61
Implementasi Algoritma TF-IDF untuk
Pencarian Pedoman Akademik dan
Penentuan Sanksi Pada Jurusan
Teknik Informatika UIN
Sunan Gunung Djati
Bandung
Firman Abdurrahman
1, Mohamad Irfan
2, Rian Andrian
3Teknik Informatika, Fakultas Sains dan Teknologi UIN SGD Bandung
Jl. A.H. Nasution No. 105, Kota Bandung 40614
1
[email protected],
2[email protected],
3[email protected]
Abstract- Implementation System Searching Academic Guidance and Sanction Determination At Department of Informatics UIN Sunan Gunung Djati Bandung is designed to obtain information about academic guidelines for students and lecturers efficiently and can determine recommendations for sanctions against violators of the prevailing rules. The algorithm for this system is using the Frequency-Inverse Document Frequency (TF-IDF) algorithm which is the calculation of the value of a document that is very useful in the process of searching and giving sanction recommendation.
System built using PHP web programming framework and implementation of Term Frequency-Inverse Document Frequency (TF-IDF) Algorithm. Documents used as test data have a good accuracy, so the tfidf algorithm is perfect for searching a term.
Keywords- Web Framework, Term Frequency Inverse Document Frequency (TF-IDF).
Abstrak- Sistem Implementasi Pencarian Panduan Akademik dan Penentuan Sanksi Pada Jurusan Teknik Informatika UIN Sunan Gunung Djati Bandung didesain untuk mendapatkan informasi tentang pedoman akademik bagi mahasiswa maupun dosen secara efisien dan dapat menentukan rekomendasi sanksi terhadap pelanggar tata tertib yang berlaku. Algoritma untuk sistem ini adalah menggunakan algoritma Frequency-Inverse Document Frequency(TF-IDF) yaitu perhitungan nilai suatu dokumen yang sangat berguna dalam proses hasil pencarian dan pemberian rekomendasi sanksi. Sistem yang dibangun dengan menggunakan framework web bahasa pemrograman PHP dan implementasi Algoritma Term Frequency-Inverse Document Frequency (TF-IDF). Dokumen yang digunakan sebagai data uji memiliki tingkat akurasi yang baik, sehingga algoritma tfidf sangat tepat untuk pencarian suatu term.
Kata kunci- Framework Web, Term Frequency Inverse Document Frequency(TF-IDF).
I. PENDAHULUAN
Saat ini Teknologi Informasi berkembang dan menyebar hampir di setiap sendi kehidupan, sehingga membuat teknologi pada saat ini menjadi bagian yang penting di dalam kehidupan manusia. Hal tersebut didasarkan pada perkembangan zaman menuju arah yang lebih modern dan dinamis [1][2]. Dengan adanya internet, informasi dapat dengan mudah disebarluaskan dan diakses oleh banyak orang. Banyaknya informasi yang beredar tentu membuat kebutuhan akan informasi semakin meningkat.[3]
Dengan membaca buku-buku panduan akademik dan tata tertib, mahasiswa maupun dosen bisa mendapatkan informasi tentang panduan-panduan akademik yang telah ditetapkan oleh jurusan. Namun masih banyak mahasiswa maupun dosen yang tidak mendapatkan informasi tentang
tata tertib itu sendiri, maka dengan perkembangan teknologi yang semakin canggih saat ini dan ketergantungan kebanyakan orang terhadap teknologi akan lebih baik penyebaran informasi tentang tata tertib disebarkan melalui jaringan internet [4], [5].
Pada saat ini, untuk mendapatkan informasi tentang pedoman akademik, mahasiswa maupun dosen bisa mencarinya secara manual dengan cara membaca buku-buku pedoman akademik, akan tetapi hal itu sangat tidak efisien terhadap waktu. Mahasiswa terkadang malas untuk membaca, bahkan umumnya mahasiswa maupun dosen tidak memiliki buku pedoman akademik tersebut.
