9
Pada Bab 2 ini, penulis menjelaskan beberapa teori yang berhubungan dengan perancangan aplikasi analisis sistem koreksi soal esai ini. Teori-teori tersebut antara lain adalah Taksonomi Bloom yang digunakan untuk mengetahui tipe soal ujian mengarah pada level kognitif, pengertian tentang database serta intelegensia semu, tahapan dan proses-proses dalam Natural Language Processing, kaidah-kaidah dalam tata bahasa Indonesia, Unified Modelling Language beserta diagram-diagram, serta metodologi penelitian dengan System Development Life Cycle.
2.1 Taksonomi Bloom
2.1.1 Pengertian Taksonomi Bloom
Menurut Benjamin S. Bloom (1956), Taksonomi Bloom merujuk pada tujuan pendidikan dibagi menjadi beberapa domain (ranah, kawasan) dan setiap domain tersebut dibagi kembali ke dalam pembagian yang lebih rinci berdasarkan hirarkinya.
Beberapa istilah lain yang juga menggambarkan hal yang sama dengan ketiga domain tersebut di antaranya seperti yang diungkapkan oleh Ki Hajar Dewantoro, yaitu: cipta, rasa, dan karsa. Selain itu, juga dikenal istilah: penalaran, penghayatan, dan pengamalan.
Dari setiap ranah tersebut dibagi kembali menjadi beberapa kategori dan subkategori yang berurutan secara hirarkis (bertingkat), mulai dari tingkah laku yang sederhana sampai tingkah laku yang
paling kompleks. Tingkah laku dalam setiap tingkat diasumsikan menyertakan juga tingkah laku dari tingkat yang lebih rendah, seperti misalnya dalam ranah kognitif, untuk mencapai “pemahaman” yang berada di tingkatan kedua juga diperlukan “pengetahuan” yang ada pada tingkatan pertama.
2.1.2 Domain Kognitif / Ranah Kognitif
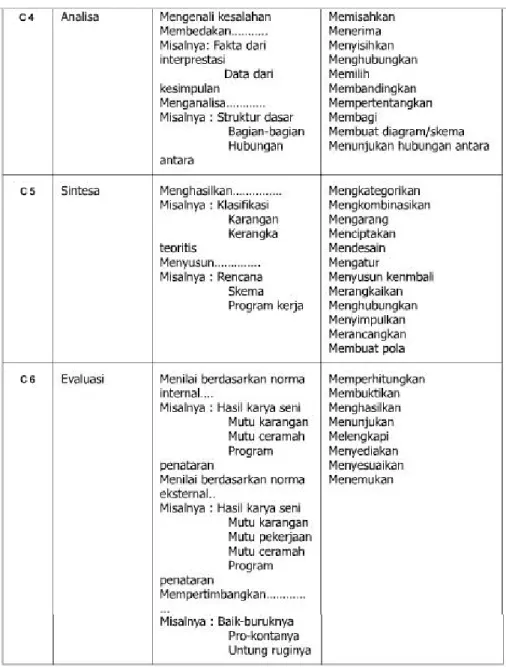
Domain yang berisi perilaku-perilaku yang menekankan aspek intelektual, seperti pengetahuan, pengertian, dan keterampilan berpikir. Domain dikognisi ke dalam 6 tingkatan. Domain ini terdiri dari dua bagian, yaitu Bagian pertama adalah berupa Pengetahuan (C1) dan bagian kedua berupa Kemampuan dan Keterampilan Intelektual (C2 – C6)
a. Pengetahuan (Knowledge) / C1 : Berisikan kemampuan untuk mengenali dan mengingat peristilahan, definisi, fakta-fakta, gagasan, pola, urutan, metodologi, prinsip dasar, dsb. Sebagai contoh, ketika diminta menjelaskan manajemen kualitas, orang yang berada di level ini bisa menguraikan dengan baik definisi dari kualitas, karakteristik produk yang berkualitas, standar kualitas minimum untuk produk, dsb.
b. Pemahaman (Comprehension) / C2 : Dikenali dari kemampuan untuk membaca dan memahami gambaran, laporan, tabel, diagram, arahan, peraturan, dsb.
c. Aplikasi (Application) / C3 : Di tingkat ini, seseorang memiliki kemampuan untuk menerapkan gagasan, prosedur, metode, rumus, teori, dsb di dalam kondisi kerja. Sebagai contoh, ketika diberi informasi tentang penyebab meningkatnya reject di produksi, seseorang yang berada di tingkat aplikasi akan mampu merangkum dan menggambarkan penyebab turunnya kualitas.
d. Analisis (Analysis) / C4 : Di tingkat analisis, seseorang akan mampu menganalisa informasi yang masuk dan membagi-bagi atau menstrukturkan informasi ke dalam bagian yang lebih kecil untuk mengenali pola atau hubungannya, dan mampu mengenali serta membedakan faktor penyebab dan akibat dari sebuah skenario yang rumit. Sebagai contoh, di level ini seseorang akan mampu memilah-milah penyebab meningkatnya reject, membanding-bandingkan tingkat keparahan dari setiap penyebab, dan menggolongkan setiap penyebab ke dalam tingkat keparahan yang ditimbulkan.
e. Sintesis (Synthesis) / C5 : Satu tingkat di atas analisa, seseorang di tingkat sintesa akan mampu menjelaskan struktur atau pola dari sebuah skenario yang sebelumnya tidak terlihat, dan mampu
mengenali data atau informasi yang harus didapat untuk menghasilkan solusi yang dibutuhkan. Sebagai contoh, di tingkat ini seorang manajer kualitas mampu memberikan solusi untuk menurunkan tingkat reject di produksi berdasarkan pengamatannya terhadap semua penyebab turunnya kualitas produk.
f. Evaluasi (Evaluation) / C6 : Dikenali dari kemampuan untuk memberikan penilaian terhadap solusi, gagasan, metodologi, dsb dengan menggunakan kriteria yang cocok atau standar yang ada untuk memastikan nilai efektivitas atau manfaatnya. Sebagai contoh, di tingkat ini seorang manajer kualitas harus mampu menilai alternatif solusi yang sesuai untuk dijalankan berdasarkan efektivitas, urgensi, nilai manfaat, nilai ekonomis, dsb.
Gambar 2.1 Contoh Kata-kata Kerja Operasional Ranah Kognitif
2.2 Basis Data
2.2.1 Pengertian Basis Data
Menurut Connolly dan Begg (2005, p15), basis data adalah sekumpulan data-data yang dapat digunakan bersama-sama dan saling
berhubungan secara logika, deskripsi dari data-data tersebut, dirancang untuk memenuhi kebutuhan informasi yang diperlukan oleh suatu perusahaan.
Menurut Abdul Kadir (2004, p6), basis data adalah suatu penyusunan terstruktur yang disimpan dalam media pengingat (harddisk) yang tujuannya adalah agar data tersebut dapat diakses dengan mudah dan cepat.
Menurut Whitten (2004, p58), basis data adalah file yang saling berhubungan di mana setiap baris pada suatu basis data juga harus saling terhubung dengan baris pada file lain. Dapat disimpulkan bahwa basis data menyimpan data yang saling berhubungan yang dibutuhkan oleh suatu organisasi untuk menyediakan informasi-infomasi yang berguna.
Basis data adalah sekumpulan data yang terstruktur, dirancang untuk memenuhi kebutuhan informasi sebuah organisasi dan dapat diakses dengan mudah dan cepat. Suatu sistem basis data terdiri dari empat komponen yaitu data, yang secara fisik menyimpan informasi-informasi; Database Management System (DBMS), Data Description Language (DDL), dan Data Manipulation Language (DML). Berikut adalah keuntungan, kelemahan, dan tujuan basis data.
Keuntungan Basis Data:
a. Data dapat digunakan secara bersama-sama b. Data dapat distandarisasi
d. Kemandirian data
e. Keamanan data dapat dijaga f. Integritas data dapat dipertahankan g. Menyediakan recovery
h. Mencegah ketidakkonsistenan
Kelemahan Basis Data:
a. Storage yang digunakan menjadi besar
b. Dibutuhkan tenaga yang teampil dalam mengolah data c. Perangkat lunaknya mahal
d. Kerusakan pada sistem basis data dapat mempengaruhi departemen yang terkait
e. Terjadi deadlock
Tujuan Basis Data:
a. Efisiensi meliput speed, space, dan accurancy b. Menangani data dalam jumlah besar
c. Kebersamaan pemakaian (shareability)
d. Meniadakan duplikasi dan data yang tidak konsisten
2.2.2 Database Management System (DBMS)
Menurut Connolly dan Begg (2005, p16), DBMS adalah sistem piranti lunak yang memungkinkan pengguna untuk menentukan, menciptakan, memelihara, dan mengendalikan akses ke dalam database (basis data).
Menurut Whitten (2004, p554), sebuah basis data yang besar memerlukan sebuah perangkat lunak untuk mengatur basis data tersebut secara keseluruhan. Perangkat lunak yang dapat digunakan untuk membuat, mengakses, mengontrol, dan mengatur suatu basis data dinamakan sistem manajemen basis data, biasa disebut dengan database management system, disingkat DBMS.
