Seminar Nasional dan Rapat Tahunan Bidang MIPA 2014 | SEMIRATA
xi KEMAMPUAN REPRESENTASI MATEMATIS MAHASISWA PADA MATA
KULIAH KALKULUS PEUBAH BANYAK
Yerizon ... 371 ANALISIS PENGETAHUAN METAKOGNITIF SISWA TIPE KEPRIBADIAN
PHLEGMATIS DALAM MENYELESAIKAN SOAL MATERI LIMIT FUNGSI ALJABAR DI KELAS XI IPA SMA ISLAM ALFALAH KOTA JAMBI
Dewi Iriani, Marni Zulyanty ... 377 ANALISIS KEMAMPUAN PEMECAHAN MASALAH MATEMATIS SISWA TIPE EKSTROVERT PADA MATERI FAKTORISASI SUKU ALJABAR DI KELAS VIII SMP
Nizlel Huda, Lily Wahyuni Novika ... 384 ANALISIS MISKONSEPSI SISWA TIPE KOLERIS DALAM PEMECAHAN
MASALAH MATEMATIKA PADA MATERI ALJABAR SISWA KELAS VIII SMP Yunidar, Roseli Theis ... 392 KONTRIBUSI KEGIATAN LESSON STUDY MATEMATIKA DALAM
IMPLEMENTASI KURIKULUM 2013 DAN PENDIDIKAN BERBASIS KARAKTER Armiati ... 400 PERANCANGAN PROTOTIPE AWAL BUKU KERJA KALKULUS BERBASIS PENEMUAN TERBIMBING
Zulfaneti, Rina Febriana ... 408 PENGEMBANGAN TUGAS MATEMATIKA SEBAGAI ALAT UKUR PENALARAN DAN PEMAHAMAN KONSEP SISWA SEKOLAH MENENGAH ATAS
Mukhtar, Muliawan Firdaus ... 416 MODEL REGRESI POISSON TERGENERALISASI DENGAN STUDI KASUS KECELAKAAN KENDARAAN BERMOTOR DI LALU LINTAS
Irwan, Devni Prima Sari ... 423 KORELASI BEBERAPA ASPEK PROGRAM KELUARGA BERENCANA DI
PUSAT KESEHATAN MASYARAKAT KELURAHAN SUKAMERINDU KOTA BENGKULU
Syahrul Akbar ... 434 PENGARUH PEMBELAJARAN CONNECTING, ORGANIZING, REFLECTING, EXTENDING (CORE) TERHADAP KEMAMPUAN KOMUNIKASI MATEMATIS SISWA KELAS X SMAN 9 PADANG TAHUN PEMBELAJARAN 2013/2014
Jazwinarti, Suherman, Fadhilah Al Humaira ... 437 ESTIMASI TINGKAT KEMATIAN BAYI DAN HARAPAN HIDUP BAYI PROVINSI JAWA BARAT 2010 DENGAN MENGGUNAKAN METODE BRASS
Ahmad Iqbal Baqi ... 446 PERANCANGAN MODEL ZONA TARIF BRT TRANS MUSI ZONE TARIFF
DESIGN MODEL OF BRT TRANS MUSI
A qilah Zainab, Sisca Octarina dan Putra BJ Bangun ... 452 SOLUSI POLINOMIAL PERSAMAAN DIFERENSIAL HERMIT YANG
MODEL REGRESI POISSON TERGENERALISASI
DENGAN STUDI KASUS KECELAKAAN KENDARAAN BERMOTOR DI LALU LINTAS
Irwan1, Devni Prima Sari2
Jurusan Matematika FMIPA Univ. Negeri Padang1,2 [email protected], [email protected]
Intisari: Model regresi Poisson telah lama digunakan untuk penggolongan resiko. Metode regresi Poisson mempunyai asumsi equi-dispersion, yaitu kondisi dimana nilai mean dan variansi dari variabel respon bernilai sama. Pada kenyataannya, seringkali dijumpai pada data dengan variansi dari variabel respon lebih besar dari pada nilai rataannya (overdispersi). Sehingga model regresi Poisson dianggap kurang tepat untuk mengatasi masalah tersebut. Sehingga digunakan model regresi Poisson Tergeneralisasi untuk mengatasi masalah overdispersi.
