LAPORAN KEMAJUAN
PENELITIAN HIBAH BERSAING
PROTOTIPE EKSTRAKSI OBJEK VIDEO SEMI OTOMATIS
BERBASIS DIGITAL MATTING MENGGUNAKAN
SPECTRAL ANALYSIS
Tahun ke 1 dari rencana 2 tahun
Oleh :
1. RURI SUKO BASUKI, S.Kom, M.Kom (NIDN : 0617027801)
2. MOCH. ARIEF SOELEMAN, S.Kom, M.Kom. (NIDN : 0628027101)
3. AURIA FARANTIKA YOGANANTI, S.Sn, M.TDesign (NIDN : 0624098201)
UNIVERSITAS DIAN NUSWANTORO SEMARANG
JUNI, 2014
iii
RINGKASAN
Munculnya standar televisi digital seperti DTV, DVB-T dan ISDB-T mendorong berkembangnya industri televise digital. Secara teknis, perbandingan bandwidth yang digunakan pada televisi analog dan digital adalah 1:6, sehingga dapat memancarkan sebanyak 6 sampai 8 saluran transmisi dengan program yang berbeda dalam saat yang sama, hal ini membuat efisiensi penggunaan spektrum frekuensi. Dampaknya bermunculan stasiun televisi baru yang mengudara, sehingga perusahaan yang bergerak dalam industri konten televisi yang berfungsi sebagai pemasok acara untuk stasiun televise akan tumbuh. Program televisi yang terdiri dari film, iklan dan berita harus efektif dan efisien untuk mengurangi biaya produksi sehingga dapat bersaing secara kompetitif. Upaya yang dapat dilakukan untuk menekan biaya produksi salah satunya dengan meminimalkan proses editing video dengan mengurangi campur tangan manusia. Munculnya standardisasi baru dalam video yang didefinisikan dalam MPEG-4 dan MPEG-7 menyediakan standar teknologi untuk mewakili dan memanipulasi data video. Kemampuan manipulasi obyek dalam frame sekuensial pada standar MPEG-4 merupakan inovasi penting, karena objek video, audio dideskripsikan, diatur dalam sebuah scene yang dapat dikodekan dalam standar tersebut, sementara MPEG-7 memberikan dukungan multimedia untuk index database dan memberikan meta data terstruktur dalam konten media penuh dengan semantik. Proses pemisahan objek dalam video editing seperti yang dilakukan dalam industri film, iklan dan produksi berita tidak efisien jika semua proses yang dilakukan oleh manusia (seperti pemisahan objek dilakukan frame by frame). Oleh karena itu, penelitian ini bertujuan untuk menghasilkan sebuah sistem semi-otomatis yang dapat memisahkan object foreground dalam video sekuensial. Pemisahan dilakukan dengan mengambil frame pertama dari video sekuensial yang dijadikan frame referensi, yang selanjutnya dilakukan operasi matting. Operasi ini dilakukan dengan user-spesified constraint sebagai parameter yang mewakili daerah foreground dan background yang selanjutnya dipisahkan dengan analysis spektral. Untuk melakukan melakukan replikasi pada semua frame, teknik frame difference digunakan untuk menetukan pergerakan constraint dengan algoritma background subtraction dan dilakukan dengan proses yang sama seperti dalam frame reference dan direplikasi pada semua frame video yang memiliki koherensi.
iv PRAKATA
Assalamu’alaikum wr.wb,
Segala puji syukur senantiasa kami panjatkan kehadirat Alloh S.W.T atas limpahan karunia terhadap umat-Nya. Pada kesempatan ini kami ingin mengucapkan terima kasih yang sebesar-besarnya kepada beberapa pihak yang telah membantu dan memberikan kontribusi dalam penelitian ini. Ucapan terima kasih kami persembahkan kepada Bapak / Ibu :
1. Dr. Ir. Edi Noersasongko, M.Kom selaku rektor Universitas Dian Nuswantoro Semarang.
2. Dr. Abdul Syukur, selaku Dekan Fakultas Ilmu dan Bisnis Universitas DianNuswantoro Semarang.
3. Y. Tyas Catur Pramudi, S.Si, M.Kom, selaku kepala LPPM atas motivasi dan dukungannya yang tiada terhingga sehingga laporan kemajuan ini dapat terselesaikan dengan baik.
4. Moch. Hariadi, S.T, M.Sc, Ph.D, selaku supervisor sekaligus mentor yang telah memberikan bagian dari roadmap penelitiannya untuk kami.
5. Prof. Dr. Ir. Mauridhi Hery Purnomo, selaku supervisor yang senantiasa memberikan motivasi dan bimbingan.
6. Moch. Arief Soeleman, S.Kom, M.Kom, dan Auria Farantika Yogananti, S.Sn, M.TDesign atas partisipasinya sebagai anggota.
Semoga atas segala dorongan, doa dan dukungan dari semuanya penelitian ini memberikan kontribusi dan manfaat bagi perkembangan ilmu pengetahuan dan kehidupan manusia. Amin.
Wassalamu’alaikum wr.wb Semarang, 2013
v DAFTAR ISI HALAMAN SAMPUL ... i HALAMAN PENGESAHAN ... ii RINGKASAN ... iii PRAKATA ... iv DAFTAR ISI ...v
DAFTAR GAMBAR ... vii
DAFTAR TABEL ... viii
BAB I : PENDAHULUAN ...1
1.1 Latar Belakang ...1
1.2 Perumusan Masalah ...5
BAB II : TINJAUAN PUSTAKA ...7
2.1 Matting Component ...7 2.2 Spectral Analysis ...7 2.2.1 Matting Laplacian ...9 2.2.2 Linear Transformation ...11 2.2.3 Groupig Componenet ...11 2.2.4 Fuzzy C-Means ...12 2.3 Mekanisme Tracking ...14 2.3.1 Background Subtraction ...14
2.3.2 Otsu Adaptive Threshold ...14
2.4 Performance Evaluation ...16
BAB III : TUJUAN DAN MANFAAT PENELITIAN ...17
3.1 Tujuan Penelitian ...17
3.2 Manfaat Penelitian ...17
BAB IV : METODE PENELITIAN ...18
4.1 Metode Pengumpulan Data ...18
4.2 Matting Object ...19
4.3 Determine of Moving Scribble ...20
4.4 Evaluasi dan Hasil ...21
vi
5.1 Keyframe Development ...22
5.2 Tracking Mechanism ...24
BAB VI : RENCANA TAHAPAN BERIKUTNYA ...27
DAFTAR PUSTAKA ...28
vii
DAFTAR GAMBAR
Gambar 1.1. Extraction result on natural imaga ...3
Gambar 1.2. Proses matting pada frame pertama ...4
Gambar 2.1. Derajat matrik ...8
Gambar 4.1. Roadmap penelitian ...18
Gambar 4.2. Alur diagram ekstraksi obyek video sekuensial ...19
Gambar 4.3. Proses matting ...20
Gambar 5.1. Proses pemisahan obyek pada citra diam ...22
Gambar 5.2. Proses pemisahan obyek pada frame awal ...24
viii
DAFTAR TABEL
1
BAB I
PENDAHULUAN
1.1. Latar Belakang
Munculnya standar televisi digital seperti DTV, DVB-T dan ISDB-T mendorong perkembangan industri televisi digital, sehingga untuk mempercepat implementasi di Indonesia, Kementrian Informatika dan Komunikasi membuat roadmap implementasi yang dimulai dari tahun 2009 – 2018. Keberadanan teknologi televisi digital memberikan dampak efisiensi dalam pemanfaatan spektrum frekuensi. Secara teknis, perbandingan lebar pita frekuensi yang digunakan TV analog dan digital adalah 1:6, artinya apabila pada teknologi analog memerlukan pita selebar 8 MHz untuk satu kanal transmisi, maka pada teknologi digital dengan lebar pita frekuensi yang sama dengan teknik multiplex, dapat memancarkan sebanyak 6 hingga 8 kanal transmisi sekaligus dengan program yang berbeda.
Sebagai dampak dari efisiensi pita frekuensi pada televisi digital, maka akan bermuculan stasiun-stasiun televisi baru yang akan mengudara, sehingga hal ini akan menimbulkan munculnya perusahaan-perusahaan baru yang bergerak dalam industri konten pertelevisian yang berfungsi sebagai supplier acara untuk stasiun televisi. Konten acara televisi yang terdiri dari film, iklan maupun berita seharusnya diupayakan efektif dan efisien untuk menekan biaya produksi sehingga dapat bersaing secara kompetitif. Untuk tujuan efektifitas maupun efisiensi produksi, salah satu usaha yang dapat dilakukan adalah meminimalkan proses video editing dengan mengurangi peran manusia.
