ATA 15/16
Fakultas Ekonomi | Universitas Gunadarma | Depok
L
ABORATORIUM
MANAJEMEN
Team Distribusi Normal
1. Hayyu Annisa
2. Ivo Zola Vinola
3. Ledhyra Permata
4. Reffien Febrianto
5. Vien Aulia R
Team Chi Square
1. Lulu Sorayah
2. Maharani Kinanti
3. Maya Utama
4. Pria Yoga
5. Fredy Haryo S
6. Dimas Setya A
Team ANOVA
1. Tia Ayu N
2. Natessa Sharen
3. Fakhri Fayadhi
4. Ilham Saputra
5. Desy Atikah S
6. Achmad Sandy P
1. Yustia K. Sandra
2. Marini Hartina
3. Prema Sanjaya
4. Nurlaela Phoneo
5.
Hambali Syahrul
Team RLS
TEAM LITBANG
STATISTIKA 2
ATA 15/16
Penanggung Jawab
1. Desty Dirnaeni
2. Amelia Pujaastuti
KATA PENGANTAR
Assalamu’alaikum Wr. Wb.
Puji syukur kami panjatkan kepada Tuhan Yang Maha Esa atas limpahan rahmat dan karunia-Nya sehingga modul praktikum Statistika 2 ini dapat terselesaikan.
Modul praktikum ini merupakan penyempurnaan dari modul praktikum sebelumnya dan diharapkan dengan adanya modul praktikum ini dapat meningkatkan pemahaman dasar materi praktikum serta sebagai pedoman bagi mahasiswa dalam melakukan penelitian-penelitian ekonomi. Selain itu, modul ini juga dapat digunakan sebagai dasar suatu pandangan mahasiswa dalam melihat keadaan perekonomian dan disesuaikan dengan teori-teori ekonomi yang ada.
Dengan penuh kesadaran, bahwa modul praktikum ini masih perlu disempurnakan lagi, sehingga saran dan kritik untuk penyajian serta isinya sangat diperlukan.
Akhir kata, kami ucapkan terima kasih kepada tim Litbang Statistika 2 Laboratorium Manajemen Dasar yang turut berpartisipasi dalam penulisan modul praktikum ini. Ucapan terima kasih juga kami sampaikan kepada seluruh pihak yang berpartisipasi sehingga pelaksanaan praktikum ini dapat berjalan dengan lancar.
Wassalamu’alaikum Wr. Wb.
Depok, Januari 2015
DAFTAR ISI
Cover modul
Team Litbang Statistika 2 ATA 15/16 ... i
Kata Pengantar ... ii
Daftar Isi ... iii
Daftar Gambar ... v
Daftar Tabel ... vii
Materi Distribusi Normal ... 1
I. Pendahuluan ... 1
II. Rumus Distribusi Normal ... 3
III. Langkah-Langkah Pengujian Hipotesis ... 4
IV. Kurva Normal... 6
V. Contoh Kasus ... 7
Materi Chi Square ... 31
I. Pendahuluan ... 16
II. Analisis yang diperlukan ... 16
III. Uji Independensi ... 18
IV. Contoh Kasus . ... 18
V. Uji Keselarasan ... 22
VI. Contoh Kasus ... 22
Tabel Chi Square ... 30
Materi Distribusi F / Anova ... 31
I. Pendahuluan ... 31
II. Rumus Distribusi F / Anova ... 31
III. Langkah-langkah Uji Hipotesis ... 35
IV. Contoh Kasus ... 37
Materi Regresi Linier Sederhana ... 53
I. Pendahuluan ... 54
II. Rumus RLS ... 54
IV. Manfaat RLS . ... 57
V. Contoh Kasus ... 57
Tabel Nilai t ... 65
DAFTAR GAMBAR
Gambar 1.1 Tampilan awal R-Commander………..………. 8
Gambar 1.2 Tampilan output window………... 9
Gambar 1.3 Tampilan awal R-Commander……… 11
Gambar 1.4 Tampilan output window……… 12
Gambar 1.5 Tampilan awal R-Commander………. 14
Gambar 1.6 Tampilan output window………... 15
Gambar 2.1. Tampilan awal R-Commander ... 20
Gambar 2.2. Tampilan Bar Statistik ... 21
Gambar 2.3. Tampilan Bar Statistik setelah input data ... 21
Gambar 2.4. Tampilan Hasil Akhir ... 22
Gambar 2.5. Tampilan awal R-Commander ... 25
Gambar 2.6. Tampilan pilihan New Data Set ... 26
Gambar 2.7. Hasil Input di table Data set ... 27
Gambar 2.8. Tampilan Bin Numeric ... 27
Gambar 2.9 Tampilan ubah data di Bin Numeric ... 28
Gambar 2.10 Tampilan data yang sudah berubah ... 28
Gambar 2.11 Tampilan Frequency Distribution ... 29
Gambar 2.12 Tampilan Goodness Of Fit Test ... 29
Gambar 2.13. Tampilan Hasil Akhir ... 29
Gambar 3.1. Tampilan awal R-Commander ... 39
Gambar 3.2. Tampilan menu New Data Set ... 39
Gambar 3.3. Tampilan New Data Set ... 40
Gambar 3.4. Tampilan Data Editor ... 40
Gambar 3.5. Tampilan mengubah nama Variabel Editor (Skor) ... 41
Gambar 3.6. Tampilan mengubah nama Variabel Editor (Varietas) ... 41
Gambar 3.7. Tampilan isi Data Editor ... 41
Gambar 3.8. Tampilan sub menu Manage Variables ... 42
Gambar 3.10 Tampilan menu olah data ... 43
Gambar 3.11 Tampilan One Way ANOVA ... 43
Gambar 3.12 Hasil akhir One Way ANOVA ... 44
Gambar 3.13. Tampilan awal R-Commander ... 47
Gambar 3.14. Tampilan menu New Data Set ... 47
Gambar 3.15. Tampilan kotak dialog New Data Set ... 48
Gambar 3.16. Tampilan Data Editor ... 48
Gambar 3.17. Tampilan mengubah nama Variabel Editor (Skor) ... 49
Gambar 3.18. Tampilan mengubah nama Variabel Editor (Varietas) ... 49
Gambar 3.19. Tampilan isi Data Editor ... 49
Gambar 3.20. Tampilan sub menu Manage Variables ... 50
Gambar 3.21 Tampilan Bin a Numeric Variables dan Bin Names ... 50
Gambar 3.22 Tampilan menu olah data ... 51
Gambar 3.23 Tampilan One Way ANOVA ... 51
Gambar 3.24 Hasil akhir One Way ANOVA ... 52
Gambar 4.1 Tampilan awal R-Commander …..……… 61
Gambar 4.2 Tampilan new data set …..……… 61
Gambar 4.3 Tampilan data editor …..……….. 62
Gambar 4.4 Tampilan Variabel 1 …..………... 62
Gambar 4.5 Tampilan Variabel 2 …..………... 62
Gambar 4.6 Tampilan isi Data Editor …..……… 63
Gambar 4.7 Tampilan Box Linier Regression …..……… 63
DAFTAR TABEL
Table 2.1. Tabel Soal Uji Independensi ... 18
Table 2.2. Tabel Kontingensi Uji Independensi ... 19
Table 2.3. Tabel Frekuensi ... 24
Table 2.4. Tabel Kontingensi Uji Keselarasan ... 24
Table 2.5. Tabel Chi (X2) ... 30
Table 3.1. Tabel Satu Arah data Sama ... 32
Table 3.2. Tabel Satu Arah data Tidak Sama ... 33
Table 3.3. Tabel Dua Arah Tanpa Interaksi ... 34
Table 3.4. Tabel Satu Arah Dengan Interaksi ... 35
DISTRIBUSI NORMAL
I. PENDAHULUAN
Bidang inferensia statistik membahas generalasi/penarikan kesimpulan dan prediksi/peramalan. Generalisasi atau prediksi tersebut melibatkan sampel sebagai contoh, dan sangat jarang menyaangkut populasi. Sampling disebut juga pendataan sebagian anggota populasi/penarikan contoh/pengambilan sampel. Dalam modul ini akan dibahas tentang hipotesis dalam sebuah pengambilan suatu sampel, untuk dapat mengambil kesimpulan/keputusan suatu parameter populasi yang sedang diteliti, maka pada umumnya ada perumpamaan (asumsi) mengenai distribusi atau parameter populasi. Asumsi dalam populasi ini disebut hipotesis statistik. Benar tidaknya hipotesis ini harus di uji. Maka perlu diambil sampel populasi, berdasarkan sampel ini dilakukan uji statistik yang disebut uji hipotesis. Keputusan yang diambil adalah menerima/menolak hipotesis.
