C: In a Nutshell
By Tony Crawford, Peter Prinz
... Publisher: O'Reilly
Pub Date: December 2005
ISBN: 0-596-00697-7
Pages: 618
Table of Contents | Index
Learning a language--any language--involves a process wherein you learn to rely less and less on instruction and more increasingly on the aspects of the language you've mastered. Whether you're learning French, Java, or C, at some point you'll set aside the tutorial and attempt to converse on your own. It's not necessary to know every subtle facet of French in order to speak it well, especially if there's a good dictionary available. Likewise, C programmers don't need to memorize every detail of C in order to write good programs. What they need instead is a reliable, comprehensive reference that they can keep nearby. C in a Nutshell is that reference.
This long-awaited book is a complete reference to the C programming language and C runtime library. Its purpose is to serve as a convenient, reliable companion in your day-to-day work as a C programmer. C in a Nutshell covers virtually everything you need to program in C, describing all the elements of the language and illustrating their use with numerous examples.
The book is divided into three distinct parts. The first part is a fast-paced description, reminiscent of the classic Kernighan & Ritchie text on which many C programmers cut their teeth. It focuses specifically on the C language and preprocessor directives, including extensions introduced to the ANSI standard in 1999. These topics and others are covered:
Numeric constants
Implicit and explicit type conversions
Expressions and operators
Functions
Fixed-length and variable-length arrays
Dynamic memory management
Input and output
The second part of the book is a comprehensive reference to the C runtime library; it includes an overview of the contents of the standard headers and a description of each standard library function. Part III provides the necessary knowledge of the C
programmer's basic tools: the compiler, the make utility, and the debugger. The tools described here are those in the GNU software collection.
C: In a Nutshell
By Tony Crawford, Peter Prinz
... Publisher: O'Reilly
Pub Date: December 2005
ISBN: 0-596-00697-7
Pages: 618
Table of Contents | Index
Copyright
Preface
How This Book Is Organized
Further Reading
Conventions Used in This Book
Using Code Examples
Safari® Enabled
Your Questions and Comments
Acknowledgments
Part I: Language
Chapter 1. Language Basics
Section 1.1. Characteristics of C
Section 1.2. The Structure of C Programs
Section 1.3. Source Files
Section 1.4. Comments
Section 1.5. Character Sets
Section 1.6. Identifiers
Section 1.7. How the C Compiler Works
Chapter 2. Types
Section 2.1. Typology
Section 2.2. Integer Types
Section 2.3. Floating-Point Types
Section 2.4. Complex Floating-Point Types (C99)
Section 2.5. Enumerated Types
Chapter 3. Literals
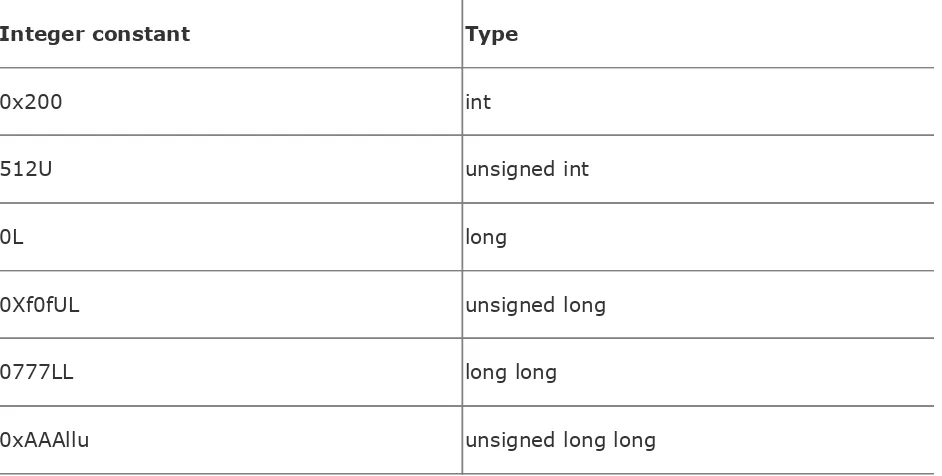
Section 3.1. Integer Constants
Section 3.2. Floating-Point Constants
Section 3.3. Character Constants
Section 3.4. String Literals
Chapter 4. Type Conversions
Section 4.1. Conversion of Arithmetic Types
Section 4.2. Conversion of Nonarithmetic Types
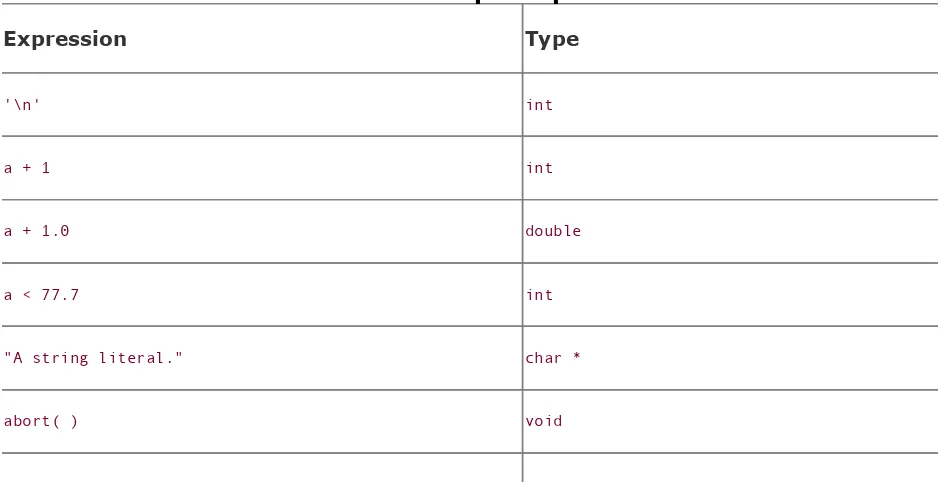
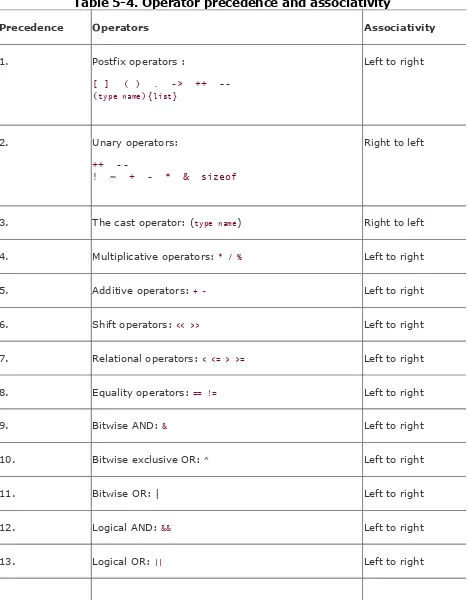
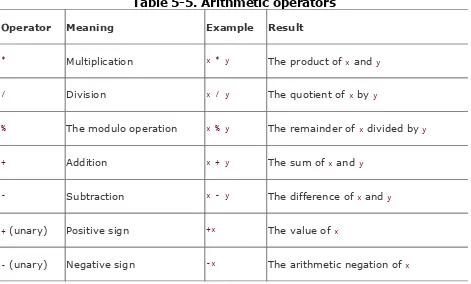
Chapter 5. Expressions and Operators
Section 5.1. How Expressions Are Evaluated
Section 5.2. Operators in Detail
Section 5.3. Constant Expressions
Chapter 6. Statements
Section 6.1. Expression Statements
Section 6.2. Block Statements
Section 6.3. Loops
Section 6.4. Selection Statements
Section 6.5. Unconditional Jumps
Chapter 7. Functions
Section 7.1. Function Definitions
Section 7.2. Function Declarations
Section 7.3. How Functions Are Executed
Section 7.4. Pointers as Arguments and Return Values
Section 7.5. Inline Functions
Section 7.6. Recursive Functions
Section 7.7. Variable Numbers of Arguments
Chapter 8. Arrays
Section 8.1. Defining Arrays
Section 8.2. Accessing Array Elements
Section 8.3. Initializing Arrays
Section 8.4. Strings
Section 8.5. Multidimensional Arrays
Section 8.6. Arrays as Arguments of Functions
Chapter 9. Pointers
Section 9.1. Declaring Pointers
Section 9.2. Operations with Pointers
Section 9.3. Pointers and Type Qualifiers
Section 9.4. Pointers to Arrays and Arrays of Pointers
Chapter 10. Structures and Unions and Bit-Fields
Section 10.1. Structures
Section 10.2. Unions
Section 10.3. Bit-Fields
Chapter 11. Declarations
Section 11.1. General Syntax
Section 11.2. Type Names
Section 11.3. typedef Declarations
Section 11.4. Linkage of Identifiers
Section 11.5. Storage Duration of Objects
Section 11.6. Initialization
Chapter 12. Dynamic Memory Management
Section 12.1. Allocating Memory Dynamically
Section 12.2. Characteristics of Allocated Memory
Section 12.3. Resizing and Releasing Memory
Section 12.4. An All-Purpose Binary Tree
Section 12.5. Characteristics
Section 12.6. Implementation
Chapter 13. Input and Output
Section 13.1. Streams
Section 13.2. Files
Section 13.3. Opening and Closing Files
Section 13.4. Reading and Writing
Section 13.5. Random File Access
Chapter 14. Preprocessing Directives
