BAB 2
LANDASAN TEORI
2.1 Teori-teori Dasar
Berikut ini merupakan teori-teori umum yang digunakan dalam penelitian: 2.1.1 Visi Komputer (Computer Vision)
Visi Komputer (Computer vision) adalah transformasi data dari bentuk gambar atau video menjadi sebuah representasi yang baru. Semua jenis transformasi berfungsi untuk mencapai tujuan tertentu. Data yang diinput dapat berupa informasi yang sesuai dengan keadaan, misalnya “Kamera yang dipasang di dalam mobil”. Sebuah representasi yang baru dapat seperti mengubah gambar yang berwarna menjadi gambar dengan warna abu-abu (grayscale) atau menghilangkan pergerakan kamera dari gambar yang berurutan (Bradski and Kaehler, 2008).
Salah satu pengembangan dalam bidang computer vision yang telah dikembangkan adalah kemampuan komputer untuk mengamati dan memahami gambar secara elektronik (Moris, 2004). Pemahaman gambar ini dapat dilihat sebagai penguraian informasi yang berbentuk simbol dari gambar menggunakan konstruksi model dengan bantuan geometri, fisika, statistik dan teori pembelajaran (Sonka, Hlavac and Boyle, 2008).
Pemahaman gambar juga dideskripsikan sebagai sebuah proses yang terdiri dari 4 proses kecil yang saling bekerja sama dalam melaksanakan tugas tertentu, dimana setiap proses tersebut membutuhkan representasi menengah. Analisa gambar yang utama berjalan dari gambar raster digital dimana karakteristik radiometrik (intensitas dan warna) dari setiap pixel disimpan, menuju ke determinasi dari elemen-elemen gambar (tepi, area yang sama, tekstur, dan sebagainya).
Proses dari interpretasi gambar tingkat rendah adalah untuk menyelesaikan tugas utama dari pemahaman gambar: mengeluarkan unsur-unsur nyata dari sebuah gambar.
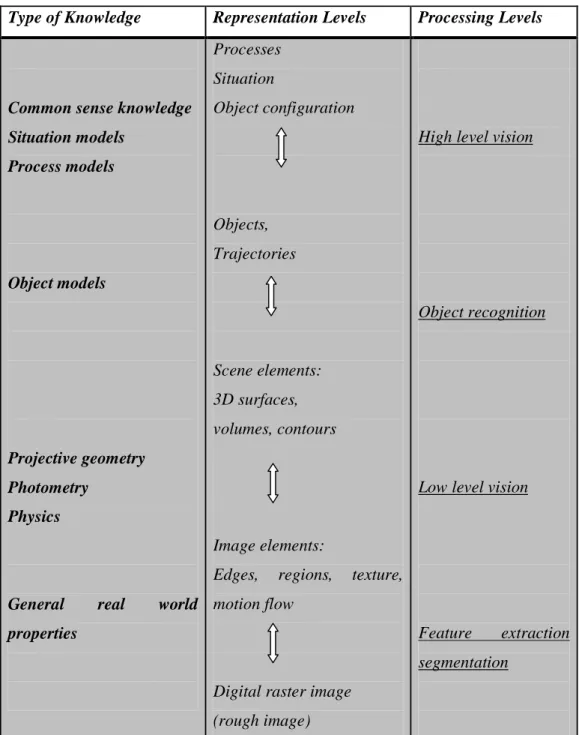
Tabel 2.1 Pemahaman Gambar sebagai Hirarkhi, Proses Berbasis Pengetahuan.
Type of Knowledge Representation Levels Processing Levels
Common sense knowledge Situation models Process models Object models Projective geometry Photometry Physics
General real world properties Processes Situation Object configuration Objects, Trajectories Scene elements: 3D surfaces, volumes, contours Image elements:
Edges, regions, texture, motion flow
Digital raster image (rough image)
High level vision
Object recognition
Low level vision
Feature extraction
segmentation
Tabel 2.1 merupakan jenis-jenis pengetahuan yang digunakan untuk menyimpulkan deskripsi dari gambar (kiri), dan representasi tingkat menengah dari tiap level (tengah), yang dihasilkan dari langkah-langkah proses yang sesuai (kanan) (Neumann, 1993).
Hasil dari interpretasi gambar pada tingkat yang lebih tinggi tidak hanya bergantung pada gambar tersebut, tetapi juga pada pertanyaan
maupun konteks dimana hasil output tersebut akan digunakan (Matthies, Malchow and Kriz, 2001).
2.1.2 Kecerdasan Buatan (Artificial Intelligence)
Kecerdasan buatan (artificial intelligence) adalah semua kegiatan yang ditujukan untuk membuat sebuah mesin yang cerdas, dimana kecerdasan adalah kualitas yang memungkinkan suatu entitas dapat berfungsi secara tepat dengan kondisi di lingkungan (Nilsson, 2009).
Kecerdasan buatan telah berkembang secara tidak menentu dan walaupun terkadang merupakan suatu pekerjaan awal yang menakjubkan, kini telah mengalami pemberhentian sementara hingga batas waktu tertentu. Pakar kecerdasan buatan, Marvin Minsky, belakangan ini menyatakan dalam sebuah pidato di Boston University bahwa “artificial intelligence telah menjadi otak-mati sejak tahun 1907.” ‘otak-mati’ artificial intelligence bukan disebabkan karena batasan komputasi, melainkan karena sebuah fakta bahwa terdapat masalah lain yang lebih menguntungkan. Namun, area yang lebih menguntungkan pada artificial intelligence, misalnya penerjemah bahasa, memang terus bersaing dengan prestasi pemrograman yang lain dalam beberapa dekade terakhir. (Engle, 2004)
2.1.3 Android
Android merupakan sebuah sistem operasi berbasis Java yang berjalan pada kernel Linux 2.6. Sistem ini sangat ringan dan memiliki fitur yang lengkap (DiMarzio, 2008). Awalnya, sistem operasi ini dikembangkan oleh Android, Inc, yang dibiayai oleh Google dan kemudian dibeli pada tahun 2005. Secara resmi pada tahun 2007, Android diresmikan bersamaan dengan Open Handset Alliance (OHA) yang merupakan sebuah perusahaan yang bergerak dibidang hardware, software, dan telekomunikasi yang ditujukan untuk memajukan open source pada perangkat mobile (Elgin and Ben, 2005).