Dalam tulisan ini, model regresi Poisson dan Poisson Tergeneralisasi akan diterapkan pada data kasus kecelakaan kendaraan bermotor di lalu lintas. Berdasarkan hasil estimasi parameter dispersi, a, pada model regresi Poisson Tergeneralisasi diketahui bahwa terjadi kasus overdispersi. Setelah model regresi Poisson dan Poisson Tergeneralisasi di uji dengan menggunakan uji deviance, Pearson Chi-Square, AIC, BIC, maka disimpulkan bahwa model regresi terbaik dihasilkan oleh model regresi Poisson Tergeneralisasi.
Kata kunci: model regresi Poisson, Poisson Tergeneralisasi, overdispersi A. PENDAHULUAN
Penggolongan resiko adalah proses dari pemodelan alternatif dengan menggolongkan resiko menurut rating factors dengan karakteristik-karakteristik yang dibentuk ke dalam rating classes. Sebagai contoh, di dalam kecelakaan kendaraan bermotor yang diperlakukan sebagai faktor penilaian dapat dilihat pada faktor pengemudi, kendaraan, jalan, cuaca dan faktor lainnya.
Model regresi Poisson secara luas telah banyak digunakan untuk memodelkan penggolongan resiko. Sebagai contoh, McCullagh dan Nelder dalam buku Generalized
Linear Models (1989) menggunakan model regresi Poisson untuk memodelkan jumlah
klaim pada peristiwa kerusakan muatan yang dibawa kapal-kapal di dalam asuransi laut. Di dalam asuransi motor, Brockman dan Wright dalam penelitiannya tahun 1992 menerapkan model itu pada klaim kerusakan kepemilikan motor di UK, dan Renshaw
tahun 1994 memakai model tersebut untuk klaim-klaim motor yang disediakan oleh suatu perusahaan asuransi yang terkemuka di dalam UK. Selanjutnya, model regresi Poisson diterapkan oleh Ismail dan Jemain tahun 2003 pada himpunan dari klaim kerusakan mobil milik pribadi yang disediakan oleh satu perusahaan asuransi di Malaysia.
Bagaimanapun, model regresi Poisson berasumsi bahwa rata-rata dan variansi dari variabel dependen adalah sama, E(Y)=Var(Y), atau disebut juga equidispersi. Dalam praktek, data itu boleh ditampilkan overdispersion atau extra – variasi Poisson, yaitu, suatu situasi di mana variansi melebihi rata-rata, Var(Y)>E(Y). Selain itu, data juga dapat disajikan underdispersi, yaitu keadaan dimana variansi kurang dari rata-rata, Var(Y)<E(Y). Pembebanan yang tidak sesuai pada Poisson mengabaikan standar error dan terlalu menekankan makna dari parameter-parameter regresi, dan sebagai konsekuensi, memberikan kesimpulan salah tentang parameter-parameter regresi. Oleh karena itu, sasaran dari penelitian ini untuk menggunakan model regresi Poisson Tergeneralisasi sebagai satu alternatif untuk penggolongan resiko. Selanjutnya, model-model regresi Poisson dan Poisson Tergeneralisasi dicoba, diuji dan dibandingkan pada jenis data jumlah kecelakaan kendaraan bermotor di lalu lintas.
B. MATERI DAN METODE 1. Generalized Linear Model (GLM)
Agresi (2002) menyatakan ada tiga komponen dalam GLM, yaitu :
a) Variabel respon Y1, Y2, ... , YN yang diasumsikan memiliki distribusi yang termasuk ke dalam keluarga eksponensial.
b) Sekumpulan parameter 𝛽 = [𝛽1… 𝛽𝑝]𝑇 dan variabel penjelas (explanatory
variable) 𝑋 = [
𝑥1𝑇 ⋮
𝑥𝑝𝑇] yang kemudian membentuk fungsi linear T i x .
c) Fungsi link monoton g sedemikian sehingga ( ) T i i
g x dengan i E Y[ ].i
Fungsi link menentukan model yang menghubungkan i E Y[ ]i dengan fungsi linear x β . Suatu fungsi link di sebut sebagai fungsi link kanonik (canonical link iT
function) apabila g(i) dengan adalah parameter kanonik dalam
( ) ( ; ) exp ( , ) ( ) y b f y c y a
Dalam hal ini, adalah parameter dispersi dan ( ; )f y merupakan fungsi probabilitas variabel random Y yang termasuk dalam keluarga eksponensial.
