3. METODE PENELITIAN
3.1 Jenis Penelitian
Penelitian ini adalah penelitian kuantitatif deskriptif yang tujuannya untuk menyajikan gambaran lengkap mengenai setting sosial atau dimaksudkan untuk eksplorasi dan klarifikasi mengenai suatu fenomena atau kenyataan sosial, dengan jalan mendeskripsikan sejumlah variabel yang berkenaan dengan masalah dan unit yang diteliti antara fenomena yang diuji. Digunakan penelitian kuantitatif karena hasil dan data yang digunakan dirupakan dalam angka dan menggunakan pengolahan statistika.
(Sugiyono, 2003).
3.2 Gambaran Populasi dan Sampel 3.2.1. Populasi
Populasi adalah keseluruhan objek yang akan diteliti (Tampomas, Husein, 2004). Sekaran (2007) juga menyatakan bahwa populasi mengacu pada keseluruhan kelompok orang, kejadian, atau hal minat yang ingin penulis investigasi. Untuk penelitian ini, populasi yang digunakan adalah masyarakat di kota Surabaya.
3.2.2. Sampel dan Teknik Penarikan Sampel
Populasi dalam penelitian ini tergolong populasi tidak terbatas (indefinite population) karena jumlah unit analisisnya tidak dapat dihitung, terlalu banyak, atau karena tak terdefinisi. Disebabkan jumlah populasi yang terlalu besar, maka penulis menarik kesimpulan dari unit analisis yang jumlahnya lebih kecil yang disebut dengan sampel. Definisi sampel adalah sebagian dari populasi yang benar-benar diteliti (Tampomas, Husein, 2004).
Dalam pengambilan sampel untuk penelitian ini, penulis menggunakan metode non probability sampling yang berarti penggunaan teknik pengambilan sampel dimana pengambilan sampel tidak memberikan kesempatan yang sama bagi setiap anggota populasi untuk dipilih menjadi sampel (Sugiyono, 2007).
Selain itu, penulis juga menggunakan metode judgemental sampling, yaitu pengambilan sampel di mana penulis memilih sampel berdasarkan penilaian terhadap beberapa karakteristik anggota sampel yang disesuaikan dengan maksud penelitian (Sugiyono, 2010). Karakteristik yang digunakan oleh penulis dalam penetapan sampel adalah sebagai berikut:
1. Responden berusia minimal 17 tahun karena dianggap usia yang sudah dewasa dalam melakukan transaksi.
2. Responden pernah makan di sebuah restoran yang menggunakan buku menu minimal 1 kali dalam jangka waktu 6 bulan terakhir.
Dikarenakan jumlah populasi penelitian secara pasti tidak diketahui, maka banyaknya sampel ditentukan berdasarkan rumus sampel (Cochran dan Tohari, 2005, p.37) :
𝑁 = d2 . p . q (3.1.)
Keterangan
N = Banyak sampel
= 1,96
d2 = Sampling error
p = Estimasi proporsi populasi (0,5) q = 1-p
Banyak sampel yang diambil adalah : N = 1.962 . 100 . 0,5 . 0,5 = (384,16) 0,25
.= 96,04
Dari penghitungan menggunakan rumus sampel tersebut diketahui sampel yang dibutuhkan berjumlah 96 responden. Sampel yang digunakan pada penelitian ini berjumlah 150 responden untuk mengantisipasi adanya kesalahan dalam pengisian kuesioner.
3.3 Jenis dan Sumber Data 3.3.1 Jenis Data
Jenis data yang digunakan dalam penelitian ini berjenis kuantitatif, yang dimaksud dengan data kuantitatif adalah data yang menggambarkan realita menggunakan bentuk angka. Data kuantitatif adalah daya yang berbentuk angka atau data kualitatif yang diangkakan (Kuncoro, 2003). Data tersebut kemudian akan digunakan untuk menjabarkan data kuantitatif yang ditransformasikan ke dalam angka atau skor.
Data kualitatif yang diangkakan digolongkan menjadi dua, yaitu data nominal dan data ordinal. Penulis menggunakan data ordinal dalam penelitian ini. Data ordinal adalah data yang dinyatakan dalam bentuk kategori namun posisi data tidak sama derajatnya karena dinyatakan dalam skala peringkat.
