17 3.1 Gambaran Umum
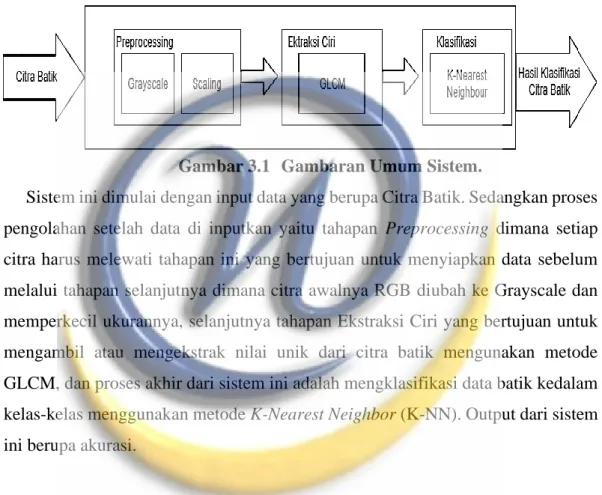
Dalam melakukan analisis dan kelasifikasi citra batik secara garis besar dapat dikelompokan menjadi 3 tahap utama, yaitu tahap Preprocessing, Ekstraksi Ciri dan Klasifikasi. Berikut adalah gambaran umum sistem pada Gambar 3.1.
Gambar 3.1 Gambaran Umum Sistem.
Sistem ini dimulai dengan input data yang berupa Citra Batik. Sedangkan proses pengolahan setelah data di inputkan yaitu tahapan Preprocessing dimana setiap citra harus melewati tahapan ini yang bertujuan untuk menyiapkan data sebelum melalui tahapan selanjutnya dimana citra awalnya RGB diubah ke Grayscale dan memperkecil ukurannya, selanjutnya tahapan Ekstraksi Ciri yang bertujuan untuk mengambil atau mengekstrak nilai unik dari citra batik mengunakan metode GLCM, dan proses akhir dari sistem ini adalah mengklasifikasi data batik kedalam kelas-kelas menggunakan metode K-Nearest Neighbor (K-NN). Output dari sistem ini berupa akurasi.
3.2 Analisis Sumber Data
Data citra yang digunakan dalam penelitian ini adalah citra batik yang diperoleh dari situs mesin pencarian benama Google Image. Proses untuk mendapatkan data dari situs Google Image menggunkan API yang ada di sediakan melalui ekstensi tambahan google chrome yang bernama Fatkun Batch.
Pada penelitian ini batik yang digunakan adalah batik mega mendung, ceplok, kawung, sido luhur, nitik, parang, semen, wahyu tamurun dan sido mukti. Dengan
jumlah dataset secara keseluhuran berjumlah 1052 citra batik. Berikut adalah beberapa dataset citra batik yang ditunjukan pada Gambar 3.2.
Gambar 3.2 Dataset Citra Batik 3.3 Analisis Kebutuhan Sistem
Analisis kebutuhan berfungsi untuk mengetahui kebutuhan sistem yang menunjang dalam proses kelasifikasi citra batik. Kebutuhan tersebut antara lain: Kebutuhan perangkat keras:
A. Komputer / Laptop B. Processor 2,70 GHz C. Memory : 8 GB D. Storage : 500 GB
E. Graphic : NVIDIA GEFORCE GTX 1050 Kebutuhan perangkat lunak:
A. MATLAB 2017b B. Rapidminer C. Browser D. Excel
3.4 Preprocessing
Pada tahap ini, citra perlu melewati tahap preprocessing yang berfungsi memperisapkan citra agar dapat mempreoleh nilai ektraksi ciri yang lebih baik untuk tahap selanjutnya. Dalam preprocessing ada beberapa proses yang dilakukan yaitu Grayscale dan Scaling, berikut adalah alur proses pra pengolahan:
Gambar 3.3 Diagram Alir Preprocessing
1. Grayscale
Proses pengubahan warna citra yang semula RGB menjadi citra Grayscale. Citra berwarna terdiri dari 3 layer matrik yaitu R-layer, G-layer dan B-layer. Sehingga bila setiap proses perhitungan menggunakan tiga layer, berarti dilakukan tiga perhitungan yang sama. Sehingga konsep ini diubah dengan mengubah 3 layer diatas menjadi 1 leyer matrik grayscale dan hasilnya adalah citra keabu-abuan. Berikut adalah hasil preprocessing yang ditunjukan pada Gambar 3.11.
