BAB I
PENDAHULUAN
1.1 Algoritma FP-Growth
Algoritma FP-Growth merupakan pengembangan dari algoritma Apriori.
Sehingga kekurangan yang dimiliki oleh algoritma Apriori diperbaiki oleh
algoritma FP-Growth. Frequent Pattern Growth (FP-Growth) adalah salah satu
alternatif algoritma yang dapat digunakan untuk menentukan himpunan data yang
paling sering muncul (frequent itemset) dalam sebuah kumpulan data. Pada
algoritma Apriori diperlukan generate candidate untuk mendapatkan frequent
itemset, tetapi algoritma FP-Growth generate candidate tidak dilakukan kerena
FP-Growth menggunakan konsep pembangunan tree dalam pencarian frequent
itemset. Hal inilah yang menyebabkan algoritma FP-Growth lebih cepat jika
dibandingkan dengan algoritma Apriori. Algoritma Apriori harus melakukan
pattern matching berulang-ulang sedangkan dalam algoritma FP-Growthterdapat
banyak kelebihan yang terbukti efisien karena hanya melakukan pemetaan data
atau scan database sebanyak 2 kali untuk membangun struktur tree. Dengan
menggunakan struktur tree algoritma FP-Growth dapat langsung mengekstrak
frequent itemsetdari susunan FP-Treeyang telah terbentuk.
Penggalian frequent itemset menggunakan algoritma FP-Growth akan
dilakukan dengan cara membangkitkan struktur data treeatau disebut dengan
FP-Tree. Algoritma FP-Growthdapat dibagi menjadi tiga tahapan utama yaitu :
1. Tahapan pembangkitan conditional pattern base
2. Tahapan pembangkitan conditional FP-Tree
3. Tahapan pencarian frequent itemset
1.2 Perbandingan Algoritma FP-Growthdan Algoritma Apriori
1. Algoritma FP-Growthlebih cepat karena hanya melakukan scan database
dua kali sedangkan algoritma Apriorimelakukan scan database
berulang-ulang
2. Algoritma FP-Growth menggunakan kode barang pada prosesnya
sedangkan algoritma Apriorimenggunakan nama barang.
3. Algroritma FP-Growth memliliki akurasi rules yang lumayan sedangkan
BAB II
PEMBAHASAN
2.1 Data
Misalnya data yang digunakan adalah data transaksi penjualan sebuah
supermarket dalam satu periode waktu, datanya sebagai berikut :
Tabel 2.1 Data Transaksi
1401 20015838 POCARI SWEAT,MINUMAN ISOTONIK 350mL BTL
20009722 POCARI SWEAT,MINUMAN ISOTONIK 500mL BTL
10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
1402 20045099 DIPLOMAT,ROKOK PREMIUM MILD FILTER 16'S BKS
10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
1403 10000316 BENG-BENG,WAFER CHOCOLATE 20g PCK
10023789 SEDAAP MIE,MIE INSTANT GORENG 90g PCK
10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
14701 20009722 POCARI SWEAT,MINUMAN ISOTONIK 500mL BTL
10023789 SEDAAP MIE,MIE INSTANT GORENG 90g PCK
10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
14702 20037766 HANSAPLAST,PLESTER PLASTIK (10'S) MICKEY
10000316 BENG-BENG,WAFER CHOCOLATE 20g PCK
20015838 POCARI SWEAT,MINUMAN ISOTONIK 350mL BTL
14703 10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
20009722 POCARI SWEAT,MINUMAN ISOTONIK 500mL BTL
1501 20037766 HANSAPLAST,PLESTER PLASTIK (10'S) MICKEY
20009722 POCARI SWEAT,MINUMAN ISOTONIK 500mL BTL
1502 10006861 UBM,BISCUIT ARROW BRAND SQUAREPUFF 400g PCK
20009722 POCARI SWEAT,MINUMAN ISOTONIK 500mL BTL
1503 10000316 BENG-BENG,WAFER CHOCOLATE 20g PCK
3001 20037766 HANSAPLAST,PLESTER PLASTIK (10'S) MICKEY
2.2 Langkah-Langkah membangun FP-Tree
1. Generate Frequent Itemset
Tabel 2.2 Generate Frequent Itemset
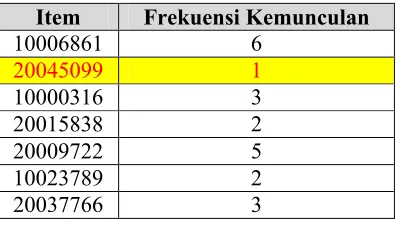
Misalnya telah ditentukan minimum supportnya 20% atau minimal 2 transaksi
maka kode barang 22045009 harus dieliminasi. Selanjutnya data yang memiliki
minimum support di urutkan berdasarkan frekuensinya. Hasilnya akan terlihat
seperti tabel di bawah ini :
Tabel 2.2 FP-List
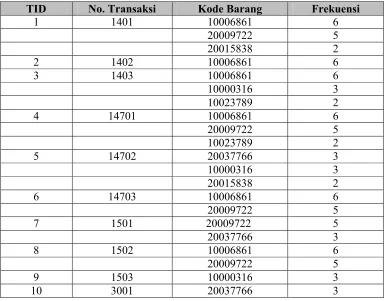
minimum support. Fungsi dari TID adalah untuk memberikan nomor urut pada
transaksi setelah membuat FP-List. Urutkan item pada setiap transaksi
berdasarkan frekuensi paling tinggi ke frekuensi yang paling rendah. Kemudian
mulailah membuat treesecara urut berdasarkan TID nya.