3.3.2 Sumber Data
1) Sumber Data Primer
Sumber data primer merupakan data yang didapat dari sumber pertama, misalnya dari individu atau perseorangan (Sekaran, 2007). Dalam penelitian ini sumber data primer akan didapat melalui penyebaran kuisioner terhadap sampel penelitian. Data primer penelitian ini berupa hasil jawaban dari responden yang terdapat dalam kuesioner. Jawaban tersebut meliputi data latar belakang responden serta jawaban yang terkait dengan variabel penelitian
2) Sumber Data Sekunder
Sumber data sekunder adalah data berupa informasi yang didapat dari perpustakaan maupun internet serta referensi-referensi dan sumber-sumber yang relevan. Menurut Sekaran (2007) data primer mengacu pada informasi yang dikumpulkan dari sumber yang telah ada. Data sekunder yang digunakan di dalam penelitian ini meliputi teori-teori pendukung yang terkait dengan variabel penelitian. Data-data tersebut diperoleh dari buku, literatur, jurnal, dan internet.
3.4 Metode dan Prosedur Pengumpulan Data 3.4.1 Metode Pengumpulan Data
Proses pengumpulan data dalam penelitian ini menggunakan metode survei dengan alat bantu kuesioner. Kuesioner untuk penelitian ini akan dibagikan secara langsung di kampus, mall, dan rekan-rekan yang merupakan relasi penulis di Surabaya.
Kuesioner yang dibagikan merupakan kuesioner dengan close-ended question, di mana jawaban responden telah dibatasi dengan alternatif jawaban yang telah disediakan oleh peneliti dengan metode Five Likert Scale.
3.4.2 Prosedur Pengumpulan Data
Penulis melakukan studi di perpustakaan untuk mendapatkan data atau informasi yang digunakan sebagai landasan teori dengan membaca berbagai literature atau media lainnya yang berhubungan dengan pokok permasalahan yang akan dibahas.
Data primer dalam penelitian ini diambil melalui penyebaran kuesioner.
Prosedur pengumpulan data dalam penelitian ini adalah sebagai berikut:
1. Responden diberi tiga buku menu restoran fiksional dimana tidak tertulis nama maupun harga pada buku menu tersebut.
2. Kuesioner akan diberikan kepada responden setelah mereka selesai mengamati ketiga buku menu tersebut.
3. Kuesioner yang telah diisi responden dikumpulkan, disortir, dan diberi skor.
Kuesioner yang dibagikan terdiri dari tiga bagian kuesioner dengan close-ended question, yaitu latar belakang responden, persepsi desain, dan persepsi atas kualitas service yang akan diberikan restoran. Kuesioner bagian close-ended question yang dibagikan memuat hal-hal sebagai berikut:
1. Pertanyaan mengenai profil responden
Pertanyaan ini meliputi jenis kelamin, usia, pendidikan terakhir, pekerjaan, dan berapa kali berkunjung ke restoran dalam satu tahun terakhir. Pengukuran profil responden ini menggunakan skala nominal dan ordinal.
2. Pertanyaan mengenai persepsi desain
Pertanyaan meliputi pendapat konsumen tentang font style, warna background, serta penggunaan descriptive labelling pada buku menu.
Pengukuran terhadap faktor-faktor yang mempengaruhi persepsi konsumen tesebut menggunakan Likert Scale Method. Menurut Sugiyono (2004, p.84) skala likert dapat digunakan untuk mengukur sikap, pendapat, dan persepsi seseorang atau sekelompok orang mengenuai fenomena sosial. Penggunaan skala likert memungkinan responden untuk mengekspresikan intensitas perasaan konsumen dengan alternative jawaban yang disediakan dan diberi skor sesuai dengan jawaban responden. Pilihan jawaban yang disediakan adalah sebagai berikut:
1 = STS (Sangat tidak setuju) 2 = TS (Tidak setuju)
3 = N (Cukup Setuju) 4 = S (Setuju)
5 = SS (Sangat Setuju)
3. Pertanyaan mengenai persepsi atas kualitas service
Pertanyaan ini meliputi pendangan yang ditangkap responden mengenai kualitas dari restoran dalam buku menu tersebut, dengan menggunakan skala Likert seperti:
“Restoran ini termasuk restoran mewah”
3.5 Variabel dan Definisi Operasi Variabel
Variabel yang digunakan dalam penelitian adalah variabel bebas (independent variables) dan variabel yang dipengaruhi (dependent variables). Variabel bebas adalah faktor-faktor yang membentuk persepsi konsumen yang terdiri dari dimensi font style, warna background, dan penggunaan descriptive labelling pada buku menu. Variabel yang dipengaruhi pada penelitian ini adalah persepsi konsumen.
