11
BAB II
KAJIAN PUSTAKA
2.1 State of The Art Review
2.1.1 Sistem Pengenalan Biometrik Iris
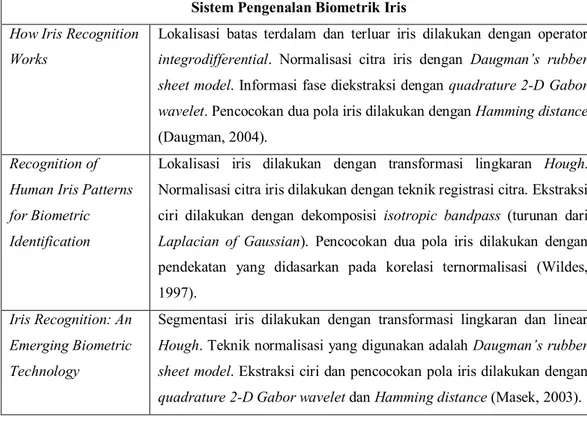
Penelitian-penelitian yang terkait dengan sistem pengenalan biometrik iris membahas mengenai tahap-tahap yang digunakan untuk membangun sistem pengenalan biometrik iris. Tahap-tahap yang dibahas umumnya terdiri dari metode segmentasi (lokalisasi) wilayah iris, metode normalisasi citra iris, metode ekstraksi ciri, dan metode pencocokan pola iris. Tabel 2.1 berisi rangkuman penelitian-penelitian sebelumnya yang terkait dengan sistem pengenalan biometrik iris.
Tabel 2.1 State of The Art: Sistem Pengenalan Biometrik Iris Sistem Pengenalan Biometrik Iris
How Iris Recognition Works
Lokalisasi batas terdalam dan terluar iris dilakukan dengan operator
integrodifferential. Normalisasi citra iris dengan Daugman’s rubber sheet model. Informasi fase diekstraksi dengan quadrature 2-D Gabor wavelet. Pencocokan dua pola iris dilakukan dengan Hamming distance
(Daugman, 2004).
Recognition of Human Iris Patterns for Biometric Identification
Lokalisasi iris dilakukan dengan transformasi lingkaran Hough. Normalisasi citra iris dilakukan dengan teknik registrasi citra. Ekstraksi ciri dilakukan dengan dekomposisi isotropic bandpass (turunan dari
Laplacian of Gaussian). Pencocokan dua pola iris dilakukan dengan
pendekatan yang didasarkan pada korelasi ternormalisasi (Wildes, 1997).
Iris Recognition: An Emerging Biometric Technology
Segmentasi iris dilakukan dengan transformasi lingkaran dan linear
Hough. Teknik normalisasi yang digunakan adalah Daugman’s rubber sheet model. Ekstraksi ciri dan pencocokan pola iris dilakukan dengan quadrature 2-D Gabor wavelet dan Hamming distance (Masek, 2003).
2.1.2 Segmentasi Iris
Penelitian-penelitian yang terkait dengan segmentasi iris khusus membahas mengenai metode yang digunakan untuk melakukan segmentasi wilayah iris. Tabel 2.2 berisi rangkuman penelitian-penelitian sebelumnya yang terkait dengan segmentasi iris.
Tabel 2.2 State of The Art: Segmentasi Iris Segmentasi Iris
Iris Segmentation Using Geodesic Active Contours
Wilayah iris disegmentasi dengan metode geodesic active contours. Persentase metode tersebut mampu melakukan segmentasi iris dengan benar sebesar 56,6% (682 citra), segmentasi yang meleset sebesar 7,6% (92 citra), dan tidak bisa tersegmentasi sebesar 35,8% (431 citra) (Shah and Ross, 2009).
A New Iris Segmentation Method Based on Improved Snake Model and Angular Integral Projection
Wilayah iris disegmentasi dengan menggunakan metode berbasis active
contours, yaitu snake model yang dikombinasikan dengan angular integral projection. Hasilnya lebih baik dibandingkan dengan metode
Daugman dan Masek. Akurasi penentuan titik pusat sebesar 84,8%, akurasi penentuan radius sebesar 96,88%, dan rata-rata waktu proses segmentasi 0,49 detik (Jarjes, et al., 2011).
2.1.3 Metode Hybrid untuk Segmentasi Citra
Penelitian-penelitian yang terkait dengan metode hybrid untuk segmentasi citra membahas mengenai kombinasi metode yang digunakan untuk melakukan segmentasi citra. Tabel 2.3 berisi rangkuman penelitian-penelitian sebelumnya yang terkait dengan metode hybrid untuk segmentasi citra.
Tabel 2.3 State of The Art: Metode Hybrid untuk Segmentasi Citra Metode Hybrid untuk Segmentasi Citra
Genetic Algorithms for Image
Segmentation using Active Contours
Metode active contours dikombinasikan dengan algoritma genetika untuk menemukan wilayah berbentuk lingkaran konsentris dalam segmentasi citra ultrasound. Algoritma genetika digunakan untuk mencegah snakes terpaku pada keadaan minimum lokal (Panwar and Gulati, 2013).
An Overview of PSO-Based Approaches in Image Segmentation
Ulasan mengenai berbagai jenis metode segmentasi citra berbasis
particle swarm optimization (PSO) yang dikombinasikan dengan
metode lain, antara lain thresholding, berbasis fuzzy, PSO-algoritma genetika, PSO-berbasis wavelet, PSO-berbasis clustering,
PSO-berbasis rough set, dan PSO-berbasis jaringan syaraf tiruan. Ulasan
tersebut menyimpulkan bahwa PSO yang dikombinasikan dengan metode lain akan menghasilkan pendekatan yang lebih efektif (Kaur and Singh, 2012).
Application of Particle Swarm Optimization and Snake Model Hybrid on Medical Imaging
Skema baru dari particle swarm optimization (PSO) yang digunakan untuk mengubah kurva snake dari waktu ke waktu untuk mengurangi kompleksitas waktu sekaligus meningkatkan kualitas hasil yang diperoleh. Skema ini mengintegrasikan konsep active contour model ke
PSO sehingga setiap partikel akan merepresentasikan sebuah snaxel
pada active contour. Persamaan velocity update pada algoritma PSO dimodifikasi agar mencakup kinematika dari snake (Shahamatnia and Ebadzadeh, 2011).
PSO-based Fractal Image Compression and Active Contour Model
Penelitian ini dibagi menjadi dua, yaitu pemanfaatan PSO untuk kompresi citra fraktal dan pemanfaatan PSO untuk active contour model.
PSO dan active contour model digunakan untuk mengidentifikasi garis
batas objek secara otomatis. Teknik PSO dengan multi-populasi diadopsi untuk meningkatkan kemampuan pencarian kelengkungan dan mengurangi waktu pencarian, tetapi dengan window pencarian yang lebih luas. Hasil percobaan menunjukkan bahwa metode tersebut mampu meningkatkan pencarian kelengkungan objek tanpa waktu komputasi ekstra (Tseng, 2008).
2.1.4 Klasifikasi Berbasis K-NN untuk Pengenalan Iris
Penelitian-penelitian yang terkait dengan klasifikasi berbasis K-NN untuk pengenalan iris khusus membahas mengenai teknik klasifikasi dengan metode
K-NN yang digunakan pada pengenalan iris. Tabel 2.4 berisi rangkuman
penelitian-penelitian sebelumnya yang terkait dengan klasifikasi berbasis K-NN untuk pengenalan iris.
Tabel 2.4 State of The Art: Klasifikasi Berbasis K-NN untuk Pengenalan Iris Klasifikasi Berbasis K-NN untuk Pengenalan Iris
A Statistical Approach for Iris Recognition Using K-NN Classifier
Metode klasifikasi yang digunakan dalam pengenalan iris adalah algoritma klasifikasi K-NN. Euclidean distance digunakan untuk menghitung kedekatan jarak (kemiripan) antara dua pola iris yang dibandingkan. Unjuk kerja sistem menghasilkan akurasi klasifikasi yang baik terhadap 500 citra iris yang disertai dengan penurunan nilai FAR/FRR (Choudhary, et al., 2013).
2.2 Sistem Biometrik 2.2.1 Biometrik
Suatu ungkapan yang identik dengan istilah biometrik adalah “badanmu adalah password-mu” karena dalam biometrik seseorang dikenali berdasarkan karakteristik alami yang melekat pada tubuhnya. Secara harfiah, biometrik (biometrics) berasal dari kata bio dan metrics. Bio memiliki arti sesuatu yang hidup, sedangkan metrics berarti mengukur. Biometrik memiliki arti mengukur karakteristik pembeda pada badan atau perilaku seseorang yang digunakan untuk melakukan pengenalan secara otomatis (dengan menggunakan teknologi terkomputerisasi) terhadap identitas orang tersebut, dengan membandingkannya
dengan karakteristik yang sebelumnya telah disimpan pada suatu database (Putra, 2009:21).
