10
BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Teoritis 2.1.1 Autisme
Monks dkk., mengungkapkan bahwa autisme berasal dari kata autos yang berarti aku. Pada pengertian nonilmiah kata tersebut dapat ditafsirkan bahwa semua anak yang mengarah pada dirinya sendiri disebut dengan autisme. Sementara itu, Berk mengartikan autisme dengan istilah absorbed in the self atau keasyikan dalam dirinya sendiri. Sementara Wall mengartikan autisme sebagai aloof atau withdrawn, yang mana anak-anak dengan gangguan autisme ini tidak tertarik dengan dunia di sekelilingnya. Kemudian, Tilton mengungkapkan bahwa pemberian nama autisme karena hal ini diyakini dari “keasyikan yang berlebihan” dalam dirinya sendiri. (Novan Ardy, 2014)
Autisme adalah suatu gangguan perkembangan secara menyeluruh yang mengakibatkan hambatan dalam kemampuan sosialisasi, komunikasi, dan juga perilaku. Gejala autis ini pada umumnya muncul sebelum mencapai usia 3 tahun. Pada umumnya penyandang autis mengacuhkan suara, pengelihatan ataupun kejadian yang melibatkan mereka, dan mereka menghindari atau tidak merespon kontak sosial misalnya pandangan mata, sentuhan kasih sayang, bermain dengan anak.(Sri Muji, 2014)
2.1.1.1 Sejarah Autisme
Deskripsi klinis pertama kali tentang kondisi khusus anak-anak muncul tahun 1800-an yang jika dikaji kondisi tersebut disebut autisme. Di tahun 1943, Leo Karner, psikiater pertama yang diakui sebagai psikiater anak, menerbitkan sebuah investigasi tentang autisme. Artikelnya ‘Autistic Disturbances of Affective Contact’ begitu berpengaruh untuk sejumlah waktu, namun ia mengkategorikannya ke dalam ‘sindrom Kanner’. Dalam artikelnya Kanner meyakinkan kondisi ini berkaitan
dengan kurangnya kehangatan ibu dan kemelekatan pada anak, menghasilkan teori ‘ibu pendingin’ untuk autisme namun sekarang sudah ditinggalkan. (Anjali Sastri, 2012)
Di tahun 1964 psikolog Bernard Rimland, memiliki anak dengan autisme, menentang penjelasan Kanner di bukunya Infantille Autism: The Syndrom and Its
Implications for a Neursl Theory of Behavior. Untuk pertama kalinya autisme dilihat
berbasiskan neurologis, disebabkan perbedaan di dalam otak dan bukannya pola pengasuhan. (Anjali Sastri, 2012)
Pandangan modern muncul di tahun 1979 di Inggris ketika seorang dokter, Lorna Wing, dan seorang psikiater, Judith Gould, meneliti banyak sampel anak-anak dengan kelemahan interaksi sosial timbal balik. Dari sampel yang sama mereka juga menemukan kalau anak-anak ini juga mengalami kesulitan dalam berkomunikasi dan berimajinasi. Setelah penelitian ini kemudian dikenal konsep ‘triadik’ yang menjadi landasan dalam melihat autisme sampai saat ini. (Anjali Sastri, 2012)
2.1.2 Data Mining
Data mining dapat didefinisikan sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar yang membantu dalam pengambilan keputusan. Teknik data mining menelusuri data yang ada untuk membangun sebuah model dan menggunakan model tersebut agar dapat mengenali pola data yang lain yang tidak berada dalam data yang tersimpan. Pengelompokan data juga dapat dilakukan menggunakan data mining untuk mengetahui pola keseluruhan data-data yang dapat diambil. (Eko Prasetyo, 2012)
2.1.2.1 Posisi Data Mining dalam Berbagai Disiplin Ilmu
Terdapat kesamaan antara sebagian bahasan dalam data mining dengan bahasan di bidang ilmu yang lain. Kesamaan bidang data mining dengan statistic adalah penyampelan, estimasi, dan pengujian hipotesa. Kesamaan dengan kecerdasan buatan adalah pengenalan pola dan mesin pembelajaran adalah algoritma pencarian, teknik pemodelan, dan teori pembelajaran. (Eko Prasetyo, 2012)
2.1.2.2 Pekerjaan dalam Data Mining
Terdapat empat kelompok pekerjaan yang berkaitan dengan data mining, yaitu : (Eko Prasetyo, 2012)
1. Model prediksi
Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variable ke setiap targetnya, kemudian menggunakan model tersebut untuk memberikan nilai target pada himpunan baru yang didapat. Terdapat dua jenis model prediksi, yaitu klasifikasi dan regresi. Klasifikasi digunakan untuk variable target diskret, sedangkan regresi untuk variable target kontinu.
