BAB II
LANDASAN TEORI
2.1 Sistem Informasi Geografi (SIG) 2.1.1 Pengertian Sistem
Sistem adalah sekelompok komponen yang saling berhubungan dan bekerja sama untuk menghasilkan tujuan bersama dengan menerima input dan menghasilkan output dalam sebuah proses transformasi yang terorganisir. (O’Brien, 2003, p8)
Sistem adalah sekelompok elemen yang terintegrasi dengan maksud yang sama untuk mencapai suatu tujuan. (Raymond McLeod, 2001, p9)
Dari definisi diatas dapat disimpulkan bahwa sistem terdiri dari komponen yang saling berinteraksi satu sama lain untuk mencapai suatu tujuan.
2.1.2 Pengertian Informasi
Informasi adalah data yang sudah di proses atau data yang memiliki arti. (Raymond McLeod, 2001, p12)
Informasi adalah data yang telah dibentuk menjadi bentuk yang berarti dan berguna bagi manusia. (Laudon, 2004, p8)
Dari definisi diatas dapat diambil kesimpulan bahwa informasi adalah kumpulan data yang telah diproses menjadi sesuatu yang berguna dan memiliki arti.
2.1.3 Pengertian Sistem Informasi
Sistem informasi secara teknik dapat didefinisikan sebagai sekumpulan komponen yang saling berhubungan dalam mengumpulkan (atau menerima), proses, menyimpan, dan mendistribusikan informasi untuk mendukung pengambilan keputusan, koordinasi, dan pengaturan dalam sebuah organisasi. (Laudon, 2004, p8)
Sistem informasi adalah penggabungan dari manusia, hardware, software, dan jaringan komunikasi dan sumber daya data yang mampu mengumpulkan, mengubah, dan membagikan informasi dalam sebuah organisasi. (O’brien, 2005, p6)
Jadi dari definisi diatas dapat diambil kesimpulan sistem informasi adalah sekumpulan komponen yang melakukan pengumpulan data dan analisa data yang ada untuk menghasilkan suatu informasi yang dapat digunakan oleh penerimanya dalam pengambilan keputusan.
2.1.4 Pengertian Geografi
Menurut Richthoffen (Prahasta, 2002, p12), geografi adalah ilmu yang mempelajari permukaan bumi sesuai dengan referensinya, atau studi mengenai area - area yang berbeda di permukaan bumi.
Menurut Kamus Besar Bahasa Indonesia (2001, p271), geografi adalah ilmu tentang permukaan bumi, iklim, penduduk, flora, fauna, serta hasil yang diperoleh dari bumi.
2.1.5 Pengertian Sistem Informasi Geografi (SIG)
Sistem informasi geografi merupakan suatu kesatuan formal yang terdiri dari berbagai sumber daya fisik dan logika yang berkenaan dengan objek - objek yang terdapat di permukaan bumi. (Prahasta, 2002, p49)
Sistem informasi geografi merupakan sekumpulan peralatan yang digunakan untuk mengumpulkan, menyimpan, mentransformasi, dan menampilkan data spasial dari dunia nyata untuk tujuan tertentu. (Burrough, 1986, p6)
Menurut definisi diatas dapat diambil kesimpulan bahwa sistem informasi geografi merupakan sekumpulan komponen yang memiliki kemampuan untuk mengambil, menyimpan, dan mengolah data, baik data spasial maupun data tekstual dan juga menampilkan hasil dengan cepat, akurat, dan tepat waktu.
2.1.6 Subsistem Sistem Informasi Geografi (SIG)
(Prahasta, 2002, p56) Sistem informasi geografi dapat diuraikan menjadi beberapa subsistem, yaitu:
1. Data input
Subsistem ini bertugas untuk mengumpulkan dan mempersiapkan data spasial dan atribut dari berbagai sumber. Subsistem ini pula yang bertanggung jawab dalam mengkonversi atau mentransformasikan format-format data - data aslinya ke dalam format yang dapat digunakan oleh sistem informasi geografi.
2. Data Output
Subsistem ini menampilkan atau menghasilkan keluaran seluruh atau sebagian basis data baik dalam bentuk softcopy maupun dalam bentuk hardcopy seperti tabel, grafik, peta, dll.
3. Data manajemen
Subsistem ini mengorganisasikan baik data spasial maupun atribut ke dalam sebuah basis data sedemikian rupa sehingga mudah dipanggil, diperbaharui, dan diperbaiki.
4. Manipulasi dan analisa data
Subsistem ini menentukan informasi - informasi yang dapat dihasilkan oleh sistem informasi geografi. Selain itu, subsistem ini juga melakukan manipulasi dan pemodelan data untuk menghasilkan informasi yang diharapkan.
Subsistem-subsistem tersebut dapat digambarkan sebagai berikut:
Gambar 2.1 Uraian subsistem - subsistem SIG
2.1.7 Komponen Sistem Informasi Geografi (SIG)
Ada lima komponen untuk melakukan suatu proyek agar saling bekerjasama, yaitu: hardware, software, data, sumber daya manusia, dan prosedur.
2.1.7.1 Perangkat Keras / Hardware
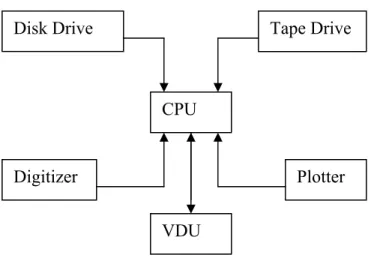
Hardware pada SIG terdiri dari CPU, Disk drive, Digitizer, Plotter (Printer), Tape Drive, Visual Display Unit (VDU).
Tabel Laporan Foto Udara Peta (tematik, topografi, dll) Data Digital Lain Pengukuran Lapangan Citra Satelit Data Lainnya Input Informasi Digitasi (softcopy) Laporan Tabel Peta Processing Retrieval Basis Data Output
Data Input Data
Manajemen &
Manipulasi
1. CPU
Merupakan pusat proses data yang terhubung dengan media penyimpanan dengan ruang yang cukup besar dengan sejumlah perangkat lainnya.
2. Disk Drive
Menyediakan tempat untuk membantu jalannya penginputan, membaca, proses dan penyimpanan data.
3. Digitizer
Digunakan untuk mengkonversi data dari peta ke dalam bentuk digital dan memasukannya ke dalam komputer.
4. Plotter / Printer
Digunakan untuk mencetak hasil dari data yang telah diolah. 5. Tape Drive
Digunakan untuk menyimpan data / program kedalam pita magnetik atau untuk berkomunikasi dengan sistem lainnya.
6. VDU
Digunakan untuk memudahkan user utnuk mengontrol komputer dan perangkat - perangkat lainnya.
Gambar 2.2 Komponen Perangkat Keras Sistem Informasi Geografi
2.1.7.2 Perangkat Lunak / Software
Software SIG berfungsi untuk memasukkan, menganalisa, dan menampilkan informasi SIG. Software SIG memiliki beberapa kemampuan utama, antara lain:
Memanipulasi / menyajikan data geografis atau peta berupa layer Berfungsi untuk analisa, query dan visualisasi geografis
Penyimpanan data dan manajemen database (DBMS) Graphical User Interface (GUI)
2.1.7.3 Data
Data merupakan bagian yang terpenting dari SIG, karena tanpa adanya data, maka SIG tidak dapat dimanfaatkan secara optimal. Data yang diperlukan dalam SIG meliputi peta dan data atribut.
CPU Tape Drive Plotter VDU Disk Drive Digitizer
2.1.7.3.1 Pengertian Data
Data adalah aliran dari fakta - fakta kasar yang merepresentasikan kejadian - kejadian yang terjadi dalam organisasi atau lingkungan fisik sebelum di susun dalam sebuah bentuk yang dapat dimengerti dan digunakan oleh manusia. (Laudon, 2004, p8)
2.1.7.3.2 Jenis-jenis Data Pada Sistem Informasi Geografi
Jenis data yang digunakan dalam sistem informasi geografi adalah data spasial ( peta / geometris ) dan data atribut ( keterangan / non-spasial). Perbedaan diantara 2 jenis data tersebut adalah sebagai berikut:
a. Data atribut
Data atribut adalah data yang mendeskripsikan karakteristik atau fenomena yang dikandung pada suatu objek data dalam peta dan tidak mempunyai hubungan dengan posisi geografis. Contoh: data atribut sebuah sungai berupa kedalaman, kualitas air, habitat, komposisi kimia, konfigurasi biologis, dan lain sebagainya.
Atribut dapat dideskripsikan secara kualitatif dan kuantitatif. Pada pendeskripsian secara kualitatif, kita mendeskripsikan tipe, klasifikasi, label suatu objek agar dapat dikenal dan dibedakan dengan objek yang lain, misalnya rumah sakit, sekolah, hotel, dan sebagainya. Bila dilakukan secara
kuantitatif, data objek dapat diukur atau dinilai berdasarkan skala ordinat atau tingkatan, interval atau selang, dan rasio atau perbandingan dari suatu titik tertentu. Contohnya populasi sungai 10-15 ekor ikan, kadar kimia air pada sungai tersebut buruk, dan sebagainya.
b. Data Spasial
Data spasial adalah data sistem informasi yang terpaut pada dimensi ruang, dapat digambarkan dengan berbagai komponen data spasial. Komponen tersebut adalah:
1. Titik
Titik merupakan representasi grafis yang paling sederhana untuk suatu objek. Representasi ini tidak memiliki dimensi tetapi dapat diidentifikasi diatas peta dan dapat ditampilkan pada layar monitor dengan menggunakan simbol - simbol. Titik dapat mewakili objek tertentu berdasarkan skala yang ditentukan, misalnya sudut - sudut bangunan, atau suatu gedung pada peta yang memiliki skala besar.
