PERBANDINGAN VERTEX DISCRIMINANT ANALYSIS (VDA)
DAN QUADRATIC DISCRIMINANT ANALYSIS (QDA)
(Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di
Pulau Sumatera Berdasarkan Tingkat Kemiskinan)
HELGA KURNIA
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul Perbandingan Vertex Discriminant Analysis (VDA) dan Quadratic Discriminant Analysis (QDA) (Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di Pulau Sumatera Berdasarkan Tingkat Kemiskinan) adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2015
Helga Kurnia
RINGKASAN
HELGA KURNIA. Perbandingan Vertex Discriminant Analysis (VDA) dan
Quadratic Discriminant Analysis (QDA) (Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di Pulau Sumatera Berdasarkan Tingkat Kemiskinan). Dibimbing oleh I MADE SUMERTAJAYA dan FARIT M. AFENDI.
Analisis diskriminan merupakan suatu analisis pada data peubah ganda yang digunakan untuk mengklasifikasikan setiap observasi ke dalam kelas yang saling bebas berdasarkan peubah-peubah pencirinya. Analisis diskriminan yang sering digunakan adalah Linear Discriminant Analysis (LDA) dengan pendekatan Fisher. Pembentukan fungsi diskriminan pada LDA melibatkan komponen matriks kovarian bersama. Struktur matriks kovarian antarkelas harus sama sehingga dapat digabungkan membentuk matriks kovarian bersama. Apabila matriks kovarian antarkelas berbeda, penggunaan LDA menjadi tidak valid.
Quadratic Discriminant Analysis (QDA) dapat mengatasi masalah ini. Pada saat jumlah peubah lebih banyak daripada observasi (n < p), LDA dan QDA tidak dapat dilakukan karena rank dari matriks lebih kecil dari jumlah peubah. Hal ini mengakibatkan matriks kovarian singular, sehingga tidak memiliki invers. Hal tersebut dapat diatasi dengan Vertex Discriminant Analysis (VDA). Oleh karena itu, pada penelitian ini dilakukan perbandingan antara VDA dan QDA dengan menggunakan data simulasi dan data kasus terapan. Pada data dengan jumlah observasi lebih besar dari jumlah peubah (n > p), secara umum kemampuan klasifikasi VDA dan QDA hampir sama. Akan tetapi, VDA memiliki ketepatan klasifikasi lebih kecil dibandingkan QDA pada saat keragaman antarkelas besar dan jarak nilai tengah antarkelas dekat. Pada data dengan jumlah observasi lebih kecil dari jumlah peubah (n < p), hanya VDA yang dapat dilakukan. Hasil kajian terapan sesuai dengan hasil kajian simulasi.
SUMMARY
HELGA KURNIA. Comparison of Vertex Discriminant Analysis (VDA) and Quadratic Discriminant Analysis (QDA) (Case Study of Province and City Clasification in Sumatera Based on Poverty Level). Supervised by I MADE SUMERTAJAYA and FARIT M. AFENDI.
Discriminant analysis is one of the multivariate analysis concerned with separating distinct sets of observations and with allocating new observations to previously defined groups based on its feature variables. One of the discriminant analysis that frequently used is Fisher linear discriminant analysis (LDA). The development of discriminant function on LDA involve the pooled covariance matrix component. Structure of covariance matrix each classes have to similar in order to be able to be merged as pooled covariance matrix. When the structure of covariance matrix each classes are different, LDA will be invalid. Alternatively quadratic discriminant analysis (QDA) will be the solution of this. However, when the number of variables is more than number of observations (n < p) both LDA & QDA could not be executed due to rank of matrix lower than number of variables, thus covariance matrix become singular and have no invers. To solve the issue, we can use vertex discriminant analysis (VDA). In this research, we are comparing the VDA and QDA using simulated and case study data. When the number of observations more than number of variables (n > p), in overall the VDA and QDA performance are relatively similar. However the VDA classification accuracy lower than QDA when interclass variance is big and interclass means are near. When the number of observation less than number of variables (n < p), only VDA can be executed. Case study data shows the same results as simulated data.
© Hak Cipta Milik IPB. Tahun 2015
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
PERBANDINGAN
VERTEX DISCRIMINANT ANALYSIS
(VDA)
DAN
QUADRATIC DISCRIMINANT ANALYSIS
(QDA)
(Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di
Pulau Sumatera Berdasarkan Tingkat Kemiskinan)
HELGA KURNIA
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Tesis : Perbandingan Vertex Discriminant Analysis (VDA) dan
Quadratic Discriminant Analysis (QDA)
(Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di Pulau Sumatera Berdasarkan Tingkat Kemiskinan)
Nama : Helga Kurnia
NIM : G151120211
Disetujui oleh Komisi Pembimbing
Dr Ir I Made Sumertajaya, MSi Ketua
Dr Farit M Afendi, SSi MSi Anggota
Diketahui oleh
Ketua Program Studi Statistika
Dr Ir Kusman Sadik, MSi
Dekan Sekolah Pascasarjana
Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis ucapkan kehadirat Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penulis dapat menyelesaikan tesis yang berjudul “Perbandingan Vertex Discriminant Analysis (VDA) dan Quadratic Discriminant Analysis (QDA) (Studi Kasus Pengklasifikasian Provinsi dan Kabupaten/Kota di Pulau Sumatera Berdasarkan Tingkat Kemiskinan)”. Keberhasilan penulisan tesis ini tidak lepas dari bantuan, bimbingan, dan petunjuk dari berbagai pihak.
Terima kasih penulis ucapkan kepada Bapak Dr Ir I Made Sumertajaya, M.Si dan Bapak Dr Farit M. Afendi, S.Si., M.Si selaku pembimbing yang telah banyak memberi bimbingan, arahan, serta saran kepada penulis. Terimakasih juga kepada Kementerian Pendidikan dan Kebudayaan yang telah memberikan penulis Beasiswa Unggulan untuk staf dan telah memberikan tugas belajar kepada penulis. Ungkapan terima kasih terkhusus penulis sampaikan kepada suami, orang tua, anak-anak, seluruh keluarga, dosen-dosen, dan teman-teman atas do’a, dukungan, dan kasih sayangnya. Terima kasih pula kepada seluruh staf Program Studi Statistika dan rekan-rekan di Pusat Kurikulum dan Perbukuan Balitbang Kementerian Pendidikan dan Kebudayaan atas bantuan, dukungan, dan kebersamaannya.