1. Variabel Terikat (Dependent Variable)
Persepsi konsumen sebagai dependent variable yang digunakan dalam penelitian ini adalah persepsi kualitas yang ditangkap responden akan sebuah restoran berdasarkan buku menunya. Dimana pada penelitian ini penulis menggunakan buku
menu restoran fiktif agar dapat lebih mengisolasi pengaruh persepsi yang ditimbulkan dari buku menu tanpa dipengaruhi persepsi yang responden dapatkan dari bentuk fisik restoran. Hal ini bertujuan agar hasil penelitian ini dapat menggambarkan secara akurat seberapa besarnya pengaruh buku menu dalam membentuk persepsi konsumen.
Indikator yang digunakan untuk mengukur variabel persepsi konsumen yang digunakan pada penelitian ini adalah sebagai berikut:
Y1. Font Style
Penggunaan font style italic akan meningkatkan persepsi konsumen akan kualitas suatu restoran
Y2. Background Color
Penggunaan background color hitam akan meningkatkan persepsi konsumen akan kualitas suatu restoran
Y3. Descriptive Label
Penggunaan descriptive label akan meningkatkan persepsi konsumen akan kualitas suatu restoran
2. Variabel Bebas (Independent Variables) X1. Font style
Variabel font style pada penelitian ini dibedakan menjadi buku menu yang menggunakan font style “Times New Roman” standar dan menu yang menggunakan font style “Times New Roman” italic. Indikator font syle yang digunakan pada penelitian ini adalah:
X1.1. Kemenarikan
Buku menu yang menggunakan font italic lebih menarik untuk dilihat.
X1.2. Kemewahan
Buku menu yang menggunakan font italic memberikan kesan restoran yang mewah.
X1.3. Antisipasi service
Buku menu yang menggunakan font italic akan mengakibatkan pembacanya mengantisipasi service yang lebih baik.
X2. Warna background
Variable warna background pada penelitian ini menggunakan background putih polos sebagai acuan dasar dan buku menu yang menggunakan warna background hitam yang diindikasikan dapat memberikan kesan lebih mewah dan berkelas (Allen, 2013). Indikator yang digunakan pada variabel warna background untuk penelitian ini adalah:
X2.1. Harga
Buku menu yang menggunakan warna background hitam akan membuat pembacanya merasa produk yang disediakan adalah produk yang mahal.
X2.2. Elegan
Buku menu yang menggunakan warna background hitam memberikan kesan restoran yang elegan.
X2.3. Kemewahan
Buku menu yang menggunakan warna background hitam memberikan kesan restoran yang mewah.
X3. Descriptive label
Variable descriptive label pada penelitian ini diukur berdasarkan ada tidaknya penggunaan label descriptive pada buku menu tersebut. Indikator yang digunakan pada variabel descriptive label untuk penelitian ini adalah:
X3.1. Kemewahan
Buku menu yang menggunakan descriptive label memberikan kesan restoran yang mewah.
X3.2. Kualitas
Buku menu yang menggunakan descriptive label memberikan kesan restoran yang menyediakan produk berkualitas.
X3.3. Antisipasi rasa
Buku menu yang menggunakan descriptive label menyebabkan pembacanya mengantisipasikan produk yang lezat.
3.6 Teknik Analisis Data
Setelah data-data terkumpul akan dilakukan pengujian validitas dan realibilitas agar hasil kesimpulan penelitian akurat. Pengujian validitas dan realibilitas dilakukan untuk setiap faktor atau variabel yang ada dalam kuesioner, bila dalam sebuah kuesioner terdapat enam faktor, maka pengujian validitas dan reliabilitas harus dilakukan enam kali. Apabila hasil dari pengujian tersebut tidak valid dan reliabel maka pengujian validitas dan reliabilitas ini diulang dengan mengeluarkan pertanyaan yang sama dan menggunakan prosedur yang sama sampai hasil dari pengujian tersebut valid dan reliabel.
3.6.1 Uji Validitas
Uji validitas digunakan untuk menguji apakah suatu kuesioner valid atau tidak.