2. Garis
Garis adalah bentuk linier yang akan menghubungkan paling sedikit 2 titik dan digunakan untuk merepresentasikan objek - objek satu dimensi. Batas - batas poligon merupakan
garis - garis, demikian pula dengan jaringan listrik, komunikasi pipa air minum, saluran buangan, dan keperluan lainnya.
3. Poligon
Poligon digunakan untuk merepresentasikan objek - objek dua dimensi. Suatu danau, batas provinsi, batas kota, batas - batas persil tanah milik adalah tipe - tipe entity yang pada umumnya direpresentasikan sebagai poligon. Suatu poligon paling sedikit dibatasi oleh 3 garis yang saling terhubung diantara ketiga titik tersebut.
●titik garis poligon
Gambar 2.3 Komponen data spasial
2.1.7.4 Sumber Daya Manusia
Sumber daya manusia sangat diperlukan untuk mendefinisikan, menganalisa, mengoperasikan serta menyimpulkan masalah yang sedang dihadapi dalam pembuatan SIG.
2.1.7.5 Prosedur (Method)
Untuk menghasilkan SIG sesuai dengan yang diinginkan, maka SIG harus direncanakan dengan matang dengan menggunakan metodologi yang benar.
2.2 Peta Sistem Informasi Geografi 2.2.1 Definisi Peta
Menurut http://www.cybermap.co.id/index.php?map= jkt&content=ar&id=30 Peta merupakan gambaran wilayah geografis, biasanya bagian permukaan bumi. Peta bisa disajikan dalam berbagai cara yang berbeda, mulai dari peta konvensional yang tercetak hingga peta digital yang tampil di layar komputer. Peta dapat menunjukkan banyak informasi penting, mulai dari suplai listrik di daerah anda sampai di daerah Himalaya yang berbukit - bukit atau sampai kedalaman dasar laut.
Menurut Rockville (Prahasta, 2002, p129), Peta adalah suatu representasi konvensional (miniatur) dari unsur - unsur fisik (alamiah dan buatan manusia) dari sebagian atau keseluruhan permukaan bumi di atas media bidang datar dengan skala tertentu.
2.2.2 Jenis - jenis Peta
Jenis - jenis peta pada dasarnya dapat dibedakan berdasarkan skalanya dan data yang dimunculkannya. Berdasarkan skalanya, peta dapat diklasifikasikan menjadi 5, yaitu:
1. Peta kadaster, berskala 1:100 sampai dengan 1:5000 menggambarkan peta - peta tanah dan peta dalam sertifikat tanah.
2. Peta skala besar, berskala 1:5000 sampai dengan 1:250.000 menggambarkan daerah wilayah - wilayah yang relatif sempit.
3. Peta skala sedang, berskala 1:250.000 sampai dengan 1:500.000 menggambarkan daerah yang agak luas.
4. Peta skala kecil, berskala 1:500.000 sampai dengan 1:1.000.000 menggambarkan daerah - daerah yang cukup luas.
5. Peta skala geografis, berskala lebih dari 1:1.000.000 menggambarkan kelompok negara, benua, dan dunia.
Berdasarkan data yang dimunculkan ada 2 macam bentuk peta:
1. Peta umum / peta ikhtisiar
Peta umum merupakan peta yang menggambarkan topografi daerah ataupun batas - batas administrasi suatu Wilayah / Negara yang biasa digunakan untuk bermacam - macam tujuan.
2. Peta khusus / peta tematik
Peta tematik merupakan peta yang menampilkan hubungan keruangan, kenampakan dalam bentuk atribut tunggal atau hubungan atribut seperti geologi, geografis, pertanahan, dan sebagainya.
2.2.3 Model Data Spasial Di Dalam Sistem Informasi Geografi
(Prahasta, 2002, p146) Data Spasial direpresentasikan di dalam basis data sebagai raster atau vektor. Lebih lanjut kita akan membahas mengenai keduanya.
1. Model data raster
Model data raster menampilkan, menempatkan, dan menyimpan data spasial dengan menggunakan struktur matriks atau piksel - piksel yang membentuk grid. Dengan model ini, dunia nyata disajikan sebagai elemen matriks atau sel - sel grid yang homogen. Dengan demikian, secara konseptual, model data raster merupakan model data spasial yang paling sederhana.
2. Model data vektor
Model data vektor menampilkan, menempatkan, dan menyimpan data spasial dengan menggunakan titik - titik, garis-garis atau kurva, atau poligon beserta atribut - atributnya. Bentuk - bentuk dasar representasi data spasial ini, di dalam sistem model vektor, di definisikan oleh sistem
koordinat kartesian dua dimensi (x,y). Di dalam model data spasial vektor, garis - garis atau kurva (busur
atau arcs) merupakan sekumpulan titik - titik terurut yang dihubungkan.
2.2.4 Pemetaan
Kompilasi dan penyajian fakta wilayah dari berbagai sektor yang memanfaatkan penggunaan sistem informasi geografi dilakukan melalui prosedur kompilasi data spasial dan non spasial. Dengan analisis overlay dan
pengolahannya dilaksanakan secara komputerisasi. Oleh karena sistem informasi geografi merupakan sistem yang berbasiskan pada penggunaan komputer dan peta, untuk penyajian wilayah dalam sistem informasi geografi harus benar-benar memperhatikan kaidah pemetaan.
Hasil dari suatu proses pemetaan adalah peta itu sendiri. Sedangkan fungsi dari pemetaan adalah untuk dapat memvisualisasikan suatu data yang berbentuk daftar atau tabel yang dapat divisualisasikan sesuai dengan keinginan dan juga dapat mengubahnya ke dalam bentuk grafik sehingga mudah untuk dianalisis.
2.2.5 Metode Analisis Peta
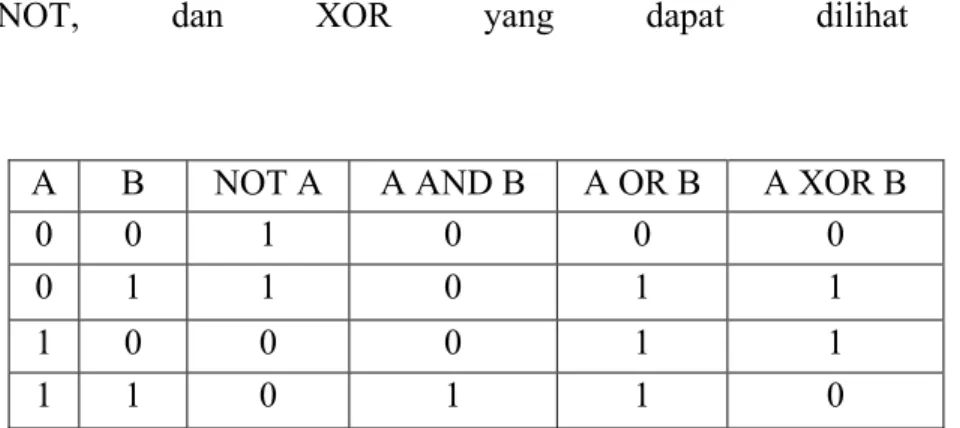
Sistem informasi geografi menganalisa data yang tersimpan pada basis data dengan menggunakan satu atau beberapa peta. Metode analisis yang sering dipakai pada beberapa peta dikenal sebagai metode tumpang susun (overlay method). Metode overlay tersebut menggunakan prinsip - prinsip aljabar Boolean dengan menggunakan operator hubungan AND, OR, NOT, dan XOR yang dapat dilihat melalui:
A B NOT A A AND B A OR B A XOR B
0 0 1 0 0 0
0 1 1 0 1 1
1 0 0 0 1 1
1 1 0 1 1 0
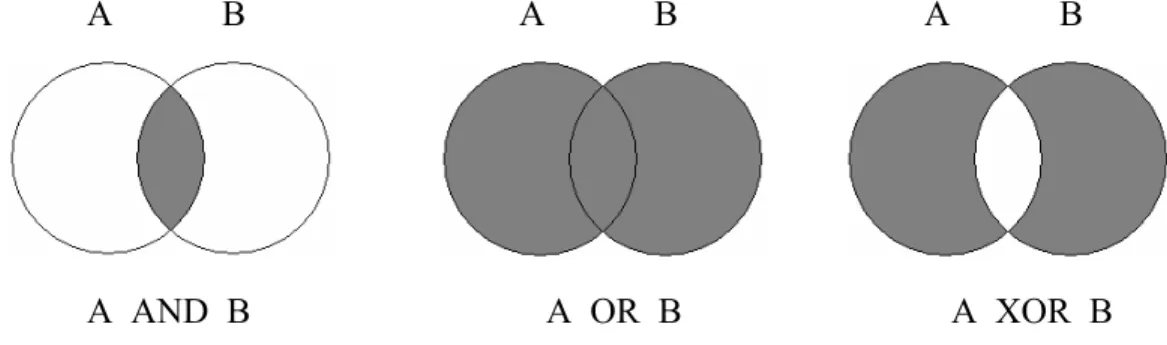
Apabila digambarkan dengan diagram Venn, maka sebagian hasil yang dapat diperoleh adalah daerah yang diarsir seperti pada gambar berikut:
Gambar 2.4 Diagram Venn Metode Analisis Peta
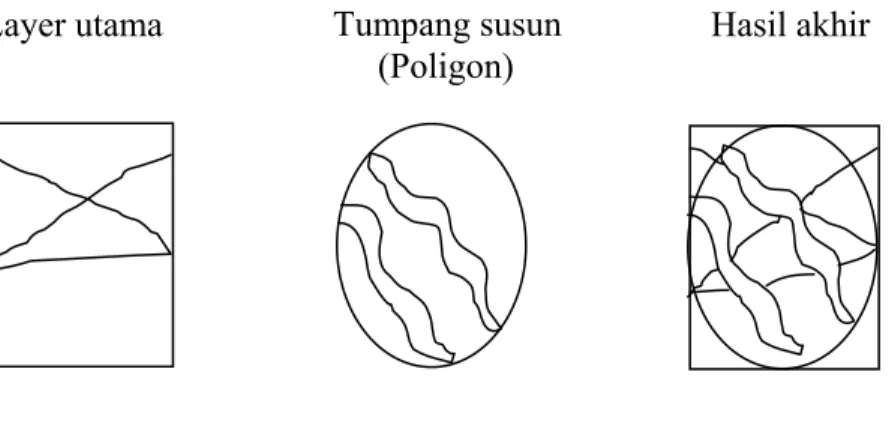
2.2.6 Teknik Tumpang Susun (overlay)
Teknik overlay sering digunakan pada sistem informasi geografi untuk menganalisis peta. Definisi overlay adalah suatu proses pada data spasial, yang terjadi pada suatu layer yang berisi peta tematik lain dan akhirnya membentuk layer peta tematik baru dengan poligon yang baru dari hasil perpotongan bidang - bidang pada proses - proses penumpukan dan penyusunan - penyusunan tersebut. Sudut pada poligon yang baru merupakan hasil perpotongan sisi poligon - poligon lama yang telah “ditumpangkan dan disusun“. Seluruh titik dan garis lain dengan perpotongan dan topologi serta tabel atribut baru yang disesuaikan dengan hasil overlay poligon.