Hipotesis adalah sebuah asumsi/argumen/pemikiran dari sebuah data atau
populasi yang akan diuji. Hipotesis nol adalah hipotesis yang dirumuskan dengan harapan akan ditolak, dinotasikan dengan H0 Hipotesis lainya dari Ha disebut hipotesis alternatif adalah hipotesis alternatif apabila Ho ditolak.
Pengaplikasian Distribusi Normal digunakan dalam berbagai penelitian seperti :
Observasi tinggi badan
Observasi isi sebuah botol
Nilai hasil ujian
Ciri-ciri distribusi normal
1. n (jumlah sampel) ≥ 30 2. n.p ≥ 5
Apa yang dipersoalkan atau yang akan diuji, tidak selamanya menjadi H0 sangat sering kalimat pengujian menjadi Ha. Apakah suatu kalimat pengujian akan menjadi H0 atau Ha, tergantung pada tanda yang tersirat didalamnya.
Contoh:
a. Uji dua arah
Ujilah apakah rata-rata populasi sama dengan 55, maka: H0 : μ = 55
Ha : μ ≠ 55
Disini kalimat pengujian menjadi Ho.
b. Uji satu arah
Ujilah apakah beda dua rata-rata populasi lebih besar dari 1, maka: H0 : μ1 - μ2 ≤ 1
Ha : μ1 - μ2 > 1
Disini kalimat pengujian menjadi Ha.
c. Uji satu arah
Ujilah apakah proporsi populasi sekurang-kurangnya 0,5, maka: H0 : μ ≥ 0,5
Ha : μ < 0,5
II. RUMUS DISTRIBUSI NORMAL Satu rata-rata Keterangan x = rata-rata sampel μ = rata-rata populasi σ = simpangan baku n = jumlah sampel Dua rata-rata = – Satu proporsi p = proporsi berhasil q = proporsi gagal q = 1 – p Dua Proporsi = / = /
III. LANGKAH-LANGKAH PENGUJIAN HIPOTESIS 1. Tentukan Ho dan Ha Satu rata-rata H0 : μ ≥ Ha : μ < → Z < - Zα H0 : μ ≤ Ha : μ > → Z > Zα H0 : μ = Ha : μ ≠ → Z < - dan Z > Dua rata-rata H0 : - ≥ Ha : - < → Z < -Zα H0 : - ≤ Ha : - > → Z > Zα H0: - = Ha : - ≠ → Z < - dan Z > Satu proporsi H0 : p ≥ Ha : p < → Z < - Zα H0 : p ≤ Ha : p > → Z > Zα
: p = Ha : p ≠ → Z < - dan Z > Dua proporsi H0 : - ≥ Ha : - < → Z < -Zα H0 : - ≤ Ha : - > → Z > Zα H0: - = Ha : - ≠ → Z < - dan Z >
2. Pilih arah uji hipotesis : 1 arah atau 2 arah
3. Menentukan taraf nyata (α) : a. Jika 1 arah α tidak dibagi 2
b. Jika 2 arah α dibagi 2
4. Menentukan nilai kritis Z tabel 5. Menentukan nilai hitung Z hitung 6. Keputusan dan gambar
IV. KURVA NORMAL
μ x
Kurva normal berbentuk seperti lonceng dan simetris terhadap rata–rata (μ )
a. Kurva distribusi normal dua arah H0 : μ = dan Ha : μ ≠
b. Kurva distribusi normal satu arah sisi kiri H0 : μ ≥ dan Ha : μ <
c. Kurva distribusi normal satu arah sisi kanan H0 : μ ≤ dan Ha : μ >
Ho Ho Ha Ha Ho Ho Ha Ho Ho Ha
V. CONTOH KASUS
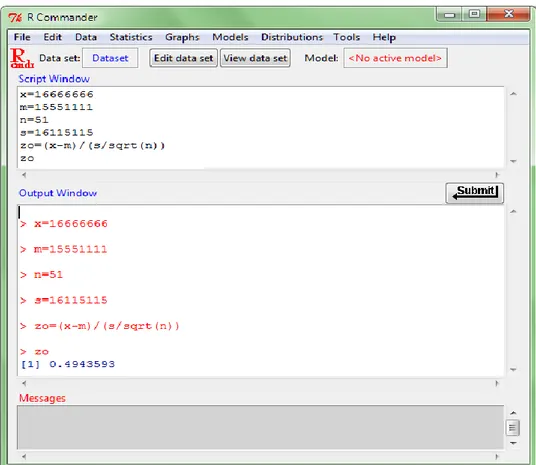
1. Seorang manajer pabrik roti menyatakan laba penjualan yang diperoleh tiap bulannya mencapai Rp 15.551.111 dengan mengambil sampel sebanyak 51 bulan. Diketahui rata-rata laba penjualan yang diperoleh sebesar Rp 16.666.666 dengan simpangan baku sebesar Rp 16.115.115. Ujilah hipotesa dengan taraf nyata 5%!
Diketahui: n = 51
μ = Rp 15.551.111 x = Rp 16.666.666 = Rp 16.115.115 α = 5%
Ditanya: Uji hipotesa dan Analisis
Jawab:
Langkah-langkah pengujian hipotesa: 1. H0 : μ = Rp 15.551.111 Ha : μ ≠ Rp 15.551.111 2. Uji hipotesis 2 arah 1 rata-rata 3. Taraf nyata α = 5% = 0,05 : 2 = 0,025 0,5 – 0,025 = 0,475 4. Wilayah kritis Z(0,475) = ±1,96 5. Nilai hitung
0,49
6. Gambar dan keputusan
-1,96 0,49 1,96 Keputusan: Terima H0, tolak Ha 7. Kesimpulan:
Pernyataan bahwa laba yang diperoleh sebesar Rp 15.551.111 pada tiap bulannya adalah benar.
