103 KOMPARASI ALGORITMA C4.5 DENGAN NAÏVE BAYES UNTUK KLASIFIKASI
KELULUSAN MAHASISWA TEPAT WAKTU DI PTS “KZX” Satrio Agung Prakoso1 , Eli Tias Tutik 2
[email protected] Abstrak
Perguruan tinggi merupakan satuan pendidikan yang menjadi terminal terakhir bagi seseorang yang berpeluang belajar setinggi-tingginya melalui jalur pendidikan sekolah (Nawawi & Martini, 1994). Perguruan tinggi saat ini dituntut untuk memiliki keunggulan bersaing dengan memanfaatkan semua sumber daya yang dimiliki.Sistem informasi adalah salah satu sumber daya yang dapat digunakan untuk meningkatkan keunggulan bersaing.
Tingginya tingkat keberhasilan mahasiswa dan rendahnya tingkat kegagalan mahasiswa merupakan cermin kualitas dari suatu perguruan tinggi. Tingkat kelulusan dianggap sebagai salah satu efektivitas kelembagaan (Qudri & Kalyankar, 2010). Sehingga memerhatikan jumlah kelulusan suatu perguruan tinggi menjadi hal penting. Saat ini perguruan tinggi berada dalam lingkungan yang sangat kompetitif. Setiap perguruan tinggi berusaha untuk terus memperbaiki manajemennya untuk meningkatkan mutu pendidikan.
Data mining merupakan analisis dari peninjuauan kumpulan data untuk menemukan hubungan yang tidak diduga dan meringkas data dengan cara yang berbeda dari sebelumnya, yang dapat dipahami dan bermanfaat bagi pemilik data (Larose, 2005). Salah satu teknik data mining adalah teknik klasifikasi..
Teknik klasifikasi adalah teknik pembelajaran untuk mengklasifikasikan suatu nilai dari target variabel kategori. Algoritma yang digunakan dalam teknik klasifikasi adalah algoritma C4.5 dan Naïve Bayes. Algoritma C4.5 merupakan algoritma yang digunakan untuk membentuk decision tree. Sedangkan klasifikasi Bayesian adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class
Kata kunci : Tingkat kelulusan, Datamining,Klasifikasi, C4.5, Bayesian.
1. Pendahuluan
Kebutuhan akan informasi pada saat
ini semakin meningkat bersamaan dengan
perkembangan teknologi yang semakin pesat.
Semakin banyak informasi yang dibutuhkan
maka data yang dibutuhkan juga semakin
banyak dan jumlahnya akan semakin besar.
Kebutuhan akan jumlah data yang besar dapat
ditemukan dalam dunia pendidikan. Hal ini
dikarenakan, setiap tahun ajaran terjadi
peningkatan data. Terutama data-data siswa
dan mahasiswa yang terus bertambah dari
tahun ke tahun. Jumlah data yang terus
meningkat ini memerlukan beberapa metode
untuk mengolah dan mengambil kesimpulan
dan informasi dari data tersebut. Banyak
sekali data-data yang dihasilkan oleh
teknologi informasi mengenai mahasiswa dan
103 Tingginya tingkat keberhasilan
mahasiswa dan rendahnya tingkat kegagalan
mahasiswa merupakan cermin kualitas dari
suatu perguruan tinggi. Tingkat kelulusan
dianggap sebagai salah satu efektivitas
kelembagaan (Qudri & Kalyankar, 2010).
Sehingga memerhatikan jumlah kelulusan
suatu perguruan tinggi menjadi hal penting.
Saat ini instansi perguruan tinggi berada
dalam lingkungan yang sangat kompetitif.
Setiap perguruan tinggi berusaha untuk terus
memperbaiki manajemennya untuk
meningkatkan mutu.Selain itu wisuda tepat
waktu merupakan isu yang penting karena
tingkat kelulusan sebagai dasar efektifnya
suatu perguruan tinggi. Namun, kendala yang
sering terjadi adalah banyaknya mahasiswa
yang tidak lulus sesuai dengan waktu studi
yang telah ditetapkan. Untuk mengetahui
tingkat kelulusan mahasiswa dalam satu tahun
ajaran dapat dilakukan suatu klasifikasi
berdasarkan data-data mahasiswa pada tingkat
atau tahun ajaran pertama.
Data mining merupakan analisis dari
peninjuauan kumpulan data untuk menemukan
hubungan yang tidak diduga dan meringkas
data dengan cara yang berbeda dari
sebelumnya, yang dapat dipahami dan
bermanfaat bagi pemilik data (Larose, 2005).
Salah satu teknik data mining adalah teknik
klasifikasi. Teknik klasifikasi adalah teknik
pembelajaran untuk prediksi suatu nilai dari
target actor i kategori. Algoritma yang
digunakan dalam teknik klasifikasi adalah
algoritma C4.5 dan Naïve Bayes. Algoritma
C4.5 merupakan algoritma yang digunakan
untuk membentuk decision tree. C4.5 adalah
algoritma yang sudah banyak dikenal dan
digunakan untuk klasifikasi data yang
memiliki atribut-atribut actor dan
kategorial. Sedangkan klasifikasi Bayesian
adalah pengklasifikasian actor ic yang
dapat digunakan untuk memprediksi
probabilitas keanggotaan suatu class.
2. Kajian Pustaka
Literatur mengenai pembahasan
klasifikasi kelulusan mahasiswa telah
banyak dilakukan dengan beberapa
metode. Berikut dijabarkan beberapa
metode yang pernah digunakan untuk
menyelesaikan masalah kelulusan
mahasiswa al:
Penelitian yang dilakukan oleh Qudri dan
104 Drop Out Feature of Student Data for
Academic Performance Using Decision Tree techniques. Masalah dalam penelitian ini adalah prestasi akademik siswa sangat
penting bagi lembaga pendidikan karena
program-program strategis dapat
direncanakan untuk meningkatkan atau
mempertahankan kinerja siswa selama
periode mereka studi. Kinerja akademik
dalam penelitian ini diukur oleh indek
kumulatif rata-rata setelah lulus. Hal ini
penting untuk memahami actor-faktor
penentu tingkat penyelesaian yang sukses
dan tepat waktu. Metode yang digunakan
adalah Decision Tree, yakni algoritma
C4.5. Hasil penelitian ini adalah sebuah
pohon keputusan yang dapat dijadikan rule
bagi prediksi siswa yang putus sekolah
(Qudri & Kaylanyar, 2010)
Penelitian yang dilakukan oleh Suhartina
dan Ernastuti pada tahun 2010 dengan
judul Graduation Prediction of
Gunadarma University Students Using Algorithm and Naïve Bayes C4.5
Algoritmh. Masalah dalam penelitian ini adalah banyaknya mahasiswa yang tidak
lulus sesuai dengan waktu studi yang telah
ditetapkan. Untuk mengetahui tingkat
kelulusan mahasiswa dalam satu tahun
ajaran dapat dilakukan suatu prediksi
berdasarkan data-data mahasiswa pada
tingkat atau tahun ajaran pertama.