Section 14.1. Inserting the Contents of Header Files
Section 14.2. Defining and Using Macros
Section 14.3. Conditional Compiling
Section 14.4. Defining Line Numbers
Section 14.5. Generating Error Messages
Section 14.6. The #pragma Directive
Section 14.7. The _Pragma Operator
Section 14.8. Predefined Macros
Part II: Standard Library
Chapter 15. The Standard Headers
Section 15.1. Using the Standard Headers
Section 15.2. Contents of the Standard Headers
Chapter 16. Functions at a Glance
Section 16.2. Mathematical Functions
Section 16.3. Character Classification and Conversion
Section 16.4. String Processing
Section 16.5. Multibyte Characters
Section 16.6. Converting Between Numbers and Strings
Section 16.7. Searching and Sorting
Section 16.8. Memory Block Handling
Section 16.9. Dynamic Memory Management
Section 16.10. Date and Time
Section 16.11. Process Control
Section 16.12. Internationalization
Section 16.13. Nonlocal Jumps
Section 16.14. Debugging
Section 16.15. Error Messages
Chapter 17. Standard Library Functions
fwscanf fwrite getc getchar getenv gets getwc getwchar gmtime hypot ilogb imaxabs imaxdiv isalnum isalpha isblank iscntrl isdigit isfinite isgraph isgreater, isgreaterequal isinf
isless, islessequal, islessgreater
sqrt srand sscanf strcat strchr strcmp strcoll strcpy strcspn strerror strftime strlen strncat strncmp strncpy strpbrk strrchr strspn strstr
strtod, strtof, strtold
toupper towctrans towlower towupper trunc ungetc ungetwc
va_arg, va_copy, va_end, va_start
vfprintf, vprintf, vsnprintf, vsprintf
vfscanf, vscanf, vsscanf
vfwprintf, vswprintf, vwprintf
vfwscanf, vswscanf, vwscanf
wcrtomb wcscat wcschr wcscmp wcscoll wcscpy wcscspn wcsftime wcslen wcsncat wcsncmp wcsncpy wcspbrk wcsrchr wcsrtombs wcsspn wcsstr
wcstod, wcstof, wcstold
wcstoimax
wcstok
wcstol, wcstoll
wcstold
wcstombs
wcstoul, wcstoull
wcstoumax
wcsxfrm
wctob
wctomb
wctrans
wctype
wmemchr
wmemcmp
wmemcpy
wmemmove
wmemset
wprintf
wscanf
Part III: Basic Tools
Chapter 18. Compiling with GCC
Section 18.1. The GNU Compiler Collection
Section 18.2. Obtaining and Installing GCC
Section 18.3. Compiling C Programs with GCC
Section 18.4. C Dialects
Section 18.5. Compiler Warnings
Section 18.6. Optimization
Section 18.7. Debugging
Section 18.8. Profiling
Section 18.9. Option and Environment Variable Summary
Chapter 19. Using make to Build C Programs
Section 19.1. Targets, Prerequisites, and Commands
Section 19.2. The Makefile
Section 19.3. Rules
Section 19.4. Comments
Section 19.5. Variables
Section 19.6. Phony Targets
Section 19.8. Macros
Section 19.9. Functions
Section 19.10. Directives
Section 19.11. Running make
Chapter 20. Debugging C Programs with GDB
Section 20.1. Installing GDB
Section 20.2. A Sample Debugging Session
Section 20.3. Starting GDB
Section 20.4. Using GDB Commands
About the Authors
Colophon
C in a Nutshell
by Peter Prinz and Tony Crawford
Copyright © 2006 O'Reilly Media, Inc. All rights reserved. Printed in the United States of America.
Published by O'Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472.
O'Reilly books may be purchased for educational, business, or sales promotional use. Online editions are also available for most titles (safari.oreilly.com). For more information, contact our corporate/institutional sales department: (800) 998-9938 or
Editor: Jonathan Gennick
Production Editor: A. J. Fox
Cover Designer: Karen Montgomery
Interior Designer: David Futato
Printing History:
December 2005: First Edition.
Nutshell Handbook, the Nutshell Handbook logo, and the
The In a Nutshell series designations, C in a Nutshell, the image of a cow, and related trade dress are trademarks of O'Reilly Media, Inc.
Many of the designations used by manufacturers and sellers to distinguish their products are claimed as trademarks. Where those designations appear in this book, and O'Reilly Media, Inc. was aware of a trademark claim, the designations have been printed in caps or initial caps.
While every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions, or for damages resulting from the use of the information contained herein.
ISBN: 0-596-00697-7
Preface
This book is a complete reference to the C programming language and the C runtime library. As a Nutshell book, its purpose is to serve as a convenient, reliable companion for C programmers in their day-to-day work. It describes all the elements of the language and illustrates their use with numerous examples.
The present description of the C language is based on the 1999 international C standard, ISO/IEC 9899:1999, including the Technical Corrigenda, TC1 of 2001 and TC2 of 2004. This
standard, widely known as C99, is an extension of the ISO/IEC 9899:1990 standard and the 1995 Normative Addendum 1 (ISO/IEC 9899/AMD1:1995). The 1990 ISO/IEC standard
corresponds to the ANSI standard X3.159, which was ratified in late 1989 and is commonly called ANSI C or C89.
The new features of the 1999 C standard are not yet fully supported by all compilers and standard library
implementations. In this book we have therefore labeled 1999 extensions, such as new standard library functions that were not mentioned in earlier standards, with the abbreviation C99.
