i
PENERAPAN ALGORITME MODIFIED K-NEAREST NEIGHBOR UNTUK MEMPREDIKSI KATEGORI NILAI UJIAN SEKOLAH
BERSTANDAR NASIONAL SISWA SMA BERDASARKAN NILAI RAPOR
Disusun Oleh : Yakobus Aris Arvanto
NIM 165314001
PROGRAM STUDI INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2020
ii
THE IMPLEMENTATION OF MODIFIED K-NEAREST NEIGHBOR ALGORITHM TO PREDICT NATIONAL STANDARDIZED
EXAMINATION SCORES CATEGORIES FOR HIGH SCHOOL STUDENTS BASED ON REPORT CARDS
By :
Yakobus Aris Arvanto NIM 165314001
INFORMATICS STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2020
vi MOTTO
Serahkanlah perbuatanmu kepada TUHAN, maka terlaksanalah segala rencanamu.
Amsal 16:3
vii
HALAMAN PERSEMBAHAN
Karya ini saya persembahkan untuk:
Yulius Samijo & Bertha Marjiem
ix ABSTRAK
Munculnya kebijakan penghapusan Ujian Nasional membawa dampak pada meningkatnya kedudukan Ujian Sekolah Berstandar Nasional (USBN). Hasil USBN digunakan sebagai salah satu pertimbangan penentuan kelulusan peserta didik dan sebagai evaluasi pembelajaran bagi guru maupun sekolah dalam upaya peningkatan mutu pendidikan. Oleh karena itu, dilakukan penelitian untuk memprediksi nilai USBN berdasarkan nilai rapor, dimana nilai tersebut merupakan rekam jejak siswa dalam menempuh pendidikan. Penelitian ini menggunakan teknik data mining dengan menerapkan metode Modified K-Nearest Neighbor (MKNN) yang merupakan pengembangan dari metode K-Nearest Neighbor (KNN).
Dataset yang digunakan, yaitu nilai rapor kelas X sampai kelas XII, dan nilai ujian sekolah berstandar nasional siswa SMA BOPKRI 1 Yogyakarta yang lulus tahun 2019. Uji akurasi penelitian ini menggunakan cross validation dan confusion matrix. Pada penelitian ini, dilakukan percobaan pada data dengan membagi menjadi beberapa dataset tiap mata pelajaran dengan 3-fold dan menggunakan jumlah tetangga terdekat 1,3,5,7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27 29, 31, 33, 35, 37, 39, 41. Dari hasil percobaan didapatkan akurasi tertinggi pada dataset mata pelajaran Bahasa Inggris aspek keterampilan sebesar 88.5789% diperoleh ketika k
= 5,7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27 29, 31, 33, 35, 37, 39, 41. Akurasi terendah didapatkan pada mata pelajaran Sosiologi rata-rata penilaian aspek pengetahuan dan keterampilan sebesar 45.4545% diperoleh ketika k = 3.
Kata kunci: prediksi USBN, nilai rapor, data mining, modified k-nearest neighbor.
x ABSTRACT
The emergence of the National Exam elimination policy has had an impact on the increasing standing of the National Standardized School Exam (USBN). USBN results are used as one of the considerations of the determination of the graduation of students and as a learning evaluation for teachers and schools in an effort to improve the quality of education. Therefore, research was conducted to predict USBN value based on the value of the report, which is the track record of students in education. This research uses data mining techniques by applying modified K- Nearest Neighbor (MKNN) method which is the development of K-Nearest Neighbor (KNN) method. The dataset used, namely grade X to grade XII, and national standard school test scores of BOPKRI 1 Yogyakarta High School students who graduated in 2019. The accuracy was obtained by using cross validation and confusion matrix. In this study, experiments were conducted on data by dividing into several datasets per subject with 3-fold and using the number of nearest neighbors 1,3,5,7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27 29, 31, 33, 35, 37, 41. The highest accuracy of 88.5789% is obtained from English subjects aspect skills at values of 5.7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27 29, 31, 33, 35, 37, 39, 41. The lowest accuracy of 45.4545% is obtained from Sociology subjects averaged an aspect assessment of knowledge and skills at values of 3.
Keywords: USBN prediction, report value, data mining, modified k-nearest neighbor.
xiii DAFTAR ISI
JUDUL ... i
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
PERNYATAAN KEASLIAN KARYA ... v
MOTTO ... vi
HALAMAN PERSEMBAHAN... vii
PERNYATAAN PERSETUJUAN PUBLIKASI ... viii
ABSTRAK ... ix
ABSTRACT ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiii
DAFTAR TABEL ... xvi
DAFTAR GAMBAR ... xvii
DAFTAR RUMUS... xix
DAFTAR LAMPIRAN ... xx
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang... 1
1.2 Rumusan Masalah ... 2
1.3 Tujuan ... 3
1.4 Manfaat ... 3
1.5 Batasan Masalah ... 3
1.6 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA ... 5
2.1 Knowledge Discovery in Databases ... 5
2.2 Penambangan Data ... 6
2.1 Klasifikasi Pada Data Mining ... 7
2.4 Modified K-Nearest Neighbor ... 8
xiv
2.5 Evaluasi dan Validasi ... 10
BAB III METODOLOGI PENELITIAN... 13
3.1 Sumber Data ... 13
3.2 Spesifikasi Alat ... 14
3.2.1 Hardware ... 14
3.2.2 Software... 15
3.3 Tahap-tahap KDD (Knowledge Discovery in Database) ... 15
3.4 Diagram Use Case ... 20
3.4.1 Gambaran Umum Use case ... 21
3.4.2 Narasi Use Case ... 22
3.5 Flowchart Algoritma Modified k-Nearest Neighbor ... 23
3.6 Algoritma per Function ... 24
3.8 Komposisi Data Latih dan Data Uji ... 29
3.9 Perancangan Antar Muka Sistem ... 31
BAB IV IMPLEMENTASI DAN ANALISIS HASIL ... 36
4.1 Implementasi Use Case ... 36
4.2 Uji Validasi Perhitungan Akurasi Modified k-Nearest Neighbor... 40
4.2.1 Penghitungan Akurasi Modified k-Nearest Neighbor Secara Manual ………. 40
4.2.2 Penghitungan Akurasi Modified k-Nearest Neighbor Menggunakan Perangkat Lunak ... 41
4.2.3 Evaluasi Penghitungan Akurasi Modified k-Nearest Neighbor Secara Manual dengan Perangkat Lunak ... 42
4.3 Uji Validasi Prediksi Modified k-Nearest Neighbor ... 42
4.3.1 Prediksi Modified k-Nearest Neighbor Secara Manual ... 42
4.3.2 Prediksi Modified k-Nearest Neighbor Menggunakan Perangkat Lunak ... 42
4.3.3 Evaluasi Prediksi Modified k-Nearest Neighbor Secara Manual dengan Perangkat Lunak ... 43
4.4 Analisis Hasil... 44
4.4.1 Dataset ... 44
4.4.2 Hasil Akurasi Modified k-Nearest Neighbor... 44
xv
4.4.3 Analisis Hasil Akurasi Modified k-Nearest Neighbor ... 58
BAB V PENUTUP ... 64
5.1 Simpulan ... 64
5.2 Saran ... 64
DAFTAR PUSTAKA ... 66
xvi
DAFTAR TABEL
Tabel 2. 1 Tabel confusion matrix... 11
Tabel 3. 1 Jumlah Data Mentah Sebelum Proses Data Cleaning ... 15
Tabel 3. 2 Jumlah Data Mentah Setelah Proses Data Cleaning ... 16
Tabel 3. 3 Nama dan Penjelasan Data Siswa ... 16
Tabel 3. 4 Contoh Data Pengetahuan Hasil Seleksi ... 17
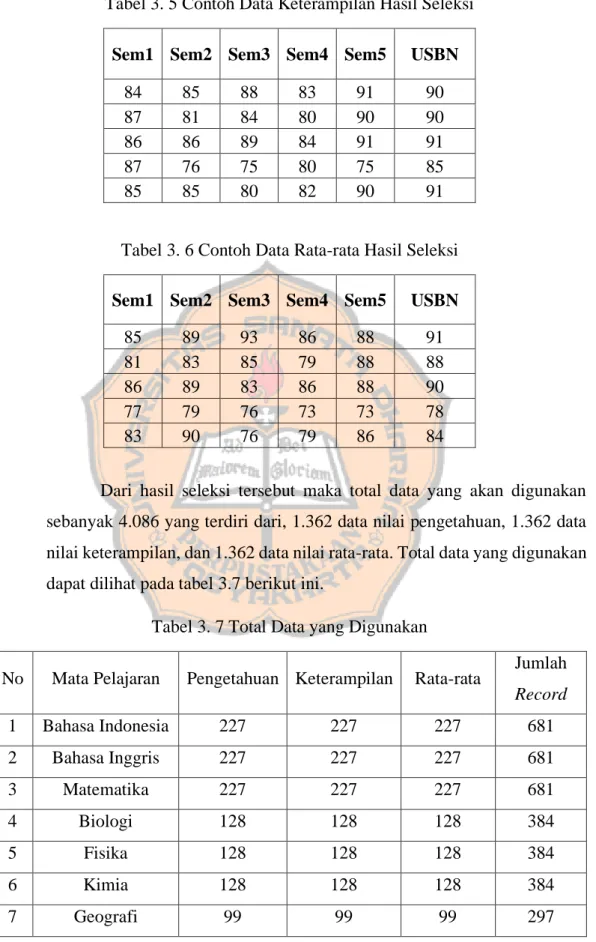
Tabel 3. 5 Contoh Data Keterampilan Hasil Seleksi... 18
Tabel 3. 6 Contoh Data Rata-rata Hasil Seleksi ... 18
Tabel 3. 7 Total Data yang Digunakan ... 18
Tabel 3. 8 Range Nilai ... 19
Tabel 3. 9 Gambaran Umum Use Case ... 21
Tabel 4. 1 Hasil Akurasi Terbaik ... 59
Tabel 4. 2 Hasil Akurasi Terbaik Aspek Pengetahuan ... 60
Tabel 4. 3 Hasil Akurasi Terbaik Aspek Keterampilan ... 61
Tabel 4. 4 Hasil Akurasi Terbaik Rata-rata Aspek Pengetahuan dan Keterampilan ... 62
xvii
DAFTAR GAMBAR
Gambar 2. 1 3-fold cross validation dengan k sebesar 3 ... 11
Gambar 3. 1 Diagram Use Case ... 21
