ANALISIS DATA TRANSAKSI PENJUALAN UNTUK KLASIFIKASI
JENIS BARANG DAN RELASI DAYA BELI RELATIF MASYARAKAT
MENGGUNAKAN ALGORITMA K-MEANS SERTA ASOSIASI APRIORI
Lilis Diana1 dan Guruh Fajar Shidik2
1,2Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
Abstract
Use of transaction data in large amounts in a company is not only for the recording and materials of a report, but also required the analysis to explore the potentials in the data transaction to be processed by using a specific algorithm. One of the method in the association rules is Aprori association algorithm that can be used to explore the potential of inter-related data. In this study , the number of transactions with a lot of the items of goods and consumer purchasing power that varies, are grouped first by using the k-means algorithm, the results of cluster in the goods of item formed into 60 clusters and consumer purchasing power is formed into three relative purchasing power clusters there are low , medium and high relative purchasing power of consumers. From the results of the clustering is then performed with the association process and the results of support value and the highest confidence value for two or three items that are in the cluster of high purchasing power. For the two-item support values of 36% and 70%
confidence, the three-item support values of 21% and 80% confidence. When it is compared with the purchasing power that is clustered and not (general purchasing power) , the result is the clustered purchasing power is better.
Keywords: Association Apriori, K-means, Data Mining, Confusion Matrix 1. PENDAHULUAN
Situasi kondisi perekonomian yang ada pada saat ini menunjukkan adanya perkembangan dunia usaha semakin pesat yang memicu kepada tingkat persaingan bisnis juga semakin meningkat . Begitu juga bisnis di bidang ritel meningkat, kenaikan jumlah gerai ritel terutama dipicu oleh pertumbuhan gerai minimarket yang fenomenal. Jika pada tahun 2007 total gerai minimarket hanya 8.889 maka pada tahun 2010 melonjak pesat hingga mencapai sekitar 15.538 buah. Sedangkan pada tahun 2011 diperkirakan akan meningkat menjadi 16.720 gerai.[13].
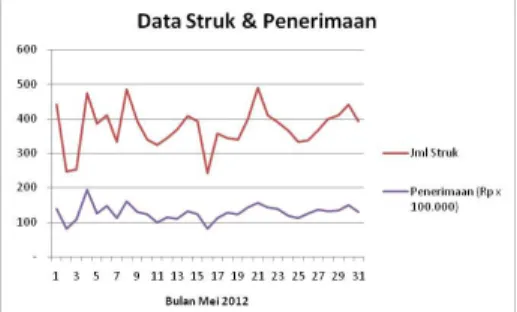
Pemanfaatan data dalam jumlah besar yang ada dalam sebuah system informasi untuk menunjang kegiatan pengambilan keputusan tidak cukup hanya mengandalkan data operasional sebagai pencatatan dan bahan pembuatan suatu laporan saja, akan tetapi diperlukan penggalian potensi – potensi yang ada dalam data transaksi untuk diolah dengan menggunakan metode algoritma tertentu. Salah satu metode yang ada pada association rules adalah metode algoritma Apriori yang bisa digunakan untuk menggali potensi data yang saling berkaitan . Gambar 1 memberikan gambaran tentang jumlah transaksi yang dibuktikan dengan banyaknya jumlah struk setiap harinya yang berpengaruh terhadap penerimaan perusahaan [16].
Pemilihan data transaksi penjualan barang dijadikan objek untuk dianalisis dikarenakan dalam data transaksi penjualan barang tersimpan potensi – potensi atau fakta yang didokumentasikan untuk digali dan diproses menjadi informasi yang bermanfaat bagi perusahaan. Dari setiap receipt tercantum jenis barang yang dibeli, harga barang yang dibeli, jumlah barang yang dibeli, total belanja, tanggal dan waktu transaksi. Dalam penelitian ini akan menganalisis potensi – potensi dari setiap receipt tentang hubungan atau asosiasi antara jenis barang yang satu dengan jenis barang yang lainnya yang direlasikan dengan kemampuan daya beli masyarakat.
