i
PENERAPAN ALGORITMA NAÏVE BAYES
UNTUK MEMPREDIKSI NILAI UJIAN NASIONAL SISWA SMA
BERDASARKAN NILAI RAPOR DAN NILAI UJI COBA NASIONAL
(Studi Kasus Pada SMA Kristen Bentara Wacana)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Theresia Edhi Wahyuning Pratiwi
07 5314 027
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
IMPLEMENTATION OF NAÏVE BAYES ALGORITHM TO PREDICT
THE NATIONAL EXAMINATION GRADES FOR SECONDARY
SCHOOL STUDENTS BASED ON STUDENT EVALUATION
AND NATIONAL TRY OUT GRADES
(Case Study At SMA Kristen Bentara Wacana)
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the
Sarjana Komputer
Degree
In Study Program of Informatics Engineering
By :
Theresia Edhi Wahyuning Pratiwi
07 5314 027
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
“ Kau mungkin saja kecewa jika percobaanmu gagal,
Tetapi kau pasti takkan berhasil jika tidak mencoba ”
-Beverly Sills-
“ Tugas di hadapan kita tak pernah sebesar kekuatan
di belakang kita ”
-Anonim-
Karya ini ku persembahkan untuk :
Almarhum Bapak FX. Poerwaka Djati Walujo, S.IP
Ibuku : Margareta Emy Yurida
Kedua Kakakku : Krispina Fitri Prawesti, S.Si
Kornelia Asri Tyas Prasasti, S.E
vii
PENERAPAN ALGORITMA NAÏVE BAYES
UNTUK MEMPREDIKSI NILAI UJIAN NASIONAL SISWA SMA
BERDASARKAN NILAI RAPOR DAN NILAI UJI COBA NASIONAL
Studi Kasus Pada SMA Kristen Bentara Wacana
ABSTRAK
Tujuan dari penelitian ini adalah untuk memprediksi nilai Ujian Nasional
(UN) siswa menggunakan algoritma
Naïve Bayes
. Data yang dipakai untuk
penelitian ini diperoleh dari SMA Bentara Wacana, Muntilan yakni data nilai
rapor, Uji Coba Nasional (UCO), dan Ujian Nasional (UN) siswa sejak tahun
2008-2010. Pengujian dilakukan pada 705
record
data dengan menggunakan
3-fold cross-validation
dan 5-
fold cross-validation
, sehingga menghasilkan tingkat
keakuratan masing-masing sebesar 67,92% dan 71,11% yang merupakan rata-rata
dari 9 mata pelajaran.
viii
IMPLEMENTATION OF NAÏVE BAYES ALGORITHM TO PREDICT
THE NATIONAL EXAMINATION GRADES FOR SECONDARY
SCHOOL STUDENTS BASED ON STUDENT EVALUATION
AND NATIONAL TRY OUT GRADES
Case Study At SMA Kristen Bentara Wacana
ABSTRACT
This study aimed to predict students’ National Examination (UN) value using the
Naive Bayes algorithm. Data used were obtained from Bentara Wacana Senior
High School, Muntilan and involved of students’ value of grades, the National
Trial (UCO), and the National Examination (UN) since 2008-2010. Tests had
performed on the 705 recorded data using 3-fold cross-validation and 5-fold
cross-validation methods, resulting each level of accuracy 67,92% and 71,11%
which is an average of nine lesson subjects.
x
KATA PENGANTAR
Salam Sejahtera,
Puji dan syukur kehadirat Tuhan Allah yang telah menganugerahkan cinta
kasihNya yang melimpah lewat kekuatan, kelancaran dan kemudahan dalam
penulisan skripsi dengan judul “ PENERAPAN ALGORITMA NAÏVE BAYES
UNTUK MEMPREDIKSI NILAI UJIAN NASIONAL SISWA SMA
BERDASARKAN NILAI RAPOR DAN NILAI UJI COBA NASIONAL (Studi
Kasus Pada SMA Bentara Wacana) ”.
Skripsi ini disusun dalam rangka memenuhi salah satu syarat untuk
memperoleh Gelar Sarjana Komputer di Program Studi Teknik Informatika
Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta.
Penulisan skripsi ini tidak dapat terselesaikan dengan baik tanpa bantuan
dari berbagai pihak. Oleh karena itu terima kasih yang sebesar-besarnya penulis
sampaikan kepada :
1.
Ibu P.H. Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma sekaligus dosen penguji atas kritik
dan saran yang telah diberikan.
2.
Ibu Ridowati Gunawan, S.Kom., M.T., selaku Ketua Program Studi
Teknik Informatika sekaligus dosen pembimbing Tugas Akhir yang selalu
sabar dan selalu memberikan semangat, nasihat, dan motivasi penuh
sehingga penulis dapat menyelesaikan Tugas Akhir ini dengan lancar.
3.
Bapak Drs. J. Eka Priyatma, M.Sc. selaku dosen penguji atas kritik dan
saran yang telah diberikan.
4.
Dosen-dosen Fakultas Sains dan Teknologi Universitas Sanata Dharma
Yogyakarta
5.
Pihak sekretariat dan laboran Fakultas Sains dan Teknologi Universitas
xi
6.
Almarhum Bapak FX. Poerwaka Djati Walujo, S.IP : “…..
ini semua aku
persembahkan
untuk Bapak….” Dan untuk Ibuku tercinta : Magareta Emy
Yurida. Terima kasih atas kasih sayang, semangat, dan doa yang selalu
mendampingi dan menguatkan setiap langkahku.
7.
Kedua kakakku : Krispina Fitri Prawesti, S.Si. dan Kornelia Asri Tyas
Prasasti, SE. Terima kasih atas doa dan motivasinya. Terima kasih juga
untuk kakak iparku mas Ign. Pricher A.N Samane, S.Si, M.Mc yang telah
membatu dalam memberikan doa, ide dan motivasinya.
8.
Keponakan tercintaku : Katarina Prisha Syafira Putri Samane. Trima kasih
untuk keceriaannya.
9.
Seseorang yang telah memberi warna dalam hidupku Antonius Yunanto
Dwicaksono, S.T. Terima kasih untuk cinta, kasih sayang, doa, dan
motivasinya.
10.
Teman-teman kuliah, Ditha, Sari, Ana, Tia, Leona serta teman-teman TI
2007 lainnya atas keceriaan, doa, semangat, dan kebersamaannya.
11.
Sahabat-sahabatku : Dodi, Monita, Resti dan Yustina. Terima kasih untuk
doa, dukungan dan kebersamaannya.
12.
Semua pihak yang telah memberikan bantuannya hingga terselesaikannya
penulisan skripsi ini.
Akhir kata penulis menyadari sepenuhnya bahwa penulisan skripsi ini
masih jauh dari kesempurnaan. Oleh karena itu, kritik dan saran yang bersifat
membangun sangat penulis harapkan. Semoga skripsi ini dapat bermanfaat bagi
pembaca.