Gambar 3. 2 Flowchart Modified K-Nearest Neighbor ... 23
Gambar 3. 3 Fungsi Prediksi ... 28
Gambar 3. 4 Contoh Tabel Label yang Mendominasi ... 28
Gambar 3. 5 Tabel Frekuensi ... 29
Gambar 3. 6 Pembagian Komposisi data dengan total data 227 ... 29
Gambar 3. 7 Pembagian Komposisi data dengan total data 128 ... 30
Gambar 3. 8 Pembagian Komposisi data dengan total data 99 ... 30
Gambar 3. 9 Halaman Utama (home) ... 31
Gambar 3. 10 Halaman Admin ... 32
Gambar 3. 11 Halaman Prediksi Nilai ... 33
Gambar 3. 12 Halaman Bantuan ... 34
Gambar 3. 13 Halaman Tentang ... 35
Gambar 4. 1 Implementasi Halaman Utama ... 36
Gambar 4. 2 Implementasi Halaman Admin... 37
Gambar 4. 3 Implementasi Halaman Prediksi Nilai... 38
Gambar 4. 4 Implementasi Halaman Bantuan ... 39
Gambar 4. 5 Implementasi Halaman Tentang... 40
Gambar 4. 6 Hasil Akurasi Menggunakan Perangkat Lunak ... 41
Gambar 4. 7 Hasil Prediksi Menggunakan Perangkat Lunak ... 43
Gambar 4. 8 Hasil Akurasi Bahasa Indonesia Aspek Pengetahuan ... 45
Gambar 4. 9 Hasil Akurasi Bahasa Indonesia Aspek Keterampilan ... 45
Gambar 4. 10 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Bahasa Indonesia ... 46
Gambar 4. 11 Hasil Akurasi Bahasa Inggris Aspek Pengetahuan ... 46
Gambar 4. 12 Hasil Akurasi Bahasa Inggris Aspek Keterampilan ... 47
Gambar 4. 13 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Bahasa Inggris ... 47
Gambar 4. 14 Hasil Akurasi Matematika Aspek Pengetahuan ... 48
xviii
Gambar 4. 15 Hasil Akurasi Matematika Aspek Keterampilan ... 48 Gambar 4. 16 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Matematika ... 49 Gambar 4. 17 Hasil Akurasi Biologi Aspek Pengetahuan ... 49 Gambar 4. 18 Hasil Akurasi Biologi Aspek Keterampilan ... 50 Gambar 4. 19 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Biologi ... 50 Gambar 4. 20 Hasil Akurasi Fisika Aspek Pengetahuan ... 51 Gambar 4. 21 Hasil Akurasi Fisika Aspek Keterampilan ... 51 Gambar 4. 22 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Fisika ... 52 Gambar 4. 23 Hasil Akurasi Kimia Aspek Pengetahuan ... 52 Gambar 4. 24 Hasil Akurasi Kimia Aspek Keterampilan ... 53 Gambar 4. 25 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Kimia ... 53 Gambar 4. 26 Hasil Akurasi Geografi Aspek Pengetahuan ... 54 Gambar 4. 27 Hasil Akurasi Geografi Aspek Keterampilan... 54 Gambar 4. 28 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Geografi ... 55 Gambar 4. 29 Hasil Akurasi Sosiologi Aspek Pengetahuan ... 55 Gambar 4. 30 Hasil Akurasi Sosiologi Aspek Keterampilan ... 56 Gambar 4. 31 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Sosiologi ... 56 Gambar 4. 32 Hasil Akurasi Ekonomi Aspek Pengetahuan ... 57 Gambar 4. 33 Hasil Akurasi Ekonomi Aspek Keterampilan ... 57 Gambar 4. 34 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Ekonomi ... 58 Gambar 4. 35 Grafik Batang Hasil Akurasi Terbaik Setiap Mata Pelajaran ... 63
xix
DAFTAR RUMUS
Rumus 2.1 Rumus Jarak Euclidean ………. 8
Rumus 2.2 Rumus Validitas ……… 9
Rumus 2.3 Rumus Fungsi S ……….………. 9
Rumus 2.4 Rumus Weighted Voting …..………..…..……… 10
Rumus 2.5 Rumus Accuracy ……….…..……… 12
xx
DAFTAR LAMPIRAN
Lampiran 1 Narasi Use Case ……… 67
Lampiran 2 Perhitungan Manual Akurasi ……… 76 Lampiran 3 Perhitungan Manual Prediksi …..………..……… 95
1 BAB I PENDAHULUAN
1.1 Latar Belakang
Dalam setiap penyelenggaraan kegiatan pembelajaran di sekolah berpedoman pada kurikulum yang sudah ditetapkan untuk mencapai tujuan pendidikan. Untuk melihat tingkat pencapaian tujuan pendidikan tersebut diperlukan suatu bentuk evaluasi pendidikan. Evaluasi tersebut sebelumnya adalah Ujian Nasional. Setelah Menteri Pendidikan dan Kebudayaan, Bapak Nadiem Makarim menghapuskan Ujian Nasional maka evaluasi diganti melalui nilai Ujian Sekolah Berstandar Nasional (USBN).
Munculnya kebijakan tentang penghapusan Ujian Nasional membawa dampak pada meningkatnya kedudukan Ujian Sekolah Berstandar Nasional pada jenjang pendidikan. Hasil USBN digunakan sebagai salah satu pertimbangan penentuan kelulusan peserta didik dan sebagai evaluasi pembelajaran bagi guru maupun sekolah dalam upaya peningkatan mutu pendidikan. Hal tersebut juga diterapkan pada SMA BOPKRI 1 Yogyakarta.
Oleh karena itu, diharapkan peserta didik mendapat hasil USBN yang memuaskan.
Kesiapan siswa dalam menghadapi USBN sangat penting agar nilai yang dihasilkan dapat memuaskan. Oleh sebab itu, sebagai salah satu persiapan dalam menghadapinya dapat dibuat sebuah sistem yang dapat membantu guru maupun sekolah untuk mengantisipasi siswa mendapatkan nilai yang kurang memuaskan.
Berdasarkan hal tersebut, sebenarnya kita dapat melakukan proses data mining berupa prediksi kategori nilai Ujian Sekolah Berstandar Nasional. Pada SMA BOPKRI 1 Yogyakarta, kategori nilai tersebut digunakan sebagai nilai rapor siswa. Data yang dibutuhkan berupa nilai rapor semester 1 sampai 5, dimana nilai tersebut merupakan rekam jejak siswa dalam menempuh pendidikan. Salah satu metode prediksi yang cukup dikenal adalah K-Nearest
Neighbor dan dikembangkan oleh Parvin menjadi Modified K-Nearest Neighbor. Algoritme modified k-nearest neighbor menambahkan 2 proses baru yaitu, perhitungan nilai validitas antar data latih dan perhitungan weight voting.
Algoritme modified k-nearest neighbor sendiri sudah pernah digunakan untuk memprediksi penyakit Kanker Payudara. Penelitian tersebut dilakukan oleh Putra (2019) pada tugas akhirnya, dimana menghasilkan akurasi sebesar 97,61% dengan k = 1. Ia menyebutkan bahwa nilai k sangat mempengaruhi akurasi dan pada penelitiannya rata-rata akurasi cenderung menurun jika nilai k semakin tinggi.
Berdasarkan hal diatas, maka penulis tertarik untuk membuat sistem dengan mengimplementasikan algoritme modified k-nearest neighbor untuk memprediksi kategori nilai USBN berdasarkan nilai rapor kelas X, XI, dan XII.
Jika kategori nilai USBN dapat diprediksi lebih dini maka dapat membantu para siswa untuk meningkatkan semangat belajar dan keinginan untuk lulus dengan hasil yang maksimal. Selain itu, hal ini juga dapat dijadikan sebagai salah satu sarana untuk guru maupun sekolah dalam mengantisipasi siswa mendapatkan nilai yang kurang memuaskan.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, maka permasalahan yang dapat diambil dalam penelitian ini adalah :
1. Bagaimana mengimplementasikan algoritme modified k-nearest neighbor untuk memprediksi kategori nilai ujian sekolah berstandar nasional?
2. Berapakah akurasi dari hasil implementasi algoritme modified k-nearest neighbor dalam memprediksi kategori nilai ujian sekolah berstandar nasional?
3. Berapakah nilai k yang menghasilkan akurasi tertinggi dalam memprediksi kategori nilai ujian sekolah berstandar nasional?
1.3 Tujuan
Tujuan yang diharapkan dengan penelitian ini adalah sebagai berikut :
1. Mengimplementasikan algoritme modified k-nearest neighbor untuk memprediksi kategori nilai ujian sekolah berstandar nasional.
2. Mengetahui akurasi dari hasil implementasi algoritme modified k-nearest neighbor untuk memprediksi kategori nilai ujian sekolah berstandar nasional.
