39
METODOLOGI PENELITIAN
Bab ini tersusun ke dalam delapan sub-bab, yang meliputi desain penelitian, operasionalisasi variabel penelitian, jenis dan sumber data penelitian, teknik pengumpulan data, teknik pengambilan sampel, teknik pengolahan sampel, metode analisis, dan rancangan uji hipotesis.
3.1 Desain Penelitian
Desain penelitian adalah kerangka atau framework untuk mengadakan suatu penelitian. Berdasarkan tujuan yang ingin dicapai, maka penelitian ini termasuk ke dalam penelitian kausal yang bersifat asosiatif, dimana pada penelitian ini akan coba dijelaskan hubungan diantara variabel independen (variabel bebas) terhadap variabel dependen (variabel bergantung). Metode yang digunakan pada penelitian ini adalah metode survei. Menurut Indriantoro dan Supomo (2002, p.26), metode survei adalah teknik pengumpulan dan analisis data berupa opini dari subyek yang diteliti (responden) melalui tanya-jawab. Unit analisis pada penelitian ini adalah individu, yaitu konsumen Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park. Sedangkan horizon waktu dalam penelitian ini adalah cross-sectional, dimana data pada penelitiaan ini hanya dikumpulkan satu kali dalam suatu kurun waktu tertentu, yaitu selama bulan Oktober 2013. Desain penelitian mengenai jenis
penelitian, metode penelitian, unit analisis, dan horizon waktu berdasarkan tujuan penelitian ini secara ringkas dijelaskan pada Tabel 3.1.
Tabel 3.1 Desain Penelitian Tujuan Penelitian Jenis Penelitian Metode Penelitian Unit Analisis Time Horison
T-1 Penelitian Kausal Survei Individu Cross-Sectional T-2 Penelitian Kausal Survei Individu Cross-Sectional T-3 Penelitian Kausal Survei Individu Cross-Sectional T-4 Penelitian Kausal Survei Individu Cross-Sectional T-5 Penelitian Kausal Survei Individu Cross-Sectional
Sumber: Peneliti (2013) Keterangan:
T-1: Untuk mengetahui apakah private label berpengaruh secara langsung terhadap value consciousness.
T-2: Untuk mengetahui apakah value consciousness berpengaruh secara langsung terhadap store traffic.
T-3: Untuk mengetahui apakah store traffic berpengaruh secara langsung terhadap store loyalty.
T-4: Untuk mengetahui apakah private label berpengaruh terhadap store traffic, baik secara langsung maupun tidak langsung yang dimediasi oleh value consciousness.
T-5: Untuk mengetahui apakah private label berpengaruh terhadap store loyalty, baik secara langsung maupun tidak langsung yang dimediasi oleh value consciousness.
3.2 Operasionalisasi Variabel Penelitian
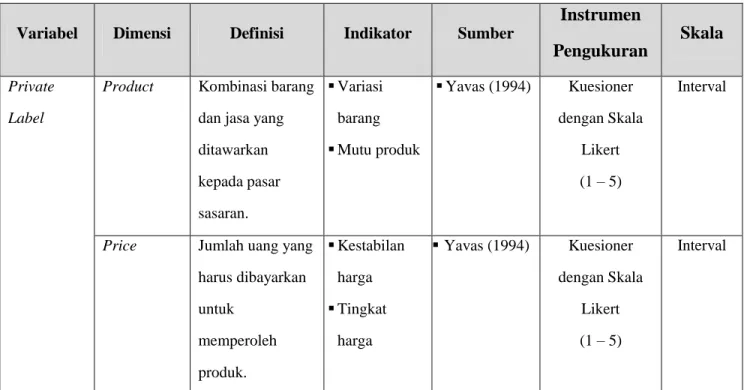
Operasionalisasi variabel penelitian merupakan penjelasan atau pengertian dari teori variabel yang digunakan di dalam penelitian ini, sehingga dapat diamati dan diukur dengan menentukan hal-hal yang diperlukan untuk mencapai tujuan tertentu. Terdapat empat variabel yang akan diteliti dalam penelitian ini, yaitu variabel private label, value consciousness, store traffic, dan store loyalty. Operasionalisasi variabel dari penelitian ini akan dijelaskan pada Tabel 3.2 berikut ini.