Citra RGB Citra grayscale
Gambar 3.4 Contoh Hasil Grayscale
2. Scaling
Scaling atau pengubahan ukuran gambar adalah tahapan dari
preprocessing yang bertujuan untuk mengubah ukuran citra yang semula berukuran besar menjadi 128 x 128 piksel, sehingga citra yang akan di gunakan tidak memperlambat proses klasifikasi. Berikut contoh gambar sebelum Scaling dan setalah Scaling yang ditunjukan pada Gambar 3.10.
580 x 435 pixsel 128x128 pixsel
Gambar 3.5 Contoh Hasil Scaling Diubah
3.5 Ekstraksi Fitur
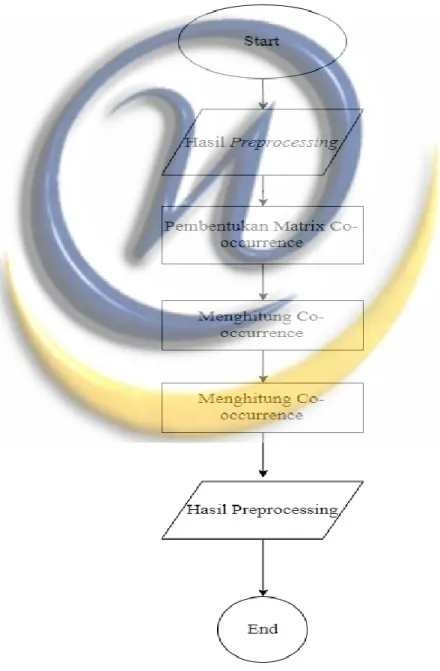
Tahapa selanjutnya yaitu ekstraksi ciri merupakan langkah awal dalam melakukan klasifikasi dan interpretasi citra. Bertujuan untuk mengambil atau mengekstraksi nilai-nilai unik dari suatu objek yang membedakan dengan objek yang lain. Metode ekstraksi fitur yang digunakan adalah Gray Level Co-occurrence Matrix (GLCM). GLCM merupakan matriks persegi yang dapat menjelaskan sifat-sifat tertentu dengan distribusi spasial. Berikut diagram alir ekstraksi ciri yang ditunjukan pada Gambar :
3.6 Klasifikasi
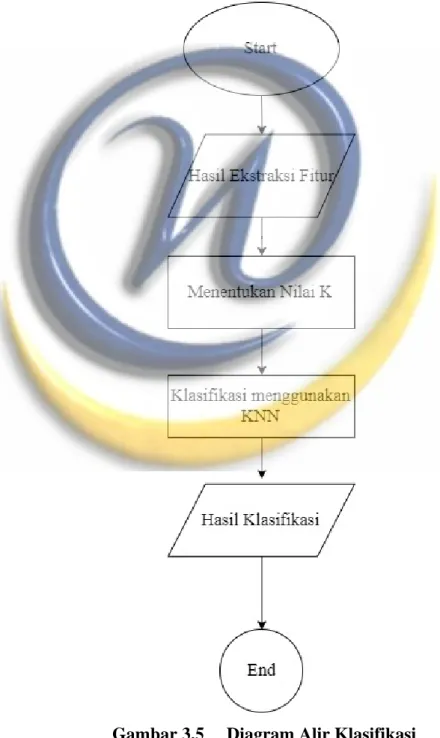
Proses terakhir dalam pengenalan pola adalah klasifikasi. Proses klasifikasi yang digunakan pada pelelitian ini adalah metode K-Nearest Neighbor (KNN). KNN merupakan sebuah sebuah metode klasifikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasi sebelumnya. Metode KNN bekerja dengan berdasarkan pada jarak terdekat antara data latih dengan data uji untuk menentukan ketetanggaan terdekat. Berikut diagram alir klasifikasi menggunakan KNN yang ditunjukan pada Gambar 3.5
3.7 Analisis Perhitungan 3.7.1 Analisis data masukan
Analasisi data masukan yang digunakan berupa citra batik dengan berbagai motif yang selanjutnya akan melalui beberapa tahapan proses. Proses pertama yaitu
preprocessing yang diantaranya terdapat Grayscale dan Scale. Berikut adalahg data masukan :
Gambar 3.6 Citra Batik
1. Scaling
Untuk mempercepat proses analisis,citra masukan awal diubah menjadi citra berukuran 128 x 128 pixel dengan model warna RGB (Red, Green, Blue) yang artinya setiap pixsel terdapat 3 nilai warna.
