BAB 2
LANDASAN TEORI
2.1. Sistem Informasi Geografis
Sistem Informasi Geografi (SIG) atau Geographic Information System (GIS) adalah suatu sistem informasi yang dirancang untuk bekerja dengan data yang bereferensi spasial atau berkoordinat geografi atau dengan kata lain suatu SIG adalah suatu sistem basis data dengan kemampuan khusus untuk menangani data yang bereferensi keruangan (spasial) bersamaan dengan seperangkat operasi kerja (Barus dan Wiradisastra, 2000). Sementara menurut Heywood (2002) Sistem Informasi Geografi (SIG) adalah sistem komputer yang dapat menyimpan dan menggunakan
data untuk menggambarkan tempat – tempat dipermukaan bumi. Disamping itu, SIG juga dapat menggabungkan data, mengatur data dan melakukan analisis data yang akhirnya akan menghasilkan keluaran yang dapat dijadikan acuan dalam pengambilan keputusan pada masalah yang berhubungan dengan geografi.
Dengan memperhatikan pengertian Sistem Informasi, maka SIG merupakan suatu kesatuan formal yang terdiri dari berbagai sumber daya fisik dan logika yang berkenaan dengan objek-objek yang terdapat di permukaan bumi. SIG bertujuan untuk menyimpan dan memanipulasi informasi-informasi geografis. SIG dirancang untuk mengumpulkan, menyimpan dan menganalisa objek serta fenomena yang posisi geografisnya merupakan karakteristik yang penting untuk dianalisis (Fathansyah, 2005).
Ciri utama data yang bisa dimanfaatkan dalam Sistem Informasi Geografis adalah data yang telah terikat dengan lokasi dan merupakan data dasar yang belum dispesifikasi (Dulbahri, 1993).
Barus dan Wiradisastra (2000) juga mengungkapkan bahwa SIG adalah alat yang handal untuk menangani data spasial, dimana dalam SIG data dipelihara dalam bentuk digital sehingga data ini lebih padat dibanding dalam bentuk peta cetak, tabel atau dalam bentuk konvensional lainnya yang akhirnya akan mempercepat pekerjaan dan meringankan biaya yang diperlukan.
Aronoff (1989) menjelaskan model data vektor yang digunakan untuk merepresentasikan fitur-fitur spasial permukaan bumi, antara lain :
a. Model Data Spaghetti
Pada model vektor data spaghetti ini, data spasial ditranslasikan garis per garis ke dalam sistem koordinat kartesian XY. Sebuah titik diencoding sebagai satu pasangan koordinat XY, sebuah garis sebagai deretan pasangan koordinat XY dan area direpresentasikan oleh poligon tertutup sempurna. Perekaman batas antara poligon yang berdampingan dengan merekam titik-titik setiap segmen tersebut pada setiap poligon.
Model spaghetti sangat sederhana dan mudah dimengerti, dimana model data tersebut secara nyata merupakan peta yang diekspresikan pada koordinat kartesian walaupun model spaghetti tidak merekam relasi spasial antar fitur geografis. Misalnya untuk analisis poligon yang berdampingan harus dilakukan searching semua fitur geografis kemudian baru dihitung apakan fitur-fitur tersebut saling berdampingan atau tidak. Hal ini menyebabkan model spaghetti tidak efisien untuk analisis data spasial dalam jumlah besar.
b. Model Data Topological
Model topologi banyak digunakan untuk encoding relasi spasial pada SIG. Topologi merupakan metode matematis untuk mendefinisikan relasi spasial antar fitur geografis. Bentuk dasar model ini yaitu :
• Arc berupa susunan titik (point) yang berawal dan berakhir pada node;
• Node merupakan titik pertemuan antar dua arc atau lebih dan node juga terletak pada ujung arc;
Topologi direkam pada 3 (tiga) data tabel untuk arc, node, dan poligon, sedangkan data koordinat disimpan pada tabel tersendiri. Titik dan polygon disimpan pada layer yang sama, sedang garis disimpan pada layer berbeda, dimana set topologi dan tabel koordinat saling terkait dengan setiap layer data.