How This Book Is Organized
This book is divided into three parts. The first part describes the C language in the strict sense of the term; the second part
describes the standard library; and the third part describes the process of compiling and testing programs with the popular tools in the GNU software collection.
Part I
Part I, which deals with the C language, includes Chapters 1
through 14. After Chapter 1, which describes the general
concepts and elements of the language, each chapter is devoted to a specific topic, such as types, statements, or pointers.
Although the topics are ordered so that the fundamental
concepts for each new topic have been presented in an earlier chaptertypes, for example, are described before expressions and operators, which come before statements, and so onyou may sometimes need to follow references to later chapters to fill in related details. For example, some discussion of pointers and arrays is necessary in Chapter 5 (which covers expressions and operators), even though pointers and arrays are not
described in full detail until Chapters 8 and 9.
Chapter 1, Language Basics
Chapter 2, Types
Provides an overview of types in C and describes the basic types, the type void, and enumerated types.
Chapter 3, Literals
Describes numeric constants, character constants, and string literals, including escape sequences.
Chapter 4, Type Conversions
Describes implicit and explicit type conversions, including integer promotion and the usual arithmetic conversions.
Chapter 5, Expressions and Operators
Describes the evaluation of expressions, all the operators, and their compatible operands.
Chapter 6, Statements
Describes C statements such as blocks, loops, and jumps.
Chapter 7, Functions
Chapter 8, Arrays
Describes fixed-length and variable-length arrays, including strings, array initialization, and multidimensional arrays.
Chapter 9, Pointers
Describes the definition and use of pointers to objects and functions.
Chapter 10, Structures, Unions, and Bit-Fields
Describes the organization of data in these user-defined derived types.
Chapter 11, Declarations
Describes the general syntax of a declaration, identifier linkage, and the storage duration of objects.
Chapter 12, Dynamic Memory Management
Describes the standard library's dynamic memory
management functions, illustrating their use in a sample implementation of a generalized binary tree.
Chapter 13, Input and Output
Chapter 14, Preprocessing Directives
Describes the definition and use of macros, conditional compiling, and all the other preprocessor directives and operators.
Part II
Part II, consisting of Chapters 15, 16, and 17, is devoted to the
C standard library. It provides an overview of standard headers and also contains a detailed function reference.
Chapter 15, The Standard Headers
Describes contents of the headers and their use. The headers contain all of the standard library's macros and type definitions.
Chapter 16, Functions at a Glance
Provides an overview of the standard library functions, organized by areas of application, such as "Mathematical Functions," "Time and Date Functions," and so on.
Chapter 17, Standard Library Functions
Describes each standard library function in detail, in
Part III
The third part of this book provides the necessary knowledge of the C programmer's basic tools: the compiler, the make utility, and the debugger. The tools described here are those in the GNU software collection.
Chapter 18, Compiling with GCC
Describes the principal capabilities that the widely used compiler offers for C programmers.
Chapter 19, Using make to Build C Programs
Describes how to use the make program to automate the compiling process for large programs.
Chapter 20, Debugging C Programs with GDB
Further Reading
In addition to works mentioned at appropriate points in the text, there are a number of resources for readers who want more technical detail than even this book can provide. The
international working group on C standardization has an official home page at http://www.open-std.org/jtc1/sc22/wg14, with links to the latest version of the C99 standard and current projects of the working group.
For readers who are interested in not only the what and how of C, but also the why, the WG14 site also has a link to the "C99 Rationale": this is a nonnormative but current document that describes some of the motivations and constraints involved in the standardization process. The C89 Rationale is online at
http://www.lysator.liu.se/c/rat/title.html. Furthermore, for
those who may wonder how C "got to be that way" in the first place, the originator of C, Dennis Ritchie, has an article titled "The Development of the C Language" as well as other historical documents on his Bell Labs web site,
http://cm.bell-labs.com/cm/cs/who/dmr.
Readers who want details on floating-point math beyond the scope of C may wish to start with David Goldberg's thorough introduction, "What Every Computer Scientist Should Know About Floating-Point Arithmetic," currently available online at
Conventions Used in This Book
The following typographical conventions are used in this book:
Italic
Highlights new terms; indicates filenames, file extensions, URLs, directories, and Unix utilities.
Constant width
Indicates all elements of C source code: keywords,
operators, variables, functions, macros, types, parameters, and literals. Also used for console commands and options, and the output from such commands.
Constant width bold
Highlights the function or statement under discussion in code examples. In compiler, make, and debugger sessions, this font indicates command input to be typed literally by the user.
Constant width italic
Plain text
Indicates keys such as Return, Tab, and Ctrl.
This icon signifies a tip, suggestion, or general note.
Using Code Examples
This book is here to help you get your job done. In general, you may use the code in this book in your programs and
documentation. You do not need to contact us for permission unless you're reproducing a significant portion of the code. For example, writing a program that uses several chunks of code from this book does not require permission. Selling or
distributing a CD-ROM of examples from O'Reilly books does
require permission. Answering a question by citing this book and quoting example code does not require permission.
Incorporating a significant amount of example code from this book into your product's documentation does require
permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: "C in a Nutshell by Peter Prinz and Tony Crawford. Copyright 2006 O'Reilly Media, Inc., 0-596-00697-7."
If you feel that your use of code examples falls outside fair use or the permission given here, feel free to contact us at
Safari® Enabled
When you see a Safari® Enabled icon on the cover of your favorite technology book, that means the book is available online through the O'Reilly Network Safari Bookshelf.
Your Questions and Comments
Please address comments and questions concerning this book to the publisher:
O'Reilly Media, Inc.
1005 Gravenstein Highway North Sebastopol, CA 95472
(800) 998-9938 (in the United States or Canada) (707) 829-0515 (international or local)
(707) 829-0104 (fax)
We have a web page for this book, where we list errata,
examples, and any additional information. You can access this page at:
http://www.oreilly.com/catalog/cinanut
To comment or ask technical questions about this book, send email to:
For more information about our books, conferences, Resource Centers, and the O'Reilly Network, see our web site at:
Acknowledgments
Both of us want to thank Jonathan Gennick, our editor, for originally bringing us together and starting us off on this book, and for all his guidance along the way. We also thank our
technical reviewers, Matt Crawford, David Kitabjian, and Chris LaPre, for their valuable criticism of our manuscript, and we're grateful to our production editor, Abby Fox, for all her attention to making our book look good.
Peter
I would like to thank Tony first of all for the excellent
collaboration. My heartfelt thanks also go to all my friends for the understanding they showed again and again when I had so little time for them. Last but not least, I dedicate this book to my daughters, Vivian and Jeanetteboth of them now students of computer sciencewho strengthened my ambition to carry out this book project.
Tony
I have enjoyed working on this book as a very rewarding
Part I: Language
Chapter 1: Language Basics
Chapter 2: Types
Chapter 3: Literals
Chapter 4: Type Conversions
Chapter 5: Expressions and Operators
Chapter 6: Statements
Chapter 7: Functions
Chapter 8: Arrays
Chapter 9: Pointers
Chapter 10: Structures, Unions, and Bit-Fields
Chapter 11: Declarations
Chapter 12: Dynamic Memory Management
Chapter 13: Input and Output
Chapter 1. Language Basics
1.1. Characteristics of C
C is a general-purpose, procedural programming language. Dennis Ritchie first devised C in the 1970s at AT&T Bell Laboratories in Murray Hill, New Jersey, for the purpose of implementing the Unix operating system and utilities with the greatest possible degree of independence from specific
hardware platforms. The key characteristics of the C language are the qualities that made it suitable for that purpose:
Source code portability
The ability to operate "close to the machine"
Efficiency
As a result, the developers of Unix were able to write most of the operating system in C, leaving only a minimum of system-specific hardware manipulation to be coded in assembler.
