LAPORAN PENELITIAN
Oo
Oleh :
Dra. Nonong Amalita, M.Si
Drs. Lutfian Almash, MS
Yenni Kurniawati, S.Si, M.Si
PROGRAM STUDI STATISTIKA
JURUSAN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS NEGERI PADANG
2012
STATISTIKA
Penerapan Regresi Dummy dalam Memprediksi Performansi
Akademik Mahasiswa
HALAMAN PENGESAHAN PROPOSAL PENELITIAN DOSEN PEMULA
1.
Judul Penelitian
: Penerapan Regresi Dummy dalam Memprediksi
Performansi Akademik Mahasiswa
(Studi Kasus Pada Mahasiswa Jurusan Matematika
FMIPA UNP)
2.
Bidang Penelitian
: Statistika
3.
A. Ketua Peneliti
1.
Nama Lengkap
: Dra. Nonong Amalita. M.Si
2.
Jenis Kelamin
: Perempuan
3.
NIP
: 19690615 199303 2 001
4.
Disiplin Ilmu
: Statistika
5.
Pangkat / Golongan
: Penata Tk I / III d
6.
Jabatan Fungsional
: Lektor
7.
Fakultas / Jurusan
: FMIPA/ Matematika
8.
Alamat
: Jl. Prof. Dr.Hamka Air Tawar Padang
9.
Telepon/Faks/E-mail :
(0751)
7057420
10.
Alamat Rumah
: Perum. Griya Insani Ambacang B/6 Padang
11.
Telepon/Faks/E-mail :
08126636820/-/
B. Anggota
: 1. Drs. Lutfian Almash, MS
2. Yenni Kurniawati, S.Si, M.Si
4.
Lokasi Penelitian
: Jurusan Matematika FMIPA UNP
Jumlah Biaya Penelitian`
: Rp. 4.000.000,-
(Empat Juta Rupiah)
Padang, 14 Maret 2013
Disetujui
Oleh,
Ketua
Peneliti
Dekan FMIPA UNP
Prof. Dr. Lufri, MS
Dra. Nonong Amalita, M.Si
NIP. 19610510 198703 1 002
NIP. 19690615 199303 2 001
Mengetahui,
Ketua Lembaga Penelitian
Universitas Negeri Padang
RINGKASAN
Pendidikan Tinggi sebagai lembaga pencipta generasi yang berkualitas, selalu berusaha
meningkatkan mutu lulusannya agar menghasilkan lulusan yang mampu bersaing diera
globalisasi. Salah satu indikator yang dapat dijadikan sebagai penentu dalam mutu pendidikan
tinggi adalah prestasi akademik atau IPK yang dicapai mahasiswa. Keberhasilan suatu perguruan
tinggi dalam menghasilkan output yang bagus dapat dilihat dari prestasi akademik. Input
merupakan sumberdaya yang akan ditransformsi menjadi output. Kualitas input mahasiswa yang
di terima oleh Jurusan Matematika FMIPA UNP juga dapat mempengaruhi kualitas outputnya.
Salah satu parameter untuk mengukur kualitas input mahasiswa dari sisi akademik adalah nilai
Ujian Nasional (UN). Indikator lain yang diasumsikan dapat mengukur kualitas input mahasiswa
adalah asal sekolahnya yang digambarkan dengan status asal sekolah (negeri / swasta). Selain
dari parameter di atas, ada beberapa parameter yang juga dianggap dapat mempengaruhi IPK
mahasiswa, yaitu jenis jalur masuk dan jenis kelamin dari mahasiswa. Penerimaan mahasiswa
pada jurusan matematika saat ini dibagi atas 4 jenis jalur masuk, yaitu PMDK, SMPTN, Seleksi
UNP, BIDIK MISI. Karena peubah yang dianggap dapat mempengaruhi IPK ini memiliki 2
jenis peubah, yaitu kuantitatif dan kualitatif, maka pada penelitian ini akan dibentuk model
regresi dummy untuk melihat keterkaitan antar peubah-peubah.
Dummy (Peubah boneka) merupakan cara yang sederhana untuk mengkuantifikasi peubah
kualitatif dalam model regresi. Untuk peubah kualitatif yang mempunyai k kategori bisa
dibangun k-1 peubah boneka. Pendugaan parameter dan uji inferensinya sama dengan analisis
regresi linier sederhana. Ketika faktor interaksi dimasukkan dalam model maka bisa
membandingkan fungsi regresi untuk masing-masing kategori. Persamaan regresi dummy untuk
setiap angkatan 2009-2011 digambarkan sebagai berikut:
a.
Angkatan 2009
IPK = 3,95 - 0,287 UN Mat - 0,922 D1(1=L) - 1,11 D3(SNM) + 0,118 D1X + 0,174 D2X + 0,183 D3X
b.
Angkatan 2010
IPK = - 14,6 + 1,92 UN Mat + 16,7 D2(1=N) + 3,37 D3(SNM) + 0,389 D4(PMDK)- 0,0321 D1X - 1,82 D2X - 0,339 D3X
c.
Angkatan 2011
Dari ketiga persamaan diatas, Nilai UN Matematika ternyata tidak menjadi faktor penentu
kualitas calon mahasiswa dari jurusan matematika FMIPA UNP. Walaupun selama tahun
2010-2011 rata-rata nilai UN matematika dari mahasiswa meningkatbdari pada tahun sebelumnya,
namun pada tingkat IPK dua angkatan ini tidak sebanding dengan nilai rata-rata UN yang
diperoleh. Oleh karena itu, dalam usaha peningkatan input dari jurusan perlu kajian mendalam
lagi, sehingga nilai UN tidak lagi menjadi dasar utama dalam menyaring calon mahasiswa.
1
BAB I
PENDAHULUAN
A.
Latar Belakang
Pendidikan Tinggi sebagai lembaga pencipta generasi yang berkualitas,
memiliki misi membentuk manusia berbudaya, berkemampuan, profesional dan
mampu mengembangkan potensinya melalui peningkatan mutu (Afifuddin, 2004).
Setiap Perguruan Tinggi berusaha meningkatkan mutu lulusannya, agar
menghasilkan lulusan yang mampu bersaing di era globalisasi sekarang ini. Salah
satu indikator yang dapat dijadikan sebagai penentu dalam mutu pendidikan tinggi
adalah prestasi akademik dari mahasiswa atau lulusan Pergurugan Tinggi tersebut.
Indeks Prestasi Komulatif (IPK) merupakan salah satu tolak ukur dalam prestasi
akademik tersebut.
IPK lulusan juga dapat mencerminkan performansi dari suatu Perguruan
Tinggi, karena IPK merupakan hasil komponen pendidikan yang diperoleh
mahasiswa selama menempuh jenjang perkuliahan. Komponen-komponen
pendidikan dapat berupa komponen konteks pendidikan, komponen input,
komponen proses, komponen output dan komponen outcome (Nastuti, 2010).
Semua komponen tersebut saling mempengaruhi dalam pencapaian kualitas suatu
perguruan tinggi. Seperti pada kualitas input mahasiswa yang diterima oleh
sebuah perguruan tinggi yang tentunya akan menjadi salah satu faktor yang
mempengaruhi kualitas outputnya.
Lulusan Perguruan Tinggi merupakan output dari suatu proses pendidikan.
Keberhasilan suatu perguruan tinggi dalam menghasilkan output yang bagus dapat
dilihat dari prestasi akademik. Input merupakan sumberdaya yang akan
ditransformsi menjadi output. Dalam arti sempit input ini merupakan calon
mahasiswa. Output yang akan dicapai pada umumnya digolong menjadi dua, yaitu
output prestasi akademik
(academic achievement)
dan prestasi non-akademik
(non-academicachievement).
Prestasi ini dapat tercapai apabila sekolah memiliki
proses belajar mengajar efektivitas tinggi, manajemen baik, lingkungan aman
tertib, pengelolaan tenaga kependidikan efektif, memiliki budaya mutu, mandiri,
2
perbaikan berkesinambungan,
trend setter
, komunikasi yang baik (Anonimous,
2003).
Jurusan Matematika sebagai salah satu jurusan favorit yang dimiliki oleh
Universitas Negeri Padang setiap tahun menghasilkan lulusan yang memiliki
kompetensi dalam bidangnya. Melalui penyaringan input atau calon mahasiswa
tentunya diharapkan mahasiswa yang diterima pada Jurusan Matematika memiliki
kualitas yang baik dari segi akademik. Karena kualitas input mahasiswa yang di
terima oleh sebuah jurusan juga dapat mempengaruhi kualitas outputnya. Salah
satu parameter untuk mengukur kualitas input mahasiswa dari sisi akademik
adalah nilai Ujian Nasional (UN). Indikator lain yang diasumsikan dapat
mengukur kualitas input mahasiswa adalah asal sekolahnya yang digambarkan
dengan status asal sekolah (negeri / swasta).
