7 LANDAS AN TEORI
2.1 Data
Data adalah sebuah representasi penyimpanan dari obyek-obyek dan kejadian-kejadian yang berarti dan penting di lingkungan pemakai. (Hoffer, Prescott, dan M cFadden, 2005, p5).
Data merupakan sesuatu yang belum mempunyai arti bagi penerimanya dan masih memerlukan adanya suatu pengolahan. Data bisa berwujud suatu keadaan, gambar, suara, huruf, angka, matematika, bahasa ataupun simbol-simbol lainnya yang bisa kita gunakan sebagai bahan untuk melihat lingkungan, obyek, kejadian ataupun suatu konsep. (http://kuliah.dinus.ac.id).
Data adalah bentuk jamak dari datum, berasal dari bahasa Latin yang berarti "sesuatu yang diberikan". Dalam penggunaan sehari-hari data berarti suatu pernyataan yang diterima secara apa adanya. Pernyataan ini adalah hasil pengukuran atau pengamatan suatu variabel yang bentuknya dapat berupa angka, kata-kata, atau citra. (http://id.wikipedia.org)
M enurut Hoffer, Prescott, dan M cFadden (2005, p5), informasi adalah data yang telah diproses melalui beberapa cara untuk meningkatkan pengetahuan dari orang yang menggunakan data.
Informasi merupakan hasil pengolahan dari sebuah model, formasi, organisasi, ataupun suatu perubahan bentuk dari data yang memiliki nilai tertentu, dan bisa digunakan untuk menambah pengetahuan bagi yang menerimanya. Dalam hal ini, data bisa dianggap sebagai obyek dan informasi adalah suatu subyek yang bermanfaat bagi penerimanya. Informasi juga bisa disebut sebagai hasil pengolahan ataupun pemrosesan data. (http://kuliah.dinus.ac.id)
Informasi adalah istilah dengan banyak arti bergantung pada konteks, tetapi sebagai aturan berhubungan erat dengan konsep seperti arti, pengetahuan, negentropy, komunikasi, kebenaran, representasi, dan rangsangan mental.
Sekalipun banyak orang menyatakan munculnya "era informasi", "masyarakat informasi," dan teknologi informasi, dan sungguhpun ilmu informasi dan ilmu komputer sering disorot, kata "informasi" sering dipakai tanpa pertimbangan hati-hati dari berbagai arti yang dimiliki. (http://id.wikipedia.org).
2.2. Database dan DBMS (Database Management System) 2.2.1 Definisi Database
M enurut Conolly dan Begg (2005, p15), database merupakan suatu kumpulan data logikal yang terhubung satu sama lain dan deskripsi dari suatu data yang dirancang sebagai informasi yang dibutuhkan oleh organisasi, sedangkan menurut M cLeod dan Schell (2004, p196), database adalah kumpulan seluruh sumber data berbasis komputer milik
organisasi. Database yang dikendalikan oleh sistem manajemen database adalah satu set catatan data yang berhubungan dan saling menjelaskan.
Database sangat penting untuk membedakan database dan tempat penyimpanan. Tempat penyimpanan tersebut berisi tentang pengertian-pengertian dari data.
Database adalah kumpulan informasi yang disimpan di dalam komputer secara sistematis sehingga dapat diperiksa menggunakan suatu program komputer untuk memperoleh informasi dari database tersebut. Perangkat lunak yang digunakan untuk mengelola dan memanggil query basis data disebut sistem manajemen basis data (Database Management System / DBM S). Database system dipelajari dalam ilmu informasi. (http://id.wikipedia.org)
Dari teori-teori di atas dapat disimpulkan bahwa sistem database adalah sekelompok elemen yang berupa data, saling terintegrasi dan berhubungan untuk mencapai tujuan tertentu.
2.2.2. Definisi DBMS (Database Management System)
Conolly dan Begg (2005, p16) mengemukakan DBM S adalah suatu system software yang memungkinkan user dapat mengidentifikasikan, membuat, memelihara, dan mengatur akses dari database.
M cLeod dan Schell (2004, p196) menyimpulkan, sistem manajemen basis data (DBM S) adalah aplikasi perangkat lunak yang
menyimpan struktur database, hubungan antar-data dalam database, serta berbagai formulir dan laporan yang berkaitan dengan database itu.
Sedangkan menurut Hoffer, Prescott, dan M cFadden (2005, p7), DBM S merupakan sebuah system software yang digunakan untuk menciptakan, memelihara dan menyediakan akses kontrol untuk pengguna database.
2.2.3. Kelebihan DBMS (Database Management System)
Conolly dan Begg (2005, pp26-29) menguraikan beberapa kelebihan penggunaan Sistem M anajemen Basis Data (DBM S), yaitu: - Kontrol terhadap pengulangan data
- Data yang dihasilkan konsisten
- Pada beberapa data yang sama akan semakin banyak informasi yang diperoleh
- Data dapat dipakai secara bersama-sama - M eningkatkan integritas data
- M eningkatkan keamanan - Penetapan standarisasi - Perbandingan skala ekonomi - M engatasi konflik kebutuhan
- M emperbaiki pengaksesan data secara bersama-sama - M eningkatkan produktivitas
- M emperbaiki pemeliharaan data melalui data yang tidak tergantung dari data lain
- M emiliki backup data dan recovery
2.2.4. Kekurangan DBMS (Database Management System)
Sedangkan kekurangan penggunaan DBM S menurut Conolly dan Begg (2005, pp29-30) adalah :
- M emiliki sistem yang kompleks
- Karena sistem yang kompleks mengakibatkan DBM S memiliki ukuran yang semakin besar
- DBM S memiliki harga yang bervariasi tergantung fungsi dan kebutuhan
- Penambahan biaya untuk perangkat keras yang dibutuhkan - Penambahan biaya konversi
- Karena DBM S dirancang untuk mengakses lebih dari satu aplikasi sehingga performasinya menurun
- Kegagalan DBM S mengakibatkan operasi tidak dapat berjalan
2.2.5. Fasilitas yang disediakan DBMS (Database Management System) M enurut Connolly dan Begg (2005, p40) DBM S menyediakan fasilitas-fasilitas, yaitu :
- DDL (Data Definition Language) adalah suatu bahasa yang memperbolehkan DBA (Database Administrator) atau user untuk mendeskripsikan nama dari suatu entitas, atribut, dan relasi data yang diminta oleh aplikasi, bersamaan dengan integritas data dan batasan keamanan datanya.
- DM L (Data Manipulation Language) adalah suatu bahasa yang memberikan fasilitas pengoperasian data yang ada dalam basis data., misalnya : insert, edit, delete, dan update.
- SQL (Struktur Query Language) adalah sebuah fasilitas yang digunakan untuk melayani pengaksesan data. Bahasa query yang paling baik adalah secara de facto yang merupakan standar bagi DBM S.
2.3. Data Warehouse
2.3.1. Definisi Data Warehouse
M enurut Connolly dan Begg (2005, p1151), data warehouse merupakan sekumpulan data yang berorientasi subyek, terintegrasi, tidak mudah berubah, dan berdasarkan kepada suatu rentang waktu tertentu yang berguna untuk mendukung dalam proses pengambilan keputusan. Sebuah data warehouse merupakan data manajemen dan teknologi analisis data.
