BAB II
LANDASAN TEORI
Suatu teori pada hakekatnya adalah hubungan dua fakta atau lebih, atau pengaturan fakta menurut cara-cara tertentu. Fakta tersebut merupakan sesuatu yang dapat diamati dan pada umumnya dapat diuji secara empiris. Oleh sebab itu dalam bentuknya yang paling sederhana, suatu teori merupakan hubungan antara dua variabel atau lebih, yang telah diuji kebenarannya. Suatu variabel merupakan karakteristik dari orang-orang, benda, atau keadaan yang mempunyai nilai-nilai yang berbeda, misalkan usia, jenis kelamin, dan lain sebagainya. Suatu teori akan sangat berguna dalam mengembangkan sistem klasifikasi fakta, membina struktur konsep-konsep serta mengembangkan definisi-definisi yang penting untuk penelitian.
Pada penelitian ini, penulis menyajikan teori yang berisikan pengertian dan penjelasan tentang statistik, tentang metode pengumpulan data, tentang metode perhitungan statistik dan tentang penyajian data. Sehingga penelitian ini memiliki arah yang benar dan hasil yang meyakinkan serta dapat dipertanggungjawabkan.
2.1 PERKEMBANGAN UPAH MINIMUM
Pengertian ataupun rumusan mengenai upah dan upah minimum masih bermacam-macam, oleh karena itu pemerintah menentukan definisi sebagai berikut:
“Upah adalah suatu penerimaan sebagai imbalan dari pengusaha kepada karyawan untuk suatu pekerjaan atau jasa yang telah dan akan dilakukan dan dinyatakan atau dinilai dalam bentuk uang yang ditetapkan atas dasar suatu persetujuan atau Peraturan Perundang-undangan serta dibayarkan atas dasar suatu perjanjian kerja antara pengusaha dengan karyawan termasuk tunjangan, baik untuk karyawan itu sendiri maupun untuk keluarganya” (Peraturan Pemerintah/ PP No.8 tahun 1991).
Seiring dengan perubahan era, pengertian upah mengalami perubahan, seperti yang tercantun dalam Undang-Undang No.13 tahun 2003 tentang ketenagakerjaan pada pasal 1/ No.30 diberikan pengertian tentang upah :
“Upah adalah hak pekerja/ buruh yang diterima dan dinyatakan dalam bentuk uang sebagai imbalan dari pengusaha atau pemberi kerja kepada pekerja/ buruh yang ditetapkan dan dibayarkan menurut suatu perjanjian kerja, kesepakatan, atau Peraturan Perundang-undangan, termasuk tunjangan bagi pekerja/ buruh dan keluarga atas suatu pekerjaan dan atau jasa yang telah atau akan dilakukan”.
Selain upah ada pula istilah upah minimum yang juga telah diatur oleh pemerintah melalui ketentuan Peraturan Pemerintah (PP No.8 tahun 1981). Upah minimum merupakan upah yang ditetapkan secara minimum regional, sektoral regional, maupun sub sektoral. Dalam hal ini upah minimum itu adalah upah pokok dan tunjangan. Upah pokok minimum adalah upah pokok yang diatur secara minimal oleh regional, sektoral, maupaun sub sektoral. Dalam peraturan pemerintah yang diatur secara jelas hanya upah pokoknya saja dan tidak termasuk tunjangan. Dalam perkembangannya, berdasarkan Peraturan Menteri Tenaga
Kerja No.Pen 01/MEN/1999, yang dimaksud upah minimum adalah upah bulanan terendah yang terdiri dari upah pokok, termasuk tunjangan tetap.
Sebagai perhatian negara terhadap ketimpangan dan kesenjangan ekonomi khususnya kesejahteraan pekerja, pemerintah mengatur kembali tentang pengupahan melalui Peraturan Menteri Tenaga Kerja No.Per 05/Men/1989 tanggal 29 Mei 1989 tentang upah minimum. Dalam Peraturan Menteri Tenaga Kerja ini, upah minimum dibagi dalam tiga kriteria yaitu upah minimum regional, upah minimum sektor regional, dan upah minimum sub sektor regional. Dalam perkembangannya berdasarkan Surat Keputusan Menteri Tenaga Kerja dan Transmigrasi Republik Indonesia No.Kep-226/MEN/2000 pasal 3 yaitu upah minimum terdiri dari upah minimum propinsi, upah minimum sektoral propinsi (UMS propinsi), upah minimum kabupaten/ kota (UMS kabupaten/ kota) telah ditentukan secara jelas mulai dari cara penentuan atau perhitungan, jenis barang, kualitas, merk sampai pada pasar mana yang dijadikan tempat untuk men-survei harga barang-barang tersebut. Ini berarti penetapan besarnya kebutuhan hidup minimum itu sendiri sudah terstandart dengan jelas. Upah minimum propinsi dan upah minimum kabupaten/ kota ini ditetapkan setahun sekali dengan SK Gubernur. UMP hanyalah batas bawah upah bagi buruh yang bekerja kurang dari 1 tahun. Bagi perusahaan yang mampu agar memberikan gaji di atas UMP serta sebaliknya memberikan hak pekerja atas gaji di atas UMP.
2.2 KOMPONEN UPAH MINIMUM
Secara empiris ada tiga komponen yang dianggap mempengaruhi besarnya upah tenaga minimum, yaitu Kebutuhan Fisik Minimum (KFM), Indeks Harga Konsumen (IHK), dan pertumbuhan ekonomi daerah (Pertek). Sebenarnya ada satu variabel lagi yang dianggap cukup berpengaruh dalam besar kecilnya upah minimum yaitu kemampuan perusahaan, namun karena data untuk mengetahui kemampuan perusahaan tersebut agak sulit ditemukan, seringkali komponen ini diabaikan.
2.2.1 Kebutuhan Fisik Minimum
Kebutuhan Fisik Minimum (KFM) adalah kebutuahn pokok seseorang untuk mempertahankan kondisi fisik dan mentalnya dalam menjalankan fungsinya sebagai salah satu faktor produksi. Kebutuhan ini merupakan kebutuhan minimum baik ditinjau dari segi jumlah maupun dari segi kualitas barang dan jasa yang dibutuhkan sehingga merupakan kebutuhan yang tidak dapat dihindari atau dikurangi jumlahnya.
Angka Kebutuhan Fisik Minimum (AKFM) mencerminkan nilai ekonomi dari barang dan jasa yang diperlukan oleh pekerja dan keluarganya dalam jangka waktu satu tahun.
Barang dan jasa ini dibagi dalam enam (6) kelompok barang yaitu: (Badan Pusat Statistik,1986).
1. Makanan dan minuman.
2. Bahan bakar, alat penerangan dan penyeduh.
3. Perumahan dan peralatan dapur.
4. Sandang atau pakaian.
5. Lian-lain termasuk di dalamnya biaya untuk transportasi, rekreasi, obat-obatan, sarana pendidikan, bacaan dan sebagainya.
Perubahan Kebutuhan Fisik Minimum (KFM) hanya terjadi bila harga barang dan jasa berubah karena Angka Kebutuhan Fisik Minimum (AKFM) ditentukan oleh harga yang berlaku pada saat penelitian dilakukan, sampai dewasa ini komponen KFM itu sendiri belum berubah.
2.2.2 Indeks Harga Konsumen
Indeks Harga Konsumen (IHK) merupakan petunjuk mengenai naik turunnya harga kebutuhan hidup. Naiknya harga kebutuhan hidup ini secara tidak langsung mencerminkan tingkat inflasi. Data mengenai harga ini dikumpulkan oleh Badan Pusat Statistik (BPS) dan mencakup 160 macam barang yang dibagi menjadi empat kelompok pengeluaran yaitu makanan, sandang, perumahan, dan aneka kebutuhan. Indeks Harga Konsumen dihitung setiap bulan dan setiap tahun, dinyatakan dalam bentuk persentase.
Pengumpulan datanya dilakukan di 17 ibukota provinsi dan hasil gabungan dari (IHK) kota-kota ini dianggap sebagai pengukur tingkat inflasi nasional. Jadi dengan kata lain, IHK suatu daerah juga mencerminkan tingkat inflasi daerah yang bersangkutan.
Adapun kota-kota tersebut adalah Medan, Padang, Palembang, Jakarta, Bandung, Semarang, Yogyakarta, Surabaya, Denpasar, Mataram, Kupang, Pontianak, Banjarmasin, Manado, Ujung Pandang, Ambon dan Jayapura.
2.2.3 Pertumbuhan Ekonomi Daerah
Petumbuhan ekonomi daerah mencerminkan keadaan perekonomian di suatu daerah. Keadaan perekonomian ini akan mempengaruhi pertumbuhan dan kondisi perusahaan yang beroperasi di daerah yang bersangkutan. Semakin tinggi tingkat pertumbuhan perekonomian di suatu daerah, maka semakin besar pula kesempatan berkembang bagi perusahaan-perusahaan yang beroperasi di daerah yang bersangkutan. Hal ini disebabkan oleh karena tingkat pertumbuhan perekonomian daerah secara tidak langsung merupakan gambaran kemakmuran suatu daerah.