Secara umum karakteristik pembeda tersebut dapat digolongkan menjadi dua, yaitu karakteristik fisiologis (fisik) dan karakteristik perilaku. Biometrik berdasarkan karakteristik fisiologis menggunakan bagian-bagian fisik dari tubuh seseorang sebagai kode unik untuk pengenalan, seperti DNA, telinga, jejak panas pada wajah, geometri tangan, pembuluh nadi pada tangan, wajah, sidik jari, iris, telapak tangan, retina, gigi, dan bau (komposisi kimia) dari keringat tubuh. Sedangkan biometrik berdasarkan karakteristik perilaku menggunakan perilaku sesorang sebagai kode unik untuk melakukan pengenalan, seperti gaya berjalan, hentakan tombol, tanda tangan, dan suara (Putra, 2009:21).
Tidak semua bagian tubuh atau perilaku seseorang dapat digunakan sebagai biometrik. Persyaratan utama yang harus dipenuhi agar bagian-bagian tubuh atau perilaku manusia dapat digunakan sebagai biometrik, antara lain (Putra, 2009:23) : 1. Universal (universality), artinya karakteristik yang dipilih harus dimiliki
oleh setiap orang.
2. Membedakan (distinctiveness), artinya karakteristik yang dipilih dapat digunakan untuk membedakan antara orang yang satu dengan yang lainnya. 3. Permanen (permanence), artinya karakteristik yang dipilih harus bersifat
konstan (tidak mudah berubah) dalam periode waktu yang lama.
4. Kolektabilitas (collectability), artinya karakteristik yang dipilih mudah diperoleh dan dapat diukur secara kuantitatif.
Selain keempat persyaratan utama tersebut, terdapat tiga persyaratan lagi yang merupakan persyaratan tambahan dalam menentukan kelayakan suatu karakteristik digunakan sebagai biometrik, antara lain (Putra, 2009:24) :
5. Unjuk kerja (performance), artinya karakteristik yang dipilih dapat memberikan unjuk kerja yang bagus, baik dari segi akurasi maupun kecepatan, termasuk sumber daya yang dibutuhkan untuk memperoleh karakteristik tersebut.
6. Dapat diterima (acceptability), artinya masyarakat mau menerima karakteristik yang digunakan.
7. Tidak mudah dikelabui (circumvention), artinya karakteristik yang dipilih tidak mudah dikelabui dengan berbagai cara yang curang.
Perbandingan karakteristik biometrik, baik karakteristik fisiologis maupun perilaku ditunjukkan pada Tabel 2.5. Masing-masing karakteristik biometrik tersebut memiliki nilai tersendiri terkait dengan ketujuh persyaratan yang telah disebutkan sebelumnya. Nilai yang digunakan adalah tinggi (T), menengah(M), dan rendah (R).
Tabel 2.5 Perbandingan Karakteristik Biometrik (Putra, 2009:31) Karakteristik Biometrik U ni ve rs al ity D is ti nc tiv en es s P er m an en ce C ol le ct ab ili ty P er fo rm an ce A cc ep ta bi li ty C ir cu m ve nt io n DNA T T T R T R R Telinga M M T M M T M Wajah T R M T R T T Thermogram Wajah T T R T M T R Sidik Jari M T T M T M M Gaya Berjalan M R R T R T M Geometri Tangan M M M T M M M
Pembuluh Nadi Tangan M M M M M M R
Iris T T T M T R R Hentakan Tombol R R R M R M M Bau T T T R R M R Telapak Tangan M T T M T M M Retina T T M R T R R Tanda Tangan R R R T R T T Suara M R R M R T T
2.2.2 Sistem Pengenalan Biometrik
Sistem pengenalan biometrik merupakan sistem otentikasi dengan menggunakan biometrik. Pengenalan terhadap identitas seseorang pada sistem biometrik dilakukan secara otomatis berdasarkan suatu ciri biometrik dengan cara mencocokkan ciri tersebut dengan ciri biometrik yang telah disimpan dalam
database. Sebagai suatu sistem otentikasi, sistem biometrik akan menghasilkan
keputusan dari hasil pengenalan/pencocokan yang diperoleh. Keputusan yang dihasilkan oleh sistem biometrik dapat berupa sah atau tidak sah, diterima atau ditolak, dan dikenali atau tidak dikenali. Secara umum, terdapat dua model sistem biometrik, yaitu sistem verifikasi dan sistem identifikasi (Putra, 2009:24).
2.2.2.1 Sistem Verifikasi
Sistem verifikasi bertujuan untuk menerima atau menolak identitas yang diklaim oleh seseorang. Pengguna membuat klaim “positif” terhadap suatu identitas. Klaim “positif” terhadap suatu identitas berarti pengguna mengklaim bahwa dirinya telah terdaftar di sistem. Pada sistem verifikasi dilakukan pencocokan “satu ke satu” dari sampel yang diberikan terhadap acuan yang terdaftar atas identitas yang diklaim tersebut. Sistem verifikasi biasanya menjawab pertanyaan “apakah identitas saya sama dengan identitas yang saya klaim?” (Putra, 2009:24).
2.2.2.2 Sistem Identifikasi
Sistem identifikasi bertujuan untuk memecahkan/mengungkapkan identitas seseorang. Pengguna dapat “tidak memberi klaim” atau memberi klaim “implisit negatif” untuk identitas yang telah terdaftar. Klaim “implisit negatif” terhadap suatu identitas berarti pengguna mengklaim tidak terdaftar di sistem. Pada klaim implisit, sampel yang diberikan memerlukan pencocokan terhadap semua acuan yang didaftarkan atau dilakukan pencocokan “satu ke banyak”. Sistem identifikasi biasanya menjawab pertanyaan “identitas siapakah ini?” (Putra, 2009:25).
2.2.3 Evaluasi Sistem Biometrik
Tidak semua sistem biometrik yang dibangun memiliki unjuk kerja yang baik. Untuk mengetahui seberapa baik unjuk kerja dari suatu sistem biometrik perlu dilakukan evaluasi. Beberapa jenis kesalahan yang dijadikan tolak ukur dalam mengevaluasi unjuk kerja sistem biometrik adalah rasio kesalahan keputusan
(decision error rate), rasio kesalahan pencocokan (matching error rate), dan rasio
kesalahan akuisisi citra (image acquisition error rate) (Putra, 2009:33).
2.2.3.1 Rasio Kesalahan Keputusan
Rasio kesalahan keputusan terdiri dari rasio kesalahan penerimaan (False
Acceptance Rate) dan rasio kesalahan penolakan (False Rejection Rate).
1. False Acceptance Rate (FAR) menyatakan proporsi dari sistem transaksi yang mengalami kesalahan penerimaan (falsely accepted) atau pengguna yang tidak terdaftar di sistem diterima oleh sistem. Dengan kata lain, FAR merupakan false match rate untuk sampel-sampel yang berhasil diakuisisi
(successfully acquired). FAR dihitung menggunakan persamaan (2.1)
(Dunstone and Yager, 2009:148).
= × (1 − )
2. False Rejecting Rate (FRR) menyatakan proporsi dari sistem transaksi yang mengalami kesalahan penolakan (falsely rejected) atau pengguna yang terdaftar di sistem ditolak oleh sistem. FRR meliputi kesalahan saat akuisisi, dan proporsi false non match untuk sampel-sampel yang berhasil diakuisisi.
FRR dihitung menggunakan persamaan (2.2) (Dunstone and Yager,
2009:148).
= × (1 − )
2.2.3.2 Rasio Kesalahan Pencocokan
Rasio kesalahan pencocokan (matching error rate) menyatakan probabilitas terjadinya kesalahan pencocokan pada sistem. Terdapat dua jenis rasio kesalahan
(2.1)
pencocokan, yaitu rasio kesalahan kecocokkan (False Match Rate) dan rasio kesalahan ketidakcocokkan (False Non Match Rate) (Putra, 2009:34).
1. False Match Rate (FMR) menyatakan probabilitas sampel yang berasal dari pengguna yang berbeda tetapi cocok dengan acuan yang terdaftar pada
database. FMR dihitung dengan menggunakan persamaan (2.3) (Putra,
2009:34).
= × 100%
2. False Non Match Rate (FNMR) menyatakan probabilitas sampel dari pengguna yang sama tetapi tidak cocok dengan acuan yang terdaftar pada
database. FNMR dihitung dengan menggunakan persamaan (2.4) (Putra,
2009:34).
