untuk dianggap relevan dengan istilah-istilah kueri tertentu dibandingkan dokumen-dokumen yang lebih pendek. Sehinggavektor dokumen perlu dinormalisasi. Ukuran kesamaan antara kueri Q dan dokumen Di menjadi persamaan: sim( , )= ∑ w .w t j=1 √∑tj=1w 2….…(4)
Formula ini merepresentasikan kosinus sudut antara vektor kueri dan vektor dokumen sebagai vektor-vektor dalam ruang t dimensi, dengan t sebagai jumlah istilah unik dalam sistem (Salton 1989).
Evaluasi Sistem
. Pada proses evaluasi hasil temu-kembali dilakukan penilaian kinerja sistem dengan melakukan pengukuran recall-precision untuk menentukan tingkat keefektifan proses temu-kembali. Dua ukuran utama untuk keefektifan penemu kembalian yang telah digunakan sejak lama adalah recall dan precision (Salton 1989). Recall adalah perbandingan jumlah materi relevan yang ditemukembalikan terhadap jumlah materi yang relevan, sedangkan precision adalah perbandingan jumlah materi relevan yang ditemukembalikan terhadap jumlah materi yang ditemukembalikan.
Tabel 1 Relevant dan retrieved documents
Relevant non relevant
retrieved true positive(tp) false positive(fp)
Non retrieved
false negative
(fn)
true negative(tn)
Berdasarkan Tabel 1, recall (R) dan precision (P) dapat dinyatakan sebagai persamaan sebagai berikut:
= t
t dan = t
t n...(5) Recall dan Precision dihitung berdasarkan persamaan(3). Average precision (AVP) dihitung berdasarkan 11 standard recall levels, yaitu 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% dengan menggunakan interpolasi maksimum (Baeza-Yates & Ribeiro-Neto 1999).
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut:
Perangkat lunak:
1 Sistem operasi Windows 7 Professional sebagai sistem operasi, 2 PHP sebagai bahasa pemrograman, 3 XAMPP version 1.7.2 sebagai web
server, dan
4 Microsoft Office 2010 sebagai aplikasi yang digunakan untuk melakukan perhitungan dalam evaluasi sistem. Perangkat keras:
1 Processor Intel Dual-Core 2.10 GHz 2 RAM 2 GB
3 Harddisk dengankapasitas 160 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen
Penelitian ini menggunakan 324 jurnal hortikultura yang berasal dari Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB. Deksripsi dokumen uji yang digunakan dapat dilihat pada Tabel 2. Gambar 2 dan Lampiran 2 menunjukkan contoh salah satu dokumen yang digunakan dalam penelitian.
Tabel 2 Deskripsi dokumen uji
Dokumen bytes
Ukuran rata-rata dokumen 1329 Ukuran seluruh dokumen 430834 Ukuran dokumen terbesar 2866
Ukuran dokumen terkecil 445
Gambar 2 Contoh dokumen.
Koleksi dokumen memiliki format teks (*.txt) dengan struktur tag XML pada masing-masing dokumen. Tag XML yang digunakan dalam koleksi dokumen, yaitu:
<DOC></DOC>, mewakili keseluruhan dokumen. Di dalamnya terdapat tag lain yang mendeskripsikan isi dokumen secara lebih jelas.
<DOC>
<docId>dok001.txt</docId> <content>Akhir-akhir ini kentang menjadi tanaman prioritas dan mempunyai nilai. ... </content> </DOC>
<docId></docId>, menunjukkan ID dari dokumen tanaman obat.
<content></content>, menunjukkan isi atau informasi dari dokumen.
Jumlah kueri uji yang akan digunakan dalam penelitian ini adalah 15 kueri uji yang berasal dari Laboratorium Temu Kembali Informasi. Daftar kueri uji yang digunakan dapat dilihat pada Lampiran 1.
