31
BAB 3
ANALISIS DAN PERANCANGAN
3.1 Analisis Masalah
Berdasarkan identifikasi masalah yang sudah dijelaskan pada latar belakang penelitian ini, terdapat permasalahan belum diketahui performa yang dihasilkan oleh metode Elman Recurrent Neural Network (ERNN) sebagai algoritma klasifikasi sentimen pada aspek di kasus Aspect Based Sentiment
Analysis (ABSA) pada dataset bahasa Indonesia. Beberapa penelitian yang telah
dilakukan diantaranya B. Wang dan M. Liu [3] menggunakan algoritma CNN dengan fitur word embedding menghasilkan akurasi 79.3%. Kemudian Minh Tran [4] menggunakan Bidirectional GRU RNN dengan fitur word embedding, SenticNet, POS Tag, dan Distance yang menghasilkan akurasi 78.7%. Arsitektur RNN lain digunakan oleh D. Tarasov [5] dengan fitur word embedding yang menghasilkan akurasi untuk Bidirectional RNN 65.10% dan LSTM 69.70%.
Dari beberapa penelitian mengenai ABSA yang telah disebutkan menggunakan CNN dan beberapa arsitektur RNN, akurasi yang dihasilkan masih dibawah 80 persen yang mana masih dapat ditingkatkan lagi nilai akurasinya. Pada kasus fine grained opinion mining P. Liu, S. Joty dan H. Meng membandingkan beberapa arsitektur RNN dengan fitur SENNA embedding yang menghasilkan akurasi 81.36% untuk Elman RNN, 79.43% untuk LSTM dan 78.83% untuk Jordan RNN, arsitektur Elman mengungguli performa arsitektur RNN yang lain [6].
Oleh karena itu, pada penelitian ini algoritma ERNN digunakan untuk klasifikasi sentimen pada aspek agar diketahuinya akurasi yang dihasilkan algoritma ERNN pada kasus ABSA dalam dataset bahasa indonesia.
3.2 Analisis Sistem
Dalam implementasi ERNN pada kasus ABSA, dataset yang digunakan diambil dari penelitian A. Cahyadi, pada data latih aspek sudah ditentukan bersama sentimennya pada setiap kalimat. Sebelum masuk pada pelatihan ERNN
32
untuk klasifikasi sentimen, perlu dilakukan proses preprocessing. Tahap
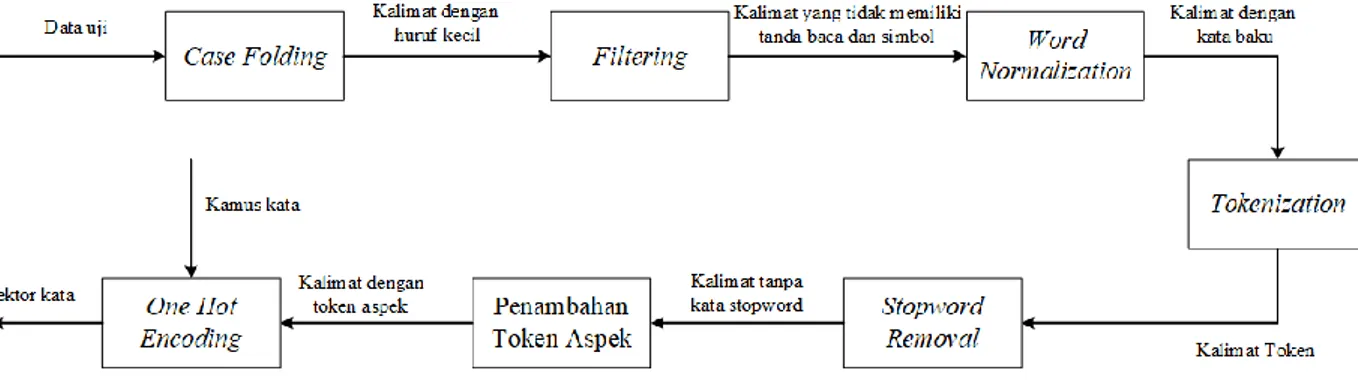
preprocessing ini meliputi tahap case folding, filtering, word normalization, tokenization, stopword removal, penambahan token aspek, pembangunan kamus
kata, dan one hot encoding. Selain kalimat pada data latih, kalimat pada data uji juga dilakukan preprocessing sebelum masuk tahap pengujian. Adapun gambaran umum dari sistem yang akan dibagun dapat dilihat pada Gambar 3.1.
33
Berikut merupakan penjelasan dari Gambar 3.1:
34
1. Data masukan (data latih dan data uji) diambil dari penelitian A. Cahyadi . Pada data latih aspek sudah ditentukan bersama sentimennya.
2. Pada proses pelatihan akan dilakukan preprocessing terhadap kalimat yang menjadi data latih, dimana dalam preprocessing dilakukan case
folding, filtering, word normalization, tokenization, stopword removal,
penambahan aspek token, pembangunan kamus kata dan one hot encoding. Pada tahap one hot encoding, setiap kata akan diubah menjadi vektor karena RNN tidak bisa memproses kata secara langsung. Vektor kata akan diproses oleh algoritma ERNN yang bertujuan menghasilkan bobot yang optimal dalam pengenalan pola yang ada pada data latih.
3. Pada proses pengujian akan dilakukan preprocessing terhadap kalimat yang menjadi data uji, preprocessing yang dilakukan pada proses pengujian sama dengan yang dilakukan di proses pelatihan. Setelah itu data uji yang sudah diubah menjadi vektor akan dilakukan pengujian menggunakan algoritma ERNN yang parameternya sudah dilatih pada tahap pelatihan sebelumnya. Hasil dari pengujian ini adalah sistem akan menampilkan akurasi dari algoritma ERNN.
3.2.1 Analisis Data Masukan
Data masukan yang akan digunakan pada penelitian ini diambil dari penelitian A. Cahyadi dimana terdapat 1584 kalimat untuk data latih dan 422 kalimat untuk data uji. Pada data latih di Tabel 3.1 Kolom Review (Ri) berisi kalimat dari review restoran yang aspeknya sudah ditentukan yaitu, Food (Fi), Price (Pi), Service (Si), dan Ambience (Ai). Masing-masing aspek pada Review (Ri) sudah dianotasi sentimennya yaitu, “0” untuk aspek yang bukan sentimen, “1” untuk aspek yang mempunyai sentimen positif, dan “2” untuk aspek yang mempunyai sentimen negatif.
Tabel 3.1 Contoh Data Latih
No Review (Ri) Food
(Fi) Price (Pi) Service (Si) Ambience (Ai)
35
tempatnya juga enak. lokasinya di tengah pusat perbelanjaan. tapi sayang harganya mahal.
2 sebenernya makanannya enak tapi harganya relatif mahal. Paling enak dimsum nya disana. MUST TRY!! :D
1 2 0 0
3 bareng makan sama temen, tempatnya enak bgt. makanannya juga enak tempatnya santai buat ngobrol.
1 0 0 1
4 Makanannya enakkkk aku sempet beli spaghetti sama pizza . Dan itu ga mengecewakann . Enakkkk keju nya kerasaaa
1 0 0 0
3.2.2 Analisis Preprocessing Data Latih
Preprocessing dilakukan untuk mengurangi noise dan menyeragamkan
data supaya memudahkan proses pelatihan dan proses pengujian. Adapun tahapan
preprocessing yang akan dilakukan yaitu, case folding, filtering, word normalization, tokenization, stopword removal, penambahan token aspek,
pembangunan kamus kata dan one hot encoding. Gambaran umum tahap
preprocessing dapat dilihat pada Gambar 3.2.
36
3.2.2.1 Case Folding
Case folding adalah proses konversi keseluruhan teks ke dalam bentuk
standar (biasanya huruf kecil atau lowercase). Pada penelitian ini semua huruf pada data masukan diubah menjadi huruf kecil agar mempermudah pengenalan kata pada proses algoritma utama. Proses case folding dapat dilihat pada Gambar
3.3.
Berdasarkan data latih pada Tabel 3.1 hasil proses case folding dapat dilihat pada Tabel 3.2. Pada tabel tersebut diperlihatkan kalimat sebelum dan sesudah melewati proses case folding.
Tabel 3.2 Hasil Case Folding
No Review (Ri) Hasil Case Folding
1 Makanannya enak banget!! juara!! tempatnya juga enak. lokasinya di tengah pusat perbelanjaan. tapi sayang harganya mahal.
makanannya enak banget!! juara!! tempatnya juga enak. lokasinya di tengah pusat perbelanjaan. tapi sayang harganya mahal.
2 Sebenernya makanannya enak tapi harganya relatif mahal. Paling enak dimsum nya disana. MUST TRY!! :D
sebenernya makanannya enak tapi harganya relatif mahal. Paling enak dimsum nya disana. must try!! :D
3 Bareng makan sama temen, tempatnya enak bgt. makanannya juga enak tempatnya santai buat ngobrol.
bareng makan sama temen, tempatnya enak bgt. makanannya juga enak tempatnya santai buat ngobrol.
4 Makanannya enakkkk aku sempet beli spaghetti sama pizza . Dan itu ga
Makanannya enakkkk aku sempet beli spaghetti sama pizza . dan itu Gambar 3.3 Proses Case Folding
37
mengecewakann . Enakkkk keju nya kerasaaa
ga mengecewakann . enakkkk keju nya kerasaaa
Berdasarkan Tabel 3.2, terdapat beberapa kata pada kalimat yang diubah setelah proses case folding, diantaranya “Makanannya” diubah menjadi “makanannya”, “Sebenernya” diubah menjadi “sebenernya”, “Bareng” diubah menjadi “bareng”, dan “Enakkkk” diubah menjadi “enakkkk”.
