IMPLEMENTASI METODE K-NEAREST NEIGHBOR
DENGAN DECISION RULE UNTUK KLASIFIKASI
SUBTOPIK BERITA
Abstract
This research is about document classification using K-Nearest Neighbor method. We will develop a classification system of news from several source websites. The research will focused on the subtopics of the news articles. This system is built using K-Nearest Neighbor as the main algorithm. Using stemming, stop words and tokenizing in the preprocessing process, it would be easier for the system to classify the documents and it also will get terms from the entire documents inside. In this research TF-IDF method will be used for weighting terms and an addition of word count bonus for IDF will make the classification more accurate. We also use a Decision Rule as the substitute for K-Nearest Neighbor majority vote. By using Decision Rule, the calculation will use Euclidean Distance similarity method. In this system, the k for K-Nearest Neighbor value will be test at 3, 5 and 7. For testing the system, we will analyzee the k value by using or without using Decision Rule. The result of this research is using Decision Rule in K-Nearest Neighbor algorithm will increase accuracy of news classification compared without using Decision Rule. The system has 89.36% accuracy rate.
Keywords : K-Nearest Neighbor, Decision Rule, TF-IDF, News Classification System.
1. Pendahuluan
Beberapa surat kabar online telah membuat pengklasifikasian beritanya per topik-topik berita sehingga membuat pencarian berita dipermudah. Bagi pembaca berita, klasifikasi topic-topik tersebut memberikan kemudahan agar saat pencarian berita, berita dapat dicari melalui kategori topik yang lebih detail. Pembuatan sistem klasifikasi topik berita otomatis berdasarkan suatu algoritma tertentu sangat dibutuhkan untuk mempercepat proses dan menggantikan proses manual yang selama ini dilakukan.
Algoritma K-Nearest Neighbor sangat umum digunakan untuk pengkategorisasian teks. Hal tersebut diketahui karena algoritmanya yang mudah dan efisien untuk klasifikasi teks. Bukan hanya mudah dan efisien, sifat dari algoritma K-Nearest Neighbor sendiri bersifat self-learning, dimana algoritma ini dapat mempelajari struktur data yang ada dan menkategorikan dirinya sendiri. Biasanya, K-Nearest Neighbor selalu menggunakan majority vote sebagai landasan penentuan dimana sebuah dokumen diklasifikasi. Permasalahannya adalah jika terdapat sebuah kategori dimana kategori tersebut sudah mempunyai banyak dokumen, maka kemungkinan besar yang terjadi jika terdapat dokumen baru yang mendekati kemiripan dengan kategori yang dimaksud akan ikut masuk dalam kategori itu karena penggunaan sistem
[1] majority vote [Mia09]. Pada penelitian ini akan dilakukan penggantian penggunaan majority vote menjadi Decision Rule dengan harapan agar penggunaan algoritma K-Nearest Neighbor dapat dimaksimalkan
Pengambilan berita sebagai data training diambil dari 3 (tiga) website yaitu: bbc.com, cnn.com, dan foxnews.com. Berita tersebut akan dikategorikan berdasarkan topik olahraga yang terbagi menjadi 7 (tujuh) subtopik Soccer, Formula 1, Basketball, Motorsport, Baseball, Tennis, dan NFL. Berita yang digunakan sebagai data training sejumlah 280 berita. Untuk pengujian akan diambil sebanyak 95 berita baru yang bersumber dari NYTIMES, CBSSPORT, dan THE GUARDIAN.