DBMS adalah software yang dirancang untuk mengatur, mengembangkan serta mengakses database dengan ukuran besar sesuai dengan kebutuhan organisasi.
Komponen Database Management System (DBMS) menurut Connolly dan Begg (2005, p18) yaitu:
a. Hardware (Perangkat Keras) : Perangkat keras yang dibutuhkan untuk menjalankan DBMS dan aplikasi-aplikasi.
Contoh : single personal computer, single mainframe, atau komputer yang menggunakan jaringan
b. Software (Perangkat Lunak) : Komponen perangkat lunak terdiri dari perangkat lunak DBMS itu sendiri dan program-program aplikasi, bersama dengan sistem operasi, termasuk perangkat lunak jaringan jika DBMS menggunakan jaringan.
Contoh : ‘C’, ‘C++’, Java, Visual Basic, COBOL. c. Data
Data merupakan komponen yang paling penting dari DBMS, khususnya dari sudut pandang pemakai akhir mengenai data.
d. Prosedur
Cara untuk menjalankan sistem, seperti bagaimana masuk ke dalam DBMS, memulai dan menghentikan DBMS, bagaimana membuat data backup
e. Manusia
Komponen terakhir adalah manusia yang terlibat dengan sistem, termasuk didalamnya adalah Database Administrator (DBA), perancangan database, pengembang aplikasi, dan pemakai akhir.
Keuntungan yang diberikan oleh DBMS seperti: a. Mengontrol duplikasi data
Database menghilangkan data yang redundan dengan menyatukan file-file, sehingga data yang ganda tidak akan disimpan.
b. Data yang konsisten
Dengan menghilangkan atau mengontrol data yang redundan, sudah mengurangi resiko data yang tidak konsisten.
c. Informasi yang sama
Dengan menggunakan DBMS, data bisa didapat dari beberapa sumber yang sama setelah data tersebut diintegrasikan.
d. Membagi data
Database tidak lagi hanya dimiliki oleh departemen atau bagian tertentu saja, tetapi database menjadi milik organisasi dan bisa di-share oleh semua user yang memiliki hak akses.
e. Meningkatkan kesatuan data
Kesatuan data menunjukan bahwa data yang disimpan adalah valid dan konsisten.
f. Meningkatkan keamanan
Keamanan melindungi database dari orang-orang yang tidak mempunyai hak akses terhadap database tersebut.
g. Meningkatkan standar
Terdiri dari sebuah standar format data dari departemen, organisasi, nasional, maupun internasional seperti fasilitas perubahan data, penamaan, dan peng-update-an prosedur.
h. Penghematan
Penghematan biaya bisa dilakukan dengan menggabungkan semua data operasional suatu organisasi ke dalam satu database, dan membuat aplikasi yang bekerja dengan satu sumber data saja. i. Menyeimbangkan kebutuhan masalah
Database Administrator (DBA) akan membuat keputusan tentang rancangan dan penggunaan database secara operasional yang menyediakan kebutuhan yang terbaik untuk seluruh organisasi. j. Meningkatkan pengaksesan data
DBMS menyediakan query language atau report writers yang memungkinkan user untuk bertanya tentang pertanyaan-pertanyaan ad-hoc dan memperoleh informasi yang dibutuhkan tanpa melibatkan programmers untuk mengambil informasi tersebut ke dalam database.
k. Meningkatkan produktivitas
DBMS dapat menyederhanakan pengembangan dari suatu aplikasi database sehingga dapat meningkatkan produktivitas programmer dan mengurangi waktu pengembang.
l. Meningkatkan pemeliharaan data independen
DBMS memisahkan deskripsi database dari program aplikasi, sehingga program aplikasi tidak dapat mengubah database.
m. Meningkatkan ketepatan
Sering kali lebih dari satu user mengakses file yang sama, dengan adanya DBMS ketepatan database akan diatur.
n. Meningkatkan backup dan perbaikan
File-based system menyediakan batasan-batasan terhadap user untuk menjaga data dari kesalahan dari sistem komputer atau program aplikasi. Jika terjadi kesalahan, backup akan di-restore dan pekerjaan setelah backup akan dihilangkan
Kelemahan yang dimiliki oleh DBMS seperti : a. Kompleks
DBMS merupakan bagian dari software yang sangat kompleks. Kesalahan terhadap pengertian sistem akan mengakibatkan rancangan keputusan yang buruk pada suatu organisasi.
b. Ukuran
Karena DBMS sangat kompleks membuat harus menyediakan disk dan memory dengan kapasitas yang besar.
c. Biaya DBMS
Biaya sebuah DBMS tergantung dari lingkungan dan fungsi yang disediakan.
d. Harga hardware
Untuk mendapatkan tampilan yang bagus, membutuhkan mesin yang bagus dengan menambahkan hardware yang harganya tidak murah.
e. Biaya perubahan
Jika terjadi perubahan akan memakan banyak biaya seperti biaya hardware, DBMS yang baru, termasuk biaya pelatihan karyawan. f. Tampilan
DBMS hanya bisa dijalankan pada beberapa aplikasi saja. g. Tingkat kegagalan tinggi
Dengan adanya sentralisasi penyimpanan akan mengakibatkan sistem cepat rusak. Penggunaan DBMS akan mengakibatkan operasi berhenti jika terjadi kesalahan.
2.2.3 Entity Relationship Modelling
Menurut Connolly dan Begg (2005, p342), salah satu aspek yang sulit dalam perancangan basis data adalah kenyataan bahwa perancang, programmer, dan pemakai akhir cenderung melihat data dengan cara yang berbeda. Untuk memastikan pemahaman secara alamiah dari data dan bagaimana data digunakan oleh perusahaan dibutuhkan sebuah bentuk komunikasi yang non-teknis dan bebas dari kebingungan.
2.2.3.1 Entity Type
Tipe entity adalah kumpulan objek-objek dengan property yang sama, yang di definisikan oleh perusahaan yang keberadaannya tidak tergantung.
Konsep dasar dari bentuk Entity Relationship adalah tipe entitas. Sebuah tipe entitas memiliki keberadaan yang bebas dan menjadi objek dengan keberadaan fisik atau menjadi objek dengan keberadaan konseptual. Ini berarti perancang yang berbeda mungkin mengidentifikasi entitas yang berbeda.
Entity Occurrence adalah objek dan tipe entitas yang dapat diidentifikasikan secara unik.
2.2.3.2 Relationship Type
Tipe relationship adalah sebuah gabungan yang mempunyai arti diantara tipe-tipe entitas. Setiap tipe relationship diberi nama sesuai dengan fungsinya. Relationship occurrence adalah suatu gabungan yang dapat diidentifikasi secara unik, yang meliputi suatu kejadian dari setiap tipe entitas yang berpartisipasi.
2.2.3.3 Attributes
Attribute adalah sifat dari sebuah entitas atau sebuah tipe relationship. Atribut menyimpan nilai dari setiap entity occurence dan mewakili bagian utama dari data yang disimpan
dalam basis data. Attribute domain adalah satuan nilai-nilai untuk satu atau beberapa atribut. Setiap atribut yang dihubungkan dengan sejumlah nilai disebut domain. Domain mendefinisikan nilai-nilai yang dimiliki oleh sebuah atribut dan sama dengan konsep domain pada model relational.
Simple attribute adalah atribut yang terdiri dari komponen tunggal dengan keberadaan yang bebas. Simple attribute tidak dapat dibagi lagi ke dalam komponen yang lebih kecil lagi, misalnya posisi dan gaji dari entitas pegawai.
Composite attribute adalah atribut yang terdiri dari banyak komponen dengan sebuah keberadaan yang bebas. Contohnya atribut alamat dari kantor cabang yang mengandung nilai (jalan, kota, kode pos) bisa dipecahkan menjadi atribut sederhana jalan, kota, dan kode pos.
Single value attribute adalah atribut yang memiliki nilai tunggal untuk masing-masing kejadian dari entitas. Multi value attribute adalah atribut yang memiliki banyak nilai untuk masing-masing kejadian dari entitas.
Derived attribute adalah atribut yang menggantikan sebuah nilai yang diturunkan dari nilai sebuah atribut yang berhubungan, tidak perlu pada jenis entitas yang sama.
2.2.3.4 Keys
Candidate key adalah kunci yang secara unik mengenali setiap kejadian di dalam tipe entitas. Sebuah
candidate key tidak boleh NULL. Sebuah entitas mungkin punya lebih dari satu candidate key.
Primary key adalah candidate key yang dipilih sebagai kunci primer untuk mengenali secara unik setiap occurence dari sebuah tipe entity.
Pemilihan primary key untuk sebuah entitas berdasarkan pada pertimbangan panjang atribut, jumlah minimal dari kebutuhan atribut dan memiliki keunikan. Candidate key yang tidak terpilih sebagai primary key akan disebut sebagai alternative key.