Tabel 3.2 Operasionalisasi Variabel Penelitian
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran
Skala
Private Label
Product Kombinasi barang dan jasa yang ditawarkan kepada pasar sasaran. Variasi barang Mutu produk Yavas (1994) Kuesioner dengan Skala Likert (1 – 5) Interval
Price Jumlah uang yang harus dibayarkan untuk memperoleh produk. Kestabilan harga Tingkat harga Yavas (1994) Kuesioner dengan Skala Likert (1 – 5) Interval
Lanjutan Tabel 3.2
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran
Skala
Private Label
Place Lokasi dimana gerai peritel berada. Lokasi mudah dijangkau Waktu tempuh Yavas (1994) Kuesioner dengan Skala Likert (1 – 5) Interval
Promotion Aktivitas yang menyampaikan manfaat produk dan membujuk pelanggan membelinya. Potongan harga/diskon khusus Hadiah langsung Informasi brosur yang terpercaya Engel, Blackwell, dan Miniard (1995) Kuesioner dengan Skala Likert (1 – 5) Interval
Value Consciousness Proses konsumen membandingkan nilai produk yang diterima dengan harga yang dikorbankan Fokus terhadap harga dan kualitas. Melakuk an perbandinga n harga dengan produk lainnya Rahmawati (2013) Kuesioner dengan Skala Likert (1 – 5) Interval
Lanjutan Tabel 3.2
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran
Skala
Value Consciousness Proses konsumen membandingkan nilai produk yang diterima dengan harga yang dikorbankan Selalu berusaha mendapatk an kualitas terbaik dengan uangnya Selalu memastikan mendapatka n sesuatu yang berharga Selalu berkeliling untuk dapat harga termurah tapi dengan tetap memperhati kan kualitas Rahmawati (2013) Kuesioner dengan Skala Likert (1 – 5) Interval
Lanjutan Tabel 3.2
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran
Skala
Value Consciousness Proses konsumen membandingkan nilai produk yang diterima dengan harga yang dikorbankan Selalu membanding kan informasi tentang harga produk yang akan dibeli Selalu mengecek harga pada toko atau peritel yang benar-benar memberikan nilai terbaik dengan uang yang dimiliki Yamit (2004) Kuesioner dengan Skala Likert (1 – 5) Interval
Lanjutan Tabel 3.2
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran Skala Store Traffic Aksesibilita s Kemudahan untuk masuk dan keluar dari gerai peritel. Jam operasi toko Arus lalu lintas Sarana transportasi Berman dan Evans (2010) Kuesioner dengan Skala Likert (1 – 5) Interval
Atmosphere Suasana di dalam
toko. Pencahayaan toko Tata letak rak Utami (2006) Kuesioner dengan Skala Likert (1 – 5) Interval Lingkunga n Suasana di sekitar toko. Keamanan sekitar toko Kebersihan sekitar toko Engel, Blackwell, dan Miniard (1995) Kuesioner dengan Skala Likert (1 – 5) Interval
Personil Pramuniaga toko. Pengetahuan pramuniag Pramuniaga yang ramah dan sopan Engel, Blackwell, dan Miniard (1995) Kuesioner dengan Skala Likert (1 – 5) Interval Store Loyalty Behavioura l Loyalty Loyalitas dalam bentuk kebiasaan. Niat pembelian ulang/kunju ngan toko Aaker (1991) Kuesioner dengan Skala Likert (1 – 5) Interval
Lanjutan Tabel 3.2
Variabel Dimensi Definisi Indikator Sumber
Instrumen Pengukuran Skala Store Loyalty Attitudinal Loyalty Loyalitas konsumen dalam bentuk komitmen. Word-of-mouth Rela membayar di harga premium Aaker (1991) Kuesioner dengan Skala Likert (1 – 5) Interval
Menurut Riduwan dan Kuncoro (2008, p.20), skala likert digunakan untuk mengukur sikap, pendapat dan persepsi seseorang atau sekelompok tentang kejadian atau gejala sosial. Pada skala likert, setiap jawaban dihubungkan dengan bentuk pernyataan atau dukungan sikap yang diungkapkan dengan kata-kata. Pada penelitian ini, pernyataan yang digunakan adalah pernyataan positif dengan penilaian seperti yang dinyatakan pada Tabel 3.3.
Tabel 3.3 Penilaian Pernyataan Positif pada Skala Likert
Keterangan Singkatan Nilai
Sangat Setuju SS 5
Setuju S 4
Netral N 3
Tidak Setuju TS 2
Sangat Tidak Setuju STS 1
3.3 Jenis dan Sumber Data
Data yang dimaksud di dalam penelitian ini adalah data subyek (self-report data), yang berupa opini, sikap, pengalaman, atau karakteristik dari seseorang atau sekelompok orang yang menjadi subyek penelitian (responden) (Indriantoro dan Supomo, 2002, p.145). Data yang diperoleh nantinya akan diolah hingga menjadi sumber informasi dalam penelitian ini. Sumber informasi dalam penelitian ini terbagi ke dalam tiga kategori sebagai berikut.
1. Sumber Primer
Menurut Cooper dan Schindler (2006, p.166), sumber primer adalah data mentah yang belum diinterpretasikan ke dalam bentuk pernyataan yang mewakili suatu pendapat. Sumber primer pada penelitian ini diperoleh melalui penyebaran kuesioner penelitian private label Carrefour Indonesia pada Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park.
2. Sumber Sekunder
Menurut Cooper dan Schindler (2006, p.166), sumber sekunder adalah interpretasi dari data primer. Sumber sekunder pada penelitian ini diperoleh melalui hasil studi pustaka, laporan, dan data historis perusahaan serta dokumen dari berbagai instansi yang berhubungan dengan topik penelitian ini.
3. Sumber Tersier
Menurut Cooper dan Schindler (2006, p.167), sumber tersier dapat diartikan sebagai data sekunder yang didapatkan melalui indeks, bibliografi, dan alat bantu
lainnya (misalnya: online search engine). Sumber tersier pada penelitian ini diperoleh melalui beberapa artikel online di internet.