2. Landasan Teori 2.1. TF-IDF
Tahapan awal Text Mining sebelum dilakukan proses TF-IDF adalah tahap tokenisasi dan stop word removal [Wei05]. Berdasarkan [Her09] dalam jurnalnya yang berjudul "Aplikasi Pengkategorian Dokumen dan Pengukuran Tingkat Similaritas Dokumen Menggunakan Kata Kunci Pada Dokumen Penulisan Ilmiah” dari Universitas Gunadarma, pembobotan sebuah term yang spesifik dikenal sebagai IDF (Inverse Document Frequency). Pembobotan dilakukan berdasarkan pada penomoran dokumen, dimana dari tiap dokumen, tiap kata yang digunakan dibobotkan berdasarkan banyaknya kata dari tiap dokumen. Semakin banyak kata dalam dokumen, semakin besar bobot kata tersebut, begitu pula sebaliknya. TF-IDF (Term Frequency-Inverse Document Frequency) merupakan pembobotan sebuah kata dalam satu dokumen agar dapat diproses lebih lanjut oleh beberapa algoritma lain yang membutuhkan. TF merupakan Term Frequency dari sebuah dokumen. Penggunaan TF-IDF ini akan menggunakan word count bonus sebagai hasil dari IDF. Jika IDF sudah didapati, maka akan ditambah dengan 1.
= ∗ = log
Dimana :
d = dokumen ke-d
t = kata ke-t dari kata kunci
W = bobot dokumen ke-d terhadap kata ke-t
tf = banyaknya kata yang dicari pada sebuah dokumen D = total dokumen
2.2. Algoritma K-Nearest Neighbor
Algoritma K-Nearest Neighbor merupakan sebuah algoritma yang sering digunakan untuk klasifikasi teks dan data. Penggunaan K-Nearest Neighbor mempunyai sifat self-learning dimana jika semakin banyak dokumen, maka
makin banyak pula sumber yang dapat digunakan untuk dibandingkan. Nearest Neighbor berarti mencari tetangga yang paling dekat dengan sets yang akan di klasifikasi [Mia09].
Contoh :
Gambar 1. K-Nearest Neighbor
Dikutip dari : "Improved k-NN for text classification" 1. Dari gambar 1 di atas dilihat bahwa dokumen uji
diharapkan memiliki kelas yang sama dengan dokumen sekitarnya.
2. Probabilitas dari gambar 1 di atas adalah sebagai berikut : P(segitiga dalam lingkaran|segitiga) = 2/3 • P(biru dalam lingkaran|kotak) = 1/3 3. Penggunaan nilai k sebagai nilai jumlah kluster
dengan nilai ganjil, misal k=1 k=3 k=5
4. Penghitungan distance yang dicari akan menggunakan [Mia09].
5. Untuk mengukur bobot vote, K-Nearest Neighbor majority vote atau cosine [Mia09].
Algoritma K-Nearest Neighbor merupakan algoritma yang mempunyai kebiasaan dimana jika sudah ada banyak dokumen yang masuk kedalam 1 kategori, maka dokumen baru yang muncul dapat dengan mudah masuk kedalam majority vote yang ada. Maka dari itu penulis berusaha mencoba untuk menggunakan Improved K-Nearest Neighbor with Decision Rule
cara penghitungan similarity dokumen menggunakan [Mia09] :
, =
Dimana Q adalah dokumen tes, relevan dengan dokumen tes dan w adalah
ada. Cosine biasanya digunakan untuk perhitungan dalam
untuk menghitung distance yang sama dilakukan oleh Euclidean Distance satu dimensi :
, ∑ ! ,
[2] [2]
makin banyak pula sumber yang dapat digunakan untuk dibandingkan. K-berarti mencari tetangga yang paling dekat dengan sets yang
Nearest Neighbor dengan 2 (dua) neighbor NN for text classification" [Mia09]
dilihat bahwa dokumen uji d (berbentuk lingkaran) diharapkan memiliki kelas yang sama dengan dokumen latih yang ada di
adalah sebagai berikut : |segitiga) = 2/3 |kotak) = 1/3
sebagai nilai jumlah kluster biasanya menggunakan k =5
yang dicari akan menggunakan Euclidean Distance Nearest Neighbor biasa menggunakan merupakan algoritma yang mempunyai kebiasaan dimana jika sudah ada banyak dokumen yang masuk kedalam 1 kategori, maka dokumen baru yang muncul dapat dengan mudah masuk kedalam majority vote yang ada. Maka dari itu penulis berusaha mencoba untuk Nearest Neighbor with Decision Rule. Berikut adalah cara penghitungan similarity dokumen menggunakan cosine yang diberikan oleh
∑ "#,$ "%,$& "'#.$ "'%.$
&
adalah dokumen tes, D adalah dokumen training yang adalah term frequency dari keyword yang biasanya digunakan untuk perhitungan dalam k-Nearest Neighbor untuk menghitung distance yang sama dilakukan oleh Euclidean Distance satu
[2]
Dimana i,j adalah records yang sudah ada dan m sebagai banyaknya variabel data. x merepresentasikan nilai dari record i,k dan j,k.