Composite key adalah candidate key yang terdiri dari dua atribut atau lebih. Foreign key adalah atribut pada satu relasi yang cocok pada candidate key dari beberapa relasi.
2.3 Intelegensia Semu
2.3.1 Pengertian Intelegensia Semu
Intelegensia Semu (IS) atau Artificial Intelligence (AI) atau Kecerdasan Buatan merupakan bagian dari Ilmu Komputer yang menciptakan kecerdasan pada mesin (komputer) agar dapat melakukan pekerjaan seperti yang dilakukan oleh manusia.
Kecerdasan buatan (Artificial Intelligence) dapat diartikan sebagai kecerdasan yang ditunjukkan oleh suatu entitas buatan. Sistem seperti ini umumnya dianggap sebagai komputer. Kecerdasan buatan ini bukan hanya ingin mengerti apa itu sistem kecerdasan, tapi juga mengkonstruksinya.
Menurut John McCarthy (1965), Artificial Intelligence adalah untuk mengetahui dan memodelkan proses – proses berpikir manusia dan mendesain mesin agar dapat menirukan perilaku manusia.
Menurut Russell dan Norvig (2003, p5) definisi tentang kecerdasan buatan dikembangkan berdasarkan empat kelompok kategori, yaitu :
a. Sistem yang berpikir selayaknya manusia berfikir (thinking humanly).
b. Sistem yang bertindak selayaknya manusia bertindak (acting humanly).
c. Sistem yang berpikir secara rasional (thinking rationally). d. Sistem yang bertindak secara rasional (actingt rationally).
Untuk melakukan aplikasi kecerdasan buatan ada dua bagian utama yang sangat dibutuhkan, yaitu :
a. Basis Pengetahuan (Knowledge Base), berisi fakta – fakta, teori, pemikiran dan hubungan antara satu dengan yang lainnya. b. Motor Inferensi (Inference Engine), yaitu kemampuan menarik
kesimpulan berdasarkan pengalaman.
Kelebihan dan kelemahan Intelegensia Semu atau Kecerdasan Buatan dapat dilihat pada table 2.1 berikut ini :
Tabel 2.1 Kelebihan dan Kelemahan Kecerdasan Buatan
Kelebihan Kecerdasan Buatan Kelemahan Kecerdasan Buatan 1. Lebih bersifat permanen
2. Lebih mudah diduplikasi dan disebarkan 3. Lebih murah 4. Bersifat konsisten 5. Dapat didokumentasi 6. Lebih cepat 7. Lebih baik
1. Tidak Kreatif, karena untuk menambah pengetahuan harus dilakukan melalui sistem yang dibangun
2. Harus bekerja dengan input – input simbolik, sehingga tidak
memungkinkan untuk menggunakan pengalaman secara langsung. 3. Pemikiran
sangat terbatas.
2.3.2 Bidang – bidang Cakupan Intelegensia Semu
a. Game Playing : Game Playing (permainan game) merupakan bidang AI yang sangat populer berupa permainan antara manusia melawan mesin yang mempunyai intelektual untuk berpikir. Komputer dapat bereaksi dan menjawab tindakan-tindakan yang diberikan oleh lawan mainnya.
b. General Problem Solving : Bidang AI ini berhubungan dengan pemecahan masalah terhadap suatu situasi yang akan diselesaikan oleh komputer. Permasalahan yang diungkapkan dalam suatu cara yang sedemikian rupa sehingga komputer dapat mengerti dengan semua deskripsi-deskripsi yang diinginkan juga diberikan kepada
komputer. Biasanya permasalahan tersebut dapat diselesaikan secara trial and error sampai solusi yang diinginkan didapatkan. c. Natural Language Processing : Studi mengenai AI mencoba
supaya komputer dapat mengerti bahasa alamiah yang diketikkan lewat keyboard. Bahasa alamiah (natural language) adalah bahasa sehari-hari yang dipergunakan oleh orang untuk berkomunikasi. Komputer yang dapat menerjemahkan satu bahasa ke bahasa lainnya merupakan contoh penerapan AI di bidang ini.
d. Speech Recognition : Bidang ini juga masih dikembangkan dan terus dilakukan penelitiannya. Kalau bidang ini berhasil dengan baik dan sempurna, alangkah hebatnya komputer. Kita dapat berkomunikasi dengan komputer hanya dengan bicara, kita bisa mengetik sebuah buku hanya dengan bicara, dan selanjutnya komputer yang akan menampilkan tulisan hasil pembicaraan kita. Akan tetapi bidang ini masih belum sempurna seperti yang diharapkan. Hal ini dikarenakan jenis suara manusia berbeda-beda. e. Visual Recognition : Bidang ini merupakan kemampuan suatu komputer yang dapat menangkap signal elektronik dari suatu kamera dan dapat memahami apa yang dilihat tersebut. Penerapan AI ini misalnya pada komputer yang dipasang di peluru kendali, sehingga peluru kendali dapat diprogram untuk selalu mengejar sasarannya yang tampak di kamera. Pada era globalisasi saat ini, bidang Visual Recognition dapat kita jumpai pada komputer-komputer laptop terbaru. Mula-mula komputer-komputer dipasang alat
untuk mendeteksi sidik jari (fingerprints password). Sekarang ini sudah banyak digunakan face detector, sehingga untuk mengakses sebuah laptop yang sudah dipasangi password dari gambar wajah orang pemiliknya.
f. Robotics : Robot adalah suatu mesin yang dapat diarahkan untuk mengerjakan bermacam-macam tugas tanpa campur tangan lagi dari manusia. Secara ideal robot diharapkan dapat melihat, mendengar, menganalisa lingkungannya dan dapat melakukan tindakan-tindakan yang terprogram. Dewasa ini robot digunakan untuk maksud-maksud tertentu dan yang paling banyak adalah untuk keperluan industri. Diterapkannya robot untuk industri terutama untuk pekerjaan 3D yaitu Dirty, Dangerous, atau Difficult (kotor, berbahaya dan pekerjaan yang sulit).
g. Sistem Pakar atau Expert System : Kemampuan, keahlian dan pengetahuan tiap orang berbeda-beda. Komputer dapat diprogram untuk berbuat seperti orang yang ahli dalam bidang tertentu. Komputer yang demikian dapat dijadikan seperti konsultan atau tenaga ahli di bidang tertentu yang dapat menjawab pertanyaan dan memberikan nasehat-nasehat yang dibutuhkan. Untuk mengembangkan expert system, harus diciptakan terlebih dahulu suatu knowledge base yang dibutuhkan oleh aplikasinya. Suatu knowledge base terdiri dari kumpulan data tertentu untuk permasalahan yang spesifik dan aturan-aturan bagaimana memanipulasi data yang disimpan tersebut. Berbeda dengan database biasa, knowledge base mungkin dapat juga terdiri dari
asumsi-asumsi, kepercayaan-kepercayaan, pendugaan-pendugaan dan metode-metode heuristic. Untuk membuat knowledge base perencanaan sistem harus bekerja sama atau meminta nasehat dari ahli di bidangnya. Orang yang menciptakan expert system disebut dengan knowledge engineer.
h. Fuzzy Logic : komputer yang dapat mengambil keputusan dalam hal-hal yang tidak jelas atau kondisi diantara Ya atau Tidak. i. Jaringan Saraf Tiruan : sistem yang didasarkan pada operasi
jaringan syaraf biologis, dengan kata lain, adalah emulasi sistem syaraf biologis.
2.4 Natural Language Processing
2.4.1 Pengertian Natural Language Processing
Membuat suatu sistem komputer yang dapat memahami bahasa ilmiah seperti Bahasa Inggris bukanlah suatu pekerjaan yang mudah. Jika saja komputer dapat memahami kalimat-kalimat baik yang diketikkan melalui keyboard ataupun yang diucapkan, maka kita tidak akan pernah menemukan kesulitan dalam menggunakannya. Natural Language Processing menghilangkan semua keterbatasan yang ada yang mungkin timbul dalam menggunakan komputer. Selain itu juga dengan adanya Natural Language Processing ini seseorang tidak perlu berlajar suatu bahasa pemrograman tertentu karena dia bisa memprogram komputer tersebut dengan bahasa sehari-harinya. Sebagai contoh, sebuah komputer harus mampu membuat model morfologi (struktur kata) supaya mengerti kalimat dalam bahasa
Inggris, tetapi sebuah model morfologi juga diperlukan untuk menghasilkan kalimat dalam bahasa Inggris yang benar secara gramatikal.
Natural Language Processing memiliki overlap yang signifikan dengan bidang linguistik komputasional, dan sering dipertimbangkan sebagai sub bidang dari IS. Terminologi bahasa alami digunakan untuk membedakan bahasa manusia (seperti bahasa Indonesia, Inggris, atau Spanyol, dan sebagainya) dari bahasa formal atau bahasa komputer (seperti C++, Java, atau LISP).
2.4.2 Tahap – Tahap Natural Language Processing 1. Analisis Morfologi
Proses yang menganalisa setiap kata menjadi bagian masing-masing, sesuai dengan jenisnya dan memisahkan antara token dan non token. Contoh jenis non token adalah tanda baca.