2.3 KEBUTUHAN HIDUP MINIMUM
Konsep Kebutuhan Fisik Minimum (KFM) di Indonesia telah diperkenalkan sejak tahun 1956 yaitu melalui konsensus secara tripartit dan para ahli dalam bidang gizi. Seperti tahun 1994, KFM ini masih dijadikan standart atau acuan dalam menetapkan upah atau menentukan tingkat kenaikan upah. Dalam KFM itu dihitung berapa kebutuhan minimum seorang pekerja, agar dapat hidup sehat dan mampu bekerja dengan baik. Karena itu telah ditetapkan dengan jumlah kebutuhan kalori sejumlah 2.600 kalori untuk seorang pekerja. Berdasarkan hal itu
maka Dewan Penelitian Pengupahan Nasional (DPPN) menyarankan agar KFM disesuaikan dengan kondisi yang ada yaitu 3.000 kalori untuk kebutuhan hidup pekerja. DPPN telah memaparkan konsep Kebutuhan Hidup Minimum (KHM) yang baru di hadapan Menteri Tenaga Kerja pada 22 Maret 1995, yang hasilnya sebagai berikut :
1. Konsep atau draft KHM dapat disetujui dengan pertimbangan komponen, jenis kebutuhan, dan kalori disesuaikan dengan perkembangan zaman.
2. Dasar penetapan upah minimum yang akan datang akan berpedoman pada KHM.
3. Upaya KHM ini ditetapkan dengan ketentuan hukum.
Kemudian pada tanggal 29 Mei 1995 lahirlah Surat Keputusan Menteri Tenaga Kerja No.81/MFN/1995 tentang penetapan komponen kebutuhan hidup minimum. Surat keputusan menteri tersebut yang merupakan dasar bagi penetapan komponen hidup minimum sangat besar artinya, dalam upaya meningkatkan kesejahteraan. Di dalam komponen kebutuhan tersebut tidak hanya mempertimbangkan kebutuahan hidup untuk tenaga kerja pria, tetapi juga tenaga kerja wanita antara lain adanya pakaian kerja/ blouse, rok dan pakaian dalam wanita. Di samping itu KHM juga memperhatikan aneka kebutuhan yang lain seperti pendidikan, sarana kesehatan, dan media informasi. Di dalam pelaksanaan survei harga untuk menetapkn KHM tidak hanya harga yang ada di pasar induk, tetapi juga harga di pasar umum dan mempertimbangkan data dari kantor statistik daerah. Berdasarkan Surat Keputusan tersebut, KHM dihitung atas dasar 43 komponen yang terdiri atas 4 kelompok :
1. Makanan dan minuman : 11 jenis 2. Perumahan : 19 jenis 3. Sandang : 8 jenis 4. Aneka kebutuhan : 5 jenis
2.4 PENGERTIAN STATISTIK
“Statistik adalah data yang diperoleh dengan cara pengumpulan, pengolahan, penyajian dan analisis serta sebagai sistem yang mengatur keterkaitan antara unsur dalam penyelenggaraan statistik” (Undang-undang Republik Indonesia No.16 tahun 1997 tentang Statistik, Bab I, pasal 1, ayat 1).
“Data adalah informasi yang berupa angka tentang karakteristik (ciri-ciri khusus) suatu populasi” (Undang-undang Republik Indonesia No.16 tahun 1997 tentang Statistik, Bab I, pasal 1, ayat 2).
Selain itu pada pasal 3, kegiatan statistik diarahkan untuk : 1. Mendukung pembangunan nasional.
2. Mengembangkan sistem statistik nasional yang handal, efektif dan efisien.
3. Meningkatkan kesadaran masyarakat akan arti dan kegunaan statistik.
4. Mendukung pengembangan ilmu dan teknologi.
“Sembarang nilai yang menjelaskan ciri suatu contoh disebut statistic” (Walpole, Ronald E, 1993).
2.4.1 Arti dan Kegunaan Data
“Data statistik adalah data ringkasan berbentuk angka seperti jumlah, rata-rata presentase, pemerintah memerlukan data statistik seperti pendapatan nasional maupun regional, pendapatan perkapita, jumlah penduduk, jumlah investasi, jumlah penerimaan negara, jumlah bantuan luar negeri, jumlah ekspor non migas. Sedangkan perusahaan memerlukan data jumlah penjualan, jumlah produksi, jumlah karyawan, jumlah kebutuhan modal, rata-rata tingkat kepuasan pelanggan” (Supranto, J.
2001).
Menurut bahasa inggris data merupakan bentuk jamak “datum”
Dalam Webster’s New World Dictionary tertulis bahwa datum: something known assumed. Artinya datum (dalam bentuk tunggal data) merupakan suatu yang diketahui/ dianggap. Diketahui berarti sesuatu yang sudah terjadi atau merupakan fakta. Sedangkan anggapan bisa berupa sesuatu yang telah terjadi akan tetapi belum diketahui disebut hipotesis atau sesuatu yang belum terjadi, bisa juga terjadi bisa juga tidak, disebut perkiraan.
Kegunaan data pada umumnya adalah sbb :
1. Data bermanfaat untuk mengetahui atau memperoleh suatu gambaran mengenai suatu keadaan atau persoalan. Misalnya setelah dilakukan analisis dengan jalan membandingkan jumlah penduduk dengan produksi beras, diketahui masih ada kekurangan beras. Hasil
penjualan merosot, harga bahan mentah meningkat, biaya atau modal kurang, gedung sekolah kurang, dan lain sebagainya.
2. Untuk membuat keputusan atau memecahkan persoalan. Setiap soal yang timbul pasti mempunyai faktor penyebab. Memecahkan persoalan berarti menghilangkan faktor penyebabnya. Faktor penyebab bisa lebih dari satu. Pekerja tidak produktif, karena sudah lama tidak naik pangkat, gaji yang tidak mencukupi kebutuhan, dan lain sebagainya. Pemecahan persoalan biasanya dilakukan melalui perencanaan. Dengan demikian data berguna untuk dasar perencanaan dalam rangka pemecahan persoalan.
Data diperlukan untuk perencanaan agar :
a. Kita dapat mengetahui persoalan apa saja yang harus dipecahkan.
b. Perencanaan sesuai dengan kemampuan sehingga dapat dihindari perencanaan yang ambisius yang sulit dicapai.
2.4.2 Syarat Data Yang Baik
Penggunaan data yang salah sebagai dasar pembuat keputusan, menghasilkan keputusan yang salah (perencanaan tidak tepat, kontrol tidak efektif, dan evaluasi tidak mengenai sasaran). Keputusan yang baik hanya berasal dari pembuatan keputusan yang baik (jujur, berani, objektif dan mengetahui persoalannya). Dan didukung dengan data yang baik pula.
Data yang tidak baik dapat menyesatkan.
Syarat data yang baik dan berguna adalah sebagai berikut :
1. Data harus objektif, artinya data itu dapat menggambarkan keadaan seperti apa adanya, sesuai dengan apa yang terjadi.
2. Data harus dapat mewakili. Data prakiraan dikatakan mewakili, apabila nilai data tersebut dekat dengan data sebenarnya yang diperkirakan.
3. Data harus mempunyai kesalahan (sampling error) yang kecil (apabila data merupakan suatu perkiraan). Kesalahan sampling merupakan kesalahan yang terjadi pada data prakiraan dan digunakan untuk mengukur tingkat ketelitian.
4. Data harus tepat waktu. Syarat tepat waktu penting sekali apabila data akan digunakan untuk mengontrol pelaksanaan sutu perencanaan sehingga persoalan yang terjadi dapat diketahui untuk segera diatasi, dikoreksi dan dipecahkan.
5. Data harus mempunyai hubungan dengan persoalan yang akan dipecahkan.
2.4.3 Berbagai Jenis Data
Data dapat dibagi menurut sifatnya, menurut sumbernya, dan menurut waktu pengumpulannya. Menurut sifatnya, data dapat dibagi menjadi dua, yaitu :
1. Data Kuantitatif.
Adalah data yang berbentuk angka, seperti keterangan tentang jumlah rata-rata, persentase dan rasio. Misalkan produksi beras pada tahun 2006 adalah 30.000.000 ton, kenaikan penduduk Jakarta per tahun adalah 3,4 %, keuntungan perusahaan “Z” adalah 18 % per tahun, rata-rata upah pekerja perusahaan “Y” adalah Rp 800.000,00 sebulan, jumlah karyawan di Departemen “X” adalah 3.000 orang, dan rata-rata kenaikan produksi barang “A” adalah 4
% per bulan.
