Vol 4, No 2 September 2021
Studi Ekstraksi Fitur Data Teks Rencana
Pelaksanaan Pembelajaran Memanfaatkan Model Word2Vec
Daniel Eliazar Latumaerissa1
#Program Magister Sains Data, Universitas Kristen Satya Wacana Jln Diponegoro No 52 – 60. Salatiga. Jawa Tengah
1632020001@students.uksw.edu
Abstrak— Natural Language Processing (NLP) adalah bidang dalam ilmu computer yang mencoba menjembatani mesin dan manusia melalui analisis bahasa manusia, misalnya dalam bentuk teks. Data berupa teks sebelum digunakan dalam pelatihan mesin perlu dirubah terlebih dahulu menjadi vektor (trasnformasi) bermakna sehingga dapat dihitung secara matematis. Pemilihan teknik transformasi atau dikenal juga dengan Vector Space Model (VSM) menjadi penting karena dapat berpengaruh terhadap proses pelatihan mesin. Telah dilakukan uji transformasi teks ke vektor menggunakan model Word2Vec pada dataset Rencana Pelaksanaan Pembelajaran (RPP) dan didapatkan bahwa variasi Bag of Centroids Based Word2Vec adalah pilihan Teknik terbaik untuk melakukan transformasi teks dataset RPP berdasarkan analisis matriks hasil perhitungan cosine similarity.
Kata kunci
—
Vektorisasi, Vector Space Model, Word2Vec, Bags of Centroids Based Word2vec, Cosine SimilarityI. PENDAHULUAN
Natural Language Processing (NLP) di masa kini telah menjadi salah satu cabang dari ilmu Komputer yang mendapatkan banyak perhatian. Berbagai tugas komputasi yang berkaitan dengan bahasa natural manusia dapat diselesaikan menggunakan metode–metode yang ada dalam NLP, misalnya seperti klasifikasi teks, penerjemahan, speech recognition, image captioning, speech tagging, adalah sebagian dari contoh penerapan NLP dalam praktek riil di lapangan [1]. Riset–riset tentang klasifikasi teks misalnya telah banyak memberikan sumbangsih baik di bidang sosial, lingkungan, pendidikan, hiburan (entertainment), sains maupun kesehatan. Oleh karena itu di tengah derasnya arus informasi dan data yang terjadi di saat ini, data teks telah berubah menjadi salah satu sumber daya yang berharga [2].
Namun perlu dipahami bahwa data teks yang masih mentah tidak dapat langsung digunakan untuk proses komputasi misalnya dalam pelatihan suatu algoritma machine learning. Langkah awal yang perlu dilakukan
adalah dengan melakukan vektorisasi. Vektorisasi yang dimaksudkan di sini adalah transformasi data teks menjadi vektor yang berarti yang dapat digunakan untuk berkomunikasi dengan mesin dalam menyelesaikan tugas komputasi dengan NLP secara matematis [3]. Salah satu Teknik yang umum digunakan untuk melakukan transformasi ini adalah vector space representation atau vector space model (VSM). Tujuan utamanya adalah untuk menghasilkan fitur–fitur sederhana yang dapat digunakan dalam proses komputasi. Aspek utama dari VSM adalah cara mendefinisikan teks ke dalam vektor dan ukuran seberapa besar dimensi vektor yang dihasilkan [3]. Dalam beberapa penelitian terdahulu, VSM dapat dilakukan dengan berbagai model misalnya seperti Term Frequency–
Inverse Document Frequency (TF–IDF) pada dataset teks email untuk berikutnya digunakan dalam pelatihan riset klasifikasi Naïve-Bayes [2]. Ataupun model Word2Vec yang divariasikan menjadi Average Based Word2Vec, Sum based Word2Vec, dan Bags of Centroid Based Word2Vec, maupun gabungan keduanya [4].
Dalam penelitian ini, telah dikumpulkan data teks dari dokumen 42 dokumen RPP Fisika kelas X semester 1.
