Fakultas Ilmu Komputer
Universitas Brawijaya
273
Optimasi Parameter Support Vector Regression Dengan Algoritme Genetika
Untuk Prediksi Harga Emas
Muthia Azzahra1, Budi Darma Setiawan2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Emas merupakan salah satu logam mulia yang banyak diminati masyarakat sebagai komoditi untuk berinvestasi dikarenakan ketahanannya terhadap laju inflasi yang cukup baik. Namun Seiring perkembangan zaman ada kalanya fluktuasi terjadi begitu ekstrim sehingga mempengaruhi nilai emas. Oleh karena itu mengetahui prospek nilai emas dimasa yang akan datang bagi para investor merupakan suatu yang cukup penting. Salah satu metode untuk memprediksi adalah Support Vector Regression (SVR), namun sensitifitas parameter masukannya cukup mempengaruhi hasil prediksi, oleh karena itu dapat diterapkan metode Algoritme Genetika (GA) yang cukup fleksibel untuk dihibridisasikan. Penelitian ini membahas tentang pengoptimasian parameter SVR menggunakan GA untuk memprediksi harga emas. Hasil pengujian menunjukkan mean absolute percentage error (MAPE) terbaik yang dihasilkan mencapai 0.2407 % dengan iterasi SVR 50, generasi GA 95, population size 70, crossover
rate 0.01, mutation rate 0.99, persentase elitism 80%, rentang 𝜀 1x10-7–1x10-4, rentang 𝑐 0.01-5, rentang λ 1x10-7–1x10-4, rentang 𝛾 1x10-5–1x10-4, dan rentang 𝜎 1x10-3–0.1.
Kata kunci: Optimasi, Support Vector Regression, Algoritme Genetika, Prediksi, Harga Emas. Abstract
Gold is one of the precious metals that many people interested as commodity to invest because of its resistance to inflation. Fluctuations can occur so extreme that affect the value of gold. Therefore, prospect of gold value in the future is quite important for the investors. One of prediction methods is Support Vector Regression (SVR), but the sensitivity of SVR parameters could influence the prediction result, therefore Genetics Algorithm (GA) can be applied, this method is flexible enough to be hybridized. This study discuss about the optimization of SVR parameters using GA to predict gold prices. Based on the testing result, the best mean absolute percentage error (MAPE) is 0.2407% with SVR loop 50, GA’s generation 95, population size 70, crossover rate 0.01, mutation rate 0.99, elitism percentange 80%, range of 𝜀 1x10-7–1x10-4, range of 𝑐 0.01-5, range of 𝜆 1x10-7–1x10-4, range of 𝛾 1x10-5–1x10-4,
and range of 𝜎 1x10-3–0.1.
Keywords: Optimization, Support Vector Regression, Genetic Algorithm, Prediction, Gold price.
1. PENDAHULUAN
Emas merupakan suatu logam mulia yang sangat diminati masyarakat. Seiring perkembangan zaman emas mengalami perubahan nilai pula, ketahanannya pada laju inflasi menjadi salah satu alasan mengapa emas sering dijadikan pilihan untuk melakukan investasi. Namun, fluktuasi yang ekstrim juga dapat mempengaruhi sehingga harga emas dapat berubah cukup drastis. Berdasarkan penelitian harga emas 73,96% dipengaruhi oleh variabel-variabel bebas yang diteliti. London gold price merupakan faktor yang mendominasi, variabel
ini memiliki pengaruh yang signifikan dengan koefisien determinasi mencapai 0.976354 atau setara dengan 95.3267% terhadap harga emas di Indonesia. Untuk kurs USD-IDR memiliki pengaruh positif pada minat pembelian emas namun pengaruh kurs EURO–IDR dinyatakan berbanding terbalik yang memberikan dampak negatif terhadap harga emas. Untuk itu bagi investor mengetahui prospek harga emas di masa yang akan datang merupakan sesuatu yang dibutukan untuk melakukan pertimbangan dalam investasinya (Eni & Halim, 2014).