2.3. Decision Rule
Decision Rule yang diberikan oleh [Mia09] dalam jurnalnya menyatakan bahwa jika ada satu kelas yang mempunyai jumlah dokumen yang jauh lebih banyak dibandingkan dokumen lain, maka dokumen uji baru yang akan masuk bisa salah dalam klasifikasinya. Dimisalkan menggunakan Decision Rule awal k-NN. Maka dokumen tersebut akan masuk kedalam kelas yang jumlahnya banyak. Maka dari itu, Decision Rule diubah agar dapat meningkatkan keakuratan bagi k-NN. Memberikan bobot yang lebih besar kepada kelas dengan jumlah dokumen yang banyak dalam top-k buffer dan menghilangkan dokumen yang jauh dari dokumen uji. Setelah mendapatkan akhir dari top-k buffer, barulah dihitung menggunakan Euclidean Distance dari dokumen uji dengan top-k buffer. Berikut adalah formula yang digunakan oleh [Mia09] sebagai formula bagi decision rule yang diberikan :
, - ∗ . / Dimana :
Cj = tiap kelas j dalam masing - masing klasifikasi
A = banyaknya kelas di array A[] yang termasuk kedalam kelas Cj B = euclidean distance dari dokumen yang termasuk kedalam kelas Cj
3. Hasil dan Analisis Sistem 3.1. Pemrosesan Berita
Berita training yang sudah siap dimasukan ke dalam database harus memenuhi syarat bahwa berita tersebut sudah masuk ke dalam salah satu subtopik yang telah diberikan pada tiap sumber. Hasil berita training yang didapat akan diuji dengan berita baru yang masih belum mendapatkan subtopik berita.
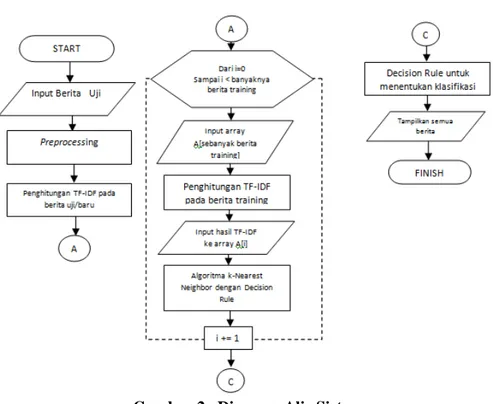
Diagram alir sistem secara keseluruhan dapat dilihat pada gambar 2 sebagai berikut:
Gambar 2. Diagram Alir Sistem
Jika semua berita training sudah masuk kedalam database yang dapat dilihat pada gambar 3, maka akan dipreproses dengan tokenizing, stopwords, dan stemming. Setelah mendapat hasil term, maka akan diberlakukan pembobotan pada tiap term. Pembobotan dilakukan dengan TF-IDF (lihat rumus [1]). Setelah TF-IDF dilakukan, maka akan diberlakukan perhitungan cosine dan euclidean distance.
Setelah mendapatkan hasil, maka berita dapat diketahui hasil subtopiknya. Penggunaan Decision Rule sebagai salah satu perhitungan dianggap akan menambahkan persentase dari hasil K-Nearest Neighbor.