A B A B A B
Gambar 2.5 Overlay Poligon
Untuk dapat melakukan overlay, maka peta - peta tematik itu harus mempunyai satu patokan dan sistem koordinat yang sama, sehingga peta tematik baru dihasilkan dengan baik.
2.2.7 Proyeksi Peta
Menurut Rockville (Prahasta, 2002, p131), proyeksi peta merupakan suatu fungsi yang merelasikan koordinat dari titik - titik yang terletak di atas permukaan suatu kurva (biasanya berupa ellipsoid atau bola) ke koordinat titik - titik yang terletak di atas bidang datar.
Sebagaimana telah kita ketahui secara umum, bahwa hasil suatu proses pemetaan adalah peta itu sendiri. Menurut Rockville (Prahasta, 2002, p129) Peta adalah suatu representasi konvensional (miniatur) dari unsur - unsur fisik (alamiah dan buatan manusia) dari sebagian atau keseluruhan permukaan bumi di atas media bidang datar dengan skala tertentu. Tetapi permukaan bumi ini secara keseluruhan merupakan permukaan yang melengkung dan sama sekali tidak memungkinkan dapat dibentangkan
Layer utama Tumpang susun (Poligon)
sehingga menjadi bidang datar sempurna tanpa mengalami perubahan atau kerusakan. Walaupun demikian, untuk kondisi - kondisi tertentu kita masih bisa mengusahakan pembuatan peta yang ideal. Kaidah ideal itu menurut Umar (Prahasta, 2002, p130), peta adalah:
1. Jarak antara titik - titik yang terletak di atas peta harus sesuai dengan jarak aslinya di permukaan bumi (dengan memperhatikan skala peta). 2. Luas suatu unsur yang direpresentasikan di atas peta harus sesuai
dengan luas sebenarnya (yang dengan mempertimbangkan skala petanya).
3. Sudut atau arah suatu garis yang direpresentasikan di atas peta harus sesuai dengan arah yang sebenarnya (seperti di permukaan bumi). Bentuk suatu unsur yang direpresentasikan di atas peta harus sesuai dengan bentuk yang sebenarnya (juga mempertimbangkan faktor skalanya).
2.2.8 Pemilihan Proyeksi Peta
Melihat banyaknya macam proyeksi peta, para pengguna yang tidak biasa dengan konsep - konsep proyeksi peta kemungkinan akan mengalami sedikit keraguan dalam memilihnya. Walaupun demikian, ada beberapa faktor yang dapat dipertimbangkan atau dapat dijadikan petunjuk di dalam pemilihan proyeksi peta, terutama untuk kebutuhan peta topografi, sebagai berikut:
a) Tujuan penggunaan dan ketelitian peta yang diinginkan.
b) Lokasi geografi, bentuk, dan luas wilayah yang akan dipetakan. c) Ciri - ciri atau karakteristik asli yang ingin tetap dipertahankan.
2.3 Rekayasa Perangkat Lunak (RPL)
Perangkat lunak dapat didefinisikan sebagai perintah (program komputer) yang bila dieksekusi memberikan fungsi dan unjuk kerja seperti yang diinginkan. Selain itu didefinisikan juga sebagai struktur data yang memungkinkan program memanipulasi informasi secara proporsional. Tetapi perangkat lunak juga dapat didefinisikan sebagai dokumen yang menggambarkan operasi dan kegunaan program.
(Pressman, 2001, p26) Model proses untuk rekayasa perangkat lunak dipilih berdasarkan sifat aplikasi dan proyeknya, metode, dan alat - alat bantu yang dipakai, dan kontrol serta penyampaian yang dibutuhkan. Untuk menyelesaikan masalah aktual di dalam sebuah setting industri, rekayasa perangkat lunak atau tim perekayasa harus menggabungkan strategi pengembangan yang melingkupi lapisan proses, metode, dan alat-alat bantu. Waterfall atau Classic Life Cycle adalah paradigma rekayasa perangkat lunak yang paling luas dipakai dan paling tua.
Model Waterfall melakukan aktifitas - aktifitas sebagai berikut : 1. Rekayasa sistem
Yaitu dengan menentukan kebutuhan sistem secara keseluruhan, antara lain dengan menentukan komponen - komponen sistem (Entity), atribut komponen dan hubungan antara komponen. Secara umum Entity dibedakan atas data, algoritma dan interface.
2. Analisa Sistem
Yaitu mencari dan menentukan kriteria aplikasi yang tepat untuk memenuhi kebutuhan sistem.
3. Desain Sistem
Yaitu mendefinisikan hasil analisa dengan merancang modul aplikasi perancangan dilakukan pada tiga bagian, yaitu :
Struktur data, rancangannya didefinisikan dalam Entity Relationship Diagram (ERD) dan kamus data.
Arsitektur aplikasi, rancangan didefinisikan dalam Data Flow Diagram (DFD). Hierachical Modul Diagram dan rancangan layar.
Prosedur secara detail, rancangannya didefinisikan dalam pseudocode. 4. Pemrograman
Yaitu mengimplementasikan rancangan atau desain dengan menuliskan code program sesuai bahasa pemrograman yang dipilih.
5. Ujicoba
Yaitu melakukan pengujian program aplikasi yang telah selesai dibuat dengan memperhatikan konsep logika untuk mengetahui kinerja aplikasi apakah sesuai dengan kebutuhan sistem dan melakukan pencegahan terjadinya kesalahan seminimal mungkin.
6. Pemeliharaan
Yaitu memungkinkan terjadinya perubahan data, lingkungan sistem dan kebutuhan penggunaan agar aplikasi tetap bisa dikembangkan sesuai perubahan yang terjadi.
Hubungan tahap – tahap tersebut dapat dijelaskan melalui gambar dibawah ini :
Gambar 2.6 Konsep metode rekayasa perangkat lunak tipe Waterfall
2.4 Data Flow Diagram (DFD)
(Pressman, 2001, p311) Diagram alir data atau Data Flow Diagram adalah sebuah teknik grafis yang menggambarkan aliran informasi dan transformasi yang diaplikasikan pada saat data bergerak dari input menjadi output. DFD tingkat 0, yang disebut juga dengan model konteks, merepresentasikan seluruh elemen sistem sebagai sebuah bubble tunggal dengan data input dan output yang ditunjukkan oleh anak panah yang masuk dan keluar secara berurutan. Proses tambahan (bubble) dan jalur aliran informasi direpresentasikan pada saat DFD tingkat 0 dipartisi untuk mengungkap detail yang lebih. Contohnya, sebuah DFD tingkat 1 dapat berisi lima
Rekayasa sistem Analisa sistem Design sistem Pemrograman Ujicoba Pemeliharaan
atau enam bubble dengan anak panah yang saling menghubungkan. Setiap proses yang direpresentasikan pada tingkat 1 merupakan subfungsi dari seluruh sistem yang digambarkan di dalam model konteks.