Pemisahan objek dari frame video sekuensial dengan kualitas tinggi yang memiliki kemampuan mendekati mata manusia dalam memberikan semantik pada daerah yang
2
diobservasi merupakan tujuan dari ekstraksi. Tingkat akurasi proses ekstraksi objek menentukan kualitas hasil ekstraksi, oleh karena itu hal ini akan memiliki dampak yang positif dalam post-processing (compositing). Hasil ekstraksi objek dapat dikombinasikan dengan background yang berbeda di setiap frame video sehingga dapat menekan biaya produksi dalam pembuatan film dan iklan (mengurangi waktu editing dan pengambilan adegan sehingga menekan biaya produksi). Sedangkan untuk produksi acara televisi, pemanfaatan ekstraksi objek dapat mengurangi jumlah properti studio sehingga penyediaan ruangan untuk properti studio dapat dikurangi. Untuk melakukan proses pemisahan objek foreground dari background pada still image, operasi dilakukan dengan melibatkan sebagian atau seluruh piksel dalam sebuah image. Sebagai dasar untuk proses ekstraksi, Porter dan Duff pada tahun 1984 [27] memperkenalkan alpha channel yang digunakan untuk mengontrol interpolasi linear pada warna foreground dan background. Penelitian yang terkait dengan ekstraksi objek disebut dengan “pulling matte” atau “digital matting” telah dilakukan berdasarkan pendekatan
color-sampling dan pendekatan defining-affinity. Dalam pendekatan berbasis color-color-sampling [21],
[32], [12], [14], [13], nilai piksel yang berdekatan dengan known foreground dan background dikumpulkan dan digunakan sebagai sampel warna untuk estimasi nilai alpha. Pendekatan
color-sampling ini dapat bekerja dengan baik ketika karakteristik input image terdiri dari
daerah yang smooth dan trimap didefinisikan dengan baik oleh user. Keterbatasan dari pendekatan ini adalah terjadinya kesalahan klasifikasi sampel warna pada image yang komplek. Oleh karena itu, untuk meningkatkan kemampuan pendekatan ini, diperkenalkan pendekatan berbasis defining-affinity [11], [6], [18], [29], [33], [2], [1] yang dilakukan dengan menggunakan model statistik pada local image. Perhitungan nilai alpha dilakukan dengan estimasi gradient matte yang secara intrinsik tidak dihitung secara langsung, namun dimodelkan di seluruh kisi-kisi image dengan menentukan kemiripan antara berbagai piksel yang bertetangga. Dibandingkan dengan pendekatan sebelumnya, pendekatan berbasis
3
defining-affinity lebih kuat (robust), karena afinitas ditentukan pada local windows, sehingga
asumsi tersebut dapat dijadikan basis untuk image yang komplek.
Closed-Form Matting [2] yang dipadukan dengan spectral analysis [1] merupakan pendekatan dengan basis afinitas, nilai threshold pada channel alpha diestimasi dengan algoritma FCM (Fuzzy C-Means) [24] dengan input image terdiri dari original image dan
scribble image. User-specified constraint dilakukan dengan memberikan scribble warna putih
untuk objek foreground dan hitam untuk background. Teknik ini telah berhasil diimplementasikan dalam natural image pada warna yang komplek. Dalam kontek segmentasi objek pada aplikasi video, proses dilakukan dengan mempartisi frame video sequences ke dalam bentuk objek dan background yang memiliki semantik [20], hal ini dapat dilakukan dengan model intra-frame (spatial) maupun inter-frame (temporal). Ekstraksi objek video pada
computer vision seperti human pose estimation, event recognition, dan video annotation
dianggap sebagai teknik pre-processing tingkat tinggi sehingga hasilnya akan membantu mesin dalam menterjemahkan konten data video [16] .
Gambar 1.1. Extraction result on natural image [12]
Frame tunggal dari video sekuensial dalam penelitian ini diperlakukan sebagai still
image dan dijadikan input image dalam proses segementasi seperti gambar 1.2. Berdasarkan user interaction, teknik ini dapat diklasifikasikan ke dalam kategori automatic (unsupervised)
4
dan semi-automatic (supervised). Automatic object extraction tidak memerlukan campur tangan user dalam mengarahkan atau meningkatkan proses ekstraksi, oleh karena itu tidak semua image dapat ditangani, hanya image yang memiliki warna background terpisah yang dapat diproses dengan teknik ini [9]. Pada umumnya automatic object extraction cocok digunakan pada aplikasi vehicle tracking maupun surveillance. Sementara dalam
semi-automatic object extraction atau metode supervised memiliki kemampuan pengenalan dan
kecerdasan seperti manusia, sehingga mampu memberi peranan dalam inisialisasi dan proses ekstraksi. User-specified constraint dalam teknik ini dilakukan dengan memberikan label dalam bentuk scribble pada daerah objek foreground dan daerah background seperti yang diilustrasikan pada gambar 1.1.
Gambar 1.2. Proses matting pada frame pertama
Untuk ekstraksi objek sebagai tujuan dalam penelitian ini, teknik semi-automatic
object extraction diusulkan, ekstraksi objek dilakukan dengan asumsi frame pertama dari video
sekuensial diperlakukan sebagai still image. User memberikan scribble (supervised) untuk daerah yang dianalysis, (daerah objek dan daerah background). Agar hasil ekstrasi mendapatkan kualitas yang optimal, proses ekstraksi dilakukan dengan spectral analysis [1].
5
dilakukan pada semua frame secara supervised, oleh karena itu untuk memberikan constraint pada current frame dilakukan secara otomatis dengan mendefinisikan scribble baru.
Dengan asumsi temporal coherence yang menunjukkan bahwa pergerakan objek dalam video sekuensial tidak bergerak secara cepat atau tiba-tiba, namun bergerak secara halus dan antara current frame dengan frame sebelum dan sesudahnya memiliki koherensi, maka piksel dari suatu objek akan menempati koordinat tertentu dan akan bergerak pada koordinat yang terdekat terlebih dahulu sebelum bergerak ke koordinat yang jauh, sehingga untuk ekstraksi frame berikutnya dapat memanfaatkan perbedaan antara current frame dengan previous frame dengan menggunakan algoritma background subraction. Karena terdapat selisih antara current
frame dan previous frame, maka perbedaan tersebut dapat dipertimbangkan sebagai label
untuk menentukan moving scribble (posisi koordinat scribble pada current frame), sehingga posisi scribble pada current frame dapat didefinisikan, selanjutnya proses ekstraksi objek dilakukan dengan teknik matting menggunakan spectral analysis.
Proses pemisahan objek dalam video editing seperti yang biasa dilakukan dalam industri film, iklan maupun produksi berita tidak efisien jika semua proses dilakukan oleh manusia (seperti pemisahan objek yang dilakukan frame by frame). Oleh karena itu, penelitian ini ditujukan untuk menghasilkan aplikasi yang dapat memisahkan objek dalam video sekuensial semi otomatis, sehingga dapat digunakan untuk proses compositing dapat dilakukan lebih efektif sehingga dapat menekan biaya produksi.
1.2. Perumusan Masalah
Dari latar belakang yang telah diuraikan, permasalahan yang harus dipecahkan dalam penelitian ini adalah :
1. Dalam proses video editing, pemisahan obyek dari frame sequences tidak efisien apabila dilakukan dengan manual segmentation, karena volume video yang besar
6
jumlah frame yang banyak sehingga tidak memungkinkan untuk dilakukan segmentasi manual secara keseluruhan.
2. Sementara itu, karakteristik obyek dalam sebuah frame yang tidak memiliki informasi semantik (ill-posed problem) juga menjadi permasalahan tersendiri jika dilakukan segmentasi otomatis. Oleh karena itu pendekatan berbasis semi otomatis diperlukan untuk memisahkan obyek dalam frame pada video sequences.
7
BAB II
TINJAUAN PUSTAKA
2.1. Matting Component
Ekstraksi obyek baik pada image maupun video menjadi perhatian menarik untuk diteliti. Porter and Duff [27, 2, 1] memperkenalkan channel alpha yang digunakan sebagai alat untuk mengontrol linear interpolation dari warna foreground dan background. Selanjutnya channel alpha didefinisikan sebagai algoritma matting dengan mengasumsikan bahwa setiap piksel 𝐼𝑖 pada input image merupakan kombinasi linear dari warna foreground 𝐹𝑖, dan warna background 𝐵𝑖, sedangkan 𝛼𝑖 adalah tingkat keburaman pada piksel foreground.