2. Analisis Sintaktik
Hasil proses dari analisis morfologi yang berupa urutan kata-kata kemudian akan diolah lebih lanjut pada proses analisis sintatik yang akan mentransformasikan urutan kata-kata tersebut menjadi sebuah struktur yang menggambarkan hubungan antara kata-kata tersebut.
3. Analisis Semantik
Struktur yang telah dihasilkan pada proses analisis semantik akan dianalisa lebih lanjut untuk mendapatkan arti dari kalimat tersebut. Proses pencarian arti dari kalimat tersebut dilakukan dengan cara
memetakan (map) masing-masing kata ke dalam knowledge base yang ada.
4. Discourse Integration
Pada proses analisis semantic sudah dilakukan pencarian arti dari kalimat, namun bisa saja ada beberapa kata yang belum mempunyai arti yang jelas, karena ada arti beberapa kata atau kalimat yang bergantung pada arti kata atau kalimat sebelumnya. Arti dari kata-kata atau kalimat-kalimat tersebut akan dicari pada tahap discourse integration ini.
5. Analisis Pragmatik
Pada tahap ini akan dilakukan eksekusi untuk mendapatkan hasil dari arti kalimat yang ada.
2.4.3 Context Free Grammar
Parser dapat mengenali suatu kalimat apabila kalimat tersebut mengikuti suatu kaidah tata bahasa atau grammar. Tata bahasa adalah suatu kaidah untuk menentukan struktur kalimat suatu bahasa.
Context Free Grammar merupakan kaidah suatu tata bahasa yang berguna untuk menggambarkan suatu struktur kalimat. Dengan Context Free Grammar, suatu grammar disusun sebagai serangkaian Production Rule atau Kaidah Produksi yang membentuk kalimat dalam bahasa yang dijelaskan oleh grammar tersebut.
Context Free Grammar mempunyai empat komponen sebagai berikut :
a. Terminal Symbol adalah simbol dasar yang membentuk suatu kalimat. Terminal Symbol ditulis dengan menggunakan huruf (dengan huruf kecil), angka, atau tanda khusus.
b. Non-Terminal Symbol adalah simbol khusus yang menunjuk pada kata-kata yang telah dikenal pada suatu bahasa. Non-Terminal Symbol ditulis dengan menggunakan huruf (dengan huruf kapital), angka, atau tanda khusus.
c. Start Symbol adalah salah satu dari Non-Terminal Symbol yang merupakan awal dari penguraian kalimat.
d. Production Rule adalah kaidah produksi yang menggambarkan bagaimana struktur tata bahasa dapat dirancang dari Terminal Symbol yang satu ke Terminal Symbol yang lainnya.
Menurut Russel dan Norvig (2003, p795-797), sebelum membuat suatu grammar, pertama didefinisikan lexicon terlebih dahulu. Lexicon adalah daftar dari kata-kata yang diizinkan. Kata-kata ini dikelompokkan ke dalam kategori atau bagian dari percakapan familiar bagi user. Berikut contoh lexicon dalam fragmen bahasa Inggris:
Noun : flights | breeze | trip | morning | . . . Verb : is | prefer | like | need | . . .
Adjective : cheapest | first | other | direct | . . . Adverb : here | there | nearby | ahead
Pronoun : me | I | you | it | . . .
Name : Mike | Albert | Stephanie | … Conjunction : and | or | but | …
ProperNoun : Alaska | Baltimore | Chicago | Garuda | . . . Article : the | a | an | this | . . .
Preposition : from | to | on | near | . . . Digit : 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Tahap selanjutnya adalah membuat grammar. Contoh grammar:
S Æ NP VP I + prefer a morning flight NP Æ Pronoun I
| ProperNoun Los Angeles | Det Nominal a + flight
Nominal Æ Noun Nominal morning + flight | Noun flights
VP Æ Verb do
| Verb NP prefer a morning flight | Verb NP PP leave Boston in the morning | Verb PP leave in the morning
PP Æ Prep NP from Los Angeles
2.4.4 Analisis Morfologi
Untuk menganalisis kalimat input-an, program pertama kali memecah kalimat tersebut ke dalam kata tunggal. Program memeriksa
input dan mencari spasi dan tanda baca untuk mengidentifikasi kata tunggal. Pada tahap ini, kata input-an dibagi ke dalam unit yang lebih kecil yang disebut morfem. Morfem merupakan unit terkecil dari bahasa. Sebuah morfem dapat berupa kata itu sendiri, yang disebut dengan morfem bebas. Sebagai contoh, kata ”keyboard” adalah sebuah morfem. Di sisi lain, ”keyboards” terdiri dari dua morfem, kata dasarnya sendiri ”keyboard”, dan huruf ”s” yang ditambahkan di akhir kata yang mengidetifikasikan jamak. Huruf ”s” merupakan tipe morfem yang disebut bound morpheme. Bound Morpheme biasanya merupakan awalan dan akhiran yang digunakan pada kata dasar untuk memodifikasi arti. (Turban, 1992, p282).
Tidak berbeda jauh dengan pendapat Turban, menurut Rich dan Knight (1991, p381), analisis morfologi harus dapat melakukan hal berikut:
Memisahkan kata ”keyboard’s” ke dalam kata benda yang benar ”keyboard” dan akhiran kepunyaan ”’s”.
Mengenal deretan ”.init” sebagai ekstensi file yang berfungsi sebagai kata sifat dalam kalimat.
Dalam menganalisis struktur morfologi dari kata-kata dalam n-bahasa Indonesia, diperlukan suatu algoritma stemming yang sesuai. Stemming digunakan untuk mengubah variasi kata ke bentuk kata dasarnya dengan mengaplikasikan aturan-aturan morfologi. Tidak seperti bahasa Inggris, dimana peran akhiran mendominasi pembentukan kata asal, bahasa Indonesia bergantung baik pada awalan maupun akhiran untuk menghasilkan kata-kata baru. Karena
itu, untuk stemming sebuah kata asal dalam bahasa Indonesia untuk memperoleh kata dasarnya, perlu diperhatikan awalan dan akhiran pada kata asal tersebut.
2.4.4.1 Nazief dan Adriani's Algorithm
Algoritma Nazief dan Adriani berdasar pada aturan morphology komprehensif yang mengelompokan dan mengenkapsulasi imbuhan yang diperbolehkan dan yang tidak diperbolehkan, termasuk awalan, akhiran, sisipan dan imbuhan gabungan. Algoritma ini juga mendukung pengkodean ulang sebuah pendekatan untuk mengembalikan sebuah huruf awal yang telah dibuang sebelumnya dari kata dasar untuk menunda terlebih dahulu sebuah awalan. Pada algoritma ini juga digunakan kamus kata-kata dasar untuk memeriksa jika stemming sudah mencapai kata dasar. Pernyataan tersebut berdasar pada penelitian Asian, William, dan Tahaghoghi (2005, pp2-3)
Ada tiga komponen dasar dalam algoritma Nazief dan Adriani, yaitu:
1. Pengelompokan Imbuhan
Pada pengelompokan imbuhan dibentuk menjadi kategori berikut:
a. Inflection Suffix
Kumpulan akhiran yang tidak mengubah kata dasar. Inflection Suffix dibagi lagi menjadi:
Particle (P): -lah, -kah. Misalnya pada kata ”tidurlah”. Possesive Pronoun (PP): -ku, -mu, -nya. Misalnya
pada kata ”ayahmu”.
P dan PP dapat muncul bersama, di mana PP muncul sebelum P. Sebuah kata dapat memiliki lebih dari satu P maupun PP, dan dapat diaplikasikan secara langsung ke kata dasar atau ke kata yang memiliki derivation suffix.
b. Derivation Suffix
Kumpulan akhiran yang diaplikasikan secara langsung ke kata dasar. Hanya ada satu derivation suffix per kata. Sebagai contoh, kata ”lapor” dapat diberi akhiran –kan sehingga menjadi ”laporkan”. Selain itu, dapat pula diberi akhiran dengan inflection suffix –lah sehingga menjadi ”laporkanlah”.
c. Derivation Prefix
Kumpulan awalan yang diaplikasikan baik secara langsung ke kata dasar maupun ke kata yang memiliki sampai dua derivation prefix lainnya. Misalnya derivation prefix ”mem-” dan ”per-” dapat ditambahkan pada kata ”indahkannya” sehingga menjadi ”memperindahkannya”.
2. Penggunaan aturan serta pengecualiannya
Terdapat aturan dan pengecualian dalam algoritma ini yaitu:
a. Tidak semua kombinasi diperbolehkan. Misalnya, setelah kata yang memiliki awalan di-, maka tidak diperbolehkan untuk dipakai akhiran –an. Untuk selengkapnya dapat dilihat pada table berikut.