= × 100%
2.2.3.3 Rasio Kesalahan Akuisisi Citra
Kesalahan akuisisi citra (image acquisition error rate) mencakup kegagalan saat proses pendaftaran (Failure to Enroll Rate) dan kegagalan saat akuisisi citra
(Failure to Acquire Rate). Kedua rasio kesalahan tersebut berpengaruh terhadap
nilai FAR/FRR sistem, namun tidak pada nilai FMR/FNMR (Putra, 2009:40). 1. Failure to Enroll Rate (FTE) menyatakan proporsi dari transaksi enrollment
yang mengalami kegagalan, termasuk di dalamnya kegagalan dalam menghasilkan ciri (feature) biometrik, kegagalan dalam mendapatkan citra yang berkualitas dalam tahap pendaftaran, dan kegagalan dalam menghasilkan acuan yang cocok.
(2.3)
2. Failure to Acquire Rate (FTA) menyatakan proporsi dari transaksi verifikasi/identifikasi yang mengalami kegagalan saat melakukan akuisisi citra.
2.2.3.4 Nilai Ambang (Threshold Value)
Nilai ambang (threshold value) yang biasanya dilambangkan dengan T, memiliki peran penting dalam memutuskan terjadinya kesalahan dalam pencocokan. Nilai FAR/FRR atau FMR/FNMR bergantung pada besarnya nilai ambang yang digunakan. Keputusan (cocok atau tidak cocok, sah atau tidak sah) dihasilkan berdasarkan kondisi berikut (Putra, 2009:35) :
= ℎ, ℎ, ≥<
Selain didasarkan pada persamaan (2.5), ada juga yang menggunakan kondisi sebaliknya untuk menyatakan pengguna yang sah, seperti yang ditunjukkan pada persamaan (2.6) (Putra, 2009:35).
= ℎ, ℎ, ≤>
Hal tersebut disebabkan oleh penggunaan asumsi yang berbeda terhadap skor yang digunakan. Kondisi pada persamaan (2.5) digunakan jika asumsi yang digunakan terhadap skor adalah semakin besar skor berarti kedua sampel semakin mirip. Sebaliknya, kondisi pada persamaan (2.6) digunakan jika asumsi yang digunakan terhadap skor adalah semakin kecil skor berarti kedua sampel semakin mirip (Putra, 2009:35).
(2.5)
2.2.3.5 Grafik Receiver Operation Characteristics (ROC)
Grafik ROC merupakan grafik yang digunakan untuk menunjukkan unjuk kerja suatu sistem biometrik dan memiliki tiga jenis model grafik. Pada Gambar 2.1 (a), sumbu-x menyatakan nilai ambang dan sumbu-y menyatakan FAR/FRR atau
FMR/FNMR. Pada Gambar 2.1 (b), x menyatakan FRR (FNMR) dan sumbu-y mensumbu-yatakan FAR (FMR). Pada Gambar 2.1 (c), sumbu-x mensumbu-yatakan FAR (FMR)
dan sumbu-y menyatakan GAR (Genuine Acceptance Rate). Salah satu dari ketiga model grafik tersebut dapat digunakan untuk mewakili unjuk kerja suatu sistem biometrik (Putra, 2009:37).
(a)
(c)
Gambar 2.1 Berbagai Model Grafik ROC (Putra, 2009:36)
GAR menyatakan tingkat kesuksesan suatu sistem biometrik dalam
mengenali pengguna dengan benar. Untuk menghitung nilai GAR digunakan persamaan (2.7) atau persamaan (2.8) (Putra, 2009:37).
= 1 − atau = 1 −
Pada Gambar 2.1 (a), terlihat bahwa semakin tinggi nilai ambang maka rasio kesalahan penolakan akan berkurang dan rasio kesalahan penerimaan akan bertambah. Semakin rendah nilai ambang maka kesalahan penolakan akan bertambah dan kesalahan penerimaan akan berkurang. Kedua jenis kesalahan ini berbanding terbalik secara berimbang. Kedua kurva FAR (FMR) dan FRR (FNMR) menyilang pada suatu titik dengan nilai FAR sama dengan FRR. Nilai pada titik perpotongan ini disebut dengan tingkat kesalahan sama (equal error rate-EER) atau
crossover error rate (CER).
(2.7)
Kebutuhan akan tingkat akurasi suatu sistem biometrik sangat bergantung pada aplikasinya. Dalam aplikasi forensik, seperti identifikasi pelaku kriminal, yang diutamakan adalah FRR (FNMR) yang sekecil mungkin agar jangan sampai salah dalam mengidentifikasi seorang pelaku kriminal meskipun dengan risiko terjadi kesalahan yang cukup besar dalam verifikasi. Di sisi lain, FAR (FMR) yang sekecil mungkin menjadi hal paling penting dalam aplikasi keamanan tingkat tinggi karena tujuan utamanya adalah untuk menolak para penipu (meski dengan risiko pengguna yang sah juga ditolak oleh sistem karena tingginya FRR). Salah satu aplikasi publik yang unjuk kerjanya berada di antara kedua hal di atas adalah aplikasi verifikasi kartu ATM. Kesalahan FAR yang tinggi berarti kehilangan beberapa ratus dollar, sementara tingginya FRR mengarah pada hilangnya kepercayaan pelanggan penting (Putra, 2009:37).
2.2.4 Sistem Pengenalan Biometrik Iris
Menurut Tang, iris adalah daerah berbentuk gelang pada mata yang dibatasi oleh pupil (bagian pusat mata yang berwarna hitam) dan sclera (bagian putih dari mata) (Tang, et al., 2009). Sedangkan menurut Daugman, iris merupakan organ internal mata yang terlindungi, terletak di belakang kornea dan aqueous humor, dan berada di depan lensa. Iris merupakan satu-satunya organ internal dari tubuh yang dapat dilihat secara normal dari luar (Fouad, 2012).
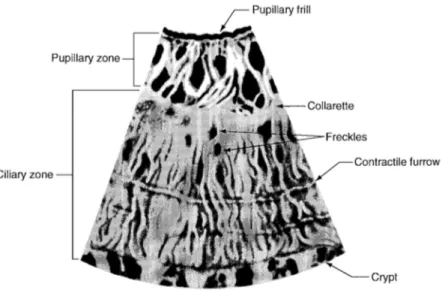
Gambar 2.2 Anatomi Mata (Fouad, 2012)
Lapisan striated anterior yang melindungi trabecular meshwork menghasilkan tekstur utama yang terlihat dengan cahaya seperti yang ditunjukkan pada Gambar 2.2 (Fouad, 2012). Sedangkan Gambar 2.4 menampilkan struktur iris jika dilihat dari tampak depan.
Gambar 2.3 Contoh Pola Iris yang Terlihat (Fouad, 2012)
Tekstur visual dari iris dibentuk selama perkembangan janin di dalam kandungan dan selanjutnya tekstur tersebut menstabilkan diri sepanjang dua tahun pertama kehidupan janin tersebut di luar kandungan (setelah lahir). Tekstur iris yang kompleks mengandung informasi yang bersifat sangat unik dan dapat dimanfaatkan untuk pengenalan individu (Putra, 2009:76).
Sifat-sifat yang menyebabkan iris sesuai digunakan untuk sistem identifikasi dengan tingkat kepercayaan yang tinggi diantaranya, (i) sifatnya yang terisolasi dan terlindungi dari lingkungan luar; (ii) tidak mungkin dimodifikasi dengan operasi tanpa risiko yang mempengaruhi penglihatan; (iii) adanya respon fisiologis terhadap cahaya yang dapat digunakan sebagai salah satu tes alami untuk menghindari kelicikan (Fouad, 2012).
Iris tidak dipengaruhi oleh faktor genetik sehingga iris-iris yang berasal dari
genotype yang sama (saudara kembar identik, atau pasangan iris kiri dan kanan dari
individu) tidak memiliki keterhubungan sama sekali. Hal ini menyebabkan iris bersifat unik untuk setiap orang, bahkan untuk iris dari mata kiri dan kanan. Kelebihan yang dimiliki iris dibandingkan dengan biometrik yang lain diantaranya (i) kemudahan dalam registrasi citra dari jarak tertentu tanpa terjadi kontak fisik; (ii) geometri polar dari bentuk iris sesuai dengan sistem koordinat alami dan titik asal koordinat; (iii) pola iris memiliki tingkat acak yang tinggi, mencapai 266 spot yang unik (Fouad, 2012).