𝐼𝑖 = 𝛼𝑖𝐹𝑖 + (1 − 𝛼𝑖)𝐵𝑖, dimana 0 ≤ 𝛼 ≤ 1 (1)
Selanjutnya dari persamaan compositing (1) bahwa setiap piksel diasumsikan sebagai kombinasi convex dari layer image K dengan 𝐹1, … , 𝐹𝑘.
𝐼𝑖 = ∑𝐾𝑘=1𝛼𝑖𝑘𝐹𝑖𝑘 (2)
Dimana 𝐹𝑖𝑘merupakan komponen matting sebanyak k pada image, sedangkan 𝛼𝑖𝑘 untuk menentukan kontribusi fractional dari setiap layer pada warna yang diamati di setiap piksel.
2.2. Spectral Analysis
Dalam analisis spectral selanjutnya nilai eigenvector terkecil dari matting Laplacial L merupakan komponen matting tersendiri sehingga dapat memulihkan komponen-komponen matting image yang setara dengan melakukan transformasi linear pada eigenvector. Selajutnya matrik 𝐴 yang merepresentasikan image berukuran 𝑁 𝑥 𝑁 yang terdiri dari beberapa kompenen
8
yeng berhubungan (connected components) yang diasumsikan 𝐴(𝑖,𝑗)= 𝑒−𝑑𝑖𝑗/𝜎
2
dengan 𝑑𝑖𝑗 merupakan ukuran jarak diantara piksel (seperti warna dan jarak geodesic). Sedangkan L adalah matrik semidefinite positif simetris yang dapat menangkap banyak struktur image.
𝐿 = 𝐷 − 𝐴 (3)
Di mana 𝐷 merupakan derajat matrik dari graph (diilustrasikan dalam gambar 2.1)
𝐺 = (𝑉, 𝐸) 𝑤𝑖𝑡ℎ‖𝑉‖ = 𝑛 (4)
Gambar 2.1 Derajat matrik
yang dinotasikan sebagai matrik diagonal
𝐷(𝑖,𝑗)= ∑ 𝐴(𝑖, 𝑗)𝑗 , dimana 𝑑𝑖,𝑗={deg(𝑣𝑖) if 𝑖 = 𝑗
0 Otherwise (5)
𝐷(𝑖,𝑗) berisi informasi derajat setiap vertex (node) dengan 𝐷 untuk 𝐺 sebagai matrik bujur sangkar berukuran 𝑛 𝑥 𝑛 . Matrik afinitas A dapat menangkap informasi bahwa sebuah image terdiri dari beberapa cluster yang berbeda atau connected components. Subset 𝐶 pada piksel image merupakan connected component dari image 𝐴(𝑖,𝑗)= 0 untuk setiap (𝑖, 𝑗) sehingga 𝑖 ∈ 𝐶 dan 𝑗 ∉ 𝐶, sehingga tidak ada subset 𝐶 yang dapat memenuhi properti ini. Jika vektor indikator komponen 𝐶 dinotasikan sebagai 𝑚𝐶 maka
9
𝑚𝑖𝐶 = {1 𝑖 ∈ 𝐶
0 𝑖 ∉ 𝐶 (6)
𝑚𝐶selanjutnya merepresentasikan 0-eigenvector (eigenvector dengan eigenvalue 0) dari 𝐿.
Dengan asumsi bahwa image terdiri dari connected components 𝐾, 𝐶1, … , 𝐶𝐾 sehingga {1, … , 𝑁} = ⋃𝐾𝑘=1𝐶𝑘 dengan 𝐶𝑘 disjoint subset pada piksel. Vektor indicator 𝑚𝐶1, … , 𝑚𝐶𝐾
semua independen dan orthogonal 0-eigenvector dari 𝐿. Vektor indicator yang dihasilkan dari perhitungan eigenvector pada 𝐿 hanya sampai rotasi, karena rotasi matrik 𝑅 dengan ukuran 𝐾 𝑥 𝐾, dan vektor [𝑚𝐶1, … , 𝑚𝐶𝐾]𝑅 merupakan basis nullspace pada 𝐿. Ekstraksi
komponen-komponen berbeda dari eigenvector terkecil disebut dengan “Spectral Rounding” dan menjadi perhatian dalam beberapa penelitian [15], [26], [19], [3], [7]. Pendekatan sederhana untuk clustering piksel image menggunakan algoritma K-Means [28] dan analysis perturbation untuk membatasi kesalahan algoritma sebagai funsi konektivitas dalam dan antar cluster.
2.2.1. Matting Laplacian
Untuk mengevaluasi kualitas matte, Levin dkk Matting [2] menggunakan matting Laplacian. Kualitas matte dievaluasi tanpa mengestimasi warna foreground dan background seperti dalam persamaan 2.1. Warna background dan foreground image dalam local window 𝑤 membentuk dua garis yang berbeda dalam domain RGB. Selanjutnya nilai 𝛼 dalam 𝑤 dinyatakan sebagai linear combination dari channel warna.
∀𝑖 ∈ 𝑤 𝛼𝑖 = 𝑎𝑅𝐼𝑖𝑅+ 𝑎𝐺𝐼𝑖𝐺+ 𝑎𝐵𝐼𝑖𝐵+ 𝑏 (7)
Selanjutnya alpha matte meminimalkan deviasi dari model linear (7) di seluruh image windows wq :
10 𝐽(𝛼, 𝑎, 𝑏) = ∑ ∑ (𝛼𝑖− 𝑎𝑞𝑅𝐼𝑖𝑅+ 𝑎𝐺𝑞𝐼𝑖𝐺+ 𝑎𝑞𝐵𝐼𝑖𝐵+ 𝑏𝑞) 2 + 𝜀‖𝑎𝑞‖ 2 𝑖𝜖𝑤𝑞 𝑞𝜖𝐼 (8) 𝜀‖𝑎𝑞‖ 2
adalah persyaratan regularisasi pada 𝛼. Koefisien model linear 𝑎, 𝑏 memungkinkan untuk dieliminasi dari (2.8 ), dan menghasilkan quadratic cost pada 𝛼
𝐽(𝛼) = 𝛼𝑇𝐿𝛼, (9)
𝐽(𝛼)merupakan parameter yang diminimalkan dalam user constraint [2], digunakan dalam framework user-assisted (9) memiliki trivial minimum yang merupakan konstanta dalam vektor 𝛼. Sedangkan 𝐿 adalah matting Laplacian, matrik symmetric semidefinite positive 𝑁 𝑥 𝑁 yang merupakan matrik yang memasukkan fungsi input image dalam local windows dan tergantung pada unknown foreground dan warna background pada koefisien model linear. 𝐿 didefinisikan penjumlahan matrik 𝐿 = ∑ 𝐴𝑞 𝑞, yang masing-masing berisi afinitas diantara piksel dalam local window 𝑤𝑞
𝐴𝑞(𝑖, 𝑗) = { 𝛿𝑖𝑗− 1 |𝑤𝑞|(1 + (𝐼𝑖− 𝜇𝑞) 𝑇 (∑ +𝑞 𝜀 |𝑤𝑞|𝐼3𝑥3) −1 (𝐼𝑗− 𝜇𝑞)) 0 𝑂𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒 (𝑖, 𝑗) ∈ 𝑤𝑞 (10)
𝛿𝑖𝑗 merupakan Kronecker delta, 𝜇𝑞 adalah rata-rata vektor warna diseluruh piksel 𝑞, ∑ 𝑞 adalah covarian matrix berukuran 3 x 3 pada window yang sama, |𝑤𝑞| merupakan jumlah piksel dalam window, dan 𝐼3 adalah matrik identitas berukuran 3 x 3. Dengan munculnya eigenvector terkecil, kegunaan lain properti matting Laplacian (10), adalah untuk menangkap informasi job fuzzy cluster pada piksel image, termasuk sebelum penentuan batasan dengan user-specified juga diperhitungkan [2].
11 2.2.2. Linear Transformation
Pencarian transforasi linear pada eigenvector akan menghasilkan satu set vektor yang nilainya mendekati binner. Formulasinya dinotasikan sebagai 𝐸 = [𝑒1, … , 𝑒𝑘] menjadi matrik 𝑁 𝑥 𝐾 dari eigenvector. Selanjutnya untuk menemukan satu set dari kombinasi linear 𝐾, vektor 𝑦𝑘 meminimalkan
∑|𝛼𝑖𝑘|𝛾 𝑖,𝑘
+ |1 − 𝛼𝑖𝑘|𝛾, where 𝛼𝑘 = 𝐸𝑦𝑘
subject to ∑ 𝛼𝑘 𝑖𝑘 = 1. (11)
Jika 0 < 𝛾 < 1 maka nilai 𝛾 = 0,9, selanjutnya |𝛼𝑖𝑘|𝛾+ |1 − 𝛼𝑖𝑘|𝛾 adalah nilai pengukuran yang robust pada komponen matting [1]. Karena cost function (11.) tidak convex, hasil dari proses Newton bergantung pada proses inisialisasi. Untuk menginisialisasi dapat dilakukan dengan menerapkan algoritma K-means pada eigenvector yang terkecil dalam matting Laplacian dan memproyeksikan vektor indicator dari cluster yang dihasilkan dari eigenvector
E
𝛼𝑘 = 𝐸𝐸𝑇𝑚𝐶𝑘 (12)
Hasil matting komponen selanjutnya dijumlahkan sehingga memberikan solusi untuk persamaan (11).
