VI-1
BAB VI
PENGUJIAN SISTEM
Bab ini berisi penjelasan mengenai pengujian yang dilakukan terhadap sistem pengenal tulisan tangan huruf Katakana menggunakan metode Induct/RDR (KaRe) yang telah dibangun. Pengujian ditujukan untuk memeriksa kesesuaian antara sistem yang telah dibangun dengan tujuan awal pengembangan sistem. Bab ini juga akan menjelaskan mengenai analisis terhadap hasil pengujian sistem.
VI.1 Persiapan Pengujian
Subbab ini menjelaskan mengenai persiapan yang diperlukan sebelum melakukan pengujian terhadap sistem. Persiapan yang diperlukan meliputi lingkungan pengujian, tujuan pengujian, bahan pengujian, skenario dan kriteria pengujian, dan metode pengukuran.
VI.1.1 Lingkungan Pengujian
Lingkungan pengujian meliputi lingkungan perangkat keras dan lingkungan perangkat lunak yang digunakan sama dengan lingkungan yang digunakan pada implementasi.
VI.1.2 Tujuan Pengujian
Tujuan dilakukannya pengujian sistem adalah:
1. Memeriksa kesesuaian antara implementasi sistem dengan hasil analisis dan perancangan dan apakah sistem dapat menjalankan fungsinya.
2. Membandingkan akurasi penerapan algoritma praproses terhadap huruf dengan praproses secara manual.
3. Mengetahui akurasi penerapan algoritma Induct/RDR untuk memproses data huruf dalam representasi struktural berupa segmen dan faktor-faktor yang dapat memperngaruhi besarnya nilai akurasi.
VI.1.3 Bahan Pengujian
Bahan pengujian yang digunakan adalah:
1. Data penulisan huruf Jepang secara on-line dari [NAK97] berjumlah 10 file data dengan format nama file adalah MDB00YY.txt dengan YY adalah angka bernilai antara 01 sampai dengan 10.
2. Data segmentasi huruf Jepang secara manual pada 46 (empat puluh enam) silabel dasar huruf Katakana.
VI.1.4 Skenario dan Kriteria Pengujian
Pengujian pada pelaksanaan Tugas Akhir ini dibagi menjadi tiga bagian:
1. Pengujian implementasi kelas untuk memenuhi tujuan pengujian poin 1. Skenario dan kriteria pengujian ini dapat dilihat pada Lampiran.
Pengujian terhadap fungsionalitas sistem dilakukan dengan memeriksa apakah seluruh fitur dalam sistem dapat bekerja dengan baik atau tidak. Rincian pengujian ini dapat dilihat pada Lampiran.
2. Pengujian perbandingan akurasi penerapan algoritma praproses dengan praproses secara manual untuk memenuhi tujuan pengujian poin 2. Pada pengujian ini dilakukan dua jenis perbandingan, yaitu:
a. Perbandingan terhadap hasil ekstraksi fitur oleh sistem, dengan ekstraksi fitur secara manual. Ekstraksi fitur secara manual dilakukan berdasarkan pada urutan ideal penulisan huruf Katakana dan fitur ideal yang diperoleh. Pengekstraksian fitur secara manual menggunakan teori yang sama bahwa sebuah segmen didapat dengan memutuskan sebuah stroke pada segmentation point. Pengekstraksian fitur ideal dilakukan terhadap data ideal, yaitu font yang disediakan komputer. Dalam pengujian ini digunakan font MS PMincho. Penjelasan mengenai pengujian ini dapat dilihat pada Lampiran.
b. perbandingan terhadap feature segmen yang dihasilkan oleh sistem, yaitu jenis segmen, posisi relatif antar segmen, dan perpotongan antar segmen. Penjelasan mengenai pengujian ini dapat dilihat pada Lampiran.
3. Pengujian akurasi pengetahuan Induct/RDR untuk memenuhi tujuan pengujian poin 3. Pengujian ini dilakukan dengan kelas WEKA yang mengimplementasi algoritma
Induct/RDR, yaitu Ridor. Pengujian dilakukan dengan menggunakan skema pengujian yang disediakan oleh sistem, yaitu skema use training set (menggunakan seluruh data untuk pelatihan) dan skema 10-fold-cross-validation. Pengujian dilakukan dengan menggunakan bahan pengujian poin 1. Pengujian dilakukan terhadap masing-masing file, gabungan beberapa file, dan gabungan semua file. Nilai akurasi dinyatakan dalam persen dengan nilai akurasi maksimum adalah 100% yaitu jika semua data (100% data) diklasifikasikan dengan benar.