Menggunakan R-Commander
Langkah-langkah Penyelesaian Kasus :
1. Jalankan aplikasi R-Commander, kemudian akan muncul tampilan seperti dibawah ini:
Gambar 1.1 Tampilan awal R-Commander H0 H0
2. Ketikkan data seperti pada jendela skrip (script window) bawah ini, setelah itu blok semua tulisan dan klik submit (kirim), maka hasilnya akan terlihat pada output window seperti berikut:
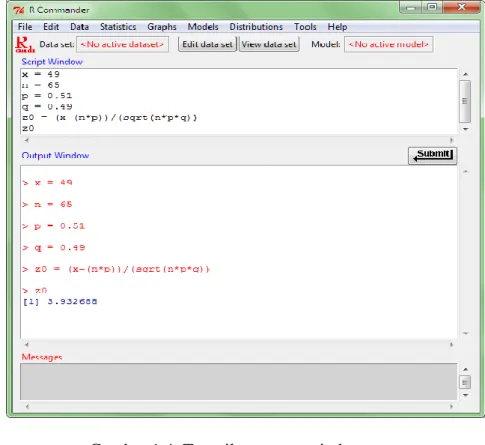
2. Dalam kasus perbankan yang terdapat di Indonesia diperkirakan paling banyak 51% bank swasta yang terdeteksi bebas dari likuidasi. Jika dari 65 bank ada 16 bank yang terancam di likuidasi. Maka ujilah hipotesis yang menyatakan bahwa paling banyak 51% Bank akan terbebas dari likuidasi. Gunakan tingkat signifikan 5%!
Diketahui: p ≤ 0,51 n = 65
x = 65 – 16 = 49 α = 5%
Ditanya: Uji Hipotesis dan Analisis Jawab:
1. H0 : p ≤ 0,51
Ha : p > 0,51
2. Uji Hipotesis 1 arah 1 proporsi 3. Taraf Nyata α = 5 % = 0,05 0,5 – 0,05 = 0,45 4. Wilayah Kritis Z(0,45) = 1,65 5. Nilai Hitung
6. Gambar dan Keputusan
1,65 3,93 Keputusan: Terima Ha Tolak H0
7. Kesimpulan
Bahwa anggapan paling banyak 51% perbankan akan terbebas dari likuidasi adalah salah.
Menggunakan R-Commander
Langkah-langkah Penyelesaian Kasus :
1. Jalankan aplikasi R-Commander, lalu akan muncul tampilan seperti dibawah ini:
2. Ketikkan data yang ada pada script window seperti di bawah ini, setelah itu blok semua tulisan dan klik submit, maka hasilnya akan terlihat pada output window seperti berikut:
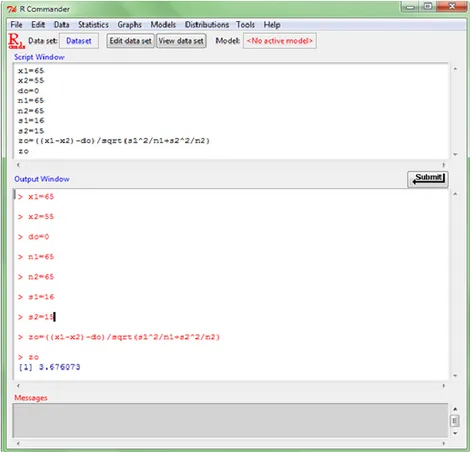
3. Seorang penjual pisang molen ingin menguji dua merk minyak untuk menggoreng pisang molen dagangannya. Pengujian dengan taraf nyata 5% dilakukan untuk menentukan apakah ada perbedaan rata-rata pada hasil gorengannya akibat adanya perbedaan penggunaan merk minyak.
Minyak Bomili : =65 = 65 = 16 Minyak Filmi : = 65 = 55 = 15 Diketahui: = 65 = 55 = 65 = 65
= 16 = 15 Ditanya:
Apakah ada perbedaan rata-rata pada hasil gorengan akibat adanya perbedaan penggunaan merk minyak?
Jawab:
Langkah-langkah pengajian Hipotesis 1. H0 : - = 0 Ha : - ≠ 0 2. Uji Hipotesis 2 arah 2 rata-rata 3. Taraf nyata α = 5 % = 0,05 : 2 = 0,025 0,5 – 0.025 = 0,475 4. Wilayah Kritis Z ( 0,475 ) = ± 1,96 5. Nilai Hitung
6. Gambar dan Keputusan
-1,96 1,96 3,676 Keputusan: H0 ditolak, Ha diterima
7. Kesimpulan
Ada perbedaan pada hasil goreng pisang molen dari penggunaan dua merk minyak yang berbeda.
Menggunakan R-Commander
1. Langkah-langkah Penyelesaian Kasus :Jalankan aplikasi R-Commander, lalu akan muncul tampilan seperti disamping ini:
2. Ketikkan data yang ada pada jendela skrip (script window) seperti di bawah ini, setelah itu blok semua tulisan dan klik submit, maka hasilnya akan terlih at pada output window seperti berikut:
MODUL UJI NON PARAMETRIK (CHI-SQUARE/X2)
I. PENDAHULUAN
Dalam uji statistik dikenal uji parametrik dan uji nonparametrik. Uji statistik parametrik hanya bisa digunakan bila data yang ada menyebar secara normal, atau tidak ditemukannya petunjuk pelanggaran kenormalan. Untuk data yang tidak memenuhi syarat tersebut maka akan digunakan uji lain yaitu uji statistika nonparametrika. Pada modul ini uji statistika nonparametrik yang akan dibahas adalah Chi-Square (X2).
Chi-Square digunakan terutama untuk Uji Homogenitas, Uji Keselarasan (Goodness Of Fit Test), dan Uji Independensi. Untuk materi ini, akan dibahas adalah Uji Keselarasan dan Uji Independensi.
II. ANALISIS YANG DIPERLUKAN
Rumus untuk Uji Chi-Square yaitu sebagai berikut :
Keterangan :
fo : frekuensi observasi fe : frekuensi harapan
Distribusi X2 digunakan untuk menguji :
a. Apakah frekuensi observasi berbeda secara signifikan terhadap frekuensi ekspektasi
b. Apakah dua variable independent atau tidak
c. Apakah data sampel menyerupai distribusi hipotesis tertentu seperti distribusi normal, binomial, poisson atau yang lain
Nilai X2 selalu positif karena didapat dari penjumlahan kuadrat dari variable normal standar Z sehingga kurva Chi kuadrat (X2) tidak mungkin berada disebelah kiri nilai nol. Bentuk distribusi X2 tergantung dari Derajat
Bebas (Db) atau Degree of Freedom (Df). Distribusi X2 bukan suatu kurva probabilitas tunggal tetapi merupakan suatu keluarga dari kurva bermacam-macam distribusi X2.
Uji Chi Square dibagi menjadi :
1. Uji Kecocokan = Uji Kebaikan = Test goodness of fit
Hanya terdapat satu baris
Db = k-m-1
Dengan :
k : jumlah kategori data sampel
m : jumlah nilai-nilai parameter yang diestimasi.
2. Uji kebebasan / Uji Independensi
Jika terdapat lebih dari satu baris
Db = (k-1)(b-1)
Dengan :
k : jumlah kolom b : jumlah baris
III. UJI INDEPENDENSI
Uji ini digunakan untuk menguji ada atau tidaknya interpendensi antara variable kunatitatif yang satu dengan yang lainnya berdasarkan observasi yang ada.