2. Model Regresi Poisson
Pada regresi Poisson diasumsikan bahwa variabel dependen Y yang menyatakan jumlah (cacah) kejadian berdistribusi Poisson, diberikan sejumlah variabel independen
x1,x2,...,xk.
𝑃(𝑌 = 𝑦|𝑥1, … , 𝑥𝑘) =𝜇𝑦.𝑒−𝜇
𝑦! , 𝑦 = 0,1,2, … (1) Atau dengan kata lain, 𝑌𝑖~𝑃𝑜𝑖(𝜇𝑖), 𝑖 = 1,2,3, … , 𝑛.
Salah satu tujuan dari analisis regresi adalah untuk menentukan pola hubungan antara variabel respon dengan variabel penjelas. Selanjutnya, dalam regresi Poisson hubungan tersebut dapat dituliskan dalam bentuk:
𝐸[𝑌𝑖|𝑥𝑖] = 𝜇𝑖 = 𝛽0 + 𝑥1𝛽1+ ⋯ + 𝑥𝑘𝛽𝑘 (2) Atau 𝐸[𝑌𝑖|𝑋𝑖] = 𝜇𝑖 = T
i
x β .
Karena nilai 𝜇𝑖 > 0, maka digunakan fungsi link 𝜂𝑖= log( T i
x β) atau 𝜂𝑖 = 𝑙𝑜𝑔𝜇𝑖=
T i
x β untuk menghubungkan 𝜇𝑖= 𝐸[𝑌𝑖|𝑋𝑖] dengan fungsi linear T i
hubungan antara 𝜇𝑖 = 𝐸[𝑌𝑖|𝑋𝑖] dan T i
x β menjadi tepat. Dengan demikian, model regresi dapat ditulis dalam bentuk:
𝐸[𝑌𝑖|𝑋𝑖] = 𝜇𝑖= exp(x βiT ), 𝑖 = 1,2, … , 𝑛 (3)
Dengan 𝛽 merupakan parameter yang tidak diketahui dalam model dan harus di estimasi.
Untuk memasukkan covariates dan untuk menjamin non-negatif, mean atau
fitted value diasumsikan sebagai perkalian, yaitu,
𝐸(𝑌𝑖|𝒙𝒊) = 𝜆𝑖 = 𝑒𝑖𝑒𝑥𝑝(𝒙𝒊𝑻𝜷) (4) di mana ei menunjukkan ukuran paparan (exposure), xi merupakan vektor p x 1 dari
variabel penjelas, dan β merupakan vektor p x 1 dari parameter regresi. 3. Model Regresi Poisson Tergeneralisasi
Definisi 1 Jika Y adalah suatu variabel random berdistribusi Poisson Tergeneralisasi dengan parameter 𝜃 dan 𝜆, maka fungsi kepadatan peluang dinyatakan sebagai berikut:
𝑃(𝑌 = 𝑦|𝜃, 𝜆) = { 𝜃(𝜃 + 𝜆𝑦)𝑦−1 𝑒−(𝜃+𝜆𝑦) 𝑦! , 𝑦 = 0,1,2, … 0, 𝑦 > 𝑚, 𝜆 < 0 0, 𝑦yang lain (5)
dengan 𝜃 > 0, 𝑚𝑎𝑥(−1, − 𝜃 4⁄ ) ≤ 𝜆 ≤ 1; dan m adalah bilangan bulat positif terbesar sedemikian sehingga 𝜃 + 𝑚𝜆 > 0 bila 𝜆 bernilai negatif.