Proses asosiasi dilakukan menggunakan algoritma Apriori untuk mencari pembentukan dua itemset atau tiga itemset dari setiap cluster jenis barang dengan menghitung berapa nilai support cluster jenis barang yang dibeli secara bersamaan dengan cluster jenis barang lainnya dan seberapa besar nilai kepastian atau nilai confidence cluster jenis barang dibeli secara bersamaan dengan cluster jenis barang lainnya baik secara umum maupun berdasarkan cluster daya beli masyarakat. Nilai support dan confidence yang dihasilkan dari setiap cluster dievaluasi untuk mendapatkan nilai terbesar yang akan dijadikan sebagai kesimpulan dari penelitan yang dilakukan.
2. LANDASAN TEORI
2.1. Konsep Dasar Aturan Asosiasi Algoritma
Asosiasi aturan pertambangan untuk mencari korelasi antara item dalam dataset telah banyak mendapat perhatian terutama sejak publikasi AIS dan algoritma Apriori [2][3] yang awal penelitian sebagian besar didorong oleh analisis data keranjang pasar, hasil yang memungkinkan perusahaan lebih memahami perilaku pembelian sehingga berdampak pada pencapaian target pasar.
Ada dua langkah dasar yang penting untuk aturan asosiasi, dukungan ( s ) dan kepercayaan ( c ). Karena database besar dan kekhawatiran pengguna tentang barang yang sering dibeli, biasanya ambang dukungan dan kepercayaan yang telah ditetapkan oleh pengguna untuk menetapkan aturan – aturan yang menarik atau berguna. Dukungan ( s ) dari suatu aturan asosiasi didefinisikan sebagai prosentasi yang berisi X U Y terhadap total jumlah record dalam database. Misalkan dukungan dari item adalah 0.1%, itu berarti hanya 0,1 persen dari transaksi mengandung pembelian item ini [14].
Keyakinan atau kepercayaan adanya aturan asosiasi didefinisikan sebagai prosentasi ber transaksi yang mengandung X U Y dengan jumlah total transaksi yang mengandung X. Keyakinan adalah ukuran kekuatan aturan asosiasi, misalnya keyakinan dari aturan asosiasi X → Y adalah 80%, itu berarti bahwa 80% dari transaksi yang mengandung X juga mengandung Y bersama-sama [14].
2.2. Teknik Clustering
Tujuan utama dari metode cluster adalah pengelompokkan sejumlah data/obyek ke dalam cluster ( group ) sehingga dalam setiap cluster akan berisi data yang semirip mungkin. Dalam clustering kita berusaha untuk menempatkan obyek yang mirip ( jaraknya dekat ) dalam satu cluster dan membuat jarak antar cluster sejauh mungkin. Ini berarti obyek dalam satu cluster sangat mirip satu sama lain dan berbeda dengan obyek dalam cluster – cluster yang lain.[22].
2.3. Algoritma Klasifikasi K-Means
Algoritma klasifikasi K-Means merupakan metode clustering berbasis jarak yang mempartisi data ke sejumlah kelompok dan bekerja pada atribut numerik Algoritma ini dimulai dengan pemilihan jumlah kelompok ( k ) secara acak serta pengambilan sebagian populasi sejumlah ( k ) untuk dijadikan sebagai titik pusat awal. Salah satu metode perhitungan jarak yang bisa digunakan adalah Euclidean Distance. Perhitungan jarak menggunakan metode Euclidean dinyatakan sebagai berikut.
Keterangan: x ; obyek ke – 1 y ; obyek ke – 2
n ; banyaknya atribut obyek ke – 1, obyek ke – 2.