Semoga tesis ini bermanfaat serta dapat menambah wawasan bagi para pembaca. Kritikan yang membangun sangat penulis harapkan demi perbaikan tesis ini dimasa yang akan datang.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 2
Analisis Diskriminan 2
Analisis Diskriminan Linier dan Non-linier 2
Quadratic Discriminant Analysis (QDA) 3
Vertex Discriminant Analysis (VDA) 4
Vertex pada Ruang −1 4
Meminimumkan Fungsi Kerugian (Loss Function) 5
Fungsi Tujuan pada VDA 5
Algoritma MM (Majorize-Minimize) pada VDA 6
Mayorisasi dari Jarak ϵ-insensitif dan Fungsi Tujuan 6
Algoritma VDA 7
3 DATA DAN METODE 7
Data 7
Data Simulasi 8
Data Kasus Terapan 9
Metode Analisis 9
4 HASIL DAN PEMBAHASAN 11
Kajian Simulasi 11
Kajian Kasus Terapan 13
Deskripsi Data 13
Hasil Uji Box’s 16
Hasil Analisis Diskriminan Kuadratik (QDA) 16
VDA pada Data Kabupaten 17
VDA pada Data Kabupaten dengan Penambahan Komponen Kuadratik 18
VDA pada Data Provinsi 19
VDA pada Data Provinsi dengan Penambahan Komponen Kuadratik 19 Perbandingan Ketepatan Klasifikasi antara QDA dan VDA 21
5 SIMPULAN DAN SARAN 22
Simpulan 21
Saran 21
DAFTAR PUSTAKA 23
LAMPIRAN 25
DAFTAR TABEL
1 Skenario simulasi 8
2 Perbandingan rataan ketepatan klasifikasi antara VDA dan QDA 11 3 Jumlah kabupaten/kota setiap kelas dan karakteristik masing-masing
kelas 14
4 Jumlah provinsi setiap kelas dan karakteristik masing-masing kelas 15 5 Ketepatan klasifikasi pada data training kabupaten/kota 16 6 Ketepatan klasifikasi QDA pada data testing kabupaten/kota 16 7 Ketepatan klasifikasi VDA pada data training kabupaten/kota 17 8 Ketepatan klasifikasi VDA pada data testing kabupaten/kota 17 9 Ketepatan klasifikasi VDA pada data training kabupaten/kota dengan
penambahan komponen kuadratik 18
10 Ketepatan klasifikasi VDA pada data testing kabupaten/kota dengan
penambahan komponen kuadratik 18
11 Ketepatan klasifikasi VDA pada data testing provinsi 20% 19 12 Ketepatan klasifikasi VDA pada data testing provinsi 40% 19 13 Ketepatan klasifikasi VDA pada data testing provinsi 50% 19 14 Ketepatan klasifikasi VDA pada data testing provinsi 20% dengan
penambahan komponen kuadratik 21
15 Ketepatan klasifikasi VDA pada data testing provinsi 40% dengan
penambahan komponen kuadratik 21
16 Ketepatan klasifikasi VDA pada data testing provinsi 50% dengan
penambahan komponen kuadratik 21
17 Perbandingan ketepatan klasifikasi antara QDA, VDA, dan VDA
dengan penambahan komponen kuadratik pada data kabupaten/kota 22 18 Perbandingan ketepatan klasifikasi antara QDA, VDA, dan VDA
dengan penambahan komponen kuadratik pada data provinsi 22
DAFTAR GAMBAR
1 Penentuan indikator vertex untuk tiga kelas 5
2 Boxplot ketepatan klasifikasi data simulasi 12 3 Perbandingan persentase kebaikan klasifikasi antara QDA dan VDA
dari 100 kali ulangan data simulasi 12
4 Histogram tingkat kemiskinan kabupaten/kota di Sumatera 13
DAFTAR LAMPIRAN
1 Daftar kabupaten/kota di Sumatera dan klasifikasinya 25 2 Daftar provinsi di Sumatera dan klasifikasi berdasarkan tingkat kemiskinan 29 3 Rataan peubah-peubah di setiap kelas pada data kabupaten/kota 30 4 Rataan peubah-peubah di setiap kelas pada data provinsi 31
1
1 PENDAHULUAN
Latar Belakang
Analisis diskriminan merupakan suatu analisis pada data peubah ganda yang digunakan untuk mengklasifikasikan setiap observasi ke dalam kelas yang saling bebas berdasarkan peubah-peubah pencirinya. Analisis diskriminan sampai saat ini masih mengalami perkembangan secara aktif. Analisis diskriminan yang sering digunakan adalah linear discriminant analysis (LDA) dengan pendekatan Fisher. Pembentukan fungsi diskriminan pada LDA melibatkan komponen matriks kovarian bersama. Matriks kovarian bersama dapat dibentuk jika struktur matriks kovarian antarkelas sama sehingga dapat digabungkan. Bila matriks kovarian antarkelas berbeda penggunaan LDA menjadi tidak valid. quadratic discriminant analysis (QDA) dapat mengatasi masalah ini. Pada saat jumlah peubah lebih banyak daripada observasinya (n < p). LDA dan QDA tidak dapat dilakukan karena rank dari matriks lebih kecil dari jumlah peubah, mengakibatkan matriks kovarian singular, sehingga tidak memiliki invers. Menurut Wu & Lange (2008) hal tersebut dapat diatasi dengan vertex discriminant analysis (VDA). Pada penelitian ini akan dilakukan perbandingan antara VDA dan QDA, sementara penelitian tentang perbandingan antara VDA dan LDA sudah dilakukan oleh Nurmaleni (2015).
Kajian kasus pada penelitian ini menggunakan data tentang kemiskinan di pulau Sumatera yang dipublikasikan oleh Tim Nasional Percepatan Penanggulangan Kemiskinan (TNP2K) pada website www.tnp2k.go.id. Data ini diambil berdasarkan pertimbangan bahwa kemiskinan merupakan permasalahan bangsa. Pemerintah telah melaksanakan penanggulangan kemiskinan melalui berbagai program baik di tingkat pusat maupun di daerah. Program pemerintah dalam penanggulangan kemiskinan di daerah diharapkan dapat berjalan optimal dan lebih bermanfaat jika ada kebijakan yang berbeda antardaerah. Perbedaan kebijakan tersebut disesuaikan dengan tinggi rendahnya tingkat kemiskinan daerah dan kebutuhan daerah yang bersangkutan. Oleh karena itu, dibutuhkan identifikasi pengklasifikasian tingkat kemiskinan daerah-daerah yang ada di Indonesia baik provinsi maupun kabupaten/kota.
2
Tujuan Penelitian
Tujuan penulisan dalam penelitian ini adalah membandingkan vertex discriminant analysis (VDA) dengan quadratic discriminant analysis (QDA) pada data n < p dan n > p, dengan n adalah jumlah observasi dan p adalah jumlah peubah.
2 TINJAUAN PUSTAKA
Analisis Diskriminan
Analisis diskriminan adalah teknik peubah ganda yang berhubungan dengan pemisahan sekelompok objek (observasi) dan penempatan objek (observasi) ke dalam kelompok yang telah ditentukan terlebih dahulu (Johnson & Wichern 2007). Pada analisis diskriminan pengelompokan dan identifikasi sifat khas suatu kelompok dapat dilakukan sekaligus. Model dasar analisis diskriminan adalah sebuah persamaan yang menunjukkan suatu kombinasi linier dari berbagai peubah penjelas, yaitu :
= 0+ 1 1+ 2 2+⋯+ (1)
dengan : = skor diskriminan
= koefisien diskriminan atau bobot ke-i
= predictor atau peubah penjelas ke-i
Koefisien yang diduga adalah b sehingga nilai setiap kelas sedapat mungkin berbeda. Berdasarkan nilai itulah keanggotaan sebuah observasi diprediksi. (Mattjik & Sumertajaya 2011)
Analisis Diskriminan Linier dan Non-linier
Kelinieran pada analisis diskriminan ditentukan oleh matriks ragam-peragamnya (∑). Jika matriks ragam-peragam antarkelas sama, maka dapat dikatakan analisis diskriminan linier, dan sebaliknya disebut analisis diskriminan non-linier. Untuk menguji kesamaan matriks ragam-peragam antarkelas digunakan statistik uji Box’s berikut:
−2 ln�∗ = − ln �
− − ∑ −1 ln (2)
dengan: �∗ =
−1 2
� − − 2 k = banyaknya kelas
= jumlah semua observasi
= jumlah observasi pada kelas ke-j, dengan j=1,2,...,k
� − = matriks ragam-peragam dalam kelas gabungan = matriks ragam-peragam kelas ke-j.
Bila matriks ragam-peragam sama, maka −2 ln�∗ akan mengikuti sebaran F
3
p = jumlah peubah pembeda dalam fungsi diskriminan
Oleh karena itu apabila −2 ln�∗ 1. 2.� atau − > � maka dapat disimpulkan bahwa semua kelas mempunyai matriks ragam-peragam yang sama atau dapat dianalisa dengan analisis diskriminan linier. (Mattjik & Sumertajaya 2011)
Quadratic Discriminant Analysis (QDA)
Analisis dikskriminan dengan pendekatan Fisher untuk data normal multivariat dan matriks ragam-peragam tidak sama adalah analisis diskriminan kuadratik atau quadratic discriminant analysis (QDA). Menurut Johnson & Wichern (2007), untuk dua kelas (k=2), himpunan dari kemungkinan semua hasil pada contoh dibagi menjadi dua wilayah, 1 dan 2. Misalkan 1 � dan 2 � fungsi kepekatan peluang dari �× 1 vektor peubah acak X untuk populasi �1 dan
�2. 1 adalah serangkaian nilai x untuk objek yang kita klasifikasikan sebagai �1 sehingga 2 = � − 1, dengan Ω adalah ruang contoh yang berisi kumpulan dari semua observasi yang mungkin dari x. Jika rasio harga kesalahan klasifikasi tidak ditentukan, maka rasio tersebut diambil bernilai satu. Daerah klasifikasinya menjadi 1: 1 �
. Skor diskriminan kuadratik didefinisikan sebagai:
� = ln� −1
2 � − � ′∑
− � − � −1
2ln ∑ (3)
Karena � dan ∑ tidak diketahui, sehingga dicari estimasi dari contohnya. Jadi, estimasi dari skor diskriminan kuadratik dapat menjadi:
4
dengan � = rataan populasi kelas ke-j, j = 1,2,...,k ,
� = peluang prior, apabila nilainya tidak diketahui maka � = 1 ,
� = matriks ragam-peragam kelas ke-j.
Karena � dan � tidak diketahui, sehingga dapat menggunakan estimasi dari contohnya. Jadi, estimasi dari skor diskriminan kuadratik dapat menjadi
� = � = ln� −1
Maka, pendugaan pengelompokannya dengan menentukan kelas mana yang memiliki skor maksimum seperti persamaan (8) berikut:
� = maks 1 � , 2 � , …, � . (8)
Vertex Discriminant Analysis (VDA)
Salah satu pengembangan metode dari analisis diskriminan adalah vertex discriminant analysis (VDA). Dalam masalah ruang berdimensi tinggi (high dimensional) atau jumlah peubah lebih banyak dari jumlah observasi, kelemahan yang mungkin terjadi adalah overfitting. Meskipun demikian, hal tersebut dapat ditangani dengan baik melalui pengaturan pendugaan koefisien regresi dengan menambahkan syarat penalti yang menyusutkan pendugaan mendekati nilai aslinya. Jumlah penyusutan dapat dikalibrasi dengan validasi silang ( cross-validation). (Wu & Lange 2008)
Vertexpada Ruang −
Pemilihan indikator kelas dilakukan dengan membentuk equidistant points
(titik-titik dengan jarak yang sama) pada ruang −1, dimana adalah jumlah kelompok/kelas. Jumlah equidistant points yang harus ditemukan sebanyak kelas. Equidistant points tersebut untuk selanjutnya dinamakan dengan vertex.