Teorema 1 Jika Y merupakan suatu variabel random GPD yang dinotasikan dengan 𝑌~𝐺𝑃(𝜃, 𝜆), maka nilai mean dan variansinya adalah sebagai berikut:
,
1 E Y
2
3 , (1 ) Var Y Definisi 2 Asumsikan bahwa variabel dependen yi yang menyatakan jumlah kejadian adalah berdistribusi Poisson Tergeneralisasi. Diberikan sejumlah variabel independen x1,x2,...,xp. 𝑃(𝑌𝑖= 𝑦𝑖|𝑥1, 𝑥2, … , 𝑥𝑝) = { 𝜃(𝜃 + 𝜆𝑖𝑦𝑖)𝑦𝑖−1 𝑒 −(𝜃+𝜆𝑖𝑦𝑖) 𝑦𝑖! , 𝑦𝑖 = 0,1,2, … 0, 𝑦𝑖> 𝑚, 𝜆𝑖 < 0 0, 𝑦𝑖yang lain (6)
Persamaan (6) dinotasikan dengan 𝑌𝑖~𝐺𝑃(𝜃𝑖, 𝜆𝑖), 𝑖 = 1,2, … , 𝑛; nilai rata-rata dan
variansi dinyatakan dengan 2
( |i i) i ( ) dan i ( |i i) i ( ,i i)
E Y x x Var Y x .
Wang dan Famoye (1997) menyatakan bahwa fungsi kepadatan peluang dari distribusi GP I adalah
(1 ) 1 (1 ) exp , 0,1, (7) 1 ! 1 i i y y i i i i i i i i i i ay ay P Y y y a y a dengan Yi sebagai variabel random untuk distribusi GP I.
Mean diasumsikan ke dalam persamaan 𝐸[𝑌𝑖|𝑥𝑖] = 𝜇𝑖= ℯ𝑖exp(𝒙𝒊𝑻𝜷), sedangkan variansi bersyarat ekuivalen dengan 𝑉𝑎𝑟[𝑌𝑖|𝑥𝑖] = 𝜇𝑖(1 + 𝑎𝜇𝑖)2. Ketika parameter dispersi, a, sama dengan nol, fungsi kepadatan peluang pada persamaan (7) akan beralih menuju Poisson, sehingga mean sama dengan variansi, yaitu 𝐸[𝑌𝑖|𝑥𝑖] = 𝑉𝑎𝑟[𝑌𝑖|𝑥𝑖]. Untuk a>0, variansi lebih besar daripada mean, 𝐸[𝑌𝑖|𝑥𝑖] > 𝑉𝑎𝑟[𝑌𝑖|𝑥𝑖], dan untuk kondisi ini model regresi merepresentasikan data cacah dengan overdispersi. Sedangkan untuk a<0, variansi lebih kecil daripada mean, 𝐸[𝑌𝑖|𝑥𝑖] < 𝑉𝑎𝑟[𝑌𝑖|𝑥𝑖], dan untuk kondisi ini model regresi merepresentasikan data cacah dengan underdispersi.
Jika 𝛽 di estimasi dengan metode maksimum likelihood dan log likelihood dinotasikan dengan , maka persamaan yang terkait adalah:
exp( ) exp( (1 ) { log 1 log 1 1 1 log( ) ( , ) exp( ) exp( ) !)} T T i i T T i i i i i i i i ay y y ay a x a x y x x a
Selanjutnya, apabila persamaan tersebut diturunkan terhadap j, maka diperoleh persamaan sebagai berikut:
2 ; (1 ) 1, 2, , i i ij i j i y x j p a
Persamaan terakhir di set sama dengan nol, sehingga diperoleh
2 ( ) 0; 1, 2, , (1 ) i i ij i i y x j p a
(8)Karena persamaan (8) adalah juga ekuivalen dengan kuadrat terkecil terbobot, dengan suatu pengabaian modifikasi, estimasi dari dapat diselesaikan dengan prosedur IWLS.
Di dalam penelitian ini, akan digunakan dua metode untuk memecahkan parameter dispersi, a, yaitu dengan metode maksimum likelihood dan metode moment. Persamaan untuk penyelesaian metode maksimum likelihood dapat diperoleh dengan menurunkan persamaan log likelihood terhadap 𝑎, adalah sebagai berikut:
2 2 2 2 2 2 2 2 3 ( 1) ( ) 0 (9) 1 1 (1 ) ( 1) 2 ( ) (10) (1 ) (1 ) (1 )
i i i i i i i i i i i i i i i i i i i i i i y y y y a a ay a y y y y a a ay a Di bawah metode moment, a bisa di estimasi dengan persamaan Pearson
Chi-Squares dengan derajat kebebasan, yaitu: 2 2 ( ) ( ) 0 (11) (1 )
i i i i i y n p a di mana n menandakan banyaknya kelas penilaian maksimum dan p banyaknya parameter-parameter regresi. Prosedur iterasi urutan serupa dengan di atas dapat juga digunakan untuk menghasilkan estimasi maksimum likelihood dari dan estimasi moment dari a.