Tabel 2.3 TID
TID No. Transaksi Kode Barang Frekuensi
3. Membentuk Frequent Pattern Tree (FP-Tree). FP-Tree merupakan struktur
penyimpanan data yang dimampatkan. FP-Tree dibangun dengan memetakan
setiap data transaksi ke setiap lintasan tertentu dalam FP-Tree. Karena dalam
setiap transaksi yang dipetakan, mungkin ada transaksi yang memiliki item
yang sama, maka lintasannya memungkinkan untuk saling menimpa. Semakin
banyak data transaksi yang memiliki item yang sama, maka proses
pemampatan dengan struktur FP-Treesemakin efektif. Kelebihan dari FP-Tree
adalah hanya memerlukan dua kali pemindaian data transaksi yang terbukti
sangat efisien. FP-Tree dibentuk oleh sebuah akar yang diberi label null,
sekumpulan pohon yang beranggotakan item-item tertentu dari sebuah tabel
frequent header. Setiap simpul dalam FP-Tree mengandung tiga informasi
penting yaitu label item yang menginformasikan jenis item yang
direpresentasikan item tersebut. Support count, merepresentasikan jumlah
lintasan transaksi yang melalui simpul tersebut. Dan pointerpenghubung yang
menghubungkan simpul-simpul dengan label item yang sama antar lintasan
ditandai dengan garis panah putus-putus. Langkah-langkah membangun
FP-Treeadalah sebagai berikut :
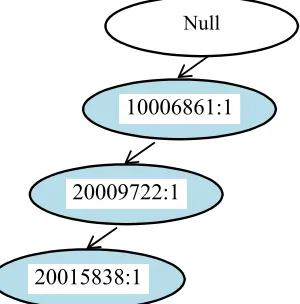
a. Pembacaan TID 1
Pada TID 1 terdapat nilai {10006861, 20009722, 20015838} yang kemudian
membentuk lintasan null → 10006861 → 20009722 → 20015838 dengan
support count awal bernilai 1. Untuk lebih lengkapnya dapat dilihat pada
gambar dibawah ini :
Gambar 2.1 FP-TreeTID 1 10006861:1
20009722:1
20015838:1
b. Pembacaan TID 2
Setelah pembacaan TID 1, maka selanjutnya membaca TID 2 yaitu
{10006861} sehingga nilai dari 10006861 akan bertambah satu sehingga
menjadi 2, tetapi nilai yang lainnya tetap karena tidak ada transaksi dengan
kode barang yang sama dengan pembacaan TID pertama.
Gambar 2.2 FP-TreeTID 2
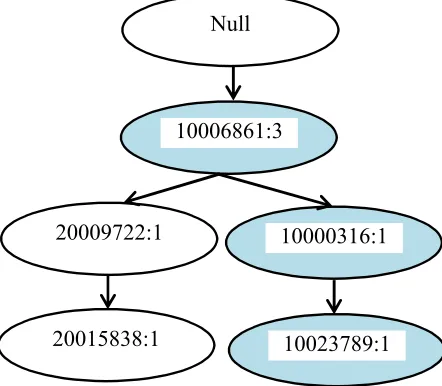
c. Pembacaan TID 3
Setelah pembacaan TID 2, maka selanjutnya membaca TID 3 yaitu
{10006861, 10000316, 10023789} sehingga nilai 10006861 akan
bertambah satu, sehingga menjadi 3 dan akan membentuk cabang baru
untuk kode transaksi 10000316 dan 10023789 nilai awalnya adalah 1,
seperti gambar di bawah ini.