c. Triangulated Irregular Network (TIN)
TIN adalah model data topologi berbasis vektor untuk merepresentasikan data permukaan bumi (terrain) dalam bentuk rangkaian segitiga yang berhubungan. Pada setiap titik direkam lokasi geografis dalam koordinat XY dan elevasi dalam koordinat Z. TIN direpresentasikan pada tabel Node (menyebutkan nama segitiga dan node yang menyusunnya), tabel Edge (menyebutkan daftar tiga segitiga yang berbatasan), tabel koordinat XY dan tabel koordinat Z (menyimpan nilai koordinat tiap node).
Komponen Sistem Informasi Geografis
Menurut Prahasta (2005) Komponen-komponen pendukung SIG terdiri dari lima komponen yang bekerja secara terintegrasi yaitu perangkat keras (hardware), perangkat lunak (software), data, manusia, dan metode yang dapat diuraikan sebagai berikut:
1. Perangkat Keras (hardware)
Perangkat keras SIG adalah perangkat-perangkat fisik yang merupakan bagian dari sistem komputer yang mendukung analisis goegrafi dan pemetaan. Perangkat keras SIG mempunyai kemampuan untuk menyajikan citra dengan resolusi dan kecepatan yang tinggi serta mendukung operasioperasi basis data dengan volume data yang besar secara cepat. Perangkat keras SIG terdiri dari beberapa bagian untuk menginput data, mengolah data, dan mencetak hasil proses. Berikut ini pembagian berdasarkan proses :
Input data: mouse, digitizer, scanner
Olah data: harddisk, processor, RAM, VGA Card
2. Perangkat Lunak (software)
Perangkat lunak digunakan untuk melakukan proses menyimpan, menganalisa, memvisualkan data-data baik data spasial maupun non-spasial. Perangkat lunak yang harus terdapat dalam komponen software SIG adalah:
Alat untuk memasukkan dan memanipulasi data SIG
Data Base Management System (DBMS)
Alat untuk menganalisa data-data
Alat untuk menampilkan data dan hasil analisa
3. Data
Pada prinsipnya terdapat dua jenis data untuk mendukung SIG yaitu :
Data Spasial
Data spasial adalah gambaran nyata suatu wilayah yang terdapat di permukaan bumi. Umumnya direpresentasikan berupa grafik, peta, gambar dengan format digital dan disimpan dalam bentuk koordinat x,y (vektor) atau dalam bentuk image (raster) yang memiliki nilai tertentu.
Data Non Spasial (Atribut)
Data non spasial adalah data berbentuk tabel dimana tabel tersebut berisi informasi- informasi yang dimiliki oleh obyek dalam data spasial. Data tersebut berbentuk data tabular yang saling terintegrasi dengan data spasial yang ada.
4. Manusia
5. Metode
Metode yang digunakan dalam SIG akan berbeda untuk setiap permasalahan. SIG yang baik tergantung pada aspek desain dan aspek realnya.
2.2. Pengertian Garis Lintang dan Garis Bujur
Garis lintang (latitude) dan garis bujur (longitude) adalah garis-garis khayal di permukaan bumi yang dilukis di atas peta, atlas atau bola dunia untuk membantu menunjukkan kedudukan suatu tempat. Letak dan posisi tempat dirujuk oleh titik persilangan (koordinat) antara garis lintang dengan garis bujur. Nilai garis lintang dinyatakan terlebih dahulu, kemudian diikuti oleh nilai garis bujur (Hartono, 2007).