Selain parameter di atas, ada beberapa parameter yang juga dianggap dapat
mempengaruhi IPK mahasiswa, yaitu jenis jalur masuk dan jenis kelamin dari
mahasiswa. Penerimaan mahasiswa pada jurusan matematika saat ini dibagi atas 4
jenis jalur masuk, yaitu PMDK, SMPTN, Seleksi UNP, BIDIK MISI. Karena
peubah yang dianggap dapat mempengaruhi IPK ini memiliki 2 jenis peubah,
yaitu kuantitatif dan kualitatif, maka pada penelitian ini akan dibentuk model
regresi dummy untuk melihat keterkaitan antar peubah-peubah.
Dummy variable
(Peubah boneka) merupakan cara yang sederhana untuk
mengkuantifikasi peubah kualitatif dalam model regresi. Untuk peubah kualitatif
yang mempunyai k kategori bisa dibangun k-1 peubah boneka. Pendugaan
parameter dan uji inferensinya sama dengan analisis regresi linier sederhana.
Ketika faktor interaksi dimasukkan dalam model maka kita bisa membandingkan
fungsi regresi untuk masing-masing kategori.
Dalam analisis regresi sering kali bukan hanya peubah penjelas kuantitatif
yang mempegaruhi peubah tak bebas (Y), tetapi ada juga peubah kualitatif yang
ikut juga mempengaruhi (Gasperz, V, 1996). Oleh karena itu, peubah dummy
digunakan sebagai upaya untuk melihat bagaimana klasifikasi-klasifikasi dalam
sampel berpengaruh terhadap parameter pendugaan. Peubah dummy mencoba
3
Penelitian ini menerapkan analisis regresi dummy untuk memprediksi IPK
mahasiswa Jurusan Matematika, sehingga diperoleh model terbaik dalam
memprediksi performansi akademik mahasiswa. Asumsi indikator yang
mempengaruhi IPK adalah nilai matematika UN, status asal sekolah, jenis jalur
masuk dan jenis kelamin. Nilai UN merupaka peubah kuantitatif, sedangkan
peubah kualitatif adalah status asal sekolah, jenis jalur masuk, dan jenis kelamin.
B.
Perumusan Masalah
Berdasarkan uraian pada pendahuluan di atas, maka dapat dikemukakan
rumusan masalah sebagai berikut:
1.
Bagaimana membentuk model regresi dummy dari peubah-peubah bebas
yang diasumsikan?
2.
Bagaimana memperoleh model terbaik dari regresi dummy?
3.
Apakah peubah-peubah bebas yang diasumsikan berpengaruh signifikan
terhadap IPK mahasiswa jurusan matematika?
C.
Tujuan Penelitian
Tujuan Penelitian ini adalah untuk:
1.
Membentuk model regresi dummy dari peubah-peubah bebas yang
diasumsikan?
2.
Memperoleh model terbaik dari regresi dummy?
3.
Menentukan peubah-peubah bebas yang berpengaruh signifikan terhadap
4
BAB II
TINJAUAN PUSTAKA
Dalam melengkapi pemahaman mengenai regresi
dummy
, perlu dikaji
analisis regresi berganda terlebih dahulu, kemudian proses kodifikasi peubah
dummy dan model regresi dummy.
A.
Analisis Regresi Linear Berganda
Pada setiap pengamatan, yang diwakili pengamatan ke
i
, berlaku persamaan :
Y
i=
β
0+
β
1X
1i+
β
2X
2i+
β
3X
3i+ … +
β
pX
pi+
ε
i(1)
Sistem persamaan (1) dapat ditulis dalam bentuk matrik, dengan mendefinisikan
matrik-matrik berikut:
atau dapat ditulis dalam bentuk matrik sebagai berikut :
Y = X
β
+
(3)
Berdasarkan asumsi yaitu
~ 0,
, maka kita dapat menulis
persamaan (1) dalam bentuk nilai harapan :
5
Pada analisis regresi linier berganda ada beberapa uji asumsi klasik yang
harus dipenuhi, yaitu asumsi kenormalan galat, heteroskedasitas, autokorelasi dan
multikoliniritas.
1.
Uji Kenormalan.
Berdasarkan teori statistika model linier hanya peubah dependen dan galat
yang mempunyai distribusi dan dapat diuji normalitasnya. Sedangkan peubah
independen diasumsikan bukan merupakan fungsi distribusi, jadi tidak perlu diuji
normalitasnya. Salah satu cara untuk menguji kenormalan data yaitu dengan uji
Kolmogorov-Smirnov.
Hipotesis:
H
0: Peubah menyebar mengikuti sebaran normal
H
1: Peubah menyebar tidak mengikuti sebaran normal
Selain itu kenormalan data dapat juga dideteksi dari penyebaran data (titik)
pada sumbu diagonal pada kertas peluang. Jika data menyebar di sekitar garis
diagonal dan mengikuti arah garis histograf menuju pola distribusi normal, maka
model regresi memenuhi asumsi normalitas (Sukestiyarno, 2008).
2.
Uji Heteroskedastisitas
Heteroskedastisitas terjadi apabila
error
atau
residual
dari model yang
diamati tidak memiliki varian yang konstan dari satu observasi ke observasi
lainnya. Pengujian heteroskedastisitas dilakukan dengan melihat diagram
residual
terhadap peubah bebas pada output Scatterplot. Jika nilai
error
membentuk pola
tertentu tidak bersifat acak terhadap nol maka dikatakan terjadi heteroskedasti
(Sukestiyarno 2008).
3.
Uji Autokorelasi
Uji autokorelasi bertujuan menguji apakah dalam model regresi linier ada
korelasi antar
error
satu dengan
error
yang lainnya. Ada beberapa cara untuk
mendeteksi gejala autokorelasi yaitu uji Durbin Watson (DW test), uji Langrage
Multiplier (LM test), uji statistik Q, dan Run Test.
4.
Uji Multikolinearitas
Uji multikolinearitas bertujuan untuk menguji apakah model regresi
ditemukan adanya korelasi antara peubah bebas. Jadi uji multikolinearitas terjadi
6
korelasi tinggi diantara peubah bebas. Gejala multikolinearitas dapat dideteksi
dengan melihat nilai
Variance Inflasi Factor
(VIF). Multikolinearitas terjadi jika
VIF berada di atas 10 (Sukestiyarno 2008).
B.
Estimasi Parameter dan Pengujian Hipotesis
Estimasi parameter dapat kita peroleh dengan menggunakan metode kuadrat
terkecil, sehinnga dari bentuk persamaan (3) dapat kita tulis dalam bentuk matriks
yaitu :
1
1
1
1
1
1
1
1
1
X’X = X’Y
(6)
Solusi dari persamaan di atas adalah dengan mengalikan kedua ruas dengan
(X’X)
-1didapatkan :
= (X’X)
-1X’Y
(7)
Uji keseluruahan parameter regresi sebagai berikut:
H
0:
β
1=
β
2….=
β
k= 0
H
1: minimal ada satu
β
j≠
0
Jumlah kuadrat total (JKT) merupakan penjumlahan dari jumlah kuadrat regresi
(JKR) dan jumlah kuadrat kesalahan (JKG), atau dapat ditulis:
JKT = JKR + JKG
(8)
Statistik uji :
F =
JKR/ R
JKG/ G
=
KTR
KTG
H
0ditolak jika F > F
(α,
k, n-k-1)Dengan meminimumkan jumlah kuadrat kesalahan, maka diperoleh :
7
JKT =
∑
2(10)
Oleh karena itu JKR = ’X’Y –
∑(11)
Tabel 1. Analisis Ragam dalam Analisis Regresi Linier Berganda
Sumber
Keragaman
Jumlah
Kuadrat (JK)
Derajat Bebas
(db)
Kuadrat Tengah
(KT)
F
hitRegresi JKR
K
KTR=JKR/k KTR/KTG
Galat JKG n-k-1 KTG=JKG/n-k-1
Total JKT n-1
Bila peubah bebas dimasukkan satu per satu secara bertahap ke dalam suatu
persamaan regresi, maka dilakukan uji F sekuensial (Draper dan Smith,1982).