M enurut M cleod dan Schell (2004, p205), data warehouse adalah perkembangan dari konsep database yang menyediakan suatu sumber data, data yang lebih baik bagi para pemakai dan memungkinkan pemakai untuk memanipulasi dan menggunakan data tersebut secara intuitif. Data warehouse berukuran sangat besar, kualitas datanya tinggi, dan sangat mudah diambil datanya. Beberapa data warehouse berisi sebanyak 200 gigabyte atau 200 juta byte data, tetapi ukuran besar tidak menyebabkan kualitas data tidak bagus. Karena data cleaning yang ekstensif,
penghilangan data-data yang salah dan data yang tidak konsisten dapat mentransformasi data menjadi data dengan kualitas yang lebih tinggi daripada yang terdapat dalam database komersial
2.3.2. Karakteristik Data Warehouse
Dari definisi oleh Connolly dan Begg (2005, p1151), karakteristik dari data warehouse yaitu:
- Subject-oriented artinya data warehouse harus berorientasi pada subyek yaitu data warehouse dibuat berdasarkan subjek-subjek utama di dalam bisnis (seperti pelanggan, produk, dan penjualan) dibandingkan dengan area-area aplikasi utama (seperti bon pembayaran pelanggan, kontrol stok, dan produk penjualan).
- Integrated artinya data warehouse harus terintegrasi karena sumber-sumber data warehouse berasal dari berbagai lingkungan bisnis dengan sistem aplikasi yang berbeda. Sumber data yang terintegrasi harus dibuat konsisten untuk menampilkan tampilan data kepada user. - Time variant berarti data warehouse hanya akurat dan valid pada
beberapa poin dalam waktu atau dalam interval waktu tertentu.
- Non-volatile yaitu data tidak di-update dalam waktu nyata (real time) tetapi data di-refresh dari sistem operasional. Data baru selalu ditambahkan sebagai sebuah suplemen ke dalam database, dibandingkan sebagai pergantian data. Database data warehouse akan selalu mengambil data baru, dan secara berkala diintegrasi dengan data yang sudah ada.
2.3.3. Pengertian OLTP (Online Transaction Processing)
M enurut Connolly and Begg (2005, p1153), sebuah organisasi menerapkan beberapa sistem OLTP yang berbeda untuk menjalankan proses bisnis seperti kendali inventori, invoicing, dan point-of-sale. Sistem ini menghasilkan data operasional yang mendetil, up-to-date, dan dapat diubah-ubah. Data di dalam OLTP diorganisir berdasarkan kebutuhan transaksi yang berhubungan dengan aplikasi bisnis serta mendukung pengambilan keputusan operasional harian.
2.3.4. Model Data Warehouse
M enurut Connoly dan Begg (2002, p1182), setiap model data warehouse (model dimensional) terdiri dari sebuah tabel dengan primary key composite yang disebut fact table, dan sebuah kumpulan tabel-tabel kecil yang disebut dimension table.
M odel dimensional merupakan suatu teknik desain logical yang bertujuan untuk menampilkan data dalam bentuk standar dan intuitif, yang memungkinkan akses ke performansi yang tinggi.
M odel dimensional untuk desain data warehouse yaitu: - Star schema
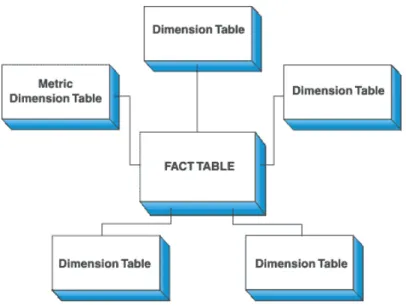
Star schema merupakan struktur logical yang memiliki sebuah tabel fakta (fact table) yang berisi data faktual yang diletakkan di tengah (pusat), dikelilingi oleh tabel-tabel dimensi yang berisi data referensi (dimana dapat didenormalisasi).
Gambar 2.1 Star Schema
Sumber : (http://publib.boulder.ibm.com) - Snowflake schema
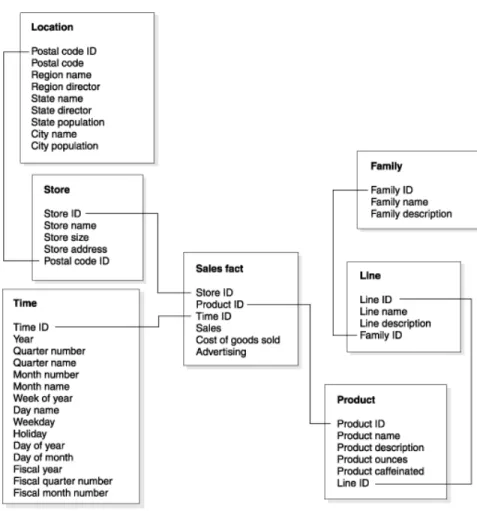
Snowflake schema merupakan variasi dari star schema dimana tabel dimensi tidak mengandung data denormalisasi yang memungkinkan sebuah dimensi untuk mempunyai dimensi lagi.
Gambar 2.2 Contoh dari Snowflake Schema Sumber : (http://publib.boulder.ibm.com)
2.3.5. Arsitektur Data Warehouse
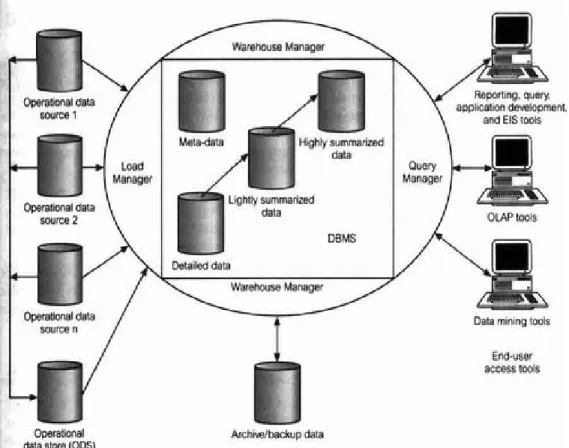
Connolly dan Begg (2005, pp1156-1161) mengidentifikasi 8 komponen data warehouse yang terdapat pada arsitektur data warehouse, yaitu:
- Operational data
Data operasional berfokus pada fungsi-fungsi transaksional. Data ini merupakan bagian dari infrastruktur perusahaan, detil, tidak ada
redudansi (data tidak berulang-ulang), dapat di-update (diubah-ubah), dan data ini merefleksikan nilai sekarang.
- Operational datastore (ODS)
ODS adalah tempat penyimpanan sementara dari data operasional saat ini yang terintegrasi yang digunakan untuk analisis. M embangun ODS dapat merupakan tahap yang berguna dalam membangun data warehouse karena sebuah ODS dapat menyuplai data yang sudah diekstrak dari sistem sumber dan dibersihkan. Ini berarti pekerjaan mengintegrasi dan merestrukturisasi data untuk data warehouse menjadi lebih sederhana.