Andy Rubin (2007) juga mengumumkan bahwa platform Android lebih signifikan dan lebih ambisius daripada handphone pada umumnya. Platform ini dibuat dengan konsep pemrograman yang sangat dasar,
sehingga hal ini memungkinkan para developer membuat aplikasi mobile yang menarik dan semua fitur didalamnya dapat developer gunakan. Android benar-benar dibuat untuk semua orang. Sebagai contoh, aplikasi yang dibuat ini dapat memanggil fitur-fitur utama dari handphone tersebut seperti melakukan panggilan telepon, mengirim pesan singkat, atau bahkan menggunakan kamera agar dapat memperkaya developer dalam menciptakan aplikasi yang berguna bagi user.
2.1.4 File Base
Sistem berbasis file pada awalnya berkembang pada tahun 1960-an sebelum database dikembangkan, dan sistem ini merupakan upaya awal untuk mengkomputerisasi sistem pengarsipan secara manual. Pada masa itu, masih banyak perusahaan yang menggunakan file tertulis untuk penyimpanan data yang berkaitan dengan proyek, produk, tugas, klien, ataupun karyawan. Namun seiring bertambah besarnya perusahaan, sistem pengarsipan ini akan mendapat kendala apabila perusahaan perlu mencari informasi dalam file tertulis. Semakin banyak file yang tersimpan, maka akan membutuhkan karyawan serta waktu yang lebih banyak untuk me-manage file tersebut. Oleh karena itu, dibangun sebuah sistem berbasis file untuk menjawab kebutuhan perusahaan terhadap pencarian data yang lebih efisien. (Connolly, 2008)
2.1.5 Extensible Markup Language (XML)
XML adalah data berformat hirarki yang berfungsi sebagai tempat pertukaran data di dalam world wide web (www). Sebuah dokumen XML terdiri dari struktur elemen yang berulang, mulai dari elemen yang paling awal atau biasa disebut root. Elemen data tersebut dapat diisi dengan atribut atau dapat juga diisi dengan sub-elemen.
Gambar 2.1. Contoh struktur XML
Pada gambar 2.1 elemen book merupakan elemen paling awal atau disebut root. Elemen book sendiri mempunyai dua sub-elemen book title dan author.
Sama seperti HTML, XML merupakan kumpulan dari SGML. Namun, ketika tag HTML mempunyai tujuan utama untuk menampilkan data item, tag XML justru mendeskripsikan dirinya sendiri. Walaupun perbedaan ini sangat tipis, namun hal ini cukup penting, karena data XML berfokus pada pendeskripsian isi dari XML itu sendiri, oleh karena itu hal ini memungkinkan program untuk menginterpretasi data dari XML tersebut (Shanmugasundaram et al, 2008).
2.1.6 Diagram Alir (Flowchart)
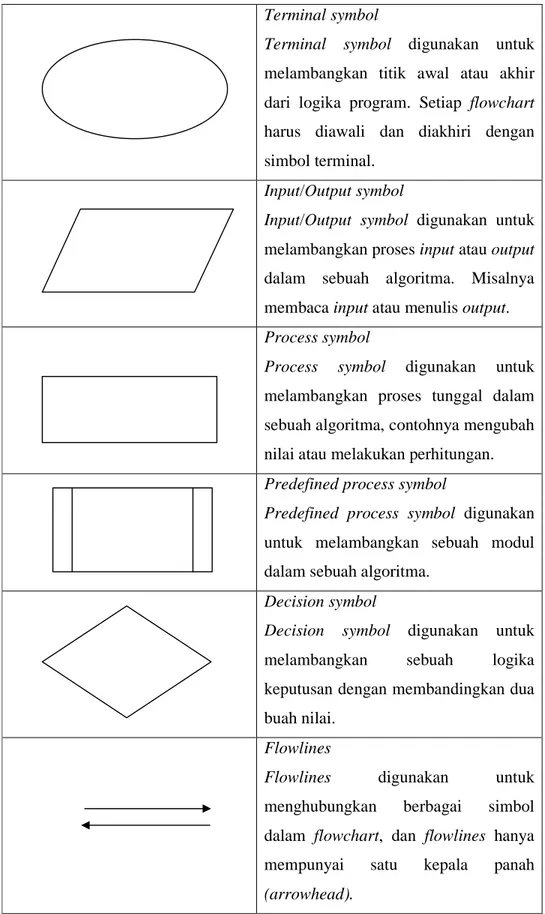
Flowchart sering digunakan sebagai metode alternatif untuk menampilkan algoritma. Flowchart juga sangat populer, dikarenakan flowchart menampilkan logika program dalam bentuk simbol geometri dan garis penghubung. Flowchart sangat mudah untuk dipahami dan merupakan sebuah metode untuk menampilkan aliran kontrol dalam algoritma. Berikut merupakan 6 flowchart standard yang digunakan untuk menampilkan algoritma-algoritma (Robertson, 2006) :
Tabel 2.2 6 jenis flowchart standard Terminal symbol
Terminal symbol digunakan untuk melambangkan titik awal atau akhir dari logika program. Setiap flowchart harus diawali dan diakhiri dengan simbol terminal.
Input/Output symbol
Input/Output symbol digunakan untuk melambangkan proses input atau output dalam sebuah algoritma. Misalnya membaca input atau menulis output. Process symbol
Process symbol digunakan untuk
melambangkan proses tunggal dalam sebuah algoritma, contohnya mengubah nilai atau melakukan perhitungan. Predefined process symbol
Predefined process symbol digunakan untuk melambangkan sebuah modul dalam sebuah algoritma.
Decision symbol
Decision symbol digunakan untuk melambangkan sebuah logika keputusan dengan membandingkan dua buah nilai.