Implementasi Algoritma TF-IDF untuk Pencarian Pedoman Akademik dan
Penentuan Sanksi Pada Jurusan Teknik Informatika UIN Sunan Gunung Djati Bandung (Firman Abdurrahman, Mohamad Irfan, Rian Andrian)
62 menggunakan pembobotan term. Metode pembobotan
term yang diterapkan pada aplikasi panduan akademik ini melakukan pencarian data dengan cara mencocokan seluruh kata/ term yang terdapat pada dokumen kemudian menampilkan kata yang dicari. Dengan metode tf-idf pencarian suatu kata (term) akan lebih mudah, efisien dan memiliki hasil yang akurat [6], [7].
A. Text Mining
Text Mining adalah sebuah penerapan yang berasal dari information retrieval (IR) dan natural language processing (NLP)[8]. Definisi text mining secara sempit hanya berupa metode yang dapat menemukan informasi baru yang tidak jelas atau mudah diketahui dari sebuah kumpulan dokumen [9][10]. Sedangkan secara lebih luas, text mining mencakup teknik text-processing yang lebih umum, seperti pencarian, pengambilan intisari, dan pengkategorian.[11]
Permasalahan yang dihadapi pada text mining adalah jumlah data yang besar, dimensi yang tinggi, data dan struktur yang terus berubah, serta data noise. Sehingga sumber data yang digunakan pada text mining adalah kumpulan teks yang memiliki bentuk yang tidak terstruktur atau setidaknya semi terstruktur [12]. Tujuan dari text mining adalah untuk mendapatkan informasi yang berguna dari sekumpulan dokumen dalam bentuk teks.[11]
Tahapan-tahapan yang dilakukan dalam proses text mining antara lain:
a. Tokenizing
Tahap tokenizing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.
b. Filtering
Tahap filtering adalah tahap mengambil kata - kata penting dari hasil tokenizing. Proses filtering dapat menggunakan algoritma stoplist (membuang kata yang kurang penting) atau wordlist (menyimpan kata penting). Stoplist / stopword adalah kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh stopword adalah “yang”, “dan”, “di”,
“dari” dan lain – lain.[13]
c. Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu.[4] Stemming kebanyakan digunakan pada teks berbahasa inggris dikarenakan teks berbahasa inggris memiliki struktur imbuhan yang tetap dan mudah untuk diolah sementara stemming untuk proses bahasa Indonesia memiliki struktur imbuhan yang rumit / kompleks sehingga agak lebih susah untuk diolah.[13]
d. Tagging
Tahap tagging adalah tahap mencari bentuk awal atau root dari tiap kata lampau atau kata hasil stemming. e. Analyzing
Tahap analyzing merupakan tahap penentuan seberapa jauh keterhubungan antar kata-kata dan dokumen yang ada.
B. Pembobotan Kata (TF-IDF)
Term vector dari suatu dokumen adalah tuple bobot semua term pada dokumen. Nilai bobot suatu term menyatakan kepentingan term tersebut dalam merepresentasikan dokumen. Metode pembobotan term ada tiga jenis yaitu Binary weighting, TF dan TF-IDF [5].
a. Binary weighting
Pembobotan dengan metode ini hanya terdiri dari 2 nilai yaitu 0 jika term i tidak berada pada dokumen dan 1 jika sebaliknya. Binary weighting dapat dilihat pada Persamaan 1 di bawah ini:
0 : term i does not occur in document j aij =
1 : term i occurs in the document j
b. TF (Term Frequency)
Pembobotan dengan metode ini berdasarkan freskuensi term i muncul dalam dokumen. TF dapat dilihat pada persamaan 2 di bawah ini:
Tf(t,d) = frekuensi kemunculan t pada dokumen d
c. TF-IDF (Term Frequency – Invers Document Frequency)
Invers Document Frequency (IDF) adalah jumlah dokumen yang mengandung sebuah term didasarkan pada seluruh dokumen yang ada pada dataset. IDF dapat dilihat pada Persamaan 3 di bawah ini:
𝑖𝑑𝑓 = 𝐿𝑜𝑔 (
𝑑𝑓𝑖)
𝑁
Keterangan :
• N adalah jumlah dokumen yang terdapat pada kumpulan dokumen yang diamati.