Gambar 2.3 FP-TreeTID 3 10006861:2
20009722:1
20015838:1
Null
10006861:3
20009722:1
20015838:1
Null
10000316:1
d. Pembacaan TID 4
Setelah pembacaan TID 3, maka selanjutnya membaca TID 4 yaitu
{10006861, 20009722, 10023789}. Nilai 10006861 akan bertambah 1 lagi
sehingga menjadi 4, dan nilai 20009722 akan bertambah 1 menjadi 2, dan
akan membentuk akar baru atau cabang baru untuk kode barang 10023789
dan nilai awalnya adalah 1. Untuk lebih jelasnya dapat dilihat pada gambar
Gambar 2.4 FP-TreeTID 4
e. Pembacaan TID 5
Setelah pembacaan TID 4, maka selanjutnya membaca TID 5 yaitu
{20037766, 10000316, 20015838}. Disini harus membuat lintasan baru
lagi dengan nilai awal 1, karena kode barang 20037766 belum pernah
terlewati sama sekali. Lebih jelasnya dapat di lihat pada gambar
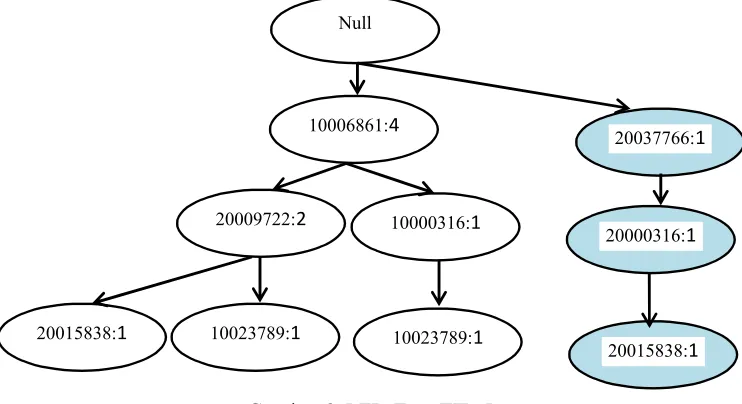
Gambar 2.5 FP-TreeTID 5 10006861:4
20009722:2
20015838:1
Null
10000316:1
10023789:1 10023789:1
10006861:4
20009722:2
20015838:1
Null
10000316:1
10023789:1
10023789:1
20037766:1
20000316:1
f. Pembacaan TID 6
Setelah pembacaan TID 5, maka selanjutnya membaca TID 6 yaitu
{10006861, 20009722}, nomer transaksi ini pernah di lewati dan sudah
mempunyai nilai sehingga tinggal di tambahkan saja, nilainya menjadi
10006861 : 5 dan 20009722: 3. Lebih jelasnya langsung lihat gambar
Gambar 2.6 FP-TreeTID 6
g. Pembacaan TID 7
Setelah pembacaan TID 6, maka selanjutnya membaca TID 7 yaitu
{20009722, 20037766}. Kode barang 20009722, 20037766 sama sekali
belum terlewati, maka harus membuat cabang baru dengan nilai awal 1.
Lebih jelasnya langsung lihat pada gambar
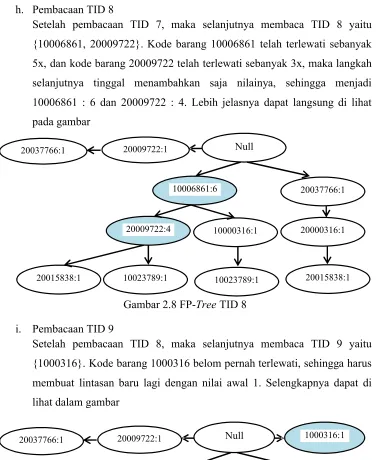
h. Pembacaan TID 8
Setelah pembacaan TID 7, maka selanjutnya membaca TID 8 yaitu
{10006861, 20009722}. Kode barang 10006861 telah terlewati sebanyak
5x, dan kode barang 20009722 telah terlewati sebanyak 3x, maka langkah
selanjutnya tinggal menambahkan saja nilainya, sehingga menjadi
10006861 : 6 dan 20009722 : 4. Lebih jelasnya dapat langsung di lihat
pada gambar
Gambar 2.8 FP-TreeTID 8
i. Pembacaan TID 9
Setelah pembacaan TID 8, maka selanjutnya membaca TID 9 yaitu
{1000316}. Kode barang 1000316 belom pernah terlewati, sehingga harus
membuat lintasan baru lagi dengan nilai awal 1. Selengkapnya dapat di
lihat dalam gambar
Gambar 2.9 FP-TreeTID 9
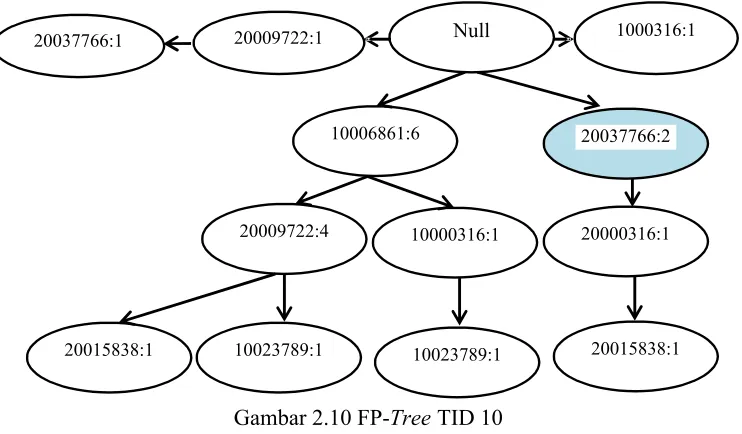
j. Pembacaan TID 10
Setelah pembacaan TID 9, maka selanjutnya membaca TID 10 yaitu
{20037766}. Sebelumnya kode barang ini telah di lewati sebanyak 1x,
maka langkah selanjutnya tinggal menambahkan saja nilai nya, sehingga