Pengujian ini juga meliputi pengujian terhadap pengetahuan yang dihasilkan dengan menggunakan beberapa sampel yang diambil dari hasil praproses. Pengujian ini untuk membandingkan solusi yang diharapkan oleh data dengan solusi yang dihasilkan oleh sistem.
4. Pengujian akurasi pengetahuan KaRe dengan sistem [AMI99]. Pengujian ini dilakukan dengan membandingkan hal-hal mengenai kedua sistem dan akurasi akhir yang diperoleh untuk memenuhi tujuan pengujian pada poin 4.
VI.2 Pelaksanaan Pengujian
Subbab ini akan menjelaskan hasil pelaksanaan pengujian berdasarkan skenario pada subbab sebelumnya. Penjelasan mengenai pelaksanaan pengujian ini terdiri atas hasil pengujian, analisis hasil, dan kesimpulan pengujian.
VI.2.1 Hasil Pengujian
Pelaksanaan pengujian dilakukan berdasarkan penjelasan pada persiapan pengujian, untuk mengukur keberhasilan implementasi kelas, implementasi algoritma segmentasi, dan tingkat akurasi algoritma Induct/RDR terhadap permasalahan pengenalan tulisan tangan huruf Jepang.
Hasil pengujian implementasi kelas dapat dilihat pada Lampiran E. Hasil pengujian implementasi algoritma praproses dapat dilihat pada Lampiran G dan Lampiran H. Hasil pengujian tingkat akurasi algoritma Induct/RDR pada permasalahan terpilih dapat dilihat pada lampiran I.
VI.2.2 Analisis Hasil Pengujian
VI.2.2.1 Analisis Hasil Pengujian Implementasi Algoritma Praproses
Hasil perbandingan algoritma praproses dapat dilihat pada Lampiran. Perbandingan hasil penerapan algoritma segmentasi ini dilakukan terhadap subset huruf Katakana, yaitu 46 (empat puluh enam) huruf yang merupakan bentuk dasar silabel Katakana pada gambar huruf Katakana pada subbab III.2.3. Perbandingan tidak dilakukan terhadap subset Dakuon, Handakuon, dan Yoon.
Proses segmentasi manual dilakukan terhadap huruf dalam bentuk ideal, yaitu bukan huruf hasil penulisan tangan. Oleh karena itu, bentuk huruf ideal ini sama sekali tidak mengandung guratan-guratan yang tidak perlu. Bentuk huruf ideal yang dipilih adalah font MS PMincho. Font ini dipilih karena bentuknya yang termasuk dalam jenis huruf Serif. Huruf Serif mempunyai bentuk seperti kail di ujung-ujung huruf. Bentuk kail ini dijumpai pada penulisan huruf-huruf Katakana. Sehingga, dengan menggunakan font ini, perbandingan yang dilakukan dianggap cukup sepadan. Namun demikian, bentuk seperti kail di ujung-ujung huruf dalam font MS PMincho ini tidak dianggap sebagai sebuah segmen.
Proses segmentasi dengan menggunakan algoritma segmentasi yang dirancang, dilakukan terhadap huruf dari sebuah file data yang dipilih secara acak (tanpa kriteria). Untuk bahan perbandingan, diambil satu sampel image untuk setiap huruf dari hasil proses segmentasi sistem.
Perbandingan dilakukan terhadap dua aspek, yaitu jumlah segmen dan jenis segmen sesuai dengan urutannya. Hasil perbandingan dari tiap aspek adalah sebagai berikut:
1. Jumlah segmen
Berdasarkan jumlah segmen, proses segmentasi oleh sistem menghasilkan jumlah segmen maksimal adalah 5 (lima) buah segmen, yaitu pada huruf ネ (Ne). Proses segmentasi ideal menghasilkan jumlah segmen maksimum 5 (lima) buah segmen, yaitu pada huruf ホ(Ho) dan ネ(Ne). Huruf hasil proses segmentasi KaRe yang mempunyai jumlah segmen yang sama dengan jumlah segmentasi secara manual adalah 38 huruf (82,60%). Hasil pengujian ini dapat dilihat pada Lampiran F.
