BAB 3
METODE PENELITIAN
3.1. Desain Penelitian
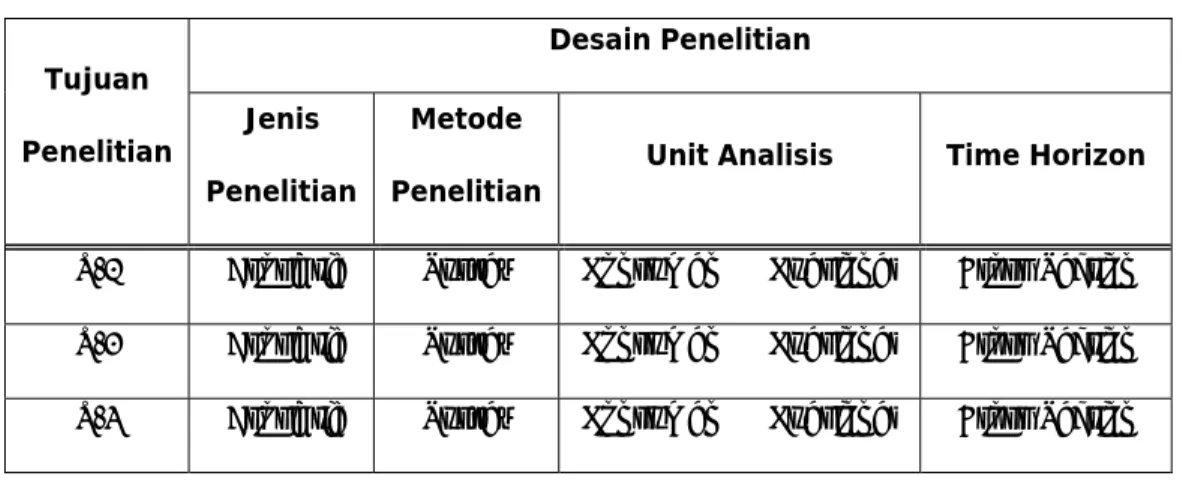
Tabel 3.1. Desain Penelitian
Tujuan Penelitian Desain Penelitian Jenis Penelitian Metode
Penelitian Unit Analisis Time Horizon T-1 Asosiatif Survey Konsumen → Kuesioner Cross Section T-2 Asosiatif Survey Konsumen → Kuesioner Cross Section T-3 Asosiatif Survey Konsumen → Kuesioner Cross Section
(Sumber : Sugiyono, 2006)
Keterangan :
T-1 : Untuk mengetahui dan menganalisis pengaruh program Corporate Social Responsibility terhadap sikap konsumen The Body Shop.
T-2 : Untuk mengetahui dan menganalisis pengaruh program Corporate Social Responsibility terhadap loyalitas merek The Body Shop
T-3 : Untuk mengetahui dan menganalisis pengaruh sikap konsumen terhadap loyalitas merek The Body Shop setelah adanya program Corporate Social Responsibility
Berdasarkan metode penelitian, jenis penelitian yang digunakan merupakan penelitian survei. Penelitian survei merupakan penelitian yang dilakukan pada populasi besar maupun kecil, tetapi data yang dipelajari adalah data dari sample yang diambil dari populasi tersebut, sehingga ditemukan kejadian-kejadian relatif, distribusi, dan hubungan-hubungan antar variabel sosiologis maupun psikologis.
Berdasarkan tingkat eksplanasi, penelitian ini merupakan penelitian asosiatif. Penelitian asosiatif adalah penelitian yang bertujuan untuk mengetahui hubungan antara 2 (dua) variabel atau lebih. Dengan penelitian ini, maka akan dapat dibangun suatu teori yang dapat berfungsi untuk menjelaskan, meramalkan dan mengontrol suatu gejala.
3.2. Operasionalisasi Variabel Penelitian
Dalam penelitian ini variabel yang diteliti dibagi menjadi dua kelompok besar, yaitu variabel bebas (independen variable) dan variabel terikat (dependent variable). Definisi operasional untuk masing-masing variabel adalah sebagai berikut:
1. Variabel bebas (independent variable)
variabel yang mempengaruhi atau yang menjadi penyebab terjadinya perubahan atau timbulnya variabel terikat (Sugiono, 2001:33). Dalam penellitian ini variabel bebasnya adalah program Corporate Social Responsibility (X)
2. Variabel intervening
Variabel yang secara teoritis mempengaruhi hubungan antara variabel bebas dan variabel terikat, namun sulit untuk diukur. Dalam penelitian ini
yang digunakan sebagai variabel intervening adalah sikap konsumen terhadap program Corporate Social Responsibility The Body Shop (Y). 3. Variabel terikat (dependent variable)
Variabel terikat merupakan variabel yang dipengaruhi atau yang menjadi akibat, karana adanya variabel bebas (Sugiono, 2001:33). Dalam penelitian ini yang digunakan sebagai variabel terikat (Z) adalah loyalitas merek terhadap Body Shop setelah perusahaan menerapkan kegiatan Corporate Social Responsibility
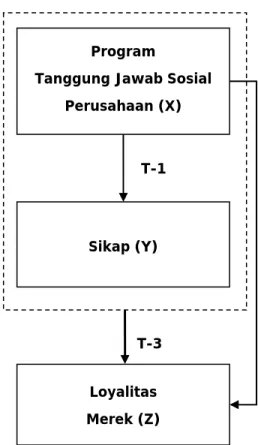
Gambar 3.1. Hubungan Antar Variabel T-3
Program
Tanggung Jawab Sosial Perusahaan (X) Sikap (Y) Loyalitas Merek (Z) T-1 T-2
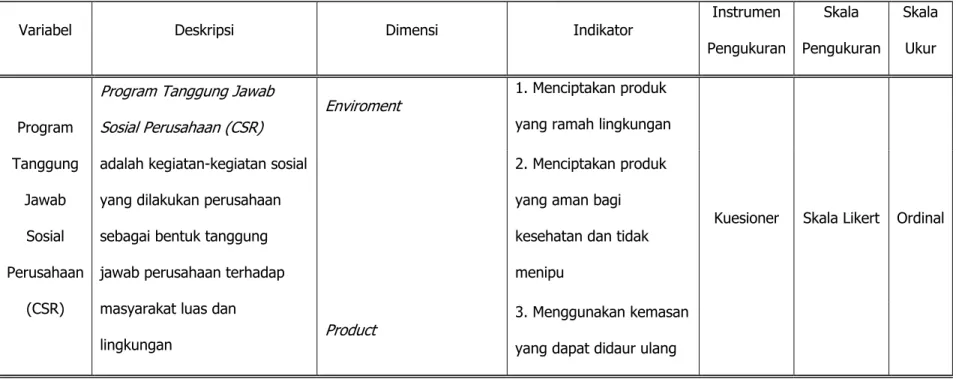
Tabel 3.2. Operasionalisasi Variabel Model Penelitian
Variabel Deskripsi Dimensi Indikator Instrumen
Pengukuran Skala Pengukuran Skala Ukur Program Tanggung Jawab Sosial Perusahaan (CSR)
Program Tanggung Jawab Sosial Perusahaan (CSR)
adalah kegiatan-kegiatan sosial yang dilakukan perusahaan sebagai bentuk tanggung jawab perusahaan terhadap masyarakat luas dan lingkungan
Enviroment 1. Menciptakan produk
yang ramah lingkungan
Kuesioner Skala Likert Ordinal 2. Menciptakan produk
yang aman bagi kesehatan dan tidak menipu
Product 3. Menggunakan kemasan
Variabel Deskripsi Dimensi Indikator Instrumen Pengukuran Skala Pengukuran Skala Ukur Sikap
Sikap (attitude) didefinisikan
sebagai evaluasi konsep secara menyeluruh yang dilakukan oleh seseorang
Komponen kognitif
Informasi dan
kepercayaan konsumen terhadap motivasi dan kesesuaian program CSR yang dilakukan oleh The Body Shop.