Algoritma yang digunakan adalah C45 dan
naïve bayes. Hasil dari penelitian ini
adalah akurasi dengan dua metode tersebut
yakni akurasi untuk metode naïve bayes
adalah 80,85% dengan presentasi
kesalahan 19,05% Akurasi ketepatan hasil
prediksi C4.5 85.7%, dan presentasi
kesalahannya adalah 14,3% (Suhartina &
Ernastuti, 2010)
2.1 Kelulusan Mahasiswa
Dalam setiap fakultas ataupun
105 sekali bahkan tidak pernah terjadi dimana
jumlah mahasiswa yang diterima akan
mengakhiri masa perkuliahannya pada
waktu bersamaan dengan jumlah yang
sama pula pada saat diterima di fakultas
tersebut (Siregar, 2006).
Kelulusan mahasiswa adalah hal
yang penting diperhatikan, karena
penurunan jumlah kelulusan akan
menghilangkan jumlah pendapatan
institusi dan mempengaruhi penilaian
pemerintah serta memperngaruhi status
akreditasi institusi (Karamouiz & Vrettos,
2008). Beberapa faktor dapat
mempengaruhi kelulusan mahasiswa
antara lain adalah nilai akhir SMA,
Indeks Prestasi Semester (IPS), gaji orang
tua dan pekerjaan orang tua (Suhartinah
& Ernastuti, 2010).
Pada penelitian ini parameter yang
digunakan adalah usia, jenis kelamin, indeks
prestasi
2.2.Data Mining
Data mining adalah proses yang
menggunakan statistik, matematika,
kecerdasan buatan, dan machine learning
untuk mengekstraksi dan
mengidentifikasi informasi yang
bermanfaat dan pengetahuan yang terkait
dari berbagai database besar (Turban,
dkk, 2005).
Data mining merupakan proses untuk
mendapatkan informasi yang berguna
dari gudang basis data yang besar (Tan,
2006). Data mining, sering juga disebut
knowledge discovery in database (KDD),
adalah kegiatan yang meliputi
pengumpulan, pemakaian data historis
untuk menemukan pola keteraturan, pola
hubungan dalam set data berukuran besar
(Santosa, 2007). Proses KDD secara garis
besar dapat dijelaskan sebagai berikut
(Fayyad, 1996) :
106 Pemilihan (seleksi) data dari
sekumpulan data operasional perlu
dilakukan sebelum tahap
penggalian informasi dalam KDD
dimulai. Data hasil seleksi yang
akan digunakan untuk proses data
mining, disimpan dalam suatu
berkas, terpisah dari data
operasional.
2. Pre- processing / Cleaning
Sebelum proses data mining dapat
dilaksanakan, perlu dilakukan
proses cleaning pada data yang
menjadi fokus KDD. Proses
cleaning mencakup antara lain
membuang duplikasi data,
memeriksa data yang inkonsisten,
dan memperbaiki kesalahan pada
data, seperti kesalahan cetak
(tipografi). Juga dilakukan proses
enrichment, yaitu proses
memperkaya data yang sudah ada
dengan data atau informasi lain
yang relevan dan diperlukan untuk
KDD, seperti data atau informasi
eksternal.
3. Transformation
Coding adalah proses transformasi
pada data yang telah dipilih,
sehingga data tersebut sesuai untuk
proses data mining.
4. Data Mining
Adalah proses mencari pola atau
informasi menarik dalam data
terpilih dengan menggunakan
teknik atau metode tertentu.
Teknik, metode, atau algoritma
dalam data mining sangat
bervariasi. Pemilihan metode atau
algoritma yang tepat sangat
bergantung pada tujuan dan proses
KDD secara keseluruhan.
107 Pola informasi yang dihasilkan dari proses
data mining perlu ditampilkan dalam bentuk
yang mudah dimengerti oleh pihak yang
berkepentingan. Tahap ini merupakan bagian
dari proses KDD yang disebut interpretation.
Tahap ini mencakup pemeriksaan apakah pola
atau informasi yag ditemukan bertantangan
dengan fakta atau hipotesis yang ada
sebelumnya
Sejarah Data mining bukanlah suatu
bidang yang sama sekali baru. Gambar
2.1 menunjukkan bahwa data mining
memiliki akar yang panjang dari bidang
ilmu seperti kecerdasan buatan (artificial
intelligent), machine learning, statistic,
database dan juga information retrieval
(Pramudiono, 2006).
Gambar 2.1 Hubungan Data Mining
dengan bidang ilmu lain
2.3.Metode Pelatihan
Metode pelatihan adalah cara
berlangsungnya pembelajaran atau
pelatihan dalam data mining. Secara garis
besar metode pelatihan dibedakan ke
dalam dua pendekatan :
a. Pelatihan yang terawasi
(Supervised learning)
Pada pembelajaran terawasi,
kumpulan input yang digunakan,
108 b. Pelatihan tak terawasi
(Unsupervised Learning)
Dalam pelatihan tak terawasi, metode
diterapkan tanpa adanya latihan (training) dan
tanpa ada guru (teacher). Guru disini adalah
label dari data.
2.3.1 Metode Klasifikasi Data Mining Klasifikasi merupakan salah satu
tujuan yang banyak dihasilkan dalam data
mining. Klasifikasi merupakan proses
pengelompokkan sebuah variabel
kedalam kelas yang sudah ditentukan
(Larose, 2005: 95). Data mining mampu
mengolah data dalam jumlah besar, setiap
data terdiri dari kelas tertentu bersama
dengan variable dan faktor faktor penentu
kelas variabel tersebut. Dengan data
mining, peneliti dapat menentukan suatu
kelas dari variabel data yang dimiliki.