2. Jenis segmen benar sesuai urutan yang tepat
Perbandingan dilakukan pada urutan yang bersesuaian, yaitu keluaran sistem urutan pertama, dibandingkan dengan keluaran proses manual urutan pertama, demikian seterusnya. Yang menjadi patokan perbandingan adalah keluaran sistem yang ideal. Jika jumlah segmen keluaran sistem yang dihasilkan lebih besar daripada jumlah segmen ideal, maka kelebihan segmen sistem yang dihasilkan tidak diperhitungkan.
Sebaliknya jika segmen keluaran sistem lebih sedikut daripada jumlah segmen ideal, maka kekurangan dari sistem dianggap sebagai ketidaksesuain.
Hasil pengujian ini dapat dilihat pada Lampiran F. Nilai rata-rata akurasi urutan dan jenis segmen ini adalah 69,35%. Ringkasan hasil pengujian dapat dilihat pada Tabel VI-1.
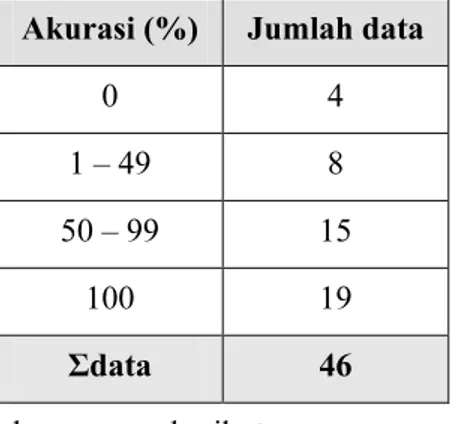
Tabel VI-1 Akurasi pengujian praproses pada kesesuaian jenis dan urutan segmen
Akurasi (%) Jumlah data
0 4
1 – 49 8
50 – 99 15
100 19
Σdata 46
Nilai akurasi dihitung dengan cara berikut:
Akurasi = n segmen_tepat_benar / n segmen_ideal x 100%
Segmen_tepat_benar adalah segmen yang mempunyai jenis dan urutan yang sama dengan jumlah dan jenis segmen ideal.
Akurasi tertinggi dimiliki oleh 41,30% data yang memiliki urutan dan jenis segmen sama dengan praproses manual. Sedangkan 58,70% data memiliki urutan dan jenis segmen tidak tepat sama atau tidak sama, dengan perincian: 15 (lima belas) data yang memiliki akurasi 50% sampai dengan 99%, artinya urutan dan jenis segmen hasil praproses sistem yang sama dengan praproses manual lebih banyak daripada urutan dan jenis segmen yang tidak sama. 8 (delapan) data memiliki akurasi 1%-49% artinya data tersebut memiliki urutan dan jenis segmen berbeda lebih banyak daripada urutan dan jenis segmen yang sama.
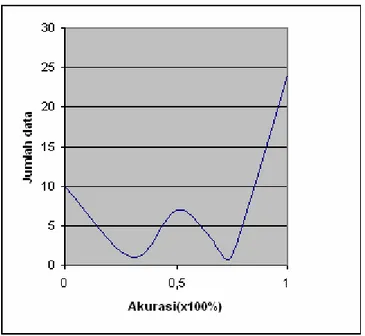
Gambar VI-1.menunjukkan distribusi nilai akurasi terhadap jumlah data. Grafik menunjukkan bahwa distribusi tidak bersifat eksponensial.
Gambar VI-1 Distribusi Akurasi terhadap Jumlah Data
3. Pengujian posisi relatif antar segmen.
Hasil pengujian ini dapat dilihat pada Lampiran G. Nilai akurasi rata-rata yang dihasilkan adalah 68,61%. Distribusi data terhadap akurasi dapat dilihat pada Tabel VI-2 dan Gambar VI-2.
Tabel VI-2 Distribusi Data Terhadap Akurasi Berdasarkan Posisi Relatif antar Segmen
Akurasi (%) Jumlah data
0 10
1 – 49 1
50 – 99 11
100 24
Gambar VI-2 Distribusi Data Terhadap Akurasi Berdasarkan Posisi Relatif antar Segmen
Dari hasil pengujian, diketahui bahwa 52,17% data mempunyai posisi relatif antar segmen keluaran sistem sama dengan keluaran ideal. Sisanya, yaitu 47,83% data mempunyai posisi relatif antar segmen keluaran sistem yang tidak persis sama dengan keluaran ideal.