3.2.2.2 Filtering
Filtering adalah proses penghilangan simbol-simbol yang tidak diperlukan
dalam kalimat seperti tanda baca, angka dan emoticon. Proses ini dilakukan supaya menghilangkan noise yang terdapat pada kalimat agar tidak mengganggu
proses algortima utama. Proses filtering dapat dilihat pada Gambar 3.4.
Setelah melalui proses filtering maka kalimat sudah tidak memiliki simbol-simbol seperti tanda baca, angka, dan emoticon yang tidak diperlukan. Berikut adalah proses filtering yang dapat dilihat pada Tabel 3.3.
Tabel 3.3 Hasil Filtering
No Review (Ri) Hasil Filtering
1 makanannya enak banget!! juara!! tempatnya juga enak. lokasinya di tengah pusat perbelanjaan. tapi sayang harganya mahal.
makanannya enak banget juara tempatnya juga enak lokasinya di tengah pusat perbelanjaan tapi sayang harganya mahal
2 sebenernya makanannya enak tapi harganya relatif mahal. Paling enak dimsum nya disana. must try!! :D
sebenernya makanannya enak tapi harganya relatif mahal Paling enak dimsum nya disana must try 3 bareng makan sama temen, tempatnya
enak bgt. makanannya juga enak
bareng makan sama temen tempatnya enak bgt makanannya Gambar 3.4 Proses Filtering
38
tempatnya santai buat ngobrol. juga enak tempatnya santai buat ngobrol
4 makanannya enakkkk aku sempet beli spaghetti sama pizza . dan itu ga mengecewakann . enakkkk keju nya kerasaaa
Makanannya enakkkk aku sempet beli spaghetti sama pizza dan itu ga mengecewakann enakkkk keju nya kerasaaa
Berdasarkan Tabel 3.3 dapat dilihat tanda baca seperti tanda seru (!), titik (.), dan koma (,) dihilangkan dan emoticon “:D” juga dihilangkan sehingga kalimat bersih dari tanda baca dan emoticon yang tidak diperlukan.
3.2.2.3 Word Normalization
Word normalization adalah proses mengubah kata-kata tidak baku menjadi
kata baku. Pada proses ini kata-kata yang tidak baku seperti kata “enakkkk” akan diubah menjadi “enak” dan kata “ga”, “engga”, “gak”, “enggak” dan “gk” menjadi “tidak” agar pada proses pembentukan kamus kata, kata tersebut tidak dianggap berbeda. Gambaran proses word normalization ditunjukan pada Gambar 3.5.
Berdasarkan dari proses word normalization, hasil dari word
normalization dapat dilihat pada Tabel 3.4.
Tabel 3.4 Hasil Word Normalization
No Review (Ri) Hasil Word Normalization
1 makanannya enak banget juara tempatnya juga enak lokasinya di
makanannya enak banget juara tempatnya juga enak lokasinya di Gambar 3.5 Proses Word Normalization
39
tengah pusat perbelanjaan tapi sayang harganya mahal
tengah pusat perbelanjaan tapi sayang harganya mahal
2 sebenernya makanannya enak tapi harganya relatif mahal Paling enak dimsum nya disana must try
sebenernya makanannya enak tapi harganya relatif mahal Paling enak dimsum nya disana must try 3 bareng makan sama temen tempatnya
enak bgt makanannya juga enak tempatnya santai buat ngobrol
bareng makan sama temen tempatnya enak bgt makanannya juga enak tempatnya santai buat ngobrol
4 Makanannya enakkkk aku sempet beli spaghetti sama pizza dan itu ga mengecewakann enakkkk keju nya kerasaaa
makanannya enak aku sempet beli spaghetti sama pizza dan itu tidak mengecewakann enak keju nya kerasa
Pada proses word normalization, kata tidak baku seperti kata “enakkkk” diubah menjadi “enak” dan kata “engga” diubah menjadi “tidak.
3.2.2.4 Tokenization
Tokenization adalah proses pemisahan kata-kata dalam kalimat supaya
menjadi token kalimat. Pemisahan tersebut dilakukan dengan mengandalkan
karakter spasi pada kalimat. Proses tokenization ditunjukan pada Gambar 3.6. Setelah melalui proses tokenization kata-kata dalam kalimat dipecah menjadi sebuah token. Untuk lebih jelasnya proses tokenization dapat dilihat pada Tabel 3.5.
40
Tabel 3.5 Hasil Tokenization
No Review (Ri) Hasil Tokenization
1 makanannya enak banget juara tempatnya juga enak lokasinya di tengah pusat perbelanjaan tapi sayang harganya mahal
[“makanannya”, “enak”, “banget”, “juara”, “tempatnya”, “juga”, “enak”, “lokasinya”, “di”,
“tengah”, “pusat”,
“perbelanjaan”, “tapi”, “sayang”, “harganya”, “mahal”]
2 sebenernya makanannya enak tapi harganya relatif mahal paling enak dim sum nya disana must try
[“sebenernya”, “makanannya”, “enak”, “tapi”, “harganya”, “relatif”, “mahal”, “paling”, “enak”, “dimsum”, “nya”, “disana”, “must”, “try”]
3 bareng makan sama temen tempatnya enak bgt makanannya juga enak tempatnya santai buat ngobrol
[“bareng”, “makan”, “sama”, “temen”, “tempatnya”, “enak”, “bgt”, “makananya”, “juga”, “enak” “tempatnya”, “santai”. “buat”, “ngobrol”]
4 Makanannya enak aku sempet beli spaghetti sama pizza dan itu tidak mengecewakann enak keju nya kerasa
[“makananya”, “enak”, “aku”, “sempet”, “beli”, “spaghetti”, “sama”, “pizza”, “dan”, “itu”, “tidak”, “mengecewakan”, “enak”, “keju”, “nya”, “kerasa”]
3.2.2.5 Stopword Removal
Setelah melewati tahap tokenization, tahapan selanjutnya hasil dari proses
41
Proses stopword removal pada penelitian ini adalah penghilangan kata yang terdapat list stopword. Kata “stopword” biasanya merujuk pada kata-kata yang paling umum seperti kata “dan”, “dengan”, “di”, dan lain-lain. Proses stopword
removal dapat dilihat pada Gambar 3.7.
Setelah melalui proses stopword removal kalimat tidak mengandung kata stopword yang dapat membuat dimensi kamus kata menjadi besar. Hasil dari proses stopword removal dapat dilihat pada Tabel 3.6.
Tabel 3.6 Hasil Stopword Removal
No Review (Ri) Hasil Stopword Removal
1 [“makanannya”, “enak”, “banget”, “juara”, “tempatnya”, “juga”, “enak”, “lokasinya”, “di”, “tengah”, “pusat”, “perbelanjaan”, “tapi”, “sayang”, “harganya”, “mahal”]
[“makanannya”, “enak”,
“tempatnya”, “enak”, “lokasinya”, “perbelanjaan”, “harganya”, “mahal”]
2 [“sebenernya”, “makanannya”, “enak”, “tapi”, “harganya”, “relatif”, “mahal”, “paling”, “enak”, “dim”, “sum”, “nya”, “disana”, “must”, “try”]
[“makanannya”, “enak”, “harganya”, “mahal”, “enak”, “dimsum”]
3 [“bareng”, “makan”, “sama”, “temen”, “tempatnya”, “enak”, “bgt”, “makanannya”, “juga”, “enak” “tempatnya”, “santai”. “buat”, “ngobrol”]
[“makan”, “tempatnya”, “enak”, “makanannya”,“enak”
“tempatnya”, “santai”]
4 [“makanannya”, “enak”, “aku”, [“makanannya”, “enak”, Gambar 3.7 Proses Stopword Removal
42
“sempet”, “beli”, “spaghetti”, “sama”, “pizza”, “dan”, “itu”, “tidak”, “mengecewakan”, “enak”, “keju”, “nya”, “kerasa”]
“spaghetti”, “pizza”, “tidak”, “mengecewakan”, “enak”, “keju”]
3.2.2.6 Penambahan Token Aspek
Proses penambahan token aspek merupakan proses penambahan token yang merepresentasikan aspek pada setiap kalimat yang terdiri dari aspek FOOD, PRICE, SERVICE, DAN AMBIENCE sehingga setiap kalimat akan mempunyai 4 token aspek pada akhir kalimatnya yang bertujuan supaya algoritma ERNN (many to many) dapat melakukan prediksi terhadap aspek yang ada dalam kalimat. Pada penelitian ini kasus analisis sentimen berdasarkan aspek diasumsikan sebagai kasus multi label classification dimana setiap data masukan yang berupa kalimat mempunyai lebih dari 1 target label. Token aspek ditambahkan pada akhir kalimat secara otomatis oleh sistem baik pada data latih maupun pada data uji. Berikut token aspek yang akan ditambahkan di setiap kalimat ditunjukan oleh Tabel 3.7.