Yogyakarta, 14 Juni 2012
xii
DAFTAR ISI
HALAMAN JUDUL... i
HALAMAN JUDUL (INGGRIS) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ...iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ...vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERSETUJUAN PUBLIKASI ...ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL... xv
DAFTAR GAMBAR ... xvi
DAFTAR LAMPIRAN ... xviii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang ... 1
1.2 Rumusan Masalah... 4
1.3 Tujuan ... 4
1.4 Batasan Masalah ... 4
1.5 Metodologi Penelitian ... 5
1.6 Sistematika Pembahasan ... 5
BAB II LANDASAN TEORI ... 7
2.1 Ujian Nasional (UN) ... 7
2.2 Buku Rapor ... 8
2.3 Penambangan Data (
Data Mining
) ... 8
2.4 Teorema
Bayes
... 11
2.5 Klasifikasi
Naïve Bayes
... 12
2.6 Karakteristik Klasifikasi
Naïve Bayes
... 18
xiii
BAB III ANALISIS DAN PERANCANGAN SISTEM ... 19
3.1 Analisis Sistem ... 19
3.2 Sumber Data ... 19
3.3 Tahap-Tahap KDD (
Knowledge Discovery in Database
) ... 21
3.4 Diagram Model
Use Case
... 27
3.5 Narasi
Use Case
... 27
3.6 Activity Diagram ... 42
3.6.1 Activity Diagram Login ... 42
3.6.2 Activity Diagram Olah Data Admin (Simpan) ... 42
3.6.3 Activity Diagram Olah Data Admin (Ubah) ... 43
3.6.4 Activity Diagram Olah Data Admin (Hapus) ... 44
3.6.5 Activity Diagram Input Data
Training
... 45
3.6.6 Activity Diagram Evaluasi Sistem ... 46
3.6.7 Activity Diagram Input
Range
Nilai ... 47
3.6.8 Activity Diagram Prediksi UN (Prediksi Kelompok untuk
admin
) ... 48
3.6.9 Activity Diagram Prediksi UN (Prediksi Tunggal untuk
admin
) ... 49
3.6.10 Activity Diagram Cetak Hasil Prediksi (untuk
admin
) ... 50
3.6.11 Activity Diagram Prediksi Nilai UN (Prediksi Kelompok untuk
user
) ... 51
3.6.12 Activity Diagram Prediksi Nilai UN (Prediksi Tunggal untuk
user
) ... 52
3.6.13 Activity Diagram Cetak Hasil Prediksi UN (untuk
user
) ... 53
3.7 Desain Basis Data ... 54
3.8 Desain Antar Muka ... 55
3.8.1 Halaman Utama ... 55
3.8.2 Halaman Login ... 55
3.8.3 Halaman Utama Admin ... 56
3.8.4 Halaman Olah Data Admin ... 57
3.8.5 Halaman Input Data
Training
... 57
3.8.6 Halaman Prediksi UN... 59
3.8.7 Halaman
Range
Nilai ... 61
3.8.8 Halaman Tentang ... 61
xiv
BAB IV IMPLEMENTASI SISTEM ... 63
4.1 Spesifikasi
Software
dan
Hardware
... 63
4.2 Implementasi
Use Case
... 63
4.3 Implementasi Diagram Kelas ... 76
BAB V ANALISIS HASIL ... 101
5.1 Analisis Hasil Program ... 101
5.2 Perbandingan Akurasi
Naïve Bayes
dan
C4.5
... 107
5.3 Kelebihan dan Kekurangan ... 110
BAB VI PENUTUP ... 111
6.1 Kesimpulan ... 111
6.2 Saran ... 111
DAFTAR PUSTAKA ... 113
LAMPIRAN ... 115
Lampiran I ... 116
xv
DAFTAR TABEL
Tabel 2.1 Data Mobil Tercuri ... 15
Tabel 3.1 Jumlah data Mentah Sebelum Dilakukan proses Data
Cleaning
... 21
Tabel 3.2 Jumlah data Mentah Setelah Dilakukan proses Data
Cleaning
... 22
Tabel 3.3 Contoh Data Awal ... 23
Tabel 3.4 Contoh
Range
Nilai ... 24
Tabel 3.5 Contoh Hasil Transformasi Data ... 24
Tabel 5.1 Perhitungan 3-
fold Cross Validation
untuk Matematika ... 102
Tabel 5.2 Perhitungan 5-
fold Cross Validation
untuk Matematika ... 102
Tabel 5.3 Perhitungan 3-
fold Cross Validation
untuk Bhs.Indonesia ... 102
Tabel 5.4 Perhitungan 5-
fold Cross Validation
untuk Bhs.Indonesia ... 102
Tabel 5.5 Perhitungan 3-
fold Cross Validation
untuk Bhs.Inggris ... 103
Tabel 5.6 Perhitungan 5-
fold Cross Validation
untuk Bhs. Inggris ... 103
Tabel 5.7 Perhitungan 3-
fold Cross Validation
untuk Biologi ... 103
Tabel 5.8 Perhitungan 5-
fold Cross Validation
untuk Biologi ... 103
Tabel 5.9 Perhitungan 3-
fold Cross Validation
untuk Kimia ... 104
Tabel 5.10 Perhitungan 5-
fold Cross Validation
untuk Kimia ... 104
Tabel 5.11 Perhitungan 3-
fold Cross Validation
untuk Fisika ... 104
Tabel 5.12 Perhitungan 5-
fold Cross Validation
untuk Fisika ... 104
Tabel 5.13 Perhitungan 3-
fold Cross Validation
untuk Ekonomi ... 105
Tabel 5.14 Perhitungan 5-
fold Cross Validation
untuk Ekonomi ... 105
Tabel 5.15 Perhitungan 3-
fold Cross Validation
untuk Sosiologi ... 105
Tabel 5.16 Perhitungan 5-
fold Cross Validation
untuk Sosiologi ... 105
Tabel 5.17 Perhitungan 3-
fold Cross Validation
untuk Geografi ... 106
Tabel 5.18 Perhitungan 5-
fold Cross Validation
untuk Geografi ... 106
Tabel 5.19 Perbandingan Hasil Akurasi 3-
fold
dan 5-
fold
... 106
Tabel 5.20 Perbandingan Akurasi 3-
fold
dengan Algoritma
Naïve Bayes
dan
Algoritma
C4.5
... 108
Tabel 5.21 Perbandingan Akurasi 5-
fold
dengan Algoritma
Naïve Bayes
dan
Algoritma
C4.5
... 108
xvi
DAFTAR GAMBAR
Gambar 2.1. Tahapan Proses
Data Mining
... 9
Gambar 3.1
Use-Case
... 27
Gambar 3.2 Activity Diagram Login ... 42
Gambar 3.3 Activity Diagram Olah Data Admin (Simpan) ... 42
Gambar 3.4 Activity Diagram Olah Data Admin (Ubah) ... 43
Gambar 3.5 Activity Diagram Olah Data Admin (Hapus)... 44
Gambar 3.6 Activity Diagram Input Data
Training
... 45
Gambar 3.7 Activity Diagram Evaluasi Sistem... 46
Gambar 3.8 Activity Diagram Input
Range
Nilai ... 47
Gambar 3.9 Activity Diagram Prediksi UN (Prediksi Kelompok untuk admin)... 48
Gambar 3.10 Activity Diagram Prediksi UN (Prediksi Tunggal untuk admin) ... 49
Gambar 3.11 Activity Diagram Cetak Hasil Prediksi (untuk admin) ... 50
Gambar 3.12 Activity Diagram Prediksi Nilai UN (Prediksi Kelompok untuk
user
) .... 51
Gambar 3.13 Activity Diagram Prediksi Nilai UN (Prediksi Tunggal untuk
user
) ... 52
Gambar 3.14 Activity Diagram Cetak Hasil Prediksi UN (untuk
user
) ... 53
Gambar 3.15 Desain Fisik Basis Data ... 54
Gambar 3.16 Halaman Utama ... 55
Gambar 3.17 Halaman Login ... 55
Gambar 3.18 Halaman Utama Admin... 56
Gambar 3.19 Halaman Olah Data Admin ... 57
Gambar 3.20 Halaman Input Data
Training
... 58
Gambar 3.21 Halaman Akurasi Data ... 58
Gambar 3.22 Halaman Prediksi UN (1) ... 59
Gambar 3.23 Halaman Prediksi UN (2) ... 60
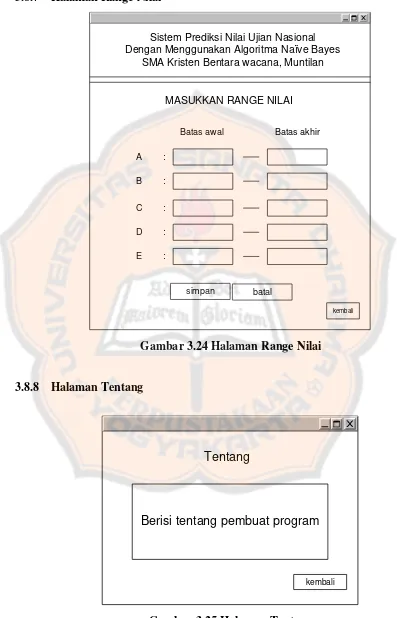
Gambar 3.24 Halaman
Range
Nilai ... 61
Gambar 3.25 Halaman Tentang ... 61
Gambar 3.26 Halaman Bantuan ... 62
Gambar 4.1 Implementasi Halaman Utama ... 64