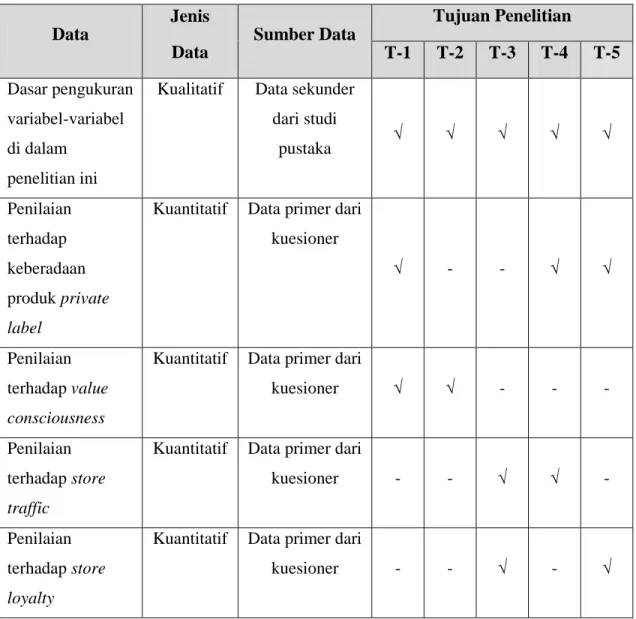
Jenis dan sumber data yang dapat mendukung penelitian ini akan dijelaskan pada Tabel 3.4 sebagai berikut.
Tabel 3.4 Jenis dan Sumber Data Penelitian
Data Jenis Data Sumber Data Tujuan Penelitian T-1 T-2 T-3 T-4 T-5 Dasar pengukuran variabel-variabel di dalam penelitian ini
Kualitatif Data sekunder dari studi pustaka √ √ √ √ √ Penilaian terhadap keberadaan produk private label
Kuantitatif Data primer dari kuesioner
√ - - √ √
Penilaian terhadap value consciousness
Kuantitatif Data primer dari
kuesioner √ √ - - -
Penilaian terhadap store traffic
Kuantitatif Data primer dari
kuesioner - - √ √ -
Penilaian terhadap store loyalty
Kuantitatif Data primer dari
kuesioner - - √ - √
3.4 Teknik Pengumpulan Data
Berikut adalah beberapa teknik pengumpulan data yang digunakan di dalam penelitian ini.
1. Observasi
Peneliti melakukan observasi singkat di Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park untuk mengamati reaksi masyarakat terhadap kehadiran produk private label Carrefour Indonesia, serta mengumpulkan beberapa informasi seputar produk private label Carrefour Indonesia.
2. Wawancara
Peneliti mengadakan wawancara awal dengan konsumen Carrefour Indonesia di Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park untuk mendapatkan informasi mengenai isu-isu yang sedang diteliti saat ini. 3. Kuesioner
Menurut Sekaran (2006, p.82), kuesioner adalah daftar pertanyaan tertulis yang telah dirumuskan sebelumnya yang akan responden jawab, biasanya dalam alternatif yang didefinisikan dengan jelas untuk mengukur variabel penelitian. Kuesioner penelitian ini akan dibagikan kepada konsumen Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park.
4. Studi Pustaka
Data sekunder di dalam penelitian ini diperoleh melalui studi pustaka dengan membaca, mengumpulkan, mencatat, mempelajari buku cetak dan buku–buku pelengkap atau referensi, seperti jurnal di perpustakaan ataupun melalui internet.
3.5 Teknik Pengambilan Sampel
Menurut Indriantoro dan Supomo (2002, p.115) populasi (population) adalah sekelompok orang, kejadian atau segala sesuatu yang memiliki karakteristik tertentu. Karena jumlah populasi relatif banyak, maka penggunaan sampel (elemen-elemen populasi) yang jumlahnya relatif lebih sedikit namun dapat mewakili keseluruhan populasi, lebih diutamakan dalam penelitian ini. Populasi dalam penelitian ini adalah konsumen Carrefour Indonesia di daerah Jakarta.
Menurut Schumacker dan Lomax (2010, pp.41-42), model persamaan struktural (SEM) membutuhkan ukuran sampel yang besar untuk mempertahankan kekuatannya dan memperoleh estimasi parameter dan standard error yang stabil. Kebutuhan akan ukuran sampel yang lebih besar merupakan sebagian persyaratan dari SEM untuk mendefinisikan variabel laten. Ding, Velicer, dan harlow (1995) sepakat bahwa 100 sampai 150 subyek adalah ukuran sampel minimum yang pas untuk melakukan SEM. Menurut Kelloway dan Marsh et. al. (dikutip oleh Riduwan dan Kuncoro, 2008, p.56), ukuran sampel untuk SEM paling sedikit adalah 200 pengamatan. Hubungan antara banyaknya variabel dan ukuran sampel minimal dalam SEM dapat dilihat pada Tabel 3.5 berikut ini.