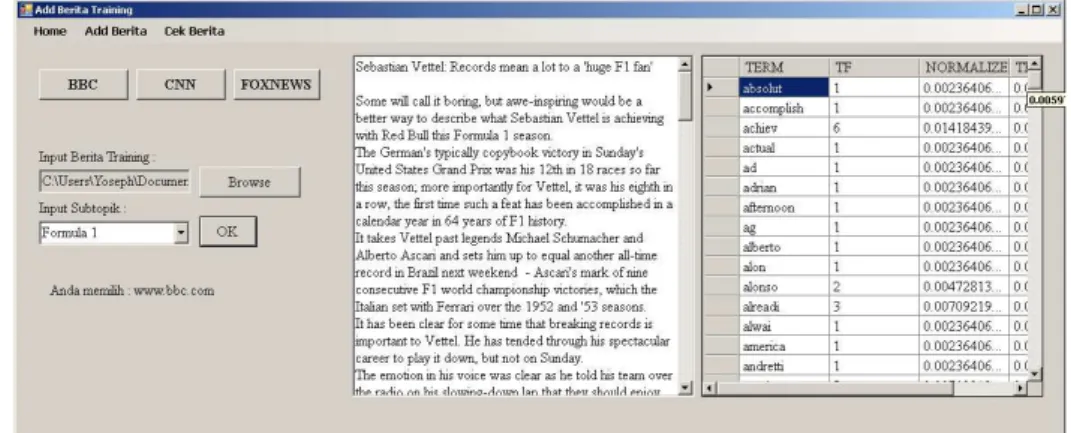
Program yang dibangun dibuat menggunakan Visual Basic.NET 2010 dan gambar 4 di bawah ini adalah contoh implementasi penambahan berita pada sistem yang dibangun.
Gambar 4. Tampilan Program Bagian Tambah Berita
3.2. Analisis Sistem
Pada bagian ini akan dilakukan beberapa analisis, dan pengujian terhadap sistem dengan cara melihat hal - hal yang mempengaruhi hasil dari proses klasifikasi yang dilakukan oleh algoritma K-Nearest Neighbor dengan menggunakan Decision Rule dan algoritma K-Nearest Neighbor tanpa menggunakan Decision Rule.
Sesuai dengan penjelasan di bagian pendahuluan, berita training diambil 40 per subtopik. Seluruh berita training berjumlah 7 x 40 berita yaitu total 280 berita training yang terbagi berdasarkan sumber dan subtopik yang telah disebutkan sebelumnya. Total keseluruhan berita baru yang akan diuji adalah 94 berita. Pengujian terhadap berita baru akan dibandingkan dari persentase keakuratan hasil klasifikasi dari tiap sumber sehingga dapat diketahui sumber mana yang klasifikasinya paling baik. Pengujian juga akan dilakukan untuk mencari term mana saja yang menjadi titik tumpu dari berita tersebut sehingga dapat masuk ke dalam subtopik yang ada.
Tabel 1, 2, dan 3 di bawah ini merupakan hasil dari klasifikasi sistem yang menggunakan perhitungan K-Nearest Neighbor. Diasumsikan bahwa berita sumber adalah benar, maka persentase yang didapat sebagai berikut: diketahui 3 berita sumber berita yang mempunyai cara pengklasifikasian yang berbeda beda dan dapat terbukti bahwa ada beberapa sumber yang tidak cocok untuk dilakukan klasifikasi menggunakan K-Nearest Neighbor.
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan k = 3
Sumber Benar Salah Total Persentase
BBC 15 0 15 100%
CNN 13 2 15 86,66%
FOXNEWS 14 1 15 93,33%
OTHER 41 8 49 83,67%
Total 83 11 94 88,29%
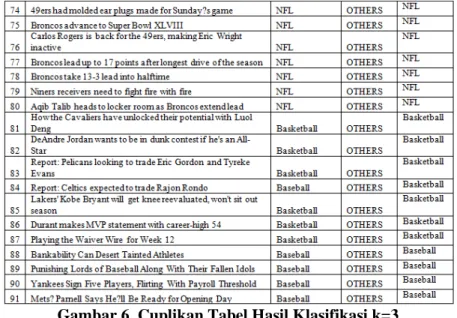
Dari tabel 1 di atas dapat terlihat bahwa hasil pengklasifikasian menunjukan angka yang sudah cukup memuaskan. Tabel 1 tersebut merupakan hasil klasifikasi hanya menggunakan K-Nearest Neighbor dan menggunakan k = 3. Percobaan juga dilakukan terhadap k = 5 dan k = 7.