Berdasarkan penelitian dalam memprediksi harga emas dengan metode Al-Alaoui
Backpropagation menghasilkan akurasi sebesar
64% (Bumi, 2016). Tingkat akurasi yang cukup rendah dikarenakan kurangnya data untuk pelatihan data, sehingga pengenalan pola-pola data kurang maksimal. Pada umumnya, data harga emas dari waktu ke waktu tersusun secara berurut dalam jangka waktu tertentu, yang mana data ini sering disebut dengan data-time series. Dari data-time series tersebut dapat dilakukan pembelajaran dengan suatu pendekatan tertentu untuk menggali dan memperoleh suatu pola-pola yang dapat dipakai untuk memprediksi harga emas.
Ada beberapa pendekatan atau metode yang dapat digunakan untuk melakukan prediksi yaitu
Support Vector Regression (SVR) dan Multi Layer Perceptron (MLP). SVR ialah suatu
pengembangan dari metode Support Vector
Machine (SVM) untuk kasus regresi, konsep dari
SVR sendiri ialah mendapatkan data yang dipakai sebagai support vector dengan mencari
hyperlane yang paling maksimal (Yasin, et al.,
2014), sedangkan MLP merupakan suatu metode untuk melakukan prediksi dengan pemetaan set-set dari data input dan output berdasarkan fungsi aktivasi non-linier (Meinanda, et al., 2009).
Berdasarkan penelitian yang dilakukan dengan membandingan metode SVM untuk kasus regresi dan MLP untuk memprediksi indeks saham menyatakan bahwa metode SVR memiliki tingkat akurasi yang lebih baik (Hidayatulloh, 2014). Dihasilkan nilai Root
Mean Squared Error (RMSE) terkecil yang
diperoleh ialah 317, 89 dan untuk Mean absolute
percentage error (MAPE) sebesar 1,81.
Keunggulan algoritme SVR dikarenakan MLP sangat tergantung pada pemilihan jumlah variabel untuk prediksi serta pemodelan topologi jaringan. Kelemahan dari penelitian ini adalah kurang memaksimalkan penggunaan jumlah lag data sebagai variabel input untuk pelatihan serta pemilihan parameter–parameter bebas yang digunakan dalam perhitungan kurang optimal sehingga hasil yang diberikan belum maksimal.
Berdasarkan penelitian dengan menggunakan metode Support Vector Regression (SVR) untuk meramalkan harga
emas dalam pasar berjangka, terdapat beberapa faktor dan kriteria sendiri dalam perdangan pasar emas berjangka tersebut (Gumilar, 2016). Dalam penelitian tersebut dihasilkan nilai evaluasi dari MAPE terkecil sebesar 0,324378 dengan batasan iterasi 1000, 10 hari data uji dan 30 hari untuk data latih. Kelemahan dari penelitian ini adalah
nilai parameter dari SVR yang cukup sensitif sehingga mudah terjebak dalam local optimum.
Permasalahan yang kerap dijumpai pada metode SVR ialah parameter yang digunakan dalam proses perhitungan cukup mempengaruhi tingkat keakuratan sistem. Oleh karena itu dibutuhkan suatu metode yang mampu mengoptimalkan parameter tersebut, salah satu metode untuk optimasi ialah Genetic Algorithm (GA). Pada Komputasi saat ini (GA merupakan metode yang sangat dikenal, GA sendiri ialah suatu pendekatan untuk pencarian stokhastik dan teknik optimasi Gen & Cheng, 2000). Akan tetapi masyarakat lebih banyak menerapkan metode ini untuk masalah optimasi pada industri teknologi dalam beberapa tahun terakhir. Dari hasil penelitian yang dilakukan dalam memprediksi volume penjualan dinyatakan bahwa penggunaan GA untuk mengoptimalkan parameter pada metode SVR memberikan nilai akurasi sistem yang lebih baik (Yuan, 2012).
Diharapkan dengan penambahan metode GA untuk mendapatkan parameter yang tepat dari SVR dalam memprediksi harga emas berdasarkan data-time series mampu meningkatkan keakuratan yang dihasilkan dari sistem.