Pengindeksan Dokumen
Pemrosesan dokumen dilakukan melalui tiga tahapan, yaitu: tokenisasi, pembuangan stopword, dan pembobotan. Pembobotan yang dilakukan adalah pembobotan sebaran kata. Tokenisasi
Tahap tokenisasi dilakukan pada fungsi get_token. Fungsi tersebut melakukan pemecahan kata pada dokumen koleksi, penghilangan karakter yang bersifat separator seperti titik, koma, tanda seru, tanda tanya, dan karakter lainnya yang dianggap kurang representatif dalam mencirikan suatu dokumen.
Dokemen koleksi diproses secara sekuensial per karakter dari awal sehingga menghasilkan sebuah token. Tahapan untuk memperoleh token adalah sebagai berikut: 1 Sistem menggolongkan karakter menjadi 4
jenis, yaitu :
a whitespace, berarti karakter ini merupakan karakter pemisah token b alpha, berarti karakter ini merupakan
huruf
c numeric, berarti karakter ini merupakan angka
d other, berarti karakter ini tidak termasuk jenis-jenis a,b,dan c.
2 Sistem mengubah jenis karakter numeric dan other menjadi whitespace.
3 Sistem melakukan pemisahan kata berdasarkan whitespace.
4 Kata yang dianggap token adalah yang mempunyai panjang lebih dari dua. Pembuangan Stopword
Pembuangan stopword dilakukan setelah proses tokenisasi pada dokumen koleksi. Prosesnya dengan melakukan perbandingan antara kata hasil tokenisasi dengan stopword. Jika terdapat stopword dalam daftar token, maka dilakukan penghapusan kata. Daftar stopword yang digunakan dalam penelitian ini diperoleh dari Herdi (2010) dan dilampirkan
pada Lampiran 3. Hasil dari tahap ini akan digunakan sebagai input pada tahap selanjutnya yaitu pembobotan.
Pembobotan Sebaran Kata
Pembobotan yang dilakukan dalam skripsi ini adalah pembobotan sebaran kata. Pembobotan sebaran kata terdiri atas tiga tahap, yaitu pembobotan kata lokal, pembobotan kata global, dan perkalian antara lokal dan global. Pada tulisan ini, akan diberikan contoh 5 dokumen (dok001, dok002, dok003, dok006, dan dok248) dan 5 kata (organik, pupuk, kentang, tanaman, dan pertanian). Contoh tersebut digunakan untuk menggambarkan tahap pengerjaan dan hasil perhitungan pada penelitian ini.
Pembobotan Kata Lokal
Pembobotan kata lokal merupakan pencarian bobot kata berbasis sebaran pada suatu dokumen. Secara umum, bobot kata lokal terdiri atas 2 bagian, yaitu luas distribusi seragam kata (Uj) dan perluasan penyebaran kata (Sj) pada suatu dokumen. Untuk mengukur luas keseragaman sebaran kata digunakan teori K.Pearson Chi Square.
Tahap awal yang dilakukan pada penelitian ini untuk mendapatkan hasil Chi Square adalah membuat paragraf dari isi dokumen yang ada. Proses pembuatan paragraf pada penelitian ini adalah parsing dokumen. Setiap paragraf berisi lima kalimat. Hasil dari proses parsing dokumen disimpan dalam parsing.txt. Parsing.txt digunakan sebagai input untuk mendapatkan frekuensi kata per paragraf pada setiap dokumen. Tabel 3 Contoh hasil parsing kalimat
Dokumen Jumlah Kalimat Jumlah Paragraf dok001 11 3 dok002 11 3 dok003 4 1 dok006 9 2 dok248 17 4
Pada Tabel 3 dapat dilihat hasil parsing kalimat pada 5 dokumen contoh. Tabel 3 juga menggambarkan bahwa jumlah paragraf yang dihasilkan oleh dokumen beragam, mulai dari satu paragraf hingga empat paragraf tergantung jumlah kalimat yang dimiliki oleh dokumen.