Tabel 2
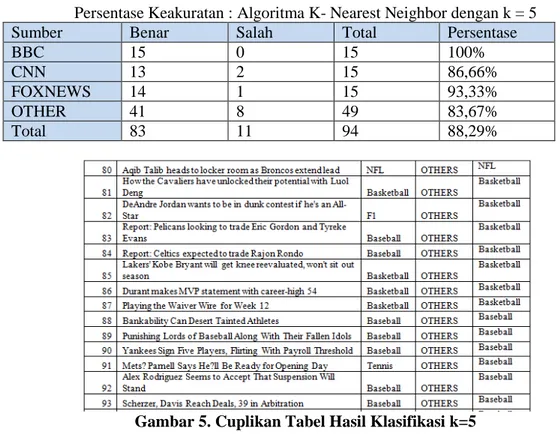
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan k = 5
Sumber Benar Salah Total Persentase
BBC 15 0 15 100%
CNN 13 2 15 86,66%
FOXNEWS 14 1 15 93,33%
OTHER 41 8 49 83,67%
Total 83 11 94 88,29%
Gambar 6. Cuplikan Tabel Hasil Klasifikasi k=3
Dari tabel 2 di atas, ternyata setelah dilakukan klasifikasi menggunakan k = 5, tidak ada perubahan signifikan yang terjadi pada sumber berita. Jika dilihat pada cuplikan hasil klasifikasi sesuai gambar 5, perubahan terjadi pada berita yang ada pada sumber OTHERS, beberapa berita memiliki kesamaan tetapi ada beberapa berita dimisalkan pada id ke-82 dimana jika k = 3 (Gambar 6), subtopik berita tersebut adalah basketball, tapi pada saat k = 5 subtopik terganti menjadi F1, jika dilihat dari vote yang ada, pada k = 3 mempunyai 2 vote untuk basketball dan 1 vote untuk F1. Tapi pada saat k bertambah menjadi 5, dua berita tambahan memberikan vote kepada F1 dimana F1 sendiri akan menjadi pemenang vote tersebut.
Tabel 3
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan k = 7
Sumber Benar Salah Total Persentase
BBC 14 1 15 93,33%
CNN 15 0 15 100%
FOXNEWS 14 1 15 93,33%
OTHER 39 10 49 79,59%
Total 82 12 94 87,23%
Setelah diketahui hasil akhir dari ketiga k dari table 1, 2, dan 3, maka dapat disimpulkan bahwa nilai k tidak banyak berpengaruh pada hasil akhir K-Nearest karena persentase keakuratan rata-rata masih diatas 80% (tergolong baik).
Berikut akan ditampilkan hasil klasifikasi pada k yang sama tetapi menggunakan Decision Rule sebagai metode tambahan dalam uji coba agar hasil dapat lebih baik. Hasil klasifikasi dapat dilihat lebih lanjut pada tabel 4, 5, dan 6.
Tabel 4
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan Decision Rule k = 3
Sumber Benar Salah Total Persentase
BBC 15 1 15 100% CNN 13 2 15 86,66% FOXNEWS 14 1 15 93,33% OTHER 42 7 49 85,71% Total 84 10 94 89,36% Tabel 5
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan Decision Rule k = 5
Sumber Benar Salah Total Persentase
BBC 15 1 15 100% CNN 13 2 15 86,66% FOXNEWS 14 1 15 93,33% OTHER 39 10 49 79,59% Total 81 13 94 86,17% Tabel 6
Persentase Keakuratan : Algoritma K- Nearest Neighbor dengan Decision Rule k = 7
Sumber Benar Salah Total Persentase
BBC 14 1 15 93,33%
CNN 14 1 15 93,33%
FOXNEWS 14 1 15 93,33%
OTHER 40 9 49 81,63%
Total 82 12 94 87,23%
Dari tabel 4, 5, 6 didapati bahwa ada penurunan persentase keakuratan pada table 5 dan 6, juga terdapat kenaikan persentase keakuratan dari tabel 4. Akhirnya pada tabel 7 ditulis kesimpulan dari hasil analisis keenam tabel sebelumnya.