- Load Manager
Load manager menampilkan semua operasi yang terkait dengan ekstraksi dan loading data ke dalam data warehouse. Data bisa saja diekstrak secara langsung dari sumber data atau secara umum dari ODS.
- Warehouse manager
Warehouse manager menampilkan semua operasi yang terkait dengan manajemen data dari data warehouse. Operasi yang ditampilkan oleh warehouse manager meliputi:
9 Analisis data untuk menjamin konsistensi
9 Transformasi dan penggabungan sumber data dari tempat penyimpanan sementara ke tabel data warehouse
9 Pembuatan indeks dan view pada tabel base. 9 Membuat denormalisasi (jika perlu)
9 Membuat agregasi (jika perlu) 9 Backing-up dan archiving data - Query manager
Query manager menampilkan semua operasi yang terkait dengan manajemen query pengguna. Operasi yang ditampilkan oleh komponen ini meliputi mengarahkan query pada tabel yang cocok dan menjadwalkan pelaksanaan query.
- Detailed data
Komponen ini menyimpan semua detail data dalam skema database. Detail data terbagi 2 yaitu :
9 Current detail data
Data ini berasal langsung dari operasional database, dan selalu mengacu pada data perusahaan sekarang. Current detail data diatur sepanjang sisi-sisi subyek seperti data profil pelanggan, data aktivitas pelanggan, data sales, data demografis, dan lain-lain.
9 Old detail data
Data ini menampilkan current detail data yang berumur atau histori dari subjek area. Data ini yang dipakai untuk menganalisis trend yang akan dihasilkan.
- Lightly and highly summarized data
Area data warehouse ini menyimpan semua data lightly dan highly summarized yang sudah terdefinisi sebelumnya yang dibuat oleh
warehouse manager. Tujuan informasi yang terangkum ini adalah untuk meningkatkan performansi query.
- Archive / backup data
Area warehouse ini menyimpan detail data dan summarized data dengan tujuan mengarsip dan melakukan backup data.
- Meta data
Meta data merupakan data mengenai data yang mendeskripsikan data warehouse. Meta data digunakan untuk membangun, memelihara, mengatur, dan menggunakan data warehouse. Meta data mengandung lokasi dan deskripsi dari komponen- komponen data warehouse; nama, definisi, struktur, dan isi dari data warehouse dan end user view; identifikasi dari pembuat sumber-sumber data (record system); aturan-aturan integrasi dan transformasi yang digunakan untuk mempopulasikan data warehouse; histori dari update dan refresh data warehouse; pola-pola matriks yang digunakan untuk performa menganalisis data warehouse; dan seterusnya.
- end-user access tool Tool ini mencakup:
9 Reporting and query tool 9 Application development tool
9 Executive information system (EIS) tool 9 Online analytical processing (OLAP) tool 9 Data mining tool
Gambar 2.3 Arsitektur Data warehouse Sumber: Connolly dan Begg (2005, p1157 )
2.3.6. Keuntungan penggunaan Data Warehouse
M enurut Connolly dan Begg (2005, p1152), kesuksesan pengimplementasian data warehouse dapat memberikan keuntungan bagi organisasi maupun perusahaan antara lain :
- Adanya kemungkinan balik modal yang tinggi pada investasi Suatu organisasi harus memberikan sumber daya yang besar untuk menjamin kesuksesan pengimplentasian data warehouse dan biayanya bervariasi tergantung dari solusi teknis yang ada. Namun kemungkinan adanya kondisi balik modal terhadap biaya yang
dikeluarkan untuk penginvestasian data warehouse relatif lebih besar. Sehingga tidak perlu ada kekhawatiran akan anggapan adanya pemborosan untuk investasi data warehouse ini.
- Keuntungan yang kompetitif
Adanya kemungkinan balik modal yang besar terhadap investasi merupakan bukti adanya keuntungan yang kompetitif dengan adanya teknologi ini. Keuntungan kompetitif ini dicapai dengan memungkinkan para pengambil keputusan untuk mengakses data yang sebelumnya tidak tersedia, tidak diketahui, atau informasi yang tidak tercatat
- Meningkatkan produktivitas para pengambil keputusan di perusahaan.
Data warehouse dapat memungkinkan hal ini dengan mentransformasikan data menjadi informasi yang berarti. Teknologi ini menyediakan para manajer bisnis untuk dapat melakukan analisis yang lebih konsisten sehingga pada akhirnya terjadi peningkatan produktivitas.
2.4. Data Mining
2.4.1. Definisi Data Mining
Banyak sekali definisi mengenai apa itu data mining. Secara garis besar data mining merupakan suatu alat yang memungkinkan para pengguna untuk mengakses secara cepat data dengan jumlah yang besar. Pengertian yang lebih khusus lagi dari data mining yaitu suatu alat dan
aplikasi dengan menggunakan analisis statistik pada data. Data mining juga dikenal sebagai KDD (Knowledge Data Discovery) di dalam basis data.
M enurut Conolly dan Begg (2005, p1233), data mining adalah suatu proses ekstraksi atau penggalian data dan informasi yang besar, yang belum diketahui sebelumnya, namun dapat dipahami dan berguna dari database yang besar serta digunakan untuk membuat suatu keputusan bisnis yang sangat penting.
M enurut Berson dan Smith (2001, p.333) Data mining menggambarkan sebuah pengumpulan teknik-teknik dengan tujuan untuk menemukan pola-pola yang tidak diketahui pada data yang telah dikumpulkan. Data mining memungkinkan pemakai "menemukan pengetahuan" dalam database yang tidak mungkin diketahui keberadaannya oleh pemakai.
Beberapa pengertian data mining yang berhasil dihimpun dari beberapa pendapat adalah sebagai berikut :
1. Secara sederhana dapat didefinisikan bahwa data mining adalah suatu proses ekstraksi dari informasi atau pola yang penting atau menarik dari data yang ada di database yang besar sehingga menjadi informasi yang sangat berharga. (http://ikc.cbn.net.id)
2. Data mining merupakan proses penemuan yang efisien sebuah pola terbaik yang dapat menghasilkan sesuatu yang bernilai dari suatu koleksi data yang sangat besar. (http://www.thearling.com)
3. Data mining adalah suatu pola yang menguntungkan dalam melakukan search pada sebuah database yang terdapat pada sebuah model. Proses ini dilakukan berulang-ulang (iterasi) hingga didapat satu set pola yang memuaskan yang dapat berfungs i sesuai yang diharapkan (http://www.db.cs.ucdavis.edu).
Berdasarkan beberapa pengertian diatas dapat ditarik kesimpulan bahwa data mining adalah suatu algoritma di dalam menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui.
2.4.2. Fungsi Data Mining
Data mining mengidentifikasikan fakta-fakta atau kesimpulan-kesimpulan yang disarankan berdasarkan penyaringan melalui data untuk menjelajahi pola-pola atau anomali-anomali data. M enurut Turban, Rainer, dan Potter (2005, p265), data mining mempunyai lima fungsi yaitu:
1. Classification
Classification yaitu menyimpulkan definisi-definisi karakteristik dari sebuah grup. Contoh: pelanggan-pelanggan perusahaan yang telah berpindah ke saingan perusahaan yang lain.