Flowlines
Flowlines digunakan untuk
menghubungkan berbagai simbol dalam flowchart, dan flowlines hanya mempunyai satu kepala panah (arrowhead).
2.1.7 Extreme Programming
Nama extreme programming pertama kali diciptakan oleh Kent Beck (2000). Pendekatan ini dikembangkan dengan mendorong suatu kebiasaan yang baik seperti melakukan pengembangan secara terus menerus sampai mencapai tingkat ‘extreme’. Sebagai contohnya, dalam extreme programming, beberapa jenis sistem, dikembangkan dengan banyak programmer yang terintegrasi dan dilakukan test dalam hari itu juga (Pressman, 2010). Kunci aktivitas dari extreme programming disimpulkan menjadi 4 proses, antara lain:
a. Planning
Tahap planning ini diawali dengan aktivitas ‘mendengarkan’. Mendengarkan yang dimaksud disini ialah sebuah aktivitas mengumpulkan informasi mengenai kebutuhan dari aplikasi agar anggota-anggota teknikal dari tim extreme programming dapat memahami konteks bisnis dan juga untuk mendapatkan ketegasan dari output, fitur utama dan fungsionalitasnya yang dihasilkan. Selanjutnya, tim extreme programming akan menentukan lamanya pengembangan dari tiap modul di dalam aplikasi.
b. Design
Design pada extreme programming mengikuti prinsip KIS (Keep It Simple). Design yang simple selalu diutamakan ketimbang design yang lebih kompleks. Selain itu, tahap design menyediakan panduan untuk mengimplementasikan aplikasi sesuai perencanaan yang ada tanpa menambahkan atau mengurangi dari yang sudah ada (nothing less, nothing more). Design dengan fungsionalitas yang tinggi sangat dihindarkan (karena para developer mengasumsikan bahwa design tersebut akan dibutuhkan kemudian). Metode extreme programming menganjurkan untuk melakukan refactoring, yakni sebuah teknik konstruksi dan juga merupakan sebuah teknik untuk mengoptimisasi design. Fowler (2000) mendeskripsikan refactoring sebagai sebuah proses pergantian sistem dari software tersebut, dimana pergantian ini tidak mempengaruhi pihak eksternal yang tidak berkaitan dengan teknikal untuk meningkatkan struktur internal.
c. Coding
Kunci utama selama aktivitas koding adalah pair programming. Extreme programming merekomendasikan bahwa dua orang yang bekerja sama dalam sebuah komputer untuk membuat penggalan code. Metode ini menyediakan sebuah mekanisme untuk menyelesaikan masalah secara real-time (dua orang lebih baik dari satu orang) dan menjamin kualitas juga secara real-time (kode langsung di-review setelah dibuat). Dalam praktiknya, setiap orang memiliki peran yang berbeda. Sebagai contohnya, orang yang satu akan memikirkan detail koding dari design yang dibuat sementara yang satu lagi memastikan koding yang dibuat mengikuti standard atau mungkin saja memastikan koding yang dibuat sesuai perencanaan awal.
d. Testing
Pada tahap ini dilakukan testing terhadap aplikasi yang dibuat pada tahap coding. Tujuan dari tahap ini ialah untuk memastikan semua fitur yang telah dirancang sesuai dan dapat digunakan dengan baik. Setelah itu, diadakan tes uji kelayakan extreme programming, yang biasa disebut juga customer tests, yang ditentukan oleh customer dan berfokus pada semua fitur dan fungsionalitas dalam sistem yang di-review juga oleh customer.
2.1.8 Diagram UML (Unified Modeling Language) 2.1.8.1 Use Case Diagram
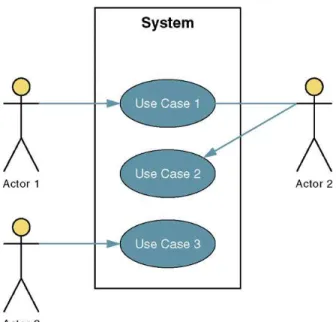
Use case diagram merupakan sebuah diagram yang menggambarkan interaksi antara sistem, sistem luar, dan users. Dengan kata lain, hal ini menggambarkan siapa yang akan menggunakan sistem dan dengan cara apa user menginginkan berinteraksi dengan sistem (Whitten and Bentley, 2005).
Gambar 2.2. Contoh use case diagram aplikasi
2.1.8.2 Use Case Narative
Use case narative merupakan pendeskripsian tertulis mengenai suatu kejadian bisnis dan bagaimana user dapat berinteraksi dengan sistem untuk dapat menyelesaikan tugas (Whitten and Bentley, 2005).
2.1.8.3 Activity Diagram
Dalam UML, activity diagram digunakan untuk memodelkan setiap langkah-langkah atau aktivitas dari sistem. Activity diagram mirip seperti flowchart karena memberikan gambaran langkah-langkah secara berurutan dalam sebuah proses bisnis atau sebuah use case. Namun yang membedakan activity dengan flowchart ialah activity menyediakan sebuah mekanisme untuk menggambarkan aktivitas yang terjadi secara paralel.
Whitten (2005) dalam bukunya memberikan guideline untuk membuat activity diagram. Berikut adalah proses untuk membuat suatu activity diagram:
• Tambahkan titik awal dan titik akhir dari suatu use case. • Tambahkan activity untuk setiap langkah umum dari use case
(atau setiap langkah inisiasi aktor)
• Tambahkan transisi dari setiap activity ke activity yang lain, titik keputusan, atau titik akhir.
• Tambahkan sebuah bar sinkronisasi untuk activity yang terjadi secara paralel.