Untuk menguji apakah signifikan atau tidak dalam model, maka dapat
dilakukan degan mempartisi koefisien regresi seperti di bawah ini :
Hipotesis pengujian:
H
0:
0
H
1:
0
Model (3) dapat ditulis menjadi :
Y = X
(13)
Untuk model (12), berdasarkan persamaan (7) diperoleh:
JKR = ’X’Y –
∑dan KTG =
Untuk menguji bahwa H
0:
0
adalah benar, maka model (13) direduksi
menjadi:
Y
=
(14)
penduga kuadrat terkecil dari
yang direduksi dalam model (14) tersebut adalah
:
(X
1’X
1)
-1X
1’Y dengan JKR(
) =
X
1’Y -
∑
8
Jumlah kuadrat regresi untuk
apabila
dimasukkan ke dalam model:
JKR(
|
) = JKR ( ) – JKR(
Statistik ujinya:
F
hit=
| /
H
0ditolak jika F
hit>
, ,Sedangkan pengujian hipotesis untuk parameter koefisien regresi secara
individual dapat dilakukan dengan menggunakan uji parsial. Dengan hipotesis
berikut:
H
0:
β
j= 0
H
1:
β
j≠
0
Statistik uji :
t
hit=
H
0ditolak jika
|t
hit| > t
(α/2; n-k-1)Koefisien determinasi berganda R
2mengukur proporsi keragaman total
dalam peubah tak bebas Y yang dapat dijelaskan oleh model persamaan regresi
secara bersama. Besaran koefisien determinasi ditentukan oleh formula :
R
2=
JKRJKT
C.
Analisis Regresi dengan Peubah Kualitatif
Ada banyak cara untuk membangun model regresi yang peubah bebasnya
mengandung peubah kualitatif, salah satunya adalah menggunakan peubah
boneka. Misalnya jika ingin memperkirakan nilai peubah Y yang dipengaruhi
oleh satu peubah kuantitatif (X) dan satu peubah bebas kualitatif yang mempunyai
9
Peubah dummy digunakan sebagai upaya untuk melihat bagaimana
klasifikasi-klasifikasi dalam sampel berpengaruh terhadap parameter pendugaan.
Peubah dummy juga mencoba membuat kuantifikasi dari peubah kualitatif.
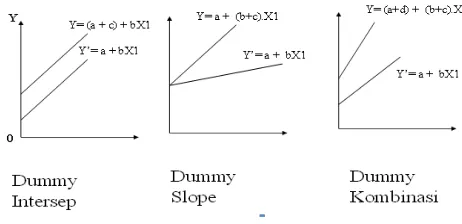
Beberapa jenis model dummy:
I. Y = a + bX + c D1 (Model Dummy Intersep)
II. Y = a + bX + c (D1X) (Model Dummy Slope)
III. Y = a + bX + c (D1X) + d D1 (Model Dummy Intersep dan Slope)
Penentuan pendugaan model yang sesuai dapat dilihat secara visual dengan
sebaran data (plot)nya. Bentuk sebaran datan yang sesuai dengan model
dugaannya dapat dilihat dalam gambar berikut :
Gambar 1. Model-model plot yang menggambarkan regresi dummy
D.
Pemilihan Model Terbaik
Prosedur-prosedur yang dapat digunakan dalam membentuk model
terbaik adalah: (1) semua kemungkinan regresi
(all possible regression)
dengan menggunakan tiga kriteria:
R
2, s
2,
dan
C
pMallow, (2) regresi
himpunan bagian terbaik
(best subset regression)
dengan menggunakan
R
2, R
2(terkoreksi), dan Cp, (3) eliminasi langkah mundur, (4) regresi bertatar
(step-wise regression).
1.
Prosedur Semua Kemungkinan Regresi
(All Possible Regression)
Pertama-tama prosedur ini menentukan semua kemungkinan persamaan
regresi.Setiap persamaan regresi harus dievaluisi menurut kriterium tertentu,
tiga kriteria yang akan dibahas adalah
a.
nilai
R
2yang dicapai,
10
regresi, nilai R
2yang besar menjadi salah satu bahan pertimbangan dalam
memilih model terbaik.
b.
nilai s
2, sebagai pertimbangan adalah jumiah kuadrat sisa yang terkecil.
c.
statistik
C
p.
Model "terbaik" ditentukan setelah memeriksa tebaran Cp. Sebagai bahan
pertimbangan adalah persamaan regresi dengan nilai Cp rendah yang kira-kira
sama dengan p (banyaknya parmeter dalam model termasuk
β
o) .
2.
Prosedur Regresi "Himpunan Bagian Terbaik"
("Best Subset"
Regression)
Tiga kriteria dapat digunakan untuk menentukan himpunan bagian
"K
terbaik", yaitu:
a.
Nilai
R2
maksimum,
b.
Nilai
R2
terkoreksi maksimum
R2
terkoreksi = 1- (1-R2){(n-1)/n-p)}
c.
Statistik
Cp
Mallows yang rendah yang kir-kira sama dengan p.
3.
Prosedur Eliminasi Langkah Mundur (
Backward Elimination
)
Tahap pemilihannya :
a.
Tuliskan persamaan regresi yang mengandung semua variabel
b.
Hitung nilai t parsialnya
c.
Banding nilai t parsialnya
i.
Jika t
L< t
Omaka buang variabel L yang menghasilkan t
L, kemudian
hitung kembali persamaan regresi tanpa menyertakan variabel L
ii.
Jika t
L> t
Omaka ambil persamaan regresi tersebut
4.
Prosedur Regresi Bertatar (Stepwise Regression)
Prosedure ini dilakukan dengan menambahkan satu variabel independen
pada setiap step dalam model. Pada prosedur ini, setiap step dilakukan :
a.
Pembentukan persamaan regresi
b.
Penambahan atau penghapusan suatu variabel independen
11
1)
Variabel independen yang menjelaskan paling besar variasi dari variabel
dependen yang akan masuk model pertama kali.
2)
Variabel selanjutnya yang menjelaskan paling besar variasi dengan
variabel pertama yang masuk model, dan seterusnya.
3)
Statistik F-parsial digunakan untuk mengevaluasi apakan suatu variabel
tetap dipertahankan dari model atau dikeluarkan dari model.
12
BAB III
TUJUAN, LUARAN DAN KONTRIBUSI PENELITIAN
Tujuan dari penelitian ini adalah:
1.
Membentuk model yang menggambarkan performance mahasiswa jurusan
matematika menggunakan regresi dummy.
2.
Memperoleh model terbaik dari semua kemungkinan regesi dummy.
3.
Mengkaji faktor-faktor yang mempengaruhi nilai IPK mahasiswa Jurusan
Matematika UNP.
Target luaran yang ingin dicapai dari penelitian ini adalah publikasi ilmiah
dalam jurnal lokal yang mempunyai ISSN atau jurnal nasional terakreditasi.
Kemudian diharapkan hasil penelitian ini juga dapat diseminarkan dan dimuat
dalam proseding dalam
seminar ilmiah baik yang berskala lokal, regional maupun
nasional.
Kontribusi penelitian ini adalah 1) memberikan tambahan wawasan
terutama bagi penulis sendiri tentang model regresi dummy. 2) memberikan
informasi bagi pihak-pihak terkait dalam peningkatan performansi Jurusan
Matematika di masa akan datang, 3) bahan masukkan bagi peneliti selanjutnya
dalam mengembangkan cakupan penelitian ini dengan menggunakan penerapan
13
BAB IV
METODE PENELITIAN
Penelitian dibagi menjadi 5 tahapan. Tahapan 1 melakukan pengumpulan
data penelitian berupa data nilai UN mahasiswa pada jurusan matematika, jenis
jalur masuk, status asal sekolah, dan jenis kelamin. Sebagai peubah terikatnya
diambil data nilai IPK mahasiswa dari angkatan 2009, 2010 dan 2011.
Keterbatasan dalam pengumpulan data penelitian, mengakibatkan data pada
penelitian ini tidak lengkap. Pada angkatan 2009, data yang tersedia hanya 68 dari
120 mahasiswa yang terdaftar. Data yang tersedia untuk mahasiswa angkatan
2010 dan 2011 masing-masing adalah 118 dari 160 dan 105 dari 150. Oleh karena
itu, diperlukan penentuan ukuran sampel dalam penelitian ini, maka pada tahapan
ke dua adalah menentukaan jumlah sampel yang akan digunakan dalam penelitian
menggunakan persamaan:
⁄
(Walpole, 1995)
. Berdasarkan persamaan tersebut, dengan nilai g = 0,1 dan Z
α/2= 1, 96
maka diperoleh banyak sampel pada penelitian ini yaitu 47, 62, dan 68 sampel.