Garis lintang adalah garis-garis paralel pada bola dunia yang sejajar dengan Garis Ekuator. Garis lintang diukur dalam kiraan (˚) dari Garis Khatulistiwa atau Ekuator (0˚) tanpa sudut. Garis-garis lintang utama di dunia terdiri dari Garis Khatulistiwa, Garis Sartan, Garis Jadi, Garis Artik, dan Garis Anartik. Semua garis lintang berbentuk lingkaran cincin, kecuali Kutub Utara (90˚LU) dan Kutub Selatan (90˚LS) yang berbentuk titik untuk menggambarkan poros bumi. Jadi Lintang Utara (LU) berarti semua posisi atau tempat yang terletak di sebelah Utara Ekuator, sedangkan Lintang Selatan (LS) berarti semua tempat yang terletak di sebelah Selatan Ekuator (Hartono, 2007).
2.3. Citra Satelit
Menurut Hornby (Sutanto, 1994), citra merupakan gambaran yang terekam oleh kamera atau oleh sensor lainnya. Sedangkan Simonett mengutarakan dua pengertian tentang citra yaitu : Gambaran obyek yang dibuahkan oleh pantulan atau pembiasan sinar yang difokuskan oleh sebuah lensa atau sebuah cermin. Gambaran rekaman suatu obyek (biasanya berupa gambaran pada foto) yang dibuahkan dengan cara optik, elektro-optik, optik mekanik, atau elektronik. Pada umumnya ia digunakan bila radiasi elektromagnetik yang dipancarkan atau dipantulkan dari suatu obyek tidak langsung direkam pada film.” (Sutanto, 1994).
Menurut Lintz Jr. dan Simonett dalam Sutanto (1994), ada tiga rangkaian kegiatan yang diperlukan dalam pengenalan obyek yang tergambar pada citra, yaitu:
1. Deteksi, adalah pengamatan adanya suatu objek, misalnya pada gambaran sungai terdapat obyek yang bukan air.
2. Identifikasi, adalah upaya mencirikan obyek yang telah dideteksi dengan menggunakan keterangan yang cukup. Misalnya berdasarkan bentuk, ukuran, dan letaknya, obyek yang tampak pada sungai tersebut disimpulkan sebagai perahu motor.
3. Analisis, yaitu pengumpulan keterangan lebih lanjut. Misalnya dengan mengamati jumlah penumpangnya, sehingga dapat disimpulkan bahwa perahu tersebut perahu motor yang berisi dua belas orang.
Berdasarkan resolusi yang digunakan, citra hasil penginderaan jarak jauh bisa dibedakan atas (Jaya, 2002):
Resolusi spasial Merupakan ukuran terkecil dari suatu bentuk (feature) permukaan bumi yang bisa dibedakan dengan bentuk permukaan disekitarnya, atau sesuatu yang ukurannya bisa ditentukan. Kemampuan ini memungkinkan kita untuk mengidentifikasi (recognize) dan menganalisis suatu objek di bumi selain mendeteksi (detectable) keberadaannya.
Resolusi radiometrik Merupakan ukuran sensitifitas sensor untuk membedakan aliran radiasi (radiation flux) yang dipantulkan atau diemisikan suatu objek oleh permukaan bumi.
Resolusi Temporal Merupakan frekuensi suatu sistem sensor merekam suatu areal yang sama (revisit). Seperti Landsat TM yang mempunyai ulangan setiap 16 hari, SPOT 26 hari dan lain sebagainya
Citra, sebagai dataset, bisa dimanipulasi menggunakan algoritma (persamaan matematis). Manipulasi bisa merupakan pengkoreksian error, pemetaan kembali data terhadap suatu referensi geografi tertentu, ataupun mengekstrak informasi yang tidak langsung terlihat dari data. Data dari dua citra atau lebih pada lokasi yang sama dikombinasikan secara matematis untuk membuat composite dari beberapa dataset. Produk data ini, disebut derived products, bisa dihasilkan dengan beberapa penghitungan matematis atas data numerik mentah (DN) (Puntodewo, 2003)
2.4. Digitasi
Menurut Khomsin (2004) digitasi adalah proses untuk mengubah informasi grafis yang tersedia dalam kertas ke formal digital. Dalam prosesnya, digitasi memerlukan waktu, tenaga, biaya, dan menuntut adanya tenaga ahli yang cukup menguasai tekniknya sedangkan menurut Puntodewo (2003) digitasi citra adalah proses mengkonversi fitur-fitur spasial pada peta menjadi kumpulan koordinat x,y.