Proses selanjutnya adalah perhitungan peluang(r) dari setiap paragraf di suatu
dokumen. Peluang ditentukan dengan jumlah kata pada paragraf(Ci) dibagi jumlah token pada dokumen(Cm). Hasil perhitungan dari 5 contoh dokumen dapat dilihat pada Tabel 4. Pada dok002, paragraf 2 memiliki jumlah kata lebih banyak sehingga peluang(r) paragraf 2 lebih besar dari paragraf lain. Dokumen yang hanya memiliki 1 paragraf(dok003), maka peluang(r) paragraf tersebut adalah 1. Pada dok248, paragraf 1 dan 3 memiliki jumlah kata yang sama, sehingga dihasilkan peluang(r) yang sama.
Tabel 4 Hasil perhitungan peluang(r) Dokumen Paragraf Jumlah
Kata r dok001 1 42 0.442 2 44 0.463 3 9 0.095 dok002 1 45 0.346 2 71 0.546 3 14 0.108 dok003 1 40 1.000 dok006 1 62 0.564 2 48 0.436 dok248 1 50 0.338 2 40 0.270 3 50 0.338 4 8 0.054
Perhitungan selanjutnya adalah frekuensi kata pada setiap paragraf(v), dan dokumen(n). Hasil perhitungan dok001 pada kata organik, pupuk, kentang, tanaman, dan pertanian dapat dilihat pada Tabel 5. Nilai v, n, dan r digunakan untuk menghitung nilai chi-square. Tabel 5 Hasil perhitungan v dan n pada
dokumen dok001 Kata v1 v2 v3 n chij organik 2 5 1 8 1.197 pupuk 1 6 0 7 4.427 kentang 4 1 1 6 2.150 tanaman 2 0 0 2 2.523 pertanian 0 0 1 1 9.555 Kata organik mempunyai nilai chi-square(chij) yang terendah. Nilai terendah tersebut menyatakan kata organik mendekati distribusi seragam, dan memiliki nilai distribusi seragam(Uj) yang tinggi. Terbukti
pada Tabel 6 organik memiliki nilai U yang terbesar.
Pada perhitungan perluasan penyebaran kata(Sj) sebuah kata, harus dilihat kata tersebut tersebar di dokumen atau tidak. Nilai yang diperlukan adalah total paragraf yang mengandung kata tersebut(p) dan total paragraf pada dokumen(N). Berdasarkan Tabel 5 kata organik dan kentang merupakan kata yang tersebar di ke-3 paragraf sehingga nilai S adalah 1.
Proses terakhir tahap ini adalah perhitungan bobot kata lokal pada setip kata j ( ( )). Hasil tahap ini berupa lokal.txt yang digunakan pada tahap selanjutnya. Hasil perhitungan bobot kata lokal dapat dilihat pada Tabel 6. Kata organik mendapat nilai tertinggi, artinya organik merupakan kata penting dalam dokumen dok001. Sebaliknya pada kata pertanian mendapat nilai terendah, artinya pertanian bukan merupakan kata penting dalam dokumen dok001.
Tabel 6 Hasil perhitungan Uj, Sj, dan bobot lokal pada dokumen dok001
Kata Uj Sj Lokal organik 0.455 1.000 0.54 pupuk 0.184 0.736 0.18 kentang 0.317 1.000 0.39 tanaman 0.283 0.415 0.16 pertanian 0.094 0.415 0.05 Tabel 7 Perbandingan hubungan distribusi
dan bobot lokal
Kata p n Uj Lokal organik 3 8 0.455 0.54 pupuk 2 7 0.184 0.18 kentang 3 6 0.317 0.39 tanaman 1 2 0.283 0.16 pertanian 1 1 0.094 0.05 Pada Xia dan Chai (2011), hubungan antara luas distribusi seragam dan bobot kata pada suatu dokumen adalah korelasi positif non linear. Pada penelitian ini hal tersebut terbukti pada kata organik yang memiliki luas distribusi seragam yang tinggi dan bobot lokal yang dihasilkan juga tinggi. Hasil perbandingan hubungan distribusi seragam dan bobot kata tersebut dapat dilihat pada Tabel 7.
