SISTEM QUR’AN RETRIEVAL TERJEMAHAN BAHASA INDONESIA
BERBASIS WEB DENGAN REORGANISASI KORPUS
Surya Agustian1, Imelda Sukma Wulandari2 1,2
Jurusan Teknik Informatika, Fakultas Sains dan Teknologi, UIN Sultan Syarif Kasim Riau
1,2 Jl. HR. Soeberantas km 11.5 Simpang Baru Panam, Pekanbaru 1 [email protected], 1 [email protected]
Abstrak
Al-Qur’an sebagai kitab suci dan sumber hukum wajib diimani oleh lebih dari satu miliar umat Islam di dunia. Namun karena berbentuk dokumen yang panjang dan diturunkan dalam bahasa Arab, menyebabkan orang awam yang tidak memahami bahasa Arab semakin sulit untuk menemukan topik tertentu untuk mempelajari isi kandungan Al-Qur’an. Penelitian ini bertujuan mengembangkan sistem pencarian ayat Al-Qur’an berbasis web berdasarkan terjemahan Bahasa Indonesia, dengan melakukan reorganisasi korpus berdasarkan tema dan sub tema, sehingga dapat memenuhi preferensi pengguna dalam menemukan topik yang diinginkan. Metode yang digunakan adalah sistem information retrieval dengan model ruang vektor yang telah dinyatakan efisien dan produktif dalam menemukan dokumen relevan. Hasil pengujian menunjukkan bahwa sistem telah memberikan performa yang baik dalam menemukan dokumen-dokumen relevan di urutan teratas. Pembuktian dengan menghitung nilai precision dan recall serta menggambarkan grafik profil performa sistem juga menunjukkan hasil yang memuaskan. Sistem ini menjadi solusi masa depan bagi umat dalam menemukan referensi ayat Al-Qur’an tentang suatu masalah kehidupan beragama, bermasyarakat, berbangsa dan bernegara.
Kata kunci : information retrieval, precision, recall, korpus, model ruang vektor
1. Pendahuluan
Al-Qur’an merupakan suatu sumber hukum yang menjadi panduan umat Islam dalam menjalani kehidupan beragama, bermasyarakat dan bernegara. Namun, sebagai dokumen yang sangat panjang, terdiri atas 30 juz, 114 surat, dan 6236 ayat, dan berbahasa Arab pula, menjadi hambatan besar bagi kebanyakan umat Islam di Indonesia untuk me-mahaminya. Bagi sivitas dan akademisi di madrasah atau perguruan tinggi agama pun, jika harus merujuk dan membuat sitasi dari literatur Al-Qur’an untuk masalah tertentu, sering membutuhkan waktu lama untuk menemukan ayat yang sesuai, bila kurang memahami bahasa Arab sebagai bahasa Al-Qur’an.
Para pengembang perangkat lunak di dunia telah mencoba mendigitalkan dokumen Al-Qur’an, membuat transliterasi dan terjemahannya ke dalam berbagai bahasa. Beberapa perangkat lunak buatan Indonesia, seperti Lidwa1 juga sudah menyertakan fitur pencarian terhadap ayat Al-Qur’an sesuai dengan masalah yang akan didalami. Namun teknik pencarian masih terbatas pada pencarian kata (exact
match), sehingga untuk kueri berupa frase atau
beberapa kata, sering tidak mendapatkan hasil.
1 http://id.lidwa.com/app/
F. Ataa Allah [1] mengusulkan sistem
infor-mation retrieval (IR) bahasa Arab dari korpus surat
kabar berbahasa Arab, dengan mempelajari dan membentuk indeks dari frase kata benda. Zainab [2] mengukur efektivitas penggunaan thesaur dan
stemming (pemotongan imbuhan) pada sistem IR
terjemahan Al-Qur’an berbahasa Malaysia. Metode yang digunakan adalah conflation, yang mencari berdasarkan inputan kueri bahasa natural manusia dari inverse document frequency yang disusun menurut inverted file structure.