2. Grayscale
Merubah warna objek menjadi keabu-abuan atau disebut juga grayscale
bertujuan untuk menyederhanakan nilai pixel pada sebuah citra. Perhitungan yang digunakan dalam mengubah RGB ke Grayscale dengan menggunakan rumus (1), berikut contoh perhitunganya:
𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 0.2989𝑅 + 0.5870𝐺 + 0.1140𝐵 ... (1)
Keterangan :
R = Nilai pada matriks warna merah G = Nilai pada matriks warna hijau B = Nilai pada matriks warna biru
Tabel 3.1 Matriks RGB 3x3 A=255, R=177, G=163 ,B=119 A=255, R=179 , G=166 ,B=122 A=255, R=178, G=163 ,B=120 A=255, R=178, G= 163,B=119 A=255, R=179, G=166 ,B=122 A=255, R=178, G=163 ,B=120 A=255, R=177, G= 163,B=119 A=255, R=179, G=166 ,B=122 A=255, R=178, G=163 ,B=119
Setalah mendapatkan nilai RGB dari citra maka matrik dihitung dengan rumus (1). Berikut hasil perhitunganya:
Piksel (0,0): 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 0.2989* 177 + 0.5870 * 163 + 0.1140*119 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 52.91 + 95.68 + 13.57 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 163 Piksel (0,1): 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 0.2989* 179 + 0.5870 * 166 + 0.1140*122 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 =54 + 97 + 14 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 165 Piksel (0,2): 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 0.2989* 178 + 0.5870 * 163 + 0.1140*120 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 53 + 96 + 14 𝐺𝑟𝑎𝑦𝑠𝑐𝑎𝑙𝑒 = 163
Dengan menggunakan rumus yang sama pada semua piksel maka akan di dapatkan hasil sebagai berikut :
Matriks Hasil Grayscale Citra Batik 3X3
[
𝟏𝟔𝟑 𝟏𝟔𝟓 𝟏𝟔𝟑
𝟏𝟔𝟑 𝟏𝟔𝟓 𝟏𝟔𝟑
𝟏𝟔𝟑 𝟏𝟔𝟓 𝟏𝟔𝟑
3.7.2 Ekstraksi Ciri
3.7.2.1 Ekstaksi Co-Occurrence Matrix
Metode Matrix Co-occurrence merupakan metode untuk ekstraksi ciri, dimana nilai ekstraksi ciri yang akan dicari adalah nilai Contrast, Homogeneity, Corelation, dan Energy. Sebagai contoh, maka dibuat matriks 4x4 dengan derat keabuan 5 piksel dengan rentang 0-3. Berikut matriks grayscale yang ditunjukan pada Gambar 3.8: Matriks Grayscale 4X4