IV. CONTOH KASUS
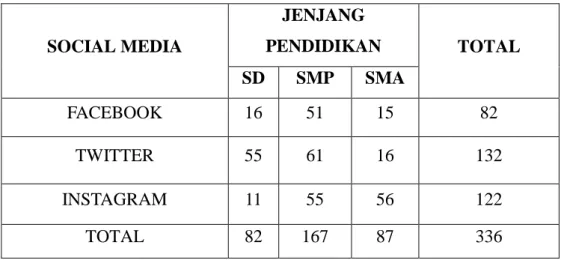
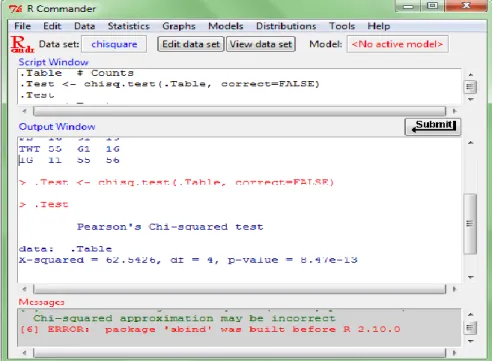
Dalam suatu penelitian yang bertujuan untuk mengetahui apakah ada hubungan antara social media dengan jenjang pendidikan, diperoleh data sebagai berikut : SOCIAL MEDIA JENJANG PENDIDIKAN TOTAL SD SMP SMA FACEBOOK 16 51 15 82 TWITTER 55 61 16 132 INSTAGRAM 11 55 56 122 TOTAL 82 167 87 336
Tabel 2.1 Tabel Soal Uji Independensi
Dengan taraf nyata 5%, ujilah hipotesis tersebut !
Pengujian Hipotesis :
a) H0 = Tidak ada hubungan antara social media dengan jenjang pendidikan.
Ha = Ada hubungan antara social media dengan jenjang pendidikan. b) Menetapkan tingkat signifikansi dari derajat bebas
α = 5%
db = (k – 1) (b – 1) = (3 – 1) (3 – 1)
c) Menentukan nilai kritis X2 tabel = (α ; db)
= (0,05 ; 4) = 9,488
d) Menentukan nilai tes statistik (nilai hitung)
Fe = Jumlah menurut baris x Jumlah menurut kolom Jumlah seluruh baris dan kolom
Feij i = baris j = kolom Fe11 = (82x82) / 336 = 20.012 Fe12 = (82x167) / 336 = 40.756 Fe13 = (82x87) / 336 = 21.232 Fe21 = (132x82) / 336 = 32.214 Fe22 = (132x167) / 336 = 65.607 Fe23 = (132x87) / 336 = 34.179 Fe31 = (122 x 82) / 336 = 29.774 Fe32 = (122 x 167) / 336 = 60.637 Fe33 = (122 x 87) / 336 = 31.589
Rumus : X2 = ∑ (Fo – Fe)2 Fe
Fo Fe (Fo - Fe) (Fo-Fe)2 (Fo - Fe)2 / Fe
16 20,012 -4,012 16,0961 0,804 51 40,756 10,244 104,940 2,575 15 21,232 -6,232 38,838 1,829 55 32,214 22,786 519,202 16,117 61 65,607 -4,607 21,224 0,324 16 34,179 -18,179 330,476 9,669 11 29,774 -18,774 352,463 11,838 55 60,637 -5,637 31,776 0,524 56 31,589 24,411 595,897 18,864 TOTAL 62,544
e) Gambar dan Keputusan Keputusan : Ha Diterima H0 Ditolak 9,488 62,544
Kesimpulan : Ada hubungan antara social media dengan jenjang pendidikan.
Langkah pengerjaan dengan software :
Untuk mencari nilai-nilai data tersebut dengan menggunakan program R Commander, ikutilah langkah-langkah berikut :
1. Klik ikon R Commander pada desktop kemudian akan muncul tampilan seperti berikut ini:
Gambar 2.1 Tampilan awal R-Commander
Ho
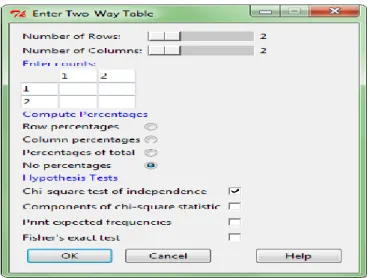
2. Pada R Commander pilih menu bar Statistics, Contigency Tables, dan Enter and analyze two-way table maka akan muncul tampilan seperti dibawah ini.
Gambar 2.2 Tampilan Bar Statistik
3. Kemudian isi kotak tersebut sesuai contoh kasus, Number of Row di geser ke kanan sehingga berubah dari 2 menjadi 3, Kemudian isi Enter Counts. Tampilan data yang sudah diisi sebagai berikut. Kemudian pilih OK.
4. Kemudian akan muncul tampilan seperti ini
Gambar 2.4 Tampilan Hasil Akhir
V. UJI KESELARASAN / UJI KEBAIKAN ( GOODNESS OF FIT)
Uji Keselarasan merupakan pengujian hipotesa tentang perbandingan antara frekuensi sampel yang benar-benar terjadi (selanjutnya disebut dengan frekuensi observasi) dengan frekuensi harapan ( expected frequency). Uji keselarasan pada prinsipnya bertujuan untuk mengetahui apakah sebuah distribusi data dari sampel mengikuti sebuah distribusi teoritis tertentu atau tidak.
VI. CONTOH KASUS
Seorang Manajer Pemasaran toko bunga HARUM FLORIST selama ini menganggap bahwa konsumen menyukai tiga warna bunga mawar yang dijual, yaitu Merah, Putih, Kuning. Untuk mengetahui apakah pendapat Manajer tersebut benar, maka kepada enam belas responden ditanya warna bunga mawar yang paling disukainya.
Berikut adalah data kuisioner tersebut :
RESPONDEN WARNA KESUKAAN
Yuni Merah Amel Putih Dita Kuning Puspa Kuning Yuna Merah Adilah Merah Puti Kuning Lulu Putih Sandra Merah Hana Merah Rani Kuning Oka Putih Hayyu Putih Nalla Kuning Trias Putih Tia Putih
a) Tabel frekuensi Pilihan Warna
Bunga Merah Putih Kuning
Frekuensi 5 6 5
Tabel 2.3 Tabel Frekuensi
b) H0 : jumlah konsumen yang menyukai ketiga warna bunga mawar merata Ha : jumlah konsumen yang menyukai ketiga warna bunga mawar tidak merata c) α = 5% db = k-m-1 = 3-0-1 = 2 d) Nilai kritis : 5,991 e) Nilai hitung
Fe = jumlah data / banyaknya kolom = 16 / 3 = 5,33
Rumus : X2 = ∑ (Fo – Fe)2 Fe
Fo Fe (fo-fe) (fo-fe)2 (fo-fe)2 / fe
5 5,33 -0,33 0,1089 0,0204
6 5,33 0,67 0,4489 0,0842
5 5,33 -0,33 0,1089 0,0204
TOTAL 0,125
f) Gambar dan keputusan
Keputusan : H0 diterima
H0 Ha Ha ditolak
0,125 5,991
Kesimpulan : jumlah konsumen yang menyukai ketiga warna bunga mawar merata
Langkah pengerjaan dengan software :
Untuk mencari nilai-nilai data tersebut dengan menggunakan program R,
ikutilah langkah-langkah berikut :
1. Klik ikon R Commander pada desktop kemudian akan muncul tampilan seperti ini.
2. Pilih menu Data. Pilih new data set. Masukkan nama dari data set adalah responden kemudian klik OK.
Gambar 2.6 Tampilan pilihan New Data Set
3. Masukkan data dengan var1 untuk responden, var2 untuk kode warna, var3 untuk warna pilihan. Jika Data Editor tidak aktif maka dapat diaktifkan dengan menekan Rgui di Taskbar windows pada bagian bawah layar monitor. Jika sudah selesai dalam pengisian data tekan tombol Close. Untuk mengubah nama dan tipe variable, dapat dilakukan dengan cara double click pada variable yang ingin di setting. Pemilihan type, dipilih numeric pada variable kode warna dan character untuk responden. Kemudian isi masing-masing variable sesuai dengan data soal setelah isi data kemudian tekan tombol X (close).