2. Clustering
Clustering yaitu mengidentifikasikan kelompok-kelompok dari barang-barang atau produk-produk yang berbagi karakteristik yang khusus (clustering berbeda dengan classification dimana pada clustering tidak terdapat definisi-definisi karakteristik awal yang diberikan pada waktu classification).
3. Association
Association yaitu mengidentifikasikan hubungan antara kejadian-kejadian yang terjadi pada suatu waktu seperti isi-isi dari keranjang belanja.
4. Sequencing
Hampir sama dengan association, sequencing mengidentifikasikan hubungan-hubungan yang berada pada suatu periode waktu tertentu seperti pelanggan-pelanggan yang mengunjungi supermarket secara berulang-ulang.
5. Forecasting
Forecasting memperkirakan nilai pada masa yang akan datang berdasarkan pola-pola dengan sekumpulan data yang besar seperti peramalan permintaan pasar.
2.4.3 Tujuan Data Mining
Tujuan dari data mining menurut Hoffer, Prescott, dan M cFadden (2005, p482) antara lain :
1. Explanatory
Untuk menjelaskan beberapa kondisi penelitian, seperti mengapa penjualan truk pick-up meningkat di Colorado.
2. Confirmatory
Untuk mempertegas hipotesis, seperti halnya 2 kali pendapatan keluarga lebih suka dipakai untuk membeli peralatan keluarga dibandingkan dengan 1 kali pendapatan keluarga.
3. Exploratory
Untuk menganalisa data untuk hubungan yang baru dan tidak diharapkan, seperti halnya pola apa yang cocok untuk kasus penggelapan kartu kredit.
2.4.4 Penerapan Data Mining
M enurut Berson dan Smith (2001, p123), banyak perusahaan-perusahaan menggunakan data mining untuk :
- Correct data
Pada saat proses menggabungkan basis data secara besar-besaran, banyak perusahaan menemukan data yang digabungkan tersebut tidak lengkap, dan terdiri dari informasi yang salah dan bertentangan. Dengan menggunakan teknik data mining, dapat membantu untuk mengidentifikasi dan membetulkan kesalahan dengan cara yang konsisten.
- Discover Knowledge
Proses mencari pengetahuan bertujuan untuk menentukan dengan jelas relationship, pattern, atau correlations yang tersembunyi dari berbagai tempat penyimpanan data di dalam basis data.
- Visualize Data
Seorang analis harus bisa merasakan sebuah informasi yang besar yang disimpan di dalam basis data. Tujuannya untuk “mempermanusiakan” data yang banyak dan menemukan cara yang terbaik untuk menampilkan data.
2.4.5 Metodologi Data Mining
Sebagai salah satu bagian dari sistem informasi, data mining menyediakan perencanaan dari ide hingga implementasi akhir. Komponen-komponen dari rencana data mining menurut Seidman (2001, p9) adalah sebagai berikut :
1. Analisa Masalah (Analyzing the Problem)
Data asal atau data sumber harus bisa ditaksir untuk dilihat apakah data tersebut memenuhi kriteria data mining.
Kualitas kelimpahan data adalah faktor utama untuk memutuskan apakah data tersebut cocok dan tersedia sebagai tambahan. Hasil yang diharapkan dari dampak data mining harus dengan hati-hati dimengerti dan dipastikan bahwa data yang diperlukan membawa informasi yang bisa diekstrak.
2. Mengekstrak dan Membersihkan data (Extracting and Cleansing The Data)
Data pertama kali diekstrak dari data aslinya, seperti dari OLTP basis data, text file, Microsoft Access Database, dan bahkan dari spreadsheet, kemudian data tersebut diletakkan dalam data warehouse yang mempunyai struktur yang sesuai dengan data model secara khas.
Data Transformation Services (DTS) dipakai untuk mengekstrak dan membersihkan data dari tidak konsistennya dan tidak kompatibelnya dengan format yang sesuai.
3. Validitas Data (Validating The Data)
Sekali data telah diekstrak dan dibersihkan, ini adalah latihan yang bagus untuk menelusuri model yang telah kita ciptakan untuk memastikan bahwa semua data yang ada adalah data sekarang dan tetap
4. Membuat dan melatih model (Creating and Training The Model) Ketika algoritma diterapkan pada model, struktur telah dibangun. Hal ini sangatlah penting pada saat ini untuk melihat data yang telah dibangun untuk memastikan bahwa data tersebut menyerupai fakta di dalam data sumber.
5. Query data dari model data mining (Querying the Model Data) Ketika model yang cocok telah diciptakan dan dibangun, data yang telah dibuat tersedia untuk mendukung keputusan. Hal ini biasanya
melibatkan penulisan front end query aplikasi dengan program aplikasi / suatu program basis data.
6. Evaluasi validitas dari mining model (Maintaining The Validity of The Data Mining Model)
Setelah model data mining terkumpul, lewat beberapa waktu karakteristik data awal seperti granularitas dan validitas mungkin berubah. Karena model data mining dapat terus berubah seiring perkembangan waktu.
2.4.6 Pengertian OLAP (Online Analytical Processing)
M enurut Connolly dan Begg (2005, p1205), OLAP adalah sebuah perangkat yang menggambarkan teknologi menggunakan gambaran multidimensi sejumlah data untuk menyediakan akses yang lebih cepat bagi strategi informasi dengan tujuan mempercepat analisis.
M enurut M cleod dan Schell (2004, p204), OLAP makin menjadi fitur umum dalam perangkat lunak sistem manajemen database. Para penjual memasukkan fitur ini untuk memungkinkan analisis data yang serupa dengan tabulasi silang statistik.
OLAP adalah teknologi yang memperbolehkan para user untuk menganalisa basis data yang besar untuk mendapatkan setiap informasi yang lebih spesifik. Basis data untuk sistem OLAP disusun terstruktur agar lebih efisien dalam penyimpanan data statis. Karena penyimpanan OLAP adalah multidimensi, biasanya disebut cube, yang berlawanan dengan tabel. Yang membuat OLAP unik yaitu kemampuannya untuk
menyimpan kumpulan data secara hirarki. Dimensi-dimensi ini memberikan informasi secara kontekstual dalam bentuk bilangan atau perhitungan yang diteliti.
OLAP (On-Line Analytical Processing) adalah suatu pernyataan yang bertolak belakang atau kontras dengan OLTP (On-Line Transaction Processing). OLAP menggambarkan sebuah kelas teknologi yang dirancang untuk analisa dan akses data secara khusus. Apalabila pada proses transaksi pada umumnya semata-mata adalah pada relational database, OLAP muncul dengan sebuah cara pandang multidimensi data. Cara pandang multimensi ini didukung oleh teknologi multidimensi database. Cara ini memberikan teknik dasar untuk kalkulasi dan analisa oleh sebuah aplikasi bisnis. (http://www.informatika.lipi.go.id )
OLAP adalah sebuah perangkat yang bagus untuk memberikan pengertian tentang bagaimana cara menghitung yang baik yang terhubung dengan dimensi. Karena perhitungan yang telah dikalkulasi terlebih dahulu, maka OLAP membuat navigasi melalui data dengan segera. Ada dua poin penting dalam data relasional dan OLAP. Pertama adalah OLAP cenderung memindahkan bagian-bagian yang kecil dari sebuah data di level manapun. Yang kedua adalah OLAP cenderung memerlukan definisi yang sukar dari struktur data, dibandingkan dengan apa yang telah dikerjakan oleh basis data relasional.