Tabel 3.5 Jumlah Variabel dan Ukuran Sampel Minimal Jumlah Variabel Ukuran Sampel Minimal
3 200
5 200
10 200
Lanjutan Tabel 3.5
Jumlah Variabel Ukuran Sampel Minimal
20 630
25 975
30 1395
Sumber: Riduwan dan Kuncoro (2008, p.56)
Berdasarkan beberapa penjelasan di atas, maka ukuran sampel minimum yang dibutuhkan dalam penelitian ini adalah sejumlah 200 orang responden yang akan disebar kepada konsumen Carrefour Cempaka Mas, Carrefour Duta Merlin, dan Carrefour Central Park dengan komposisi sebagai berikut:
Tabel 3.6 Komposisi Pembagian Kuesioner Penelitian Gerai Carrefour Indonesia Presentase
Carrefour Cempaka Mas 50% Carrefour Duta Merlin 25% Carrefour Central Park 25% Sumber: Hasil Pengolahan Data (2013)
3.6 Teknik Pengolahan Sampel
Setelah indikator-indikator yang mengukur setiap variabel telah dinyatakan dalam bentuk pertanyaan-pertanyaan pada kuesioner, maka pengujian kelayakan kuesioner (pre-test) perlu dilakukan terlebih dahulu terhadap 30 orang responden dengan bantuan program IBM SPSS Statistics versi 22.0. Setelah setiap indikator pada kuesioner penelitian telah dinyatakan valid dan relibel berdasarkan pengujian
kelayakan kuesioner (pre-test), maka penyebaran kuesioner terhadap 200 orang responden yang dibutuhkan dalam penelitian ini dapat dilakukan. Data-data yang terkumpul nantinya akan diolah menggunakan metode structural equation modeling (SEM) dengan bantuan program LISREL versi 8.8.
3.7 Metode Analisis
Seluruh variabel dalam penelitian ini, yaitu private label, value consciousness, store traffic, dan store loyalty merupakan variabel laten yang memerlukan variabel manifest (variabel teramati/indikator) untuk mengukurnya. Oleh karena itu, peneliti akan menggunakan metode structural equation modeling (SEM) dalam penelitian ini. Hal ini didasari oleh pernyataan Gurajati (1995, dikutip oleh Wijanto, 2008, p.7) bahwa penggunaan variabel-variabel laten pada regresi berganda akan menimbulkan kesalahan-kesalahan pengukuran (measurement errors) yang berpengaruh pada estimasi parameter dari sudut biased-unbiased dan besar kecilnya variance. Menurut Yamin dan Kurniawan (2009, p.3), SEM adalah suatu teknik statistik yang mampu menganalisis pola hubungan antara variabel laten dan indikatornya, variabel laten yang satu dengan lainnya, serta kesalahan pengukuran secara langsung.
Metode analisis yang digunakan untuk mencapai tujuan dalam penelitian ini disajikan pada Tabel 3.7.
Tabel 3.7 Metode Analisis Tujuan Penelitian Metode Analisis
T-1 s/d T-5 Structural Equation Modeling
3.7.1 Definisi Structural Equation Modeling (SEM)
Ghozali dan Fuad (2008, pp.3-4) mendefinisikan, “Model persamaan struktural (Structural Equation Modeling) adalah generasi kedua teknik analisis multivariat yang memungkinkan peneliti untuk menguji hubungan antara variabel yang kompleks baik recursive maupun non-recursive untuk memperoleh gambaran menyeluruh mengenai keseluruhan model. Tidak seperti analisis multivariat biasa (regresi berganda, analisis faktor), SEM dapat menguji model struktural dan model pengukuran secara bersama-sama. Digabungkannya pengujian struktural dan pengukuran tersebut memungkinkan peneliti untuk menguji kesalahan pengukuran (measurement error) sebagai bagian yang tidak terpisahkan dari structural equation modeling dan melakukan analisis faktor bersamaan dengan pengujian hipotesis.
Singgih (2007, p.12) mendefinisikan, “SEM adalah teknik statistik multivariat yang merupakan kombinasi antara analisis faktor dan analisis regresi (korelasi), yang bertujuan untuk menguji hubungan-hubungan antar variabel yang ada pada sebuah model, baik itu antarindikator dengan konstraknya, ataupun hubungan antarkonstrak”. SEM mempunyai karakteristik yang bersifat sebagai teknik analisis untuk lebih menegaskan (confirm) daripada untuk menerangkan. Oleh karena itu, peneliti cenderung menggunakan SEM untuk menentukan apakah suatu model tertentu valid atau tidak daripada menggunakannya untuk menemukan suatu model tertentu cocok atau tidak, meski analisis SEM sering pula mencakup elemen-elemen yang digunakan untuk menerangkan.
3.7.2 Keunggulan SEM
Menurut Yamin dan Kurniawan (2009, pp.3-4), 2 alasan yang mendasari digunakannya SEM adalah:
1. SEM mempunyai kekuatan untuk mengestimasi hubungan antarvariabel yang bersifat multiple relationship. Hubungan ini dibentuk dalam model struktural (hubungan antara variabel dependen dan independen).
2. SEM mempunyai kemampuan untuk menggambarkan pola hubungan antara variabel laten (unobserved) dan variabel manifest (indikator).
Kline dan Klammer (2001, dikutip oleh Wijanto, 2008, p.8) lebih mendorong penggunaan SEM dibandingkan regresi berganda karena 5 alasan sebagai berikut: 1. SEM memeriksa hubungan diantara variabel-variabel sebagai sebuah unit, tidak
seperti pada regresi berganda yang pendekatannya sedikit demi sedikit (piecemeal).
2. Asumsi pengukuran yang andal dan sempurna pada regresi berganda tidak dapat dipertahankan, dan pengukuran dengan kesalahan dapat ditangani dengan mudah oleh SEM.