Selanjutnya data teks RPP ini akan ditranformasi menjadi vektor dengan menggunakan model Word2Vec. Analisis digunakan untuk mengetahui variasi mana yang menghasilkan vektor yang paling baik dengan cara membandingkan nilai cosine similarity.
II. TINJAUAN PUSTAKA
Dalam bagian ini akan coba dijelaskan beberapa konsep penting yang berkaitan dengan penelitian.
A. Data Teks
Diantara berbagai sumber dan jenis data, data teks merupakan data jenis data yang paling banyak digunakan untuk melakukan komunikasi (surat menyurat, postingan di media social, dokumen, dll) itulah mengapa di masa
atau kepentingan komputasi lainnya [5]. TF-IDF adalah salah satu model yang dapat digunakan dikarenakan kemudahan dan cukup sederhana untuk diterapkan sehingga cukup terkenal [5]. Namun TF-IDF memiliki beberapa kesulitan seperti kelemahan dalam mengenali pola n-gram, kesulitan pada proses update dataset (jika
continuous skip-gram. Yang menjadi masukan dari model Word2Vec adalah corpus teks sedangkan yang menjadi luarannya adalah vektor dari kata, dapat dilihat pada Gambar 1.
Gambar. 1 Contoh vector hasil transformasi Word2Vec Inti dari prinsip kerja model Word2Vec adalah
memprediksi makna dari sebuah kata berdasarkan peluang kemunculannya pada teks. Word2Vec juga dapat melakukan asosiasi untuk melihat hubungan satu kata dengan kata lain berdasarkan persamaan kemunculannya [2].
C. Similarity Metric (Cosine Similarity)
Similarity metric adalah sebuah ukuran yang digunakan untuk menentukan kesamaan dua buah vektor.
Ada beberapa cara yang bisa dilakukan misalnya seperti menghitung jarak Euclid, besar separasi sudut, korelasi maupun cara lainnya [5]. Di dalam penelitian ini similarity Metric dilakukan menggunakan perhitungan cosine similarity, yaitu dengan menghitung besar sudut di antara dua buah vektor.
III. METODOLOGI PENELITIAN
Rencana dan tahapan kerja yang dilakukan dalam penelitian kali dapat dijelaskan sebagai berikut. Proses pertama yang perlu dilakukan dalam setiap penelitian NLP atau machine learning lainnya adalah membangun dataset. Di dalam penelitian kali, dataset yang digunakan adalah data teks berisi tahapan pembelajaran beberapa topik pelajaran Fisika yang diajarkan di jenjang pertama SMA, yaitu kelas X.
Dataset ini memiliki dua fitur yaitu fitur topik yang menentukan topik pembahasan dan fitur tahapan pembelajaran yang berisi langkah–langkah pembelajaran (Gambar 2). Fitur topik nantinya dapat membantu jika dilakukan klasifikasi teks. Sedangkan fitur tahapan pembelajaran (Gambar 3) dapat dianalisis dengan terlebih dahulu melakukan transformasi dengan VSM.
Gambar. 2 Tampilan dataset RPP Fisika
Gambar 3. Contoh Tahapan Pembelajaran Setelah dataset yang dibuthkan berhasil dikumpulkan,
proses penelitian dilanjutkan dengan preprocessing, yang dimaksud disini adalah melakukan pembersihan data (misalnya memperbaiki data yang rusak), removing yaitu menyingkirkan karakter dari data, case folding membuat data teks menjadi bentuk standar (misalnya dengan mengganti semua huruf besar dengan huruf kecil), hal ini penting karena dalam komputasi kata “Makan” dan
“makan” akan dianggap sebagai dua kata berbeda.
Dilanjutkan dengan proses tokenizing, yaitu merubah data dari bentuk kalimat menjadi suku kata dan terakhir adalah dengan melakukan transformasi dengan menggunakan model Word2Vec. Dalam penelitian ini digunakan library Gensim dengan Bahasa pemrograman Python untuk membantu tugas komputasi.