Menurut Sarwono (2006), ada beberapa pertimbangan dalam penyusunan kuesioner yang akan menetukan validitas kuesioner tersebut. Pertama, sampai sejauh mana pertanyaan dapat mempengaruhi responden menunjukkan sikap yang positif terhadap hal-hal yang ditanyakan. Kedua, sampai sejauh mana suatu pertanyaan dapat mempengaruhi responden agar dengan suka rela membantu penulis dalam menemukan hal-hal yang akan dicari oleh penulis. Ketiga, sampai sejauh mana suatu pertanyaan menggali informasi yang responden sendiri tidak meyakini kebenarannya.
Lebih lanjut, uji validitas sebuah kuesioner dapat dilakukan dengan menghitung korelasi secara parsial dari masing-masing indikator dengan total variabel yang diteliti.
Apabila nilai korelasi tersebut menunjukkan signifikansi ≤0.05 maka item-item pertanyaan tersebut dikatakan valid dan dapat digunakan untuk analisis selanjutnya (Ghozali, 2005). Uji validitas dilakukan dengan menggunakan perangkat lunak SPSS (Statistic Package for Social Science) versi 15.00.
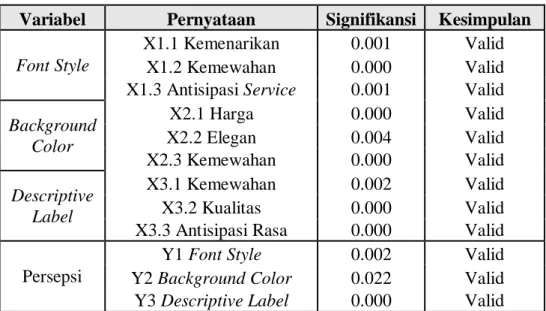
Pada uji validitas ini semua indikator dinyatakan valid karena nilai korelasi tiap indikator menunjukkan tingkat signifikansi dibawah ≤0.05. Nilai signifikansi tiap indikator dapat dilihat pada tabel berikut.
Tabel 3.1. Hasil Uji Validitas
Variabel Pernyataan Signifikansi Kesimpulan
Font Style
X1.1 Kemenarikan 0.001 Valid
X1.2 Kemewahan 0.000 Valid
X1.3 Antisipasi Service 0.001 Valid Background
Color
X2.1 Harga 0.000 Valid
X2.2 Elegan 0.004 Valid
X2.3 Kemewahan 0.000 Valid
Descriptive Label
X3.1 Kemewahan 0.002 Valid
X3.2 Kualitas 0.000 Valid
X3.3 Antisipasi Rasa 0.000 Valid Persepsi
Y1 Font Style 0.002 Valid
Y2 Background Color 0.022 Valid Y3 Descriptive Label 0.000 Valid
3.6.2 Uji Reliabilitas
Menurut Singarimbun dan Effendi (2006: 122) reliabilitas adalah istilah yang dipakai untuk menunjukan sejauh mana suatu hasil pengukuran relatif konsisten apabila pengukuran diulangi dua kali atau lebih. Dalam hal ini berarti hasil kuesioner diharapkan dapat menghasilkan nilai yang sama jika digunakan pada masa mendatang.
Uji reliabilitas akan dilakukan dengan menggunakan uji statistik cronbach’s alpha (𝛼) dengan ketentuan bahwa variabel yang diteliti dinyatakan reliabel apabila nilai cronbach’s alpha adalah di atas 0,6 (Ghozali, 2009, p.133).
Hasil uji reliabilitas yang telah dilakukan pada penilitian ini memunjukkan bahwa setiap pertanyaan dinyatakan reliabel. Nilai cronbach’s alpha kedua variabel dapat dilihat pada tabel berikut :
Tabel 3.2. Hasil Uji Reliabilitas
Variabel Alpha Kesimpulan
Font Style 0.704 Reliabel
Background Color 0.739 Reliabel
Descriptive Label 0.690 Reliabel
Persepsi 0.649 Reliabel
3.6.3 Analisis Statistik Deskriptif
Analisis statistik deskriptif adalah statistik yang digunakan untuk menganalisis data dengan cara mendeskripsikan atau menggambarkan data yang telah terkumpul sebagaimana adanya tanpa bermaksud membuat kesimpulan yang berlaku untuk umum (Sarwono, 2006, p.78). Dalam penelitian ini, analisis statistik deskriptif meliputi analisis frekuensi yang digunakan untuk melihat profil demografis dan profil perilaku responden.