3. Modification index yang dihasilkan oleh SEM menyediakan lebih banyak isyarat tentang arah penelitian dan pemodelan yang perlu ditindaklanjuti dibandingkan pada regresi.
4. Interaksi juga dapat ditangani oleh SEM.
Selain itu, menurut Schumacker dan Lomax (2010, pp.7-8) SEM menjadi begitu populer karena:
1. Peneliti menjadi lebih sadar akan kebutuhan untuk menggunakan multiple observed variables untuk lebih memahami kebutuhan pada penelitian ilmiah. 2. Pengakuan yang lebih besar diberikan kepada validitas dan reliabilitas skor yang
diamati dari instrumen pengukuran. Secara khusus, kesalahan pengukuran telah menjadi isu utama dalam banyak disiplin ilmu, tapi kesalahan pengukuran dan analisis statistik data telah diperlakukan secara terpisah.
3. SEM telah berkembang selama 30 tahun terakhir, terutama kemampuan untuk menganalisis model teoritis yang lebih maju. Model tersebut telah memberikan banyak peneliti kemampuan lebih untuk menganalisis model teoritis dengan fenomena yang kompleks.
4. Program perangkat lunak SEM semakin user-friendly.
3.7.3 Model-model dalam SEM
Menurut Schumacker dan Lomax (2010, p.2), structural equation modeling (SEM) menggunakan beragam jenis model untuk menggambarkan hubungan diantara variabel laten dan variabel laten dengan variabel manifest, dengan tujuan untuk menguji model teoritis yang telah dihipotesiskan oleh peneliti secara kuantitatif. Menurut Sitinjak dan Sugiarto (2006, pp.45-77), terdapat 3 jenis model dalam SEM, yaitu:
Menurut Wijanto (2008, p.12), model struktural menggambarkan hubungan-hubungan yang ada diantara variabel-variabel laten. Hubungan-hubungan-hubungan ini umumnya linier, meskipun perluasan SEM memungkinkan untuk mengikutsertakan hubungan non-linier. Pada umumnya, variabel laten bebas yang dimasukkan dalam model tidak dapat secara sempurna menjelaskan variabel laten terikatnya, sehingga dalam model struktural biasanya ditambahkan komponen kesalahan struktural, yang diberi label dalam huruf Yunani, zeta “ ”
2. Model Pengukuran
Model pengukuran menggambarkan hubungan variabel laten dengan variabel-variabel teramati atau variabel-variabel indikator. Pada umumnya setiap variabel-variabel laten memiliki beberapa variabel teramati. Variabel teramati dari variabel laten eksogen dilambangkan dengan X, sedangkan variabel teramati dari variabel laten endogen dilambangkan dengan Y. Muatan-muatan faktor (factor loadings) yang menghubungkan variabel laten dan variabel teramati diberi notasi (lambda). Pada umumnya, variabel-variabel teramati dari suatu variabel laten tidak dapat merefleksikan variabel latennya secara sempurna, dengan demikian penambahan kesalahan pengukuran dalam model sangat diperlukan agar model pengukuran menjadi lengkap. Notasi matematik bagi kesalahan pengukuran yang berkaitan dengan variabel teramati X adalah (delta), sedangkan yang berkaitan dengan variabel teramati Y adalah (epsilon). Semakin kecil nilai kesalahan pengukuran semakin baik.
Model hybrid merupakan gabungan model struktural dan model pengukuran. Dalam model hybrid, selain digambarkan hubungan-hubungan yang ada di antara variabel laten, juga digambarkan hubungan variabel laten dengan variabel-variabel teramati yang terkait.
3.7.4 Tahapan dalam prosedur SEM
Menurut Yamin dan Kurniawan (2009, p.14), secara umum ada 5 tahap dalam prosedur SEM, yaitu:
1. Spesifikasi model
Tahap ini berkaitan dengan pembentukan model awal persamaan struktural, sebelum dilakukan estimasi. Model awal ini diformulasikan berdasarkan suatu teori atau penelitian sebelumnya. Spesifikasi model menggambarkan sifat dan jumlah parameter yang diestimasi di dalam penelitian. Menurut Yamin dan Kurniawan (2009, p.14), terdapat 5 tahap dalam spesifikasi model, yaitu:
1. Peneliti mengungkapkan sebuah konsep permasalahan penelitian dalam bentuk sebuah pernyataan atau dugaan hipotesis terhadap suatu masalah. 2. Mendefinisikan variabel-variabel yang akan terlibat dalam penelitian dan
mengkategorikannya sebagai variabel eksogen (bebas) dan variabel endogen (terikat).
3. Menentukan metode pengukuran untuk variabel tersebut, apakah bisa diukur secara langsung (measurable variable) atau membutuhkan variabel manifest (variabel teramati atau indikator-indikator untuk mengukur variabel laten).
4. Mendefinisikan hubungan kausal struktural antarvariabel (antar variabel eksogen dan variabel endogen), apakah hubungan recursive atau hubungan struktural nonrecursive. Menurut Yamin dan Kurniawan (2009, p.69), model hubungan recursive adalah pola hubungan antarvariabel yang memiliki satu arah, sedangkan (p.109) model hubungan non-recursive adalah pola hubungan antarvariabel yang memiliki dua arah (timbal balik).