Proses klasifikasi didasarkan pada empat
komponen mendasar:
1. Kelas: variabel dependen dari
model yang merupakan variabel
kategori mewakili yang 'label'
memakai objek setelah
klasifikasinya. Contoh kelas
adalah: adanya infark miokard,
loyalitas pelanggan, kelas bintang
(galaksi), kelas gempa bumi
(badai), dll.
2. Prediktor: variabel bebas dari
model-diwakili oleh karakteristik
(atribut) dari data yang harus
diklasifikasikan dan berdasarkan
klasifikasi yang dibuat. Contoh
prediktor tersebut adalah:
merokok, konsumsi alkohol, darah
tekanan, frekuensi pembelian,
status perkawinan, karakteristik
(satelit) gambar, catatan geologi
tertentu, dan kecepatan angin
arah, musim, lokasi fenomena
109 3. Training dataset: training dataset
yang merupakan sekumpulan data
yang berisi nilai untuk dua
sebelumnya komponen, dan
digunakan untuk 'pelatihan' model
untuk mengenali sesuai kelas,
berdasarkan prediksi tersedia.
Contoh set tersebut adalah:
kelompok pasien diuji pada
serangan jantung, kelompok
pelanggan dari supermarket
(diselidiki oleh internal polling).
4. Pengujian dataset: pengujian
dataset yang berisi data baru yang
akan diklasifikasikan oleh
(classifier) Model dibangun di
atas, dan akurasi klasifikasi
(kinerja model) sehingga dapat
dievaluasi (Gorunescu, 2011).
2.4 Algoritma C4.5
2.5 Decision tree merupakan metode klasifikasi dan prediksi yang sangat kuat
dan terkenal. Metode decision tree
mengubah fakta yang sangat besar
menjadi pohon keputusan yang
merepresentasikan aturan. Aturan dapat
dengan mudah dipahami dengan bahasa
alami. Decision tree juga berguna untuk
mengeksplorasi data, menemukan
hubungan tersembunyi antara sejumlah
calon variabel input dengan sebuah
variabel target. Karena decision tree
memadukan antara eksplorasi data dan
pemodelan. Decision tree digunakan
untuk kasus-kasus dimana outputnya
bernilai diskrit.
Sebuah decison tree adalah sebuah
struktur yang dapat digunakan untuk
membagi kumpulan data yang besar
menjadi himpunan-himpunan record yang
lebih kecil dengan menerapkan
serangkaian aturan keputusan. Dengan
110 anggota himpunan hasil menjadi mirip
dengan yang lain (Berry & Linoff, 2004).
Proses pada decision tree adalah
mengubah bentuk data (tabel) menjadi
model pohon, mengubah model pohon
menjadi rule, dan menyederhanakan rule
(Basuki & Syarif, 2003).
Sebuah model decision tree terdiri
dari sekumpulan aturan untuk membagi
sejumlah populasi yang heterogen
menjadi lebih kecil, lebih homogen
dengan memperhatikan pada variabel
tujuannya. Variabel tujuan biasanya
dikelompokkan dengan pasti dan lebih
mengarah pada perhitungan probabilitas
dari tiap-tiap record terhadap
kategori-kategori tersebut atau untuk
mengklasifikasi record dengan
mengelompokkannya dalam satu kelas.
Data dalam decision tree biasanya
dinyatakan dalam bentuk tabel dengan
atribut dan record. Atribut menyatakan
suatu parameter yang dibuat sebagai
kriteria dalam pembentukan pohon.
Atribut ini juga memiliki nilainilai yang
terkandung didalamnya yang disebut
instance. Dalam decision tree setiap
atribut akan menempati posisi simpul.
Selanjutnya setiap simpul akan memiliki
jawaban yang dibentuk dalam
cabang-cabang, jawaban ini adalah instance dari
atribut (simpul) yang ditanyakan. Pada
saat penelusuran, pertanyaan pertama
akan ditanyakan pada simpul akar.
Selanjutnya akan dilakukan penelusuran
ke cabang-cabang simpul akar dan
simpul-simpul berikutnya. Penelusuran
setiap simpul ke cabang-cabangnya akan
berakhir ketika suatu cabang telah
menemukan simpul kelas atau obyek
yang dicari.
Algoritma C4.5 merupakan algoritma
yang cocok digunakan untuk
111 kedalam kelas kelas tertentu berdasarkan
pola data yang ada (Wu & Kumar, 2009 :
7). Di dalam data mining dan machine
learning C4.5 digunakan untuk
mempelajari data dalam jumlah besar,
membuat model pembelajaran berupa
pohon keputusan yang dapat diterapkan
untuk memprediksi data yang belum
muncul.
Algoritma C4.5 merupakan algoritma
yang digunakan untuk membentuk
decision tree. C4.5 adalah algoritma yang
sudah banyak dikenal dan digunakan
untuk klasifikasi data yang memiliki
atribut-atribut numerik dan kategorial.
Hasil dari proses klasifikasi yang berupa
aturan-aturan dapat digunakan untuk
memprediksi nilai atribut bertipe diskret
dari record yang baru. Ada beberapa hal
yang perlu diperhatikan dalam membuat
decision tree, yaitu :
a. Atribut mana yang akan dipilih untuk
pemisahan obyek.
b. Urutan atribut mana yang akan
dipilih terlebih dahulu.
c. Struktur tree.
d. Kriteria pemberhentian.
e. Pruning.
Desicion Tree menyerupai struktur
flowchart, yang masing-masing internal
node-nya dinyatakan sebagai atribut
pengujian, setiap cabang mewakili output
dari pengujian, dan setiap node daun
(terminal node) menentukan label class.
Node paling atas dari sebuah pohon
adalah node akar (Han & Kamber, 2007).
Salah satu metode klasifikasi yang
menarik melibatkan konstruksi pohon
keputusan, koleksi node keputusan,
terhubung oleh cabang-cabang,
memperpanjang bawah dari simpul akar
sampai berakhir di node daun. Dimulai di
112 ditempatkan di bagian atas dari diagram
pohon keputusan, atribut diuji pada node
keputusan, dengan setiap hasil yang
mungkin dihasilkan dalam suatu cabang.