• dfi adalah jumlah dokumen yang mengandung term i.
Pembobotan tf-idf untuk sebuah term i untuk dokumen n didapatkan dari hasil perkalian nilai tf dan idf. Metode TF-IDF ini merupakan pengintegrasian antar TF dan IDF (Invers Document Frequency).
II. METODE PENELITIAN
Metode penelitian ini direncanakan ke dalam tahap langkah-langkah secara sistematis. Penelitian dilakukan dengan beberapa tahap :
A. Tahap Pengumpulan Data
63 a. Studi literatur
1. Panduan Kode Etik dan Tata Tertib Mahasiswa Fakultas Sains dan Teknologi (UIN) Sunan Gunung Djati Bandung 2015.
2. Panduan Pelaksanaan Pembinaan, Pelatihan dan Ujian Tahfidz Al-Quran UIN Sunan Gunung Djati Bandung
3. Pedoman Akademik FST 2016 Rev 4.
4. Pedoman Organisasi Kemahasiswaan Intra Universitas
5. Pedoman Orientasi Pengenalan Akademik (OPAK) 6. Pedoman Umum Panitia Kegiatan Kemahasiswaan 7. Peraturan Menteri Agama Tentang Ijazah, Transkrip Akademik, dan Surat Keterangan Pendamping Ijazab Perguruan Tinggi Keagamaan 8. Standar Mutu Universitas Islam Negeri Sunan
Gunung Djati Bandung
9. Standar Operasi dan Prosedur Kegiatan Kemahasiswaan
10.Standar Operasi dan Prosedur Pengelolaan Beasiswa
11.Buku Himpunan Peraturan Tentang Perguruan Tinggi Di Indonesia
12.Pedoman Akademik UIN Sunan Gunung Djati Bandung 2015
13.Administrasi Surat Keterangan 14.Buku Kurikulum Pendidikan Tinggi
15.Pedoman Penghitungan dan Beban Kerja Dosen UIN SGD Bandung
b. Metode Observasi
Teknik pengumpulan data dengan mengadakan pengamatan atau kegiatan yang sistematis terhadap objek yang dituju secara langsung.
c. Metode Wawancara
Adalah suatu metode penelitian dengan mengadakan tanya jawab dengan Anggota SENAT UIN Bandung Bapak Mohammad Irfan, Bapak Cecep Hidayat dan Bapak Nanang Ismail.
B. Tahap Pendekatan Sistem
Untuk menggambarkan sistem yang akan dibangun, maka perlu menggunakan alat bantu pemodelan sistem, berupa Use Case Diagram, Class Diagram, Sequence Diagram dan Activity Diagram [14].
C. Tahap Pengembangan Sistem
Dalam pembangunan aplikasi web ini mengikuti tahapan-tahapan berdasarkan metode Throwaway Prototype.
Throwaway Prototyping adalah suatu metode yang sama persis dengan metode prototyping dimana throwaway prototype merupakan hasil perkembangan dari prototype, tetapi throwaway prototype lebih mengarah pada hasil persentasi saja, yang dimana bertujuan untuk memvisualisasikan sebuah system yang sedang dibangun dan bedasarkan komentar pengguna, prototipe berikutnya terus dibangun sampai dapat memvisualisasikan sistem kerja nyata.
Gambar 1 Kriteria metode pengembangan.[15]
Pembangunan aplikasi ini menggunakan metode throwaway prototype karena menurut gambar 1 di atas, throwaway prototype memiliki nilai terbaik dari metode yang lain dalam memenuhi kriteria yang sama seperti aplikasi yang akan dibangun ini.
Gambar 2Throwaway Prototyping[15]
Model ini digunakan karena mempunyai phase analisis yang cukup relative yang digunakan sebagai informasi dan pengembangan ide untuk konsep sebuah sistem. Sehingga lebih mudah dan cepat untuk memberikan sebuah feedback.
Berikut adalah tahapan dalam metode prototype : 1. Komunikasi dan pengumpulan data awal, yaitu
analisis terhadap kebutuhan pengguna.