5. Langkah opsional, yaitu membuat diagram jalur hubungan antarvariabel laten dan antarvariabel laten beserta indikator-indikatornya.
2. Identifikasi model
Tahap ini berkaitan dengan pengkajian tentang kemungkinan diperolehnya nilai yang unik untuk setiap parameter yang ada di dalam model dan kemungkinan persamaan simultan tidak ada solusinya. Informasi yang diperoleh dari data diuji untuk menentukan apakah cukup untuk mengestimasi parameter dalam model. Wijanto (2008, p.39) mendefinisikan identifikasi di dalam SEM sebagai berikut: 1. Under-identified model (df = negatif) adalah model dengan jumlah parameter
yang diestimasi lebih besar dari jumlah data yang diketahui (data tersebut merupakan variance dan covariance dari variabel-variabel teramati).
2. Just-identified model (df = nol) adalah model dengan jumlah parameter yang diestimasi sama dengan data yang diketahui.
3. Over-identified model (df = positif) adalah model dengan jumlah parameter yang diestimasi lebih kecil dari jumlah data yang diketahui.
Menurut Wijanto (2008, p.40), untuk variabel teramati dalam sebuah model yang berjumlah n, maka jumlah data yang diketahui adalah (n x (n + 1))/2; sedangkan
jumlah parameter yang diestimasi dapat diperoleh dari output parameter specifications program LISREL versi 8.8. Menurut Ghozali dan Fuad (2008, p.45), suatu model dapat dikatakan baik apabila memiliki satu solusi yang unik untuk estimasi parameter (over-identified model).
3. Estimasi parameter
Tahap ini berkaitan dengan estimasi terhadap model untuk menghasilkan nilai-nilai parameter dengan menggunakan salah satu metode estimasi yang tersedia. Dari kelima metode estimasi yang tersedia, yaitu Menurut maximum likelihood (ML), generalized least square (GLS), instrumen variable (IS), two stage least square (2SLS), unweight least square (DWLS) (Yamin dan Kurniawan, 2009, p.16); peneliti akan menggunakan metode maximum likelihood apabila data penelitian memiliki distribusi normal dan metode robust maximum likelihood apabila data penelitian tidak memiliki distribusi normal.
Menurut Ghozali dan Fuad (2008, p.35) metode estimasi yang paling populer digunakan pada penelitian SEM, dan secara default digunakan oleh LISREL adalah maximum likelihood (ML). Metode maximum likelihood (ML) membutuhkan asumsi data yang memiliki distribusi multivariat normal, sedangkan metode Robust Maximum Likelihood (RML) membutuhkan asumsi data yang tidak memiliki distribusi multivariat tidak normal dengan ukuran sampel antara 100– 200 atau 10 sampai 20 kali jumlah parameter bebas.
4. Uji kecocokan
Tahap ini berkaitan dengan pengujian kecocokan antara model dengan data. Menurut Hair et. al. (1998, dikutip oleh Wijanto, 2008, p.49) evaluasi terhadap
tingkat kecocokan uji data dengan model dilakukan melalui beberapa tahapan, yaitu:
1. Kecocokan keseluruhan model (overall model fit)
Tahap pertama dari uji kecocokan ini ditunjukan untuk mengevaluasi secara umum derajat kecocokan atau goodness of fit (GOF) antara data dengan model. Yamin dan Kurniawan (2009, p.174) membagi ukuran-ukuran uji kecocokan model ke dalam 3 kelompok, antara lain:
1. Ukuran kecocokan mutlak (absolute fit measures); menentukan derajat prediksi model keseluruhan (model struktural dan pengukuran) terhadap matrik korelasi dan kovarian.
2. Ukuran kecocokan inkremental (incremental atau relative fit measures); membandingkan model yang diusulkan dengan model dasar (baseline model) yang sering disebut null model atau independence model.
3. Ukuran kecocokan parsimoni (parsimonious atau adjusted fit measures); model dengan parameter relatif sedikit.
Di luar ketiga kelompok tersebut, Hoelter’s (1983, dikutip oleh Wijanto, 2008, p.60) menyebutkan uji kecocokan model lainnya, yaitu Critical “N” atau CN adalah ukuran sampel terbesar yang dapat digunakan untuk menerima hipotesis bahwa model tersebut benar.
SEM tidak mempunyai satu uji statistik terbaik yang dapat menjelaskan “kekuatan” prediksi model. Oleh karena itu, di dalam penelitian ini peneliti akan menggunakan beberapa ukuran GOF yang dirangkum pada Tabel 3.8.