2.2.3. Grouping Component
Hasil ekstraksi foreground matte secara lengkap selanjutnya ditentukan dengan penambahan sederhana komponen pada foreground. Misalkan 𝛼𝑘1, … , 𝛼𝑘𝑛 dirancang sebagai
komponen foreground, maka
12
(13) Jika eigenvector yang terkecil tidak sama dengan nol, pengukuran kualitas hasil α-matte dilakukan dengan 𝛼𝑇𝐿𝛼, yang mana L adalah matting Laplacian. Kalkulasi awal korelasi diantara komponen matting dengan L dan penyimpanan dalam matrik 𝐾 𝑥 𝐾 didefinisikan
(𝑘, 𝑙) =𝛼𝑘𝑇𝐿𝛼𝑙 (14)
Selanjutnya matte cost dihitung sebagai
𝐽(𝛼) = 𝑏𝑇𝑏 (15)
Dimana 𝑏 adalah vektor biner K-dimensional yang mengindikasikan komponen yang dipilih.
2.2.4. FCM (Fuzzy C-Means)
Fuzzy C-Means (FCM adalah suatu teknik pengklasteran data yang keberadaan
tiap-tiap data dalam suatu cluster ditentukan oleh nilai/derajat keanggotaan tertentu. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981 [34]. Berbeda dengan teknik pengklasteran secara klasik (dimana suatu obyek hanya akan menjadi anggota suatu klaster tertentu), dalam FCM setiap data bisa menjadi anggota dari beberapa cluster. Batas-batas
cluster dalam FCM adalah lunak (soft). Konsep dasar FCM, pertama kali adalah menentukan
pusat cluster yang akan menandai lokasi rata-rata untuk tiap-tiap cluster. Pada kondisi awal, pusat cluster ini masih belum akurat. Tiap-tiap data memiliki derajat keanggotaan untuk tiap-tiap cluster. Dengan cara memperbaiki pusat cluster dan nilai keanggotaan tiap-tiap-tiap-tiap data secara berulang, maa akan terlihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulangan ini didasarkan pada minimasi fungsi obyektif. Fungsi Obyektif yang digunakan pada FCM adalah [34]
2 1 1, ;
'
, '
(1, )
n c m m ik ik k iJ
U V X
d
m
(16)13 dengan
1/ 2 2 1 m ik k i kj ij jd
d x
v
x
v
(17)x adalah data yang akan diklaster :
11 1 1 m m nm x x x x x (18)
dan v adalah matriks pusat cluster :
11 1 1 m m mm v v v v v (19)
Fungsi objektif yang minimum menunjukkan hasil cluster yang terbaik, sehingga
* * *
( , ; ) min ( , ; ) m
J U V X J U V X (20)
Jika dik 0, i k m, ; 1, dan X setidaknya memiliki m elemen, maka ( , )U V dapat
meminimalkan Jm hanya jika
1 1 1 1 2 1 1 1 ;1 ;1 m m ij kj j ik m m m ij kj k j i m k nV
X
V
X
(21) dan
1 1 ;1 ;1 n m ij i n kj m ik i ik i m j m X V
(22)14 2.3. Mekanisme Tracking
2.3.1. Background Subtraction
Untuk mengidentifikasi perbedaan intensitas pada current frame dengan background dilakukan dengan menggunakan algoritma background subtraction [35]. Teknik frame
differences ini dilakukan pada background subtraction dengan memanfaatkan teknik rekursif.
Model ini diasumsikan sebagai 𝐵𝐹 yang merupakan nilai binner pada foreground object yang dinotasikan sebagai :
1,
, ,
, ,
1
( , , )
0,
if I x y n
I x y n
BF x y n
otherwise
(23)Nilai (𝛼) digunakan sebagai threshold (ambang batas) untuk mengklasifikasi foreground object dan background. Untuk menghasilkan nilai threshold digunakan algoritma Otsu.
2.3.2. Otsu Adaptive Threshold
Metode Otsu [36] berbasis histogram yang menunjukkan nilai intensitas yang berubah-ubah di setiap pixel image satu dimensi. Sumbu x digunakan untuk menyatakan perbedaan level intensitas, sedangkan sumbu y digunakan untuk menyatakan jumlah pixel yang memiliki nilai intensitas. Dengan menggunakan histogram dapat dilakukan pengelompokan pixel image berdasarkan nilai threshold (ambang batas). Threshold yang optimal dapat diperoleh ketika
pixel memiliki perbedaan intensitas sehingga dapat dipisahkan kelompok-kelompoknya. Dua
informasi dapat diperoleh dengan memanfaatkan histogram, yaitu jumlah perbedaan tingkat intensitas (dinotasikan dengan L), dan jumlah pixel untuk setiap tingkat intesitas (dinotasikan dengan n(k), dengan k=0 .. 255). Tahapan pencarian nilai threshold dalam algoritma Otsu adalah sebagai berikut :
1. Menghitung normalisasi histogram image yang dinotasikan dengan 𝑝𝑖, dengan i = 0,1,2...L-1.
15 𝑝𝑖 = 𝑛𝑖
𝑀𝑁 (24)
dimana 𝑛𝑖 adalah jumlah pixel pada masing-masing intensitas, dan MN adalah jumlah dari 𝑛𝑖 yang dimulai dari 𝑛0 hingga 𝑛𝐿−1.
2. Menghitung jumlah komulatif dari 𝑃1(𝑘), untuk k=0,1,2 ...L-1.
𝑃1(𝑘) = ∑𝑘𝑖=0𝑝𝑖 (25)
3. Menghitung rata-rata komulatif 𝑚(𝑘), untuk k=0,1,2 ..., L-1.
𝑚(𝑘) = ∑𝑘𝑖=0𝑖𝑝𝑖 (26)
4. Menghitung rata-rata intensitas global 𝑚𝐺 menggunakan ;
𝑚𝐺 = ∑𝐿−1𝑖=0𝑖𝑝𝑖 (27)
5. Menghitung varian antar kelas, 𝜎𝐵2(𝑘), untuk k=0,1,2 ..., L-1.
𝜎𝐵2 =[𝑚𝐺𝑃1(𝑘)−𝑚(𝑘)]2
𝑃1(𝑘)[1−𝑃1(𝑘)] (28)
6. Memilih nilai threshold dari k * di mana nilai index dari varian antar kelas maksimum (𝜎𝐵2 -> max), jika lebih dari satu nilai dari k*, maka nilai threshold ditentukan dari rata-rata nilai k*.
7. Menghitung ukuran pemisahan * dengan k=k*
(𝑘) =𝜎𝐵2(𝑘)
𝜎𝐺2 (29)
sedangkan
𝜎𝐺2 = ∑𝐿−1𝑖=0(1 − 𝑚𝐺)2𝑝𝑖 (30)
Catatan : nilai dari k diperoleh ketika 𝜎𝐵2(𝑘) maksimum, selanjutnya nilai threshold yang dilakukan dengan metode Otsu diberikan untuk α (dalam persamaan 24).
16 2.4. Performance Measurement
Pengukuran akurasi obyek yang terekstraksi yang dilakukan dengan membandingkan antara output dengan human perceptual ground truth maupun noise image output terhadap original image [5]. Evaluasi secara kuantitatif untuk algoritma yang diusulkan dilakukan dengan menghitung nilai PSNR (Peak Signal Noise to Ratio), dimana noise pada obyek yang terekstraksi terhadap original image diformulasikan seperti pada persamaan (24).