C's ancestors are the typeless programming languages BCPL (the Basic Combined Programming Language), developed by Martin Richards; and B, a descendant of BCPL, developed by Ken Thompson. A new feature of C was its variety of data types : characters, numeric types, arrays, structures, and so on. Brian Kernighan and Dennis Ritchie published an official description of the C programming language in 1978. As the first de facto
standard, their description is commonly referred to simply as "K&R."[*] C owes its high degree of portability to a compact core
these purposes.
[*] The second edition, revised to reflect the first ANSI C standard, is available as The C Programming Language, 2nd ed., by Brian W. Kernighan and Dennis M. Ritchie (Englewood Cliffs, N.J.: Prentice Hall, 1988).
This language design makes the C compiler relatively compact and easy to port to new systems. Furthermore, once the
compiler is running on a new system, you can compile most of the functions in the standard library with no further
modification, because they are in turn written in portable C. As a result, C compilers are available for practically every
computer system.
Because C was expressly designed for system programming, it is hardly surprising that one of its major uses today is in
1.2. The Structure of C Programs
The procedural building blocks of a C program are functions, which can invoke one another. Every function in a well-designed program serves a specific purpose. The functions contain
statements for the program to execute sequentially, and
statements can also be grouped to form block statements, or
blocks. As the programmer, you can use the ready-made
functions in the standard library, or write your own whenever no standard function fulfills your intended purpose. In addition to the standard C library, there are many specialized libraries available, such as libraries of graphics functions. However, by using such nonstandard libraries, you limit the portability of your program to those systems to which the libraries
themselves have been ported.
Every C program must define at least one function of its own, with the special name main( ): this is the first function invoked
when the program starts. The main( ) function is the program's
top level of control, and can call other functions as subroutines.
Example 1-1 shows the structure of a simple, complete C
program. We will discuss the details of declarations, function calls, output streams and more elsewhere in this book. For now, we are simply concerned with the general structure of the C source code. The program in Example 1-1 defines two
functions, main( ) and circularArea( ). The main( ) function calls circularArea( ) to obtain the area of a circle with a given radius,
and then calls the standard library function printf( ) to output
the results in formatted strings on the console.
Example 1-1. A simple C program
#include <stdio.h> // Preprocessor directive
double circularArea( double r ); // Function declaration (prototype form)
int main( ) // Definition of main( ) begins {
double radius = 1.0, area = 0.0;
printf( " Areas of Circles\n\n" ); printf( " Radius Area\n" "---\n" );
area = circularArea( radius );
printf( "%10.1f %10.2f\n", radius, area );
radius = 5.0;
area = circularArea( radius );
printf( "%10.1f %10.2f\n", radius, area );
return 0; }
// The function circularArea( ) calculates the area of a circle // Parameter: The radius of the circle
// Return value: The area of the circle
double circularArea( double r ) // Definition of circularArea( ) begins {
const double pi = 3.1415926536; // Pi is a constant return pi * r * r;
}
Areas of Circles
Radius Area 1.0 3.14 5.0 78.54
Note that the compiler requires a prior declaration of each function called. The prototype of circularArea( ) in the third line
of Example 1-1 provides the information needed to compile a
statement that calls this function. The prototypes of standard library functions are found in standard header files. Because the header file stdio.h contains the prototype of the printf( )
function, the preprocessor directive #include <stdio.h> declares
the function indirectly by directing the compiler's preprocessor to insert the contents of that file. (See also the section "How
the C Compiler Works," at the end of this chapter.)
You may arrange the functions defined in a program in any order. In Example 1-1, we could just as well have placed the function circularArea( ) before the function main( ). If we had,
then the prototype declaration of circularArea( ) would be
superfluous, because the definition of the function is also a declaration.
1.3. Source Files
The function definitions, global declarations and preprocessing directives make up the source code of a C program. For small programs, the source code is written in a single source file. Larger C programs consist of several source files . Because the function definitions generally depend on preprocessor directives and global declarations, source files usually have the following internal structure:
1. Preprocessor directives
2. Global declarations
3. Function definitions
C supports modular programming by allowing you to organize a program in as many source and header files as desired, and to edit and compile them separately. Each source file generally contains functions that are logically related, such as the
program's user interface functions. It is customary to label C source files with the filename suffix .c .
Examples 1-2 and 1-3 show the same program as Example 1-1,
but divided into two source files.
Example 1-2. The first source file, containing the
main( ) function
// circle.c: Prints the areas of circles. // Uses circulararea.c for the math
#include <stdio.h>
int main( ) {
/* ... As in Example 1-1 ... */ }
Example 1-3. The second source file, containing
the circularArea( ) function
// circulararea.c: Calculates the areas of circles. // Called by main( ) in circle.c
double circularArea( double r ) {
/* ... As in Example 1-1 ... */ }
When a program consists of several source files, you need to declare the same functions and global variables, and define the same macros and constants, in many of the files. These
declarations and definitions thus form a sort of file header that is more or less constant throughout a program. For the sake of simplicity and consistency, you can write this information just once in a separate header file, and then reference the header file using an #include directive in each source code file. Header
files are customarily identified by the filename suffix .h . A header file explicitly included in a C source file may in turn include other files.
names and operators. See the section "Tokens," at the end of this chapter for more detail.
Any number of whitespace characters can occur between two successive tokens, allowing you a great deal of freedom in
formatting the source code. There are no rules for line breaks or indenting, and you may use spaces, tabs, and blank lines
liberally to format "human-readable" source code. The
preprocessor directives are slightly less flexible: a preprocessor directive must always appear on a line by itself, and no
characters except spaces or tabs may precede the hash mark (#) that begins the line.
There are many different conventions and "house styles" for source code formatting. Most of them include the following common rules:
Start a new line for each new declaration and statement.
1.4. Comments
You should use comments generously in the source code to document your C programs. There are two ways to insert a comment in C: block comments begin with /* and end with */,
and line comments begin with // and end with the next new line
character.
You can use the /* and */ delimiters to begin and end comments
within a line, and to enclose comments of several lines. For example, in the following function prototype, the ellipsis (...)
signifies that the open( ) function has a third, optional
parameter. The comment explains the usage of the optional parameter:
int open( const char *name, int mode, ... /* int permissions */ );
You can use // to insert comments that fill an entire line, or to
write source code in a two-column format, with program code on the left and comments on the right:
const double pi = 3.1415926536; // Pi is constant
These line comments were officially added to the C language by the C99 standard, but most compilers already supported them even before C99. They are sometimes called "C++-style"
comments, although they originated in C's forerunner, BCPL.