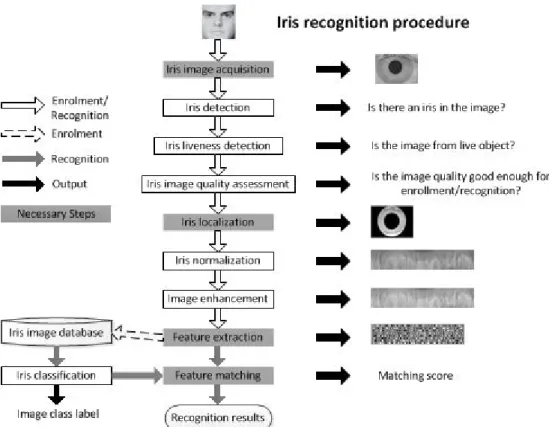
Menurut T. Tan, et al., dalam bukunya yang berjudul Iris Recognition:
Fundamentals and State-Of-the-Art menggambarkan bahwa algoritma pengenalan
Gambar 2.5 Algoritma Sistem Pengenalan Iris (Putra, 2009:77)
Berdasarkan Gambar 2.5 tersebut, terdapat beberapa proses penting yang harus dilakukan dalam membangun suatu sistem pengenalan biometrik iris. Proses-proses tersebut adalah akuisisi citra iris (iris image acquisition), lokalisasi iris (iris
localization) atau sering disebut juga dengan istilah segmentasi iris, ekstraksi ciri (feature extraction), dan pencocokan ciri (Putra, 2009:77).
1. Akuisisi citra iris, yaitu proses untuk mendapatkan citra iris dari individu yang digunakan untuk pendaftaran maupun pengujian.
2. Lokalisasi iris dan zona perhitungan. Lokalisasi iris, yaitu proses menemukan lokasi iris. Sedangkan zona perhitungan adalah daerah di antara luar pupil dan di dalam sclera.
3. Ekstraksi ciri, yaitu proses mengekstrak informasi dari citra iris yang akan digunakan sebagai ciri unik dari iris tersebut.
4. Pencocokan, yaitu proses menghitung jarak antara dua sampel iris. Hasil dari pencocokan ini adalah skor yang akan menentukan hasil pengenalan.
2.3 Pengolahan Citra Digital
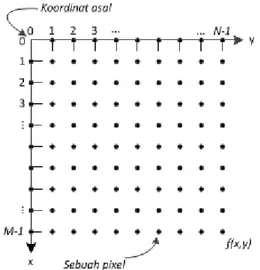
Secara umum, pengolahan citra digital mengacu pada pemrosesan gambar dua dimensi dengan menggunakan komputer. Suatu citra dapat didefinisikan sebagai fungsi f(x,y) berukuran M baris dan N kolom, dengan x dan y merupakan koordinat spasial, dan amplitudo f di titik koordinat (x,y) merupakan intensitas atau tingkat keabuan dari citra pada titik koordinat tersebut. Jika x, y, dan amplitudo f secara keseluruhan memiliki nilai yang berhingga (finite) dan bernilai diskrit maka dapat dikatakan bahwa citra tersebut adalah citra digital (Putra, 2010:20).
Gambar 2.6 menunjukkan posisi koordinat yang digunakan pada citra digital. Hal ini sedikit berbeda dengan koordinat Cartesian pada umumnya, dalam hal ini sumbu-x biasanya berada pada bidang horizontal, dan sumbu-y berada pada bidang vertikal. Pada koordinat citra digital, seperti yang ditunjukkan pada Gambar 2.6, sumbu-x berada pada bidang vertikal, dan sumbu-y berada pada bidang horizontal, hal ini karena koordinat citra digital menggunakan koordinat pada layar monitor. Dalam bentuk matematis, citra digital dapat direpresentasikan dalam bentuk matriks sebagai berikut :
( , ) = (0,0) (1,0) ⋮ ( − 1,0) (0,1) (1,1) ⋮ ( − 1,1) ⋯ ⋯ ⋯ (0, − 1) (1, − 1) ⋮ ( − 1, − 1)
Nilai pada suatu irisan antara baris dan kolom (pada posisi (x,y)) disebut dengan istilah picture elements, image elements, pels, atau pixel (Putra, 2010:20).
2.3.1 Tapis Median
Tapis median menghitung nilai dari setiap piksel baru, yaitu nilai piksel pada pusat koordinat sliding window dengan nilai tengah (median) dari piksel di dalam window. Nilai tengah dari piksel di dalam window tergantung pada ukuran
sliding window. Untuk ukuran window m baris dan n kolom maka banyaknya piksel
dalam window adalah × . Akan lebih baik jika ukuran window adalah bilangan ganjil karena piksel pada posisi tengahnya dapat diperoleh dengan lebih pasti, yaitu piksel pada posisi ( × + 1)/2. Semua piksel tetangga harus diurutkan sebelum
menentukan piksel pada posisi tengah. Secara matematis, tapis median dapat dinyatakan sebagai berikut (Putra, 2010:147):
( , ) = { ( + − 1, + − 1), ( , ) ∈ } dengan,
= matriks citra input
= matriks citra output = matriks window
, = indeks matriks citra input dan output , = indeks window
2.3.2 Tapis Gaussian
Tapis Gaussian secara meluas telah digunakan dalam bidang analisis citra terutama untuk proses penghalusan (smoothing), pengaburan (blurring), menghilangkan detil, dan menghilangkan derau (noise). Citra diproses menggunakan tapis Gaussian dengan parameter ukuran kernel dan standard deviasi () yang telah ditentukan untuk mengurangi noise yang terdapat pada citra. Tapis
Gaussian 2-D dihasilkan melalui persamaan berikut :
( , ) = 1 2 dengan,
= matriks tapis Gaussian
, = indeks matriks Gaussian
= standard deviasi
(2.8)
Proses penghalusan terhadap citra dapat dilakukan dengan proses konvolusi citra input dengan kernel Gaussian. Tingkat atau derajat kehalusan citra hasil tapis
Gaussian dapat diatur dengan mengubah-ubah nilai (Putra, 2010:143).
2.3.3 Tapis Gabor 2-D
Tapis Gabor didefinisikan oleh fungsi harmonic yang dimodulasi oleh distribusi Gaussian. Penggunaan tapis Gabor 2-D dalam computer vision diperkenalkan oleh Daugman di akhir tahun 1980-an. Sejak saat itu, tapis Gabor telah sering digunakan pada aplikasi pengolahan citra yang meliputi kompresi citra, deteksi tepi, pengenalan objek dan wajah, segmentasi dan klasifikasi tekstur, dan analisis tekstur. Dalam hal ekstraksi ciri, tapis Gabor telah sukses diaplikasikan pada banyak aplikasi pengenalan pola seperti pengenalan wajah, iris, dan sidik jari. Salah satu hal yang menyebabkan tapis Gabor banyak digunakan adalah karena frekuensi dan representasi orientasi dari tapis Gabor mirip dengan sistem visual manusia (Singh et al., 2012).
Tapis Gabor merupakan tapis linier di mana respon impulsnya didefinisikan oleh fungsi harmonic dikalikan dengan fungsi Gaussian. Tapis Gabor 2-D dalam domain spasial dirumuskan dengan persamaan berikut (Putra, 2010:151) :
( , , , , ) = − {2. . ( . . cos + . . sin )}
dengan, = √−1
= frekuensi dari gelombang sinusoidal
= kontrol terhadap orientasi dari fungsi Gabor
= standard deviasi dari Gaussian envelope
, = koordinat dari tapis Gabor
Persamaan tapis Gabor 2-D tersebut dibentuk dari dua komponen, yaitu
Gaussian envelope dan gelombang sinusoidal dalam bentuk kompleks. Fungsi Gaussian dari persamaan tersebut adalah sebagai berikut :
( , ) = . . −
Sedangkan gelombang sinusoidal pada persamaan tersebut ditunjukkan oleh persamaan berikut:
( , ) = 2. ( . . cos + . . sin )
Dari fungsi gelombang sinusoidal tersebut, maka diperoleh dua fungsi terpisah yang dinyatakan dengan bagian real dan imajiner dari fungsi kompleks yang ditunjukkan oleh persamaan berikut (Putra, 2010:151):
( , ) = cos{2. ( . . cos + . . sin )} ( , ) = sin{2. ( . . cos + . . sin )}
Pada ekstraksi ciri persamaan (2.10) digunakan untuk membentuk tapis
Gabor 2-D. Parameter , mengacu pada koordinat tapis Gabor 2-D yang disesuaikan dengan ukuran tapis yang hendak dihasilkan. Parameter mengacu pada besar sudut orientasi untuk mengontrol garis-garis paralel pada fungsi Gabor. Jika tapis Gabor dengan beragam frekuensi (u) dan sudut orientasi ( ) diterapkan
(2.11)
(2.12)
(2.14) (2.13)
pada suatu titik tertentu pada citra, maka akan diperoleh banyak respon tapis untuk titik tersebut sesuai dengan jumlah frekuensi dan sudut orientasi yang digunakan. Setiap respon tapis yang dihasilkan dikonvolusi dengan citra yang menjadi objek ekstraksi ciri. Hasil konvolusi akan memunculkan fitur-fitur tertentu yang merupakan karakteristik citra. Fitur-fitur tersebut terdiri dari bagian real dan
imaginary berdasarkan persamaan (2.13) dan (2.14).
