6
BAB II
LANDASAN TEORI
2.1. Tinjauan Pustaka
Untuk mendukung pembuatan laporan ini, maka perlu dikemukakan hal-hal dan teori yang berkaitan dengan definisi atau pengertian Data Mining, Naïve Bayes untuk mendapatkan kesamaan mengenai persepsi pembahasan pada penelitian ini. Agar pembuatan laporan ini lebih terarah dalam mencari solusi dari permasalahan yang ada.
2.1.1. Data Mining
A. Pengertian Data Mining
Data Mining sebernarnya mulai dikenal sejak tahun 1990, ketika pekerjaan pemanfaatan data menjadi sesuatu yang penting dalam berbagi bidang, mulai dari bidang akademik, bisnis, hingga medis. Data Mining merupakan istilah yang sering dikatakan sebagai suatu cara untuk menguraikan serta mencari penemuan berupa pengetahuan didalam suatu database. Data mining adalah sebuah bidang ilmu yang berupaya menemukan pola,kaidah, aturan, dan informasi berharga yang menarik dan belum diketahui sebelumnya dari sekumpulan besar data (Indrawan, Sarjana, Pendidikan, Studi, & Komputer, 2016).
“Data Mining merupakan kecerdasan buatan yang memanfaatkan data dengan teknik statistik untuk menemukan dan mengidentifikasi informasi yang bermanfaat dan pengetahuan baru yang didapat dari pengolahan database yang besar” (Sidik, Rasminto, & Manongga, 2018).
Menurut (Meilani et al., 2014) “Data Mining adalah kegiatan menemukan pola yang menarik dari data dalam jumlah besar, data dapat disimpan dalam database, data warehouse, atau penyimpanan informasi lainnya”.
Data Mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik-teknik, metode metode, atau algoritma dalam Data Mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses Knowledge Discovery in Database (KDD) secara keseluruhan (Mardi, 2017).
B. Pengelompokan Data Mining
Ada beberapa pengelompokan data mining berdasarkan fungsi yang diteliti antara lain (Sidik et al., 2018).
1. Deskripsi mancari cara untuk menentukan sebuah pola dan kecenderungan yang ada dalam data. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan. 2. Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi
lebih kearah numerik dari pada kearah kategori. Model dibangun menggunakan record lengkap yang menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
3. Prediksi hampir sama dengan klasifikasi dan estimasi. Kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang.
4. Klasifikasi Dalam klasifikasi variabel, tujuan bersifat kategorik. Misalnya, kita akan mengklasifikasikan suhu dalam tiga kelas, yaitu suhu panas, suhu sejuk, suhu dingin.
5. Pengklusteran merupakan pengelompokkan sebuah record, pengamatan dan membentuk kelas kedalam sebuah objek yang mempunyai kemiripan.
6. Asosiasi dalam data mining, menemukan atribut yang muncul dalam suatu waktu.
C. Tahap-Tahap Data Mining
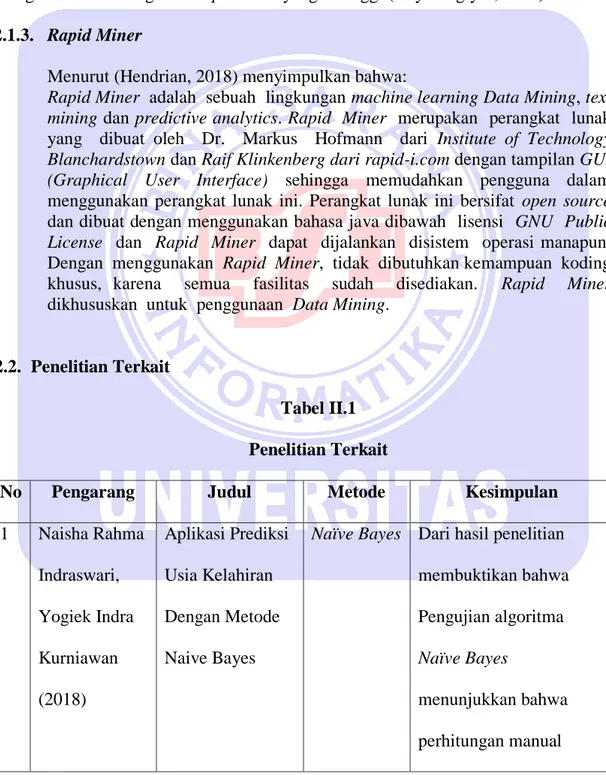
Menurut (Meilani et al., 2014) tahap-tahap Data Mining ada 7 yaitu:
1. Pembersihan data (data cleaning) Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. 2. Integrasi data (data integration) Integrasi data merupakan penggabungan data
dari berbagai database ke dalam satu database baru.