Gambar 2.7 Hasil input di tabel Data Set
4. Pada R Commander, pilih menu bar data, pilih Manage Variables In active data set, pilih Bin numeric variable.
Akan muncul tampilan sebagai berikut, kemudian klik OK
5. Akan muncul tampilan berikut dengan mengubah terlebih dahulu 1 : Merah
2 : Putih 3 : Kuning Kemudian klik OK
Gambar 2.9 Tampilan ubah data di Bin Numeric
6. Pada R Commander pilih menu bar Edit data set. Maka akan muncul tampilan sebagai berikut. Sebelumnya kolom warna pilihan tidak terisi data. Close data editor.
7. Pada menu bar pilih Statistics, Summaries, pilih Frequency Distribution.
Maka akan tampil sebagai berikut, beri tanda Check list pada Chi-square goodness of fit test. Kemudian klik OK.
Gambar 2.11 Tampilan Frequency Distribution
8. Maka akan muncul tampilan sebagai berikut. Kemudian klik OK.
Gambar 2.12 Tampilan Goodness Of Fit test 9. Maka tampilan R commander sebagai berikut.
DISTRIBUSI F (ANOVA)
I. PENDAHULUAN
Anova merupakan kepanjangan dari Analysis of Variance. Ditemukan oleh seorang ahli statistik yang bernama Ronald Aylmer Fisher pada tahun 1920.
Distribusi F/ANOVA adalah prosedur statistika untuk mengkaji (mendeterminasi) apakah rata-rata hitung (mean) dari 3 (tiga) populasi atau lebih, sama atau tidak. Digunakan untuk menguji rata-rata atau nilai tengah dari tiga atau lebih populasi secara sekaligus, apakah rata-rata atau nilai tengah tersebut sama atau tidak sama.
Ada beberapa asumsi yang digunakan pada pengujian ANOVA, yaitu :
Data dari populasi-populasi (sampel) berjenis interval atau rasio.
Populasi-populasi (sampel) yang akan diuji lebih dari 2 populasi.
Populasi-populasi yang akan diuji berdistribusi normal.
Varians setiap populasi (sampel) harus sama.
II. RUMUS-RUMUS DISTRIBUSI F / ANOVA
A. Klasifikasi Satu Arah (One Way ANOVA)
Klasifikasi satu arah, adalah klasifikasi pangamatan yang hanya didasarkan pada satu kriteria. Misalnya saja varietas pakaian. Dalam klasifikasi satu arah ini, rumus-rumus yang digunakan adalah :
1. Ukuran Data Sama
JKT = JKK =
Keterangan :
JKT : Jumlah Kuadrat Total JKK : Jumlah Kuadrat Kolom JKG : Jumlah Kuadrat Galat
x2ij : Pengamatan ke-j dari sampel ke-i
T2 : Total semua pengamatan
T2i : Total semua pengamatan dalam contoh dari sampel ke-i nk : Banyaknya anggota secara keseluruhan
n : Banyaknya pengamatan / anggota baris
Analisis ragam dalam klasifikasi satu arah dengan data sama:
Sumber Keragaman
Jumlah Kuadrat
Derajat
Bebas Kuadrat Tengah
F Hitung Nilai Tengah Kolom JKK k-1 Galat JKG k(n-1) Total JKT nk-1
Tabel 3.1 Analisis ragam dalam klasifikasi satu arah dengan data sama
2) Ukuran Data Tidak Sama
JKT = JKK =
Analisis ragam dalam klasifikasi satu arah dengan data tidak sama :
Sumber Keragaman
Jumlah
Kuadrat DerajatBebas Kuadrat Tengah F Hitung
Nilai Tengah
Kolom JKK k-1
Galat JKG N-k
Total JKT N-1
Tabel 3.2 Analisis ragam dalam klasifikasi satu arah dengan data tidak sama
2. Klasifikasi Dua Arah (Two Way ANOVA )
Klasifikasi dua arah adalah klasifikasi pengamatan yang didasarkan pada 2 kriteria, seperti varietas dan jenis pupuk. Segugus pengamatan dapat diklasifikasikan menurut dua kriteria dengan menyusun data tersebut dalam baris dan kolom. Kolom menyatakan kriteria klasifikasi yang satu, sedangkan baris menyatakan kriteria klasifikasi yang lain. Rumus-rumus yang digunakan dalam klasifikasi 2 arah adalah :
1) Tanpa Interaksi
JKT = JKK =
JKG = JKT – JKB – JKK Keterangan :
JKT : Jumlah Kuadrat Total JKB : Jumlah Kuadrat Baris JKK : Jumlah Kuadrat Kolom JKG : Jumlah Kuadrat Galat T2 : Total semua pengamatan
T2i : Jumlah/total pengamatan pada baris T2i : Jumlah/total pengamatan pada kolom T2ij : Jumlah/total pengamatan pada baris kolom
x2i : Jumlah/total keseluruhan dari baris dan kolom K : Jumlah kolom
bk : Jumlah kolom dan baris b : Jumlah baris
Analisis ragam dalam klasifikasi dua arah tanpa interaksi :
Sumber Keragaman
Jumlah
Kuadrat DerajatBebas Kuadrat Tengah F Hitung
Nilai Tengah Baris JKB b-1 Nilai Tengah Kolom JKK k-1 Galat JKG (b-1)(k-1) Total JKT bk-1
Tabel 3.3 Analisis ragam dalam klasifikasi dua arah dengan tanpa interaksi
2) Dengan Interaksi JKT = JKK = JKB = JK(BK) = JKG = JKT – JKB – JKK – JK(BK)
Analisis ragam dalam klasifikasi dua arah dengan interaksi :
Sumber Keragaman
Jumlah
Kuadrat DerajatBebas Kuadrat Tengah
F Hitung Nilai Tengah Baris JKB b-1 Nilai Tengah Kolom JKK k-1 Interaksi JK (BK) (b-1)(k-1) Galat JKG bk(n-1) Total JKT bkn-1
Tabel 3.4 Analisis ragam dalam klasifikasi dua arah dengan interaksi
III. LANGKAH-LANGKAH PENGUJIAN HIPOTESIS
Langkah-langkah dalam pengujian hipotesis dalam Distribusi F/Anova dengan klasifikasi satu arah atau dua arah adalah sebagai berikut :
1. Tentukan H0 dan Ha
H0 : Rata-rata ketiga sampel sama atau identik
Ha : Rata-rata ketiga sampel tidak sama atau tidak identik 2. Tentukan tingkat signifikan (α)
3. Tentukan derajat bebas (db)
a. Klasifikasi 1 arah data sama :
V1 = k – 1 V2 = k (n – 1) b. Klasifikasi 1 arah data tidak sama :
c. Klasifikasi 2 arah tanpa interaksi :
V1 (baris) = b – 1 V1 (kolom) = k – 1 V2 = (k – 1) (b – 1)
d. Klasifikasi 2 arah dengan interaksi :
V1 (baris) = b – 1 V2 = bk(n – 1) V1(interaksi) = (k – 1) (b – 1)
V1 (kolom) = k – 1
Ket : k = kolom ; b = baris
4. Tentukan wilayah kritis (F tabel) ƒ > ( α ; V1 ; V2)
5. Kriteria pengujian
H0 diterima jika Fo ≤ F tabel Ha diterima jika Fo > F tabel 6. Nilai hitung (F hitung) 7. Keputusan
8. Kesimpulan
Ha
H0
IV. CONTOH KASUS (Satu Arah Data Sama)
1.