Tabel 7
Persentase Keakuratan : Hasil Keakuratan
Sumber K = 3 K = 5 K = 7
KNN 88,29% 88,29% 87,23%
Dari tabel 7 di atas, persentase paling besar didapat pada k = 3, menggunakan K-Nearest dengan Decision Rule. Penggunaan k yang lebih kecil memungkinkan sistem klasifikasi tidak ambigu untuk mencari hasil klasifikasi yang dihasilkan. Dengan penggunaan Decision Rule sebagai pengganti majority vote ternyata mampu meningkatkan keakuratan sebesar hamper sekitar 2%. Hasil ini memang kecil dan kurang memuaskan karena hanya menggunakan algoritma K-Nearest Neighbor saja sudah mendapatkan hasil yang cukup baik, mencapai lebih dari 88% tingkat keakuratan.
Pada tabel 8 ditampilkan beberapa kata yang sangat mempengaruhi hasil perhitungan klasifikasi karena tingginya frekuensi kemunculannya.
Tabel 8
5 term yang paling banyak muncul pada berita training
term DF season 190 time 169 team 163 game 158 win 151
Didapati term season, time, team, game dan win merupakan term yang paling banyak muncul dari 280 berita training. Dari data tersebut dapat disimpulkan bahwa kata - kata tersebut merupakan kata umum yang dapat digunakan oleh semua subtopik yang ada. Dari term tersebut, setiap berita baru akan diproses dan melalui term - term yang sudah ditetapkan dan hasil yang didapat juga cukup memuaskan.
4. KESIMPULAN
Berdasarkan hasil penelitian yang dilakukan maka dapat disimpulkan : 1. Penggunaan K-Nearest Neighbor sebagai klasifikasi menunjukan
persentasi yang baik, dengan nilai k = 3, menunjukan hasil persentase 88,29%. Dari k yang sama, digunakan Decision Rule yang ada dan persentase hasil akhir dari keakuratan K-Nearest Neighbor dengan Decision Rule adalah 89,36%. Dari hasil tersebut dapat disimpulkan menggunakan k = 3 merupakan k yang paling tinggi keakuratannya dalam Nearest Neighbor maupun K-Nearest Neighbor with Decision Rule.
2. Penggunaan Decision Rule hanya akan menambah keakuratan sekitar 2% dan kurang mampu memaksimalkan performa
K-Nearest Neighbor sendiri. Algoritma K-K-Nearest Neighbor saja sudah memberikan hasil keakuratan yang baik sekitar 88%.
3. TF.IDF selalu akan digunakan sebagai pembobotan dalam K-Nearest Neighbor dengan diingat bahwa terdapat word count bonus dimana hasil IDF akan ditambah dengan 1. Selain itu penggunaan Euclidean Distance sebagai Decision Rule merupakan metode yang dapat meningkatkan hasil klasifikasi.
Daftar Pustaka
[Fra06] Francis, A.L., FCAAS, MAAA. (2006). Taming Text : An introduction to Text Mining. Casuality Acutuarial Society Forum
[Gro04] Grosman, A.D., & Frieder, ). (2004). Information Retrieval : Algorithms and Heuristics. Netherland : Springer, Inc
[Han01] Han, E., Karypis, & Kumar. (2001) Text Categorization Using Weight Adjusted K-Nearest Neighbor Classification. Journal Department of Computer Science and Engineering Army HPC Research Center. University of Minnesota.
[Her09] Herwansyah, A. (2009). Aplikasi Pengkategorian Dokumen dan Pengukuran Tingkan Similaritas Dokumen Menggunakan Kata Kunci pada Dokumen Penulisan Ilmiah. Jurnal Sistem Informasi. Universitas Gunadarma.
[Mia09] Miah, M. (2009). Improved k-nn Algorithm for Text Classification. Journal Department of Science and Engineering. University of Texas.
[Rob04] Robertson, S. (2004). Understanding Inverse Document Frequency : On Theorethical Argument for IDF. Journal of Documentation 60 no. 5, pp 503-520. Cambridge.
[Wei05] Weiss, M.S., Indurkhya, Zhang & Damerau. (2005). Text Mining : Predictive Methods for Analyzing Unstructured Information. New York: Springer, Inc.