2. Quick design (desain cepat), yaitu pembuatan desain secara umum untuk selanjutnya dikembangkan kembali.
3. Pembentukan prototype, yaitu pembuatan perangkat prototype termasuk pengujian dan penyempurnaan.
4. Evaluasi terhadap prototype, yaitu mengevaluasi prototype dan memperhalus analisis terhadap kebutuhan pengguna.
5. Perbaikan prototype, yaitu pembuatan tipe yang sebenarnya berdasarkan hasil dari evaluasi prototype.
6. Produksi akhir, yaitu memproduksi perangkat secara benar sehingga dapat digunakan oleh pengguna.
III.HASIL DAN PEMBAHASAN
A. Analisis Algoritma TFIDF
Terdapat kalimat :
Implementasi Algoritma TF-IDF untuk Pencarian Pedoman Akademik dan
Penentuan Sanksi Pada Jurusan Teknik Informatika UIN Sunan Gunung Djati Bandung (Firman Abdurrahman, Mohamad Irfan, Rian Andrian)
64 Langkah awal sebelum melakukan perhitungan tf-idf
sistem terlebih dahulu melakukan proses text mining yaitu tokenizing, filtering, dan stemming. Proses selanjutnya yaitu menghitung tf kemudian df dan idf, dan terakhir tf.idf.
a. Tokenizing
Tahap tokenizing / parsing adalah tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.[13]
Tabel 1 Proses Tokenizing
Kalimat Hasil Tokenizing
Melakukan
Tahap filtering adalah tahap mengambil kata - kata penting dari hasil tokenizing. Kata-kata yang tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh stopwordadalah “yang”, “dan”, “di”,
“dari” dan lain – lain.[13]
Tabel 2 Proses Filtering
Hasil Tokenizing Hasil Filtering
Kata diambil melakukan ilmiah kegiatan stempel kegiatan orang sikap ijazah
yang lain nilai surat
bertentangan mempalsukan nilai surat dengan nilai kejujuran berharga
sikap tanda ilmiah administr
asi
dan tangan tindakan akademi
k
nilai cap plagiat
nilai stempel karya
kejujuran ijazah ilmiah
Hasil Tokenizing Hasil Filtering
Kata diambil
ilmiah dan dibuatka
n
seperti atau orang
tindakan surat karya
plagiat surat membuat
kan karya berharga karya ilmiah lainnya ilmiah
dibuatkan yang orang
oleh terkait mempals
ukan
orang dengan nilai
lain administrasi tanda membuatkan akademik tangan
karya cap
c. Stemming
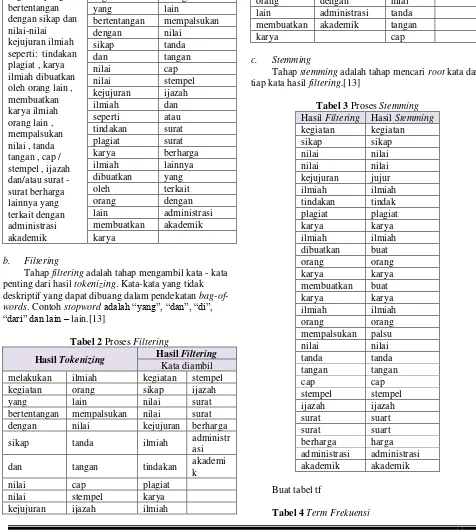
Tahap stemming adalah tahap mencari root kata dari tiap kata hasil filtering.[13]
Tabel 3 Proses Stemming Hasil Filtering Hasil Stemming kegiatan kegiatan
65
Kemudian menghitung dokumen frekuensi (df)
Tabel 5 Data Frekuensi
Setelah mendapatkan df kemudian menghitung Invers dokumen frekuensi (IDF)
