Manajemen | Fakultas Ekonomi Universitas Maritim Raja Ali Haji 073500104000000280
Teks penuh
Gambar
Dokumen terkait
The correlation analysis of 70 developing countries finds that the degree of crisis is sensitive to change in certain economic governance elements, while the frequency of crises is
To this end, we introduce a GMM estimator as a flexible and versatile estimation method for multifractal parameters and compare its performance to that of ML (where applicable), and
It is well known that the realized daily vari- ance is not a consistent estimator of the integrated variance in the presence of jumps in the price process; using squared re- turns
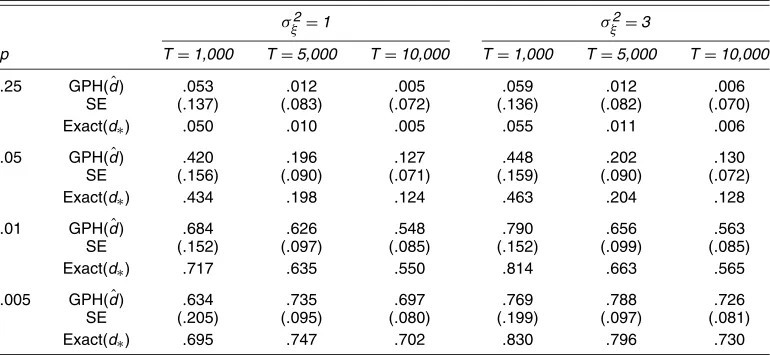
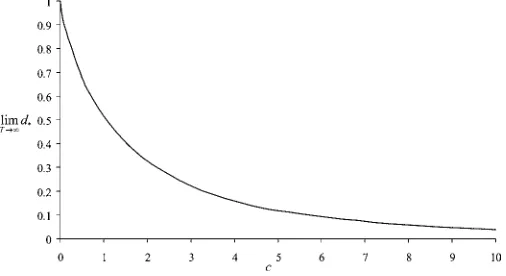
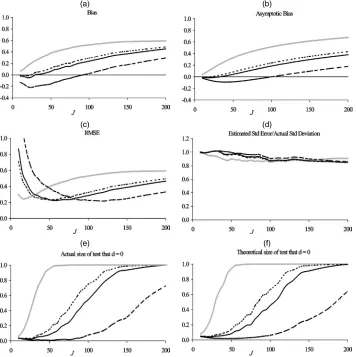
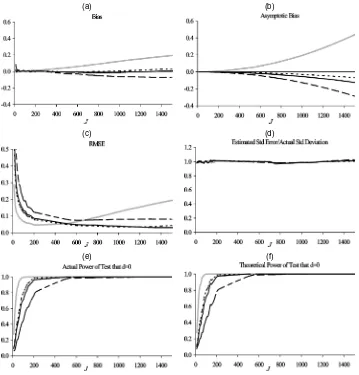
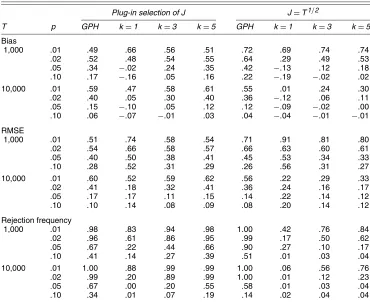
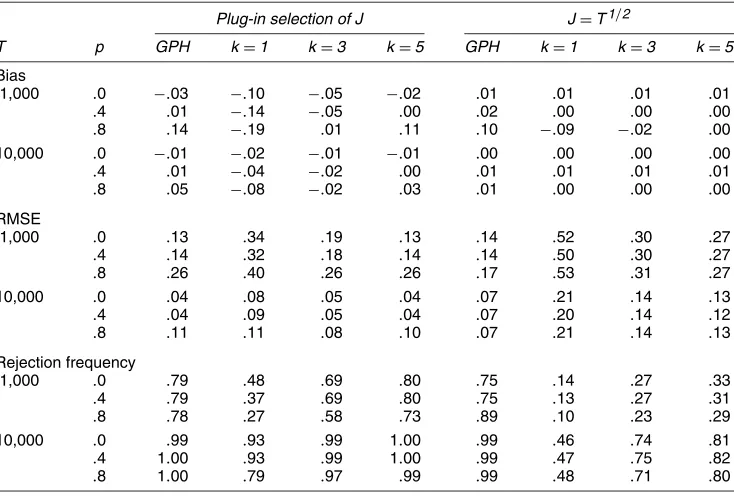
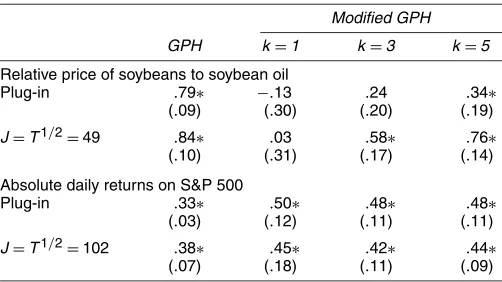
In this section we compare the performance of the bias- corrected estimator (32), denoted by bc , with some alterna- tive estimators in a first-order dynamic panel model with
The proposed model is in sharp contrast with the commonly used time series models and the regime- switching model of Hamilton (1989), in that it is capable of describing both
Third, in comparison with the nonparametric estimator of Ziegelmann ( 2002 ), our estimator can result in bias reduction as long as the parametric model can capture some
Rather, we are modeling spatial error across the re- gion using a nonstationary process created through locally de- termined weighted sums of stationary processes.. The number
Furthermore, empirical and simula- tion evidence reported herein suggests that the efciency gains of our estimator vis-à-vis the Q-MLE are quite modest for estimation of
