Perbandingan 5 Algoritma Data Mining untuk Klasifikasi Data Peserta Didik
Imam Sutoyo AMIK BSI JAKARTA e-mail: [email protected]
Abstrak - Klasifikasi peserta didik merupakan kegiatan yang sangat penting untuk dilaksanakan oleh penyelengara program pendidikan agar kegiatan pembelajaran menjadi lebih efektif. Berdasarkan hasil klasifikasi ini nantinya penyelengara program pendidikan dapat mengelompokkan peserta program pendidikannya sehingga kegiatan pembelajaran dapat disesuaikan dengan kelompok-kelompok tersebut. Metode tradisional untuk melaksanakan klasifikasi ini adalah dengan mengurutkan peserta didik berdasarkan nilai akhir mereka kemudian membagi mereka berdasarkan ukuran tertentu. Metode yang lebih baik adalah dengan menggunakan algoritma Data Mining. Pada paper ini akan dibahas lima jenis algoritma Data Mining untuk melaksanakan proses klasifikasi. Lima algoritma Data Mining tersebut akan dibandingkan satu sama lain untuk mencari algoritma terbaik. Validasi dilaksanakan menggunakan 10-Fold Cross Validation untuk menentukan algoritma yang memberikan akurasi paling tinggi.
Berdasarkan percobaan, didapatkan hasil bahwasanya Decision Tree C 4.5 memberikan hasil terbaik dengan akurasi 96.73 %.
Kata Kunci: Data Mining, Klasifikasi, Perbandingan, 10-Fold Cross Validation
I. PENDAHULUAN
Pada saat sebuah penyelengara program pendidikan membuka sebuah program pendidikan, banyak faktor yang akan mempengaruhi efektifitas program pendidikan tersebut. Efektifitas disini artinya adalah ukuran tercapai atau tidaknya tujuan dari program pendidikan tersebut. Beberapa faktor penting yang mempengaruhi efektifitas tersebut selain kurikulum, materi, pengajar, sarana dan prasarana, faktor yang sangat penting lainnya adalah pengelompokkan peserta didik.
Metode yang paling sederhana untuk pengelompokkan ini adalah dengan mengurutkan peserta didik berdasarkan nilai akhir mereka kemudian membagi mereka berdasarkan ukuran tertentu, misalnya jumlah maksimal dalam satu kelas. Misalnya, jika dibagi menjadi 3 kelas maka kelas pertama yang merupakan kelas atas berisi peserta didik dengan nilai akhir tertinggi, kelas ketiga yang merupakan kelas bawah berisi peserta didik dengan nilai terendah, dan kelas kedua berisi dengan peserta didik dengan nilai diantara kedua kelas atas dan kelas bawah tersebut.
Jadi, metoda klasifikasi sederhana tersebut hanya menggunakan satu attribut saja untuk menentukan seorang peserta didik akan masuk ke kelas yang mana, yakni nilai akhir yang sifat attribut-nya numerik. Meskipun nilai akhir tersebut mungkin dihitung berdasarkan beberapa variabel yang tidak semuanya merupakan hasil evaluasi seperti ujian, misalnya jumlah kehadiran. Namun, para peneliti di bidang Data Mining telah menghasilkan banyak algoritma klasifikasi yang dapat digunakan untuk melaksanakan klasifikasi dengan cara yang lebih baik dengan menggunakan beragam attribut, baik sifatnya numerik maupun nominal.
Untuk mengetahui algoritma klasifikasi yang paling efektif untuk melaksanakan klasifikasi ini maka
mereka perlu dibandingkan. Berdasarkan hasil perbandingan nantinya dapat dipilih algoritma yang paling tinggi akurasinya. Algoritma terpilih ini nantinya dapat digunakan untuk membuat model klasifikasi yang selanjutnya dapat digunakan untuk melaksanakan pengelompokkan peserta didik.
II. LANDASAN TEORI 2.1. Definisi Klasifikasi
Klasifikasi adalah sebuah proses analisa data yang menghasilkan model-model untuk menggambarkan kelas-kelas yang terkandung dari data tersebut (Han, 2012). Model - model tersebut disebut classifier. Jadi, classifier inilah yang akan digunakan untuk menyusun kelas-kelas yang terkandung dari data, misalnya untuk Decision Tree maka kelas-kelas tersebut digambarkan dalam bentuk pohon.
Para peneliti di bidang Data Mining telah memperkenalkan banyak jenis dari classifier. Berikut daftar lima jenis classifier yang akan dibandingkan pada paper ini.