2. Data Kualitatif.
Adalah data yang tidak berbentuk angka, seperti lancar, beres, bersemangat, naik, turun, bergairah dan lain sebagainya. Misalkan, distribusi beras di Banten lancar, persoalan tuntutan pekerja sudah beres, pekerja perusahaan “Z” bersemangat, rakyat bergairah membangun, pembagian keuntungan tidak adil, pengikut demonstrasi banyak, dll.
2.4.4 Sumber Data
Menurut sumber datanya, bisa dibagi menjadi dua yaitu : 1. Data Internal
Adalah data yang dikumpulkan oleh suatu organisasi untuk menggambarkan keadaan atau kondisi perusahaan yang
bersangkutan, serta berguna untuk keperluan kegiatan harian dan pengawasan internal.
2. Data Eksternal
Adalah data yang dikumpulkan untuk menggambarkan keadaan atau kegiatan di luar organisasi tersebut. Data eksternal menggambarkan faktor-faktor yang yang mungkin menjadi penyebab merosotnya penjualan. Data eksternal yang dimaksud di sini misalnya, data penduduk, data pendapatan nasional dan data harga-harga, termasuk indeks biaya hidup dan harga sembilan macam bahan pokok, yang dikumpulkan oleh Badan Pusat Statistik (BPS).
2.4.5 Data Menurut Waktu
Menurut waktu pengumpulannya, data dibagi menjadi dua, yaitu : 1. Data Cross Section
Adalah data yang dikumpulkan pada suatu waktu tertentu.
Misalnya pada bulan atau tahun yang bisa menggambarkan keadaan waktu tersebut.
Data Cross Section hanya menggambarkan keadaan pada waktu yang bersangkutan, tidak menggambarkan perubahan-perubahan yang diakibatkan perubahan waktu sehingga sifatnya statis.
Walaupun demikian, data cross section tetap berguna untuk analisis-analisis.
2. Data Deret Waktu (Time Series)
Adalah data yang dikumpulkan dari waktu ke waktu (hari ke hari, minggu ke minggu, bulan ke bulan, atau dari tahun ke tahun).
Data deret waktu bisa digunakan untuk melihat perkembangan kegiatan tertentu, misalnya perkembangan produksi, perkembangan pelayaran nasional, perkembangan harga, perkembangan penduduk. Selain itu data deret waktu juga bisa digunakan sebagai dasar untuk menarik suatu trend, yaitu garis yang menunjukkan arah perkembangan secara umum, misalnya menarik atau menurun.
Apabila trend sudah dibuat maka data deret waktu bisa digunakan untuk membuat perkiraan-perkiraan yang sangat berguna bagi dasar perencanaan.
2.5 ARTI DAN KEGUNAAN STATISTIK DALAM HUBUNGANNYA DENGAN RISET
Telah diuraikan tentang arti dan penggunaan data, uraian mengenai data adalah sekedar untuk menimbulkan apresiasi. Setelah seseorang mempunyai apresiasi terhadap data seharusnya seseorang itupun mempunyai apresiasi terhadap statistika, karena kalau seseorang tidak mempunyai apresiasi terhadap data, maka orang tersebut tidak akan mempunyai apresiasi terhadap statistika dan riset. Sebab pada prinsipnya riset adalah usaha pengumpulan informasi atau data secara almiah. Apabila kita sebagai suatu bangsa kurang menghargai riset, maka
kitapun tidak akan maju, pembangunan akan lambat, sebab hal-hal yang baru hanya bisa diperoleh melaui riset atau penelitian-penelitian.
Banyak sekali definisi tentang statistika salah satu diantaranya adalah statistika adalah suatu ilmu yang mempelajari cara pengumpulan, pengolahan, penyajian dan analisis data serta cara pengambilan keputusan kesimpulan dengan memperhitungkan unsur ketidakpastian berdasarkan konsep probabilitas. Definisi tersebut didasarkan atas keperluan praktis dan ditekankan pada kegiatan-kegiatan yang dicakup, yaitu :
1. Pengumpulan 2. Pengolahan 3. Penyajian 4. Analisis
Banyak sekali orang menganggap bahwa statistika adalah tabel-tabel dan grafik-grafik yang memusingkan saja. Padahal dari definisi tersebut jelas sekali, tabel dan grafik hanya merupakan salah satu aspek saja, yaitu aspek penyajian.
Benar memang jika data yang sudah didapat dan diolah seharusnya disajikan dan dianalisis. Yang penting sebetulnya, bukanlah bentuk grafik yang menarik dengan berbagai macam warna yang indah-indah serta tabel-tebel yang rapi, melainkan apakah data tersebut hasil suatu pengumpulan dan pengolahan yang baik.
Pengumpulan dan pengolahan data selain memerlukan keterampilan teknis, juga memerlukan syarat-syarat non teknis seperti peralatan (mesin hitung, kertas), biaya yang tidak sedikit dan kerjasama yang baik dengan responden.
Hubungan statistika dan riset, perlu diketahui, statistika tidak hanya berguna untuk keperluan rutin saja melainkan untuk memberikan teori-teori atau metode-metode untuk prakiraan yang sangat berguna untuk perencanaan dan juga teori-teori tentang pengujian hipotesis serta pembuatan prakiraan interval.
Riset pada dasarnya suatu usaha dalam usaha mencari fakta melalui pengumpulan informasi. Ada lagi definisi yang lebih tegas yang mengatakan bahwa riset adalah usaha pengumpulan data atau informasi secara ilmiah untuk menguji suatu hipotesis atau untuk memecahkan suatu persoalan-persoalan tertentu (khusus untuk riset terapan yang bersifat eksperimen). Di sini peranan statistika dalam riset yaitu dalam usaha pengumpulan data secara ilmiah, dalam pengujian hipotesis dan dalam analisis data-data yang telah didapat.
Seorang peneliti yang tidak menguasai metode-metode statistika biasanya kurang bisa memanfaatkan data yang telah terkumpul, dalam arti kata tidak bisa mengambil informasi semaksimal mungkin, khususnya informasi yang menyangkut hubungan variabel-variabel. Analisis-analisis statistika yang penting untuk riset misalnya analisis cross section, analisis deret waktu, analisis regresi dan korelasi, serta analisis varians.
Kontribusi ilmu statistika terhadap riset dimungkinkan karena statistika didasarkan atas probabilitas yang berguna untuk membahas hal-hal yang mengandung unsur ketidakpastian.
2.6 POPULASI DAN SAMPEL 1. Populasi
Populasi adalah wilayah generalisasi yang terdiri atas subyek/
obyek yang mempunyai kuantitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk dipelajari kemuadian ditarik kesimpulannya.
Jadi populasi bukan hanya orang tetapi juga benda-benda alam yang lain.
Populasi juga bukan hanya sekedar jumlah yang ada pada obyek/ subyek yang dipelajari, tetapi meliputi seluruh karakteristik/ sifat yang dimiliki oleh subyek atau obyek itu.
Misalnya penelitian dilakukan di lembaga X, maka lembaga X ini merupakan populasi. Lembaga X mempunyai sejumlah orang/ subyek dan obyek yang lain. Hal ini berarti populasi dalam arti jumlah/ kuantitas.
Tetapi lembaga X juga mempunyai karakteristik orang-orangnya, misalnya motivasi kerjanya, disiplin kerjanya, gaya kepemimpinannya, iklim organisasinya, dll; dan juga memiliki karakteristik obyek yang lain misalnya, kebijakan, prosedur kerja, tata ruang, produk yang dihasilkan, dll. Satu orangpun dapat digunakan sebagai populasi, karena satu orang itu mempunyai berbagai karakteristik, misalnya gaya bicaranya, disiplin pribadi, hobi, cara bergaul, kepemimpinannya, dll.
2. Sampel
Sampel adalah sebagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut. Bila populasi besar, peneliti tidak mungkin
mempelajari semua yang ada pada populasi, misalnya karena keterbatasan dana, tenaga dan waktu, maka peneliti dapat menggunakan sample yang diambil dari populasi itu. Apa yang dipelajari dari sample itu akan diberlakukan untuk populasi. Untuk itu sample yang diambil dari populasi harus benar-benar representative (mewakili).
2.7 TEKNIK SAMPLING
Teknik sampling adalah merupakan teknik pengambilan sample untuk menentukan sample yang akan digunakan dalam penelitian. Terdapat beberapa teknik sampling yang dipergunakan yaitu probability sampling dan non probability sampling.
2.7.1 Probability Sampling
Adalah teknik sampling yang memberikan peluang yang sama bagi setiap unsur (anggota) populasi untuk dipilih menjadi anggota sample.
Teknik probability sampling ini meliputi :
a) Simple Random Sampling (Sampel Acak Sederhana)
Teknik ini sangat sederhana (simple) karena pengambilan sample anggota populasi dilakukan secara acak tanpa memperhatikan strata yang ada dalam populasi itu. Teknik seperti ini dilakukan apabila anggota populasi dianggap homogen.