Noordin [3] mengusulkan desain sistem
information retrieval mengenai Al-Qur’an dengan
mengevaluasi 125 situs web sebagai korpusnya. Sebelumnya, Surra Binti Ahmad Sufyan [4] meneliti pencarian ayat Al-Qur’an dari terjemahan berbahasa Malaysia berdasarkan thesaur dan relevance
feed-back. Sistem perankingan hasil pencarian dilakukan
berdasarkan feedback dari pengguna yang dihitung secara probabilistik. Kinerja sistem sangat ber-gantung kepada umpan balik dari pengguna, se-hingga apabila pengguna salah memberikan umpan balik, relevansi hasil pencarian selanjutnya bisa keliru.
Yunus [5] mengemukakan rancangan sistem
information retrieval untuk Al-Qur’an pada bahasa
word matching (pencocokan kata) tanpa menghitung term frequency (frekuensi kata), dengan memperluas
kata yang dicari berdasarkan semantik kata (menggunakan thesaur). Hal ini dapat meningkatkan jumlah hasil pencarian, namun mengurangi relevansi dokumen hasil pencarian.
Peneliti dari Indonesia, Nuk Ghurroh Setyo-ningrum [6] mengusulkan purwarupa sistem pener-jemah bahasa Arab ke bahasa Indonesia berdasarkan masukan dari admin ke sistem secara manual, untuk pengaturan dokumen (ayat Al-Qur’an) dan memilih proses konversi karakter bahasa Arab, pengaturan terjemahan dan seterusnya. Sehingga purwarupa yang dibangun hanya baru dapat diujicoba sampai Surat Al-Baqarah ayat 46. Ahmad Al-Taani [7] mengemukakan konsep pencarian Qur’an dengan kueri berbahasa Arab, juga menggunakan metode
pattern matching pada indeks yang dibangun dengan
proses stemming dan stopword removal (peng-hilangan kata hubung dan kata-kata yang tidak me-miliki arti/tidak penting dalam pencarian).
Penelitian ini bertujuan untuk menghasilkan suatu sistem pencarian ayat Al-Qur’an berdasarkan terjemahan bahasa Indonesia yang lengkap (30 juz) versi Departemen Agama [8], yang selalu dipakai sebagai buku terjemahan Al-Qur’an hadiah jamaah Haji dari Raja Arab Saudi. Sistem ini juga mengatasi kekurangan atau kelemahan penelitian-penelitian se-belumnya, yang hanya menguji terhadap beberapa surat panjang saja sebagai dokumen, tetapi tidak dapat mengatasi surat-surat pendek dengan ayat-ayat yang juga pendek.
2. Sistem Qur’an Retrieval
Bagi masyarakat muslim di Indonesia yang tidak memahami bahasa Arab, dibutuhkan suatu sistem Qur’an Retrieval (QR), yang dapat menemu-kan ayat Al-Qur’an yang ingin dicari, dengan menggunakan kueri bahasa Indonesia. Sistem QR tersebut dibangun berdasarkan metode IR
(infor-mation retrieval), yang dapat memberikan hasil
pen-carian lebih baik dari segi relevansi, dan lebih banyak dokumen dari segi jumlah hasil pencarian.
2.1 Korpus Al-Qur’an dan Terjemahan
Sumber korpus Al-Qur’an dan terjemahannya ke dalam berbagai bahasa, telah dipelihara dan disebarluaskan oleh berbagai yayasan, foundation, dan lembaga studi Al-Qur’an di dunia melalui inter-net [9-11]. Beberapa sumber sudah memisahkan dokumen Al-Qur’an antara surat, ayat, dan terje-mahan, yang disusun menurut hirarki direktori surat dan file-file ayat, satu ayat satu file. Sumber lainnya, sudah menyusun surat dan ayat ke dalam bentuk database. Di samping itu, sumber yang masih me-nyediakan file tunggal maupun berbentuk gambar juga masih banyak ditemukan.