3. Mengetahui jumlah k yang menghasilkan akurasi tertinggi dalam memprediksi kategori nilai ujian sekolah berstandar nasional.
1.4 Manfaat
Manfaat yang diharapkan dengan adanya penelitian ini adalah kategori nilai Ujian Sekolah Berstandar Nasional siswa dapat diprediksi lebih dini sehingga guru dapat mengambil langkah-langkah yang tepat sesuai hasil yang didapatkan setiap siswa.
1.5 Batasan Masalah
Berdasarkan rumusan masalah maka dapat ditentukan batasan masalah sebagai berikut :
1. Data yang digunakan adalah data nilai rapor mulai dari semester 1 sampai semester 5 dan nilai USBN siswa SMA BOPKRI 1 Yogyakarta yang lulus tahun 2019.
2. Algoritme yang digunakan adalah algoritme modified k-nearest neighbor.
3. Implementasi program menggunakan bahasa pemrograman Matlab.
4. Nilai yang diprediksi hanya nilai mata pelajaran Bahasa Indonesia, Bahasa Inggris, Matematika, Biologi, Fisika, Kimia, Ekonomi, Geografi, dan Sosiologi.
5. Pengklasifikasian kategori nilai dibagi menjadi 4, yaitu A, B, C, dan D.
1.6 Sistematika Penulisan 1. BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang, rumusan masalah, tujuan penelitian, manfaat, batasan masalah, dan sistematika penulisan.
2. BAB II TINJAUAN PUSTAKA
Bab ini berisi tentang teori-teori yang berkaitan dengan penelitian serta metode yang digunakan.
3. BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang metodologi penelitian yang digunakan pada penelitian, yang terdiri dari analisis sistem, data yang digunakan, spesifikasi perangkat lunak dan perangkat keras yang digunakan serta tahap-tahap Knowledge Discovery in Database (KDD), yaitu pembersihan data, integrasi data, seleksi data, dan transformasi data. Pada bab ini juga berisi perancangan perangkat lunak.
4. BAB IV ANALISIS DAN HASIL PEMBAHASAN
Bab ini membahas tentang hasil serta analisa tentang hasil yang didapat pada penelitian yang dilakukan.
5. BAB V PENUTUP
Bab ini berisi kesimpulan dari hasil penelitian serta saran yang diusulkan untuk penelitian selanjutnya.
5 BAB II
TINJAUAN PUSTAKA
2.1 Knowledge Discovery in Databases
Istilah lain dari data mining adalah Knowledge Discovery in Database (KDD). Walaupun sebenarnya data mining merupakan bagian dari tahapan proses dalam KDD (Han & Kamber, 2011).
Tahapan dalam Knowledge Discovery in Database (KDD) (Han & Kamber, 2011).
a. Pembersihan data (Data cleaning)
Pembersihan data digunakan untuk menghilangkan data noise dan tidak konsisten seperti data salah ketik, data tidak akurat, maupun data kosong.
b. Integrasi data (Data integration)
Integrasi data adalah penggabungan data yang didapatkan dari beberapa sumber, hal ini dimaksudkan untuk merangkum seluruh data dalam satu tabel utuh.
c. Seleksi data (Data selection)
Seleksi data adalah proses seleksi data-data yang relevan untuk digunakan dalam proses analisis.
d. Transformasi data (Data transformation)
Data yang telah didapatkan diubah menjadi bentuk yang sesuai untuk proses selanjutnya.
e. Penerapan teknik data mining (Data mining)
Pada tahap ini merupakan proses penting dimana metode data mining diterapkan untuk mengekstrak pola data.
f. Evaluasi pola yang ditemukan (Pattern evaluation)
Pada tahap ini dilakukan identifikasi pola yang khas ataupun model prediksi, dievaluasi untuk menilai apakah hipotesa yang ada tercapai.
g. Presentasi pengetahuan (Knowledge presentation)
Pada tahap ini dilakukan teknik visualisasi dan pengetahuan untuk menyampaikan hasil yang didapatkan.
2.2 Penambangan Data
Penambangan data dilatarbelakangi oleh pertumbuhan pesat dari volume data yang tersedia dan berasal dari berbagai bidang. Pertumbuhan yang sangat pesat membuat ledakan informasi sehingga informasi berharga dari data tersebut sulit ditemukan. Berdasarkan hal tersebut maka dibutuhkan sebuah alat yang secara otomatis mendapatkan informasi berharga dari data yang besar dan mengubah data tersebut menjadi pengetahuan yang terorganisir (Han &
Kamber, 2011).
Penambangan data adalah teknik yang relatif cepat dan mudah untuk menemukan pengetahuan, pola dan/atau relasi antar data, secara otomatis (Suyanto, 2019). Secara fungsional, penambangan data (data mining) adalah proses menemukan pola menarik dan pengetahuan dari sejumlah besar data yang bersumber dari database, gudang data, web, atau tempat penyimpanan informasi lainnya (Han & Kamber, 2011).
Kegunaan Penambangan data
Secara umum, kegunaan penambangan data dibagi menjadi 2 (Suyanto, 2019), yaitu :
a. Deskriptif
Penambangan data digunakan untuk mencari pola-pola yang dapat dipahami manusia yang menjelaskan karakteristik data.
b. Prediktif
Penambangan data digunakan untuk membentuk sebuah model pengetahuan yang akan digunakan untuk melakukan prediksi.
2.1 Klasifikasi Pada Data Mining
Bagian penting dalam data mining adalah teknik klasifikasi, yaitu bagaimana mempelajari sekumpulan data sehingga dihasilkan aturan yang bisa mengklasifikasi atau mengenali data-data baru yang belum pernah dipelajari.
Klasifikasi dapat didefinisikan sebagai proses untuk menyatakan suatu objek data sebagai salah satu kategori (kelas) yang telah didefinisikan sebelumnya (Zaki dkk, 2013).
Proses klasifikasi didasarkan pada empat buah komponen (Gorunescu, 2011):
a. Kelas.
Variabel dependen yang berupa kategorikal yang merepresentasikan “label” yang terdapat pada objek setelah pengelompokan.
Contohnya : jenis bintang, kesetiaan pelanggan, jenis gempa.
b. Predictor.
Variabel independent yang direpresentasikan oleh karakteristik (atribut) dari data untuk dikelompokkan berdasarkan klasifikasi yang dibuat.
Contohnya : merokok, konsumsi alcohol, status perkawinan, arah angin dan kecepatan, musim.
c. Training dataset.
Satu set data yang berisi nilai-nilai dari dua komponen diatas dan digunakan untuk “pelatihan” dan mengenali kelas yang sesuai berdasarkan predictor.
d. Testing dataset.
Berisi data baru yang akan diklasifikasikan oleh model yang telah dibuat dan keakuratan klasifikasi dapat dievaluasi.
Berikut ini adalah algoritme klasifikasi yang paling popular yaitu (Gorunescu, 2011) :
a. Decision/Classification Trees
b. Bayesian Classifiers/Naïve Bayes Classifiers c. Neural Networks
d. Statistical Analysis e. Genetic Algorithm f. Rough Sets
g. K-Nearest Neighbor Classifier h. Rule-Based Methods
i. Memory Based Reasoning j. Support Vector Machines
2.4 Modified K-Nearest Neighbor
Algoritme modified k-nearest neighbor (MKNN) merupakan pengembangan dari metode KNN dengan penambahan 2 buah proses, yaitu perhitungan nilai validitas dan perhitungan bobot. Algoritme KNN dilakukan dengan mencari kelompok k objek dalam data latih yang paling dekat (mirip) dengan objek pada data baru atau data uji (X Wu et al, 2008). Berikut ini langkah-langkah proses klasifikasi algoritme modified k-nearest neighbor :
1. Perhitungan Jarak Euclidean
Untuk menghitung jarak antar data dapat menggunakan beberapa cara, salah satunya menggunakan Euclidean Distance. Metode pengukuran jarak ini cocok diimplementasikan terhadap data yang memiliki nilai atribut bersifat numerikal, khususnya dengan atribut kontinu (Gorunescu, 2011). Euclidean Distance dihitung dengan rumus:
𝑑(𝑥, 𝑦) = √∑𝑛𝑖=1(𝑥𝑖− 𝑦𝑖)2 ………...………...(2.1) di mana :
d(x,y) = jarak
n = dimensi data i = variabel data
xi = data uji yi = sampel data
2. Perhitungan Nilai Validitas
Dalam algoritme MKNN, setiap data pada data latih harus divalidasi pada langkah pertama. Validitas setiap data bergantung pada setiap tetangganya. Proses validasi dilakukan untuk semua data latih. Setelah dihitung validitas tiap data maka nilai validitas tersebut digunakan sebagai informasi lebih mengenai data tersebut (Parvin, 2008).