Tabel 3.7 Token Aspek No Token Aspek Keterangan
1 <FOOD> untuk memprediksi sentimen makanan dari restoran pada kalimat
2 <PRICE> untuk memprediksi sentimen harga dari restoran pada kalimat
3 <SERVICE> untuk memprediksi sentimen pelayanan dari restoran pada kalimat
4 <AMBIENCE> untuk memprediksi sentimen tempat/suasana dari restoran pada kalimat
43
Adapun proses penambahan token aspek dapat dilihat pada Gambar 3.8 Setelah melalui proses penambahan token aspek maka setiap array token akan mempunyai 4 token tambahan yang berupa token aspek. Hasil dari penambahan token aspek dapat dilihat pada Tabel 3.8.
Tabel 3.8 Hasil Penambahan Token Aspek
No Review (Ri) Hasil Penambahan Token Aspek
1 [“makanannya”, “enak”, “tempatnya”, “enak”, “lokasinya”, “perbelanjaan”, “harganya”, “mahal”]
[“makanannya”, “enak”,
“tempatnya”, “enak”, “lokasinya”, “perbelanjaan”, “harganya”, mahal”, “<FOOD>”, “<PRICE>”, “<SERVICE>”,
“<AMBIENCE>”] 2 [“makanannya”, “enak”, “harganya”,
“mahal”, “enak”, “dimsum”]
[“makanannya”, “enak”, “harganya”, “mahal”, “enak”, “dimsum” , “<FOOD>”, “<PRICE>”, “<SERVICE>”, “<AMBIENCE>”]
3 [“makan”, “tempatnya”, “enak”, “makananya”,“enak” “tempatnya”, “santai”]
[“makan”, “tempatnya”, “enak”, “makananya”,“enak”
“tempatnya”, “santai” , “<FOOD>”, “<PRICE>”, “<SERVICE>”,
“<AMBIENCE>”] 4 [“makananya”, “enak”, “spaghetti”, [“makananya”, “enak”,
44
“pizza”, “tidak”, “mengecewakan”, “enak”, “keju”]
“spaghetti”, “pizza”, “tidak”, “mengecewakan”, “enak”, “keju” , “<FOOD>”, “<PRICE>”, “<SERVICE>”,
“<AMBIENCE>”]
3.2.2.7 Pembangunan Kamus Kata
Pembangunan kamus kata adalah proses mengambil semua token berbeda dari data masukan untuk membentuk kamus kata yang unik. Kamus ini dibentuk karena untuk melakukan vektorisasi token pada proses one hot encoding mengandalkan kamus kata. Adapun gambaran pembentukan kamus dapat dilihat pada Gambar 3.9.
Untuk membangun kamus kata, data masukan adalah hasil dari proses
preprocessing “penambahan token aspek”. Data masukan akan dibaca per kalimat
kemudian per kata, kata-kata tersebut dimasukan kedalam kamus jika ada kata yang sudah ada dalam kamus maka tidak akan dimasukan lagi ke kamus sehingga kamus akan menghasilkan kumpulan kata unik atau berbeda. Pada pembangunan kamus kata akan ada penambahan token <UNKNOWN> dimana token tersebut berfungsi untuk mengatasi unseen word pada data uji [22] (kata yang tidak pernah ada dalam proses pelatihan) sehingga jika ada kata dalam data uji yang tidak ada dalam kamus kata data latih maka akan dianggap token <UNKNOWN>. Besar kamus kata berukuran K akan sama dengan jumlah kata unik atau berbeda pada data latih. Hasil kamus kata dapat dilihat pada Tabel 3.9.
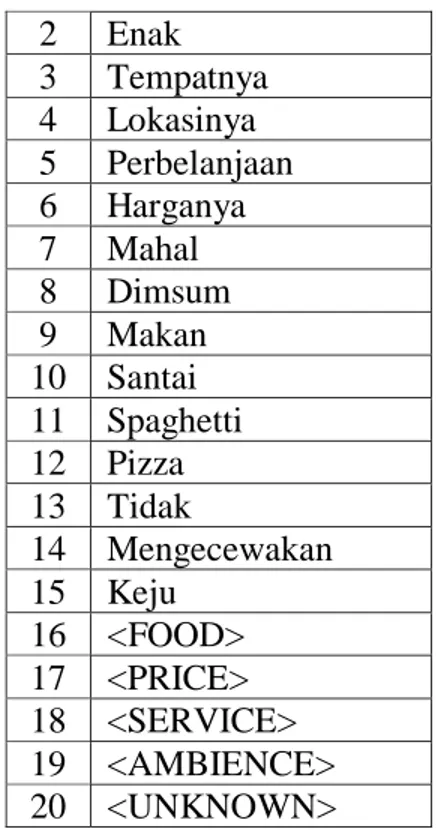
Tabel 3.9 Kamus Kata No Token
1 Makanannya
45 2 Enak 3 Tempatnya 4 Lokasinya 5 Perbelanjaan 6 Harganya 7 Mahal 8 Dimsum 9 Makan 10 Santai 11 Spaghetti 12 Pizza 13 Tidak 14 Mengecewakan 15 Keju 16 <FOOD> 17 <PRICE> 18 <SERVICE> 19 <AMBIENCE> 20 <UNKNOWN> 3.2.2.8 One Hot Encoding
Algoritma machine learning tidak bisa memproses data teks secara langsung. Oleh karena itu perlu dilakukan proses konversi data teks menjadi data numerik supaya bisa diproses oleh algoritma ERNN. One hot encoding akan memberikan ID kepada setiap token. ID adalah representasi angka yang akan menjadi vektor. Angka dari ID tersebut merupakan posisi kata dalam kamus kata
yang sudah dibangun. Proses one hot encoding ditunjukan pada Gambar 3.10. Setelah melewati tahap one hot encoding setiap token akan menjadi vektor berukuran K dimana semua elemen bernilai 0 kecuali hanya satu elemen yang bernilai 1 yaitu, posisi elemen yang sama dengan kata pada kamus kata.
46
Kalimat yang lain juga akan melalui proses one hot encoding supaya data latih yang sebelumnya berupa teks akan menjadi angka untuk dapat di proses algoritma ERNN. Token yang sudah menjadi vektor dapat dilihat pada tabel one
47
Tabel 3.10 Hasil One Hot Encoding Seluruh Token Data Latih
Kamus Kata Token maka nanny a enak tempa tnya lokasi nya perbel anjaa n harga nya mahal dimsu m maka n santai spagh
etti pizza tidak meng ecewa kan keju <FOO D> <PRI CE> <SER VICE > <AM BIEN CE> makanannya 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 enak 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 tempatnya 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 lokasinya 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 perbelanjaan 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 harganya 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 mahal 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 dimsum 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 makan 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 santai 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 spaghetti 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 pizza 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 tidak 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 mengecewak an 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 keju 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 <FOOD> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 <PRICE> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 <SERVICE> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 <AMBIENC E> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 <UNKNOW N> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
48
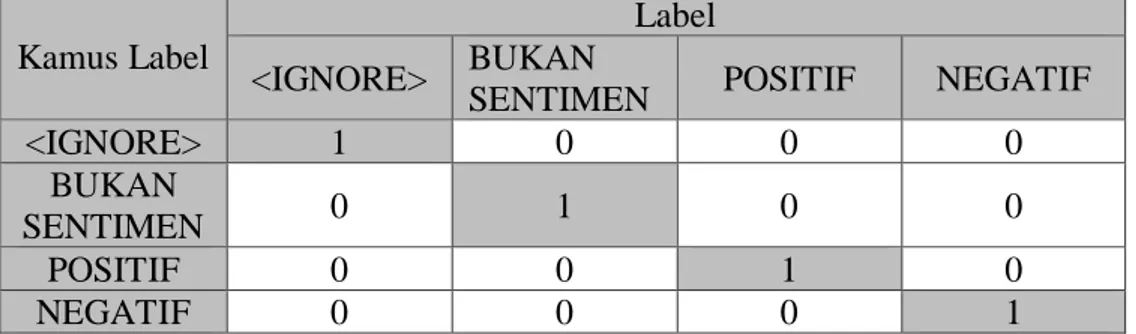
One hot encoding juga dilakukan pada label dengan cara yang sama
seperti yang dilakukan pada data latih. Setiap aspek memiliki positif, negatif, dan bukan sentimen yang akan dibuat kamus label sebagai berikut.
Tabel 3.11 Tabel Label Aspek
No Label
1 <IGNORE> 2 BUKAN SENTIMEN
3 POSITIF
4 NEGATIF
Pada Tabel 3.11 terdapat label <IGNORE>. Penambahan label <IGNORE> bertujuan untuk menyesuaikan bentuk arsitektur RNN many to many dimana token selain token aspek akan mempunyai label <IGNORE> pada saat menghitung keluaran nilai di output layer. Hasil one hot encoding setiap label dapat dilihat pada Tabel 3.12.