Tabel 2.2 Imbuhan Gabung yang Tidak Dibolehkan Awalan Akhiran yang tidak dibolehkan
be- -i di- -an
ke- -i, -kan
me- -an
se- -i, -kan
te- -an
b. Tidak ada perulangan pada imbuhan yang sama. Misalnya, setelah sebuah kata diberi awalan te-, maka tidak mungkin untuk mengulang menggunakan awalan te- lagi pada kata tersebut. Contohnya pada kata teteh, tetek, dst.
c. Tidak dilakukan stemming, jika sebuah kata memiliki satu atau dua karakter.
d. Menambah sebuah awalan mungkin mengubah kata dasar atau awalan yang telah digunakan sebelumnya. Pertimbangkan meng-, yang memiliki variasi mem-, meng-, meny-, dan men-. Beberapa diantaranya dapat mengubah awalan dari suatu kata. Misalnya, pada kata dasar ”sapu”. Jika digunakan awalan meny- untuk menghasilkan kata ”menyapu”, berarti telah membuang huruf ”s”.
3. Kamus
Proses stemming dalam algoritma Nazief dan Adriani adalah sebagai berikut:
1. Kata input-an dicari di dalam kamus. Jika ditemukan, maka diasumsikan bahwa kata tersebut merupakan kata dasar.
2. Membuang inflection suffix (-lah, -kah, -ku, -mu, -nya). Jika berhasil dan akhirnya adalah P (-lah, -kah), maka tahap ini diulangi lagi untuk membuang inflection suffix PP (-ku, -mu, atau -nya).
3. Membuang derivation suffix (-i, -an). Jika berhasil, maka dilakukan tahap 4. Jika tahap 4 tidak berhasil:
a. Jika akhiran –an dibuang dan huruf terakhir dari kata adalah –k, maka –k juga dibuang dan diulangi lagi tahap keempat. Jika gagal, lakukan tahap 3b.
b. Akhiran yang telah dibuang sebelumnya (-i, -an, -kan), dikembalikan.
4. Membuang derivation preffix
a. Jika akhiran dibuang pada tahap 3, maka dilakukan pemeriksaan imbuhan gabungan yang tidak diperbolehkan berdasar tabel 2.2. Jika ditemukan yang sesuai, maka algoritma mengeluarkan hasil.
b. Jika awalan saat ini sesuai dengan awalan apapun sebelumnya, maka algoritma mengeluarkan hasil.
c. Jika tiga awalan sebelumnya telah dibuang maka algoritma mengeluarkan hasil.
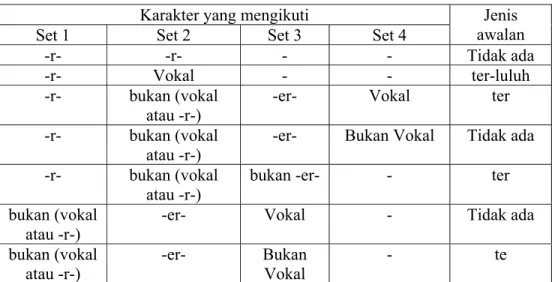
d. Jenis awalan ditentukan dengan cara berikut:
Jika awalan kata adalah di-, ke-, se-, maka jenis awalannya berturut-turut adalah di, ke, se.
Jika awalan kata adalah te-, be-, me-, pe-, maka dibutuhkan proses tambahan dalam menghasilkan kumpulan karakter untuk menentukan jenis awalan. Sebagai contoh, aturan untuk awalan te- pada tabel berikut:
Tabel 2.3 Jenis Awalan untuk Kata Berawalan te-
Karakter yang mengikuti Jenis
awalan
Set 1 Set 2 Set 3 Set 4
-r- -r- - - Tidak ada
-r- Vokal - - ter-luluh
-r- bukan (vokal
atau -r-) -er- Vokal ter
-r- bukan (vokal
atau -r-)
-er- Bukan Vokal Tidak ada
-r- bukan (vokal
atau -r-)
bukan -er- - ter
bukan (vokal
atau -r-) -er- Vokal - Tidak ada
bukan (vokal atau -r-)
-er- Bukan Vokal
- te
Misalkan pada kata ”terlambat”. Setelah membuang te-, akan dihasilkan ”rlambat”, kumpulan pertama karakter dihasilkan dari awalan menutur aturan Set 1. Dalam kasus ini, huruf yang mengikuti awalan te- adalah ”r”, dan ini cocok dengan lima baris pertama dari tabel 2.3 tersebut.
Setelah ”r” adalah ”l” pada Set 2, maka cocok dengan baris ketiga sampai kelima. Setelah ”l” adalah ”-ambat”, mengeliminasi baris ketiga dan keempat untuk Set 3 dan menentukan bahwa jenis awalan ”ter-” ditunjukkan pada kolom paling kanan. Jika dua karakter pertama tidak cocok dengan di-,
ke-, se-, te-, be-, me-, atau pe-, maka algoritma mengeluarkan hasil.
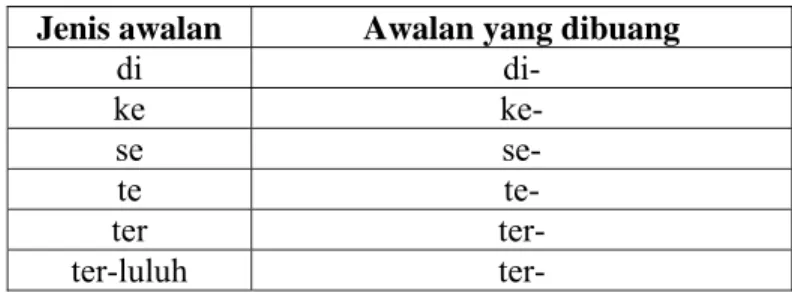
e. Jika jenis awalan adalah ”tidak ada”, maka algoritma mengeluarkan hasil. Jika bukan, maka jenis awalan dapat pada tabel 2.4, awalan yang dibuang pun ditemukan, dan awalan tersebut dibuang dari kata. tabel 2.4 hanya menunjukkan kasus sederhana dan yang sesuai pada tabel 2.3.
Tabel 2.4 Menentukan Awalan dari Jenis Awalan Jenis awalan Awalan yang dibuang
di di- ke ke- se se- te te- ter ter- ter-luluh ter-
f. Jika tidak menemukan kata dasar, lakukan tahap 4 secara berulang untuk pembuangan awalan lebih lanjut. Jika kata dasar ditemukan, maka algoritma mengeluarkan hasil.
g. Lakukan pengkodean ulang. Tahap ini bergantung pada jenis awalan dan dapat menghasilkan awalan yang berbeda pada kata yang di-stem dan dicek pada kamus. Misal pada jenis awalan ”terluluh” pada tabel 2.2 dan tabel 2.3. Pada kasus ini, setelah membuang ”ter-” , sebuah ”r” ditambahkan pada kata. Jika kata baru ini tidak terdapat di dalam kamus, maka ulangi Langkah 4 untuk kata baru tersebut. Jika kata dasar tidak ditemukan, maka ”r” dibuang dan ”ter-” dikembalikan. Awalan di-set ke ”tidak ada” dan algoritma mengeluarkan hasil.
5. Jika semua tahapan di atas berhasil dilalui, maka algoritma akan mengeluarkan hasil berupa kata dasar yang asli.
2.4.5 Analisis Sintaksis
Analisis sintaksis adalah proses menganalisa deretan token untuk menentukan struktur gramatikal berdasarkan formal grammar yang tersedia. Pada tahap ini, akan dilakukan analisis terhadap struktur sintaksis dari kalimat-kalimat. Parsing memverifikasi bahwa kalimat-kalimat terbentuk dengan baik secara sintaksis dan juga menentukan struktur bahasa. Dengan mengidentifikasi relasi lingustik yang utama seperti subjek-kata kerja, kata kerja-objek, dan kata benda-modifer, parser menyediakan sebuah framework untuk interpretasi semantik. Ini sering direpresentasikan dengan parse tree.
Sebuah parse adalah salah satu komponen interpreter atau compiler yang mengecek sintaks yang tepat dan membangun struktur data (seperti parse tree, abstrak syntax tree, atau struktur hirarki lainnya) secara implisit di dalam input token. Parse sering menggunakan lexical analyser untuk membuat token dari deretan input-an karakter. Parser dapat diprogram sendiri atau dihasilkan semi otomatis dengan menggunakan alat seperti Yacc dari grammar yang ditulis dalam Backus-Naur form.
2.4.5.1 Teknik dasar penjabaran
Dua teknik yang sering digunakan dalam penjabaran adalah metode penjabaran dari atas ke bawah (top-down parsing) dan metode penjabaran dari bawah ke atas (bottom-up parsing).