OLAP memungkinkan untuk digunakan sebagai penunjang keputusan tentang tindakan apa yang akan diambil selanjutnya dan sistem OLAP juga banyak dipergunakan dalam bidang bisnis untuk
menghasilkan suatu keputusan yang efektif. Di dalam model data OLAP, informasi digambarkan secara konseptual seperti kubus (cube), yang terdiri dari kategori deskriptif (dimensions) dan nilai kuantitif (measures). Dimensi menggambarkan atribut dari setiap ukuran, biasanya berupa text dan mempunyai ciri-ciri tersendiri. Sedangkan measure merupakan suatu data, biasanya berupa numerik, yang menjadi tolak ukuran suatu kejadian bisnis.
Empat kategori OLAP menurut Conolly dan Begg (2005, pp1214-1216) :
1. Multidimensional On-Line Analytical Processing (M OLAP)
MOLAP digunakan untuk membangun cube multidimensional dari data yang disimpan dalam data warehouse. M etode ini sering dipilih jika data set awal terlalu besar sehingga pemrosesan cube dari data warehouse asli memerlukan proses batch. Alasan utama menggunakan metode ini adalah karena mekanisme penyimpanan MOLAP sangat efektif dalam me-retrieve data secara cepat.
2. Relational On-Line Analytical Processing (ROLAP)
M ekanisme penyimpanan ROLAP menggunakan DBM S orisinil, seperti SQL Server 2000, untuk menyimpan agregasi dalam bentuk tabung yang kemudian dapat digunakan oleh mesin OLAP.
M etode penyimpanan ini memiliki beberapa kekurangan. Struktur tabung ROLAP tidak cukup efisien bagi mesin OLAP untuk melakukan query. Ketidakefisienan itu memicu performansi yang buruk pada sistem.
3. Hybrid On-Line Analytical Processing (HOLAP)
HOLAP didesain dengan mengkombinasikan keuntungan M OLAP dan ROLAP dengan menyimpan agregasi level tinggi pada cube MOLAP dan menyimpan agregasi level rendah dan line item pada tabel relational database. Karena HOLAP membuat tabel jauh dari kompleks untuk mengatur bagian relational database, data lebih mudah dioptimasi melalui indexing.
4. Desktop On-Line Analytical Processing (DOLAP)
Peningkatan kategori yang terkenal dari OLAP adalah DOLAP (Desktop OLAP). System DOLAP menyimpan data OLAP didalam file berbasis klien dan mendukung proses multi dimensi menggunakan sebuah sistem multi dimensi klien. Kebutuhan-kebutuhan ekstrak data untuk DOLAP relatif kecil yang berada pada mesin klien.
2.4.7 OLAP vs Data Mining
Baik data mining maupun OLAP merupakan komponen dari Microsoft Analysis Services. Keduanya menyediakan decision support tools, namun masing-masing didesain untuk penggunaan yang berbeda. OLAP pada dasarnya didesain untuk menyimpan data dalam tabel yang ringkas untuk memfasilitasi retrieve dan navigasi data tersebut oleh end user.
OLAP dapat digunakan untuk mencoba menemukan data baru, namun sejak penemuan data telah dilakukan oleh end user, dengan
bantuan tool OLAP, penemuan data menjadi berantakan dan tidak kompeten. Data mining secara otomatis menemukan pola baru dan aturan yang dapat diterapkan untuk mendapatkan hasil yang akan datang. Intinya, OLAP adalah tempat penyimpanan dan mekanisme retrieval yang efisien, sedangkan data mining adalah alat untuk menemukan knowledge.
Teknologi yang ada di data warehouse dan OLAP dimanfaatkan penuh untuk melakukan data mining.
Increasing potential to support
business decisions End User
Business Analyst Data Analyst DBA Making Decisions Data Presentation Visualization Techniques Data Mining Information Discovery Data Exploration OLAP, MDA
Statistical Analysis, Querying and Reporting Data Warehouses / Data Marts
Data Sources
Paper, Files, Information Providers, Database Systems, OLTP Increasing potential
to support
business decisions End User
Business Analyst Data Analyst DBA Making Decisions Data Presentation Visualization Techniques Data Mining Information Discovery Data Exploration OLAP, MDA
Statistical Analysis, Querying and Reporting Data Warehouses / Data Marts
Data Sources
Paper, Files, Information Providers, Database Systems, OLTP
Gambar 2.4. OLAP vs Data Mining Sumber : (http://ikc.cbn.net.id)
Dari gambar diatas terlihat bahwa teknologi data warehouse untuk melakukan OLAP, sedangkan data mining digunakan untuk melakukan information discovery yang informasinya lebih ditujukan untuk seorang Data Analyst dan Business Analyst (dengan ditambah
visualisasi tentunya). Dalam prakteknya, data mining juga mengambil data dari data warehouse. Hanya saja aplikasi dari data mining lebih khusus dan lebih spesifik dibandingkan OLAP mengingat database bukan satu-satunya bidang ilmu yang mempengaruhi data mining.
Dengan memadukan teknologi OLAP dengan data mining diharapkan pengguna dapat melakukan hal-hal yang biasa dilakukan di OLAP seperti drilling / rolling untuk melihat data lebih dalam atau lebih umum, pivoting, slicing dan dicing. Semua hal tersebut dapat diharapkan nantinya dapat dilakukan secara interaktif dan dilengkapi dengan visualisasi. (www.computing.edu.au).
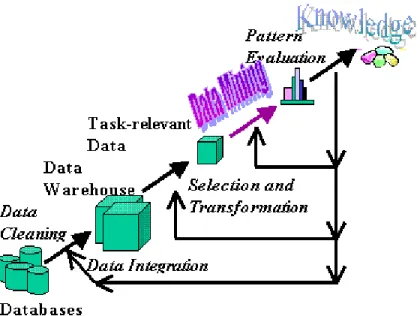
2.4.8 Proses Data Mining
Gambar 2.5. Proses Data Mining Sumber: (http://www.cs.ualberta.ca)
Fase-fase dimulai dari data mentah dan berakhir dengan pengetahuan atau informasi yang telah diolah yang didapatkan sebagai hasil dari tahapan-tahapan berikut (www.csualberta.ca) :
- Data Cleansing, juga dikenal sebagai data cleansing, ini adalah sebuah fase dimana data-data tidak lengkap, mengandung error dan tidak konsisten dibuang dari koleksi data, sehingga data yang telah bersih dan relevan dapat digunakan untuk diproses ulang untuk penggalian pengetahuan (discovery knowledge).