Menurut Wu & Lange (2008), suatu cara yang mungkin untuk mengkontruksi vertex tersebut dengan menggunakan formula berikut:
= −1 −
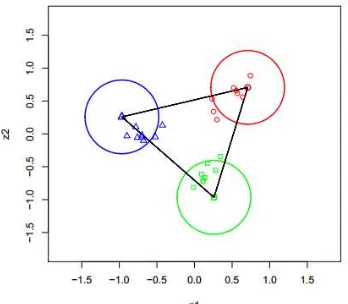
Sebagai ilustrasi, jika jumlah ada tiga kelas, maka tiga titik yang terbentuk pada 2, adalah
5
Gambar 1 Penentuan indikator vertex untuk tiga kelas
Meminimumkan Fungsi Kerugian (Loss Function)
Fungsi tujuan merupakan nilai harapan dari fungsi kerugian (loss function). Fungsi kerugian yang digunakan pada VDA adalah kerugian ϵ-insensitif. Kerugian ϵ-insensitif pada regresi diformulakan menjadi:
L , = y− − ∈ (10)
dengan ∈= −∈,0 (Vapnik 1995; Hastie et al. 2001).
Kerugian ϵ-insensitif lebih resisten terhadap pencilan dibandingkan dengan
squared error loss (Liu et al 2005). Pengklasifikasian dilakukan dengan memilih jarak terdekat antara penduga linier dengan indikator kelas yang mungkin. Kerugian ϵ-insensitif baik digunakan pada dimensi tinggi.
Agar nilai dugaan dapat mendekati nilai populasi, maka fungsi kerugian diminimumkan. Misalkan Y menunjukkan indikator kelas dan X menunjukkan vektor peubah penciri dari observasi acak. Vektor Y bertepatan dengan salah satu simpul (vertex) tersebut. Diketahui fungsi kerugian (loss function) L(y,x), analisis diskriminan berusaha untuk meminimumkan nilai harapan kerugian sebagai berikut:
� , = � , | .
Untuk meminimalkan kerugian dapat dilakukan diferensiasi/turunan. Tetapi fungsi kerugian ϵ-insensitif tidak dapat diturunkan. Hal ini sulit dilakukan, sehingga untuk pendugaan parameter dilakukan dengan cara meminimumkan rata-rata kerugian bersyarat −1×∑=1� , dengan menambahkan batas penalti.
Fungsi Tujuan pada VDA
VDA linier mengasumsikan model regresi linier ( ) =� + , dengan
�= adalah matriks koefisien kemiringan berukuran ( −1) ×�, dan = adalah vektor kolom dari intersep yang berukuran ( −1) × 1. Fungsi diskriminan VDA adalah:
� � =��+ . (11)
Overfitting dapat dihindari dengan menerapkan penalti pada slope tetapi bukan pada intersep .
6
Fungsi kerugian ϵ-insensitif jarak Euclid dapat didefinisikan sebagai berikut:
Algoritma MM (Majorize-Minimize) pada VDA
Algoritma MM mensubstitusikan masalah optimasi sederhana untuk masalah optimasi yang sulit. Dalam meminimumkan singkatan MM berarti mayorisasi-minimum (Majorize-Minimize), sedangkan dalam maksimal singkatan MM berarti minorisasi-maksimum (Minorize-Maximize). Sebuah algoritma MM beroperasi dengan menciptakan fungsi pengganti yang memayorisasi atau meminorisasi fungsi tujuan. Ketika fungsi pengganti dioptimalkan, fungsi tujuan akan didorong agar meningkat atau menurun sesuai kebutuhan. Pada VDA algoritma MM dibutuhkan untuk meminimumkan fungsi tujuan, sehingga MM berarti mayorisasi-minimum (Majorize-Minimize).
Fungsi asal mengikuti definisi � +1 � +1|� � |� =
� . Algoritma MM minimalisasi memenuhi fungsi asal � +1 �
dengan pertidaksamaan yang sempurna. kecuali memenuhi kedua syarat berikut:
� +1|� = � |� dan � +1 = � +1|� . (14) Fungsi asal membuat algoritma MM sangat stabil.
Mayorisasi dari Jarak ϵ-insensitif dan Fungsi Tujuan
7 Mayorisasi dari fungsi tujuan dengan meminimalisasi fungsi pengganti. Minimalisasi fungsi pengganti dengan cara mereduksi menjadi pendugaan kuadrat terkecil terboboti:
Proses perhitungan pada VDA cukup rumit bila dilakukan secara manual karena melibatkan proses iterasi, sehingga dibutuhkan bantuan program perangkat lunak. yaitu program R dengan paket VDA. Algoritma VDA dapat dituliskan sebagai berikut (Wu & Lange 2008):
i. Tentukan nilai awal iterasi = 0, dan inisialisasi �0 = 0 dan 0 = 0 ; ii. Definisikan = jika subjek ke-i menjadi kategori ke-j, dimana
didefinisikan pada persamaan (9);
iii. Mayorisasi fungsi tujuan dengan sisaan ke-i = − � − ; iv. Meminimumkan fungsi pengganti dan menentukan � +1 dan +1
dengan dengan cara menyelesaikan k set persamaan linier.
v. Jika � +1 − � <� dan � +1 . +1 − � . < � keduanya sampai � = 10−4, kemudian berhenti. Jika tidak ulangi langkah ke-iii sampai dengan langkah ke-v.
3 DATA DAN METODE
Data
8
dengan n < p dan n > p, maka data terapan terdiri dari dua pengelompokan. Pengelompokan kabupaten/kota untuk memenuhi kondisi data n > p dan pengelompokan provinsi untuk memenuhi kondisi n < p. Tetapi kedua kondisi tersebut tidak dapat dilakukan pada data simulasi karena metode QDA tidak dapat mengklasifikasikan objek pada n < p, karena matriks ragam-peragamnya bersifat singular sehingga tidak memiliki invers, sehingga tidak dapat dilakukan perhitungan.
Data Simulasi
Proses pembangkitan data simulasi terdiri dari dua tahap, yaitu: Tahap I : Menentukan skenario simulasi
Skenario simulasi disajikan pada Tabel 1. Keragaman berbeda kecil ditentukan dengan perbedaan keragaman yang tidak nyata, berbeda sedang ditentukan dengan perbedaan yang mulai nyata, sedangkan keragaman berbeda besar ditentukan dengan perbedaan keragaman antarkelas yang jelas nyata.
Tabel 1 Skenario simulasi Skenario Keragaman
Tahap II : Membangkitkan data
Langkah-langkah pada tahap membangkitkan data adalah sebagai berikut: a. Menentukan jumlah kelas yang akan dibentuk, yaitu 3 kelas.
b. Menentukan ukuran contoh untuk masing-masing kelas, yaitu 20. c. Menentukan jumlah peubah bebas (X), yaitu 3 peubah.
d. Menentukan vektor simpangan baku masing-masing kelas ( ) sesuai dengan skenario simulasi yang ditentukan pada tahap I, dengan j adalah indeks kelas. e. Menentukan vektor rataan untuk masing-masing kelas � =(µ1j,µ2j,µ3j) yaitu
�1 = 3, 6, 9 ,�2 = �1+ 1, dan �3 =�2+ 2 2. f. Menentukan matriks korelasi �=
1 0.1 0.4
0.1 1 0.8
0.4 0.8 1
, matriks korelasi ini sama untuk ketiga kelas.
g. Membentuk matriks diagonal dari vektor simpangan baku � = �. h. Membentuk matriks ragam-peragam dengan formula j = � ��. i. Membangkitkan peubah acak normal ganda �~� .�
j. Menguraikan setiap matriks j menjadi U`U dengan dekomposisi Cholesky.
k. Membentuk Xj dengan � =�� +� dan � ~ N(� , ).
l. Menggabungkan semua data kelas menjadi satu data simulasi.