2. Analisis Kelompok
Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok berdasarkan keamanan karakteristik masing-masing data pada kelompok-kelompok yang ada. Data-data yang masuk dalam batas kesamaan dengan kelompoknya akan bergabung dalam kelompok tersebut, dan akan terpisah dalam kelompok yang berbeda jika keluar dari batas kesamaan dengan kelompok tersebut. 3. Analisis Asosiasi
Analisis asosiasi digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Pola yang ditemukan biasanya merepresentasikan bentuk aturan implikasi atau subset fitur. Tujuannya adalah untuk menemukan pola yang menarik dengan cara yang efisien.
4. Deteksi Anomali
Pekerjaan deteksi anomaly berkaitan dengan pengamatan sebuah data dari sejumlah data secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain. Data –data yang karakteristiknya menyimpang dari data yang lain disebut outlier. Algoritma deteksi anomali yang baik harus mempunyai laju deteksi yang tinggi dan laju error yang rendah.
2.1.2.3 Konsep Klasifikasi
Klasifikasi merupakan suatu pekerjaan menilai objek data untuk memasukannya ke dalam kelas tertentu dari sejumlah kelas yang tersedia. Terdapat dua pekerjaan utama dalam klasifikasi, yaitu pembangunan model sebagai prototype untuk disimpan sebagai memori dan penggunaan model tersebut untuk melakukan pengenalan/klasifikasi/prediksi pada suatu objek data lain agar diketahui di kelas mana objek data tersebut dalam model yang sudah disimpannya. (Eko Prasetyo, 2012) 2.1.3 Algoritma Naïve Bayes
Algoritma Naive Bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi. Naive Bayes merupakan pengklasifikasian dengan metode probabilitas dan statistik yang dikemukan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai Teorema Bayes. Teorema tersebut dikombinasikan dengan Naïve dimana diasumsikan kondisi antar atribut independen.(Eko Prasetyo, 2012) 2.1.3.1 Teorema Bayes
Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada teorema Bayes dengan asumsi independensi yang kuat (naif). Naïve Bayes menggunakan model fitur independen. Maksud independensi yang kuat (terutama Naïve Bayes) pada fitur adalah bahwa sebuah fitur pada suatu data tidak berkaitan dengan ada atau tidaknya suatu fitur lain pada data yang sama (Eko Prasetyo, 2012).
Formula umum teorema Bayes sebagai berikut : 𝑃(𝐻|𝐸) = 𝑃(𝐸|𝐻). 𝑃(𝐻)
𝑃(𝐸) … … … . … … … . (2.1) Keterangan :
P(H | E) : probabilitas akhir bersyarat suatu hipotesis H terjadi jika diberikan bukti (evidence) E terjadi
P(E | H) : probabilitas munculnya bukti (evidence) E terjadi akan mempengaruhi hipotesis H
P(H) : probabilitas awal (priori) hipotesis H terjadi tanpa memandang evidence apapun
P(E) : probabilitas awal (priori) evidence E terjadi Terdapat beberapa hal penting dari aturan Bayes, yaitu