2.1.1. Decision Tree
Decision Tree digunakan untuk mempelajari klasifikasi dan prediksi pola dari data dan menggambarkan relasi dari variabel attribut x dan variabel target y dalam bentuk pohon (Ye, 2014).
Decision Tree adalah struktur menyerupai flowchart dimana setiap internal node (node yang bukan leaf atau bukan node terluar) merupakan pengujian terhadap variabel attribut, tiap cabangnya merupakan hasil dari pengujian tersebut, sedangkan node terluar yakni leaf menjadi labelnya (Han, 2012).
Gambar 1. Decision Tree
2.1.2. Naive Bayes
Naive Bayes adalah algoritma yang cara kerjanya berdasarkan Theorema Bayes dengan mengasumsikan bahwa pengaruh dari nilai sebuah attribut dari sebuah kelas sifatnya independen dari nilai attribut-attribut lainnya (Han, 2012). Asumsi tersebut dibuat untuk menyederhanakan proses komputasi (Han, 2012). Intisari dari Theorema Bayes adalah untuk mencari probabilitas sebuah tupel X untuk menjadi bagian dari sebuah kelas C dengan syarat deskripsi attribut dari X telah diketahui dengan jelas (Han, 2012).
Sumber: en.wikipedia.org
Gambar 2. Theorema Bayes
2.1.3. k-NN
Algoritma k-NN bekerja dengan belajar berdasarkan analogi, yakni dengan membandingkan test tuple dengan training tuple yang serupa dengannya. Seluruh training tuple disimpan dalam sebuah ruang n-dimensi pola. Saat diberikan tupel yang tidak diketahui, k-NN akan mencari sejumlah (k) training tuple yang terdekat dengan tuple yang tidak diketahui tersebut (Han, 2012).
Sumber: en.wikipedia.org Gambar 3. k-NN
2.1.4. Random Forest
Random Forest bekerja dengan membangun
sejumlah Decision Tree dengan memilih attribut secara acak. Setiap individual Decision Tree disusun dengan cara memilih attribut-attribut secara acak pada tiap node untuk menentukan pemecahan pada node tersebut (Han, 2012).
2.1.5. Artificial Neural Networks (ANNs)
Artificial Neural Networks (ANNs) didesain untuk meniru cara kerja dari otak manusia dengan tujuan untuk membuat kecerdasan buatan yang meniru kecerdasan manusia. Arsitektur ANNs seperti halnya otak manusia, yakni terdiri dari neuron-neuron yang saling berhubungan. Pada ANNs, neuron-neuron ini adalah unit-unit pemrosesan (Ye, 2014). Unit-unit pemrosesan ini dapat saling bertukar pesan satu sama lain dan mereka masing-masing memiliki bobot yang dapat berubah sesuai dengan pengalaman atau hasil belajar.
Sumber: en.wikipedia.org
Gambar 4. Artificial Neural Networks
III. Metode Penelitian
Seluruh algoritma klasifikasi melaksanakan prinsip dasar klasifikasi, yakni mereka akan membagi kelas-kelas dari dataset yang diberikan. Pada paper ini, kelima algoritma yang telah dipaparkan pada bagian sebelumnya akan dibandingkan untuk membuat classifier dari sebuah dataset yang sama dalam bentuk sebuah studi kasus di sebuah lembaga penyelenggara program pendidikan.
Sebuah lembaga penyelengara program pendidikan melaksanakan kegiatan pembelajaran secara offline dan online. Peserta program pendidikan tersebut mengikuti pemaparan materi ajar melalui metode tatap muka di kelas sedangkan untuk evaluasi materi yang telah diberikan dilaksanakan secara online. Lembaga ini ingin mengklasifikasikan peserta program tersebut menjadi tiga kelas, yakni kelas atas, kelas tengah, dan kelas bawah.
3.1. Dataset
Dataset yang akan digunakan untuk training adalah data pengerjaan evaluasi secara online. Berikut attribut dari dataset:
1. ID_SISWA: Nomor induk peserta didik, sifatnya numerik, mengidentifikasikan setiap peserta didik secara unik.
2. NAMA_SISWA: Nama peserta didik.
3. JUMLAH_SESI: Jumlah sesi pengerjaan quiz online, sifatnya numerik. Jumlah minimalnya 0 artinya siswa
tersebut tidak pernah mengerjakan dan maksimal 50.
4. NILAI_RATA-RATA: Nilai rata-rata dari seluruh sesi pengerjaan quiz, sifatnya numerik. Nilai minimalnya 0 dan maksimalnya 100.