Kuesioner Skala Likert Ordinal Komponen afektif
Perasaan (senang atau tidak senang) konsumen pada penerapan program CSR The Body Shop.
Komponen konatif
Kecenderungan tindakan konsumen pada
penerapan program CSR The Body Shop.
Variabel Deskripsi Dimensi Indikator Instrumen Pengukuran Skala Pengukuran Skala Ukur Loyalitas Merek
Loyalitas merek (brand loyalty)
adalah komitmen yang
dipegang teguh untuk membeli ulang atau berlangganan dengan produk atau jasa yang disukai secara konsisten di masa mendatang, sehingga menimbulkan pembelian merek yang sama secara berulang
Switcher
(berpindah-pindah)
Price Kuesioner Skala Likert Ordinal Sejumlah pembeli yang
menggunakan merek tersebut, karena harga yang ditawarkan lebih murah daripada merek lain.
Variabel Deskripsi Dimensi Indikator Instrumen Pengukuran Skala Pengukuran Skala Ukur
Habitual Buyer (pembeli
yang bersifat kebiasaan)
Habitual response Kuesioner Skala Likert Ordinal Sejumlah pembeli yang
kurang mengalami kepuasan dalam menggunakan merek tersebut. Jika pembeli tersebut masih
mengkonsumsinya, hal tersebut atas dasar kebiasaannya selama ini.
Variabel Deskripsi Dimensi Indikator Instrumen Pengukuran Skala Pengukuran Skala Ukur
Satisfied Buyer (pembeli
yang puas dengan biaya peralihan)
Satisfaction Kuesioner Skala Likert Ordinal Sejumlah pembeli yang
rela menggunakan merek lain dengan menanggung biaya perolehan, karena merek lain tersebut menawarkan manfaat yang lebih besar.
Variabel Deskripsi Dimensi Indikator Instrumen Pengukuran Skala Pengukuran Skala Ukur
Liking the brand (pembeli
yang menyukai merek)
Liking the brand
Kuesioner Skala Likert Ordinal Sejumlah pembeli yang
menyukai merek dengan didasari asosiasi - asosiasi merek pada produk
Commited buyer (pembeli
yang berkomitmen) Commitment Aktualisasi loyalitas pembeli ditunjukkan denagn tindakan merekomedasikan dan mempromosikan merek tersebut kepada pihak lain.
3.3. Jenis dan Sumber Data Penelitian
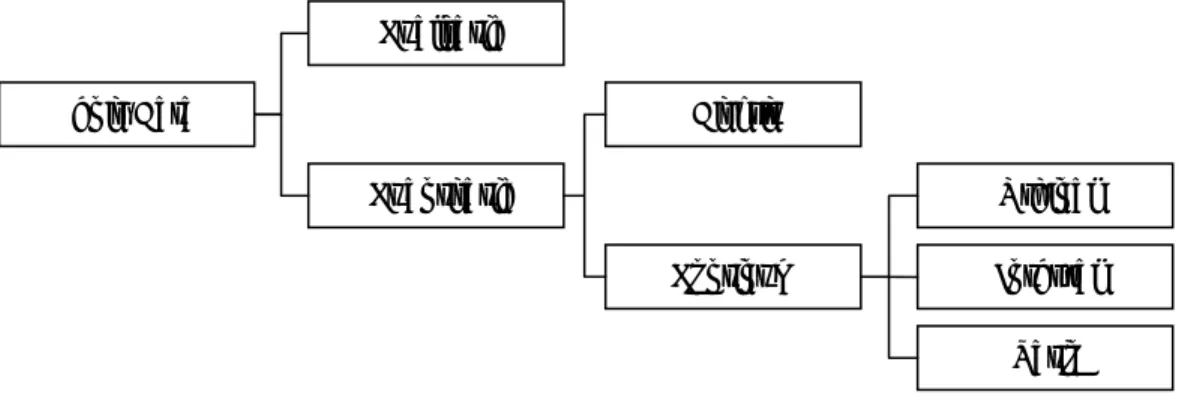
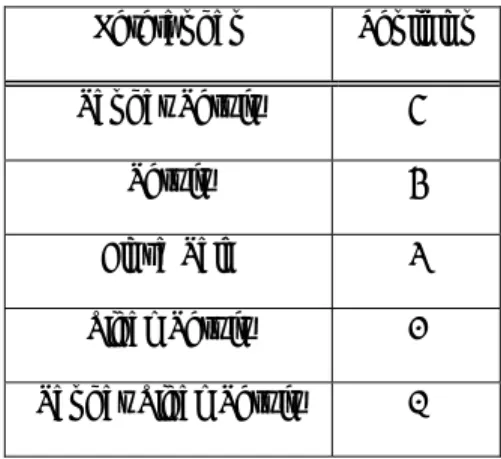
Untuk mendapatkan data yang valid untuk penelitian,kita perlu mengetahui jenis-jenis data seperti yang terdapat pada gambar 3.2. Berdasarkan pembagian diatas, data-data yang diperoleh dalam penelitian ini berupa data kuantitatif.
Gambar 3.2. Jenis-jenis Data
Sumber : Sugiyono (2006, p14)
Tabel 3.3. Jenis dan Sumber Data
No. Data yang diambil Jenis Data Sumber Data 1 Program Tanggung Jawab Sosial Perusahaan Kuantitatif Primer
2 Sikap Konsumen Kuantitatif Primer
3 Loyalitas Merek Kuantitatif Primer
3.4. Tehnik Pengumpulan Data
Teknik yang digunakan untuk pengumpulan data dalam penelitian ini adalah sebagai berikut:
Ratio
Jenis Data Diskrit
Kualitatif
Kuantitatif
Kontinum
Ordinal Interval
1. Angket (kuisioner)
Teknik yang menggunakan angket atau kuisioner adalah suatu cara pengumpulan data dengan memberikan dan menyebarkan daftar pertanyaan kepada responden, dengan harapan mereka dapat memberikan respon atas daftar pertanyaan tersebut.