1. Sebuah probabilitas awal (priori) H atau P(H) adalah probabilitas dari suatu hipotesis sebelum evidence diamati.
2. Sebuah probabilitas akhir H atau P(H|E) adalah probabilitas dari suatu hipotesis setelah evidence diamati.
2.1.3.2 Naïve Bayes untuk Klasifikasi
Kaitan antara Naïve Bayes dengan klasifikasi, korelasi hipotesis, dan evidence dengan klasifikasi adalah hipotesis dalam teorema Bayes merupakan label kelas yang menjadi target pemetaan dalam klasifikasi, sedangkan evidence merupakan fitur-fitur yang menjadi masukan dalam model klasifikasi. Jika X adalah vector masukan yang berisi fitur dan Y adalah label kelas, Naïve Bayes ditulis dengan notasi P(X|Y) yang artinya probabilitas label kelas Y didapatkan jika fitur-fitur X yang diamati merupakan kelas Y. Notasi ini dapat juga disebut probabilitas akhir (posterior probability) untuk Y, sedangkan P(Y) disebut probabilitas awal (prior probability) Y (Eko Prasetyo, 2012).
Formulasi Naïve Bayes untuk klasifikasi adalah
𝑃(𝑌|𝑋) = 𝑃(𝑌). ∏
𝑞
𝑖=1 𝑃(𝑋𝑖|𝑌)
𝑃(𝑋) … … … . … … … . . (2.2) Keterangan :
𝑃(𝑌|𝑋) : probabilitas data dengan vector X pada kelas Y.
∏𝑞𝑖=1 𝑃(𝑋𝑖|𝑌) : probabilitas independen kelas Y dari semua fitur dalam vector X.
P(X) : probabilitas awal (priori) vector fitur P(Y) : probabilitas awal (priori) kelas Y
Persamaan (2.2) merupakan model dari Naïve Bayesian yang akan digunakan untuk proses klasifikasi. Untuk fitur tipe numeric (kontinu) terdapat perhitungan khusus sebelum dimasukan ke dalam Naïve Bayes dengan menggunakan Densitas
Gauss. (Eko Prasetyo, 2012).
2.1.4 Peningkatan Performa Algoritma Naïve Bayes dengan Korelasi
Algoritma naïve bayes merupakan salah satu algoritma klasifikasi yang terkenal dan menghasilkan akurasi yang bagus. Pengklasifikasian dengan naïve bayes dapat dengan mudah diinduksi dari data set. Namun jika kekuatan independen atribut yang kurang dan hanya menggunakan distribusi probabilitas untuk mendapatkan hasil klasifikasi akan membuat akurasi naïve bayes menjadi buruk. (Nurnberger, 1999) Untuk itu dibutuhkan satu parameter tambahan untuk menentukan posterior probability dengan analisis korelasi setiap atribut terhadap suatu kelas.
Analisis korelasi merupakan alat statistik yang digunakan untuk mengetahui derajat hubungan linier suatu variable dengan variable lainnya. Tujuan analisis korelasi adalah untuk mencari hubungan variable bebas (X) dengan variable terikat (Y). Berikut adalah persamaan untuk menentukan korelasi : (Harinaldi, 2005)
𝑟𝑥𝑦= 𝑁𝛴𝑥−(∑𝑥)(∑𝑦)
√(𝑁𝛴𝑥2−(∑𝑥)2)(𝑁𝛴𝑦2−(𝛴𝑦)2) ………. (2.3)
Keterangan:
𝑟𝑥𝑦 =Koefisien korelasi antara variabel X dan variabel Y
N = jumlah data
𝛴𝑥y = Jumlah perkalian antara variabel x dan Y ∑𝑥2 = Jumlah dari kuadrat nilai X
∑𝑦2 = Jumlah dari kuadrat nilai Y
(∑𝑥)2 = Jumlah nilai X kemudian dikuadratkan
2.1.5 Metode Pembobotan Nilai Parameter
Pembobotan parameter mewakilkan seberapa besar pengaruh suatu parameter terhadap parameter yang lainnya. Salah satu metode pembobotan yaitu metode ranking. Dalam metode ranking setiap parameter akan disusun berdasarkan ranking. Penentuan ranking bersifat subjektif dari yang paling penting ke yang kurang atau sebaliknya. Setelah ranking ditetapkan, maka penentuan bobot dilakukan dengan pendekatan jumlah ranking dengan persaman berikut : (Muhammad Banda, 2002)
𝑤𝑗 = ( n − 𝑟𝑗 + 1 )
𝛴 ( 𝑛− 𝑟𝑝 + 1 ) ………... (2.4)
𝑤𝑗 = bobot normal untuk parameter ke j n = banyak parameter yang sedang dikaji p = parameter
𝑟𝑗= posisi ranking suatu parameter
Setiap parameter diberi bobot senilai ( n − 𝑟𝑗 + 1 ) dan dinormalisasi dengan 𝛴 ( 𝑛 − 𝑟𝑝 + 1 ).