Gambar 2.4. Contoh Activity Diagram
2.1.8.4 Class Diagram
Menurut Whitten dan Bentley (2005), Class diagram adalah gambaran grafis mengenai objek dan hubungan antara objek-objek tersebut dalam sebuah sistem. Yang perlu dilakukan sebelum membuat class diagram ialah mengidentifikasi objek-objek apa saja yang menjadi kebutuhan dari sistem. Setelah objek-objek telah ditentukan, maka objek-objek tersebut dikelompokan dengan menggunakan bantuan class diagram. Ada beberapa langkah
yang harus dilakukan untuk membuat sebuah class diagram, diantaranya:
1. Identifikasi Asosiasi dan Multiplicity
Pada langkah ini, perlu diidentifikasi hubungan yang terjadi antara objek-objek dan kelas-kelas. Maksud dari hubungan ini ialah “apa yang perlu ketahui” dari sebuah kelas terhadap kelas lainnya. Hubungan ini membuat sebuah kelas dapat saling bereferensi dengan kelas lainnya dan bertukar informasi. Setelah menentukan hubungan, selanjutnya tentukan multiplicity dari hubungan yang telah diidentifikasi. Multiplicity ialah angka minimum dan maximum kejadian dari sebuah kelas untuk satu kejadian tunggal dari kelas lain yang berhubungan.
2. Identifikasi hubungan Generalisasi/Spesialisasi
Setelah Asosiasi dan multiplicity berhasil ditentukan, perlu ditentukan juga hubungan generalisasi/spesialisasi. Hubungan generalisasi dan spesialisasi disebut juga hubungan “is a” yang terdiri dari kelas supertype (kelas abstrak atau parent) dan subtype (anak). Sebuah kelas supertype pada umumnya mengandung atribut dan behavior yang umum. Sedangkan sebuah kelas subtype mempunyai atribut dan behavior yang unik terhadap objek namun kelas ini juga diwarisi atribut dan behavior yang dimiliki oleh kelas supertype.
3. Identifikasi hubungan Agregasi
Pada tahap ini, akan ditentukan hubungan agregasi dan komposisi. Agregasi adalah sebuah jenis hubungan dimana sebuah kelas merupakan bagian dari kelas lainnya.
4. Siapkan class diagram
Pada langkah ini akan dibuat bentuk akhir dari class diagram. Dalam langkah ini perlu ditentukan kelas-kelas mana yang merupakan kelas persistence dan kelas transient. Yang dimaksud dengan kelas persistence ialah objek dari kelas akan disimpan secara permanen dalam database.
Sedangkan objek yang terbentuk secara temporer oleh sebuah program software disebut objek transient.
Gambar 2.5. Contoh Class Diagram
2.1.9 Pendeteksian Wajah
Metode yang digunakan untuk mendeteksi wajah lebih menekankan kepada teknik pembelajaran statistik dan penggunaan fitur penampilan, termasuk real-time Viola-Jones face detector, dimana metode ini dapat dikategorikan sebagai metode yang paling umum digunakan dalam mendeteksi wajah secara otomatis. Viola-Jones face
detector terdiri dari classifier yang di training oleh algoritma AdaBoost (Valstar, 2002).
Sebuah classifier itu sendiri berasal dari hasil training ratusan sampel gambar terhadap objek tertentu. Setelah classifier di training, classifier ini dapat diaplikasikan ke daerah-daerah dalam sebuah input gambar. Kemudian classifier ini akan menghasilkan output “1” pada daerah-daerah yang menyerupai objek yang digunakan |pada saat classifier di training, dan akan menghasilkan output “0” pada daerah lain yang dianggap tidak menyerupai objek tersebut (Maghraby et al, 2013).
Gambar 2.6. Berbagai jenis fitur Viola-Jones face detector
OpenCV hadir dengan filter cascade classifier yang terdiri dari lima jenis variasi pendeteksian wajah. Empat diantaranya dibuat berdasarkan Viola-Jones, menggunakan Ada-Boost dengan fitur Haar-like. Classifier yang kelima juga merupakan classifier yang ditraining oleh Ada-Boost, tetapi menggunakan fitur Local Binary Pattern (LBP). Fitur LBP dikenalkan oleh Ojala et al untuk mendeskripsikan pola tekstur lokal. Fitur LBP membuat deskripsi dari pixel berukuran 3x3 dengan melakukan threshold pada pixel bagian luar menggunakan nilai pada pixel tengah.
Gambar 2.7. Fitur LBP yang dibuat dengan melakukan threshold pada pixel tengah dari pixel berukuran 3x3.
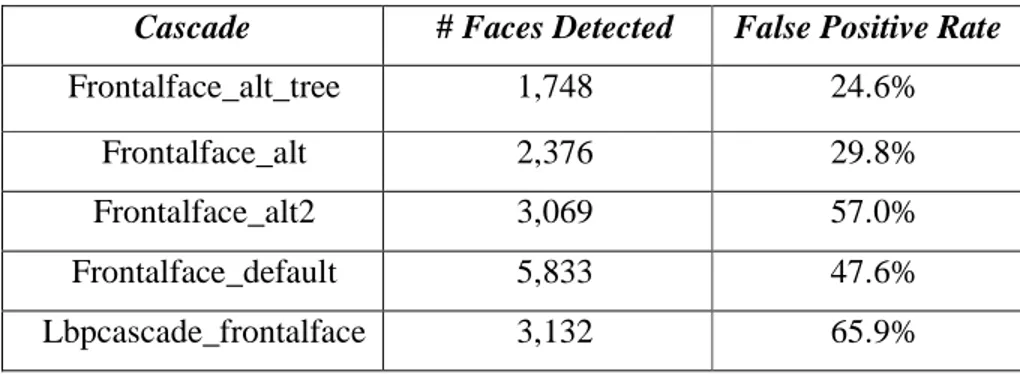
Tabel 2.3 Statistika Jumlah Wajah yang Terdeteksi dari 12.521 Gambar dengan Menggunakan Cascade yang Berbeda.
Cascade # Faces Detected False Positive Rate
Frontalface_alt_tree 1,748 24.6% Frontalface_alt 2,376 29.8% Frontalface_alt2 3,069 57.0% Frontalface_default 5,833 47.6% Lbpcascade_frontalface 3,132 65.9% 2.1.10 Pengolahan Citra
Pengolahan citra merupakan segala bentuk pengolahan sinyal yang mempunyai input sebuah citra dalam bentuk foto ataupun video dan menghasilkan output berupa citra yang telah diolah atau sekumpulan karakteristik yang berkaitan dengan citra tersebut. Sebagai besar teknik pengolahan citra dilakukan dengan menganggap citra sebagai sinyal dwimatra (2 dimensi) dan kemudian melakukan teknik pengolahan sinyal ke sinyal dwimatra tersebut (Byeong-Ho KANG, 2007).