4. Pengujian perpotongan antar segmen.
Hasil pengujian ini dapat dilihat pada lampiran pengujian algoritma praproses bagian III. Distribusi akurasi terhadap jumlah data dapat dilihat pada Tabel VI-3 dan Gambar VI-3.
Tabel VI-3 Distribusi Data Terhadap Akurasi Berdasarkan Perpotongan Antar Segmen
Akurasi (%) Jumlah data
0 10
1 – 49 1
50 – 99 11
100 24
Gambar VI-3 Distribusi Data Terhadap Akurasi Berdasarkan Perpotongan Antar Segmen
Dari hasil pengujian, terdapat delapan data dengan akurasi 0% (tidak ada perpotongan antar segmen yang tepat), tiga data dengan akurasi 1% sampai dengan 49% (jumlah perpotongan tepat kurang dari jumlah perpotongan tidak tepat), 13 (tiga belas) data dengan akurasi 50% sampai dengan 99% (jumlah perpotongan tepat lebih besar atau sama dengan jumlah perpotongan tidak tepat), dan 23 (duapuluh tiga) data dengan nilai akurasi 100% (semua jenis perpotongan tepat). Sehingga, terdapat 50% data yang mempunyai perpotongan antar segmen keluaran sistem yang sama dengan keluaran ideal dan 50% data yang mempunyai perpotongan antar segmen keluaran sistem tidak persis sama dengan keluaran ideal. Nilai rata-rata akurasi pengujian ini adalah 67,43%.
Untuk keempat jenis pengujian algoritma praproses, nilai rata-rata akurasi dapat dihitung sebagai berikut:
82,60%+69,35% + 68,61%. + 67,43%
4 = 71,99%
Jika ditinjau dari jumlah segmen dan jenis segmen yang dihasilkan dalam urutan yang bersesuaian dengan keluaran ideal, nilai akurasi algoritma segmentasi dapat dikatakan cukup baik. Adanya ketidaksesuaian baik dari jumlah segmen maupun dari jenis segmen yang dihasilkan disebabkan oleh beberapa hal, di antaranya:
1. Perbedaaan penulisan ideal dengan penulisan sesungguhnya oleh responden. 2. Adanya beberapa kecenderungan yang mempengaruhi, yaitu:
a. Kecenderungan untuk menjadikan dua guratan terpisah menjadi dua guratan yang tersambung.
b. Kecenderungan untuk menambahkan bentuk seperti kait di setiap akhir penulisan sebuah guratan.
c. Kecenderungan untuk menuliskan garis lurus sebagai garis miring, dan sebaliknya. Hal ini banyak dijumpai pada data.
3. Nilai rata-rata akurasi terendah terdapat pada pengujian perpotongan antar segment. Hal ini dapat diartikan bahwa pada data, perpotongan antar segmen yang tepat tidak terlalu diperhatikan oleh responden penulis. Contohnya, pada huruf ム (Mu), jika seharusnya segmen kedua dan ketiga ditulis sebagai perpotongan, untuk alasan kepraktisan maka segmen kedua dan ketiga ditulis sebagai segmen yang successive (ditulis berurutan).
4. Responden juga cenderung menuliskan segmen Right-Horizontal sebagai Down-Backslash (segmen pertama huruf ア (A)). Namun demikian nilai akurasi untuk urutan dan jenis segmen merupakan nilai tertinggi di antara tiga jenis pengujian praproses yang berbasis nilai ketepatan dan kebenaran. Meskipun pada contoh file yang digunakan untuk pengujian, terdapat urutan penulisan yang terbalik sehingga jenis segmen yang dihasilkan pun tidak sesuai. Contohnya pada huruf メ (Me) yang seharusnya dituliskan sebagai Down-Slash dan Down-Backslash, namun dituliskan oleh responden dengan urutan terbalik.
5. Dengan nilai rata-rata akurasi sebesar 71,99% maka diperoleh kesimpulan sementara bahwa algoritma praproses yang digunakan cukup mampu untuk menghasilkan feature yang mendekati fitur yang ideal.