Proses digitasi secara umum dibagi dalam dua macam (Puntodewo, 2003): 1. Digitasi menggunakan digitizer.
Dalam proses digitasi ini memerlukan sebuah meja digitasi atau digitizer. 2. Digitasi onscreen di layar monitor
Digitasi onscreen paling sering dilakukan karena lebih mudah dilakukan, tidak memerlukan tambahan peralatan lainnya, dan lebih mudah untuk dikoreksi apabila terjadi kesalahan.
2.5. Karakteristik Citra Satelit Quickbird
Sensor satelit QuickBird DigitalGlobe berhasil diluncurkan 18 Oktober 2001 di Vandenberg Air Force Base, California, USA. (Digital Globe, 2014).
Menggunakan state-of-the-art BGIS 2000 sensor (PDF), satelit QuickBird mengumpulkan data gambar dari 0.65m tingkat resolusi detail piksel. Satelit ini merupakan sumber yang sangat baik dari data lingkungan berguna untuk analisis perubahan penggunaan lahan, pertanian dan iklim hutan (Digital Globe, 2014)..
Selama bulan Juni 2014 DigitalGlobe mendapat izin dari Departemen Perdagangan AS untuk mengumpulkan dan menjual citra di resolusi terbaik yang tersedia. Selain itu, enam bulan setelah WorldView-3 beroperasi DigitalGlobe akan diijinkan untuk menjual citra sampai dengan 25 cm pankromatik dan multispektral 1,0 m GSD (Digital Globe, 2014).Karakteristik citra quickbird seperti pada tabel 2.1. 2.6 Data Vektor
Dalam data vektor bumi direpresentasikan sebagai suatu mosaik garis (arcline), polygon (daerah yang dibatasi oleh garis yang berawal dan berakhir pada titik yang sama), titik (Edy Irwansyah, 2013).
Model data vektor merupakan model data yang paling banyak digunakan, model mi berbasiskan pada titik (points) dengan nilai koordinat (x,y) untuk
membangun obyek spasialnya. Obyek yang dibangun terbagi menjadi tiga bagian lagi yaitu berupa titik (point), garis (line), dan area (polygon) (Edy Irwansyah, 2013).
1. Titik-titik.
Entity titik meliputi semua objek grafis atau geografis yang dikaitkan dengan koordinat. Di samping koordinat-koordinat, data atau informasi yang diasosiasikan dengan „titik‟ tersebut juga harus disimpan untuk menunjukkan jenis titik yang bersangkutan.
2. Garis-garis atau kurva.
Tabel 2.1. Karakteristik Citra Quickbird
Launch Date October 18, 2001 Launch Vehicle Boeing Delta II
Launch Location Vandenberg Air Force Base, California, USA Orbit Altitude 450 Km / 482 Km - (Early 2013)
Orbit Inclination 97.2°, sun-synchronous
Speed 7.1 Km/sec (25,560 Km/hour)
Equator Crossing Time 10:30 AM (descending node)
Orbit Time 93.5 minutes
Revisit Time 1-3.5 days, depending on latitude (30° off-nadir) Swath Width (Nadir) 16.8 Km / 18 Km - (Early 2013)
Metric Accuracy 23 meter horizontal (CE90)
Digitization 11 bits
Resolution
Pan: 65 cm (nadir) to 73 cm (20° off-nadir)
MS: 2.62 m (nadir) to 2.90 m (20° off-nadir)