Tahap pertama dalam penelitian ini adalah mengorganisasikan kembali korpus Al-Qur’an de-ngan memadukan beberapa sumber dokumen, yaitu mengambil struktur terjemahan dalam bentuk teks latin, dan ayat (tulisan Arab) dalam bentuk gambar untuk penampilan.
Kebanyakan peneliti [4-6, 12], menggunakan satu ayat sebagai satu dokumen. Mereka hanya me-nguji beberapa surat panjang (misalnya Al-Baqarah sampai An-Nisa’) sebagai dokumen pada koleksi (korpus), tapi tidak memperhitungkan ayat-ayat pendek karena di luar kajian penelitiannya. Fakta-nya, banyak ayat pendek justru tidak selesai kali-matnya, atau tidak mengandung suatu makna yang jelas, sehingga tidak cocok dijadikan dokumen. Di samping itu, hal ini hanya akan menyebabkan besar-nya indeks menjadi membengkak, sehingga waktu pemrosesannya menjadi sangat lama.
Untuk mengatasi hal ini, korpus terjemahan disusun kembali dengan memisahkan tema atau sub-sub tema menjadi satuan dokumen terkecil. Sebagai contoh, merujuk Terjemahan Al-Qur’an [8] pada Surat Al-Baqarah, di halaman 8-11, ayat 1 sampai dengan 20 dijadikan 3 dokumen, yaitu berdasarkan sub tema Golongan Mu’min (ayat 1-5), Golongan Kafir (ayat 6-7) dan Golongan Munafik (ayat 8-20). Hal ini akan lebih baik dibandingkan membentuk 20 dokumen, 1 dokumen 1 ayat. Seterusnya, proses penyusunan korpus dengan cara ini dilakukan sampai ayat terakhir dari Al-Qur’an.
Tercatat 800 dokumen pada korpus yang baru, masing-masingnya mengandung jumlah ayat yang bervariasi, namun tetap merupakan satu kesatuan cerita yang utuh dari suatu tema atau sub tema pada Al-Qur’an.
2.2 Proses Indexing
Arsitektur sistem IR secara umum dapat digambarkan sepert Gambar 1 berikut [13].
Gambar 1. Arsitektur sistem IR [13]
Proses yang terjadi di dalam sistem IR terdiri dari 2 bagian utama, yaitu subsistem indexing dan subsistem searching/retrieving (matching system) [13 , 14].
Mengacu kepada literatur IR [14, 15], proses
indexing yang telah dilakukan untuk membentuk
Sistem Qur’an Retrieval ini adalah:
1. Penyusunan kembali dokumen (reorganisasi korpus).
2. Pembersihan dokumen dari tanda baca, format maupun markup tag bila ada.
3. Tokenisasi, memecah dokumen menjadi kata per kata (term) dan dikonversi ke dalam huruf kecil semuanya.
4. Filtrasi, dalam hal ini dilakukan penghilangan
stop word (kata-kata yang tidak memiliki makna
dalam IR), seperti kata hubung atau kata yang paling sering muncul.
5. Preproses linguistik, melakukan stemming atau pemotongan imbuhan dan mengembalikan term ke bentuk kata dasar. Dalam hal ini digunakan algoritma stemming dari Nazief dan Adriani [16] yang merupakan pengembangan dari Porter Stemmer.
6. Pemberian bobot terhadap term menggunakan
tf-idf (term frequency - inverse document fre-quency).
Langkah keenam ini merupakan suatu kustomisasi yang berbeda antara satu model IR dengan model lainnya. Perhitungan tf dan idf sangat cocok digunakan untuk memprediksi kemiripan antara dokumen dengan kueri berdasarkan vektor yang dibentuk dari term-term penyusunnya.
Term frequency (tf) adalah jumlah kemunculan
sebuah term pada sebuah dokumen. Hipotesanya, semakin sering suatu term disebutkan dalam suatu dokumen, semakin penting term tersebut.
Inverse Document Frequency (idf) adalah jumlah
dokumen yang mengandung term yang dicari dari kumpulan dokumen yang ada. Semakin sedikit dokumen yang mengandung term, semakin khusus dokumen tersebut.