Setiap cabang kemudian mengarah baik
ke node lain keputusan atau ke node daun
untuk mengakhiri (Larose, 2005).
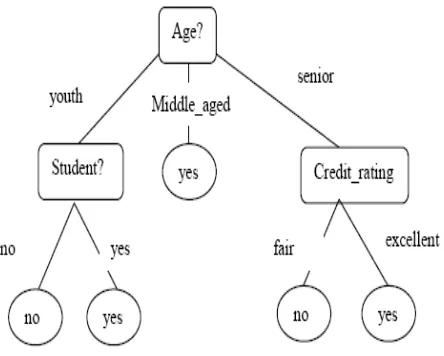
Gambar 2.3 Contoh Decision
Tree
Algoritma C4.5 dan pohon keputusan
(decision tree) merupakan dua mode yang
tidak terpisahkan, karena untuk
membangun sebuah pohon keputusan,
dibutuhkan algoritma C4.5.
Ada beberapa tahap dalam membuat
sebuah pohon keputusan dengan
algoritma C4.5 (Kusrini & Lutfi, 2009),
yaitu:
1. Menyiapkan data training. Data
training biasanya diambil dari data
histori yang pernah terjadi
sebelumnya dan sudah
dikelompokan ke dalam kelaskelas
tertentu.
2. Menentukan akar dari pohon. Akar
akan diambil dari atribut yang
terpilih, dengan cara menghitung
nilai gain dari masing-masing
atribut, nilai gain yang paling tinggi
yang akan menjadi akar pertama.
Sebelum menghitung gain dari
atribut, hitung dahulu nilai entropy
113 Entropy(S) =
Keterangan: S : himpunan kasus
A : atribut
N : jumlah partisi S
Pi : proporsi dari Si terhadap S
3. Kemudian hitung nilai gain dengan
metode informasi gain:
Gain(S,A) = Entropy(S) -
4. Ulangi langkah ke-2 hingga semua
tupel terpartisi.
5. Proses partisi pohon keputusan akan
berhenti saat:
a. Semua tupel dalam node N
mendapat kelas yang sama.
b. Tidak ada atribut di dalam
tupel yang dipartisi lagi.
c. Tidak ada tupel di dalam
cabang yang kosong.
2.5.1 Proses Pengujian Atribut
Dalam proses pengujian atribut,
cabang baru yang terbentuk akan
diperhatikan dari tipe atribut (Han &
Kamber, 2006 : 307). Berikut 3 jenis
cabang yang mungkin muncul dalam
pohon keputusan adalah :
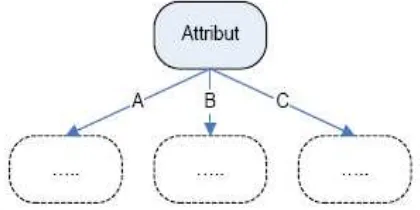
a. Jika atribut bernilai diskrit, maka
cabang yang terbentuk akan selalu
sama dengan jumlah variasi nilai yang
terdapat pada atribut tersebut.
Gambar 2.4 Cabang pohon
114 b. Jika cabang bernilai kontinyu, maka
akan dipecahkan menurut titik
perpecahan, sedangkan titik
perpecahan dikalkulasi dengan
masing masing algoritma penyusun
pohon keputusan. Cabang perpecahan
yang terbentuk akan berpola seperti ≤
attribute, dan satu cabang lagi >
attribute.
Gambar 2.5 Cabang pohon keputusan yang dibuat
dari nilai kontinyu
c. Jika atribut yang diuji bernilai biner,
maka cabang yang terbentuk pasti dua
dan melibatkan nilai ya atau tidak.
Gambar 2.6Cabang pohon
yang terbentuk dari nilai
biner
2.5.2 Prunning pada Pohon Keputusan
Ada dua pendekatan pruning yang
digunakan :
a. Prepruning menghentikan proses
pembuatan cabang pada titik tertentu.
Semakin besar perulangan pembuatan
cabang yang diperbolehkan, semakin
besar pula kompleksitas dari pohon
keputusan yang didapat jika data
115 perulangan terlalu kecil, diagram
pohon yang dihasilkan menjadi kurang
akurat.
b. Postpruning memotong cabang pohon
yang kurang mereprensentasikan data
setelah sebuah pohon keputusan
terbentuk. Biasanya cabang yang
dipotong adalah cabang yang
mengandung persentase klasifikasi
benar yang paling kecil. Kelas yang
diberikan akan diukur dari jumlah
persebaran label yang ada pada cabang
tersebut.
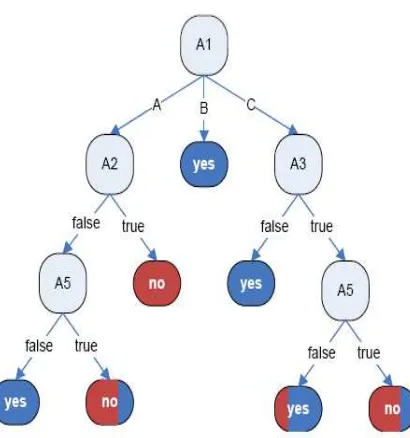
Gambar 2.7 Pohon keputusan dengan cabang dari atribut A5
tidak konsisten
Gambar 2.8 Pohon keputusan
setelah di pruning
Algoritma C4.5 menggunakan
pessimistic pruning yang mampu
mengkalkulasi tingkat error yang
digunakan sebagai acuan dalam
pemangkasan cabang pohon keputusan.
Baik postpruning dan prepruning dapat
116 yang lebih baik antara keduanya (Han &
Kamber, 2006 : 310). Karena itu pohon
keputusan yang rumit, ataupun cabang
yang kurang berpengaruh biasany
dipruning agar menghasilkan model yang
lebih baik dan lebih mudah dibaca.
2.6 Algoritma Naïve Bayes
Teorema keputusan bayes adalah
pendekatan statistik yang fundamental
dalam pengenalan pola (pattern
recoginition). Klasifikasi Bayes juga
dikenal dengan Naïve Bayes, memiliki
kemampuan sebanding dengan dengan
pohon keputusan dan neural network
(Han & Kamber, 2007). Klasifikasi Bayes
adalah pengklasifikasian statistik yang
dapat digunakan untuk memprediksi
probabilitas keanggotaan suatu kelas
(Kusrini, 2009).