Berikut adalah notasi - notasi dasar yang digunakan dalam DFD:
Gambar 2.7 Model aliran informasi
2.5 Entity Relationship Diagram (ERD)
ERD adalah diagram yang digunakan untuk menggambarkan struktur logika dari database secara keseluruhan. Menurut Korth (Prahasta, 2002, p107) simbol - simbol dan notasi yang digunakan di dalam penulisan diagram ini adalah :
• Persegi panjang yang mewakili entity set
• Elips yang menyatakan atribut - atribut entity set Entity eksternal
proses
Objek data
penyimpanan data
Informasi yang ada diluar sistem yang dimodelkan
Transfer informasi yang ada di dalam sistem untuk dimodelkan
Objek data; anak panah menunjukkan arah aliran data
Repositori data yang disimpan untuk digunakan oleh satu atau lebih proses
• Belah ketupat (diamond) yang menggambarkan relationship set
• Garis yang menghubungkan antara entity set dengan atribut-atributnya dan antara entity set dengan relationship setnya.
2.6 State Transition Diagram (STD)
Tujuan dari STD adalah mewakili sistem dengan sejumlah state dan serangkaian aktivitas yang berhubungan, menggambarkan hubungan antara state, menunjukan bagaimana sistem bergerak dari satu state ke state yang lain dan mendokumentasikan urutan dan prioritas dari state. STD pertama kali dikembangkan untuk membantu merancang kompiler. (Davis and Yen, 1999, p235)
2.7 Database
Adalah koleksi bersama dari data logikal yang saling berhubungan, dan deskripsi dari data tersebut di desain untuk menemui kebutuhan informasi suatu organisasi. (Connolly, 2002, p14)
2.7.1 Database Management System (DBMS)
Definisi DBMS menurut Connoly (2002, p16) ialah suatu system perangkat lunak yang bisa mendefinisikan, membuat, memelihara, dan mengontrol akses ke database.
• Terdapat fasilitas untuk mendefinisikan database, biasanya menggunakan suatu Data Definition Language (DDL). Suatu DDL memberian fasilitas kepada user untuk menspesifikasikan tipe data dan strukturnya dan batasan aturan mengenai data yang bisa disimpan ke dalam database tersebut.
• Terdapat fasilitas yang memperbolehkan user untuk menambah, mengedit, menghapus data, dan mendapatkan kembali data. Biasanya dengan menggunakan suatu Data Manipulation Language (DML). Biasanya ada suatu fasilitas untuk melayani mengaksesan data yang disebut sebagai Query Language. Bahasa query yang paling ialah Structured Query Language (SQL), yang secara de fakto merupakan standard bagi DBMS.
• Terdapat fasilitas untuk mengontrol akses ke database. Sebagai contoh: - Suatu sistem keamanan yang mencegah user yang tidak punya
otoritas untuk mengakses data
- Suatu sistem teritegrasi yang mana memelihara konsistensi penyimpanan data
- Suatu sistem kontrol yang mana memperbolehkan akses ke database - Suatu sistem kontrol pengembalian data yang mana dapat
mengembalikan data ke keadaan sebelumnya apabila terjadi kegagalan perangkat keras atau perangkat lunak
- Terdapat suatu katalog yang dapat diakses oleh user yang mana mendeskripsikan data di dalam database tersebut.
Adapun keuntungan dan kekurangan penggunaan DBMS, yaitu:
Keuntungan dari DBMS, antara lain : 1. Kontrol terdapat pengulangan data 2. Data yang konsisten
3. Semakin banyak informasi yang didapat dari data yang sama 4. Data yang dibagikan
5. Menambah integritas data 6. Menambah keamanan data 7. Penetapan standarisasi 8. Pengurangan biaya
9. Mempermudah pengoperasian data
10. Memperbaiki pengaksesan data dan hasilnya 11. Menambah produktivitas
12. Memperbaiki pemeliharaan data melalui indepedensi data 13. Memperbaiki pengaksesan data secara bersama – sama
Adapun kerugian penggunaan DBMS, antara lain : 1. Kompleksitas
2. Size / Ukuran
3. Biaya dari suatu DBMS
2.7.2 Normalisasi
Tujuan dari langkah ini ialah untuk menvalidasi relasi dalam Lokal Logikal Data Model dengan menggunakan teknik dai normalisasi.
Tujuan dari normalisasi adalah sebagai berikut :
(a) Menghilangkan kumpulan relasi dari inserting, updating, dan delection dependency yang tidak diharapkan.
(b) Mengurangi kebutuhan restrukturisasi kumpulan relasi dan meningkatkan life spam program aplikasi
(c) Membuat model relasional lebih informatif
Tahapan Normalisasi :
1. Normalisasi pertama (1 NF) menghilangkan perulangan
2. Normalisasi kedua (2 NF), bentuk ini mempunyai syarat yaitu data harus memenuhi kriteria 1 NF dan setiap data item yang bukan kunci harus functional dependency pada kunci utamanya
3. Normalisasi ketiga (3 NF) menghilangkan transitif dependensi
4. Normalisasi keempat (4 NF/BCNF) suatu relasi dikatakan BCNF bila didalamnya berisi atribut yang berfungsi sebagai candidate key sehingga salah satu dari candidate key tersebut menjadi kunci utama (Primary Key).
Selanjutnya akan dijelaskan tentang hal - hal khusus yang terdapat pada sistem informasi geografi, yang merupakan topik penulisan kami.
2.8 Graph
Graph adalah pasangan berurutan dari (V,E), dimana V adalah kumpulan vertex (nodes) dan E adalah kumpulan edge / arc atau kumpulan dari garis yang menghubungkan antara vertex yang satu dengan yang lain. (Wiitala, 1987, p178)
C
A
D
B E
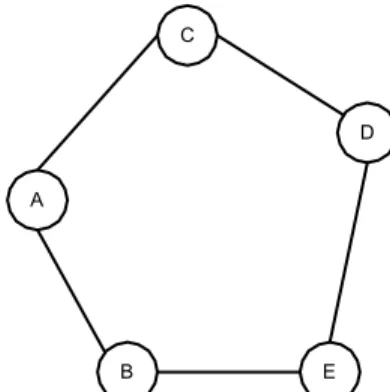
Gambar 2.8 Vertex dan Edge pada Graph
Gambar 2.9 merupakan contoh Graph dengan : V = {A,B,C,D,E}
E = {e1,e2,e3,e4,e5,e6}
Pada gambar 2.9, edge e1 adalah pasangan vertex [A,B], edge e2 adalah pasangan vertex [B,C], edge e3 adalah pasangan vertex [C,D], demikian seterusnya sampai edge e6 adalah pasangan vertex [B,E].
B A C E E e1 e2 e3 e4 e5 e6 Gambar 2.9 Graph
Graph juga dapat diartikan sebagai suatu struktur data yang berbentuk jaringan (Network) dimana hubungan antara elemen – elemennya adalah hubungan many to many.
Terkadang bagian dari graph dapat dituliskan G = (V,E). Asumsikan bahwa e = [u,v]. Maka nodes u dan v disebut dengan end points dari e, kemudian u dan v disebut dengan adjacent nodes atau neighbours. Derajat dari sebuah node u, ditulis dengan deg(u), adalah banyaknya edge yang terhubung dengan u. jika deg (u) = 0 maka u tidak mempunyai edge, maka u disebut dengan isolated node.
Path adalah rangkaian vertex pada graph dimana setiap pasangan vertex yang saling bersambungan adalah edge dari graph.
Path P dengan panjang N dari node u ke node v didefinisikan dengan urutan n + 1 node.
Sebuah cycle adalah path sederhana tertutup dengan panjang 3 atau lebih. Sebuah cycle dengan panjang k disebut k – cycle.
Elementary path adalah path yang tidak mempunyai vertex yang berulang. Circuit adalah path yang dimulai dan diakhiri pada vertex yang sama.
Walk adalah lintasan yang mungkin dilalui dari vertex awal ke vertex tujuan. Trail adalah walk yang semua edgenya berubah.
Sebuah graph dapat dikatakan multigraph jika pada graph tersebut terdapat loop atau terdapat lebih dari satu edge yang menghubungkan sepasang vertex.
Sebuah graph G dikatakan terhubung jika setiap node mempunyai path ke node lain. Graph G dikatakan lengkap jika semua node u didalam G berhubungan dengan setiap node lain v dalam G. Graph lengkap mempunyai edge sebanyak : N (N-1) / 2 node.
2.8.1 Penggolongan Graph
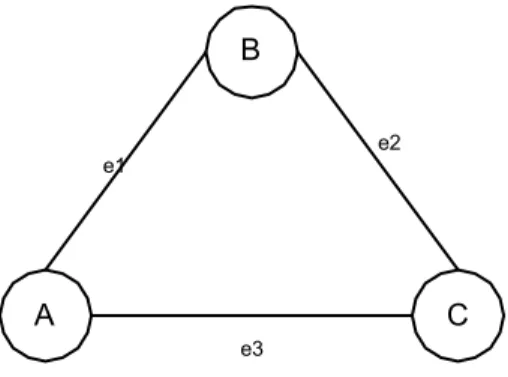
2.8.1.1 Undirected Graph (Graph Tidak Berarah)
Undirected Graph adalah graph yang edgenya tidak mempunyai arah. Jika (v,w) adalah undirected edge, maka (v,w) = (w,v).
B
A C
e1 e2
e3
Pada gambar 2.10 adalah graph tidak berarah. Edge e1 dapat merupakan pasangan vertex [A,B] atau [B,A], edge e3 dapat merupakan pasangan vertex [A,C] atau [C,A] , hal ini dikarenakan edgenya tidak mempunyai informasi arah.
