PENERAPAN ALGORITMA ID3 UNTUK PREDIKSI MINAT STUDI MAHASISWA TEKNIK INFORMATIKA PADA UNIVERSITAS DIAN NUSWANTORO - UDiNus Repository
Teks penuh
Gambar
![gambar proses siklus pada hidup pengembangan CRISP-DM [8]:](https://thumb-ap.123doks.com/thumbv2/123dok/899379.613599/8.595.188.457.477.717/gambar-proses-siklus-pada-hidup-pengembangan-crisp-dm.webp)
Dokumen terkait
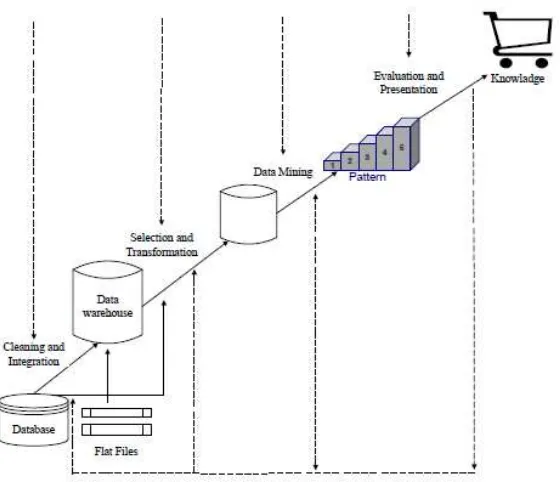
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database atau sering disebut Knowledge Discovery in Database
pengguna diharuskan mengimpor dataset sebagai inputan untuk proses mining, setelah pengguna berhasil melakukan proses mining, hasil proses yang terbentuk dapat
Menyatakan bahwa karya ilmiah saya yang berjudul:* PENERAPAN ALGORITMA ID3 UNTUK PREDIKSI MINAT STUDI MAHASISWA TEKNIK INFORMATIKA PADA UNIVERSITAS DIAN NUSWANTORO
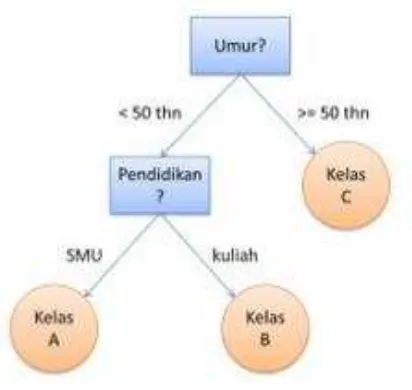
minat apa yang sesuai dengan bakat sehingga mereka memilih minat studi.. berdasarkan yang paling banyak di pilih
Istilah data mining dan knowledge discovery in databases (KDD) seringkali digunakan untuk menjelaskan proses penggalian informasi yang tersembunyi dalam suatu
Dalam menganalisis data pada penelitian ini menggunakan Teknik analisis data mining menggunakan proses tahapan knowledge discovery in databases (KDD) yang terdiri
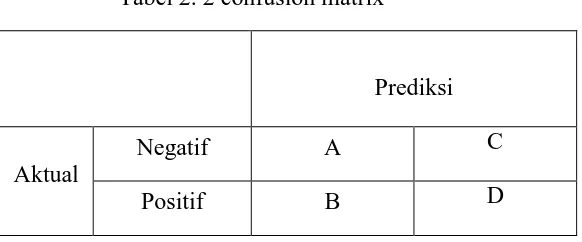
Adalah tahap penilaian secara objektif yang dilakukan dengan penyerahan program dan pengisian kuisoner seputar performa program prediksi data mining pada mahasiswa
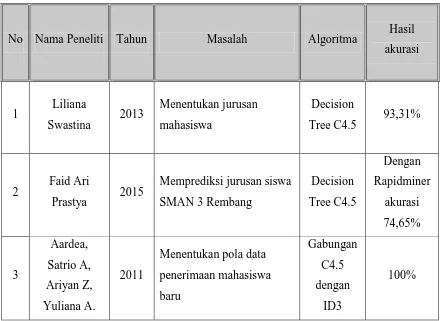
Pada penelitian sebelumnya yang dilakukan terhadap penggunaan Data Mining dalam memprediksi suatu kasus dan memiliki kesamaan pada penelitian yang akan diajukan di antaranya adalah