Menurut Larose (Larose, 2007: 205),
pendekatan Bayesian digunakan untuk
menentukan kemungkinan terhadap
asumsi disekitarnya. Dalam statistik
Bayesian, parameter dipertimbangkan
terhadap variabel yang acak dan data
dipertimbangkan terhadap hasil
kemungkinan.
Teknik Naïve Bayes (NB) adalah
salah satu bentuk sederhana dari Bayesian
yang jaringan untuk klasifikasi. Sebuah
jaringan Bayes dapat dilihat sebagai
diarahkan sebagai tabel dengan distribusi
probabilitas gabungan lebih dari satu set
diskrit dan variabelstokastik (Pearl 1988)
(Liao, 2007).
Penggunaan teorema Bayes pada
algoritma Naïve Bayes yaitu dengan
mengkombinasikan prior probability dan
probabilitas bersyarat dalam sebuah
rumus yang bisa digunakan untuk
menghitung probabilitas tiap klasifikasi
yang mungkin (Bramer, 2007). model
independence ini menghasilkan
117 Bayes didasarkan pada teorema Bayes,
diambil dari nama seorang ahli
matematika yang juga menteri
Prebysterian Inggris, Thomas Bayes
(1702-1761), yaitu (Bramer, 2007):
P(x|y) =
Keterangan :
y = Data dengan kelas yang
belum diketahui
x = Hipotesis data y merupakan
suatu kelas spesifik.
P(x|y) =Probabilitas hipotesis x
berdasarkan kondisi y (posteriori
probability)
P(x) = Probabilitas hipotesis x (prior
probability).
P(y|x) = Probabilitas y berdasarkan
kondisi pada hipotesis x.
P(y) = Probabilitas dari y.
Naïve bayes adalah penyederhanaan
metode bayes. Teorema bayes
disederhanakan menjadi:
P(x|y) = P(y|x) P(x)
Beberapa keuntungan dari algoritma
klasifikasi Naive Bayes adalah (Gorunescu, 2011) :
1) Kuat terhadap pengisolasi
gangguan pada data
2) Jika terjadi kasus missing value
ketika proses komputasi sedang
berlangsung, maka objek tersebut
akan diabaikan
3) Dapat digunakan untuk data yang
tidak relevan
y
x4
x3
x2
x1
118 Gambar 2.9 Relasi Variabel Pada Naïve
Bayes
Diberikan sebuah sampel x dengan nilai probabilitas prior terbesar. Dimana
sampel x dapat dihitung berdasarkan teorema Bayes sebagai berikut:
Dimana P(x) adalah konstan untuk semua kelas, hanya saja P(Ci|x)=P(x|Ci)P(Ci) membutuhkan nilai maksimum. Asumsi
sederhana yang di ambil dari atribut,
dimana k adalah kondisi yang independen.
Jika banyak atribut memiliki kondisi
probabilitas 0, maka klasifikasi Naive Bayes menjadi:
Gunakan sebuah estimator dengan
menambahkan 1 pada kasus yang lain:
Selanjutnya gunakan probabilitas estimasi
M:
Dimana nc adalah total nilai dari contoh sampel pada atribut yang dimiliki kelas
C, n merupakan total nilai pada keseluruhan sampel yang berada pada
kelas C dan m adalah sebuah nilai ekivalen yang konstan dari ukuran sampel
yang diberikan. Sedangkan p adalah probabilitas prior yang menggunakan set
1/k sebagai informasi tambahan dimana k adalah nilai dari kemungkinan yang
muncul pada atribut-atribut pada sampel
119 3. Metode
3.1. Metode Pengumpulan Data
Metode dalam hal ini adalah cara yang
digunakan untuk mendapatkan dan
mengumpulkan data.
1. Metode Pengamatan (observasi)
Observasi adalah teknik atau pendekatan
untuk mendapatkan data primer dengan
cara mengamati langsung obyek datanya
(Jogiyanto, 2005).
2. Wawancara (Interwiew)
Wawancara adalah komunikasi dua arah
untuk mendapatkan data dari responden
(Jogiyanto, 2005). Wawancara dilakukan
dengan nara sumber .
3. Studi Pustaka
Merupakan adalah metode pengumpulan
data yang berbentuk tulisan, yang
meliputi surat-surat, catatan harian,
laporan-laporan dan foto (Marzuki, 2002:
59).
3.2.Sumber Data
Sumber data meliputi sebagai berikut :
1. Data Primer
Data primer adalah data yang
diperoleh secara langsung dari sumber,
diamati dan dicatat untuk pertama
kalinya. Data tersebut akan menjadi
sekunder kalau dipergunakan orang
yang tidak berhubungan langsung
dengan penelitian yang bersangkutan
(Marzuki, 2002: 55).
2. Data Sekunder
Data sekunder adalah data yang
diperoleh secara tidak langsung dari
sumbernya melainkan dengan pihak
lain atau apa yang diperoleh dari
sumber lain diluar lokasi penelitian.
Data ini diperoleh dari buku maupun
literatur lain seperti internet yang
berhubungan dengan masalah yang
dibahas (Marzuki, 2002: 56). 4. Hasil dan Pembahasan
Berdasarkan analisa yang terjadi salah satu
faktor yang menentukan kualitas perguruan
tinggi adalah kemampuan mahasiswa untuk
menyelesaikan studi tepat waktu. Masalah
kegagalan studi siswa dan faktor-faktor
penyebabnya menjadi topik yang menarik
untuk diteliti (Marquez-Vera, Romero, &
Ventura, 2011). Salah satunya masalah
keterlambatan atau kegagalan studi mahasiswa
dan faktor-faktor penyebabnya perlu di deteksi
perilaku mahasiswa yang memiliki status “tidak diinginkan” tersebut sehingga dapat diketahui faktor-faktor penyebab
120 mahasiswa diantaranya rendahnya
kemampuan akademik, faktor pembiayaan,
status yang dimiliki dan faktor faktor lainnya.