Inside the quotation marks that delimit a character constant or a string literal, the characters /* and // do not start a comment.
printf( "Comments in C begin with /* or //.\n" );
The only thing that the preprocessor looks for in examining the characters in a comment is the end of the comment; thus it is not possible to nest block comments. However, you can insert /*
and */ to comment out part of a program that contains line
comments:
/* Temporarily removing two lines:
const double pi = 3.1415926536; // Pi is constant
area = pi * r * r // Calculate the area Temporarily removed up to here */
If you want to comment out part of a program that contains block comments, you can use a conditional preprocessor directive (described in Chapter 14):
#if 0
const double pi = 3.1415926536; /* Pi is constant */ area = pi * r * r /* Calculate the area */ #endif
1.5. Character Sets
C makes a distinction between the environment in which the compiler translates the source files of a programthe translation environment and the environment in which the compiled
program is executed, the execution environment. Accordingly, C defines two character sets : the source character set is the set of characters that may be used in C source code, and the
execution character set is the set of characters that can be interpreted by the running program. In many C
implementations, the two character sets are identical. If they are not, then the compiler converts the characters in character constants and string literals in the source code into the
corresponding elements of the execution character set.
Each of the two character sets includes both a basic character set and extended characters . The C language does not specify the extended characters, which are usually dependent on the local language. The extended characters together with the basic character set make up the extended character set .
The basic source and execution character sets both contain the following types of characters:
The letters of the Latin alphabet
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
a b c d e f g h i j k l m n o p q r s t u v w x y z
The decimal digits
The following 29 punctuation marks
! " # % & ' ( ) * + , - . / : ; < = > ? [ \ ] ^ _ { | } ~
The five whitespace characters
Space, horizontal tab, vertical tab, new line, and form feed
The basic execution character set also includes four
nonprintable characters : the null character, which acts as the termination mark in a character string; alert; backspace; and
carriage return. To represent these characters in character and string literals, type the corresponding escape sequences
beginning with a backslash: \0 for the null character, \a for alert, \b for backspace, and \r for carriage return. See Chapter 3 for
more details.
The actual numeric values of charactersthe character codes may vary from one C implementation to another. The language itself imposes only the following conditions:
Each character in the basic character set must be representable in one byte.
The null character is a byte in which all bits are 0.
The value of each decimal digit after 0 is greater by one than that of the preceding digit.
1.5.1. Wide Characters and Multibyte Characters
where the dominant character set was the 7-bit ASCII code. Since then, the 8-bit byte has become the most common unit of character encoding, but software for international use generally has to be able to represent more different characters than can be coded in one byte, and internationally, a variety of multibyte character encoding schemes have been in use for decades to represent non-Latin alphabets and the nonalphabetic Chinese, Japanese, and Korean writing systems. In 1994, with the
adoption of "Normative Addendum 1," ISO C standardized two ways of representing larger character sets: wide characters , in which the same bit width is used for every character in a
character set, and multibyte characters , in which a given
character can be represented by one or several bytes, and the character value of a given byte sequence can depend on its context in a string or stream.
Although C now provides abstract mechanisms to manipulate and convert the different kinds of encoding schemes, the language itself doesn't define or specify any encoding scheme, or any character set except the basic source and execution character sets described in the previous section. In other words, it is left up to individual
implementations to specify how to encode wide characters, and what multibyte encoding schemes to support.
Since the 1994 addendum, C has provided not only the type
char, but also wchar_t, the wide character type. This type, defined
in the header file stddef.h, is large enough to represent any element of the given implementation's extended character sets.
Although the C standard does not require support for Unicode character sets, many implementations use the Unicode
transformation formats UTF-16 and UTF-32 (see
http://www.unicode.org) for wide characters. The Unicode
including the 7-bit ASCII code. When the Unicode standard is implemented, the type wchar_t is at least 16 or 32 bits wide, and
a value of type wchar_t represents one Unicode character. For
example, the following definition initializes the variable wc with
the Greek letter .
wchar_t wc = '\x3b1';
The escape sequence beginning with \x indicates a character
code in hexadecimal notation to be stored in the variablein this case, the code for a lowercase alpha.
In multibyte character sets, each character is coded as a
sequence of one or more bytes. Both the source and execution character sets may contain multibyte characters . If they do, then each character in the basic character set occupies only one byte, and no multibyte character except the null character may contain any byte in which all bits are 0. Multibyte characters can be used in character constants, string literals, identifiers,
comments, and header filenames. Many multibyte character sets are designed to support a certain language, such as the Japanese Industrial Standard character set (JIS) . The multibyte UTF-8 character set , defined by the Unicode Consortium, is capable of representing all Unicode characters. UTF-8 uses from one to four bytes to represent a character.
The key difference between multibyte characters and wide characters (that is, characters of type wchar_t) is that wide
characters are all the same size, and multibyte characters are represented by varying numbers of bytes. This representation makes multibyte strings more complicated to process than strings of wide characters. For example, even though the
character 'A' can be represented in a single byte, finding it in a
could be part of a different character. Multibyte characters are well suited for saving text in files, however (see Chapter 13).
C provides standard functions to obtain the wchar_t value of any
multibyte character, and to convert any wide character to its multibyte representation. For example, if the C compiler uses the Unicode standards UTF-16 and UTF-8, then the following call to the function wctomb( ) (read: "wide character to
multibyte") obtains the multibyte representation of the character :
wchar_t wc = L'\x3B1'; // Greek lower-case alpha, char mbStr[10] = "";
int nBytes = 0;
nBytes = wctomb( mbStr, wc );
After the function call, the array mbStr contains the multibyte
character, which in this example is the sequence "\xCE\xB1". The wctomb( ) function's return value, assigned here to the variable nBytes, is the number of bytes required to represent the
multibyte character, namely 2.
1.5.2. Universal Character Names
C also supports universal character names as a way to use the extended character set regardless of the implementation's encoding. You can specify any extended character by its
universal character name, which is its Unicode value in the form:
or:
\UXXXXXXXX
where XXXX or XXXXXXXX is a Unicode code point in hexadecimal
notation. Use the lowercase u prefix followed by four
hexadecimal digits, or the uppercase U followed by exactly eight
hex digits. If the first four hexadecimal digits are zero, then the same universal character name can be written either as \uXXXX
or as \U0000XXXX.
Universal character names are permissible in identifiers,
character constants, and string literals. However, they must not be used to represent characters in the basic character set.
When you specify a character by its universal character name, the compiler stores it in the character set used by the
implementation. For example, if the execution character set in a localized program is ISO 8859-7 (8-bit Greek) , then the
following definition initializes the variable alpha with the code \xE1:
char alpha = '\u03B1';
However, if the execution character set is UTF-16, then you need to define the variable as a wide character:
wchar_t alpha = '\u03B1';
In this case, the character code value assigned to alpha is
Not all compilers support universal character names .
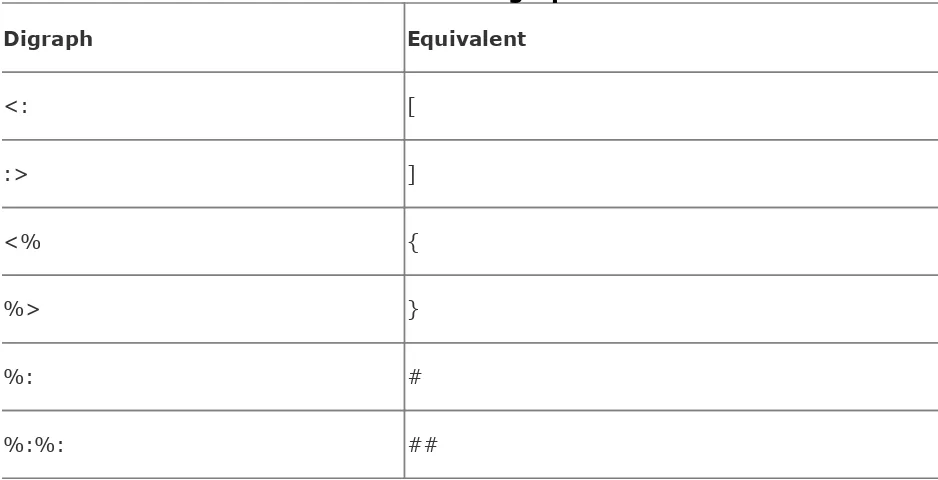
1.5.3. Digraphs and Trigraphs
C provides alternative representations for a number of
punctuation marks that are not available on all keyboards . Six of these are the digraphs , or two-character tokens, which represent the characters shown in Table 1-1.