Untuk menggambarkan skala penelitian yang lebih detail, maka penulis akan mengkategorikan mean yang didapat menggunakan interval poin yang dibedakan menjadi kelas – kelas berdasarkan hasil nilai maksimal dikurangi nilai minimal dan dibagi dengan jumlah kelas interval, yaitu (5-1)/5, sehingga akan didapati interval 0,8 poin, yang akan dibedakan menjadi kelas – kelas sebagai berikut:
Nilai 4,21 < 𝑥̅ ≤ 5,00 = Sangat setuju Nilai 3,41 < 𝑥̅ ≤ 4,20 = Setuju
Nilai 2,61 < 𝑥̅ ≤ 3,40 = Cukup Setuju Nilai 1,81 < 𝑥̅ ≤ 2,60 = Tidak setuju Nilai 1,00 < 𝑥̅ ≤ 1,80 = Sangat tidak setuju
Menurut Kuncoro (2003), standar deviasi adalah ukuran penyimpangan yang diperoleh dari akar kuadrat dari rata-rata jumlah kuadrat deviasi antara masing-masing nilai dengan rata-ratanya. Standar deviasi digunakan untuk mengetahui keragaman dari responden dengan hasil bahwa semakin kecil nilai standar deviasi, maka semakin homogen jawaban responden dan sebaliknya.
3.6.4. Analisa Regresi Linier Berganda
Analisa regresi berganda adalah suatu teknik ketergantungan (Sulaiman, 2004, pp. 79-80). Sehingga, dalam penggunaannya variabel penelitian harus dapat dibagi menjadi variabel dependen dan variabel independen. Analisis regresi juga merupakan alat statistik yang digunakan bila variabel dependen dan independen berbentuk metrik.
Walaupun dalam keadaan tertentu variabel independen yang berupa data non-metrik dapat juga digunakan.
3.6.4.1.Uji Asumsi Klasik
Uji asumsi klasik digunakan untuk memastikan persyaratan untuk menggunakan formulasi regresi berganda. Adapun persyaratan ini bahwa diantara variabel bebas penelitian tidak boleh terjadi multikolinearitas, normalitas, heterokedastisitas (Algifari, 2000, pp. 84-89).
1. Multikolinearitas
Pengujian ini bertujuan untuk menguji apakah dalam model regresi ditemukan adanya korelasi antar variabel independen. Model regresi yang baik seharusnya tidak terjadi korelasi di antara variabel independen. Multikolinieritas dapat disebabkan karena adanya efek kombinasi dua atau lebih variabel independen. Untuk mendeteksinya di dalam model, berikut adalah kriterianya:
a. Nilai R2 yang dihasilkan oleh suatu estimasi model regresi empiris sangat tinggi namun secara individual variabel independen tidak signifikan mempengaruhi variabel dependen.
b. Jika dalam matriks korelasi variabel independen, ada korelasi variabel independen yang cukup tinggi, umumnya di atas 0.9, maka hal ini merupakan indikasi adanya multikolinieritas.
c. Multikolinieritas dapat juga dilihat dari nilai toleransi dan lawannya variance inflation factor (VIF). Nilai yang umum digunakan untuk menunjukkan adanya multikolinieritas adalah nilai toleransi kurang dari 0,1 atau VIF lebih dari sama dengan 10.
2. Normalitas
Uji normalitas bertujuan untuk menguji apakah dalam model regresi, variabel pengganggu atau residual memiliki distribusi normal. Dalam uji t dan uji F mengasumsikan bahwa nilai residual mengikuti distribusi normal. Apabila asumsi ini dilanggar, maka uji statistik menjadi tidak valid untuk jumlah sampel kecil. Normalitas dapat dideteksi dengan melihat penyebaran data (titik) pada sumbu diagonal dari grafik
atau dengan melihat histrogram dari residualnya. Jika data menyebar di sekitar garis diagonal dan mengikuti arah garis diagonal atau grafik histogramnya menunjukkan pola distribusi normal maka model regresi memenuhi asumsi normalitas. Namun jika data menyebar jauh dari diagonal dan atau tidak mengikuti arah garis diagonal atau grafik histogram tidak menunjukkan pola distribusi normal, maka model regresi tidak memenuhi asumsi normalitas (Ghozali, 2009, pp.147-149).