Gambar 2.1 Teknik Simple Random Sampling
b) Proportioned Stratified Random Sampling (Sampel Acak Berlapis) Teknik ini digunakan bila populasi mempunyai anggota/ unsur yang tidak homogen dan berstrata secara proporsional. Suatu organisasi yang mempunyai pegawai dari latar belakang pendidikan, maka populasi pegawai itu berstrata. Misal jumlah pegawai yang lulus S1 = 45, S2 = 30, STM = 800, ST = 900, SMEA = 400, SD = 300. Jumlah sample yang harus diambil meliputi strata pendidikan tersebut yang diambil secara proporsional. Teknik Proportioned Stratified Random Sampling dapat digambarkan sbb :
Gambar 2.2 Teknik Proportioned Stratified Random Sampling
c) Disproportioned Stratified Random Sampling
Teknik ini digunakan untuk menentukan jumlah sample, bila populasi berstrata tetapi kurang proporsional. Misalnya pegawai dari PT tertentu mempunyai 3 orang lulusan S3, 4 orang lulusan S2, 90 orang lulusan S1, 800 orang lulusan SMU dan 700 orang lulusan SMP, maka 3 orang lulusan S3 dan 4 orang lulusan S2 itu diambil semuanya sebagai sample. Karena kedua kelompok ini terlalu kecil bila dibandingkan dengan kelompok S1, SMU, dan SMP.
d) Cluster Sampling (Area Sampling)
Teknik sampling daerah digunakan untuk menentukan sample bila obyek yang akan diteliti atau sumber data sangat luas, misal penduduk dari suatu negara, propinsi atau kabupaten. Untuk menentukan penduduk mana yang akan dijadikan sumber data, maka pengambilan sampelnya berdasarkan daerah populasi yang telah ditetapkan.
Misalkan di Indonesia terdapat 27 propinsi, dan sampelnya akan menggunakan 10 propinsi, maka pengambilan 10 propinsi tersebut dilakukan secara random. Tetapi perlu diingat, karena propinsi- propinsi di Indonesia itu berstrata maka pengambilan sampelnya perlu menggunakan stratified random sampling.
Teknik sampling daerah ini sering digunakan melalui 2 tahap, yaitu tahap pertama menentukan sample daerah, dan tahap berikutnya
menentukan orang-orang yang ada pada daerah tersebut secara sampling juga. Teknik ini dapat digambarkan seperti gambar berikut:
Gambar 2.3 Teknik Cluster Sampling (Area Sampling)
2.7.2 Non Probability Sampling
Adalah teknik sampling yang tidak memberi peluang/ kesempatan sama bagi setiap setiap unsur (anggota) populasi untuk dipilih menjadi sample.
Teknik ini meliputi :
e) Sampling Sistematis
Adalah teknik penentuan sample berdasarkan urutan dari anggota populasi yang telah diberi nomor urut. Misalnya anggota populasi yang terdiri dari 100 orang. Dari semua anggota itu diberi nomor urut yaitu dari nomor 1 sampai nomor 100. Pengambilan sample dapat dilakukan dengan nomor ganjil saja, genap saja, atau kelipatan dari bilangan tertentu, misalnya kelipatan dari bilangan 5.
Untuk ini maka yang diambil sebagai sample adalah nomor 5, 10, 15, 20, dan seterusnya sampai dengan 100.
f) Sampling Kuota
Adalah teknik untuk menentukan sample dari populasi yang mempunyai ciri-ciri tertentu sampai jumlah (kuota) yang diinginkan. Sebagai contoh akan melakukan penelitian terhadap pegawai golongan II dan penelitian dilakukan secara kelompok.
Setelah jumlah sample ditentukan sejumlah 100 dan jumlah anggota peneliti sejumlah 5 orang maka setiap anggota peneliti dapat memilih sample secara bebas sesuai dengan karakteristik g) Sampling Aksidental
Adalah teknik pengumpulan sample berdasarkan kebetulan, yaitu siapa saja yang secara kebetulan bertemu dengan peneliti dapat digunakan sebagai sample, bila dipandang orang yang kebetulan ditemui itu cocok sebagai sumber data.
h) Sampling Purposive
Adalah teknik penentuan sample dengan pertimbangan tertentu, misalnya akan melakukan penelitian tentang disiplin pegawai, maka sample yang dipilih adalah orang yang ahli dalam bidang kepegawaian saja.
i) Sampling Jenuh
Adalah teknik penentuan sample bila semua anggota populasi digunakan sebagai sample. Hal ini sering dilakukan bila jumlah populasi relatif kecil, kurang dari 30 orang. Istilah lain sample
jenuh adalah sensus, dimana semua anggota populasi dijadikan sample.
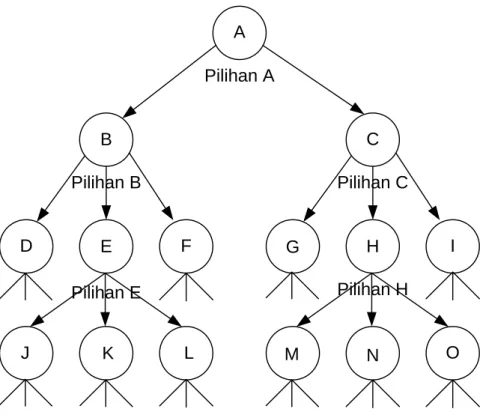
j) Snowball Sampling
Adalah teknik penentuan sample yang mula-mula jumlahnya kecil, kemudian sample ini disuruh memilih teman-temannya untuk dijadikan sample. Begitu seterusnya sehingga jumlah sample semakin banyak. Ibarat bola salju yang menggelinding, makin lama makin besar. Teknik sample ditunjukkan pada gambar berikut.
O I Pilihan A
Pilihan B Pilihan C
A
B C
D E F G H
J K L M N
Pilihan E Pilihan H
Sample Pertama
Gambar 2.4 Teknik Snowball Sampling
2.8 MENENTUKAN UKURAN SAMPEL
Jumlah anggota sample sering dinyatakan dengan ukuran sample. Jumlah sample yang 100 % mewakili populasi adalah sama dengan populasi. Jadi bila jumlah populasi 1000 dan hasil penelitian itu akan diberlakukan untuk 1000 orang tersebut tanpa ada kesalahan maka jumlah sample yang diambil sama dengan jumlah populasi tersebut yaitu 1000 orang. Makin besar jumlah sample mendekati populasi maka peluang kesalahan generalisasi semakin kecil dan sebaliknya makin kecil jumlah sample menjauhi populasi maka makin besar kesalahan generalisasi.
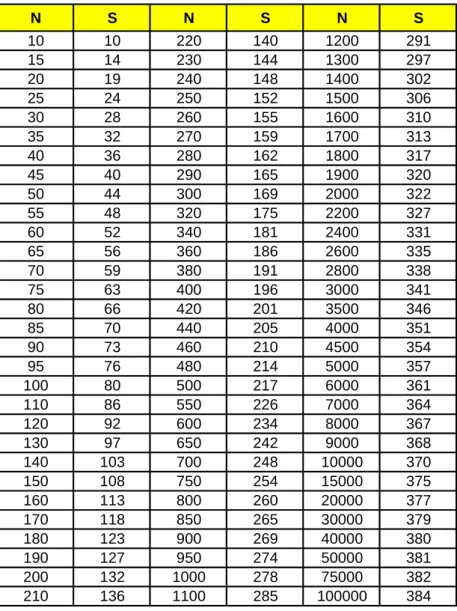
Untuk menentukan ukuran sample dengan praktis dapat menggunakan Tabel Krejcie dan Nomogram Harry King.
Krejcie dalam melakukan perhitungan ukuran sample didasarkan atas kesalahan 5 %. Jadi sample yang diperoleh itu mempunyai tingkat kepercayaan 95
% terhadap populasi. Tabel Krejcie ditunjukkan dengan tabel 2.1 di bawah ini, dimana terlihat bila jumlah populasi 100 maka sampelnya 80, bila populasi 1000 maka sampelnya 278, bila sampelnya 10.000 maka sampelnya 370, bila populasi 100.000 maka sampelnya 384. Dengan demikian makin besar populasi maka makin kecil prosentase sample. Oleh karena itu tidak tepat bila ukuran populasinya berbeda, prosentase sampelnya sama, misalnya 10 %.