[
𝟎 𝟎 𝟏 𝟏
𝟎 𝟎 𝟏 𝟏
𝟎 𝟐 𝟐 𝟐
𝟐 𝟐 𝟑 𝟑
]
Berikut adalah langkah-langkah ekstraksi ciri dengan metode co-occurrence matriks:
1. Membuat matrix co-occurrence,
Pada tahap ini matriks yang digunakan menggunakan 4 derajat keabuan, maka jumlah piksel ketetanggan dan piksel referensi pada area kerja matriks juga berjumlah 4. Seperti yang ditunjukan pada Gambar 3.8 berikut:
Gambar 3.6 Area Kerja Matriks 0-15
2. Membentuk matrix co-occurrence
Setelah membuat area kerja matriks maka tahapan selanjutnya adalah mengitung nilai dari matriks dengan menjumlahkan hubungan spasial. Matriks kookuresi yang akan dibuat adalah hubungan spasial untuk d=1 dan sudut 00. Matriks dibuat dengan cara menghubungkan jumlah spasial yang ada pada matriks grayscale, Maka didapatkan matriks kookuresi seperti pada tabel berikut:
Matriks Co-occurrence Matrix
[
𝟐 𝟐 𝟏 𝟎
𝟎 𝟐 𝟎 𝟎
𝟎 𝟎 𝟑 𝟏
𝟎 𝟎 𝟎 𝟏
]
3. Mentranspose Co-Occurrence Matrix
Transpose merupakan proses mengubah matriks baris menjadi kolom, tujuan dari proses ini adalah untuk mendapatkan sudut simetris yaitu sudut 1800. Berikut hasil
matriks co-occurrence ke matriks transpose: Tranpose Co-occurrence Matrix
[
𝟐 𝟎 𝟎 𝟎
𝟐 𝟐 𝟎 𝟎
𝟏 𝟎 𝟑 𝟎
𝟎 𝟎 𝟏 𝟏
]
4. Matriks SimetrisPada proses ini matriks co-occurrence dijumlahkan dengan matriks transpose agar membentuk sudut 00 dan 1800 . Berikut tabel hasil matriks simetris:
Matrix Simetris [ 𝟒 𝟐 𝟏 𝟎 𝟐 𝟒 𝟎 𝟎 𝟏 𝟎 𝟔 𝟏 𝟎 𝟎 𝟏 𝟐 ] 5. Normalisasi Matriks
Melakukan normalisasi matriks dengan cara menghitung kemungkinan
(probability) setiap elemen matriks. Cara untuk menghitung kemungkinan setiap elemen matriks adalah dengan membagi setiap elemen dengan jumlah total seluruh nilai pada matiks, adapun tahapanya dapat dilihat pada table 3.6
Normalisasi Matrix
[
𝟒/
𝟐𝟒𝟐/
𝟐𝟒𝟏/
𝟐𝟒𝟎/
𝟐𝟒𝟐/
𝟐𝟒𝟒/
𝟐𝟒𝟎/
𝟐𝟒𝟎/
𝟐𝟒𝟐/
𝟐𝟒𝟎/
𝟐𝟒𝟔/
𝟐𝟒𝟏/
𝟐𝟒𝟎/
𝟐𝟒𝟎/
𝟐𝟒𝟏/
𝟐𝟒𝟐/
𝟐𝟒]
Perhitungan normalisasi matriks:
Normalisasi = (I , J) / Total jumlah pasangan Dimana jumalah total pasangan = 24
Contoh perhitungan :
Normalisasi = 4 / 24 = 0.166667