xvii
Gambar 4.3 Implementasi Halaman Peringatan ... 64
Gambar 4.4 Implementasi Halaman Utama Admin... 65
Gambar 4.5 Implementasi Halaman Olah Data Admin ... 66
Gambar 4.6 Implementasi Halaman Range Nilai ... 67
Gambar 4.7 Implementasi Halaman Input Data
Training
(1) ... 68
Gambar 4.8 Implementasi Halaman Input Data
Training
(2) ... 68
Gambar 4.9 Implementasi Halaman Input Data
Training
(3) ... 69
Gambar 4.10 Implementasi Halaman Input Data
Training
(4) ... 69
Gambar 4.11 Implementasi Halaman Input Data
Training
(5) ... 70
Gambar 4.12 Implementasi Halaman Akurasi Data ... 71
Gambar 4.13 Implementasi Halaman Prediksi UN (1) ... 72
Gambar 4.14 Implementasi Halaman Prediksi UN (2) ... 72
Gambar 4.15 Implementasi Halaman Prediksi UN (3) ... 73
Gambar 4.16 Implementasi Halaman Prediksi UN (4) ... 74
Gambar 4.17 Implementasi Halaman Laporan Hasil Prediksi ... 75
Gambar 4.18 Implementasi Halaman Bantuan ... 75
xviii
DAFTAR LAMPIRAN
1
BAB I
PENDAHULUAN
Pada bab ini dijelaskan mengenai latar belakang dari penelitian. Tujuan
pengerjaan tugas akhir memberikan penjelasan mengenai hasil yang ingin
diketahui serta batasan dalam pengerjaan. Tahapan dalam metodologi penelitian
dan sistematika penulisan laporan.
1.1
Latar Belakang
Sekarang ini dunia pendidikan dituntut untuk berperan serta dalam
usaha mencapai cita-cita pembangunan yaitu meningkatkan mutu kehidupan
bangsa dan mewujudkan masyarakat yang adil dan makmur. Salah satu yang
dilakukan adalah dengan memperluas muatan program pendidikan yang
mampu menunjang cita-cita dari pembangunan yang ingin dicapai.
Pendidikan merupakan salah satu sektor penting dalam pembangunan
di setiap negara. Menurut Undang-Undang No. 20 Tahun 2004 pendidikan
merupakan usaha sadar dan terencana untuk mengembangkan segala potensi
yang dimiliki siswa melalui proses pembelajaran. Pendidikan bertujuan untuk
mengembangkan potensi anak agar memiliki kekuatan spiritual keagamaan,
pengendalian diri, berkepribadian, memiliki kecerdasan, berakhlak mulia,
serta memiliki keterampilan yang diperlukan sebagai anggota masyarakat dan
warga
Negara.
Kurikulum
digunakan
sebagai
pedoman
dalam
penyelenggaraan kegiatan pembelajaran untuk mencapai tujuan pendidikan
yang telah ditentukan. Untuk melihat tingkat pencapaian tujuan pendidikan
diperlukan suatu bentuk evaluasi. Evaluasi pendidikan merupakan salah satu
Pemerintah telah mengambil kebijakan untuk menerapkan Ujian Akhir
Nasional (UAN) sebagai salah satu bentuk evaluasi pendidikan. Menurut
Keputusan Menteri Pendidikan Nasional No. 153/U/2003 tentang Ujian Akhir
Nasional Tahun Pembelajaran 2003/2004 disebutkan bahwa tujuan Ujian
Akhir Nasional adalah untuk mengukur pencapaian hasil belajar peserta didik
melalui pemberian tes pada siswa khususnya siswa sekolah menengah atas.
Selain itu Ujian Akhir Nasional bertujuan untuk mengukur mutu pendidikan
dan mempertanggungjawabkan penyelenggaraan pendidikan di tingkat
nasional, provinsi, kabupaten, sampai tingkat sekolah. (Hermawanov,2008)
Di zaman teknologi modern yang semakin canggih, pendidikan
sangatlah diperlukan untuk meningkatkan kualitas kehidupan. Berbicara
tentang pendidikan maka tidak akan pernah lepas dari kegiatan
belajar-mengajar yang dilakukan antara siswa dengan pengajar. Selain kegiatan
belajar dan mengajar, pendidikan juga tidak pernah lepas dari sekolah.
Sekolah merupakan bangunan atau lembaga untuk belajar dan mengajar serta
tempat menerima dan memberi pelajaran. Hasil kegiatan belajar-mengajar
tersebut biasanya dievaluasi oleh pengajar dengan memberikan ujian terhadap
siswa. Hasil ujian tersebut berupa nilai akademik yang biasanya dilaporkan
pada sebuah buku laporan kemajuan belajar siswa atau rapor setiap semester.
Rapor digunakan untuk melaporkan hasil kemajuan siswa selama mengikuti
kegiatan belajar-mengajar. Selain itu dalam rapor dapat diketahui sejauh mana
prestasi belajar seorang siswa, apakah siswa tersebut berhasil atau gagal dalam
suatu mata pelajaran.
Beberapa hari terakhir dimana-mana banyak orang membicarakan
Ujian Akhir Nasional (UAN), terutama para orang tua yang mempunyai anak
usia sekolah. Para orang tua khawatir nilai Ujian Nasional (UN) yang
diperoleh anaknya tidak mencapai standar nilai yang ditetapkan oleh
pemerintah. Hal ini terjadi karena SMA merupakan pintu gerbang dalam
melanjutkan ke jenjang berikutnya seperti melanjutkan pendidikan ke
siswa dinyatakan lulus SMA. Banyak orang beranggapan jika nilai mata
pelajaran siswa tiap semester baik yakni di atas rata-rata, maka siswa tersebut
akan lulus dengan nilai yang baik. Tapi sebaliknya, jika nilai mata pelajaran
tiap semester di bawah rata-rata kemungkinan besar siswa tersebut tidak lulus
sekolah. Hal ini menimbulkan pertanyaan mengenai pengaruh antara prestasi
siswa di sekolah (nilai rapor tiap semester dan nilai uji coba ujian nasional)
dengan hasil nilai Ujian Nasional (UN).
Perkembangan sistem informasi yang makin pesat, muncul pula
teknologi baru, yaitu teknik
data mining
.
Data mining
adalah serangkaian
proses untuk mengekstrak pola yang penting atau menarik dari sejumlah data
yang sangat besar berupa pengetahuan yang selama ini tidak diketahui secara
manual. Banyak algoritma yang dapat digunakan untuk menyelesaikan
persoalan pada
data mining.
Salah satu teknik
data mining
yang akan
digunakan dalam penelitian ini adalah teknik klasifikasi dengan algoritma
Naïve Bayes.
Naïve Bayes
merupakan salah satu metode
data mining
yang
digunakan pada persoalan klasifikasi. Algoritma
naïve bayes
akan menghitung
probabilitas
posterior
untuk setiap nilai kejadian dari atribut target pada setiap
sampel data. Kemudian,
naïve bayes
akan mengklasifikasikan sampel data
tersebut ke kelas yang mempunyai nilai probabilitas
posterior
tertinggi. Maka
yang akan dilakukan dengan algoritma
naïve bayes
adalah menghitung
probabilitas
posterior
pada sampel data untuk UN dengan nilai A, UN dengan
nilai B, UN dengan nilai C, UN dengan nilai D, dan UN dengan nilai E.