Tetangga terdekatnya perlu dipertimbangkan dalam menghitung validitas data latih. Di antara tetangga terdekat dengan data, validitas digunakan untuk menghitung jumlah titik dengan label yang sama dengan data tersebut. Untuk menghitung validitas dari setiap titik pada data latih menggunakan persamaan (Parvin, 2008) :
𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑦(𝑥) = 1
𝐻∑𝐻𝑖=1𝑆(𝑙𝑏𝑙(𝑥), (𝑙𝑏𝑙(𝑁𝑖(𝑥))) .………(2.2) di mana :
H = jumlah titik terdekat lbl(x) = kelas x
lbl(Ni(x)) = label kelas titik terdekat x
Fungsi S digunakan untuk menghitung kemiripan antara titik x dan data ke-i dari tetangga terdekat. Yang dituliskan dengan persamaan (Parvin, 2008) :
𝑆(𝑎, 𝑏) = {1 𝑎 = 𝑏, 0 𝑎 ≠ 𝑏} ………...………(2.3) Keterangan :
a = kelas a pada data latih
b = kelas lain selain kelas a pada data latih
3. Perhitungan Weighted Voting
Dalam metode MKNN, pertama-tama weight masing-masing tetangga dihitung menggunakan 1 / (de + 0.5). Kemudian, validitas dari tiap data pada data latih dikalikan dengan weighted berdasarkan pada jarak Euclidean. Dalam metode MKNN, weight voting masing-masing tetangga dihitung menggunakan persamaan (Parvin, 2008) :
𝑊(𝑖) = 𝑉𝑎𝑙𝑖𝑑𝑖𝑡𝑦(𝑖) × 1
𝑑𝑒(𝑖)+0.5 ………...………(2.4) di mana :
W(i) = Perhitungan Weight Voting Validity(i) = Nilai Validitas
de(i) = Jarak Euclidean
Teknik weight voting ini mempunyai pengaruh yang lebih penting terhadap data yang mempunyai nilai validitas lebih tinggi dan paling dekat dengan data uji. Selain itu, perkalian validitas dengan jarak dapat mengatasi kelemahan dari setiap data yang mempunyai jarak dengan weight yang memiliki banyak masalah dalam outlier. Jadi, algoritme MKNN yang diusulkan secara signifikan lebih kuat daripada metode KNN tradisional yang didasarkan hanya pada jarak (Parvin, 2008).
2.5 Evaluasi dan Validasi
Tahap selanjutnya setelah terbentuknya model prediksi perlu mengukur akurasi dari model tersebut. Untuk menghitung akurasi dari suatu algoritme terdapat beberapa metode, antara lain cross-validation dan confusion matrix.
Cross-validation membagi data ke dalam k buah kelompok dengan jumlah data tiap kelompok sama. Masing-masing kelompok tersebut akan mengalami posisi sebagai data uji dan sebagai data latih secara bergantian. k-fold cross- validation bisa digambarkan seperti berikut ini :
Gambar 2. 1 3-fold cross validation dengan k sebesar 3
Confusion matrix memberikan nilai kinerja model klasifikasi berdasarkan perhitungan objek yang diklasifikasikan dengan benar dan objek yang diklasifikasikan dengan salah (Gorunescu, 2011). Hasil perhitungan digambarkan ke dalam sebuah tabel seperti berikut ini.
Tabel 2. 1 Tabel confusion matrix Kelas Prediksi
Ya Tidak Total
Kelas Aktual Ya TP FN P
Tidak FP TN N
Total P’ N’ P+N
Keterangan :
TP (true positif) = jumlah tuple positif yang dilabeli dengan benar oleh classifier.
TN (true negatif) = jumlah tuple negatif yang dilabeli dengan benar oleh classifier.
FP (false positif) = jumlah tuple positif yang dilabeli dengan salah oleh classifier.
FN (false negatif) = jumlah tuple negatif yang dilabeli dengan salah oleh classifier.
Setelah data uji dimasukkan ke dalam confusion matrix, hitung nilai-nilai yang telah dimasukkan tersebut untuk dihitung akurasinya. Untuk menghitung akurasi digunakan persamaan di bawah ini (Han & Kamber, 2011) :
𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 =TP+TN
P+N …….…..……….(2.5) di mana :
TP = jumlah true positif TN = jumlah true negatif P = jumlah record positif N = jumlah record negatif
13 BAB III
METODOLOGI PENELITIAN
3.1 Sumber Data
Data yang akan digunakan dalam penelitian ini adalah data nilai rapor siswa, dan nilai Ujian Sekolah Berstandar Nasional yang diperoleh dari SMA BOPKRI 1 Yogyakarta yang lulus tahun 2019. Data nilai yang didapatkan terdiri dari nilai rapor semester 1-5 dan nilai USBN. Pada nilai rapor setiap semester terdapat nilai aspek pengetahuan dan aspek keterampilan, pada nilai USBN terdapat nilai aspek pengetahuan, aspek keterampilan, dan nilai rata- rata aspek pengetahuan dan keterampilan. Data yang diberikan berupa data berekstensi .xlsx. Data yang diperoleh meliputi :
a. Nilai Pendidikan Agama dan Budi Pekerti semester 1-5 (aspek pengetahuan dan aspek keterampilan).
b. Nilai Pendidikan Pancasila dan Kewarganegaraan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
c. Nilai Bahasa Indonesia semester 1-5 (aspek pengetahuan dan aspek keterampilan).
d. Nilai Sejarah Indonesia semester 1-5 (aspek pengetahuan dan aspek keterampilan).
e. Nilai Matematika semester 1-5 (aspek pengetahuan dan aspek keterampilan).
f. Nilai Bahasa Inggris semester 1-5 (aspek pengetahuan dan aspek keterampilan).
g. Nilai Seni Budaya semester 1-5 (aspek pengetahuan dan aspek keterampilan).
h. Nilai Pendidikan Jasmani, Olahraga dan Kesehatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
i. Nilai Prakarya dan Kewirausahaan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
j. Nilai Bahasa Jawa semester 1-5 (aspek pengetahuan dan aspek keterampilan).
k. Nilai Matematika Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
l. Nilai Biologi Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
m. Nilai Fisika Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
n. Nilai Kimia Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
o. Nilai Geografi Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
p. Nilai Sejarah Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
q. Nilai Sosiologi Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
r. Nilai Ekonomi Peminatan semester 1-5 (aspek pengetahuan dan aspek keterampilan).
s. Nilai Lintas Minat semester 1-5 (aspek pengetahuan dan aspek keterampilan).
t. Nilai Ujian Sekolah Berstandar Nasional semester 1-5 (aspek pengetahuan, aspek keterampilan dan rata-rata nilai aspek pengetahuan dan keterampilan).
3.2 Spesifikasi Alat 3.2.1 Hardware
Hardware yang digunakan dalam penelitian ini adalah laptop ACER E5-476G dengan spesifikasi processor Intel Core i5 8250U, RAM 12 GB, SSD 256 GB.
3.2.2 Software
Software yang digunakan dalam penelitian ini adalah Sistem Operasi Windows 10 Home 64-bit, Microsoft Excel 2016, dan Matlab R2014b.
3.3 Tahap-tahap KDD (Knowledge Discovery in Database) 1. Pembersihan data (Data Cleaning)
Pembersihan data dilakukan terlebih dahulu terhadap data yang didapatkan dari sekolah sebelum data tersebut ditambang. Pembersihan data dilakukan terhadap data yang tidak lengkap (missing value) serta data dari siswa-siswi yang melakukan pindah sekolah. Pada data mentah yang didapatkan dari sekolah terdapat data yang tidak lengkap, yaitu pada nilai ujian sekolah berstandar nasional. Data yang tidak lengkap tersebut selanjutnya dibuang. Jumlah data awal yang didapatkan sebanyak 1368 record dan setelah proses data cleaning didapatkan sebanyak 1362 record untuk 9 mata pelajaran. Jumlah data dapat dilihat pada tabel berikut ini.
Tabel 3. 1 Jumlah Data Mentah Sebelum Proses Data Cleaning No Mata Pelajaran Jumlah
Record 1 Bahasa Indonesia 228
2 Bahasa Inggris 228
3 Matematika 228
4 Biologi 129
5 Fisika 129
6 Kimia 129
7 Geografi 99
8 Sosiologi 99
9 Ekonomi 99
Jumlah 1368
Tabel 3. 2 Jumlah Data Mentah Setelah Proses Data Cleaning No Mata Pelajaran Jumlah
Record 1 Bahasa Indonesia 227
2 Bahasa Inggris 227
3 Matematika 227
4 Biologi 128
5 Fisika 128
6 Kimia 128
7 Geografi 99
8 Sosiologi 99
9 Ekonomi 99
Jumlah 1362
2. Integrasi data (Data Integration)
Data yang diperoleh dari SMA BOPKRI 1 Yogyakarta masih terpisah dalam beberapa tabel sesuai dengan mata pelajaran, jurusan, dan kelas. Pada tahap ini data akan digabungkan sesuai dengan mata pelajaran yang sama menjadi satu tabel yang berisi kolom No, NIS, Nama Siswa, Mata Pelajaran, Sem 1 P, Sem 1 K, Sem 2 P, Sem 2 K, Sem 3 P, Sem 3 K, Sem 4 P, Sem 4 K, Sem 5 P, Sem 5 K, USBN P, USBN K, dan USBN rata- rata. Tabel 3.3 berikut ini menjelaskan nama kolom dan penjelasan tiap kolom.
Tabel 3. 3 Nama dan Penjelasan Data Siswa Nama Kolom Penjelasan
No Nomor Urut Siswa
NIS Nomor Induk Siswa
Nama Siswa Nama Lengkap Siswa Mata Pelajaran Nama Mata Pelajaran
Sem 1 P Nilai Semester 1 Pengetahuan Sem 1 K Nilai Semester 1 Keterampilan Sem 2 P Nilai Semester 2 Pengetahuan
Sem 2 K Nilai Semester 2 Keterampilan Sem 3 P Nilai Semester 3 Pengetahuan Sem 3 K Nilai Semester 3 Keterampilan Sem 4 P Nilai Semester 4 Pengetahuan Sem 4 K Nilai Semester 4 Keterampilan Sem 5 P Nilai Semester 5 Pengetahuan Sem 5 K Nilai Semester 5 Keterampilan USBN P Nilai USBN Pengetahuan USBN K Nilai USBN Keterampilan USBN Rata-rata Nilai USBN Rata-rata
3. Seleksi data (Data Selection)
Pada tahap ini dilakukan penyeleksian atribut yang tidak relevan terhadap penelitian, seperti nomor, NIS, nama siswa, mata pelajaran dan data nilai mata pelajaran yang tidak digunakan dalam proses prediksi. Mata pelajaran yang digunakan adalah pelajaran Bahasa Indonesia, Bahasa Inggris, Matematika, Biologi, Fisika, Kimia, Ekonomi, Geografi, dan Sosiologi. Pada tahap ini akan menghasilkan 3 buah variasi tabel untuk setiap mata pelajaran yaitu, pengetahuan, keterampilan, dan rata-rata (pengetahuan dan keterampilan). Contoh tabel hasil seleksi dapat dilihat di bawah ini.