menjadi 2. Selengkapnya dapat di lihat pada gambar
Gambar 2.10 FP-TreeTID 10
Pembacaan TID 10 merupakan proses pembacaan tree yang terakhir dan didapatkan hasil akhir FP-Tree.
2.3 Menentukan Frequent Itemset
Algoritma FP-Growthmenemukan frequent itemsetyang berakhiran suffix
tertentu dengan menggunakan metode divide and conquer untuk memecah
problem menjadi subproblem yang lebih kecil. Untuk lebih jelas dapat dilihat
contoh menemukan frequent itemsetyang berakhiran 10023789 sebagai berikut.
Setelah mengetahui bahwa item 10023789 adalah item yang frequent, maka
subproblem selanjutnya adalah menemukan frequent itemset dengan akhiran
{10006861,10023789},{20009722,10023789},{20037766,10023789},{10000316
,10023789},{20015838,10023789} dengan cara membangun FP-Tree yang
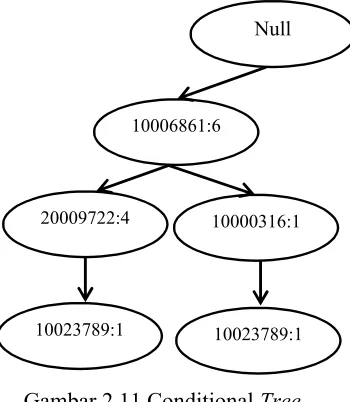
menyertakan lintasan 10023789 yang disebut dengan Conditional Tree.
Conditional Tree dimaksudkan untuk mencari frequent itemset yang berakhiran
item tertentu. Untuk lebih jelasnya dapat dilihat pada gambar Conditional Tree
berikut ini :
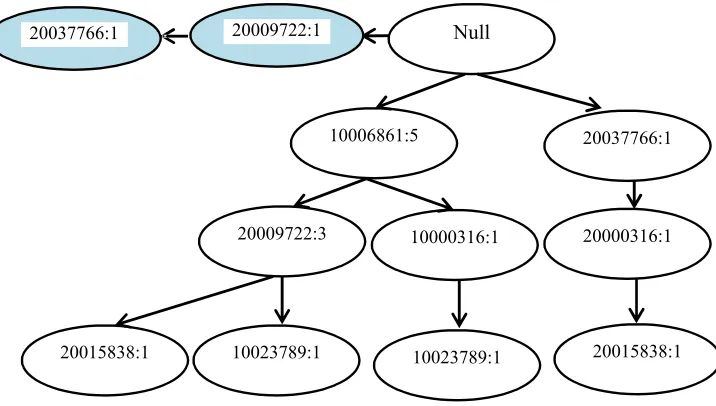
1000316:1 20009722:1
20037766:1 Null
10006861:6
20009722:4
20015838:1
10000316:1
10023789:1 10023789:1
20037766:2
20000316:1
Gambar 2.11 Conditional Tree
Setelah Conditional Tree terbentuk maka langkah selanjutnya adalah mencari
frequent itemset yang berakhiran 10023789 dengan cara menggabungkannya
dengan item yang lain yang masih dalam satu lintasan baik digabung menjadi 2
itemset maupun menjadi tiga itemset. Sehingga didapatkan hasil frequent itemset
untuk item 10023789 adalah {10023789}, {20009722, 10023789}, {10006861,
20009722,10023789}, {10000316,10023789}, {20037766, 10000316, 10023789}
Seperti itulah langkah yang harus dilakukan untuk menemukan frequent itemset
dari item-item yang lainnya. Setelah didapatkan semua frequent itemsetdari setiap
item maka dapat dilihat dalam tabel dibawah ini :
Tabel 2.4 Frequent Itemset
Item Frequent Itemset
10006861 {10006861}
20009722 {20009722},{10006861, 20009722} 20037766 {20037766},{20009722, 20037766}
10000316 {10000316},{20037766, 10000316},{10006861, 10000316}
20015838
{20015838},{20009722,
20015838},{10006861,20009722,20015838},{10000316,20015838} ,{20037766,10000316,20015838}
10023789
{10023789},{20009722,10023789},{10006861,20009722,10023789 },{10000316,10023789},{10006861,10000316,10023789}
Dengan metode divide and conquer ini, maka pada setiap langkah rekursif,
algoritma FP-Growth akan membangun sebuah Conditional Tree yang baru dan
membuang item-item yang tidak frequentlagi.