2. KAJIAN PUSTAKA 2.1 Investasi Emas
Pola pikir masyarakat yang semakin maju menimbulkan keinginan untuk terus mengelola pendapatannya agar tetap terjaga guna keperluan yang akan datang dengan berinvestasi. Investasi sendiri dikatakan adalah suatu langkah yang diharapkan dapat menghasilkan gain atau keuntungan pada masa yang akan datang sebagai kompensasi atas penundaan konsumsi pada masa ini dimana terdapat ketidakpastian serta risiko yang tidak dapat diabaikan (Gunawan & Putu, 2013).
Ada banyak jenis dalam berinvestasi salah satunya ialah emas, untuk berinvestasi pada logam mulia ini dapat berbentuk emas batangan maupun saham pada suatu perusahaan yang memberikan sertifikat. Berinvestasi pada instrumen emas cenderung lebih menguntungkan karena tingkat risikonya yang kecil dibanding berinvestasi saham pada suatu perusahaan pertambangan dimana tidak terdapat perbedaan yang berarti pada return-nya (Anita, 2015).
2.2 Algoritme Genetika
Salah satu metode dalam cabang ilmu kecerdasan buatan yang sering digunakan untuk optimasi, metode ini ditemukan oleh John Holland. Ide awal GA sendiri berasal dari sesuatu yang terjadi secara alami. Dapat diambil contoh seperti kelinci-kelinci yang lebih cepat dan lebih pintar dari kelinci-kelinci lainnya. Kelinci-kelinci yang lebih cepat dan lebih pintar ini memiliki peluang lebih kecil untuk dimakan oleh rubah sehingga kemampuannya untuk bertahan lebih besar, namun tidak menutup kemungkinan kelinci yang lebih lemah juga mampu bertahan karena faktor keberuntungan. Populasi yang bertahan ini akan berkembang biak dimana keturunan yang dihasilkan membawa gen dari orang sehingga bisa jadi lebih cepat atau lebih pintar dari orang tuanya atau pun sebaliknya, dan siklus bertahan hidup ini terus berulang. Langkah-langkah dalam GA sangat mirip seperti kisah para kelinci ini Michalewicz, 1999).
2.2.1 Crossover
Crossover yang digunakan dalam penelitian
adalah Extended intermediate crossover
dikarenakan cocok dengan tiap gen mewakili parameter dari SVR yang akan dioptimasi yang mana tiap parameter memiliki rentang yang berbeda-beda sehingga tidak memungkinkan untuk dilakukan dengan One-cut point Crossover.
Offspring dihasilkan dengan memilih 2 parent, sebagai contoh jika P1 dan P2 adalah parent yang terpilih, maka C1 dan C2 (Offspring
ke-1 dan ke-2) dapat dibangkitkan dengan (Rahmi, et al., 2015):
C1 = P1 + α (P2 – P1)
C2 = P2 + α (P1 – P2) (1)
Nilai dari variabel α dipilih secara acak pada interval [-0,25, 1,25].
2.2.2 Mutasi
Mutasi yang akan digunakan pada penelitian ini adalah random mutation
dikarenakan pada kasus ini gen-gen yang membentuk satu individu berbentuk real coded. Proses dilakukan dengan mengubah salah satu gen pada parent yang terpilih secara acak dengan (Rahmi, et al., 2015):
x’ = x’i + r (maxi – mini) (2) Untuk x’ merupakan gen yang akan diubah,
r adalah bilangan random yang dibangkitkan
pada rentang yang sudah ditetapkan, maxi dan
mini ialah batas atas dan bawah dari gen tersebut.
2.2.3 Seleksi
Proses seleksi pada penelitian ini dilakukan dengan Elitism Selection dengan persentase yang akan diujikan dari population size, sisanya dilakukan dengan Binary Tournament Selection. 1. Elitism Selection
Proses seleksi dilakukan dengan mengurutkan seluruh individu dari parent dan
Offspring yang dihasilkan berurut dari fitness
terbaik, kemudian individu sebanyak population
size dipilih sebagai generasi baru. Seleksi jenis
ini memastikan individu dengan fitness terbaik akan selalu bertahan ke generasi selanjutnya.
2. Binary Tournament Selection
Dua individu akan dipilih secara acak dari keseluruhan individu baik dari parent maupun
Offspring yang terbentuk, kemudian fitness dari
kedua parent tersebut dibandingkan. Individu dengan fitness terbaik akan terpilih, proses ini dilakukan sampai jumlah individu yang terpilih memenuhi population size. Seleksi jenis ini tidak memastikan individu dengan fitness yang baik akan selalu terpilih.