2. Wawancara
Pengumpulan data dilakukan dengan cara melakukan wawancara langsung dengan perwakilan dari pihak perusahaan secara sistematis dan sesuai dengan tujuan penelitian.
3. Studi Pustaka
Studi pustaka dilakukan dengan mempelajari dan mengambil data dari literatur terkait dan sumber-sumber lain yang dianggap dapat memberikan informasi mengenai penelitian ini seperti majalah dan internet.
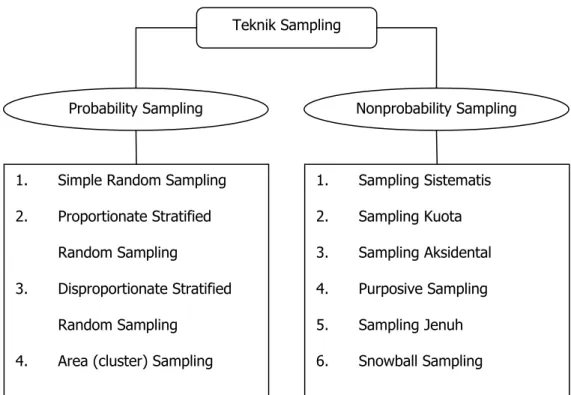
3.5. Teknik Pengambilan Sampel
Berdasarkan pendapat Sugiyono (2006, p72), populasi adalah wilayah generalisasi yang terdiri atas : obyek atau subyek yang mempunyai kualitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari dan kemudian ditarik kesimpulannya. Sedangkan sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut. Teknik sampling atau Teknik pengambilan sampel merupakan teknik penentuan sampel yang akan digunakan dalam penelitian.
Teknik Sampling Nonprobability Sampling 1. Sampling Sistematis 2. Sampling Kuota 3. Sampling Aksidental 4. Purposive Sampling 5. Sampling Jenuh 6. Snowball Sampling 1. Simple Random Sampling
2. Proportionate Stratified Random Sampling
3. Disproportionate Stratified Random Sampling
4. Area (cluster) Sampling Probability Sampling
Gambar 3.3. Teknik Pengambilan Sample
Teknik sampling pada dasarnya dapat dikelompokkan menjadi 2 (dua), yaitu probability sampling dan nonprobability sampling. Probability sampling adalah teknik pengambilan sampel (teknik sampling) yang memberikan peluang yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sampel. Nonprobability sampling adalah teknik pengambilan sampel yang tidak memberi peluang atau kesempatan sama bagi setiap unsur atau anggota populasi untuk dipilih menjadi sampel. Semakin besar jumlah sampel mendekati populasi, maka peluang kesalahan generalisasi semakin kecil dan sebaliknya, semakin kecil jumlah sampel menjauhi populasi, maka semakin besar kesalahan generalisasi (diberlakukan umum).
Dalam penelitian ini teknik sampling yang digunakan adalah nonprobability sampling dan sampling aksidental. Sampling aksidental adalah teknik penentuan sampel
berdasarkan kebetulan, yaitu siapa saja yang bertemu dengan peneliti dapat digunakan sebagai sampel, jika dipandang orang yang kebetulan itu cocok sebagai sumber data.
3.6. Teknik Penentuan Jumlah Sampel
Menghitung ukuran sampel dengan menggunakan rumus slovin (Umar,2003,p146) adalah : 2 Ne 1 N n + = di mana : n = Ukuran sample N = Ukuran populasi
E = Persentase kelonggaran ketidaktelitian karena kesalahan pengambilan sampel yang masih dapat ditolelir atau diinginkan.
Populasi adalah para anggota forum WebGaul Forum: A ZEIN Company (http://forum.wgaul.com/index.php), terutama yang bergabung di topik The Body Shop sebanyak 987 anggota. Saat ini anggota WebGaul Forum adalah 70,513 orang, dengan rata-rata online user 412 anggota per hari.
2 Ne 1 N n + =
( )
987( )
0,12 1 987 n + = responden 91 800368 , 90 87 , 10 987 n= = ≈Berdasarkan perhitungan di atas, maka penulis memutuskan untuk mengambil sampel sebanyak 150 responden.
3.7. Teknik Pengukuran Variabel
Bentuk pertanyaan yang digunakan dalam kuesioner adalah structured non disguised, yaitu bentuk pertanyaan yang merupakan kombinasi pilihan berganda dan berpedoman pada skala likert. Skala Likert biasanya digunakan untuk mengukur sikap, pendapat, dan persepsi bagi seorang responden. Bentuk penilaian jawaban kuesioner menggunakan pembobotan dengan lima buah skala. Bobot dan kategori pengukuran atas tanggapan responden terdapat pada tabel 3.4.
Tabel 3.4. Bobot Penilaian dengan Skala Likert Keterangan Penilaian Sangat Setuju 5
Setuju 4 Biasa Saja 3
Tidak Setuju 2 Sangat Tidak Setuju 1
3.8. Metode Analisis
Pengujian Validitas dilakukan untuk mengetahui atau mengukur sejauh mana suatu alat ukut dapat mengukur apa yang ingin kita ukur. Hasil penelitian dapat dikatakan
valid apabila terdapat suatu kesamaan antara data yang terkumpul dengan data yang sesungguhnya terjadi pada obyek yang diteliti. Pengujian Reliabilitas dilakukan untuk mengetahui sejauh mana kuesioner yang digunakan dapat dipercaya atau dapat memberikan perolehan hasil penelitian yang konsisten apabila alat ukur ini digunakan kembali dalam pengukuran gejala sama.
Adapun metode yang digunakan untuk memecahkan permasalahan sesuai dengan tujuan yang dicapai, yaitu model persamaan struktural (Structural Equation Modeling – SEM) dengan software LISREL 8.54 sebagai alat dari pengolahannya
3.8.1. Model Persamaan Struktural
Model persamaan struktural (Struktural Equation Modeling - SEM) merupakan suatu teknik statistik yang mampu menganalisis variabel laten, variabel indikator, dan kesalahan pengukuran secara langsung. Dengan Structural Equation Modeling kita mampu menganalisis hubungan antara variabel laten dengan indikatornya. Hubungan antara variabel laten yang satu dengan variabel laten lainnya juga mengetahui besarnya kesalahan pengukuran. Di samping hubungan kausal searah Structural Equation Modeling juga memungkinkan kita menganalisis hubungan dua arah yang sering kali muncul dalam ilmu sosial dan perilaku.
Structural Equation Modeling termasuk keluarga multivariat statistik dependensi yang memungkinkan dilakukannya analisis satu atau lebih variabel independent dengan satu atau lebih variabel independen yang dilibatkan boleh berbentuk variabel kontinu ataupun diskrit, dalam bentuk variabel laten atau teramati. Dalam prakteknya, Structural Equation Modeling merupakan gabungan dari dua metode statistika yang terpisah yang melibatkan analisis faktor, yang dikembangkan di psikologi dan psikometri, dan model persamaan stimultan, yang dikembangkan di ekonometrika.