Null
10006861:6
20009722:4 10000316:1
BAB III
HASIL PEMBAHASAN
3.1 Implementasi Algoritma FP-GrowthManggunakan Software Weka 3.7.4
Data transaksi penjualan ini diolah dengan softwareweka 3.7.4, untuk bisa
menggunakan software ini, data yang digunakan sebagai masukkan harus dalam
format *.arff ataupun *.csv. untuk mengganti format data dapat digunakan
pengolah data microsoft excel untuk mengganti menjadi format *.csvdan dengan
menggunakan software weka 3.7.4 itu sendiri untuk mengganti menjadi format
*arff.
Gambar 3.1 Tamilan utama weka 3.7.4
Sebelum melakukan proses mining terlebih dahulu dilakukan tahapan
preprocessing yaitu merubah format data agar dapat digunakan dalam software.
Gambar 3.2 Preprocessing
Gambar 3.3 Hasil Algoritma FP-Growth
Dari hasil yang didapatkan menggunakan software WEKA 3.7.4 dihasilkan 10
rulesdan ditampilkan 10 rulesyang paling kuat. Berikut rulesyang ditemukan :
1. [10023789=true]: 2 ==> [10006861=true]: 2 <conf:(1)> lift:(1.67) lev:(0.08)
conv:(0.8)
2. [20045099=true]: 1 ==> [10006861=true]: 1 <conf:(1)> lift:(1.67) lev:(0.04)
conv:(0.4)
3. [10006861=true, 20015838=true]: 1 ==> [20009722=true]: 1 <conf:(1)>
lift:(2) lev:(0.05) conv:(0.5)
4. [20009722=true, 20015838=true]: 1 ==> [10006861=true]: 1 <conf:(1)>
lift:(1.67) lev:(0.04) conv:(0.4)
5. [20009722=true, 10023789=true]: 1 ==> [10006861=true]: 1 <conf:(1)>
lift:(1.67) lev:(0.04) conv:(0.4)
6. [10006861=true, 10000316=true]: 1 ==> [10023789=true]: 1 <conf:(1)>
lift:(5) lev:(0.08) conv:(0.8)
7. [10000316=true, 10023789=true]: 1 ==> [10006861=true]: 1 <conf:(1)>
lift:(1.67) lev:(0.04) conv:(0.4)
8. [20037766=true, 10000316=true]: 1 ==> [20015838=true]: 1 <conf:(1)>
9. [20037766=true, 20015838=true]: 1 ==> [10000316=true]: 1 <conf:(1)>
lift:(3.33) lev:(0.07) conv:(0.7)
10. [10000316=true, 20015838=true]: 1 ==> [20037766=true]: 1 <conf:(1)>
lift:(3.33) lev:(0.07) conv:(0.7)
3.2 Kesimpulan
Berdasarkan penelitian yang telah dilakukan, maka dapat ditarik beberapa
kesimpulan sebagai berikut :
1. FP-Tree yang terbentuk dapat memampatkan data transaksi yang memiliki
itemset yang sama, sehingga penggunaan memory komputer lebih sedikit dan
proses pencarian frequent itemsetmenjadi lebih cepat.
2. Dengan menggunakan algoritma FP-Growth maka pemindaian kumpulan
data transaksi hanya dilakukan dua kali, jauh lebih efisien dibandingkan
algoritma dengan paradigma Apriori.
3. FP-Growth merupakan salah satu algoritma yang menjadi dasar
perkembangan beberapa algoritma baru yang lebih efektif, karena
kelebihannya yaitu tidak melakukan pemindaian data transaksi secara