Restoran Mala merupakan rumah makan yang menjual berbagai jenis makanan. Restoran tersebut ingin mengetahui tingkat penjualan pada barang dagangannya pada 4 bulan terakhir. Maka dilakukan pengamatan, berikut data yang disajikan :Bulan Seafood Bebek Nasi
Goreng Soto April 155 155 116 111 Mei 111 151 161 155 Juni 161 161 115 151 Juli 166 111 111 151 Total 593 578 503 568 2242
Dengan taraf nyata 5%. ujilah apakah ada perbedaan yang signifikan pada tingkat penjualan tiap-tiap varietas makanan ?
Penyelesaian :
1. H0 : Rata-rata tingkat penjualan tiap-tiap varietas makanan sama Ha : Rata-rata tingkat penjualan tiap-tiap varietas makanan tidak sama 2. α = 0,05 3. Derajat Bebas V1 = (k-1) = (4 – 1) = 3 V2 = k(n – 1) = 4(4 – 1) = 12 4. Daerah Kritis F table (0,05 ; 3 ; 12) = 3,49 5. Kriteria pengujian
H0 diterima jika Fo ≤ F tabel Ha diterima jika Fo > F tabel
6. Nilai Hitung JKT = (155² + 111² + 161² + 166² + 155² + 151² + 161² + 111² + 116² + 161² + 115² +111²+111²+155²+151²+151²) - (2242²/ 16) = 7601,7 JKK = (593² + 578² + 503²+568²) / 4) - (2242²/ 16) = 1181,2 JKG = 7601,7 – 1181,2 = 6420,5
Analisis ragam dalam klasifikasi satu arah dengan data sama
Sumber Keragaman
Jumlah
Kuadrat DerajatBebas Kuadrat Tengah F Hitung
Nilai Tengah
Kolom 1181,2 3 393,733
0,7359
Galat 6420,5 12 535,042
Total 7602,7 15
7. Keputusan : H0 diterima, Ha ditolak
8. Kesimpulan
Rata-rata tingkat penjualan tiap-tiap varietas makanan sama.
H0 Ha
3,49 0,7359
B. Cara Software :
1. Buka software r-commander, lalu pilih menu Data - New Data Set, muncul kotak dialog New Data Set – OK.
Gambar 3.1 Tampilan awal R-Commander
2.
Pilih menu Data, New Data Set. Masukkan nama “Anova”. OkGambar 3.3 Tampilan New Data set
Gambar 3.4 Tampilan Data Editor
Ubah nama var 1 dengan “skor” dan var 2 dengan “varietas” dengan cara klik pada var1 dan var 2.
Gambar 3.5 Tampilan Mengubah nama Variabel Editor (skor)
Gambar 3.6 Tampilan Mengubah nama Variabel Editor (varietas)
3. Masukkan data dengan cara memberi permisalan. Di kolom “Skor” ketikkan data sesuai tiap tiap kolom. Pada kolom “Varietas” tuliskan angka 1 dari baris 1 sampai 4 (sesuai banyaknya baris), angka 2 dari baris 5 sampai 8, dst. Kemudian klik tanda close.
4. Untuk mengecek kebenaran data yang sudah di input. Klik View Data
Set. Jika ada data yang salah tekan tombol “edit set” lalu perbaiki data
yang salah. Setalah selesai mengecek, close data editor tersebut. 5. Klik Data – Manage variables in active data set – Bin numeric
variable.
Gambar 3.8 Tampilan sub menu Manage Variables
6. Pada Variable to bin pilih “Varietas”, pada Number of bin pilih 4 (sesuai permisalan, varietas 1, 2, 3, 4), OK, maka akan muncul kotak dialog nama bin. Ketikkan sesuai dengan soal, OK.
7. Klik Statistics – Means – One-way ANOVA, di kolom Peubah respon klik “Skor” dan aktifkan Pairwise comparisons of means. OK.
Gambar 3.10 Tampilan menu olah data
8. Hasilnya adalah sebagai berikut :
Gambar 3.12 Hasil akhir One Way ANOVA
CONTOH KASUS (Satu Arah Data Tidak Sama)
2.
Dilakukan pengamatan di Rental MT untuk mengetahui rata-rata tingkat penyewaan mobil yang diantarannya yaitu Anova, Grand Livani, Kojang, CVR, dan Avinza . Data yang diperoleh yaitu :Anova Grand
Livani Kojang CVR Avinza
51 66 - 66 15
55 - 15 - 61
61 - 51 65 -
51 66 55 - 61
218 132 121 131 137 739
Dengan taraf nyata 5%. ujilah apakah ada perbedaan yang signifikan pada tingkat penyewaan tiap-tiap varietas mobil ?
Penyelesaian :
1. H0 : Rata-rata tingkat penyewaan tiap-tiap varietas mobil sama Ha : Rata-rata tingkat penyewaan tiap-tiap varietas mobil tidak sama 2. α = 0,05 3. Derajat Bebas V1 = (k-1) = (5 – 1) = 4 V2 = (N – k) = (14 – 5 ) = 9 4. Daerah Kritis F table (0,05 ; 4 ; 9) = 3,63 5. Kriteria pengujian
H0 diterima jika Fo ≤ F tabel Ha diterima jika Fo > F tabel
6. Nilai Hitung
JKT = (51² + 55² + 61² + 51² + 66² + 66² + 15² + 51²
+ 55² + 66² + 65² +15²+61²+61²) - (739²/ 14) = 3750,35 JKK= (218²/4+132²/2+121²/3+131²/2+137²/3)-(739²/14)= 1301,52 JKG = 3750,35 – 1301,52 = 2448,83
Analisis ragam dalam klasifikasi satu arah dengan data tidak sama :
Sumber Keragaman
Jumlah
Kuadrat DerajatBebas Kuadrat Tengah F Hitung
Nilai Tengah
Kolom 1301,52 4 325,38
1,1958
Galat 2448,83 9 272,0922
Total 3750,35 13
7. Keputusan : H0 diterima, Ha ditolak
8. Kesimpulan
Rata-rata tingkat penyewaan tiap-tiap varietas mobil sama.
H0 Ha
3,63 1,19
Cara Software :
1. Buka software r-commander, lalu pilih menu Data - New Data Set,
muncul kotak dialog New Data Set – OK.
Gambar 3.13 Tampilan awal R-Commander 2. Pilih menu Data, New Data Set. Masukkan nama “Anova”. Ok
Gambar 3.15 Tampilan New Data set
a. Ubah nama var 1 dengan “skor” dan var 2 dengan “varietas” dengan cara klik pada var1 dan var 2.