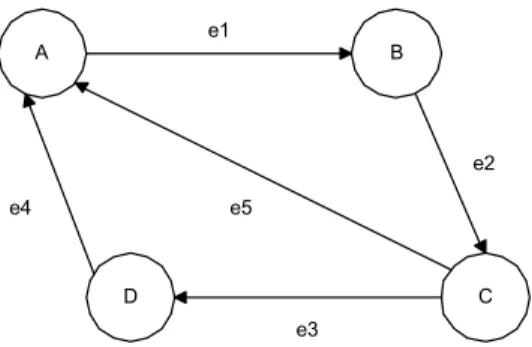
2.8.1.2 Directed Graph (Graph Berarah)
(Aho and Hopcroft and Ullman, 1987, p198) Directed graph adalah graph yang edge nya mempunyai arah. Directed graph adalah graph yang arc / edge nya merupakan vertex yang berurutan dari (v,w), v disebut tail dan w adalah head dari edge, edge (v,w) diekspresikan dengan v Æ w dan digambarkan sebagai berikut :
v w
Gambar 2.11 Directed Graph
Pada gambar 2.12 arah yang dimiliki tiap edge ditunjukkan oleh anak panah. Edge e1 ditunjukkan oleh pasangan vertex [A,B], edge e2 oleh pasangan vertex [B,C], demikian seterusnya sampai edge e5 yang ditunjukkan oleh pasangan vertex [C,A].
A B D C e1 e2 e3 e4 e5
Gambar 2.12 Directed Graph
(lipschutz, 1986, p279) Sebuah directed graph G atau graph disebut juga digraph sama seperti multigraph kecuali setiap edge e dalam G diberi arah. Dengan kata lain, e digambarkan dengan pasangan node berurut (u,v), bukan sebagai pasangan berurut [u,v]. Asumsikan G adalah directed graph dengan edge e = (u,v) maka e disebut juga dengan arc dan aturan – aturan dibawah ini berlaku :
a. e dimulai pada u dan berakhir pada v.
b. u adalah tempat awal atau initial point dari e, dan v adalah tujuan atau titik terminal dari e.
c. u adalah predecessor v, dan p adalah successor atau neighbour dari u. d. u berhubungan dengan v, dan v berhubungan dengan u.
A
D
C
B
Gambar 2.13 Outdegree
Pada gambar 2.13, banyaknya outdegree dari node A adalah 3, dapat ditulis outdeg(3) atau outdeg(A) = 3.
Serupa dengan itu, indegree dari u, dituliskan indeg(u), adalah jumlah edge yang berakhir pada u, atau dikatakan juga sebagai banyaknya edge yang diterima suatu node.
Pada gambar 2.13, indegree dari node C adalah 3 dan dapat dituliskan indeg(3) atau indeg(C) = 3.
Sebuah node dikatakan source jika outdegree-nya positif dan indegree-nya nol. Sebaliknya, sebuah node dikatakan sink, jika ia mempunyai indegree positif, namun outdegree-nya nol.
Pada gambar 2.13, diatas terlihat bahwa node A disebut source karena outdeg(3) yang artinya positif tetapi indeg(0). Sementara node C adalah sink karena indeg(3) tetapi outdeg(0).
Konsep path, simple path, dan cycle diambil dari undirected graph ke directed graph, kecuali kini arah dari masing – masing edge di dalam sebuah path harus sesuai dengan arah path tersebut. Sebuah node v
dikatakan reachable dari sebuah node u apabila ada sebuah directed path dari u ke v. Directed graph G dikatakan connected jika untuk tiap pasangan (u,v) dari node dalam graph G terdapat sebuah path dari v ke u. Connected graph adalah graph yang vertex – vertex nya terhubung dalam path (johnsonbaugh, 2001, p274).
Subgraph dari suatu graph (V,E) adalah graph (V’,E’) dimana V’ adalah subset dari V dan E’ terdiri dari edges pada E yang terhubung oleh vertex V’.
Vertex pada digraph dapat digunakan untuk merepresentasikan objek, dan edge sebagai hubungan antar objek tertentu. Sebagai contoh : vertex untuk merepresentasikan kota dan edge untuk merepresentasikan jalur penerbangan antar kota tersebut.
2.9 Array
Array adalah tipe data struktur yang terdiri dari beberapa data items yang saling berhubungan dan mempunyai jenis yang sama (Deitel, 2001, p197). Array ini merupakan tipe data linier.
Pada umumnya letak elemen array secara logical dan physical (dalam memori) adalah sama.
Dua bagian utama array adalah index dan komponen. Setiap index selalu berisi hanya satu komponen (one to one relationship).
Array dapat diakses secara Positional Access yaitu pengambilan elemen berdasarkan posisi index. Jika pengambilan elemen dilakukan secara acak maka disebut Random Access.
2.10 Algoritma pencarian
Pada dasarnya algortima pencarian jarak ada dua macam yaitu :
• Uninformed Search Algorithm yaitu algoritma yang tidak memiliki keterangan tentang jarak atau biaya dari path dan tidak memiliki pertimbangan akan path mana yang lebih baik. Algoritma ini hanya dapat membedakan yang mana goal dan mana yang bukan goal. Karena itu algorima ini disebut juga Blind-Search Algorithm (Algoritma Pencarian Buta)
Strategi pencarian dengan menggunakan algoritma uninformed search, antara lain : breadth-first search, uninform cost search.
• Informed Search Algorithm adalah algoritma yang memiliki keterangan tentang jarak atau biaya dari path dan menggunakan pertimbangan berdasarkan pengetahuan akan path mana yang lebih baik. Yang termasuk strategi pencarian dengan menggunakan algoritma informed search adalah greedy search dan A Star search.
2.11 Breadth First Search
Breadth First Search (BFS) merupakan sebuah strategi sederhana dimana titik akar (root node) ditelusuri lebih dahulu, baru kemudian node di bawah root node akan ditelusuri . Secara umum, semua node pada suatu level tertentu akan ditelusuri lebih dahulu sebelum menelusuri node pada level berikutnya.
BFS dapat diimplementasikan dengan menggunakan node pada tree yang merupakan tipe antrian FIFO, dengan anggapan bahwa node yang pertama kali
dikunjungi akan ditelusuri pertama. Dengan kata lain BFS menggunakan metode yang sama dengan metode pencarian pada tree (Russel and Norvig, 2003, p73).
Breadth First Search (BFS) adalah algoritma yang digunakan untuk mencari jarak pada suatu graph. Ide dasar dibalik Breadth First Search yang dimulai dari node a adalah sebagai berikut. Pertama node a diperiksa terlebih dahulu. Lalu diperiksa semua node yang berhubungan dengan a, dan seterusnya. Pada dasarnya, semua node tetangga dari a harus dicatat, dan dan dipastikan bahwa tidak ada satu node yang diproses lebih dari satu kali. Ini dilakukan dengan cara menggunakan queue untuk menampung node yang akan diproses berikutnya, dan menggunakan STATUS yang menyatakan status dari setiap node. Algoritma sebagai berikut :
1. Set semua status node menjadi ready state (Status 1).
2. Taruh node a di dalam queue dan ubah statusnya menjadi waiting state (Status 2).
3. Hapus node N paling atas dari queue. Proses N dan ubah status N jadi processed state (Status 3).
4. Tambahkan di belakang queue semua neighbour dari N yang berada pada ready state (Status 1) dan ubah statusnya menjadi waiting (Status 2).
5. Ulangi langkah 3 dan 4 sampai queue empty. 6. Exit.
2.12 Depth First Search
Depth First Search adalah algoritma yang cara kerjanya mirip dengan BFS yang dimulai dari node a adalah sebagai berikut :
Pertama node a diperiksa terlebih dahulu. Kemudian kita memeriksa masing – masing node N sepanjang path p yang dimulai dari node a, yaitu, kita memeriksa neighbour dari node a, lalu neighbour dari neighbour node a dan seterusnya. Setelah tiba pada jalan buntu, yaitu sampai akhir dari path p, kita mundur sepanjang path p sampai dapat menemukan path p’, seterusnya. Algoritmanya sangat mirip dengan Breadth First Search, namun kita akan menggunakan Stack daripada Queue. Field STATUS juga dibutuhkan untuk menyatakan status sementara node.
Algoritmanya sebagai berikut :
1. Set semua status node menjadi ready state (Status 1)
2. Taruh node a di dalam stack dan ubah statusnya menjadi waiting state (Status 2)
3. Hapus node N paling atas dari stack. Proses N dan ubah status N jadi processed state (Status 3).
4. Tambahkan ke dalam stack semua neighbour dari N yang berstatus not processed (Status 1) dan ubah statusnya menjadi waiting (Status 2).
5. Ulangi langkah 3 dan 4 sampai queue empty. 6. Exit.
DFS selalu menelusuri node di level yang terdalam dari semua node dalam suatu tree. Proses ini akan langsung munuju node dengan level yang paling dalam
yang tidak memiliki child node atau node dengan level dibawahnya. Setelah ditelusuri, proses pencarian bergerak naik ke level di atasnya (Russel and Norvig, 2003, p75).
2.13 Heuristic
Menurut George Polya (Luger, 2002, p123), heuristic adalah suatu ilmu mengenai metode dan aturan pencarian. Dalam konteks pencarian path, heuristic dapat diartikan sebagai aturan untuk memilih cabang – cabang dalam suatu kemungkinan – kemungkinan yang paling mendekati solusi masalah yang dapat diterima.