Penelitian ini diharapkan membantu admisi
perguruan tinggi untuk memberikan
peringatan dini dan pembimbingan awal bagi
mahasiswa yang kemungkinan tidak dapat
lulus tepat waktu dan membantu perguruan
tinggi dalam membuat kebijakan untuk bisa
meningkatkan kelulusan tepat waktu
mahasiswa. Database PTS “KZX” menyimpan
data akademik, data kelulusan, administrasi
dan biodata mahasiswa, dari data tersebut
apabila digali dengan tepat maka dapat
diketahui pola atau pengetahuan untuk
mengambil keputusan. Penelitian ini
menggunakan dataset yang diambil dari
dataset kelulusan mahasiswa yang memiliki
data yang besar
4.1.Evaluasi Naïve Bayes 4.1.1.Dengan Data Sampel
Pengujian menggunakan data sampel
yang diambil dari dataset dengan: 2 label
class (tepat dan terlambat), 1 record (7
class tepat dan 3 class terlambat) dan 13
attribute.
Berikut ini adalah contoh perhitungan
mencari nilai akurasi dari atribut
kelompok dengan menggunakan metode
Cross-Validation (X-Validation).
Training 1:
Tabel 4.2 : Data Training Cross Validation Naïve Bayes
Status Kelulusan Kelompok
Tepat Akademik
Tepat Reguler
Tepat Reguler
Tepat Akademik
Tepat Reguler
Tepat Akademik
Tepat Reguler
Terlambat GBAP
121 Dari data diatas didapatkan Probabilitas
kelas:
P(Tepat) = 7/9 = 0.777777777
P(Terlambat) = 2/9 = 0.222222222
Dari data diatas didapatkan Probabilitas
Kelompok terhadap masing masing kelas:
P(Akademik|Tepat) = 3/7 = 0.428571429
P(Reguler|Tepat) = 4/7 = 0.571428572
P(GBAP|Tepat) = 0/7 = 0
P(Akademik|Terlambat) = 0/2 = 0
P(Reguler|Terlambat) = 0/2 = 0
P(GBAP|Terlambat) = 2/2 = 1
Testing 1:
Data testing dari status kelulusan dengan
Kelompok GBAP:
Prediction GBAP :
P(X|Tepat) = 0/7 = 0
P(X|Terlambat) = 2/2 = 1
Perhitungan dilakukan 10 kali sampai
training 10 dan testing 10 sesuai metode
Cross-Validation (X-Validation).
Dari hasil klasifikasi menggunakan data
sample (2 label class. 1 record dan 13
attribute) dengan metode Naïve Bayes
diperoleh hasil nilai akurasi sebesar
90.00%, berikut ini hasil perhitungannya
seperti dapat dilihat pada gambar 4.1.
Gambar 4.1: Validasi Naïve Bayes Data Sampel
=
= 0.9
= 90%
4.1.2.Dengan Data Lengkap
Hasil klasifikasi menggunakan data
lengkap (dataset) dengan metode Naïve
122 83.33%, berikut ini hasil perhitungannya
seperti dapat dilihat pada gambar 4.2.
Gambar 4.2. Validasi Naïve Bayes Data Lengkap
=
= 0.8333
= 83.33%
Evaluasi dan validasi pada penelitian ini
mengikuti aturan AUC, dengan
perhitungan nilai AUC:
Gambar 4.3. AUC Naïve Bayes Data Lengkap
Kappa / AUC =
Keterangan :
Pr(a) adalah proporsi unit yang dua Rater
yang sama.
Pr(e) adalah proporsi yang diharapkan
secara kebetulan.
AUC =
123 AUC = 0.839 termasuk kategori AUC
excellent.
4.2.Evaluasi C4.5
Decision Tree yaitu metode untuk
mengubah data menjadi pohon keputusan
dengan aturan-aturannya (rules).
Algoritma C4.5 untuk model yang pertama
dilakukan. Berikut akan dibahas
langkah-langkah perhitungan klasifikasi
mahasiswa lulus tepat waktu atau tidak
dengan menggunakan algoritma C4.5.
Adapun langkah-langkah yang akan
dilakukan sebagai berikut:
1. Hitung nilai entropy keseluruhan total
kasus TEPAT lulus dan
TERLAMBAT lulus. Dari data
training yang ada diketahui jumlah
kasus yang lulus TEPAT pada
waktunya sebanyak 190 record, dan
jumlah kasus yang lulus
TERLAMBAT adalah sebanyak 20
record total kasus keseluruhan adalah
210 kasus. Sehingga didapat entropy
keseluruhan:
Entropy(S) =
=
= 0.248
2. Hitung nilai entropi dan nilai gain
masing-masing atribut. Nilai gain
tertinggi adalah atribut yang menjadi
root dari pohon keputusan yang akan
dibuat. Misalkan menghitung entropi
bagi atribut konsentrasi.
EWebDeveloping [75,14] = ( ) +
( )
= 7.653
EMobileDeveloping [51,4] = ( ) +
( )
= 0.275
ESistemEnterprise [30,1] = ( ) +
124 = 0.281
ESistemAudit [34,1] = ( )
+ ( )
= 3.058
Kemudian hitung gain konsentrasi sebagai
berikut :
Gain(S, A) = Entropy(S)
= 0.248 –
((
= 3.617
Gain atribute konsentrasi = 3.617
Dari perhitungan tersebut diperoleh pohon
keputusan seperti gambar 4.4
Gambar 4.4. Pohon Keputusan Data Kelulusan mahasiswa
Dari pohon keputusan pada gambar 4.4
didapat rule untuk prediksi data kelulusan
mahasiswa, berikut rule:
R1 = Jika IPK > 2.825 maka hasil Tepat.
R2 = Jika IPK ≤ 2.825 dan Kelompok =
Akademik maka hasil Tepat.
R3 = Jika IPK ≤ 2.825 dan Kelompok =
GBAP dan SKS > 145 dan NIM > 22305
125 R4 = Jika IPK ≤ 2.825 dan Kelompok =
GBAP dan SKS > 145 dan NIM ≤
223055071 dan NIM > 2225 maka hasil
Terlambat.
R5 = Jika IPK ≤ 2.825 dan Kelompok =
GBAP dan SKS > 145 dan NIM ≤
22305071 serta NIM ≤ 222575087 maka
hasil Tepat.