=
(1) dengan N adalah jumlah seluruh dokumen pada koleksi, dan Df(i) adalah jumlah dokumen yang mengandung term ke-i.
Bobot Term wij untuk sebuah term i pada dokumen j didapatkan dari hasil perkalian antara tf dan idf.
(2)
2.3 Proses Retrieving
Model yang digunakan pada proses retrieving berkaitan erat dengan pembobotan term yang dipakai pada proses indexing. Dalam penelitian ini, model yang digunakan adalah Vector Space Model (model ruang vektor), yang cukup sederhana dan sangat produktif untuk menemukan kemiripan antara
kueri dengan dokumen [14, 15]. Kata-kata pada kueri dan dokumen direpresentasikan dalam bentuk vektor bobot yang dinormalisasi terhadap panjang dokumen, dengan persamaan berikut,
=
(3) dengan i adalah term ke-i dan j mewakili dokumen ke-j atau kueri.Di dalam ruang berdimensi n, dengan n adalah jumlah term pada kueri, maka vektor bobot w dapat digambarkan pada arah tertentu, sehingga dokumen yang paling mirip dengan kueri adalah dokumen yang vektor bobotnya paling dekat arahnya dengan vektor bobot kueri. Ilustrasi Gambar 2 di bawah ini untuk jumlah term=3. Dari ilustrasi tersebut, maka dokumen yang paling mirip dengan kueri adalah dokumen D2.
q
t
3t
1t
2D
1D
2Q
q
1 2Gambar 2. Ilustrasi arah vektor bobot antara kueri dan dokumen D1 dan D2
Kemiripan antara kueri dan dokumen dapat dihitung dengan mengukur sudut θ terkecil. Sudut 0o menyatakan bahwa kueri sama dengan dokumen. Sehingga berdasarkan persamaan kosinus, similarity atau kemiripan antara dokumen dan kueri dapat dihitung sebagai berikut,
(4)
Dokumen yang paling mirip dengan kueri, adalah yang nilai cosine similarity-nya mendekati 1 (atau sudut antara vektor kueri dan dokumen mendekati 0o).
2.4 Kualitas Hasil Pencarian
Untuk mengukur kualitas hasil pencarian, dokumen yang ditemukan akan dinilai relevansinya terhadap keinginan pengguna. Dalam hal ini, kebanyakan penilaian adalah bersifat subjektif, sesuai dengan preferensi pengguna. Untuk itu, ukuran penilaian yang dapat digunakan adalah berapa jumlah dokumen relevan yang dapat dihasilkan (ketepatan atau precision) dari seluruh hasil pencarian, dan berapa banyak dokumen relevan
yang dapat dihasilkan dari sejumlah dokumen relevan di dalam koleksi yang ada (recall).
(5)
R
=
(6)Precision dan recall sebagaimana persamaan
(5) dan (6) kemudian dievaluasi, misalnya untuk 10 atau 20 dokumen pertama hasil pencarian, karena tidak memungkinkan untuk membaca seluruh isi koleksi untuk mengetahui dokumen mana saja yang dapat ditemukan, dan mana yang tidak. Kemudian, hasil ini digambarkan dalam grafik Precision-Recall terhadap 11 titik interpolasi (0 sampai 1). Penilaian unjuk kerja yang terbaik adalah sejauh mana dokumen relevan dapat ditemukan sebelum sistem memberikah hasil dokumen yang tidak relevan.
3. Implementasi dan Pengujian
Sistem Qur’an Retrieval ini dibangun berbasis web, dengan PHP sebagai skrip pemrograman dan MySQL sebagai databasenya. Beberapa flat file juga diakses sebagai sumber korpus untuk kebutuhan penampilan. Sebagaimana search engine (mesin pencari) pada umumnya, sistem ini hanya akan memberikan kotak pencarian untuk user, dan meminimalisasi hal-hal yang tidak diperlukan untuk mempercepat waktu akses. Namun demikian, untuk kebutuhan penelitian, beberapa utilitas masih di-tampilkan untuk memudahkan evaluasi, seperti ter-lihat pada Gambar 3 dan 4 berikut ini.