Pengolahan citra sering dikaitkan sebagai pengolahan citra secara digital meskipun sebenarnya pengolahan citra dapat juga dilakukan secara analog dan optikal. Pengolahan citra secara digital mempunyai banyak kelebihan dibandingkan pengolahan citra secara analog. Kelebihannya antara lain semakin banyak algoritma yang dapat diterapkan dan dapat menghindari beberapa masalah seperti noise dan distorsi sinyal saat pengolahan (Manish Joshi, 2012).
Gambar 2.8. Penggunaan pengolahan citra untuk memisahkan objek manusia dengan latar belakang
Pada gambar 2.8 terlihat sebuah contoh dari pengolahan citra dimana objek manusia dapat dipisahkan dengan latar belakang. Untuk memisahkan objek tersebut, perlu dilakukan beberapa proses. Proses ini diklasifikasikan menjadi tingkat rendah, menengah dan tinggi. Proses pada tingkat rendah berkaitan dengan peningkatan citra (image enhancement), sedangkan proses pada tingkat menengah dilakukan segmentasi citra dan klasifikasi objek. Setelah tingkat rendah dan menengah, proses tingkat tinggi akan mencari objek tertentu yang ingin ditemukan (Zhou et al, 2010).
2.1.11 Pengenalan Wajah (Face Recognition)
Face recognition telah menjadi topik penting dalam berbagai aplikasi, seperti sistem keamanan, verifikasi kartu kredit, dan untuk mengidentifikasi pelaku kriminal. Sebagai contohnya, face recognition ini mampu untuk membandingkan suatu wajah tertentu dari sekumpulan wajah yang disimpan sehingga dapat membantu dalam mengindentifikasi pelaku kriminal (Dashore and Raj, 2012).
Face recognition adalah proses pengenalan pemilik dari wajah seseorang yang telah dikenali. Seperti bagaimana manusia mengenali keluarga mereka, teman, dan selebritis hanya dengan melihat wajah mereka, terdapat beberapa teknik bagi komputer untuk mengenali wajah
seseorang. Secara umum, teknik ini dibagi menjadi 4 langkah utama, antara lain:
1. Face Detection: suatu proses pencarian daerah yang terdapat wajah pada sebuah gambar. Dalam langkah ini, komputer hanya mendeteksi wajah tanpa perlu mengetahui siapa pemilik wajah tersebut.
Gambar 2.9. Face detection
2. Face Preprocessing: suatu proses mengatur gambar wajah agar terlihat semakin jelas dan menyerupai wajah lain. Face preprocessing sendiri dibagi menjadi beberapa bagian:
a. Transformasi geometri dan pemotongan gambar: proses ini terdiri dari pengaturan ukuran gambar, rotasi gambar, dan perpindahan gambar sehingga mata menjadi sejajar, dengan cara menghilangkan bagian kening, dagu, telinga, dan latar dari gambar wajah.
b. Pemerataan histogram pada sisi kiri dan kanan gambar: proses ini mengatur kecerahan dan kekontrasan pada sisi kiri dan kanan dari wajah.
c. Smoothing: proses ini mengurangi noise pada gambar menggunakan bilateral filter.
d. Elliptical mask: elliptical mask bertujuan untuk menghilangkan rambut dari wajah dan latar dari gambar wajah.
3. Collect and learn faces: suatu proses menyimpan banyak wajah preprocessing dan selanjutnya komputer belajar untuk mengenali gambar tersebut.
4. Face recognition: suatu proses memeriksa sekumpulan gambar yang paling menyerupai wajah pada kamera. (Baggio et al, 2012)
2.1.12 Pengenalan Ekspresi Wajah
Wajah menyimpan informasi berharga seperti emosi dan keinginan seseorang. Ekspresi wajah merupakan sarana alami dan langsung bagi manusia untuk berinteraksi dengan orang lain. Mereka berkomunikasi dengan emosi, menjelaskan dan menekankan apa yang ingin dikatakan, dan memahami sinyal yang diberikan orang lain, ketidaksetujuan dan keinginan (Ekman and Ronsenberg, 2005).
Ada dua pendekatan utama untuk mengenali ekspresi wajah dalam bidang psikologi, yaitu melalui pesan dan tanda-tanda yang dihasilkan oleh wajah (Cohn and Ekman, 2005). Pesan bertujuan untuk menyimpulkan apa yang mendasari ekspresi wajah seseorang, misalnya kepribadian orang tersebut, sementara tanda yang dihasilkan oleh wajah bertujuan untuk mendeskripsikan perilaku yang ditampilkan, seperti pergerakan wajah, atau bentuk komponen wajah (Pantic, 2009).
Facial Action Coding System (FACS) adalah pendekatan terbaik dan paling sering digunakan untuk mengenali ekpresi wajah dengan menggunakan tanda-tanda pada wajah. Secara umum FACS mendefinisikan 32 otot wajah yang diberi nama Action Unit (AU). Dengan FACS, setiap kemungkinan ekspresi wajah dapat dideskripsikan sebagai kombinasi dari AU dan himpunan kecil dari Action Descriptor (seperti pada gambar 2.11).
Gambar 2.11. Contoh AU yang terdeteksi menggunakan FACS
Secara umum, pengenalan ekspresi wajah terdiri dari 3 tahap, antara lain: pre-processing, feature extraction, dan classification. Tahap pre-processing berkaitan dengan lokalisasi, penelusuran dan pencatatan wajah untuk menghilangkan variabilitas yang terjadi karena adanya perubahan pose kepala dan pencahayaan. Feature extraction merupakan tahap yang paling penting agar pengenalan ekspresi wajah dapat sukses. Tujuan dari feature extraction adalah untuk mengubah data berbentuk pixel menjadi representasi tingkat yang lebih tinggi terhadap bentuk, gerakan, warna dan tekstur, yang meminimalkan variasi dalam kelas sembari memaksimalkan variasi antar kelas. Pada tahap classification bertujuan untuk mendeteksi action unit yang terdapat pada wajah.