Prosedur dasar clustering K-Means adalah sebagai berikut. a. Menentukan k sebagai jumlah cluster yang ingin dibentuk.
b. Membangkitkan k centroid ( titik pusat cluster ) awal secara random. c. Menghitung jarak setiap data ke masing – masing centroids.
d. Setiap data memilih centroid yang terdekat.
e. Menentukan posisi centroid baru dengan cara menghitung nilai rata – rata dari data – data yang berada pada centroid yang sama.
f. Kembali ke langkah 3 jika posisi centroid baru dengan centroid lama tidak sama. 2.4. Algoritma Apriori
Analisis asosiasi atau association rule mining adalah teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Biasanya digunakan untuk analisis pembelian barang di pasar swalayan dengan maksud untuk mengetahui berapa besar kemungkinan seorang konsumen membeli satu jenis barang bersamaan dengan jenis barang yang lainnya. Sehingga perusahaan dapat mengatur strategi promosi dengan penempatan barang yang saling berhubungan ditempatkan secara berdekatan dan menetapkan strategi harga promosi untuk barang – barang tertentu yang saling berhubungan.
Metode dasar analisis asosiasi terbagi menjadi dua tahap [15] : a. Analisis pola frekuensi tinggi
Tahap ini mencari kombinasi item yang memenuhi syarat minimum dari nilai support dalam database. Nilai support sebuah item diperoleh dengan rumus berikut.
Support A = ...( 2 )
Sementara itu, nilai support dari 2 item diperoleh dari rumus 2 berikut : Support ( A,B ) = P ( A B )
Support ( A,B ) = ..(3)
b. Pembentukan Aturan Asosiasi
Setelah semua pola frekuensi tinggi dtemukan, barulah dicari aturan asosiasi yang memenuhi syarat minimum untuk confidence dengan menghitung confidence aturan asosiatif A B.
Nilai confidence dari aturan A B diperoleh dari rumus berikut.
Confidence = P ( B | A ) = ..(4)
2.5. Confusion Matrix
Confusion Matrix menunjukkan jumlah prediksi yang benar dan salah yang dibuat oleh model klasifikasi dibandingkan dengan hasil yang sebenarnya ( nilai target ) dalam data. Matrix adalah n x n, dimana n adalah jumlah nilai target ( kelas ). Kinerja model seperti ini biasanya dievaluasi dengan menggunakan data dalam matrix. Tabel berikut menampilkan confusion matrix 2 x 2 untuk dua kelas ( positif dan negatif ).[12].
Tabel 1. Confusion Matrix
Confusion Matrix Tar get
Positive Negative
Model Positive a b Positive Predictive value a/(a+b) Negative c d Negative Predictive Value d/(c+d)
sensitivity Specificity
a/(a+c) d/(b+d) Accuracy = (a+d)/(a+b+c+d) Akurasi : proporsi jumlah prediksi yang benar.[12]
a. Positif presisi nilai prediktif atau proporsi kasus positif yang diidentifikasi dengan benar. b. Negatif prediktif value : proporsi kasus negatif yang diidentifikasi dengan benar.
c. Sensitivitas : proporsi kasus positif sebenarnya yang diidentifikasi dengan benar. d. Kekhususan : proporsi kasus negatif yang sebenarnya yang diidentifikasi dengan benar. 3. HASIL EKSPERIMEN
3.1. Hasil Cluster Item Barang
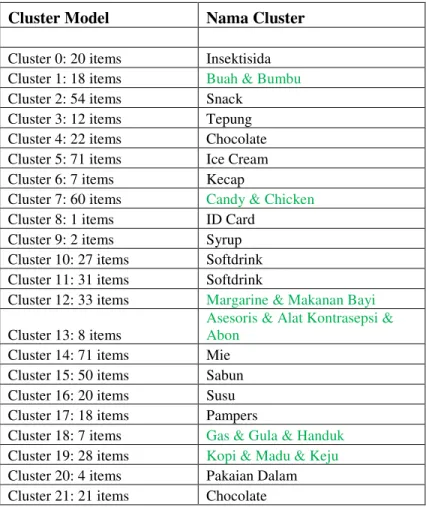
Dari data kode barang yang diproses dengan tools rapidminer menggunakan metode algoritma K-Means didapat hasil 60 cluster sebagai berikut.