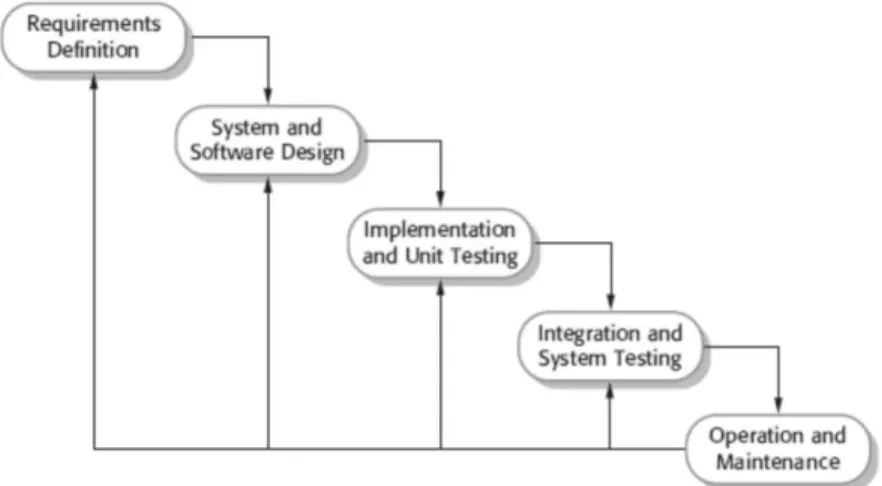
2.1.6 Metode Pengembangan Waterfall
Metode pengembangan perangkat lunak Waterfall merupakan salah satu model proses perangkat lunak yang mengambil kegiatan proses dasar seperti spesifikasi, pengembangan, validasi, dan evolusi. Model ini kemudian merepresentasikannya ke dalam bentuk fase-fase proses yang berbeda seperti analisis dan pendefinisian kebutuhan, perancangan perangkat lunak, implementasi, pengujian unit, integrasi sistem, pengujian sistem, serta operasi dan pemeliharaan (Sommerville, 2011).
Gambar 2. 1 Model Proses Waterfall (Sumber : Sommerville, 2011)
Adapun penjelasan tahapan-tahapan dari model waterfall yang ditunjukkan pada gambar 2.1 menurut Sommerville (2011) adalah sebagai berikut :
1. Analisis dan Penentuan Kebutuhan
Merupakan tahap pengumpulan informasi mengenai kebutuhan sistem yang didapat dari pengguna (user). Proses ini mendefinisikan secara rinci mengenai fungsi-fungsi, batasan dan tujuan dari perangkat lunak sebagai spesifikasi sistem. 2. Desain Sistem dan Perangkat Lunak
Tahap desain merupakan tahap yang melibatkan proses perancangan sistem yang difokuskan pada empat atribut, yaitu struktur data, arsitektur perangkat lunak, representasi antarmuka, dan detail (algoritma) prosedural. Yang dimaksud struktur data adalah representasi dari hubungan logis antara elemen-elemen data individual. 3. Implementasi dan Pengujian
Pada tahap ini, perancangan perangkat lunak direalisasikan sebagai serangkaian program atau unit program. Kemudian proses pengujian melibatkan verifikasi bahwa setiap unit program telah memenuhi kebutuhan yang telah didefinisikan pada tahap pertama.
