BAB 2
TINJAUAN PUSTAKA
2.1. Kompresi Data
Kompresi data adalah proses mengkodekan informasi menggunakan bit atau information-bearing unit yang lain yang lebih rendah daripada representasi data yang tidak terkodekan dengan suatu sistem enkoding tertentu. Contoh kompresi sederhana yang biasa kita lakukan misalnya adalah menyingkat kata-kata yang sering digunakan tapi sudah memiliki konvensi umum (Saputro, 2011). Misalnya: kata “dan sebagainya” dikompres menjadi kata “dsb”.
Pengiriman data hasil kompresi dapat dilakukan jika pihak pengirim/yang melakukan kompresi dan pihak penerima memiliki aturan yang sama dalam hal kompresi data. Pihak pengirim harus menggunakan algoritma kompresi data yang sudah baku dan pihak penerima juga menggunakan teknik dekompresi data yang sama dengan pengirim sehingga data yang diterima dapat dibaca di-decode kembali dengan benar (Saputro, 2011).
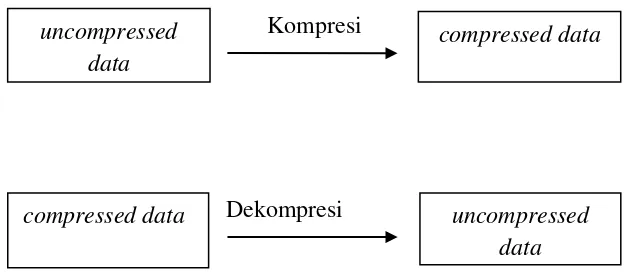
Proses kompresi dan dekompresi data dapat ditunjukan melalui diagram blok seperti pada Gambar 2.1.
Kompresi
Dekompresi
Gambar 2.1. Diagram Blok Proses Kompresi dan Dekompresi Data
Kompresi data dibagi menjadi dua kategori yaitu:
1. Kompresi data bersifat loseless
Algoritma kompresi tergolong lossless jika memungkinkan data yang sudah dikompres dapat direkonstruksi kembali persis sesuai dengan data original. Teknik ini menjamin tidak ada kehilangan sedikitpun detil atau kerusakan pada data (Saputro, 2011). Lossless compression disebut juga dengan reversible compression karena data asli bisa dikembalikan dengan sempurna. Akan tetapi rasio kompresinya sangat rendah, misalnya pada gambar seperti GIF dan PNG (Sarifah, 2010). Contoh data yang cocok adalah gambar medis, teks, program, spreadsheet dan lain-lain. Beberapa algoritma yang tergolong dalam jenis ini adalah algoritma Shannon-Fano, algoritma Run Length Coding, algoritma Variable Length Binary Encoding, algoritma Fixed Length Binary Encoding, algoritma Huffman, algoritma LZW, dan algoritma Arithmetic Coding (Saputro, 2011).
2. Kompresi data bersifat lossy
Algoritma kompresi tergolong lossy jika tidak memungkinkan data yang sudah dikompres dapat direkonstuksi kembali persis sesuai dengan data asli.
uncompressed data
compressed data
compressed data uncompressed
Kehilangan detil-detil yang tidak berarti dapat diterima pada waktu proses kompresi. Hal ini memanfaatkan keterbatasan panca indera manusia. Maka, sebuah perkiraan yang mendekati keadaan original dalam membangun kembali data merupakan hal yang diperlukan untuk mencapai keefektifan kompresi. Contoh data yang cocok adalah gambar, suara dan video. Adapun beberapa algoritma yang tergolong dalam jenis ini adalah algoritma Wavelet Compression, CELP, JPEG, MPEG-1 dan WMA (Saputro, 2011).
2.2. Text File
Text file (disebut juga dengan flat file) adalah salah satu jenis file komputer yang tersusun dalam suatu urutan baris data teks biasanya diwakili oleh 8 bit kode ASCII atau pun kode EBCDIC (Pu, 2006).
American Standard Code for Information Interchange (ASCII) dan Extended Binary Coded Decimal Interchange Code (EBCDIC) merupakan cikal bakal dari set karakter lainnya. ASCII merupakan set karakter yang paling umum digunakan hingga sekarang. Set karakter ASCII terdiri dari 128 buah karakter yang masing-masing memiliki lebar 7-bit atau tujuh angka 0 dan 1, dari 0000000 sampai dengan 1111111. Alasan mengapa lebar set karakter ASCII sebesar 7 bit adalah karena komputer pada awalnya memiliki ukuran memori yang sangat terbatas, dan 128 karakter dianggap memadai untuk menampung semua huruf Latin dengan tanda bacanya, dan beberapa karakter kontrol. ASCII terdiri dari huruf-huruf, angka-angka, dan tanda-tanda baca (Sudewa, 2003).