Table 1-1. Digraphs
Digraph Equivalent
<: [
:> ]
<% {
%> }
%: #
%:%: ##
These sequences are not interpreted as digraphs if they occur within character constants or string literals. In all other
perfectly equivalent, and produce the same output. With digraphs:
int arr<::> = <% 10, 20, 30 %>;
printf( "The second array element is <%d>.\n", arr<:1:> );
Without digraphs:
int arr[ ] = { 10, 20, 30 };
printf( "The second array element is <%d>.\n", arr[1] );
Output:
The second array element is <20>.
C also provides trigraphs , three-character representations, all of them beginning with two question marks. The third character determines which punctuation mark a trigraph represents, as shown in Table 1-2.
Table 1-2. Trigraphs
Trigraph Equivalent
??( [
??) ]
??< {
??= #
??/ \
??! |
??' ^
??- ~
Trigraphs allow you to write any C program using only the characters defined in ISO/IEC 646, the 1991 standard
corresponding to 7-bit ASCII . The compiler's preprocessor replaces the trigraphs with their single-character equivalents in the first phase of compilation. This means that the trigraphs, unlike digraphs, are translated into their single-character equivalents no matter where they occur, even in character constants, string literals, comments, and preprocessing directives. For example, the preprocessor interprets the statement's second and third question marks below as the beginning of a trigraph:
printf("Cancel???(y/n) ");
Thus the line produces the following preprocessor output:
printf("Cancel?[y/n) ");
printf("Cancel\?\?\?(y/n) ");
If the character following any two question marks is not one of those shown in Table 1-2, then the sequence is not a trigraph, and remains unchanged.
1.6. Identifiers
The term identifier refers to the names of variables, functions, macros, structures and other objects defined in a C program. Identifiers can contain the following characters:
The letters in the basic character set, a-z and A-Z. Identifiers
are case-sensitive.
The underscore character, _.
The decimal digits 0-9, although the first character of an
identifier must not be a digit.
Universal character names that represent the letters and digits of other languages.
The permissible universal characters are defined in Annex D of the C standard, and correspond to the characters defined in the ISO/IEC TR 10176 standard, minus the basic character set.
Multibyte characters may also be permissible in identifiers . However, it is up to the given C implementation to determine exactly which multibyte characters are permitted and what universal character names they correspond to.
The following 37 keywords are reserved in C, each having a specific meaning to the compiler, and must not be used as identifiers:
auto
enum
unsigned
break
extern
return
void
case
float
short
volatile
char
for
signed
while
const
goto
sizeof
_Bool
continue
if
static
_Complex
default
inline
_Imaginary
do
int
switch
double
long
typedef
else
register
union
The following examples are valid identifiers:
x dollar Break error_handler scale64
The following are not valid identifiers:
1st_rank switch y/n x-ray
If the compiler supports universal character names, then is also an example of a valid identifier, and you can define a variable by that name:
double = 0.5;
Your source code editor might save the character in the source file as the universal character \u03B1.
See Chapter 15 for details.
The C compiler provides the predefined identifier _ _func_ _,
which you can use in any function to access a string constant containing the name of the function. This is useful for logging or for debugging output; for example:
#include <stdio.h>
int test_func( char *s ) {
if( s == NULL) { fprintf( stderr,
"%s: received null pointer argument\n", _ _func_ _ ); return -1;
}
/* ... */ }
In this example, passing a null pointer to the function test_func( ) generates the following error message:
test_func: received null pointer argument
There is no limit on the length of identifiers. However, most compilers consider only a limited number of characters in identifiers to be significant. In other words, a compiler might fail to distinguish between two identifiers that start with a long identical sequence of characters. To conform to the C standard, a compiler must treat at least the first 31 characters as
1.6.1. Identifier Name Spaces
All identifiers fall into exactly one of the following four categories, which constitute separate name spaces:
Label names.
Tags, which identify structure, union and enumeration types.
Names of structure or union members. Each structure or union constitutes a separate name space for its members.
All other identifiers, which are called ordinary identifiers.
Identifiers that belong to different name spaces may be the same without causing conflicts. In other words, you can use the same name to refer to different objects, if they are of different kinds. For example, the compiler is capable of distinguishing between a variable and a label with the same name. Similarly, you can give the same name to a structure type, an element in the structure, and a variable, as the following example shows:
struct pin { char pin[16]; /* ... */ }; _Bool check_pin( struct pin *pin )
{
int len = strlen( pin->pin ); /* ... */
}
The first line of the example defines a structure type identified by the tag pin, containing a character array named pin as one of
pointer to a structure of the type just defined. The expression
pin->pin in the fourth line designates the member of the
structure that the function's parameter points to. The context in which an identifier appears always determines its name space with no ambiguity. Nonetheless, it is generally a good idea to make all identifiers in a program distinct, in order to spare human readers unnecessary confusion.
1.6.2. Identifier Scope
The scope of an identifier refers to that part of the translation unit in which the identifier is meaningful. Or to put it another way, the identifier's scope is that part of the program that can "see" that identifier. The type of scope is always determined by the location at which you declare the identifier (except for
labels, which always have function scope ). Four kinds of scope are possible:
File scope
If you declare an identifier outside all blocks and parameter lists, then it has file scope . You can then use the identifier anywhere after the declaration and up to the end of the translation unit.
Block scope
declarations do not have to be placed before all statements in a function block. The parameter names in the head of a function definition also have block scope, and are valid within the corresponding function block.
Function prototype scope
The parameter names in a function prototype have function prototype scope . Because these parameter names are not significant outside the prototype itself, they are meaningful only as comments, and can also be omitted. See Chapter 7
for further information.
Function scope
The scope of a label is always the function block in which the label occurs, even if it is placed within nested blocks. In other words, you can use a goto statement to jump to a
label from any point within the same function that contains the label. (Jumping into nested blocks is not a good idea, though: see Chapter 6 for details.)
The scope of an identifier generally begins after its declaration. However, the type names, or tags, of structure, union, and
enumeration types and the names of enumeration constants are an exception to this rule: their scope begins immediately after their appearance in the declaration, so that they can be
referenced again in the declaration itself. (Structures and
unions are discussed in detail in Chapter 10; enumeration types are described in Chapter 2.) For example, in the following
declaration of a structure type, the last member of the
structure, next, is a pointer to the very structure type that is
struct Node { /* ... */
struct Node *next; }; // Define a structure type void printNode( const struct Node *ptrNode); // Declare a function
int printList( const struct Node *first ) // Begin a function definition {
struct Node *ptr = first;
while( ptr != NULL ) { printNode( ptr ); ptr = ptr->next; }
}
In this code snippet, the identifiers Node, next, printNode, and printList all have file scope . The parameter ptrNode has function
prototype scope , and the variables first and ptr have block
scope .