Namun dalam proses pengambilan data sampel dilakukan pembulatan ukuran
sampel yaitu masing-masing 50, 65, dan 70 sampel. Setelah ukuran sampel
ditentukan kemudian sampel dipilih secara acak yang dibutuhkan dalam
penelitian.
Tahapan ke tiga adalah kodifikasi peubah kualitatif ke dalam peubah
dummy. Peubah bebas jenis kelamin dan status asal sekolah memiliki 2 kategori,
sehingga masing-masing peubah kualitatif tersebut dapat ditransformasi kedalam
satu peubah dummy. Sedangkan peubah status jalur masuk membentuk 3 peubah
dummy karena peubah tersebut terdiri dari 4 kategori. Kemudian pada tahapan ke
empat, melakukan pengolahan data dengan metode analisis regresi
dummy.
Tahapan terakhir dalam penelitian ini dalah menentukan model dummy terbaik
yang dapat menggambarkan hubungan setiap peubah bebas terhadap peubah tak
bebas (Y). Sehingga dapat diperoleh model yang dapat menggambarkan IPK
14
B AB V
HASIL DAN PEMBAHASAN
A.
Deskriptif data
Nilai Ujian Nasional merupakan salah satu indikator yang menjadi cerminan
kualitas dari input suatu perguruan tinggi, sehingga kualitas calon mahasiswa
dapat dilihat dari prestasi dalam bidang pendidikan yang diraihnya pada jenjang
pendidikan sebelumnya. Dari angkatan 2009, 2010, dan 2011 terlihat bahwa
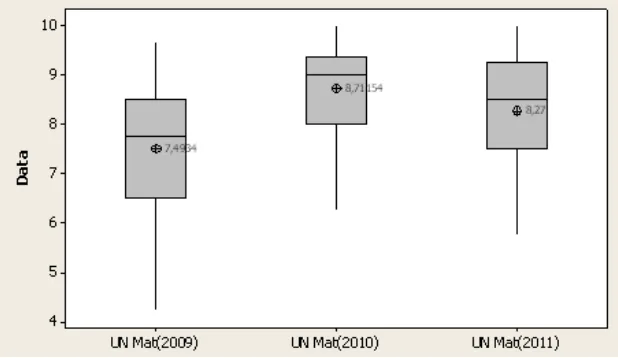
rata-rata nilai UN Matematika relatif tinggi. Hal ini terlihat pada Gambar 2, dimana
rata-rata nilai UN matematika untuk ketiga angkatan ini berturut-turut adalah
7,493; 8,711 dan 8,27. Rata-rata nilai UN Matematika tertinggi terdapat pada
angkatan 2010, kemudian diikuti oleh angkatan 2011 dan 2009.
Gambar 2. Boxplot Nilai UN Matematika Mahasiswa Angkatan 2009-2011
Boxplot pada Gambar 2 memperlihatkan keragaman terbesar dialami pada
mahasiswa angkatan 2009, dengan simpangan baku sebesar 1,21. Angkatan 2011
juga memiliki ragam yang cukup besar dibandingkan angkatan 2010, yaitu
masing-masing 1,046 dan 0,931. Kondisi ini memperlihatkan rata-rata input
mahasiswa pada angkat 2010 lebih tinggi dan relatif seragam dibandingkan
dengan 2 angkatan lainnya.
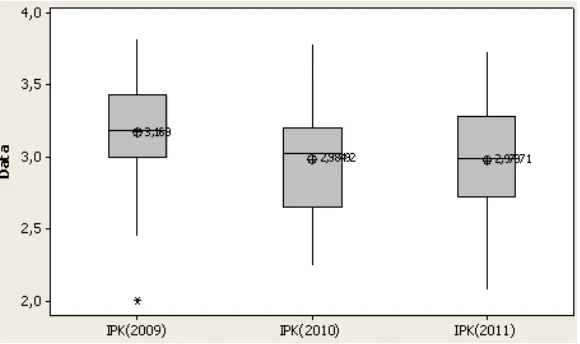
IPK yang dihasilkan oleh mahasiswa jurusan Matematika sampai dengan
semester genap (Januari – Juni) 2012 digambarkan oleh Boxplot pada gambar 3.
Berdasarkan sampel yang dianalisis, ternyata nilai rata-rata IPK untuk masing-
15
tertinggi dicapai oleh angkatan 2009, sedangkan untuk angkatan 2010 dan 2011,
nilai rata-rata IPK tidak terlalu jauh berbeda. Kondisi ini berbanding terbalik
dengan nilai UN Matematika yang diperoleh oleh masing-masing angkatan.
Angkatan 2009 unggul dalam rata-rata IPK, sendangkan nilai UN Matematika
pada angkatan ini memiliki nilai paling rendah.
Gambar 3. Boxplot IPK Mahasiswa Angkatan 2009-2011 Jurusan Matematika
FMIPA UNP
Nilai UN Matematika merupakan salah satu karakteristik yang dapat
menggambarkan kondisi input dari mahasiswa dalam suatu perguruan tinggi.
Sedangkan salah satu karakteristik dari output suatu perguruan tinggi adalah IPK.
Unversitas yang merupakan salah satu pencetak generasi bangsa yang berkualitas,
mengharapakan setiap output dari perguruan tinggi tersebut dapat menjadi
outcome yang diharapkan oleh
stakeholders
. Indikator yang dapat
menggambarkan output dari perguruan tinggi, salah satunya adalah IPK
mahasiswa. Ouput yang baik biasanya juga dipengaruhi oleh kualitas dari
inputnya. Beberapa perguruan tinggi di Indonesia menggunakan beberapa metode
untuk memperoleh input yang baik, salah satunya dengan melakukan seleksi baik
berupa ujian masuk perguruan tinggi, ataupun hanya dengan menggunakan seleksi
hasil nilai UN.
Analisis Regresi Dummy yang digunakan pada penelitian ini memberikan
hasil yang beragam untuk setiap angkatan pada mahasiswa jurusan matematika.
Tahap awal analisis pada penelitian ini, semua data sampel untuk masing-masing
16
adalah nilai UN matematika (X) sebagai peubah kuantitatif. Sedangkan jenis
kelamin, status asal sekolah, dan status jalur masuk mahasiswa merupakan peubah
kualitatif yang diasumsikan juga mempengaruhi IPK mahasiswa.
Status asal sekolah dibedakan menjadi 2 kategori, yaitu Negeri dan
Swasta, sehingga dapat dijadikan kedalam satu peubah dummy. Begitu juga
dengan jenis kelamin, dijadikan kedalam satu peubah dummy. Sedangkan status
jalur masuk yang dipilih untuk menjadi mahsiswa UNP dijadikan kedalam dua
peubah dummy. Karena pada penelitian ini, jalur masuk mahasiswa jurusan
matematika FMIPA UNP dibedakan kedalam 3 kategori, yaitu SNMPTN, PMDK,
Bidik Misi dan Seleksi UNP.
Persamaan regresi dummy pada angkatan 2009 didapat digambarkan pada
persamaan berikut ini:
IPK = 4,43 - 0,372 UN Mat - 0,608 D1(1=L) - 0,92 D2(1=N) - 0,675 D3(SNM) - 0,11 D4(PMDK) + 0,085 D1X + 0,300 D2X + 0,129 D3X + 0,028 D4X
Untuk persamaan regresi di atas, tidak ada koefisien regresi yang signifikan.
Terlihat dari uji parsial terhadap koefisien regresi yang nilai p-valuenya di atas
0,05. Hanya parameter
β
0yang signifikan dengan p-value 0,031. Bedasarkan
analisis sisaan (lampiran 3, dan 4), terlihat ada beberapa asumsi yang dilanggar.
Nilai VIF yang besar mencerminkan adanya pelanggaran asumsi multikolinieritas.
Bedasarkan plot dari sisaan juga terlihat ada kecengdrungan pelanggaran asumsi
kenormalan.
Unusual observasi
juga mengindikasikan terdapat pencilan (
outlier
)
dan data berpengaruh (
influence
). Oleh karena itu perlu dilakukan penanganan
terhadap pencilan tersebut (lampiran 5). Pencilan dapat dihilangkan dari data
sehingga tidak terdapat lagi pencilan dalam analisis regresi tersebut, agar
diperoleh hasil yang shahi. Pelanggaran asumsi dapat terjadi akibat adanya
pencilan. Proses eliminir pencilan dapat dilihat pada lamipran 6 sampai lampiran
8.