Tabel 3.12 Hasil One Hot Encoding Setiap Label
Kamus Label
Label <IGNORE> BUKAN
SENTIMEN POSITIF NEGATIF
<IGNORE> 1 0 0 0 BUKAN SENTIMEN 0 1 0 0 POSITIF 0 0 1 0 NEGATIF 0 0 0 1 3.2.2.9 Hasil Preprocessing
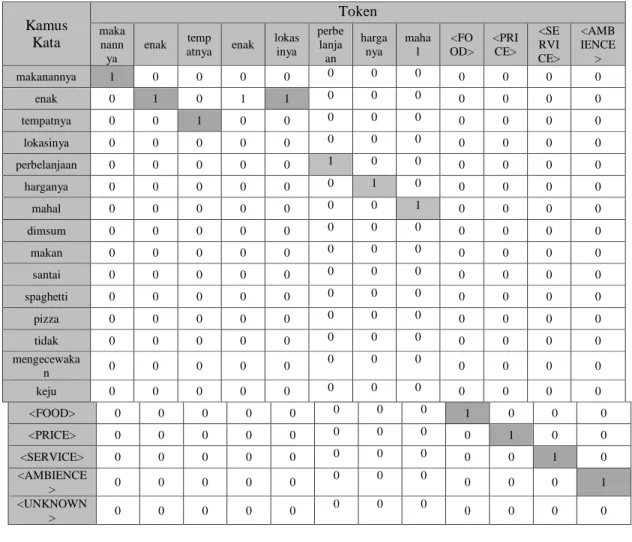
Hasil dari preprocessing adalah berupa vektor kata yang nantinya akan di proses oleh algoritma ERNN. Pada penelitian ini data latih 1 (kalimat 1) sebagai contoh yang akan diproses algoritma ERNN dimana hasil vektorisasi dari data latih 1 ditujukan pada Tabel 3.13.
49
Tabel 3.13 One Hot Encoding Data Latih 1
Kamus Kata Token maka nann ya enak temp atnya enak lokas inya perbe lanja an harga nya maha l <FO OD> <PRI CE> <SE RVI CE> <AMB IENCE > makanannya 1 0 0 0 0 0 0 0 0 0 0 0 enak 0 1 0 1 1 0 0 0 0 0 0 0 tempatnya 0 0 1 0 0 0 0 0 0 0 0 0 lokasinya 0 0 0 0 0 0 0 0 0 0 0 0 perbelanjaan 0 0 0 0 0 1 0 0 0 0 0 0 harganya 0 0 0 0 0 0 1 0 0 0 0 0 mahal 0 0 0 0 0 0 0 1 0 0 0 0 dimsum 0 0 0 0 0 0 0 0 0 0 0 0 makan 0 0 0 0 0 0 0 0 0 0 0 0 santai 0 0 0 0 0 0 0 0 0 0 0 0 spaghetti 0 0 0 0 0 0 0 0 0 0 0 0 pizza 0 0 0 0 0 0 0 0 0 0 0 0 tidak 0 0 0 0 0 0 0 0 0 0 0 0 mengecewaka n 0 0 0 0 0 0 0 0 0 0 0 0 keju 0 0 0 0 0 0 0 0 0 0 0 0 <FOOD> 0 0 0 0 0 0 0 0 1 0 0 0 <PRICE> 0 0 0 0 0 0 0 0 0 1 0 0 <SERVICE> 0 0 0 0 0 0 0 0 0 0 1 0 <AMBIENCE > 0 0 0 0 0 0 0 0 0 0 0 1 <UNKNOWN > 0 0 0 0 0 0 0 0 0 0 0 0
Adapun label dari masing-masing token pada data latih 1 ditunjukan Tabel 3.14.
Tabel 3.14 One Hot Encoding Label Data Latih 1
Kamus Label Token maka nann ya enak temp atnya enak lokas inya perbe lanja an harga nya maha l <FO OD> <PRI CE> <SE RVI CE> <AMBI ENCE> <IGNORE> 1 1 1 1 1 1 1 1 0 0 0 0 BUKAN SENTIMEN 0 0 0 0 0 0 0 0 0 1 1 0 POSITIF 0 0 0 0 0 0 0 0 1 0 0 0 NEGATIF 0 0 0 0 0 0 0 0 0 0 0 1
50
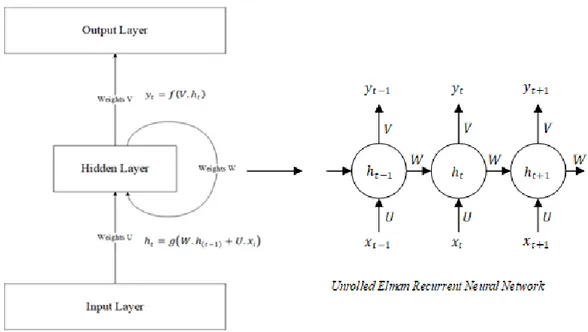
3.2.3 Analisis Elman Recurrent Neural Network
Kalimat yang sebelumnya telah melalui proses preprocessing akan digunakan sebagai data latih oleh algoritma ERNN. ERNN diimplementasikan untuk melakukan klasifikasi sentimen berdasarkan aspek pada kalimat. Pada proses klasifikasi kalimat dapat mempunyai lebih dari 1 aspek dengan sentimennya dimana data masukan mempunyai lebih dari 1 label target pada implementasinya. Sebelum masuk kedalam tahap pemrosesan algoritma ERNN kalimat akan melalui tahap one hot encoding pada tahap preprocessing data latih, ini bertujuan untuk mengubah teks menjadi vektor karena algoritma ERNN tidak dapat memproses teks secara langsung.
Token pada kalimat yang sudah menjadi vektor akan masuk satu persatu kedalam ERNN yang akan di proses dari input layer, hidden layer, sampai output
layer. Masing-masing token akan melakukan output nilai pada output layer yang
akan dihitung nilai error antara label prediksi dengan label sebenarnya (true
label).
3.2.3.1 Arsitektur ERNN
Permasalahan analisis sentimen berdasarkan aspek dapat dianggap sebagai kasus multi label classification yang dimana setiap kalimat akan mempunyai target label lebih dari satu. Oleh karena itu arsitektur many to many dipilih karena akan memprediksi sentimen dari 4 aspek yang terdapat pada kalimat. Semua token selain token aspek akan mempunyai nilai target <IGNORE> sedangkan aspek token akan mempunyai true label (bukan sentimen, positif, dan negatif).
51
Arsitektur ini terdiri dari input layer, hidden layer, dan output layer karena ERNN masih dalam keluarga neural netwotk. Berikut adalah penjelasan dari arsitektur ERNN Gambar 3.11.
1. Input layer, layer ini menerima data masukan yang berupa rangkaian token dari sebuah kalimat dimana token ini sudah menjadi vektor yang dilambangkan dengan (vektor ke t). Vektor ini harus berukuran tetap (fixed length) di seluruh masukan ERNN dengan kata lain ukuran seluruh token yang akan masuk ke dalam ERNN berukuran sama. Setiap vektor token yang akan masuk ke hidden layer akan dilakukan perkalian matrix dengan bobot U. Pada penelitian ini data masukan yang berupa kalimat akan dijadikan vektor menggunakan one hot encoding dengan panjang ukuran vektor kata sama pada semua kata pada kalimat.
2. Hidden layer, hidden layer terdiri dari satu layer dimana terdapat
activation function. Activation function yang digunakan pada penelitian ini
adalah Tanh. Setiap hidden state ( saling terhubung dengan hidden
state sebelumnya yang ( ) yang bertujuan agar dapat mengalirkan informasi dari masa lalu ke saat ini. Bobot W akan dipakai oleh setiap
52
hidden state ( . Hidden state pertama akan diinisialisasi dengan nilai 0 karena tidak terdapat hidden state sebelumnya.
3. Output layer, pada output layer setiap hasil dari hidden state akan dilakukan perkalian matrix dengan bobot V kemudian dimasukan kedalam
activation function softmax, activation function softmax yang digunakan
untuk menormalisasi keluar dari hidden layer agar berubah menjadi nilai probabilitas antara 0 sampai 1. Setiap nilai output ke t ( digunakan sebagai nilai prediksi algoritma.
3.2.3.2 Pelatihan ERNN
Pada tahap ini algoritma ERNN akan mempelajari pola dari data latih yang digunakan. Pola-pola tersebut akan direkam yang direprensentasikan dalam bentuk bobot (weights). Adapun gambaran dari proses pelatihan ERNN ditunjukan Gambar 3.12
Pada Gambar 3.12, proses pelatihan ERNN dilakukan untuk mendapatkan bobot yang optimal yaitu yang memiliki nilai error terkecil dari hasil pelatihan data latih. Bobot akan diperbaharui sebanyak epoch sampai ditemukan error paling minimum. Untuk melakukan pelatihan algoritma ERNN melakukan
forward propagation, forward propagation bertujuan untuk mendapatkan nilai hidden layer dan nilai output layer , nilai yang didapat dari hasil forward
propagation akan dihitung errornya dengan menggunakan cross entropy untuk
mengetahui seberapa besar error yang didapat dari bobot yang digunakan. Kemudian algoritma ERNN melakukan Truncated Backpropagation Through
Time (TBPTT) untuk menurunkan bobot-bobot awal (U, W, dan V) yang masih
mempunyai error yang besar, Truncated BPTT digunakan untuk mengatasi masalah vanishing dan exploding gradient, dan pada proses optimasi
53
pembelajaran ERNN akan menggunakan Minibatch Stochastic Gradient Descent untuk mempercepat waktu pelatihan pada data yang sangat banyak karena algorima ini hanya mengambil sebagian data untuk proses pelatihannya. Pembaharuan bobot akan terus dilakukan sampai mendapatkan bobot optimal yang errornya paling minimum atau sampai sebanyak epoch yang sudah ditentukan.