5. KELAS: Kelas dari siswa yang didapatkan dengan mengurutkan siswa berdasarkan 2 variabel, yaitu Nilai Rata-rata dan Jumlah Pengerjaan Quiz. Sifatnya nominal, yaitu A untuk Kelas Atas, B untuk Kelas Menengah ke Atas, dan C untuk Kelas Menengah ke Bawah, dan D untuk Kelas Bawah.
3.2. Kerangka Kerja Perbandingan
Untuk melaksanakan perbandingan digunakan Rapidminer. Kerangka kerja perbandingan ditunjukkan pada gambar 5.
Gambar 5. Kerangka kerja perbandingan
Berikut ini keterangan kerangka kerja perbandingan pada gambar 5.
1. Attribut-attribut dari dataset yang digunakan adalah JUMLAH_SESI dan NILAI_RATA-RATA.
2. Algoritma klasifikasi yang digunakan adalah Decision Tree, Naive Bayes, k-NN, Random Forest, dan Artificial Neural Networks (ANNs) .
3. Model validasi yang digunakan adalah 10-fold cross- validation, artinya data training dibagi menjadi 10 bagian yang sama dan proses pembelajaran dilaksanakan sebanyak 10 kali.
4. Model evaluasi yang digunakan menggunakan accuracy sebagai indikator kinerja dari classifier.
5. Untuk uji beda digunakan T-Test.
IV. PEMBAHASAN
Berdasarkan kerangka kerja yang telah dijelaskan pada bagian sebelumnya didapatkan hasil percobaan sebagai berikut:
4.1. Hasil Klasifikasi k-NN
k-NN menunjukkan presisi yang kurang bagus, terutama untuk klasifikasi kelas C. Hasil lengkapnya disajikan pada confusion matrix berikut ini.
Tabel 1. Confusion Matrix k-NN
Penjelasan perhitungan accuracy dari Confusion Matrix k-NN di atas adalah sebagai berikut:
1. pred A – true A: Jumlah record yang diprediksi masuk ke kelas A dan ternyata benar record tersebut termasuk kelas A sebanyak 27 record.
2. pred B – true B: Jumlah record yang diprediksi masuk ke kelas B dan ternyata benar record tersebut termasuk kelas B sebanyak 24 record.
3. pred C – true C: Jumlah record yang diprediksi masuk ke kelas C dan ternyata benar record tersebut termasuk kelas C sebanyak 24 record.
4. pred D – true D: Jumlah record yang diprediksi masuk ke kelas D dan ternyata benar record tersebut termasuk kelas D sebanyak 29 record.
Jumlah dari A + B + C + D disebut True Positive (TP). 27 + 24 + 24 + 29 = 104. Jadi, jumlah record yang berhasil diprediksi dengan tepat oleh Classifier k-NN sebanyak 104 record. Jumlah seluruh record adalah 123 record sehingga accuracy dihitung dengan (104/123)*100% = 85%.
4.2. Hasil Klasifikasi Naive Bayes
Naive Bayes menunjukkan presisi yang kurang bagus, bahkan lebih buruk dibandingkan k-NN untuk klasifikasi kelas C. Hasil lengkapnya disajikan pada confusion matrix berikut ini.
Tabel 2. Confusion Matrix Naive Bayes
Penjelasan perhitungan accuracy dari Confusion Matrix Naïve Bayes di atas adalah sebagai berikut:
1. pred A – true A: Jumlah record yang diprediksi masuk ke kelas A dan ternyata benar record tersebut termasuk kelas A sebanyak 29 record.
2. pred B – true B: Jumlah record yang diprediksi masuk ke kelas B dan ternyata benar record tersebut termasuk kelas B sebanyak 27 record.
3. pred C – true C: Jumlah record yang diprediksi masuk ke kelas C dan ternyata benar record tersebut termasuk kelas C sebanyak 28 record.
4. pred D – true D: Jumlah record yang diprediksi masuk ke kelas D dan ternyata benar record tersebut termasuk kelas D sebanyak 28 record.
Jumlah dari A + B + C + D disebut True Positive (TP). 29 + 27 + 28 + 28 = 112. Jadi, jumlah record yang berhasil diprediksi dengan tepat oleh Classifier Naïve Bayes sebanyak 112 record. Jumlah seluruh record adalah 123 record sehingga accuracy dihitung dengan (112/123)*100% = 91%.