Diharapkan dengan dilakukannya penelitian ini dapat memprediksi
nilai Ujian Nasional (UN) berdasarkan nilai rapor kelas X, XI, dan XII serta
nilai Uji Coba Nasional yang diselenggarakan oleh pemerintah. Jika nilai
Ujian Nasional dapat diprediksi lebih dini maka dapat membantu para siswa
yang diprediksi mendapatkan nilai dibawah standar nilai yang ditentukan oleh
sekolah dapat mengetahui prediksi nilai UN siswa-siswinya agar dapat
dilakukan antisipasi jikalau ada siswa-siswanya yang diprediksi mendapatkan
nilai dibawah standar nilai yang ditentukan pemerintah.
1.2
Rumusan Masalah
Dari latar belakang masalah yang ada, maka didapatkan sebuah
rumusan masalah yaitu bagaimana memprediksi nilai Ujian Nasional (UN)
siswa SMA berdasarkan nilai rapor dan nilai uji coba nasional dengan
algoritma
Naïve Bayes
?
1.3
Tujuan
Tujuan dari penelitian ini adalah menerapkan algoritma
Naïve Bayes
sebagai salah satu metode
Classification Data Mining
untuk memperoleh hasil
prediksi nilai Ujian Nasional (UN) siswa SMA berdasarkan nilai rapor dan
nilai Uji Coba Nasional (UCO).
1.4
Batasan Masalah
Batasan masalah pada tugas akhir ini adalah sebagai berikut :
1.
Data-data yang dibutuhkan adalah data nilai rapor dan data nilai uji
coba nasional siswa 3 angkatan terakhir yaitu tahun 2008, 2009, dan
2010.
2.
File inputan berupa
file
dengan format .csv
3.
Algoritma yang digunakan untuk memprediksi nilai Ujian Nasional
(UN) adalah algoritma
Naïve Bayes.
4.
Pengklasifikasian nilai dibagi menjadi 5, yaitu A, B, C, D, dan E.
5.
Atribut yang akan dipilih adalah nilai rapor kelas X semester 1 dan
semester 2, nilai rapor kelas XI semester 1 dan semester 2, nilai rapor
1.5
Metodologi Penelitian
Metodologi penelitian dilakukan dengan menerapkan proses KDD
(
Knowledge Discovery in Databases
) dengan tahapan sebagai berikut :
a.
Pembersihan data, menghilangkan
noise
dan data yang tidak konsisten.
b.
Integrasi data, menggabungkan data dari berbagai sumber data yang
berbeda.
c.
Seleksi data dan transformasi data, untuk menentukan kualitas dari
hasil
data mining
, sehingga data diubah menjadi bentuk sesuai untuk
di-
mining
.
e.
Penerapan teknik
data mining
Penerapan teknik data mining sendiri hanya merupakan salah satu
bagian dari proses
data mining
. Ada beberapa teknik
data mining
yang
sudah umum dipakai. Teknik yang akan digunakan oleh penulis adalah
teknik
Naïve Bayes
.
f.
Evaluasi pola yang ditemukan
Dalam tahap ini hasil dari teknik
data mining
berupa pola yang khas
maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang
ada memang tercapai.
g.
Presentasi pengetahuan
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap
terakhir dari proses data mining adalah bagaimana menformulasikan
keputusan atau aksi dari hasil analisa yang didapat
1.6
Sistematika Pembahasan
BAB I. PENDAHULUAN
Dalam bab ini akan dijelaskan mengenai latar belakang masalah,
rumusan masalah, batasan masalah, tujuan, metodologi penelitian, dan
BAB II. LANDASAN TEORI
Dalam bab ini akan dibahas mengenai dasar teori yang berkaitan
dengan tugas akhir ini.
BAB III. ANALISIS DAN PERANCANGAN SISTEM
Dalam bab ini berisi tentang cara penerapan konsep dasar yang telah
diuraikan pada Bab II untuk menganalisis dan merancang tentang
sistem yang dibuat.
BAB IV. IMPLEMENTASI SISTEM
Dalam bab ini memuat implementasi ke program komputer
bardasarkan hasil perancangan telah dibuat.
BAB V. ANALISIS HASIL
Dalam bab ini berisi mengenai analisis perangkat lunak yang telah
dibuat, beserta kelebihan dan kekurangan pada sistem.
BAB VI. PENUTUP
Dalam bab ini memuat kesimpulan dan saran dari keseluruhan
7
BAB II
LANDASAN TEORI
Pada bab ini dijelaskan landasan teori yang terkait dengan penelitian dan
algoritma yang digunakan dalam tugas akhir untuk memprediksi nilai Ujian
Nasional (UN).
2.1
Ujian Nasional (UN)
Ujian Nasional biasa disingkat UN adalah sistem evaluasi standar
pendidikan dasar dan menengah secara nasional dan persamaan mutu tingkat
pendidikan antar daerah yang dilakukan oleh Pusat Penilaian Pendidikan,
Depdiknas di Indonesia berdasarkan Undang-Undang Republik Indonesia No.
20 tahun 2003 menyatakan bahwa dalam rangka pengendalian mutu
pendidikan secara nasional dilakukan evaluasi sebagai bentuk akuntabilitas
penyelenggaraan pendidikan kepada pihak-pihak yang berkepentingan. Lebih
lanjut dinyatakan bahwa evaluasi dilakukan oleh lembaga yang mandiri secara
berkala, menyeluruh, transparan, dan sistematik untuk menilai pencapaian
standar nasional pendidikan dan proses pemantauan evaluasi tersebut harus
dilakukan secara berkesinambungan.
Proses pemantauan evaluasi tersebut dilakukan secara terus menerus
dan berkesinambungan pada akhirnya akan dapat membenahi mutu
pendidikan. Pembenahan mutu pendidikan dimulai dengan penentuan standar.
Penentuan standar yang terus meningkat diharapkan akan mendorong
peningkatan mutu pendidikan, yang dimaksud dengan penentuan standar
pendidikan adalah penentuan nilai batas. Seseorang dikatakan sudah
lulus/kompeten bila telah melewati nilai batas tersebut berupa nilai batas
antara peserta didik yang sudah menguasai kompetensi tertentu dengan peserta
nasional atau sekolah maka nilai batas berfungsi untuk memisahkan antara
peserta didik yang lulus dan tidak lulus disebut batas kelulusan, kegiatan
penentuan batas kelulusan disebut
standard setting
. (Wikipedia,2011)
2.2
Buku Rapor
Buku rapor adalah suatu cara pengukuran kinerja siswa. Umumnya
laporan ini diberikan oleh sekolah kepada siswa atau orang tua siswa dua kali
hingga empat kali dalam setahun. Suatu buku rapor biasanya menggunakan
skala pemeringkatan untuk menentukan kualitas hasil kerja murid di sekolah.
Sistem skala ini dapat berupa huruf (misalnya A, B, C, D, E, dan F, dengan A
adalah kinerja tertinggi dan F berarti gagal) atau angka (misalnya A=90-100,
B=80-89, C=70-79, D=60-69, E=50-59, dan F=0-49). (Wikipedia,2011)
2.3
Penambangan Data (Data Mining)
Penambangan Data (
data mining
) adalah suatu istilah yang digunakan
untuk menguraikan penemuan pengetahuan di dalam
database
.