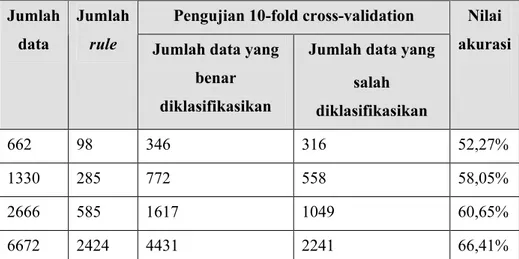
VI.2.2.2 Analisis Hasil Pengujian Akurasi Pengetahuan Induct/RDR pada KaRe Pengujian ini dilakukan dengan metode 10-fold-cross-validation, dengan menggunakan implementasi Induct/RDR pada WEKA, yaitu Ridor. Data yang digunakan berasal dari 10 (sepuluh) data titik koordinat tulisan tangan huruf Jepang. Pengujian ini bertujuan untuk mengetahui kemampuan Induct/RDR dalam membangun pengetahuan dari data penulisan tangan huruf Katakana yang direpresentasikan dalam komponen struktural penyusunnya, yaitu segmen dan relasinya. Selain itu, pengujian ini bertujuan untuk mengetahui pengaruh jumlah data terhadap jumlah rule dan tingkat akurasi yang dihasilkan. Nilai akhir akurasi pengujian sistem ini akan dibandingkan dengan nilai akhir akurasi penelitian [AMI99] yang
menggunakan Induct/RDR untuk pengenalan tulisan tangan huruf Latin yang dicetak (bukan dituliskan pada TabletPC).
Percobaan akan dilakukan sebanyak lima kali. Percobaan pertama menggunakan satu buah file data. Percobaan kedua menggabungkan dua buah file data. Percobaan ketiga menggabungkan lima buah file data. Percobaan keempat menggabungkan sepuluh file data. Setiap file data berisi ±662 buah sampel image huruf Katakana dari 11962 sampel image karakter Jepang, dengan ±88 (delapan puluh delapan) karakter Katakana (distinct). Hasil pengujian dapat dilihat pada Tabel VI-4 & Tabel VI-5.
Tabel VI-4 Hasil pelatihan dengan berbagai macam ukuran data
Pelatihan Jumlah
data
Jumlah
rule Jumlah data yang
benar diklasifikasikan
Jumlah data yang salah diklasifikasikan Nilai akurasi pelatihan 662 98 384 278 58,01% 1330 285 772 558 64,81% 2666 585 1800 866 67,52% 6672 2424 4687 1985 70,25%
Tabel VI-5 Hasil pengujian 10-fold-cross-validation dengan data yang sama dengan pengujian pelatihan
Pengujian 10-fold cross-validation Jumlah
data
Jumlah
rule Jumlah data yang
benar diklasifikasikan
Jumlah data yang salah diklasifikasikan Nilai akurasi 662 98 346 316 52,27% 1330 285 772 558 58,05% 2666 585 1617 1049 60,65% 6672 2424 4431 2241 66,41%
Pelatihan menghasilkan akurasi yang lebih besar pada data yang sama dibandingkan pengujian dengan cross-validation. Cross-validation melakukan partisi random yang berbeda untuk setiap iterasi sebanyak k-fold yang digunakan. Nilai akurasi ini dapat diperbaiki dengan memperbanyak jumlah data, seperti pada percobaan ketiga dan keempat. Penambahan data
yang akan akan memberikan pengaruh yang signifikan terhadap akurasi sistem adalah penambahan data dalam jumlah yang cukup besar. Selain itu, pada beberapa percobaan yang telah dilakukan sebelumnya, urutan data sangat mempengaruhi nilai akurasi pada pengujian sistem.
Penambahan jumlah data dapat berpengaruh pada kenaikan akurasi sistem. Namun demikian, dengan bertambahnya jumlah data, maka bertambah pula ukuran pengetahuan yang dihasilkan. Ini merupakan salah satu kelemahan RDR karena melakukan pembangunan pengetahuan berbasis kasus. Di samping kelemahan ini, RDR memiliki kelebihan yaitu waktu pemrosesan yang cukup cepat untuk ukuran data yang besar. Waktu pemrosesan ini adalah waktu pembangunan pengetahuan dari data.
Untuk memeriksa kebenaran pengetahuan yang telah dibangun, maka diambil sampel pengetahuan yang telah dibangun. Sampel pengetahuan ini dapat dilihat pada Gambar VI-4. character = ー (2666.0/2410.0)
Except (side_Seg0-Seg1 = SOUTH) => character = ス (587.0/0.0) [287.0/0.0]
Except (isect_Seg0-Seg1 = NO-INTERSECT) => character = ン (330.0/0.0) [165.0/0.0]
Except (Seg1 = R-HOR) and (Seg0 = R-HOR) => character = キ (132.0/0.0) [68.0/0.0]
Gambar VI-4 Sampel pengetahuan yang berhasil dibangun
Pengecekan kebenaran pengetahuan dapat dilihat pada Tabel VI-6.