Image Bands
Pan: 450-900 nm
Blue: 450-520 nm
Green: 520-600 nm
Red: 630-690 nm
Near IR: 760-900 nm
3. Poligon/luasan beserta atribut-atributnya.
Keuntungan utama dari format data vektor adalah ketepatan dalam merepresentasikan fitur titik, batasan dan garis lurus. Hal ini sangat berguna untuk analisa yang membutuhkan ketepatan posisi, misalnya pada basis data batas-batas katasder. Kelemahan data vektor yang utama adalah ketidakmampuannya dalam mengakomodasi perubahan gradual (Puntodewo, 2003).
2.8 K Means Clustering
Pendeteksian objek pada suatu citra memerlukan suatu proses segmentasi. Segmentasi akan membagi citra menjadi beberapa bagian atau objek, bagian yang menjadi hasil dari segmentasi citra ini sangat bergantung pada apa yang diinginkan. Tujuan segmentasi yang ideal adalah mengidentifikasikan komponen dari suatu citra dan menggolongkan piksel-piksel didalamnya ke komponen yang telah ditentukan.
2.8.1 Clustering
Clustering adalah membagi data ke dalam grup-grup yang mempunyai obyek
yang karakteristiknya sama (Berkhin dan Pavel). Garcia Molina dan Hector menyatakan clustering adalah mengelompokkan item data ke dalam sejumlah kecil grup sedemikian sehingga masing-masing grup mempunyai sesuatu persamaan yang esensial.
Clustering memegang peranan penting dalam aplikasi data mining, misalnya
eksplorasi data ilmu pengetahuan, pengaksesan informasi dan text mining, aplikasi basis data spasial, dan analisis web. Clustering diterapkan dalam mesin pencari di Internet. Web mesin pencari akan mencari ratusan dokumen yang cocok dengan kata kunci yang dimasukkan. Dokumen-dokumen tersebut dikelompokkan dalam cluster-cluster sesuai dengan kata-kata yang digunakan.
Tan, dkk. membagi clustering dalam dua kelompok, yaitu hierarchical and partitional clustering. Partitional Clustering disebutkan sebagai pembagian
obyek-obyek data ke dalam kelompok yang tidak saling overlap sehingga setiap data berada tepat di satu cluster. Hierarchical clustering adalah sekelopok cluster yang bersarang seperti sebuah pohon berjenjang (hirarki).
1. Partitioning algorithms: algoritma dalam kelompok ini membentuk bermacam partisi dan kemudian mengevaluasinya dengan berdasarkan beberapa kriteria. 2. Hierarchy algorithms: pembentukan dekomposisi hirarki dari sekumpulan data
menggunakan beberapa kriteria.
3. Density-based: pembentukan cluster berdasarkan pada koneksi dan fungsi densitas.
4. Grid-based: pembentukan cluster berdasarkan pada struktur multiple-level granularity
5. Model-based: sebuah model dianggap sebagai hipotesa untuk masing-masing cluster dan model yang baik dipilih diantara model hipotesa tersebut.
2.8.2 Algoritma k means clustering
Algoritma K-Means diperkenalkan oleh James B MacQueen pada tahun 1967 dalam proceedings of the 5 th berkeley symposium on Mathematical Statistics and Probability (Johnson & Wichern, 1992).
Algoritma K-Means adalah metode clustering berbasis jarak yang membagi data ke dalam sejumlah cluster. Algoritma ini hanya bekerja pada atribut numerik.
Dasar pengelompokan dalam metode ini adalah menempatkan objek berdasarkan rata-rata (mean) klaster terdekat. Untuk itu digunakan Algoritma K-Means yang di dalamnya memuat aturan sebagai berikut :
1 Jumlah cluster perlu diinputkan.
2 Hanya memiliki atribut bertipe numerik.
Algoritma K-Means pada dasarnya melakukan 2 proses yakni proses pendeteksian lokasi pusat tiap cluster dan proses pencarian anggota dari tiap-tiap cluster.