Dalam masalah intelegensia semu, heuristic diterapkan dalam dua posisi dasar, yaitu :
1. Suatu masalah yang mungkin tidak memiliki solusi pasti disebabkan ketidak-jelasan dalam pernyataan masalah atau data yang tersedia.
2. Suatu masalah yang memiliki solusi yang tepat, namun biaya yang diperlukan tinggi, dalam banyak masalah (seperti catur), pertumbuhan kemungkinan – kemungkinan bersifat eksponensial. Dalam kasus ini, metode – metode pencarian sepanjang path yang paling “menjanjikan” adalah melalui node – node. Dengan mengeliminasi node dan turunannya dari pencarian, algoritma heuristic dapat mengurangi ledakan eksponensial ini dan menemukan solusi yang dapat diterima.
Namun, seperti semua aturan dan metode pencarian, heuristic dapat gagal. Hal ini disebabkan karena heuristic hanya menginformasikan perkiraan langkah
selanjutnya yang perlu diambil dalam menyelesaikan permasalahan. Heuristic seringkali berdasarkan pengalaman atau intuisi. Hal ini dikarenakan heuristic menggunakan informasi yang terbatas, sehingga heuristic jarang sekali dapat menduga sifat node yang tepat sepanjang pencarian. Jadi heuristic dapat mengarahkan algoritma pencarian ke solusi yang cukup optimal atau gagal untuk menemukan solusi apa saja.
Ada tiga macam heuristic yang umum dipakai : • Manhattan Distance
Heuristic yang dapat digunakan untuk pengerakan 4 arah (atas, bawah, kiri, kanan). Tidak ada gerakan diagonal.
H(n) = c *(abs(Xn – Xgoal) + (Yn – Ygoal)) C = fungsi biaya
N = node saat ini
X dan Y = Posisi dalam koordinat • Diagonal Distance
Heuristic yang dapat digunakan untuk pergerakan 8 arah (atas, bawah, kiri, kanan, dan 4 arah diagonal).
H(n) = b * max (abs(Xn – Xgoal), abs (Yn – Ygoal)) • Straight Line Distance
Heuristic yang dapat digunakan untuk segala arah / segala sudut H(n) = sqrt((X n – Xgoal)2 (Yn – Ygoal)2)
2.14 Algoritma A star
Algoritma A Star ini adalah pengembangan Algoritma Dijkstra dan merupakan salah satu contoh algoritma Depth First Search (DFS).
Ditemukan pertama kali oleh Hart, Nilsson dan Raphael pada tahun 1968. Fungsi A Star adalah fungsi yang menggabungkan fungsi heuristic dan uniformcost dengan greedy search.
Fungsi uniform cost search menggunakan nilai yang pasti dan sudah diketahui, digunakan dalam A Star untuk menghitung jalur yang sudah dilalui (c(n)). Fungsi heuristic adalah fungsi perkiraan, digunakan untuk mrnghitung jarak
dari node sekarang ke node akhir (H
(n)). Dengan diketahui kedua jarak diatas, diperkirakan jarak total dari titik awal ke titik akhir melalui node yang sekarang sedang dilalui adalah f(n). Dengan perhitungan : f(n) = c(n) + h(n) C(n) H(n) N Awal AKhir F(n) F(n) = C(n) + H(n) Gambar 2.14 Heuristic
F(n) adalah nilai yang dibandingkan di dalam perhitungan A Star. Jalur yang mempunyai F(n) terkecil dianggap sebagai jalur terbaik. Nilai H(n) mungkin
salah, karena itu hanya nilai perkiraan. Maka untuk mendapat hasil yang terbaik, digunakan Underestimate. Underestimate beranggapan bahwa H(n) yang dihitung selalu lebih kecil daripada jalan yang seharusnya dilewati. Jarak terdekat antara dua titik adalah suatu garis, sehingga dalam algoritma ini digunakan Straight – line distance heuristic. Dengan menggunakan HSLD maka heuristic yang didapat selalu
terkecil atau setidaknya sama dengan jarak yang seharusnya ditempuh. Dengan menggunakan underestimate, maka dapat dihasilkan jalur yang optimal.
Ada 2 List yang digunakan pada A Star, yaitu :
• Open List, berisi node yang telah ditelusuri dan telah dihitung nilai fungsi heuristic-nya, tetapi belum diperiksa (misalnya successor suatu node).
2.14.1 Cara Kerja Algoritma A Star
Berikut ini adalah contoh kasus dari suatu node, anggap bahwa node awal adalah A dan node tujuan adalah L
A B D F E C G I J H L K Awal Tujuan
Gambar 2.15 Contoh Kasus Rute
Koordinat dari masing – masing node adalah :
Node X Y A 17,5 275 B 25 262,5 C 17,5 247,5 D 50 267,5 E 47,5 255 F 87,5 265 G 65 255 H 40 240 I 67,5 232,5 J 40 217,5 K 67,5 207,5 L 90 222,5
Perhitungan nilai H(n) atau heuristic secara straight-line dari setiap node ke node tujuan adalah sebagai berikut :
H(n) = sqrt (power(Xn - Xtujuan) + power(Yn - Ytujuan))
Node Heuristic A 89.51527 B 76.32169 C 76.68931 D 60.20797 E 53.50234 F 42.57347 G 41.00305 H 52.97405 I 24.62214 J 50.24938 K 27.04163 L 0
Tabel 2.3 Tabel Nilai Heuristic
Tahap inisialisasi dalam mengerjakan algoritma A star adalah memasukkan node awal ke dalam open list. Set semua C menjadi 0 (nol) dan set H dengan heuristic nya masing – masing. Sehingga data akan menjadi sebagai berikut:
Tabel 2.4 Tabel Data Inisialisasi
Node A B C D E F G H I J K L
Status 0
C 0 0 0 0 0 0 0 0 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
Keterangan status :
O = Open, menandakan node berada di open list. C = Close, menandakan node berada di close list. (empty) = menandakan node belum diproses.
Perulangan pertama :
Ambil node terbaik dari open list, karena baru ada satu node, maka node terbaik pasti node awal, sehingga ambil node tersebut dan ubah status nya menjadi close list. Ambil semua node anak dari node A, yaitu node B. Masukkan node B ke dalam open list dan hitung C nya. Sehingga hasil akhir dari perulangan pertama adalah :
Node A B C D E F G H I J K L
Status C
C 0 14.58 0 0 0 0 0 0 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
Tabel 2.5 Tabel Data Hasil Perulangan Pertama
Perulangan Kedua :
Ambil node terbaik dari open list, karena hanya ada satu node di dalam open list, maka node terbaik adalah B. ganti status node B menjadi close. Ambil semua node anak dari B yaitu node C dan D. Node C belum ada di dalam list sehingga masukkan ke dalam open list. Node D belum ada di dalam list sehingga masukkan ke dalam list. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0
C 0 14.58 31.35 40.07 0 0 0 0 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 53.5 42.57 41 52.97 24.62 50.25 27.04 0
Tabel 2.6 Tabel Data Hasil Perulangan Kedua
Perulangan Ketiga :
Ambil node ketiga dari open list, yaitu node D, karena node D mempunyai F yang lebih kecil dibandingkan dengan node C. Ganti status node menjadi close. Ambil semua node anak dari D yaitu E dan F. Node E belum ada di list sehingga masukkan node E ke dalam list. Node F belum ada di dalam list, sehingga masukkan node F ke dalam list. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0 0 0
C 0 14.58 31.35 40.07 52.82 77.65 0 0 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 106.3 120.2 41 52.97 24.62 50.25 27.04 0
Tabel 2.7 Tabel Hasil Perulangan Ketiga
Perulangan Keempat :
Node terbaik adalah node E. Masukkan E ke dalam close list. Ambil semua node anak dari node E. Node G belum ada di list sehingga masukkan node G ke dalam list. Node H belum ada di list sehingga masukkan node H ke dalam list. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0 0 0 0 0
C 0 14.58 31.35 40.07 52.82 77.65 70.32 69.59 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 106.3 120.2 111.3 122.6 24.62 50.25 27.04 0
Tabel 2.8 Tabel Hasil Perulangan Keempat
Perulangan Kelima :
Node terbaik adalah node C. Masukkan node C ke dalam close list. Ambil semua anak dari node C yaitu node H. Node H sudah pernah ada di dalam close list. Sehingga harus dibandingkan manakah yang lebih baik, apakah node H yang melalui node C atau melalui node E. Ternyata hasil nya lebih baik yang melalui node C, sehingga ganti nilai – nilai dari node H dengan nilai yang baru. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0 0 0 0 0
C 0 14.58 31.35 40.07 52.82 77.65 70.32 55.07 0 0 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 106.3 120.2 111.3 108 24.62 50.25 27.04 0
Tabel 2.9 Tabel Hasil Perulangan Kelima
Perulangan Keenam :
Node terbaik adalah node H. Masukkan node H ke dalam close list. Ambil semua anak dari node H yaitu node E, G, dan J. Node E ada di dalam closed list, sehingga check nilai f(n) yang baru apakah lebih baik dari f(n) yang lama. Ternyata nilai yang baru lebih besar, sehingga biarkan nilai node E. Node G ada di open list, bandingkan nilai f(n) yang baru dengan yang
lama, ternyata nilai yang lama lebih baik, sehingga biarkan nilai dalam node G. Node J tidak ada di dalam list, masukkan node J ke dalam open list. Hasilnya adalah : Node A B C D E F G H I J K L Status C C 0 0 0 0 0 0 0 C 0 14.58 31.35 40.07 52.82 77.65 70.32 55.07 0 77.57 0 0 H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0 F =C+H 89.51 90.9 108 100.3 106.3 120.2 111.3 108 24.62 127.8 27.04 0
Tabel 2.10 Tabel Data Hasil Perulangan Keenam
Perulangan Ketujuh :
Node terbaik adalah node G. Masukkan node G ke dalam close list. Ambil semua anak dari node G, yaitu node I dan F. Node I belum ada di list, masukkan node I ke dalam open list. Node F sudah ada di dalam open list, check dan bandingkan. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0 0 0 0 0 0 0
C 0 14.58 31.35 40.07 52.82 77.65 70.32 55.07 92.96 77.57 0 0
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 106.3 120.2 111.3 108 117.6 127.8 27.04 0
Tabel 2.11 Tabel Data Hasil Perulangan Ketujuh
Perulangan Kedelapan :
Node terbaik adalah node I. Masukkan node I ke dalam close list. Ambil semua node anak dari I. Node K belum ada di list, masukkan node K ke dalam open list. Node L belum ada di list, masukkan node L, ke dalam open list. Hasilnya adalah :
Node A B C D E F G H I J K L
Status C C 0 0 0 0 0 0 0 0
C 0 14.58 31.35 40.07 52.82 77.65 70.32 55.07 92.96 77.57 118 117.6
H 89.51 76.32 76.69 60.21 53.5 42.57 41 52.97 24.62 50.25 27.04 0
F =C+H 89.51 90.9 108 100.3 106.3 120.2 111.3 108 117.6 127.8 145 117.6
Tabel 2.12 Tabel Data Hasil Perulangan Kedelapan
Perulangan kesembilan :
Node terbaik adalah node L, sedangkan L adalah node tujuan, sehingga lakukan back tracking sampai ke node semula dan laporkan bahwa hasil sudah ditemukan. Jalur yang ditempuh A Star adalah :
A B D F E C G I J H L K Awal Tujuan
2.14.2 Prosedur Algoritma A Star
1. Inisialisasi
Masukkan node awal ke dalam open list. Set semua cost menjadi 0 (Nol). Hitung semua Heuristic dari masing – masing node.