- Data Integration, pada tahap ini terjadi integrasi data, dimana sumber-sumber data yang berulang (multiple data), file-file yang berulang (multiple file), dapat dikombinasikan dan digabungkan kedalam suatu sumber.
- Data Selection, pada langkah ini, data yang relevan terhadap analisis dapat dipilih dan diterima dari koleksi data yang ada.
- Data Transformation, juga dikenal sebagai data consolidation. Pada tahap ini, dimana data-data yang telah terpilih, ditransformasikan kedalam bentuk-bentuk yang cocok untuk prosedur penggalian (mining procedure) dengan cara melakukan normalisasi dan agregasi data
- Data mining, tahap ini adalah tahap yang paling penting, dengan menggunakan teknik-teknik yang diaplikasikan untuk mengekstrak pola-pola potensial yang berguna.
- Pattern Evaluation, pada tahap ini, pola-pola menarik dengan jelas merepresentasikan pengetahuan telah diidentifikasi berdasarkan measure yang telah diberikan
- Knowledge representation, ini merupakan tahap terakhir dimana pengetahuan yang telah ditemukan secara visual ditampilkan kepada user. Tahap penting ini menggunakan teknik visualisasi untuk membantu user dalam mengerti dan menginterpretasikan hasil dari data mining.
2.5. Teknik Data Mining
M enurut Connolly dan Begg (2005, pp1233-1239), sebelum mengetahui teknik-teknik yang dapat digunakan dalam data mining, terdapat empat operasi yang dapat dihubungkan dengan data mining, yaitu:
1. Predictive modeling
Predictive modeling merupakan penjelajahan manusia dalam mengadakan observasi atau penelitian untuk membentuk sebuah model dari karakteristik-karakteristik yang penting dari beberapa fenomena. Predictive modeling dapat digunakan untuk menganalisa database yang sudah ada untuk menentukan beberapa karakteristik esensial pada data set.
Ada dua teknik yang dapat dilakukan dalam predictive modeling yaitu: - Classification
Classification digunakan untuk membuat dugaan awal tentang class yang spesifik untuk setiap record dalam database dari satu set nilai class yang mungkin.
- Value Prediction
Value prediction digunakan untuk memperkirakan nilai numerik yang kontinu yang terasosiasi dengan record database. Teknik ini menggunakan teknik statistik klasik dari linear regression dan nonlinear regression.
2. Database segmentation
Tujuan database segmentation adalah untuk mempartisi database menjadi sejumlah segmen, cluster, atau record yang sama, dimana, record tersebut berbagi sejumlah properti dan karenanya record-record tersebut diharapkan homogen.
3. Link analysis
Tujuan link analysis adalah untuk membuat hubungan antara record yang individual atau sekumpulan record dalam database. Aplikasi pada link analysis meliputi product affinity analysis, direct marketing, dan stock price movement.
4. Deviation detection
Teknik ini seringkali merupakan sumber dari penemuan yang benar karena teknik ini mengidentifikasi outlier yang mengekspresikan deviasi dari ekspektasi yang telah diketahui sebelumnya. Operasi ini dapat ditampilkan dengan menggunakan teknik statistik dan visualisasi.
Aplikasi deviation detection misalnya pada deteksi penipuan dalam penggunaan kartu kredit dan klaim asuransi, quality control, dan defect tracing.
M enurut Berson dan Smith (2001, pp336-378) dalam data mining terdapat dua tipe teknik antara lain :
2.5.1. Teknik Klasik (Classical Technique) 2.5.1.1. Statistic
M enurut M cClave dan Sincich (2003, p2), statistik adalah ilmu pengetahuan atau ilmiah tentang data, atau ilmu yang mempelajari tentang data. Hal ini meliputi pengumpulan, pengklarifikasian, perangkuman, pengorganisasian, penganalisaan, dan penterjemahan informasi tentang perhitungan atau numerik.
M enurut Kvanli, Pavur, dan Keeling (2003, p2), Statistik adalah ilmu yang terdiri dari peraturan-peraturan dan ketentuan-ketentuan dalam hal mengumpulkan, menjelaskan, menganalisa dan menterjemahkan data-data numerik.
M enurut Berson dan Smith (2001, p291), Statistik adalah cabang ilmu matematika yang mempelajari tentang sekumpulan dan deskripsi data yang akan digunakan dalam membuat laporan tentang informasi yang penting agar seseorang dapat membuat keputusan yang berguna. Salah satu keuntungan statistik adalah menampilkan database dalam tampilan ber-level tinggi yang menyediakan
informasi-informasi yang berguna tanpa perlu mengerti setiap record secara detil.
2.5.1.2. Nearest Neighbour
Teknik prediksi pengelompokan dan nearest neighbour merupakan teknik tertua yang digunakan dalam data mining. Nearest neighbour merupakan teknik prediksi yang hampir sama dengan pengelompokan, untuk memperkirakan apakah nilai prediksi ada dalam satu record, mencari kesamaan nilai prediktor di dalam basis data historis dan menggunakan nilai prediksi dari record yang “terdekat” untuk tidak membagi-bagikan record.
2.5.1.3. Pengelompokan (Clustering)
Pengelompokan merupakan metode yang mengklasifikasikan data ke dalam kelompok-kelompok berdasarkan kriteria dari masing-masing data. Biasanya, teknik ini dipakai untuk memberikan pengguna akhir sebuah gambaran level atas dari apa yang telah terjadi di dalam basis data. Pengelompokan terkadang digunakan untuk segmentasi.
Gambar 2.6 Grafik Teknik Pengelompokan Sumber : (http://www.togaware.com)
2.5.2. Teknik Generasi Selanjutnya (The Next generation Technique) 2.5.2.1. Decision Tree (Pohon Keputusan)
Pohon keputusan merupakan model prediktif yang dapat digambarkan seperti pohon, dimana setiap node di dalam struktur pohon tersebut mewakili sebah pertanyaan yang digunakan untuk menggolongkan data. Struktur ini dapat digunakan untuk membantu memperkirakan kemungkinan nilai dari setiap atribut data.
Gambar 2.7 Contoh Pohon Keputusan Sumber : (http://www.axi.ca) Beberapa hal menarik tentang tree:
9 Tree ini membagi data pada setiap cabangnya tanpa kehilangan data sedikitpun. Jumlah total record pada node parent sama dengan jumlah total record yang ada pada node children.
9 Sangat mudah dimengerti bagaimana sebuah model dibangun, kebalikan dengan model dari neural network atau dari statistik standar.
9 Mudah untuk menggunakan model ini jika kita mempunya target pelanggan yang sepertinya tertarik dengan penawaran marketing.
Dari perspektif bisnis, decision tree dapat dilihat sebagai pembuatan segmentasi dari data set yang orisinil. Segmentasi ini dilakukan untuk beberapa alasan tertentu, misalnya untuk prediksi dari beberapa potong informasi yang penting. M eskipun decision tree sendiri dan algoritma yang membuat decision tree itu mungkin saja sangat kompleks, namun hasil yang ditampilkan dengan cara yang mudah dimengerti sangat membantu untuk pengguna bisnis.