9
Data Kasus Terapan
Data kasus terapan adalah data sekunder yang diperoleh dari data Indikator Kesejahteraan Daerah Provinsi-provinsi di Sumatera yang diambil dari data publikasi Tim Nasional Percepatan Penanggulangan Kemiskinan (TNP2K) tahun 2011 melalui situs www.tnp2k.go.id, diunduh pada tanggal 12 Mei 2014. Peubah yang diambil mencakup peubah yang berhubungan dengan indikator kemiskinan masyarakat yang berada di pulau Sumatera sebagai peubah penjelas (X). Peubah-peubah tersebut adalah:
X1 : Tingkat pengangguran terbuka (%)
X2 : Pekerja yang bekerja selama kurang dari 14 jam seminggu (%)
X3 : Pekerja di sektor informal (%)
X4 : Pengeluaran per kapita (ribu rupiah)
X5 : Persentase balita kekurangan gizi (%)
X6 : Angka kematian bayi per1000 kelahiran hidup (jiwa)
X7 : Angka harapan hidup (tahun)
X8 : Persentase kelahiran ditolong oleh tenaga medis (%)
X9 : Penduduk dengan keluhan kesehatan (%)
X10 : Angka morbiditas (%)
X11 : Rata-rata lama sakit (%)
X12 : Penduduk yang melakukan pengobatan sendiri (%)
X13 : Penduduk tanpa akses pada fasilitas sarana kesehatan (%)
X14 : Penduduk tanpa akses pada air bersih (%)
X15 : Angka partisipasi pendidikan SD
X16 : Angka partisipasi pendidikan SMP
X17 : Angka partisipasi pendidikan SMA
X18 : Angka putus sekolah usia 7-15 tahun (%)
X19 : Angka melek huruf (%)
Masing-masing observasi dikelompokkan ke dalam tiga kelas berdasarkan sebaran tingkat kemiskinan daerah (Y) dari tingkat kemiskinan terendah sampai ke tingkat kemiskinan tertinggi.
Unit observasi dibedakan menjadi dua kasus berdasarkan jumlah observasi (n) dan jumlah peubah (p), yaitu:
a. n < p, unit observasi adalah provinsi, terdiri dari 10 provinsi di pulau Sumatera.
b. n > p, unit observasi adalah kabupaten/kota, terdiri dari 151 kabupaten/kota di pulau Sumatera.
Metode Analisis
Metode analisis yang digunakan pada penelitian ini mencakup tahapan-tahapan berikut:
1. Melakukan eksplorasi data.
a. Pada data simulasi. Eksplorasi data dilakukan untuk memastikan data bangkitan sudah sesuai dengan skenario simulasi, yaitu: cek keragaman antarkelas, rataan, dan uji Box’s.
10
cek keragaman antarkelas, rataan setiap peubah pada masing-masing kelasnya, dan uji Box’s.
2. Membagi dua data menjadi data training dan data testing dengan perbandingan 4:1, kecuali pada data provinsi dilakukan variasi jumlah data
testing, yaitu 20%, 40%, dan 50%. Data training digunakan untuk membentuk fungsi diskriminan, lalu fungsi yang terbentuk dapat memprediksi kelas jika data setiap peubah dimasukkan. Sehingga perbandingan kelas prediksi dan kelas sebenarnya menghasilkan ketepatan klasifikasi. Sedangkan data testing digunakan untuk menguji ketepatan klasifikasi seakan-akan menentukan kelas pada data baru. Pemilihan data
training dan data testing dilakukan secara acak.
3. Pengepasan fungsi diskriminan pada data training, yaitu dengan metode VDA dan QDA. Proses perhitungan pada VDA cukup rumit bila dilakukan secara manual karena melibatkan proses iterasi, sehingga dibutuhkan bantuan program perangkat lunak, yaitu program R dengan paket VDA. Proses perhitungan QDA juga dilakukan dengan bantuan program R dengan paket MASS. Algoritma VDA dapat dituliskan sebagai berikut (Wu &
iv. Meminimumkan fungsi pengganti dan menentukan � +1 dan +1 dengan cara menyelesaikan k set persamaan linier.
v. Jika � +1 − � <� dan � +1 , +1 − � , <� keduanya sampai � = 10−4, kemudian berhenti. Jika tidak ulangi langkah ke-iii sampai dengan langkah ke-v.
Algoritma pembentukan fungsi diskriminan pada QDA adalah sebagai berikut (Johnson & Wichern 2007; Venables & Ripley 2002):
i. Membentuk fungsi diskriminan kuadratik k kelas yang didefinisikan
� = ln� −1 estimasi dari contohnya. Jadi, estimasi dari skor diskriminan kuadratik dapat menjadi
11 antara penduga dengan indikator kelas yang mungkin (titik vertex ke-j), dengan formula y=argminj=1....k vj-Axi-b . Pada QDA aturan pengelompokannya adalah mengalokasikan � ke dalam kelas ke-j jika
� = maks 1 � , 2 � ,…, � .
5. Menghitung persentase ketepatan klasifikasi baik data training maupun data
testing. Ketepatan klasifikasi merupakan persentase ketepatan antara kelas prediksi dan kelas sebenarnya pada semua unit observasi. Ketepatan klasifikasi merupakan indikator untuk melihat kemampuan klasifikasi pada metode analisis diskriminan yang digunakan.
6. Membandingkan VDA dengan QDA. Perbandingan didasarkan pada kemampuan klasifikasi yang lebih baik. Kemampuan klasifikasi dapat dilihat dari persentase ketepatan klasifikasi. Pada data simulasi perbandingan dilakukan berdasarkan keragaman antarkelas.
4 HASIL DAN PEMBAHASAN
Kajian Simulasi
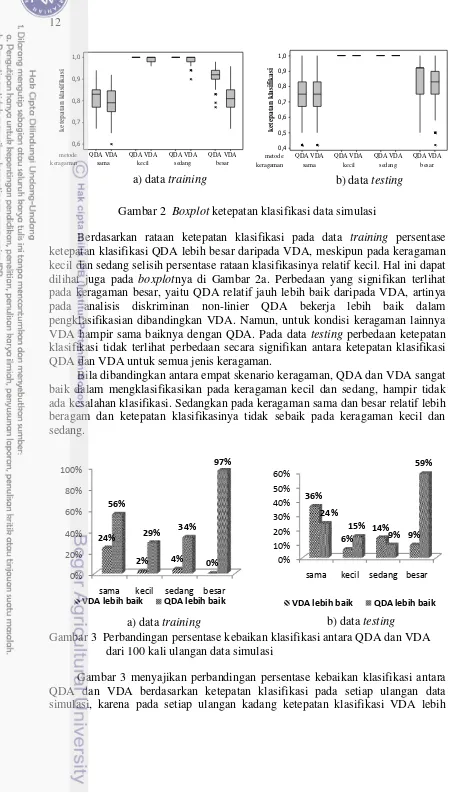
Pada kajian simulasi ada empat kelompok skenario. Masing-masing kelompok skenario simulasi dianalisis menggunakan metode QDA dan VDA untuk masing-masing data training dan data testing dengan 100 kali ulangan. sehingga masing-masingnya menghasilkan 100 ketepatan klasifikasi. Perbandingan rataan ketepatan klasifikasi antara metode QDA dan VDA pada data training dan data testing disajikan pada Tabel 2 dan boxplot ketepatan klasifikasi pada data training dan data testing disajikan pada Gambar 2 berikut.
Tabel 2 Perbandingan rataan ketepatan klasifikasi antara VDA dan QDA
Skenario
simulasi Keragaman
Rataan Ketepatan Klasifikasi QDA data
training
VDA data
training
QDA data
testing
VDA data
testing
1 sama 82.2% 79.5% 73.4% 75.4%
2 kecil 99.9% 99.3% 99.1% 98.3%
3 sedang 99.6% 98.8% 98.0% 98.4%
12
Gambar 2 Boxplot ketepatan klasifikasi data simulasi
Berdasarkan rataan ketepatan klasifikasi pada data training persentase ketepatan klasifikasi QDA lebih besar daripada VDA, meskipun pada keragaman kecil dan sedang selisih persentase rataan klasifikasinya relatif kecil. Hal ini dapat dilihat juga pada boxplotnya di Gambar 2a. Perbedaan yang signifikan terlihat pada keragaman besar, yaitu QDA relatif jauh lebih baik daripada VDA, artinya pada analisis diskriminan non-linier QDA bekerja lebih baik dalam pengklasifikasian dibandingkan VDA. Namun, untuk kondisi keragaman lainnya VDA hampir sama baiknya dengan QDA. Pada data testing perbedaan ketepatan klasifikasi tidak terlihat perbedaan secara signifikan antara ketepatan klasifikasi QDA dan VDA untuk semua jenis keragaman.
Bila dibandingkan antara empat skenario keragaman, QDA dan VDA sangat baik dalam mengklasifikasikan pada keragaman kecil dan sedang, hampir tidak ada kesalahan klasifikasi. Sedangkan pada keragaman sama dan besar relatif lebih beragam dan ketepatan klasifikasinya tidak sebaik pada keragaman kecil dan sedang.