3. Seleksi Data (Data Selection) Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database.
4. Transformasi data (Data Transformation) Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam Data Mining.
5. Proses mining, Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
6. Evaluasi pola (pattern evaluation), Untuk mengidentifikasi pola-pola menarik kedalam knowledge based yang ditemukan.
7. Presentasi pengetahuan (knowledge presentation), Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
Sumber: (Meilani et al., 2014).
Gambar II.1
Tahap-Tahap Data Mining
D. Metode Pelatihan Data Mining
Secara garis besar metode pelatihan yang digunakan dalam teknik-teknik data mining dibedakan ke dalam dua pendekatan, yaitu:
1. Unsupervised learning, metode ini diterapkan tanpa adanya latihan (training) dan tanpa ada guru (teacher). Guru di sini adalah label dari data.
2. Supervised learning, yaitu metode belajar dengan adanya latihan dan pelatih. Dalam pendekatan ini, untuk menemukan fungsi keputusan, fungsi pemisah atau fungsi regresi, digunakan beberapa contoh data yang mempunyai output atau label selama proses training (Mustafa, Ramadhan, & Thenata, 2018).
2.1.2. Naïve Bayes
Naive Bayes merupakan sebuah pengklasifikasian probabilistik sederhana yang menghitung sekumpulan probabilitas dengan menjumlahkan frekuensi dan kombinasi nilai dari dataset yang diberikan. Algoritma Naive Bayes adalah salah satu metode data mining yang termasuk kedalam sepuluh klasifikasi data mining yang paling popular diantara algoritma-algoritma lainnya. Metode Naive Bayes juga dinilai berpotensi baik dalam mengklasifikasi dokumen dibandingkan metode pengklasifikasian yang lain dalam hal akurasi dan efisiensi komputasi (Saputra, Taufik, Ramdhani, Oktapiani, & Marsusanti, 2018).
(Hayuningtyas, 2019) Metode Naïve Bayes merupakan metode yang memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes. Naïve Bayes merupakan metode pengklasifikasian yang sangat sederhana dengan mengasumsikan klasifikasi atribut. Dengan metode Naive Bayes terlebih dahulu mencari Nilai Probabilitas dan likelihood maksimum dari setiap atribut untuk masing-masing kelas.
Persamaan dari teorema bayes (Saputra et al., 2018).
Dimana:
X : Data dengan class yang belum diketahui H : Hipotesis data merupakan suatu class spesifik
P(H|X) : Probabilitas Hipotesis H berdasarkan kondisi X (posterior probabilitas)
P(H) : Probabilitas hipotesis H (prior probabilitas)
P(X) : Probabilitas X
Penentuan class dilakukan dengan cara membandingkan nilai probabilitas suatu sampel berada di class yang satu dengan nilai probabilitas suatu sampel berada di class yang lain. Untuk menentukan class yang cocok dari suatu sampel dilakukan dengan cara membandingkan nilai posterior untuk masing-masing class, dan mengambil class dengan nilai posterior yang tertinggi (Hayuningtyas, 2019).