Ismail dan Jemain (2007) menyatakan bahwa goodness of fit test model regresi Poisson dan Poisson tergeneralisasi dapat dilihat dari nilai Deviance, Pearson
Chi-Square, Akaike Information Criteria (AIC) dan Bayesian Schwartz Information Criteria (BIC).
a. Deviance
Deviance yaitu logaritma dari uji rasio likelihood-nya (McCullagh & Nelder,
1989). Uji rasio likelihoodnya membandingkan current model-nya dengan saturated
model-nya. Deviance dituliskan sebagai berikut:
𝐷 = 2(𝑙(𝒚; 𝒚) − 𝑙(𝝁; 𝒚)) (12)
di mana 𝑙(𝒚; 𝒚)dan 𝑙(𝝁; 𝒚)adalah model log likelihood yang dievaluasi masing-masing di bawah 𝝁 dan 𝒚. Untuk model yang memadai, D juga memiliki asimtotik distribusi chi-squre dengan n - p derajat kebebasan. Oleh karena itu, jika nilai-nilai untuk kedua Pearson Chi-Square dan D adalah dekat dengan derajat kebebasan, model dapat dianggap memadai.
b. Pearson Chi-Square
Ukuran lain yang bisa digunakan untuk goodness of fit test yaitu statistik
Pearson Chi- Square (McCullagh & Nelder, 1989) yang didefinisikan sebagai
𝑋2 = ∑(𝑦𝑖− 𝜇𝑖) 2 𝑉𝑎𝑟(𝑌𝑖) 𝑛 𝑖=1 (13) c. AIC dan BIC
Ketika beberapa model cocok, dapat membandingkan performa model-model alternatif berdasarkan beberapa kemungkinan langkah-langkah yang telah diusulkan dalam literatur statistik. Dua yang paling sering digunakan adalah ukuran Akaike
Information Criteria (AIC) dan Bayesian Schwartz Information Criteria (BIC). AIC
didefinisikan sebagai
AIC = −2l + 2p (14)
dimana lmenunjukkan log-likelihood dievaluasi di bawah μ dan p jumlah parameter. Untuk ukuran ini, semakin kecil AIC, semakin baik model.
BIC didefinisikan sebagai (Schwarz, 1978),
BIC = −2l + p log(n) (15)
mana l menunjukkan log-likelihood dievaluasi di bawah μ, p jumlah parameter dan n jumlah rating classes. Untuk ukuran ini, semakin kecil BIC, semakin baik model. C. APLIKASI NUMERIK
1. Data Penelitian
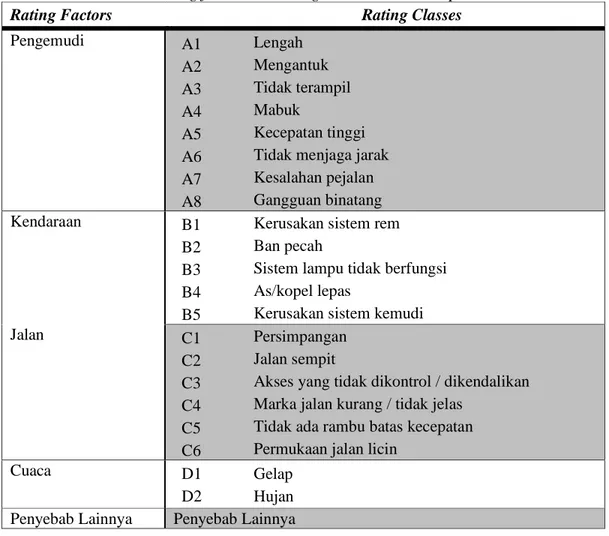
Data yang digunakan dalam penelitian ini adalah data sekunder dari laporan Unit Lakalantas Poltabes Padang selama tahun 2012. Rating factor dan rating classes yang dipakai dalam penelitian ini berdasarkan pada penelitian sebelumnya serta berdasarkan data yang tersedia di Lakalantas Poltabes Padang.