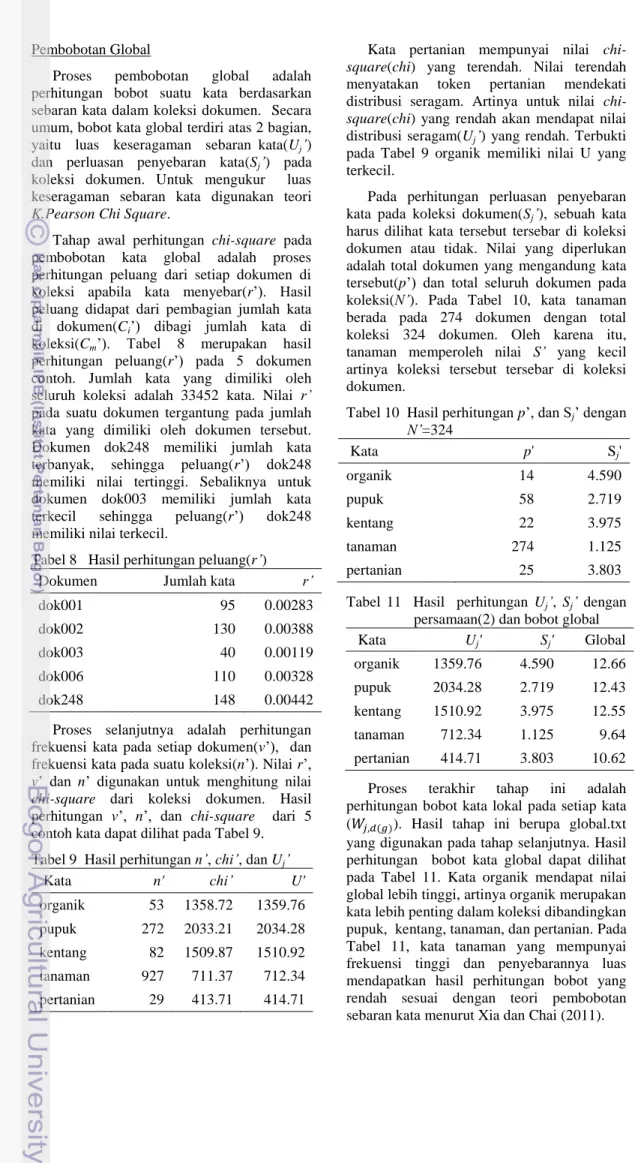
Pembobotan Global
Proses pembobotan global adalah perhitungan bobot suatu kata berdasarkan sebaran kata dalam koleksi dokumen. Secara umum, bobot kata global terdiri atas 2 bagian, yaitu luas keseragaman sebaran kata(Uj’) dan perluasan penyebaran kata(Sj’) pada koleksi dokumen. Untuk mengukur luas keseragaman sebaran kata digunakan teori K.Pearson Chi Square.
Tahap awal perhitungan chi-square pada pembobotan kata global adalah proses perhitungan peluang dari setiap dokumen di koleksi apabila kata menyebar(r’). Hasil peluang didapat dari pembagian jumlah kata di dokumen(Ci’) dibagi jumlah kata di koleksi(Cm’). Tabel 8 merupakan hasil perhitungan peluang(r’) pada 5 dokumen contoh. Jumlah kata yang dimiliki oleh seluruh koleksi adalah 33452 kata. Nilai ’ pada suatu dokumen tergantung pada jumlah kata yang dimiliki oleh dokumen tersebut. Dokumen dok248 memiliki jumlah kata terbanyak, sehingga peluang(r’) dok248 memiliki nilai tertinggi. Sebaliknya untuk dokumen dok003 memiliki jumlah kata terkecil sehingga peluang(r’) dok248 memiliki nilai terkecil.