Pemakaian 2 metode seleksi ini dikarenakan offspring yang baik cenderung dihasilkan dari parent yang dengan fitness yang baik pula, namun individu yang optimal dapat terkadang dihasilkan dari parent dengan fitness yang rendah.
2.3 Support Vector Regression
Algoritme ini merupakan aplikasi lanjutan atau dapat dikatakan sebagai pengembangan dari
Support Vector Machine (SVM), yang mana
SVR sendiri ialah untuk model regresi dengan mengenalkan formulasi ε-sensitif loss function oleh Vapink (1995). SVM sendiri ialah algoritma pembelajaran pada fitur berdimensi tinggi dengan mengaplikasikan fungsi-fungsi linier dalam pelatihannya, dimana SVM memiliki konsep untuk menemukan hyperlane tunggal sebagai pemisah data yang biasa digunakan untuk pengklasifikasian. SVR menerapkan konsep risk minimization, dengan membuat seminimal mungkin nilai dari batas atas pada generalization error, hal ini bertujuan untuk mengetimasi fungsi sehingga overfitting mampu diatasi. Overfitting sendiri terjadi saat nilai error yang dihasilkan sangat kecil sehingga tidak realistis untuk digunakan dalam memprediksi data baru.
Berbanding terbalik dengan neural network dimana algoritme tersebut mencoba mendefinisikan fungsi yang kompleks pada ruang input-nya, tujuan SVR ialah menemukan fungsi f(x) dengan memetakan data ke dimensi yang lebih tinggi menggunakan fungsi kernel dan dengan menggunakan fungsi linier sederhana dihasilkan batasan keputusan linier pada ruang hipotesis yang baru. SVR dengan
ε-sensitif loss function akan menghasilkan suatu
model regresi, y = f (x) yang mana dapat digunakan untuk memprediksi suatu keluaran yang berhubungan dengan titik data set nya. Nilai dari fungsi prediksi f (xi) merupakan perluasan dari sub-set pada data latih, yang disebut sebagai support vectors (Mirzae, et al., 2016).
Pada SVR secara umum digunakan rumus sebagai berikut.
f (x) = w t a + b (3)
Vector pembobot disimbolkan dengan wt , fungsi yang memetakan x ialah a dan b untuk bias. Untuk regresi non-linier diaplikasikan fungsi kernel untuk memetakan data ke dimensi yang lebih tinggi. Dengan penambahan dimensi
vector untuk variabel λ nilai bias dapat
direformulasi menjadi:
f (x) = ∑𝑙𝑗=1(𝛼𝑗∗− 𝛼)(K (xi, xj) + λ2) (4) 𝛼𝑗∗ dan 𝛼 merupakan simbol dari lagrange
multipliers, K(xi, xj) untuk kernel yang akan digunakan, dan λ melambangkan simpangan data.
2.4 Fungsi Kernel
Umumnya permasalahan yang sering dijumpai di dunia nyata ialah kasus non-linier untuk itu data yang didapat perlu ditransformasikan ke dimensi yang lebih tinggi sehingga secara linier data dapat dipisahkan dalam feature spaces baru. Pada kasus seperti ini dapat digunakan fungsi kernel (Yasin, et al., 2014)
2.5 Sequential Learning Algorithm
Pada SVR untuk pelatihan datanya menggunakan proses sequential learning,
dimana untuk kasus regresi langkahnya adalah sebagai berikut (Vijayakumar & Si, 1999) (Fattahi, 2015):
1. Penginisialisasian nilai dari parameter pada SVR yang akan digunakan. Kemudian hitung
[R]ij = (K (xi, xj) + λ2) (5)
2. Selanjutnya, untuk tiap titik pelatihan lakukan:
Ei = yi−Σ(𝛼𝑗∗−𝛼)Rij (6) yang mana i, j dimulai dari 1 sampai
ke-n.