2.3.4 Laplacian of Gaussian (LoG)
Tepian dari suatu citra mengandung informasi penting dari citra yang bersangkutan. Tepian citra dapat merepresentasikan objek-objek yang terkandung dalam citra tersebut, bentuk, dan ukurannya serta terkadang juga informasi tentang teksturnya. Tepian citra adalah posisi di mana intensitas pixel dari citra berubah dari nilai rendah ke nilai tinggi atau sebaliknya. Deteksi tepi umumnya adalah langkah awal dalam melakukan segmentasi citra. Terdapat berbagai operator deteksi tepi yang telah dikembangkan berdasarkan turunan pertama (first order
derivative), di antaranya operator Robert, operator Sobel, operator Prewitt, dan
operator Canny. Selain operator turunan pertama, terdapat operator deteksi tepi yang dikembangkan berdasarkan turunan kedua (second order derivative). Deteksi tepi dari turunan kedua dapat menghasilkan tepian citra yang lebih baik karena menghasilkan tepian yang lebih tipis. Salah satu operator dari turunan kedua adalah
Laplacian of Gaussian (LoG).
Operator LoG sangat berbeda dengan operator yang lainnya, karena operator Laplacian berbentuk omny directional (tidak horizontal, tidak vertikal). Operator ini akan menangkap tepian dari semua arah dan menghasilkan tepian yang
lebih tajam dari operator yang lainnya. LoG terbentuk dari proses Gaussian yang diikuti oleh operasi Laplace. Hasil yang diperoleh tidak terlalu terpengaruh oleh derau karena fungsi Gaussian adalah mengurangi derau. Laplacian mask meminimumkan kemungkinan kesalahan deteksi tepi. Fungsi dari LoG ditunjukkan oleh persamaan berikut (Putra, 2010:209):
( , ) = 1 1 − + 2 dengan,
= matriks tapis Laplacian of Gaussian , = indeks tapis Laplacian of Gaussian = standard deviasi
2.3.5 Pengambangan Citra (Threshold)
Proses pengambangan akan menghasilkan citra biner, yaitu citra yang memiliki dua nilai tingkat keabuan yaitu hitam dan putih. Secara umum proses pengambangan citra grayscale untuk menghasilkan citra biner adalah sebagai berikut :
( , ) = 1 0
( , ) ≥ ( , ) <
Dengan g(x,y) adalah citra biner dari citra grayscale f(x,y), dan T menyatakan nilai ambang. Nilai T memegang peranan yang sangat penting dalam proses pengambangan. Kualitas hasil citra biner sangat tergantung pada nilai T yang digunakan (Putra, 2010:211).
(2.16) (2.15)
2.3.6 Penandaan Komponen Terhubung
Pixel p adalah adjacent (berbatasan) dengan pixel q jika keduanya terhubung (pengertian terhubung tergantung pada jenis keterhubungan yang digunakan). Dua himpunan bagian citra S1 dan S2 adalah adjacent jika beberapa
pixel pada S1 adalah adjacent ke beberapa pixel pada S2. Suatu jalur dari pixel p
dengan koordinat (x,y) ke pixel q dengan koordinat (s,t) adalah suatu urutan atau deretan dari pixel berbeda (distinct pixel) dengan koordinat (x0,y0), (x1,y1), ..., (xn
,yn) dengan (x0,y0)=(x,y) dan (xn ,yn)=(s,t) adalah adjacent ke (xi-1,yi-1), 1 ≤ ≤ ,
dan n menyatakan panjang dari jalur. Jika p dan q adalah pixel pada suatu himpunan bagian citra S, maka p adalah terhubung ke q dalam S bila ada suatu jalur dalam S yang menghubungkan p ke q. Untuk setiap pixel p dalam S yang terhubung ke p disebut dengan komponen terhubung (connected component) dari S (Putra, 2010:217).
Berikut ini dijelaskan tahapan dalam melakukan penandaan komponen terhubung dengan aturan 4-connected :
1. Periksa (scan) citra dengan bergerak sepanjang baris sampai menemukan pixel p (nilai p berada dalam himpunan citra biner V, dengan V={1}). Bila
p sudah ditemukan maka periksa nilai pixel tetangga dari p, yaitu pixel di
atas dan di kiri dari p, kemudian lakukan pemeriksaan berikut :
a. Bila kedua pixel tetangga bernilai 0 maka berilah tanda (label) baru pada p.
b. Jika hanya satu saja dari pixel tetangga tersebut bernilai 1 maka berilah tanda dari pixel tetangga tersebut pada p.
c. Bila kedua pixel tetangga bernilai 1 dan memiliki tanda sama maka berilah tanda dari pixel tetangga tersebut pada p.
d. Bila kedua pixel tetangga bernilai 1 dan memiliki tanda berbeda maka berilah tanda dari salah satu pixel tetangga tersebut pada p dan buat catatan bahwa kedua tanda yang berbeda tersebut adalah ekuivalen.
Pada akhir proses, semua pixel bernilai 1 (untuk citra biner) telah mendapat tanda tetapi beberapa tanda-tanda tersebut mungkin masih ada yang ekuivalen. Oleh karena itu proses selanjutnya yang harus dilakukan adalah mengurutkan pasangan-pasangan tanda yang ekuivalen ke dalam kelas-kelas ekuivalen kemudian memberi tanda yang berbeda pada setiap kelas ekuivalen (Putra, 2010:218).
Berikut ini dijelaskan ketentuan dalam melakukan penandaan komponen terhubung dengan aturan 8-connected:
1. Bila keempat piksel tetanggaan bernilai 0 maka berilah tanda baru pada
p.
2. Bila hanya salah satu piksel tetangga bernilai 1 maka berilah tanda dari piksel tetangga tersebut pada p.
3. Bila dua atau lebih piksel tetangga bernilai 1 maka berilah salah satu tanda dari piksel tetangga tersebut pada p, kemudian buat catatan bahwa semua tanda dari piksel tetangga bernilai 1 tersebut adalah ekuivalen. Proses berikutnya adalah membuat kelas-kelas ekuivalen seperti pada
4-connected dan memberi setiap kelas ekuivalen tanda yang berbeda. Langkah
pemeriksaan (scanning) kembali pada citra dan ganti setiap tanda dengan tanda dari kelas ekuivalen.
2.4 Active Contours (Snake Model)
Active contours digunakan dalam domain pengolahan citra untuk
menemukan lokasi kontur dari suatu objek. Mencoba menemukan lokasi suatu kontur objek hanya dengan menjalankan pengolahan citra tingkat rendah seperti menggunakan deteksi tepi Canny sesungguhnya tidak selalu berhasil. Seringkali tepian yang dihasilkan tidak kontinyu, misalkan terdapat rongga-rongga sepanjang tepian, dan tepian yang dihasilkan bukanlah tepian sesungguhnya karena adanya
noise pada citra. Active contours mencoba mengatasi hal-hal tersebut dengan cara
menambahkan properti-properti yang dibutuhkan seperti continuity dan smoothness pada kontur objek. Suatu active contours dimodelkan sebagai kurva parametrik, di mana kurva tersebut diarahkan untuk meminimumkan energi internalnya dengan cara bergerak ke lokal minimum (Tiilikainen, 2007:6).
Menurut Kass et al., model active contours (snakes) merupakan pendekatan untuk ekstraksi ciri yang sangat berbeda. Suatu active contour merupakan sekumpulan titik yang digunakan untuk melingkupi fitur target (fitur yang akan diekstrak). Active contour dapat dianalogikan sebagai sebuah balon yang digunakan untuk ‘menemukan’ suatu bentuk dengan cara balon ditempatkan di luar bentuk yang akan dicari, dalam hal ini balon tersebut melingkupi bentuk yang akan dicari tersebut. Selanjutnya, udara dikeluarkan dari balon tersebut hingga ukurannya semakin mengecil. Bentuk yang dicari ditemukan pada saat balon berhenti
mengalami penyusutan, yaitu pada saat bentuk balon tersebut sesuai dengan bentuk target yang dicari (Nixon and Aguado, 2008:244).