Tabel 3. 4 Contoh Data Pengetahuan Hasil Seleksi Sem1 Sem2 Sem3 Sem4 Sem5 USBN
85 89 93 86 88 91
81 83 85 79 88 85
86 89 83 86 88 89
77 79 76 73 73 70
83 90 76 79 86 76
Tabel 3. 5 Contoh Data Keterampilan Hasil Seleksi Sem1 Sem2 Sem3 Sem4 Sem5 USBN
84 85 88 83 91 90
87 81 84 80 90 90
86 86 89 84 91 91
87 76 75 80 75 85
85 85 80 82 90 91
Tabel 3. 6 Contoh Data Rata-rata Hasil Seleksi Sem1 Sem2 Sem3 Sem4 Sem5 USBN
85 89 93 86 88 91
81 83 85 79 88 88
86 89 83 86 88 90
77 79 76 73 73 78
83 90 76 79 86 84
Dari hasil seleksi tersebut maka total data yang akan digunakan sebanyak 4.086 yang terdiri dari, 1.362 data nilai pengetahuan, 1.362 data nilai keterampilan, dan 1.362 data nilai rata-rata. Total data yang digunakan dapat dilihat pada tabel 3.7 berikut ini.
Tabel 3. 7 Total Data yang Digunakan
No Mata Pelajaran Pengetahuan Keterampilan Rata-rata Jumlah Record
1 Bahasa Indonesia 227 227 227 681
2 Bahasa Inggris 227 227 227 681
3 Matematika 227 227 227 681
4 Biologi 128 128 128 384
5 Fisika 128 128 128 384
6 Kimia 128 128 128 384
7 Geografi 99 99 99 297
8 Sosiologi 99 99 99 297
9 Ekonomi 99 99 99 297
Jumlah 4086
4. Transformasi data
Pada tahap transformasi dilakukan pengubahan data ke dalam bentuk yang sesuai untuk ditambang. Transformasi dilakukan terhadap atribut nilai Ujian Sekolah Berstandar Nasional menjadi kategori A, B, C, dan D berdasarkan jangkauan (range) tertentu. Data nilai USBN akan dikelompokkan berdasarkan range yang sudah ditetapkan oleh pihak sekolah SMA BOPKRI 1 Yogyakarta seperti pada tabel 3.8 berikut ini.
Tabel 3. 8 Range Nilai Range Nilai Kategori
91-100 A
82-90 B
73-81 C
<73 D
5. Penerapan Teknik data mining
Data-data yang sudah diolah pada tahap sebelumnya kemudian diolah menggunakan algoritme modified k-nearest neighbor. Langkah awal pada tahap ini adalah menentukan variabel yang akan digunakan, yaitu variabel input dan output. Penjabaran variabel tersebut antara lain sebagai berikut :
1. Variabel input, terdiri dari :
a. Nilai mata pelajaran pada rapor tiap semester dari kelas X sampai kelas XII.
i. Untuk jurusan IPA : Bahasa Indonesia, Matematika, Bahasa Inggris, Kimia, Fisika, dan Biologi.
ii. Untuk jurusan IPS : Bahasa Indonesia, Matematika, Bahasa Inggris, Ekonomi, Geografi, dan Sosiologi.
2. Variabel output
Proses prediksi akan menghasilkan hasil prediksi nilai ujian sekolah berstandar nasional siswa sesuai mata pelajaran berdasarkan jangkauan (range) nilai USBN yang telah ditentukan sebelumnya. Range nilai ini akan menentukan perkiraan kategori nilai USBN yang akan diterima siswa. Pada penelitian ini, kategori nilai akan menjadi hasil atau keluaran yang berupa prediksi nilai USBN seorang siswa.
3.4 Diagram Use Case
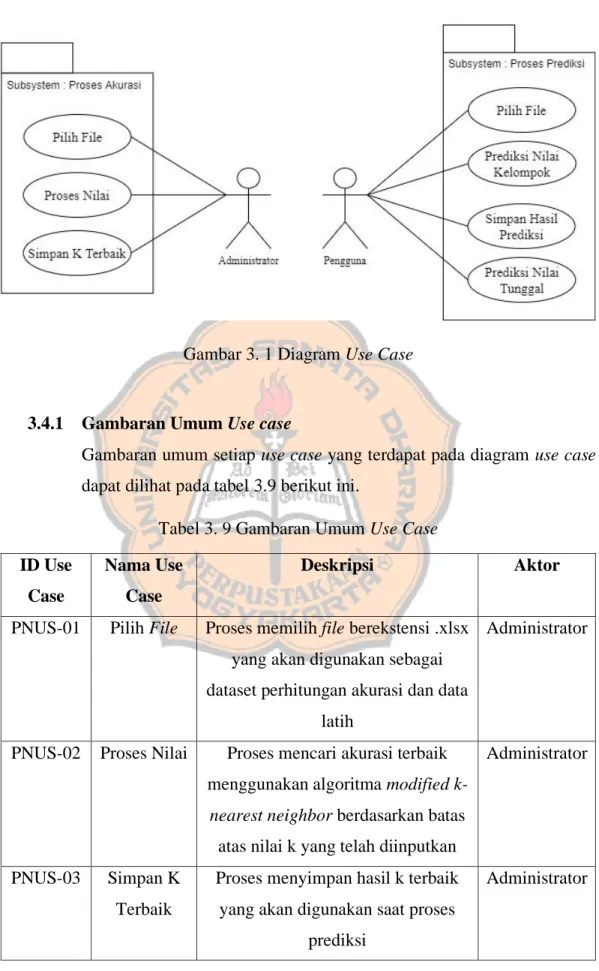
Terdapat 2 aktor untuk menjalankan sistem, yaitu administrator dan pengguna. Administrator bertugas menjalankan sistem yang berkaitan dengan proses akurasi, sedangkan pengguna yang bertugas untuk menjalankan sistem yang berkaitan dengan proses prediksi. Agar program dapat berjalan dengan baik, maka administrator harus memasukkan dataset terlebih dahulu, kemudian administrator memasukkan nilai k yang akan digunakan. Administrator dapat melihat hasil akurasi yang diberikan oleh sistem berdasarkan nilai rapor yang telah dimasukkan, lalu menyimpan nilai k terbaik yang nantinya akan menjadi model pada proses prediksi. Pada proses prediksi pengguna dapat melakukan prediksi nilai secara kelompok maupun tunggal. Gambar 3.1 merupakan diagram use case.
Gambar 3. 1 Diagram Use Case
3.4.1 Gambaran Umum Use case
Gambaran umum setiap use case yang terdapat pada diagram use case dapat dilihat pada tabel 3.9 berikut ini.
Tabel 3. 9 Gambaran Umum Use Case ID Use
Case
Nama Use Case
Deskripsi Aktor
PNUS-01 Pilih File Proses memilih file berekstensi .xlsx yang akan digunakan sebagai dataset perhitungan akurasi dan data
latih
Administrator
PNUS-02 Proses Nilai Proses mencari akurasi terbaik menggunakan algoritma modified k-
nearest neighbor berdasarkan batas atas nilai k yang telah diinputkan
Administrator
PNUS-03 Simpan K Terbaik
Proses menyimpan hasil k terbaik yang akan digunakan saat proses
prediksi
Administrator
PNUS-04 Pilih File Proses memilih file berekstensi .xlsx yang akan digunakan sebagai data
uji
Pengguna
PNUS-05 Prediksi Nilai Kelompok
Proses prediksi kategori nilai USBN siswa berdasarkan file nilai rapor
yang telah dipilih
Pengguna
PNUS-07 Simpan Hasil Prediksi
Proses menyimpan hasil prediksi kelompok berdasarkan nama file
yang telah diinputkan
Pengguna
PNUS-07 Prediksi Nilai Tunggal
Proses prediksi kategori nilai USBN siswa berdasarkan nilai rapor yang
telah diinputkan
Pengguna
3.4.2 Narasi Use Case
Narasi Use Case berisi langkah-langkah aksi dari pengguna dan reaksi sistem setiap use case. Narasi use case terlampir pada lampiran 1.
3.5 Flowchart Algoritma Modified k-Nearest Neighbor
Flowchart algoritma modified k-nearest neighbor dapat dilihat pada gambar 3.2 berikut ini.