Gambar 3. Halaman awal sistem Qur’an Retrieval
Gambar 4. Halaman administrasi untuk evaluasi
Pengujian dilakukan dengan memberikan bebe-rapa kueri, maka sistem memberikan hasil seperti di-tunjukkan pada Gambar 5 dan 6 berikut ini.
Gambar 5. Hasil pencarian untuk kueri “kisah musa”
Gambar 6. Ketika dokumen dengan nomor urut 1 dipilih/diklik.
3.1 Hasil Pengujian
Pengujian dilakukan terhadap 3 kueri berikut: Q1: Kisah musa
Q2: Menunaikan zakat
Q3: Berpuasa di bulan Ramadhan
Dari ketiga kueri tersebut, kemudian dilakukan penilaian hasil pencarian secara subjektif menurut peneliti, apakah dokumen yang dihasilkan benar-benar sesuai dengan yang diinginkan atau tidak. Hasilnya kemudian di-plot dalam grafik
Precision-Recall 11 titik.
Hasil pengujian untuk masing-masing kueri menemukan dokumen-dokumen seperti pada Tabel 1 di bawah ini.
Tabel 1. Jumlah Dokumen Ditemukan
Kueri Jml dokumen relevan
ditemukan Jml dokumen ditemukan Q1 67 90 Q2 31 39 Q3 1 42
Pada kueri ketiga, kelihatannya hasil pencarian kurang memuaskan karena hanya 1 dokumen yang dianggap relevan. Namun tidaklah demikian, karena hal ini disebabkan bahwa ayat-ayat tentang puasa di bulan Ramadhan memang hanya berada pada 1 topik di dalam Al-Qur’an, dan juga merupakan satu-satunya nama bulan yang disebutkan di dalam Al-Qur’an di antara ke-12 bulan Hijriyah yang ada. Sehingga topik yang sangat relevan dengan kueri hanya satu. Tetapi ayat-ayat yang berhubungan dengan puasa secara umum dapat ditemukan pada 42 dokumen di antara total 800 dokumen di dalam koleksi.
Sedangkan untuk dua kueri yang lain, simulasi menunjukkan hasil yang sangat memuaskan, yang menempatkan dokumen-dokumen relevan di pering-kat teratas atau halaman awal hasil pencarian.
3.2 Analisa
Lebih mendalam, dokumen hasil pencarian di-periksa satu persatu apakah relevan atau tidak, kemudian dihitung nilai precision terhadap recall-nya, seperti dituliskan (sebagian) di dalam Tabel 2-4 berikut ini.
Tabel 2. Analisa Precision-Recall untuk kueri Q1
Rank Relevan? Precision (P) Recall (R)
1 ya 1/1 = 1,0000 1/67 = 0,0149 2 ya 2/2 = 1,0000 2/67 = 0,0299 3 ya 3/3 = 1,0000 3/67 = 0,0448 4 ya 4/4 = 1,0000 4/67 = 0,0597 5 ya 5/5 = 1,0000 5/67 = 0,0746 6 ya 6/6 = 1,0000 6/67 = 0,0896 7 ya 7/7 = 1,0000 7/67 = 0,1045 8 Ya 8/8 = 1,0000 8/67 = 0,1194 … … … … 89 tidak 67/89= 0,7528 67/67= 1,0000 90 tidak 67/90= 0,7444 67/67= 1,0000
Tabel 3. Analisa Precision-Recall untuk kueri Q2
Rank Relevan? Precision (P) Recall (R)