𝑃𝑆𝑁𝑅(𝐸𝑥𝑡. 𝑂𝑏𝑗, 𝑂𝑟𝑖. 𝐼𝑚𝑔) = 10𝑙𝑜𝑔10𝑆2
𝑀𝑆𝐸(𝐸𝑥𝑡.𝑂𝑏𝑗,𝐺𝑟𝑑.𝐼𝑚𝑔) (31)
Selanjutnya nilai MSE (Mean Square Error) dari object yang terekstraksi dikalkulasi seperti persamaan (25). 𝑀𝑆𝐸(𝐺𝑟𝑑. 𝐼𝑚𝑔, 𝐸𝑥𝑡. 𝑂𝑏𝑗) =(∑ ∑ [𝐺𝑟𝑑.𝑖𝑚𝑔(𝑖,𝑗)−𝐸𝑥𝑡.𝑂𝑏𝑗(𝑖,𝑗)] 2 𝑗=1 𝑖=1 ) 3 𝑁𝑀 (32)
17
BAB III
TUJUAN DAN MANFAAT PENELITIAN
3.1. Tujuan Penelitian
Tujuan yang akan dicapai dalam penelitian ini adalah :
1. Membangun aplikasi ekstraksi objek video yang dapat memisahkan antara daerah foreground dan daerah background di setiap frame video sehingga dapat digunakan sebagai data input dalam proses compositing.
2. Menerapkan teknik semi-otomatis dengan memberikan semantik pada frame pertama dalam video sekuensial sebagai label yang merepresentasikan daerah foreground dan daerah background, selanjutnya proses pemisahan dilakukan dengan analysis spectral yang hasilnya dijadikan frame referensi untuk proses ekstraksi di frame-frame berikutnya.
3.2. Manfaat Penelitian
Adapun manfaat dari penilitian ini adalah:
1. Manfaat praktis dari penelitian ini yaitu implementasi sistem semi otomatis untuk pemisakan obyek foreground dalam video sekuensial yang dapat bermanfaat bagi pekerja di industri film, periklanan maupun pertelevisian dalam melakukan proses video editing.
2. Manfaat teoritis dari penelitian ini adalah membantu memecahkan permasalahan ekstraksi semi otomatis pada video sekuensial menggunakan spectral analysis.
18
BAB IV
METODE PENELITIAN
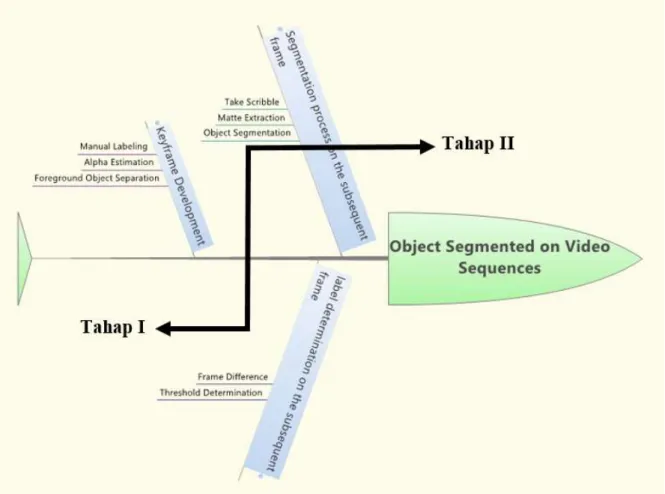
Roadmap semi-automatic video object extraction seperti yang diilustrasikan dalam diagram fishbone pada gambar 4.1 menunjukkan alur dan langkah-langkah ekstraksi obyek video dalam sudut pandang secara umum. Berdasarkan roadmap yang telah didesain, tahapan demi tahapan penelitian akan disajikan hingga tingkat yang rendah.
Gambar 4.1. Roadmap Penelitian
4.1. Metode Pengumpulan Data
Untuk memperoleh data yang akurat, maka diperlukan penentuan jenis dan sumber data. Oleh karena itu, jenis dan sumber data pada penelitian ini ditentukan sebagai berikut:
19 1. Data Primer
Data primer merupakan data yang diperoleh dari penelitian. Data primer pada penelitian ini yaitu 150 frame video sekuensial yang diambil dari natural scene.
2. Data Sekunder
Data sekunder merupakan data yang diperoleh dari studi literatur yang dilakukan. Sumber dari studi literatur yaitu jurnal, makalah ilmiah atau buku yang membahas tentang penelitian computer vision, image processing, dan video processing. Salah satunya diambil dari UCF Sport Action.
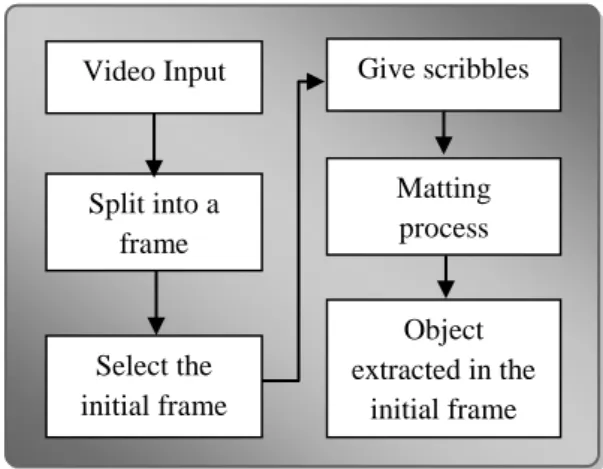
Tahapan detail dari penelitian yang diusulkan disajikan dalam flowchart yang ditunjukkan pada gambar 4.2
Gambar 4.2. Alur diagram ekstraksi obyek video semi-otomatis
4.2. Matting Object
Untuk melakukan ekstraksi obyek pada video sekuensial seperti dalam gambar 4.2, beberapa pengetahuan dalam area computer vision harus dipelajari agar hasil ekstraksi dapat diteliti dengan akurasi yang tinggi. Tahapan penelitian diawali dengan membaca data video sekuensial yang selanjutnya dipecah-pecah dalam bentuk frame. Frame pertama dari video
Start
Video sequences
Matting object in the
initial frame Get next frame
Detection of moving scribble Extraction of video object End End of frame Yes No
20
sekuensial diperlakukan sebagai frame referensi untuk frame-frame berikutnya, dimana ekstraksi obyek pada frame pertama dilakuka proses matting dengan tahapan seperti ditunjukkan dalam gambar 4.3.
Gambar 4.3. Proses matting
Langkah awal dilakukan dengan membaca data video dalam format .avi yang selanjutnya data tersebut dipecah dalam bentuk frame-frame. Frame pertama dari frame sekuensial, dipilih sebagai referensi untuk ekstraksi pada frame-frame berikutnya, dimana proses ekstraksi dilakukan dengan pendekatan semi otomatis sehingga diperlukan teknik marking atau labeling untuk memisahkan object dan background. Teknik labeling dilakukan dengan memberikan scribbles atau coretan (putih untuk object dan hitam untuk background) yang dilakukan oleh manusia (human assistance).
Scribble digunakan untuk menentukan parameter piksel yang masuk dalam area background dan piksel yang masuk pada area object. Namun ada daerah yang tidak masuk dalam area object maupun area background yang disebut dengan unknown area atau unknown region, dimana pada daerah ini mengandung parameter object dan parameter background, sehingga untuk memisahkan keduanya diperlukan teknik penentuan ambang batas (threshold).
4.3. Determine of Moving Scribble
Ekstraksi obyek pada frame kedua hingga frame ke-n dilakukan seperti proses ekstraksi pada frame pertama, namun karena sudah terjadi pergerakan object maka pergerakan scribble pada object maupun background perlu diperhitungkan untuk menjaga akurasi obyek yang diekstraksi. Penentuan moving scribble dilakukan menggunakan algoritma background subtraction dengan teknik frame difference. Nilai threshold ditentukan secara adaptive dengan algoritma Otsu. Video Input Split into a frame Select the initial frame Give scribbles Matting process Object extracted in the initial frame
21 4.4. Evaluasi dan Validasi Hasil
Teknik evaluasi yang digunakan pada penelitian ini yaitu dengan mengukur feedback hasil penilaian ekstraksi dari persepsi manusia kemudian akan dibandingkan dengan hasil ekstraksi semi otomatis dari prototipe yang dibuat. Dilakukan dengan mengukur akurasi obyek yang terekstraksi yang dilakukan dengan membandingkan antara ouput dengan human perceptual ground truth maupun noise image output terhadap original image. Evaluasi secara kuantitatif untuk algoritma yang diusulkan dilakukan dengan menghitung nilai PSNR (Peak
22
BAB V
HASIL YANG DICAPAI
5.1. Keyframe Development
Untuk memisahkan foreground object dalam frame video sekuensial dilakukan dalam dua tahapan. Tahap pertama (yang dilakukan dalam tahun pertama) dilakukan untuk membangun keyframe (frame kunci) yang digunakan sebagai frame reference untuk mekanisme tracking pada frame-frame berikutnya. Sedangkan tahap kedua (yang dilakukan dalam tahun kedua) adalah membangun mekanisme tracking dan melakukan segmentasi pada frame-frame berikutnya.