It is possible to use an identifier again in a new declaration nested within its existing scope, even if the new identifier does not have a different name space. If you do so, then the new declaration must have block or function prototype scope, and the block or function prototype must be a true subset of the outer scope. In such cases, the new declaration of the same identifier hides the outer declaration, so that the variable or function declared in the outer block is not visible in the inner scope. For example, the following declarations are permissible:
double x; // Declare a variable x with file scope
long calc( double x ); // Declare a new x with function prototype scope
int main( ) {
if( x < 0 ) // Here x refers to the long variable
{ float x = 0.0F; // Declare a new float variable x with block scope /*...*/
}
x *= 2; // Here x refers to the long variable again /*...*/
}
In this example, the long variable x delcared in the main( )
function hides the global variable x with type double. Thus there
is no direct way to access the double variable x from within main( ). Furthermore, in the conditional block that depends on the if
statement, x refers to the newly declared float variable, which in
1.7. How the C Compiler Works
Once you have written a source file using a text editor, you can invoke a C compiler to translate it into machine code. The
compiler operates on a translation unit consisting of a source file and all the header files referenced by #include directives. If
the compiler finds no errors in the translation unit, it generates an object file containing the corresponding machine code.
Object files are usually identified by the filename suffix .o or
.obj . In addition, the compiler may also generate an assembler listing (see Part III).
Object files are also called modules. A library, such as the C standard library, contains compiled, rapidly accessible modules of the standard functions.
The compiler translates each translation unit of a C programthat is, each source file with any header files it includesinto a
separate object file. The compiler then invokes the linker, which combines the object files, and any library functions used, in an
executable file. Figure 1-1 illustrates the process of compiling and linking a program from several source files and libraries. The executable file also contains any information that the target operating system needs to load and start it.
1.7.1. The C Compiler's Translation Phases
The compiling process takes place in eight logical steps. A given compiler may combine several of these steps, as long as the results are not affected. The steps are:
1. Characters are read from the source file and converted, if necessary, into the characters of the source character set. The end-of-line indicators in the source file, if different from the new line character, are replaced. Likewise, any trigraph sequences are replaced with the single characters they represent. (Digraphs, however are left alone; they are not converted into their single-character equivalents.)
to continue a directive, such as a macro definition, on the next line.
Every source file, if not completely empty, must end with a new line character.
3. The source file is broken down into preprocessor tokens (see the next section, "Tokens") and sequences of
whitespace characters. Each comment is treated as one space.
4. The preprocessor directives are carried out and macro calls are expanded.
Steps 1 through 4 are also applied to any files inserted by #include directives. Once the
compiler has carried out the preprocessor directives, it removes them from its working copy of the source code.
5. The characters and escape sequences in character constants and string literals are converted into the corresponding
characters in the execution character set.
6. Adjacent string literals are concatenated into a single string.
7. The actual compiling takes place: the compiler analyzes the sequence of tokens and generates the corresponding
8. The linker resolves references to external objects and functions, and generates the executable file. If a module refers to external objects or functions that are not defined in any of the translation units, the linker takes them from the standard library or another specified library. External objects and functions must not be defined more than once in a program.
For most compilers, either the preprocessor is a separate
program, or the compiler provides options to perform only the preprocessing (steps 1 through 4 in the preceding list). This setup allows you to verify that your preprocessor directives have the intended effects. For a more practically oriented look at the compiling process, see Chapter 18.
1.7.2. Tokens
A token is either a keyword, an identifier, a constant, a string literal, or a symbol. Symbols in C consist of one or more
punctuation characters, and function as operators or digraphs, or have syntactic importance, like the semicolon that terminates a simple statement, or the braces { } that enclose a block
statement. For example, the following C statement consists of five tokens:
printf("Hello, world.\n");
The individual tokens are:
printf (
"Hello, world.\n" )
The tokens interpreted by the preprocessor are parsed in the third translation phase. These are only slightly different from the tokens that the compiler interprets in the seventh phase of translation:
Within an #include directive, the preprocessor recognizes the
additional tokens <filename> and "filename".
During the preprocessing phase, character constants and string literals have not yet been converted from the source character set to the execution character set.
Unlike the compiler proper, the preprocessor makes no distinction between integer constants and floating-point constants.
In parsing the source file into tokens, the compiler (or preprocessor) always applies the following principle: each
successive non-whitespace character must be appended to the token being read, unless appending it would make a valid token invalid. This rule resolves any ambiguity in the following
expression, for example:
a+++b
Because the first + cannot be part of an identifier or keyword
starting with a, it begins a new token. The second + appended to
the first forms a valid tokenthe increment operatorbut a third +
does not. Hence the expression must be parsed as:
Chapter 2. Types
Programs have to store and process different kinds of data, such as integers and floating-point numbers, in different ways. To this end, the compiler needs to know what kind of data a given value represents.
2.1. Typology
The types in C can be classified as follows:
Basic type
Standard and extended integer types
Real and complex floating-point types
Enumerated types
The type void
Derived types
Pointer types
Array types
Structure types
Union types
Function types
A function type describes the interface to a function; that is, it specifies the type of the function's return value, and may also specify the types of all the parameters that are passed to the function when it is called.
All other types describe objects. This description may or may not include the object's storage size: if it does, the type is
properly called an object type ; if not, it is an incomplete type . An example of an incomplete type might be an externally
defined array variable:
extern float fArr[ ]; // External declaration
This line declares fArr as an array whose elements have type float. However, because the array's size is not specified here, fArr's type is incomplete. As long as the global array fArr is
defined with a specified size at another location in the
programin another source file, for examplethis declaration is sufficient to let you use the array in its present scope. (For more details on external declarations, see Chapter 11.)
This chapter describes the basic types, enumerations and the type void.
The derived types are described in Chapters 7 through 10.
Some types are designated by a sequence of more than one keyword, such as unsigned short. In such cases, the keywords can
2.2. Integer Types
There are five signed integer types . Most of these types can be designated by several synonyms, which are listed in Table 2-1.
Table 2-1. Standard signed integer types
Type Synonyms
signed char
int signed, signed int
short short int, signed short, signed short int
long long int, signed long, signed long int
long long (C99) long long int, signed long long, signed long long int
For each of the five signed integer types in Table 2-1, there is also a corresponding unsigned type that occupies the same amount of memory, with the same alignment: in other words, if the compiler aligns signed int objects on even-numbered byte
addresses, then unsigned int objects are also aligned on even
addresses. These unsigned types are listed in Table 2-2.
Table 2-2. Unsigned standard integer types
Type Synonyms
_Bool bool (defined in stdbool.h )
unsigned int unsigned
unsigned short unsigned short int
unsigned long unsigned long int
unsigned long long unsigned long long int
C99 introduced the unsigned integer type _Bool to represent
Boolean truth values. The Boolean value true is coded as 1, and
false is coded as 0. If you include the header file stdbool.h in a program, you can also use the identifiers bool, TRue, and false,
which are familiar to C++ programmers. The macro bool is a
synonym for the type _Bool, and true and false are symbolic
constants equal to 1 and 0.
The type char is also one of the standard integer types.
However, the one-word type name char is synonymous either
with signed char or with unsigned char, depending on the compiler.
Because this choice is left up to the implementation, char, signed char, and unsigned char are formally three different types.