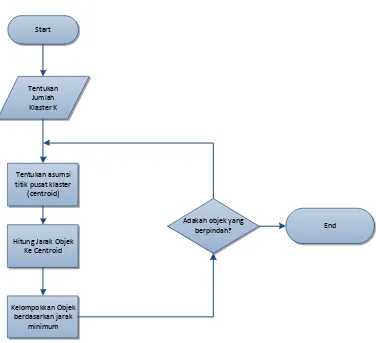
Algoritma K-Means, melakukan tiga langkah utama dalam melakukan pengelompokan :
1 Menentukan koordinat titik pusat untuk masing-masing klaster. Jumlah klaster K sudah ditentukan sebelumnya, sehingga terdapat K koordinat titik pusat. Inisialisasi koordinat titik pusat dapat dilakukan secara sekuensial dengan mengambil sejumlah data pertama sebagai titik pusat, atau secara acak (random) pada sembarang nomor urut data
2 Menghitung jarak setiap objek terhadap semua titik pusat klaster
3 Mengelompokkan objek berdasarkan jarak minimum atau jarak ke titik pusat terdekat Langkah 1-3 di atas dilakukan dalam perulangan (iterasi) sampai tidak ditemukan lagi objek yang berpindah klaster akibat perhitungan kembali titik-titik pusat klaster pada iterasi terakhir
Start
Tentukan Jumlah Klaster K
Tentukan asumsi titik pusat klaster
(centroid)
Hitung Jarak Objek Ke Centroid
Kelompokkan Objek berdasarkan jarak
minimum
Adakah objek yang
berpindah? End
Gambar 2.1. Diagram Alir algoritma K Means Clustering
Algoritma K- Means memerlukan 3 komponen yaitu: 1. Jumlah Klaster
K-Means merupakan bagian dari metode non-hirarki sehingga dalam metode ini jumlah I harus ditentukan terlebih dahulu. Jumlah klaster I dapat ditentukan melalui pendekatan metode hirarki. Namun perlu diperhatikan bahwa tidak terdapat aturan khusus dalam menentukan jumlah klaster I, terkadang jumlah klaster yang diinginkan tergantung pada subjektif seseorang.
2. Klaster Awal
Berdasarkan Hartigan (1975), pemilihan klaster awal dapat ditentukan berdasarkan interval dari jumlah setiap observasi.
Berdasarkan Rencher (2002), pemilihan klaster awal dapat ditentukan melalui pendekatan salah satu metode hirarki.
Oleh karena adanya pemilihan klaster awal yang berbeda ini maka kemungkinan besar solusi klaster yang dihasil akan berbeda pula.
3. Ukuran Jarak
Dalam hal ini, ukuran jarak digunakan untuk menempatkan observasi ke dalam klaster berdasarkan sentrid terdekat. Ukuran jarak yang digunakan dalam metode K-Means adalah jarak Euclid.
Adapun algoritma K-means dalam pembentukan klaster sebagai berikut:
Misalkan diberikan matriks data X = {xij} berukuran dengan i=1,2,3,..n, j=1,2,3,…p dan asumsikan jumlah klaster awal K
1. Tentukan sentroid.
Hitung jarak setiap objek ke setiap centroid dengan menggunakan jarak euclid atau dapat ditulis sebagai berikut:
( ) √( )
Setiap objek disusun ke sentroid terdekat dan kumpulan objek tersebut akan membentuk klaster.
2. Tentukan sentroid baru dari klaster yang baru terbentuk, di mana sentroid baru itu diperoleh dari rata-rata setiap objek yang terletak pada klaster yang sama.