1 Ya 1/1 = 1,0000 1/31 = 0,0323 2 Ya 2/2 = 1,0000 2/31 = 0,0645 3 Ya 3/3 = 1,0000 3/31 = 0,0968 4 Ya 4/4 = 1,0000 4/31 = 0,1290 5 Ya 5/5 = 1,0000 5/31 = 0,1613 6 Ya 6/6 = 1,0000 6/31 = 0,1935 7 Ya 7/7 = 1,0000 7/31 = 0,2258 8 Ya 8/8 = 1,0000 8/31 = 0,2581 … … … … 38 Ya 31/38= 0,8158 31/31= 1,0000 39 tidak 31/39= 0,7949 31/31 1,0000
Tabel 4. Analisa Precision-Recall untuk kueri Q2
Rank Relevan? Precision (P) Recall (R)
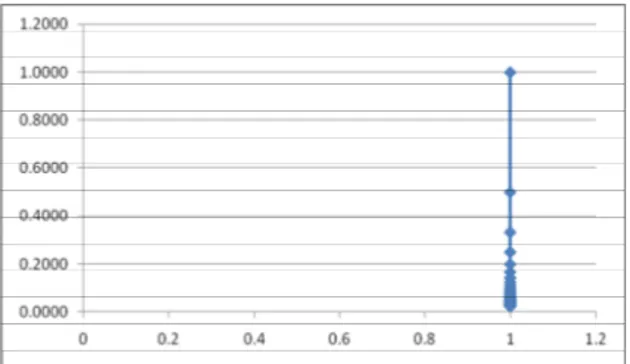
1 Ya 1/1 = 1,0000 1/1 = 1 2 tidak 1/2 = 0,5000 1/1 = 1 3 tidak 1/3 = 0,3333 1/1 = 1 4 tidak 1/4 = 0,2500 1/1 = 1 5 tidak 1/5 = 0,2000 1/1 = 1 6 tidak 1/6 = 0,1667 1/1 = 1 7 tidak 1/7 = 0,1429 1/1 = 1 8 tidak 1/8 = 0,1250 1/1 = 1 … … … … 41 tidak 1/41= 0,0244 1/1 = 1 42 tidak 1/42= 0,0238 1/1 = 1
Untuk mengetahui unjuk kerja sistem IR yang dibangun, profil hubungan Precision-Recall dibuat dalam bentuk grafik berdasarkan Tabel 2-4, seperti ditunjukkan pada Gambar 7-9 di bawah ini.
Gambar 7 dan 8 menunjukkan bahwa dokumen-dokumen yang dihasilkan pada urutan teratas adalah dokumen relevan (direpresentasikan oleh grafik yang mendatar/horizontal). Beberapa penurunan
precision menggambarkan adanya dokumen tidak
relevan yang terselip di antara dokumen relevan yang dihasilkan mesin pencari.
Gambar 7. Grafik Precision-Recall untuk Q1
Untuk Q1, yaitu “kisah musa”, sistem telah
memberikan banyak dokumen relevan di urutan-urutan teratas atau halaman awal hasil pencarian, ditandai dengan landainya grafik P-R yang dihasilkan.
Gambar 8. Grafik Precision-Recall untuk Q2
Sedangkan untuk Q2, yaitu “menunaikan zakat”,
baik, yang ditunjukkan dengan landainya grafik P-R sampai titik terakhir (titik Recall = 1). Kisaran precision terhadap recall adalah dari 0.8 sampai 1, menandakan bahwa performa sistem sudah baik.
Gambar 9. Grafik Precision-Recall untuk Q3
Seperti telah disampaikan sebelumnya, khusus untuk pencarian terhadap Q3, yaitu “berpuasa di
bulan ramadhan”, dapat dikatakan dari segi presisi, sistem telah memberikan hasil yang relevan pada urutan pertama, yaitu dokumen dengan sub tema “puasa” (lihat kembali [8]), yang menampilkan ayat 183-188, dan tidak ada lagi topik mengenai puasa Ramadhan di ayat-ayat yang lainnya. Namun, bahasan tentang puasa secara umum banyak ditemukan, tetapi bukan puasa ramadhan. Dalam hal ini, recall yang dihasilkan sistem juga baik, karena dapat mengembalikan hasil pencarian tentang puasa yang cukup banyak jumlahnya, yaitu 41 dokumen.