3.2.3.3 Inisialisasi Bobot
Sebelum memulai pelatihan algoritma ERNN, diperlukan bobot awal yang akan digunakan oleh ERNN pada perhitungannya. Bobot awal biasanya diinisialisasi secara random, inisialisasi bobot random mengacu pada [16]. Oleh karena itu ketika ERNN melakukan perhitungan error pada bobot awal ini akan didapatkan error yang besar yang akan membuat ERNN jauh dari prediksi sebenarnya. Dalam mengatasi ini ERNN melakukan pelatihan untuk memperbaharui bobot awal pada setiap epochnya dan diharapkan errornya akan semakin mengecil. Pada ERNN terdapat 3 bobot yang akan digunakan dalam perhitungannya yaitu, U, W, dan V. Adapun aturan inisialisasi bobot ditunjukan pada Tabel 3.15.
Tabel 3.15 Aturan Inisialisasi Bobot Awal
Bobot Keterangan
U adalah sebuah matrix berukuran NxM dimana N adalah dimensi hidden dan M adalah dimensi input.
W adalah sebuah matrix berukuran NxN dimana N dimensi hidden yang ditentukan manual.
V adalah sebuah matrix berukuran OxN dimana O dimensi output dan N dimensi hidden.
54
Berikut adalah teknik inisialisasi yang direkomendasikan yang digunakan oleh penelitian ini.
adalah angka acak yang berada pada interval dan adalah angka acak yang berada pada interval dan adalah angka acak yang berada pada interval dan Dimana:
I = Dimensi input H = Dimensi hidden
Pada laporan ini dimensi yang digunakan pada contoh data latih yaitu, (dimana M berukuran 20 karena kamus kata berdimensi 20, N berukuran 2 ditentukan manual), (N berukuran 2 dipilih agar perhitungan tidak terlalu complex pada laporan), dan (O berukuran 4 karena terdapat 4 label (bukan sentimen, positif, negatif, dan <IGNORE>). Berikut hasil inisialisasi bobot awal.
Pada penulisan laporan ini bobot matrix U akan ditulis berbentuk vertikal (tranpose) agar tidak memakan ruang pada penulisan laporan (notasi T pada matrix).
55
3.2.3.4 Ambil Sebagian Data Secara Acak
Pada penelitian ini dalam mendapatkan perhitungan turunannya menggunakan Minibatch Stochastic Gradient Descent. Pada prosesnya hanya mengambil sebagian data dalam menghitung nilai turunan. Minibatch SGD digunakan supaya dalam melakukan pelatihan menjadi lebih efisien dari segi waktu dan komputasi daripada menggunakan seluruh data latih dalam mencari nilai turunan (versi Batch).
Pengambilan sebagian data dilakukan setiap epoch dimana jumlah data yang diambil sebesar d, d adalah banyaknya data (minibatch size).
3.2.3.5 Forward propagation ERNN
Diantara proses pelatihan ERNN, proses forward propagation adalah proses awal dari algoritma ERNN dimana setiap token dari kalimat akan masuk satu persatu ke dalam algortima ERNN. Setiap token akan masuk mulai input layer menuju hidden layer dan yang terakhir sampai output layer.
Pada proses pelatihan akan memakai sebagian data dari data latih di setiap
epoch dan pada contoh pelatihan ini akan menggunakan satu kalimat pada setiap epoch. Untuk epoch pertama menggunakan kalimat sebagai berikut yang sudah
melalui proses preprocessing .
Tabel 3.16 Contoh Kalimat Untuk Pelatihan
No Token 1 makanannya 2 enak 3 tempatnya 4 enak 5 lokasinya 6 perbelanjaan 7 harganya
56 8 mahal 9 <FOOD> 10 <PRICE> 11 <SERVICE> 12 <AMBIENCE>
Vektor hasil preprocesing dari kalimat diatas dapat dilihat pada Tabel 3.13. Berikut adalah proses forward propagation akan dimulai dengan token pertama.
1. Token 1
Pertama, menghitung nilai perkalian matrix antara bobot U dengan vektor token “makanannya” yang diberi simbol .
Kedua, menghitung nilai perkalian matrix antara bobot W dengan hidden
state sebelumnya . Karena hidden state sebelumnya belum ada nilai maka akan diinisialisasi dengan .
Ketiga, menghitung hidden state saat ini dengan menjumlahkan hasil dengan hasil . Kemudian hasil hidden state saat ini akan dimasukan ke aktivasi fungsi Tanh dengan rumus pada persamaan (2.3).
57
Perhitungan aktivasi fungsi Tanh akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.3).
Hasil dari perhitungan adalah sebagai berikut.
Keempat, menghitung nilai perkalian matrix antara bobot V dengan hidden
state saat ini dimana t=1.
Kelima, menghitung nilai output hasil perhitungan yang akan di masukan kedalam aktivasi fungsi softmax dengan rumus pada persamaan (2.4).
Perhitungan aktivasi fungsi softmax akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.4).
58
Hasil dari perhitungan adalah sebagai berikut.
2. Token Sisanya
Untuk token sisanya (token 2 sampai 12) akan dilakukan forward
propagation sama seperti yang dilakukan pada token 1 diatas. Berikut adalah hasil forward propagation dari kalimat 1.
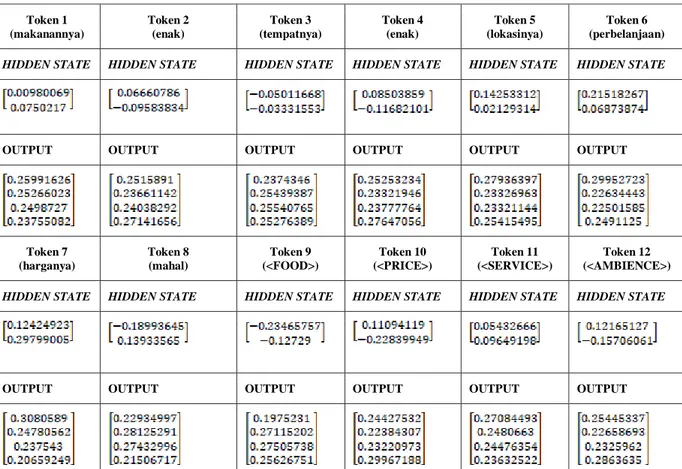
Tabel 3.17 Hasil Perhitungan Forward propagation Setiap Token
Token 1 (makanannya) Token 2 (enak) Token 3 (tempatnya) Token 4 (enak) Token 5 (lokasinya) Token 6 (perbelanjaan) HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
OUTPUT OUTPUT OUTPUT OUTPUT OUTPUT OUTPUT
Token 7 (harganya) Token 8 (mahal) Token 9 (<FOOD>) Token 10 (<PRICE>) Token 11 (<SERVICE>) Token 12 (<AMBIENCE>) HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
59
3.2.3.6 Backward propagation ERNN
Setelah melakukan forward propagation dan didapatkan error masih besar, maka akan dilakukan pembaruan bobot dengan melakukan backward propagation agar nilai error menjadi lebih kecil. Bobot yang akan diperbaharui yaitu, U, W, dan V dimana untuk mencari nilai turunannya sebanyak tiga buah yaitu, ,
, dan .
1. Menghitung Turunan Bobot V
Rumus menghitung turunan bobot V dapat dilihat pada persamaan (2.8).
Perhitungan turunan akan dilakukan pada setiap token. Iterasi untuk menghitung turunan dilakukan secara mundur mulai dari token terakhir, token 12 hingga token awal, token 1.
Token 12 (<AMBIENCE>)
Dalam menghitung turunan dimana t=12 membutuhkan hasil perhitungan pada hidden layer dan output layer dengan menggunakan persamaan (2.9).
Token Sisanya
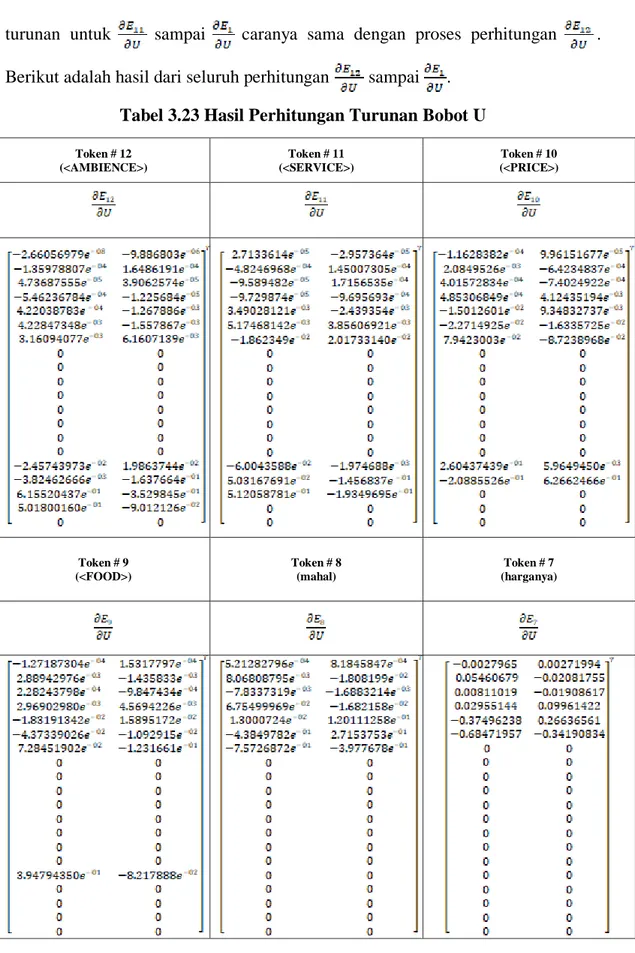
Menghitung backward propagation dilakukan dari token terakhir, token 12 sampai token awal, token 1. Perhitungan diatas baru dilakukan pada token 12, token sisanya akan dihitung menggunakan persamaan (3.1) seperti perhitungan token 12. Berikut hasil perhitungan turunan seluruh token.