Data mining
berkenaan dengan mengekstrak atau menambang informasi/pengetahuan dari
sejumlah data dengan jumlah yang sangat besar. Secara fungsional,
penambangan data (
data mining
) adalah proses dari pengumpulan informasi
penting dari sejumlah data yang besar yang tersimpan di database, gudang
data, atau tempat penyimpanan informasi lainnya. (Han&Kamber,2001)
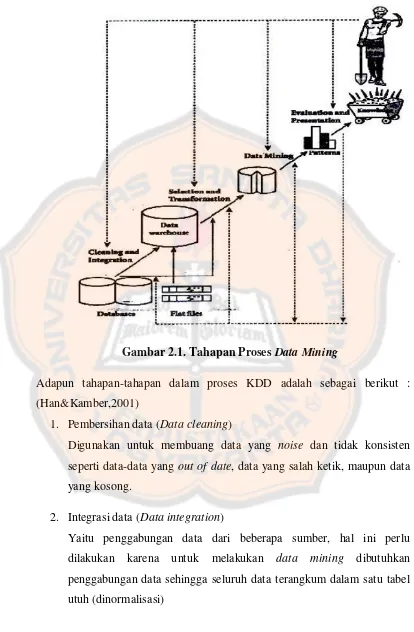
Gambar 2.1. Tahapan Proses Data Mining
Adapun tahapan-tahapan dalam proses KDD adalah sebagai berikut :
(Han&Kamber,2001)
1.
Pembersihan data (
Data cleaning
)
Digunakan untuk membuang data yang
noise
dan tidak konsisten
seperti data-data yang
out of date
, data yang salah ketik, maupun data
yang kosong.
2.
Integrasi data (
Data integration
)
Yaitu penggabungan data dari beberapa sumber, hal ini perlu
dilakukan karena untuk melakukan
data mining
dibutuhkan
penggabungan data sehingga seluruh data terangkum dalam satu tabel
3.
Seleksi data dan Transformasi (
Data selection and trasformastion
)
Seleksi data dan Transformasi ini untuk menentukan kualitas dari hasil
data mining
, sehingga data diubah menjadi bentuk sesuai untuk
di-mining
.
4.
Penerapan teknik
data mining
(
Data mining
)
Penerapan teknik
data mining
sendiri hanya merupakan salah satu
bagian dari proses
data mining
. Ada beberapa teknik
data mining
yang
sudah umum dipakai.
5.
Evaluasi pola yang ditemukan (
Pattern evaluation
)
Dalam tahap ini hasil dari teknik
data mining
berupa pola yang khas
maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang
ada memang tercapai.
6.
Presentasi pengetahuan (
Knowledge presentation
)
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap
terakhir dari proses
data mining
adalah bagaimana menformulasikan
keputusan atau aksi dari hasil analisa yang didapat.
Pada dasarnya penambangan data dibedakan menjadi dua
fungsionalitas, yaitu deskripsi dan prediksi. Berikut ini beberapa
fungsionalitas penggalian data yang sering digunakan : (Wikipedia, 2010)
1.
Karakterisasi dan Diskriminasi yaitu menggeneralisasi, merangkum,
dan mengkontraskan karakteristik data.
2.
Penggalian pola berulang yaitu pencarian pola asosiasi (
association
rule
) atau pola intra-transaksi, atau pola pembelian yang terjadi dalam
satu kali transaksi.
3.
Klasifikasi
yaitu
membangun
suatu
model
yang
bisa
mengklasifikasikan suatu objek berdasar atribut-atributnya. Kelas
adalah bagaimana mempelajari data yang ada agar klasifikator bisa
mengklasifikasikan sendiri.
4.
Prediksi yaitu memprediksi nilai yang tidak diketahui atau nilai yang
hilang, menggunakan model dari klasifikasi.
5.
Penggugusan/
Cluster analysis
yaitu mengelompokkan sekumpulan
objek data berdasarkan kemiripannya. Kelas target tidak tersedia
dalam data sebelumnya, sehingga fokusnya adalah memaksimalkan
kemiripan intra kelas dan meminimalkan kemiripan antar kelas.
6.
Analisis
outlier
yaitu proses pengenalan data yang tidak sesuai dengan
perilaku umum dari data lainnya.
7.
Analisis
trend
dan evolusi : meliputi analisis regresi, penggalian pola
sekuensial, analisis periodisitas, dan analisis berbasis kemiripan.
2.4
Teorema Bayes
Teorema
Bayes
menurut Han&Kamber (2001) mengungkapkan bahwa
hasil probabilitas
posterior
sebanding dengan hasil perkalian antara
likelihood
dengan probababilitas
prior
. Probabilitas
posterior
adalah probabilitas
bersyarat dari sebuah hipotesis jika diberikan data.
Likelihood
adalah
probabilitas bersyarat dari sebuah data jika diberikan hipotesis. Probabilitas
prior
adalah probabilitas bahwa hipotesis itu benar sebelum data terlihat.
Jika
X
adalah bukti atau kumpulan data pelatihan dan
𝑌
adalah
hipotesis. Jika
class variable
memiliki hubungan tidak
deterministic
dengan
atribut, maka dapat diperlukan
X
dan
𝑌
sebagai variabel acak dan
menangkap hubungan peluang menggunakan
𝑃 𝑌 𝑋
. Peluang bersyarat ini
juga dikenal dengan probabilitas
posterior
untuk
𝑌
, dan
𝑃
(
𝑌
)
adalah
probabilitas
prior
.
Untuk mengestimasi peluang
posterior
secara akurat untuk setiap
kombinasi label kelas yang mungkin dan nilai atribut adalah masalah sulit
karena membutuhkan
training set
sangat besar, meski untuk jumlah
moderate
bermanfaat karena menyediakan pernyataan istilah peluang
posterior
dari
peluang
prior
𝑃
(
𝑌
)
, peluang kelas bersyarat
𝑃 𝑋 𝑌
dan bukti
𝑃
(
𝑋
)
seperti
pada Rumus 2.1 berikut : (Han&Kamber,2001)
𝑃 𝑌 𝑋
=
𝑃 𝑋 𝑌 𝑃
(
𝑌
)
𝑃
(
𝑋
)
...……… (
Rumus 2.1 )
Dalam hal ini :
X
= himpunan data
training
Y
= hipotesis.
𝑃 𝑌 𝑋
= probabilitas
posterior
, yaitu probabilitas bersyarat dari
hipotesis Y berdasarkan kondisi X.
𝑃
(
𝑌
)
= probabilitas
prior
dari hipotesis Y, yaitu probabilitas
bahwa hipotesis Y bernilai benar sebelum data X muncul.
𝑃
(
𝑋
)
= probabilitas dari data X.
𝑃 𝑋 𝑌
= probabilitas bersyarat dari X berdasarkan kondisi pada
hipotesis Y, dan biasa disebut dengan
likelihood
.
Likelihood
ini mudah untuk dihitung ketika memberikan
nilai 1 saat X dan Y konsisten, dan memberikan nilai 0
saat X dan Y tidak konsisten.
2.5
Klasifikasi Naïve Bayes
Menurut Han&Kamber (2001) metode klasifikasi
Naïve Bayes
merupakan salah satu metode pengklasifikasi yang berdasarkan pada
penerapan Teorema
Bayes
dengan asumsi antar variabel penjelas saling bebas
(
independen
). Algoritma ini memanfaatkan metode probabilitas dan statistik
yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi
Klasifikasi
Naïve Bayes
diasumsikan dimana nilai atribut dari sebuah
kelas dianggap terpisah dan
independen
dengan nilai atribut lainnya, kondisi
seperti ini dinyatakan dengan Rumus 2.2 seperti berikut ini :
(Han&Kamber,2001)
𝑃 𝑌 𝑋
=
𝑃 𝑋1 𝑌 𝑃 𝑋2 𝑌 …𝑃 𝑋𝑛 𝑌 𝑃(𝑌)𝑃(𝑋)
…….. (
Rumus 2.2 )
Keterangan :
X
= himpunan data
training
Y
= hipotesis.