Tabel 8 Hasil perhitungan peluang(r’)
Dokumen Jumlah kata ’
dok001 95 0.00283
dok002 130 0.00388
dok003 40 0.00119
dok006 110 0.00328
dok248 148 0.00442
Proses selanjutnya adalah perhitungan frekuensi kata pada setiap dokumen(v’), dan frekuensi kata pada suatu koleksi(n’). Nilai r’, v’ dan n’ digunakan untuk menghitung nilai chi-square dari koleksi dokumen. Hasil perhitungan v’, n’, dan chi-square dari 5 contoh kata dapat dilihat pada Tabel 9. Tabel 9 Hasil perhitungan n’, ch ’, dan Uj’
Kata n' ch ’ U' organik 53 1358.72 1359.76 pupuk 272 2033.21 2034.28 kentang 82 1509.87 1510.92 tanaman 927 711.37 712.34 pertanian 29 413.71 414.71
Kata pertanian mempunyai nilai chi-square(chi) yang terendah. Nilai terendah menyatakan token pertanian mendekati distribusi seragam. Artinya untuk nilai chi-square(chi) yang rendah akan mendapat nilai distribusi seragam(Uj’) yang rendah. Terbukti pada Tabel 9 organik memiliki nilai U yang terkecil.
Pada perhitungan perluasan penyebaran kata pada koleksi dokumen(Sj’), sebuah kata harus dilihat kata tersebut tersebar di koleksi dokumen atau tidak. Nilai yang diperlukan adalah total dokumen yang mengandung kata tersebut(p’) dan total seluruh dokumen pada koleksi( ’). Pada Tabel 10, kata tanaman berada pada 274 dokumen dengan total koleksi 324 dokumen. Oleh karena itu, tanaman memperoleh nilai ’ yang kecil artinya koleksi tersebut tersebar di koleksi dokumen.
Tabel 10 Hasil perhitungan p’, dan Sj’ dengan ’=324 Kata p' Sj' organik 14 4.590 pupuk 58 2.719 kentang 22 3.975 tanaman 274 1.125 pertanian 25 3.803
Tabel 11 Hasil perhitungan Uj’, Sj’ dengan persamaan(2) dan bobot global
Kata Uj' Sj' Global organik 1359.76 4.590 12.66 pupuk 2034.28 2.719 12.43 kentang 1510.92 3.975 12.55 tanaman 712.34 1.125 9.64 pertanian 414.71 3.803 10.62 Proses terakhir tahap ini adalah perhitungan bobot kata lokal pada setiap kata ( ( )). Hasil tahap ini berupa global.txt yang digunakan pada tahap selanjutnya. Hasil perhitungan bobot kata global dapat dilihat pada Tabel 11. Kata organik mendapat nilai global lebih tinggi, artinya organik merupakan kata lebih penting dalam koleksi dibandingkan pupuk, kentang, tanaman, dan pertanian. Pada Tabel 11, kata tanaman yang mempunyai frekuensi tinggi dan penyebarannya luas mendapatkan hasil perhitungan bobot yang rendah sesuai dengan teori pembobotan sebaran kata menurut Xia dan Chai (2011).
Berbeda dengan hasil pembobotan global dengan perhitungan pada Tabel 12, kata tanaman organik tidak mendapat bobot tinggi. Tabel 12 merupakan hasil perhitungan pembobotan global dengan perhitungan Sj’ menggunakan persamaan(1). Nilai terbesar diperoleh kata tanaman. Hal tersebut terjadi karena dengan persamaan(1), kata yang menyebar pada banyak dokumen dikoleksi menghasilkan ’ yang tinggi sehingga tanaman mendapatkan bobot yang lebih besar. Hasil dari perhitungan ini tidak sesuai dengan teori pembobotan sebaran kata menurut Xia dan Chai (2011) sehingga, pada tahap selanjutnya digunakan hasil pada Tabel 11, yaitu dengan perhitungan Sj’ menggunakan persamaan (2).