Tabel 3.18 Hasil Perhitungan Turunan Bobot V
Token # 12 (<AMBIENCE>) Token # 11 (<SERVICE>) Token # 10 (<PRICE>)
60
Setiap hasil turunan dari setiap t (timestep) akan dijumlahkan untuk mendapatkan turunan dari V.
Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya) Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak) Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
61
Hitung Bobot Baru V
Dalam menghitung bobot baru V dibutuhkan hasil turunan dari
backward propagation. Bobot baru dihasilkan dari bobot lama dikurangi dengan
hasil perkalian turunan dengan learning rate. Rumus perhitungan bobot baru V ditunjukan persamaan (2.15).
Dimana learning rate perhitungan hasil bobot baru V adalah sebagai berikut.
2. Hitung Turunan Bobot
Rumus untuk menghitung turunan bobot W ditunjukan persamaan (2.10)
Pada penurunan bobot W dilakukan pada setiap token seperti yang dilakukan pada bobot V. Penurunan bobot W memiliki kesamaan dengan penurunan bobot U. Penurunan bobot W dilakukan pada setiap token dari token terakhir menuju token awal, token-token tersebut akan melalui hidden state
62
sebelumya dalam melakukan penurunan. Berikut adalah proses perhitungan turunan bobot W.
Token 12 (<AMBIENCE>)
Pada penurunan bobot dimulai dari token 12 hingga token 1 dan akan diterapkan chain rule dimana variabel bergantung pada , dan variabel bergantung pada sehingga laju perubahan terhadap dapat dihitung.
Hitung pada hidden state 12
1. Menghitung nilai dimana t=12, variabel t disini menunjukan posisi token yang akan diturunkan seperti yang ditunjukan pada persamaan (2.12). Berikut ini rumus dalam mengitung .
Dimana adalah sebagai label sebenarnya dan sebagai label prediksi.
2. Setelah didapat maka nilai turunan dapat dihitung menggunakan rumus pada persamaan (2.11).
Sisa perhitungan turunan pada
Perhitungan yang telah dilakukan baru pada token 12 sedangkan
backward propagation dilakukan pada semua token dari token 12, yaitu sampai
63
perhitungan pada . Berikut adalah hasil perhitungan backward pada pada
65
Tabel 3.19 Hasil Perhitungan BPTT W pada Token # 12 (<AMBIENCE>) Token # 11 (<SERVICE>) Token # 10 (<PRICE>) Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya) Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak) Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
66
Untuk mendapatkan perhitungan , hasil dari penurunan seluruh token dijumlahkan. Berikut adalah hasil akhir perhitungan .
Token 11 (<SERVICE>)
Untuk mendapatkan turunan sama seperti yang telah dilakukan terhadap turunan (token 12). Perhitungan dilakukan dari token 11 sampai token 1 dimana diterapkan chain rule seperti saat menghitung turunan .
Hitung pada hidden state 11
1. Menghitung nilai dimana t=11, variabel t disini menunjukan posisi token yang akan diturunkan seperti pada persamaan (2.12). Berikut ini rumus dalam mengitung .
2. Setelah makan nilai turunan dapat dihitung menggunakan rumus pada persamaan (2.14).
67
Sisa perhitungan turunan pada
Perhitungan yang telah dilakukan pada token 11 sedangkan
backward propagation dilakukan pada semua token dari token 11, yaitu
sampai token 1, yaitu . Perhitungan pada t lainnya (10 sampai 1) sama saja seperti perhitungan pada . Berikut adalah hasil perhitungan backward
propagation pada pada setiap token ditunjukan pada Tabel 3.20.
Tabel 3.20 Hasil Perhitungan BPTT W pada Token # 11 (<SERVICE>) Token # 10 (<PRICE>) Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya) Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak) Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
68
Untuk mendapatkan perhitungan , hasil dari penurunan seluruh token dijumlahkan sebagaimana rumus dari persamaan (3.9). Berikut adalah hasil akhir perhitungan .
Hasil Seluruh Turunan W
Pada perhitungan turunan diatas dan sudah didapatkan hasil turunannya tetapi hanya untuk t=12 dan t=11. Untuk mendapatkan turunan W maka harus melakukan turunan dari sampai . Berikut adalah hasil turunan W dari seluruh t (timestep).
Tabel 3.21 Hasil Perhitungan Turunan Bobot W
Token # 12 (<AMBIENCE>) Token # 11 (<SERVICE>) Token # 10 (<PRICE>) Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya) Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak)
69
Setelah mendapatkan hasil turunan disetiap t (timestep), maka didapat dari penjumlahan turunan pada setiap t (timestep). Hasil adalah sebagai berikut.
Hitung Bobot Baru W
Dalam menghitung bobot baru W dibutuhkan hasil turunan dari
backward propagation. Bobot baru dihasilkan dari bobot lama dikurangi dengan
hasil perkalian turunan dengan learning rate. Rumus perhitungan bobot baru W ditunjukan persamaan (2.15). Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
70
Dimana learning rate perhitungan hasil bobot baru W adalah sebagai berikut.
3. Hitung Turunan Bobot
Pada perhitungan turunan bobot U hampir mirip dengan penurunan bobot W. Jika bobot W diturunkan terhadap sedangkan bobot U diturunkan terhadap .
Perhitungan turunan akan dilakukan dari token terakhir, yaitu token 12 sampai token pertama, yaitu token 1. Berikut adalah proses penurunan Bobot U yang dimulai dari token 12 (token terakhir).
Token 12 (<AMBIENCE>)
Perhitungan turunan yang dilakukan akan dihitung terhadap semua
hidden state , mulai dari hidden state terakhir hingga hidden state awal. Pada
prosesnya ada diterapkan chain rule sama seperti proses perhitungan bobot W. Berikut adalah rumus dari perhitungan bobot .
Hitung pada hidden state 12
1. Menghitung nilai dimana t=12, variabel t disini menunjukan posisi token yang akan diturunkan seperti yang ditunjukan pada persamaan (2.12). Berikut ini rumus dalam mengitung .
71
2. Setelah didapat maka nilai turunan dapat dihitung menggunakan rumus pada persamaan (2.14).
Sisa perhitungan turunan pada
Perhitungan backward propagation harus dilakukan terhadapa seluruh token (token 12 sampai token 1). Perhitungan turunana diatas baru dilakukan pada token 12, perhitungan turunan pada token selanjutnya (token 11 sampai token 1) akan dilakukan sama seperti perhitungan turunan pada . Perhitungan seluruh turunan ditunjukan pada Tabel 3.22.
72
Tabel 3.22 Hasil Perhitungan BPTT U pada
Token # 12 (<AMBIENCE>) Token # 11 (<SERVICE>) Token # 10 (<PRICE>) Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya) Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak)
73
Setelah didapatkan perhitungan dari seluruh token, maka untuk mendapatkan hasil seluruh hasil perhitungan token tersebut dijumlahkan. Berikut hasil penjumlahan seluruh token untuk mendapatkan .
Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
75
+
76
Hasil Seluruh Turunan U
Pada perhitungan turunan diatas baru hanya pada (token 12) dimana dalam backward propagation seluruh token harus diturunkan. Proses perhitungan
77
turunan untuk sampai caranya sama dengan proses perhitungan . Berikut adalah hasil dari seluruh perhitungan sampai .
Tabel 3.23 Hasil Perhitungan Turunan Bobot U
Token # 12 (<AMBIENCE>) Token # 11 (<SERVICE>) Token # 10 (<PRICE>) Token # 9 (<FOOD>) Token # 8 (mahal) Token # 7 (harganya)
78
Setelah mendapatkan hasil turunan disetiap t (timestep), maka didapat dari penjumlahan turunan pada setiap t (timestep). Hasil adalah sebagai berikut.
Token # 6 (perbelanjaan) Token # 5 (lokasinya) Token # 4 (enak) Token # 3 (tempatnya) Token # 2 (enak) Token # 1 (makanannya)
79
80
81
Hitung Bobot Baru U
Dalam menghitung bobot baru U dibutuhkan hasil turunan dari backward propagation. Bobot baru dihasilkan dari bobot lama dikurangi dengan hasil perkalian turunan dengan learning rate. Rumus perhitungan bobot baru U ditunjukan persamaan (2.15).
Dimana learning rate perhitungan hasil bobot baru W adalah sebagai berikut.
82
3.2.3.7 Bobot Baru (Epoch 1)
Bobot baru yang didapat dari hasil backward propagation epoch 1 sebagai berikut.
Pada penulisan laporan ini bobot matrix U akan ditulis berbentuk vertikal (tranpose) agar tidak memakan ruang pada penulisan laporan (notasi T pada matrix).
3.2.3.8 Ringkasan Proses Pelatihan
Pada kalimat kalimat selanjutnya juga dilakukan forward propagation dan
backward propagation sama seperti kalimat kalimat diatas. Bobot baru yang
didapat dari epoch 1 akan digunakan pada epoch 2 dan bobot baru yang didapat dari epoch 2 akan digunakan pada epoch 3 begitupun epoch selanjutnya. Setelah melakukan proses pelatihan hingga epoch 100 didapat bobot baru yang akan digunakan pada tahap pengujian. Adapun bobot baru yang didapat setelah epoch 100 adalah sebegai berikut.