2.1.3. Rapid Miner
Menurut (Hendrian, 2018) menyimpulkan bahwa:
Rapid Miner adalah sebuah lingkungan machine learning Data Mining, text mining dan predictive analytics. Rapid Miner merupakan perangkat lunak yang dibuat oleh Dr. Markus Hofmann dari Institute of Technology Blanchardstown dan Raif Klinkenberg dari rapid-i.com dengan tampilan GUI (Graphical User Interface) sehingga memudahkan pengguna dalam menggunakan perangkat lunak ini. Perangkat lunak ini bersifat open source dan dibuat dengan menggunakan bahasa java dibawah lisensi GNU Public License dan Rapid Miner dapat dijalankan disistem operasi manapun. Dengan menggunakan Rapid Miner, tidak dibutuhkan kemampuan koding khusus, karena semua fasilitas sudah disediakan. Rapid Miner dikhususkan untuk penggunaan Data Mining.
2.2. Penelitian Terkait
Tabel II.1 Penelitian Terkait
No Pengarang Judul Metode Kesimpulan
1 Naisha Rahma Indraswari, Yogiek Indra Kurniawan (2018) Aplikasi Prediksi Usia Kelahiran Dengan Metode Naive Bayes
Naïve Bayes Dari hasil penelitian membuktikan bahwa Pengujian algoritma Naïve Bayes
menunjukkan bahwa perhitungan manual
dibandingkan dengan perhitungan aplikasi memiliki hasil yang sama. Dengan nilai accuracy tertinggi pada aplikasi ini ada pada angka 78.69%.
Sedangkan nilai precision tertinggi ada pada angka 70.14 % dan nilai recall tertinggi ada pada angka 63.64%. 2 Putu Gede Surya Cipta Nugraha, I Wayan Aribawa, I Putu Okta Priyana, Gede Indrawan (2016) Penerapan Metode Decision Tree (Data Mining) Untuk Memprediksi Tingkat Kelulusan Siswa SMPN 1 Kintamani
C4.5 Dari hasil penelitian membuktikan bahwa C4.5 membantu untuk membuat suatu keputusan dalam menentukan prediksi hasil kelulusan siswa baik itu siswa yang lulus maupun siswa yang tidak lulus. 3 Sri Mulyati, Syepry Maulana Rancang Bangun Aplikasi Data Mining Prediksi Euclidean Distance
Aplikasi ini memiliki nilai accuracy 96,26% nilai precision sebesar
Husein, Ramdhan (2020) Kelulusan Ujian Nasional Menggunakan Algoritma (KNN) K-Nearest Neighbor Dengan Metode Eulidean Distance Pada SMPN 2 Pagedangan 96,17% dan recall sebesar 97,32%. Dengan ini dapat disimpulkan bahwa dari pengujian yang telah dilakukan dengan menggunakan dataset siswa/i SMPN 2 Pagedangan sistem dapat memprediksi dan
mengklasifikasi dengan baik dan cepat.
4 Lastarina Pasaribu (2019) Sistem Pakar Mendiagnosa Hama Dan Penyakit Tanaman Mentimun Menggunakan Metode Naïve Bayes
Naïve Bayes Dengan menerapkan metode naïve bayes dalam mendiagnosa hama dan penyakit pada
tanaman mentimun dengan cara menghitung satu persatu gejala yang disebabkan hama dan penyakit pada tanaman mentimun. 5 Dicky Nofriansyah, Kamil Penerapan Data Mining dengan Algoritma Naive
Naïve Bayes Sistem klasifikasi data kartu internet ini digunakan untuk
Erwansyah, Mukhlis Ramadhan (2016) Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL (Studi Kasus di CV. Sumber Utama Telekomunikasi) menampilkan informasi klasifikasi minat atau tidak minat pada kartu internet yang baru di luncurkan dengan menggunakan algoritma Naive Bayes. Dengan mengetahui minat atau tidak minat kartu internet yang baru diluncurkan, akan meminimalisir kerugian pada
perusahaan. Perusahaan juga akan lebih selektif dalam meluncurkan produk baru.
