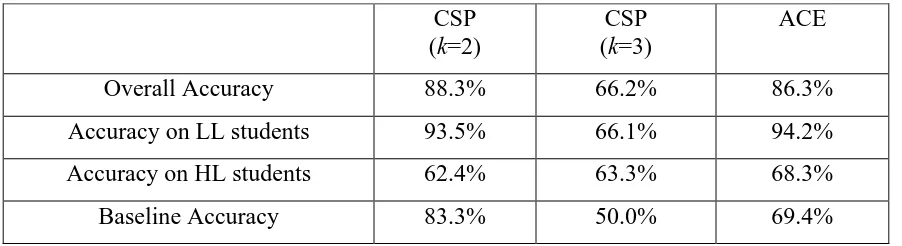
Tabel 3.3: Summary of classification accuracies averaged over time CSP
(k=2)
CSP (k=3)
ACE
Overall Accuracy 88.3% 66.2% 86.3% Accuracy on LL students 93.5% 66.1% 94.2% Accuracy on HL students 62.4% 63.3% 68.3% Baseline Accuracy 83.3% 50.0% 69.4%
Tabel 3.3 laporan ketepatan dalam mengklasifikasikan HL dan mahasiswa LL, rata-rata dari waktu ke waktu. Tabel ini juga menunjukkan akurasi model dasar yang sesuai yang digunakan untuk kemungkinan strategi klasifikasi kelas. Dalam semua kasus, k-berarti pengguna berbasis model mengungguli dasar yang sesuai memprediksi model di kelas yang benar untuk perilaku siswa baru.
3.3.7 Penelitian dalam bidang Pemasaran
Kim (2006) melakukan penelitian untuk memprediksi apakah seorang pelanggan yang diberikan mail atau katalog suatu produk akan menanggapi atau tidak, berdasarkan database informasi demografi pelanggan dan sejarah pembelian, menggunakan support vector regression.
Sebuah model respon, mengingat kampanye surat, memprediksi apakah setiap pelanggan akan merespon atau berapa banyak setiap pelanggan akan menghabiskan uang berdasarkan database informasi demografi pelanggan dan atau sejarah pembelian. Pemasar akan mengirimkan mail atau katalog kepada pelanggan yang diperkirakan akan merespon atau untuk menghabiskan uang dalam jumlah besar.
Berbagai metode telah digunakan untuk respon pemodelan seperti teknik statistik (Bentz dan Merunka, 2000), teknik pembelajaran mesin, (Wang et al, 2005). Dan jaringan saraf (NN) (Potharst et al., 2000). Sejauh ini, model respon telah biasanya dirumuskan sebagai kation biner, masalah diklasifikasikan karena keterusterangan nya. Para pelanggan dibagi menjadi dua kelas, responden dan non-responden. Sebuah Classifier dibangun untuk memprediksi apakah seorang pelanggan yang diberikan akan merespon atau tidak.
Dalam penelitian ini, diterapkan SVR untuk pemodelan respon untuk memprediksi jumlah total uang yang dihabiskan masing-masing responden. Seper