Berikut table matriks hasil perhitungan normalisasi: Matriks Hasil Normalisasi
[ 𝟎. 𝟏𝟔𝟔𝟕 𝟎. 𝟎𝟖𝟑𝟑 𝟎. 𝟎𝟒𝟏𝟕 𝟎 𝟎. 𝟎𝟖𝟑𝟑 𝟎. 𝟏𝟔𝟔𝟕 𝟎 𝟎 𝟎. 𝟎𝟒𝟏𝟕 𝟎 𝟎. 𝟐𝟓𝟎𝟎 𝟎. 𝟎𝟒𝟏𝟕 𝟎 𝟎 𝟎. 𝟎𝟒𝟏𝟕 𝟎. 𝟎𝟖𝟑𝟑 ]
3.7.2.2 Ekstraksi Ciri Fitur
Pada tahap ini adalah menghitung co-occurrence matriks untuk manpatkan nilai ciri statistiknya. Ciri statistik yang akan dihitung pada penelitian ini adalah contras, homogenity, correlation, dan energy. Berikut adalah perhitungan fitur tekstur: 1. Contras (kontras)
Untuk menghitung kontras, digunakan rumus (2) sebagai berikut:
𝐶𝑜𝑛𝑡𝑟𝑎𝑠𝑡 = ∑ ∑𝑔−1(𝑖 − 𝑗)2𝑝(𝑖, 𝑗) 𝑗=0 𝑔−1 𝑖=0 ... (2) Keterangan : i = array index ke i j = array index ke j G = Ukuran Citra
P(i ,j) = Nilai pixsel pada index i dan j
Syarat Ketika nilai I dan J sama, sel berada pada diagonal dan (i-j) = 0. Nilai-nilai ini merepresentasikan pixel yang keseluruhannya mirip dengan tetangga mereka,sehingga mereka diberi bobot 0.
Contoh perhitungan :
𝐶𝑜𝑛𝑡𝑟𝑎𝑠𝑡 = ((2 − 3)2) 𝑥 0,041666667 = 0,041666667
Matriks Kontas [ 𝟎 𝟎. 𝟎𝟖𝟑 𝟎. 𝟏𝟔𝟕 𝟎 𝟎. 𝟎𝟖𝟑 𝟎 𝟎 𝟎 𝟎. 𝟏𝟔𝟕 𝟎 𝟎 𝟎. 𝟎𝟒𝟐 𝟎 𝟎 𝟎. 𝟎𝟒𝟐 𝟎 ] 2. Homogenity (homogenitas)
Berikut adalah rumus (5) untuk menghitung homogenitas:
𝐻𝑜𝑚𝑜𝑔𝑒𝑛𝑡𝑦 = ∑ ∑ 𝑝(𝑝,𝑗) 1+|𝑖−𝑗|2 𝑔−1 𝑗=0 𝑔−1 𝑖=0 ... (5) Keterangan : i = array index ke i j = array index ke j G = Ukuran Citra
P(i ,j) = Nilai pixsel pada index i dan j
Contoh perhitungan :
𝐻𝑜𝑚𝑜𝑔𝑒𝑛𝑡𝑦 = 0,041666667 / 1 + |2 − 3|2 = 0.01041666675
Berikut tabel hasil perhitungan homogenitas: Matriks Homogenitas [ 𝟎. 𝟏𝟔𝟕 𝟎. 𝟎𝟒𝟐 𝟎. 𝟎𝟎𝟖 𝟎 𝟎. 𝟎𝟒𝟐 𝟎. 𝟏𝟔𝟕 𝟎 𝟎 𝟎. 𝟎𝟎𝟖 𝟎 𝟎. 𝟐𝟓𝟎 𝟎. 𝟎𝟐𝟏 𝟎 𝟎 𝟎. 𝟎𝟐𝟏 𝟎. 𝟎𝟖𝟑 ] 3. Correlation
Pada tahap ini digunakan rumus (3) sebagai berikut :
𝐶𝑜𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛 = ∑ ∑ (𝑖−𝜇𝑥)(𝑗−𝜇𝑦)𝑝(𝑖,𝑗) 𝜎𝑥𝜎𝑦 𝑔−1 𝑗=0 𝑔−1 𝑖=0 ... (3) Keterangan: i = array index ke i j = array index ke j G = Ukuran Citra
µx , µy = Mean pada matriks GLCM
σx = Standar deviasi pada matriks GLCM vertical
σy = Standar deviasi pada matriks GLCM Horizontal
Contoh perhitungan:
𝐶𝑜𝑟𝑒𝑙𝑎𝑡𝑖𝑜𝑛 =(0,16667−0.072917)∗(0.16667−0.072917)∗0.16667
0.071159∗0.071159 = 0.02059