Tabel 2. Hasil Cluster Item Barang Cluster Model Nama Cluster
Cluster 0: 20 items Insektisida
Cluster 1: 18 items Buah & Bumbu
Cluster 2: 54 items Snack
Cluster 3: 12 items Tepung
Cluster 4: 22 items Chocolate
Cluster 5: 71 items Ice Cream
Cluster 6: 7 items Kecap
Cluster 7: 60 items Candy & Chicken
Cluster 8: 1 items ID Card
Cluster 9: 2 items Syrup
Cluster 10: 27 items Softdrink
Cluster 11: 31 items Softdrink
Cluster 12: 33 items Margarine & Makanan Bayi
Cluster 13: 8 items
Asesoris & Alat Kontrasepsi & Abon
Cluster 14: 71 items Mie
Cluster 15: 50 items Sabun
Cluster 16: 20 items Susu
Cluster 17: 18 items Pampers
Cluster 18: 7 items Gas & Gula & Handuk
Cluster 19: 28 items Kopi & Madu & Keju
Cluster 20: 4 items Pakaian Dalam
Cluster 22: 1 items Mushrooms
Cluster 23: 11 items Pembersih
Cluster 24: 16 items Pampers
Cluster 25: 18 items Susu
Cluster 26: 53 items Perkakas & Pewangi
Cluster 27: 26 items Pembalut
Cluster 28: 53 items Snack
Cluster 29: 19 items Susu
Cluster 30: 15 items Rokok
Cluster 31: 25 items Softdrink
Cluster 32: 5 items Sozzis
Cluster 33: 27 items Pasta Gigi
Cluster 34: 14 items Rokok
Cluster 35: 2 items Jam
Cluster 36: 27 items Softdrink
Cluster 37: 28 items Softdrink
Cluster 38: 57 items Kecantikan
Cluster 39: 23 items Susu
Cluster 40: 36 items Shampoo
Cluster 41: 25 items Roti
Cluster 42: 51 items Snack
Cluster 43: 26 items Pudding & Pulsa & Ponsel
Cluster 44: 36 items Elektronik & Detergent
Cluster 45: 21 items Susu
Cluster 46: 55 items Kecantikan
Cluster 47: 80 items Obat
Cluster 48: 6 items Sardines & Santan
Cluster 49: 15 items Teh & Telur
Cluster 50: 13 items Minyak Goreng
Cluster 51: 29 items Softdrink
Cluster 52: 56 items Kecantikan
Cluster 53: 14 items Sikat Gigi
Cluster 54: 14 items ATK & Beras
Cluster 55: 1 items Corned
Cluster 56: 15 items Rokok
Cluster 57: 17 items Susu
Cluster 58: 19 items Sambal & Sandal
Cluster 59: 15 items Mainan & Majalah
Total number of items: 1549
Dari cluster jenis barang tersebut selanjutnya diproses asosiasi menggunakan algoritma Asosiasi Apriori dan tools Java.
3.2. Hasil Cluster Daya Beli Relatif
Hasil cluster daya beli relatif masyarakat terbagi menjadi tiga, yakni : Daya Beli Reatif Tinggi, Daya Beli Relatif Menengah dan Daya Beli Relatif Rendah.