𝛿𝛼𝑖∗=min {max[𝛾(𝐸𝑖− 𝜀),− 𝛼𝑖∗],𝐶−𝛼𝑖∗}
𝛿𝛼𝑖=min {max[𝛾(𝐸𝑖− 𝜀),−𝛼𝑖],𝐶−𝛼𝑖} (7)
𝛼𝑗∗=𝛼𝑗∗+ 𝛼𝑗∗𝑗∗𝛼𝑖
𝛼𝑖 = 𝛼𝑖 + 𝛿𝛼𝑖 (8)
3. Ketika sudah mencapai iterasi maksimum atau saat max(|𝛿𝛼 | < 𝜀) dan max(|𝛿𝛼𝑖∗| <
𝜀) menuju langkah berikutnya, jika belum ulangi langkah ke-2.
4. Hitung fungsi regresi dengan rumus yang telah dijabarkan pada persamaan 4. 5. Selesai.
Keterangan:
[R]ij ialah Matriks-Hessian
K (xi, xj) ialah Kernel yang dipakai yaitu
Radial Basis Function (RBF)
dengan rumus:
K (xi, xj) = exp -
||x− xi|| 2
2 σ2 (9)
Untuk xi, xj melambangkan data pada baris ke-i pada kolom ke
j.
𝛼𝑗∗ ialah lagrange multiplier. 𝛼𝑖 ialah lagrange multiplier.
Λ ialah simpangan data untuk mencari nilai [R]ij.
Ei ialah nila error pada indeks ke-
i.
𝑦𝑖 ialah nilai asli data latih untuk
indeks ke-i.
𝜀 ialah nilai dari deviasi.
c ialah nilai dari kompleksitas. xi ialah nilai dari data pada indeks ke-i.
𝑥 ialah representasi dari data.
2.6 Normalisasi Data
Untuk menghindari penyimpangan data yang terlalu jauh atau data yang dinilai kurang baik sebelum proses perhitungan dilakukan tahap pre-processing data untuk memastikan data mentah yang diambil cocok untuk digunakan pada suatu pemodelan tertentu. Hal ini bertujuan untuk melunakkan prosedur pelatihan serta upaya untuk meningkatkan akurasi sistem. Keseluruhan data akan
dinormalisasi dengan fungsi linier sebagai berikut (Fattahi, 2015):
X’= 𝑥− 𝑥𝑚𝑖𝑛
𝑥𝑚𝑎𝑥− 𝑥𝑚𝑖𝑛 (10)
Keterangan :
X’ ialah hasil normalisasi dengan nilai antara 0 sampai 1.
X ialah data asli.
Xmin ialah nilai minimum dari data asli.
Xmax ialah nilai maksimum dari data asli.
3. METODOLOGI
Gambar 1 Alir Sistem
Untuk alir sistem, pertama akan diinisialisasikan parameter dari GA yaitu
population size (popSize), crossover rate (cr)
dan mutation rate (mr), jumlah generasi, kemudian pembangkitan generasi awal sebanyak
popSize kemudian menghitung fitness populasi
awal dengan SVR kemudian proses reproduksi, setelah itu dilakukan perhitungan fitness kembali untuk Offspring yang terbentuk dengan metode SVR, selanjutnya proses seleksi menggunakan
Elitism dengan persentase yang telah ditentukan
lalu sisanya dengan Binary Tournament
Selection yang akan dilakukan sampai nilai
population size terpenuhi, terbentuklah generasi
baru dan proses ini diulang mulai dari tahap reproduksi hingga mencapai iterasi maksimum atau jumlah generasi dari GA yang telah ditetapkan.