R6= Jika IPK ≤ 2.825 dan Kelompok =
GBAP dan SKS ≤ 145 maka hasil
Terlambat.
R7 = Jika IPK ≤ 2.825 dan Kelompok =
Reguler dan NIM >222550072.5 serta
NIM > 22309001 maka hasil Tepat.
R8 = Jika IPK ≤ 2.825 dan Kelompok =
Reguler dan NIM > 222550072.5 serta
NIM ≤ 223090012.500 dan NIM > 22300
maka hasil Terlambat.
R9 = Jika IPK ≤ 2.825 dan Kelompok =
Reguler dan NIM > 222550072.5 serta
NIM ≤ 223090012.500 dan NIM > 223065
serta NIM ≤ 223080021.500 maka hasil
Tepat.
R10 = Jika IPK ≤ 2.825 dan Kelompok =
Reguler dan NIM > 222550072.5 dan
NIM ≤ 223090012.500 dan NIM ≤
223065019 maka hasil Terlambat.
R11 = Jika IPK ≤ 2.825 dan Kelompok =
Reguler dan NIM ≤ 222550072.500 maka
hasil Tepat.
Setelah diolah maka dilakukan teknik
pengujian dengan metode cross-validation
pada tools RapidMiner diperoleh hasil
nilai akurasi sebesar 90.95%, hasil
pengujian untuk metode algoritma C4.5
126 Gambar 4.5. Cross-Validation Algoritma
C4.5 Menggunakan Data Lengkap
Evaluasi dan validasi pada pengolahan
data diatas mengikuti aturan Kappa/AUC,
berikut ini hasil perhitungannya seperti
dapat dilihat pada gambar 4.5:
Gambar 4.6 AUC Algoritma C4.5 Menggunakan Data Lengkap 4.3.Hasil Evaluasi
Metode klasifikasi bisa dievaluasi
berdasarkan kriteria seperti tingkat
akurasi, kecepatan, kehandalan, skabilitas
dan interpretabilitas (Vecellis, 2009).
Setelah data diolah maka dapat diuji
tingkat akurasinya untuk melihat kinerja
dari masing-masing metode.
Pada penelitian ini menguji
keakuratan klasifikasi kelulusan
mahasiswa dengan membandingkan hasil
algoritma Naïve Bayes dan algoritma C4.5
dari dataset yang diambil dataset kelulusan mahasiswa PTS”KZX”. Seperti diketahui sebelumnya bahwa algoritma
Naïve Bayes dan C4.5 bisa memecahkan
masalah data class imbalance. Sehingga
tidak semua atribut relevan dengan
masalah karena beberapa dari atribut
tersebut mengganggu dan dapat
mengurangi akurasi.
Tujuan dari penelitian ini adalah
untuk melihat akurasi analisis kelulusan
mahasiswa di PTS”KZX”, menilai apakah
127 dapat lulus tepat waktu atau tidak serta
untuk mendapatkan model atribut
parameter yang relevan dengan algoritma
Naïve Bayes dan algoritma C4.5. Data di
analisa dengan melakukan dua
perbandingan yaitu menggunakan
algoritma Naïve Bayes dan algoritma
C4.5. Pada eksperimen tahap awal,
dilakukan untuk mencari nilai akurasi dari
masing-masing atribut yang dimiliki oleh
dataset berdasar metode X-Validation.
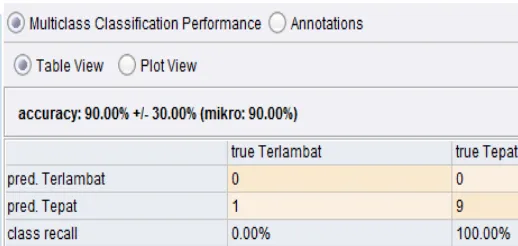
Hasil pengujian menggunakan metode
Naïve Bayes diperoleh accuracy 83.33%,
dan dari 210 data sebanyak 12 data
diprediksi sesuai yaitu terlambat, dan
sebanyak 27 data diprediksi terlambat
tetapi ternyata tepat, 8 data diprediksi tepat
tetapi terlambat, 163 data diprediksi tepat
tepat, seperti terlihat pada Gambar 4.2
Gambar 4.3 adalah grafik AUC dari
metode algoritma Naïve Bayes dengan
nilai AUC 0.839 dan termasuk kategori
AUC excellent. Sedangkan hasil pengujian
menggunakan algoritma C4.5 diketahui
tingkat akurasinya 90.95%, dan dari 210
data sebanyak 10 data diprediksikan sesuai
yaitu terlambat dan 9 data diprediksikan
terlambat tetapi ternyata tepat, dan
sebanyak 10 data diprediksi tepat tetapi
ternyata termasuk klasifikasi terlambat,
dan sebanyak 181 data diprediksi sesuai
yaitu tepat.seperti terlihat pada Gambar
4.5 dan Gambar 4.6 adalah grafik AUC
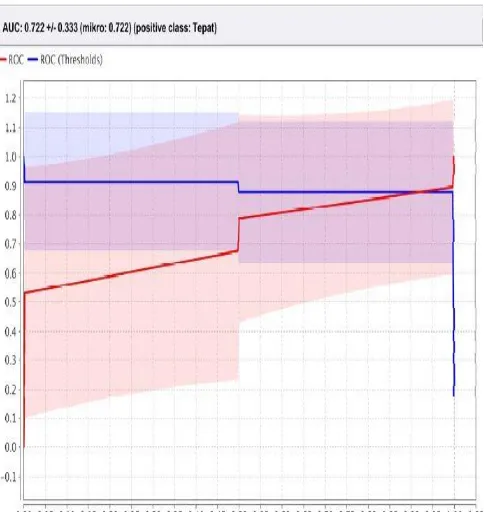
dari metode algoritma C4.5 garis
horizontal adalah false positif dan garis
vertikal false negative dengan nilai AUC
0.722 dan termasuk kategori AUC good.
Dari hasil eksperimen tersebut dapat
disimpulkan ke dalam tabel berikut :
Tabel 4.3 : Hasil Eksperimen Dataset Kelulusan Mahasiswa
Algoritma Naïve Bayes
128
dapat diketahui metode yang terbaik
adalah metode algoritma Naïve Bayes
dengan nilai akurasi 83.33% dan AUC
0.839.