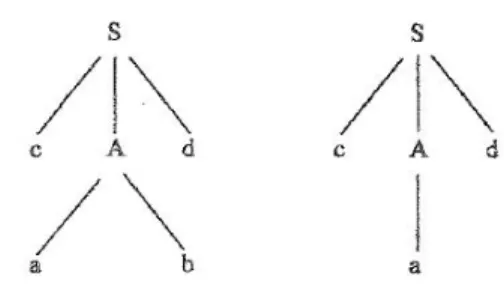
a. Top-Down Parsing
Pada metode penjabaran ini pembentukan pohon parser dimulai dari atas ke bawah. Jadi proses penguraian kalimat masukan dimulai dari start symbol sentence. Pada sebelah kiri dari kaidah Context Free Grammar dilakukan pembentukan non-terminal symbol, yang kemudian ditransformasikan ke bagian kanan terus menerus sampai ditemukan suatu terminal symbol. Perhatikan grammar berikut ini :
S Æ cAd A Æ ab | a
Gambar 2.2 Langkah-langkah dalam top-down parsing b. Bottom-Up Parsing
Pada metode penjabaran ini proses penguraian terjadi dari kalimat masukan. Kaidah Context Free Grammar ditransformasikan dari bagian kanan ke bagian kiri sampai pada start symbol sentence yang merupakan tujuan akhir dari proses penguraian. Perhatikan grammar berikut ini :
S Æ aABe A ÆAbc | b B Æ d
Mengikuti grammar tersebut, kalimat abbcde dapat direduksi ke S dengan langkah-langkah sebagai berikut :
abbcde aAbcde aAde aABe S 2.4.5.2 Algoritma Earley
Earley parser merupakan jenis bagan parser yang fungsi utamanya adalah untuk pengolahan parsing dalam ,
yang menarik dari Earley parser adalah karena dapat mem-parsing semua bahasa dalam konteks yang bebas. Waktu eksekusi dari Earley parser berjalan dalam waktu kompleksitas. Waktu komplesitas adalah jumlah waktu yang dibutuhkan oleh sebuah algoritma untuk menjalankan sebagai fungsi dari ukuran masukan untuk masalah ini, dan waktu kompleksitas dari suatu algoritma biasanya dinyatakan menggunakan notasi O besar, Cubic time (O (n 3), di mana n adalah panjang string yang diurai) dalam kasus umum, quadratic time (O (n 2)) untuk tata bahasa yang ambigu, dan linear time untuk hampir semua LR (k) tata bahasa. Earley parser dapat bekerja secara optimal ketika aturan tertulis secara rekursif kiri.
Pada sumber tertentu, algoritma Earley merupakan baik algoritma bottom-up yang menggabungkan beberapa elemen prediksi down, maupun algoritma prediksi top-down yang memiliki pemeriksaan bottom-up. Dengan demikian, algoritma Earley terlihat seperti perkawinan antara pendekatan bottom-up dan top-down. Dari akar bottom-up, Earley menjaga runtime untuk kasus terburuk pada (O (n 3), tetapi karena kekuatan dari elemen prediksi top-down, dalam banyak kasus memiliki runtime pada O(n). (Sandstrom, 2004, p4).
Berdasarkan algoritma Earley ini, pertama kali dilakukan inisialisasi aturan top-down berikut (Loper, 2005, p30-33):
Untuk setiap aturan grammar S Æ α, maka tambahkan SÆ·α ke queue[0]. Kemudian, scan dari kiri ke kanan dengan menerapkan satu dari 3 aturan ini:
Prediksi Æ top-down rule
Scanning Æ fundamental rule on terminals
Penyelesaian Æ fundamental rule on nonterminals
Intialization Prediction Scanner Completer
Gambar 2.3 Aturan dalam Algoritma Earley
SÆ ·AB AÆB·E EÆ·CD AÆ·W AÆW· DÆE·A DÆEA· AÆBC·
Berikut adalah algoritma sederhana dari algoritma Earley: For each rule SÆα in the grammar:
Add SÆ·α to chart[0,0] For i = 0 to N:
for edge in queue[i]:
if edge is incomplete and edge.next is a part of speech:
scanner(edge)
if edge is incomplete and edge.next not a POS: predictor(edge)
if edge is complete:
completer(edge)
2.4.6 Analisis Semantik
Analisis semantik yang merupakan salah satu tahap analisis pada NLP adalah dengan mencari suatu pola dalam kalimat yang akan mewakili makna dari kalimat tersebut. Metode ini dapat digunakan dalam memproses input-an user untuk mendapatkan suatu dokumen yang sesuai dengan input-an tersebut. Selain itu dapat juga digunakan untuk menganalisis isi dari suatu informasi atau dokumen dan menggunakannya untuk membuat knowlegde base yang terperinci lengkap dengan indexnya, yang dapat diakses oleh user untuk mendapatkan informasi yang tepat.
Untuk bisa mendapatkan hasil yang sesuai, sistem memproses bahasa alami dari input-an user dan/atau suatu dokumen untuk
mendapatkan pola SPO (Subjek-Predikat-Objek) dan menyimpannya. Selain itu, link antara pola yang didapatkan dengan sumber informasi juga harus disimpan untuk digunakan dalam tahap selanjutnya, yaitu pencocokan data. Pencarian pola ini bertujuan untuk mendapatkan makna dari suatu bahasa. Tujuannya adalah memperbesar ketepatan hasil pada proses pencocokan, di mana informasi yang dianggap cocok adalah hanya yang memiliki makna serupa.
Pengembangan dari proses ini adalah dengan menggunakan pola yang lebih komprehensif, yaitu perluasan dari pola SPO yang dapat terdiri dari Sifat, Keterangan, dan sebagainya. Contohnya: Input : Does the cat always fight the same place with the dog? Output:
Subjek : cat
Predikat : fight
Objek : same place
Preposisi : with
Objek Tak Langsung : dog Sifat : -
Keterangan : always
2.5 Tata Bahasa Indonesia 2.5.1 Hakikat Bahasa
Bahasa adalah suatu lambang berupa bunyi, bersifat arbitrer, digunakan oleh suatu masyarakat untuk bekerja sama, berkomunikasi, mengidentifikasi diri. Sebagai sebuah sistem, maka bahasa terbentuk
oleh suatu aturan, kaidah, atau pola-pola tertentu, baik dalam bidang tata bunyi, tata bentuk kata, maupun tata kalimat. Bila aturan, kaidah, atau pola ini dilanggar, maka komunikasi dapat terganggu.
Bahasa terdiri dari dua lapisan, yaitu lapisan bentuk dan lapisan makna dari lapisan bentuk tersebut. Bentuk bahasa terdiri atas satuan-satuan yang dapat dibedakan menjadi satuan fonologi dan satuan gramatikal. Satuan fonologi meliputi fonem dan suku kata. Sedangkan satuan gramatikal meliputi wacana, kalimat, kluasa, frase, kata, dan morfem.
2.5.2 Kata
Kata merupakan unsur yang paling penting didalam bahasa. Tanpa kata, mungkin tidak ada bahasa. Sebab kata itulah yang merupakan perwujudan bahasa. Setiap kata mengandung konsep makna dan mempunyai peranan di dalam pelaksanaan bahasa. Konsep dan peran apa yang dimiliki tergantung dari jenis atau macam kata-kata itu, serta penggunaannya di dalam kalimat.
Dilihat dari konsep makna yang dimiliki dan peran yang harus dilakukan, kata-kata dapat dibedakan atas beberapa jenis yaitu : a. Kata kerja
Kata-kata yang dapat diikuti oleh frase “dengan..”, baik yang menyatakan alat, keadaan, maupun penyerta, disebut kata kerja. Misalnya: pergi (dengan baik), pulang (dengan gembira), menulis (dengan spidol). Dilihat dari strukturnya, ada dua macam kata kerja, yaitu kata kerja dasar dan kata kerja berimbuhan.
Kata Kerja dasar adalah kata kerja yang belum diberi imbuhan, seperti pergi, pulang, tulis, tanya. Sementara kata kerja berimbuhan adalah kata kerja yang terbentuk dari kata dasar yang mungkin kata benda, kata kerja, kata sifat, atau jenis kata lain dan imbuhan. Imbuhan yang lazim digunakan dalam pembentukan kata kerja adalah:
- Awalan me-, seperti menulis, melihat. - Awalan ber-, seperti berdiri, berkuda. - Awalan di-, seperti ditulis, dibaca. - Awalan ter-, seperti tertulis, terlihat. - Awalan per-, seperti perpanjang, percepat. - Akhiran –kan, seperti tuliskan, damaikan. - Akhiran –i, seperti diami, tinggali.
b. Kata benda
Kata-kata yang dapat diikuti dengan frase “yang..” atau “yang sangat..” disebut kata benda. Misalnya: jalan (yang bagus), murid (yang rajin), pelayanan (yang sangat memuaskan). Selain itu yang disebut kata benda turunan atau bentuk dapat dikenali dari bentuknya yang mungkin:
- Berawalan pe-, seperti pemuda, pemenang. - Berakhiran –an, seperti bendungan, bantuan. - Berakhiran –nya, seperti besarnya, naiknya.
- Berimbuhan gabungan pe-an, seperti pembangunan, pelebaran. - Berimbuhan gabungan per-an, seperti pertemuan, persatuan.