Gambar 2.7 Ilustrasi Kurva Snake Parametrik (Tiilikainen, 2007:7)
2.4.1 Basic Snake Model
Snake model diekspresikan sebagai proses untuk meminimumkan energi.
Fitur target merupakan fungsi energi yang minimum. Fungsi energi tersebut tidak hanya mengandung informasi tepi, tetapi juga mengandung properti yang mengontrol cara kontur meregang (stretch) dan melengkung (curve). Dalam snake
model, fungsi energi merupakan penjumlahan dari fungsi energi internal kontur (Eint), energi batasan (Econ), dan energi citra (Eimage). Fungsi dari himpunan titik
koordinat yang menyusun suatu snake, v(s), yang terdiri dari himpunan titik koordinat x dan y pada snake ditunjukkan pada persamaan berikut (Nixon and Aguado, 2008:245):
( ) = ∫ ( ) + ( ) + ( ) d (2.17)
Sedangkan posisi dari snake direpresentasikan dengan menggunakan persamaan berikut, dengan ∈ [0,1] merupakan panjang snake yang telah dinormalisasi (Jarjes, et al., 2011) :
( ) = [ ( ), ( )], ∈ [0,1]
Sejak pertama kali diperkenalkan, model active contours (snakes) telah digunakan secara luas untuk mendeteksi dan mensegmentasi kontur dari objek target. Snake didefinisikan sebagai metode yang bertujuan untuk meminimumkan energi yang secara iteratif mengalami penyusutan dengan meminimumkan fungsi energi ( ) . Kontur snake yang baru adalah kontur dengan energi terendah dan memiliki kecocokkan yang lebih baik dengan kontur objek target dibandingkan dengan kontur inisialisasi. Terkait dengan pemilihan kontur snake baru, himpunan titik ( ) yang dipilih adalah yang memenuhi kondisi berikut (Nixon and Aguado, 2008:245):
d
d ( ) = 0
Pada persamaan (2.17), energi internal, , mengontrol perilaku alami dari
snake berupa pengaturan titik koordinat yang membentuk snake. Representasi dari
energi internal ditunjukkan oleh persamaan berikut:
( ) = ( ) d ( ) d + ( ) d ( ) d (2.18) (2.19) (2.20)
Turunan pertama, d ( )/d , merupakan ukuran dari energi yang berkaitan dengan peregangan (energi elastis) wilayah dari kontur. Turunan kedua, d ( )/d , merupakan ukuran dari energi yang berkaitan dengan pelekukan (energi curvature). Parameter ( ) mengatur kontribusi energi elastis terhadap pengaturan jarak antar titik pada snake. Nilai yang semakin rendah mengakibatkan perubahan jarak antar titik menjadi semakin besar, sebaliknya semakin tinggi nilai maka semakin kecil perubahan jarak yang terjadi antar titik. Parameter ( ) mengatur kontribusi energi
curvature terhadap variasi titik pada snake. Semakin rendah nilai akan
mengakibatkan curvature tidak diminimumkan dan kontur dapat membentuk sudut pada garis kelilingnya, sedangkan semakin tinggi nilai maka semakin halus kontur snake yang didapat (Nixon and Aguado, 2008:246).
Pada persamaan (2.17), energi eksternal ditunjukkan oleh dan (khusus bersifat opsional). Energi citra, , merepresentasikan energi yang menarik snake menuju ke fitur low-level yang diinginkan pada citra, seperti kecerahan atau data tepi. Formulasi asli dari energi citra ditunjukkan pada persamaan berikut (Nixon and Aguado, 2008:246) :
= + +
Energi line ( ) dapat ditetapkan sebagai intensitas citra pada titik
tertentu. Energi tepi ( ) dapat dihitung dengan menggunakan operator deteksi
tepi. Energi termination jarang digunakan, sehingga hanya energi line dan energi tepi saja yang disertakan dalam snake model (Nixon and Aguado, 2008:246).
2.4.2 Greedy Snake Model
Implementasi dari snake untuk meminimumkan persamaan (2.17) dapat menggunakan elemen yang berhingga. Salah satu implementasi yang paling mudah adalah dengan menggunakan algoritma greedy. Algoritma greedy
mengimplementasikan proses meminimumkan energi semata-mata sebagai algoritma diskrit. Proses dimulai dengan menspesifikasikan kontur awal. Algoritma
greedy selanjutnya mengembangkan snake secara iteratif dengan melakukan
pencarian terhadap titik-titik koordinat kontur pada local neighborhood untuk memilih kontur baru dengan energi snake yang lebih rendah. Pada setiap iterasi, semua titik-titik koordinat kontur diubah dan proses ini diulang untuk titik kontur yang pertama. Indeks titik-titik koordinat snake dihitung dengan melakukan modulo terhadap S (jumlah titik-titik snake) (Nixon and Aguado, 2008:246).
Untuk suatu himpunan titik-titik snake , ∈ 0, − 1, minimasi fungsi energi untuk setiap titik snake ditunjukkan oleh persamaan berikut :
( ) = ( ) + ( )
Persamaan (2.22) dapat dijabarkan sebagai berikut :
( ) = ( ) + ( ) + ( )
dalam hal ini turunan pertama dan kedua merupakan pendekatan untuk setiap titik yang dicari pada local neighborhood dari titik kontur terpilih saat ini (Nixon and Aguado, 2008:247).
(2.22)
2.4.2.1 Energi Continuity
Turunan pertama merupakan pembagian antara selisih jarak rata-rata titik-titik kontur (dievaluasi dengan euclidean distance), dengan nilai euclidean distance antara titik koordinat kontur saat ini, , dan titik kontur selanjutnya. Pemilihan nilai ( ) yang tepat untuk setiap titik koordinat kontur, , dapat mengatur jarak antara titik-titik kontur. Penjabaran dari turunan pertama ditunjukkan oleh persamaan berikut (Nixon and Aguado, 2008:248) :
d
d = ‖ − ‖ / − ‖ − ‖
= ( − ) + ( − ) / − ( − ) + ( − )
Setelah persamaan (2.24) dihitung untuk setiap piksel pada koordinat ( , )
di wilayah neighborhood dari sebuah snake control point, setiap nilai yang dihasilkan dibagi dengan nilai energi continuity terbesar di wilayah neighborhood. Hal tersebut menunjukkan bahwa wilayah neighborhood dinormalisasi sehingga hanya terdiri dari energi continuity pada rentang nilai [0,1]. Perhitungan energi
continuity ini akan mendorong snake control points memiliki jarak yang merata di
sepanjang kurva dan menjaga kurva tetap dipengaruhi oleh parameter panjang busur (Tiilikainen, 2007:23).
2.4.2.2 Energi Curvature
Turunan kedua dapat diimplementasikan sebagai estimasi dari curvature antara titik-titik kontur selanjutnya dan sebelumnya, dan , dan titik koordinat pada local neighborhood dari titik koordinat snake saat ini, . Penjabaran dari turunan kedua ditunjukkan oleh persamaan berikut (Nixon and Aguado, 2008:249) :
d
d = |( − 2 + )|
= ( − 2 + ) + ( − 2 + )
Persamaan (2.25) digunakan untuk menghitung energi curvature dari setiap
points di wilayah neighborhood dari snake control point. Energi curvature tidak
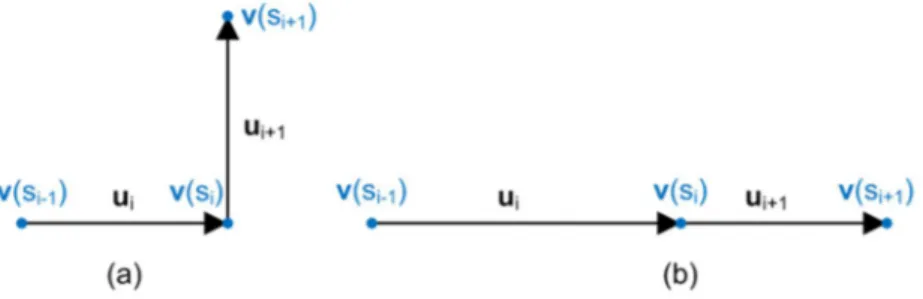
mengukur curvature secara akurat jika snake tidak dipengaruhi oleh parameter panjang busur. Hal tersebut ditunjukkan oleh ilustrasi pada Gambar 2.7. Gambar 2.7(a) menunjukkan bahwa ketika persamaan (2.25) menghasilkan nilai lebih besar dari 0, kurva benar-benar melengkung dan hasil yang sesuai memang tercapai. Gambar 2.7(b) menunjukkan bahwa points pada kurva tidak memiliki jarak yang merata dan meskipun kurva tidak melengkung, persamaan (2.25) menghasilkan nilai lebih besar dari 0 (Tiilikainen, 2007:23).