Agar dapat dilakukan analisis yang lebih mendalam, maka digunakan beberapa variasi dari model Word2Vec, yaitu:
1. Average Based Word2Vec
Adapun yang dimaksudkan dengan Average based Word2Vec adalah vector dari sebuah kalimat ditentukan dengan menghitung rerata dari fitur vektor tiap kata yang terdapat di dalam kalimat tersebut.
Pada Tabel I, vektor dari kalimat “Guru memulai pelajaran” adalah rerata dari tiap fitur vektor kata–kata penyusun kalimat tersebut.
TABEL I
TRANSFORMASI AVERAGE BASED WORD2VEC
Teks X1 X2 X3 Xn
Guru 0.1 0.23 0.9 …
Memulai 2.6 0.23 0.78 …
Pelajaran 3.4 1.02 0.21 …
“Guru memulai pelajaran” 2.03 0.49 0.63 …
2. Sum Based Word2Vec
Adapaun cara kerja Sum based Word2Vec adalah menghitung jumlah tiap fitur vektor kata–kata penyusun suatu kalimat untuk mendapat vektor dari kalimat tersebut (Tabel II).
TABEL III
TRANSFORMASI SUM BASED WORD2VEC
Teks X1 X2 X3 Xn
Guru 0.1 0.23 0.9 …
Memulai 2.6 0.23 0.78 …
Pelajaran 3.4 1.02 0.21 …
“Guru memulai pelajaran”
6.1 1.48 1.89 …
Dapat dilihat bahwa vektor dari kalimat “Guru memulai pelajaran” merupakan penjumlahan dari tiap fitur vektor kata–kata penyusun kalimat tersebut.
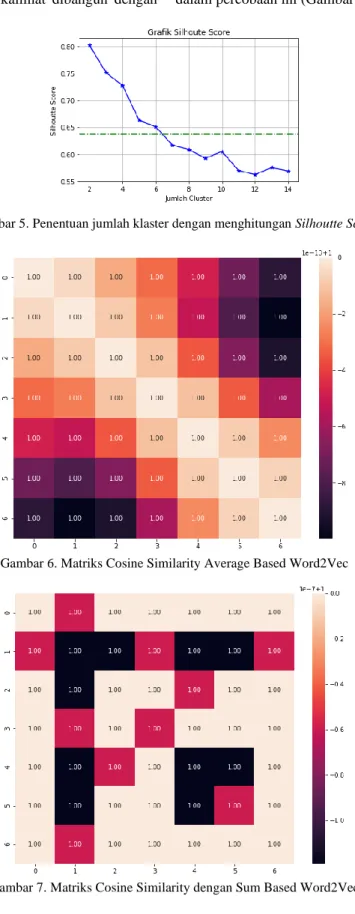
Gambar 4. Hasil Klasterisasi dengan KMeans terhadap vektor seluruh kata dalam dataset
Gambar 5. Penentuan jumlah klaster dengan menghitungan Silhoutte Score
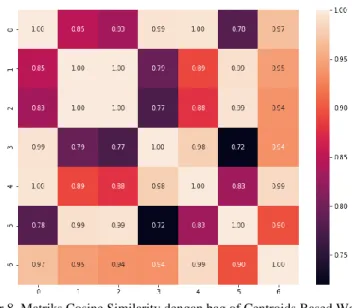
Gambar 6. Matriks Cosine Similarity Average Based Word2Vec
Gambar 7. Matriks Cosine Similarity dengan Sum Based Word2Vec
Gambar 8. Matriks Cosine Similarity dengan bag of Centroids Based Word2Vec
Adapun vektor kalimat yang dihasilkan menggunakan car aini adalah sebagai berikut.