2.2 Teori-teori Khusus
Berikut ini merupakan teori-teori khusus yang digunakan dalam penelitian: 2.2.1 OpenCV Library
OpenCV adalah sebuah library visi komputer yang open source dan dapat diperoleh dari http://sourceforge.net/projects/opencvlibrary. Library ini ditulis dalam bahasa C dan C++ yang dapat dioperasikan dalam OS Linux, Windows, Mac OS X.
OpenCV dirancang untuk efisiensi dalam komputasi dan mempunyai tujuan yang sangat kuat dalam membuat aplikasi secara real-time. Salah satu tujuan OpenCV ialah untuk menyediakan infrastruktur visi komputer yang mudah digunakan untuk menolong orang-orang dalam membuat aplikasi visi yang cukup canggih dan cepat. Library OpenCV mengandung lebih dari 500 fungsi yang mencakup area visi, termasuk keamanan, user interface, kalibrasi kamera, maupun robotika.
Sejak dirilis pada Januari 1999 dengan versi alpha, OpenCV telah banyak digunakan dalam banyak aplikasi, produk, dan menghasilkan penelitian. Aplikasi-aplikasi yang telah dibuat ini seperti aplikasi untuk menggabungkan gambar dalam satelit dan peta di halaman web, pengurangan noise pada gambar dalam medis, sistem keamanan dan pendeteksian gangguan, sistem pemantauan dan pengamanan secara otomatis, aplikasi militer, kendaraan udara, daratan, dan laut tanpa awak. Aplikasi ini juga digunakan untuk mengenali suara dan musik, dimana teknik pengenalan visi diterapkan pada gambar-gambar spektogram suara (Bradski and Kaehler, 2008).
2.2.2 Android NDK (Native Development Kit)
Android NDK adalah sebuah perangkat yang dapat menyisipkan komponen dengan menggunakan native library dari bahasa C/C++ dalam aplikasi android. Android NDK memungkinkan pengembang aplikasi android menggunakan kode native untuk performa atau bagian yang sangat penting dari aplikasi mereka dan juga agar pengembang aplikasi android dapat menggunakan kembali kode yang pernah ditulis dalam bahasa C (Sangchul Lee and Jae Wook Jeon, 2010).
Pengembang aplikasi android perlu mempertimbangkan keuntungan dan kerugian dalam menggunakan kode native. Menggunakan kode native tidak selalu meningkatkan performa aplikasi, melainkan biasanya kompleksitas dari aplikasi menjadi bertambah. Android NDK cukup efektif dalam pengoperasian CPU secara intensif, seperti simulasi physics, dan pengolahan sinyal. Hal ini terbukti efektif ketika menggunakan kembali kode yang pernah ditulis dalam bahasa C/C++ pada skala yang besar (Sangchul Lee and Jae Wook Jeon, 2010).
2.2.3 Eigenface
Metode eigenface untuk mengenali wajah manusia dapat terbilang bersih dan cukup sederhana. Konsep dasar dari metode eigenface adalah pengurangan informasi. Dari sebuah gambar kecil yang dievaluasi, terdapat banyak informasi yang bisa didapatkan. Sebagai contohnya, kita bisa mendapatkan informasi bahwa terdapat wajah seseorang dalam sebuah gambar. Berdasarkan informasi yang didapatkan, metode eigenface memecah gambar sehingga tidak lagi berfokus pada gambar secara keseluruhan melainkan langsung pada wajah. Untuk melakukan pemecahan ini perlu dibentuk ‘base-faces’ dan kemudian mengubah bentuk dari gambar-gambar yang dianalisa oleh komputer menjadi kombinasi linear dari ‘base-faces’. Dari ‘base-faces’ yang terbentuk maka kompleksitas masalah dari analisis gambar berkurang menjadi masalah umum yaitu pengelompokan. Setiap wajah dapat dikelompokan dengan memproyeksikan wajah menjadi ‘face-space’ dan kemudian menganalisanya sebagai vektor. Secara umum teknik eigenface dapat dikelompokan menjadi beberapa bagian :
a. Membuat eigenfaces
b. Memproyeksikan data training ke dalam ‘face-space’ yang kemudian dikelompokan dengan metode yang ditentukan terlebih dahulu (k-nearest-neighbor, neural network, atau simply Euclidian distance measure )
c. Melakukan evaluasi terhadap elemen yang di proyeksikan ke dalam ‘face-space’ dan membandingkannya dengan data yang di-training. (Sandhu et al, 2009)
2.2.4 Fisherface
Pendekatan fisherface telah berkembang secara luas sebagai metode untuk pengekstrasian fitur dalam gambar wajah. Konsep dasar dari fisherface adalah menentukan arah dari proyeksi dimana gambar-gambar yang diproyeksi ke berbagai kelas akan tersebar secara maksimal. Secara matematis, metode ini akan mencari matriks proyeksi (weights) agar rasio matriks penyebaran antar kelas dan matriks penyebaran dalam kelas dari gambar yang diproyeksi menjadi maksimal.
Diskriminan linier pada fisherface merupakan sebuah metode penspesifikasian kelas karena metode ini mencoba untuk menyatukan penyebaran agar dapat lebih mudah untuk dikelompokkan. Selain itu, diskriminan linier ini juga memaksimalkan rasio matriks dari penyebaran antar kelas dan penyebaran dalam kelas.