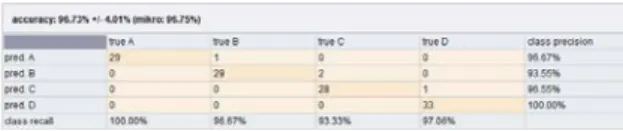
4.3. Hasil Klasifikasi C 4.5
C 4.5 menunjukkan presisi yang sempurna untuk klasifikasi kelas D. Hasil lengkapnya disajikan pada confusion matrix berikut ini.
Tabel 3. Confusion Matrix C 4.5
Penjelasan perhitungan accuracy dari Confusion Matrix C 4.5 di atas adalah sebagai berikut:
1. pred A – true A: Jumlah record yang diprediksi masuk ke kelas A dan ternyata benar record tersebut termasuk kelas A sebanyak 29 record.
2. pred B – true B: Jumlah record yang diprediksi masuk ke kelas B dan ternyata benar record tersebut termasuk kelas B sebanyak 29 record.
3. pred C – true C: Jumlah record yang diprediksi masuk ke kelas C dan ternyata benar record tersebut termasuk kelas C sebanyak 28 record.
4. pred D – true D: Jumlah record yang diprediksi masuk ke kelas D dan ternyata benar record tersebut termasuk kelas D sebanyak 33 record.
Jumlah dari A + B + C + D disebut True Positive (TP). 29 + 29 + 28 + 33 = 119. Jadi, jumlah record yang berhasil diprediksi dengan tepat oleh Classifier Decision Tree sebanyak 119 record. Jumlah seluruh record adalah 123 record sehingga accuracy dihitung dengan (119/123)*100% = 97 %.
4.4. Hasil Klasifikasi Random Forest
Random Forest menunjukkan presisi yang sempurna untuk klasifikasi kelas D, seperti C 4.5.
Hasil lengkapnya disajikan pada confusion matrix berikut ini.
Tabel 4. Confusion Matrix Random Forest
Penjelasan perhitungan accuracy dari Confusion Matrix Random Forest di atas adalah sebagai berikut:
1. pred A – true A: Jumlah record yang diprediksi masuk ke kelas A dan ternyata benar record tersebut termasuk kelas A sebanyak 29 record.
2. pred B – true B: Jumlah record yang diprediksi masuk ke kelas B dan ternyata benar record tersebut termasuk kelas B sebanyak 28 record.
3. pred C – true C: Jumlah record yang diprediksi masuk ke kelas C dan ternyata benar record tersebut termasuk kelas C sebanyak 28 record.
4. pred D – true D: Jumlah record yang diprediksi masuk ke kelas D dan ternyata benar record tersebut termasuk kelas D sebanyak 33 record.
Jumlah dari A + B + C + D disebut True Positive (TP). 29 + 28 + 28 + 33 = 118. Jadi, jumlah record yang berhasil diprediksi dengan tepat oleh Classifier Random Forest sebanyak 118 record.
Jumlah seluruh record adalah 123 record sehingga accuracy dihitung dengan (118/123)*100% = 96 %.
4.5. Hasil Klasifikasi ANNs
ANNs menunjukkan presisi yang sempurna untuk klasifikasi kelas D, seperti C 4.5 dan Random Forest. Namun, presisi untuk kelas A tidak bagus.
Hasil lengkapnya disajikan pada confusion matrix berikut ini.
Tabel 5. Confusion Matrix ANNs
Penjelasan perhitungan accuracy dari Confusion Matrix ANNs di atas adalah sebagai berikut:
1. pred A – true A: Jumlah record yang diprediksi masuk ke kelas A dan ternyata benar record tersebut termasuk kelas A sebanyak 28 record.
2. pred B – true B: Jumlah record yang diprediksi masuk ke kelas B dan ternyata benar record tersebut termasuk kelas B sebanyak 23 record.
3. pred C – true C: Jumlah record yang diprediksi masuk ke kelas C dan ternyata benar record tersebut termasuk kelas C sebanyak 30 record.
4. pred D – true D: Jumlah record yang diprediksi masuk ke kelas D dan ternyata benar record tersebut termasuk kelas D sebanyak 32 record.
Jumlah dari A + B + C + D disebut True Positive (TP). 28 + 23 + 30 + 32 = 113. Jadi, jumlah record yang berhasil diprediksi dengan tepat oleh Classifier ANNs sebanyak 113 record. Jumlah seluruh record adalah 123 record sehingga accuracy dihitung dengan (113/123)*100% = 92 %.