4. PENGUJIAN DAN ANALISIS
Pengujian untuk mendapat parameter-parameter SVR yang optimal, pengujian yang dilakukan meliputi:
a. Kombinasi Crossover Rate (cr) dan
Mutation Rate (mr) b. Persentase Elitism c. Jumlah Populasi d. Jumlah Generasi e. Rentang 𝜺 f. Rentang c g. Rentang 𝝈 h. Rentang 𝝀 i. Rentang 𝜸 j. Rentang SVR
Untuk tiap pengujian diulang sebanyak 5 kali untuk guna mendapatkan nilai fitness rata-rata terbaik yang mana parameter terbaik tersebut akan dipakai untuk pengujian berikutnya. Untuk pengujian awal digunakan parameter sebagai berikut:
a. Iterasi SVR: 50 b. Generasi: 50 c. Population size: 30 d. Persentase Elitism: 90% e. Rentang 𝜺: 1x10-7–1x10-4 f. Rentang c: 0.01-1 g. Rentang 𝝈: 0.5-1 h. Rentang 𝝀: 1x10-7–1x10-4 i. Rentang 𝜸: 1x10-5–1x10-4
4.1 Hasil dan Analisis Pengujian Kombinasi Crossover Rate (cr) dan Mutation Rate (mr)
Gambar 2 Hasil Pengujian Kombinasi cr dan mr
Berdasarkan hasil uji coba kombinasi cr dan mr terbaik berada pada kombinasi 0.01 dan 0.99. Nilai mr yang tinggi cenderung
menghasilkan rerata fitness yang lebih baik hal ini dikarenakan meningkatkan pula level GA dalam mengeksplorasi sehingga menghasilkan
Offspring yang beragam.
4.2 Hasil dan Analisis Pengujian Persentase Elitism
Gambar 3 Hasil Pengujian Persentase Elitism
Berdasaran dari hasil uji coba semakin besar persentase elitism rerata fitness yang dihasilkan cenderung lebih baik, hal ini menandakan individu dengan fitness baik cenderung menghasilkan offspring dengan
fitness yang baik pula. Namun elitism dengan
persentase 100% tidak lebih baik dari persentase 80% dikarenakan terkadang individu dengan
fitness yang optimal dihasilkan dari parent
dengan fitness yang rendah.
4.3 Hasil dan Analisis Pengujian Jumlah Populasi
Gambar 4 Hasil Pengujian Jumlah Populasi
Berdasarkan hasil uji coba jumlah populasi yang optimal berada pada jumlah generasi 70. Jumlah populasi yang semakin besar cenderung memberikan hasil rerata fitness yang lebih baik karena peluang individu dengan fitness yang baik semakin besar pula, namun jumlah populasi yang terlampau besar tidak menjamin individu yang terbentuk menghasilkan fitness yang lebih baik.
4.4 Hasil dan Analisis Pengujian Jumlah Generasi
Gambar 5 Hasil Pengujian Jumlah Generasi
Berdasarkan hasil uji coba jumlah populasi yang optimal berada pada jumlah generasi 95. Jumlah populasi yang semakin besar tidak menjamin fitness yang dihasilkan semakin baik pula. Hal ini dikarenakan ketika jumlah generasi meningkat sebanding dengan eksplorasi solusi yang mana memungkinkan GA mengeksplorasi pada rentang yang tidak terdapat individu yang baik.
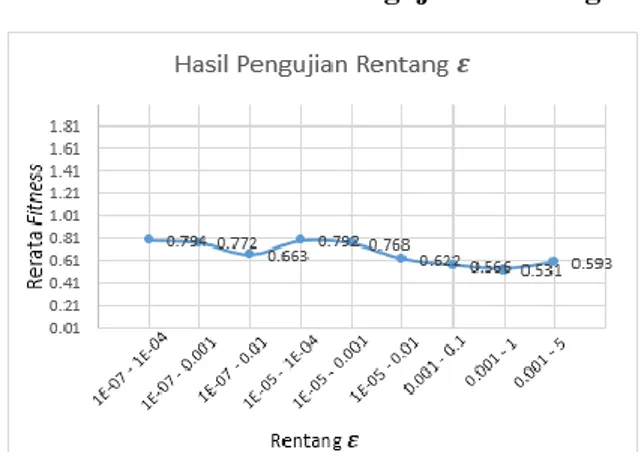
4.5 Hasil dan Analisis Pengujian Rentang 𝜺
Gambar 6 Hasil Pengujian Rentang 𝜺
Berdasarkan hasil uji coba rentang 𝜀 terbaik berada pada batas minimal 1x10-7 dan maksimal 1x10-4 semakin tinggi nilai rentang cenderung memberikan nilai rerata fitness yang menurun. Parameter 𝜀 sendiri berpengaruh dalam pengaturan batas kesalahan dari fungsi
4.6 Hasil dan Analisis Pengujian Rentang c
Gambar 7 Hasil Pengujian Rentang c
Berdasarkan hasil uji coba rentang 𝑐 terbaik berada pada batas minimal 0.01 dan maksimal 5. Parameter c sendiri berpengaruh terhadap nilai pinalti yang diberikan pada suatu data set. Nilai c yang rendah menunjukan toleransi kesalahan yang juga kecil begitu pula sebaliknya nilai c yang tinggi mengakibatkan toleransi kesalahan prediksi pun tinggi.