5. Kesimpulan
Dari dataset kelulusan mahasiswa pada
PTS”KZX” dapat diketahui metode
terbaik dalam klasifikasi ketepatan
kelulusan mahasiswa. Untuk
mengukur kineja model digunakan
rapidminner, dan diketahui bahwa
Metode algoritma C4.5 menghasilkan
nilai akurasi yaitu 90.95% dan nilai
AUC 0.722. Sedangkan metode naïve
bayes menghasilkan nilai akurasi yaitu
83.33% dan nilai AUC 0.839.
Dengan demikian pada penelitian ini
metode naive bayes adalah metode yang
terbaik untuk pemecahan masalah klasifikasi
ketepatan kelulusan mahasiswa dengan nilai
akurasi 83.33% dan AUC 0.839 yang
termasuk kategori AUC excellent
Sementara beberapa saran yang dapat
disampaikan adalah:
1. Membantu administrasi PTS”KZX” untuk
memberikan peringatan dini dan
pembimbingan awal bagi mahasiswa yang
kemungkinan tidak lulus tepat waktu dan
membantu perguruan tinggi dalam
membuat kebijakan untuk bisa
129 2. Penelitian ini dapat dikembangkan
dengan metode klasifikasi data mining
lainnya.
3. sistem sehingga dapat dilakukan
penyesuian terhadap sistem.
6. Daftar Pustaka
Basuki, A dan Syarif, I.2003. Decision Tree.Online: diakses dari http://www2.eepisits.edu/~basuki/lecture/
DecisionTree.pdf, pada 3 April 2017.
Berndtsson, M., Hansson, J., Olsson, B., &
Lundell, B.Thesis Projects A Guide for Students in Computer Science and Information Systems (2nd ed.). London: Springer.2008.
Bramer, M.Principles of Data Mining.London:Springer.2007.
B. Santoso.Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Surabaya: Graha Ilmu.2007.
Carlo Vercellis.Business Intelligent: Data Mining and Optimization for Decision Making.Southern Gate, Chichester:John Willey & Sons, Ltd.,2009.
Daniel T. Larose.Discovering Knowledge in Data: An Introduction to Data Mining.New Jersey:Wiley Interscience. 2005.
Daniel T. Larose.Data Mining Methods and Models.Hoboken, New Jersey:John Wiley & Sons, Inc.2007.
(n.d).Retrived from Data fakultas ilmu
komputer 2011/2014.
(n.d).Retrived from Data Perpustakaan
Universitas AKI 2014/2015.
(n.d.). Retrieved from
http://iasol.unaki.ac.id:9090/IasolWeb/.
130 http://www2.eepisits.edu/~basuki/lecture/
DecisionTree.pdf, pada 3 April 2017.
Berndtsson, M., Hansson, J., Olsson, B., &
Lundell, B.Thesis Projects A Guide for Students in Computer Science and Information Systems (2nd ed.). London: Springer.2008.
Bramer, M.Principles of Data Mining.London:Springer.2007.
B. Santoso.Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Surabaya: Graha Ilmu.2007.
Carlo Vercellis.Business Intelligent: Data Mining and Optimization for Decision Making.Southern Gate, Chichester:John Willey & Sons, Ltd.,2009.
Daniel T. Larose.Discovering Knowledge in Data: An Introduction to Data Mining.New Jersey:Wiley Interscience. 2005.
Daniel T. Larose.Data Mining Methods and Models.Hoboken, New Jersey:John Wiley & Sons, Inc.2007.
E. Prasetyo.Data Mining Konsep dan Aplikasi menggunakan MATLAB.pdf. Yogyakarta: Andi.2012.
Florin Gorunescu.Data Mining: Concepts,
Model and Techniques, Prof. Janusz Kacprzyk and Prof. Lakhmi C. Jain, Eds.
Berlin. Jerman: Springer.2011.
Han J. & Kamber M.Data Mining: Concepts and Techniques (Second Edition ed.).San Francisco: Elsevier Inc.2006.
Han J, Kamber M.Data Mining: Concepts and Techniques 2nd Edition.Elsevier.2007.
131 Jiawei Han.Data Mining Concept And
Technique, 2nd ed., Asma Stephan, Ed.Champaign, United States of America: Multiscience Press.2007.
Karamouzis T. S., Vrettos A. An Artificial Neural Network for Predicting Student Graduation Outcomes.Preceeding of World Congress on Engineering and
Computer Science ,
978-988-98671-02.2008.
Kusrini, Taufiq Emha Luthfi.Algoritma Data Mining.Yogyakarta: Andi.2009.
L. Ladha and T. Deepa.Feature Selection Methods And Algorithms.International Journal on Computer Science and
Engineering (IJCSE).2011.
Liao.Recent Advances in Data Mining of
Enterprise Data: Algorithms and Application.Singapore: World Scientific
Publishing.2007.
Maimon, O., & Rokach, L. Data Mining and Knowledge Discovery Handbook (2nd ed.). Springer. 2010.
Marquez-Vera, C., Romero, C., & Ventura,
S.Predicting School Failure Using Data Mining. Department of Computer Science. 2011.
Marzuki.Metodologi Riset .Yogyakarta:BPEE-UII.2003.
M. J. A. Berry and G. S. Linoff. Data Mining Techniques For Marketing, Sales, Customer Relationship Management Second Editon.United States of America: Wiley Publishing Inc.2004.
Nawawi H, Martini M.Kebijaksanaan Pendidikan di Indonesia di tinjau dari Sudut Hukum.Yogyakarta:Gajah Mada University Press.1994.
132 Pramudiono. 2006. Indo Datamining. Online:
di akses dari http://datamining.japati.net,
pada 15 April 2017.
Qudri M. N., Kalyankar N. V.Drop Out Feature of Student Data for Academic Performance Using Decision Tree techniques.Global Journal of Computer Science and Technology , 2-4.2010.
Siregar A R.Motivasi Belajar Mahasiswa ditinjau dari Pola Asuh.Medan:Usu Repository.2006.
Suhartinah S M., Ernastuti.Graduation Prediction of Gunadarma University Students Using Algorithm and Naive Bayes C4.5 Algoritmh.2010.
Turban, E, dkk.Decicion Support Systems and
Intelligent Systems.
Yogyakarta:Andi.2005.