Proses pemilihan model terbaik menggunakan
All possible regression
,
diperoleh persamaan regresi terbaik sebagai berikut:
IPK = 3,95 - 0,287 UN Mat - 0,922 D1(1=L) - 1,11 D3(SNM) + 0,118 D1X + 0,174 D2X + 0,183 D3X
17
Uji parsial untuk koefisien regresi menujukkan bahwa semua peubah pada
persamaan regresi diatas memiliki nilai p-value < 0,05 kecuali D1 yang
menyatakan peubah dummy untuk jenis kelamin (lampiran 9). Berdasarkan plot
residual terlihat tidak terdapat pelanggaran asumsi, dan melalui uji kenormalan
sisaan menggunakan uji kolmogorov-smirnov juga terlihat sisaan secara
signifikan menyebar mengikuti sebaran normal dengan p-value > 0,15.
R
2- adjusted juga menunjukkan nilai yang cukup besar yaitu 76,2 %. Hal
ini menunjukkan bahwa peubah independen (Nilai UN matematika) dan 5 peubah
dummy lainnya dapat menerangkan nilai IPK mahasiswa jurusan matematika
FMIPA UNP angkatan 2009 sebesar 76,2%.
Analisis regresi dummy untuk angkatan 2010 digambarkan pada
persamaan berikut ini:
IPK = - 14,6 + 1,91 UN Mat - 0,24 D1(1=L) + 16,6 D2(1=N) + 2,94 D3(SNM) + 1,74 D4(PMDK) + 0,003 D1X - 1,81 D2X - 0,318 D3X - 0,153 D4X
Koefisien regresi yang signifikan untuk persamaan regresi diatas hanya .
Unusual Observasi dari persamaan (17) pada lampiran (13) memperlihatkan
terdapat pencilan. Oleh karena itu, perlu dilakukan penanganan terhadap pencilan
tersebut. Setelah mendeteksi pencilan melalui nilai DEFITS, HI (leverage),
COOK’S distance, dan SRES (lampiran 14), maka diketahui dari persamaan
regresi yang diperoleh terdapat 2 pencilan yaitu observasi 1 dan 64. Pencilan yang
terdeteksi di eliminir satu persatu secara bertahap (lampiran 15) sampai masalah
pencilan dapat teratasi. Pembentukan model terbaik dilakukan dengan
menggunakan metode
All posibble regression
, sehingga diperoleh model regresi
terbaik yang dipilih berdasarkan kriteria R
2adjyang terbesar, S terkecil dan Cp
Mallow yang mendekati parameter, yaitu:
IPK = - 14,7 + 1,92 UN Mat + 16,8 D2(1=N) + 3,94 D3(SNM) + 0,414 D4(PMDK) - 0,0356 D1X - 1,82 D2X - 0,407 D3X
(17)
Uji Parsial untuk semua parameter regresi pada persamaan (17) diatas
memperlihatkan bahwa semua paremeter tersebut memberikan pengaruh terhadap
peubah Y (IPK) pada taraf nyata 10%, namun untuk taraf nyata 5% ada satu
peubah yang tidak signifikan yaitu peubah dummy interaksi jenis kelamin dengan
18
pada Anova lampiran 17, dengan nilai P-value 0,000. Peubah bebas UN Mat,
Status sekolah asal, jalur masuk UNP mampu menerangkan keragaman dari nilai
IPK mahasiswa sebesar 44 % dan R
2adjsebesar 36,8 %. Setelah masalah pencilan
diatasi, maka nilai R
2dan R
2adjmeningkat masing-masing sebesar 44,6 % dan
37,3%.
Kenaikan nilai UN Matematika sebesar satu satuan mempengaruhi kenaikan
IPK mahasiwa jurusan matematika sebesar 1,92. Begitu juga dengan 3 peubah
dummy lainnya, juga terlihat bahwa mahasiswa yang berasal dari sekolah negeri
dan atau masuk UNP melewati jalur SNMPTN atau PMDK, cendrung
memberikan pengaruh positif terhadap kenaikan IPK. Semua peubah dummy
tersebut memberikan penambahan kepada intersep (
β
0) dari persamaan (17)
sebesar 2,1.
IPK mahasiswa jurusan matematika angkatan 2011 digambarkan oleh
persamaan regresi dummy berikut ini:
IPK = 2,78 - 0,024 UN Mat + 1,88 D1(1=L) - 1,18 D2(1=N) - 0,252 D3(SNM) + 0,64 D4(PMDK) - 0,246 D1X + 0,179 D2X + 0,0682 D3X - 0,027 D4X
(18)
Persamaan 18 pada lampiran 21 ini belum memenuhi kriteria yang baik, karena
hasil
Unusual Observation
mengindikasikan adanya pencilan dan data
berpengaruh. Hal itu harus diatasi, sehingga pencilan dalam penelitian dieliminir
satu persatu, seperti yang terlihat pada lampiran 22.
Kemudian dibentuk model
terbaik menggunakan metode
All Possible Regression
(Lampiran 23). Sehingga
diperoleh persamaan regresi terbaik, yaitu:
IPK = 2,60 + 2,04 D1(1=L) - 1,47 D2(1=N) - 0,690 D3(SNM) + 0,427 D4(PMDK) - 0,255 D1X + 0,208 D2X + 0,117 D3X
(19)
Peubah bebas yang berpengaruh signifikan pada persamaan di atas adalah
peubah dummy jenis kelamin (D1/laki-laki), status sekolah asal (D2/negeri), jalur
masuk (D4/PMDK). Dan interaksi dari peubah boneka dengan nilai UN
Matematika yaitu, D1X dan D2X. Semua koefisien regresi dari peubah tersebut
nilai P-valuenya kecil dari 0,05 (Lampiran 24).
Nilai UN Matematika ternyata tidak memberikan pengaruh signifikan
terhadap IPK mahasiswa pada angkatan 2011. Mahasiswa laki-laki atau
19
mereka lebih tinggi daripada mahasiswa perempuan atau mahasiswa yang berasal
20
BAB VI
KESIMPULAN DAN SARAN
A.
Kesimpulan
Berdasarkan hasil penelitian dapat disimpulakan beberapa hal yang
berkaitan dengan IPK mahasiswa jurusan matematika angkatan 2009-2011:
1.
Nilai UN ternyata tidak berpengaruh signifikan terhadap keberhasilan IPK
mahasiswa. Hal ini dibuktikan dengan persamaan regresi yang terbentuk dari
setiap angkatan, yaitu masing-masing sebagai berikut:
a.
Angkatan 2009
IPK = 3,95 - 0,287 UN Mat - 0,922 D1(1=L) - 1,11 D3(SNM) + 0,118
D1X + 0,174 D2X + 0,183 D3X
b.
Angkatan 2010
IPK = - 14,6 + 1,92 UN Mat + 16,7 D2(1=N) + 3,37 D3(SNM) + 0,389
D4(PMDK)- 0,0321 D1X - 1,82 D2X - 0,339 D3X
c.
Angkatan 2011
IPK = 2,60 + 2,04 D1(1=L) - 1,47 D2(1=N) - 0,690 D3(SNM) + 0,427
D4(PMDK)- 0,255 D1X + 0,208 D2X + 0,117 D3X
Dari ketiga persamaan di atas, Nilai UN Matematika ternyata hanya
signifikan mempengaruhi IPK mahasiswa pada Angkatan 2009 dan 2010. R
2untuk masing-masing persamaan di atas adalah 79,9 %, 44,6% dan 60,3%.
2.
Faktor yang mempengaruhi IPK Mahasiswa Jurusan Matematika untuk
masing-masing angkatan adalah:
a.
Angkatan 2009: Nilai UN Matematika pada angkatan ini berpengaruh
signifikan terhadap IPK mahasiswa, walaupun nilai koefisiennya
negatif, namun koefisien untuk D1X, D2X, dan D3X bernilai positif.
Hal ini menandakan nilai UN Matematika bagi mahasiswa laki-laki atau
bagi mahasiswa yang berasal dari SLTA negeri, ataupun mahasiswa
yang masuk UNP melalui jalur SNMPTN memberikan pengaruh
signifikan terhadap peningkatan IPK.
b.
Angkatan 2010: Nilai UN Matematika, mahasiswa yang berasal dari
SLTA Negeri,atau mahasiswa yang memilih jalur masuk SNMPTN
atau PMDK memberikan pengaruh positif terhadap IPK.
c.
Angkatan 2011: Nilai UN Matematika tidak mempengaruhi IPK
21
tersebut tinggi, namun tidak memberikan pengaruh positif. Mahasiswa
laki-laki, atau mahasiswa yang berasal dari jalur masuk PMDK ternyata
memberikan pengaruh positif terhadap IPK, namun nilai koefisien bagi
peubah mahasiswa yang berasal dari SLTA negeri adalah negatif. Hal
ini menandakan, ternyata bahwa nilai IPK menurun untuk mahasiswa
yang berasala dari SLTA negeri.