Tabel 3. Nilai Nominal Cluster Daya Beli Relatif
Cluster Nilai Rupiah
Daya Beli Relatif Tinggi DBRT >= 105.000 Daya Beli Relatif
Menengah 43.000 =< DBRM =< 103.000
Daya Beli Relatif
Rendah DBRR=<42.000
3.3. Hasil Asosiasi
Tabel 4. Jumlah Asosiasi yang Dihasilkan
DBR Min S Min C Jml Data Jml 2 itemset Jml 3 itemset DBRU 0.327 0.222 98 5 asosiasi 5 asosiasi DBRR 0.311 0.200 45 5 asosiasi 2 asosiasi DBRM 0.370 0.290 46 5 asosiasi 6 asosiasi DBRT 0.368 0.417 19 5 asosiasi 6 asosiasi
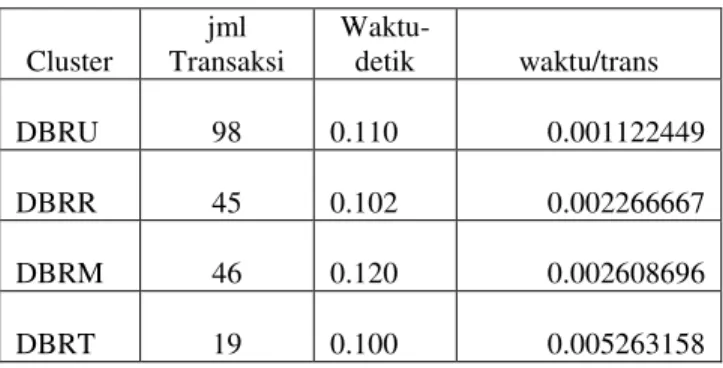
3.4. Waktu Proses Asosiasi
Tabel 5. Cluster Daya Beli dan Waktu Proses Asosiasi
Cluster jml Transaksi Waktu-detik waktu/trans DBRU 98 0.110 0.001122449 DBRR 45 0.102 0.002266667 DBRM 46 0.120 0.002608696 DBRT 19 0.100 0.005263158
3.5. Nilai Support Satu Item
Tabel 6. Nilai Support Tertinggi Satu Item
Uraian Nama Barang Nilai Support
DBRU Mie 0.531
DBRT Mie 0.632
DBRM Mie 0.674
3.6. Nilai Support & Confidence Dua Item
Tabel 7. Nilai Support & Confidence Dua Item
Uraian Nama Barang NS NC NS*N C DBRU Obat+Mie 0.194 0.500 0.097 DBRT Sabun+ Nano2a 0.368 0.700 0.258 DBRM Snack2+ Mie 0.261 0.706 0.184 DBRR Softdrink +Ice ream 0.222 0.556 0.123
3.7. Nilai Support & Confidence Tiga Item
Tabel 8. Nilai Support & Confidence Tiga Item
Uraian Nama Barang NS NC NS*NC
DBRU Ice Cream+Softdrink+Snack
0.041 0.308 0.013 DBRT Sabun+Nano2b (C26)+ Nano2a ( C44 ) 0.211 0.800 0.170 DBRM Obat+Sabun+Mie 0.087 0.444 0.039 DBRR Snack+Softdrink+Ice Cream 0.067 0.500 0.034
3.8. Evaluasi Accuracy Cluster K-Means
Jumlah item barang sebanyak 1.549 item yang secara manual diberi label dan kode barang menjadi 60 kelompok jenis barang. Sedangkan hasil proses pengelompokkan dengan algoritma K-Means dan tools rapidminer menghasilkan 46 cluster yang terdefinisi dengan sempurna dan 14 cluster yang terdefinisi tidak sempurna. Dari 46 cluster tersebut ada beberapa cluster yang berisi jenis barang yang sama, berikut daftar cluster yang berisi jenis barang yang sama.
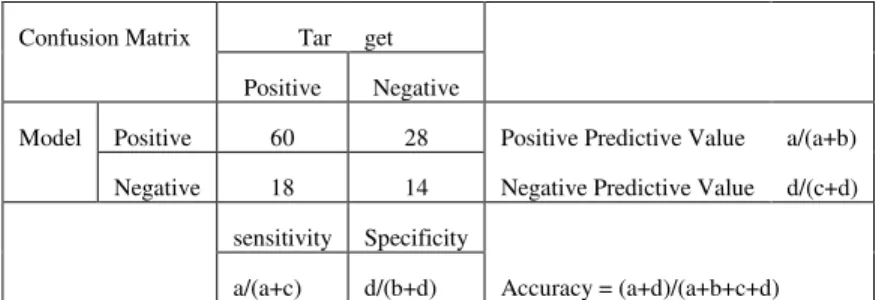
Dari hasil tersebut bisa dihitung Accuracy cluster K-Means dengan Confusion Matrix sebagai berikut.