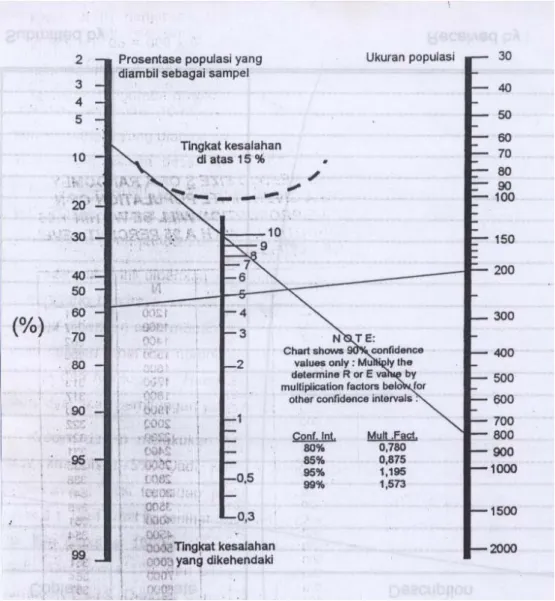
Harry King menghitung sample tidak hanya didasarkan atas kesalahan 5 % saja, tetapi bervariasi sampai 15 %, tetapi jumlah populasi paling tinggi hanya 2.000. Nomogram ini ditunjukkan pada gambar 2.5. Dari gambar tersebut diberikan contoh bila populasi 200, kepercayaan sample 95 %, maka jumlah
sample sekitar 58 % dari populasi. Jadi 0,58 x 200 = 116. Bila populasi 800, kepercayaan sample 90 % atau kesalahan 10 %, maka jumlah sample = 7,5 % dari populasi. Jadi 0.075 x 800 = 60. Terlihat di sini semakin besar kesalahan akan semakin kecil jumlah sample.
Tabel 2.1 Table for determining needed size S of a randomly chosen sample from a given finite population of N cases such that sample proportion will be within + 0.5 of the population proportion P with a 95 percent level of confidence.
N S N S N S
10 10 220 140 1200 291
15 14 230 144 1300 297
20 19 240 148 1400 302
25 24 250 152 1500 306
30 28 260 155 1600 310
35 32 270 159 1700 313
40 36 280 162 1800 317
45 40 290 165 1900 320
50 44 300 169 2000 322
55 48 320 175 2200 327
60 52 340 181 2400 331
65 56 360 186 2600 335
70 59 380 191 2800 338
75 63 400 196 3000 341
80 66 420 201 3500 346
85 70 440 205 4000 351
90 73 460 210 4500 354
95 76 480 214 5000 357
100 80 500 217 6000 361
110 86 550 226 7000 364
120 92 600 234 8000 367
130 97 650 242 9000 368
140 103 700 248 10000 370
150 108 750 254 15000 375
160 113 800 260 20000 377
170 118 850 265 30000 379
180 123 900 269 40000 380
190 127 950 274 50000 381
200 132 1000 278 75000 382
210 136 1100 285 100000 384
Catatan :
N = jumlah sample
S = sample
Contoh :
Bila populasi 200 maka sampelnya 132. Tabel ini khusus untuk tingkat kesalahan 5 %, atau tingkat kepercayaan 95 %.
Gambar 2.5 Nomogram Harry King untuk menentukan ukuran sample dari populasi sampai 2.000
Contoh :
Misal populasi berjumlah 200. Bila dikehendaki kepercayaan sample terhadap populasi 95 % atau tingkat kesalahan 5 %, maka jumlah sample yang diambil 0,58 x 200 = 16 orang. (Tarik dari angka 200 melewati taraf kesalahan 5 %, maka akan ditemukan titik di atas angka 60. Titik itu kurang lebih 58).
Bila ukuran sample lebih dari 100.000 maka peneliti tidak bisa melihat tabel lagi, oleh karena itu peneliti harus dapat menghitung sendiri dengan rumus :
1. 2
p
n pq
≥σ rumus 2.1
Dimana :
n = ukuran sample yang diperlukan
p = prosentase hipotesis (H0) dinyatakan dalam peluang yang besarnya 0,50
q = 1 - 0,50 = 0,50
σp = perbedaan antara yang ditaksir dengan pada hipotesis kerja (Ha) dengan hipotesis nol (H0), dibagi dengan z pada tingkat
kepercayaan tertentu.
2.
. 2
⎥⎦⎤
⎢⎣⎡
≥ b n σ z
rumus 2.2
Dimana :
n = ukuran sample yang diperlukan
b = perbedaan antara yang ditaksir dengan tolok ukur penafsiran.
Z = harganya tergantung pada taraf kepercayaan yang ditetapkan. Pada taraf kepercayaan 68 %, z = 1; 95 % , z = 1,96; dan 99 %, z = 2,58. Untuk harga-harga yang lain bisa dilihat pada tabel kurva normal standart didasarkan pada z1/2 taraf kepercayaan. Taraf kepercayaan 95 % berarti z1/2. 95 % = z 0,475 dalam tabel ditemukan 1,96.
σ = simpangan baku
2.9 METODE PENGUMPULAN DATA
Hal-hal yang perlu diperhatikan dalam pengumpulan data:
1. Elemen (unit sampling atau unit analisis)
Adalah sesuatu yang menjadi obyek penelitian, elemen bisa berupa orang (mahasiswa, karyawan, ibu rumah tangga, petani, nelayan), bisa juga barang atau unit/ satuan organisasi (perusahaan, hewan, kendaraan bermotor), dan sebagainya. Yang penting apakah pengumpulan data dari elemen yang bersangkutan itu berguna atau tidak.
2. Karakteristik
Adalah sifat-sifat, ciri-ciri semua keterangan tentang elemen atau hal-hal apa saja yang dimiliki oleh elemen. Misalkan tabel di bawah ini:
Tabel 2.2 Tabel Karakteristik
Jenis Elemen Karakteristik
Orang Umur, jenis kelamin, pendapatan
Barang Harga barang, mutu barang, berat barang
Perusahaan Jumlah karyawan, jumlah produksi, hasil penjualan Universitas Jumlah mahasiswa, jumlah dosen, ruang kelas
Mengumpulkan data berarti melakukan penyelidikan untuk mengetahui karakteristik elemen-elemen yang menjadi obyek penyelidikan atau mencatat peristiwa/ kejadian atau mencatat karakteristik elemen atau mencatat nilai variabel. Apabila dalam pengumpulan data itu menggunakan kuesioner, maka apa yang ditanyakan dalam kuesioner tersebut sebetulnya merupakan karakteristik yaitu keterangan-keterangan mengenai elemen. Karakteristik yang ditanyakan sangat bergantung pada tujuan penyelidikan, untuk menjamin diperolehnya data yang relevan.
2.10 PENTINGNYA PENYAJIAN DATA
Data statistik tidak cukup dikumpulkan, diolah dan dianalisis, akan tetapi perlu disajikan dalam bentuk yang mudah dibaca dan dimengerti. Penyajian data bisa dalam bentuk tabel-tabel atau gambar-gambar grafik. Banyak orang berpendapat bahwa suatu gambar sama nilainya dengan seribu kata, maksudnya adalah penyajian data akan lebih cepat bisa ditangkap atau dimengerti daripada dengan kata-kata. Itulah sebabnya seringkali dalam suatu laporan harus disertai
dengan tabel-tabel dan grafik-grafik. Bentuk penyajian data lebih bersifat seni daripada sains dan sangat dipengaruhi oleh tujuan pengumpulan data yaitu apa yang ingin kita ketahui dari pengumpulan data itu. Selain itu, juga dipengaruhi oleh analisis data yang akan kita buat. Penyajian data memang bisa berupa angka- angka ringkasan secara terpisah, misalkan jumlah pekerja 100 orang produksi 600 unit, biaya Rp 100.000.000,00; hasil penjualan Rp 200.000.000,00; dan lain sebagainya. Penyajian data berupa angka ringkasan tersebut walaupun berguna akan tetapi manfaatnya masih kurang, sebab sukar untuk digunakan sebagai bahan analisis. Dari 100 orang pekerja itu misalkan berapa yang laki-laki dan berapa yang perempuan, berapa yang tamatan sarjana, SLTA, SMP, dan SD. Dari 600 unit berapa yang jenis A dan berapa yang jenis B, misalkan televisi 14 inch dan 21 inch. Dari biaya sebanyak Rp 100.000.000,00 berapa untuk biaya produksi, misalkan peralatan bahan baku, berapa untuk biaya investasi, misalkan pembelian mesin, perabot kantor. Dari hasil penjualan Rp 200.000.000,00 berapa untuk barang jenis A dan berapa barang untuk jenis B.
Selain berupa angka-angka, ringkasan penyajian data juga bisa dalam bentuk tabel dan grafik. Tabel merupakan kumpulan angka-angka yang disusun sedemikian rupa menurut kategori-kategori misalkan, jumlah pekerja menurut jenis kelamin, menurut pendidikan, dan lain sebagainya. Bentuk tabel bisa bermacam-macam mulai dari bentuk yang sederhana sampai bentuk yang rumit serta sukar membacanya. Tabel yang paling sederhana adalah tabel satu arah, yaitu tabel yang menunjukkan satu hal saja. Tabel dua arah menunjukkan dua hal
sekaligus dan tabel tiga arah menunjukkan tiga hal sekaligus. Tabel mana yang akan digunakan tergantung dari tujuan pengumpulan dan analisis data.