Segmentasi foreground object pada frame awal yang diperlakukan sebagai keyframe dilakukan dengan mengacu metode “Closed-form Solution” [1] dengan memodifikasi beberapa parameter. Modifikasi dilakukan dengan algoritma Fuzzy C-Means (FCM) sebagai teknik untuk menentukan threshold pada unknown area sebuah image secara adaptive. Hasil ujicoba ini telah diseminarkan pada CITEE (Conference of Information Technology and Electrical Engineering), Juli 2012. Berikut contoh hasil segmentasi foreground object dan evaluasi kinerja algoritma dengan membandingkan antara hasil segmentasi sistem dengan ground truth.
Input image Scribble image Matte extraction Extracted object
Gambar 5.1. Proses pemisahan obyek pada citra diam
23
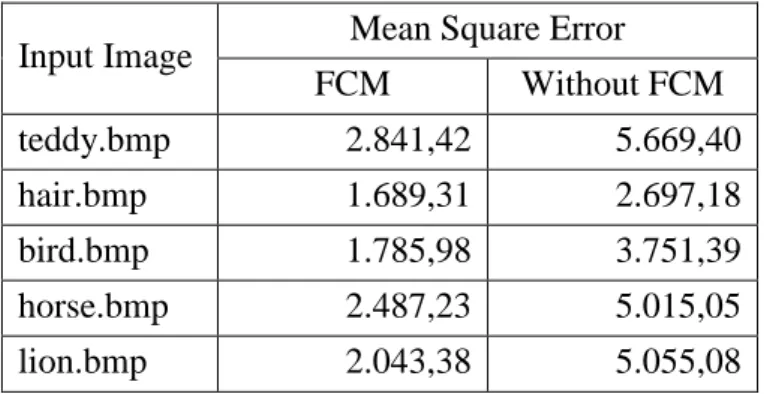
Dari ilustrasi hasil ekstraksi obyek di atas, dapat disimpulkan bahwa pemisahan obyek dalam citra diam dengan tingkat akurasi yang cukup impresif (dapat dilihat helai rambut pun bisa dipisahkan dari keseluruhan image). Sehingga kami berpendapat jika dalam citra diam proses pemisahan obyek dapat dilakukan, maka dalam video pun dapat hal yang serupa dapat dilakukan, karena pada prinsipnya video sekuensial terdiri dari frame-frame yang memiliki karakteristik seperti citra diam. Adapun hasil evaluasi dari pengukuran kinerja algoritma dari sistem yang diusulkan sebagai berikut :
Table 5.1. Nilai MSE dari modifikasi sistem
Input Image Mean Square Error
FCM Without FCM teddy.bmp 2.841,42 5.669,40 hair.bmp 1.689,31 2.697,18 bird.bmp 1.785,98 3.751,39 horse.bmp 2.487,23 5.015,05 lion.bmp 2.043,38 5.055,08
Pengujian dengan menggunakan MSE (Mean Squared Error) merupakan uji perbedaan hasil pemisahan obyek diantara sistem dengan algoritma yang dibangun dengan ground truth (hasil pemisahan manual), yang dilakukan dengan formulasi sebagai berikut :
𝑀𝑆𝐸(𝐺𝑟𝑑. 𝐼𝑚𝑔, 𝐸𝑥𝑡. 𝑂𝑏𝑗) = (∑ ∑ [𝐺𝑟𝑑.𝑖𝑚𝑔(𝑖,𝑗)−𝐸𝑥𝑡.𝑂𝑏𝑗(𝑖,𝑗)]
2 𝑗=1
𝑖=1 )
3 𝑁𝑀
Dengan demikian dengan nilai perbedaan yang semakin kecil maka akurasi pemisahan obyek semakin baik. Oleh karena itu proses pemisahan obyek dengan metode closed-form solution dengan peningkatan adaptive threshold menggunakan algoritma FCM dipertimbangkan sebagai algoritma dalam pembangunan keyframe dalam segmentasi / ekstraksi obyek video.
24 5.2. Tracking Mechanism
Mekanisme tracking merupakan cara penelusuran pergerakan obyek yang sifatnya temporal coherence, artinya pergerakan foreground object dalam frame video (antara previous frame dengan current frame) tidak berlangsung secara tiba-tiba atau koordinat pikselnya tidak berubah secara drastis, tetapi bergerak secara halus, sehingga perubahan nilai koordinatnya pun juga tidak begitu signifikan.
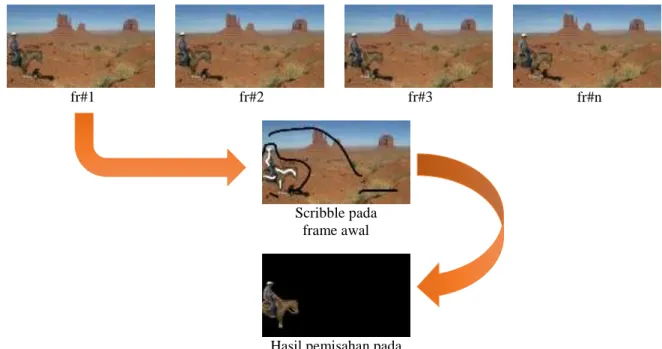
Berdasarkan asusmsi bahwa pergerakan frame dalam video sekuensial bersifat
temporal coherence, maka untuk melakukan pemisahan foreground object dilakukan dengan
menggabungkan teknik segmentasi manual dan segmetasi otomatis (semi-otomatis). Proses manual dilakukan pada frame awal yang dilakukan dengan memecah video menjadi beberapa frame. Frame awal diperlakukan seperti citra diam yang selanjutnya diberi label yang berupa coretan (putih mewakili foreground, dan hitam mewakili background) yang dilakukan oleh user. Ilustrasi pemberian label digambarkan dalam gambar 5.2.
fr#1 fr#2 fr#3 fr#n
Scribble pada frame awal
Hasil pemisahan pada frame awal
25
Sebelum melakukan pemisahan foreground object pada frame berikutnya (subsequent
frame), terlebih dahulu scribble harus didefinisikan. Hal ini dilakukan karena proses pemisahan
foreground object pada subsequent frame dilakukan dengan teknik matting, dimana frame input harus diikuti oleh label. Permasalahannya tidak memungkinkan apabila video yang memiliki volume yang besar penentuan label selalu dilakukan oleh user. Sehingga diperlukan pendekatan agar subsequent frame dilakukan secara otomatis. Untuk melakukan pelabelan secara otomatis dilakukan dengan algoritma background subtraction dengan asumsi bahwa teknik perbedaan frame yang dilakukan secara rekursif dalam algoritma tersebut dapat menentukan nilai perbedaanya. Untuk memperjelas nilai perbedaan tersebut dilakukan binerisasi pada setiap frame yang diproses, sehingga terlihat jelas bahwa nilai perbedaan dapat disimbolkan dengan nilai 1 dan 0 untuk sebaliknya. Karena nilai perbedaan hasil dari background subtraction bernilai 1, maka label akan nampak berwarna putih, hal ini dapat mempermudah dalam proses pemisahan dengan teknik matting (teknik menarik matte dari keseluruhan image). Algoritma background subtraction didefinisikan sebagai berikut :
1,
, ,
, ,
1
( , , )
0,
if I x y n
I x y n
BF x y n
otherwise
Selanjutnya untuk pemisahan foreground object pada video sekuensial kami uji coba dengan dataset yang kami dapatkan dari UCF Sport Action, yaitu foreman, riding horse, skateboarding dan lifting masing-masing 30 frame. Karena label dalam subsequent frame telah diperoleh dari background subtraction, maka pemisahan obyek pun juga bisa dilakukan pada subsequent frame dengan teknik matting menggunakan algoritma closed-form solution dan FCM adaptive threshold pada daerah alpha. Hasil pemisahan foreground object diilustrasikan sebagai berikut
26
fr#15 fr#20 fr#25 fr#30
Gambar 5.3. Hasil pemisahan foreground object pada video sekuensial
Dari eksperimen tersebut kami elaborasi menjadi sebuah paper yang berjudul “Spectral-based Video Object Segmentation Using Alpha Matting and Background Subtraction” dan telah kami submit (kirim) dalam konferensi internasional “Image Electronics and Visual Computing 2014 (IEVC2014)”.
27
BAB VI
RENCANA TAHAPAN BERIKUTNYA
Rencana kegiatan penelitian selanjutnya yaitu :
1. Melakukan uji coba sistem yang dibuat dengan data primer.
2. Mengkaji ulang kinerja algoritma yang digunakan dalam sistem yang hasil kajiannya digunakan untuk meningkatkan kemampuan algoritma untuk tahapan tahun berikutnya. 3. Menyelesaikan pembuatan laporan yang diperkirakan akan selesai pada akhir Nopember
2014
Melakukan presentasi paper dalam konferensi international Image Electronics and Visual Computing yang diperkirakan dilakukan pada tanggal 7 Oktober 2014.