Umumnya teknik analisis statistik hanya mengolah variabel-variabel indikatornya saja tanpa melibatkan variabel laten, dan juga jarang dalam pengolahannya sekaligus melibatkan kekeliruan pengukuran variabel. Umumnya kekeliruan pengukuran hanya diperhatikan pada saat uji coba dengan menghitung reliabilitas dan validitasnya. Dalam pengolahan selanjutnya, masalah kekeliruan pengukuran sering dilupakan saja atau diasumsikan bahwa kekeliruan pengukuran “tidak ada”, padahal selama alat ukur tersebut tidak memiliki tingkat realibilitas dan validitas yang “sempurna” maka besarnya kekeliruan pengukuran akan berpengaruh kepada hasil analisisnya. Kita semua tahu bahwa dalam ilmu sosial dan perilaku tidak memiliki suatu alat ukur yang benar-benar baku, tidak seperti tehnik dan sains yang memiliki alat ukur yang baku di mana-mana dan sepengetahunan penulis tidak ada lembaga semacam metrologi yang bertugas mengkalibrasi alat ukur ilmu-ilmu sosial. Dengan demikian kita perlu suatu alat analisis statistik yang sekaligus melibatkan kekeliruan pengukuran.
Seperti sudah dijelaskan bahwa dalam ilmu sosial untuk mengukur suatu konstruk umumnya secara tidak langsung, yaiotu melalui indikator-indikatornya. Selama ini variable-variabel indikator inilah yang diproses untuk menjelaskan bagaimana hubungan antara konstruk yang satu dengan konstruk lainnya, tetapi hubungan tersebut tetap samar-samar, artinya hubungan antara indikator-indikator dan konsep tersebut tidak secara eksplisit dinyatakan dalam suatu persamaan. Dengan demikian perlu suatu analisis statistik yang secara stimultan melibatkan variabel indikator dan variabel laten.
Suatu teknik statistik yang menganalisis variabel indikator, variabel laten, dan kekeliruan pengukurannya adalah pemodelan persamaan struktural (SEM). Dengan SEM kita dapat menganalisis bagaimana hubungan antara variabel indikator dengan variabel latennya yang dikenal sebagai persamaan pengukuran (measurement equation), hubungan antara variabel laten yang lain dikenal sebagai persamaan struktural (structural equation) yang
secara bersama-sama melibatkan kekeliruan pengukuran. Selain itu, model persamaan struktural dapat menganalisis hubungan dua arah (reciprocal) yang sering terjadi pada ilmu sosial. Dalam SEM dikenal juga dengan variabel laten eksogen (independent latent variable) dan variabel laten endogen (dependent latent variable).
Sekarang ini, penggunaan Structural Equation Modeling dalam penelitian sosial semakin banyak. Ada tiga alasan mengapa Structural Equation Modeling banyak digunakan dalam penelitian (Kelloway, 1998) yaitu
1. Penelitian sosial umumnya menggunakan pengukuran-pengukuran untuk menjabarkan konstruk. Hampir semua penelitian ilmu sosial tertarik dalam pengukuran dan teknik pengukuran. Salah satu bentuk dari SEM Structural Equation Modeling berurusan secara langsung dan dapat menjawab pertanyaan sejauh mana pengukuran yang dilakukan dapat merefleksikan konstruk yang diukur. Singkatnya, pengolahan data dengan SEM sekaligus dapat mengevaluasi kualitas pengukuran yaitu keandalan dan validitas suatu alat ukur.
2. Peneliti sosial sangat tertarik terhadap prediksi. Dalam melakukan prediksi tidak hanya melibatkan model dua variabel, tetapi dapat melibatkan model yang lebih rumit berupa struktur hubungan antara beberapa variabel penelitian.
3. Structural Equation Modeling dapat melayani sekaligus merupakan suatu analisis kualitas pengukuran dan prediksi. Khususnya, dalam mode-mode variabel laten, model ini merupakan suatu model yang fleksibel dan sangat ampuh secara simultan memeriksa kualitas pengukuran dan hubungan prediktif antarkonstruk.
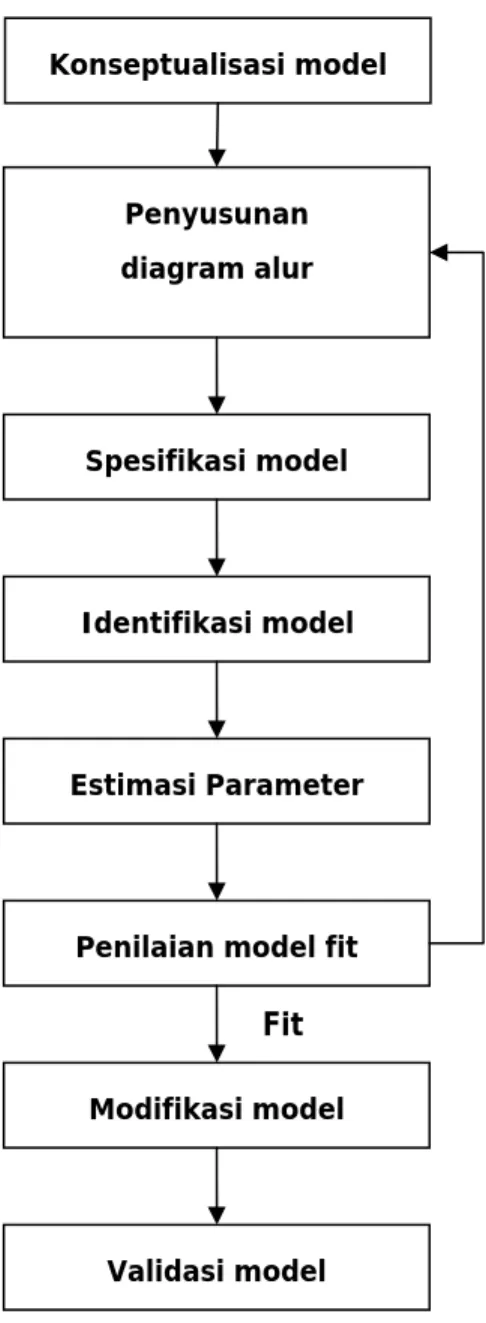
3.8.2. Prosedur Structural Equation Modeling
Gambar 3.4. Tahap-tahap dalam SEM
Sumber : Ghozali,2005,p9 Konseptualisasi model Penyusunan diagram alur Spesifikasi model Identifikasi model Estimasi Parameter
Penilaian model fit
Modifikasi model
Tidak fit
Fit
Konseptualisasi model
Tahap ini berhubungan dengan pengembangan hipotesis (berdasarkan teori-teori) sebagai dasar dalam menghubungkan variabel laten dengan variabel laten lainnya, dan juga dengan indikator-indikatornya. Dengan kata lain model yang dibentuk adalah persepsi kita mengenai bagaimana variabel laten dihubungkan berdasarkan teori dan bukti yang diperoleh dari ilmu kita. Konseptualisasi model ini juga harus merefleksikan pengukuran variabel laten melalui berbagai indikator yang dapat diukur. Perlu diperhatikan bahwa sukses tidaknya analisis Structural Equation Modeling harus didasari pada kuatnya teori yang mendukung.