Di database memiliki 36 data jadi N=36, Maka dengan rumus idf
𝑖𝑑𝑓 = 𝐿𝑜𝑔 (
𝑑𝑓𝑖)
𝑁
Mendapatkan hasil idf pada tabel berikut :
Tabel 6 Invers dokumen frekuensi
Term
Df
N
IDF
administrasi
1
36
log(36/1)=1,556
akademik
1
36
log(36/1)=1,556
Ini hasil akhir dari perhitungan tf.idf
Tabel 7TF.IDF
IDF
Tf
Tf.idf
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/3)=0,518
3
0,518x3=1,554
log(36/1)=1,556
1
1,556x1=1,556
log(36/3)=0,518
3
0,518x3=1,554
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/3)=0,518
3
0,518x3=1,554
log(36/2)=0,778
2
0,778x2=1,556
log(36/2)=0,778
2
0,778x2=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=0,778
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
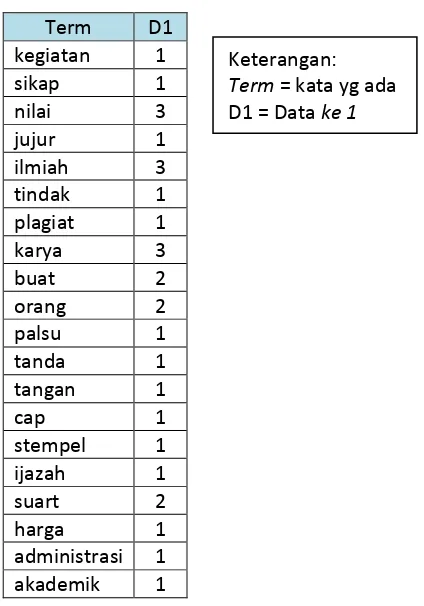
Keterangan:
Term
= kata yg ada
Df = Data
frekuensi
Keterangan:
Implementasi Algoritma TF-IDF untuk Pencarian Pedoman Akademik dan
Penentuan Sanksi Pada Jurusan Teknik Informatika UIN Sunan Gunung Djati Bandung (Firman Abdurrahman, Mohamad Irfan, Rian Andrian)
66
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/2)=0,778
2
0,778x2=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
log(36/1)=1,556
1
1,556x1=1,556
Untuk pencarian kata dengan menginputkan keyword
“Plagiat”
Tabel 8 Pencarian dengan tf-idf
Kata Pencarian Plagiat
Perhitungan :
Term : Plagiat
TF (Term Frequency) = 1
IDF (Inverse Document Frequency) = log (N / Df) = log (36/1) = 1.556
Tabel 1 sampai Tabel 7 menjelaskan proses tf-idf dari mulai pemecahan kata sampai pemberian nilai terhadap kata sehingga menghasilkan nilai df dan idf.
B. Perancangan Sistem
• Arsitektur Sistem
Arsitektur sistem digunakan untuk menyatakan sebagaimana mendefinisikan komponen-komponen yang spesifikasi secara arsitektur seperti pada Gambar 2
Gambar 2 Arsitektur Sistem
• Use Case Diagram
Use case diagram digunakan untuk memodelkan dan menyatakan unit fungsi/layanan yang disediakan oleh sistem (or bagian sistem: subsistem atau class) ke pemakai.
Gambar 3Use Case Diagram
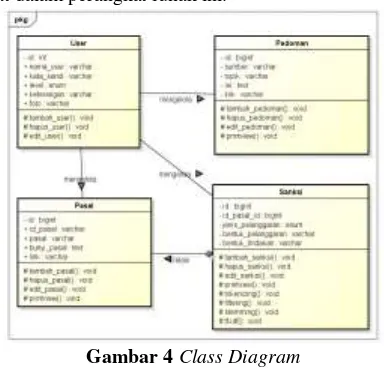
• Class Diagram
Class diagram ini akan menjelaskan bagaimana memodelkan data dalam bentuk class diagram yang menunjukan sekumpulan class object, class diagram yang terdapat dalam perangkat lunak ini.
Gambar 4Class Diagram
• ERD (Entity Relationship Diagram)
Entity Relationship Diagram (ERD) adalah gambaran pada sistem dimana di dalam terdapat hubungan antar entity beserta relasinya.