3. Heterokedastisitas
Heterokedastisitas adalah variasi variabel dalam model tidak sama. Uji ini dimaksudkan untuk mengetahui apakah terjadi penyimpangan model karena penafsiran (estimator) yang diperoleh tidak efisien. Mendeteksi heterokedastisitas dapat dilakukan dengan melakukan pengujian korelasi ranking Spearman. Korelasi ranking Spearman (rs) dapat dihitung dengan formula:
𝑟3 = 1 − 6 ( ∑ 𝒅𝟏
𝟐 𝑵 (𝑵𝟐−𝟏))
yang menyatakan bahwa:
𝑑1 : Selisih ranking standar deviasi (S) dan ranking nilai mutlak error (e) Nilai e = Y – Y
𝑁 : Banyaknya sampel
Pengujian ini menggunakan distribusi t dengan membandingkan nilai t hitung dengan t tabel. Jika nilai t hitung lebih besar dari t tabel, maka pengujian menolak H0
yang menyatakan tidak terdapat heterokedastisitas pada model regresi. Artinya, model tersebut mengandung heterokedastisitas. Nilai t hitung dapat ditentukan dengan formula:
𝑡 = 𝑟3√𝑁−2
√1− 𝑟32
(3.2.)
(3.3.)
Nilai t hitung ini dibandingkan dengan nilai t tabel yang ditentukan melalui tabel distribusi t pada yang digunakan dan degree freedom (df) = N-2. Selain itu, diagnosis terhadap kemungkinan adanya heterokedastisitas dalam suatu model regresi adalah dengan melakukan uji Glejser, yaitu dengan melibatkan nilai absolute residual (|𝑒|) sebagai variabel terikat terhadap semua variabel bebas. Jika semua variabel bebas signifikan secara statistik, maka dalam model terdapat heteroskedastisitas. Uji Park juga dapat digunakan untuk diagnosis ini. Uji Park dilakukan dengan membuat model regresi yang melibatkan nilai logaritma residual kuadrat (log 𝑒2) sebagai variabel terikat terhadap semua variabel bebas. Jika semua variabel bebas signifikan secara statistik, maka dalam model terdapat heterokedastisitas.
3.6.4.2. Regresi Linier Berganda
Analisa regresi mengukur hubungan antara variabel dependen yang bersifat metrik dengan satu atau lebih variabel independen yang juga bersifat metrik. Analisis regresi berganda menguji secara serempak kemampuan variabel independen dalam menjelaskan variasi nilai variabel dependen (Cooper & Schindler, 2008, pp. 546-547).
Berikut adalah penjabaran dari rumus regresi berganda:
𝑌 = 𝛼 + 𝛽1𝑋1 + 𝛽2𝑋2+ 𝛽3𝑋3+ ⋯ + 𝛽𝑘𝑋𝑘
Keterangan:
𝑌 : Variabel dependen
𝑋 : Variabel independen (prediktor)
: Konstanta
: Koefisien regresi variabel (𝑋)
3.6.4.3.Analisa Korelasi dan Determinasi secara serempak
Digunakan untuk mencari keeratan hubungan antara semua variabel bebas secara serempak (simultan) terhadap variabel terikat digunakan koefisien korelasi
(3.4.)
berganda. Informasi mengenai nilai korelasi dan determinasi simultan ini berdasarkan pada hasil pengolahan data menggunakan SPSS. Nilai R terletak antara 0 dan 1 (0 < R
< 1), yang mana apabila nilai R = 1, maka kontribusi variabel-variabel bebas terhadap variabel terikat adalah 100%, sedangkan bila R mendekati 0, berarti tidak ada kontribusi dari variabel-variabel bebas terhadap variabel terikat (Ghozali, 2009, p.97).
3.6.4.4. Analisa Koefisien Determinasi Berganda Disesuaikan (Adjusted R2)
Menurut Pratisto (2004, p.118) adjusted R2 merupakan koreksi dari R2 sehingga gambarannya lebih mendekati ketepatan model dalam populasi, R2 yang disesuaikan dirumuskan sebagai berikut:
𝑎𝑑𝑗𝑢𝑠𝑡𝑒𝑑 𝑅2 = 1 − (1 − 𝑅2) [𝑛−1
𝑛−𝑘]
Keterangan:
𝑛 : Jumlah sampel 𝑘 : Jumlah parameter
Dalam penelitian ini besarnya koefisien determinasi berganda disesuaikan (adjusted R2) dicari dengan menggunakan alat bantu perangkat lunak komputer dengan program SPSS.