Konseptualisasi model mengharuskan dua hal yang harus dilakukan, yaitu: a. Menentukan hubungan yang dihipotesiskan antara variabel laten. Tahap
pengembangan model ini berfokus pada pengembangan model struktural,dan harus merepresentasikan kerangka teoritis untuk diuji. Dalam penelitian ini Tanggung Jawab Sosial Perusahaan merupakan variabel exogenus (variabel eksogen), karena variabel tanggung jawab sosial perusahaan tidak dipengaruhi variabel lainnya dalam model. Sedangkan variabel sikap dan loyalitas merek merupakan variabel endogenus (variabel endogen), karena keduanya dipengaruhi oleh variabel lain dalam model penelitian. Namun variabel sikap merupakan variabel endogenus yang independen, yang mempengaruhi variabel endogenus lain dalam model; dengan kata lain, variabel sikap merupakan variabel intervening. Karena variabel endogenus tidak secara sempurna dipengaruhi oleh variabel yang dihipotesiskan (masih terdapat kemungkinan variabel endogenus tersebut dipengaruhi oleh variabel
selain yang dihipotesiskan), maka error term (atau residual) juga dihipotesiskan mempengaruhi variabel endogenus dalam model.
b. Memfokuskan pada pengukuran model dan menghubungkannya dengan operasionalisasi variabel laten. Sehingga dikenal beberapa indikator (manifest variabel) yang digunakan untuk mengukur variabel laten (unobserved variabel). Variabel manifest dalam LISREL biasanya menggunakan refflective indicators (effect indicators), yang berarti konstruk laten dianggap mempengaruhi variabel observed.
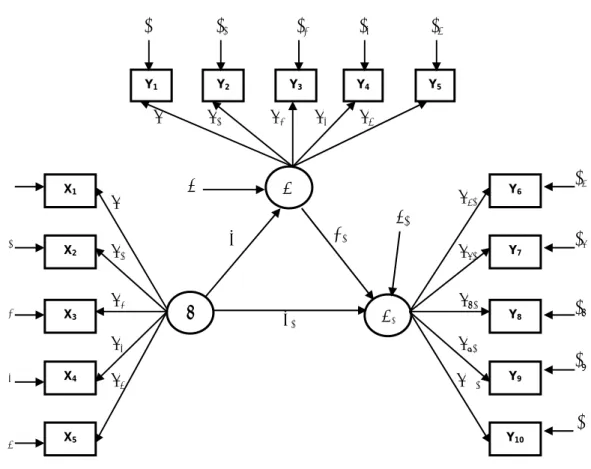
Penyusunan diagram alur
Gambar 3.5. Diagram Alur (Path Diagram) Sumber: Sumber : Ghozali,2005,p20
λ
5λ
4λ
3λ
2λ
1λ
51λ
41λ
31λ
21λ
11λ
102λ
92λ
82λ
72λ
62γ
2γ
1β
21ξ
η
2η
1ζ
1ζ
2 X3 X2 X1 X5 X4δ
1δ
2δ
3δ
4δ
5 Y1 Y2 Y3 Y4 Y5ε
1ε
2ε
3ε
4ε
5 Y7 Y6 Y10 Y9 Y8ε
6ε
7ε
9ε
10ε
8Keterangan :
ξ = Variabel laten eksogen
η1 = Variabel laten endogen independen η2 = Variabel laten endogen dependen X = Indikator variabel laten eksogen Y = Indikator variabel laten endogen
δ = Kesalahan pengukuran (measurement error) dari indikator variabel laten
eksogen
ε = Kesalahan pengukuran (measurement error) dari indikator variabel laten endogen
γ = Hubungan langsung variabel laten eksogen terhadap variabel laten endogen β = Hubungan langsung varibel laten endogen terhadap variabel laten endogen λ = Hubungan antara variabel laten baik eksogen maupun endogen terhadap variabel observed atau indikatornya
ζ1 = Kesalahan dalam persamaan antara variabel eksogen terhadap variabel endogen ζ2 = Kesalahan dalam persamaan antara variabel endogen terhadap variabel
endogen lainnya
Spesifikasi model
Spesifikasi model dilaukan terhadap permasalahan yang diteliti. Sangat disarankan agar penetapan model tidak dilakukan secara asal tetapi didasarkan pada rujukan yang relevan. Model yang dibentuk akan kuat bila sudah ada teori yang mendasarinya. Meski demikian untuk paradigma baru, teori bagi topik yang terkait mungkin belum ada sehingga temuan-temuan baru yang relevan bisa dijadikan dasar rujukan yang bermakna. Spesifikasi model secara garis besar dijalankan dengan menspesifikasikan model struktural. Spesifikasi
model secara garis besar dijalankan dengan mnspesifikasikan model struktural. Spesifikasi model pengukuran meliputi aktivitas mendefinisi hubungan antar variabel laten dengan variabel-variabel teramati. Spesifikasi model struktural dilakukan dengan mendefinisikan hubungan kausal diantara variabel-variabel laten.
Identifikasi model
Informasi yang diperoleh dari data diuji untuk menentukan apakah cukup untuk mengestimasi parameter dalam model. Di sini kita harus dapat memperoleh nilai yang unik untuk seluruh parameter dari data yang telah kita peroleh. Jika hal ini tidak dapat dilakukan, maka modifikasi model mungkin harus dilakukan untuk dapat diidentifikasi sebelum melakukan estimasi parameter. Untuk menentukan apakah model dalam penelitian ini mengandung atau tidak masalah identifikasi, maka harus dipenuhi keadaan berikut :
t ≤ 2 s
di mana :
t : jumlah parameter yang diestimasi
s : jumlah varians dan kovarians antara variabel manifes p : jumlah indikator variabel endogen
q : jumlah indikator variabel eksogen
Jika t
≥
2
s, maka model tersebut adalah unidentified atau under-identified.
Under-identified model adalah model dengan jumlah parameter yang diestimasi lebih besar dari ada jumlah data yang diketahui. Pada kondisi under-identified model yang dispesifikasikan tidak memiliki penyelesaian yang unik.
Jika t =
2
s, maka model tersebut adalah just-identified. Just-identified model
adalah model dengan jumlah parameter yang diestimasi sama dengan data yang diketahui. Pada kondisi just-identified model yang dispesifikasi hanya memiliki satu penyelesaian.