Gambar 3 Perbandingan persentase kebaikan klasifikasi antara QDA dan VDA dari 100 kali ulangan data simulasi
Gambar 3 menyajikan perbandingan persentase kebaikan klasifikasi antara QDA dan VDA berdasarkan ketepatan klasifikasi pada setiap ulangan data simulasi, karena pada setiap ulangan kadang ketepatan klasifikasi VDA lebih
0%
a) data training b) data testing
13 baik, kadang sebaliknya. atau bisa terjadi ketepatan klasifikasi VDA dan QDA sama. Setiap data simulasi dibandingkan ketepatan klasifikasinya, jika ketepatan klasifikasi VDA lebih besar dibandingkan QDA maka “VDA lebih baik”, begitu juga sebaliknya. Berdasarkan Gambar 3a, pada data training persentase QDA lebih baik daripada VDA untuk semua keragaman, terlihat dari garis “QDA lebih baik” selalu di atas garis “VDA lebih baik”. Pada keragaman besar 97% QDA lebih baik dibandingkan VDA, hal ini sesuai dengan bahasan sebelumnya berdasarkan Gambar 2a. Berdasarkan Gambar 3b, pada keragaman sama dan sedang persentase VDA lebih baik daripada QDA. Seperti halnya pada data
training, untuk keragaman besar persentase kebaikan QDA terhadap VDA lebih besar secara signifikan. Sehingga dapat disimpulkan untuk n > p metode QDA lebih baik dibandingkan VDA terutama pada keragaman besar (analisis diskriminan non-linier), namun ketepatan klasifikasi VDA masih cukup baik, sehingga masih dapat dipakai sebagai analisis pilihan. Jika kondisi data dengan jumlah peubah lebih banyak dibandingkan jumalh obseravasi p > n. VDA merupakan pilihan mutlak, karena pada QDA matriks ragam-peragamnya akan bersifat singular sehingga tidak memiliki invers. Berdasarkan perbandingan antara tabel 2 dengan gambar 3 dapat disimpulkan bahwa rataan ketepatan klasifikasi mirip dengan persentase kebaikan klasifikasi tiap ulangan.
Kajian Kasus Terapan
Deskripsi Data
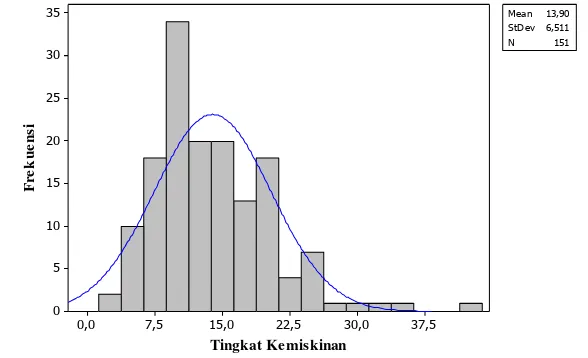
Pulau Sumatera terdiri dari 10 provinsi dan 151 kabupaten/kota. Data tingkat kemiskinan kabupaten di Sumatera berkisar antara 2.47% (Kota Sawahlunto) sampai dengan 42.56% (Kepulauan Meranti), dengan rataan 13.9% dan simpangan baku 6.5%. Tingkat kemiskinan provinsi berkisar antara 6.51% (Bangka Belitung) sampai dengan 20.98% (Aceh), dengan rataan 12.61% dan simpangan baku 5.31%. Semakin kecil tingkat kemiskinan maka semakin sejahtera kehidupan masyarakat di daerah tersebut.
Tingkat Kemiskinan
14
Pada penelitian ini, tingkat kemiskinan merupakan peubah yang dijadikan kelas diskriminasi, sehingga tingkat kemiskinan tersebut dikelompokkan menjadi tiga kelas dengan pertimbangan sebaran datanya. Sebaran data tingkat kemiskinan kabupaten dapat dilihat pada Gambar 4. Tiga kelas tersebut adalah:
kelas 1 (kaya) : tingkat kemiskinan kurang dari 10%.
kelas 2 (menengah) : tingkat kemiskinan 10% sampai dengan 15%. kelas 3 (miskin) : tingkat kemiskinan lebih dari 15%.
Penamaan kelas “kaya”, “menengah”, dan “miskin” dibuat oleh penulis hanya untuk memudahkan interpretasi. Daftar kabupaten/kota di Sumatera dengan klasifikasi berdasarkan tiga kelas di atas dapat dilihat pada Lampiran 1.
Berdasarkan tiga kelas diskriminasi yang ditentukan, ada 41 kabupaten/kota termasuk ke dalam tingkat kemiskinan kelas 1, 55 kabupaten/kota di kelas 2, dan 55 kabupaten/kota di kelas 3. Jumlah kabupaten/kota pada setiap kelas tersebut dan peubah-peubah yang menonjol pada masing-masing kelas disajikan pada Tabel 3. Lampiran 3 menyajikan rataan masing-masing peubah di setiap kelas pada data kabupaten/kota.
Tabel 3 Jumlah kabupaten/kota setiap kelas dan karakteristik peubah masing-masing kelas
15 Jika mengikuti pengelompokan tingkat kemiskinan seperti data kabupaten/kota, maka untuk data provinsi ada lima provinsi di dalam kelas kaya, yaitu Sumatera Barat, Riau, Jambi, Bangka Belitung, dan Kepualauan Riau; hanya ada satu provinsi di kelas menengah, yaitu Sumatera Utara; dan empat provinsi di kelas miskin, yaitu Aceh, Sumatera Selatan, Bengkulu, dan Lampung. Tersaji pada Tabel 4 jumlah provinsi pada masing-masing kelas dan peubah yang menjadi karakteristiknya. Nilai rataan peubah-peubah di setiap kelas pada data provinsi dapat dilihat pada Lampiran 4.
Tabel 4 Jumlah provinsi setiap kelas dan karakteristik masing-masing kelas Kelas Jumlah provinsi Peubah yang menonjol
kelas 1 (kaya) 5 X3, X6, X13
kelas 2 (menengah) 1 X1, X5, X8, X9, X17, X18, X19
kelas 3 (miskin) 4 X4, X12, X14, X15
Peubah yang menonjol pada kelas kaya adalah persentase pekerja di sektor informal (X3) yang rendah, yaitu rata-rata 51.08%. Lalu peubah angka kematian bayi (X6) yang paling rendah dibandingkan kelas lainnya, yaitu rata-rata 28,8 jiwa per1000 kelahiran hidup. Peubah ketiga yang menjadi karaktistik kelas kaya adalah penduduk tanpa akses pada fasilitas sarana kesehatan (X13) yang rendah, yaitu hanya 9,82%.
Pada kelas menengah, peubah yang menonjol mecerminkan karakteristik dari provinsi Sumatera Utara, karena hanya ada satu provinsi pada kelas tersebut. Ada beberapa peubah yang menarik, yaitu tingkat pengangguran (X1) yang tertinggi dibandingkan kelas lainnya; dan persentase balita kekurangan gizi (X5) yang juga tinggi, bahkan lebih tinggi daripada rata-rata di kelas miskin. Namun, kesadaran terhadap pentingnya kesehatan pada masyarakat relatif tinggi, ditandai dengan persentase kelahiran ditolong oleh tenaga medis (X8) yang tinggi (88.68%), dan penduduk dengan keluhan kesehatan (X9) yang paling rendah dibandingkan kelas lainnya, yaitu 29.11%. Selain itu, pendidikan masyarakat juga relatif baik, ditandai dengan angka melek huruf (X19) yang sangat tinggi (97.32%), angka putus sekolah usia 7-15 tahun (X18) yang sangat rendah (1.6%), dan angka partisipasi pendidikan SMA (X17) yang cukup tinggi dibandingkan kelas lainnya (55.3%).
Kelas miskin dicirikan oleh empat peubah. Pengeluaran per kapita (X4) yang paling rendah dibandingkan kelas lainnya, yaitu rata-rata Rp 621,990. Penduduk yang melakukan pengobatan sendiri (X12) sangat tinggi, rata-rata 72.28%. Persentase penduduk tanpa akses pada air bersih (X14) masih cukup tinggi (54.17%). Angka partisipasi pendidikan SD (X15) paling tinggi dibandingkan kelas lainnya. Peubah-peubah tersebut mencerminkan bahwa pada kelas miskin kesadaran terhadap kesehatan masih rendah, sanitasi masih rendah, demikian juga tingkat pendidikan masyarakatnya.
Dalam analisis diskriminan dibutuhkan data training dan data testing
dengan proporsi 20% data testing. Sehingga ada 30 kabupaten/kota pada data
16
sedangkan data testing berguna untuk menguji ketepatan fungsi diskriminan bila akan menentukan kelas pada data baru.