Penelitian ini meneliti tentang prediksi kelulusan sama seperti penelitian yang menggunakan metode naïve bayes adalah seperti nomor dua dan tiga. Nomor satu, empat dan lima menggunakan metode yang berbeda, dari ketiga penelitian terkait yang menjadi pembeda dengan skripsi ini yaitu penelitian ini menggunakan metode Naïve Bayes, penggunaan metode naïve bayes dipilih karena metode tersebut merupakan metode yang menggunakan probabilitas statistik yang sederhana tetapi menghasilkan hasil yang akurat.
2.3. Tinjauan Organisasi/Objek Penelitian 2.3.1. Sejarah Instansi
Pada awal berdirinya, pada tahun 2006 s.d 2009 sekolah ini masih menginduk ke SMAN 1 Cisolok dan kegiatan belajar mengajar dilaksanakan di SMPN 1 Cikakak dan pada saat itu Bapak Zhairy Andhryanto, S.Pd. di tunjuk sebagai PLH di SMAN 1 Cikakak, Pada tanggal 12 Mei 2010, Pemerintah melalui Dinas Pendidikan Kabupaten Sukabumi dengan no SK 421.3/Kep.359/Disdik/2010 telah meresmikan berdirinya SMAN 1 Cikakak dan sudah mempunyai gedung sendiri yang beralamat di Jl. Padurenan Km.1 Cikakak dan Bapak Zhairy Andhryanto, S.Pd. di angkat sebagai Kepala Sekolah Pertama dan masih menjabat sampai sekarang.
Visi dan Misi:
Visi dari sekolah SMAN 1 Cikakak yaitu untuk mewujudkan sekolah yang unggul bidang akademik dan non akademik di Kabupaten Sukabumi Tahun 2020. A. Misi:
1. Menghasilkan lulusan yang cerdas, terampil dan berakhlak mulia. 2. Meningkatkan profesionalisme tenaga pendidik dan kependidikan.
3. Mewujudkan sarana dan prasarana yang memadai bagi pengembangan
kompetensi peserta didik.
4. Menjalin kerjasama dengan berbagai pihak dalam membentuk akhlak mulia,
mengembangkan ilmu pengetahuan dan teknologi sesuai dengan perkembangan dan kebutuhan masyarakat.
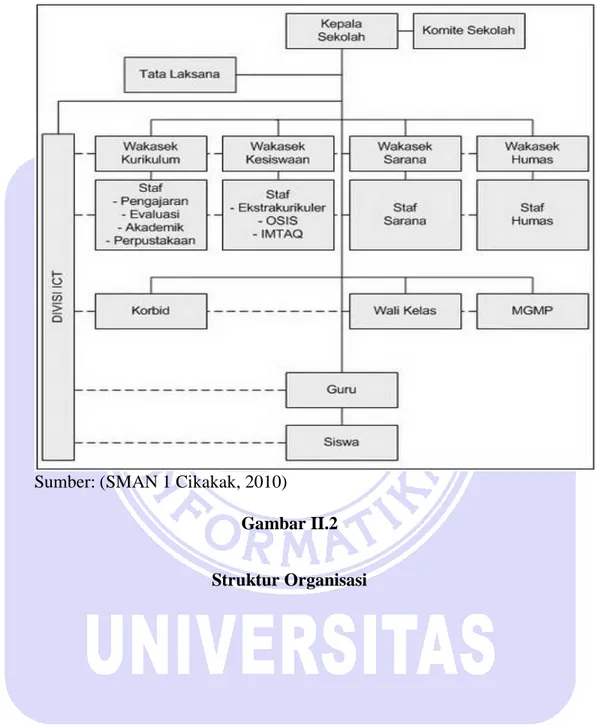
2.3.2. Struktur Organisasi
Struktur organisasi SMAN 1 Cikakak:
Sumber: (SMAN 1 Cikakak, 2010)
Gambar II.2