Tabel 1. Rating factors dan rating classes untuk data penelitian
Rating Factors Rating Classes
Pengemudi A1 Lengah
A2 Mengantuk A3 Tidak terampil
A4 Mabuk
A5 Kecepatan tinggi A6 Tidak menjaga jarak A7 Kesalahan pejalan A8 Gangguan binatang Kendaraan B1 Kerusakan sistem rem
B2 Ban pecah
B3 Sistem lampu tidak berfungsi B4 As/kopel lepas
B5 Kerusakan sistem kemudi
Jalan C1 Persimpangan
C2 Jalan sempit
C3 Akses yang tidak dikontrol / dikendalikan C4 Marka jalan kurang / tidak jelas
C5 Tidak ada rambu batas kecepatan C6 Permukaan jalan licin
Cuaca D1 Gelap
D2 Hujan Penyebab Lainnya Penyebab Lainnya
Tabel 1 menunjukkan rating factors dan rating classes untuk jumlah kecelakaan. Berdasarkan laporan dari Unit Lakalantas Poltabes Padang selama tahun 2012 terdapat 540 kasus kecelakaan lalu lintas yang terjadi di Kota Padang. Data tersebut kemudian dikelompokkan berdasarkan faktor penyebabnya.
Variabel dalam penelitian ini terdiri dari variabel respon dan prediktor. Adapun variabel yang digunakan pada penelitian ini adalah:
1. Variabel respon (dependent variable)
Dalam penelitian ini yang menjadi variabel respon adalah data angka jumlah kecelakaan tahun 2012.
2. Variabel bebas (independent variable) atau variabel penjelas
Variabel bebas terdiri dari faktor penyebab terjadinya kecelakaan lalu lu lintas pada kendaraan bermotor. Faktor-faktor tersebut didapatkan dari Unit Lakalantas Poltabes Padang dan dikutip dari Direktorat Jenderal Perhubungan Darat Departemen Perhubungan, www.dephub.go.id.
Ada kalanya kita melakukan suatu regresi dimana variabel penjelas berupa data kualitatif. Jika data kualitatif tersebut memiliki m kategori, maka jumlah variabel dummy yang dicantumkan di dalam model adalah (m - 1).
2. Hasil Analisis Data
Untuk menguji signifikansi tiap rating classes digunakan analisis deviance. Berikut ini akan disajikan hasil analisis deviance model regresi Poisson yang memuat tiap rating classes.
Tabel 2. Analisis deviance model regresi Poisson tiap rating classes
Df Deviance P(>|Chi|)
NULL 42 371.7
A1 Lengah 1 33.998 5.52E-09 ***
A3 Tidak terampil 1 28.561 9.08E-08 ***
A4 Mabuk 1 14.501 0.00014 ***
A5 Kecepatan tinggi 1 51.037 9.06E-13 ***
A6 Tidak menjaga jarak 1 12.516 0.000403 ***
A7 Kesalahan pejalan 1 10.184 0.001417 **
A8 Gangguan binatang 1 11.286 0.000781 ***
B1 Kerusakan sistem rem 1 11.279 0.000784 ***
B2 Ban pecah 1 5.088 0.024094 *
B3 Sistem lampu tidak berfungsi 1 1.927 0.165139
B4 As/kopel lepas 1 0.524 0.469311
B5 Kerusakan sistem kemudi 1 5.248 0.021972 *
C1 Persimpangan 1 14.557 0.000136 ***
C2 Jalan sempit 1 0.315 0.574905
C3 Akses yang tidak dikontrol / dikendalikan
1 1.129 0.287979 C4 Marka jalan kurang / tidak jelas 1 1.136 0.286422 C5 Tidak ada rambu batas kecepatan 1 5.752 0.016474 * C6 Permukaan jalan licin 1 0.033 0.855014
D1 Gelap 1 13.23 0.000276 ***
D2 Hujan 1 0.341 0.559401
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
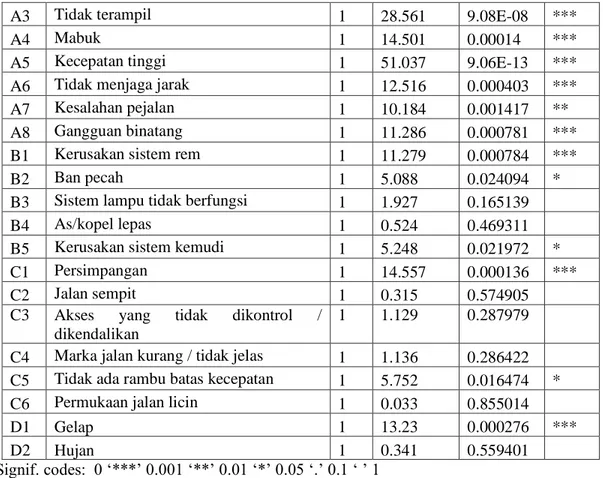
Dari tabel 2 terlihat bahwa terdapat rating classes yang tidak signifikan. Sehingga harus dilakukan kembali analisis deviance dengan membuang pasangan rating classes yang tidak signifikan. Berikut adalah ini adalah analisis deviance model regresi Poisson untuk tiap rating classes yang telah signifikan.