DAFTAR PUSTAKA
[1]. A. Levin, A. Rav-Acha, and D. Lischinski, “Spectral matting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 30, No. 10, 2008
[2]. A. Levin, D. Lischinski, Y. Weiss, “A Closed-Form Solution to Natural Image Matting,” IEEE Transactions on Pattern Analysis And Machine Intelligence, Vol. 30, No. 2, February 2008, pp: 1-15.
[3]. A. Ng, M. Jordan, and Y. Weiss, “On Spectral Clustering: Analysis and an Algorithm,” Proc. Advances in Neural Information Processing Systems, 2001. [4]. Ahmad Sanmorino, “Clustering Batik Images using Fuzzy C-Means Algorithm
Based on Log-Average Luminance, “ Computer Engineering and Applications Vol. 1, No. 1, June 2012
[5]. C. Mythili, V.Kavitha, “Color Image Segmentation using ERKFCM, “ International Journal of Computer Applications, Volume 41– No.20, March 2012
[6]. Carsten Rother, Vladimir Kolmogorov and Andrew Blake, "GrabCut: interactive foreground extraction using iterated graph cuts, " ACM Transactions on Graphics (TOG) Volume 23 Issue 3, August 2004
[7]. D. Tolliver and G. Miller, “Graph Partitioning by Spectral Rounding: Applications in Image Segmentation and Clustering,”Proc. IEEE Int’l Conf. Computer Vision and Pattern Recognition, pp. 1053-1060, 2006.
[8]. David G. Lowe, “Distinctive image features from scale-invariant key-points, “ International Journal of Computer Vision, Vol. 60, No. 2, 2004.
[9]. Ediz Şaykol, Uğur Güdükbay, and Özgür Ulusoy. A Semi-Automatic Object Extraction Tool for Querying in Multimedia Databases. In Proceedings of the 7th Workshop on Multimedia Information Systems (MIS '01), pp. 11–20, Villa Orlandi, Capri, Italy, November 2001.
[10]. H. Kosch, “Distributed Multimedia Database Technologies supported by MPEG-7 and MPEG- 21”, CRC Press, 2003.
[11]. J. Sun, J. Jia, C.-K. Tang, and H.-Y. Shum, “Poisson matting,” ACM Transactions on Graphics (TOG) Volume 23 Issue 3, pages 315-321, 2004.
[12]. J. Wang and M. Cohen, “An iterative optimization approach for unified image segmentation and matting,” in Proceedings of ICCV 2005, pp. 936–943, 2005. [13]. J. Wang and M. Cohen, “Optimized color sampling for robust matting,” in
[14]. J. Wang, M. Agrawala, and M. Cohen, “Soft scissors: an interactive tool for realtime high quality matting,” ACM Transactions on Graphics (TOG), Volume 26 Issue 3, 2007.
[15]. K. Lang, “Fixing Two Weaknesses of the Spectral Method,” Proc. Advances in Neural Information Processing Systems, vol. 18, 2005.
[16]. Kuo-Chin Lien, Yu-Chiang Frank Wang, “Automatic Object Extraction in Single-Concept Videos, “ Research Center for Information Technology Innovation , Academia Sinica , Taipei , Taiwan, 2011.
[17]. L. Chiariglione, “The MPEG-4 Standard”, Journal of China Institute of Communications, pp.54-67, September 1998.
[18]. L. Grady, T. Schiwietz, S. Aharon, R. Westermann, “Random Walks for Interactive Alpha-Matting,” Proc. Fifth IASTED International Conference Visualization, Imaging, and Image Processing. 2005.
[19]. L. Zelnik-Manor and P. Perona, “Self-Tuning Spectral Clustering,”Proc. Advances in Neural Information Processing Systems, 2005
[20]. M. Khasari, H.R Rabiee, M. Asadi, M. Nosrati, M. Amiri, M. Ghanbari, “An Adaptive Semi-Automatic Video Object Extration Algorithm based on Joint Transform and Spatial Domains Features, “Digital Media Lab , Computer Engineering Department , Sharif University of Technology, 2005
[21]. M. Ruzon and C. Tomasi, “Alpha estimation in natural images,” in Proceedings of IEEE CVPR, pp. 18–25, 2000.
[22]. Muhammad Bilal Ahmad, Dong Yoon Kim, Kyoung Sig Roh and Tae Sun Choi , “Motion Vector Estimation Using Edge Oriented Block Matching Algorithm for Video Sequences, “ Proceeding of IEEE International Conference on Signal Processing and Analysis, 2000
Proc. of IEEE CVPR, 2007.
[23]. R. Koenen, F. Pereira, and L. Chiariglione, MPEG-4: Context and Objectives”, Signal Processing: Image Communication, Vol.9, pp. 295- 304, 1997.
[24]. R. Suko Basuki, Moch. Hariadi, R. Anggi Pramunendar, “Fuzzy C-Means Algorithm for Adaptive Threshold on Alpha Matting,” in Proc of Computer Society CITEE, 2012
[25]. S. Negahdaripour and H. Madjidi, "Stereovision Imaging on Submersible Platforms for 3D Mapping of Benthic Habitats and Sea Floor Structures", Oceanic Engineering, IEEE Journal vol.28, no 4, 2003.
[26]. S.X. Yu and J. Shi, “Multiclass Spectral Clustering,” Proc. Int’lConf. Computer Vision, pp. 313-319, 2003.
[27]. T. Porter and T. Duff, “Compositing digital images,” Computer Graphics, Volume 18, No. 3, 1984.
[28]. Tung-Yu Wu, Hung-Hui Juan and Henry Horng-Shing Lu, “IEEE International Conference on Speech and Signal Processing, 2012.
[29]. X. Bai and G. Sapiro, “A geodesic framework for fast interactive image and video segmentation and matting,” in Proc. of IEEE ICCV, 2007.
[30]. X. He and P. Niyogi, “Locality preserving projections,” in Proc. of Advances in Neural Information Processing Systems (NIPS), 2003.
[31]. Xiaohui Shen and Ying Wu, "Scribble Tracker: A Matting-Based Approach for Robust Tracking, " IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 34, No. 8, August 2012
[32]. Y. Chuang, B. Curless, D.H. Salesin, R. Szeliski, “A Bayesian Approach to Digital Matting,” Proc. IEEE Conference Computer Vision and Patter Recognition. 2001 [33]. Y. Zheng, C. Kambhamettu, J. Yu, T. Bauer, and K. Steiner, “Fuzzymatte: A
computationally efficient scheme for interactive matting,” in Proc. of IEEE Computer Vision and Pattern Recognition, 2008.
[34]. Kusumadewi, S., Hartati, S., 2006, Fuzzy Multi Atribute Decision Making, Graha Ilmu, Yogyakarta.
[35]. M. Soeleman, M. Hariadi and M. Purnomo, "Adaptive Threshold for Background Subtraction in Moving Object Detection using Fuzzy C-Means Clustering," in
Tencon Int'l Conference, Cebu, Philippines, 2012.
[36]. R. C. Gonzalez and R. E. Woods, Digital Image Processing 3rd edition, Pearson Prentice Hall, 2007.
SPECTRAL-BASED VIDEO OBJECT SEGMENTATION USING ALPHA MATTING AND BACKGROUND SUBTRACTION
aRuri Suko Basuki, bMoch. Arief Soeleman, cMochamad Hariadi, dMauridhi Hery Purnomo
eRicardus Anggi Pramunendar, fAuria Farantika Yogananti,
a,b,c,d Faculty of Industrial Technology, Dept. of Electrical Engineering, Institut Teknologi Sepuluh Nopember, Surabaya, Indonesia
a,b,e,f Faculty of Computer Science, Dian Nuswantoro University, Semarang, Indonesia E-mail: [email protected], [email protected]
ABSTRACT
The main objective of this study is to separate object from video sequences. To separate the object from the video data is performed by combine several algorithms. The first stages, the video data is split into several frames, and the initial frame is treated as a keyframe. Object extraction on the keyframe require human intervention, namely by giving scribble on the regions of foreground and background. Matting technique uses a closed-form solution method applied in this stage. Further, the results used as a reference for object extraction in subsequent frames. To get the labels on the next frames, background subtraction algorithm is applied, and the result is used as the input image on the next frames. So that the object extraction in subsequent frames can be performed repeatedly using matting techniques. The experimental results show that the object extraction at the initial frame shows good results. However, the accuracy decreases when the object moves too fast and suddenly.