Metode fisherface sama seperti metode eigenface namun dengan peningkatan dalam mengelompokkan kelas gambar (classes image) yang berbeda-beda. Namun, pada fisherface yang menggunakan FLD (Fisher Linear Discriminant), pengelompokkan dapat dilakukan dengan berbagai pose dan dengan orang yang berbeda-beda. Tingkat akurasi yang dihasilkan oleh fisherface lebih baik jika dibandingkan dengan eigenface dalam berbagai pose. Selain itu, fisherface juga menghilangkan tiga komponen utama yang terpengaruhi oleh intensitas cahaya, sehingga fisherface lebih tidak mudah terpengaruh oleh cahaya (Sandhu et al, 2009).
Gambar 2.13. Hasil dari face recognition yang dilakukan dengan metode fisherface.
2.2.5 Local Binary Pattern Histogram (LBPH)
Ahonen et al (2004) menerapkan algoritma LBPH untuk melakukan pengenalan wajah dan mendapatkan hasil yang sangat baik dengan menggunakan database FERET. Dalam metode mereka, pertama-tama LBP histogram diekstrak terlebih dahulu, dan setelah itu gambar wajah dipecah menjadi bagian yang lebih kecil. Kemudian gambar wajah digabungkan kembali menjadi satu, dan dilakukan peningkatan histogram yang menggambarkan tekstur lokal dan bentuk wajah secara global. Pengenalan ini dilakukan menggunakan classifier nearest-neighbor (Ahonen et al, 2004).
Selanjutnya, Zhang et al (2004) mengindentifikasi dua kelemahan dari pendekatan Ahonen. Pertama, ukuran dari wilayah pada metode Ahonen terbatas atas posisi dan ukuran dari area lokal. Kedua, bobot dari daerah dioptimalkan secara manual. Oleh karena itu, Zhang dan kawan-kawan mengusulkan untuk menggunakan classifier boosting untuk memilih histogram diskriminatif dari area yang diperoleh dengan mengekstrasi LBP histogram dengan cara menggeser dan mengatur ukuran area disekitar intra-personal dan inter-personal wajah. Jika dibandingkan dengan metode yang dilakukan oleh Ahonen, metode ini lebih sedikit menggunakan histogram dan menghasilkan akurasi yang sama.
2.2.6 Active Shape Model (ASM)
Algoritma Active Shape Model (ASM) merupakan sebuah metode yang cepat dan tangguh dalam menyesuaikan sekumpulan titik yang diatur oleh sebuah bentuk model pada sebuah gambar (T.F. Cootes et al, 1999). Ketika melakukan pemodelan wajah, landmark terdiri dari titik-titik yang terletak disepanjang batas-batas bentuk fitur suatu wajah, misalnya mata, bibir, hidung, mulut, dan alis.
Tahap training dari ASM biasanya melibatkan pembangunan model wajah statistik dari sekumpulan training yang mengandung wajah
dimana model tersebut berisi gambar dengan landmark yang terhubung secara manual. Landmark yang digunakan isi terdiri dari 79 titik wajah seperti pada gambar 2.12. Data hasil training ini terdiri dari 500 gambar pada 115 subject yang terdapat pada database MBGC-2008. Bentuk kumpulan training ini kemudian digunakan untuk menghasilkan rata-rata bentuk wajah (J. C. Gower, 1975). Selanjutnya, model statistik pada tingkat grayscale yang terdapat di sekitar landmark dibangun dengan menggunakan profil 2D yang dihasilkan oleh sampling gambar pada area masing-masing persegi di sekitar landmark. Profil tersebut dihasilkan untuk setiap titik landmark pada gambar dan empat tingkatan yang berbeda dalam sebuah piramida gambar.
Pada tahap testing, implementasi OpenCV dari Viola Jones face detector (Intel, 2007) digunakan untuk mencari wajah dalam sebuah gambar. Ketika wajah terdeteksi, rata-rata wajah diubah ukuran, rotasi dan translasi dengan menggunakan kesamaan bentuk yang sesuai dengan gambar wajah yang telah diuji. Wajah dengan multi-level akan dibentuk dengan cara yang sama seperti pada tahap training. Landmark akan dipindahkan sampai tidak terdapat perubahan yang signifikan untuk mendapatkan wajah rata-rata yang paling sesuai. Proses ini berlanjut sampai konvergensi berada pada tingkat terbaik dimana landmark diperoleh. Gambar 2.15 mengilustrasikan proses fitting ASM dari suatu gambar yang tidak terlihat.
Gambar 2.15. Langkah-langkah pada tahap pengujian di ASM
2.2.7 Support Vector Machine (SVM)
Support Vector Machine merupakan metode klasifikasi suatu bidang yang diperkenalkan pada tahun 1992 oleh Boser, Guyon dan Vapnik (1992). Classifier SVM digunakan secara luas dalam bidang bioinformatika (dan bidang yang lain) karena tingkat akurasinya yang tinggi, serta kemampuan untuk menangani data berdimensi tinggi seperti ekspresi gen, dan fleksibilitas dalam pemodelan berbagai sumber data (B. Scholkopf et al, 2004).
SVM termasuk ke dalam kategori umum pada metode kernel (J. Shawe-Taylor, 2004). Sebuah metode kernel merupakan algoritma yang bergantung pada data yang memiliki produksi titik. Tetapi produksi titik dapat digantikan oleh sebuah fungsi kernel yang dapat menghitung produksi titik pada beberapa fitur dimensi yang tinggi. Dengan menggunakan fungsi kernel akan terdapat dua keuntungan: pertama, kemampuan untuk meng-generate batasan-batasan keputusan non-linear dengan menggunakan method yang didesign untuk classifier linear. Kedua, menggunakan fungsi kernel memungkinan pengguna untuk menggunakan classifier pada sebuah data yang tidak memiliki representasi ruang vektor dimensi tetap yang jelas. Contoh utama dari data tersebut yang berurutan misalnya DNA atau protein, dan struktur protein.
Tugas klasifikasi biasanya melibatkan pemisahan data kedalam data training dan testing. Setiap objek dalam data training mengandung sebuah “nilai target” (contoh label kelas) dan beberapa “attribute” (contoh variabel yang diutamakan atau diamati). Tujuan dari SVM ialah untuk menghasilkan sebuah model (berdasarkan data training) yang memprediksi nilai target dari data test yang hanya berupa attribute.