Gambar 3.17 Tampilan Mengubah nama Variabel Editor (skor)
Gambar 3.18 Tampilan Mengubah nama Variabel Editor (varietas) 4. Masukkan data dengan cara memberi permisalan. Di kolom “Skor”
ketikkan data sesuai tiap tiap kolom. Pada kolom “Varietas” tuliskan angka 1 dari baris 1 sampai 4 (sesuai banyaknya baris), angka 2 dari baris 5 sampai 8, dst. Kemudian klik tanda close.
5. Untuk mengecek kebenaran data yang sudah di input. Klik View
Data Set. Jika ada data yang salah tekan tombol “edit set” lalu
perbaiki data yang salah. Setalah selesai mengecek, close data editor tersebut. Klik Data – Manage variables in active data set – Bin
numeric variable.
Gambar 3.20 Tampilan sub menu Manage Variables
6. Pada Variable to bin pilih “Varietas”, pada Number of bin pilih 4 (sesuai permisalan, varietas 1, 2, 3, 4), OK, maka akan muncul kotak dialog nama bin. Ketikkan sesuai dengan soal, OK.
7. Klik Statistics – Means – One-way ANOVA, di kolom Peubah respon klik “Skor” dan aktifkan Pairwise comparisons of means. OK.
Gambar 3.22 Tampilan menu olah data
8. Hasilnya adalah sebagai berikut :
Gambar 3.24 Hasil akhir One Way ANOVA
REGRESI LINIER SEDERHANA
I. PENDAHULUAN
Di dalam analisa ekonomi dan bisnis, dalam mengolah data sering digunakan analisis regresi dan korelasi. Analisa regresi dan korelasi telah dikembangkan untuk mempelajari pola dan mengukur hubungan statistik antara dua atau lebih variabel. Namun karena bab ini hanya membahas tentang regresi linier sederhana, maka hanya dua variabel yang
digunakan. Sedangkan sebaliknya jika lebih dari dua variabel yang terlibat maka disebut regresi dan korelasi berganda. Analisa ini akan
memberikan hasil apakah antara variabel-variabel yang sedang diteliti atau sedang dianalisis terdapat hubungan, baik saling berhubungan, saling mempengaruhi dan seberapa besar tingkat hubungannya. Pada dasarnya analisis ini menganalisis hubungan dua variabel dimana membutuhkan dua kelompok hasil observasi atau pengukuran sebanyak n (data).
Data hubungan antara variabel X dan Y berdasarkan pada dua hal yaitu: 1. Penentuan bentuk persamaan yang sesuai guna meramalkan rata-rata Y
melalui X atau rata-rata X melalui Y dan menduga kesalahan selisih peramalan. Hal ini menitikberatkan pada observasi variabel tertentu, sedangkan variabel-variabel lain dikonstantir pada berbagai tingkat atau keadaan, hal inilah yang dinamakan Regresi.
2. Pengukuran derajat keeratan antara variabel X dan Y. Derajat ini tergantung pada pola variasi atau interelasi yang bersifat simultan dari variabel X dan Y. Pengukuran ini disebut Korelasi.
Hubungan antara variabel X dan Y kemungkinan merupakan hubungan dependen sempurna dan kemugkinan merupakan hubungan independen sempurna. Variabel X dan Y dapat dikatakan berasosiasi atau berkorelasi secara statistik jika terdapat batasan antara dependen dan
independen. Salah satu contohnya adalah untuk menganalisis hubungan antara tingkat pendapatan dan tingkat konsumsi.
II. RUMUS REGRESI LINIER SEDERHANA
Persamaan regresi linier sederhana:
Dimana : a = konstanta
b = koefisien regresi
Y = Variabel dependen (variabel terikat) X = Variabel independen (variabel bebas)
Untuk mencari rumus a dan b dapat digunakan metode Least Square sbb:
a = ΣY – b ΣX b = n ΣXY – ΣX . ΣY
n n ΣX2 – (ΣX)2
Jika (X) 0 nilai a dan b dapat dicari dengan metode:
1. Metode Least Square
a = ΣY b = ΣXY
n ΣX2
2. Metode Setengah Rata-rata
a = rata-rata K1 (rata-rata kelompok 1) b = (rata-rata K2 – rata-rata K1) / n
n = jarak waktu antara rata-rata K1 dan K2
3. Koefisien Korelasi
Untuk mencari koefisien relasi dapat digunakan rumusan koefisien korelasi Pearson yaitu:
r = n ( ∑XY ) – (∑X (∑Y)__ _____
[ n (∑X2) - (∑X)2 ] 1/2 [ n (∑Y2) - (∑Y)2 ] 1/2
Dimana:
1) Jika r mendekati 0 maka tidak ada hubungan antara kedua variabel. 2) Jika r mendekati (-1) maka hubungan sangat kuat dan bersifat tidak
searah.
3) Jika r mendekati (+1) maka hubungannya sangat kuat dan bersifat searah.
4. Koefisien Determinasi
Koefisien determinasi dilambangkan dengan r2, merupakan
kuadrat dari koefisien korelasi. Koefisien ini dapat digunakan untuk menganalisis apakah variabel yang diduga / diramal (Y) dipengaruhi oleh variabel (X) atau seberapa variabel independen (bebas) mempengaruhi variabel dependen (tak bebas).
5. Kesalahan Standar Estimasi
Untuk mengetahui ketepatan persamaan estimasi dapat digunakan dengan mengukur besar kecilnya kesalahan standar estimasi. Semakin kecil nilai kesalahan standar estimasi maka semakin tinggi ketepatan persamaan estimasi dihasilkan untuk menjelaskan nilai variabel yang sesungguhnya.
Dan sebaliknya, semakin besar nilai kesalahan standar estimasi maka semakin rendah ketepatan persamaan estimasi yang dihasilkan untuk menjelaskan nilai variabel dependen yang sesungguhnya. Kesalahan standar estimasi diberi simbol Se yang dapat ditentukan dengan rumus berikut:
H0 Ha Ha H0
H0 Ha Ha
III. LANGKAH-LANGKAH UJI HIPOTESIS
1. Tentukan hipotesis nol (H0) dan hipotesis alternatif (Ha). 1) H0 : β ≤ k Ha : β > k
2) H0 : β ≥ k Ha : β < k 3) H0 : β = k Ha : β ≠ k
2. Tentukan arah uji hipotesis (1 arah atau 2 arah) dan Tentukan tingkat signifikan (α).
1) Jika 1 arah α tidak dibagi dua 2) Jika 2 arah α dibagi dua ( α / 2 ) 3. Tentukan wilayah kritis (t tabel).
t tabel = ( α ; db ) db = n – 2 4. Tentukan nilai hitung (t hitung). 5. Gambar dan keputusan.
6. Kesimpulan. Gambar : 1) H0 : β ≤ k ; Ha : β > k 2) H0 : β ≥ k ; Ha : β < k 3) H0 : β = k ; Ha : β ≠ k 0 t tabel - t tabel 0 0 t tabel - t tabel
IV. MANFAAT REGRESI LINIER SEDERHANA
Salah satu kegunaan dari regresi adalah untuk memprediksi atau meramalkan nilai suatu variabel, misalnya kita dapat meramalkan konsumsi masa depan pada tingkat pendapatan tertentu. Selain itu analisis regresi sederhana juga digunakan untuk mengetahui apakah variabel-variabel yang sedang diteliti saling berhubungan. Dimana keadaan satu variabel membutuhkan adanya variabel yang lain dan sejauh mana pengaruhnya, serta dapat mengestimasi tentang nilai suatu variabel.