B.
Saran
Penilaian input (mahasiswa) Jurusan Matematika berdasarkan nilai UN
Matematika ternyata belum mencerminkan kualitas dari output dari jurusan
matematika. Oleh karena itu, jika Jurusan Matematika menginginkan kualitas
yang bagus untuk cerminan output yang bagus pula, perlu dikaji sebagai bahan
pertimbangan dalam menyeleksi input mahasiswa. Penelitian ini juga dapat
dikembangkan kembali menggunakan beberapa metode statistika lainnya, seperti:
Analisis pohon, analisis data kategorik dan lain-lain. Penggunaan peubah
pendukung juga dapat ditambahkan kembali agar model yang terbentuk lebih
representatif.
DAFTAR PUSTAKA
Afifuddin, 2004. Berfikir Sistem dalam Peningkatan Mutu Pendidikan Tinggi. Media
Pendidikan, Vol. XVIII No.1 Juni 2004: 23-38.
Anonimous, 1992,
World Scientists: Warning to Humanity
, Union of Concerned Scientists, New
York. pp. 1-6.
__________, 2003,
Kurikulum Berbasis Kompetensi Mata Pelajaran Ekonomi,
PusatPengembangan Kurikulum
, Depatemen Pendidikan Nasional, Jakarta.
Draper, N. dan Smith H, (1992),
Analisis Regresi Terapan (terjemahan),
Edisi ke-2,Penerbit PT
Gramedia Pustaka Utama Jakarta.
Gasperz, V. 1996. Ekonometrika Terapan I. Bandung, Transito Bandung.
Montgomery D.C. & Peck E.A, (1991),
Introduction to Linear Regression Analysis,
New
York:Jhon Willey & Sonc, 2
ndedition.
Myers, R.H. (1990),
Classical and Modern with Application
. Thomson Information Publishing
Group, 2
ndedition.
Nastuti, A dan Ariadi, B.Y. (2010). Pengaruh Kondisi Sosial Ekonomi Orang Tua Siswa
Terhadap Hasil Belajar Ilmu Pengetahuan Sosial.
Volume 13 Nomor 2 Juli - Desember 2010
Sukestiyarno, 2008.
Workshop Olah Data Penelitian dengan SPSS
. Semarang: UNNES.
Lampiran 1.Deskriptif Nilai UN Matematika dan IPK Mahasiswa Jurusan Matematika FMIPA UNP
Angkatan 2009-2011
Descriptive Statistics: UN Mat(2009)
Variable N Mean StDev Minimum Median Maximum UN Mat(2009) 50 7,493 1,216 4,250 7,750 9,670
Descriptive Statistics: UN Mat(2010)
Variable N Mean StDev Minimum Median Maximum UN Mat(2010) 65 8,712 0,931 6,250 9,000 10,000
Descriptive Statistics: UN Mat(2011)
Variable N Mean StDev Minimum Median Maximum UN Mat(2011) 70 8,270 1,046 5,750 8,500 10,000
Descriptive Statistics: IPK(2009)
Variable N Mean StDev Minimum Median Maximum IPK(2009) 50 3,1690 0,3514 2,0100 3,1850 3,8200
Descriptive Statistics: IPK(2010)
Variable N Mean StDev Minimum Median Maximum IPK(2010) 65 2,9849 0,3730 2,2500 3,0300 3,7800
Descriptive Statistics: IPK(2011)
Lampiran 2. Data Mahasiswa Jurusan Matematika Angkatan 2009
RAHMAWATI P SNMPTN Pend. Matematika 3,43 8,25
SMAN 2 Muaro
No Nama Mahasiswa JK Jalur
Masuk PRODI IPK
UN
Mat SLTA
Status Sekolah
D1 (1=L)
D2 (1=N)
D3 (SNM)
D4
(PMDK) D1X D2X D3X D4X
46 RAHMADALENI P SNMPTN Pend. Matematika 2,91 6,5 SMAN 3
Batusangkar Negeri 0 1 1 0 0 6,5 6,5 0
47 ELVI SYUKRINA E P SNMPTN Pend. Matematika 3,57 8 SMAN 1
Bukittinggi Negeri 0 1 1 0 0 8 8 0
48 MEINARTI SASTRIA
U P SNMPTN Matematika 2,93 8,75 SMAN 1 Padang Negeri 0 1 1 0 0 8,75 8,75 0
49 INNE SYAFRIAN
PUTRI P SNMPTN Pend. Matematika 3,59 8,25 SMAN 2 Painan Negeri 0 1 1 0 0 8,25 8,25 0
50 FEBRINA ERMI P SNMPTN Pend. Matematika 3,41 8,75 SMAN 1
Lampiran 3. Hasil Output MINITAB 15 dari Analisis Regresi Dummy (n = 50)
The regression equation is
IPK = 4,43 - 0,372 UN Mat - 0,608 D1(1=L) - 0,92 D2(1=N) - 0,675 D3(SNM) - 0,11 D4(PMDK) + 0,085 D1X + 0,300 D2X + 0,129 D3X + 0,028 D4X
Predictor Coef SE Coef T P VIF Constant 4,429 1,979 2,24 0,031
UN Mat -0,3722 0,3242 -1,15 0,258 93,500 D1(1=L) -0,6082 0,8989 -0,68 0,503 59,710 D2(1=N) -0,916 1,602 -0,57 0,571 60,478 D3(SNM) -0,6748 0,9141 -0,74 0,465 123,082 D4(PMDK) -0,112 1,075 -0,10 0,918 121,774 D1X 0,0853 0,1091 0,78 0,439 61,456 D2X 0,3001 0,2769 1,08 0,285 163,485 D3X 0,1287 0,1212 1,06 0,295 138,626 D4X 0,0275 0,1459 0,19 0,851 109,793
S = 0,285431 R-Sq = 46,2% R-Sq(adj) = 34,0%
Analysis of Variance
Source DF SS MS F P Regression 9 2,79323 0,31036 3,81 0,002 Residual Error 40 3,25882 0,08147
Total 49 6,05205
Source DF Seq SS UN Mat 1 0,60807 D1(1=L) 1 0,05128 D2(1=N) 1 0,98725 D3(SNM) 1 0,60392 D4(PMDK) 1 0,17814 D1X 1 0,05491 D2X 1 0,15370 D3X 1 0,15306 D4X 1 0,00290
Unusual Observations
Obs UN Mat IPK Fit SE Fit Residual St Resid 7 6,50 2,0100 2,0100 0,2854 0,0000 * X 9 7,00 2,4500 3,0088 0,1178 -0,5588 -2,15R 12 8,25 2,6900 3,3060 0,0634 -0,6160 -2,21R 13 4,75 2,6800 2,6800 0,2854 0,0000 * X 28 6,25 3,8000 3,1926 0,0873 0,6074 2,24R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Lampiran 4. Analisis Sisaan Semua Data Pengamatan Mahasiswa Angkatan 2009 (n = 50)
Normal Probabilit y Plot Versus Fit s
Hist ogram Versus Order
Lampiran 5. Analisis Sisaan
Obs
RESI
SRES
TRES
HI
COOK
DFIT
1
0,1382
0,4946
0,4899
0,0424
0,0011
0,1030
2
0,2170
0,9778
0,9772
0,3953
0,0625
0,7901
3
‐
0,0169
‐
0,0637
‐
0,0629
0,1384
0,0001
‐
0,0252
4
0,3190
1,1534
1,1583
0,0610
0,0086
0,2951
5
0,2198
0,7943
0,7906
0,0600
0,0040
0,1998
6
‐
0,1914
‐
0,7302
‐
0,7259
0,1570
0,0099
‐
0,3133
7
0,0000
1,0000
8
0,2440
0,8767
0,8741
0,0494
0,0040
0,1993
9
(3)‐
0,5588
‐
2,1493
‐
2,2566
0,1704
0,0949
‐
1,0228
10
0,2253
0,8596
0,8567
0,1569
0,0138
0,3696
11
0,1533
0,5985
0,5936
0,1948
0,0087
0,2920
12
(2)‐
0,6160
‐
2,2135
‐
2,3333
0,0494
0,0255
‐
0,5319
Lampiran 6. Proses Eliminir Pencilan dari model lampiran 1.