Gambar 5Entity Relationship Diagram
C. Perancangan User Interface
• Halaman User
a. Halaman Search Pedoman Akademik
Halaman search pedoman akademik merupakan halaman yang pertama kali muncul ketika menggunakan sistem pedoman akademik, menu ini menu yang akan digunakan oleh user. Tampilan halaman search seperti Gambar 6.
Gambar 6 Halaman Search Pedoman Akademik
67 Halaman ini merupakan halaman yang berfungsi
untuk menampilkan pedoman akademik yang dicari oleh user. Seperti pada Gambar 7
Gambar 7 Halaman Hasil Search Pedoman
c. Halaman Tampilan Detail Pedoman Akademik Halaman tampilan detail merupakan halaman yang berfungsi untuk menampilkan pedoman akademik yang dipilih oleh user. Seperti pada Gambar 8
Gambar 8 Halaman Detail Pedoman
• Halaman Dosen
a. Halaman Search Pelanggaran Akademik
Halaman search pelanggaran akademik merupakan halaman yang pertama kali muncul ketika dosen masuk login ke menu pelanggaran, menu ini menu yang akan digunakan oleh dosen. Tampilan halaman search seperti Gambar 9.
Gambar 9 Halaman Search Pelanggaran
b. Halaman Hasil Search Pelanggaran Akademik
Halaman ini merupakan halaman yang berfungsi untuk menampilkan pelanggaran akademik yang dicari oleh dosen. Seperti pada Gambar 10.
Gambar 10 Halaman Hasil Search Pelanggaran.
c. Halaman Tampilan Detail Pelanggaaran Halaman tampilan detail merupakan halaman yang berfungsi untuk menampilkan pelanggarn akademik yang dipilih oleh dosen. Seperti pada Gambar 11.
Gambar 11 Halaman Detail Pelanggaran
• Halaman Admin 1. Halaman Login
Halaman ini merupakan halaman login dari sistem. Halaman ini digunakan untuk admin masuk ke dalam sistem. Adapun tampilan halaman login seperti pada Gambar 12.
Gambar 12 Halaman Login
2. Halaman Home Pengolahan Data
Implementasi Algoritma TF-IDF untuk Pencarian Pedoman Akademik dan
Penentuan Sanksi Pada Jurusan Teknik Informatika UIN Sunan Gunung Djati Bandung (Firman Abdurrahman, Mohamad Irfan, Rian Andrian)
68 Gambar 13 Halaman Home Pengolahan Data
IV.PENUTUP Kesimpulan
Setelah melalui tahapan-tahapan yang sesuai dengan model pengembangan prototype dalam membangun sistem implementasi, dapat disimpulkan beberapa hal sebagai berikut :
1. Algoritma tf-idf memiliki tingkat akurasi yang baik, sehingga algoritma tfidf sangat tepat untuk pencarian suatu term.
2. Dari hasil penelitian yang telah dilakukan, pencarian pedoman akademik dengan menggunakan algoritma tf-idf pada Jurusan Informatika UIN Sunan Gunung Djati Bandung berfungsi dengan cukup baik sesuai dengan yang diharapkan dan pelanggaran akademik dengan menggunakan algoritma tfidf berfungsi dengan sangat baik sesuai dengan yang diharapkan. Saran
Setelah mengevaluasi terhadap proses dan hasil dari sistem, maka terdapat beberapa saran untuk pengembangan sistemnya antara lain :
1. Sistem ini mengharuskan update data terbaru pedoman akademik, sehingga data yang ada di dalam sistem merupakan data peraturan terkini. 2. Kedepannya dalam menampilkan data yang dicari
dengan cara mengetikan keyword sistem harus lebih mengutamakan padanan kata yang lebih banyak kecocokan katanya tampil pada bagian teratas.
3. Sistem dapat dikembangkan dengan menggunakan bahasa pemograman lain. .
V. REFERENSI
[1] Mms. Fauziah, S.Kom, Pengantar Teknologi Informasi. Bandung: Muara Indah, 2010.
[2] Y. A. Gerhana, W. B. Zulfikar, A. H. Ramdani, and M.