Hasil Uji Box’s
Seperti telah dijelaskan pada bab tinjauan pustaka, uji Box’s digunakan untuk menguji kehomogenan matriks ragam-peragam antarkelas pada analisis diskriminan. Jika semua kelas mempunyai matriks ragam-peragam yang homogen, maka analisis diskriminan tersebut linier. Tetapi, jika ada kelas yang matriks ragam-peragamnya tidak homogen, lebih cocok menggunakan analisis diskriminan non-linier.
Hasil uji Box’s terhadap data kabupaten/kota menunjukkan bahwa = 0.000 lebih kecil dari �= 0.05, dapat disimpulkan bahwa matriks ragam-peragam yang berbeda, sehingga data ini lebih cocok jika menggunakan analisis diskriminan non-linier. Pada penelitian ini akan digunakan QDA dan VDA. Tetapi, karena menurut Wu & Wu (2012) VDA lebih ditujukan untuk analisis diskriminan linier, maka dibandingkan juga dengan VDA bila data dimodifikasi dengan penambahan komponen kuadratik di dalamnya.
Hasil Analisis Diskriminan Kuadratik (QDA)
Data kemiskinan kabupaten/kota dianalisis dengan QDA dengan bantuan program R. Pada analisis QDA tidak ditampilkan fungsi diskriminannya, tetapi langsung menghitung hasil prediksi kelas pada data training. Sehingga dapat dihitung ketepatan klasifikasi data training yaitu 91.74%, dengan rincian ketepatan klasifikasinya dapat dilihat pada Tabel 5 berikut.
Tabel 5 Ketepatan klasifikasi pada data training kabupaten/kota
Kelas sebenarnya Kelas prediksi
1 2 3
1 28 3 1
2 0 44 2
3 0 4 39
Tabel 6 Ketepatan klasifikasi QDA pada data testing kabupaten/kota
Kelas sebenarnya Kelas prediksi
1 2 3
1 1 8 0
2 1 8 0
3 0 5 7
Setelah itu prediksi terhadap data testing juga dapat dilakukan, sehingga dapat dihitung ketepatan klasifikasi pada data testing sebesar 53.3%. Rincian kesalahan klasifikasinya disajikan pada Tabel 6. Ketepatan klasifikasi QDA untuk data testing lebih kecil dibandingkan pada data training.
Data kemiskinan provinsi di Sumatera tidak mungkin dianalisa dengan
17 sehingga tidak dapat dilakukan proses analisis diskriminan kuadratik lebih lanjut. Tetapi hal ini dapat diatasi oleh VDA, karena pada VDA besaran kategorik ditransformasi ke besaran empirik.
VDA pada Data Kabupaten
VDA dapat digunakan pada data dengan > � maupun <�. Sehingga pada penelitian ini dapat digunakan untuk menganalisis data kabupaten/kota dan juga data provinsi. Sebagai pembanding, data kabupaten/kota dianalisis dengan metode VDA menggunakan program R. Pada keluaran program R dihasilkan dugaan koefisien (estimated coefficients), sehingga dapat dibentuk fungsi diskriminan vertex Axi-b sebagai berikut:
Hasil prediksi kelas setiap kabupaten/kota juga sudah ditampilkan pada keluaran, sehingga dapat dibandingkan dengan kelas sebenarnya untuk menghitung ketepatan klasifikasi pada data training, karena kebaikan model diskriminan dapat dilihat dari ketepatan klasifikasi masing-masing kelas. Semakin besar jumlah klasifikasi yang sama antara kelas prediksi dengan kelas sebenarnya atau semakin kecil persentase kesalahan klasifikasi, maka model diskriminan tersebut semakin baik. Ketepatan klasifikasi VDA pada data training sebesar 74.4%, dengan rinciannya pada tabel 7 berikut.
Tabel 7 Ketepatan klasifikasi VDA pada data training kabupaten/kota
Kelas sebenarnya Kelas prediksi
1 2 3
1 20 8 4
2 3 39 4
3 3 9 31
Berdasarkan fungsi diskriminan yang dihasilkan VDA, selanjutnya dapat dilakukan prediksi klasifikasi untuk data testing. Kemudian dapat dibandingkan dengan klasifikasi sebenarnya untuk menghitung besarnya ketepatan klasifikasi. Pada Tabel 8 dapat dilihat rincian ketepatan klasifikasi setiap kelas pada data
testing, sehingga dapat dihitung besar ketepatan klasifikasi 0.6667 atau 66.67%. Tabel 8 Ketepatan klasifikasi VDA pada data testing kabupaten/kota
Kelas sebenarnya Kelas prediksi
1 2 3
1 5 3 1
2 2 5 2
18
VDA pada Data Kabupaten dengan Penambahan Komponen Kuadratik
Pada proses analisis diskriminan kuadratik (QDA) terjadi pembentukan komponen kuadratik, sedangkan pada VDA tidak. Agar pembandingan lebih adil, maka dilakukan penambahan komponen kuadratik pada data yang akan dianalisa dengan VDA. Komponen kuadratik merupakan kuadrat dari peubah X1 sampai dengan X19 yang sebelumnya distandarisasi, sehingga pada data ini ada 38 peubah.
Berdasarkan dugaan koefisien (estimated coefficients), fungsi diskriminan vertex yang terbentuk sebagai berikut: dibandingkan VDA tanpa penambahan komponen kuadratik. Rincian ketepatan klasifikasi tersebut disajikan pada Tabel 9 berikut.
Tabel 9 Ketepatan klasifikasi VDA pada data training kabupaten/kota dengan
19 Tabel 10, sehingga dapat dihitung ketepatan klasifikasi, yaitu sebesar 60%. Lebih kecil dibandingkan ketepatan klasifikasi data testing tanpa penambahan komponen kuadratik.
VDA pada Data Provinsi
Salah satu kelebihan VDA dibandingkan QDA adalah mampu melakukan analisis pada kondisi data dengan � , seperti pada data kemiskinan provinsi di Sumatera, jumlah peubah (19 peubah) lebih banyak daripada jumlah provinsi (10 provinsi). Data provinsi tersebut dibagi menjadi dua, yaitu data training dan data
testing. Pemilihan data testing dilakukan secara acak. Pada data provinsi ini dicobakan beberapa pilihan persentase data testing, yaitu 20%, 40%, dan 50%, Perbedaan jumlah provinsi pada data training dan data testing mengakibatkan perbedaan fungsi diskriminannya.
Tabel 11 Ketepatan klasifikasi VDA pada data testing provinsi 20%
Kelas sebenarnya Kelas prediksi
1 2 3
1 - - 1
2 - - -
3 - - 1
Tabel 12 Ketepatan klasifikasi VDA pada data testing provinsi 40%
Kelas sebenarnya Kelas prediksi
1 2 3
1 - 1 1
2 - - -
3 - 1 1
Tabel 13 Ketepatan klasifikasi VDA pada data testing provinsi 50%
Kelas sebenarnya Kelas prediksi
1 2 3
1 - 1 1
2 - - -
3 - 1 2
Ketepatan klasifikasi data training untuk ketiga persentase data testing
adalah 100%, artinya tidak ada kesalahan klasifikasi sama sekali. Tetapi ketepatan klasifikasi pada data testing beragam untuk masing-masing proporsi data testing. Secara berurutan proporsi data testing 20%, 40%, dan 50% ketepatan klasifikasinya adalah 50%, 25%, dan 40%. Ketepatan klasifikasi terbesar adalah analisis yang terbaik. Pada kasus ini proporsi data testing 20% adalah yang terbaik. Sehingga ada indikasi bahwa semakin banyak jumlah data training
20
Pada pemilihan data testing 20% (Tabel 11), provinsi yang terpilih sebagai data testing adalah Sumatera Barat dari kelas 1 dan Sumatera Selatan dari kelas 3. Pada pemilihan data testing 40% (Tabel 12), provinsi yang terpilih adalah Riau dan Jambi dari kelas 1 serta Aceh dan Sumatera Selatan dari kelas 3. Selanjutnya pada pemilihan data testing 50% (Tabel 13), provinsi yang terpilih adalah Sumatera Barat dan Jambi dari kelas 1 serta Aceh, Sumatera Selatan, dan Bengkulu dari kelas 3.
Ketepatan klasifikasi data training tersebut relatif kecil. Ada indikasi VDA baik pada klasifikasi data training tetapi kurang baik pada klasifikasi data testing. Hal ini disebabkan jumlah data training yang sedikit sehingga model yang dihasilkan kurang baik. Sebagai perbandingan dilakukan justifikasi dengan melihat jarak antar-propinsi, jarak yang digunakan adalah jarak Euclid. Tabel jarak antar-propinsi pada Lampiran 5a.