Akhir dari sebuah text file sering ditandai dengan penempatan satu atau lebih karakter – karakter khusus yang dikenal dengan tanda end-of-file setelah baris terakhir di suatu file teks. Text file biasanya mempunyai jenis Multipurpose Internet Mail Extension (MIME) "text/plain", biasanya sebagai informasi tambahan yang menandakan suatu pengkodean. Pada sistem operasi Windows, suatu file dikenal sebagai suatu text file jika memiliki extention misalnya txt, rtf, doc, docx dan lain – lain (Khairi, 2011).
Gambar 2.2.Text File Sederhana
2.3. Algoritma
2.4.Algoritma Fixed Length Binary Encoding (FLBE)
Algoritma Fixed Length Binary Encoding (FLBE) sering dikenal sebagi kode blok yang sangat mudah diterapkan di dalam perangkat lunak. Sangat mudah untuk mengganti simbol asli dengan kode FLBE dan untuk memulai dengan string kode tersebut dan memecahnya menjadi kode yang individual kemudian digantikan oleh simbol-simbol asli (Salomon, 2007).
Algoritma Fixed Length Binary Encoding adalah algoritma kompresi data yang mengkodekan tiap karakter dengan menggunakan beberapa rangkaian bit. Pembentukan bit yang mewakili masing-masing karakter dibuat berdasarkan frekuensi kemunculan tiap karakter (Salomon, 2010).
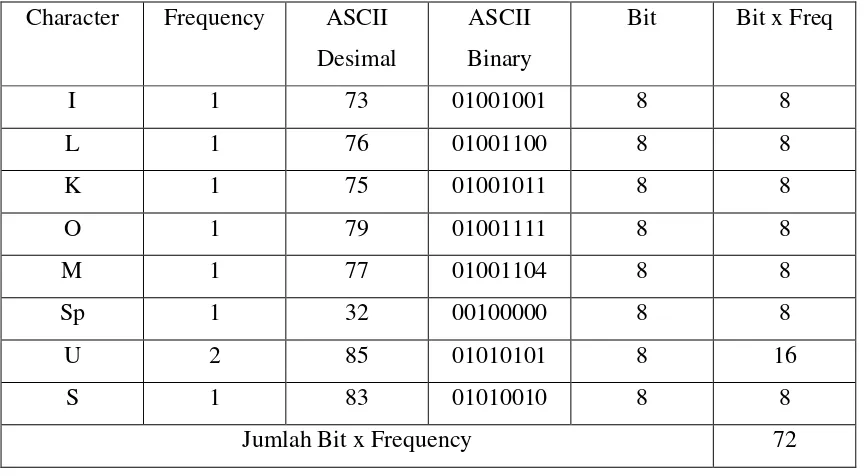
Contoh: ILKOM USU
Data sebelum dikompresi
Character Frequency ASCII Desimal
Jumlah Bit x Frequency 72
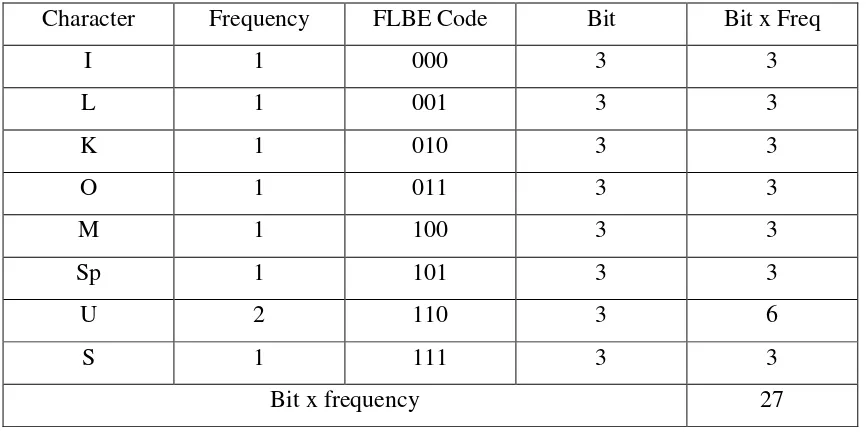
Data setelah dikompresi menggunakan algoritma Fixed Length Binary
Tabel 2.2. Tabel Data setelah Dikompresi dengan algoritma FLBE
2.5.Algoritma Variable Length Binary Encoding (VLBE)
Algoritma Variable Length Binary Encoding (FLBE)dalam teori pengkodean adalah kode yang memetakan simbol sumber untuk sejumlah variabel bit. Kode variabel-panjang dapat memungkinkan sumber yang akan dikompresi dengan nol kesalahan (kompresi data lossless) dan masih dapat dibaca kembali oleh simbol-simbol. (Salomon,2007).