- Berimbuhan gabungan ke-an, seperti keadilan, kekayaan.
c. Kata ganti
Kata benda yang menyatakan orang sering kali diganti kedudukannya di dalam pertuturan dengan sejenis kata yang lazim di sebut kata ganti. Misalnya: “Kemarin ayah pergi ke pasar. Dia membeli sebuah cangkul.” Kata “dia” pada kalimat kedua adalah kata ganti. Kata “dia” menggantikan kedudukan kata “ayah” yang disebutkan pada kalimat pertama.
d. Kata sifat
Kata-kata yang dapat diikuti dengan kata keterangan “sesekali” serta dibentuk menjadi kata ulang berimbuhan gabung “se-nya” disebut kata sifat. Misalnya: indah (indah sekali, seindah-indahnya), besar (besar sekali, sebesar-besarnya), baik (baik sekali, sebaik-baiknya).
e. Kata sapaan
Kata-kata yang digunakan untuk menyapa, menegur, atau menyebut orang kedua, atau orang yang diajak bicara, disebut kata sapaan. Kata-kata sapaan ini tidak mempunyai perbendaharaan kata sendiri, tetapi menggunakan kata-kata dari perbendaharaan kata nama diri dan kata nama perkerabatan. Misalnya: San (bentuk utuh : Hasan), Ti (bentuk utuh: Siti), Nek (bentuk utuh: Nenek).
f. Kata penunjuk
Kata-kata yang digunakan untuk menunjuk benda disebut kata penunjuk. Ada dua macam kata penunjuk, yaitu “ini”dan “itu”. Kata penenjuk “ini” digunakan untuk menunjuk benda yang letaknya relatif dekat dari si pembicara. Sedangkan kata penunjuk “itu” untuk menunjuk benda yang letaknya relatif jauh dari si pembicara.
g. Kata penyangkal
Kata-kata yang digunakan untuk menyangkal atau mengingkari terjadinya suatu peristiwa atau adanya suatu hal disebut kata penyangkala. Misalnya: tidak, tak, tiada, bukan, tanpa.
h. Kata bilangan
Kata-kata yang menyatakan jumlah, nomor, urutan, atau himpunan disebut kata bilangan. Menurut bentuk dan fungsinya, ada dua macam kata bilangan:
- Kata bilangan utama, seperti satu, dua tiga, tiga puluh satu. - Kata bilangan tingkat, seperti pertama, kedua, kedua puluh
satu.
i. Kata depan
Kata-kata yang digunakan dimuka kata benda untuk merangkaikan kata benda itu dengan bagian kalimat lain, disebut kata depan.
Dilihat dari fungsinya, kata depan dapat dibedakan menjadi kata depan yang menyatakan:
- Tempat berada, yaitu: di, pada, dalam, atas, antara. - Arah asal: yaitu: dari.
- Arah tujuan, yaitu: ke, kepada, akan, terhadap. - Pelaku: yaitu: oleh.
- Alat, yaitu: dengan, berkat. - Perbandingan, yaitu: daripada.
- Halatau masalah, yaitu: tentang, mengenai. - Akibat, yaitu: hingga, sampai.
- Tujuan, yaitu: untuk, buat, guna, bagi.
j. Kata penghubung
Kata-kata yang digunakan untuk menghubungkan kata dengan kata, klausa dengan klausa, atau kalimat dengan kalimat, disebut kata penghubung. Dilihat dari fungsinya, ada dua macam kata penghubung, yaitu:
- Kata penghubung setara, yang menggabungkan: Biasa: dan, dengan, serta.
Memilih: atau.
Mempertentangkan: tetapi, namun, sedangkan, sebaiknya. Membetulkan: melainkan, hanya.
Menegaskan: bahkan, malah (malahan), lagipula, apalagi, jangankan.
Mengurutkan: lalu, kemudian, selanjutnya. Menyamakan: yaitu, yakni, bahwa, adalah, ialah. Menyimpulkan: jadi, karena itu, oleh sebab itu. - Kata penghubung bertingkat, yang menyatakan:
Sebab: sebab, karena.
Syarat: kalau, jikalau, jika, bila, apabila, asal. Tujuan: agar, supaya.
Waktu: ketika, sewaktu, sebelum, sesudah, tatkala. Akibat: sampai, hingga, sehingga.
Sasaran: untuk, guna.
Perbandingan: seperti, sebagai, laksana. Tempat: tempat.
k. Kata keterangan
Kata-kata yang digunakan untuk memberikan penjelasan pada kalimat atau bagian kalimat lain, yang sifatnya tidak menerangkan keadaan atau sifat, disebut kata keterangan. Ada dua macam kata keterangan:
- Kata keterangan yang menerangkan keseluruhan kalimat, berfungsi untuk menyatakan:
Kepastian: memang, pasti, tertentu.
Keraguan atau kesangsian: barangkali, mungkin, kiranya, rasanya, agaknya, rupanya.
Harapan: semoga, moga-moga, mudah-mudahan, hendaknya.
Frekuensi: seringkali, sekali-kali, sesekali, sekali-kali, acapkali, jarang.
- Kata keterangan yang menerangkan unsur kalimat, berfungsi untuk menyatakan:
Waktu: sudah, telah, sedang, lagi, tengah, akan, belum, masih, baru, pernah, sempat
Sikap batin: ingin, mau, hendak, suka, segan.
Perkenan: boleh, wajib, mesti, harus, jangan, dilarang. Frekuensi: jarang, sering, sekali, dua kali.
Kualitas: sangat, amat, sekali, lebih paling, kurang , cukup. Kuantitas dan jumlah: banyak, sedikit, kurang, cukup,
semua, beberapa, seluruh, sejumlah, sebagian, separuh, kira-kira, sekitar, kurang lebih, para, kaum.
Penyangkalan: tidak, tak, tiada, bukan. Pembatasan: hanya, cuma.
l. Kata tanya
Kata-kata yang digunakan sebagai pembantu di dalam kalimat yang menyatakan pertanyaan disebut kata Tanya. Misalnya: apa, siapa, mengapa, kenapa, begaimana, berapa, mana, kapan, bila, bilamana.
m. Kata seru
Kata-kata yang digunakan untuk mengungkapkan perasaan batin, misalnya karena kaget, terharu, kagum, marah, atau sedih, disebut kata seru. Dilihat dari strukturnya, ada dua macam kata seru: - Kata seru yang berupa kata singkat: wah, cih, hai, o, oh, nah,
ha, hah.
- Kata seru yang berupa kata biasa: adih, celaka, gila, kasihan, ya ampun, astaga, dan lain-lain.
n. Kata sandang
Kata-kata yang berfungsi menjadi penentu disebut kata sandang. Yaitu: si, sang.
o. Kata partikel
Morfem-morfem yang digunakan untuk menegaskan disebut partikel penegas. Yaitu: kah, tah, lah, pun, per.
2.5.3 Imbuhan
Acapkali sebuah kata dasar atau bentuk dasar perlu diberi imbuhan dulu untuk dapat digunakan di dalam penuturan. Imbuhan ini dapat mengubah makna, jenis, dan fungsi sebuah kata dasar atau bentuk dasar menjadi kata lain, yang fungsinya berbeda dengan kata dasar atau bentuk dasarnya. Imbuhan mana yang harus digunakan tergantung pada keperluan penggunaannya di dalam penuturan. Untuk keperluan penuturan itu malah sering pula sebuah kata dasar atau
bentuk dasar yang sudah diberi imbuhan dibubuhi pula dengan imbuhan lain.
Imbuhan yang ada dalam bahasa Indonesia adalah: i. Akhiran: -kan, -I, -nya, -an.
ii. Awalan: ber-, per-, me-, di-, ter-, ke-, se-, pe-. iii. Sisipan: -el, -em, -er.
iv. Imbuhan gabung: ber-kan, ber-an, per-kan, per-i, me-kan, me-i, memper-, memper-kan, memper-i, di-kan, di-i, diper-, diper-kan, diper-i, ter-kan, ter-i, ke-an, se-nya, pe-an, per-an.
2.5.4 Kalimat
Menurut Putrayasa (p20, 2007), dalam bahasa Indonesia, kalimat ada yang terdiri dari satu kata, dua kata, tiga kata, empat kata, dan seterusnya. Dalam wujud lisan, kalimat diucapkan dengan suara naik turun dan keras lembut, disela jeda, dan diakhiri dengan intonasi akhir yang diikuti oleh kesenyapan yang mencegah terjadinya perpaduan asimilasi bunyi ataupun proses fonologi lainnya. Dalam wujud tulisan, kalimat dimulai dengan huruf kapital dan diakhiri dengan tanda titik, tanda tanya, dan tanda seru. Berdasarkan uraian tersebut, dapat disimpulkan bahwa yang dimaksud dengan kalimat adalah satuan gramatikal yang dibatasi oleh adanya jeda panjang yang disertai nada akhir naik dan turun.
Sementara menurut Chaer (p327, 2006), kalimat adalah satuan bahasa yang berisi suatu pikiran atau amanat yang lengkap. Langkah berarti di dalam kalimat itu terdapat unsur atau bagian yang:
- Menjadi pokok pembiacaraan, disebut subjek (S). Misalnya: Adik menulis buku.
- Menjadi komentar tentang subjek, disebut predikat (P). Misalnya: Adik menulis buku.