TABEL IIIII
HASIL KLASTER KATA DENGAN KMEANS
Teks Klaster
Guru 0
Memulai 2
Pelajaran 1
TABEL IVV
TRANSFORMASI DENGAN BAG OF CENTROID BASED WORD2VEC
Teks Klaster
0 1 2 3 4 5
“Guru memulai pelajaran”
1 1 1 0 0 0
Dengan demikian dihasilkan vektor seperti seperti pada Tabel IV.
Langkah terakhir diambil sampel untuk dilakukan penghitungan nilai cosine similarity. Perhitungan nilai similaritas ini dibantu dengan pustaka sklearn Python.
IV. HASIL DAN PEMBAHASAN
Hasil perhitungan nilai cosine similarity adalah berupa matriks berukuran n x n dengan n adalah jumlah sampel yang digunakan dalam perhitungan. Adapun hasil yang didapat untuk masing–masing variasi dari model Word2Vec dapat dilihat pada diagram catur dalam Gambar 6.
Pada diagram catur dalam Gambar 6, dapat dilihat bahwa nilai cosine similarity dari sampel bervariasi dan banyak yang mendekati nilai 0 (nol) bahkan terdapat nilai negatif (bandingkan garis warna). Perlu diketahui jika dua vektor memiliki nilai nol itu berarti sudut di antara mereka sebesar 90o, artinya kedua vektor saling tegak lurus. Jika nilai kosinus sudutya 1 itu berarti besar sudutnya 0o dan
kedua vektor searah. Sedangkan jika bernilai negatif itu berarti besar sudut > 90o, dan kedua vektor saling menjauh Dari sini dapat dilihat bahwa hasil transformasi dengan cara Average Based Word2Vec masih memiliki nilai cosine similarity yang negatif (kedua vektor tidak searah) yang dapat berpengaruh kepada hasil pelatihan machine learning.
Berikutnya hasil transformasi dengan variasi Sum Based Word2Vec dapat dilihat pada Gambar 7.
Hasil tranformasi dengan Sum Based Word2Vec juga masih menunjukkan nilai negatif yang menunjukkan bahwa variasi ini tidak cocok untuk dataset RPP.
Terakhir dibentuklah matriks cosine similarity untuk variasi Bag of Centroids Based Word2Vec.
Dari grafik yang ditampilkan dalam Gambar 8 dapat dilihat bahwa nilai cosine similarity bervariasi antar sampel dan semua nilai lebih besar dari nol (0), atau dengan kata lain bernilai positif. Dalam sebuah referensi dikatakan bahwa batas toleransi penerimaan nilai cosine similiraity antara dua vektor adalah ≤ 0.5. Dari sini dapat dilihat bahwa semua nilai cosine similarity antar vektor sampel yang berbeda saling berhubungan dan searah sehingga baik untuk digunakan dalam pelatihan machine learning.
V. KESIMPULAN
Telah dilakukan penelitian untuk mengetahui pengaruh variasi model VSM Word2Vec terhadap similarity score dataset RPP. Dari hasil penelitian yang didapat dapat disimpulkan bahwa variasi Bag of Centroids Based Word2Vec adalah variasi terbaik untuk digunakan dalam melakukan trasnformasi teks menjadi vektor pada dataset RPP.
10.14569/ijacsa.2019.0100742.
[4] M. Rusli, “Ekstraksi Fitur Menggunakan Model Word2Vec Pada Sentiment Analysis Kolom Komentar Kuisioner Evaluasi Dosen Oleh Mahasiswa,” Klik - Kumpul. J. Ilmu Komput., vol. 7, no. 1, p.
35, 2020, doi: 10.20527/klik.v7i1.296.
[5] O. Shahmirzadi, A. Lugowski, and K. Younge, “Text similarity in vector space models: A comparative study,” Proc. - 18th IEEE Int.
Conf. Mach. Learn. Appl. ICMLA 2019, pp. 659–666, 2019, doi:
10.1109/ICMLA.2019.00120.