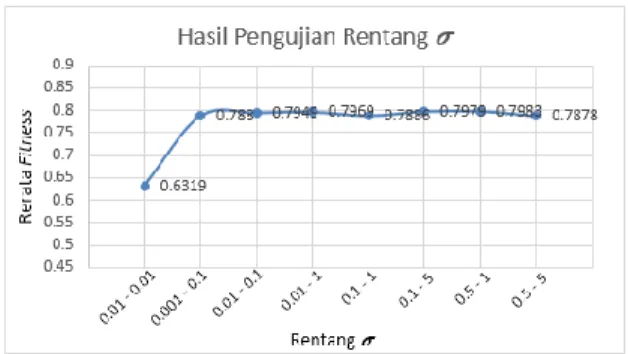
4.7 Hasil dan Analisis Pengujian Rentang 𝝈
Gambar 8 Hasil Pengujian Rentang 𝝈
Berdasarkan hasil uji coba rentang 𝜎 terbaik berada pada batas minimal 0.5 dan maksimal 1. Parameter 𝜎 sendiri ialah variabel yang tedapat pada kernel RBF yang berpengaruh terhadap persebaran data. Nilai 𝜎 yang kecil akan membentuk garis prediksi yang tajam, sebaliknya nilai 𝜎 yang besar membentuk garis prediksi yang cukup halus.
4.8 Hasil dan Analisis Pengujian Rentang 𝝀
Gambar 9 Hasil Pengujian Rentang 𝝀
Berdasarkan hasil uji coba rentang λ terbaik berada pada batas minimal 1x10-5 dan maksimal 1x10-4. Parameter 𝜆 sendiri berpengaruh dalam penskalaan kernel, λ yang semakin besar cenderung memberikan hasil regresi yang baik namun jika nilai 𝜆 terlalu tinggi akan membuat proses pembelajaran menjadi tidak stabil dan berjalan lambat.
4.9 Hasil dan Analisis Pengujian Rentang 𝜸
Gambar 10 Hasil Pengujian Rentang 𝜸
Berdasarkan hasil uji coba rentang 𝛾 terbaik berada pada batas minimal 1x10-5 maksimal 1x10-4. Parameter 𝛾 berpengaruh terhadap pengaturan kecepatan pembelajaran. Semakin tinggi nilai 𝛾 pembelajaran akan berlangsung cepat namun dapat mengabaikan nilai minimum sehingga cepat mencapai konvergensi.
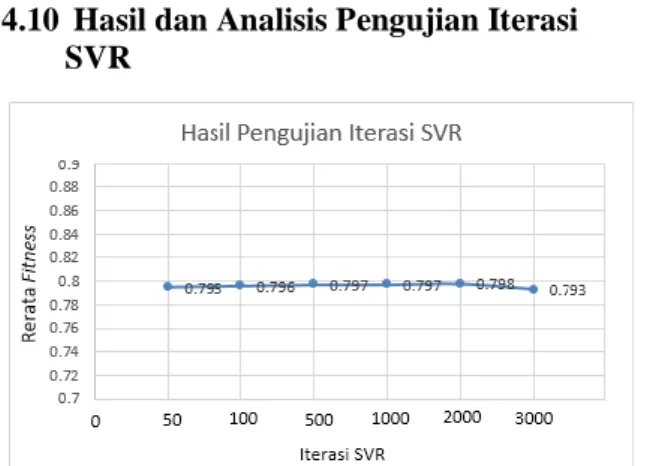
4.10 Hasil dan Analisis Pengujian Iterasi SVR
Gambar 21 Pengujian Iterasi SVR
Berdasarkan hasil uji coba iterasi terbaik berada pada iterasi ke-2000. Semakin tinggi iterasi membuat kemampuan SVR cenderung meningkat untuk mempelajari pola-pola data dan memperbaiki nilai error-nya untuk menghasilkan prediksi yang lebih baik.