4. Integrasi dan Uji Coba Sistem
Unit program/program individual diintegrasikan menjadi sebuah kesatuan sistem dan kemudian dilakukan pengujian. Dengan kata lain, pengujian ini ditujukan untuk menguji keterhubungan dari tiap-tiap fungsi perangkat lunak sudah memenuhi kebutuhan. Setelah pengujian sistem selesai dilakukan, perangkat lunak dikirim kepada pelanggan/user.
5. Operasi dan Pemeliharaan Sistem
Tahap ini biasanya memerlukan waktu yang paling lama, di mana sistem diterapkan dan digunakan. Pemeliharaan mencakup proses pengoreksian beberapa kesalahan yang tidak ditemukan pada tahap-tahap sebelumnya ataupun penambahan kebutuhan-kebuthan baru yang diperlukan.
2.2 Tinjauan Empiris
Pada penelitian ini, peneliti menggunakan beberapa penelitian terkait yang pernah dilakukan oleh peneliti lain sebagai tinjauan studi, yaitu sebagai berikut : 1. Komparasi Algoritma Klasifikasi Data Mining Untuk Memprediksi Penyakit
Tuberulosis Studi Kasus Puskesmas Karawang Sukabumi. (Saputra, Rizal. 2014).
Pada penelitian ini penulis melakukan komparasi algoritma klasifikasi data mining untuk memprediksi penyakit tuberculosis dengan empat metode data mining yaitu algoritma C4.5, naïve bayes classifier, neural network, dan logistic regression. Hasil evaluasi dan validasi, diketahui bahwa naïve bayes classifier memiliki nilai akurasi tertinggi sebesar 91,61%.
2. Klasifikasi Status Gizi Menggunakan Naïve Bayes Classification. (Sri Kusumadewi, 2009)
Pada penelitian yang dilakuakn Sri Kusumadewi mengatakan bahwa dalam metode naïve bayes classifier semua atribut memberikan kontribusi dalam pengambilan keputusan dengan bobot yang sama pentingnya untuk setiap atribut.
3. Pembobotan Korelasi Pada Naïve Bayes Classifier. (Burhan Alfironi, 2015) Pada penelitian ini dilakukan sebuah pengembangan algoritma naïve bayes dengan memperhitungkan nilai korelasi dari masing-masing attribute vector X terhadap kelas Y. Sehingga yang menjadi parameter penentuan pemetaan suatu vector X yang belum diketahui kelasnya terhadap kelas yang sudah ditentukan menjadi dua hal, yaitu :
a. Probabilitas : frekuensi kemunculan data dari setiap fitur vector X dalam data training
b. Korelasi : besar kecilnya pengaruh setiap fitur vector X terhadap kelas
4. Penerapan Forward Chaining Pada Program Diagnosa Anak Penderita Autis. (Gusti Ayu Kadek, 2009)
Pada penelitian ini dilakukan diagnosa anak penderita autis dengan melakukan penarikan kesimpulan berdasarkan pada fakta yang ada dengan metode forward chaining. Penelusuran dimulai dari fakta-fakta yang ada baru kesimpulan diperoleh, aturan yang ada ditelusuri satu persatu hingga penelusuran dihentikan karena kondisi terakhir telah terpenuhi. Penelitian dengan penerapan forward chaining ini menghasil akurasi sebesar 72,73%.
5. Sistem Pakar Deteksi Autisme Pada Anak Menggunakan Metode Fuzzy Tsukomoto. (Melifa Gardenia, 2016)
Berdasarkan pengujian yang dilakukan terhadap sistem diketahui bahwa sistem pakar yang dibangun valid dengan tingkat akurasi sebesar 73,33% dalam hasil deteksi yang sesuai dengan pakar.