Tabel VI-6 Pengecekan kebenaran pengetahuan Induct/RDR
Huruf Feature yang muncul Solusi KaRe Evaluasi
ス Seg2_1 South ス Benar
ン Seg2_1 South Isect2_1 No-Intersect ン Benar キ Seg2_1 South Isect2_1 No-Intersect Seg1 Right-Horizontal Seg2 Right-Horizontal キ Benar
Dari potongan pengetahuan yang diambil sebagai contoh pengujian, dapat dilihat bahwa pengetahuan dapat memberikan akurasi 100%. Dengan demikian, dapat dikatakan bahwa pengetahuan RDR yang dibangun terhadap data tulisan tangan ini cukup valid.
VI.2.2.3 Analisis Hasil Perbandingan Pengujian KaRe dengan Sistem [AMI99] Hasil pengujian KaRe dapat dilihat pada tabel-tabel di subbab sebelumnya. Tabel VI-7 menunjukkan hasil pelatihan dan pengujian pada sistem [AMI99].
Tabel VI-7 Akurasi sistem [AMI99]
Jumlah data latih
Jumlah rule Akurasi
pelatihan Jumlah data uji Akurasi pengujian 252 67 89,6% 84 83,9% 382 88 92,9% 127 86,0% 512 92 95,3% 170 89,1% 780 101 98,1% 260 90,2%
Untuk membandingkan kedua implementasi Induct/RDR pada permasalahan pengenalan tulisan tangan, berikut ini diberikan aspek-aspek pembeda yang berpengaruh pada perbedaan akurasi yang dihasilkan.
Tabel VI-8 Perbandingan sistem [AMI99] dengan KaRe
Aspek pembeda [AMI99] KaRe
Objek penelitian Huruf Latin tulisan tangan yang dicetak
Data penulisan on-line huruf Jepang
Jumlah data 1040 6672
Jumlah kategori segmen
30 8
Basis segmentasi Ukuran segmen Sudut inklinasi Akurasi tertinggi
pada pengujian
90,2% 66,41%
Berdasarkan tabel di atas, diketahui bahwa jumlah kategori segmen yang digunakan pada KaRe jauh lebih sedikit, yaitu kurang dari sepertiga jumlah kategori segmen yang digunakan pada [AMI99]. Aspek ini dapat menjadi salah satu penyebab jauhnya nilai akurasi antara dua sistem. Dengan kategori segmen yang lebih banyak, segmen yang serupa akan terpisahkan ke kategori yang berbeda.
VI.2.3 Kesimpulan Pengujian
Berdasarkan penjelasan hasil pengujian di atas, dapat disimpulkan beberapa hal berikut: 1. Sistem yang dibangun dapat menjalankan fungsinya dengan baik dan sesuai dengan
analisis dan perancangan sistem.
2. Algoritma praproses yang dirancang dapat merepresentasikan huruf Katakana dengan baik, dengan nilai akurasi mencapai 71,99%. Akurasi dipengaruhi oleh faktor-faktor
penulisan dan kecenderungan responden penulis. Selain itu, kualitas data juga memberikan pengaruh yang cukup besar, yaitu adanya noise (derau).
3. Algoritma Induct/RDR memberikan akurasi tertinggi 66,41%, jika representasi huruf Katakana diperbaiki, yaitu dengan meminimalisir kehadiran-kehadiran segmen yang tidak seharusnya ada. Hal ini menunjukkan bahwa proses segmentasi yang dapat mengekstraksi lebih banyak informasi dari huruf Katakana dapat membantu sistem dalam melakukan pembangunan pengetahuan yang baik.
4. Akurasi sistem yang dibangun lebih rendah dibandingkan dengan akurasi sistem pada penelitian [AMI99]. Perbedaan ini kemungkinan disebabkan oleh faktor-faktor seperti data asal dan teknik pemrosesan data.



![Tabel VI-8 Perbandingan sistem [AMI99] dengan KaRe](https://thumb-ap.123doks.com/thumbv2/123dok/3754775.2461905/12.892.123.788.467.761/tabel-vi-perbandingan-sistem-ami-dengan-kare.webp)