Kebanyakan tabel yang dibuat dalam prakteknya merupakan tabel satu arah atau tabel dua arah, jarang sekali menggunakan tabel tiga arah atau lebih.
Memang perlu diakui banyak informasi yang diperoleh dari suatu tabel maka makin rumit pula bentuk tabelnya, juga seringkali membingungkan bagi yang membacanya. Sebetulnya tabel tiga arah saja sudah cukup rumit, akan tetapi manfaat atau kegunaannya akan lebih besar daripada tabel satu arah atau dua arah.
Grafik merupakan gambar-gambar yang menunjukkan data secara visual berupa angka (mungkin juga dengan simbol-simbol) yang biasanya juga berasal dari tabel-tabel yang telah dibuat. Baik grafik maupun tabel bisa digunakan untuk menyajikan cross section data dan time series data.
Grafik memiliki banyak ragam, sebagai ilustrasi antara lain:
1. Diagram garis (diagram garis tunggal dan diagram garis ganda).
2. Diagram batang (diagram batang tunggal dan diagram batang ganda).
3. Diagram lingkaran (diagram lingkaran tunggal dan ganda).
4. Kartogram merupakan grafik berupa peta.
5. Piktogram merupakan grafik berupa gambar, di dalam bidang koordinasi sumbu XY dinyatakan dalam gambar-gambar dengan suatu ciri khusus untuk suatu karakteristik.
2.11 OBYEK PENELITIAN
Dalam Undang-undang No.13 tahun 2003 tentang Ketenagakerjaan pada pasal satu (1) No.2 dan 3 diberikan pengertian tentang :
“Tenaga kerja adalah setiap orang yang mampu melakukan pekerjaan guna menghasilkan barang/ jasa, baik untuk memenuhi kebutuhan sendiri maupun untuk masyarakat” dan “ Pekerja atau buruh adalah setiap orang yang bekerja dengan menerima upah atau imbalan dalam bentuk lain”. Di zaman penjajahan dahulu istilah buruh disama-artikan dengan orang-orang yang mengerjakan tangan atau pekerjaan “kasar” seperti kuli, mandor, tukang, dan lain sebagainya, yang sejenis dengan pekerjaan kasar, yang di dunia barat sering disebut “blue collar workes”. Sebagai lawan kata dari mereka yang melakukan pekerjaan “halus”
sering disebut sebagai pegawai atau employees dan mereka tergolong “white collar workes”. Employee di negara barat digunakan untuk menamakan orang yang dipekerjakan oleh orang lain.
Dalam Undang-undang No.13 tahun 2003 dibedakan antara tenaga kerja dengan pekerja atau buruh. Tenaga kerja adalah mereka yang potensial untuk bekerja, berarti bahwa mereka bisa belum bekerja. Sedangkan pekerja atau buruh adalah potensi yang sudah terikat hubungan pekerjaan dengan pengusaha dengan menerima upah atau imbalan dalam bentuk lain. Dengan demikian dihindari timbulnya perbedaan antara “blue collar workes” dan “white collar workes”
antara buruh dengan pelayan, walaupun banyak pengertian tentang siapa itu buruh, namun pada dasarnya dapat disimpulkan buruh itu adalah seorang yang
menjalankan pekerjaan untuk orang lain atau badan, dalam hubungan kerja dengan menerima upah atau imbalan dalam bentuk lain.
2.12 ARTI SENSUS DAN SAMPLING
Sebelumnya sudah disebutkan, apabila populasi sudah jelas, kemudian harus ditentukan cara pengumpulan datanya, apakah seluruh elemen harus diselidiki satu persatu atau hanya cukup menyelidiki sampelnya saja. Dengan perkataan lain, kita gunakan teknik sensus atau sampling.
Sensus adalah cara pengambilan data kalau seluruh elemen populasi diselidiki satu persatu sehingga sensus sering disebut pencatatan atau perhitungan yang lengkap dari seluruh elemen populasi. Menurut definisi, sensus memberikan hasil data dengan nilai sebenarnya (true value atau parameter).
Sedangkan sampling adalah cara pengumpulan data jika hanya elemen sampelnya saja yang diselidiki, tidak seluruhnya. Hasil sampling merupakan data dengan nilai perkiraan (estimate value).
Kalau kita mendengar sensus, kita selalu menghubungkan dengan kegiatan nasional seperti sensus penduduk, sensus industri, sensus pertanian, dan sebagainya. Sebenarnya, walaupun bukan kegiatan nasional tetapi seluruh elemen populasi diselidiki, sebenarnya kegiatan sensus sudah dilakukan. Misalkan seluruh pegawai di suatu perusahaan diselidiki untuk mengetahui persentase sebenarnya yang tamatan SLTA, Universitas, dan sebagainya.
Yang jelas pada umumnya biaya sensus itu mahal, tenaga yang dibutuhkan banyak, sedangkan waktu yang diperlukan untuk pengolahan juga lama. Ada
kemungkinan data hasil sensus tidak up to date lagi. Sebetulnya pengolahan data bisa dipercepat dengan menggunakan komputer elektronik tetapi biayanya pasti mahal. Untuk menghemat waktu dan tenaga, teori statistik modern telah mengembangkan beberapa teknik sampling yang merupakan metode pengumpulan data yang efisien. Maksudnya dengan biaya, tenaga, dan waktu yang sama, metode yang efisien bisa memberikan data dengan tingkat ketelitian yang tinggi.
Untuk mudahnya suatu nilai perkiraan dikatakan baik kalau selisihnya atau jarak terhadap nilai sebenarnya kecil. Selisih tersebut dinamakan kesalahan prakiraan (error estimate) atau kesalahan sampling (sampling error). Misalkan rata-rata pendapatan atau upah pekerja sebulan sebesar Rp 10.000,00 kemudian diprakirakan dengan berbagai cara, misalkan cara (1) Rp 9.000,00; cara (2) Rp 10.500,00; cara (3) Rp 9.500,00; cara (4) Rp 10.300,00; cara (5) Rp 9.999,00.
Walaupun semua prakiraan tadi salah, akan tetapi cara (5) memberikan cara prakiraan yang lebih baik, sebab jaraknya terhadap nilai yang sebenarnya paling kecil yaitu 10.000 – 9.999 = 1.
Dengan bahasa teknis statistika, bisa dikatakan bahwa suatu prakiraan dengan kesalahan baku (standart error) yang terkecil dan rata-rata sama dengan
“nilai yang sebenarnya”, dikatakan sebagai prakiraan terbaik. Kesalahan baku merupakan suatu nilai yang secara rata-rata mengukur jarak nilai prakiraan dari seluruh kemungkinan sampel terhadap nilai sebenarnya yang sering disebut nilai harapan (expected value).
2.13 PERHITUNGAN STATISTIK
Agar hasil perhitungan itu bisa berlaku umum, maka perlu menggunakan rumusan-rumusan yang sudah dibuat untuk keperluan penelitian. Perlu diperhatikan bahwa perhitungan-perhitungan hanya untuk sampel. Oleh karena penyelidikan statistik pada umumnya merupakan penyelidikan terhadap sampel.
Penelitian ini menggunakan perhitungan rata-rata, sedangkan dalam statistik ada tiga jenis rata-rata yang amat penting digunakan dalam statistik, yaitu:
1. Mean (rata-rata hitung)
Adalah suatu nilai yang diperoleh dengan jalan membagi seluruh nilai pengamatan dengan banyaknya pengamatan.
Dengan rumus sebagai berikut :
n
Xn Xi
X
X = X1+ 2+...+ +...+
∑
== n
i
n Xi X
1
1
Misalkan ada 5 orang sebagai suatu sampel dari pekerja di perusahaan kontraktor “J”, gaji mereka perhari masing-masing sebesar Rp 50.000,00;
Rp 45.000,00; Rp 47.000,00; Rp 43.000,00; Rp 40.000,00 5
, 4 , 3 , 2 , 1
:X X X X X sampel
→ (X menunjukkan gaji).
5
5 4 3 2
1 X X X X
rata X
Rata− = + + + +
→
5
40000 43000
47000 45000
50000+ + + +
=
−
→Rata rata
45000
=
−
→Rata rata
Jadi rata-rata prakiraan gaji pekerja perhari dari perusahaan kontraktor “J”
sebesar Rp 45.000,00.
2. Median
Adalah suatu nilai tengah setelah data statistik diurutkan dari yang terkecil sampai yang terbesar atau dari yang terbesar sampai yang terkecil.
Pengamatan yang tepat di tengah bila banyaknya pengamatan ganjil, atau rata-rata kedua pengamatan yang di tengah bila banyaknya pengamatan genap.