83
Pada penulisan laporan ini bobot matrix U akan ditulis berbentuk vertikal (tranpose) agar tidak memakan ruang pada penulisan laporan (notasi T pada matrix).
3.2.4 Analisis Preprocessing Data Uji
Pada tahap preprocessing data uji akan sama seperti tahap preprocessing yang dilakukan pada data latih tetapi pada tahap preprocessing data uji tidak ada proses pembangunan kamus kata. Kamus kata pada preprocessing data uji diambil dari tahap pembangunan kamus kata yang sudah dibentuk pada tahap pelatihan. Proses preprocessing data uji ditunjukan pada Gambar 3.13.
84
Adapun data testing yang digunakan ditunjukan pada Tabel 3.24. Tabel 3.24 Data Uji
No Review (Ri)
1 Makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk. 2 Makanannya enak sih walaupun tempatnya tidak enak .
Data uji akan melewati setiap tahapan preprocessing supaya dapat di proses algoritma ERNN. Tahapan preprocessing data uji sebagai berikut.
3.2.4.1 Case Folding
Proses case folding akan mengkorversi keseluruhan teks menjadi huruf kecil (lower case) sama seperti yang dilakukan pada saat tahap preprocessing data latih. Adapun hasil proses case folding dapat dilihat pada Tabel 3.25.
Tabel 3.25 Hasil Case Folding Data Uji
No Review (Ri) Hasil Case Folding
1 Makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk.
makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk. 2 Makanannya enak sih walaupun
tempatnya tidak enak .
makanannya enak sih walaupun tempatnya tidak enak .
3.2.4.2 Filtering
Hasil dari proses case folding akan masuk ke proses filtering dimana proses filtering akan menghilangkan simbol-simbol yang tidak diperlukan, seperti
85
tanda baca, angka, dan emoticon seperti saat proses filtering di tahapan
preprocessing data latih. Hasil proses filtering data uji dapat dilihat pada Tabel
3.26.
Tabel 3.26 Hasil Filtering Data Uji
No Review (Ri) Hasil Filtering
1 makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk.
makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk 2 makanannya enak sih walaupun
tempatnya tidak enak .
makanannya enak sih walaupun tempatnya tidak enak
3.2.4.3 Word Normalization
Pada proses word normalization akan mengubah kata yang tidak baku menjadi kata baku sama seperti yang dilakukan pada proses processing di tahap pelatihan dimana kalimat yang masuk pada proses word normalization adalah hasil dari proses case folding dan filtering. Hasil proses word normalization dapat dilihat pada Tabel 3.27.
Tabel 3.27 Hasil Word normalization Data Uji
No Review (Ri) Hasil Word Normalization
1 makan disini harganya mahal tapi tempatnya sangat enaaaaakkkkk
makan disini harganya mahal tapi tempatnya sangat enak
2 makanannya enak sih walaupun tempatnya tidak enak
makanannya enak sih walaupun tempatnya tidak enak
3.2.4.4 Tokenization
Sama seperti saat preprocessing data latih, proses tokenization akan memisahkan kata-kata dalam kalimat dengan mengandalkan delimiter spasi. Hasil dari tokenization berupa token-token kalimat. Hasil dari proses tokenization ditunjukan Tabel 3.28.
86
Tabel 3.28 Hasil Tokenization Data Uji
No Review (Ri) Hasil Tokenization
1 makan disini harganya mahal tapi tempatnya sangat enak
[“makan”, “disini”, “harganya”, “mahal”, “tapi”, “tempatnya”, “sangat”, “enak”]
2 makanannya enak sih walaupun tempatnya tidak enak
[“makanannya”, “enak”, “sih”, “walaupun”, “tempatnya”, “tidak”, “enak”]
3.2.4.5 Stopword Removal
Setelah melewati proses tokenization, kalimat akan melewati proses
stopword removal dimana kata-kata yang terdapat pada list stopword akan
dihilangkan dari kalimat. Adapaun hasil dari proses stopword removal dapat dilihat pada Tabel 3.29.
Tabel 3.29 Hasil Stopword Removal Data Uji
No Review (Ri) Hasil Stopword Removal
1 [“makan”, “disini”, “harganya”, “mahal”, “tapi”, “tempatnya”, “sangat”, “enak”]
[“makan”, “harganya”, “mahal”, “tempatnya”, “enak”]
2 [“makanannya”, “enak”, “sih”, “walaupun”, “tempatnya”, “tidak”, “enak”]
[“makanannya”, “enak”, “tempatnya”, “tidak”, “enak”]
3.2.4.6 Penambahan Token Aspek
Proses penambahan token aspek bertujuan agar algoritma ERNN dapat memprediksi sentimen dari aspek didalam kalimat. Token aspek yang ditambahkan sama seperti pada Tabel 3.7 di preprocessing data latih dimana sistem akan secara otomatis menambahkan token aspek jika kalimat melewati proses penambahan token aspek. Hasil dari proses penambahan token aspek dapat dilihat pada Tabel 3.30.
87
Tabel 3.30 Hasil Penambahan Token Aspek Data Uji
No Review (Ri) Hasil Penambahan Token Aspek
1 [“makan”, “harganya”, “mahal”, “tempatnya”, “enak”]
[“makan”, “harganya”, “mahal”, “tempatnya”,“enak”,
“<FOOD>”,“<PRICE>”, “<SERVICE>”,
“<AMBIENCE>”] 2 [“makanannya”, “enak”, “tempatnya”,
“tidak”, “enak”]
[“makanannya”, “enak”, “tempatnya”, “tidak”, “enak”, “<FOOD>”, “<PRICE>”, “<SERVICE>”,
“<AMBIENCE>”]
3.2.4.7 One Hot Encoding
Proses one hot encoding dilakukan untuk mengkorversi data teks menjadi data numerik, karena algoritma machine learning atau neural network tidak dapat memproses data teks secara langsung. Proses kerjanya dengan memberikan ID kepada setiap token. ID adalah sebuah angkan yang akan menjadi vektor. Angka tersebut adalah posisi kata pada kamus. Kamus yang digunakan pada proses pengujian diambil dari kamus kata yang sudah dibangun pada tahap pelatihan. Adapun hasil proses one hot encoding dari data uji ditunjukan pada Tabel 3.31.
84
Tabel 3.31 Hasil One Hot Encoding Seluruh Token Data Uji
Kamus Kata Token maka n harga nya mahal tempa tnya enak maka nanny a tidak <FOO D> <PRI CE> <SER VICE > <AM BIEN CE> makanannya 0 0 0 0 0 1 0 0 0 0 0 enak 0 0 0 0 1 0 0 0 0 0 0 tempatnya 0 0 0 1 0 0 0 0 0 0 0 lokasinya 0 0 0 0 0 0 0 0 0 0 0 perbelanjaan 0 0 0 0 0 0 0 0 0 0 0 harganya 0 1 0 0 0 0 0 0 0 0 0 mahal 0 0 1 0 0 0 0 0 0 0 0 dimsum 0 0 0 0 0 0 0 0 0 0 0 makan 1 0 0 0 0 0 0 0 0 0 0 santai 0 0 0 0 0 0 0 0 0 0 0 spaghetti 0 0 0 0 0 0 0 0 0 0 0 pizza 0 0 0 0 0 0 0 0 0 0 0 tidak 0 0 0 0 0 0 1 0 0 0 0 mengecewak an 0 0 0 0 0 0 0 0 0 0 0 keju 0 0 0 0 0 0 0 0 0 0 0 <FOOD> 0 0 0 0 0 0 0 1 0 0 0 <PRICE> 0 0 0 0 0 0 0 0 1 0 0 <SERVICE> 0 0 0 0 0 0 0 0 0 1 0 <AMBIENC E> 0 0 0 0 0 0 0 0 0 0 1 <UNKNOW N> 0 0 0 0 0 0 0 0 0 0 0
3.2.4.8 Hasil Preprocessing Kalimat
Setelah melewati setiap tahapan preprocessing , kalimat yang sebelumnya berupa data teks akan menjadi data numerik setelah melewati tahap one hot encoding. Kalimat yang sudah menjadi data numerik atau vektor sudah dapat di proses oleh ERNN yang nantinya pada proses pengujian ini ERNN akan memprediksi sentimen dari aspek yang terdapat pada kalimat. Adapun hasil
preprocessing pada data uji kalimat 1 dapat dilihat pada Tabel 3.32 dan data uji
85
Tabel 3.32 One Hot Encoding Data Uji 1
Kamus Kata maka Token
n harganya mahal tempatny a enak <FOOD > <PRICE > <SERVI CE> <AMBI ENCE> makanannya 0 0 0 0 0 0 0 0 0 enak 0 0 0 0 1 0 0 0 0 tempatnya 0 0 0 1 0 0 0 0 0 lokasinya 0 0 0 0 0 0 0 0 0 perbelanjaan 0 0 0 0 0 0 0 0 0 harganya 0 1 0 0 0 0 0 0 0 mahal 0 0 1 0 0 0 0 0 0 dimsum 0 0 0 0 0 0 0 0 0 makan 1 0 0 0 0 0 0 0 0 santai 0 0 0 0 0 0 0 0 0 spaghetti 0 0 0 0 0 0 0 0 0 pizza 0 0 0 0 0 0 0 0 0 tidak 0 0 0 0 0 0 0 0 0 mengecewakan 0 0 0 0 0 0 0 0 0 keju 0 0 0 0 0 0 0 0 0 <FOOD> 0 0 0 0 0 1 0 0 0 <PRICE> 0 0 0 0 0 0 1 0 0 <SERVICE> 0 0 0 0 0 0 0 1 0 <AMBIENCE> 0 0 0 0 0 0 0 0 1 <UNKNOWN> 0 0 0 0 0 0 0 0 0
Tabel 3.33 One Hot Encoding Data Uji 2
Kamus Kata makana Token
nnya enak tempatny a tidak enak <FOOD > <PRICE > <SERVI CE> <AMBI ENCE> makanannya 1 0 0 0 0 0 0 0 0 enak 0 1 0 0 1 0 0 0 0 tempatnya 0 0 1 0 0 0 0 0 0 lokasinya 0 0 0 0 0 0 0 0 0 perbelanjaan 0 0 0 0 0 0 0 0 0 harganya 0 0 0 0 0 0 0 0 0 mahal 0 0 0 0 0 0 0 0 0 dimsum 0 0 0 0 0 0 0 0 0 makan 0 0 0 0 0 0 0 0 0 santai 0 0 0 0 0 0 0 0 0 spaghetti 0 0 0 0 0 0 0 0 0 pizza 0 0 0 0 0 0 0 0 0 tidak 0 0 0 1 0 0 0 0 0 mengecewakan 0 0 0 0 0 0 0 0 0 keju 0 0 0 0 0 0 0 0 0
86 <FOOD> 0 0 0 0 0 1 0 0 0 <PRICE> 0 0 0 0 0 0 1 0 0 <SERVICE> 0 0 0 0 0 0 0 1 0 <AMBIENCE> 0 0 0 0 0 0 0 0 1 <UNKNOWN> 0 0 0 0 0 0 0 0 0 3.2.5 Pengujian ERNN
Pada tahap ini algoritma ERNN akan diuji kemampuannya terhadap data uji yang belum pernah dipelajari sebelumnya. Proses pengujian juga bertujuan untuk mengetahui seberapa besar performa algoritma ERNN yang dihasilkan terhadap memprediksi label sentimen pada aspek didalam kalimat. Adapun proses
pengujian ditunjukan Gambar 3.14.