2.3 Related Works
2.3.1 Enhanced Local Texture Feature Sets for Face Recognition under Difficult Lighting Conditions
Tan dan Triggs (2009) mencoba untuk melakukan rekognisi / pengenalan wajah ketika kondisi cahaya tidak terkontrol. Mereka mengatasi hal tersebut dengan menggabungkan normalisasi pencahayaan yang kuat, representasi tekstur lokal berbasis wajah, penyesuaian transformasi jarak, ekstrasi fitur berbasis kernel, dan penyatuan dari banyak fitur. Dalam penelitiannya, Tan dan Triggs melakukan pengolahan citra yang dapat menghilangkan efek cahaya sebanyak mungkin tapi tetap dapat menjaga bagian detail citra yang akan dibutuhkan dalam proses pengenalan wajah. Tan dan Triggs juga memperkenalkan Local Ternary Patterns (LTP), sebuah pengembangan dari LBP yang dapat membedakan pixel-pixel dengan lebih baik dan cukup sensitif pada noise di wilayah yang rata. Tan dan Triggs menunjukan bahwa dengan mengganti perbandingan pada histogram spasial lokal dengan transformasi jarak yang memiliki kesamaan metrik, akan meningkatkan akurasi rekognisi wajah yang menggunakan LBP / LTP. Lebih lanjut Tan dan Triggs juga meningkatkan metode mereka dengan menggunakan Kernel PCA (Principal Component Analysis) pada saat mengekstraksi fitur dan menggabungkan Gabor wavelets dengan LBP. Gabungan dari Gabor wavelets dengan LBP ini menghasilkan akurasi yang lebih baik daripada Gabor wavelets atau LBP sendiri.
Hasil dari penelitian Tan dan Triggs diujikan pada dataset FRGC-204 (Face Recognition Grand Challenge versi 2, eksperimen ke-4) menghasilkan tingkat akurasi sebesar 88.1% dan 0.1% tingkat kesalahan yang diterima (False Accept Rate).
2.3.2 Fully Automatic Recognition of the Temporal Phases of Facial Actions Valstar dan Pantic (2012) melakukan penelitian dalam pengenalan ekspresi wajah berdasarkan action unit. Action unit merupakan pergerakan wajah terkecil yang dapat dilihat secara visual. Pada penelitian yang mereka lakukan, pertama-tama gambar dari video akan diproses untuk mencari posisi wajah pada gambar. Kemudian setelah mendapatkan posisi wajah pada gambar, akan dicari lokasi 20 titik acuan wajah (facial fiducial points) secara automatis dengan menggunakan classifier yang berbasiskan fitur Gabor.
Gambar 2.16. Lokasisasi titik acuan wajah
Kemudian lokasi setiap titik-titik wajah (facial points) akan dipantau secara berkelanjutan saat melakukan perubahan ekspresi.
Gambar 2.17. Pergerakan facial point
Data-data pergerakan facial points ini akan diklasifikasikan oleh Support Vector Machine dan disimpan sebagai sebuah action unit. Sejauh ini, Valstar dan Pantic telah mengembangkan 3 versi untuk mendeteksi pergerakan action unit, yaitu versi 2005, 2006 dan 2007. Versi 2005 dibuat dengan harapan dapat mendeteksi 15 action unit secara otomatis, namun versi ini belum sepenuhnya dapat mendeteksi secara otomatis
karena tidak dapat mendeteksi saat wajah mengalami perubahan ekspresi. Kemudian versi 2005 ini dikembangkan lagi, dan pada tahun 2006, Valstar dan Pantic berhasil sepenuhnya mendeteksi action unit pada wajah. Pada akhirnya Valstar dan Pantic berhasil mendeteksi 22 action unit dan mendeteksinya secara otomatis pada tahun 2007.
Gambar 2.18. Klasifikasi facial points menggunakan Support Vector Machine
Selanjutnya, untuk setiap action unit yang terdeteksi pada wajah, akan dibuat sebuah model aktivasi sementara yang berasal dari beberapa tahap (neutral, onset, apex, offset). Action unit pada beberapa tahap ini diklasifikasikan oleh Support Vector Machine untuk menentukan ekspresi wajah.
Gambar 2.19. Aktivasi AU pada saat neutral, onset, apex, dan offset.
Hasil dari penelitian yang dilakukan oleh Valstar kemudian diujikan dan menghasilkan persentase pengenalan Action Unit sebesar
95.3% pada citra yang menampilkan ekspresi wajah dan sebesar 72% pada citra yang menampilkan ekspresi wajah secara spontan.
2.3.3 A Dynamic Appearance Descriptor Approach to Facial Actions Temporal Modelling
Jurnal ini dibuat oleh Bihan Jiang, Michel Valstar, Brais Martinez dan Maja Pantic (2011). Pada penelitian ini, terdapat pendekatan baru untuk analisa eksplisit dinamika temporer pada gerakan yang dihasilkan oleh wajah dengan menggunakan sebuah descriptor yang dapat mendeskripsikan perubahan dinamis pada wajah yang dinamakan Local Phase Quantisation dari Three Orthogonal Planes (LPQ-TOP). Sampai saat ini, sebagian besar sistem pengenalan ekspresi wajah hanya menggunakan descriptor statis, dimana jika terdapat perubahan gerakan pada wajah dan informasi lain yang terkait akan diabaikan. Jurnal ini membahas keterbatasan tersebut dengan dengan memperluas descriptor LPQ yang statis menjadi Three Orthogonal Planes (TOP) yang terinspirasi dari perluasan serupa pada Local Binary Patterns, LBP-TOP. Ekspreminen ini telah menunjukkan bahwa LPQ-TOP sangat cocok untuk masalah pendeteksian sementara action unit (AU) dan dapat mencapai pendeteksian aktivasi action unit (AU). Namun pada saat diujikan pada dataset GEMEP-FERA, Jiang et al menyimpulkan bahwa pose kepala yang tidak bervariasi menjadi kendala yang perlu diselesaikan.