Tabel 9. Accuracy Cluster K-Means
Confusion Matrix Tar get
Positive Negative
Model Positive 60 28 Positive Predictive Value a/(a+b) Negative 18 14 Negative Predictive Value d/(c+d)
sensitivity Specificity
Tabel 10. Accuracy Cluster K-Means Item Barang
No Uraian Perhitungan Hasil
1 Positive Predictive Value 60/(60+28) 0.68 2 Negative Predictive Value 14/(18+14) 0.44 3 Sensitivity 60/(60+18) 0.77 4 Specificity 14/(28+14) 0.33 5 Accuracy (60+14)/(60+28+18+14) 0.62 4. PENUTUP 4.1. Kesimpulan
a. Jumlah cluster jenis barang yang dihasilkan 60 cluster dengan 46 cluster yang terdefinisi sempurna dan 14 cluster yang terdefinisi tdak sempurna.
b. Jumlah cluster daya beli masyarakat yang dihasilkan sebanyak tiga cluster yang terdiri cluster daya beli relatif tinggi, cluster daya beli relatif menengah dan cluster daya beli relatif rendah.
c. Asosiasi dua jenis barang yang dihasilkan untuk cluster daya beli relatif umum, tinggi, menengah dan rendah sama yaitu lima asosiasi, sedangkan untuk asosiasi tiga jenis barang cluster daya beli relatif menengah dan rendah enam asosiasi dan cluster daya beli umum lima asosiasi dan cluster daya beli tinggi dua asosiasi.
d. Hasil perkalian nilai support dan nilai confidence tertinggi untuk dua item barang maupun tiga item barang berada pada cluster daya beli tinggi, yaitu yang dua item ( support 36% dan confidence 70% ) , yang tiga item ( support 21% dan confidence 80% ), artinya nilai kepastian konsumen untuk melakukan pembelian secara bersamaan untuk dua item barang maupun tiga item barang terdapat pada kosumen cluster tinggi dengan demikian daya beli tinggi memberikan kepastian yang lebih besar atau lebih meyakinkan.
e. Hasil penelitian Nilai Support dan Nilai Confidence daya beli umum untuk yang satu jenis barang, dua jenis barang maupun yang tiga jenis barang nilainya paling rendah baik untuk kelompok daya beli rendah, daya beli menengah maupun daya beli tinggi. Dengan demikian daya beli yang dicluster hasilnya lebih baik dibandingkan dengan yang tidak dicluster.
f. Dengan melakukan cluster menggunakan metode algoritma k-means membantu mempercepat proses asosiasi dengan algoritma apriori.
4.2. Saran
a. Untuk meningkatkan accuracy cluster jenis barang lebih baik data diambil langsung dari database perusahaan.
b. Untuk penelitian selanjutnya bisa dikembangkan dengan mengambil data transaksi dibeberapa lokasi misalnya untuk di tingkat desa, kecamatan, kabupaten dan provinsi atau mengambil data perbandingan antar waktu atau moment – moment tertentu.
c. Untuk metode algoritma bisa dikembangkan dengan algoritma yang lain sebagai perbandingan untuk mendapatkan hasil yang lebih baik.
DAFTAR PUSTAKA
[1] Afif Syaifullah Muhammad,"Implementasi Data Mining Algoritma Apriori pada Sistem Penjualan,"STMIK AMIKOM YOGYAKARTA.
[2] Agrawal,R.,Imielinski,T.,and Swami,A.N. 1993, Mining association rules between sets of items in large database. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, 207-216.