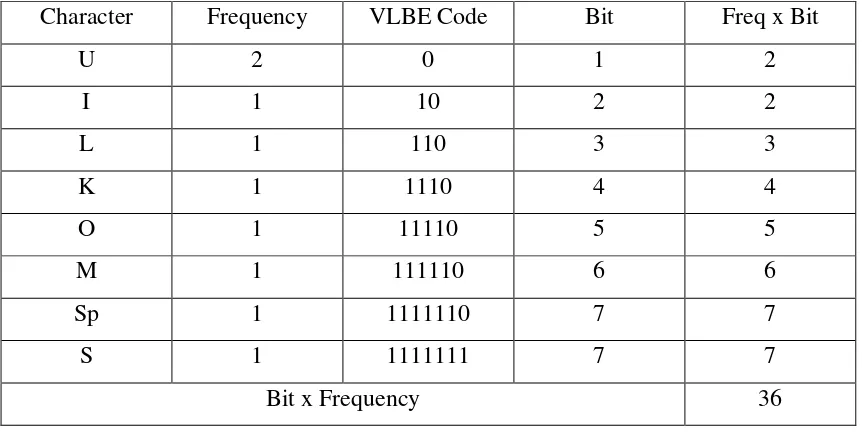
Algoritma Variable Length Binary Encoding adalah algoritma kompresi data yang mengkodekan tiap karakter dengan mengurutkan karakter berdasarkan frekuensi dan disortir secara stabil sehingga membentuk beberapa rangkaian bit(Salomon, 2010).
Contoh : ILKOM USU
Character Frequency VLBE Code Bit Freq x Bit
U 2 0 1 2
I 1 10 2 2
L 1 110 3 3
K 1 1110 4 4
O 1 11110 5 5
M 1 111110 6 6
Sp 1 1111110 7 7
S 1 1111111 7 7
Bit x Frequency 36
Tabel 2.3. Tabel Data setelah Dikompresi dengan Algoritma VLBE
2.6.Parameter Pembanding
Ada 4 parameter pembanding yang digunakan dalam peneltiaan ini, yaitu Ratio of Compression (RC), Compression Ratio (CR), Space Savings (SS) dan waktu kompresi.
a. Ratio of Compression (RC)
Ratio of Compression (RC) adalah hasil perbandingan antara data yang belum
dikompresi dengan data setelah dikompresi (Salomon, 2007)
RC = 𝒖𝒌𝒖𝒓𝒂𝒏𝒅𝒂𝒕𝒂𝒔𝒆𝒃𝒆𝒍𝒖𝒎𝒅𝒊𝒌𝒐𝒎𝒑𝒓𝒆𝒔𝒊𝒖𝒌𝒖𝒓𝒂𝒏𝒅𝒂𝒕𝒂𝒔𝒆𝒕𝒆𝒍𝒂𝒉𝒅𝒊𝒌𝒐𝒎𝒑𝒓𝒆𝒔𝒊
Contoh :
1. Ratio of Compression dari contoh menggunakan algoritma Fixed Length Binary Encoding (FLBE)
2. Ratio of Compression dari contoh menggunakan algoritma Variable Length Binary Encoding (VLBE)
RC = 7236 = 2
b. Compression Ratio (CR)
Compression Ratio (CR) adalah persentase besar data terkompresi, hasil perbandingan
antara data yang sudah dikompresi dengan data yang belum dikompresi (Salomon, 2007).
CR =𝒖𝒌𝒖𝒓𝒂𝒏𝒖𝒌𝒖𝒓𝒂𝒏𝒅𝒂𝒕𝒂𝒅𝒂𝒕𝒂𝒔𝒆𝒃𝒆𝒍𝒖𝒎𝒔𝒆𝒕𝒆𝒍𝒂𝒉𝒅𝒊𝒌𝒐𝒎𝒑𝒓𝒆𝒔𝒊𝒅𝒊𝒌𝒐𝒎𝒑𝒓𝒆𝒔𝒊×𝟏𝟎𝟎%
Contoh :
1. Compression Ratio dari contoh menggunakan algoritma Fixed Length Binary Encoding (FLBE)
CR = 2772× 100% = 37,5 %
2. Compression Ratio dari contoh menggunakan algoritma Variable Length Binary Encoding (VLBE)
CR = 3672× 100% = 50 %
c. Space Savings(SS)
Space Savings adalah persentase selisih antara data yang belum dikompresi dengan besar data yang dikompresi (Salomon, 2007).
Contoh:
1. Space Savings dari contoh menggunakan algoritma Fixed Length Binary Encoding (FLBE)
Rd = 100% - 37,5% = 62,5%
2. Space Savingsdari contoh menggunakan algoritma Variable Length Binary Encoding (VLBE)
Rd = 100% - 50% = 50%
d. Waktu Kompresi