Berikut hasil perhitungan correlation: Matriks Correllation [ 𝟎. 𝟎𝟐𝟎𝟓𝟗 𝟎. 𝟎𝟎𝟎𝟏𝟑 𝟎. 𝟎𝟎𝟎𝟓𝟕 𝟎 𝟎. 𝟎𝟎𝟎𝟏𝟑 𝟎. 𝟎𝟐𝟎𝟓𝟗 𝟎 𝟎 𝟎. 𝟎𝟎𝟎𝟓𝟕 𝟎 𝟎. 𝟏𝟏𝟎𝟏𝟕 𝟎. 𝟎𝟎𝟎𝟓𝟕 𝟎 𝟎 𝟎. 𝟎𝟎𝟎𝟓𝟕 𝟎. 𝟎𝟎𝟎𝟏𝟑 ] 4. Energy
Berikut adalah rumus (4) untuk mengitung energi:
𝐸𝑛𝑒𝑟𝑔𝑦 = ∑𝑔−1𝑖=0 ∑𝑔−1𝑗=0(𝑝(𝑖, 𝑗))2 ... (4)
Keterangan :
i = array index ke i j = array index ke j
G = Ukuran Citra
P(i ,j) = Nilai pixsel pada index i dan j
Contoh perhitungan:
Energy = (0,041666667)2 = 0.001736 Berikut tabel hasil perhitungan energi: Matriks energy [ 𝟎. 𝟎𝟐𝟖 𝟎. 𝟎𝟎𝟕 𝟎. 𝟎𝟎𝟐 𝟎 𝟎. 𝟎𝟎𝟕 𝟎. 𝟎𝟐𝟖 𝟎 𝟎 𝟎. 𝟎𝟎𝟐 𝟎 𝟎. 𝟎𝟔𝟑 𝟎. 𝟎𝟎𝟐 𝟎 𝟎 𝟎. 𝟎𝟎𝟐 𝟎. 𝟎𝟎𝟕 ]
Setalah melewati semua proses perhitungan fitur, maka langkah selanjutnya adalah menjumlahkan tiap matriks dari fitur tersebut sehingga didapatkan hasil pembentukan Co-occurrence sebagi berikut:
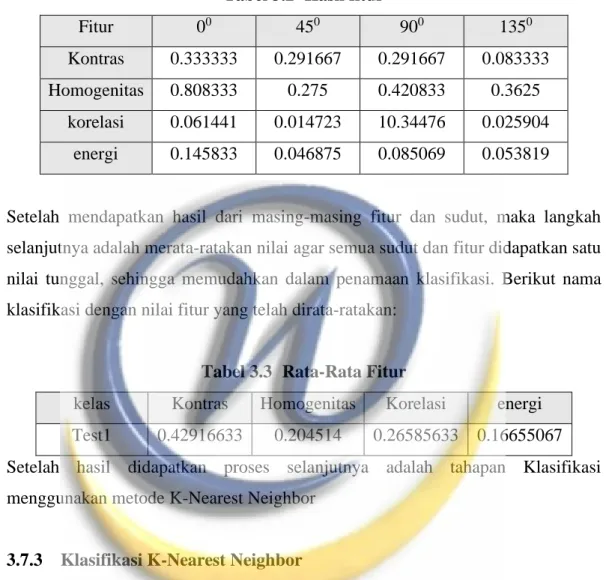
Tabel 3.2 Hasil fitur
Fitur 00 450 900 1350
Kontras 0.333333 0.291667 0.291667 0.083333 Homogenitas 0.808333 0.275 0.420833 0.3625
korelasi 0.061441 0.014723 10.34476 0.025904 energi 0.145833 0.046875 0.085069 0.053819
Setelah mendapatkan hasil dari masing-masing fitur dan sudut, maka langkah selanjutnya adalah merata-ratakan nilai agar semua sudut dan fitur didapatkan satu nilai tunggal, sehingga memudahkan dalam penamaan klasifikasi. Berikut nama klasifikasi dengan nilai fitur yang telah dirata-ratakan:
Tabel 3.3 Rata-Rata Fitur
kelas Kontras Homogenitas Korelasi energi Test1 0.42916633 0.204514 0.26585633 0.16655067 Setelah hasil didapatkan proses selanjutnya adalah tahapan Klasifikasi menggunakan metode K-Nearest Neighbor
3.7.3 Klasifikasi K-Nearest Neighbor
K-Nearest Neighbor merupakan salah satu metode algoritma supervised learning yaitu metode klasfikasi terhadap sekumpulan data berdasarkan pembelajaran data yang sudah terklasifikasi. K-NN berkerja dengan cara mengklasifikasi suatu objek yang memiliki kemiripan paling dekat dengan objek lainya. Pada tahapan simulasi ini menggunakan data hasil fitur ekstraksi citra batik dengan data uji yang berjumlah 4 data citra dan data latih 20 data citra. Berikut adalah data yang digunakan sebagi simulasi:
Tabel 3.4 Data Latih Klasifikasi
No contrast homogeneity correlation energy label
1 0.7169 0.784122785 0.84212692 0.11166 megamendung 2 0.75221 0.780223712 0.85895338 0.07161 megamendung 3 0.84289 0.71152395 0.38761963 0.13676 parang 4 0.98911 0.714449024 0.62523991 0.09524 parang 5 1.09547 0.70746186 0.78375848 0.0655 megamendung 6 1.33219 0.673071481 0.745746 0.05223 megamendung 7 1.60046 0.651763451 0.71698164 0.05236 megamendung 8 1.63078 0.609228387 0.43704407 0.06289 parang 9 1.74785 0.621461819 0.69859847 0.03785 parang 10 1.82603 0.654030307 0.76987357 0.06463 megamendung 11 2.23173 0.677296588 0.794478 0.09091 parang 12 3.44353 0.601442105 0.69459512 0.05691 parang 13 1.00652 0.713075172 0.70670794 0.08776 parang 14 1.39641 0.694317995 0.82421132 0.05374 parang 15 0.71223 0.780915764 0.89335697 0.08681 parang 16 1.65699 0.687795276 0.54394741 0.12708 megamendung 17 1.20294 0.655005331 0.75240949 0.05402 megamendung 18 0.78377 0.800897105 0.72762038 0.19928 megamendung 19 0.4813 0.845003896 0.90084364 0.14241 parang 20 0.50566 0.807809424 0.81668902 0.16108 megamendung
Tabel 3.5 Data Uji Klasifikasi
No contrast homogeneity correlation energy Bobot 1 3.7158 0.64051 0.400027296 0.127698481 ? 2 5.32413 0.53251 0.599373861 0.042358224 ? 3 2.79577 0.62685 0.730436036 0.069512962 ? 4 1.32136 0.67386 0.742368269 0.052004564 ?
Betikut tahapan-tahapan untuk mengklasifikasi menggunakan KNN: 1. Penentuan Nilai K
Langkah pertama dalam melakukan kelasifikasi adalah menentukan nilai K tetangga terdekat. Nilai K tidak memiliki aturan baku pada penentuanya namun secara umum nilai K yang tinggi akan mengurangi efek noise pada kelasifikasi akan tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur.
K yang dugunakan pada simulasi ini adalah K = 1.
2. Menentukan Jarak antara data latihdan data uji
Tehnik yang digunakan dalam metode klasifikasi ini adalah Euclidean Distance. Berikut adalah rumus untuk menghitung Euclidean Distance:
𝑑(𝑖, 𝑦) = √∑𝑖𝑘=1(𝑥𝑘− 𝑦𝑘)2 ... (20)
Keterangan :
d(i,y) = Jarak Euclidean Distance antara vektor i dan y.