Tabel 12 Hasil perhitungan Uj’, Sj’ dengan persamaan(1) dan bobot Global Kata Uj' Sj' Global organik 1359.76 0.061 6.39 pupuk 2034.28 0.237 8.92 kentang 1510.92 0.095 7.17 tanaman 712.34 0.884 9.30 pertanian 414.71 0.107 5.51 Pada Xia dan Chai (2011), hubungan antara luas distribusi seragam dan bobot kata pada suatu koleksi adalah korelasi negatif non linear. Pada penelitian ini, hal tersebut terbukti pada kata tanaman yang memiliki luas distribusi seragam yang tinggi dan bobot global yang rendah. Hasil perbandingan hubungan distribusi seragam dan bobot tersebut dapat dilihat pada Tabel 13
Tabel 13 Perbandingan hubungan distribusi seragam dan bobot global
Kata n' p' Global organik 53 14 12.66 pupuk 272 58 12.43 kentang 82 22 12.55 tanaman 927 274 9.64 pertanian 29 25 10.62
Perkalian antara lokal dan global
Tahap terakhir dalam pembobotan persebaran kata adalah perhitungan nilai keseluruhan pembobotan persebaran kata. Perhitungan yang dilakukan pada tahap ini adalah perkalian dari pembobotan lokal dan pembobotan global menggunakan persamaan(3).
Hasil dari tahap ini disimpan dalam lokalglobal.txt. Hasil perhitungan pembobotan sebaran kata dapat diliihat pada Tabel 14. Berdasarkan pembobotan sebaran kata, organik memiliki nilai tertinggi pada dokumen dok001. Oleh karena itu, organik merupakan kata penciri dari dokumen dok001.
Tabel 14 Hasil perhitungan bobot lokal, global, dan sebaran kata pada dok001
Kata Lokal Global Sebaran Kata organik 0.54 12.66 6.82 pupuk 0.18 12.43 2.28 kentang 0.39 12.55 4.99 tanaman 0.16 9.64 1.55 pertanian 0.05 10.62 0.59
Kesamaan Dokumen dan Kueri
Metode yang digunakan untuk pengukuran kesamaan adalah ukuran kesamaan kosinus. Pada tahap awal dalam pengukuran kesamaan dokumen, diperlukan kueri yang di masukkan ke dalam sistem oleh pengguna. Kueri diterima oleh sistem, dan dilakukan perubahan menjadi vektor kueri. Tahap selanjutnya adalah proses perhitungan kesamaan antara vektor dokumen dan kueri yang diimplementasikan menggunakan persamaan(4).
Pengujian Kinerja Sistem
Proses evaluasi dalam penelitian ini dilakukan pada koleksi jurnal hortikultura. Proses evaluasi pada koleksi jurnal hortikultura menggunakan 15 kueri uji yang terdapat pada Laboratorium Information Retrieval. Daftar kueri uji dan dokumen relevan yang digunakan pada penelitian ini terdapat pada Lampiran 1.
Pencarian dengan kueri uji ini dilakukan dengan melakukan pengukuran recall-precision dari sistem. Recall adalah rasio dokumen relevan yang ditemukembalikan dan precision adalah dokumen relevan yang ditemukembalikan. Perhitungan recall dan precision menggunakan persamaan(5). Hasil dari evaluasi recall precision masing-masing kueri diinterpolasi maksimum untuk mencari nilai average precision (AVP) dan digambarkan dalam bentuk grafik serta tabel. Proses evaluasi yang dilakukan pada penelitian ini menggunakan kode program
dari Putra (2011) dengan modifikasi oleh penulis.
Gambar 3 merupakan grafik dari 11 titik recall yang dihitung menggunakan interpolasi maksimum. Hasil temu kembali informasi menghasilkan nilai average precision (AVP) sebesar 0.848 yang artinya secara rata-rata pada tiap titik recall, 84.8% hasil temu-kembali relevan dengan kueri.