Residual Error 39 2,85186 0,07312Total 48 5,64576 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
D1X 0,05596 0,09767 0,57 0,570 Residual Error 38 2,46469 0,06486
Total 47 5,42397 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir 3 = data obs ke (9)
Residual Error 37 2,09275 0,05656Source DF Seq SS R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir 4 = data obs ke (17)
Residual Error 36 1,80872 0,0502417 6,25 2,7000 3,1727 0,0730 -0,4727 -2,23R 31 8,75 3,0600 3,4673 0,0956 -0,4073 -2,01R 44 8,75 2,9300 3,3966 0,0631 -0,4666 -2,17R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir 5 = data obs ke (17)
Residual Error 35 1,55874 0,04454Total 44 4,45579 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
UN Mat -0,4855 0,2281 -2,13 0,041 Residual Error 34 1,32418 0,03895
Total 43 4,38037 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Residual Error 33 1,11469 0,03378 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir ke 8 = data obs ke (16)
Residual Error 32 0,97901 0,03059Obs UN Mat IPK Fit SE Fit Residual St Resid 7 6,50 2,0100 2,0100 0,1749 -0,0000 * X 11 4,75 2,6800 2,6800 0,1749 -0,0000 * X 39 6,50 2,9100 3,2501 0,0543 -0,3401 -2,05R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir ke 9 = data obs ke (39)
The regression equation is
IPK = 5,12 - 0,478 UN Mat - 0,899 D1(1=L) - 1,13 D2(1=N) - 1,15 D3(SNM) - 0,525 D4(PMDK) + 0,117 D1X + 0,356 D2X + 0,192 D3X + 0,0754 D4X
Predictor Coef SE Coef T P Constant 5,118 1,174 4,36 0,000 UN Mat -0,4782 0,1919 -2,49 0,018 D1(1=L) -0,8992 0,5350 -1,68 0,103 D2(1=N) -1,1344 0,9386 -1,21 0,236 D3(SNM) -1,1458 0,5522 -2,07 0,046 D4(PMDK) -0,5252 0,6383 -0,82 0,417 D1X 0,11726 0,06529 1,80 0,082 D2X 0,3556 0,1626 2,19 0,036 D3X 0,19158 0,07246 2,64 0,013 D4X 0,07544 0,08598 0,88 0,387
S = 0,165686 R-Sq = 78,9% R-Sq(adj) = 72,8%
Analysis of Variance
Source DF SS MS F P Regression 9 3,17979 0,35331 12,87 0,000 Residual Error 31 0,85101 0,02745
Total 40 4,03080
Source DF Seq SS UN Mat 1 0,70953 D1(1=L) 1 0,02597 D2(1=N) 1 1,11394 D3(SNM) 1 0,69405 D4(PMDK) 1 0,11288 D1X 1 0,09053 D2X 1 0,17437 D3X 1 0,23739 D4X 1 0,02113
Unusual Observations
St Obs UN Mat IPK Fit SE Fit Residual Resid 7 6,50 2,0100 2,0100 0,1657 -0,0000 * X 11 4,75 2,6800 2,6800 0,1657 -0,0000 * X
Lampiran 7. Hasil Output MINITAB 15 dari Analisis Regresi Dummy setelah pencilan di eliminir
(n = 41)
The regression equation is
IPK = 5,12 - 0,478 UN Mat - 0,899 D1(1=L) - 1,13 D2(1=N) - 1,15 D3(SNM) - 0,525 D4(PMDK) + 0,117 D1X + 0,356 D2X + 0,192 D3X + 0,0754 D4X
Predictor Coef SE Coef T P Constant 5,118 1,174 4,36 0,000 UN Mat -0,4782 0,1919 -2,49 0,018 D1(1=L) -0,8992 0,5350 -1,68 0,103 D2(1=N) -1,1344 0,9386 -1,21 0,236 D3(SNM) -1,1458 0,5522 -2,07 0,046 D4(PMDK) -0,5252 0,6383 -0,82 0,417 D1X 0,11726 0,06529 1,80 0,082 D2X 0,3556 0,1626 2,19 0,036 D3X 0,19158 0,07246 2,64 0,013 D4X 0,07544 0,08598 0,88 0,387
S = 0,165686 R-Sq = 78,9% R-Sq(adj) = 72,8%
Analysis of Variance
Source DF SS MS F P Regression 9 3,17979 0,35331 12,87 0,000 Residual Error 31 0,85101 0,02745
Total 40 4,03080
Source DF Seq SS UN Mat 1 0,70953 D1(1=L) 1 0,02597 D2(1=N) 1 1,11394 D3(SNM) 1 0,69405 D4(PMDK) 1 0,11288 D1X 1 0,09053 D2X 1 0,17437 D3X 1 0,23739 D4X 1 0,02113
Unusual Observations
St Obs UN Mat IPK Fit SE Fit Residual Resid 7 6,50 2,0100 2,0100 0,1657 -0,0000 * X 11 4,75 2,6800 2,6800 0,1657 -0,0000 * X
Lampiran 8. Pemilihan Model terbaik menggunakan metode All Posible Reggresion Angkatan 2009
Response is IPK
D D D D 4 U 1 2 3 ( N ( ( ( P 1 1 S M
M = = N D D D D D Mallows a L N M K 1 2 3 4 Vars R-Sq R-Sq(adj) Cp S t ) ) ) ) X X X X 1 44,8 43,4 44,0 0,23884 X 1 42,3 40,8 47,8 0,24427 X 2 66,5 64,8 14,1 0,18841 X X 2 61,7 59,7 21,2 0,20154 X X
Lampiran 9. Model Akhir dari Regresi Dummy yang menggambarkan IPK Mahasiswa Jurusan
Matematika Angkatan 2009
The regression equation is
IPK = 3,76 - 0,254 UN Mat - 0,838 D1(1=L) - 0,934 D3(SNM) + 0,109 D1X + 0,164 D2X + 0,161 D3X
Predictor Coef SE Coef T P Constant 3,7576 0,2696 13,94 0,000 UN Mat -0,25424 0,05099 -4,99 0,000 D1(1=L) -0,8377 0,4982 -1,68 0,102 D3(SNM) -0,9340 0,3491 -2,68 0,011 D1X 0,10869 0,06096 1,78 0,084 D2X 0,16391 0,02348 6,98 0,000 D3X 0,16138 0,04615 3,50 0,001
S = 0,163146 R-Sq = 77,5% R-Sq(adj) = 73,6%
Analysis of Variance
Source DF SS MS F P Regression 6 3,12584 0,52097 19,57 0,000 Residual Error 34 0,90496 0,02662
Total 40 4,03080
Source DF Seq SS UN Mat 1 0,70953 D1(1=L) 1 0,02597 D3(SNM) 1 0,98930 D1X 1 0,04661 D2X 1 1,02897 D3X 1 0,32546
Unusual Observations
Obs UN Mat IPK Fit SE Fit Residual St Resid 7 6,50 2,0100 2,1050 0,1362 -0,0950 -1,06 X 21 6,50 3,0200 3,0392 0,1209 -0,0192 -0,18 X 26 6,00 2,9000 3,2156 0,0616 -0,3156 -2,09R R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Eliminir ke 10 = data obs ke (26)
The regression equation is
IPK = 3,95 - 0,287 UN Mat - 0,922 D1(1=L) - 1,11 D3(SNM) + 0,118 D1X + 0,174 D2X + 0,183 D3X
Predictor Coef SE Coef T P Constant 3,9483 0,2697 14,64 0,000 UN Mat -0,28734 0,05060 -5,68 0,000 D1(1=L) -0,9216 0,4736 -1,95 0,060 D3(SNM) -1,1139 0,3407 -3,27 0,003 D1X 0,11835 0,05794 2,04 0,049 D2X 0,17398 0,02272 7,66 0,000 D3X 0,18309 0,04483 4,08 0,000
S = 0,154605 R-Sq = 79,9% R-Sq(adj) = 76,2%
Source DF SS MS F P Regression 6 3,13039 0,52173 21,83 0,000 Residual Error 33 0,78879 0,02390
Total 39 3,91918
Source DF Seq SS UN Mat 1 0,62862 D1(1=L) 1 0,02466 D3(SNM) 1 0,96210 D1X 1 0,04847 D2X 1 1,06784 D3X 1 0,39871
Unusual Observations
Lampiran 10. Analisis Sisaan dari model Regresi dummy untuk angkatan 2009
Normal Probabilit y Plot Versus Fit s
Hist ogram Versus Order
Residual Plots for I PK Mahasiswa Angkatan 2 0 0 9 ( Model Akhir)
c
Normal Probabilit y Plot Versus Fit s
Hist ogram Versus Order
Lampiran 11. Uji asumsi kenormalan residual mahasiswa angkatan 2009
0,4 0,3
0,2 0,1
0,0 -0,1 -0,2
-0,3 -0,4
99
95
90
80
70
60
50
40
30
20
10
5
1
RESI 1
P
e
rc
e
n
t
Mean - 4,01901E- 15
StDev 0,1422
N 40
KS 0,104
P- Value > 0,150
uji kenormalan sisaan ( KS)
Lampiran 12. Data Mahasiswa Jurusan Matematika Angkatan 2010
Nazwir P Seleksi UNP Statistika 2,25 8,75
SMAN Pertiwi 1
DHANIAH P SNMPTN Matematika 3,13 8,25
SMAN 2
RAMAYANTI P Bidik Misi Matematika 3,15 8,00
MAN Koto Baru
No Nama
NOVITASARI P Seleksi UNP Pend.