Decision tree seringkali dikembangkan untuk statistician untuk mengotomatisasi proses menentukan field mana dari database mereka yang benar-benar berguna atau terkorelasi dengan masalah tertentu yang sedang mereka usahakan untuk mengerti. Karena itu, algoritma decision tree cenderung mengotomatisasi seluruh proses pembuatan hipotesis dan kemudian melakukan validasi yang lebih komplit dalam cara yang lebih terintegrasi dibanding dengan teknik data mining lainnya.
Decision tree biasanya digunakan untuk berbagai kebutuhan:
1. Eksplorasi
Teknologi decision tree dapat digunakan untuk eksplorasi data set dan masalah bisnis. Hal ini biasanya dilakukan dengan mencari predictor dan nilai yang dipilih untuk setiap bagian / cabang dari tree tersebut.
2. Preprocessing data
Teknologi ini juga dapat digunakan untuk mengolah dan memproses data yang dapat digunakan pada algoritma lain, misalnya neural network, nearest neighbour, dll. Hal itu dikarenakan algoritma lain memerlukan waktu yang relatif lama untuk dijalankan jika terdapat jumlah predictor dalam jumlah besar untuk digunakan sebagai model, sehingga teknik decision tree biasanya digunakan pada tahap pertama data mining untuk menciptakan subset yang berguna dari predictor baru kemudian hasil tersebut akan dapat dimasukkan pada teknik data mining yang lain. 3. Prediksi
Para analis menggunakan teknologi ini untuk membangun sebuah model prediktif yang efektif.
Decision tree mempunyai beberapa keuntungan sebagai berikut (http://en.wikipedia.org):
1. Decision tree mudah dimengerti dan diinterpretasikan. Orang dapat mengerti model decision tree setelah penjelasan yang singkat.
2. Penyiapan data untuk decision tree adalah utama dan tidak dibutuhkan. Teknik lain seringkali membutuhkan normalisasi data, variabel kosong perlu dibuat, dan nilai yang kosong harus dihapus.
3. Decision tree dapat mengatasi baik data nominal maupun kategorial. Teknik lain biasanya dispesialisasi di analisis data set yang hanya mempunyai satu tipe variabel, contohnya relation rule yang hanya dapat digunakan dengan variabel nominal atau neural network yang hanya dapat digunakan dengan variabel numerik. 4. Decision tree merupakan model white box. Jika situasi
yang diberikan kelihatan dalam model, penjelasan untuk kondisi tersebut dapat dengan mudah dijelaskan dengan boolean logic. Contoh black box adalah artificial neural network karena penjelasan untuk hasilnya sangat kompleks.
5. Decision tree dapat melakukan validasi terhadap model dengan menggunakan tes statistik. Hal itu akan memungkinkan untuk menghitung reliabilitas model. 6. Decision tree merupakan teknik yang kuat, dapat bekerja
baik dengan data yang besar dalam waktu yang singkat. Sejumlah besar data dapat dianalisis dengan menggunakan personal computer dalam waktu yang cukup pendek yang memungkinkan pemegang saham mengambil keputusan berdasarkan analisis tersebut.
Karena nilai decision tree yang sangat tinggi pada banyak faktor kritis pada data mining, teknik ini dapat
digunakan pada berbagai macam masalah bisnis, baik eksplorasi maupun prediksi.
2.5.2.2. Neural Network (Jaringan Neural)
Jaringan Neural merupakan teknik model prediktif yang paling kuat. Teknik ini dapat membuat model yang sangat kompleks yang hampir tidak mungkin untuk mengerti secara benar, meskipun seorang ahli. M odel ini disajikan dalam nilai numerik dengan perhitungan yang kompleks dan hasil akhir dari teknik ini juga berupa numerik dan perlu untuk diterjemahkan jika nilai prediksi aktual berupa kategori.
2.5.2.3. Rule Induction (Aturan Induksi)
Aturan induksi merupakan bentuk umum dari data mining dan merupakan bentuk yang sama untuk penemuan pengetahuan di dalam sistem pembelajaran unsupervised. Teknik ini dalam basis data dapat menjadi sebuah usaha besar-besaran dimana semua kemungkinan pola-pola secara sistematis keluar dari data, dan kemudian akurasi dan arti ditambahkan kedalam aturan tersebut untuk memberitahukan pengguna betapa kuat pola dan bagaimana dapat terjadi lagi.
2.6 Marketing (Pemasaran)
2.6.1. Definisi Marketing (Pemasaran)
Pemasaran adalah proses kemasyarakatan dimana individu dan kelompok memperoleh apa yang mereka butuhkan dan inginkan melalui penciptaan, penawaran dan pertukaran secara bebas produk dan jasa nilai dengan pihak lain (www.apindo.or.id )
Pemasaran menurut M cleod dan Schell (2004, p369) adalah kegiatan perorangan dan organisasi yang memudahkan dan mempercepat hubungan pertukaran yang memuaskan dalam lingkungan yang dinamis melalui penciptaan, pendistribusian, promosi, dan penentuan harga barang, jasa, dan gagasan.
2.6.2. Unsur-unsur Marketing (Pemasaran)
Unsur-unsur pemasaran menurut M cleod dan Schell (2004, p369) adalah:
- Produk (Product)
Produk adalah apa yang dibeli oleh pelanggan untuk memuaskan keinginannya atau kebutuhannya. Produk dapat berupa barang fisik, berbagai jenis jasa, atau suatu gagasan.
- Promosi (Promotion)
Promosi berhubungan dengan semua cara yang mendorong penjualan produk, termasuk periklanan dan penjualan langsung.
Tempat berhubungan dengan cara mendistribusikan produk secara fisik kepada pelanggan melalui saluran distribusi.
- Harga (Price)
Harga terdiri dari semua elemen yang berhubungan dengan apa yang dibayar oleh pelanggan untuk produk itu.
2.7. Market Basket Analysis
2.7.1 Definisi Market Basket Analysis
Market Basket Analysis adalah salah satu tipe dari analisis data untuk pemasaran yang paling berguna dan paling banyak digunakan. Market Basket Analysis digunakan untuk menemukan relasi atau korelasi diantara himpunan barang belanjaan (items) dalam keranjang belanja. Tujuan dari Market Basket Analysis itu sendiri adalah untuk menganalisa barang-barang yang dibeli oleh pelanggan secara bersamaan, konsep itu berawal dari gagasan para pelanggan yang meletakkan semua barang belanjaan mereka ke dalam sebuah kereta dorong (market basket) selama berbelanja di toko grosir.
Fungsi ini paling banyak digunakan untuk menganalisa data dalam rangka keperluan strategi pemasaran, desain katalog, dan proses pembuatan keputusan bisnis.