Tabel 3.8 Rangkuman Kriteria Uji Kecocokan Ukuran Derajat
Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Perbandingan Antarmodel Absolute Fit Measures
Satorra-Bentler Scaled Chi-Square
P > 0.05 adalah model fit
Nilai semakin kecil semakin baik Non-Centrality
Parameter (NCP)
-
Nilai semakin kecil semakin baik Goodness-of-Fit
Index (GFI)
GFI ≥ 0.90 adalah good fit 0.80 ≤ GFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik Root Mean Square
Residual (RMR)
RMR ≤ 0.05 adalah good fit -
Root Mean Square Error of Approximation
(RMSEA)
RMSEA ≤ 0.08 adalah good fit
RMSEA < 0.05 adalah close fit -
Expected Cross Validation Index
(ECVI)
ECVI < ECVI for Independence Model adalah good fit
Nilai semakin kecil semakin baik
Incremental Fit Measures
Tucker-Lewis Index atau Non-normed Fit
Index (TLI atau NNFI)
TLI ≥ 0.90 adalah good fit 0.80 ≤ TLI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik
Normed Fit Index (NFI)
NFI ≥ 0.90 adalah good fit 0.80 ≤ NFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik
Lanjutan Tabel 3.8 Ukuran Derajat
Kecocokan
Tingkat Kecocokan Yang Bisa Diterima Pada Suatu Model
Perbandingan Antarmodel Incremental Fit Measures
Adjusted Goodness of Fit Index (AGFI)
AGFI ≥ 0.90 adalah good fit 0.80 ≤ AGFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik Relative Fit Index
(RFI)
RFI ≥ 0.90 adalah good fit 0.80 ≤ RFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik Incrementak Fit
Index (IFI)
IFI ≥ 0.90 adalah good fit 0.80 ≤ IFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik Comparative Fit
Index (CFI)
CFI ≥ 0.90 adalah good fit 0.80 ≤ CFI < 0.90 adalah marginal fit
Nilai lebih tinggi adalah lebih baik Parsimonious Fit Measures
Parsimonious Goodness of Fit
(PGFI)
-
Nilai lebih tinggi adalah lebih baik
Normed ChiSquare
Batas bawah: 1.0, batas atas: 2.0 atau 3.0 dan yang lebih longgar 5.0
-
Akaike Information Criterion (AIC)
AIC < AIC for Independence Model adalah good fit
Nilai (+) lebih kecil lebih baik Consistent Akaike
Information Criterion (CAIC)
CAIC < CAIC for Independence Model adalah good fit
Nilai (+) lebih kecil lebih baik
Other GOF
Critical “N” (CN) CN ≥ 200 adalah good fit -
2. Kecocokan model pengukuran (measurement model fit)
Uji kecocokan model pengukuran akan dilakukan terhadap setiap variabel laten dengan beberapa variabel manifest/indikator secara terpisah melalui: Uji terhadap validitas (validity) dari model pengukuran
Sitinjak dan Sugiarto (2006, pp.69-70) menjelaskan bahwa validitas berhubungan dengan apakah suatu variabel teramati mengukur apa yang seharusnya diukur.
Bollen (1989, dikutip oleh Wijanto, 2008, pp.64-65) mengusulkan definisi alternatif dari validitas sebuah variabel teramati adalah muatan faktor (factor loadings) dari variabel tersebut terhadap variabel latennya. Menurut Rigdon dan Ferguson (1991), dan Doll, Xia, Torkzadeh (1994), suatu variabel dikatakan mempunyai validitas yang baik terhadap variabel latennya, jika:
Nilai t muatan faktornya (loading factors) lebih besar dari nilai kritis (atau ≥ 1,96 atau untuk praktisnya ≥2), dan
Muatan faktor standarnya (standardized loading factors) ≥ 0.70. Sedangkan Igrabia, et al. (1997) menyatakan bahwa muatan faktor standar > 0.50 adalah sangat signifikan.
Uji terhadap reliabilitas (reliability) dari model pengukuran.
Menurut Wijanto (2008, p.65) reliabilitas adalah konsistensi suatu pengukuran. Reliabilitas tinggi menunjukkan bahwa variabel teramati mempunyai konsistensi tinggi dalam mengukur variabel latennya. Pengukuran reliabilitas dalam SEM dapat dilakukan dengan menggunakan
composite realiability measure (ukuran reliabilitas komposi) dan variance extracted measure (ukuran ekstrak varian).
Untuk perhitungan construct reliability dan variance extracted, tidak secara otomatis dikeluarkan oleh program LISREL versi 8.8. Berikut adalah rumus untuk menghitung construct reliability dan variance extracted: Construct Reliability
e
loading
std
loading
std
j.
.
2 2 Variance Extracted e
loading
std
loading
std
j.
.
2 2Hair et. al. (1998, dikutip oleh Wijanto, 2008, p.66) menyatakan bahwa sebuah konstruk mempunyai reliabilitas yang baik adalah jika:
Nilai Construct Reliability (CR)-nya > 0.70, dan Nilai Variance Extracted (VE)-nya > 0.50. 3. Kecocokaan model struktural (structural model fit)
Menurut Wijanto (2008, pp.66-67), evaluasi atau analisis terhadap model struktural mencakup pemeriksaan terhadap signifikansi koefisien-koefisien yang diestimasi. Metode SEM dan LISREL versi 8.8 tidak hanya menyediakan nilai koefisien-koefisien yang diestimasi, tetapi juga nilai t-hitung untuk setiap koefisien. Sebagai ukuran menyeluruh terhadap persamaan struktural, overall coefficient of determination (R2) dihitung seperti pada regresi berganda. Meskipun tidak ada uji signifikansi statistik yang dapat
dilakukan, paling tidak memberikan gambaran ukuran kecocokan relatif dari setiap persamaan struktural.
Menurut Yamin dan Kurniawan (2009, p.16) terdapat dua metode pendekatan yang digunakan dalam pembentukan model SEM, yaitu:
1. One step approach: berarti bahwa estimasi atau pengujian model (baik pengukuran model atau model struktural) dilakukan sekaligus secara menyeluruh. Model hubungan antara konstrak dan indikatornya serta hubungan antar konstrak disetimasi secara simultan.