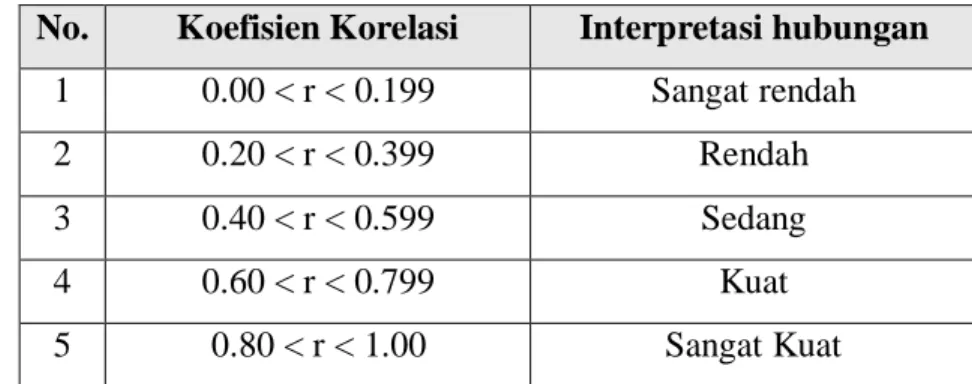
Tabel 3.3. Tabel Interpretasi Nilai Koefisien Korelasi No. Koefisien Korelasi Interpretasi hubungan
1 0.00 < r < 0.199 Sangat rendah 2 0.20 < r < 0.399 Rendah 3 0.40 < r < 0.599 Sedang
4 0.60 < r < 0.799 Kuat
5 0.80 < r < 1.00 Sangat Kuat
(3.5.)
3.6.5. Uji Hipotesis
Pengujian hipotesis dengan alat uji bertujuan untuk mengetahui seberapa besar pengaruh variabel bebas terhadap tergantung baik secara simultan maupun secara parsial. Uji hipotesis dilakukan menggunakan alat uji statistik uji F dan uji t.
3.6.5.1. Uji Fit Model
Untuk menguji apakah model penelitian memiliki azas kelayakan maka peneliti menggunakan Uji F sebagai alat pengujian (Cooper & Schindler, 2008, p.159). Adapun langkah-langkah pengujian sebagai berikut:
1. Merumuskan hipotesis statistik
H0 : Font style berpengaruh tidak signifikan terhadap persepsi konsumen akan kualitas suatu restoran
H1 : Font style berpengaruh signifikan terhadap persepsi konsumen 2. Mencari nilai F hitung
3. Mencari nilai F tabel
4. Membandingkan nilai F hitung dengan F tabel, kemudian menentukan penerimaan atau penolakan atas dasar hipotesis kerja.
5. Kriteria penolakan dan penerimaan hipotesis yaitu dengan membandingkan nilai F hitung dengan nilai F tabel:
Bila F hitung < F tabel, maka H0 diterima dan H1 ditolak
Bila F hitung > F tabel, maka H0 ditolak dan H1 diterima
3.6.5.2.Uji t
Uji t pada dasarnya digunakan untuk menunjukkan apakah satu variabel bebas secara individu atau parsial memiliki pengaruh yang signifikan terhadap variabel terikat (Kuncoro, 2003, p.218). Langkah pengujian uji-t adalah sebagai berikut:
1. Merumuskan hipotesis statistik:
H0 : Font style berpengaruh tidak signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
H1 : Font style berpengaruh signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
H0 : Background color berpengaruh tidak signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
H1 : Background color berpengaruh signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
H0 : Descriptive label berpengaruh tidak signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
H1 : Descriptive label berpengaruh signifikan terhadap persepsi konsumen akan kualitas suatu restoran.
2. Mencari nilai t hitung 3. Mencari nilai t tabel
4. Membandingkan nilai t hitung dengan t tabel, kemudian menentukan penerimaan atau penolakan atas dasar hipotesis kerja.
5. Kriteria penolakan dan penerimaan hipotesis yaitu dengan membandingkan nilai t hitung dengan nilai t tabel:
Bila t hitung < t tabel, maka H0 diterima dan H1 ditolak
Bila t hitung > t tabel, maka H0 ditolak dan H1 diterima