Gambar 2.8 Ilustrasi Kurva Snake (Tiilikainen, 2007:24)
Setelah nilai dari persamaan (2.25) dihitung untuk setiap point di wilayah
neighborhood dari sebuah snake control point, nilai-nilai yang dihasilkan
dinormalisasi dengan membagi setiap nilai tersebut dengan nilai energi curvature terbesar. Normalisasi akan menyebabkan setiap energi curvature berada pada rentang nilai [0,1], sama halnya dengan energi continuity (Tiilikainen, 2007:24).
2.4.2.3 Energi Image
dapat diimplementasikan sebagai magnitudo dari operator deteksi tepi pada titik x, y. Energi image pada greedy snake dihitung dengan menggunakan persamaan berikut:
= ‖∇[ ( , ) ∗ ( , )]‖
dengan,
( , ) = matriks tapis Gaussian pada koordinat ( , ) ( , ) = matriks citra input pada koordinat ( , )
Energi image di wilayah neighborhood dari snake control point ( ) harus dinormalisasi dengan cara memberikan nilai negatif yang tinggi ke piksel dengan
nilai gradien tinggi, sedangkan nilai negatif yang lebih rendah diberikan ke piksel dengan nilai gradien yang lebih rendah. Persamaan yang digunakan untuk normalisasi nilai energi image pada wilayah neighborhood adalah sebagai berikut:
( , ) = ( ( , ))
dengan adalah nilai minimum gradien di wilayah neighborhood, adalah nilai maksimum gradien di wilayah neighborhood, dan ( , ) adalah magnitudo gradien dari point saat ini. Ketentuan normalisasi ini akan memberikan nilai -1 pada magnitudo gradien tertinggi di wilayah neighborhood dan 0 untuk yang terendah. Untuk mencegah perbedaan nilai normalisasi yang terlalu besar akibat magnitudo gradien di wilayah neighborhood bernilai hampir seragam, maka nilai minimum ditetapkan menjadi − 5 ketika kondisi − < 5 terpenuhi (Tiilikainen, 2007:21).
2.4.2.4 Algoritma Greedy Snake Model
Pada sub bab 2.4.2.1, 2.4.2.2, dan 2.4.2.3 telah dijelaskan mengenai perhitungan masing-masing energi untuk greedy snake model. Pada bagian ini dijelaskan mengenai algoritma greedy snake model yang seutuhnya.
Gambar 2.9 Greedy Snake Model Pseudocode (Tiilikainen, 2007:26)
Untuk setiap point/piksel di wilayah neighborhood dari snake control point ( ) ketiga energi yang terdiri dari energi continuity, curvature, dan image dihitung. Langkah selanjutnya algoritma menjumlahkan ketiga nilai energi tersebut untuk mendapatkan energi kombinasi (energi snake) dengan persamaan berikut:
( , ) = ( ) ( , ) + ( ) ( , ) + ( ) ( , )
di mana ( , ) adalah energi continuity, ( , ) adalah energi curvature, ( , ) adalah energi image, dan ( , ) adalah points pada wilayah
neighborhood. Setelah energi kombinasi untuk setiap points di wilayah neighborhood dihitung, algoritma melakukan pemilihan secara greedy dan snake
% n adalah jumlah total snake control points % m adalah ukuran wilayah ketetanggaan
Indeks aritmatika untuk snake control points adalah modulo n Inisialisasi parameter alpha, beta, dan gamma
do for i = 1 to n Emin = infinity for j = 1 to m E(j) = alpha(i)*Eela(j)+beta(i)*Ecurv(j)+ gamma(i)*Eimg(j) if E(j) < Emin Emin = E(j) jmin = j end end end
Pindahkan point v(i) ke lokasi jmin
if jmin bukan lokasi saat ini then ptsmoved++ % Proses yang menentukan di mana posisi untuk % melakukan relax beta
for i = 1 to n
c(i) = ||u(i)/||u(i)||-u(i+1)/||u(i+1)|| ||^2 end
for i = 1 to n
if (c(i) > c(i-1) and c(i) > c(i+1) and c(i) > threshold1
and mag(v(i)) > threshold2
then beta(i) = 0
end end
while ptsmoved > threshold3
control point dipindahkan ke posisi yang memiliki energi kombinasi dengan nilai
paling minimum. Perilaku ini diilustrasikan pada gambar berikut:
Gambar 2.10 Ilustrasi Perpindahan Snake Control Point (Tiilikainen, 2007:25)
Setelah seluruh control points di sepanjang snake dipindahkan ke posisi baru, curvature dihitung untuk kedua kalinya. Kali ini, curvature hanya dihitung sekali untuk setiap control point di sepanjang snake dan tidak untuk seluruh points pada wilayah neighborhood. Curvature dihitung kembali untuk mencari lokasi di mana curvature bernilai tinggi dan selanjutnya nilai ( ) pada lokasi tersebut dikurangi, misalnya dikurangi menjadi 0. Dengan cara ini suatu sudut dapat dibentuk pada point tersebut. Penghitungan kembali curvature dilakukan dengan menggunakan persamaan berikut:
‖ ‖−‖ ‖ dengan: a. = [ ( ) − ( ), ( ) − ( )] b. = [ ( ) − ( ), ( ) − ( )] (2.29) (2.30) (2.31)
Persamaan (2.29) memberikan estimasi curvature yang lebih akurat karena normalisasi dilakukan dengan magnitudo dari vektor-vektor. Dengan demikian permasalahan points harus memiliki jarak yang merata untuk mendapatkan ukuran kelengkungan yang handal dapat dihindari.
Kondisi yang harus dipenuhi agar nilai dari parameter dapat dikurangi terdiri dari:
a. Curvature dari control point ( ) harus bernilai lebih besar dari curvature kedua tetangganya, yaitu ( ) dan ( )
b. Curvature dari control point ( ) harus bernilai lebih besar dari nilai
threshold (pada Gambar 2.8 dilambangkan dengan threshold1) yang telah ditetapkan sebelumnya
c. Magnitudo gradien dari control point ( ) juga harus bernilai lebih besar dari nilai threshold (pada Gambar 2.8 dilambangkan dengan threshold2) yang telah ditetapkan sebelumnya
Jika semua kondisi tersebut dipenuhi, maka nilai parameter dari control point terkait dapat dikurangi. Ketika nilai parameter telah dikurangi, curvature pada
snake control point terkait tidak lagi memiliki pengaruh pada energi kombinasi snake dan oleh karena itu sudut tajam akan dapat dibentuk.
Langkah akhir dari iterasi algoritma Greedy Snake Model adalah pemeriksaan mengenai jumlah points yang berpindah pada iterasi apakah kurang dari nilai threshold atau tidak (pada Gambar 2.8 dilambangkan dengan threshold3). Pemeriksaan ini digunakan sebagai kriteria penghentian sesuai
dengan asumsi awal bahwa snake mencapai energi minimum ketika sebagian besar
control points telah berhenti mengalami perpindahan (Tiilikainen, 2007:25).
2.5 Particle Swarm Optimization (PSO)
Particle Swarm Optimization (PSO) merupakan teknik optimasi stokastik
yang diusulkan oleh Kennedy dan Eberhart. Ide dasar dari PSO adalah perilaku sosial dari kawanan burung. Misalkan skenario yang digunakan adalah kawanan burung sedang mencari makanan dalam suatu wilayah. Semua burung yang ada dalam kawanan tersebut tidak mengetahui secara pasti di mana lokasi makanan, tetapi seiring dengan bertambahnya iterasi kawanan burung tersebut mengetahui seberapa jauh makanan tersebut berada. Strategi terbaik yang dapat dilakukan adalah dengan mengikuti burung yang posisinya dekat dengan makanan dan juga dengan mempertimbangkan posisi terbaik yang telah diperoleh sebelumnya. Salah satu kelebihan dari PSO adalah implementasinya yang mudah dan parameter yang perlu disesuaikan jumlahnya sedikit (Kaur and Singh, 2012)
PSO memiliki kemiripan dengan algoritma genetika, yakni inisialisasi pada
sistem dilakukan dengan membentuk suatu populasi yang terdiri dari solusi-solusi yang dibangkitkan secara acak. Meskipun memiliki kemiripan dengan algoritma genetika, terdapat beberapa hal yang membedakan kedua algoritma ini. Pada PSO, setiap solusi potensial (yang disebut partikel) diberi nilai berupa kecepatan
(velocity) yang dibangkitkan secara acak, kemudian partikel tersebut akan
“terbang” pada hyperspace. Setiap partikel menyimpan jalur koordinatnya pada
sejauh ini. Selain jalur koordinat, nilai fitness yang diperoleh juga disimpan. Nilai inilah yang disebut sebagai pbest. Versi “global” dari PSO menyimpan nilai terbaik
keseluruhan dan koordinatnya yang dihasilkan oleh partikel-partikel dalam populasi. Nilai inilah yang disebut gbest (Kennedy and Eberhart, 1995).