Misalkan: 97, 68, 85, 77, 95; setelah diurutkan menjadi 68, 77, 85, 95, 97;
sehingga median = 85.
Misalkan: 6, 7, 3, 1, 9, 8, 2, 4; setelah diurutkan menjadi 1, 2, 3, 4, 6, 7, 8, 9; sehingga median 5
2 6 4+ =
= .
3. Modus
Adalah suatu nilai yang terjadi paling sering atau yang mempunyai frekuensi paling tinggi.
Misalkan: 4, 5, 4, 2, 5, 5, 1 Maka, Nilai 1 ada sebanyak 1
Nilai 2 ada sebanyak 1 Nilai 4 ada sebanyak 2 Nilai 5 ada sebanyak 3
Kemudian dibuat tabel yang disebut tabel frekuensi.
Tabel frekuensi adalah suatu tabel yang menunjukkan beberapa kali nilai X terjadi.
Tabel 2.3 Tabel Frekuensi
x f 1
2 4 5
1 1 2 3
f = frekuensi (bilangan yang menunjukkan berapa nilai X terjadi) Maka modus atau X = 5 terjadi sebanyak 3 kali.
2.14 ARTI DAN KEGUNAAN HIPOTESIS SERTA CARA PENGUJIANNYA
Hipotesis adalah suatu proporsi, kondisi atau prinsip yang dianggap benar atau barangkali tanpa keyakinan, agar bisa ditarik suatu konsekuensi yang logis dan dengan cara ini kemudian diadakan pengujian (testing) tentang kebenarannya dengan menggunakan fakta-fakta (data) yang ada. Secara kuantitatif, hipotesis berarti pernyataan nilai suatu parameter yang sementara waktu dianggap benar.
Parameter adalah nilai sebenarnya (true value) yang diperoleh kalau seluruh obyek diselidiki satu persatu (Supranto.J. 2001).
Banyak sekali riset dilakukan seseorang untuk menguji hipotesis.
Hipotesis merupakan suatu pernyataan atau statement tentang sesuatu yang dibuat
oleh seseorang yang untuk sementara waktu dianggap benar. Pernyataan tersebut sebelum menjadi pernyataan resmi yang mungkin untuk dasar kebijakan selanjutnya seyogyanya diuji terlebih dahulu untuk kebenarannya dengan menggunakan data hasil pengamatan. Karena sebuah pernyataan dapat berakibat kurang baik apabila pernyataan tersebut salah, dalam arti tidak sesuai dengan hasil sebuah penelitian.
Sebetulnya pengujian hipotesis tidak hanya di dalam riset, sebab di dalam kehidupan sehari-haripun seringkali pekerja, pimpinan, atau usahawan mendasarkan kebijakannya, tindakannya, keputusannya atas pendapatnya, anggapan, atau asumsi atau hipotesis yang belum tentu kebenarannya. Jadi suatu hipotesis perlu diuji terlebih dahulu. Hipotesis yang sifatnya kualitatif sulit diuji.
Ilmu statistik memberikan kriteria-kriteria untuk pengujian kuantitatif (criteria for testing hypothesis) dalam bentuk fungsi-fungsi.
Seperti telah disebutkan berulang kali data dengan nilai yang sebenarnya hanya bisa diperoleh dengan melakukan penyelidikan satu persatu terhadap suatu karakteristik dari seluruh elemen (obyek) penyelidikan (populasi). Padahal sudah kita sadari juga, walaupun dilakukan penyelidikan satu persatu terhadap seluruh elemen belum tentu bisa diperoleh nilai sebenarnya. Hal ini disebabkan adanya kesalahan yang disebut non sampling error (kesalahan mencatat, melihat, menjawab, mengingat, menimbang, dsb).
Kebenaran hipotesis ini harus diuji menggunakan suatu criteria (biasanya berbentuk fungsi: fungsi normal, fungsi t, fungsi F, fungsi chi-kuadrat, dan sebagainya) yang harus dihitung berdasarkan sampel.
Oleh karena hasil perhitungan akan digunakan untuk memutuskan, menolak, atau menerima hipotesis (rejecting or accepting hypothesis) ini merupakan prakiraan (estimate), hasil perhitungan dari sample maka ada kemungkinan kita berbuat kesalahan (committing error), maksudnya kita menolak hipotesis padahal benar, atau kita menerima hipotesis padahal salah.
Perlu kita sadari bahwa sebagai manusia kita tidak bisa membuat keputusan selalu benar, adakalanya salah. Tujuan kita adalah harus memperkecil jumlah keputusan yang salah (minimized the member of wrong decision) misalnya dalam 100 kali membuat keputusan, mungkin 10 kali salah, mungkin 5 kali atau 1 kali salah.
Sekarang persoalannya berapa persen kita akan mentolerir kesalahan tersebut (tolerated error) sama halnya berapa persen barang kita toleransi boleh rusak (toleranted defective goods).
Kesalahan jenis I adalah besarnya kesalahan yang kita toleransi sewaktu kita menolak hipotesis nol (H0) padahal hipotesis itu benar. Sedangkan kesalahan jenis II, ialah kesalahan yang kita toleransi sewaktu menerima hipotesis nol (H0) padahal hipotesis itu salah.
Hipotesis yang akan diuji diberi symbol (hipotesis nol = null hypothesis) dengan alternative (alternative hypothesis). Kesalahan jenis ke I biasanya diberi symbol α(baca: alpha). Dalam persoalan bisnis biasanya = 0.05 (5%) bisa juga 1% atau 10%, sedangkan kesalahan jenis II dengan symbol β (baca: betha).
Pengujian Hipotesis Rata-rata:
1. Perumusan H0 : μ =
μ
0H1 : μ ≠
μ
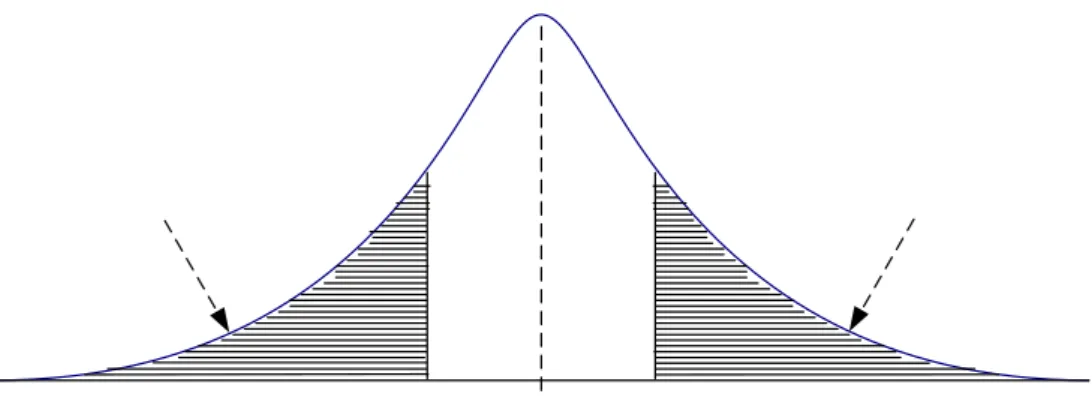
0 uji dua arah (menggunakan 2 ujung kurva normal) H1 mempunyai perumusan tidak sama dengan, maka dalam distribusi statistik yang digunakan adalah normal untuk angka Z atau student untuk t dan seterusnya. Didapat dua daerah kritis masing-masing pada ujung-ujung distribusi. Luas daerah kritis masing-masing pada ujung-ujung distribusi yaitu ½α. Karena adanya dua daerah penolakan ini, maka pengujian hipotesis dinamakan uji dua pihak.Gambar di bawah ini memperlihatkan sketsa distribusi yang digunakan disertai daerah-daerah yang penerimaan dan penolakan hipotesis. Kedua daerah ini dibatasi oleh Z1 dan Z2 yang harganya didapat dari daftar distribusi yang bersangkutan dengan menggunakan peluang yang ditentukan oleh α. Kriteria yang didapat adalah : terima hipotesis H0 jika angka statistik yang dihitung berdasarkan data penelitian berada diantara Z1 dan Z2, jika tidak demikian H0 ditolak.
Gambar 2.6 Uji Dua Arah (Two Tail Test)
2. Perumusan H0 : μ =
μ
0H1 : μ >
μ
0 uji satu arah (menggunakan satu ujung kurva normal).H1 mempunyai perumusan lebih besar, maka dalam distribusi yang digunakan didapat sebuah daerah kritis yang letaknya di ujung sebelah kanan. Luas daerah kritis atau daerah penolakan ini sama dengan α. Harga Z, didapat dari daftar distribusi yang bersangkutan dengan peluang yang ditentukan oleh α, menjadi batas antara daerah kritis dan daerah penerimaan H0. Kriteria yang dipakai adalah : tolak H0 jika angka statistik yang dihitung berdasarkan sample tidak kurang dari Z. Jika tidak demikian kita terima H0. Pengujian ini dinamakan uji satu pihak, tepatnya pihak sebelah kanan.