2. Two step approach: dilakukan secara bertahap. Pertama dilakukan pengujian terhadap pengukuran model hingga mencapai uji kelayakan model yang baik, kemudian setelah mendapatkan pengukuran model yang baik, setiap konstrak dihubungkan untuk diuji secara struktural.
Yamin dan Kurniwan (2009, p.17) menambahkan bahwa sebuah tahap analisis tunggal dengan estimasi simultan model struktural dan pengukuran adalah pendekatan yang terbaik, ketika dasar pemikirian teoritis proses model kuat dan ukuran kepercayaannya tinggi.
5. Re-spesifikasi model
Tahap ini berkaitan dengan res-pesifikasi model berdasarkan atas hasil uji kecocokan pada tahap sebelumnya. Menurut Wijanto (2008, pp.67-68) pelaksanaan re-spesifikasi sangat tergantung kepada strategi pemodelan yang akan digunakan. Ada 3 strategi pemodelan yang dapat dipilih dalam SEM, yaitu: 1. Strategi pemodelan konfirmatori. Pada strategi pemodelan ini diformulasikan
data empiris untuk diuji signifikansinya sehingga akan dihasilkan penerimaan atau penolakan terhadap model tersebut. Peneliti tidak akan menggunakan strategi ini karena strategi ini tidak memerlukan re-spesifikasi.
2. Strategi kompetisi model. Pada strategi pemodelan ini beberapa model alternatif dispesifikasikan dan berdasarkan analisis terhadap satu kelompok data empiris dipilih salah satu model yang paling sesuai. Peneliti juga tidak akan menggunakan strategi ini karena pada strategi ini re-spesifikasi hanya diperlukan jika model-model alternatif dikembangkan dari beberapa model yang ada.
3. Strategi pengembangan model. Pada strategi pemodelan ini suatu model awal dispesifikasikan dan data empiris dikumpulkan. Saat ini, strategi yang paling banyak digunakan dalam penelitian adalah strategi pengembangan model. Peneliti akan menggunakan strategi pengembangan model. Jika model awal tidak cocok dengan data empiris yang ada, maka model akan dimodifikasi dan diuji kembali dengan data yang sama. Beberapa model dapat diuji dalam proses ini dengan tujuan untuk mencari satu model yang selain cocok dengan data secara baik, tetapi juga mempunyai sifat bahwa setiap parameternya dapat diartikan dengan baik.
3.7.5 Linear Structural Relationships (LISREL)
Perkembangan SEM sangat dibantu oleh tersedianya perangkat lunak, salah satunya adalah LISREL. Menurut Ghozali dan Fuad (2008, p.4), LISREL adalah
satu-satunya program SEM yang paling banyak digunakan dan dipublikasikan pada berbagai jurnal ilmiah di berbagai disiplin ilmu. Hal tersebut karena LISREL adalah satu-satunya program SEM yang tercanggih dan dapat mengestimasi berbagai masalah SEM yang bahkan nyaris tidak mungkin dapat dilakukan oleh program lain, seperti AMOS, EQS, dan lain sebagainya. LISREL memungkinkan peneliti untuk menguji hubungan antara variabel laten dan juga indikator-indikatornya. Menurut Joreskog dan Sorbom (1989, dikutip oleh Ghozali dan Fuad, 2008, p.10), LISREL akan bekerja jauh lebih baik apabila LISREL digunakan untuk konteks confirmatory. Sedangkan untuk tujuan exploratory dengan banyak variabel dan dengan teori yang lemah, LISREL bukanlah alat statistik yang “tepat” dan berguna.
LISREL versi 8.8 diperkenalkan pada bulan Juli 2006 dengan mengandung aplikasi-aplikasi statistik sebagai berikut (www.sscicentral.com, 2006, dikutip oleh Wijanto, 2008, p.75):
LISREL for structural equation modeling.
PRELIS for data manipulations and basic statistical analyses. MULTILEV for hierarchical linear and non-linear modeling. SURVEYGLIM for generalized linear modeling.
CATFIRM for formative inference-based recursive modeling for categorical response variables.
CONFIRM for formative inference-based recursive modeling for continunous response variable.
3.8 Rancangan Uji Hipotesis
Keputusan yang diambil pada pengujian hipotesis yang telah dibahas pada bab sebelumnya akan didasarkan pada perbandingan antara nilai t-value dan t-tabel. Nilai t-tabel adalah sebesar 1.96, yang diperoleh dari tabel nilai t dengan level signifikansi 5% dan jumlah sampel 200, sedangkan nilai t-value diperoleh dari output pengolahan data dengan menggunakan software LISREL versi 8.8.
Dasar Pengambilan Keputusan:
Jika t-value terletak di antara -1.96 dan 1.96; maka H0 diterima.
Jika t-value tidak terletak di antara -1.96 dan 1.96; maka H0 ditolak dan H1 diterima.
Selain menguji perbandingan antara nilai t-value dan t-tabel, peneliti juga akan menilai arah hubungan antara variabel-variabel laten dengan memperhatikan tanda yang terletak di depan t-value ataupun koefisien (nilai) estimasi, baik positif ataupun negatif.