Jika t ≤ 2
s, maka model tersebut adalah over-identified. Over-identified model
adalah model dengan jumlah parameter yang diestimasi lebih kecil dari jumlah data yang diketahui. Pada kondisi over-identified, penyelesaian model yang diperoleh melalui proses estimasi iteratif. Penyelesaian yang diperoleh biasanya merupakan nilai-nilai yang konvergen ke nilai-nilai yang stabil. Over-identified ini dapat menggunakan persamaan yang tersisa untuk menguji fit atau tidaknya suatu model
Estimasi parameter
Tahapan ini ditujukan untuk memproleh estimasi dari setiap parameter yang dispesifikasikan dalam model yang membentuk matrix ∑
( )
θ sedemikian rupasehingga nilai parameter menjadi sedekat mungkin dengan nilai yang ada dalam matrik S (matrik kovarian sample dari variabel teramati). Matrik kovarian sample S digunakan untuk mewakili ∑ (matrik kovarian populasi) karena matrik kovarian populasi tidak diketahui. Berdasarkan hipotesis nol, diusahakan agar selisih S dengan ∑( )
θ mendekati atau sama dengan nol. Hal ini dapat dilaksanakan dengan meminimumkan suatu fungsi F(S,∑( )
θ ) melalui iterasi. Estimasi terhadap model dapat dilakukan menggunakan salah satu dari metode estimasi yang tersedia.Pada Lisrel terdapat tujuh metode yang dapat digunakan untuk mengestimasi parameter dari suatu model, yaitu Instrumental Variable (IV), Two Stage Least Square (TSLS), Unweighted Least Square (ULS), Generalized Squares (GLS), Maximum Likehood (ML), Generally Weighted Least Square (WLS), Diagonally Weighted Least Square (DWLS). Di antara berbagai metode yang tersedia, metode estimasi yang paling banyak digunakan adalah Maximum Likehood dan Weighted Least Square. Minimalisasi fungsi tersebut dapat dilakukan melalui iterasi (dimulai dengan nilai awal) sampai diperoleh nilai yang kecil atau minimal.
Penilaian model fit
Tahapan ini ditujukan untuk mengevaluasi derajat kecocokan atau Goodness of Fit (GOF) antara data dan model. Menurut Hair et al. (1995) dalam buku Lisrel (Sitinjak, Sugianto, 2006) evaluasi terhadap GOF model dilakukan melalui beberapa tingkatan yaitu:
1. Kecocokan keseluruhan model (overall model fit)
Penilaian derajat kecocokan suatu SEM secara menyeluruh tidak dapat dijalankan secara langsung sebagaimana pada teknik multivariate yang lain. SEM tidak mempunyai uji statistik terbaik yang dapat menjelaskan kekuatan prediksi model. Untuk itu telah dikembangkan beberapa ukuran derajat kecocokan yang dapat digunakan secara saling mendukung. Hair et al. (199:660, Wijanto, 2003:17-20) mengelompokkan ukuran ukuran GOF yang ada ke dalam 3 bagian yaitu :
a. Absolute fit measures (ukuran kecocokan absolute)
Menentukan derajat prediksi model keseluruhan (model struktural dan pengukuran ) terhadap matrik korelasi dan kovarian.
Membandingkan model yang diusulkan dengan model dasar yang sering disebut sebagai null model atau independence model
c. Parsimonious fit measure (ukuran kecocokan parsimony)
Mengaitkan model dengan jumlah koefisien yang diestimasi yakni yang diperlukan untuk mencapai kecocokan pada tingkat tersebut. Sesuai dengan prinsip parsimony atau kehematan berarti memperoleh degree of fit setinggi-tingginya untuk setiap degree of freedom
2. Kecocokan model pengukuran (measurement model fit)
Evaluasi ini dilakukan terhadap setiap construct secara terpisah melalui evaluasi terhadap validitas construct dan evaluasi terhadap reliabilitas construct.
a. Validitas
Validitas berhubungan dengan apakah suatu variable mengukur apa yang seharusnya diukur. Validitas dalanm penelitian menyatakan derajat ketepatan alat ukur penelitian terhadap isi atau arti sebenarnya yang diukur. Uji validitas adalah uji yang digunakan untuk menunjukkan sejauh mana alat ukur bias digunakan dalam suatu penelitian mengukur apam yang ingin diukur. Dengan uji ini dilakukan pemeriksaan apakah item-item yang dieksplorasi mendukung item total atau tidak. Suatu instrument penelitian dianggap valid jika informasi yang ada pada tiap item berkorelasi erat dengan informasi dari item item tersebut sebagai satu kesatuan.
Validitas dapat dibedakan menjadi : content validity, criterion validity, construct validity, dan convergent and discriminant validity. Bollen (1989) mengusulkan definisi alternatif dari validitas sebuah variable teramati adalah muatan faktor (factor loadings) dari variabel tersebut terhadap variabel latennya. Rigdon dan ferguson (1991), Doll, Xia, Torkzadeh (1994), menyatakan bahwa suatu variabel dikatakan mempunyai validitas yang baik terhadap konstruk atau variabel lainnya jika :
i. Nilai t muatan faktornya (factor loadings) lebih besar dari nilai kritis (>1.96 atau untuk praktisnya >=2)
ii. Muatan faktor standarnya (standardized factor loadings) lebih besar atau sama dengan 0.70
iii. Igbaria, et al. (1997) yang menggunakan guidelines dari Hair et, al. (1995) tentang relative importance dan significant of the factor loading of each items : loadings > 0.50 adalah sangat signifikan
b. Reliabilitas
Reliabilitas menunjuk pada suatu pengertian bahwa instrumen yang digunakan dalam penelitian untuk memperoleh informasi yang diinginnkan dapat dipercaya (terandal) sebagai alat pengumpul data serta mampu mengungkap informasi yang sebenarnya di lapang. Instrumen yang reliable adalah instrumen yang bilamana dicobakan secara berulang ulang kepada kelompok yang sama akan menghasilkan data yang sama dengan asumsi tidak terdapat perubahan psikologis pada responden. Instrumen yang baik tidak
bersifat tendensius mengarahkan responden untuk memilih jawaban tertentu sebagaimana dikehendaki oleh peneliti. Instrumen yang reliable akan menghasilkan data yang sesuai dengan kenyataannya, dalam artian berapa kalipun penelitian diulang dengan instrument tersebut akan tetap diperoleh “kesimpulan” yang sama (walaupun perolehan angka nominalnya tidak harus sama )
Secara prinsip reliabilitas mencerminkan konsistensi suatu pengukuran. Reliabilitas yang tinggi menunjukkan bahwa indikator-indikator (variable-variabel teramati) mampunyai konsistensi tinggi dalam mengukur variable latennya. Teknik yang paling banyak digunakan untuk mengukur reliabilitas adalah cronbach’s alpha. Meskipun demikian, Cronchbach’s alpha akan memberikan estimasi terlalu rendah jika digunakan untuk mengestimasi reliabilitas congeneric measure (bollen,1989). Menurut Hair et, al. (1995) pengukuran reliabilitas untuk SEM dapat dilakukan dengan menggunakan Composite/ Construct Reliability measure (ukuran reliabilitas komposit/konstruk) maupun variance extracted measure (ukuran ekstrak varian). Ekstrak varian mencerminkan jumlah varian keseluruhan daalam ndikator yang dijelaskan oleh construct latent. Reliabilitas construct dikatakan baik, jika nilai construct reliability-nya ≥ 0.70 dan nilai variance extractednya ≥ 0.50. 3. Kecocokan model struktural (structural model fit)
Uji kecocokan ini dilakukan terhadap koefisien-kosefisien persamaan struktural dengan menspesifikasikan tingkat signifikan tertentu. Dalam hal
tingkat signifikansi adalah 0.05, maka nilai t dari persamaan struktural harus > 1.96. selain itu juga perlu dilakukan evaluasi terhadap solusi standar dimana semua koefisien mempunyai varian yang sama dan nilai maximumnya adalah 1. Sebagai ukuran menyeluruh terhadap persamaan struktural, overall coefficient of determination (R2) dievaluasi seperti pada regresi berganda
Modifikasi model
Tahapan ini dtujukan untuk melakukan spesifikasi ulang terhadap model untuk memperoleh derajat kecocokan yang lebih baik. Respesifikasi ini sangat tergantung kepada strategi pemodelan yang dipilih. Dalam SEM tersedia 3 strategi pemodelan yang dapat dipilih. (joreskog dan sorbom 1993. hair et, al. 1995) yaitu :
Strictly confirmatory atau confirmatory modeling strategy. Untuk itu terlebih dahulu dispesifikasikan suatu model tunggal, lalu dilakukan pengumpulan data empiris. Pengujian dilakukan untuk menghasilkan penerimaan atau penolakan terhadap model tersebutsebagaimana criteria dari hipotesis nol. Model dinyatakan bagus bila mampu merepresentasikan data empiris. Dalam strategi ini tidak ada respesifikasi model.