If your program relies on char being able to hold values less than zero
or greater than 127, you should be using either signed char or unsigned char instead.
You can do arithmetic with character variables. It's up to you to decide whether your program interprets the number in a char
variable as a character code or as something else. For example, the following short program treats the char value in ch as both
char ch = 'A'; // A variable with type char.
printf("The character %c has the character code %d.\n", ch, ch); for ( ; ch <= 'Z'; ++ch )
printf("%2c", ch);
In the printf( ) statement, ch is first treated as a character that
gets displayed, and then as numeric code value of the
character. Likewise, the for loop treats ch as an integer in the
instruction ++ch, and as a character in the printf( ) function call.
On systems that use the 7-bit ASCII code, or an extension of it, the code produces the following output:
The character A has the character code 65.
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
A value of type char always occupies one bytein other words, sizeof(char) always yields 1and a byte is at least eight bits wide.
Every character in the basic character set can be represented in a char object as a positive value.
C defines only the minimum storage sizes of the other standard types: the size of type short is at least two bytes, long at least
four bytes, and long long at least eight bytes. Furthermore,
although the integer types may be larger than their minimum sizes, the sizes implemented must be in the order:
sizeof(short) sizeof(int) sizeof(long) sizeof(long long)
The type int is the integer type best adapted to the target
system's architecture, with the size and bit format of a CPU register.
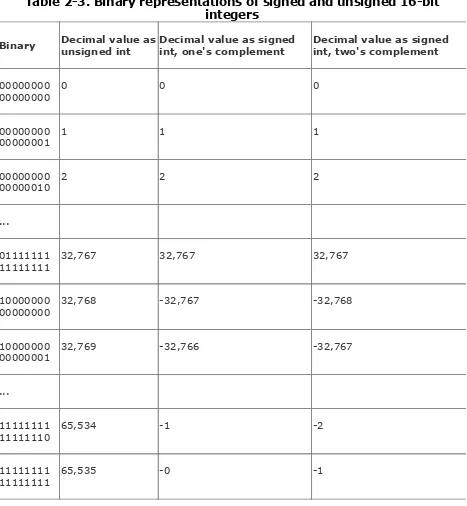
one's complement , or as a two's complement . The most common representation is the two's complement. The non-negative values of a signed type are within the value range of the corresponding unsigned type, and the binary representation of a non-negative value is the same in both the signed and
unsigned types. Table 2-3 shows the different interpretations of bit patterns as signed and unsigned integer types.
Table 2-3. Binary representations of signed and unsigned 16-bit integers
Binary Decimal value asunsigned int Decimal value as signedint, one's complement Decimal value as signedint, two's complement
00000000
00000000 0 0 0
00000000
00000001 1 1 1
00000000
00000010 2 2 2
...
01111111
11111111 32,767 32,767 32,767
10000000
00000000 32,768 -32,767 -32,768
10000000
00000001 32,769 -32,766 -32,767
...
11111111
11111110 65,534 -1 -2
11111111
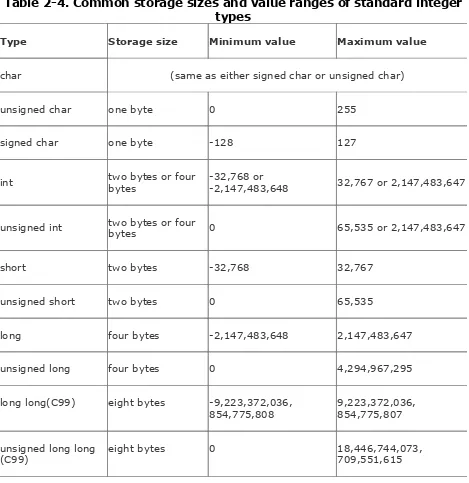
Table 2-4 lists the sizes and value ranges of the standard integer types.
Table 2-4. Common storage sizes and value ranges of standard integer types
Type Storage size Minimum value Maximum value
char (same as either signed char or unsigned char)
unsigned char one byte 0 255
signed char one byte -128 127
int two bytes or fourbytes -32,768 or-2,147,483,648 32,767 or 2,147,483,647
unsigned int two bytes or fourbytes 0 65,535 or 2,147,483,647
short two bytes -32,768 32,767
unsigned short two bytes 0 65,535
long four bytes -2,147,483,648 2,147,483,647
unsigned long four bytes 0 4,294,967,295
long long(C99) eight bytes -9,223,372,036,
854,775,808 9,223,372,036,854,775,807
unsigned long long
In the following example, each of the int variables iIndex and iLimit occupies four bytes on a 32-bit computer:
int iIndex, // Define two int variables and iLimit = 1000; // initialize the second one.
To obtain the exact size of a type or a variable, use the sizeof
operator. The expressions sizeof(type) and sizeof expression yield
the storage size of the object or type in bytes. If the operand is an expression, the size is that of the expression's type. In the previous example, the value of sizeof(int) would be the same as sizeof(iIndex): namely, 4. The parentheses around the
expression iIndex can be omitted.
You can find the value ranges of the integer types for your C compiler in the header file limits.h , which defines macros such as INT_MIN, INT_MAX, UINT_MAX, and so on (see Chapter 15). The
program in Example 2-1 uses these macros to display the minimum and maximum values for the types char and int.
Example 2-1. Value ranges of the types char and
int
// limits.c: Display the value ranges of char and int. // ---#include <stdio.h>
#include <limits.h> // Contains the macros CHAR_MIN, INT_MIN, etc.
int main( ) {
printf("Storage sizes and value ranges of the types char and int\n\n"); printf("The type char is %s.\n\n", CHAR_MIN < 0 ? "signed" :"unsigned");
"---\n"); printf(" char %8d %20d %15d\n", sizeof(char), CHAR_MIN, CHAR_MAX ); printf(" int %8d %20d %15d\n", sizeof(int), INT_MIN, INT_MAX ); return 0;
}
In arithmetic operations with integers , overflows can occur. An overflow happens when the result of an operation is no longer within the range of values that the type being used can
represent. In arithmetic with unsigned integer types, overflows are ignored. In mathematical terms, that means that the
effective result of an unsigned integer operation is equal to the remainder of a division by UTYPE_MAX + 1, where UTYPE_MAX is the
unsigned type's maximum representable value. For example, the following addition causes the variable to overflow:
unsigned int ui = UINT_MAX;
ui += 2; // Result: 1
C specifies this behavior only for the unsigned integer types. For all other types, the result of an overflow is undefined. For
example, the overflow may be ignored, or it may raise a signal that aborts the program if it is not caught.
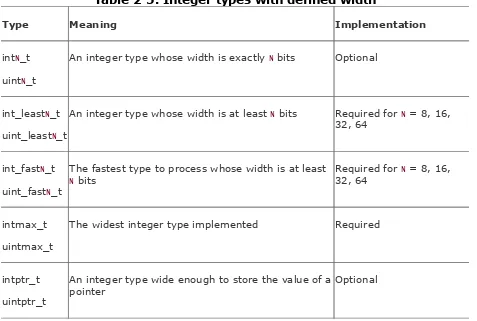
2.2.1. Integer Types with Exact Width (C99)
The width of an integer type is defined as the number of bits used to represent a value, including the sign bit. Typical widths are 8, 16, 32, and 64 bits. For example, the type int is at least
16 bits wide.
the need for known widths. These types are listed in Table 2-5.