Provinsi yang tergolong kelas 1 (kaya) adalah Sumatera Barat, Riau, Jambi, Bangka Belitung, dan Kepulauan Riau. Kelas 2 (menengah) hanya Sumatera Utara saja yang menjadi anggotanya. Provinsi yang tergolong kelas 3 (miskin) adalah Aceh, Sumatera Selatan, Bengkulu, dan Lampung. Berdasarkan jarak antar-provinsi pada Lampiran 5a, jarak terdekat adalah antara Lampung dan Bengkulu yang memang berada pada kelas yang sama. Namun, Sumatera Barat dan Sumatera Utara memiliki jarak yang dekat juga, padahal berada pada kelas yang berbeda. Ada indikasi bahwa kedekatan jarak ini yang menyebabkan kesalahan klasifikasi Sumatera Barat digolongkan ke kelas 2 pada data testing
50% di Tabel 13. Begitu juga kedekatan jarak antara Jambi (kelas 1) dengan Bengkulu dan Lampung dari kelas 3. Kedekatan jarak tersebut menyebabkan kesalahan klasifikasi Jambi digolongkan ke kelas 3 pada pemilihan data testing
40% (Tabel 12) dan 50% (Tabel 13). Provinsi Aceh dari kelas 3 memiliki jarak terdekat dengan Sumatera Utara dari kelas 2, sedangkan cukup jauh jaraknya dengan provinsi-provinsi di kelas 3. Sehingga pada klasifikasi data testing 40% (Tabel 12) dan data testing 50% (Tabel 13), Aceh diklasifikasikan ke kelas 2. Demikian halnya dengan Riau (kelas 1) diklasifikasikan ke kelas 2 pada pemilihan data testing 40% (Tabel 12) karena memiliki jarak terdekat dengan Sumatera Utara yang tergolong ke kelas 2. Dengan demikian dapat disimpulkan bahwa ada indikasi kesalahan klasifikasi pada data testing VDA disebabkan karena dari awal pengelompokan provinsi ke dalam kelas berdasarkan tingkat kemiskinan tidak mencerminkan kedekatan karakteristik peubah antar-provinsi dalam kelas yang sama.
VDA pada Data Provinsi dengan Penambahan Komponen Kuadratik
Seperti yang dilakukan pada data kabupaten/kota, pada data provinsi juga dilakukan penambahan komponen kuadratik, sehingga jumlah peubah menjadi 38. Penambahan peubah ini menyebabkan perbedaan dan � semakin jauh ( �). Data testing juga dicobakan untuk proporsi 20%, 40%, dan 50%. Provinsi-provinsi yang terpilih sebagai data testing sama dengan pemilihan pada VDA tanpa penambahan komponen kuadratik.
Ketepatan klasifikasi data training untuk ketiga persentase data testing
21 50%, 25%, dan 20%. Ketepatan klasifikasi terbesar adalah analisis yang terbaik. Pada kasus ini proporsi data testing 20% juga yang terbaik. Sehingga ada indikasi bahwa semakin banyak jumlah data training dibandingkan data testingnya, maka ketepatan klasifikasi akan semakin besar. Rincian ketepatan klasifikasi data
testing VDA dapat dilihat pada Tabel 14,15, dan 16.
Tabel 14 Ketepatan klasifikasi VDA pada data testing provinsi 20% dengan
Perbandingan dengan jarak antar-observasi juga dilakukan seperti pada data provinsi tanpa penambahan komponen kuadratik. Tabel jarak antar-provinsi pada data dengan penambahan komponen kuadratik dapat dilihat pada Lampiran 5b. Berdasarkan tabel jarak tersebut, klasifikasi berdasarkan jarak antar-propinsi mirip dengan klasifikasi kelas prediksi VDA. Perbedaan dengan hasil VDA tanpa komponen kuadratik hanya pada hasil klasifikasi data testing 50%, yaitu jarak terdekat Sumatera Selatan (kelas 3) dengan Sumatera Utara (kelas 2) menyebabkan Sumatera Selatan digolongkan ke kelas 2. Sebelumnya pada VDA tanpa komponen kuadratik, Sumatera Selatan digolongkan ke kelas 3.
Perbandingan Ketepatan Klasifikasi antara QDA dan VDA
22
Berdasarkan Tabel 17, untuk data training QDA adalah yang terbaik dibandingkan dengan VDA, karena memiliki ketepatan klasifikasi terbesar. Tetapi pada data testing QDA memiliki ketepatan klasifikasi terkecil, yang terbesar adalah VDA tanpa penambahan komponen kuadratik.
Berdasarkan Tabel 18, untuk data training tidak ada kesalahan klasifikasi sama sekali untuk kedua metode analisis VDA, tetapi VDA tanpa penambahan komponen kuadratik lebih baik dibandingkan VDA dengan penambahan komponen kuadratik. Pada proporsi data testing 50% ada perbedaan ketepatan klasifikasi, yaitu 60% untuk VDA dan 80% untuk VDA dengan penambahan komponen kuadratik. Hal ini sesuai dengan hasil kajian simulasi yang menyatakan bahwa QDA lebih baik pada keragaman antarkelas besar atau matriks ragam-peragam tidak homogen.
Tabel 17 Perbandingan ketepatan klasifikasi antara QDA, VDA, dan VDA dengan penambahan komponen kuadratik pada data kabupaten/kota
Jenis data QDA VDA Tabel 18 Perbandingan ketepatan klasifikasi antara QDA, VDA, dan VDA
dengan penambahan komponen kuadratik pada data provinsi
Jenis data QDA jumlah observasi lebih besar dari jumlah peubah (n > p), kemampuan klasifikasi
23 kecil dari jumlah peubah ( p ). Sehingga mengakibatkan matriks ragam-peragamnya singular dan mengakibatkan tidak memiliki invers.
Hasil kajian terapan sesuai dengan hasil kajian simulasi, yaitu pada data dengan keragaman antarkelas besar akan lebih baik menggunakan QDA untuk pengklasifikasian, walaupun VDA masih cukup baik dengan ketepatan klasifikasi lebih dari 70% pada data training, dan ketepatan klasifikasi yang hampir sama pada data testing. QDA tidak dapat digunakan pada data provinsi karena jumlah peubah lebih besar dibandingkan jumlah observasi, sehingga VDA adalah salah satu solusinya.
Saran
Pada penelitian ini simulasi data hanya dilakukan dengan variasi skenario keragaman antarkelas saja, untuk penelitian selanjutnya dapat dilakukan juga simulasi data dengan memasukkan unsur pengaruh dari jarak nilai tengah antarkelas pada analisis QDA dan VDA. Selain itu, analisis diskriminan non-linier
vertex pada penelitian ini menggunakan VDA, untuk penelitian selanjutnya dapat dikembangkan juga dengan metode Nonlinear Vertex Discriminant Analysis with Reproducing Kernels.
DAFTAR PUSTAKA
Hastie T, Tibshirani R, Friedman J. 2008. The Elements Of Statistical Learning,
Data Mining, Inference, and Prediction. Ed. Ke-2 [internet]. [diunduh 2014 Feb 9]; Springer. Tersedia pada : http://www.stanford.edu/~hastie/pub.htm. Hubert M, Driessen KV. 2004. Fast and Robust Discriminant Analysis.
Computational Statistics and Data Analysis. 45:301-320.
Liu Y, Shen X, Doss H. 2005. Multicategory ψ-learning and Support Vector Machine: Computational Tools. J Comput Graph Stat. 14:219-236.
Johnson RA, Wichern DW. 2007. Applied Multivariate Statistical Analysis. New Jersey (US): Pearson Prentice Hall. Ed ke-6.
Mattjik AA, Sumertajaya IM. 2011. Sidik Peubah Ganda. Bogor (ID): IPB Press. Morisson DF. 1976. Multivariate Statistical Methods. New York (US):
McGraw-Hill.
Nurmaleni. 2015. Perbandingan Metode Multikategori Vertex Discriminant Analysis dan Analisis Diskriminan Fisher [tesis]. Bogor (ID): Institut Pertanian Bogor.
Vapnik V. 1995. The Nature of Statistical Learning Theory. New York (US): Springer.
Wu TT, Lange K. 2008. An MM Algoritm For Multicategory Vertex Discriminant Analysis.J Comput Graph Stat. 17:527-544.