Gambar 3. 2 Flowchart Modified K-Nearest Neighbor
3.6 Algoritma per Function
1. Nama Fungsi : kFoldCrossvalidation Algoritma :
b. Jika model sama dengan satu
i. Simpan data mulai baris ke (hasil pembulatan sepertiga jumlah data ditambah 1) untuk semua kolom sampai akhir sebagai data latih ii. Simpan label mulai baris ke (hasil pembulatan sepertiga jumlah data
ditambah 1) sampai akhir sebagai label latih
iii. Simpan data mulai baris ke 1 sampai baris ke (hasil pembulatan sepertiga jumlah data) untuk semua kolom sebagai data uji
iv. Simpan label mulai baris ke 1 sampai baris ke (hasil pembulatan sepertiga jumlah data) sebagai label uji
c. Jika model sama dengan 2
i. Simpan data mulai baris ke1 sampai baris ke (hasil pembulatan sepertiga jumlah), data ke (hasil pembulatan sepertiga jumlah data dikali 2 ditambah 1) sampai akhir sebagai data latih
ii. Simpan label mulai baris ke1 sampai baris ke (hasil pembulatan sepertiga jumlah), data ke (hasil pembulatan sepertiga jumlah data dikali 2 ditambah 1) sebagai data latih
iii. Simpan data mulai baris ke (hasil pembulatan sepertiga jumlah data ditambah 1) sampai baris ke (hasil pembulatan sepertiga jumlah data dikali 2) untuk semua kolom sebagai data uji
iv. Simpan label mulai baris ke (hasil pembulatan sepertiga jumlah data ditambah 1) sampai baris ke (hasil pembulatan sepertiga jumlah data dikali 2) sebagai label uji
d. Jika model sama dengan 3
i. Simpan data mulai baris ke1 sampai baris ke (hasil pembulatan sepertiga jumlah data dikali 2) untuk semua kolom sebagai data latih ii. Simpan label mulai baris ke1 sampai baris ke (hasil pembulatan
sepertiga jumlah data dikali 2) sebagai label latih
iii. Simpan data mulai baris ke (hasil pembulatan sepertiga jumlah data dikali 2 ditambah 1) sampai akhir untuk semua kolom sebagai data uji
iv. Simpan label mulai baris ke (hasil pembulatan sepertiga jumlah data dikali 2 ditambah 1) sampai akhir sebagai label uji
2. Nama Fungsi : euclidean_distances Algoritma :
a. Simpan string euclidean sebagai default method ke dalam variabel method
b. Simpan data uji ke variabel b
c. Cek, jika tipe data uji bukan numerik i. Tampilkan pesan error
d. Lakukan perulangan sebanyak data uji
i. Simpan cell array 1 ke dalam variabel arg ii. Jika nilai arg merupakan karakter
1. Simpan nilai arg ke dalam variabel method iii. Hanya jika variabel arg tidak kosong
3. Simpan nilai arg ke dalam variabel b a. Hitung baris dan kolom variabel a
b. Hitung baris dan kolom variabel b
i. Lakukan pengecekan, jika jumlah kolom variabel a dan b berbeda 4. Tampilkan pesan error
c. Buat indeks matriks semua baris variabel a dan b
d. Hitung setiap baris variabel a dikurangi variabel b untuk semua kolom, lalu simpan dalam variabel delta
e. Buat matriks dmat dengan ukuran baris sebanyak baris variabel a dan kolom sebanyak baris variabel b dengan semua nilainya 0
f. Hitung akar dari jumlah setiap nilai variabel delta dipangkatkan 2 lalu simpan hasilnya dalam matriks dmat
3. Nama Fungsi : fungsi_s Algoritma :
a. Lakukan perulangan sebanyak data latih i. Inisialisasi variabel jum bernilai 0 ii. Lakukan perulangan sebanyak nilai k
iii. Bandingkan, jika label latih sama dengan label pembanding 1. Variabel jum ditambah 1
iv. Simpan nilai variabel jum ke variabel jumValiditas
4. Nama Fungsi : hitungNilaiValiditas Algoritma :
a. Lakukan perulangan sebanyak data latih
i. Setiap nilai jumlah validitas dibagi nilai k lalu simpan dalam variabel nilaiValiditas
ii. Tranpose variabel nilaiValiditas
5. Nama Fungsi : label_index Algoritma :
a. Lakukan perulangan sebanyak nilai k i. Lakukan perulangan sebanyak data latih
5. Simpan setiap label data latih setelah diurutkan sesuai dengan indeksnya ke dalam variabel labelHasil
6. Nama Fungsi : input_label Algoritma :
a. Lakukan perulangan sebanyak data uji
i. Simpan label data latih ke dalam matriks dengan kolom sebanyak data uji
7. Nama Fungsi : hitung_bobot Algoritma :
a. Lakukan perulangan sebanyak data uji i. Inisialisasi variabel bobot bernilai 0 ii. Lakukan perulangan sebanyak data latih
1. Hitung bobot menggunakan rumus weight voting lalu simpan hasilnya ke dalam variabel bobot
2. Simpan nilai bobot ke dalam matriks nilaiBobot
8. Nama Fungsi : prediksi Algoritma :
a. Lakukan perulangan sebanyak data uji
i. Hitung frekuensi label yang mendominasi setiap kolom lalu simpan dalam variabel dominasi
ii. Cari label dengan frekuensi paling tinggi lalu simpan ke dalam variabel hasil
b. Simpan label kedalam variabel hasilPrediksi
9. Nama Fungsi : label_prediksi Algoritma :
a. Ubah hasil prediksi ke dalam cell array, lalu simpan dalam variabel label
b. Lakukan perulangan sebanyak data uji
i. Jika hasil prediksi setap baris sama dengan 1 1. Simpan A ke dalam variabel label sesuai indeks ii. Jika hasil prediksi setap baris sama dengan 2
2. Simpan B ke dalam variabel label sesuai indeks iii. Jika hasil prediksi setap baris sama dengan 3
3. Simpan C ke dalam variabel label sesuai indeks iv. Jika hasil prediksi setap baris sama dengan 4
4. Simpan D ke dalam variabel label sesuai indeks
Selain fungsi diatas, terdapat juga fungsi yang digunakan oleh penulis dari library matlab. Fungsi tersebut adalah tabulate dan max, dimana kedua fungsi tersebut digunakan untuk menentukan label yang mendominasi dari label yang didapatkan sebanyak tetangga terdekatnya.
Tabulate berfungsi untuk membuat tabel frekuensi data pada vektor x, sedangkan max berfungsi untuk mendapatkan indeks dari class/label yang mendominasi. Kedua fungsi matlab tersebut terdapat di dalam fungsi prediksi yang dibuat oleh penulis. Fungsi tersebut dapat dilihat pada gambar 3.3 berikut ini.
Gambar 3. 3 Fungsi Prediksi
Apabila terdapat kasus dimana label yang mendominasi memiliki frekuensi yang sama, maka label dengan indeks paling kecil yang akan terpilih. Contoh kasus tersebut dapat dilihat pada gambar 3.4 di bawah ini.
Gambar 3. 4 Contoh Tabel Label yang Mendominasi
Berdasarkan tabel diatas maka fungsi tabulate akan menghasilkan tabel frekuensi. Tabel frekuensi tersebut dapat dilihat pada gambar 3.5 di bawah ini.
Gambar 3. 5 Tabel Frekuensi
Dari tabel frekuensi diatas maka label yang akan terpilih sebagai label yang mendominasi menggunakan fungsi max adalah label 3.
3.8 Komposisi Data Latih dan Data Uji
Total data sebanyak 1362 dari 9 mata pelajaran terbagi menjadi 3 kelompok.
Mata pelajaran Bahasa Indonesia, Bahasa Inggris, Matematika dengan masing- masing total data 227. Mata pelajaran Biologi, Fisika, Kimia dengan masing- masing total data 128. Mata pelajaran Geografi, Sosiologi, Ekonomi dengan masing-masing total data 99. Pada proses perhitungan akurasi setiap dataset akan dibagi menjadi data latih dan data uji menggunakan 3-Fold Cross Validation, maka jumlah data masing-masing kelompok akan diilustrasikan pada gambar berikut ini.
Gambar 3. 6 Pembagian Komposisi data dengan total data 227
Pada gambar 3.6 di atas merupakan pembagian komposisi data pada mata pelajaran yang memiliki total data 227.
Gambar 3. 7 Pembagian Komposisi data dengan total data 128 Pada gambar 3.7 di atas merupakan pembagian komposisi data pada mata pelajaran yang memiliki total data 128.
Gambar 3. 8 Pembagian Komposisi data dengan total data 99 Pada gambar 3.8 di atas merupakan pembagian komposisi data pada mata pelajaran yang memiliki total data 99.
3.9 Perancangan Antar Muka Sistem
Perangkat Lunak ini memiliki 5 tampilan antarmuka, yaitu halaman utama (home), halaman administrator, halaman prediksi nilai, halaman bantuan, dan halaman tentang. Antarmuka halaman utama (home) dapat dilihat pada gambar 3.9 berikut ini.
Gambar 3. 9 Halaman Utama (home)
Halaman utama (home) merupakan halaman pertama yang akan muncul ketika pengguna menjalankan perangkat lunak. Pada halaman ini terdapat tombol “Admin” untuk menuju halaman admin, tombol “Prediksi Nilai” untuk menuju halaman prediksi nilai, tombol “Bantuan” untuk menuju halaman bantuan, dan tombol “Tentang” untuk menuju halaman tentang.
PREDIKSI KATEGORI NILAI UJIANSEKOLAH BERSTANDAR NASIONAL SISWA SMA BERDASARKAN NILAI RAPOR MENGGUNAKAN ALGORITME
MODIFIED K-NEAREST NEIGHBOR
LOGO USD
Admin
Bantuan Tentang
Prediksi Nilai Home
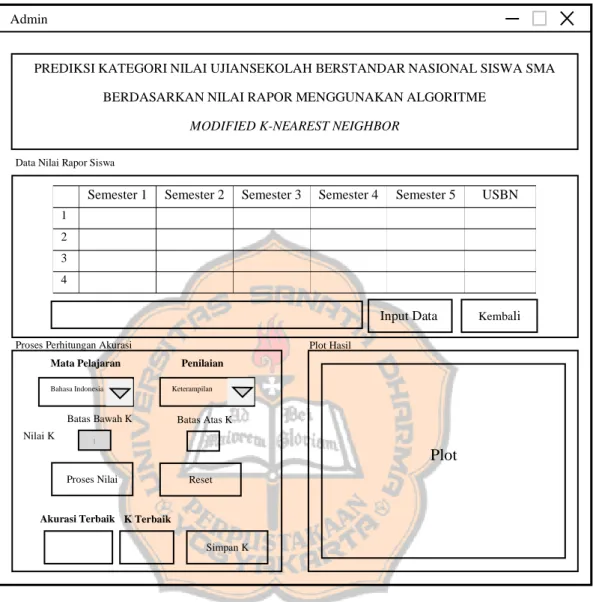
Antarmuka halaman Admin dapat dilihat pada gambar 3.10 berikut ini.