Tabel 3. Analisis deviance model regresi Poisson untuk tiap rating classes yang sudah
signifikan.
Df Deviance P(>|Chi|)
NULL 42 371.7
A1 Lengah 1 33.998 5.52E-09 ***
A2 Mengantuk 1 26.96 2.08E-07 ***
A3 Tidak terampil 1 28.561 9.08E-08 ***
A4 Mabuk 1 14.501 0.00014 ***
A5 Kecepatan tinggi 1 51.037 9.06E-13 ***
A7 Kesalahan pejalan 1 10.184 0.001417 ** B1 Kerusakan sistem rem 1 21.342 3.84E-06 *** B5 Kerusakan sistem kemudi 1 6.874 0.008748 **
C1 Persimpangan 1 12.695 0.000367 ***
D1 Gelap 1 15.544 8.06E-05 ***
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Dari hasil analisis deviansi model regresi Poisson untuk tiap rating classes hanya diperoleh beberapa rating classes yang signifikan yaitu lengah, mengantuk, tidak terampil, mabuk, kecepatan tinggi, tidak menjaga jarak, kesalahan pejalan, kerusakan sistem rem, kerusakan sistem kemudi, persimpangan dan gelap. Hasil estimasi parameter untuk rating classes yang signifikan, dapat dilihat pada Tabel 4.
Tabel 4. Estimasi parameter untuk model Poisson rating classes yang signifikan
Nilai estimasi beta tiap dummy
No. Beta Nilai_beta Standar.error Varians Pval
Intercept 1.61 0.088 0.008 0 A1 Lengah 0.83 0.13 0.017 0 A2 Mengantuk 0.56 0.152 0.023 0.00024 A3 Tidak terampil 0.77 0.157 0.025 0 A4 Mabuk 0.94 0.163 0.026 0 A5 Kecepatan tinggi 0.99 0.16 0.026 0
A6 Tidak menjaga jarak 0.63 0.17 0.029 0.00022
A7 Kesalahan pejalan 0.82 0.199 0.04 0.00004
B1 Kerusakan sistem rem 0.72 0.214 0.046 0.00077 B5 Kerusakan sistem kemudi 0.51 0.157 0.025 0.00114
C1 Persimpangan 0.71 0.173 0.03 0.00003
D1 Gelap 0.68 0.168 0.028 0.00005
df 31
Pearson's X^2 126.7225
log L -154.4214
Nilai p-value untuk semua parameter kecil dari 0.005, nilai ini mengidentifikasikan bahwa estimasi parameter sudah signifikan. Dari Tabel 4 terlihat bahwa terjadi overdispersi pada data karena nilai Pearson Chi-square dibagi dengan derajat bebas
nilainya lebih besar dari 1. Untuk mengatasi masalah overdispersi pada data cacah ini penulis mencoba memodel-ulangkan dengan regresi Poisson Tergeneralisasi.