Gambar 3 Grafik recall precision. Perbandingan Hasil Uji Kueri
Pada tahap evaluasi penelitian ini, dilakukan beberapa perbandingan hasil temu kembali pada kueri uji, yaitu perbandingan pembobotan sebaran kata menggunakan parsing 3, 4, dan 5 kalimat, serta perbandingan pembobotan sebaran kata dengan TFIDF.
Penentuan jumlah kalimat pada pembuatan sebuah paragraf diduga akan mempengaruhi kinerja sistem dalam proses temu kembali dokumen. Penelitian ini melakukan 3 percobaan, yaitu membuat parsing kalimat sebanyak 3, 4, dan 5 kalimat per paragraf. Proses parsing pada penelitian ini merupakan tahap awal pada pembobotan lokal.
Kinerja sistem pembobotan sebaran kata dengan parsing 3, 4, dan 5 kalimat memiliki hasil AVP yang berbeda. Perbedaan hasil AVP dapat ditunjukan oleh Tabel 13. AVP sistem dengan parsing sebanyak 3 kalimat sebesar 0.785, 4 kalimat sebesar 0.803, dan 5 kalimat sebesar 0.848. Pada Lampiran 4, 5 dan 6 dapat dilihat nilai AVP pada masing-masing kueri untuk parsing 3, 4, dan 5 kalimat.
Pada Tabel 15 terlihat bahwa AVP sistem yang melakukan parsing 5 kalimat per
paragraf memiliki nilai yang lebih tinggi, yaitu 0.848 atau 84,8%. Hal tersebut disebabkan oleh parsing 5 kalimat membuat setiap paragraf akan memiliki jumlah kalimat yang lebih banyak sehingga bobot dari kata penanda dokumen akan semakin bertambah. Selain itu, pada parsing 5 kalimat, dokumen harus memiliki jumlah kata yang banyak. Pada dokumen yang jumlah katanya sedikit, parsing 5 kalimat kinerjanya menurun, terlihat pada kueri hama pengerek, lalat buah, dan pupuk npk. Pada kueri tersebut lebih cocok menggunakan parsing 3 atau 4. Karena parsing 3 atau 4 kalimat, paragraf akan lebih banyak dan kata penciri lebih tersebar, sehingga bobot meningkat.
Tabel 15 Perbedaan hasil AVP untuk proses parsing 3, 4, dan 5 kalimat
Kueri
Jumlah kalimat per paragraf 3 4 5 cabai merah 0.622 0.801 0.687 buah tropika 0.508 0.675 0.730 padi 1.000 1.000 1.000 budidaya anggrek 0.227 0.555 1.000 kultur in vitro 0.280 0.336 0.474 fungisida 0.835 0.835 0.851 genotip 1.000 1.000 1.000 hama penggerek 0.894 0.864 0.769 jagung 1.000 1.000 1.000 pupuk npk 0.709 0.634 0.635 gladiol 1.000 1.000 1.000 tanah latosol 0.909 0.510 1.000 lalat buah 0.784 0.830 0.584 tunas 1.000 1.000 1.000 vaksin 1.000 1.000 1.000 Average precision(AVP) 0.785 0.803 0.848 Kinerja sistem pembobotan sebaran kata dan TFIDF menghasilkan output yang berbeda. Secara umum, sistem sebaran kata menghasilkan AVP sebesar 0.848, sedangkan TFIDF menghasilkan AVP sebesar 0.833.
Pada penelitian ini, dapat dikatakan hasil pembobotan sebaran kata lebih tinggi. Perbandingan nilai AVP dari sebaran kata dan TFIDF dapat dilihat pada Gambar 4. Pada Lampiran 6 dan 7 dapat dilihat nilai AVP pada masing-masing kueri uji untuk pembobotan sebaran kata dan TFIDF. Tabel 16 merupakan hasil perbandingan dari 15 0 0.2 0.4 0.6 0.8 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 preci si o n recall