Xk = data uji ke-j, dengan j = 1,2,…n.
Yk = data pembelajaran ke-j dengan j = 1,2,…N.
Selanjutnya urutkan berdasarkan nilai fitur terkecil dengan nilai K = 3, data uji dan latih hitung dengan menggunakan jarak Euclidean Distance.
Contoh perhitungan :
𝑑(𝑖, 𝑦)
= √((3.444 − 3.716)2) + ((0.601 − 0.641)2) + ((0.695 − 0.400)2) + ((0.057 − 0.128)2)
Berikut hasil perhitungan data uji pada table 3.4 baris ke 1: Tabel 3.6 Hasil kelasifikasi
No contrast homogeneity correlation energy label
jarak eucidian 1 1.826 0.654 0.770 0.065 megamendung 0.506 2 1.657 0.688 0.544 0.127 megamendung 0.397 3 1.600 0.652 0.717 0.052 megamendung 0.281 4 1.332 0.673 0.746 0.052 megamendung 0.011 5 1.203 0.655 0.752 0.054 megamendung 0.120 6 1.095 0.707 0.784 0.066 megamendung 0.232 7 0.784 0.801 0.728 0.199 megamendung 0.572 8 0.752 0.780 0.859 0.072 megamendung 0.591 9 0.717 0.784 0.842 0.112 megamendung 0.625 10 0.506 0.808 0.817 0.161 megamendung 0.837 11 3.444 0.601 0.695 0.057 parang 2.124 12 2.232 0.677 0.794 0.091 parang 0.913 13 1.748 0.621 0.699 0.038 parang 0.432 14 1.631 0.609 0.437 0.063 parang 0.440 15 1.396 0.694 0.824 0.054 parang 0.113 16 1.007 0.713 0.707 0.088 parang 0.321 17 0.989 0.714 0.625 0.095 parang 0.357 18 0.843 0.712 0.388 0.137 parang 0.603 19 0.712 0.781 0.893 0.087 parang 0.638 20 0.481 0.845 0.901 0.142 parang 0.877
Agar mudah diketahui data mana yang terdekat maka data diurutkan dari nilai terkecil. Berikut hasil prediksi data uji pada tabel 3.4 baris ke 1:
Tabel 3.7 Hasil kelasifikasi data ke 1
No contrast homogeneity correlation energy label
jarak eucidian 1 1.826 0.654 0.770 0.065 megamendung 0.506 2 1.657 0.688 0.544 0.127 megamendung 0.397 3 1.600 0.652 0.717 0.052 megamendung 0.281 Karena mayoritas k = 3 kemunculan prediksi terbanyak adalah megamendung ,maka data baru pada tabel 3.4 baris ke 1 adalah jenis megamendung.
Berikut hasil keseluruhan klasifikasi:
Tabel 3.8 Hasil kelasifikasi
contrast homogeneity correlation energy prediksi Bobot
3.716 0.641 0.400 0.128 parang Parang
5.324 0.533 0.599 0.042 parang Parang
2.796 0.627 0.730 0.070 parang Parang
1.321 0.674 0.742 0.052 megamendung megamendung Untuk mengetahui jumlah akurasi dari hasil klasifikasi data uji dan data latih tersebut. Digunakan rumus sebagai berikut:
%𝐴𝑐𝑐 = 𝑇𝑐𝑙𝑎𝑠𝑠𝑖𝑓𝑦
𝑇𝑖𝑚𝑎𝑔𝑒 𝑥100 ... (21)
Keterangan:
Tclassfy = Jumlah klasifikasi yang benar adalah 4 data
Tclassfy = Jumlah total data testing adalah 4 data
Maka dihitung dengan rumus (21) didapatkan hasil perhitungan:
%𝐴𝑐𝑐 = 4
4𝑥100 = 100%
Hasil akurasi dari simulasi klasifikasi citra batik didapatkan sebesar 100%, dikarnakan seluruh data uji terklasifikasi secara benar.