A. Ramdhani, “Implementation of Nearest Neighbor using HSV to Identify Skin Disease,” IOP Conf. Ser. Mater. Sci. Eng., vol. 288, no. 1, p. 012153
1234567890 Implementation, 2018.
[3] M. Herliani, “Aplikasi Pencarian Buku Dengan
Menggunakan Metode tf-idf dan Vector Space Berbasis Web Pada Perpustakaan Sekolah Menengah Atas
Negeri 2 Pangkal Pinang,” p. 8.
[4] I. Septiana, M. Irfan, and A. R. Atmadja, “Sistem Pendukung Keputusan Penentu Dosen Penguji Dan Pembimbing Tugas Akhir Menggunakan Fuzzy Multiple Attribute Decision Makingdengan Simple Additive Weighting (Studi Kasus: Jurusan Teknik
Informatika Uin Sgd Bandung),” J. Online Inform., vol. 1, no. 1, pp. 43–50, 2016.
[5] M. Irfan, Jumadi, W. B. Zulfikar, and Erik,
“Implementation of Fuzzy C-Means algorithm and
TF-IDF on English journal summary,” 2017 Second Int. Conf. Informatics Comput., pp. 1–5, 2017.
[6] R. M. Puspita, Arini, and S. U. Masrurah,
“Pengembangan Aplikasi Penjadwalan Kegiatan Pelatihan Teknologi Informasi Dan Komunikasi
Dengan Algoritma Genetika,” J. Online Inform., vol. 1, no. 2, pp. 76–81, 2016.
[7] M. Irfan, I. Z. Mutaqin, and R. G. Utomo,
“Implementation of Dynamic Time Warping Algorithm
on an Android Based Application to Write and
Pronounce Hijaiyah Letters,” IEEE CITSM, 2016. [8] D. S. A. Maylawati, M. A. Ramdhani, A. Rahman, and
W. Darmalaksana, “Incremental technique with set of
frequent word item sets for mining large Indonesian
text data,” 2017 5th Int. Conf. Cyber IT Serv. Manag. CITSM 2017, pp. 1–6, 2017.
[9] D. S. Maylawati, A. Rahman, M. I. N. Saputra, W.
Darmalaksana, and M. A. Ramdhani, “Model of
Citation Network Analysis using Sequence of Words as
Structured Text Representation,” IOP Conf. Ser. Mater. Sci. Eng., vol. 288, no. 1, p. 12048, 2018.
[10] C. Slamet, A. R. Atmadja, D. S. Maylawati, R. S. Lestari, W. Darmalaksana, and M. A. Ramdhani,
“Automated Text Summarization for Indonesian Article Using Vector Space Model,” IOP Conf. Ser. Mater. Sci. Eng., vol. 288, no. 1, p. 12037, 2018.
[11] L. Agusta, “Perbandingan Algoritma Stemming Porter Dengan Algoritma Nazief & Adriani Untuk Stemming
Dokumen Teks Bahasa Indonesia,” Konf. Nas. Sist. dan Inform. 2009, no. KNS&I09-036, pp. 196–201, 2009.
[12] D. Setiawati, I. Taufik, Jumadi, and W. Z. Budiawan,
“Klasifikasi Terjemahan Ayat Al-Quran Tentang Ilmu Sains Menggunakan Algoritma Decision Tree Berbasis
Mobile,” J. Online Inform., vol. 1, no. 1, pp. 24–27, 2016.
[13] C. Triawati, M. A. Bijaksana, and Z. A. Baizal,
“Metode Pembobotan Statistical Concept Based untuk
Klastering dan Kategorisasi Dokumen Berbahasa
Indonesia,” 2009.
[14] M. A. Ramdhani, Metodologi Penelitian untuk Riset Teknologi Informasi. Bandung: UIN Sunan Gunung Djati Bandung, 2013.
![Gambar 2 Throwaway Prototyping[15]](https://thumb-ap.123doks.com/thumbv2/123dok/2127432.1610647/3.595.320.549.79.167/gambar-throwaway-prototyping.webp)