5. KESIMPULAN
Berdasarkan hasil dari seluruh proses yang telah dilakukan dapat diambil kesimpulan sebagai berikut:
1. Berdasarkan hasil pengujian penambahan GA mampu memberikan hasil yang baik dalam mengoptimasi parameter SVR. Parameter-parameter yang menghasilkan nilai terbaik p ialah pada generasi GA 95, population size 70,
crossover rate 0.01, mutation rate 0.99,
persentase elitism 80%, rentang 𝜀 1x10-7–1x10-4 rentang c 0.01-5, rentang 𝜎 0.5-1, rentang 𝜆 1x10-5–1x10-4, rentang 𝛾 1x10-5 –1x10-4 dan Iterasi SVR 2000.
2. Berdasarkan pengujian yang dilakukan nilai MAPE terbaik yang dihasilkan sebesar 0.2407 dengan fitness sebesar 0.8059 pada uji coba rentang 𝜎, dengan parameter SVR yang menghasilkan error rate paling baik bernilai 𝜀 0.0004526, c 8.05634, 𝜎 0.771124, 𝜆 0.00032106 dan 𝛾 0.0029102.
6. DAFTAR PUSTAKA
Anita, 2015. Analisis Komparasi Investasi Logam Mulia Emas Dengan Saham Perusahaan Pertambangan Di Bursa Efek Indonesia 2010 – 2014. ESENSI
Jurnal Bisnis Manajemen, Volume 5,
No. 2.
Bumi, B. S., 2016. Implementasi Metode
Al-Alaoui Backpropagation Untuk Prediksi Harga Emas, s.l.: s.n.
Eni, Y. & Halim, J., 2014. Analisis Faktor-Faktor Yang Mempengaruhi Pergerakan Harga Emas Sebagai Alternatif Investasi Di Indonesia. Fattahi, H., 2015. Prediction Of Earthquake
Induced Displacements Of Slopes Using Hybrid Support Vector Regression With Particle Swarm Optimization.
Gen, M. & Cheng, R., 2000. Genetics Algoritm
& Engineering Optimization. s.l.:s.n.
Gumilar, G. W., 2016. Peramalan Harha Emas
Pada Pasar Berjangka Menggunakan Algoritma Support Vector Regression,
s.l.: s.n.
Gunawan, I. A. & Putu, W. N. G., 2013. Perbandingan Berinvestasi Antara Logam Mulia Emas Dengan Saham Perusahaan Pertambangan Emas. ISSN. Hidayatulloh, T., 2014. Kajian Komparasi
Penerapan Algoritma Support Vector Machine (SVM) Dan Multi Layer Perceptron (MLP) Dalam Prediksi Indeks Saham Sektor Perbankan. s.l.,
s.n.
Meinanda, M. H., Metri, A., N, M. & K, S., 2009. Prediksi Masa Studi Sarjana Dengan Artificial Neural Network.
Internetworking Indonesia Journal,
Volume 1, p. 2.
Michalewicz, Z., 1999. Algoritme Genetikas +
Data Structures = Evolution Programs.
s.l.:Spinger.
Mirzae, A., S, G. & M, B. S., 2016. Prediction Of Fe-Co-Mn/Mgo Catalytic Activity In Fischer-Tropsch Synthesis Using Nu-Support Vector Regression.
Physical Chemistry Research, Volume
4, No. 3.
Rahmi, A., Firdaus M, W. & Budi D, S., 2015.
Prediksi Harga Saham Berdasarkan Data Historis Menggunakan Model Regresi Yang Dibangun Dengan Algoritma Genetika. s.l.:s.n.
Vijayakumar, S. & Si, W., 1999. Sequential
Support Vector Classifiers And Regression. s.l.,
s.n.
Yasin, H., Alan, P. & W. T., U., 2014. Prediksi Harga Saham Menggunakan Support
Vector Regression Dengan Algoritma Grid Scearch. Volume 7, No. 1. Yuan, F.-C., 2012. Parameters Optimization
Using Algoritme Genetika In Support Vector Regression For Sales Volume Forecasting. s.l.:s.n.