𝑃 𝑌 𝑋
= probabilitas
posterior
, yaitu probabilitas
bersyarat dari hipotesis Y berdasarkan
kondisi X.
𝑃
(
𝑌
)
= probabilitas
prior
dari hipotesis Y, yaitu
probabilitas bahwa hipotesis Y bernilai
benar sebelum data X muncul.
𝑃
(
𝑋
)
= probabilitas dari data X.
𝑃 𝑋
1𝑌
,
𝑃 𝑋
2𝑌
,
𝑃 𝑋
𝑛𝑌
= probabilitas dari X
1, X
2, X
nuntuk
hipotesis Y, biasa disebut dengan
likelihood.
Karena P(X)
irrelevant
maka untuk mencari peluang hanya menggunakan
Rumus 2.3 seperti berikut ini : (Han&Kamber,2001)
𝑃 𝑌 𝑋
=
𝑃 𝑋
1𝑌 𝑃 𝑋
2𝑌 … 𝑃 𝑋𝑛
𝑌 𝑃
(
𝑌
)
…….. (
Rumus 2.3 )
Jika ada P(X
n|Y) yang memiliki nilai 0, maka P(Y|X) = 0. Maka klasifikasi
Laplace Estimator
. Rumus
Laplace Estimator
dapat dilihat pada Rumus 2.4
sebagai berikut : (Budi Santosa, 2007)
𝑃 𝑋
𝑖𝑌
𝑗=
𝑛𝑛𝑐++1𝑚…….. (
Rumus 2.4 )
Dimana :
𝑛
= total jumlah
instances
dari kelas
𝑌
𝑗𝑛
𝑐= jumlah contoh
training
dari
𝑌
𝑗yang menerima nilai
𝑋
𝑖𝑚
= parameter yang dikenal sebagai ukuran sampel ekivalen
Cara kerja klasifikasi
Naïve Bayes
:
1.
Misalkan
𝑋
adalah kumpulan data pelatihan dari
tuple
dan
𝑋
berhubungan dengan label kelas.
2.
Andaikan ada
𝑛
kelas,
𝑦
1,
𝑦
2, … ,
𝑦
𝑛. Jika disediakan
tuple x
,
klasifikasi
Naïve Bayes
memprediksi
x
ke dalam kelas yang
mempunyai probabilitas
posterior
tertinggi. Maka penggolong
Naïve
Bayes
memprediksi
tuple x
termasuk ke dalam kelas
𝑦
𝑖jika dan hanya
jika
𝑃 𝑦
𝑖𝑥
>
𝑃
(
𝑦
𝑗|
𝑥
)
untuk
1
≤ 𝑗 ≤ 𝑛
,
𝑗 ≠ 𝑖
……. (
Rumus 2.5 )
Dengan demikian
𝑃 𝑦
𝑖𝑥
akan dimaksimalkan. Kelas
𝑦
𝑖untuk setiap
𝑃 𝑦
𝑖𝑥
yang dimaksimalkan dinamakan
maximum posteriori
hypothesis
. Berdasarkan teorema
Bayes
adalah :
𝑃 𝑦
𝑖𝑥
=
𝑃 𝑥 𝑦𝑖 × 𝑃(𝑦𝑖)𝑃(𝑥)
………… (
Rumus 2.6 )
3.
Selama P(
x
) konstan untuk semua kelas maka hanya
𝑃 𝑥 𝑦
𝑖𝑃
(
𝑦
𝑖)
yang dimaksimalkan. Jika kelas probabilitas
prior
tidak diketahui,
maka kelas-kelas tersebut diasumsikan sama, yaitu
𝑃 𝑦
1=
𝑃 𝑦
2=
⋯
=
𝑃
(
𝑦
𝑛)
, oleh karena itu
𝑃 𝑥 𝑦
𝑖akan
Berikut ini diberikan contoh kasus yang akan diselesaikan dengan
algoritma
naïve bayes.
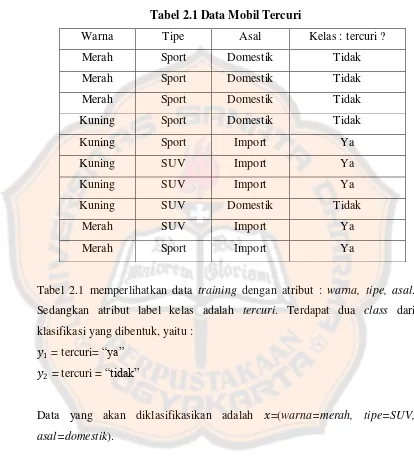
Tabel 2.1 Data Mobil Tercuri
Warna
Tipe
Asal
Kelas : tercuri ?
Merah
Sport
Domestik
Tidak
Merah
Sport
Domestik
Tidak
Merah
Sport
Domestik
Tidak
Kuning
Sport
Domestik
Tidak
Kuning
Sport
Import
Ya
Kuning
SUV
Import
Ya
Kuning
SUV
Import
Ya
Kuning
SUV
Domestik
Tidak
Merah
SUV
Import
Ya
Merah
Sport
Import
Ya
Tabel 2.1 memperlihatkan data
training
dengan atribut :
warna, tipe, asal
.
Sedangkan atribut label kelas adalah
tercuri
. Terdapat dua
class
dari
klasifikasi yang dibentuk, yaitu :
𝑦
1= tercuri=
“ya”
𝑦
2= tercuri =
“tidak”
Data yang akan diklasifikasikan adalah
𝑥
=(
warna=merah, tipe=SUV,
asal=domestik
).
Penyelesaian :
𝑃
(
𝑦
𝑖)
merupakan probabilitas
prior
(untuk setiap
class
) yang dapat dihitung
berdasarkan data
training
pada Tabel 2.1.
a.
P(
tercuri = ya
) = 5/10 = 0.5
Untuk menghitung
𝑃 𝑥 𝑦
𝑖, untuk i=1,2 akan dihitung probabilitas bersyarat
(
likelihood
) sebagai berikut :
Likelihood
atribut warna :
P(
warna=merah | tercuri = ya
)
= 2/5 = 0.4
P(
warna=merah | tercuri = tidak
)
= 3/5 = 0.6
P(
warna=kuning | tercuri = ya
)
= 3/5 = 0.6
P(
warna=kuning | tercuri = tidak
)
= 2/5 = 0.4
Likelihood
atribut tipe :
P(
tipe=SUV | tercuri = ya
)
= 3/5 = 0.6
P(
tipe=SUV | tercuri = tidak
)
= 1/5 = 0.2
P(
tipe=sport | tercuri = ya
)
= 2/5 = 0.4
P(
tipe=sport | tercuri = tidak
)
= 4/5 = 0.8
Likelihood
atribut asal :
P(
asal=domestik | tercuri = ya
)
= 0/5 = 0
P(
asal=domestik | tercuri = tidak
)
= 5/5 = 1
P(
asal=import | tercuri = ya
)
= 5/5 = 1
P(
asal=import | tercuri = tidak
)
= 0/5 = 0
Laplace Estimator
Bila ditemukan salah satu atribut yang memiliki probabilitas bersyarat
(
likelihood
)=0, maka dilakukan penambahan nilai satu ke setiap
evidence
sehingga tidak ada probabilitas yang akan bernilai 0. Berikut ialah nilai
likelihood
untuk atribut asal setelah dilakukan
laplace estimator
.