Hal ini dapat digunakan untuk mengetahui kondisi ideal suatu variabel jika variabel yang lain diketahui.
V. CONTOH KASUS
Berikut ini adalah pengaruh diskon terhadap penjualan di toko cosmetic ILY ditunjukan dalam tabel berikut ini:
Tentukan:
1. Persamaan Regresinya.
2. Hitunglah Koefisien Korelasi dan Koefisien Determinasinya. 3. Hitunglah Standar Estimasinya.
4. Dengan tingkat signifikan sebesar 5%, ujilah hipotesis yang
menyatakan bahwa pengaruh diskon terhadap penjualan sedikitnya 5%.
Diskon 5 6 11 5
Pembahasan: 1. Persamaan Regresi b = n ΣXY – ΣX . ΣY n ΣX2 – (ΣX)2 b = 4 (336) – (27) (47) 4 (207) – (27)2 b = 1344 – 1269 828 – 729 b = 0,7576 a = ΣY – b ΣX n a = (47) – 0,758 (27) 4 a = (47) – (20,466) 4 a = 6,6362 Persamaan Regresi: Y = 6,6362 + 0,7576 X 2. Koefisien Korelasi (r) r = n ( ∑XY ) – (∑X) (∑Y)__ _____ [ n (∑X2) - (∑X)2 ] 1/2 [ n (∑Y2) - (∑Y)2 ] 1/2 r = ______ _4 (336)_- (27) (47) _______ [4 (207) – (729)] 1/2 [4 (627) – (2209)] 1\2 r = 1344 – 1269 . √828 – 729 . √2508 – 2209
r = 75 . √99 . √299 r = 0,4359 Koefisien Determinasi (r2) r2 = 0,19 (19%) 3. Standar Estimasi Se = Se = Se = 5,5020
4. Langkah Pengujian Hipotesis
Langkah - langkah pengujian hipotesis: 1) Tentukan Ho dan Ha
H0 : β ≥ 0,05 Ha : β < 0,05 2) Uji hipotesis 1 arah
3) Tingkat signifikan (α = 0,05) 4) Wilayah kritis db = n-2 db = 4-2 db = 2 t tabel = (0,05 ; 2) = -2,920
Ha H0 5) Nilai hitung Sb = _____ _Se________ √(∑X2) – (∑X)2/n)) Sb = ______ 5,502______ √(207) – (729/4) Sb = 1,1060 t hitung = b/Sb = 0,6850 Kurva:
Keputusan : Terima H0, Tolak Ha
Kesimpulan : Jadi, Pendapat yang menyatakan bahwa pengaruh diskon terhadap penjualan sedikitnya dari 5% di toko cosmetic ILY adalah benar, di mana jumlah pekerja mempengaruhi jumlah output yang di produksi sebesar 19%.
0,6850 - 2,92
Langkah-langkah Software:
1. Buka Data, lalu klik New Data Set, seperti pada gambar dibawah ini
Gambar 4.1 Tampilan Awal R-Commander
2. Lalu akan muncul box lalu ganti dengan RLS, seperti pada gambar dibawah ini
Gambar 4.2 Tampilan New Data Set
Gambar 4.3 Tampilan Data Editor
4. Klik Var1 lalu ganti menjadi Diskon di type pilih numeric, lalu klik Var2 kemudian ganti menjadi Penjualan di type pilih numeric seperti gambar dibawah ini
5. Kemudian isi sesuai dengan soal seperti pada gambar dibawah ini, setelah itu close tab data editor
Gambar 4.6 Tampilan Data Editor yang telah diisi
6. Kemudian Klik Statistik, pilih Fit Model, lalu pilih linier regression, kemudian pilih Variabel terikat pada response Variable dan Variabel bebas pada explanatory variables seperti pada gambar dibawah ini
7. Kemudian Klik Ok maka akan muncul hasil output seperti pada gambar dibawah ini
TABEL NILAI t
d.f t0.10 t0.05 t0.025 t0.01 t0.005 d.f 1 3,078 6,314 12,706 31,821 63, 657 1 2 1,886 2,920 4,303 6,965 9,925 2 3 1,638 2,353 3,182 4,541 5,841 3 4 1,533 2,132 2,776 3,747 4,604 4 5 1,476 2,015 2,571 3,365 4,032 5 6 1,440 1,943 2,447 3,143 3,707 6 7 1,415 1,895 2,365 2,998 3,499 7 8 1,397 1,860 2,306 2,896 3,355 8 9 1,383 1,833 2,262 2,821 3,250 9 10 1,372 1,812 2,228 2,764 3,169 10 11 1,363 1,796 2,201 2,718 3,106 11 12 1,356 1,782 2,179 2,681 3,055 12 13 1,350 1,771 2,160 2,650 3,012 13 14 1,345 1,761 2,145 2,624 2,977 14 15 1,341 1,753 2,131 2,602 2,947 15 16 1,337 1,746 2,120 2,583 2,921 16 17 1,333 1,740 2,110 2,567 2,898 17 18 1,330 1,734 2,101 2,552 2,878 18 19 1,328 1,729 2,093 2,539 2,861 19 20 1,325 1,725 2,086 2,528 2,845 20 21 1,323 1,721 2,080 2,518 2,831 21 22 1,321 1,717 2,074 2,508 2,819 22 23 1,319 1,714 2,069 2,500 2,807 2324 1,318 1,711 2,064 2,492 2,797 24 25 1,316 1,708 2,060 2,485 2,787 25 26 1,315 1,706 2,056 2,479 2,779 26 27 1,314 1,703 2,052 2,473 2,771 27 28 1,313 1,701 2,048 2,467 2,763 28 29 1,311 1,699 2,045 2,462 2,756 29 30 1,310 1,697 2,042 2,457 2,750 30 31 1,309 1,696 2,040 2,453 2,744 31 32 1,309 1,694 2,037 2,449 2,738 32 33 1,308 1,692 2,035 2,445 2,733 33 34 1,307 1,691 2,032 2,441 2,728 34 35 1,306 1,690 2,030 2,438 2,724 35 36 1,306 1,688 2,028 2,434 2,719 36 37 1,305 1,687 2,026 2,431 2,715 37 38 1,304 1,686 2,024 2,429 2,712 38 39 1,303 1,685 2,023 2,426 2,708 39 40 1,303 1,684 2,021 2,423 2,704 40
DAFTAR PUSTAKA
Sundayana, M.Pd, Drs. H. Rostina. 2014. Statistika Penelitian Pendidikan. Bandung, Alfabeta, cv.
Walpole, R.E. 1982. Pengantar Statistika. PT. Gramedia Pustaka Utama, Jakarta. Universitas Gunadarma, Buku Diktat Statistika 2014.
Modul Matematika Ekonomi 2. Lab. Manajemen Dasar Periode ATA 2014/2015. Hasan Iqbal. Pokok-Pokok Materi Statistik 2 (Statistik Inferensif). 2003. Bumi Aksara : Jakarta
Subiyakto, Haryono. 1994. Statistika 2. Depok : Gunadarma.
Sugiyono.2015.Statistik Nonparametris Untuk Penelitian.Bandung:Alfabeta. Siregar, Ir. Syofian. 2013. Statistika Parametrik untuk Penelitiana Kuantitatif. PT. Bumi Aksara, Jakarta.