2. Hitung node tujuan ditemukan, ulangi :
Jika tidak ada node pada open list, maka laporkan error. Jika tidak ada lagi node pada open list maka laporkan jalan tidak ketemu. Jika tidak lakukan hal di bawah ini
- Ambil node terbaik dari open list. Node terbaik adalah node yang mempunyai jarak yang sudah dilalui (cost) ditambah dengan jarak perhitungan perkiraan dari node sekarang ke node tujuan (Heuristic) yang terkecil, sehingga jarak yang diperhitungkan adalah jarak node dari awal ke node tujuan melalui node sekarang.
- Jika node terbaik ini adalah node tujuannya maka hentikan pencarian dan lakukan hal ini
o Ulangi sampai node mencapai node awal. • Letakkan ID node ini ke dalam stack.
• Mundur satu node dengan menggunakan pointer yang menuju node sebelumnya (back pointer).
o Keluarkan dan tampilkan semua isi dari stack. Ini adalah hasil pencarian jalan terpendek.
o Keluar dari modul pencarian. - Masukkan node ini ke dalam closed list.
- Pencarian semua node anak dari node tersebut. Untuk setiap node anak lakukan hal di bawah ini :
o Jika node anak tersebut berada di list maka cek, apabila cost dari node yang sudah ada di list lebih baik., maka jangan lakukan apa – apa. Tetapi jika cost cari node anak lebih baik, maka hapus node itu dari list dan masukkan node anak yang baru. o Jika tidak ada di dalam list maka masukkan node ini ke dalam
open list.
o Cost dari node anak adalah cost parent ditambah dengan jarak dari parent ke anaknya.
o Heuristic di hitung dari node sekarang ke node akhir. Dipakai sebagai jarak perkiraan yang masih harus di tempuh sampai mencapai tujuannya.
o Back pointer di set ke arah parent dari node ini.
(menurut http://www.geocities.com/SiliconValley/Lakes/4929/index.html), 1 Modul A*
2 Set cost dari node = 0 // inisialisasi awal node 3 Ambil nilai heuristic dari node // hitung nilai heuristic dari node 4 Nilai f dari node = cost dari node + nilai heuristic dari node
5 Set parent dari node = null 6 Masukkan node ke Open List
7 Kerjakan bila Open List tidak kosong // rutin utama pencarian 8 Node = ambil best node dari Open List
9 Jika node tersebut adalah titik tujuan maka
10 Buat path (ikuti pointer ke parent) //penyusunan rute 11 Kembalikan nilai benar bila pencarian sukses
12 Jika tidak
13 Panggil modul NodePushSuccessor (Open List, Close List, node) 14 Masukkan node dalam Closed List
15 Akhir dari kondisi 16 Akhir dari kondisi
17 Kembalikan nilai salah, karena pencarian gagal menemukan solusi 18 Akhir dari modul
19 Modul NodePushSuccessor(Open List, Closed List, parent node)
20 Untuk setiap arah yang memiliki kemungkinan untuk membuat successor 21 Cost dari node baru = biaya node + biaya dari parent-nya
22 Ambil nilai heuristic dari node baru
23 Nilai f node baru = cost dari node baru + nilai heuristic dari node baru
24 Jika node baru ditemukan di Closed List atau Open List maka periksa nilai f – nya
25 Jika nilai f – nya lebih kecil dibandingkan di Closed List atau Open List
26 Hapus node baru itu
27 Akhir dari kondisi
28 Akhir dari kondisi 29 Masukkan node baru ke Open List
30 Akhir dari perulangan 31 Akhir dari modul
2.14.3 A Priori Analisis Algoritma A Star
Dari modul algoritma A Star diatas, dapat dijelaskan bahwa : 1. Baris Program ke-7 membutuhkan 0(n) waktu.
2. Tiap menjalankan perulangan (loop) di atas memerlukan 0(n) waktu, bila modul NodePushSuccessor dikerjakan maka baris program ke-20 membutuhkan 0(n) waktu sehingga total waktu untuk perulangan ini adalah 0(n2).
Uraian diatas memperlihatkan bahwa fungsi waktu yang terbesar adalah 0(n2) sehingga waktu yang dibutuhkan algoritma tersebut untuk memproses n titik dalam suatu graph adalah 0(n2). Walaupun algoritma A Star dan Dijkstra memiliki perbedaan mendasar terutama dalam penerapan heuristic dimana algoritma A Star menggunakan heuristic sedangkan Dikjstra tidak, tetapi bila dilihat dari order of magnitude-nya, yang terbesar tetap 0(n2). Hal itu menunjukkan bahwa algoritma A Star dan Dijkstra memiliki kelas yang setingkat.
2.15 Algoritma Dijkstra
Algoritma Dijkstra ditemukan oleh Edger Wybe Dijkstra. Algoritma ini merupakan perkembangan dari Breadth First Search, perbedaan algoritma Dijkstra dengan algoritma lain terletak pada open list nya. Open list pada Dijkstra merupakan priority queue, dimana vertex dengan prioritas tertinggi akan diproses
terlebih dahulu, yaitu vertex yang memiliki nilai terkecil pada open list. Jadi pengaturan priority queue pada Dijkstra dipengaruhi oleh nilai edge kumulatif dari vertex awal sampai vertex ke n.
Algoritma ini merupakan jenis algoritma greedy yang berarti jika terdapat pilihan, maka akan beroperasi dengan memilih pilihan yang nilainya paling baik. Algoritma Dijkstra dibuat untuk menemukan path dengan nilai terkecil dari vertex awal tunggal ke semua vertex pada graph.
Algoritma Dijkstra akan melihat vertex yang terdekat dengan vertex awal lalu melihat successor dari vertex tersebut, kemudian memperbaharui jaraknya dari awal, demikian seterusnya sampai ditemukan vertex tujuan.
2.15.1 Cara Kerja Algoritma Dijkstra
Algoritma Dijkstra menelusuri path dengan vertex awal S, ke semua vertex dalam graph (V-1). V adalah semua vertex yang terdapat dalam graph. Algoritma Dijkstra membagi vertex – vertex yang pernah ditelusuri menjadi S dan F. S terdiri dari vertex – vertex yang path terpendeknya belum ditemukan. Sedangkan vertex yang tidak termasuk dalam S dan F adalah vertex yang belum ditelusuri.
Algoritma Dijkstra terus mengupdate D, yang berisi jarak terpendek yang terbaru dari S ke masing – masing vertex. Jika sebuah vertex v termasuk dalam S, maka d[V] sudah pasti merupakan jarak terpendek menuju ke vertex tersebut. Jika v termasuk F, maka untuk sejauh ini, d[V] masih merupakan jark terpendek (masih bisa berubah). Selain itu, jika v tidak termasuk S maupun F, maka d[V] belum bernilai.
Dibawah ini adalah pseudocode dari algoritma Dijkstra. L(u,v) adalah panjang edge dari u ke v.