Dalam algoritma PSO, terdapat lima parameter utama yang harus diperhatikan. Kelima parameter tersebut dirangkum dalam Tabel 2.1, sebagai berikut :
Tabel 2.6 Parameter PSO (Kaur and Singh, 2012) Parameter Deskripsi
Particle Kandidat solusi dari permasalahan
Velocity Laju perubahan posisi
Fitness Solusi terbaik yang dicapai
pbest Nilai terbaik yang dihasilkan oleh partikel sebelumnya
gbest Nilai terbaik yang dihasilkan sejauh ini oleh partikel-partikel dalam
populasi
Algoritma particle swarm dengan model “GBEST” standard yang merupakan bentuk asli dari PSO yang dikembangkan oleh Eberhart dan Kennedy sangat sederhana. Langkah-langkahnya adalah sebagai berikut:
1. Inisialisasi sebuah array yang terdiri dari sejumlah partikel dengan posisi acak dan velocities dengan dimensi berukuran D
2. Evaluasi fungsi yang akan diminimumkan dalam variabel sejumlah D 3. Bandingkan hasil evaluasi dengan particle’s previous best value (PBEST[]),
_ < [] ℎ
[] = _
[][ ] = _
4. Bandingkan hasil evaluasi dengan group’s previous best (PBEST[GBEST]), dengan memperhatikan kondisi berikut:
_ < [ ] ℎ
= _ _
5. Perbarui velocity dengan menggunakan persamaan berikut:
[][ ] = [][ ] + _ ∗ () ∗ ( [][ ] − [][ ]) + _
∗ () ∗ ( [ ][ ] − [][ ])
6. Perbarui posisi partikel dengan menggunakan persamaan berikut:
[][ ] + [][ ] 7. Ulangi langkah 2 hingga kondisi terminasi terpenuhi
Pada penelitian yang dipublikasikan oleh Jones, ditambahkan parameter w yang digunakan untuk mengontrol perilaku konvergen dari PSO sehingga persamaan (2.34) menjadi sebagai berikut:
⃗ = ⃗ + ⃗, − ⃗ + ⃗, − ⃗
dengan ⃗ dan ⃗ berturut-turut menyatakan velocity dan posisi dari partikel i; ⃗, dan ⃗, berturut-turut menyatakan posisi dengan nilai objektif terbaik yang
(2.32)
(2.33)
(2.34)
(2.35)
ditemukan sejauh ini oleh partikel i dan keseluruhan partikel; dan merupakan variabel acak pada jangkauan nilai [0,1]; dan mengontrol seberapa jauh suatu partikel bergerak dalam sekali iterasi. Setelah diperbarui, velocity harus dicek dan dipastikan berada dalam jangkauan nilai yang telah ditentukan sebelumnya untuk menghindari random walking. Selain itu juga disebutkan bahwa kondisi terminasi yang akan menghentikan pencarian dapat berupa jumlah iterasi yang telah ditentukan atau gagal menghasilkan kemajuan dalam sejumlah iterasi. Parameter yang dijadikan solusi pada saat kondisi terminasi telah dicapai adalah ⃗ dan
( ⃗ ) (Kaur and Singh, 2012).
2.6 Daugman’s Rubber Sheet Model
Daugman’s Rubber Sheet Model digunakan untuk mengubah koordinat iris
yang telah tersegmentasi dari koordinat kartesian menjadi koordinat polar. Metode ini dilakukan dengan cara memetakan setiap titik dalam wilayah iris ke dalam koordinat polar ( , ), dalam hal ini berada dalam interval [0, 1] dan adalah sudut pada [0,2 ]. Pemetaan wilayah iris tersebut dapat dimodelkan sebagai berikut (Arvacheh, 2006) : ( , ) = (1 − ) × ( ) + × ( ) ( , ) = (1 − ) × ( ) + × ( ) dengan : ( ) = + × cos ( ) = + × sin (2.38) (2.37) (2.39) (2.40)
( ) = + × cos ( ) = + × sin
Dalam hal ini , dan , berturut-turut merupakan koordinat batas pupil dan iris di sepanjang arah . Koordinat titik pusat pupil dan iris berturut-turut disimbolkan oleh , dan , . Radius pupil dan iris berturut-turut disimbolkan oleh dan . Model ini memperhitungkan dilasi pupil dan ukuran yang tidak konsisten untuk menghasilkan dimensi iris yang konstan.
Gambar 2.11 Daugman’s Rubber Sheet Model (Masek, 2003)
Dalam hal ini, wilayah iris dimodelkan sebagai lembaran karet fleksibel yang dikaitkan pada batas iris dengan titik pusat pupil sebagai titik acuan. Sejumlah titik dipilih di sepanjang garis radial dan disebut sebagai resolusi radial ( ). Jumlah garis radial di sekitar wilayah iris disebut resolusi angular ( ). Dari wilayah iris yang menyerupai donat, normalisasi menghasilkan array 2-D dengan dimensi horizontal dari resolusi angular dan dimensi vertikal dari resolusi radial.
(2.41) (2.42)
ρ
2.7 Hamming Distance
Metode perhitungan jarak ini merupakan salah satu metode yang paling banyak digunakan pada aplikasi pengenalan iris. Pada dasarnya, langkah-langkah yang dilakukan pada metode ini terdiri dari (Szewczyk, et al, 2012) :
1) Langkah pertama, operasi logika XOR dilakukan terhadap dua vektor biner ( dan ) dengan panjang vektor N
2) Perbandingan yang bernilai 1 (perbedaan antara vektor-vektor yang dibandingkan pada posisi ke-i) dijumlahkan
3) Skor kemiripan s diperoleh dengan cara membagi hasil penjumlahan pada langkah 2) dengan N, yang dirumuskan sebagai berikut :
= , = ∑ ( ) ⊕ ( )
2.8 K-Nearest Neighbor (K-NN)
Pencarian nearest neighbor merupakan salah satu teknik klasifikasi yang paling populer dan diperkenalkan oleh Fix dan Hodges. Teknik ini telah terbukti merupakan teknik yang sederhana dan tangguh dalam algoritma pengenalan. Sebuah generalisasi dari teknik ini disebut dengan K-NN, yaitu suatu pola baru diklasifikasikan ke dalam kelas dengan kemunculan anggota terbanyak di antara k tetangga terdekat (Choudhary, 2013).
Dalam bidang pengenalan pola, K-NN merupakan salah satu algoritma non-parameter yang paling penting dan termasuk ke dalam algoritma pembelajaran terbimbing (supervised learning algorithm). Aturan klasifikasi dihasilkan oleh sampel pelatihan itu sendiri tanpa adanya data tambahan. Algoritma klasifikasi
NN memprediksi kategori (kelas) dari sampel uji berdasarkan sejumlah K sampel
pelatihan yang merupakan tetangga terdekat ke sampel uji, dan menetapkannya ke kategori yang memiliki probabilitas terbesar. Algoritma untuk mengklasifikasikan sampel X dengan K-NN adalah sebagai berikut (Choudhary, 2013) :
1. Misalkan terdapat j kategori pelatihan, yaitu C1, C2, ..., Cj dan jumlah sampel
pelatihan adalah N, dengan masing-masing vektor ciri berukuran m.
2. Hitung jarak (kemiripan) antara semua sampel pelatihan S dengan X. Misalkan sampel ke-i dari sampel pelatihan S, maka perhitungan jarak (kemiripan) S dengan X adalah sebagai berikut :
( , ) = ∑
∑ ∑
3. Pilih sejumlah K sampel yang memiliki nilai ( , ) terbesar dan perlakukan sebagai himpunan K-NN dari X. Selanjutnya, hitung probabilitas dari X berada pada tiap kategori yang ada dengan menggunakan formula berikut ini :
, = ( , ) ,
Dalam hal ini , merupakan fungsi atribut kategori, yang memenuhi kriteria berikut ini :
, = 10 ∈∉
4. Sampel X berada pada kategori yang memiliki nilai , terbesar.
(2.44)
(2.46) (2.45)