4. Kesimpulan dan Saran
Secara umum, sistem Qur’an retrieval yang dibangun dengan menggunakan model ruang vektor, telah memberikan hasil yang sangat memuaskan untuk beberapa kueri yang diuji, yang terlihat dari profil grafik Precision-Recall yang landai sampai titik Recall=1. Namun pengujian lebih mendalam perlu dilakukan oleh pihak-pihak yang lebih menge-tahui secara seksama mengenai isi kandungan Al-Qur’an, agar hasil pengujian lebih objektif.
Sistem yang dibuat sudah dapat diimplemen-tasikan secara live di internet, namun masih terdapat kekurangan dalam hal waktu akses atau waktu pencarian, belum dapat secepat Google atau Yahoo. Hal ini disebabkan karena proses perhitungan ke-miripan (nilai similarity) yang meng-update data-base cukup menyita waktu. Untuk operasional sistem secara live nantinya, proses update database dan penampilan nilai similarity tersebut tidak diperlukan lagi.
Saran untuk tahap penelitian selanjutnya, agar menyempurnakan proses indexing dan retrieving agar lebih cepat dan efisien. Antara lain dengan menggunakan bahasa pemrograman perl yang sangat efisien untuk pemrosesan teks dan pengolahan file
index yang lebih efisien dibandingkan menggunakan
database relasional.
Daftar Pustaka:
[1] F. Ataa Allah dan S. Boulaknadel, Arabic
Information Retrieval System Based on Noun Phrases, IEEE, 2006.
[2] Nurazzah Abd Rahman, Zainab A. Bakar, Tengku M.T. Sembok, Query Expansion using
Thesaurus in Improving Malay Hadith Retrieval System. IEEE, 2010
[3] Noordin, M. Fauzan and Othman, Roslina. An
Information Retrieval System for Quranic Texts: A Proposed System Design. Information &
Communication System Design, IEEE, 2006. [4] Surra binti Ahmad Sufyan, Retrieving Malay
Translated of Al-Quran using Thesaurus Technique with User Relevance Feedback, Tesis
Universiti Teknologi Mara, Malaysia, 2004 [5] Yunus, M.A., Zainuddin, R and N. Abdullah
Semantic Query for Quran Document Results.
IEEE, 2010.
[6] Nuk Ghurroh Setyoningrum, Prototipe Sistem
Penerjemahan Bahasa Arab Ke Bahasa Indonesia (Studi Kasus Al-Qur’an), Tesis
UGM, 2010
[7] Ahmad T. Al-Taani and Alaa M. Al-Gharaibeh,
Searching Concepts and Keywords in the Holy Quran, ACIT, 2011
[8] Al-Qur’an dan Terjemahan Departemen Agama RI, Yayasan Penyelenggara Penterjemah/ Pentafsir Al_Qur’an, Lembaga Pencetakan Al-Qur’an Raja Fahd, Arab Saudi.
[9] ________, http://www.qurandownload.com/
[10] ________, http://www.2muslims.com/cgi-bin/hadith/quran/quran.cgi
[11] ________, http://www.myquran.org
[12] Darmawan, Heru Adi, Akh Masturi, Rancang
Bangun Aplikasi Search Engine Tafsir Al-Qur’an Menggunakan Teknik Text Mining Dengan Algoritma VSM (Vector Space Model).
Program Studi Sistem Informasi, STIKOM Surabaya, 2011.
[13] Cios, Krzyztof J. Etc. Data Mining A
Knowledge Discovery Approach. Spinger, 2007.
[14] Ricardo Baeza-Yates, Berthier Ribeiro-Neto
Modern Information Retrieval, ACM Press,
New York: 1999.
[15] Christopher D. Manning, Prabhakar Raghavan
and Hinrich Schutze, Introduction to
Information Retrieval, Cambridge University
Press, 2008
[16] Bobby A.A. Nazief dan Mirna Adriani, Confix
Stripping: Approach to Stemming Algorithm for Bahasa Indonesia, Faculty of Computer
![Gambar 1. Arsitektur sistem IR [13]](https://thumb-ap.123doks.com/thumbv2/123dok/4909263.3478939/2.892.489.823.816.1041/gambar-arsitektur-sistem-ir.webp)