- Merupakan pelengkap dari predikat, disebut objek (O). Misalnya: Adik menulis buku.
- Merupakan penjelasan lebih lanjut terhadap predikat dan subjek, disebut keterangan (K). Misalnya: Adik menulis buku di kamar.
Menurut strukturnya, sebuah kalimat sederhana dalam bahasa Indonesia memiliki pola:
a. Subjek + Predikat
Contoh: - Ibuku menangis. - Ayahku seorang pelaut. b. Subjek + Predikat + Objek
Contoh: - Ibu memasak makanan. - Ayah membaca koran pagi c. Subjek + Predikat + Objek + Keterangan
Contoh: - Ibu memasak makanan di dapun. - Ayah membaca koran di taman. d. Subjek + Predikat + Objek + Objek
Contoh: - Ibu membelikan adik baju baru. - Ayah membukakan saya pintu.
2.6 Unified Modelling Language
Unified Modelling Language (UML) adalah bahasa spesifikasi standar untuk mendokumentasikan, menspesifikasikan, dan membangun sistem piranti lunak. UML tidak berdasarkan pada bahasa pemrograman tertentu. Standar spesifikasi UML dijadikan standar defacto oleh Object Management Group (OMG) pada tahun 1997. UML yang berorientasikan objek mempunyai beberapa notasi standar.
Spesifikasi ini menjadi populer dan standar karena sebelum adanya UML, telah ada berbagai macam spesifikasi yang berbeda. Hal ini menyulitkan komunikasi antar pengembang piranti lunak. Untuk itu beberapa pengembang spesifikasi yang sangat berpengaruh berkumpul untuk membuat standar baru. UML dirintis oleh Grandy Booch, James Rumbaugh pada tahun 1994 dan kemudian Ivan Jacobson.
UML mendeskripsikan Object Oriented programming (OOP). OOP merupakan paradigma pemrograman yang berorientasi kepada objek. Semua data dan fungsi di dalam paradigma ini dibungkus dalam kelas-kelas atau objek-objek. Berbeda dengan logika pemrograman terstruktur. Setiap objek dapat menerima pesan, memproses data, dan mengirimkan pesan ke objek lainnya. UML mendeskripsikan OOP dengan beberapa diagram, yang dapat digambarkan secara hirarki sebagai berikut:
Gambar 2.4 Diagram UML
2.6.1 Structure Diagram
Structure Diagram menekankan pada apa yang harus dimodelkan dalam sistem, yang termasuk diagram struktur adalah : a. Class Diagram
Menggambarkan struktur dari sistem dengan menunjukkan kelas-kelas dari sistem, atributnya, dan hubungan antar kelas-kelas.
b. Component Diagram
Menggambarkan bagaimana sistem piranti lunak dibagi ke dalam komponen-komponen dan menunjukkan ketergantungan antar komponen.
c. Composite Structure Diagram
Menggambarkan struktur internal dari kelas dan kolaborasi yang mungkin terjadi dari struktur tersebut.
d. Deployment Diagram
Digunakan untuk membangun model perangkat keras yang digunakan dalam implementasi sistem, komponen yang diatur dalam perangkat keras, dan asosiasi diantara komponen tersebut.
e. Object Diagram
Menunjukkan pandangan lengkap atau sebagian terhadap struktur dari sistem yang telah dibuat modelnya pada waktu tertentu.
f. Package Diagram
Menggambarkan bagaimana sistem dibagi ke dalam kelompok logika dengan menunjukkan ketergantungan antar kelompok.
2.6.2 Behavior Diagram
Behavior diagram menekankan pada apa yang harus terjadi ketika membuat permodelan sistem, yang termasuk behavior diagram adalah :
a. Activity Diagram
Mempresentasikan aliran bisnis dan operasional langkah demi langkah terhadap komponen dalam sistem. Diagram ini menunjukan keseluruhan aliran kontrol.
b. State Diagram
Notasi terstandarisasi untuk menggambarkan banyak sistem, dari program komputer sampai ke proses bisnis.
c. Use Case Diagram
Menggambarkan fungsionalitas yang disediakan oleh sistem dari sudut pandang actor, tujuan actor digambarkan dengan use case, dan segala ketergantungan antar use case.
2.6.3 Interaction Diagram
Interaction Diagram merupakan subset dari behavior diagram dan menekankan pada aliran kontrol dan data diantara hal-hal yang ada ketika membuat permodelan sistem, yang termasuk interaction diagram adalah :
a. Comunication Diagram
Menunjukkan interaksi antara objek atau bagian dalam deretan pesan. Diagram ini mempresentasikan kombinasi informasi yang diambil dari class, sequence, dan use case diagram, yang menggambarkan baik struktur statis maupun perilaku dinamis dari sistem.
b. Interaction Overview Diagram
Jenis dari activity diagram di mana node-nodenya merepresentasikan interaction diagram.
c. Sequence Diagram
Menunjukkan bagaimana objek berkomunikasi satu sama lain dalam deretan pesan. Diagram ini juga mengindikasikan bahwa umur suatu objek relatif terhadap pesan tersebut.
d. Timing Diagram
Jenis spesifik dari interaction diagram, di mana fokusnya pada batasan waktu.
2.7 System Development Life Cycle
System Development Life Cycle (SDLC) dalam system engineering dan software engineering berkaitan dengan proses dari mengembangkan sistem, model dan metodologi yang digunakan orang untuk pengembang sistem tersebut, biasanya komputer atau sistem informasi.
Dalam software engineering, konsep SDLC dikembangkan ke dalam beberapa jenis metodologi pengembangan piranti lunak, framework yang digunakan untuk membangun struktur, merencanakan, dan mengontrol proses pengembangan sistem informasi.
SDLC merupakan proses logika yang digunakan oleh system analist untuk mengembangkan sebuah sistem informasi, termasuk requirement, validation, pelatihan, dan kepemilikan user. Sebuah SDLC seharusnya menghasilkan sistem berkualitas tinggi yang sesuai dengan harapan customer, dengan perkiraan waktu dan biaya, bekerja secara efektif dan efisien dalam infrastruktur Teknologi Informasi saat ini dan yang dengan biaya pemeliharaan dan pengembangan murah.
Tahap-Tahap Pengembangan Sistem a. Inisialisasi / Perencanaan
Inisialisasi / Perencanaan digunakan untuk menghasilkan pandangan tingkat tinggi terhadap proyek dan menentukan tujuan dari proyek. Feasibility study terkadang digunakan untuk menampilkan proyek kepada manajemen tingkat atas dengan maksud mendapatkan pendanaan. Secara tipikal, proyek dievaluasi ke dalam tiga area feasibility : ekonomi, operasional, dan teknis. Lebih lanjut, feasibility juga digunakan sebagai referensi untuk menjaga proyek tetap pada jalurnya dan untuk mengevaluasi kemajuan tim manajemen sistem informasi. Fase ini disebut juga dengan fase analisis.
b. Pengumpulan dan Analisa Kebutuhan
Tujuan dari analisis sistem adalah untuk menentukan di manakah masalahnya dalam usaha memperbaiki sistem. Langkah ini melibatkan pemecahan sistem ke dalam bagian-bagian yang berbeda dan menggambarkan diagram-diagram untuk menganalisis situasi. Tujuan proyek analisis, pemecahan fungsi yang dibutuhkan untuk dibuat, dan usaha untuk mengikutsertakan user sehingga kebutuhan dapat didefinisikan.
c. Desain
Dalam mendesain sistem, fungsi dan operasi digambarkan secara detail, meliputi rancangan layar, aturan bisnis, diagram proses, dan dokumentasi
lainnya. Hasil dari tahap ini akan menggambarkan sistem baru sebagai kumpulan dari modul atau subsistem.
d. Coding
Kode programming modular dan subsistem akan diselesaikan pada tahap ini. Tahap ini dikombinasi dengan modul individual selanjutnya yang dibutuhkan untuk diuji sebelum integrasi dengan proyek utama. Perencanaan dalam SDLC melibatkan penentuan tujuan, pendefinisian target, penjadwalan, dan perkiraan modal untuk keseluruhan proyek piranti lunak.
e. Pengujian
Kode diuji dalam level yang bervariasi pada pengujian piranti lunak. Unit, sistem, dan pengujian penerimaan user dilakukan. Disini merupakan area abu-abu karena banyak pendapat berbeda muncul tergantung tahap pengujian apa yang dilakukan dan seberapa banyak jika terdapat iterasi. Iterasi bukan merupakan bagian umum dari model waterfall, tetapi terkadang terjadi pada tahap ini. Jenis-jenis pengujian :
- Automation testing - Regression testing - Module testing - White box testing - Black box testing - User acceptance testing - Integration testing
- System testing - Unit testing - Data set testing
f. Operasi dan Maintenance
Pengoperasian dan maintenance sistem mencakup perubahan dan penambahan sebelum menonaktifkan sistem. Memelihara sistem merupakan aspek penting dari SDLC. Seiring dengan perubahan posisi dari personil kunci dalam organisasi, perubahan baru akan diimplementasikan, yang membutuhkan pembaharuan sistem.