Alternative (Competing) Models atau sompeting model stratregy. Tahapan yang dilakukan sama dengan pada strictly confirmatory, hanya saja beberapa model alternatif dispesifisifikasikan dan dipilih salah satu yang paling sesuai. Respesifikasi hanya diperlukan jika model-model alternatif dikembangkan dari beberapa model yang ada.
Model generating atau model development strategy. Tahapan yang dilakukan dimulai dari spesifikasi suatu model awal, dilanjutkan dengan pengumoulan data empiris. Selanjutnya dilakukan analisis dan pengujian apakah data cocok dengan model, Jika tingkat
kecocokan kurang baik, maka model dimodifikasi dan diuji kembali dengan data yang sama. Respesifikasi model diperlukan jika modelnya tidak memiliki kemampuan yang diharapkan. Proses respesifikasi dapat dilakukan berdasarkan theory driven atau data driven, meskipun respesifikasi berdasar theory driven lebih dianjurkan. Dari ketiga strategi yang dapat dipilih, model generating merupakan strategi yang paling banyak diterapkan.
Validasi silang model
Validasi silang model menguji fit-tidaknya model penelitian terhadap suatu data baru (atau validasi sub-sampel yang diperoleh melalui prosedur pemecahan sampel).
3.8.3. LISREL (Linear Struktural Relationship)
Istilah model persamaan struktural juga dikenal dengan nama Lisrel, yang merupakan paket program statistik untuk SEM yang pertama kali diperkenalkan oleh Karl Joreskoq pada tahun 1970 dalam suatu pertemuan ilmiah. Istilah lain untuk SEM sering kali disebut juga analisis faktor konfirmatori (Confirmatory Factor Analysis), model struktur kovarians (Covariance Structure Model) dan model variabel laten (Latent Variable Modeling).
Penggunaan data dalam SEM dilakukan menggunakan prosedur interatif yang sangat memakan waktu dan penelitian jika dilakukan secara manual. Perkembangan teknologi komputer sangat membantu dalam pengolahan data dengan SEM dan menjadikan SEM semakin banyak digunakan oleh para peneliti maupun untuk bisnis. Dewasa ini telah dikembangkan beberapa program komputer yang dapat digunakan untuk menganalisis SEM, antara lain EQS. AMOS, LISREL, SAS PORT CALIS, STATISTICA-SEPATH, dan lain-lain.
LISREL merupakan salah satu program komputer yang dapat mempermudah analisis untuk menyelesaikan masalah-masalah yang tidak dapat diselesaikan oleh alat
analisis yg konvensional. LISREL adalah satu-satunya program SEM yang paling banyak digunakan dan dipublikasikan pada berbagai jurnal ilmiah pada berbagai disiplin ilmu. Hal tersebut karena LISREL adalah satu-satunya program SEM yang tercanggih dan yang dapat mengestimasi berbagai masalah SEM yang bahkan nyaris tidak mungkin dapat dilakukan oleh program lain. Di samping itu LISREL merupakan program paling informatif dalam menyajikan hasil-hasil statistik. Sehingga modifikasi model dan penyebab tidak fit atau buruknya suatu model dapat dengan mudah diketahui.
LISREL diperkenalkan oleh Karl Joreskog pd thn 1970 dan sejauh ini telah dikembangkan serta digunakan dalam berbagai disiplin ilmu pengetahuan sosial. Dalam versi yang lebih maju, penggunaan lisrel menjadi lebih interaktif, lebih mudah, banyak fitur statistik yang baru terkait dengan penangganan missing data, imputation data, serta multilevel data analysis. Terapannya pada persoalan ilmu sosial dan ilmu perilaku dapat kita temui secara luas yang sangat berguna sebagai acuan pengambilan keputusan dalam kondisi yang makin rumit. Secara umum analisis dalam LISREL dapat dipilah dalam dua bagian : pertama, yang terkait dengan model pengukuran dan kedua, yang terkait dengan model struktural.
Dengan menggunakan LISREL, kita dapat menganalisis struktur kovarians yang rumit. Variabel laten, saling ketergantungan antar variabel, dan sebab akibat yg timbal balik dapat ditangani dengan mudah dengan menggunakan model pengukuran dan persamaan yang terstruktur. Pada dasarnya mengolahan SEM dengan LISREL dapat dilakukan dengan empat cara, yaitu menggunakan prelis project, simplis project, lisrel project, maupun path diagram.