Procedur Dijkstra S = {S}; F = OUT {S};
For V in OUT {S} {d[V] = length(S,V)}; while F is not empty {
V = U such that d[U] is minimum among V in F; F = F - {V}; S = S + {V}; for W in OUT(V) { if W is not in S { new_dist = d[V] + L (V,W); if W is in F { d[W] = min{d[W], new_dist} ; } else { D[W] = new_dist; F = F + {W}; } } } } ;
Algoritma Dijkstra dimulai dari S = {S} dan V = OUT(S), selanjutnya memindahkan vertex V dalam F yang mempunyai jarak terpendek ke dalam S. Edge yang keluar dari V dalam F yang mempunyai jarak terpendek kedalam S. Edge yang keluar dari V menuju vertex – vertex W akan ditelusuri dan jarak menuju W akan di update sesuai dengan kondisi, jika W termasuk S maka d[W] sudah merupakan jarak terpendek menuju W karena itu d[W] tidak perlu di update, jika W termasuk F maka jika jarak menuju W yang baru ditemukan lebih pendek dari d[W] maka d[W] akan di update, dan jika W tidak termasuk S maupun F maka W ditambahkan ke F dan d[W] diisi dengan jarak menuju W yang baru didapatkan.
2.15.2 Perbandingan Algoritma A Star dengan Algoritma Dijkstra
Kelebihan algoritma A Star dibandingkan Dijkstra (Wijaya & Gunawan, 2001, p237) adalah sebagai berikut :
1. Waktu pencarian algoritma A Star dalam menemukan rute lebih cepat dari algoritma Dijkstra.
2. Jumlah loop A Star lebih sedikit dari algoritma Dijkstra.
3. Rute yang ditemukan berbeda tapi mempunyai biaya yang sama.
2.16 Algoritma 2-OPT
Algoritma ini membandingkan dan mengeliminasi dua rute dan menghubungkan kembali hasil dari perbandingan tersebut untuk mendapatkan rute baru yang terpendek.
A B C D E A - 5 1 10 4 B 4 - 6 8 5 C 2 1 - 5 7 D 6 8 7 - 2 E 3 4 1 3 -
Tabel 2.13 Tabel Algoritma 2-OPT
Tabel diatas menunjukkan jarak dari kota satu ke kota lainnya (garis lurus menyatakan tidak ada jarak karena dikota yang sama). Sebagai langkah awal, tetapkan kota A sebagai kota awal yang kemudian akan dicari jarak terpendek untuk mengunjungi semua kota dan akhirnya kembali kekota A. Langkah berikutnya, masukkan urutan kota - kota yang akan dikunjungi kedalam sebuah array sehingga menjadi (A,B), (B,C), (C,D), (D,E) dan (E,A). Bandingkan rute dari array pertama (A-B) dengan rute dari array ketiga (C-D, array pertama ditambah interval 2), setelah itu dari kedua array tersebut buat kombinasi untuk mendapatkan rute baru dengan cara mengambil nilai pertama dari array yang kesatu (A) dikombinasikan dengan nilai pertama dari array yang ketiga (C) dan nilai kedua dari array yang kesatu (B) dengan nilai kedua dari array ketiga(D) sehingga terbentuk dua rute baru (A-C dan B-D).
Langkah selanjutnya bandingkan jarak array pertama (A-B = 5) yang dijumlahkan dengan jarak array ketiga (C-D = 5) dengan hasil penjumlahan jarak kedua rute baru (A-C = 1 dan B-D=8). Karena jarak rute baru lebih kecil maka
tukar array pertama (A-B) dengan rute baru yang pertama (A-C) dan array ketiga (C-D) dengan rute baru yang kedua (B-D). Selanjutnya, lakukan pertukaran nilai didalam array antara array pertama dengan array ketiga dan dalam hal ini berarti array kedua (B-C) menjadi (C-B) sehingga didapat array baru (A-C), (C-B), (B-D), (D-E) dan (E-A).
Proses berlanjut dengan melakukan perbandingan dari awal kembali karena telah terjadi pertukaran didalam array. Bandingkan jarak rute dari array pertama (A-C = 1) yang dijumlahkan dengan jarak array ketiga (B-D = 8) dengan rute baru hasil kombinasi array pertama dan array ketiga (A-B = 5 dan C-D = 5). Dalam hal ini tidak terjadi pertukaran array karena jarak rute array pertama yang dijumlahkan dengan jarak rute array ketiga lebih kecil dari hasil penjumlahan rute baru.
Langkah selanjutnya, bandingkan array pertama (A-C) dengan array keempat (D-E). Dari hasil proses tersebut, jumlah jarak array pertama (A-C = 1) yang dijumlahkan dengan jarak array yang keempat (D-E = 2) lebih kecil dibandingkan dengan jumlah jarak dari rute baru (A-D = 10, C-E = 7) sehingga tidak terjadi pergeseran dalam array. Kemudian bandingkan jumlah jarak dari array pertama (A-C = 1) dan jarak array kelima (E-A = 3) dengan jumlah jarak rute baru (A-E = 4, C-A = 2). Dalam hal ini tidak terjadi pertukaran sehingga susunan arraynya tetap (A-C), (C-B), (B-D), (D-E) dan (E-A).
Proses berlanjut dengan membandingkan array kedua (C-B) dengan array keempat (D-E). Dari proses tersebut, jumlah jarak array kedua (C-B = 1) dan array keempat (D-E = 2) lebih kecil dibandingkan dengan jumlah jarak (C-D = 5, B-E = 5) yang didapat dari hasil kombinasi sehingga tidak terjadi pertukaran dalam array. Kemudian bandingkan jumlah jarak array kedua (C-B = 1) dan jarak array kelima
(E-A = 3) dengan rute baru hasil kombinasi array kedua dengan array kelima (C-E = 7, B-A = 4). Karena jumlah jarak array kedua dengan array kelima lebih kecil dari jumlah jarak rute baru, maka tidak terjadi pertukaran.
Langkah berikutnya dengan membandingkan array ketiga (B-D) dengan array kelima (E-A). Dari hasil perbandingan tersebut, jumlah jarak array ketiga (B-D = 8) dan jarak array kelima (E-A = 3) tidak lebih besar dari jarak (B-E = 5) dan (D-A = 6) yang didapat dari rute baru hasil kombinasi sehingga tidak terjadi pertukaran dalam array.
Proses selesai karena semua kota telah dikunjungi, sehingga kita mendapatkan rute A-C-B-D-E-A dengan jumlah jarak 15.
2.17 Salesman
Sales lapangan merupakan kunci utama dalam sebuah kegiatan ekonomi dan faktor penting dalam produktivitas bisnis. Seseorang yang berperan dalam aktivitas penjualan dilapangan memiliki tanggung jawab yang besar dan menantang, dimana kesuksesan dan kegagalan orang tersebut terlihat dari pencapaian penjualan dan pertumbuhan pribadi dari perwakilan sales yang mereka tangani. Sales lapangan adalah penentu terbesar kesuksesan penjualan dalam sebuah organisasi.
Sales lapangan memegang salah satu posisi paling penting dalam sebuah perusahaan bisnis dan didalam perekonomian secara umum. Salesman melakukan fungsi penting yaitu berperan sebagai penghubung komunikasi antar pembeli dan penjual, mewakili perusahaan manufaktur dan distribusi kepada para pelanggan
dan yang tak kalah penting mewakili kebutuhan dan pandangan pelanggan kembali ke perusahaan manufaktur dan distribusi.
Sales lapangan adalah mereka yang berkeliling atau berkunjung ketempat bisnis atau hunian dari pembeli. Contoh lain dari sales adalah kasir didalam sebuah toko, karyawan sales dalam sebuah perusahaan manufaktur dan distribusi yang bekerja dibalik counter sales atau hanya sebatas penerima telepon pemesanan.
Kata “Salesman“ digunakan untuk menghindari adanya perbedaan jenis kelamin. Sekarang ini wanita menguasai 30% dari pekerjaan salesman. Oleh karena itu sering juga digunakan istilah “Sales Person” atau “Sales Representatif”.
Peranan dari Salesman :
Salesman dapat diartikan menjadi banyak hal. Biasanya salesman bertanggung jawab dalam mendapatkan pesanan. Dalam beberapa perusahaan, beberapa tugas dari seorang salesman dapat diprioritaskan daripada tugas-tugas lainnya. Berikut ini adalah tugas yang menjadi tanggung jawab salesman :
• Mendapatkan pesanan.
• Menyediakan layanan bagi pelanggan. • Mengumpulkan informasi pasar.
• Menangani semua pelanggan dalam wilayah geografi tertentu. • Mendapatkan pelanggan baru.
• Memiliki pengetahuan akan pelanggan, produk dan perusahaan saingan. • Membuat rekomendasi atas harga.
2.18 Bengkel
Bengkel merupakan istilah untuk nama tempat yang seringkali digunakan seseorang atau beberapa orang sebagai ruangan untuk memperbaiki sesuatu. Umumnya orang mempergunakan istilah bengkel untuk tempat memperbaiki kendaraan. Contoh : bengkel sepeda motor, bengkel mobil, bengkel sepeda.
Pada sebuah bengkel biasanya terdapat beberapa montir yang memiliki kemampuan untuk memperbaiki kendaraan yang mengalami jenis kerusakan
ringan maupun jenis kerusakan parah.
2.19 Sparepart
Sparepart merupakan kata yang berasal dari bahasa inggris. Asal katanya adalah Spare yang berarti pengganti, dan Part yang berarti bagian. Jadi sparepart dapat diartikan bagian pengganti dari suatu bagian yang rusak. Pada sepeda motor, sparepart terdiri dari berbagai jenis bagian. Contoh : kampas rem, bearing, kampas kopling, dan masih banyak lagi.