Pada proses forward propagation bobot yang digunakan adalah bobot hasil pelatihan ERNN pada proses sebelumnya. Adapun tahapan yang dilakukan terhadap kalimat yang sudah menjadi vektor pada Tabel 3.32 dan Tabel 3.33, yaitu.
3.2.5.1 Forward Propagation Data Uji 1. Pengujian Data Uji 1
Proses forward propagation akan dilakukan pada setiap token data uji 1 dimana pada proses ini hasil preprocessing data uji 1 berupa vektor tabel yang akan di proses ERNN. Forward propagation dimulai dari token pertama sampai token terkahir, berikut proses forward propagation data uji 1.
1. Token 1
Pertama, menghitung nilai perkalian matrix antara bobot U dengan vektor token “makanannya” yang diberi simbol .
87
Kedua, menghitung nilai perkalian matrix antara bobot W dengan hidden
state sebelumnya . Karena hidden state sebelumnya belum ada nilai maka akan diinisialisasi dengan .
Ketiga, menghitung hidden state saat ini dengan menjumlahkan hasil dengan hasil . Kemudian hasil hidden state saat ini akan dimasukan ke aktivasi fungsi Tanh dengan rumus pada persamaan (2.3).
Perhitungan aktivasi fungsi Tanh akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.3).
88
Keempat, menghitung nilai perkalian matrix antara bobot V dengan hidden
state saat ini dimana t=1.
Kelima, menghitung nilai output hasil perhitungan yang akan di masukan kedalam aktivasi fungsi softmax dengan rumus pada persamaan (2.4).
Perhitungan aktivasi fungsi softmax akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.4).
89
2. Token Sisanya
Untuk token sisanya (token 2 sampai 9) akan dilakukan forward
propagation sama seperti yang dilakukan pada token 1 diatas. Berikut adalah hasil forward propagation dari data uji 1.
Tabel 3.34 Hasil Forward Propagation Data Uji 1
Token 1 (makan) Token 2 (harganya) Token 3 (mahal) Token 4 (tempatnya) Token 5 (enak) HIDDEN STATE
HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
OUTPUT OUTPUT OUTPUT OUTPUT OUTPUT
Token 6 (<FOOD>) Token 7 (<PRICE>) Token 8 (<SERVICE>) Token 9 (<AMBIENCE>) HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
OUTPUT OUTPUT OUTPUT OUTPUT
2. Pengujian Data Uji 2
Proses forward propagation akan dilakukan pada setiap token data uji 2 dimana pada proses ini hasil preprocessing data uji 2 berupa vektor pada Tabel 3.33 yang akan di proses ERNN. Forward propagation dimulai dari token pertama sampai token terkahir, berikut proses forward propagation data uji 2.
1. Token 1
Pertama, menghitung nilai perkalian matrix antara bobot U dengan vektor token “makanannya” yang diberi simbol .
90
Kedua, menghitung nilai perkalian matrix antara bobot W dengan hidden
state sebelumnya . Karena hidden state sebelumnya belum ada nilai maka akan diinisialisasi dengan .
Ketiga, menghitung hidden state saat ini dengan menjumlahkan hasil dengan hasil . Kemudian hasil hidden state saat ini akan dimasukan ke aktivasi fungsi Tanh dengan rumus pada persamaan (2.3).
Perhitungan aktivasi fungsi Tanh akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.3).
91
Keempat, menghitung nilai perkalian matrix antara bobot V dengan hidden
state saat ini dimana t=1.
Kelima, menghitung nilai output hasil perhitungan yang akan di masukan kedalam aktivasi fungsi softmax dengan rumus pada persamaan (2.4).
Perhitungan aktivasi fungsi softmax akan dilakukan pada setiap elemen vektor dengan menggunakan rumus pada persamaan (2.4).
Hasil dari perhitungan adalah sebagai berikut.
2. Token Sisanya
Untuk token sisanya (token 2 sampai 9) akan dilakukan forward
propagation sama seperti yang dilakukan pada token 1 diatas. Berikut adalah hasil forward propagation dari data uji 2.
92
Tabel 3.35 Hasil Forward Propagation Data Uji 2
Token 1 (makanannya) Token 2 (enak) Token 3 (tempatnya) Token 4 (tidak) Token 5 (enak) HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
OUTPUT OUTPUT OUTPUT OUTPUT OUTPUT
Token 6 (<FOOD>) Token 7 (<PRICE>) Token 8 (<SERVICE>) Token 9 (<AMBIENCE>) HIDDEN STATE HIDDEN STATE HIDDEN STATE HIDDEN STATE
OUTPUT OUTPUT OUTPUT OUTPUT
Data uji yang sudah melakukan proses forward propagation akan menghasilkan nilai vektor output pada setiap tokennya. Untuk mengetahui hasil dari prediksi algortima ERNN dilihat dari nilai probabilitas paling besar pada vektor output, sebagai contoh Pada vektor output tersebut nilai "0.93457014” akan diambil sebagai prediksi karena nilai probabilitasnya paling besar.
3.2.5.2 Ringkasan Hasil Pengujian
Setelah kalimat hasil preprocessing melalui hasil pengujian maka algoritma akan melakukan prediksi pada kalimat yang menjadi data uji. Adapun hasil contoh hasil prediksi untuk data uji 1 ditunjukan dan data uji 2 ditunjukan Tabel 3.36 dan Tabel 3.37.
93
Tabel 3.36 Hasil Prediksi Data Uji 1
Token Output Prediksi Label Prediksi
Label
Sebenarnya Kesimpulan
makan IGNORE IGNORE
harganya IGNORE IGNORE
mahal IGNORE IGNORE
tempatnya IGNORE IGNORE
enak IGNORE IGNORE
<FOOD> POSITIF BUKAN
SENTIMEN
<PRICE> SENTIMEN BUKAN NEGATIF
<SERVICE> SENTIMEN BUKAN SENTIMEN BUKAN
<AMBIENCE> SENTIMEN BUKAN POSITIF
JUMLAH PREDIKSI BENAR 6
Tabel 3.37 Hasil Prediksi Data Uji 2
Token Output Prediksi Label Prediksi
Label
Sebenarnya Kesimpulan
makanannya IGNORE IGNORE
94
tempatnya IGNORE IGNORE
tidak IGNORE IGNORE
enak IGNORE IGNORE
<FOOD> POSITIF POSITIF
<PRICE> SENTIMEN BUKAN SENTIMEN BUKAN
<SERVICE> SENTIMEN BUKAN SENTIMEN BUKAN
<AMBIENCE> SENTIMEN BUKAN NEGATIF
JUMLAH PREDIKSI BENAR 8
Pada Tabel 3.36 “Label Prediksi” didapat dari probabilitas paling besar pada “Output Prediksi”. Contoh token “makan” mempunyai nilai probabilitas lebih tinggi dari nilai probabilitas lainnya yaitu, ( dimana probabilitas labelnya adalah IGNORE.
Dari Tabel 3.36 dan Tabel 3.37 dapat dilihat bahwa algoritma Elman RNN dapat meprediksi label IGNORE dengan baik sehingga untuk mengetahui nilai sentimen pada setiap aspek hanya melihat pada token aspek dengan mengabaikan semua token selain token aspek.