Asumsi yang paling fundamental dalam analisis multivariate adalah normalitas yang merupakan bentuk suatu distribusi data pada suatu variable metric tunggal dalam menghasilkan distribusi normal. Suatu distribusi data yang tidak membentuk distribusi
normal, maka data tersebut tidak normal, sebaliknya data dikatakan normal apabila ia membentuk suatu distribusi norml. Apabila asumsi normalitas tidak dipenuhi dan penyimpangan normalitas tersebut besar, maka seluruh hasil uji statistik adalah tidak valid karena perhitungan uji t dan lain sebagainya, dihitung dengan asumsi data normal
Untuk menguji dilanggar atau tidaknya asumsi normalitas, maka dapat digunakan nilai statistik z untuk skewness dan kurtosisnya. Nilai z skewness dapat dihitung sebagai berikut:
N 6 skewness Zskewness =
Di mana N merupakan ukuran sample. Nilai statistic z untuk kurtosisnya dapat dihitung dengan menggunakan formula berikut ini:
N 24 kurtosis Zkurtosis =
Jika nilai z, baik zkurtosis dan/atau zskewness adalah signifikan (kurang dari 0,05 pada tingkat 5%), maka dapat dikatakan bahwa distribusi data adalah tidak normal. Sebaliknya, jika nilai zkurtosis dan/atau zskewness tidak signifikan (lebih besar dari 0,05), maka distribusi data adalah normal. Berdasarkan hal tersebut dapat disimpulkan bahwa untuk uji normalitas ini kita mengharapkan hasil yang tidak signifikan.
LISREL merupakan suatu alat bantu statistik yang paling canggih dan paling popular dalam SEM. Normalitas data tidaklah merupakan suatu permasalahn yang serius, karena LISREL memiliki beberapa solusi yang dapat dilakukan, yaitu :
1. Menambahkan estimasi asymptotic covariance matrix
Hal ini akan mengakibatkan estimasi parameter beserta goodness of fit statistics akan dianalisis berdasarkan pada keadaan data yang tidak
normal. Apabila matriks asymptotic covariance tidak dimasukkan, sedangkan data tidak normal, sebagai input data suplemen, maka model yang diestimasi berdasarkan keadaan data normal, dan tentu saja hasilnya akan bias.
2. Melakukan transformasi data
Hal ini dapat dilakukan khusus untuk data continous. Untuk data berskala ordinal, transformasi data tidak dianjurkan karena akan mengakibatkan data sulit diinterpretasikan
3. Menggunakan metode estimasi selain Maximum Likelihood (ML), seperti Generalized Least Square (GLS) atau Weighted Least Square, apabila jumlah data mencukupi.
4. Menggunakan metode Bootstrapping dan Jackniffing. Kedua metode ini adalah metode baru yang mengasumsikan data dire-sampling dan kemudian dianalisis. Standar error yang diperoleh dari metode bootstrapping tersebut kemudian dibandingkan dengan metode ML, apabila selisih signifikan, maka ketidaknormalan data mengakibatkan hasil yang sangat bias.
3.9. Rancangan Uji Hipotesis
Hipotesis diartikan sebagai jawaban sementara terhadap rumusan masalah penelitian dan pada dasarnya merupakan suatu proporsi atau anggapan yang mungkin benar dan sering digunakan sebagai dasar pembuatan keputusan atau pemecahan persoalan ataupun untuk dasar penelitian lebih lanjut. Untuk dapat diuji, suatu hipotesis haruslah dinyatakan secara kuantitatif.
Dalam menerima atau menolak suatu hipotesis yang diuji, ada satu hal yang harus dipahami, bahwa penolakan suatu hipotesis berarti menyimpulkan hipotesis itu salah, sedangkan menerima suatu hipotesis semata-mata mengimplikasikan bahwa kita mempunyai bukti untuk mempercayai sebaliknya.
Hipotesis yang dirumuskan dengan harapan akan diterima membawa penggunaan istilah hipotesis nol. Penerimaan hipotesis nol dilambangkan dengan Ho mengakibatkan penerimaan suatu hipotesis alternatif,yang dilambangkan dengan Ha atau H1. Jadi hipotesis nol adalah pernyataan tidak adanya perbedaan antara parameter dengan statistik (data sampel). Lawan dari hipotesis nol adalah hipotesis alternatif yang menyatakan adanya perbedaan antara parameter dan statistik.
Structural Equation Modeling memiliki dua tujuan utama dalam analisisnya. Tujuan pertama adalah untuk menentukan apakah model plausible (masuk akal) atau fit, sedangkan tujuan keduanya adalah untuk menguji berbagai hipotesis yang telah dibangun sebelumnya.
Berikut merupakan prosedur uji hipotesis : 1. Menentukan Ho dan H1
Variabel-variabel penelitian sebagai berikut :
X : Program tanggung jawab sosial perusahaan Y : Sikap konsumen
Z : Loyalitas merek Hipotesis sebagai berikut :
1. Program tanggung jawab sosial The Body Shop berpengaruh secara signifikan dengan sikap konsumen
Ho : Program tanggung jawab sosial The Body Shop tidak berpengaruh secara signifikan terhadap sikap konsumen
H1 : Program tanggung jawab sosial The Body Shop berpengaruh secara signifikan terhadap sikap konsumen
2. Program tanggung jawab sosial perusahaan berpengaruh secara signifikan dengan loyalitas merek
Ho : Program tanggung jawab sosial The Body Shop tidak berpengaruh secara signifikan terhadap loyalitas merek H2 : Program tanggung jawab sosial The Body Shop berpengaruh
secara signifikan terhadap loyalitas merek
3. Program tanggung jawab sosial perusahaan berpengaruh secara simultan dan signifikan terhadap sikap konsumen dan loyalitas merek The Body Shop
Ho : Program tanggung jawab sosial The Body Shop dan Sikap Konsumen tidak berpengaruh secara simultan dan signifikan terhadap loyalitas merek
H3 : Program tanggung jawab sosial The Body Shop dan Sikap Konsumen berpengaruh secara simultan dan signifikan terhadap loyalitas merek
2. Menentukan statistik tabel
Nilai statistik tabel biasanya dipengaruhi oleh : 1. Selang kepercayaan
Untuk keseragaman, biasanya digunakan tingkat kepercayaan 95%, jadi tingkat kesalahan (α) 5%.
2. Derajat kebebasan
Derajat kebebasan sangat bervariasi, tergantung pada metode yang dipakai atau jumlah sampel yang diperoleh.
3. Mengambil keputusan
Keputusan terhadap hipotesis ditentukan dengan :
1. Membandingkan tingkat signifikasi (Sig) dengan tingkat kesalahan (α)
Sig > Tingkat kesalahan, maka Ho diterima Sig < Tingkat kesalahan, maka Ho ditolak 2. Membandingkan t hitung dengan nilai t tabel
t hitung > t tabel, maka Ho ditolak t hitung < t tabel, maka Ho diterima
3.8. Rancangan Implikasi Hasil Penelitian
Jika berdasarkan analisis penelitian diketahui bahwa Program CSR berkontribusi secara simultan dan signifikan terhadap sikap konsumen dan loyalitas merek The Body Shop, maka The Body Shop harus tetap menjalankan program-program CSR secara konsisten. Kerena penerapan program CSR The Body Shop terbukti menambah nilai dan daya saing The Body Shop terhadap pesaing dan berpengaruh secara signifikan terhadap loyalitas merek The Body Shop.
![Pola penggunaan obat golongan ACEi dan ARB pada pasien diabetes nefropati di Rumkital Dr. Ramelan Surabaya. [CD-ROM] - Widya Mandala Catholic University Surabaya Repository](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)