Gambar 3. 10 Halaman Admin
Halaman admin merupakan halaman yang digunakan untuk memasukkan data nilai rapor semester 1 sampai semester 5 dan nilai USBN, lalu berdasarkan nilai tersebut akan didapatkan akurasi terbaik serta k terbaik yang nantinya akan digunakan sebagai model saat memprediksi nilai USBN.
Pada halaman ini terdapat tombol “Input Data” yang digunakan untuk memilih file berekstensi .xlsx dari direktori komputer. Tombol “Kembali” digunakan untuk kembali ke halaman awal (home). Terdapat dua buah dropdown menu yang digunakan untuk memilih mata pelajaran dan aspek penilaian sesuai dengan data yang telah dimasukkan. Tombol “Proses Nilai” digunakan untuk
Admin
PREDIKSI KATEGORI NILAI UJIANSEKOLAH BERSTANDAR NASIONAL SISWA SMA BERDASARKAN NILAI RAPOR MENGGUNAKAN ALGORITME
MODIFIED K-NEAREST NEIGHBOR
Semester 1 Semester 2 Semester 3 Semester 4 Semester 5 USBN 1
2 3 4
Input Data
Plot
Plot Hasil Data Nilai Rapor Siswa
Kembali
Proses Perhitungan Akurasi
Mata Pelajaran Penilaian
Bahasa Indonesia Keterampilan
Nilai K
Batas Bawah K Batas Atas K
1
Proses Nilai Reset
Akurasi Terbaik
Simpan K K Terbaik
memproses data nilai yang telah dimasukkan untuk menghasilkan akurasi serta k terbaik. Tombol “Reset” digunakan untuk menghapus batas atas k, hasil akurasi, dan k terbaik. Tombol “Simpan K” digunakan untuk menyimpan k terbaik yang nantinya akan menjadi model pada halaman prediksi nilai.
Antarmuka halaman Prediksi Nilai dapat dilihat pada gambar 3.11 berikut ini.
Gambar 3. 11 Halaman Prediksi Nilai
Halaman prediksi nilai digunakan untuk memprediksi nilai USBN siswa. Prediksi tersebut dapat dilakukan secara kelompok maupun tunggal.
Pada halaman ini terdapat tombol “Input Data” yang digunakan untuk memilih file nilai rapor berekstensi .xlsx dari direktori komputer. Tombol “Prediksi”
digunakan untuk memproses nilai rapor yang telah dimasukkan sehingga
PREDIKSI KATEGORI NILAI UJIANSEKOLAH BERSTANDAR NASIONAL SISWA SMA BERDASARKAN NILAI RAPOR MENGGUNAKAN ALGORITME
MODIFIED K-NEAREST NEIGHBOR Prediksi Nilai
Semester 1 Semester 2 Semester 3 Semester 4 Semester 5 USBN 1
2 3 4
Simpan Hasil Prediksi Kelompok
Nama File :
Input Data Prediksi Masukkan Data Prediksi :
Mata Pelajaran Penilaian
Bahasa Indonesia Keterampilan
Range Nilai
A = 100 - 91 B = 82 - 90 C = 73 - 81 D = <73
Semester 1
Kembali
Prediksi Tunggal
Proses Nilai Reset
Semester 2 Semester 3 Semester 4 Semester 5
Hasil Prediksi
menghasilkan prediksi nilai USBN secara kelompok. Tombol “Simpan Hasil”
digunakan untuk menyimpan hasil prediksi ke dalam sebuah file berekstensi .xlsx dengan nama file yang sudah dimasukkan. Tombol “Proses Nilai”
digunakan untuk memproses data nilai yang telah dimasukkan untuk menghasilkan prediksi tunggal nilai USBN. Tombol “Reset” digunakan untuk menghapus nilai semester 1 sampai semester 5 dan hasil prediksi. Tombol
“Kembali” digunakan untuk kembali ke halaman awal (home).
Antarmuka halaman Bantuan dapat dilihat pada gambar 3.12 berikut ini.
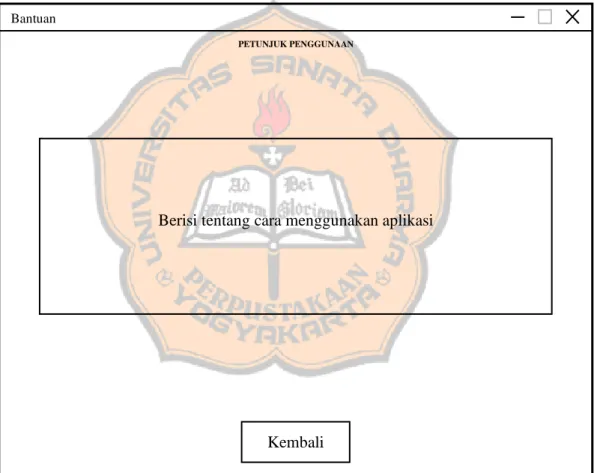
Gambar 3. 12 Halaman Bantuan
Halaman bantuan merupakan halaman yang berisi langkah-langkah bagi pengguna untuk menjalankan perangkat lunak dengan benar. Pada halaman ini terdapat tombol “Kembali” yang digunakan untuk kembali ke halaman awal (home).
Berisi tentang cara menggunakan aplikasi
Bantuan
Kembali
PETUNJUK PENGGUNAAN
Antarmuka halaman Tentang dapat dilihat pada gambar 3.13 berikut ini.
Gambar 3. 13 Halaman Tentang
Halaman bantuan merupakan halaman yang berisi profil singkat pembuat perangkat lunak. Pada halaman ini terdapat tombol “Kembali” yang digunakan untuk kembali ke halaman awal (home).
PREDIKSI KATEGORI NILAI UJIANSEKOLAH BERSTANDAR NASIONAL SISWA SMA BERDASARKAN NILAI RAPOR MENGGUNAKAN ALGORITME
MODIFIED K-NEAREST NEIGHBOR
FOTO
Tentang penulis :
Kembali
Tentang
Nama : NIM : Program Studi : Fakultas : Universitas :
36 BAB IV
IMPLEMENTASI DAN ANALISIS HASIL
4.1 Implementasi Use Case
Use case yang telah dirancang sebelumnya diimplementasikan ke dalam sebuah sistem dengan tampilan antarmuka sebagai berikut :
1. Halaman Utama (home)
Hasil implementasi halaman utama (home) dapat dilihat pada gambar 4.1 berikut ini.
Gambar 4. 1 Implementasi Halaman Utama
Pada halaman ini, pengguna diberikan pilihan untuk memilih halaman yang ingin dituju. Setiap halaman memiliki fungsi yang berbeda-beda seperti yang telah dijelaskan pada bab sebelumnya.
2. Halaman Admin
Hasil implementasi halaman admin dapat dilihat pada gambar 4.2 berikut ini.
Gambar 4. 2 Implementasi Halaman Admin
Pada halaman ini digunakan oleh admin untuk mendapatkan akurasi terbaik dan k terbaik berdasarkan data nilai yang sudah dimasukkan. Setelah itu, admin juga dapat menyimpan hasil k terbaik yang nantinya akan digunakan pada proses prediksi nilai USBN.
3. Halaman Prediksi Nilai
Hasil implementasi halaman prediksi nilai dapat dilihat pada gambar 4.3 berikut ini.
Gambar 4. 3 Implementasi Halaman Prediksi Nilai
Pada halaman ini, digunakan oleh pengguna untuk memprediksi nilai USBN berdasarkan nilai rapor siswa. Prediksi dapat dilakukan secara berkelompok maupun tunggal. Hasil prediksi kelompok dapat disimpan ke dalam sebuah file berdasarkan nama yang telah dimasukkan.
4. Halaman Bantuan
Halaman bantuan berisi langkah-langkah dalam menggunakan sistem agar pengguna dapat menjalankan sesuai dengan prosedur yang benar.
Hasil implementasi halaman bantuan dapat dilihat pada gambar 4.4 berikut ini.
Gambar 4. 4 Implementasi Halaman Bantuan
5. Halaman Tentang
Halaman tentang berisi data diri dari penulis. Hasil implementasi halaman tentang dapat dilihat pada gambar 4.5 berikut ini.
Gambar 4. 5 Implementasi Halaman Tentang
4.2 Uji Validasi Perhitungan Akurasi Modified k-Nearest Neighbor 4.2.1 Penghitungan Akurasi Modified k-Nearest Neighbor Secara
Manual
Pengujian hasil akurasi secara manual menggunakan 15 data dari 4086 data nilai rapor dan USBN siswa yang lulus tahun 2019. Sampel data tersebut merupakan nilai mata pelajaran matematika pengetahuan.
Proses perhitungan dilakukan menggunakan Microsoft Excel. Dalam perhitungan akurasi menggunakan algoritme modified k-nearest neighbor ditetapkan jumlah tetangga terdekat sebanyak 1 menggunakan 3-fold. Proses perhitungan manual dan hasil akurasi dapat dilihat pada lampiran 2.