Likelihood
atribut asal :
P(
asal=domestik | tercuri = ya
)
= 1/7 = 0.14
Dari probabilitas-probabilitas tersebut, maka diperoleh
P(
𝑋
|tercuri=ya
) = P(
warna=merah | tercuri = ya
) x
P(
tipe=SUV | tercuri = ya
) x
P(
asal=domestik | tercuri = ya
)
= 0.4 x 0.6 x 0.14
= 0.0336
P(
𝑋
|tercuri=tidak
) = P(
warna=merah | tercuri = tidak
) x
P(
tipe=SUV | tercuri = tidak
) x
P(
asal=domestik | tercuri = tidak
)
= 0.6 x 0.2 x 0.86
= 0.1032
Untuk menemukan kelas
𝑃
(
𝑦
𝑖)
, maksimalkan
𝑃 𝑥 𝑦
𝑖𝑃
(
𝑦
𝑖)
dengan menghitung
P(
𝑋
|tercuri=ya
)P(
tercuri=ya
)
= 0.0336 x 0.5 = 0.0168
P(
𝑋
| tercuri=tidak
) P(
tercuri=tidak
)
= 0.1032 x 0.5 = 0.0516
Persentasi prediksi untuk
tercuri
=”ya”
adalah :
0. 0168/(0. 0168+0. 0516) x 100% = 24.6%
Persentasi prediksi untuk
tercuri
=“tidak”
adalah :
0. 0516/(0. 0168+0. 0516) x 100% = 75.4%
Kesimpulan :
2.6
Karakteristik Klasifikasi Naïve Bayes
Naive Bayes Classifier
umumnya memiliki karakteristik sebagai berikut :
a.
Kokoh untuk atribut
irrelevant
, jika
X
iadalah atribut yang
irrelevant
,
maka
P
X
iY
menjadi hampir didistribusikan seragam. Peluang kelas
bersyarat untuk
X
itidak berdampak pada keseluruhan perhitungan
peluang
posterior
.
b.
Atribut yang dihubungkan dapat menurunkan kemampuan klasifikasi
naive bayes
karena asumsi
independen
bersyarat tidak lagi menangani
atribut tersebut.
2.7
Kelebihan dan Kekurangan Algoritma Naïve Bayes
Algoritma
Naïve Bayes
memiliki beberapa kelebihan dan kekurangan yaitu
sebagai berikut :
Kelebihan
Naïve Bayes
:
a.
Menangani kuantitatif dan data diskrit.
b.
Hanya memerlukan sejumlah kecil data pelatihan (
training
) untuk
mengestimasi parameter yang dibutuhkan untuk klasifikasi.
c.
Kokoh terhadap atribut yang tidak relevan.
Kekurangan
Naïve Bayes
:
a.
Tidak berlaku jika probabilitas kondisionalnya adalah nol, apabila nol
maka probabilitas prediksi akan bernilai nol juga.
19
BAB III
ANALISIS DAN PERANCANGAN SISTEM
Pada bab ini dijelaskan analisis sistem yang akan dibuat dan perancangan untuk
melakukan prediksi nilai Ujian Nasional (UN) dengan menggunakan algoritma
naïve bayes
.
3.1
Analisis Sistem
Sistem yang dibuat memiliki kemampuan untuk memprediksi nilai
ujian nasional siswa SMA berdasarkan nilai rapor dan nilai uji coba nasional
menggunakan algoritma
naïve bayes
. Data yang dibutuhkan adalah data nilai
rapor tiap semester dan nilai uji coba nasional siswa SMA 3 angkatan terakhir
yaitu tahun 2008, 2009, dan 2010. Data-data ini mencangkup seluruh kelas
yang ada di SMA Kristen Bentara Wacana Muntilan. Sistem ini akan
diimplementasikan ke sebuah aplikasi dengan menggunakan bahasa
pemrograman Java dan sistem manajemen basis data MySQL.
3.2
Sumber Data
Data mentah yang digunakan untuk penelitian ini adalah data nilai
rapor siswa tiap semester, nilai Uji Coba Nasional dan nilai Ujian Nasional
yang didapat dari SMA Kristen Bentara Wacana.
Data diberikan dalam
format ekstensi xls.
Data mentah yang diperoleh dari sekolah meliputi :
a.
Nomor Induk Siswa (tahun ajaran 2004/2005 sampai 2009/2010).
b.
Nama Siswa (tahun ajaran 2004/2005 sampai 2009/2010).
c.
Nilai Matematika (kelas X semester I sampai kelas XII semester I).
d.
Nilai Bahasa Indonesia (kelas X semester I sampai kelas XII semester
e.
Nilai Bahasa Inggris (kelas X semester I sampai kelas XII semester I).
f.
Nilai Pendidikan Agama (kelas X semester I sampai kelas XII
semester I).
g.
Nilai Pendidikan Kewarganegaraan (kelas X semester I sampai kelas
XII semester I).
h.
Nilai Fisika (kelas X semester I sampai kelas XII semester I).
i.
Nilai Biologi (kelas X semester I sampai kelas XII semester I).
j.
Nilai Kimia (kelas X semester I sampai kelas XII semester I).
k.
Nilai Sejarah (kelas X semester I sampai kelas XII semester I).
l.
Nilai Ekonomi (kelas X semester I sampai kelas XII semester I).
m.
Nilai Sosiologi (kelas X semester I sampai kelas XII semester I).
n.
Nilai Antropologi (kelas X semester I sampai kelas XII semester I).
o.
Nilai Geografi (kelas X semester I sampai kelas XII semester I).
p.
Nilai Kesenian (kelas X semester I sampai kelas XII semester I).
q.
Nilai Penjaskes (kelas X semester I sampai kelas XII semester I).
r.
Nilai Bahasa Jepang (kelas X semester I sampai kelas XI semester II).
s.
Nilai Bahasa Jawa (kelas X semester I sampai kelas XI semester II).
t.
Nilai Seni dan Budaya (kelas X semester I sampai kelas XI semester
II).
u.
Nilai Pendidikan Jasmani, Olah Raga (kelas X semester I sampai kelas
XII semester I).
v.
Nilai Teknologi Informasi dan Komunikasi (kelas X semester I sampai
kelas XII semester I).
w.
Nilai Uji Coba Nasional (3 tahun terakhir, yakni tahun 2008, 2009, dan
2010).
x.
Nilai Ujian Nasional (3 tahun terakhir, yakni tahun 2008, 2009, dan
3.3
Tahap-Tahap KDD (Knowledge Discovery in Database)
Setelah data mentah diperoleh maka selanjutnya dilakukan proses KDD
(
Knowledge Discovery in Database
) dengan tahapan seperti berikut ini :
1.
Pembersihan data (Data
Cleaning
)
Pembersihan data merupakan langkah awal dalam proses
data
mining
. Pembersihan data dilakukan terlebih dahulu sebelum data nilai
rapor dan nilai uji coba nasional yang didapat dari sekolah ditambang.
Pada tahap ini juga dilakukan penyeleksian atribut-atribut yang tidak
relevan terhadap penelitian, seperti nama siswa dan data nilai mata
pelajaran yang tidak dipakai dalam proses prediksi ujian nasional siswa.
Mata pelajaran yang akan digunakan adalah pelajaran Matematika, Bahasa
Indonesia, Bahasa Inggris, Biologi, Kimia, Fisika, Ekonomi, Sosiologi,
dan Geografi. Data mentah yang diperoleh dari sekolah, terdapat beberapa
record
yang mempunyai data yang tidak lengkap (
missing value
).
Data-data siswa yang tidak lengkap serta Data-data-Data-data siswa yang melakukan
pindah sekolah akan dibuang dan tidak akan digunakan pada tahap
selanjutnya. Jumlah data awal yang diperoleh adalah 1074
records
untuk 9
mata pelajaran. Jumlah data dapat dilihat pada tabel 3.1 berikut :
Tabel 3.1 Jumlah Data Mentah Sebelum Dilakukan proses Data Cleaning
No.
Mata Pelajaran
Jumlah
record
1.
Matematika
179
2.
Bahasa Indonesia
179
3.
Bahasa Inggris
179
4.
Biologi
52
5.
Kimia
52
Tabel 3.2 merupakan hasil dari proses data
cleaning
.