4.6. Hasil Uji Beda
Untuk mengetahui perbandingan dari kelima algoritma yang digunakan pada percobaan digunakan T-Test untuk menguji perbedaan dari kelima algoritma tersebut. Pengujian menggunakan T-Test akan memasangkan setiap algoritma dengan seluruh algoritma lain sehingga total ada 10 pasangan atau 10 hasil T-Test. Hasilnya ditunjukkan pada tabel berikut ini.
Tabel 6. Hasil T-Test
Setiap algoritma diwakilkan oleh nilai akurasinya dengan skala nilai 0 sampai dengan 1.
Untuk nilai hasil T-Test juga memiliki skala yang
sama.
Sebagai patokan ukuran besarnya perbedaan digunakan alpha yang nilainya 0.05. Nilai hasil T-Test yang besarnya dibawah alpha menunjukkan adanya perbedaan yang cukup signifikan dari pasangan algoritma tersebut. Pada tabel, hasil seperti ini dicetak tebal.
Hasil T-Test yang terkecil ditunjukkan oleh pasangan algoritma k-NN dengan C 4.5, yaitu 0.004.
Ini menunjukkan, hasil dari klasifikasi menggunakan k-NN jika dibandingkan dengan menggunakan C 4.5 menunjukkan perbedaan yang paling signifikan diantara pasangan algoritma yang lain.
Hasil T-Test yang terbesar ditunjukkan oleh pasangan algoritma Naïve Bayes dengan ANNs, yaitu 0.879. Ini menunjukkan, hasil dari klasifikasi menggunakan Naïve Bayes jika dibandingkan dengan menggunakan ANNs menunjukkan perbedaan yang paling tidak signifikan diantara pasangan algoritma yang lain.
Berdasarkan ukuran akurasi maka C 4.5 merupakan algoritma yang terbaik untuk melaksanakan klasifikasi dari dataset yang digunakan dengan akurasi 97%.
V. KESIMPULAN
Berdasarkan percobaan yang telah dilaksanakan dapat ditarik kesimpulan bahwa algoritma yang terbaik untuk melaksanakan klasifikasi terhadap dataset mulai dari yang terbaik adalah Decision Tree, Random Forest, ANNs, Naïve Bayes, dan terakhir k-NN.
Tabel 7. Perbandingan Akurasi Classifier
k-NN memiliki akurasi yang paling kecil.
Untuk akurasi prediksi per-kelas, akurasi yang paling rendah adalah untuk prediksi KELAS C sedangkan akurasi tertinggi untuk prediksi KELAS D.
Naïve Bayes memiliki akurasi yang lebih tinggi dibanding k-NN. Untuk akurasi prediksi per- kelas, akurasi yang paling rendah adalah untuk prediksi KELAS C sedangkan akurasi tertinggi untuk prediksi KELAS D.
ANNs memiliki akurasi yang lebih tinggi dibanding Naïve Bayes. Untuk akurasi prediksi per- kelas, akurasi yang paling rendah adalah untuk prediksi KELAS A sedangkan akurasi tertinggi untuk prediksi KELAS D.
Random Forest memiliki akurasi yang lebih tinggi dibanding ANNs. Untuk akurasi prediksi per- kelas, akurasi yang paling rendah adalah untuk prediksi KELAS B dan KELAS C sedangkan akurasi tertinggi untuk prediksi KELAS D.
Kelima classifier sepakat mampu memprediksi dengan tingkat akurasi tertinggi untuk KELAS D. Adapun untuk akurasi terendah mereka berbeda-beda.
C 4.5 memiliki akurasi yang tertinggi dibanding yang lain. Untuk akurasi prediksi per- kelas, akurasi yang paling rendah adalah untuk prediksi KELAS B sedangkan akurasi tertinggi untuk prediksi KELAS D.
Penelitian ini dapat dikembangkan dengan menggunakan lebih banyak attribut pada dataset.
Attribut-attribut yang mungkin digunakan, misalnya kehadiran, nilai UTS, nilai UAS, dan sebagainya.
Selain itu, penelitian yang dapat dilakukan juga dengan menggunakan metode data mining lainnya, misalnya clustering menggunakan algoritma k-Mean.
Berdasarkan hasil penelitian ini maka dapat diadakan penelitian lanjutan untuk mengimplementasikan algoritma terbaik, yakni C 4.5 untuk membuat model klasifikasi yang dapat digunakan untuk mengklasifikasi dan memprediksi data peserta didik.
REFERENSI
Han, Jiawei (2012). Data Mining. Concept and Techniques Third Edition. Elsevier Inc.
Ye, Nong (2014). Data Mining. Theories, Algorithms, and Examples. Taylor & Francis Group, LLC.