Keyword : Segmentation, Alpha Matting, Background Subraction
1. INTRODUCTION
The advent of digital video standards such as Digital Video Broadcasting (DVB), Digital Video Broadcasting - Terrestrial (DVB - T) and Integrated Services Digital Broadcasting - Terrestrial (ISDB - T) is pushing the demand of the video editing applications (such as video segmentation and video compositing) and rapidly increased, since it plays an important role in the production of movies, news and advertising. The object-based technology can be used in various applications, such as object
extraction, motion understanding, image recognition and augmented reality. Unfortunately, the process of object segmentation of video becomes a difficult job, since the video object has no semantic information. In other words, a video object segmentation is an ill-posed problem [1]. Therefore, the pulling of objects in video editing is performed with manual segmentation, since the semantic object can only be identified by humans vision that considers the video context. However, this method is not effective when it is applied to the video data with large volumes.
To overcome this problem, several algorithms related to video object segmentation have been developed. Generally, these algorithms are classified into two categories, namely the automatic object segmentation [2] and a semi-automatic object segmentation [3], [4]. Automatic segmentation is done without human intervention by considering specific characteristics such as color, texture and movement. The main problem of the automatic segmentation is the difficulty in objects separating which is semantically meaningful. Until today, there is no guarantee that the result of the automatic object segmentation will be satisfactory, since the semantically object has a lot of color, texture and movement [5]. [6] [7]
For this reason, several semi-automatic segmentation methods are proposed as a combination of the automatic segmentation and manual segmentation. In principle, this approach is a technique to pull the object that involves user intervention at several stages of the segmentation process. Thus semantic information can be defined directly by the user. Furthermore, object segmentation in subsequent frames is performed using a tracking mechanism by temporal
transformation. Some of methods used for tracking mechanisms has been applied in several previous studies. In a region-based method, the related areas are in accordance with the shape of semantic objects tracked by the motion, texture and color parameters [6], [7]. Weaknesses of the method are very complex tracking mechanism in maintaining relationships between regions composed of semantic object [8]. Meanwhile, the contour-based methods, such as snakes [3] will robust when track the object contours instead the whole of the object that comprising the pixels, so that these methods may not work well when the feature to be followed namely edges are not connected to each other. Whereas the model-based method apply a priori knowledge of the object shape. The drawback of this approach is not acceptable on the generic semantic video object segmentation due to the detail needs information about the object geometry [9].
In this paper, semi-automatic video segmentation framework is proposed to be applied to the general video data. Early stages in video segmentation is performed by creating a "keyframe" which is used as a reference for tracking process on the subsequent frames. Hereafter, the object segmentation on the subsequent frames is done by using the background substraction algorithm.
2. KEYFRAME CONSTRUCTION
The first stage of a video segmentation process is done by constructing the initial frame of the sequence scene which becomes a key frame. Since the object have no the semantic information, scribble is used as a label to distinguish areas that represent foreground and background (white color for foreground and black color for background). Next, the object is extracted with matting techniques.
A. General Compositing Equation
Alpha channel [10], [11], [12] is used to control the linear interpolation in the foreground and background which are depicted in matting algorithm by assuming that each pixel in the input image Ii is a
linear combination of the color of foreground Fi and
background Bi.
1
, i i i i i I F B where 0 1 (1)based compositing equation (Eq. 1) of each pixel is assumed to be a convex combination of layers K
image which denoted as
1 K k k i i i k I F
(2)the fractional contribution of each layer observed in each pixel is determined by the vector K of k which is a component of image matting.
B. Spectral Analysis
Spectral segmentation method is associated with the affinity matrix. For example, the image A, size N x N is assumed as ( , ) dij/ 2
i j
A e and d . In which ij
ij
d is the space among pixels (e.g. color and
geodesic space), which is defined as
–
L D A (3) while D is matrix degree from graph.
,
G V E withV n (4) with diagonal matrix
i j,
, , j D
A i j , deg where 0 i i j v if i j d Otherwise (5) ( , )i jD is stuffed with degree information of each vertex (node) with D for G as rectangular matrix size n x n depicted. So L is a symmetric positive semi-definite matrix with eigenvector which is able to capture a lot of image structure. Furthermore, the image is composed of some different clusters or connected components which can be captured by the affinity matrix A. Subset C in image pixel is the connected component of image
( , )i j 0
A for each ( , )i j so iC and jC, so there is no subset C that can fulfill this property.
C
m isdefined as indicator vector of component C , therefore 1 0 C i i C m i C (6)
with the assumption that the image consists of connected components of K,C1,,CK to
{1, … , 𝑁} = ⋃𝐾𝑘=1𝐶𝑘 with Ck disjoint path on the
pixel, then the C
m represents 0-eigenvector (eigenvector with eigenvalue 0) from L. Since the
1
[mC,,mCK]R is the null space base on
L, then the indicator vector mC1,,mCK resulted from
eigenvector calculation on L is only reaching the rotation. "Spectral Rounding" which is a component extraction with the smallest eigenvector becomes a concern in some studies [13], [14] [15], [16], [17]. K-Means algorithm is a simple approach used for clustering the image pixels [13], while the perturbation analysis algorithm is to limit errors as a function of connectivity within and across clusters.
1) Matting Laplacian
In order to evaluate the quality matte without considering colors of foreground and background Matting Laplacian [10] is applied by using a local window w forming two different pathways in the RGB domain as denoted in (Eq. 6). Furthermore, α in w is expressed as a linear combination of color channels.
i R iR G Gi B iB
i w a I a I a I b
(7)
The deviation of linear model (eq. 7) in all the image window wq becomes one of the findings in a matte extraction problems.
2 2 , , q R R i q i q G G B B q I i w q i q i q a I J a b a a I a I b
(8)the requirements which must be fulfilled of the alpha is 𝜀‖𝑎𝑞‖
2
which is a linear model coefficients
α,b that allows elimination from (Eq. 8) and the
result is a quadratic cost in α
T ,J L (9) It has the ordinary minimum cost which is a constant α vector, then in framework user-assisted [12], 𝐽(𝛼) is the subject minimized in user constraint. The equation L (9) is matting Laplacian. Symmetric semi-definite positive matrix N x N is the matrix inserting input image function in local windows, which depends on unknown foreground and background color in the coefficient of linear model. L is defined by the sum of matrix 𝐿 = ∑ 𝐴𝑞 𝑞
in which on each is filled with affinity among pixels in local window 𝑤𝑞 1 3 3 1 1 , , 0 T ij i q x j q q q q q I I I i j w w Otherwise A
, q where i j w (10) In which ijis Kronecker delta, qis the averagecolor vector in al pixel q, ∑ 𝒒is matrix covariant
size 3 3 in the same windows, |𝑤𝑞|is the sum of
pixels in window, and I3 is identity matrix size
3 3. By the occurrence of the smallest
eigenvector, the other use of matting Laplacian property (eq. 10) is to catch information of job fuzzy cluster on image pixel, including the calculation before the limit determent by user is specified [15].
2) Linear Transformation
The linear transformations track in eigenvector will produce a set of vector which the value is adjacent to a binary. The equation denoted as 𝐸 = [𝑒1, … , 𝑒𝑘]
is converted to matrix N x K of eigenvector. Next to locate a set of linear combination K, vector 𝑦𝑘
minimizes , 1 , where k k k k i i i k Ey
subject to k 1 i k
(11)The robust measurement value in matting component [12] is determined by |𝛼𝑖𝑘|
𝛾
+ |1 − 𝛼𝑖𝑘|
𝛾
, If 0 < 𝛾 < 1, thus, the value of 𝛾 = 0,9. Because the cost function (eq. 11) is not convex, the initialization process determine the result of Newton process. Therefore, K-means algorithm can be used in the initialization process on the smallest eigenvector in matting Laplacian and projects indicator vector of cluster resulted from eigenvector
E.
k
k T C
EE m
(12)
The matting component result (eq. 12) is then added. Thus it gives solution for (eq. 11).
3) Grouping Component
The complete results of matte extraction of the foreground object are determined by a simple summation on the foreground. For example,
1, , kn
k
is designed as a component of the foreground, so that
1 kn
k
(13)
The measurement of the results - matte is perform by T
L
when the smallest eigenvector is not equal to zero, in which L is the matting Laplacian. The first calculation of correlation among matting component and L deviation in matrix K Kis defined as
k l, k TLl
(14)
then, matte cost is calculated as
T
J b b (15) where b is the binner vector of K-dimensional
![Gambar 1.1. Extraction result on natural image [12]](https://thumb-ap.123doks.com/thumbv2/123dok/4582283.3338252/11.892.243.707.687.904/gambar-extraction-result-on-natural-image.webp)