25 Lampiran 1 Daftar kabupaten/kota di Sumatera dan klasifikasinya
Kode kabupaten/kota Nama provinsi Nama Kabupaten/Kota Kelas
1 Aceh Simeulue 3
25 Sumatera Utara Mandailing Natal 2
26 Sumatera Utara Tapanuli Selatan 2
27 Sumatera Utara Tapanuli Tengah 2
28 Sumatera Utara Tapanuli Utara 2
38 Sumatera Utara Humbang Hasundutan 2
39 Sumatera Utara Pakpak Bharat 2
26
Lampiran 1 Daftar kabupaten/kota di Sumatera dan klasifikasinya (lanjutan)
Kode kabupaten/kota Nama provinsi Nama Kabupaten/Kota Kelas
41 Sumatera Utara Serdang Bedagai 2
42 Sumatera Utara Batu Bara 2
43 Sumatera Utara Padang Lawas Utara 2
44 Sumatera Utara Padang Lawas 2
45 Sumatera Utara Labuhan Batu Selatan 2
46 Sumatera Utara Labuhan Batu Utara 2
47 Sumatera Utara Nias Utara 3
48 Sumatera Utara Nias Barat 3
49 Sumatera Utara Kota Sibolga 2
50 Sumatera Utara Kota Tanjung Balai 2
51 Sumatera Utara Kota Pematang Siantar 2
52 Sumatera Utara Kota Tebing Tinggi 2
53 Sumatera Utara Kota Medan 2
54 Sumatera Utara Kota Binjai 1
55 Sumatera Utara Kota Padang Sidempuan 2
56 Sumatera Utara Kota Gunungsitoli 3
57 Sumatera Barat Kepulauan Mentawai 2
58 Sumatera Barat Pesisir Selatan 2
59 Sumatera Barat Solok 2
60 Sumatera Barat Sawahlunto/Sijunjung 2
61 Sumatera Barat Tanah Datar 1
62 Sumatera Barat Padang Pariaman 2
63 Sumatera Barat Agam 2
64 Sumatera Barat Lima Puluh Koto 2
65 Sumatera Barat Pasaman 2
66 Sumatera Barat Solok Selatan 2
67 Sumatera Barat Dharmasraya 2
68 Sumatera Barat Pasaman Barat 2
69 Sumatera Barat Kota Padang 1
70 Sumatera Barat Kota Solok 1
71 Sumatera Barat Kota Sawah Lunto 1
72 Sumatera Barat Kota Padang Panjang 2
73 Sumatera Barat Kota Bukittinggi 1
74 Sumatera Barat Kota Payakumbuh 2
27 Lampiran 1 Daftar kabupaten/kota di Sumatera dan klasifikasinya (lanjutan)
Kode kabupaten/kota Nama provinsi Nama Kabupaten/Kota Kelas
81 Riau Kampar 2
99 Sumatera Selatan Ogan Komering Ulu 2
100 Sumatera Selatan Ogan Komering Ilir 2
101 Sumatera Selatan Muaraenim 2
102 Sumatera Selatan Lahat 2
103 Sumatera Selatan Musirawas 2
104 Sumatera Selatan Musi Banyuasin 2
105 Sumatera Selatan Banyuasin 2
106 Sumatera Selatan OKU Selatan 2
107 Sumatera Selatan OKU Timur 2
108 Sumatera Selatan Ogan Ilir 2
109 Sumatera Selatan Empang Lawang 2
110 Sumatera Selatan Kota Palembang 2
111 Sumatera Selatan Kota Prabumulih 2
112 Sumatera Selatan Kota Pagar Alam 2
113 Sumatera Selatan Kota Lubuk Linggau 2
114 Bengkulu Bengkulu Selatan 3
28
Lampiran 1 Daftar kabupaten/kota di Sumatera dan klasifikasinya (lanjutan) Kode kabupaten/kota Nama provinsi Nama Kabupaten/Kota Kelas
121 Bengkulu Kepahiang 2
122 Bengkulu Bengkulu Tengah 1
123 Bengkulu Kota Bengkulu 2
124 Lampung Lampung Barat 2
125 Lampung Tanggamus 2
126 Lampung Lampung Selatan 2
127 Lampung Lampung Timur 2
128 Lampung Lampung Tengah 2
129 Lampung Lampung Utara 3
130 Lampung Waykanan 2
131 Lampung Tulang Bawang 2
132 Lampung Pesawaran 2
133 Lampung Pringsewu 2
134 Lampung Mesuji 2
135 Lampung Tulang Bawang Barat 2
136 Lampung Kota Bandar Lampung 2
137 Lampung Kota Metro 2
138 Bangka Belitung Bangka 2
139 Bangka Belitung Belitung 2
140 Bangka Belitung Bangka Barat 1
141 Bangka Belitung Bangka Tengah 2
142 Bangka Belitung Bangka Selatan 1
143 Bangka Belitung Belitung Timur 2
144 Bangka Belitung Kota Pangkal Pinang 1
145 Kepulauan Riau Karimun 1
146 Kepulauan Riau Bintan 1
147 Kepulauan Riau Natuna 1
148 Kepulauan Riau Lingga 2
149 Kepulauan Riau Kepulauan Anambas 1
150 Kepulauan Riau Kota Batam 1
29 Lampiran 2 Daftar provinsi di Sumatera dan klasifikasi berdasarkan tingkat
kemiskinan
Kode provinsi Nama provinsi Kelas
1 Aceh 3
2 Sumatera Utara 2
3 Sumatera Barat 1
4 Riau 1
5 Jambi 1
6 Sumatera Selatan 3
7 Bengkulu 3
8 Lampung 3
9 Bangka Belitung 1
30
Lampiran 3 Rataan peubah-peubah di setiap kelas pada data kabupaten/kota
Peubah Satuan peubah
Kelas kabupaten/kota Kelas 1
(kaya)
Kelas 2 (menengah)
Kelas 3 (miskin)
X1 % 7,49% 6,22 6,20
X2 % 4,05 4,90 4,98
X3 % 54,79 65,19 67,47
X4 ribu rupiah 633,46 628,23 612,27
X5 % 17,91 20,60 22,41
X6 jiwa 30,66 34,54 34,52
X7 tahun 69,38 68,66 68,65
X8 % 84,31 82,03 78,95
X9 % 32,21 32,60 33,92
X10 % 18,23 18,87 19,76
X11 % 5,40 5,67 5,41
X12 % 68,80 71,78 74,25
X13 % 8,29 12,48 14,49
X14 % 43,94 53,58 56,64
X15 % 93,66 94,89 95,00
X16 % 66,33 71,29 71,62
X17 % 53,19 51,15 52,44
X18 % 2,34 2,19 2,18
31 Lampiran 4 Rataan peubah-peubah di setiap kelas pada data provinsi
Peubah Satuan peubah
Kelas provinsi Kelas 1
(kaya)
Kelas 2 (menengah)
Kelas 3 (miskin)
X1 % 6,72 7,43 6,30
X2 % 4,28 4,00 4,32
X3 % 51,08 61,44 66,54
X4 ribu rupiah 640,02 636,33 621,99
X5 % 16,42 21,30 18,10
X6 jiwa 29,80 31,00 31,50
X7 tahun 69,74 69,50 69,43
X8 % 82,98 88,68 81,54
X9 % 34,39 29,11 34,13
X10 % 19,74 17,53 18,49
X11 % 5,63 5,97 5,23
X12 % 68,93 70,62 72,28
X13 % 9,82 14,38 13,22
X14 % 46,83 43,48 54,17
X15 % 94,35 94,46 95,08
X16 % 66,05 74,21 70,57
X17 % 48,51 55,30 48,89
X18 % 2,79 1,60 2,55
32
Lampiran 5 Matriks jarak antar-provinsi
a) peubah tanpa komponen kuadratik
Provinsi 1 2 3 4 5 6 7 8 9 10
1 0.00 5.38 6.50 7.75 6.85 6.96 6.70 7.00 9.56 7.66 2 5.38 0.00 4.26 6.05 4.95 6.91 5.40 6.22 7.66 5.48 3 6.50 4.26 0.00 7.12 5.77 7.07 5.25 5.62 6.82 5.11 4 7.75 6.05 7.12 0.00 7.13 6.40 6.77 7.60 9.94 7.21 5 6.85 4.95 5.77 7.13 0.00 4.81 4.49 4.48 7.54 7.13 6 6.96 4.91 7.07 6.40 4.81 0.00 5.35 5.25 7.06 7.03 7 6.70 5.40 5.25 6.77 4.49 5.35 0.00 3.41 7.06 6.27 8 7.00 6.22 5.62 7.60 4.48 5.25 3.41 0.00 6.27 7.03 9 9.56 7.66 6.82 9.94 7.54 7.06 7.06 6.27 0.00 6.38 10 7.66 5.48 5.11 7.21 7.13 7.03 6.27 7.03 6.38 0.00
b) peubah dengan penambahan komponen kuadratik
Provinsi 1 2 3 4 5 6 7 8 9 10
33
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta, pada tanggal 2 Juni 1982, sebagai anak bungsu
dari empat bersaudara., putri pasangan Djismi Yed dan Daharnis. Pendidikan
sekolah menengah ditempuh di SMA Negeri 1 Suliki Gunung Mas pada Program IPA, dan lulus pada tahun 2000. Pada tahun yang sama penulis melanjutkan pendidikan sarjana pada program studi Statistika Institut Pertanian Bogor (IPB), dan menyelesaikannya pada tahun 2005 dengan gelar Sarjana Sains (S.Si).
Saat ini penulis bekerja sebagai staf di Pusat Kurikulum dan Perbukuan
Kementerian Pendidikan dan Kebudayaan. Melalui program Beasiswa Unggulan