4.2.2 Penghitungan Akurasi Modified k-Nearest Neighbor Menggunakan Perangkat Lunak
Pengujian hasil akurasi menggunakan perangkat lunak menggunakan 15 data dari 4086 data nilai rapor dan USBN siswa yang lulus tahun 2019. Sampel data tersebut merupakan nilai mata pelajaran matematika pengetahuan. Proses perhitungan dilakukan dengan memilih mata pelajaran dan aspek penilaian pada dropdown mata pelajaran dan penilaian lalu memasukkan file .xlsx dalam perangkat lunak. Setelah itu, memasukkan batas atas jumlah tetangga terdekat sebesar 1. Hasil akurasi dari perhitungan menggunakan perangkat lunak dapat dilihat pada gambar 4.6 berikut ini.
Gambar 4. 6 Hasil Akurasi Menggunakan Perangkat Lunak
4.2.3 Evaluasi Penghitungan Akurasi Modified k Nearest Neighbor Secara Manual dengan Perangkat Lunak
Hasil akurasi yang diperoleh dari perhitungan manual sama dengan hasil akurasi yang didapatkan pada perangkat lunak. Oleh karena itu dapat disimpulkan bahwa perangkat lunak dapat berjalan dengan baik sesuai dengan yang diharapkan oleh penulis.
4.3 Uji Validasi Prediksi Modified k-Nearest Neighbor
4.3.1 Prediksi Modified k-Nearest Neighbor Secara Manual
Pengujian hasil prediksi secara manual menggunakan 15 data dari 4086 data nilai rapor dan USBN siswa yang lulus tahun 2019 mata pelajaran matematika pengetahuan sebagai data model dan 1 data nilai rapor siswa yang akan diprediksi. 1 data nilai rapor yang diinputkan berisi nilai semester 1 sebesar 79, nilai semester 2 sebesar 80, nilai semester 3 sebesar 77, nilai semester 4 sebesar 84, dan nilai semester 5 sebesar 82. Proses perhitungan dilakukan menggunakan Microsoft Excel. Dalam perhitungan akurasi menggunakan algoritme modified k- nearest neighbor ditetapkan jumlah tetangga terdekat sebanyak 1 menggunakan 3-fold. Proses perhitungan manual dan hasil prediksi dapat dilihat pada lampiran 3.
4.3.2 Prediksi Modified k-Nearest Neighbor Menggunakan Perangkat Lunak
Pengujian hasil prediksi menggunakan perangkat lunak menggunakan 15 data dari 4086 data nilai rapor dan USBN siswa yang lulus tahun 2019 mata pelajaran matematika pengetahuan sebagai data model dan 1 data nilai rapor siswa yang akan diprediksi. Proses perhitungan dilakukan dengan memilih mata pelajaran dan aspek penilaian pada dropdown mata pelajaran dan penilaian dalam perangkat lunak. Lalu 1 data nilai rapor yang diinputkan berisi nilai semester 1 sebesar 79, nilai semester 2 sebesar 80, nilai semester 3 sebesar 77, nilai
semester 4 sebesar 84, dan nilai semester 5 sebesar 82. Dalam perhitungan akurasi menggunakan algoritme modified k-nearest neighbor ditetapkan jumlah tetangga terdekat sebanyak 1 menggunakan 3-fold. Hasil prediksi dari perhitungan menggunakan perangkat lunak dapat dilihat pada gambar 4.7 berikut ini.
Gambar 4. 7 Hasil Prediksi Menggunakan Perangkat Lunak
4.3.3 Evaluasi Prediksi Modified k-Nearest Neighbor Secara Manual dengan Perangkat Lunak
Hasil prediksi yang diperoleh dari perhitungan manual sama dengan hasil akurasi yang didapatkan pada perangkat lunak. Oleh karena itu
dapat disimpulkan bahwa perangkat lunak dapat berjalan dengan baik sesuai dengan yang diharapkan oleh penulis.
4.4 Analisis Hasil 4.4.1 Dataset
Penelitian ini menggunakan dataset nilai rapor siswa semester 1 sampai semester 5 jurusan IPA dan IPS SMA BOPKRI 1 Yogyakarta yang lulus tahun 2019 dengan jumlah 4086 record dan 5 atribut. Setiap dataset mata pelajaran juga terbagi atas aspek pengetahuan (1362 record), aspek keterampilan (1362 record), dan rata-rata penilaian aspek pengetahuan dan keterampilan (1362 record). Dataset dibagi menjadi beberapa dataset berdasarkan mata pelajaran, yaitu mata pelajaran Bahasa Indonesia, mata pelajaran Bahasa Inggris, mata pelajaran Matematika, mata pelajaran Biologi, mata pelajaran Fisika, mata pelajaran Kimia, mata pelajaran Geografi, mata pelajaran Sosiologi, dan mata pelajaran Ekonomi.
4.4.2 Hasil Akurasi Modified k-Nearest Neighbor
Pada penelitian ini, dilakukan pengujian untuk mencari akurasi tertinggi pada setiap dataset yang ada menggunakan algoritme modified k-nearest neighbor dan menggunakan metode 3-fold cross validation dengan jumlah tetangga terdekat sebesar 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27 29, 31, 33, 35, 37, 39, 41. Dalam menentukan nilai K sebaiknya dilihat dari jumlah klasifikasi bila jumlahnya genap maka sebaiknya menggunakan nilai K yang ganjil, dan sebaliknya jika jumlah klasifikasi ganjil maka sebaiknya menggunakan nilai K yang genap, karena jika tidak begitu maka sistem kemungkinan tidak akan mendapatkan jawaban (Denni Kurniawan, 2019). Hasil akurasi setiap dataset akan ditampilkan dalam bentuk grafik karena sistem yang dibuat dapat langsung menampilkan hasil dalam bentuk grafik. Hasil lengkap setiap dataset dapat dilihat di bawah ini.
1. Bahasa Indonesia a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Bahasa Indonesia aspek pengetahuan dapat dilihat pada gambar 4.8 berikut ini.
Gambar 4. 8 Hasil Akurasi Bahasa Indonesia Aspek Pengetahuan
b. Aspek Keterampilan
Hasil akurasi mata pelajaran Bahasa Indonesia aspek keterampilan dapat dilihat pada gambar 4.9 berikut ini.
Gambar 4. 9 Hasil Akurasi Bahasa Indonesia Aspek Keterampilan
c. Rata-rata Penilaian Aspek Pengetahuan dan Keterampilan Hasil akurasi rata-rata aspek pengetahuan dan keterampilan mata pelajaran Bahasa Indonesia dapat dilihat pada gambar 4.10 berikut ini.
Gambar 4. 10 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Bahasa Indonesia
2. Bahasa Inggris
a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Bahasa Inggris aspek pengetahuan dapat dilihat pada gambar 4.11 berikut ini.
Gambar 4. 11 Hasil Akurasi Bahasa Inggris Aspek Pengetahuan
b. Aspek Keterampilan
Hasil akurasi mata pelajaran Bahasa Inggris aspek keterampilan dapat dilihat pada gambar 4.12 berikut ini.
Gambar 4. 12 Hasil Akurasi Bahasa Inggris Aspek Keterampilan
c. Rata-rata Penilaian Aspek Pengetahuan dan Keterampilan Hasil akurasi rata-rata aspek pengetahuan dan keterampilan mata pelajaran Bahasa Inggris dapat dilihat pada gambar 4.13 berikut ini.
Gambar 4. 13 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Bahasa Inggris
3. Matematika
a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Matematika aspek pengetahuan dapat dilihat pada gambar 4.14 berikut ini.
Gambar 4. 14 Hasil Akurasi Matematika Aspek Pengetahuan b. Aspek Keterampilan
Hasil akurasi mata pelajaran Matematika aspek keterampilan dapat dilihat pada gambar 4.15 berikut ini.
Gambar 4. 15 Hasil Akurasi Matematika Aspek Keterampilan
c. Rata-rata Penilaian Aspek Pengetahuan dan Keterampilan Hasil akurasi rata-rata aspek pengetahuan dan keterampilan mata pelajaran Matematika dapat dilihat pada gambar 4.16 berikut ini.
Gambar 4. 16 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Matematika
4. Biologi
a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Biologi aspek pengetahuan dapat dilihat pada gambar 4.17 berikut ini.
Gambar 4. 17 Hasil Akurasi Biologi Aspek Pengetahuan
b. Aspek Keterampilan
Hasil akurasi mata pelajaran Biologi aspek keterampilan dapat dilihat pada gambar 4.18 berikut ini.
Gambar 4. 18 Hasil Akurasi Biologi Aspek Keterampilan
c. Rata-rata Penilaian Aspek Pengetahuan dan Keterampilan Hasil akurasi rata-rata aspek pengetahuan dan keterampilan mata pelajaran Biologi dapat dilihat pada gambar 4.19 berikut ini.
Gambar 4. 19 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Biologi
5. Fisika
a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Fisika aspek pengetahuan dapat dilihat pada gambar 4.20 berikut ini.
Gambar 4. 20 Hasil Akurasi Fisika Aspek Pengetahuan
b. Aspek Keterampilan
Hasil akurasi mata pelajaran Fisika aspek keterampilan dapat dilihat pada gambar 4.21 berikut ini.
Gambar 4. 21 Hasil Akurasi Fisika Aspek Keterampilan
c. Rata-rata Penilaian Aspek Pengetahuan dan Keterampilan Hasil akurasi rata-rata aspek pengetahuan dan keterampilan mata pelajaran Fisika dapat dilihat pada gambar 4.22 berikut ini.
Gambar 4. 22 Hasil Akurasi Rata-rata Aspek Pengetahuan dan Keterampilan mata pelajaran Fisika
6. Kimia
a. Aspek Pengetahuan
Hasil akurasi mata pelajaran Kimia aspek pengetahuan dapat dilihat pada gambar 4.23 berikut ini.
Gambar 4. 23 Hasil Akurasi Kimia Aspek Pengetahuan