α Z Gambar 2.7 Uji Satu Arah (Kanan)
3. Perumusan H0 : μ =
μ
0H1 : μ <
μ
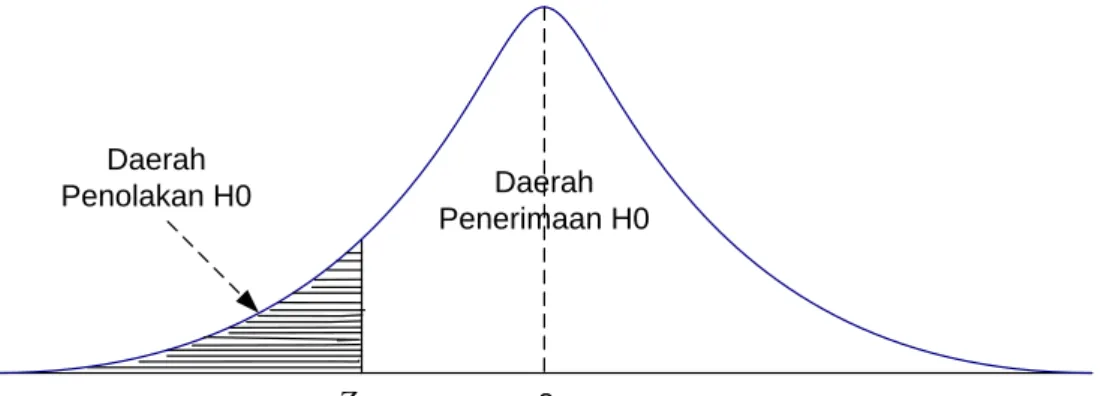
0 uji satu arah (menggunakan 1 ujung kurva normal) H1 mempunyai perumusan lebih kecil, maka daerah kritis letaknya di ujung sebelah kiri dari distribusi yang digunakan. Luas daerah ini sama dengan α yang menjadi batas daerah penerimaan H0 oleh bilangan Z yang didapat dari daftar distribusi yang bersangkutan. Peluang untuk mendapatkan Z ditentukan oleh taraf nyata α. Kriteria yang dipakai adalah : tolak H0 jika angka statistik yang dihitung berdasarkan penelitian lebih kecil dari Z.Jika tidak demikian kita terima H0. Pengujian ini dinamakan uji satu pihak, tepatnya pihak sebelah kiri.
0
Z Daerah
Penerimaan H0 Daerah
Penolakan H0
α Z
Gambar 2.8 Uji Satu Arah (Kiri)
Kriteria pengujian :
( )
σ
μ
X σμ
nn X
Z
0= − 0 = − 0Keterangan :
X = Nilai rata-rata sample (hasil penyelidikan atau pengamatan)
μ
0 = Nilai hipotesisn = Banyaknya elemen sample σ = simpangan baku
( )
21
1
∑
=
−
= n
i
X n Xi
S
Prakiraan untuk σ , kalau σ tidak diketahui
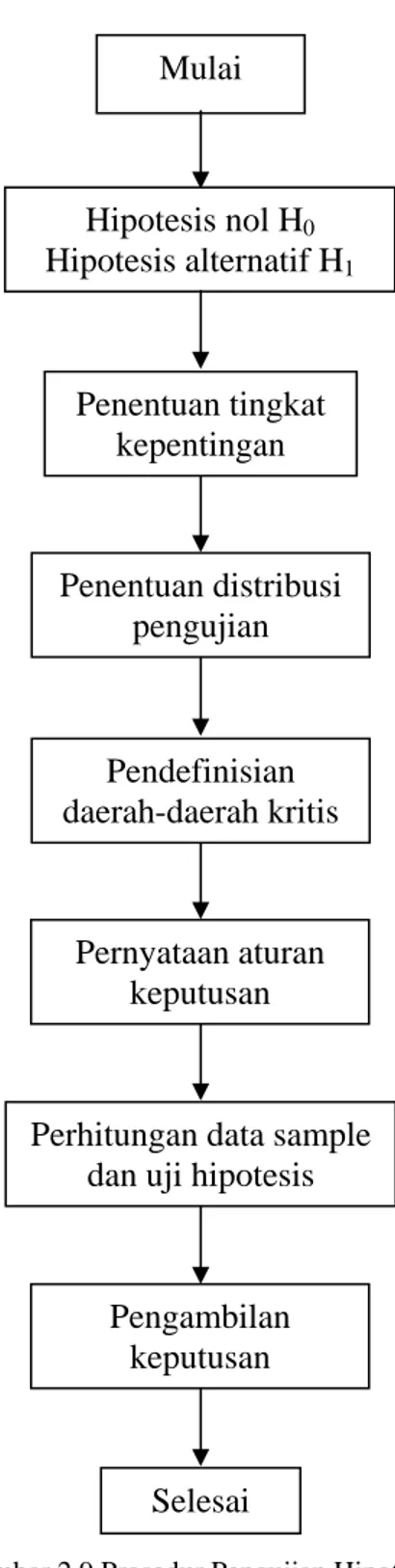
2.15 PROSEDUR UMUM UJI HIPOTESIS Terdapat tujuh langkah dalam prosedur pengujian:
1. Pernyataan hipotesis nol dan hipotesis alternatif.
Langkah pertama adalah menyatakan dengan spesifik nilai-nilai parameter yang diasumsikan sebelum sampling dilakukan.
Hipotesis nol (H0) adalah asumsi yang akan diuji. Hipotesis nol dinyatakan dalam hubungan sama dengan ( = ). Jadi hipotesis nol menyatakan bahwa suatu parameter (mean, persentase, varians, dll) bernilai sama dengan nilai tertentu. Hipotesis alternatif (H1) adalah segala hipotesis yang berbeda dari hipotesis nol. Hipotesis alternatif merupakan kumpulan hipotesis yang diterima dengan menolak hipotesis nol. Pemilihan hipotesis nol ini tergantung pada sifat dari masalah yang dihadapi.
2. Tingkat kesalahan/ taraf nyata (α).
Tingkat kesalahan menyatakan suatu tingkat resiko melakukan kesalahan atau menolak hipotesis nol. Dengan kata lain tingkat kesalahan menunjukkan probabilitas maksimum yang ditetapkan untuk mengambil resiko terjadinya kesalahan pertama. Dalam prakteknya tingkat kesalahan yang biasa digunakan adalah 0.05 atau 0.1 artinya keputusan itu bisa salah dengan probabilitas 0.05 atau 0.1.
3. Penentuan distribusi pengujian yang digunakan.
Pada pengujian hipotesis juga digunakan distribusi-distribusi probabilitas teoritas, meliputi distribusi normal standart (Z), distribusi t, distribusi chi- kuadrat.
4. Pendefinisian daerah-daerah penolakan (kritis).
Daerah penolakan (daerah kritis) adalah bagian daerah dari distribusi sampling yang dianggap tidak memuat suatu statistik sample jika hipotesis nol (H0) benar. Sedangkan daerah selebihnya disebut sebagai daerah penerimaan.
5. Pernyataan aturan keputusan.
Suatu aturan keputusan adalah pernyataan formal mengenai kesimpulan yang tepat yang akan dicapai mengenai hipotesis nol berdasarkan hasil- hasil sample format umum dari sebuah aturan keputusan adalah “Tolak H0
jika perbedaan yang telah distandarkan, misalnya antara X atau
μ
oberada di dalam daerah penolakan, jika sebaliknya terima H0”.6. Perhitungan pada data sample dan perhitungan uji hipotesis.
Setelah aturan-aturan dasar ditentukan untuk melaksanakan pengujian, langkah berikutnya adalah menganalisa data aktual. Sebuah sample dikumpulkan, statistik sample dihitung dan asumsi parameter dilakukan (hipotesis nol). Kemudian uji hipotesis dihitung yang kemudian dijadikan dasar dalam menentukan apakah hipotesis akan diterima atau ditolak.
Hipotesis uji ini adalah perbedaan antara statistik dan parameter asumsi yang dinyatakan dalam hipotesis nol yang telah distandarkan.
7. Pengambilan keputusan.
Jika nilai ratio uji berada di daerah penolakan maka hipotesis nol di tolak.
Prosedur pengujian hipotesis yang diuraikan di atas dapat digambarkan dengan diagram alir seperti yang ditunjukkan dalam gambar berikut:
Mulai
Hipotesis nol H0 Hipotesis alternatif H1
Penentuan distribusi pengujian
Pendefinisian daerah-daerah kritis
Pernyataan aturan keputusan
Perhitungan data sample dan uji hipotesis
Pengambilan keputusan
Selesai Penentuan tingkat
kepentingan
Gambar 2.9 Prosedur Pengujian Hipotesis