Tabel 3.2 Jumlah Data Mentah Setelah Dilakukan proses Data Cleaning
No.
Mata Pelajaran
Jumlah
record
1.
Matematika
134
2.
Bahasa Indonesia
134
3.
Bahasa Inggris
134
4.
Biologi
38
5.
Kimia
38
6.
Fisika
38
7.
Ekonomi
96
8.
Sosiologi
96
9.
Geografi
96
Jumlah
804
2.
Seleksi data (Data
Selection
) dan Integrasi data (Data
Integration
)
Tahap selanjutnya akan dilakukan penyeleksian data-data yang
kurang relevan dengan penelitian. Setelah dilakukan proses penyeleksian
data kemudian tahap selanjutnya melakukan penggabungan seluruh data
yang telah diperoleh yang dikenal dengan integrasi data. Data mentah
yang diperoleh disajikan secara terpisah. Data dari pelajaran yang sama
disatukan dalam satu
file
yang berekstensi .csv. Setelah disatukan dalam
satu
file
maka data dapat disimpan dalam tabel pada
database.
Hasil pada
tahap ini adalah :
a.
Nilai Matematika (kelas X semester I sampai kelas XII semester I),
Nilai Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
matematika.csv
b.
Nilai Bahasa Indonesia (kelas X semester I sampai kelas XII semester
I), Nilai Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
indonesia.csv
c.
Nilai Bahasa Inggris (kelas X semester I sampai kelas XII semester I),
Nilai Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
d.
Nilai Biologi (kelas X semester I sampai kelas XII semester I), Nilai
Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
biologi.csv
e.
Nilai Kimia (kelas X semester I sampai kelas XII semester I), Nilai Uji
Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
kimia.csv
f.
Nilai Fisika (kelas X semester I sampai kelas XII semester I), Nilai Uji
Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
fisika.csv
g.
Nilai Ekonomi (kelas X semester I sampai kelas XII semester I), Nilai
Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
ekonomi.csv
h.
Nilai Sosiologi (kelas X semester I sampai kelas XII semester I), Nilai
Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
sosiologi.csv
i.
Nilai Geografi (kelas X semester I sampai kelas XII semester I), Nilai
Uji Coba Nasional, Nilai Ujian Nasional disimpan dalam
file
geografi.csv
3.
Transformasi data
Pada tahap transformasi data, data nilai akademik diklasifikasikan
menjadi A, B, C, D, E dengan jangkauan (
range
) tertentu. Tabel 3.3 adalah
contoh data dari nilai matematika seorang siswa :
Tabel 3.3 Contoh Data Awal
siswa
sem_1
sem_2
sem_3
sem_4
sem_5
uco
un
1
57
55
64
60
54
3.5
1.8
2
70
68
67
64
78
3.3
5.5
3
64
58
68
67
71
5.0
4.5
4
60
56
66
69
67
5.3
4.8
5
54
54
60
63
61
3.0
4.3
Keterangan :
Interval untuk atribut sem_1 sampai sem_5 adalah 0-100. Sedangkan
kemudian akan dikalikan 10 agar mempermudah dalam proses
transformasi.
Untuk memudahkan proses penambangan data, maka data diatas
akan dikelompokkan berdasarkan
range
yang sudah ditetapkan oleh pihak
sekolah seperti pada tabel 3.4 berikut ini :
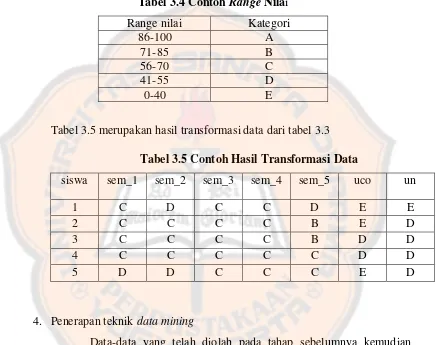
Tabel 3.4 Contoh Range Nila
i
Range nilai
Kategori
86-100
A
71-85
B
56-70
C
41-55
D
0-40
E
Tabel 3.5 merupakan hasil transformasi data dari tabel 3.3
Tabel 3.5 Contoh Hasil Transformasi Data
siswa
sem_1
sem_2
sem_3
sem_4
sem_5
uco
un
1
C
D
C
C
D
E
E
2
C
C
C
C
B
E
D
3
C
C
C
C
B
D
D
4
C
C
C
C
C
D
D
5
D
D
C
C
C
E
D
4.
Penerapan teknik
data mining
Data-data yang telah diolah pada tahap sebelumnya kemudian
akan diolah menggunakan algoritma
naïve bayes
. Data yang digunakan
untuk penelitian terbatas pada beberapa mata pelajaran yang terkait
dengan mata pelajaran yang diujikan pada ujian nasional.
a.
Variabel
input
Variabel-variabel yang digunakan antara lain sebagai beikut:
a.
Nilai beberapa mata pelajaran pada rapor kelas X semester 1
i.
Untuk jurusan IPA : Matematika, Bahasa Indonesia,
Bahasa Inggris, Kimia, Fisika, dan Biologi.
ii.
Untuk jurusan IPS : Matematika, Bahasa Indonesia,
Bahasa Inggris, Ekonomi, Geografi, Sosiologi.
b.
Nilai Uji Coba Nasional (UCO).
c.
Nilai Ujian Nasional (UN).
b.
Variabel
output
Proses prediksi akan menghasilkan hasil prediksi nilai ujian
nasional masing-masing siswa sesuai mata pelajaran yang diujiankan
berdasarkan jangkauan (
range
) nilai UN yang telah ditentukan
sebelumnya.
Range
nilai ini yang akan menentukan perkiraan nilai UN
yang akan diterima siswa. Pada penelitian ini,
range
nilai akan menjadi
hasil atau keluaran yang berupa prediksi nilai UN seorang siswa.
5.
Evaluasi pola yang ditemukan
Pada tahap ini akan dilakukan proses untuk mengukur akurasi
sistem yang telah dibuat. Proses pengukuran akan dilakukan menggunakan
teknik
k-fold cross validation
.
K-fold cross validation
merupakan salah
satu metode yang bisa digunakan untuk mengukur kinerja dari sebuah
model prediktif. Dalam
k-fold cross validation
, data akan dikelompokkan
ke dalam
k
buah partisi/kelompok dengan ukuran yang sama.
Masing-masing kelompok akan mengalami posisi sebagai data
testing
dan sebagai
data
training
. (Han&Kamber,2001).
Metode pengukuran
cross validation
dengan nilai fold = 3
Pengujian I
Kel.1 Kel.2 Kel.3
Pengujian II
Pengujian III
Hal yang sama akan dilakukan pada
cross validation
dengan nilai fold = 5.
Akhir dari tahap ini adalah diperolehnya presentase akurasi antara data
training
dengan data
testing
, sehingga dapat ditentukan tingkat
keberhasilan proses penambangan data yang telah dilakukan. Rumus untuk
menghitung akurasi dapat dilihat pada rumus (3.1) berikut :
𝑎𝑘𝑢𝑟𝑎𝑠𝑖
=
𝐷𝑎𝑡𝑎 𝑦𝑎𝑛𝑔 𝑠𝑒𝑠𝑢𝑎𝑖 𝑑𝑎𝑡𝑎 𝑡𝑒𝑠𝑡𝑖𝑛𝑔𝐷𝑎𝑡𝑎 𝑡𝑒𝑠𝑡𝑖𝑛𝑔
× 100%
…….. (3.1)
Kel.1 Kel.3 Kel.2
training testing
Kel.2 Kel.3 Kel.1
3.4
Diagram Model Use Case
Admin
Input range nilai Evaluasi sistem Input data training
<<depends on>>
Prediksi UN
Cetak hasil prediksi <<depends on>>
User
Olah data admin
Prediksi Nilai UN
Cetak hasil prediksi UN <<depends on>> Login
<<depends on>>