Aturan asosiasi menangkap barang atau kejadian dalam data berukuran besar yang berisi data transaksi. Dengan kemajuan teknologi, data penjualan dapat disimpan dalam jumlah besar yang disebut dengan “basket data." Penelitian menggunakan dua macam data : transaksional
dan non transaksional. Hasil penelitian dengan menggunakan metode Association Rule dapat ditemukan semua kombinasi dari item, yang disebut dengan frequent itemsets yang memiliki support yang lebih besar daripada minimum support. Dari hasil analisa didapatkan karakteristik nilai minimum support dan minimum confidence dari transaksi yang ada dalam keranjang belanja. Aturan asosiasi yang dihasilkan dapat digunakan untuk keperluan promosi, desain, katalog, segmentasi pelanggan dan target pemasaran.
Efek yang paling nyata Market Basket Analysis adalah peningkatan penjualan pada toko yang telah menyatukan barang untuk dijual bersamaan. Fasilitas ini meningkatkan pembelian dan membantu pelanggan yang ingin membeli barang agar tidak lupa untuk membeli ”pasangannya”. Sebagai tambahan, hal ini juga menambah kepuasan pelanggan. M ereka tidak perlu melihat seluruh isi toko untuk sesuatu yang ingin mereka beli.
Jadi dapat disimpulkan keuntungan dari Market Basket Analysis, pertama-tama adalah secara tidak langsung yaitu pelanggan tidak perlu memilih produk.
Pemilihan produk tidak diperlukan untuk menjalankan analisa keranjang. Semua produk dipertimbangkan, dan perangkat lunak data mining akan menentukan produk yang paling utama.
M etode yang digunakan adalah pertama adalah sangat penting untuk mempunyai daftar transaksi dan setiap penjualan. Untuk lebih
mudahnya kita melihat contoh beberapa dari pelanggan yang membeli beberapa barang :
Transaksi 1: Frozen pizza, cola, milk
Transaksi 2: Milk, potato chips
Transaksi 3: Cola, frozen pizza
Transaksi 4: Milk, pretzels
Transaksi 5: Cola, pretzels
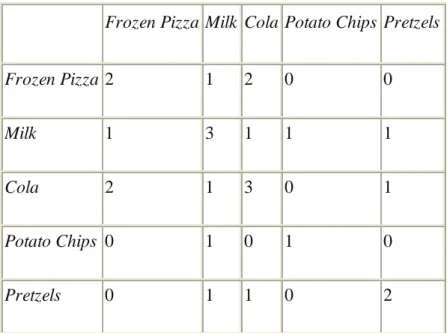
M asing-masing pelanggan membeli barang yang berbeda-beda dalam keranjang yang berbeda pula, tidak ada hubungan yang nyata antara barang-barang tersebut. Langkah pertama dari Market Basket Analysis adalah menyilangkan data di dalam tabel untuk melihat berapa seringnya barang tersebut dibeli bersama. Untuk lima pembelian, tabelnya dapat dilihat seperti ini :
Tabel 2.1. Tabel Penjualan produk dalam waktu yang sama Sumber : (www.megaputer.com)
Frozen Pizza Milk Cola Potato Chips Pretzels
Frozen Pizza 2 1 2 0 0
Milk 1 3 1 1 1
Cola 2 1 3 0 1
Potato Chips 0 1 0 1 0
Pretzels 0 1 1 0 2
Diagonal utama dari tabel di atas menunjukkan bagaimana seringnya dari setiap barang dibeli. Baris pertama dari tabel menunjukkan pelanggan yang membeli frozen pizza, satu pelanggan membeli milk, dua membeli cola, dan tidak ada yang membeli potato chips pretzels. Pada kenyataannya frozen pizza dan cola dapat dijual bersamaan, dan dapat diletakkan berdampingan di rak toko. Demikian pula apabila dilihat dari keseluruhan tabel, hal ini adalah kesempatan untuk menyilangkan penjualan. Pada baris kedua milk mempunyai penjualan yang bagus tetapi tidak untuk disilangkan dengan barang yang lain.
Hasil dari Market Basket Analysis sangat bermanfaat sebab metode ini mengambil asosiasi dengan seketika. Ini adalah perintah " jika kondisi kemudian menghasilkan."
Jika seorang pelanggan membeli frozen pizza, maka mereka kemungkinan akan membeli cola.
Jika seorang pelanggan membeli cola, maka mereka kemungkinan akan membeli frozen pizza.
Hal ini dapat dapat membuat toko untuk mempromosikan frozen pizza dan cola atau meletakkannya di samping frozen pizza, mengiklankan dua barang tersebut secara bersamaan atau meletakkan kupon diskon cola di kotak frozen pizza, kepuasan pelanggan kemungkinan akan meningkatkan penjualan kedua barang
Market Basket Analysis mempunyai beberapa pembatasan. Yang pertama adalah macam data yang diperlukan untuk melakukan suatu analisa keranjang yang efektif. Hal itu adalah mempunyai jumlah transaksi riil untuk mendapatkan data yang berarti, tetapi ketelitian data didapati jika semua produk tidak dibeli dengan frekuensi yang sama. Contohnya, jika susu dijual hampir di setiap transaksi, tetapi lem hanya terjual sekali atau dua kali per bulan, meletakkan mereka berdua ke dalam keranjang yang sama mungkin akan menghasilkan hasil yang mengesankan. Dengan hanya satu atau dua pelanggan lem, data mining software akan menyatakan bahwa lem mempunyai penjualan yang baik tetapi ini boleh saja menjadi benar untuk analisa satu atau dua pelanggan. (http://www.megaputer.com)
2.7.2 Performing Market Basket Analysis 2.7.2.1 Virtual Items
Kadang-kadang seorang marketer mempertimbangkan lebih dari satu barang untuk dijual bersama dalam mengembangkan promosi mereka. Dalam hal ini, data penjualan dapat ditambahkan dengan penambahan barang virtual. Suatu barang sebenarnya bukanlah suatu barang riil dijual, tetapi diperlakukan sebagai satu data oleh software data mining. M aka jika pelanggan baru memesan sweater dan suatu jacket, ini dapat dimasukkan ke database seperti:
Barang 1: Sweater
Barang 2: Jacket
Barang 3: (new customer)
Barang virtual juga bermanfaat untuk menguji efek promosi. Dengan menambahkan barang virtual untuk mengadakan promosi atau potongan, yang juga dapat berguna untuk melihat bagaimana pengaruh dari cross-selling. (http://www.megaputer.com)
2.7.3 Pengimplementasian Hasil 2.7.3.1 Penempatan Rak
Hasil dari penggunaan Market Basket Analysis dapat diimplementasikan oleh toko-toko atau perusahaan ritel untuk mengubah penempatan produk dalam rak mereka untuk meningkatkan keuntungan. (http://www.megaputer.com)
2.7.3.2 Product Bundling
Untuk beberapa perusahaan yang tidak mempunyai tempat penyimpanan barang (rak-rak), seperti perusahaan pengiriman barang atau surat (mail-order companies), Internet businesses, market basket analysis dapat lebih berguna jika digunakan untuk meningkatkan promosi-promosi dibandingkan dengan mengatur penempatan produk. Dengan menawarkan promosi-promosi, seperti misalnya, pembeli dari suatu produk tertentu akan mendapatkan diskon untuk produk sejenis lainnya, maka penjualan kedua produk tersebut akan mengalami peningkatan. (http://www.megaputer.com)