Hasil estimasi parameter untuk masing-masing rating classes, dapat dilihat pada tabel 5. Perbandingan antara Poisson dan Poisson Tergeneralisasi menunjukkan bahwa parameter regresi untuk semua model memberikan estimasi yang hampir sama. Nilai AIC pada model Poisson Tergeneralisasi (Moment) menunjukkan nilai lebih kecil daripada model lainnya. Ini berarti, model Poisson Tergeneralisasi (Moment) lebih baik daripada model Poisson. Tetapi nilai standar error pada model Poisson Tergeneralisasi (Moment) menunjukkan nilai paling besar dari model lainnya, sehingga mengakhibatkan parameter regresi tidak signifikan untuk A6, B1, B5 dan C1. Menurut uji statistik Pearson Chi-Square, apabila nilai Pearson Chi-Square dibagi dengan derajat bebasnya menghasilkan nilai lebih besar dari satu, maka hal ini menunjukkan bahwa terjadi overdispersi. Ternyata dari data yang ada, ketiga model yaitu model Poisson, Poisson Tergeneralisasi (MLE) dan Poisson Tergeneralisasi (Moment) masih mengindikasikan terjadinya overdispersi. Tetapi jika dilihat dari nilai
a, maka model Poisson Tergeneralisasi (MLE) lebih baik dalam mengatasi
overdispersi dimana a < 0.
D. KESIMPULAN DAN SARAN
Berdasarkan pembahasan dan aplikasi numerik yang telah disampaikan pada bab-bab sebelumnya, maka dapat di ambil beberapa kesimpulan. Pertama, model regresi Poisson Tergeneralisasi terbaik untuk penggolongan resiko pada jumlah klaim dapat diperoleh dengan cara memeriksa hubungan antar variabel prediktor, menentukan model regresi poisson, memeriksa kasus overdispersi, equidispersi, atau kah underdispersi dengan menggunakan uji Pearson Chi-Square maupun deviance, menentukan model Regresi Poisson Tergeneralisasi dan model Regresi Poisson Tergeneralisasi, mengestimasi parameter model regresi Poisson Tergeneralisasi.
Kedua, cara menguji model regresi Poisson Tergeneralisasi terbaik untuk penggolongan resiko pada jumlah klaim yaitu pengujian signifikansi parameter regresi menggunakan uji normalitas dengan melihat p-value nya. Untuk menentukan model terbaik yang menggambarkan hubungan antara variabel respon dan variabel prediktor yaitu dengan melihat nilai AIC pada masing-masing model. Model yang mempunyai nilai AIC terkecil dan parameternya signifikan merupakan model regresi terbaik.
Ketiga, hasil dari beberapa contoh analisis data pada jenis data jumlah kecelakaan kendaraan bermotor di lalu lintas menunjukkan bahwa model regresi Poisson Tergeneralisasi merupakan model yang paling tepat digunakan untuk data yang bersifat overdispersi dibandingkan dengan model regresi Poisson.
Diharapkan hasil dari penelitian ini dapat mendorong para praktisi untuk melakukan analisa serupa yang lebih lanjut, terutama berkaitan dengan model regresi lainnya. Tujuannya adalah untuk mendukung ke arah suatu ukuran akurat dari tingkat frekuensi kecelakaan.
E. DAFTAR PUSTAKA
Ismail, Noriszura, and Abdul Aziz Jemain. "Bridging Minimum Bias and Maximum Likelihood Methods through Weighted Equation." Casualty Actuarial Society
Forum, 2005: 367-394.
Ismail, Noriszura, and Abdul Aziz Jemain. "Handling Overdispersion with Negative binomial and Generalized Poisson Regression Models." Casualty Actuarial
Society Forum, 2007: 103-158.
McCullagh, P., dan J.A. Nelder. Generalized Linear Models. 2nd Edition. London: Chapman and Hall, 1989.
Sari, Devni Prima. Penanganan Overdispersi dengan Model Regresi Binomial Negatif
I Pada Faktor-Faktor yang Mempengaruhi Angka Kematian yang Disebabkan Oleh Kanker Paru-Paru. Prosiding Seminar Nasional Matematika UNS, 2010:
445-452.
Sari, Devni Prima. Kajian Overdispersi Pada Regresi Poisson dengan Menggunakan
Regresi Poisson Tergeneralisasi I. Prosiding Seminar Nasional Matematika
UNAND, 2011: 122-128.
Satyahadewi, Neva. Model Regresi Poisson Tergeneralisasi dengan Studi Kasus
Penggolongan Resiko Jumlah Klaim pada Asuransi Kendaraan di Malaysia.
Tesis Universitas Gadjah Mada, 2010.
UU RI No.22 Tahun 2009. Undang-Undang No. 22 Tahun 2009 tentang Lalu Lintas