[3] Agrawal, Rakesh and Srikant, Ramakrishnan.1994. Fast algorithms for mining associationrules. Proceeding of the 1994 International Conference Very Large Data Bases, Santiago, Chile.
[4] Borgelt Christian," Implementation of the FP-growth Algorithm, Departement of Knowledge Processing and Language Engneering School of Computer Science", Otto-Von-Guericke-Unversty of Magdeburg Universitatsplatz 2, 39106 Magdeburg,Germany,Workshop KDD 2005.
[5] Borgelt Christian, Thosten Meini, Michael Berthold," A Program for Molecular Substructure Mining", Departement of Knowledge Processing and Language Engneering School of Computer Science, Otto-Von-Guericke-Unversty of Magdeburg Universitatsplatz 2, 39106 Magdeburg,Germany, Computer Science Departement 2 University of Erlangen-Nuremberg MartenstraBe 3, 91058 Erlangen, Germany, Dept. of Computer and Information Science University of Konstanz 7857 Konstanz, Germany.Workshop KDD 2005.
[6] Ceglar Aaron and John .Roddick," Association Mining", ACM Computing Surveys, vol,38,no,2, Article 5, Publication date,July 2006.
[7] Dinda Setiawati Devi,"Penggunaan Metode Apriori Untuk Analisa Keranjang Pasar Pada Data Transaksi Penjualan Minimarket Menggunakan Java & MySQL," Tesis-Pasca Sarjana Universitas Gunadarma,2009.
[8] Erwin, “Analisis Market Basket Dengan Algoritma Apriori dan FP-Growth,” ISSN 1907-4093/@2009 Jurnal Generic.
[9] El-Hajj Mohammad and Osmar R.Zaiane," Implementing Leap Traversals of the Itemset Lattice", Departemen of Computing Science, University of Alberta Edmonton,AB Canada, Workshop KDD 2005.
[10] Fayyad,Usama,"Advances in Knowledge Discovery and Data Mning,"MIT Press,1996.
[11] Handojo Andreas, Gregorius Satia Budhi, Hendra Rusly," Aplikasi Data Mining Untuk Meneliti Item Barang Di Supermaket Dengan Metode Market Basket Analysis," Jurusan Teknik Informatika, Universitas Kristen Petra Surabaya, 2004.
[12] http://www.saedsayad.com/model evaluation c.htm tgl 06 Mei 2013.jam 7.34pm
[13] Indonesian Commercial Newsletter Juni 2011, Perkembangan Bisnis Ritel Modern ,http://www.datacon.co.id/Ritel-2011ProfilIndustri.html.
[14] Kotsiantis Sotiris, Dimitris Kanellopoulos," Tinjauan Terbaru Aturan Asosiasi Pertambangan", Software pendidikan Pengembangan Laboratorum Departemen Matematika, Universitas Patras Yunani,2006.
[15] Kusrini, Taufik Luthfi Emha,"Algoritma Data Mining",C.V.Andi Offset Yogyakarta 2009. [16] Laporan Keuangan Indomaret Wanaraja Bulan Mei 2012
[17] Larose, Daniel T," Discovering Knowledge in Data: An Introduction to Data Mining", John Willey & Sons,Inc,2005.
[18] Piatetsky,G.and Shapiro,"An introduction:Machine learning, data mining, and knowledge discovery", Course in data mining KDnuggets,2006.
[19] S.Moertini Veronica dan Marsela Yulita,"Analisis Keranjang Pasar Dengan Algoritma Hash-Based Pada Data Transaksi Penjualan Apotek,"Integral.Vol.9 No.4 November 2004.
[20] Santi Wahyuni Febriana," Penggunaan Cluster-Based Sampling Untuk Penggalian Kaidah Asosiasi Multi Obyektif," Jurusan Teknik Informatika, Fakultas Teknologi Industri , Institut Teknologi Nasional-Malang.
[21] Santosa Budi,"Data Mining Teknik Pemanfaatan Data Untuk Keperluan Bisnis," Graha Ilmu Yogyakarta,2007.