3. Ulangi langkah 3, jika sentroid awal dan baru tidak sama.
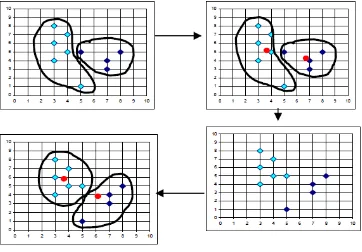
Gambar 2.2. Hasil dari proses clustering dengan menggunakan algoritma K-Means
Clustering. 2.8.3 Kelebihan dan Kelemahan algoritma K-means
Algoritma K-means dinilai cukup efisien, yang ditunjukkan dengan kompleksitasnya O(tkn), dengan catatan n adalah banyaknya obyek data, k adalah jumlah cluster yang dibentuk, dan t banyaknya iterasi. Biasanya, nilai k dan t jauh lebih kecil daripada nilai n. Selain itu, dalam iterasinya, algoritma ini akan berhenti dalam kondisi optimum lokal (William dan Graham).
Memperhatikan input dalam algoritma K-Means, dapat dikatakan bahwa algoritma ini hanya mengolah data kuantitatif. Hal tersebut juga diungkapkan oleh Berkhin , bahwa algoritma K-means hanya dapat mengolah atribut numerik.
Sebuah basis data, tidak mungkin hanya berisi satu macam type data saja, akan tetapi beragam type. William menyatakan sebuah basis data dapat berisi data-data dengan type sebagai berikut: symmetric binary, asymmetric binary, nominal, ordinal, interval dan ratio. Sedangkan Pal dan Mitra menyebutkan sebuah basis data dapat berisi data-data teks, simbol, gambar dan suara(Pal, Shankar K dan Mitra).
2.9 Median Filtering
Konsep dasarnya adalah dengan menemukan nilai pixel yang memiliki nilai intensitas dari suatu pixel yang berbeda dengan nilai pixel yang ada di daerah sekitarnya, dan menggantinya dengan nilai yang lebih cocok. (Davies, 1990).
Sesuai dengan namanya, median filter merupakan suatu metode yang menitik beratkan pada nilai median atau nilai tengah dari jumlah total nilai keseluruhan pixel yang ada di sekelilingnya. Dimisalkan terdapat data A=1, B=5, C=2, D=9, dan E=7, maka median filter akan mencari nilai tengah dari semua data yang telah diurutkan terlebih dahulu dari yang paling kecil hingga pada data yang paling besar dan kemudian diambil nilai tengahnya (1, 2, 5, 7, 9). Median dari deret tersebut adalah 5.
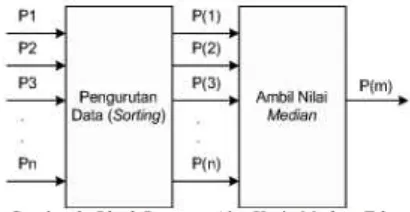
Pemrosesan median filter ini dilakukan dengan cara mencari nilai tengah dari nilai pixel tetangga yang mempengaruhi pixel tengah. Teknik ini bekerja dengan cara mengisi nilai dari setiap pixel dengan nilai median tetangganya. Proses pemilihan median ini diawali dengan terlebih dahulu mengurutkan nilai-nilai pixel tetangga, baru kemudian dipilih nilai tengahnya (Gambar 2.3).
Gambar 2.3. Block Diagram Alur Kerja Median Filter
sesuai dengan P(1) < P(2) < P(3) < P(n), sedangkan nilai m sesuai dengan rumus dimana n bernilai ganjil.
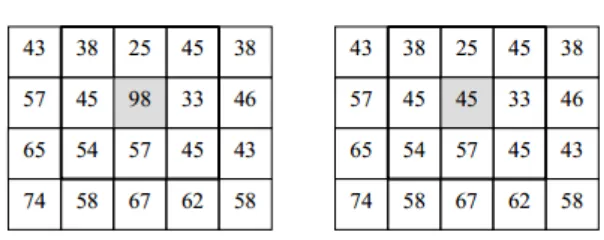
Gambar 2.4. Contoh Penerapan Median Filter