MARANALDI L SNMPTN Matematika 3,29 8,75
SMAN Agam
ANGRAINI P Bidik Misi Matematika 2,63 8,50
SMAN 1 Kec. Pangkalan Koto Baru
Negeri 0 1 0 0 0 8,5 0 0
30 Diah Pertiwi
Ningsih P Seleksi UNP Statistika 2,65 9,50
No Nama
No Nama
Mahasiswa JK
Jalur
Masuk PRODI IPK
UN
Mat SLTA
Status Sekolah
D1 (1=L)
D2 (1=N)
D3 (SNMPTN)
D4
(PMDK) D1X D2X D3X D4X
63
ALDHINI KEMALA PUTERI
P Seleksi UNP Pend.
Matematika 3,61 8,75
SMAN 3
Bukittinggi Negeri 0 1 0 0 0 8,75 0 0
64 DISTI HARLIN P SNMPTN Matematika 2,35 9,25 SMAN 1 Lubuk
Sikaping Negeri 0 1 1 0 0 9,25 9,25 0
65 CINDI
MEIDISIA P SNMPTN Matematika 3,30 8,75
SMAN 1 Kota
Lampiran 13. Hasil Out Put MINITAB 15 mengenai IPK Mahasiswa Angkatan 2010 dengan peubah
semua peubah prediktor menggunakan Analisis Regresi Dummy.
The regression equation is
IPK = - 14,6 + 1,91 UN Mat - 0,24 D1(1=L) + 16,6 D2(1=N) + 2,94 D3(SNM) + 1,74 D4(PMDK) + 0,003 D1X - 1,81 D2X - 0,318 D3X - 0,153 D4X
Predictor Coef SE Coef T P Constant -14,550 5,619 -2,59 0,012 UN Mat 1,9142 0,6202 3,09 0,003 D1(1=L) -0,237 2,229 -0,11 0,916 D2(1=N) 16,639 5,637 2,95 0,005 D3(SNM) 2,938 2,349 1,25 0,216 D4(PMDK) 1,736 4,787 0,36 0,718 D1X 0,0028 0,2596 0,01 0,991 D2X -1,8094 0,6224 -2,91 0,005 D3X -0,3177 0,2725 -1,17 0,249 D4X -0,1534 0,5255 -0,29 0,771
S = 0,338875 R-Sq = 29,0% R-Sq(adj) = 17,4%
Analysis of Variance
Source DF SS MS F P Regression 9 2,5860 0,2873 2,50 0,018 Residual Error 55 6,3160 0,1148
Total 64 8,9020
Source DF Seq SS UN Mat 1 0,3570 D1(1=L) 1 0,2238 D2(1=N) 1 0,2239 D3(SNM) 1 0,0593 D4(PMDK) 1 0,3981 D1X 1 0,1510 D2X 1 1,0071 D3X 1 0,1561 D4X 1 0,0098
Unusual Observations
Lampiran 14. Analisis sisaan
Obs
RESI
SRES
TRES
HI
COOK
DFIT
45
‐
0,5134
‐
1,6641
‐
1,6921
0,1712
0,0572
‐
0,7689
46
0,2496
0,8284
0,8260
0,2094
0,0182
0,4251
47
‐
0,1235
‐
0,4338
‐
0,4305
0,2941
0,0078
‐
0,2779
48
0,3221
0,9670
0,9664
0,0340
0,0033
0,1814
49
‐
0,0922
‐
0,3505
‐
0,3477
0,3975
0,0081
‐
0,2824
50
0,3583
1,0723
1,0738
0,0280
0,0033
0,1822
51
‐
0,1879
‐
0,5643
‐
0,5607
0,0340
0,0011
‐
0,1052
52
0,1483
0,4438
0,4405
0,0280
0,0006
0,0748
53
0,0309
0,4338
0,4305
0,9559
0,4076
2,0040
54
‐
0,3736
‐
1,1902
‐
1,1948
0,1418
0,0234
‐
0,4856
55
‐
0,1317
‐
0,3943
‐
0,3913
0,0280
0,0004
‐
0,0664
56
0,2954
0,8939
0,8923
0,0491
0,0041
0,2028
57
0,1259
0,3797
0,3767
0,0428
0,0006
0,0797
58
0,0621
0,1864
0,1847
0,0340
0,0001
0,0347
59
0,2550
1,0359
1,0366
0,4722
0,0960
0,9804
60
‐
0,0573
‐
0,1930
‐
0,1913
0,2337
0,0011
‐
0,1057
61
‐
0,2110
‐
0,6909
‐
0,6876
0,1879
0,0110
‐
0,3308
62
0,5130
1,5380
1,5579
0,0311
0,0076
0,2793
63
0,6045
1,8061
1,8452
0,0247
0,0083
0,2936
64
‐
0,7072
‐
2,6326
‐
2,7902
0,3717
0,4099
‐
2,1459
65
0,1364
0,4305
0,4273
0,1264
0,0027
0,1625
Lampiran 15. Eliminir Pencilan
Residual Error 54 5,24318 0,09710Total 63 8,65325 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
D3(SNM) 3,750 2,900 1,29 0,202 Residual Error 53 4,76523 0,08991
Total 62 8,23369 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage. The regression equation is Residual Error 52 4,39568 0,08453
Source DF Seq SS UN Mat 1 0,35645 D1(1=L) 1 0,25618 D2(1=N) 1 0,25321 D3(SNM) 1 0,44193 D4(PMDK) 1 0,63646 D1X 1 0,31624 D2X 1 1,03250 D3X 1 0,17018 D4X 1 0,00028
Unusual Observations
Lampiran 16.Pemilihan Model terbaik menggunakan metode All Posible Reggresion
Response is IPK
D D D D 4 U 1 2 3 ( N ( ( ( P 1 1 S M
M = = N D D D D D Mallows a L N M K 1 2 3 4 Vars R-Sq R-Sq(adj) Cp S t ) ) ) ) X X X X 1 4,5 2,9 30,8 0,35362 X
1 3,7 2,1 31,5 0,35511 X
Lampiran 17. Model Akhir dari Regresi Dummy yang menggambarkan IPK Mahasiswa Jurusan
Residual Error 54 4,39946 0,08147Total 61 7,85912 R denotes an observation with a large standardized residual. X denotes an observation whose X value gives it large leverage.
Analysis of Variance
Source DF SS MS F P Regression 7 3,27702 0,46815 6,10 0,000 Residual Error 53 4,06530 0,07670
Total 60 7,34232
Source DF Seq SS UN Mat 1 0,45964 D2(1=N) 1 0,20527 D3(SNM) 1 0,37410 D4(PMDK) 1 0,08076 D1X 1 0,88567 D2X 1 1,02356 D3X 1 0,24802
Unusual Observations
Lampiran 18. Analisis Sisaan dari model Regresi dummy untuk angkatan 2010
Normal Probabilit y Plot Versus Fit s
Hist ogram Versus Order
Lampiran 19. Plot kenormalan Sisaan
1,0 0,5
0,0 -0,5
-1,0
99,9
99
95
90
80
70 60 50 40 30 20
10
5
1
0,1
RESI 5
P
e
rc
e
n
t
Mean 8,415855E- 15
StDev 0,2603
N 61
KS 0,080
P- Value > 0,150
Uji Kenormalan Sisaan ( 2 0 1 0 )
21 NURUL AFIFAH
FANNY P SNMPTN Matematika 3,27 7,75
SMAN 5
SRIRAHAYU P SNMPTN Matematika 2,77 8,50
SMAN &
MUJTAHIDAH P SNMPTN Matematika 3,47 7,00
44 Maidi Satria L Seleksi
UNP Statistika 2,73 9,00 SMAN 7
Sijunjung Negeri 1 1 0 0 9 9 0 0
45 PUTRA BIN
ALDABIYAH L SNMPTN Matematika 2,80 8,50
SMAN 1
MARYENNI P SNMPTN Matematika 3,44 8,50
SMAN 1
DEWI P SNMPTN Matematika 2,81 7,25